Другие перспективные области применения АСК-анализа и систем искусственного интеллекта
В перспективе предложенные методология, технология и инструментальная программная система могут быть применены, в частности, в следующих областях:
В медицине, в том числе гомеопатии, иридодиагностике, рефлексотерапии: диагностики заболеваний по их симптоматике, в том числе при массовых профилактических обследованиях населения как с выездом в район обследования или на предприятие, так и без личного присутствия пациентов; сжатия диагностической информации, содержащейся в медицинской литературе и архивах историй болезни; проведения научных исследований по выявлению причинно–следственных зависимостей между применяемыми средствами (например, лекарственными) и методами лечения, с одной стороны, и лечебным эффектом, с другой, мониторинга состояний пациентов.
В профессиональной диагностике и профориентации в учебных заведениях, на предприятиях в отделах кадров, в центрах занятости населения (на биржах труда и в службах трудоустройства). Для психосоциальной диагностики и анализа общественного мнения, компьютерной обработки и интерпретации результатов социологических исследований (public relations). Для тестирования предметной обычности учащихся и определения решаемости контрольных заданий.
Для криминогенной профилактики физических и юридических лиц, выявления и прогнозирования "зон риска", в том числе в налоговых, финансовых и других контролирующих органах, для криминалистической и психофизиологической идентификации личности. Для классификации и типологизации преступлений, формализации фабулы (почерка), нахождения аналогов преступлений, а также автоматизированного поиска ранее проведенных проверок, в которых были получены аналогичные результаты.
Для диагностики способностей, в том числе экстрасенсорных и других парапсихологических способностей, косвенного измерения уровня развития сознания, интеллектуальной и эмоциональной сферы, способностей к специальным видам деятельности, связанных с риском, высокой ответственностью, работой на высоте, под землей, под водой, с применением оружия, в экстремальных ситуациях и т.п.
Для автоматизированного синтеза образа объекта по его фрагментам, полученным с помощью подсознательного информационного канала, в том числе при получении одной и той же информации многими людьми, ни один из которых в явной и целостной форме не осознает ее; для количественного сравнения и идентификации образов, полученных в результате дистанционной перцепции, ретрогниции и прекогниции, с образами – мишенями. Для синтеза образа объекта – мишени (и количественного его сравнения с оригиналом) при индивидуальном и коллективном восприятии по каналам телепатии, неклассической дистанционной перцепции, ретрогниции и прекогниции.
Для атрибуции анонимных и псевдонимных текстов, т.е. для установления вероятностного авторства текста или его тематической или иной принадлежности по незначительным, поврежденным, неполным и несвязанным фрагментам. В этом случае система распознавания работает как дескрипторная информационно-поисковая система с автоматическим формированием дескрипторов и поиску по нечеткому или некорректному запросу (на естественном языке, причем какой этот язык: русский, английский или какой-либо другой – роли не играет).
Для автоматической классификации химических веществ по их составу или внешним признакам. Для вероятностной идентификации элементов в смесях и при неполном или некачественном их анализе с помощью химических тестов, спектральных методов, ядерно-магнитного резонанса.
Для формирования обобщенных образов различных видов недвижимости и сопоставления конкретных объектов с этими образами в целях оценки недвижимости (развитие метода сравнительных продаж). Для разработки и применения стандарта земель в земельном кадастре.
Для автоматической классификации сортов растений и пород животных по их внешним, анатомическим, физиологическим и другим признакам, а также на основе измерения генетического расстояния.
Для прогнозирования месторождений полезных ископаемых по внешним сопутствующим признакам, в том числе и установленным с помощью биолокации.
Для синтеза образов подсознательно воспринимаемых объектов, признаки которых установлены (выведены на уровень сознания) с помощью биолокации.
Для долгосрочного и оперативного прогнозирования изменений погодных факторов, для регионов, для которых известны суточные значения этих факторов за достаточный период времени.
Для выявления влияния любых технологических приемов и условий на качество и количество хозяйственных результатов. Для анализа и прогнозирования ситуаций на сельскохозяйственном секторе натурального и фондового рынка: ценовой мониторинг и прогнозирование цен и объемов продаж продукции растениеводства, птицеводства и животноводства, а также ценных бумаг; макроэкономический анализ.
Косвенная профессиональная идентификация, прогнозирование успешности работы и совместимости сотрудников службы безопасности, других служб банка (при этом выявляются сотрудники – "опора фирмы" и "зоны риска"). Прогнозирование остатков и движения средств на счетах филиалов банка и на счетах клиентов. Прогнозирование развития фондового рынка, других сегментов рынка. Косвенная оценка рисков страхования, кредитования, инвестирования, бизнеса, других форм взаимодействия юридических и физических лиц. Косвенная профессиональная идентификация, прогнозирование успешности работы и совместимости сотрудников различных служб фонда (при этом выявляются сотрудники – "опора фирмы", а также "зоны риска"). Косвенная профессиональная идентификация и прогнозирование успешности работы клиентов фонда по распределяемым профессиям и специальностям.
Прогнозирование развития рынка труда и уровня безработицы, других сегментов рынка.
Для решения задач распознавания объектов и их состояний по признакам, в том числе и при неполном или искаженном описании. Для изучения динамики и территориальных зависимостей обобщенных образов классов распознавания. Для выявления и исследования причинно – следственных связей между событиями (признаками, технологией, составом) и их следствиями (объектами, состояниями, свойствами, эффективностью) и др.
Для аналитической обработки данных экологического мониторинга (на примере Черного моря): разработка оптимального формализованного паспорта для экологического мониторинга и экологического зонирования (районирования) побережья Черного моря; экологическая паспортизация и зонирование побережья Черного моря; разработка информационных портретов экологических зон побережья; их классификация, обобщение и сопоставительный анализ; комплексные и специальные, регламентные и инновационные аналитические исследования по данным экологического мониторинга побережья Черного моря; исследование влияния факторов различного происхождения (геофизических и биосферных; антропогенных; рекреационных и других экологических мер и технологий) на экологическое состояние побережья Черного моря; исследование динамики экологического состояния побережья Черного моря в связи с динамикой влияющих на него факторов.
Оперативное и долгосрочное прогнозирование развития экологического состояния побережья Черного моря; разработка методик подбора персонала экологических служб: оценка индивидуальных качеств сотрудников; оптимальный подбор групп по совместимости; прогнозирование успешности профессиональной деятельности в различных областях; прогнозирование рисков нежелательных проявлений; косвенная оценка рисков инвестирования, страхования, кредитования, бизнеса, других форм деятельности и взаимодействия юридических и физических лиц, в том числе в области экологической деятельности; организация Информационно–аналитического центра Public Relations, для проведения систематических (регламентных) и заказных исследований по изучению и формированию мнения различных групп населения по вопросам экологии ("экологического сознания"), а также для участия в выполнении работ по вышеупомянутым проектам; изучение аудитории и роли различных средств массовой информации в освещении экологической проблематики и формировании экологического сознания у различных групп населения.
Двухконтурная модель и обобщенная схема рефлексивной АСУ качеством подготовки специалистов
Объединение РАСУ АПК групп "А" и "Б" приводит к схеме двухуровневой РАСУ АПК, в которой первый контур управления включает управление сельхозкультурой, а второй контур управления обеспечивает управление самой агротехнологией. На уровне "А" РАСУ АПК осуществляется разработка и совершенствование агротехнологий, а на уровне "Б" – выбор и использование оптимальной агротехнологии для получения заданных количественных и качественных параметров конечного продукта.
Отметим, что в данной работе рассмотрение ведется на примере плодоводства и растениеводства, но это не является ограничением и легко обобщается на отрасли птицеводства, животноводства, рыбоводства и др.
Но и управление агротехнологиями будет беспредметным без обратной связи, содержащей информацию об эффективности как традиционных агротехнологических методов, так и инноваций, т.е. без учета их влияния на качество хозяйственных результатов.
Кроме того РАСУ АПК включает ряд обеспечивающих систем, работа которых направлена на создание наиболее благоприятных условий для выполнения основной функции РАСУ АПК, т.е. обеспечение максимальной прибыли путем производства и реализации заданного количества и качества наиболее рентабельной продукции. Это так называемые обеспечивающие подсистемы: стратегическое управление (включая совершенствование организационной структуры управления); управление инновационной деятельностью (НИР, ОКР, внедрение); управление информационными ресурсами (локальные и корпоративные сети, Internet); управление планово-экономической, финансовой и хозяйственной деятельностью, и др. Необходимо также отметить, что РАСУ АПК работает в определенной окружающей среде, которая, в частности, включает: социально-экономическую среду; рынок труда; рынок агротехнологий; рынок наукоемкой продукции.
Учитывая вышесказанное, предлагается следующая двухуровневая обобщенная модель РАСУ АПК, включающую в качестве базовых подсистем РАСУ АПК групп "А" и "Б", а также обеспечивающие подсистемы (рисунок 22).
 |
|
Рисунок 22. Обобщенная схема двухуровневой РАСУ АПК |
На рисунке 23 представлен вариант двухуровневой АСУ АПК, в котором показаны фазы развития сельскохозяйственной культуры и соответствующие агротехнологические этапы.
 |
Рисунок 23. Детализированная схема РАСУ АПК, как двухуровневой РАСУ-ТП |
Двухвходовое объединение
Исследователь может кластеризовать конкретные образы наблюдаемых объектов для определения кластеров объектов со сходными признаками.
Он может также кластеризовать признаки для определения кластеров признаков, которые связаны со сходными конкретными объектами.
В двувходовом алгоритме эти процессы осуществляются одновременно.
Формализация предметной области: разработка классификационных и описательных шкал и градаций
С учетом сформулированных замечаний к общему описанию задачи классификационные шкалы и градации будут иметь вид:
1. Млекопитающие.
2. Птицы.
3. Пресмыкающиеся.
4. Рыбы.
5. Земноводные.
6. Насекомые.
7. Многоногие.
Описательные шкалы и градации, приведенные в общем описании задачи, включают в основном булевы атрибуты, а также один количественный: код: 14, наименование: legs
(количество ног). Этот атрибут мы преобразовали в шкалу с булевыми градациями. После этого, с учетом сделанных замечаний к общему описанию задачи, описательные шкалы и градации приняли вид, представленный в таблице 89.
Таблица 89 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
| Код | Наименование | Код | Наименование | Код | Наименование | ||||||
| 2 | hair | 10 | backbone | 18 | legs-4 | ||||||
| 3 | feathers | 11 | breathes | 19 | legs-5 | ||||||
| 4 | eggs | 12 | venomous | 20 | legs-6 | ||||||
| 5 | milk | 13 | fins | 21 | legs-7 | ||||||
| 6 | airborne | 14 | legs-0 | 22 | legs-8 | ||||||
| 7 | aquatic | 15 | legs-1 | 23 | tail | ||||||
| 8 | predator | 16 | legs-2 | 24 | domestic | ||||||
| 9 | toothed | 17 | legs-3 | 25 | catsize |
Таблица 89 преобразуется из HTML-формата в Excel следующим образом:
1. Отмечаем блоком в Internet-броузере ту часть раздела 7 общего описания задачи (файл: zoo_names.htm), в которой перечислены атрибуты, копируем ее в буфер обмена, переходим в Word и вставляем из буфера обмена в документ.
2. Записываем обучающую выборку в форме TXT-файла с именем zoo_names.txt в стандарте "Текст DOS с разбиением на строки".
