Прогнозирование
Регрессия – один из двух методов прогнозирования. Данный метод использует имеющиеся фактические значения величин для прогнозирования будущих на основании трендов и имеющейся статистики. Например, объем продаж аксессуаров для спортивных машин можно спрогнозировать по количеству проданных спортивных машин в прошлом месяце.
Различие между регрессией и временными рядами состоит в том, что временные ряды предсказывают значения переменных, зависящих от времени. Например, с их помощью можно прогнозировать количество несчастных случаев во время каникул на основе аналогичных данных за прошлый период. Время в данном случае может содержать иерархии (рабочая неделя, календарная неделя, период) праздники, сезоны, интервалы дат.
Прогнозирование динамики сегмента рынка
Применение математического метода и инструментария АСК-анализа для прогнозирования динамики рынка продукции АПК рассмотрим на примере одного из сегментов фондового рынка Российской Федерации (рынок доллара США). Разработанные при этом технологии и подходы применимы и для других сегментов рынка при прогнозировании спроса и цен на различные виды продукции.
1.4.1.3.1. Предыстория исследования
В 1993-1994 годах, автором совместно с Б.Х.Шульман (США) были проведены исследования Российского фондового рынка [101]. При этом были применены предложенные технологии и специальный программный инструментарий АСК-анализа – базовая система "Эйдос" [144] и специально созданная система окружения "Эйдос-фонд" [146]. Было создано несколько вариантов приложений для различных сегментов фондового рынка и с различной детализацией прогнозов: на каждый день на 30 дней вперед, и на каждый час рабочего дня. В дальнейшем данная разработка была усовершенствована (усилены графические возможности анализа данных), разработаны режимы исследования созданной модели и др.
Прогнозирование ошибок оператора по изменениям в его электроэнцефалограмме
В настоящее время в Институтом психологии РАН, Институтом Высшей Нервной Деятельности и Нейрофизиологии РАН, Высшей Школой Экономики и Кубанским государственном аграрным университетом (Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В.) проводятся исследования, продемонстрировавшие принципиальную возможность прогнозирования ошибок оператора при работе с клавиатурой, типа "ошибочное нажатие клавиши", "ошибочное ненажатие клавиши" и т.п. по изменениям в его электроэнцефалограмме (ЭЭГ). При этом для обработки информации успешно была применена система "Эйдос" [108, 224, 225, 226].
Эти работы в перспективе позволяют создать интеллектуальные высоконадежные интерфейсы, обеспечивающие решение этих и ряда других задач идентификации и прогнозирования состояния оператора в режиме реального времени непосредственно в процессе его работы с системой. При этом система в своей работе будет гибко учитывать текущее и прогнозируемое состояние оператора, что может проявляться в адаптации как алгоритмов работы, так и вида и содержания интерфейса.
Эти работы дополняют возможности заблаговременного
отбора операторов, обладающих свойствами, необходимыми для высоко ответственных работ в экстремальных ситуациях [64, 67, 74, 77, 78, 85 – 88, 92, 104, 107, 111, 169].
Прогнозирования времени перехода системы в бифуркационное состояние
Остановимся подробнее на прогнозе перехода активного объекта в бифуркационное состояние. Прежде всего, если говорить о Российском фондовом рынке, то многолетний опыт его исследования убедительно свидетельствует, что в точках бифуркации неизменно происходит "обвал" рубля. Но в возможности прогнозирования сроков перехода системы в состояние бифуркации содержится и значительно более глубокий смысл, состоящий в том, что имеется теоретическая и практическая возможность определения сроков окончания любого дела (т.е. перехода его в иное качество) на основании сроков его начала и данных о ходе реализации. Это и прогнозирование срока окончания ВУЗа по данным о сдаче сессий, прогнозирование сроков безотказной эксплуатации различных технических систем (от мобильной энергоустановки до сложной территориально распределенной энергосистемы), "сроков жизни" различных организмов, а также экономических, общественных, военных, политических и государственных организаций, и т.п. и т.д. Примерно также по изучению участка траектории снаряда специалисты по баллистике определяют точку его вылета и предполагаемую цель.
Программный инструментарий
В 2001 автором совместно с И.А.Драгавцевой и Л.М.Лопатиной начата разработка и в настоящее время создана первая версия Автоматизированной системы мониторинга, анализа и прогнозирования развития сельхозкультур ("ПРОГНОЗ-АГРО"). Эта система содержит пять основных подсистем:
1) словари;
2) генерация метеобаз данных;
3) ввод-корректировка паспортов биологических баз данных;
4) расчеты выходных форм;
5) режим администратора системы;
6) информация о системе.
В свою очередь, подсистема "Словари" содержит 11 режимов, обеспечивающих ведение справочников: страны, регионы, районы, населенные пункты, метеостанции, типы почв, пункты выращивания, типы культур, культуры, подвои, сорта. Справочники взаимосвязаны друг с другом. Они организованы таким образом, чтобы минимизировать трудоемкость ввода информации и количество ошибок ввода.
Подсистема "Генерация метеобаз данных" преобразует метеобазы из одного стандарта в другой, удобный для пользователя и введения метеобаз данных. Это преобразование осуществляется в несколько этапов:
1) преобразование из исходного стандарта в текстовый файл;
2) преобразование из текстового файла в используемый стандарт, ведение метеобазы.
База метеоданных в настоящее время содержит более сотни тысяч записей о суточных метеоусловиях по десяткам метеопараметров в точках расположения метеостанций.
Подсистема "Ввод паспортов биологической базы данных" включает режим каталога паспортов и режим ввода-корректировки конкретного паспорта. Для ввода различных разделов паспорта реализованы вкладки:
– фазы дифференциации плодовых почек сортов,
– фенология, образование и развитие археспориальной ткани, ростовые характеристики;
– адаптивные свойства;
– агротехнические мероприятия.
Подсистема "Расчеты выходных форм" обеспечивает численные расчеты с использованием информации метео и биологических баз данных с привязкой к географическим координатам. Подсистема "Сервис" позволяет переиндексировать все базы данных и создать их архив. Режим администратора позволяет изменить права доступа пользователей к различным подсистемам и режимам системы.
Программный интерфейс для преобразования
Предлагается программный интерфейс, обеспечивающий автоматическое преобразование промежуточных DBF-файлов Zoo_data.dbf и Prizn.dbf в базы данных системы "Эйдос" (исходный текст на языке программирования – xBase приведен ниже):
********************************************************************************
*** ФОРМИРОВАНИЕ КЛАССИФИКАЦИОННЫХ И ОПИСАТЕЛЬНЫХ ШКАЛ И ГРАДАЦИЙ,
*** А ТАКЖЕ ОБУЧАЮЩЕЙ ВЫБОРКИ ИЗ DBF-Excel-файла РЕПОЗИТАРИЯ UCI ПО ЖИВОТНЫМ
*** http://ftp.ics.uci.edu/pub/machine-learning-databases/zoo/zoo.names
*** Луценко Е.В., 10/18/04 01:19pm *********************************************
scr23 = SAVESCREEN(0,0,24,79)
SET CURSOR OFF
SET DATE ITALIAN
SET DECIMALS TO 15
SET ESCAPE On
FOR J=0 TO 24
@J,0 SAY REPLICATE(" ",80) COLOR "rg+/N"
NEXT
SHOWTIME(0,60,.F.,"rg+/n",.F.,.F.)
Mess = " === ФОРМИРОВАНИЕ СПРАВОЧНИКОВ КЛАССИФИКАЦИОННЫХ ШКАЛ === "
@2,40-LEN(Mess)/2 SAY Mess COLOR "rg+/rb"
Vid = "Y"
@17, 6 SAY "Включать в признаки коды наименования животного и его вида <Y/N>? #" COLOR "w+/rb"
* 0123456789012345678901234567890123456789012345678901234567890123456789012345678
* 0 10 20 30 40 50 60 70
@17,72 GET Vid PICTURE "X" COLOR "rg+/r"
SET CURSOR ON;READ;SET CURSOR OFF
IF Vid <> "Y" .AND. Vid <> "N"
Vid = "N"
ENDIF
USE Object EXCLUSIVE NEW;ZAP
USE Zoo_data EXCLUSIVE NEW
ArObj := {}
AADD(ArObj,"МЛЕКОПИТАЮЩИЕ ")
AADD(ArObj,"ПТИЦЫ ")
AADD(ArObj,"ПРЕСМЫКАЮЩИЕСЯ?")
