Теория и реализация языков программирования
LR(1)-анализаторы
В названии LR(1) символ L указывает на то, что входная цепочка читается слева-направо, R - на то, что строится правый вывод, наконец, 1 указывает на то, что анализатор видит один символ непрочитанной части входной цепочки.
LR(1)-анализ привлекателен по нескольким причинам:
- LR(1)-анализ - наиболее мощный метод анализа без возвратов типа сдвиг-свертка;
- LR(1)-анализ может быть реализован довольно эффективно;
- LR(1)-анализаторы могут быть построены для практически всех конструкций языков программирования;
- класс грамматик, которые могут быть проанализированы LR(1)-методом, строго включает класс грамматик, которые могут быть проанализированы предсказывающими анализаторами (сверху-вниз типа LL(1)).
Схематически структура LR(1)-анализатора изображена на рис. 4.4. Анализатор состоит из входной ленты, выходной ленты, магазина, управляющей программы и таблицы анализа (LR(1)-таблицы), которая имеет две части - функцию действий (Action) и функцию переходов (Goto). Управляющая программа одна и та же для всех LR(1)-анализаторов, разные анализаторы отличаются только таблицами анализа.
Анализатор читает символы на входной ленте по одному за шаг. В процессе анализа используется магазин, в котором хранятся строки вида S0X1S1X2S2 ... XmSm (Sm - верхушка магазина). Каждый Xi - символ грамматики (терминальный или нетерминальный), а Si - символ состояния.
Заметим, что символы грамматики (либо символы состояний) не обязательно должны размещаться в магазине. Однако, их использование облегчает понимание поведения LR-анализатора.
Элемент функции действий Action[Sm; ai] для символа состояния Sm и входа

- shift S (сдвиг), где S - символ состояния,
- reduce A ? (свертка по правилу грамматики A
 ?),
?), - accept (допуск),
- error (ошибка).
Элемент функции переходов Goto[Sm; A] для символа состояния Smи входа

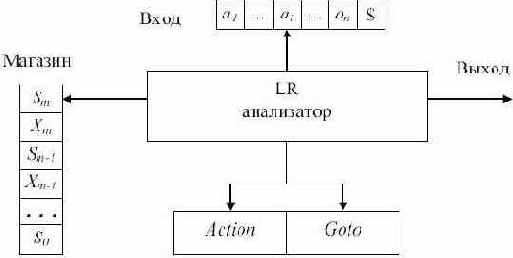
Рис. 4.6.
- S, где S - символ состояния,
- error (ошибка).
Конфигурацией LR(1)-анализатора называется пара, первая компонента которой - содержимое магазина, а вторая - непросмотренный вход:
(S0X1S1X2S2 ... XmSm, aiai+1 ... an$)
Эта конфигурация соответствует правой сентенциальной форме
X1X2 ... Xmaiai+1 ... an
Префиксы правых сентенциальных форм, которые могут появиться в магазине анализатора, называются активными префиксами. Основа сентенциальной формы всегда располагается на верхушке магазина. Таким образом, активный префикс - это такой префикс правой сентенциальной формы, который не переходит правую границу основы этой формы.
Когда анализатор начинает работу, в магазине находится только символ начального состояния S0, на входной ленте - анализируемая цепочка с маркером конца.
Каждый очередной шаг анализатора определяется текущим входным символом ai и символом состояния на верхушке магазина Sm следующим ниже образом.
Пусть LR(1)-анализатор находится в конфигурации
(S0X1S1X2S2 ... XmSm, aiai+1 ... an$)
Анализатор может проделать один из следующих шагов:
- Если Action[Sm, ai] = shift S, то анализатор выполняет сдвиг, переходя в конфигурацию То есть, в магазин помещаются входной символ ai

и символ состояния S, определяемый Action[Sm, ai]. Текущим входным символом становится ai+1. - Если Action[Sm, ai] = reduce A ?, то анализатор выполняет свертку, переходя в конфигурациюгде S = Goto[Sm-r; A] и r - длина ?, правой части правила вывода.

Анализатор сначала удаляет из магазина 2r символов (r символов состояния и r символов грамматики), так что на верхушке оказывается состояние Sm-r. Затем анализатор помещает в магазин A - левую часть правила вывода, и S - символ состояния, определяемый Goto[Sm-r, A]. На шаге свертки текущий входной символ не меняется. Для LR(1)- анализаторов последовательность символов грамматики Xm-r+1 ... Xm, удаляемых из магазина , всегда соответствует ? - правой части правила вывода, по которому делается свертка.
После осуществления шага свертки генерируется выход LR(1)-анализатора, то есть исполняются семантические действия, связанные с правилом, по которому делается свертка, например, печатаются номера правил, по которым делается свертка.
Заметим, что функция Goto таблицы анализа, построенная по грамматике G, фактически представляет собой функцию переходов детерминированного конечного автомата, распознающего активные префиксы G. - Если Action[Sm, ai] = accept, то разбор успешно завершен.
- Если Action[Sm, ai] = error, то анализатор обнаружил ошибку, и выполняются действия по диагностике и восстановлению.
Пример 4.10. Рассмотрим грамматику арифметических выражений G = ({E, T, F}, {id, +, *}, P, E) с правилами:
- E E + T
- E T
- T T * F
- T F
- F id
На рис. 4.7 изображены функции Action и Goto, образующие LR(1)-таблицу для этой грамматики. Элемент Si функции Action означает сдвиг и помещение в магазин состояния с номером i, Rj - свертку по правилу номер j, acc - допуск, пустая клетка - ошибку. Для функции Goto символ i означает помещение в магазин состояния с номером i, пустая клетка - ошибку.
На входе id + id * id последовательность состояний магазина и входной ленты показаны на рис. 4.8. Например, в первой строке LR-анализатор находится в нулевом состоянии и "видит" первый входной символ id. Действие S6 в нулевой строке и столбце id в поле Action (рис. 4.7) означает сдвиг и помещение символа состояния 6 на верхушку магазина. Это и изображено во второй строке: первый символ id и символ состояния 6 помещаются в магазин, а id удаляется со входной ленты.
Текущим входным символом становится +, и действием в состоянии 6 на вход + является свертка по F