3. Загружаем Excel и выполняем шаги:
– считываем файл zoo_names.txt
в Excel, предварительно указав в окне "Тип файлов" вариант "Все файлы";
– задаем формат файла "DOS или OS/2 (PC-8) и нажимаем кнопку: "Далее";
– задаем символ-разделитель "Символ табуляции" и "считать последовательные разделители одним" и нажимаем кнопку "Готово". После некоторой корректировки получаем вид описательных шкал и градаций, представленный на рисунке197;
– записываем Excel-файл с описательными шкалами и градациями с именем Prizn.xls.
 | |
| Рисунок 197. Справочник атрибутов в Excel-представлении |
Формализм динамики взаимодействующих
Не всегда и не все классы являются атрибутами, также не всегда и не все атрибуты являются классами по смыслу (в данной модели это может быть так в многослойной нейронной сети) Поэтому традиционное представление данных в форме одной матрицы с одинаковыми строками и столбцами представляется нецелесообразным и предлагается более общее – двухвекторное представление. В предлагаемой математической модели формальное описание объекта представляет собой совокупность его интенсионального и экстенсионального описаний.
Интенсиональное (дискретное) описание – это последовательность информативностей (но не кодов) тех и только тех признаков, которые реально фактически встретились у данного конкретного объекта.
Экстенсиональное (континуальное) описание состоит из информативностей (но не кодов) тех классов распознавания, для формирования образов которых по мнению экспертов целесообразно использовать интенсиональное описание данного конкретного объекта.
Именно взаимодействие и взаимная дополнительность этих двух взаимоисключающих видов описания объектов формирует то, что психологи, логики и философы называют "смысл".
Таким образом, формальное описание объекта в предлагаемой модели состоит из двух векторов. Первый вектор описывает к каким обобщенным категориям (классам распознавания) относится объект с точки зрения экспертов (вектор субъективной, смысловой, человеческой оценки). Второй же вектор содержит информацию о том, какими признаками обладает данный объект (вектор объективных характеристик). Необходимо особо подчеркнуть, что связь этих двух векторов друг с другом имеет вообще говоря не детерминистский, а вероятностный, статистический характер.
Если объект описан обоими векторами, то это описание можно использовать для формирования обобщенных образов классов распознавания, а также для проверки степени успешности выполнения этой задачи.
Если объект описан только вторым вектором – вектором признаков, то его можно использовать только для решения задачи распознавания (идентификации), которую можно рассматривать как задачу восстановления вектора классов данного объекта по его известному вектору признаков.
Предлагаемая модель удовлетворяет принципу соответствия, т.е. в ней одновекторный вариант описания предметной области получается как некоторое подмножество из возможных в ней вариантов, определяемое двумя ограничениями:
– справочник классов распознавания тождественно совпадает со справочником признаков;
– наличие какого-либо признака у объекта обучающей выборки однозначно (детерминистским образом) определяет принадлежность этого объекта к соответствующему классу распознавания (взаимно-однозначное соответствие классов и признаков).
Очевидно, эти ограничения приводят и к соответствующим ограничениям, накладываемым в свою очередь на варианты обработки информации и анализа данных в подобных системах.
Если говорить конкретнее, такая модель данных стирает различие между атрибутами и классами и не позволяет решать ряд задач, в которых эта абстракция является недопустимым упрощением. Эти задачи будут подробнее рассмотрены ниже.
Формализовать задачу.
Для этой цели используем 5-ю функцию 5-го режима 1-й подсистемы системы "Эйдос" (реальный исходный текст программы приводится ниже).
***************************************************************
*** Формирование модели для исследования свойств чисел ********
*** Луценко Е.В., 02/26/04 11:34am ****************************
***************************************************************
FUNCTION Div_chis()
scr_start=SAVESCREEN(0,0,24,79)
SHOWTIME(0,58,.T.,"rb/n")
Titul(.T.)
Mess = "=== ГЕНЕРАЦИЯ ИСХОДНЫХ ДАННЫХ ДЛЯ МОДЕЛИ ИССЛЕДОВАНИЯ СВОЙСТВ ЧИСЕЛ ==="
@5,40-LEN(Mess)/2 SAY Mess COLOR "rg+/rb"
* 0123456789012345678901234567890123456789012345678901234567890123456789012345678
* 0 10 20 30 40 50 60 70
@10,24 SAY "Задайте максимальное число: #####" COLOR "w+/rb"
N_Obj = 99
@10,52 GET N_Obj PICTURE "#####" COLOR "rg+/r"
SET CURSOR ON;READ;SET CURSOR OFF
IF LASTKEY()=27
RESTSCREEN(0,0,24,79,scr23)
RETURN
ENDIF
*** Формирование справочника первичных признаков
A_Pr := {}
FOR j=1 TO N_Obj
AADD(A_Pr, "Делится на "+ALLTRIM(STR(j,4)))
NEXT
FOR j=1 TO N_Obj
AADD(A_Pr, "Не делится на "+ALLTRIM(STR(j,4)))
NEXT
FOR j=1 TO N_Obj
AADD(A_Pr, "Делителей: "+ALLTRIM(STR(j,4)))
NEXT
USE Priz_per EXCLUSIVE NEW
ZAP
FOR j=1 TO LEN(A_Pr)
APPEND BLANK
REPLACE Kod WITH j
REPLACE Name WITH A_Pr[j]
NEXT
GenNtxPrp(.F.)
CLOSE ALL
*** Формирование справочника классов распознавания
USE Object EXCLUSIVE NEW
ZAP
FOR j=1 TO N_Obj
APPEND BLANK
REPLACE Kod WITH j
REPLACE Name WITH ALLTRIM(STR(j,3))
NEXT
GenNtxObj(.F.)
CLOSE ALL
*** Формирование обучающей выборки
USE ObInfZag EXCLUSIVE NEW;ZAP
USE ObInfKpr EXCLUSIVE NEW;ZAP
FOR s=1 TO N_Obj
SELECT ObInfZag
APPEND BLANK
REPLACE Kod_ist WITH s
REPLACE Name_ist WITH ALLTRIM(STR(s,4))
REPLACE Obj_1 WITH s
SELECT ObInfKpr
APPEND BLANK
REPLACE Kod_ist WITH s
p=0 && Позиция для записи в БД
N_Del=0 && Кол-во делителей
*** Проверка делимости
FOR j=1 TO N_Obj
IF s-j*int(s/j) = 0
Kod = j
++N_Del
IF p+1 <= 11
FIELDPUT(++p+1, Kod)
ELSE
APPEND BLANK
REPLACE Kod_ist WITH s
p=0
FIELDPUT(++p+1, Kod)
ENDIF
ENDIF
NEXT
************ Занесение количества делителей
IF p+1 <= 11
FIELDPUT(++p+1, N_Del+2*N_Obj)
ELSE
APPEND BLANK
REPLACE Kod_ist WITH s
p=0
FIELDPUT(++p+1, N_Del+2*N_Obj)
ENDIF
*** Проверка не делимости
FOR j=1 TO N_Obj
IF s-j*int(s/j) <> 0
Kod = j+N_Obj
IF p+1 <= 11
FIELDPUT(++p+1, Kod)
ELSE
APPEND BLANK
REPLACE Kod_ist WITH s
p=0
FIELDPUT(++p+1, Kod)
ENDIF
ENDIF
NEXT
NEXT
GenNtxOin(.F.)
@24,0 SAY REPLICATE("-",80) COLOR "rb/n"
Mess = " ПРОЦЕСС ГЕНЕРАЦИИ ШКАЛ И ОБУЧАЮЩЕЙ ВЫБОРКИ ЗАВЕРШЕН УСПЕШНО !!! "
@24,40-LEN(Mess)/2 SAY Mess COLOR "rg+/rb"
INKEY(0)
RESTSCREEN(0,0,24,79,scr_start)
SHOWTIME()
RETURN
Формальная постановка основной задачи рефлексивной АСУ активными объектами и ее декомпозиция
Рассмотрим некоторые основные понятия, необходимые для дальнейшего изложения. При этом будут использованы как литературные данные, так и результаты, полученные в предыдущих главах данной работы.
Принятие решения в АСУ – это выбор некоторого наиболее предпочтительного управляющего воздействия из исходного множества всех возможных управляющих воздействий, обеспечивающего наиболее эффективное достижение целей управления. В результате выбора неопределенность исходного множества уменьшается на величину информации, которая порождается самим актом выбора [64]. Следовательно, теория информации может быть применена как для идентификации состояний объекта управления, так и для принятия решений об управляющих воздействиях в АСУ.
Модель АСУ включает в себя: модель объекта управления, модель управляющей подсистемы, а также модель внешней среды. Управляющая подсистема реализует следующие функции: идентификация состояния объекта управления, выработка управляющего воздействия, реализация управляющего воздействия.
С позиций теории информации сложный объект управления (АОУ) может рассматриваться как шумящий (определенным образом) информационный канал, на вход которого подаются входные параметры


Одной из основных задач АСУ является задача принятия решения о наиболее эффективном управляющем воздействии. В терминах теории информации эта задача формулируется следующим образом: зная целевое состояние объекта управления, на основе его информационной модели определить такие входные параметры
С решением этой задачи тесно связана задача декодирования теории информации: "По полученному в условиях помех сообщению определить, какое сообщение было передано" [176]. Для решения данной задачи используются коды, корректирующие ошибки, а в более общем случае, - различные методы распознавания образов.
Учитывая вышесказанное, предлагается рассматривать принятие решения об управляющем воздействии в АСУ как решение обратной задачи декодирования, которая формулируется следующим образом: "Какое сообщение необходимо подать на вход зашумленного канала связи, чтобы на его выходе получить заранее заданное сообщение". Данная задача решается на основе математической модели канала связи.
Формальная постановка задачи
В рефлексивных АСУ активными объектами модели распознавания образов и принятия решений применимы в подсистемах идентификации состояния АОУ и выработки управляющего воздействия: идентификация состояния АОУ представляет собой принятие решения о принадлежности этого состояния к определенной классификационной категории (задача распознавания); выбор многофакторного управляющего воздействия из множества возможных вариантов представляет собой принятие решения (обратная задача распознавания).
Распознавание образов есть принятие решения о принадлежности объекта или его состояния к определенному классу. Если до распознавания существовала неопределенность в вопросе о том, к какому классу относится распознаваемый объект или его состояние, то в результате распознавания эта неопределенность уменьшается, в том числе может быть и до нуля (когда объект идентифицируется однозначно). Из данной постановки непосредственно следует возможность
применения методов теории информации для решения задач распознавания образов и принятия решений в АСУ.
Формирование ортонормированного базиса классов (БКОСА-
Формирование ортонормированного базиса классов реализуется с применением одного из трех итерационных алгоритмов оптимизации, относящиеся к методу последовательных приближений:
1) исключение из модели заданного количества наименее сформированных классов;
2) исключение заданного процента количества классов от оставшихся (адаптивный шаг);
3) исключение классов, вносящих заданный процент степени сформированности от оставшегося суммарного (адаптивный шаг).
Критерий остановки процесса последовательных приближений – срабатывание хотя бы одного из заданных ограничений:
а) достигнуто заданное минимальное количество классов в модели;
б) достигнута заданная полнота описания признака.
Прокрутка окна вправо позволяет просмотреть дополнительные характеристики, позволяющие оценить степень сформированности образов классов и ортонормированность пространства классов.