AADD(ArObj,"РЫБЫ ")
AADD(ArObj,"ЗЕМНОВОДНЫЕ ")
AADD(ArObj,"НАСЕКОМЫЕ ")
AADD(ArObj,"МНОГОНОГИЕ ")
SELECT Zoo_data
DBGOTOP()
DO WHILE .NOT. EOF()
AADD(ArObj,FIELDGET(2))
DBSKIP(1)
ENDDO
SELECT Object
DBGOTOP()
FOR j=1 TO LEN(ArObj)
APPEND BLANK
REPLACE Kod WITH j
REPLACE Name WITH ArObj[j]
NEXT
CLOSE ALL
Mess = " ====== ФОРМИРОВАНИЕ СПРАВОЧНИКОВ ОПИСАТЕЛЬНЫХ ШКАЛ ====== "
USE Prizn EXCLUSIVE NEW
USE Priz_per EXCLUSIVE NEW;ZAP
ArPr := {}
SELECT Prizn
DBGOTOP()
DO WHILE .NOT. EOF()
AADD(ArPr,FIELDGET(2))
DBSKIP(1)
ENDDO
SELECT Priz_per
DBGOTOP()
FOR j=1 TO IF(Vid="Y",LEN(ArPr),25)
APPEND BLANK
REPLACE Kod WITH j
REPLACE Name WITH ArPr[j]
NEXT
@24,0 SAY REPLICATE("-",80) COLOR "rb/n"
CLOSE ALL
Mess = " ============ ФОРМИРОВАНИЕ ОБУЧАЮЩЕЙ ВЫБОРКИ ============= "
CLOSE ALL
USE Zoo_data EXCLUSIVE NEW
USE ObInfZag EXCLUSIVE NEW;ZAP
USE ObInfKpr EXCLUSIVE NEW;ZAP
N_Rec = RECCOUNT()
DBGOTOP()
@24,0 SAY REPLICATE("-",80) COLOR "rb/n"
SELECT Zoo_data
DBGOTOP()
DO WHILE .NOT. EOF()
ArObj := {}
FOR j=1 TO 2
AADD(ArObj,FIELDGET(j))
NEXT
FOR j=21 TO 22
AADD(ArObj,FIELDGET(j))
NEXT
ArPr := {}
FOR j=3 TO 20
Mv = FIELDGET(j)
IF Mv > 0
IF Vid = "Y"
AADD(ArPr,Mv)
ELSE
IF Mv <= 25
AADD(ArPr,Mv)
ENDIF
ENDIF
ENDIF
NEXT
****** Запись массива кодов классов из БД Zoo_data в БД ObInfZag
SELECT ObInfZag
APPEND BLANK
FOR j=1 TO LEN(ArObj)
FIELDPUT(j,ArObj[j])
NEXT
****** Запись массива кодов признаков из БД Zoo_data в БД ObInfKpr
SELECT ObInfKpr
APPEND BLANK
FIELDPUT(1,ArObj[1])
k=2
FOR j=1 TO LEN(ArPr)
IF k <= 12
FIELDPUT(k++,ArPr[j])
ELSE
APPEND BLANK
FIELDPUT(1,ArObj[1])
k=2
FIELDPUT(k,ArPr[j])
ENDIF
NEXT
SELECT Zoo_data
DBSKIP(1)
ENDDO
RESTSCREEN(0,0,24,79,scr23)
CLOSE ALL
QUIT
Программный интерфейс автоматически заполняет исходными данными следующие базы данных системы "Эйдос":
– Object.dbf:
классы (классификационные шкалы и градации);
– Priz_per.dbf:
атрибуты (описательные шкалы и градации);
– ObInfZag.dbf:
обучающая выборка (главная база данных);
– ObInfKpr.dbf:
обучающая выборка (связанная база данных).
В результате система "Эйдос" готова к синтезу семантической информационной модели и выполнению последующих этапов работ.
Программы под MS DOS
Norton Commander (NC) – файл-менеджер;
MultiEdit (ME) – текстовый редактор.
Программы под MS Windows
MS Word – текстовый редактор;
MS Excel – табличный процессор;
PhotoShop – графический редактор;
Windows & Total Commmander.
Производство
Большинство производственных компаний используют системы интеллектуального анализа данных для решения следующих задач.
Оптимизации логистических цепочек. Data mining позволяет снизить затраты на логистику за счет эффективного прогнозирования продаж товаров и закупок сырья/комплектующих.
Проведение маркетинговых исследований.
Накопленные данные о сбыте продукции могут быть использованы при разработке новых продуктов или для повышения эффективности рекламных кампаний.
Диагностика брака на ранних стадиях. Анализ зависимостей позволяет оценить степень риска изготовления бракованного изделия на ранних стадиях производства. Очевидно, что это позволяет сэкономить существенные средства.
Простейшее понятие об информации (подход Хартли).
Будем считать, что если существует множество элементов и осуществляется выбор одного из них, то этим самым сообщается или генерируется определенное количество информации. Эта информация состоит в том, что если до выбора не было известно, какой элемент будет выбран, то после выбора это становится известным.
Найдем вид функции, связывающей количество информации, получаемой при выборе некоторого элемента из множества, с количеством элементов в этом множестве, т.е. с его мощностью.
Если множество элементов, из которых осуществляется выбор, состоит из одного-единственного элемента, то ясно, что его выбор предопределен, т.е. никакой неопределенности выбора нет. Таким образом, если мы узнаем, что выбран этот единственный элемент, то, очевидно, при этом мы не получаем никакой новой информации, т.е. получаем нулевое количество информации.
Если множество состоит из двух элементов, то неопределенность выбора минимальна. В этом случае минимально и количество информации, которое мы получаем, узнав, что совершен выбор одного из элементов. Минимальное количество информации получается при выборе одного из двух равновероятных вариантов. Это количество информации принято за единицу измерения и называется "бит".
Чем больше элементов в множестве, тем больше неопределенность выбора, тем больше информации мы получаем, узнав о том, какой выбран элемент.
Рассмотрим множество, состоящее из чисел в двоичной системе счисления длиной i двоичных разрядов. При этом каждый из разрядов может принимать значения только 0 и 1 (таблица 32).
Таблица 32 – К ЭВРИСТИЧЕСКОМУ ВЫВОДУ ФОРМУЛЫ КОЛИЧЕСТВА ИНФОРМАЦИИ ПО ХАРТЛИ
| Кол-во
двоичных разрядов (i) | Кол-во состояний N,
которое можно пронумеровать i-разрядными двоичными числами | Основание
системы счисления | |||||||
| 10 | 16 | 2 | |||||||
| 1 | 2 | 0
1 | 0
1 | 0
1 | |||||
| 2 | 4 | 0
1 2 3 | 0
1 2 3 | 00
01 10 11 | |||||
| 3 | 8 | 0
1 2 3 4 5 6 7 | 0
1 2 3 4 5 6 7 | 000
001 010 011 100 101 110 111 | |||||
| 4 | 16 | 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 0
1 2 3 4 5 6 7 8 9 A B C D E F | 0000
0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 | |||||
| *** | *** | ||||||||
| i | N=2i |
Из таблицы 32 очевидно, что количество этих чисел (элементов) в множестве равно:
 |
Примем, что выбор одного числа дает нам следующее количество информации:
 |
Это выражение и представляет собой формулу Хартли для количества информации. Отметим, что оно полностью совпадает с выражением для энтропии (по Эшби), которая рассматривалась им как количественная мера степени неопределенности состояния системы.
Сам Хартли, возможно, пришел к своей мере на основе эвристических соображений, подобных только что изложенным, но в настоящее время строго доказано, что логарифмическая мера для количества информации однозначно следует из этих двух постулированных им условий.
Таким образом, информация по своей сущности теснейшим и органичным образом связана с выбором и принятием решений.
Отсюда следует простейшее на первый взгляд заключение: "Для принятия решений нужна информация, без информации принятие решений невозможно, значение информации для принятия решений является определяющим, процесс принятия решений генерирует информацию".
Проверка адекватности семантической информационной модели
Верификацию модели предлагается проверить путем расчета внутренней дифференциальной и интегральной валидности [64].
Необходимо отметить, что внутренняя валидность варианта семантической информационной модели, не учитывающей сделанные выше замечания к общему описанию задачи, составляет 100 %.
Для измерения валидности модели выполняются следующие действия:
1. Скопировать обучающую выборку в распознаваемую в подсистеме: "F2 Обучение – ввод корректировка обучающей информации – F5 Об.инф.->Расп.анк. – F2 Перезапись БД распознаваемых анкет – F1 Копировать всю БД".
2. Выполнить пакетное распознавание в подсистеме: "F4 Распознавание – Пакетное распознавание – Критерий сходства 1-й (корреляция)".
3. Измерить внутреннюю интегральную и дифференциальную валидность информационной модели в подсистеме: "F6 Анализ".
Результаты измерения внутренней валидности семантической информационной модели приведены в таблице 90:
| Таблица 90 – ИЗМЕРЕНИЕ ВАЛИДНОСТИ СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ МОДЕЛИ | |
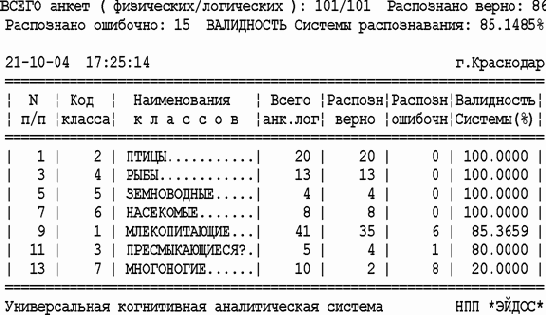 |
Обобщенные результаты распознавания представлены в таблице 91. Красным цветом и жирным шрифтом отмечены ошибочно идентифицированные объекты.
Таблица 91 – ИТОГОВЫЕ РЕЗУЛЬТАТЫ ИДЕНТИФИКАЦИИ
22-10-04 10:35:33 г.Краснодар
| № п/п | Наим.физ. источника | Результаты идентификации | |||||||||||||||||||||||||||||
| Идентифицирован как класс | Фактически является: | Уровень сходства % | Кач-во идент. | Ошибки по классам | Всего | ||||||||||||||||||||||||||
| Код | Наименование | Код | Наименование | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||||||||||||||||||
| 1 | aardvark | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 45.153 | 58.327 | 0 | |||||||||||||||||||||||
| 2 | antelope | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.860 | 72.096 | 0 | |||||||||||||||||||||||
| 3 | bass | 4 | РЫБЫ | 4 | РЫБЫ | 69.091 | 69.802 | 0 | |||||||||||||||||||||||
| 4 | bear | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 45.153 | 58.327 | 0 | |||||||||||||||||||||||
| 5 | boar | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.057 | 71.045 | 0 | |||||||||||||||||||||||
| 6 | buffalo | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.860 | 72.096 | 0 | |||||||||||||||||||||||
| 7 | calf | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 50.381 | 79.729 | 0 | |||||||||||||||||||||||
| 8 | carp | 4 | РЫБЫ | 4 | РЫБЫ | 56.509 | 60.908 | 0 | |||||||||||||||||||||||
| 9 | catfish | 4 | РЫБЫ | 4 | РЫБЫ | 69.091 | 69.802 | 0 | |||||||||||||||||||||||
| 10 | cavy | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 44.637 | 49.336 | 0 | |||||||||||||||||||||||
| 11 | cheetah | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.057 | 71.045 | 0 | |||||||||||||||||||||||
| 12 | chicken | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 68.532 | 81.600 | 0 | |||||||||||||||||||||||
| 13 | chub | 4 | РЫБЫ | 4 | РЫБЫ | 69.091 | 69.802 | 0 | |||||||||||||||||||||||
| 14 | clam | 3 | ПРЕСМЫКАЮЩИЕСЯ | 7 | МНОГОНОГИЕ | 39.293 | 22.460 | 1 | 1 | ||||||||||||||||||||||
| 15 | crab | 5 | ЗЕМНОВОДНЫЕ | 7 | МНОГОНОГИЕ | 56.552 | 56.270 | 1 | 1 | ||||||||||||||||||||||
| 16 | crayfish | 5 | ЗЕМНОВОДНЫЕ | 7 | МНОГОНОГИЕ | 31.918 | 14.669 | 1 | 1 | ||||||||||||||||||||||
| 17 | crow | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 61.940 | 73.682 | 0 | |||||||||||||||||||||||
| 18 | deer | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.860 | 72.096 | 0 | |||||||||||||||||||||||
| 19 | dogfish | 4 | РЫБЫ | 4 | РЫБЫ | 57.215 | 71.018 | 0 | |||||||||||||||||||||||
| 20 | dolphin | 4 | РЫБЫ | 1 | МЛЕКОПИТАЮЩИЕ | 45.813 | 59.973 | 1 | 1 | ||||||||||||||||||||||
| 21 | dove | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 68.532 | 81.600 | 0 | |||||||||||||||||||||||
| 22 | duck | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 62.602 | 69.240 | 0 | |||||||||||||||||||||||
| 23 | elephant | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.860 | 72.096 | 0 | |||||||||||||||||||||||
| 24 | flamingo | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 58.945 | 78.981 | 0 | |||||||||||||||||||||||
| 25 | flea | 6 | НАСЕКОМЫЕ. | 6 | НАСЕКОМЫЕ. | 57.880 | 53.753 | 0 | |||||||||||||||||||||||
| 26 | frog | 5 | ЗЕМНОВОДНЫЕ | 5 | ЗЕМНОВОДНЫЕ | 56.991 | 58.285 | 0 | |||||||||||||||||||||||
| 27 | frog | 5 | ЗЕМНОВОДНЫЕ | 5 | ЗЕМНОВОДНЫЕ | 74.297 | 59.241 | 0 | |||||||||||||||||||||||
| 28 | fruitbat | 2 | ПТИЦЫ | 1 | МЛЕКОПИТАЮЩИЕ | 29.712 | 33.413 | 1 | 1 | ||||||||||||||||||||||
| 29 | giraffe | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.860 | 72.096 | 0 | |||||||||||||||||||||||
| 30 | girl | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 37.676 | 59.877 | 0 | |||||||||||||||||||||||
| 31 | gnat | 6 | НАСЕКОМЫЕ. | 6 | НАСЕКОМЫЕ. | 70.170 | 62.829 | 0 | |||||||||||||||||||||||
| 32 | goat | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 50.381 | 79.729 | 0 | |||||||||||||||||||||||
| 33 | gorilla | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 34.549 | 50.131 | 0 | |||||||||||||||||||||||
| 34 | gull | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 53.136 | 62.059 | 0 | |||||||||||||||||||||||
| 35 | haddock | 4 | РЫБЫ | 4 | РЫБЫ | 72.286 | 74.190 | 0 | |||||||||||||||||||||||
| 36 | hamster | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 45.203 | 61.201 | 0 | |||||||||||||||||||||||
| 37 | hare | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 41.787 | 52.991 | 0 | |||||||||||||||||||||||
| 38 | hawk | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 61.940 | 73.682 | 0 | |||||||||||||||||||||||
| 39 | herring | 4 | РЫБЫ | 4 | РЫБЫ | 69.091 | 69.802 | 0 | |||||||||||||||||||||||
| 40 | honeybee | 6 | НАСЕКОМЫЕ. | 6 | НАСЕКОМЫЕ. | 77.866 | 63.618 | 0 | |||||||||||||||||||||||
| 41 | housefly | 6 | НАСЕКОМЫЕ. | 6 | НАСЕКОМЫЕ. | 68.475 | 65.459 | 0 | |||||||||||||||||||||||
| 42 | kiwi | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 45.650 | 56.201 | 0 | |||||||||||||||||||||||
| 43 | ladybird | 6 | НАСЕКОМЫЕ. | 6 | НАСЕКОМЫЕ. | 46.561 | 40.244 | 0 | |||||||||||||||||||||||
| 44 | lark | 2 | ПТИЦЫ | 2 | ПТИЦЫ | 72.585 | 82.063 | 0 | |||||||||||||||||||||||
| 45 | leopard | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.057 | 71.045 | 0 | |||||||||||||||||||||||
| 46 | lion | 1 | МЛЕКОПИТАЮЩИЕ | 1 | МЛЕКОПИТАЮЩИЕ | 46.057 | 71.045 | 0 |
Продолжение таблицы 91
|
№ п/п |
Наим.физ. источника |
Результаты идентификации |
|||||||||||||
|
Идентифицирован как класс |
Фактически является: |
Уровень сходства % |
Кач-во идент. |
Ошибки по классам |
Всего |
||||||||||
|
Код |
Наименование |
Код |
Наименование |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|||||
|
47 |
lobster |
5 |
ЗЕМНОВОДНЫЕ |
7 |
МНОГОНОГИЕ |
31.918 |
14.669 |
|
|
|
|
|
|
1 |
1 |
|
48 |
lynx |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.057 |
71.045 |
0 |
|||||||
|
49 |
mink |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
37.537 |
54.433 |
0 |
|||||||
|
50 |
mole |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
40.754 |
51.203 |
0 |
|||||||
|
51 |
mongoose |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.057 |
71.045 |
0 |
|||||||
|
52 |
moth |
6 |
НАСЕКОМЫЕ. |
6 |
НАСЕКОМЫЕ. |
68.475 |
65.459 |
0 |
|||||||
|
53 |
newt |
5 |
ЗЕМНОВОДНЫЕ |
5 |
ЗЕМНОВОДНЫЕ |
31.652 |
34.274 |
0 |
|||||||
|
54 |
octopus |
7 |
МНОГОНОГИЕ |
7 |
МНОГОНОГИЕ |
32.232 |
37.177 |
0 |
|||||||
|
55 |
opossum |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
40.754 |
51.203 |
0 |
|||||||
|
56 |
oryx |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.860 |
72.096 |
0 |
|||||||
|
57 |
ostrich |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