Формирование средневзвешенного прогноза
Каждый точечный прогноз может быть представлен в форме вектора, параллельного оси Y (величина курса доллара США), имеющего определенную направленность, т.е. знак ("+" повышение, "–" понижение), а также величину, модуль, отражающую скорость изменения курса. Кроме того, каждый точечный прогноз имеет свою достоверность, нормированную от 0 до 1. Было принято, что вклад каждого точечного прогноза в средневзвешенный зависит не только от знака и модуля вектора, но от достоверности, которая просто умножается на модуль и уменьшает его пропорционально достоверности. Таким образом, средневзвешенный прогноз является векторной суммой всех точечных прогнозов с учетом их достоверностей. Так как вектора всех точечных прогнозов параллельны оси Y, то векторную сумму можно заменить их скалярной суммой в координатной форме, в которой направление вектора учитывается просто его знаком:
 | (6. 1) |
где:
| i | – дата, с которой сделан прогноз. | ||
| j | – внутренний номер прогноза, сделанного с i-й даты. | ||
| N | – количество прогнозов, сделанных с i-й даты на дату D. | ||
| PD | – средневзвешенный прогноз курса доллара США на дату D. | ||
| Pij | – модуль и знак j-го
точечного прогноза курса доллара США, сделанного с i-й даты на дату D. | ||
| aij | – оценка достоверности j-го
точечного прогноза курса доллара США, сделанного с i-й даты на дату D (формируется системой "Эйдос" автоматически на основе данных, представленных системой окружения "Эйдос-фонд") |
Необходимо отметить, что учитываются только те точечные прогнозы, которые имеют положительное сходство с ситуацией, реально сложившейся на фондовом рынке. В результате средневзвешенный прогноз показывает, что "скорее всего произойдет на фондовом рынке". Прогнозы, имеющие отрицательное сходство, также могут быть обобщены по аналогичной методике, но полученный средневзвешенный прогноз будет означать "чего скорее всего не произойдет на фондовом рынке".
Формирование точечных прогнозов
На приведенных ниже диаграммах, которые выдает данная система, приводится фактический курс $ США, а также множество точечных прогнозов и средневзвешенный прогноз динамики курса $, рассчитанный с учетом достоверностей точечных прогнозов. Дело в том, в данном приложении на каждый конкретный день получается 30 прогнозов, первый из которых "с позиции во времени" на 30 дней назад, второй – на 29 дней назад, и т.д. Фрагмент карточки результатов прогнозирования, получающейся на основе данных, имеющихся на текущий день, приводится на рисунке89.
 | |
| Рисунок 89. Фрагмент карточки точечных прогнозов,
получающихся на основе данных, имеющихся на текущий день |
Любой прогноз основан на использовании ранее выявленных закономерностей в предметной области. Так как эти закономерности вообще говоря изменяются при прохождении активной системой точки бифуркации, то следует ожидать, что сразу после прохождения системой этой точки адекватность модели будет резко снижаться, а затем плавно возрастать со скоростью, которую называют "скоростью сходимости" за счет синтеза и адаптации новой модели (фактически исследование зависимости адекватности модели от объема выборки показывает, что погрешность модели после прохождения системой точки бифуркации уменьшается по закону близкому по форме к "затухающим колебаниям"). Из этого следует, что выявление причинно-следственных связей между событиями, между которыми было несколько точек бифуркации, вряд ли имеет смысл. Поэтому увеличение объема фактографической базы для принятия решений само по себе еще не гарантирует повышения их качества. Более того, учет данных, подчиняющихся закономерностям уже потерявшим силу, вполне может и ухудшить характеристики модели. Свойство модели сохранять адекватность при прохождении точки бифуркации будем называть устойчивостью. Результаты взвешивания "точечных прогнозов" приведены на рисунке 90, зависимость погрешности средневзвешенного прогноза курса рубля от разброса точечных прогнозов на рисунке 91.
 |
|
Рисунок 90. Точечные прогнозы курса Российского рубля к доллару США, средневзвешенный прогноз и фактический курс (1993-1995) |
 |
|
Рисунок 91. Зависимость погрешности средневзвешенного прогноза курса рубля от разброса точечных прогнозов (ММВБ, 1993-1995) |
Когда разброс точечных прогнозов незначителен (рисунок 91), средневзвешенному прогнозу можно доверять, т.к. система находится на детерминистском участке своего развития, на котором ее поведение хорошо прогнозируется, т.к. закономерности, управляющие этим поведением на детерминистском этапе известны и не изменяются. Если же разброс точечных прогнозов велик, то средневзвешенному прогнозу доверять нельзя, т.к. система находится в бифуркационном состоянии, на котором ее дальнейшее поведение неопределенно, т.к. закономерности, управляющие этим будущим поведением только формируются, еще не определены и не отражены в модели.
Формулировка идеи
Предлагаемая идея создания искусственного интеллекта очень проста и состоит в том, что для этого предлагается:
– во-первых, выявить основные моменты играющие существенную роль при создании естественного интеллекта;
– во-вторых, попробовать реализовать эти моменты на базе современных компьютерных технологий.
Наблюдения за системами естественного интеллекта позволяют сформулировать следующую гипотезу.
1. Естественный интеллект реально существует.
2. Естественный интеллект создается не мгновенно, а в течение довольно длительного времени по вполне определенной сложной технологии, которая включает три основных этапа:
– создание материальной системы поддержки естественного
интеллекта по сложной технологии в изолированных от среды условиях;
– создание активной информационной структуры, базирующейся на материальной системе поддержки, способной к развитию и саморазвитию в систему естественного интеллекта, т.е. создание системы потенциального естественного интеллекта (оболочки, инструментальной системы);
– формирование структуры и функций естественного
интеллекта во взаимодействии системы его поддержки с другими подобными системами и с окружающей средой, как с природной, так и с "социальной", т.е. созданной другими подобными системами, в результате чего происходит трансформация системы потенциального
естественного интеллекта в систему реального естественного интеллекта.
3. Системы искусственного интеллекта (СИИ) полностью функционально эквивалентные естественному
интеллекту могут быть созданы на базе другой материальной структуры системы поддержки системы и другой системы потенциального искусственного интеллекта.
4. Создание СИИ должно включать три этапа:
– создание материальной системы поддержки (эта проблема в основном решена, т.к. СИИ могут создаваться даже на базе современных персональных компьютеров);
– создание системы потенциального искусственного интеллекта, т.е. программной оболочки, инструментальной системы (таких систем в настоящее время существует пока еще очень мало);
– обучение и самообучение системы потенциального искусственного интеллекта и преобразование ее в реальную СИИ.
5. Основополагающую роль в создании системы потенциального искусственного интеллекта играет разработка научной концепции и теории, адекватно отражающей способы реализации функций естественного интеллекта и пути его трансформации из потенциального в реальный.
Генерация кластеров и конструктов атрибутов (БКОСА-.
В данном режиме имеется возможность задания ряда параметров, детально определяющих обрабатываемые данные и форму вывода результатов анализа и отображаются результаты кластерно-конструктивного анализа. Имеются также многочисленные возможности манипулирования данными (различные варианты поиска, сортировки и фильтрации).
Автоматическое выполнение режимов 1-2-3. Автоматически реализуются три вышеперечисленные режима.
Генерация кластеров и конструктов классов (БКОСА-.
В данном режиме пользователем задаются параметры для генерации кластеров и конструктов классов, позволяющие исключить из форм центральную часть конструктов (оставить только полюса), а также сформировать кластеры и конструкты для заданных (кодами или уровнями Мерлина) подматриц. В данном режиме обеспечивается отображение отчета по конструктам и вывод его в виде текстового файла. Реализован режим быстрого поиска заданного конструкта и быстрый выход на него по заданному классу.
Генезис системной (эмерджентной) теории информации
Полученное системное обобщение формулы Харкевича (3.28) учитывает как взаимосвязь между признаками (факторами) и будущими, в т.ч. целевыми состояниями объекта управления, так и мощность множества будущих состояний объекта управления. Кроме того она объединяет возможности интегрального и дискретного описания объектов, учитывает уровень системности и степень детерминированности описываемой системы (таблица 14):
| Таблица 14 – СООТВЕТСТВИЕ ТРЕБОВАНИЯМ ФОРМУЛ "КТИ / СТИ" | |
 |
При этом факторами являются управляющие факторы, т.е. управления со стороны системы управления, факторы окружающей среды, а также факторы, характеризующие текущее и прошлые состояния объекта управления. Все это делает полученное выражение (3.28) оптимальным по сформулированным критериям для целей построения содержательных информационных моделей активных объектов управления и для применения для синтеза адаптивных систем управления (см. диаграмму: "Генезис системного обобщения формулы Харкевича для количества информации", рисунок 30).
 | |
| Рисунок 30. Генезис системной (эмерджентной) теории информации |
Итак, различные выражения классической теории информации для количества информации: Хартли, Шеннона и Харкевича учитывают различные аспекты информационного моделирования объектов.
Полученное системное обобщение формулы А.Харкевича (3.28) учитывает как взаимосвязь между признаками (факторами) и будущими, в т.ч. целевыми состояниями объекта управления, так и мощность множества будущих состояний. Кроме того она объединяет возможности интегрального и дискретного описания объектов, учитывает уровень системности и степень детерминированности системы.
Различие между классическим понятием информации и его предложенным системным обобщением определяется различием между понятиями множества и системы, на основе которых они сформированы. Система при этом рассматривается как множество элементов, объединенных определенными видами взаимодействия ради достижения некоторой общей цели.
Все это делает полученное выражение (3.28) оптимальным по сформулированным критериям для целей построения содержательных информационных моделей активных объектов управления и для применения для синтеза рефлексивных АСУ активными объектами.
Гипотеза о физической природе нелокального взаимодействия нейронов в нелокальной нейронной сети
В данной работе предлагается математическая модель, численный метод и программный инструментарий нелокальных нейронных сетей (универсальная когнитивная аналитическая система "Эйдос"), успешно апробированные в ряде предметных областей. Данная система обеспечивает неограниченное количество слоев ННС при максимальном количестве весовых коэффициентов в слое до 16 миллионов (в текущей версии 9.0) и до 4000 выходных нейронов. Но если рассматривать нелокальную нейронную сеть как модель реальных "биологических" нейронных сетей, то ясно, что формальной модели недостаточно и необходимо дополнить ее физической моделью о природе каналов нелокального взаимодействия нейронов в данной сети. По мнению автора данный механизм основан на парадоксе Эйнштейна-Подольского Розена (ЭПР) [165, 219]. По мнению автора, физическая реализация нелокальных нейронов может быть осуществлена за счет соединения как минимум одного дендрида каждого нейрона с датчиком микротелекинетического воздействия, на который человек может оказывать влияние дистанционно. Некоторые из подобных датчиков описаны в работе [165]. По мнению автора, квантовые компьютеры, основанные не на математических и программных моделях, а на физических нелокальных нейронах, могут оказаться во многих отношениях функционально эквивалентными физическому организму.
Гипотеза о нелокальности нейрона и информационная нейросетевая парадигма
Модель нелокального нейрона: так как сигналы на дендридах различных нейронов вообще говоря коррелируют (или антикоррелируют) друг с другом, то, значения весовых коэффициентов, а значит и выходное значение на аксоне каждого конкретного нейрона вообще говоря не могут быть определены с использованием значений весовых коэффициентов на дендридах только данного конкретного нейрона, а должны учитывать интенсивности сигналов на всей системе дендридов нейронной сети в целом (рисунок 38).
 | |
| Рисунок 38. Модель нелокального нейрона
в обозначениях системной теории информации |
За счет учета корреляций входных сигналов (если они фактически присутствуют в структуре данных), т.е. наличия общего самосогласованного информационного поля исходных данных всей нейронной сети (информационное пространство), нелокальные нейроны ведут себя так, как будто связаны с другими нейронами, хотя могут быть и не связаны с ними синаптически по входу и выходу ни прямо, ни опосредованно. Самосогласованность семантического информационного пространства означает, что учет любого
одного нового факта в информационной модели вообще говоря приводит к изменению всех весовых коэффициентов всех нейронов, а не только тех, на рецепторе которых обнаружен этот факт и тех, которые непосредственно или опосредованно синаптически с ним связаны.