42.539 |
65.476 |
0 |
|||||||
|
58 |
parakeet |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
68.532 |
81.600 |
0 |
|||||||
|
59 |
penguin |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
25.030 |
42.429 |
0 |
|||||||
|
60 |
pheasant |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
72.585 |
82.063 |
0 |
|||||||
|
61 |
pike |
4 |
РЫБЫ |
4 |
РЫБЫ |
57.215 |
71.018 |
0 |
|||||||
|
62 |
piranha |
4 |
РЫБЫ |
4 |
РЫБЫ |
69.091 |
69.802 |
0 |
|||||||
|
63 |
pitviper |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
66.439 |
56.486 |
0 |
|||||||
|
64 |
platypus |
5 |
ЗЕМНОВОДНЫЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
14.210 |
31.316 |
1 |
|
|
|
|
|
|
1 |
|
65 |
polecat |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.057 |
71.045 |
0 |
|||||||
|
66 |
pony |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
50.381 |
79.729 |
0 |
|||||||
|
67 |
porpoise |
4 |
РЫБЫ |
1 |
МЛЕКОПИТАЮЩИЕ |
45.813 |
59.973 |
1 |
|
|
|
|
|
|
1 |
|
68 |
puma |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.057 |
71.045 |
0 |
|||||||
|
69 |
pussycat |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
49.870 |
80.029 |
0 |
|||||||
|
70 |
raccoon |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.057 |
71.045 |
0 |
|||||||
|
71 |
reindeer |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
50.381 |
79.729 |
0 |
|||||||
|
72 |
rhea |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
33.019 |
56.339 |
0 |
|||||||
|
73 |
scorpion |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
7 |
МНОГОНОГИЕ |
41.478 |
34.054 |
|
|
|
|
|
|
1 |
1 |
|
74 |
seahorse |
4 |
РЫБЫ |
4 |
РЫБЫ |
72.286 |
74.190 |
0 |
|||||||
|
75 |
seal |
4 |
РЫБЫ |
1 |
МЛЕКОПИТАЮЩИЕ |
42.257 |
46.155 |
1 |
|
|
|
|
|
|
1 |
|
76 |
sealion |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
22.089 |
34.131 |
0 |
|||||||
|
77 |
seasnake |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
52.601 |
33.745 |
0 |
|||||||
|
78 |
seawasp |
5 |
ЗЕМНОВОДНЫЕ |
7 |
МНОГОНОГИЕ |
51.925 |
13.781 |
|
|
|
|
|
|
1 |
1 |
|
79 |
skimmer |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
53.136 |
62.059 |
0 |
|||||||
|
80 |
skua |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
53.136 |
62.059 |
0 |
|||||||
|
81 |
slowworm |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
38.461 |
37.271 |
0 |
|||||||
|
82 |
slug |
4 |
РЫБЫ |
7 |
МНОГОНОГИЕ |
32.953 |
16.992 |
|
|
|
|
|
|
1 |
1 |
|
83 |
sole |
4 |
РЫБЫ |
4 |
РЫБЫ |
72.286 |
74.190 |
0 |
|||||||
|
84 |
sparrow |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
72.585 |
82.063 |
0 |
|||||||
|
85 |
squirrel |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
29.979 |
36.725 |
0 |
|||||||
|
86 |
starfish |
7 |
МНОГОНОГИЕ |
7 |
МНОГОНОГИЕ |
48.217 |
40.232 |
0 |
|||||||
|
87 |
stingray |
4 |
РЫБЫ |
4 |
РЫБЫ |
51.509 |
40.028 |
0 |
|||||||
|
88 |
swan |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
50.226 |
66.336 |
0 |
|||||||
|
89 |
termite |
6 |
НАСЕКОМЫЕ. |
6 |
НАСЕКОМЫЕ. |
57.880 |
53.753 |
0 |
|||||||
|
90 |
toad |
5 |
ЗЕМНОВОДНЫЕ |
5 |
ЗЕМНОВОДНЫЕ |
56.315 |
55.604 |
0 |
|||||||
|
91 |
tortoise |
5 |
ЗЕМНОВОДНЫЕ |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
0.892 |
15.775 |
|
|
1 |
|
|
|
|
1 |
|
92 |
tuatara |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
3 |
ПРЕСМЫКАЮЩИЕСЯ |
20.568 |
22.593 |
0 |
Продолжение таблицы 91
|
№ п/п |
Наим.физ. источника |
Результаты идентификации |
|||||||||||||
|
Идентифицирован как класс |
Фактически является: |
Уровень сходства % |
Кач-во идент. |
Ошибки по классам |
Всего |
||||||||||
|
Код |
Наименование |
Код |
Наименование |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|||||
|
93 |
tuna |
4 |
РЫБЫ |
4 |
РЫБЫ |
57.215 |
71.018 |
0 |
|||||||
|
94 |
vampire |
2 |
ПТИЦЫ |
1 |
МЛЕКОПИТАЮЩИЕ |
29.712 |
33.413 |
1 |
|
|
|
|
|
|
1 |
|
95 |
vole |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
41.787 |
52.991 |
0 |
|||||||
|
96 |
vulture |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
49.581 |
73.319 |
0 |
|||||||
|
97 |
wallaby |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
35.494 |
57.713 |
0 |
|||||||
|
98 |
wasp |
6 |
НАСЕКОМЫЕ. |
6 |
НАСЕКОМЫЕ. |
80.325 |
60.030 |
0 |
|||||||
|
99 |
wolf |
1 |
МЛЕКОПИТАЮЩИЕ |
1 |
МЛЕКОПИТАЮЩИЕ |
46.057 |
71.045 |
0 |
|||||||
|
100 |
worm |
4 |
РЫБЫ |
7 |
МНОГОНОГИЕ |
32.953 |
16.992 |
|
|
|
|
|
|
1 |
1 |
|
101 |
wren |
2 |
ПТИЦЫ |
2 |
ПТИЦЫ |
72.585 |
82.063 |
0 |
|||||||
|
ВСЕГО: |
6 |
0 |
1 |
0 |
0 |
0 |
8 |
15 |
Возможно, автор задачи разрабатывал ее с определенной долей иронии. Вместе с тем это никак не отражается на методике, предлагаемой в данном разделе.
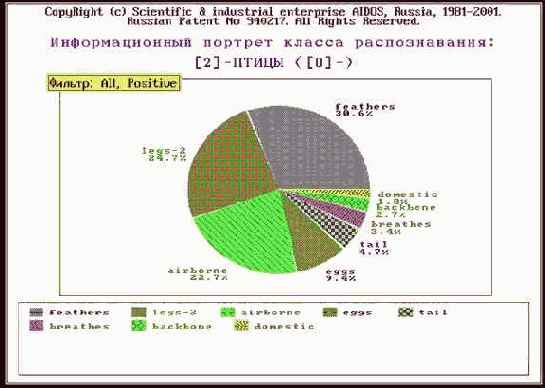
Что касается класса "Млекопитающие", то, по-видимому, необходимо включить в модель дополнительные атрибуты, характерные именно для этого класса. Это следует из анализа результатов идентификации летучей мыши и дельфина (рисунки 210 и 211). Летучая мышь отнесена к птицам, а дельфин – к рыбам, т.к. по совокупности использованных в модели атрибутов они оказались наиболее похожими на обобщенные образы именно этих классов. Это подтверждают информационные портреты классов "Vampir" и "Dolphin", приведенные на рисунках 212 и 213. Вместе с тем необходимо обратить внимание на то, что в обоих случаях на втором месте по уровню сходства стоит правильный класс "Млекопитающие".
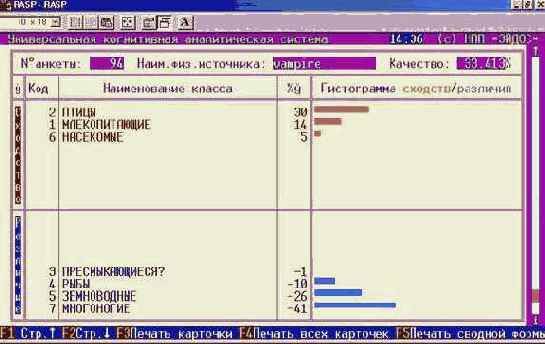 |
|
Рисунок 210. Результаты идентификации летучей мыши |
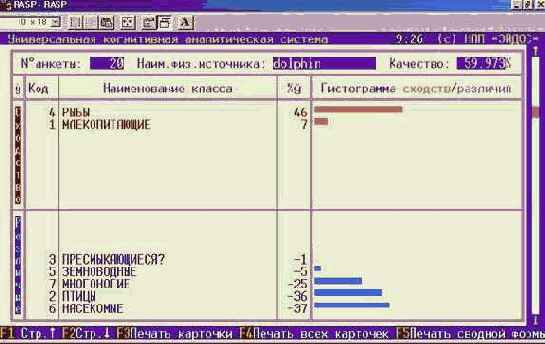 |
|
Рисунок 211. Результаты идентификации дельфина |
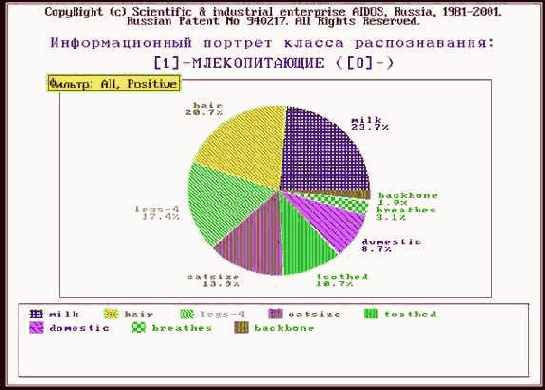 |
|
Рисунок 212. Информационный портрет класса: "Млекопитающие" |
 |
|
Рисунок 213. Информационный портрет класса: "Птицы" |
Провести кластерно-конструктивный
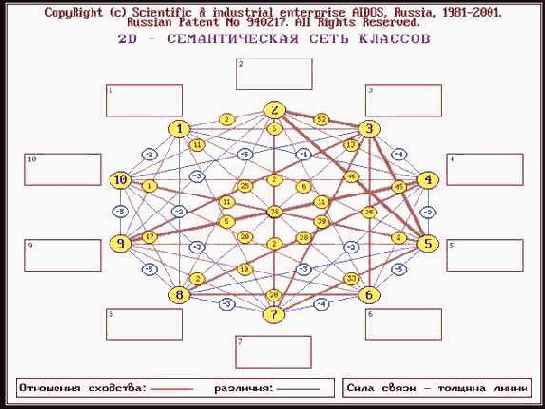
Этот анализ проводится в во 2-й функции 1-го и 2-го режимов 5-й подсистемы системы "Эйдос" (рисунок 176).
 | |
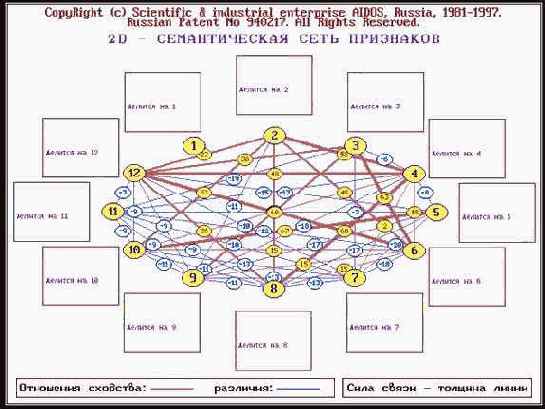 | |
| Рисунок 176. Примеры семантических сети классов и признаков |
Семантические сети отражают сходство классов по характеризующим их признакам и сходство признаков по тем классам, о принадлежности к которым они несут информацию.
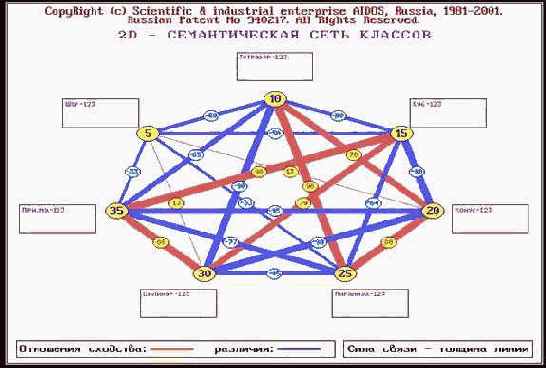
В 5-й операции 2-й функции 1-го и 2-го режимов 5-й подсистемы получим семантические сети классов и факторов (рисунок 184).
 | |
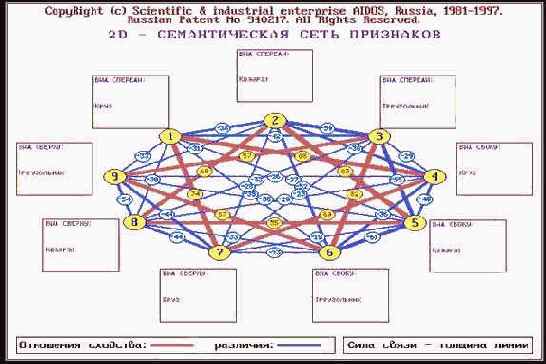 | |
| Рисунок 184. Примеры семантических сетей классов и факторов |
Интерпретацию семантических сетей дать самостоятельно.
Расчет матриц информативностей (БКОСА-
В этом режиме непосредственно на основе матрицы абсолютных частот с применением системного обобщения формулы Харкевича, предложенного автором в рамках СТИ (3.28), рассчитывается матрица информативностей, определяются значимость признаков, степень сформированности обобщенных образов классов, а также обобщенный критерий сформированности модели Харкевича (3.63) для всей матрицы информативностей в целом. На экране монитора наглядно отображается стадия выполнения процесса и структура заполнения матрицы информативностей значимыми данными (на качественном уровне). На основе матрицы абсолютных частот рассчитывается и матрица условных процентных распределений.
Автоматическое выполнение режимов 1-2-3-4. В данном пакетном режиме последовательно выполняются ранее перечисленные режимы обучения системы (кроме режима исключения артефактов).
Расчет матрицы абсолютных частот (БКОСА-
В данном режиме осуществляется последовательное считывание всех анкет обучающей выборки и использование описаний объектов для формирования статистики встреч признаков в разрезе по классам. На экране в наглядной форме отображается стадия этого процесса, который может занимать значительное время при больших размерностях задачи и объеме обучающей выборки. Кроме того на качественном уровне красным отображается заполнение матрицы абсолютных частот данными: классы соответствуют столбцам, а признаки – строкам. Поэтому значительная фрагментарность данных легко обнаруживается еще на этой стадии. Данный режим обеспечивает полную "развязку по данным" и независимость времени исполнения процессов синтеза модели и ее анализа от объема обучающей выборки. Кроме того в данном режиме выявляются 4 типа формально-обнаружимых ошибок в исходных данных и по ним формируется файл отчета.
Расчет матрицы сходства атрибутов (БКОСА-.
Стадия выполнения расчета матрицы сходства признаков наглядно отображается на мониторе.
Расчет матрицы сходства эталонов классов (БКОСА-.
В данном режиме непосредственно на основе оптимизированной матрицы информативностей рассчитывается матрица сходства классов. На экране в наглядной форме отображается информация о текущей стадии выполнения этого процесса.
Расплывчатая неопределенность
Любая задача выбора является задачей целевого сужения множества альтернатив. Как формальное описание альтернатив (сам их перечень, перечень их признаков или параметров), так и описание правил их сравнения (критериев, отношений) всегда даются в терминах той или иной измерительной шкалы (даже тогда, когда тот, кто это делает, не знает об этом).
Известно, все шкалы размыты, но в разной степени. Под термином "размытие" понимается свойство шкал, состоящее в том, что всегда можно предъявить такие две альтернативы, которые различимы, т.е. различны в одной шкале и неразличимы, т.е. тождественны в другой - более размытой. Чем меньше градаций в некоторой шкале, тем более она размыта.
Таким образом, мы можем четко видеть альтернативы, и одновременно нечетко их классифицировать, т.е. иметь неопределенность в вопросе о том, к каким классам они относятся.
Уже в первой работе по принятию решений в расплывчатой ситуации Беллман и Заде выдвинули идею, состоящую в том, что и цели, и ограничения должны представляться как размытые (нечеткие) множества на множестве альтернатив.
Разработка программы реализации
Технология когнитивного анализа и моделирования поддерживается программными комплексами "Ситуация", "Компас", "КИТ" (рисунок 86), созданными в ИПУ РАН, которые позволяют в сложных и неопределенных ситуациях быстро, комплексно и системно охарактеризовать и обосновать сложившуюся ситуацию и на качественном уровне предложить пути решения проблемы в этой ситуации с учетом факторов внешней среды.
Применение когнитивных технологий открывает новые возможности прогнозирования и управления в различных областях:
– в экономической сфере это позволяет в сжатые сроки разработать и обосновать стратегию экономического развития предприятия, банка, региона или даже целого государства с учетом влияния изменений во внешней среде;
– в сфере финансов и фондового рынка – учесть ожидания участников рынка;
– в военной области и области информационной безопасности – противостоять стратегическому информационному оружию, заблаговременно распознавая конфликтные структуры и вырабатывая адекватные меры реагирования на угрозы.
Когнитивные технологии автоматизируют часть функций процессов познания, поэтому они с успехом могут применяться во всех областях, в которых востребовано само познание. Вот лишь некоторые из этих областей:
1. Модели и методы интеллектуальных информационных технологий и систем для создания геополитических, национальных и региональных стратегий социально-экономического развития.
2. Модели выживания "мягких" систем в изменяющихся средах при дефиците ресурсов.
3. Ситуационный анализ и управление развитием событий в кризисных средах и ситуациях.
4. Информационный мониторинг социально-политических, социально-экономических и военно-политических ситуаций.
5. Разработка принципов и методологии проведения компьютерного анализа проблемных ситуаций.
6. Выработка аналитических сценариев развития проблемных ситуаций и управления ими.
7. Подготовка рекомендаций по решению первоочередных стратегических проблем на основе компьютерной системы анализа проблемных ситуаций.
8. Мониторинг проблем в социально-экономическом развитии корпорации, региона, города, государства.
9. Технология когнитивного моделирования целенаправленного развития региона РФ.
10. Анализ развития региона и мониторинг проблемных ситуаций при целенаправленном развитии региона.
11. Модели для формирования государственного регулирования и саморегулирования потребительского рынка.
12. Анализ и управление развитием ситуации на потребительском рынке.
Технология когнитивного моделирования может быть широко использована для уникальных проектов развития регионов, банков, корпораций (и др. объектов) в кризисных условиях после соответствующего обучения.
Развитие АСК-анализа с применением теории нечетких множеств и неклассической логики
Весьма перспективным является развитие результатов, полученных в данном исследовании, с применением аппарата нечетких множеств Заде-Коско [64] и основанной на этом аппарате нечеткой логики (которую иногда более удачно называют непрерывной или континуальной, в отличие от дискретной бинарной Аристотелевской логики или дискретной многозначной логики).
Эта перспектива основана на том, что матрицу информативностей (таблица 16) вполне можно рассматривать как обобщенную (в смысле нечеткой логики) таблицу решений, в которой входы (факторы) и выходы (будущие состояния АОУ) связаны друг с другом не с помощью классических (Аристотелевских) импликаций, принимающих только значения: "Итина" и "Ложь", а различными значениями истинности, выраженными в битах и принимающими значения от положительного теоретически-максимально-возможного
("Максимальная степень истинности"), до теоретически неограниченного
отрицательного ("Степень ложности").
Фактически это означает, что предложенная модель АСК-анализа позволяет осуществить синтез обобщенных таблиц решений для различных предметных областей непосредственно на основе эмпирических исходных данных и продуцировать на их основе огромное количество
прямых и обратных правдоподобных (нечетких) логических рассуждений по неклассическим схемам с различными расчетными значениями истинности, являющимся обобщением классических импликаций.
При этом в прямых рассуждениях как предпосылки рассматриваются факторы, а как заключение – будущие состояния АОУ, а в обратных – наоборот: как предпосылки – будущие состояния АОУ, а как заключение – факторы. Степень истинности i-й предпосылки – это просто количество информации Iij, содержащейся в ней о наступлении j-го будущего состояния АОУ. Если предпосылок несколько, то степень истинности наступления j-го состояния АОУ равна суммарному количеству информации, содержащемуся в них об этом. Количество информации в i-м факторе о наступлении j-го состояния АОУ, рассчитывается в соответствии с выражением (3.28) СТИ.
Прямые правдоподобные логические рассуждения позволяют прогнозировать степень достоверности наступления события по действующим факторам, а обратные – по заданному состоянию восстановить степень необходимости и степень нежелательности каждого фактора для наступления этого состояния, т.е. принимать решение по выбору управляющих воздействий на АОУ, оптимальных для перевода его в заданное целевое состояние.
Число вариантов подобных логических формул определяется по сути дела произведением числа сочетаний предпосылок на число сочетаний заключений. Однако, реально из этих формул имеет смысл использовать только полные, т.е. включающие все заданные предпосылки или все заданные заключения. В простейшем случае заданными могут считаться все предпосылки, или предпосылки, соответствующие факторам определенной группы, и т.д. Для развития этого направления, по-видимому, целесообразно задействовать логику предикатов.
Необходимо также отметить, что предложенная модель, основывающаяся на теории информации, обеспечивает автоматизированное формирования системы нечетких правил по содержимому входных данных, как и комбинация нечеткой логики Заде-Коско с нейронными сетями Кохонена. Принципиально важно, что качественное изменение модели путем добавления в нее новых классов не уменьшает достоверности распознавания уже сформированных классов. Кроме того, при сравнении распознаваемого объекта с каждым классом учитываются не только признаки, имеющиеся у объекта, но и отсутствующие у него, поэтому предложенной моделью правильно идентифицируются объекты, признаки которых образуют множества, одно из которых является подмножеством другого (как и в Неокогнитроне К.Фукушимы).
Рефлексивная АСУ АПК группы А: й контур: "Руководство – агротехнологический процесс"
АСУ, в которых сама агротехнология является объектом управления, мы отнесем к группе "А" (таблица 7):
Таблица 7 – КОМПОНЕНТЫ АСУ АГРОТЕХНОЛОГИЯМИ
| № | Элементы АСУ | РАСУ АПК | |||
| 1 | Сырье | Агротехнологии и кадры до внедрения РАСУ АПК | |||
| 2 | Объект управления | Агротехнологический процесс и руководящие кадры | |||
| 3 | Управляющие факторы | Материально-техническое и научно-методическое обеспечение агротехнологического процесса, повышение квалификации руководящих кадров | |||
| 4 | Конечный продукт | Агротехнологии и руководящие кадры после внедрения РАСУ АПК | |||
| 5 | Потребитель | Производители сельскохозяйственной продукции | |||
| 6 | Окружающая среда | Рынок труда и агротехнологий |
Технические АСУ группы "А" являются чем-то экзотическим, т.к. объект управления, как правило, представляет собой систему с медленноменяющимися параметрами. В этих областях АСУ после внедрения работают достаточно длительное время без существенных изменений.