В традиционной (т.е. локальной) модели нейрона весовые коэффициенты на его дендридах однозначно определяются заданным выходом на его аксоне и никак не зависят от параметров других нейронов, с которыми с нет прямой или опосредованной синаптической связи. Это связано с тем, что в общепринятой энергетической парадигме Хопфилда весовые коэффициенты дендридов имеют смысл интенсивностей входных воздействий. В методе "обратного распространения ошибки" процесс переобучения, т.е. интерактивного перерасчета весовых коэффициентов, начинается с нейрона, состояние которого оказалось ошибочным и захватывает только нейроны, ведущие от рецепторов к данному нейрону. Корреляции между локальными нейронами обусловлены сочетанием трех основных причин:
– наличием в исходных данных определенной структуры: корреляцией входных сигналов;
– синаптической связью локальных нейронов;
– избыточностью (дублированием) нейронной сети.
Гипотеза о законе возрастания эмерджентности и следствия из него
Численные расчеты и аналитические выкладки в соответствии с СТИ показывают, что при возрастании количества элементов в системе доля системной информации в поведении ее элементов возрастает. Это обнаруженное нами новое фундаментальное свойство систем предлагается назвать законом возрастания эмерджентности.
Закон возрастания эмерджентности: "Чем больше элементов в системе, тем большую долю содержащейся в ней информации составляет информация, содержащаяся во взаимосвязях ее элементов".
На рисунках 26 и 27 приведены графики скорости и ускорения возрастания эмерджентности в зависимости от количества элементов W в системе.
 | 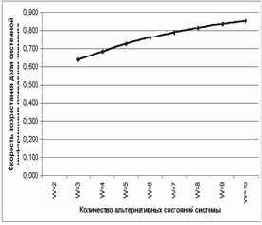 | ||
| Рисунок 26. Возрастание доли системной информации в поведении элемента системы при увеличении количества элементов W | Рисунок 27. Ускорение возрастания доли системной информации в поведении элемента системы от количества элементов W |
Более детальный анализ предполагаемого закона возрастания эмерджентности с использованием конечных разностей первого и второго порядка (таблица 11) показывает, что при увеличении количества элементов в системе доля системной информации в ней возрастает с ускорением, которое постепенно уменьшается. Это утверждение будем называть леммой 1.
Продолжим анализ закона возрастания эмерджентности. Учитывая, что:
 |
выражение (3.3) принимает вид:
 | (3. 13) |
где: 1<=М<=W.
 |
и учитывая, что Log21=0, выражение (3.13) приобретает вид:
 | (3. 14) |
Где введены обозначения:
 | (3. 15) |
С учетом (3.14) выражение (3.9) для коэффициента эмерджентности Хартли приобретает вид:
 |
Заменяя в (3.13) факториал на Гамма-функцию, получаем обобщение выражения (3.3) на непрерывный случай:
 |
Или окончательно:
 | (3. 16) |
Для непрерывного случая обозначения (3.15) принимают вид:
 | (3. 17) |
Учитывая выражения (3.9) и (3.16) получим выражение для коэффициента эмерджентности Хартли для непрерывного случая:
 |
И окончательно для непрерывного случая:
 | (3. 18) |
Графическое отображение нейронов
Для каждого технологического фактора в соответствии с предложенной моделью определяется величина и направление его влиянии на осуществление всех желаемых и не желаемых хозяйственных ситуаций. Для каждой ситуации эта информация отображается в различных текстовых и графических формах, в частности в форме нелокального нейрона (рисунок 78).
На данной и последующих графических диаграммах цвет линии означает знак связи (красный – положительная, синий – отрицательная), а толщина – ее модуль.
Паретто-подмножеством нелокальной нейронной сети будем называть ее подмножество, включающее наиболее значимые связи. Пример графического отображения такого подмножества приведен в таблицах 35 – 37.
Факторы (сигналы с рецепторов) в модели нелокального нейрона взаимосвязаны друг с другом. Эти связи графически отображаются в форме семантической сети (рисунок 78).
 | |
| Рисунок 78. Отображение результатов кластерно-конструктивного анализа факторов в форме семантической сети (когнитивной карты) в системе "Эйдос" |
Структуру любой линии связи семантической сети можно детально изучить в когнитивной диаграмме (рисунок 79).
Дополнение модели нейрона связями факторов позволяет построить классическую когнитивную карту ситуации (будущего состояния АОУ). Необходимо отметить, что все указанные графические формы генерируются системой "Эйдос" автоматически в соответствии с созданной моделью.
Нелокальный нейрон представляет собой будущее состояние объекта управления с изображением наиболее сильно влияющих на него факторов с указанием силы и направления (способствует-препятствует) их влияния (рисунок80).
 | |||
| Рисунок 79. Когнитивная диаграмма кластера факторов: "Глубина и способ обработки почвы: вспашка на 20-22 см – Предшественники: Бобовые однолетние и другие ранние предшественники", генерируемая системой "Эйдос" | |||
 | |||
| Рисунок 80. Примеры нелокальных нейронов, отражающих влияние инвестиций на уровень качества жизни в регионе (система "Эйдос") | |||
Нейронная сеть представляет собой совокупность взаимосвязанных нейронов. В классических нейронных сетях связь между нейронами осуществляется по входным и выходным сигналам, а в нелокальных нейронных сетях [82] – на основе общего информационного поля.
В таблице 35 приводится классификация причинно-следственных связей по рангам. Эта классификация использована для отображения параметров заданий на генерацию и соответствующих фрагментов нейронных сетей (таблица 36). Фрагменты нейронной сети со связями 0-го уровня опосредованности, т.е. соответствующие смежным слоям многослойной сети, показаны на голубом фоне. В пустых клетках таблицы 35 могут быть отображены фрагменты нейронной сети, аналогичные показанным. Однако новой информации, по сравнению с уже показанными, они не содержат, т.к. практически они образуются из них путем перемены местами нейронов и рецепторов (инвертирования – отражения относительно горизонтальной оси). Сгенерированные по этим заданиям фрагменты нейронной сети приведены в форме, позволяющей составить из них многослойную нейронную сеть (таблицы 36 и 37). "ти таблицы взяты из работы [202].
Система "Эйдос" обеспечивает построение любого подмножества многослойной нейронной сети с заданными или выбираемыми по заданным критериям рецепторами и нейронами, связанными друг с другом связями любого уровня опосредованности.
Таблица 35 – ВИДЫ КАУЗАЛЬНЫХ СВЯЗЕЙ МЕЖДУ ОБЪЕКТАМИ РАЗЛИЧНЫХ УРОВНЕЙ ИЕРАРХИЧЕСКОЙ МОДЕЛИ И СООТВЕТСТВУЮЩИЕ ФРАГМЕНТЫ НЕЙРОННОЙ СЕТИ
|
Факторы (наименования, коды) |
Классы (наименования, коды) |
|||
|
Уровень качества жизни |
Годы |
Частные критерии уровня качества жизни |
||
|
Наименования |
Коды |
99-103 |
86-98 |
1-85 |
|
Годы |
626-638 |
 |
||
|
Частные критерии уровня качества жизни |
541-625 |
 |
 |
|
|
Первичные факторы (инвестиции) |
1-85 |
 |
 |
 |
С НЕПОСРЕДСТВЕННЫМИ СВЯЗЯМИ
|
Уровень |
Нейронная сеть |
|
|
№ |
Наимено- вание |
|
|
4 3 |
Уровни качества Жизни (значения Интегрального критерия уровня качества жизни) Годы |
 |
|
3 2 |
Годы Вторичные факторы (частные критерии уровня качества жизни) |
 |
|
2 1 |
Вторичные факторы (частные критерии уровня качества жизни) Первичные факторы |
 |
Таблица 37 – ФРАГМЕНТЫ МНОГОУРОВНЕВОЙ СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ МОДЕЛИ И МНОГОСЛОЙНОЙ НЕЙРОННОЙ СЕТИ СО СВЯЗЯМИ РАЗЛИЧНОЙ СТЕПЕНИ ОПОСРЕДОВАННОСТИ
|
Уровень |
Нейронная сеть |
||||
|
№ |
Наимено- вание |
Слои со связями 0-го уровня опосредованности |
Слои со связями 1-го уровня опосредованности |
Слои со связями 1-го уровня опосредованности |
Слои со связями 2-го уровня опосредованности |
|
4 3 |
Уровни качества Жизни (значения Интегрального критерия уровня качества жизни) Годы |
 |
 |
 |
|
|
3 2 |
Годы Вторичные факторы (частные критерии уровня качества жизни) |
 |
 |
||
|
2 1 |
Вторичные факторы (частные критерии уровня качества жизни) Первичные факторы |
 |
Групповой выбор
Пусть имеется группа лиц, имеющих право принимать участие в коллективном принятии решений. Предположим, что эта группа рассматривает некоторый набор альтернатив, и каждый член группы осуществляет свой выбор. Ставится задача о выработке решения, которое определенным образом согласует индивидуальные выборы и в каком-то смысле выражает "общее мнение" группы, т.е. принимается за групповой выбор.
Естественно, различным принципам согласования индивидуальных решений будут соответствовать различные групповые решения.
Правила согласования индивидуальных решений при групповом выборе называются правилами голосования. Наиболее распространенным является "правило большинства", при котором за групповое решение принимается альтернатива, получившая наибольшее число голосов.
Необходимо понимать, что такое решение отражает лишь распространенность различных точек зрения в группе, а не действительно оптимальный вариант, за который вообще никто может и не проголосовать. "Истина не определяется путем голосования", самой распространенной точкой зрения может быть и заблуждение.
Кроме того, существуют так называемые "парадоксы голосования", наиболее известный из которых парадокс Эрроу.
Эти парадоксы могут привести, и иногда действительно приводят, к очень неприятным особенностям процедуры голосования: например бывают случаи, когда группа вообще не может принять единственного решения (нет кворума или каждый голосует за свой уникальный вариант, и т.д.), а иногда (при многоступенчатом голосовании) меньшинство может навязать свою волю большинству, как это было на президентских выборах в США "Буш – Гор".
Характеристика исходных данных
Из Internet по адресу: http://ftp.ics.uci.edu/pub/machine-learning-databases/zoo/zoo.names
получаем исходную информацию: общее описание тестовой задачи (файл: zoo_names.htm) и обучающую выборку (файл: zoo_data.htm), которые приводятся далее без изменений.
Характеристики клавиатурного почерка
При вводе информации пользователь последовательно нажимает и отпускает клавиши, соответствующие вводимому тексту. При этом для каждой нажимаемой клавиши можно фиксировать моменты нажатия и отпускания.
На IBM-совместимых персональных компьютерах на следующую клавишу можно нажимать до отпускания предыдущих, т.е. символ помещается в буфер клавиатуры только по нажатию клавиши, тогда как аппаратные прерывания от клавиатуры возникают и при нажатии, и при отпускании клавиши.
Основной характеристикой клавиатурного почерка следует считать временные интервалы между различными моментами ввода текста:
– между нажатиями клавиш;
– между отпусканиями клавиш;
– между нажатием и отпусканием одной клавиши;
– между отпусканием предыдущей и нажатием следующей клавиши.
Кроме того, могут учитываться производные от временных интервалов вторичные показатели, например такие как скорость и ускорение ввода.