В РАСУ АПК ситуация иная: и сам объект управления (сельхозкультуры и агротехнологии), и условия окружающей среды (природной, экономической, социальной), являются весьма динамичными, из чего с необходимостью следует и высокая динамичность агротехнологий. Следовательно РАСУ АПК группы "Б" фактически не только не может быть внедрена, но даже и разработана без одновременной разработки и внедрения РАСУ АПК группы "А", которая бы обеспечила ей высокий уровень адаптивности, достаточный для обеспечения поддержки адекватности модели как при количественных, так и при качественных изменениях предметной области. Обобщенная схема РАСУ АПК группы "А" приведена на рисунке 18.
Рефлексивная АСУ АПК группы Б: й контур: "Агротехнологии – конечный продукт"
Конкретизируем общие положения QFD-технологии (развертывание функций качества) для случая РАСУ АПК. Из этой технологии следует, что в этой РАСУ должно быть по крайней мере два уровня:
1-й уровень – управление производством конечной продукции;
2-й уровень – управление качеством технологии производства конечной продукции.
Такие АСУ, которые управляют производством конечного продукта, будем называть АСУ группы "Б" (АСУ средств потребления). Применительно к РАСУ АПК, АСУ группы "Б" – это АСУ управления производством сельхозпродукции с помощью агротехнологий (рисунок20).
 | |
| Рисунок 20. Обобщенная схема АСУ АПК группы "Б" |
Обычно считается известным влияние тех или иных традиционных агротехнологий на потребительские свойства конечного продукта и его цену. Это положение не подвергается в данной работе сомнению, однако необходимо отметить, что само понятие "известно" существенно отличается в гуманитарной и технических областях, т.е. в этих областях приняты различные критерии для классификации исследуемых закономерностей на "известные" и "неизвестные". Это приводит к тому, что в ряде случаев то, что "гуманитарии" считают для себя известным не является таковым для "естественников", т.е. они, конечно, имеют эти знания, но они их не устраивают. Как правило гуманитариев устраивает качественная
оценка связи, в результате они часто оперируют нечеткими высказываниями
типа: "Бобовые предшественники приводят к повышению урожая зерновых колосовых". И это для них приемлемо. Однако для создания АСУ знаний выраженных в такой форме недостаточно, требуется количественная
формулировка, значит специалист по созданию АСУ будет ставить вопрос о проведении специальных исследований для выявления и количественного измерения силы и направления влияния подобных связей.
Поэтому при создании РАСУ АПК возникают проблемы: количественного измерения различных параметров агротехнологических процессов и окружающей среды и выявления количественных зависимостей между этими параметрами и количественными и качественными характеристиками конечной продукции.
Причем характеристики конечной продукции могут быть выражены в интервальных величинах в натуральном или в ценовом выражении.
Во всех случаях внедрение АСУ означает прежде всего изменение (совершенствование) технологии воздействия на объект управления (рисунок 21).
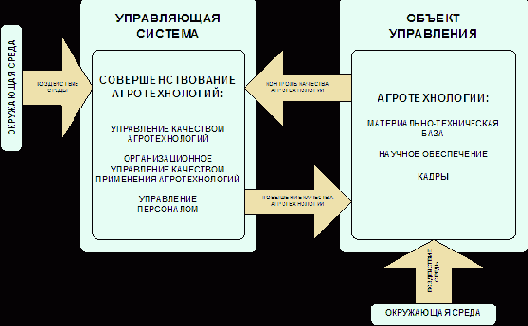 |
|
Рисунок 21. Обобщенная схема РАСУ АПК группы "А" |
можно рассматривать как процесс управления совершенствованием технологии
производства конечного продукта.
Регрессионный анализ
Регрессионный анализ позволяет исследовать формы связи, устанавливающие количественные соотношения между случайными величинами изучаемого процесса.
Регрессия наиболее часто используется для построения прогнозных моделей.
Рекламные исследования
Рекламные исследования проводятся в целях получения полной и достоверной информации, необходимой для адресного управления формой и содержанием информации, на основе которой конкретными группами потребителей принимаются решения о приобретении тех или иных товаров. Подобные исследования проводились автором по закрытой тематике на основе применения технологии АСК-анализа.
Опросный лист разрабатывается таким образом, чтобы с помощью него можно было выяснить, какими источниками информации реально пользуются различные категории потребителей, а также какие формы подачи информации они предпочитают и лучше воспринимают. В опросный лист могут быть включены фирменные знаки, ключевые слова и рекламные фразы, а также наименования источников информации, выполненные их фирменными стилями (которые можно снять с помощью сканера и отпечатать на цветном принтере). Опросный лист может служить одновременно и бланком для заполнения, но могут использоваться и специальные бланки для ответов.
Вопросы делятся на несколько групп:
– социальный и гражданский статус потребителя (пол, возраст, образование, состоит ли в браке, сколько имеет детей, форма занятости, если работает, то руководитель он или исполнитель и т.п.);
– наиболее популярные телевизионные программы и передачи; наиболее популярные радиопрограммы и передачи;
– отношение к рекламе, включаемой в состав радио и телепередач; наиболее популярные журналы и рубрики;
– наиболее популярные газеты и рубрики;
– отношение к внешней рекламе;
– роль форм, методов и фирменных стилей рекламы;
– иные источники и формы информации, на основе которой потребителями принимаются решения.
В результате проведения рекламного исследования выясняется, какими источниками информации пользуются различные потребительские группы населения и какие формы подачи информации для них предпочтительны. Например, выясняется, что определенная группа населения в основном слушает "Радио Рокс" и именно определенную передачу, которая идет с 18 до 19. Кроме того, известно, что эту группу населения раздражает, когда любимая передача прерывается рекламой товаров, которые представителями данной группы в принципе не могут быть куплены. Известно, также, что эта группа предпочитает юмор политике. На основе этой информации может быть разработан план использования этой передачи "Радио Рокс" для адресного сообщения данной группе населения информации о "ее товарах", причем в такой форме, которая будет воспринята этой группой эмоционально положительно. Регулярное проведение рекламных исследований позволяет строить свою работу, используя достоверное знание источников и форм информации, которыми реально пользуются различные категории потребителей. Имеется положительный опыт подобных исследований (по закрытой тематике).
Рекомендуемая литература
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. – 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
3. Кива Владимир, сайт: http://vlak.webzone.ru/rus/it/knowledge.html.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Орлов А.И. "Высокие статистические технологии": http://antorlov.chat.ru.
2. Луценко Е.В. Автоматизированная система распознавания образов: математическая модель и опыт применения. //В сб.: "В.И. Вернадский и современность (к 130-летию со дня рождения)". - Краснодар: КНА, 1993. - С.37-42.
3. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). – Краснодар: КЮИ МВД РФ, 1996. – 280с.
4. Луценко Е.В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). –Краснодар: КубГАУ. 2002. –605 с.
5. Пат. № 940217. РФ. Универсальная автоматизированная система распознавания образов "ЭЙДОС". /Е.В.Луценко (Россия); Заяв. № 940103. Опубл. 11.05.94. – 50с.
6. Пат. № 2003610986 РФ. Универсальная когнитивная аналитическая система "ЭЙДОС" / Е.В.Луценко (Россия); Заяв. № 2003610510 РФ. Опубл. от 22.04.2003. – 50с.
7. Луценко Е.В. Типовая методика и инструментарий когнитивной структуризации и формализации задач в СК-анализе. // Научный журнал КубГАУ. – 2004.– № 1 (3). –18 с. http://ej.kubagro.ru
8. Эфрон Б. Нетрадиционные методы многомерного статистического анализа. - М.: Финансы и статистика, 1988. – 263 с.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Завгородний В.В., Мельников Ю.Н., Идентификация по клавиатурному почерку. "Банковские Технологии", №9, 1998.
2. Иванов А.И. Биометрическая идентификация личности по динамике подсознательных движений. Пенза. Издательство Пензенского государственного университета –2000, –188 с.
3. Луценко Е.В., Лаптев В.Н., Третьяк В.Г. Прогнозирование качества специальной деятельности методом подсознательного (подпорогового) тестирования на основе семантического резонанса. //В сб.: "Материалы II межвузовской научно-технической конференции". – Краснодар: КВИ, 2001. – С.127-128.
4. Луценко Е.В., Лебедев А.Н. Диагностика и прогнозирование профессиональных и творческих способностей методом АСК-анализа электроэнцефалограмм в системе "Эйдос". // Межвузовский сборник научных трудов, том 1. –Краснодар: КВИ. 2003.–С. 227-229.
5. Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В. ЭЭГ прогноз успешности выполнения психомоторного теста при снижении уровня бодрствования: постановка задачи. // Научный журнал КубГАУ. – 2004.– №4(6). – 9 с. http://ej.kubagro.ru.
6. Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В. ЭЭГ прогноз успешности выполнения психомоторного теста при снижении уровня бодрствования: описание эксперимента. // Научный журнал КубГАУ. – 2004.– №4(6). – 13 с. http://ej.kubagro.ru.
7. Щукин Т.Н., Дорохов В. Б., Лебедев А.Н., Луценко Е.В. ЭЭГ прогноз успешности выполнения психомоторного теста при снижении уровня бодрствования: анализ результатов исследования. // Научный журнал КубГАУ. – 2004.– №4(6). – 17 с. http://ej.kubagro.ru.
8. Смирнов И., Безносюк Е., Журавлёв А. Психотехнологии: Компьютерный психосемантический анализ и психокоррекция на неосознаваемом уровне. - М.: Изд. группа Прогресс-Культура, 1995. - 416с.
9. Шагас Ч. Вызванные потенциалы мозга в норме и патологии. –М.: Мир, 1975. –314 с.
10. Сайт Луценко Е.В. http://Lc.kubagro.ru.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Перегудов Ф.И., Тарасенко Ф.П. Введение в системный анализ: Учебное пособие. – М.: Высшая школа, 1997. – 389с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
3. Бирюков А. Системы принятия решений и Хранилища Данных. //Системы управления базами данных #04/97. http://www.isuct.ru/~ivt/books/DBMS/DBMS7/dbms/1997/04/37.htm
4. Львов В. Создание систем поддержки принятия решений на основе хранилищ данных. Ж-л "Системы управления базами данных", #03, 1997 г.//Издательство "Открытые системы" (www.osp.ru). Адрес статьи: http://www.osp.ru/dbms/1997/03/30.htm
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Lutsenko E.V. Conceptual principles of the system (emergent) information theory & its application for the cognitive modelling of the active objects (entities) //2002 IEEE International Conference on Artificial Intelligence System (ICAIS 2002). –Computer society, IEEE, Los Alamos, California, Washington-Brussels-Tokyo, p. 268-269.
2. Бранский В.П. Философские основания проблемы синтеза релятивистских и квантовых принципов. –Л: ЛГУ, 1973. –175с.
3. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
4. Луценко Е.В. Интерференция последствий выбора в результате одновременного выбора альтернатив и необходимость разработки эмерджентной теории информации. //В сб.: "Материалы III всероссийской межвузовской научно-технической конференции". – Краснодар: КВИ, 2002. – С.24-30.
5. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
6. Роберт Г.Джан, Бренда Дж.Данн. Границы реальности. (Роль сознания в физическом мире). /Пер. с англ. - М.: Объединенный институт высоких температур РАН, 1995. - 287с.
7. Цехмистро И.З. Поиски квантовой концепции физических оснований сознания. –Харьков: ХГУ, 1981. - 275с.
8. Терехов С.А. Лекции по теории и приложениям искусственных нейронных сетей. Лаборатория Искусственных Нейронных Сетей НТО-2, ВНИИТФ, Снежинск, http://alife.narod.ru/lectures/neural/Neu_index.htm.
9. Ткачев А.Н., Луценко Е.В. Формальная постановка задачи и синтез многоуровневой семантической информационной модели влияния инвестиций на уровень качества жизни населения региона // Научный журнал КубГАУ. – 2004.– №4(6). –22 с. http://ej.kubagro.ru
10. Ткачев А.Н., Луценко Е.В. Исследование многоуровневой семантической информационной модели влияния инвестиций на уровень качества жизни населения региона // Научный журнал КубГАУ. – 2004.– №4(6). –28 с. http://ej.kubagro.ru
11. Сайт "Курс статистики", раздел "Нейронные сети": http://www.statsoft.ru/home/textbook/modules/stneunet.html.
1. Исаев С. Популярно о генетических алгоритмах. http://home.od.ua/~relayer/algo/neuro/ga-pop/
2. Алексей Андреев. Электродарвин. http://www.fuga.ru/articles/2004/03/genetic-pro.htm
3. СотникС.Л. Конспект лекций по курсу "Основы проектирования систем искусственного интеллекта": (1997-1998), http://neuroschool.narod.ru/books/sotnik.html.
1. Сайт: ИПУ РАН, Сектор-51 сектор "Когнитивный анализ и моделирование ситуаций": http://www.ipu.ru/labs/lab51/projects.htm.
2. Максимов В.И., Корноушенко Е.К. Знание – основа анализа. Банковские технологии, № 4, 1997.
3. Корноушенко Е.К., Максимов В.И. Управление процессами в слабоформализованных средах при стабилизации графовых моделей среды. Труды ИПУ, вып.2, 1998.
4. Максимов В.И., Корноушенко Е.К. Аналитические основы применения когнитивного подхода при решении слабоструктурированных задач. Труды ИПУ, вып.2, 1998.
5. Максимов В.И., Качаев С.В., Корноушенко Е.К. Концептуальное моделирование и мониторинг проблемных и конфликтных ситуаций при целенаправленном развитии региона. В сб. "Современные технологии управления для администраций городов и регионов". Фонд "Проблемы управления", М. 1998.
6. Максимов В.И., Корноушенко Е.К., Качаев С.В. Анализ ситуации и компенсация теневых аспектов в свободной торговле. В сб. "Современные технологии управления для администраций городов и регионов". Фонд "Проблемы управления", М. 1998.
7. Максимов В.И., Корноушенко Е.К., Качаев С.В., Григорян А.К. Когнитивный подход к анализу проблемы демонополизации в транспортном комплексе. Труды ИПУ, вып.2, 1998.
8. Райков А.Н. Аналитическим службам - информационные технологии. /Ваш выбор. 1994. № 4. - С.28-29.
9. Райков А.Н. Гносеологическая декомпозиция процессов рефлексивного управления. /"Рефлексивное управление". Тезисы международного симпозиума (17-19.10.2000). – М.: Ин-т психол. РАН, 2000. – С.89-90.
10. Райков А.Н. Интеллектуальные информационные технологии и системы. В 2-х частях. – М.: МИРЭА, 1998. – 213с.
11. Райков А.Н. Интеллектуальные информационные технологии: Учебное пособие. – М.: МГИРЭА(ТУ), 2000. - 96с.
1. Дюк В., Самойленко А. Data Mining: учебный курс (+ CD-ROM). 2001 г. Издательство: Питер. Серия: Учебный курс. – 368с.
2. Сайт компании BI Partner: http://www.bipartner.ru/services/dm.html.
3. Шапот М., Рощупкина В. Интеллектуальный анализ данных и управление процессами. // Открытые системы. –№ 4-5, 1998. –С. 29.
4. Шапот М. Интеллектуальный анализ данных в системах поддержки принятия решений. Журнал "Открытые системы", #01, 1998 год
// Издательство "Открытые системы" (www.osp.ru),
адрес статьи: http://www.osp.ru/os/1998/01/30.htm.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
1. Луценко Е.В. Теоретические основы и технология адаптивного семантического анализа в поддержке принятия решений (на примере универсальной автоматизированной системы распознавания образов "ЭЙДОС-5.1"). - Краснодар: КЮИ МВД РФ, 1996. - 280с.
2. Луценко Е. В. Автоматизированный системно-когнитивный анализ в управлении активными объектами (системная теория информации и ее применение в исследовании экономических, социально-психологических, технологических и организационно-технических систем): Монография (научное издание). – Краснодар: КубГАУ. 2002. – 605 с.
Решение как компромисс и баланс
Во всех рассмотренных выше задачах выбора и методах принятия решений проблема состояла в том, чтобы в исходном множестве найти наилучшие в заданных условиях, т.е. оптимальные в определенном смысле альтернативы.
Идея оптимальности является центральной идеей кибернетики и прочно вошла в практику проектирования и эксплуатации технических систем. Вместе с тем эта идея требует осторожного к себе отношения, когда мы пытаемся перенести ее в область управления сложными, большими и слабо детерминированными системами, такими, например, как социально-экономические системы.
Для этого заключения имеются достаточно веские основания. Рассмотрим некоторые из них.
1. Оптимальное решение нередко оказывается неустойчивым: т.е. незначительные изменения в условиях задачи, исходных данных или ограничениях могут привести к выбору существенно отличающихся альтернатив.
2. Оптимизационные модели разработаны лишь для узких классов достаточно простых задач, которые не всегда адекватно и системно отражают реальные объекты управления. Чаще всего оптимизационные методы позволяют оптимизировать лишь достаточно простые и хорошо формально описанные подсистемы некоторых больших и сложных систем, т.е. позволяют осуществить лишь локальную оптимизацию. Однако, если каждая подсистема некоторой большой системы будет работать оптимально, то это еще совершенно не означает, что оптимально будет работать и система в целом. То есть оптимизация подсистемы совсем не обязательно приводит к такому ее поведению, которое от нее требуется при оптимизации системы в целом. Более того, иногда локальная оптимизация может привести к негативным последствиям для системы в целом.
3. Часто максимизация критерия оптимизации согласно некоторой математической модели считается целью оптимизации, однако в действительностью целью является оптимизация объекта управления. Критерии оптимизации и математические модели всегда связаны с целью лишь косвенно, т.е. более или менее адекватно, но всегда приближенно.
Итак, идею оптимальности, чрезвычайно плодотворную для систем, поддающихся адекватной математической формализации, нельзя перенести на сложные системы. Конечно, математические модели, которые удается иногда предложить для таких систем, можно оптимизировать. Однако всегда следует учитывать сильную упрощенность этих моделей, а также то, что степень их адекватности фактически неизвестна. Поэтому не известно, какое чисто практическое значение имеет эта оптимизация. Высокая практичность оптимизации в технических системах не должна порождать иллюзий, что она будет настолько же эффективна при оптимизации сложных систем. Содержательное математическое моделирование сложных систем является весьма затруднительным, приблизительным и неточным. Чем сложнее система, тем осторожнее следует относится к идее ее оптимизации.
Поэтому, при разработке методов управления сложными, большими слабо детерминированными системами, основным является не оптимальность выбранного подхода с формальной математической точки зрения, а его адекватность поставленной цели и самому характеру объекта управления.
Решение проблемы интерпретируемости
В данной работе предлагается использовать такие весовые коэффициенты дендридов, чтобы активационная функция была линейной, т.е. по сути была равна своему аргументу: сумме. Этому условию удовлетворяют весовые коэффициенты, рассчитываемые с применением системного обобщения формулы Харкевича (3.28).