Хранилища данных для принятия решений
В разделе 4.2.5. данной работы мы рассматривали иерархическую систему обработки информации в которой на различных уровнях производятся различные операции по обработке данных, информации и знаний:
– на 1-м уровне
накапливаются данные мониторинга;
– на 2-м уровне
осуществляется анализ данных мониторинга с целью выявления в них зависимостей, что позволяет содержательно интерпретировать данные, т.е. генерировать
информацию путем анализа данных;
– на 3-м уровне
знание зависимостей в данных мониторинга используется для прогнозирования;
– на 4-м уровне
возможности многовариантного прогнозирования и решения обратной задачи прогнозирования позволяют вырабатывать рекомендации и решения по достижению поставленных целей, т.е. генерировать и использовать знания путем системной обработки информации.
Выполнение операций каждого последующего уровня возможно только построения предыдущего уровня. Здесь уместно провести аналогию со строительством здания: пока не выполнен фундамент – не возводят стены, пока не возведены стены – не делают крышу, пока нет крыши – не проводят отделку и т.д. Аналогично, чтобы вытащить внутреннюю матрешку сначала надо раскрыть внешнюю. Могут существовать и более сложные алгоритмы, определяющие последовательность, например, типа используемых в игре "Ханойская башня".
Таким образом, фундаментом для генерации информации и знаний являются данные мониторинга.
Хранилище Данных (ХД или
Data warehouses) – это база данных, хранящая данные, агрегированные по многим измерениям. Данные из ХД никогда не удаляются. Пополнение ХД происходит на периодической основе. При этом автоматически формируются новые агрегаты данных, зависящие от старых. Доступ к ХД организован особым образом на основе модели многомерного куба.
Итак, Хранилище Данных – это не автоматизированная система принятия решений, не экспертная система, не система логического вывода, а "всего лишь" оптимально организованная база данных, обеспечивающая максимально быстрый и комфортный доступ к информации, необходимой при принятии решений.
Принять любое управленческое решение, невозможно
Принять любое управленческое решение, невозможно не обладая необходимой для этого информацией, обычно количественной. Для этого необходимо создание хранилищ данных (Data warehouses), то есть процесс сбора, отсеивания и предварительной обработки данных с целью предоставления результирующей информации пользователям для статистического анализа (а нередко и создания аналитических отчетов). Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных сформулировал основные требования к ним:
– поддержка высокой скорости получения данных из хранилища;
– поддержка внутренней непротиворечивости данных;
– возможность получения и сравнения так называемых срезов данных (slice and dice);
– наличие удобных утилит просмотра данных в хранилище;
– полнота и достоверность хранимых данных;
– поддержка качественного процесса пополнения данных.
Типичное хранилище данных, как правило, отличается от обычной реляционной базы данных.
Во-первых,
обычные базы предназначены для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены для принятия решений. Например, продажа товара и выписка счета производятся с использованием базы данных, предназначенной для обработки транзакций, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, - с помощью хранилища данных.
Во-вторых,
обычные базы данных подвержены постоянным изменениям в процессе работы пользователей, а хранилище данных относительно стабильно: сведения в нем обычно обновляются согласно расписанию (например, еженедельно, ежедневно или ежечасно – в зависимости от потребностей). В идеале процесс пополнения представляет собой просто добавление новых данных за определенный период времени без изменения прежней информации, уже находящейся в хранилище.
В-третьих,
обычные базы данных чаще всего являются источником данных, попадающих в хранилище. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Для более полного ознакомления с концепцией хранилищ данных рекомендуется обратиться к источникам [3, 4] списка рекомендуемой литературы.
Идея решения проблемы
Это, в общем-то, вполне очевидный и естественный ход. Однако достигается этот результат дорогой ценой, т.е. путем сведения числовых величин к нечисловым, т.е. путем сведения их к "низменному типу", что приводит к утрате ряда возможностей обработки. Это происходит потому, что для числовых величин существует гораздо больше методов и возможностей обработки, чем для нечисловых.
По нашему мнению более предпочтительным является противоположный подход, основанный на введении некоторой количественной меры, позволяющей единым и сопоставимым образом описывать как числовые данные различной природы, так и нечисловые величины с использованием всего арсенала возможностей, имеющегося при обработке числовых данных.
Аналогично, если у нас есть документы стандартов "Документ Word" и "Текст-DOS" и мы хотели бы обрабатывать их все в одном редакторе, то это можно сделать либо преобразовав все документы Word в "низменный стандарт" "Текст-DOS", либо наоборот, преобразовав "досовские" документы в формат Word.
В 1979 году автором разработана [80], а в 1981 году впервые применена [66] математическая модель, обеспечивающая реализацию этой идеи. В последующем этот математический аппарат был развит в ряде работ, основной из которых является [5], был разработана соответствующая ему методика численных расчетов, включающая структуры данных и алгоритмы базовых когнитивных операций, а также создана программная система "Эйдос", реализующая математическую модель и методику численных расчетов [141, 142, 144, 145, 146].
Предложенный метод получил название "Системно-когнитивный анализ" (СК-анализ) [64]. В СК-анализе нечисловым величинам тем же методом, что и числовым, приписываются сопоставимые в пространстве и времени, а также между собой, количественные значения, позволяющие обрабатывать их как числовые.
СК-анализ включает следующие этапы:
1. Когнитивная структуризация, а затем и формализация предметной области.
2. Ввод данных мониторинга в базу прецедентов за период, в течение которого имеется необходимая информация в электронной форме.
3. Синтез семантической информационной модели (СИМ).
4. Оптимизация СИМ.
5. Проверка адекватности СИМ (измерение внутренней и внешней, дифференциальной и интегральной валидности).
6. Анализ СИМ.
7. Решение задач идентификации состояний объекта управления, прогнозирование и поддержка принятия управленческих решений по управлению с применением СИМ.
На первых двух этапах СК-анализа, детально рассмотренных в работе [64], числовые величины сводятся к интервальным оценкам, как и информация об объектах нечисловой природы (фактах, событиях). Этот этап реализуется и в методах интервальной статистики.
На третьем этапе СК-анализа всем этим величинам по единой методике, основанной на системном обобщении семантической теории информации А.Харкевича, сопоставляются количественные величины, с которыми в дальнейшем и производятся все операции моделирования.
Идентификация и аутентификация личности пользователя компьютера по клавиатурному почерку
Рассмотрим подробнее некоторые вопросы идентификации пользователей по клавиатурному почерку. При этом мы будем самым существенным образом основываться на работе: ЗавгороднийВ.В. и Мельников Ю.Н. Идентификация по клавиатурному почерку, "Банковские Технологии" №9, 1998 [37].
Проблемы идентификации и аутентификации пользователей компьютеров являются актуальными в связи с все большим распространением компьютерных преступлений. Использование для идентификации клавиатурного почерка является одним из направлений биометрических методов идентификации личности.
Подобные системы не обеспечивают такую же точность распознавания, как системы идентификации по отпечаткам пальцев или по рисунку радужной оболочки глаз, но имеют то преимущество, что система может быть полностью скрыта от пользователя, т. е. он может даже не подозревать о наличии такой системы контроля доступа.
Идентификация и аутентификация личности по почерку. Понятие клавиатурного почерка
Рассмотрим, в чем заключается различие между двумя формами представления одного и того же текста: рукописной и печатной. При этом могут исследоваться и сравниваться как сам процесс формирования текста, так и его результаты, т.е. уже сформированные тексты.
При исследовании уже сформированных текстов обнаруживается, что главное отличие рукописного текста от печатного состоит в значительно большей степени вариабельности начертаний одной и той же буквы разными людьми и одним и тем же человеком в различных состояниях, чем при воспроизведении тех же букв на различных пишущих машинках и принтерах.
Почерком будем называть систему индивидуальных особенностей начертания и динамики воспроизведения букв, слов и предложений вручную различными людьми или на различных устройствах печати.
В рукописной форме начертание букв является индивидуальным для каждого человека и зависит также от его состояния, хотя, конечно, в начертаниях каждой конкретной буквы всеми людьми безусловно есть и нечто общее, что и позволяет идентифицировать ее именно как данную букву при чтении.
К индивидуальным особенностям рукописного начертания букв в работе [125] отнесено 13 шкал с десятками градаций в каждой.
В печатной форме вариабельность начертания букв значительно меньше, чем в рукописной, но все же присутствует, особенно на печатных машинках, барабанных, знакосинтезирующих и литерных принтерах.
В СССР печатные машинки при продаже регистрировались и образец печати всех символов вместе с паспортными данными покупателя направлялся в "комптентные" органы. Это позволяло установить на какой машинке и кем напечатан тот или иной материал. Считается, что принтер тем лучше, чем меньше у него индивидуальных особенностей, т.е. чем ближе реально распечатываемые им тексты к некоторому идеалу – стандарту. Современные лазерные и струйные принтеры в исправном состоянии (новый барабан и картридж) практически не имеют индивидуальных особенностей.
На современных компьютерах основным устройством ввода текстовой информации является клавиатура. Результат ввода текста в компьютер с точки зрения начертания букв, слов и предложений не имеет особых индивидуальных особенностей (если не считать частот использования различных шрифтов, кеглей, жирностей, подчеркиваний и других эффектов, изменяющих вид текста). Поэтому необходимо ввести понятие клавиатурного почерка, под
которым будем понимать систему индивидуальных особенностей начертаний и динамики воспроизведения букв, слов и предложений на клавиатуре.
Идентификация и прогнозирование (подсистема "Распознавание") (БКОСА-
Данная подсистема реализует режимы ввода и корректировки распознаваемой выборки; пакетного распознавания; вывода результатов и межмашинного обмена данными. Ввод-корректировка распознаваемых анкет осуществляется в двухоконном интерфейсе: в левом окне показаны заголовки идентифицируемых объектов, в которых отображаются их коды и условные наименования, а в правом окне – описания объектов на языке признаков. В левом окне каждому объекту соответствует строка, а в правом – окно с прокруткой. Переход между окнами происходит по нажатию клавиши "TAB". В данном режиме каждая анкета распознаваемой выборки последовательно идентифицируется с каждым классом. Вывод результатов распознавания (идентификации и прогнозирования) возможен в двух разрезах:
а) информация о сходстве каждого объекта со всеми классами;
б) информация о сходстве каждого класса со всеми объектами.
Система генерирует обобщающий отчет по итогам идентификации, в котором в каждой строке дана информация о классе, с которым распознаваемый объект имеет наивысший уровень сходства (в процентах). Качество результата идентификации – это эвристическая оценка качества, учитывающая максимальную величину сходства, различие между первым и вторым классами по уровню сходства и в (меньшей степени) общий вид распределения классов по уровням сходства с данным объектом. Каждой строке обобщающего отчета соответствует карточка результатов идентификации (прогнозирования), которая по сути дела представляет собой результат разложения вектора объекта в ряд по векторам классов. Эти карточки распечатываются в файл с полными наименованиями классов и содержат классы, с уровнем сходства выше заданного.
Почтовая служба по распознаваемым анкетам
обеспечивает запись на дискету распознаваемой выборки и считывание распознаваемой выборки с дискеты с добавлением к имеющейся на текущем компьютере. Этот режим служит для объединения информации по идентифицируемым объектам, введенной на различных компьютерах.
Подсистема "Типология" обеспечивает типологический анализ классов и признаков.
Типологический анализ классов включает: информационные (ранговые) портреты; кластерно-конструктивный и когнитивный анализ классов.
Идентификация и прогнозирование состояния объекта управления, выработка управляющих воздействий
Данный вид работ осуществляется с помощью подсистем "Распознавание" и "Анализ". Эти подсистемы обеспечивают: ввод распознаваемой выборки; пакетное распознавание; вывод результатов распознавания и их оценку, в т.ч. с использованием данных по дифференциальной валидности модели.
Иерархическая структура данных и последовательность численных расчетов в СК-анализе
Рассмотрим 6 уровней базовых когнитивных операций системного анализа и 5-ти уровневую иерархическую структуру данных (рисунок 44), на базе которой и реализуются эти операции.
На 1-м уровне непосредственно на основе исходной информации, путем применения БКОСА 2.1 и 2.2 формируется матрица абсолютных частот.
На 2-м уровне на основе матрицы абсолютных частот путем применения БКОСА 3.1.1, 3.1.2, 3.1.3, 3.2, 3.3 формируется матрица информативностей, являющаяся основой для выполнения последующих БКОСА и обеспечивающая независимость времени их выполнения от объема обучающей выборки.
На 3-м уровне путем выполнения БКОСА 4.1 и 4.2 формируется оптимизированная матрица информативностей. Оптимизация обеспечивает экономию труда, времени и других затрат на эксплуатацию содержательной информационной модели.
На 4-м уровне с использованием оптимизированной матрицы информативностей выполняются БКОСА 9.1, 9.2, а также 10.1.1 и 10.2.1. Две последние операции обеспечивают (соответственно) создание матриц сходства классов и атрибутов, являющихся, в свою очередь, основой для реализации последующих БКОСА.
На 5-м уровне на основе матриц сходства путем выполнения БКОСА 10.1.2, 10.2.2, 10.3.1 и 10.4.1 рассчитываются базы данных, когнитивного и кластерно-конструктивного анализа.
На 6-м уровне, с использованием баз данных, созданных на 5-м уровне, реализуются БКОСА 10.1.3, 10.3.2, 10.4.2 и 10.2.3.
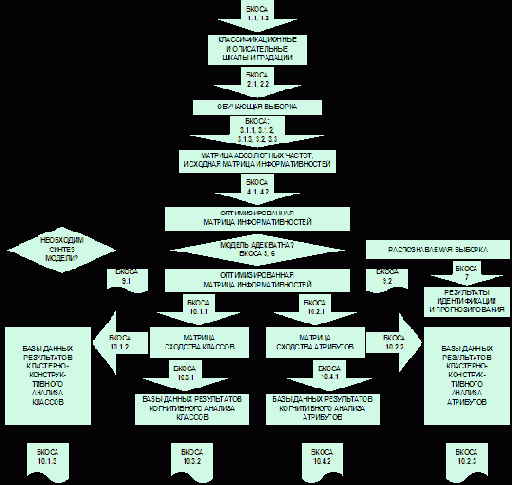 | |
| Рисунок 44. Иерархическая структура данных семантической информационной модели СК-анализа |
Информация как мера снятия неопределенности
Как было показано выше, теория информация применима в АСУ для решения задач идентификации состояния сложного объекта управления (задача распознавания) и принятия решения о выборе многофакторного управляющего воздействия (обратная задача распознавания).
Так в результате процесса познания уменьшается неопределенность в наших знаниях о состоянии объекта познания, а в результате процесса труда (по сути управления) – уменьшается неопределенность поведения продукта труда (или объекта управления). В любом случае количество переданной информации представляет собой количественную меру степени снятия неопределенности.
Процесс получения информации можно интерпретировать как изменение неопределенности в вопросе о том, от какого источника отправлено сообщение в результате приема сигнала по каналу связи. Подробно данная модель приведена в работе [64].
Информация, как сырье и как товар
Широко известны абсолютная и относительная формы информации. Абсолютная форма – это просто количество, частота. Относительная форма – это доли, проценты, относительные частоты и вероятности.
Менее знакомы специалисты с аналитической формой информации, примером которой является условные вероятности, стандартизированные статистические значения и количество информации.
Абсолютная информация – это информация содержащаяся в абсолютных числах, таких как количество чего-либо, взятого "само по себе", т.е. безотносительно к объему совокупности, к которой оно относится.
Относительная информация – это информация, содержащаяся в отношениях абсолютного количества к объему совокупности.
Относительная информация измеряется в частях, процентах, промиле, вероятностях и некоторых других подобных единицах. Очевидно, что и из относительной информации, взятой изолированно, вырванной из контекста, делать какие-либо обоснованные выводы не представляется возможным. Те, кто иногда делает это сознательно, просто вводит в заблуждение некомпетентных слушателей ("есть истина, есть заблуждение, а есть статистика").
Для того, чтобы о чем-то судить по процентам, нужен их сопоставительный анализ, т.е. анализ всего процентного распределения. Вариантов такого анализа может быть много, но суть не в этом, а в том, что такой анализ необходим. Рассмотрим один из возможных вариантов сопоставительного анализа процентных распределений на нашем примере. Этот вариант предполагает использование в качестве "базы оценки" среднего по всей совокупности (нормативный подход: норма – среднее).
Аналитическая (сопоставительная) информация – это информация, содержащаяся в отношении
вероятности (или процента) к некоторой базовой величине, например к средней вероятности по всей выборке.
Аналитическими являются также стандартизированные величины в статистике и количество информации в теории информации.
Очевидно, именно аналитическая информация является наиболее кондиционной для употребления с той точки зрения, что позволяет непосредственно делать содержательные выводы об исследуемой предметной области (точнее будет сказать, что она сама и является выводом), тогда как для того, чтобы сделать аналогичные выводы на основе относительной, и особенно абсолютной информации требуется ее значительная предварительная обработка.
Эта "предварительная обработка" и составляет значительную долю трудоемкости труда аналитиков и экспертов, которые полагаются во многом на чисто качественную (невербализуемую, интуитивную) оценку имеющейся у них сырой относительной информации, однако проводить необходимые для этого расчеты для реальных объемов данных вручную не представляется возможным.
Таким образом, есть все основания рассматривать абсолютную информацию как "информационное сырье", аналитическую – как "информационный товар". Относительная информация в этом смысле занимает промежуточное положение и может рассматриваться как "информационный полуфабрикат". Интеллектуальные информационные системы, преобразуют сырую информацию в кондиционный информационный продукт и, этим самым, многократно повышают ее потребительскую и меновую стоимость.
Для экономических исследований является естественным манипулировать понятиями "прибыль" – "убыток" или сходными понятиями теории игр: "выигрыш" – "проигрыш", измеряя их при этом, как правило, в денежных единицах.
Однако, на этом пути возникает ряд проблем:
1. Проблема выбора денежных единиц или сопоставимого во времени и пространстве способа их измерения.
2. Принципиальная проблема, состоящая в том, что не все явления, даже в экономике, уместно и целесообразно количественно оценивать (измерять) в денежных единицах.
В данной работе автор предлагает не решать эти проблемы, а обойти их, выбрав в качестве количественной меры не "стоимость", а то, что лежит в основе стоимости. Для этого предлагается раскрыть один из аспектов сущности понятия "стоимость" на основе применения аналитического понятия "информация", которое удовлетворяет всем сформулированным выше требованиям к количественной мере.
В эпоху господства капитала полагали, что "чистым товаром" является золото. Однако, если проанализировать те свойства золота, которые превратили его в основной эквивалент стоимости, то с очевидностью обнаружится, что это именно те свойства, из-за которых золото является идеальным носителем информации (информация легко "записывается" в золото, т.к.
оно достаточно мягкое; информация долго сохраняется в золоте, т.к. оно не ржавеет, не является хрупким, не подвержено другим формам "порчи", т.е. стирания). Известно, что "стоимость" является не физическим свойством той или иной вещи, стоимость - это свойство вещи, которое приписывают ей люди, которые вступают посредством нее в определенные экономические отношения друг с другом. В действительности же все отношения людей друг с другом являются информационными. Золото, как эквивалент стоимости, также является лишь "информационным пакетом", несущим определенное количество информации, соответствующее его весу. Исходя из всех этих рассуждений и учитывая информационную теорию стоимости, основные положения которой были сформулированы выше, являясь свидетелями информационного общества, победившего в развитых странах, мы можем предположить, что единственным "чистым товаром" является (а по существу всегда и являлась) только информация.
Информация является квинтэссенцией стоимости.
Кратко рассмотрим вопрос о стоимости самой
информации, имеющий самое непосредственное отношение к проблеме оценки экономической эффективности применения систем искусственного интеллекта и интеллектуальной обработки данных.
Мы знаем, как информация, в качестве рекламы, приносит деньги. Мы знаем также, что технология, "Ноу-хау", стоит значительно дороже, чем продукты ее применения.
Информация, как и нефть, может быть "сырой" или обработанной. Сырая информация может почти ничего не стоить по сравнению со стоимостью аналитически обработанной информации, т.е. информации, которая находится в форме пригодной для употребления, готовой немедленно принести громадные преимущества ее обладателю по сравнению с другими людьми, ею не обладающими.
Информационная модель деятельности
Информационная модель деятельности специалиста, представленная на рисунке 6, разработана на основе модели, впервые предложенной В.Н.Лаптевым (1984).
 | |
| Рисунок 6. Информационная модель деятельности специалиста и место систем искусственного интеллекта в этой деятельности |
На вход системы поступает задача или проблема. Толкование различия между ними также дано В.Н. Лаптевым и состоит в следующем.
Ситуация, при которой фактическое состояние системы не совпадает с желаемым (целевым) называется проблемной ситуацией
и представляет собой:
– задачу, если способ перевода системы из фактического состояния в желаемое точно известен, и необходимо лишь применить его;
– проблему, если способ перевода системы из фактического состояния в желаемое не известен, и необходимо сначала его разработать и лишь затем применить его.
Таким образом, можно считать, что проблема – это задача, способ решения которой неизвестен. Это означает, что если этот способ разработать, то этим самым проблема сводится к задаче, переводится в класс задач. Проще говоря, проблема – это сложная задача, а задача – это простая проблема.
Но и проблемы различаются по уровню сложности:
– для решения одних достаточно автоматизированной системы поддержки принятия решений;
– для решения других – обязательным является творческое участие людей: специалистов, экспертов.
Рассмотрим информационную модель деятельности специалиста, представленную на рисунке 6.
Блок 1. На вход системы поступает задача или проблема. Что именно неясно, т.к. чтобы это выяснить необходимо идентифицировать ситуацию и обратиться к базе данных стандартных решений с запросом, существует ли стандартное решение для данной ситуации.
Блок 2.
Далее осуществляется идентификация проблемы или задачи и прогнозирование сложности ее решения. На этом этапе применяется интеллектуальная система, относящаяся к классу систем распознавания образов, идентификации и прогнозирования или эта функция реализуется специалистом самостоятельно "вручную".
Блок 3.
Если в результате идентификации задачи или проблемы по ее признакам установлено, что точно имеется стандартное решение, то это означает, что на вход системы поступила точно такая же задача, как уже когда-то ранее встречалась. Для установления этого достаточно информационно-поисковой системы, осуществляющей поиск по точному совпадению параметров запроса и в применении интеллектуальных систем нет необходимости. Тогда происходит переход на блок 7, а иначе на блок 4.
Блок 4.
Если установлено, что точно такой задачи не встречалось, но встречались сходные, аналогичные, которые могут быть найдены в результате обобщенного (нечеткого) поиска системой распознавания образов, то решение может быть найдено с помощью автоматизированной системы поддержки принятия решений путем решения обратной задачи прогнозирования. Это значит, что на вход системы поступила не задача, а проблема, имеющая количественную новизну по сравнению с решаемыми ранее (т.е. не очень сложная проблема). В этом случае осуществляется переход на блок 9, иначе – на блок 5.
Блок 5.
Если установлено, что сходных проблем не встречалось, то необходимо качественно новое решение, поиск которого требует существенного творческого участия человека-эксперта. В этом случае происходит переход на блок 12, а иначе – на блок 6.
Блок 6.
Переход на этот блок означает, что возможности поиска решения или выхода из проблемной ситуации системой исчерпаны и решения не найдено. В этом случае система обычно терпит ущерб целостности своей структуре и полноте функций, вплоть до разрушения и прекращения функционирования.
Блок 7.
На этом этапе осуществляется реализация стандартного решения, соответствующего точно установленной задаче, а затем проверяется эффективность решения на блоке 8.
Блок 8.
Если стандартное решение оказалось эффективным, это означает, что на этапах 2 и 3 идентификация задачи и способа решения осуществлены правильно и система может переходить к разрешению следующей проблемной ситуации (переход на блок 1).
Если же стандартное решение оказалось неэффективным, то это означает, что проблемная ситуация идентифицирована как стандартная задача неверно и необходимо продолжить попытки ее разрешения с использованием более общих подходов, основанных на применении систем искусственного интеллекта (переход на блок 4), например, систем поддержки принятия решений.
Блок 9.
Применяется автоматизированная система поддержки принятия решений, обеспечивающая решение обратной задачи прогнозирования. Отличие подобных систем от информационно-поисковых состоит в том, что они способны производить обобщение, выявлять силу и направление влияния различных факторов на поведение системы, и, на основе этого, по заданному целевому состоянию вырабатывать рекомендации по системе факторов, которые могли бы перевести систему в это состояние (обратная задача прогнозирования).
Блок 10.
Если решение, полученное с помощью системы поддержки принятия решений, оказалось неэффективным, то это означает, что проблемная ситуация идентифицирована как аналогичная ранее встречавшимся неверно. Следовательно, что на вход системы поступила качественно новая, по сравнению с решаемыми ранее, т.е. сложная проблема. В этом случае необходимо продолжить попытки разрешения проблемы с использованием творческих неформализованных подходов с участием человека-эксперта и перейти на блок 5, иначе – на блок 11.
Блок 11.
Информация об условиях и результатах решения проблемы заносится в базу знаний, т.е. стандартизируется. После чего база знаний количественно (не принципиально) изменяется, т.е. осуществляется ее адаптация. В результате адаптации при встрече в будущем точно таких же проблемных ситуаций, как разрешенная, система уже будет разрешать ее не как проблему, а как стандартную задачу.
Блок 12.
На этом этапе с использованием неформализованных творческих подходов осуществляется поиск качественно нового решения проблемы, не встречавшейся ранее, после чего управление передается блоку 13.
Блок 13.
Если решение, полученное экспертами с помощью неформализованных подходов, оказалось неэффективным, то это означает, что система терпит крах (осуществляется переход на блок 6).
Если же адекватное решение найдено, то происходит переход на блок 14.
Блок 14. Стандартизация качественно нового решения, проблемы и пересинтез модели. Информация об условиях и результатах творческого решения проблемы заносится в базу знаний, т.е. стандартизируется. После этого база знаний качественно, принципиально изменяется, т.е. фактически осуществляется ее пересоздание (пересинтез). В результате пересинтеза базы знаний при встрече в будущем проблемных ситуаций, аналогичных разрешенной, система уже будет реагировать на них как проблемы, решаемые автоматизированными системами поддержки принятия решений.
Блоки, в которых используются системы искусственного интеллекта, на рисунке 6 показаны затемненными:
– блоки 2 и 12:
система распознавания образов, идентификации и прогнозирования;
– блоки 9, 11, 12 и 14: автоматизированная система поддержки принятия решений.
В заключение раздела, с целью повышения настроения читателей-студентов, приведем шуточный алгоритм решения проблем (рисунок 7).
 |
|
Рисунок 7. Шуточный алгоритм решения проблем (Internet-фольклор) |
Информационная (статистическая) неопределенность в исходных данных
Данные, полученные о предметной области, не могут рассматриваться как абсолютно точные. Кроме того, очевидно, эти данные нас интересуют не сами по себе, а лишь в качестве сигналов, которые, возможно, несут определенную информацию о том, что нас в действительности интересует.
То есть, реалистичнее считать, что мы имеем дело с данными, не только зашумленными и неточными, но еще и косвенными, а возможно и не полными.
Кроме того эти данные касаются не всей исследуемой (генеральной) совокупности, а лишь определенного ее подмножества, о котором мы смогли фактически собрать данные, однако при этом мы хотим сделать выводы о всей совокупности, причем хотим еще и знать достоверность этих выводов.
В этих условиях используется теория статистических решений.
В этой теории существует два основных источника неопределенности. Во-первых, неизвестно, какому распределению подчиняются исходные данные. Во-вторых, неизвестно, какое распределение имеет то множество (генеральная совокупность), о котором мы хотим сделать выводы по его подмножеству, образующему исходные данные.
Статистические процедуры это и есть процедуры принятия решений, снимающих оба эти виды неопределенности.
Необходимо отметить, что существует ряд причин, которые приводят к некорректному применению статистических методов:
1. Статистические выводы, как и любые другие, всегда имеют некоторую определенную надежность или достоверность. Но, в отличие от многих других случаев, достоверность статистических выводов известна и определяется в ходе статистического исследования.
2. Качество решения, полученного в результате применения статистической процедуры зависит, от качества исходных данных.
3. Не следует подвергать статистической обработке данные, не имеющие статистической природы.
4. Необходимо использовать статистические процедуры, соответствующие уровню априорной информации об исследуемой совокупности (например, не следует применять методы дисперсионного анализа к негауссовым данным). Если распределение исходных данных неизвестно, то надо либо его установить, либо использовать несколько различных методов и сравнить результаты. Если они сильно отличаются - это говорит о неприменимости некоторых из использованных процедур.
Информационная теория стоимости
Рассмотрим учебные вопросы:
1. Связь количества и качества информации с меновой и потребительной стоимостью.
2. Информация, как сырье и как товар: абсолютная, относительная и аналитическая информация. Данные, информация, знания.
3. Стоимость и амортизация систем искусственного интеллектуальных и баз знаний.
4. Источники экономической эффективности систем искусственного интеллекта и интеллектуальной обработки данных (Data mining) с позиций информационной теории стоимости.
Информационные портреты классов (БКОСА-
Информационный портрет класса представляет собой список признаков в порядке убывания количества информации о принадлежности к данному классу. Такой список представляет собой результат решения обратной задачи идентификации (прогнозирования). Фильтрация (F6) позволяет выделить из информационного портрета класса диапазон признаков (по кодам или уровням Мерлина) и, таким образом, исследовать влияние заданных признаков на переход активного объекта управления в состояние, соответствующее данному классу.
Кластерный и конструктивный анализ классов
обеспечивает: расчет матрицы сходства классов; генерацию кластеров и конструктов; просмотр и печать кластеров и конструктов; пакетный режим, обеспечивающий автоматическое выполнение первых трех режимов при установках параметров "по умолчанию"; визуализацию результатов кластерно-конструктивного анализа в форме семантических сетей и когнитивных диаграмм.
Информационные портреты классов (слов)
Информационные портреты классов (слов) представляют собой списки признаков (букв), проранжированных в порядке убывания количества информации, содержащихся в них о принадлежности к данным классам.
Выход на режим генерации информационных портретов классов показан на рисунке 140. На рисунке 141 приведена круговая диаграмма информационного портрета класса (слова) "Достоинству". Обращает внимание, что в 4-х буквах из 8: "У", "Д", "С", "Т" содержится более 80% информации о принадлежности к данному слову.
 | |
| Рисунок 141. Информационный портрет слова "Достоинству" |
Инструкция по установке лабораторной работы
Предварительно дадим некоторые пояснения. На учебных компьютерах, на которых проводятся лабораторные работы, на запись доступна только директория C:\WORK (или C:\STUDENT, далее будем упоминать только директорию C:\WORK). Система "Эйдос" и базы данных, подготовленные для проведения лабораторных работ, находятся не в этой директории, а в директории C:\AIDOS на диске C, которая доступна только на чтение, соответственно в поддиректориях C:\AIDOS\SYSTEM\ и C:\AIDOS\LAB_RAB\.
Это сделано для того, чтобы студенты не могли нарушить исполнимый код системы "Эйдос", а также содержание учебного пособия и баз данных лабораторных работ (что, как показывает опыт преподавания, происходит незамедлительно, если директории, где находятся эти файлы, доступны на запись). Поэтому перед выполнением каждой лабораторной работы необходимо установить в директорию C:\WORK сначала саму систему "Эйдос", а затем в директорию, где она находится – базы данных выполняемой лабораторной работы. Это можно рассматривать как своеобразную плату за неуместную активность студентов.
Здесь необходимо отметить, что:
– текущая версия системы "Эйдос" (12.5) работает с базами данных, находящимися в той же директории, где установлена сама система;
– поскольку при работе системы ее базы данных модифицируются, то рабочая директория системы "Эйдос" должна быть доступна на запись.
ИНСТРУКЦИЯ
по установке системы "Эйдос" и баз данных лабораторной работы
1. Скопировать любым файл-менеджером поддиректорию SYSTEM (целиком, а не файлы находящиеся в ней) из директории AIDOS на диске С в поддиректорию C:\WORK.
2. Скопировать все файлы из указанной преподавателем поддиректории директории C:\AIDOS\LAB_RAB\ с подготовленными базами данных выполняемой лабораторной работы (или со своего носителя, в случае продолжения лабораторной работы) в поддиректорию C:\WORK\SYSTEM. При этом файлы копируются "поверх", т.е. с заменой имеющихся в этой директории.
3. Войти в директорию C:\AIDOS\SYSTEM\ и запустить на исполнение систему "Эйдос". Исполнимый модуль запуска системы называется AIDOS.EXE.
4. Во 2-м режиме 7-й подсистемы системы "Эйдос" выполнить переиндексацию всех баз данных.
5. В 4-м подрежиме 1-го режима 7-й подсистемы системы "Эйдос" сгенерировать базы данных распознаваемых анкет.
6. В 3-м подрежиме 1-го режима 7-й подсистемы системы "Эйдос" сгенерировать базы данных обучающей информации (по указанию преподавателя).
7. Перед окончанием занятия, в случае если планируется продолжить данную работу на следующем занятии, скопировать следующие базы данных на дискету или flash-диск: object.dbf, priz_per.dbf, priz_ob.dbf, obinfzag.dbf, obinfkpr.dbf.
Интеллектуальный анализ данных
Интеллектуальный анализ данных (ИАД или data mining) – это процесс обнаружения в "сырых" данных
ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Обзор материалов Internet, посвященных ИАД показывает, что данное определение является классическим. Тем ни менее, на наш взгляд, оно содержит несколько неточностей:
– в определение этого понятия входят слова "анализ" и "знания", тогда как знания нужны для управления, т.е. достижения цели;
– для интерпретации доступны не только знания, но уже и информация (см. раздел 1.1.2.1. данной работы);
– термин "ИАД" не подразумевает какого-либо одного метода анализа данных, но является собирательным
и объединяет многие направления исследований и разработок в области СИИ.
Поэтому предлагается другое, более точное определение понятия.
Интеллектуальный анализ данных (ИАД
или data mining) – это совокупность математических моделей, численных методов, программных средств и информационных технологий, обеспечивающих обнаружение
в эмпирических данных доступной для интерпретации информации и
синтез на основе этой информации ранее неизвестных, нетривиальных и практически полезных для достижения определенных целей знаний.
Технологии data mining являются наиболее совершенным инструментом для решения сложных аналитических задач. Они основаны на мощном математическом и статистическом аппарате, корректное применение которого позволяет достичь высоких результатов.
Все большим количеством компаний предлагаются услуги в области интеллектуального анализа данных, что предполагает проведение следующих работ:
– проведение исследования накопленной статистики;
– выявление закономерностей;
– создание моделей данных;
– верификация и апробация моделей данных;
– внедрение модели в практику.
INTERNET-САЙТЫ
Сайт автора учебного пособия: http://Lc.Kubagro.ru (с сетевых станций КубГАУ скорость доступа к сайту в настоящее время составляет около 3500 Кбайт/с), выход на страничку о системе "Эйдос": http://lc.kubagro.ru/aidos/index.htm.
http://ej.kubagro.ru, статьи в электронном Научном журнале КубГАУ о применении системы "Эйдос" для решения задач СИИ в различных предметных областях: http://ej.kubagro.ru/a/viewaut.asp?id=11
Базы данных репозитория UCI: http://www.ics.uci.edu/~mlearn/MLRepository.html
http://datadiver.nw.ru/
http://www.dialog-21.ru
http://alephegg.narod.ru/Refs/Diagonal.htm
http://www.orc.ru/~stasson/neurox.html
http://www.statsoft.ru/home/textbook/modules/stneunet.html
http://www.finbridge.ru/net.shtml
http://alife.narod.ru/
http://www.businesstest.ru/default.asp?topic_id=3
А также сайты, обнаруживаемые в поисковых системах Yandex.ru, Aport.ru и Rambler.ru по запросам:
– "Интеллектуальная обработка данных (data mining)";
– "Распознавание образов";
– "Поддержка принятия решений";
– "Экспертные системы".
– "Когнитивное моделирование";
– "Нейронные сети";
– "Генетические алгоритмы";
– "Моделирование эволюции (машинная эволюция)";
– "Клавиатурный почерк";
– "Биометрическая идентификация пользователя";
– "Биологическая обратная связь";
– "Семантический резонанс".
Исходные данные для прогноза: биржевые базы данных
Система "Эйдос-фонд" относится к окружению системы Универсальной когнитивной аналитической системы "Эйдос" и представляет собой по сути дела программный интерфейс между биржевыми базами данных и базовой системой "Эйдос". Кроме того система "Эйдос-фонд" выполняет функции по визуализации результатов анализа. Система "Эйдос-фонд" обеспечивает прогнозирование динамики курсов валют и ценных бумаг на 1-й 2-й, 3-й, ... , 30-й день от текущего дня с достоверностью около 85%. Преобразование данных из стандартов биржевых баз данных в стандарт Системы "Эйдос" осуществляется автоматически с помощью специально для этого созданного автором программного интерфейса. При этом также осуществляется преобразование первичных параметров, т.е. чисел из временных рядов, характеризующих предметную область, во вторичные параметры – характеризующие наступление тех или иных экономических ситуаций (событий). Система "Эйдос" выявляет взаимосвязи между прошлыми и будущими событиями, и, на этой основе, позволяет осуществлять прогнозирование ситуаций. Технические решения, реализованные в данном программном интерфейсе, являются типовыми и могут быть использованы в других приложениях, где необходимо преобразование временных рядов, характеризующих динамику предметной области, в события, анализируемые системой "Эйдос". При использовании данного приложения были "вновь открыты" многие "сильнодействующие" закономерности валютного и фондового рынка, давно известные специалистам и вписывающиеся в так называемые "фундаментальные" (т.е. содержательные аналитические модели) и "технические" (т.е. феноменологические аналитические) модели. В то же время необходимо подчеркнуть, что было открыто много новых, как правило "более слабых" и специфических закономерностей валютного и фондового рынка, характерных именно для ММВБ на момент проведения работ. Была также обнаружена определенная динамика этих закономерностей. Подход, реализованный на базе системы "Эйдос" во многом является синтезом подходов фундаментальной и технической школ и имеет определенную новизну.
Исключение артефактов (робастная процедура) (БКОСА-
В данном режиме на основе исследования частотного распределения частот встреч признаков в матрице абсолютных частот, делаются выводы:
– об отсутствии статистики и невозможности обнаружения и исключения артефактов;
– о наличии статистики и возможности выявления артефактов (если частоты встреч признаков растут пропорционально объему обучающей выборки, то это нормально, артефактами считаются признаки, по которым эта закономерность нарушается).
На основе этих выводов рекомендуется частота, которая признается незначимой и характерной для артефактов и осуществляется переформирование баз данных с исключенными артефактами.
Исключение признаков с низкой селективной силой (БКОСА-
С этой целью реализовано три итерационных алгоритма оптимизации, относящиеся к методу последовательных приближений:
– путем исключения из модели заданного количества наименее значимых признаков;
– путем исключения заданного процента количества признаков от оставшихся (адаптивный шаг);
– путем исключения признаков, вносящих заданный процент значимости от оставшейся суммарной (адаптивный шаг).
Критерий остановки процесса исключения признаков с низкой селективной силой – срабатывание одного из заданных ограничений:
а) достигнуто заданное минимальное количество признаков в модели;
б) достигнуто заданное минимальное количество признаков на класс (полнота описания класса).
Исследование семантической информационной модели
Устойчивость модели, скорость ее сходимости и повышения степени адекватности при изменении объема обучающей выборки являются важнейшими характеристиками модели и определяются ее способностью к выявлению и учету новых закономерностей в предметной области, вступивших в действие после прохождения системой точки бифуркации. Кратко рассмотрим на примере исследования фондового рынка основные параметры семантической информационной модели предметной области: способ взвешивания точечных прогнозов; ослабление влияния факторов со временем; старение информации и периоды эргодичности процессов в предметной области; время реакции системы на изменение факторов (ригидность); автоколебания системы; детерминистские и бифуркационные участки траектории; управление фондовым рынком на детерминистских участках траектории и в точках бифуркации.
Источники экономической эффективности
Информация, содержащаяся в системе, непосредственно связана с энтропией этой системы (обратно пропорционально), а та, в свою очередь, – с количеством энергии в системе (пропорционально). Поэтому информация имеет энергетический эквивалент, т.е. в принципе возможна формула, связывающая количество информации с количеством энергии, наподобие знаменитой формулы Альберта Эйнштейна E=mc2, однако современной науке она неизвестна.
При сообщении некоторой системе определенного количества информации ее уровень системной организации возрастает и энтропия уменьшается, что приводит к выделению или экономии энергии (охлаждению системы).
Например, при внедрении системы оперативного управления процессом уборки зерновых в масштабах одного района Краснодарского края в 1983-1988 годах за счет повышения ровня системной организации объекта управления экономилось топлива на сумму около 400 тысяч рублей. Автором данной работы эти мысли высказывались в предложенной им информационной теории стоимости еще в 1979 году.
Измерение сходимости и устойчивости модели
Для измерения сходимости и устойчивости модели СК-анализа задаются параметры, определяющие исследование скорости сходимости:
– порядок выборки анкет (физический, случайный, в порядке возрастания соответствия генеральной совокупности, в порядке убывания степени многообразия, вносимого анкетой в модель);
– количество и коды признаков, по которым исследуется сходимость модели;
– интервал сглаживания для расчета скользящей погрешности.
В данном режиме организован цикл по объектам обучающей выборки, в котором после учета каждой анкеты в матрице абсолютных частот перерассчитывается матрица информативностей и в отдельной базе данных запоминаются информативности для заданных признаков. Это позволяет измерять и графически отображать скорость сходимости и семантическую устойчивость модели. В работах [64, 76], на примере прогнозирования фондового рынка, подробно рассматриваются вопросы сходимости и семантической устойчивости содержательной информационной модели.
Почтовая служба по обучающей информации
обеспечивает экспорт и импорт баз данных обучающей выборки при решении задач в системе "Эйдос" по многомашинной технологии.
ИЗУЧЕНИЕ ДИСЦИПЛИНЫ ПРИ ЗАОЧНОЙ ФОРМЕ ОБУЧЕНИЯ
Изучение дисциплины "Интеллектуальные информационные системы при заочной форме обучения имеет свои особенности, которые в основном состоят в том, что из-за значительного сокращения и без того малого количества часов на лекции и лабораторные работы существенно возрастает значение самостоятельной работы студентов, т.е. работы с данным учебным пособием и рекомендованными в нем Internet-сайтами.
В лекционном курсе читается 4 обзорных лекции, названия которых совпадают с названиями разделов 1-й части:
1. Введение в интеллектуальные информационные системы.
2. Теоретические основы и эксплуатация универсальной когнитивной аналитической системы "Эйдос".
3. Принципы построения интеллектуальных информационных систем.
4. Применение и перспективы систем искусственного интеллекта.
Практикум базируется на универсальной когнитивной аналитической системе "Эйдос", разработанной автором пособия, и включает первые 2 лабораторные работы, рекомендованные в таблицах 40 и 41 на стр. 410:
– ЛР-1: "Прогнозирование учебных достижений студентов на основе их имеджевых фотороботов" (8 часов);
– ЛР-2: "Прогнозирование вероятных пунктов назначения железнодорожных составов" (4 часа).
Язык последовательного бинарного выбора
Язык бинарных отношений является обобщением многокритериального языка и основан на учете того факта, что когда мы даем оценку некоторой альтернативе, то эта оценка всегда является относительной, т.е. явно или чаще неявно в качестве базы или системы отсчета для сравнения используются другие альтернативы из исследуемого множества или из генеральной совокупности. Мышление человека основано на поиске и анализе противоположностей (конструктов), поэтому, нам всегда проще выбрать один из двух противоположных вариантов, чем один вариант из большого и никак неупорядоченного их множества.
Таким образом, основные предположения этого языка сводятся к следующему:
1. Отдельная альтернатива не оценивается, т.е. критериальная функция не вводится.
2. Для каждой пары альтернатив некоторым образом можно установить, что одна из них предпочтительнее другой, либо они равноценны или несравнимы.
3. Отношение предпочтения в любой паре альтернатив не зависит от остальных альтернатив, предъявленных к выбору.
Существуют различные способы задания бинарных отношений: непосредственный, матричный, с использованием графов предпочтений, метод сечений и др.
Отношения между альтернативами одной пары выражают через понятия эквивалентности, порядка и доминирования.
Языки описания методов принятия решений
Об одном и том же явлении можно говорить на различных языках различной степени общности адекватности. К настоящему времени сложилось три основных языка описания выбора.
Самым простым и наиболее развитым и наиболее популярным является критериальный язык.
"Эффект присутствия" в виртуальной реальности
Эффект присутствия – это создаваемая для пользователя иллюзия его присутствия в смоделированной компьютером среде, при этом создается полное впечатление "присутствия" в виртуальной среде, очень сходное с ощущением присутствия в обычном "реальном" мире.
При этом виртуальная среда начинает осознаваться как реальная, а о реальной среде пользователь на время как бы совершенно или почти полностью "забывает". При этом технические особенности интерфейса также вытесняются из сознания, т.е. мы не замечаем этот интерфейс примерно так же, как собственное физическое тело или глаза, когда смотрим на захватывающий сюжет. Таким образом, реальная среда замещается виртуальной средой.
Исследования показывают, что для возникновения и силы эффекта присутствия определяющую роль играет реалистичность движения
различных объектов в виртуальной реальности, а также убедительность реагирования объектов виртуальной реальности при взаимодействии с ними виртуального тела пользователя или других виртуальных объектов. В то же время, как это ни странно, естественность вида объектов виртуальной среды играет сравнительно меньшую роль.