Очень важно, что данная мера, удовлетворяет известному эмпирическому закону Г.Фехнера (1860), согласно которому существует логарифмическая
зависимость между интенсивностью фактора и величиной отклика на него биологической системы (в частности, величина ощущения прямо пропорциональна логарифму интенсивности раздражителя).
Предлагается информационный подход к нейронным сетям, по аналогии с энергетическим подходом Хопфилда (1980).
Суть этого подхода состоит в том, что интенсивности входных сигналов рассматриваются не сами по себе и не с точки зрения только их интенсивности, а как сообщения, несущие определенное количество информации или дезинформации
о переходе нейрона и моделируемого им активного объекта управления в некоторое будущее состояние.
Под интенсивностью входного сигнала на определенном дендриде мы будем понимать абсолютную частоту (количество) встреч фактора (признака), соответствующего данному дендриду, при предъявлении нейронной сети объекта, соответствующего определенному нейрону. Таким образом матрица абсолютных частот рассматривается как способ накопления и первичного обобщения эмпирической информации об интенсивностях входных сигналов на дендридах в разрезе по нейронам.
Весовые коэффициенты, отражающие влияние каждого входного сигнала на отклик каждого нейрона, т.е. величину его возбуждения или торможения, представляют собой элементы матрицы информативностей, получающиеся из матрицы абсолютных частот методом прямого счета с использованием выражения для семантической меры целесообразности информации (3.28).
При этом предложенная мера семантической целесообразности информации, как перекликается с нейронными сетями Кохонена, в которых также принято стандартизировать (нормализовать) входные сигналы, что позволяет в определенной мере уйти от многообразия передаточных функций.
Наличие ясной и обоснованной интерпретации весовых коэффициентов, как количества информации, позволяет предложить в качестве математической модели для их расчета системную теорию информации (СТИ).
Решение проблемы интерпретируемости передаточной функции
Вопрос об интерпретируемости передаточной функции нейрона включает два основных аспекта:
– об интерпретируемости аргумента передаточной функции;
– об интерпретируемости вида передаточной функции.
1. Возникает естественный вопрос о том, чем обосновано включение в состав модели нейрона Дж. Маккалоки и У. Питтом именно аддитивного элемента, суммирующего входные сигналы, а не скажем мультипликативного или в виде функции общего вида. По мнению автора такой выбор обоснован и имеет явную и убедительную интерпретацию именно в том случае, когда весовые коэффициенты имеют смысл количества информации, т.к. в этом случае данная мера представляет собой неметрический критерий сходства (3.37), основанный на лемме Неймана-Пирсона. Сумма весовых коэффициентов, соответствующих набору действующих факторов (входных сигналов) дает величину выходного сигнала на аксоне каждого нейрона.
2. Вид передаточной функции содержательно в теории нейронных сетей явно не обосновывается. Предлагается гипотеза, что на практике вид передаточной функции подбирается таким образом, чтобы соответствовать смыслу подобранных в данном конкретном случае весовых коэффициентов. Так как при применении в различных предметных областях смысл весовых коэффициентов в явном виде не контролируется и может отличаться, то выбор вида передаточной функции позволяет частично компенсировать эти различия.
Предлагаемый интерпретируемый вид весовых коэффициентов обеспечивает единую и стандартную интерпретацию аргумента и значения передаточной функции независимо от предметной области. Поэтому в нелокальной нейронной модели передаточная функция нейрона всегда линейна (аргумент равен функции). Следовательно в модели нелокального нейрона блок суммирования по сути дела объединен с блоком нелинейного преобразования (точнее, второй отсутствует, а его роль выполняет блок суммирования), в отличие от стандартных передаточных функций локальных нейронов: логистической, гиперболического тангенса, пороговой линейной, экспоненциально распределенной, полиномиальной и импульсно-кодовой.
Нелокальные нейроны как бы "резонируют" на ансамбли входных сигналов, причем этот резонанс может быть обоснованно назван семантическим (смысловым), т.к. весовые коэффициенты рассчитаны на основе предложенной семантической меры целесообразности информации. Таким образом, разложение вектора идентифицируемого объекта в ряд по векторам обобщенных образов классов осуществляется на основе семантического резонанса нейронов выходного слоя на ансамбль входных сигналов (признаков, факторов).
Решение проблемы линейной разделимости
Вводятся промежуточные линейно-разделимые классы распознавания, которые рассматриваются как вторичные признаки при идентификации объектов с ранее не разделимыми классами. Это решение соответствует введению дополнительных слоев нейронной сети.
В системе "Эйдос" функция представления нейронов предыдущего слоя в качестве рецепторов последующего слоя автоматизирована, что в случае необходимости позволяет в полуавтоматическом режиме преобразовать однослойную сеть с линейно-неразделимыми классами в иерархическую нейронную сеть в которой эти классы линейно-разделены относительно вторичных признаков в слоях более высоких уровней иерархии.
Решение проблемы размерности
Вместо итерационного подбора весовых коэффициентов путем полного перебора вариантов их значений при малых вариациях (методы обратного распространения ошибки и градиентного спуска к локальному экстремуму) предлагается прямой расчет этих коэффициентов на основе процедуры и выражений, обоснованных в предложенных системной теории информации и семантической информационной модели. Выигрыш во времени и используемых вычислительных ресурсах, получаемый за счет этого, быстро возрастает при увеличении размерности нейронной сети.
Решение задачи "Адаптация модели объекта управления"
На основе обучающей выборки, содержащей информацию о том, какие факторы действовали, когда АОУ переходил в те или иные состояния, методом прямого счета формируется матрица абсолютных частот, имеющая вид, представленный в таблице 15. Необходимо отметить, что в случае АОУ в большинстве случаев нет возможности провести полный факторный эксперимент для заполнения матрицы абсолютных частот. В данной работе предполагается, что это и не обязательно, т.е. на практике достаточно воспользоваться естественной вариабельностью
факторов и состояний АОУ, представленных в обучающей выборке. С увеличением объема обучающей выборки в ней со временем будут представлены все практически встречающиеся варианты сочетаний факторов и состояний АОУ.
В соответствии с выражением (3.28), непосредственно на основе матрицы абсолютных частот ||


Количество информации в i–м факторе о наступлении j–го состояния АОУ является статистической мерой их связи и количественной мерой влияния данного фактора на переход АОУ в данное состояние.
Решение задачи "Разработка алгоритмов решения основных задач АСУ"
Как было показано в разделе 3.2, решение задачи 3 предполагает решение следующих подзадач.
Решение подзадачи 3.1: "Расчет влияния факторов на переход объекта управления в различные состояния (обучение, адаптация)"
При изменении объема обучающей выборки или изменении экспертных оценок прежде всего пересчитывается матрица абсолютных частот, а затем, на ее основании и в соответствии с выражением (3.28), - матрица информативностей. Таким образом, предложенная модель обеспечивает отображение динамических взаимосвязей, с одной стороны, между входными и выходными параметрами, а с другой, - между параметрами и состояниями объекта управления. Конкретно, это отображение осуществляется в форме так называемых векторов факторов и состояний.
В профиле (векторе) i–го фактора (строка матрицы информативностей) отображается, какое количество информации о переходе АОУ в каждое из возможных состояний содержится в том факте, что данный фактор действует.
В профиле (векторе) j–го состояния АОУ (столбец матрицы информативностей) отображается, какое количество информации о переходе АОУ в данное состояние содержится в каждом из факторов.
Решение подзадачи 3.2: "Прогнозирование поведения объекта управления при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (обратная задача прогнозирования)"
Прогнозирование состояния АОУ осуществляется следующим образом:
1. Собирается информация о действующих факторах, характеризующих состояние предметной области (активный объект управления описывается факторами, характеризующими его текущее и прошлые состояния; управляющая система характеризуется технологическими факторами, с помощью которых она оказывает управляющее воздействие на активный объект управления; окружающая среда характеризуется прошлыми, текущими и прогнозируемыми факторами, которые также оказывают воздействие на активный объект управления).
2. Для каждого возможного будущего состояния АОУ подсчитывается суммарное количество информации, содержащееся во всей системе факторов (согласно п.1), о наступлении этого состояния.
3. Все будущие состояния АОУ ранжируются в порядке убывания количества информации об их осуществлении.
Этот ранжированный список будущих состояний АОУ и представляет собой первичный результат прогнозирования.
Если задано некоторое определенное целевое состояние, то выбор управляющих воздействий для фактического применения производится из списка, в котором все возможные управляющие воздействия расположены в порядке убывания их влияния на перевод АОУ в данное целевое состояние. Такой список называется информационным портретом состояния АОУ [64].
Управляющие воздействия могут быть объединены в группы, внутри каждой из которых они альтернативны (несовместны), а между которыми - нет (совместны). В этом случае внутри каждой группы выбирают одно из фактически доступных управляющих воздействий с максимальным влиянием на достижение заданного целевого состояния АОУ.
Однако выбор многофакторного управляющего воздействия нельзя считать завершенным без прогнозирования результатов его применения. Описание АОУ в актуальном состоянии состоит из списка факторов окружающей среды, предыстории АОУ, описания его актуального (исходного) состояния, а также выбранных управляющих воздействий. Имея эту информацию по каждому из факторов в соответствии с выражением (3.39), нетрудно подсчитать, какое количество информации о переходе в каждое из состояний содержится суммарно во всей системе факторов. Данный метод соответствует фундаментальной лемме Неймана–Пирсона, содержащей доказательство оптимальности метода выбора той из двух статистических гипотез, о которой в системе факторов содержится больше информации. В то же время он является обобщением леммы Неймана–Пирсона, так как вместо информационной меры Шеннона используется системное обобщение семантической меры целесообразности информации Харкевича.
Предлагается еще одно обобщение этой фундаментальной леммы, основанное на косвенном учете корреляций между информативностями в профиле состояния при использовании среднего по профилю. Соответственно, вместо простой суммы количеств информации предлагается использовать ковариацию между векторами состояния и АОУ, которая количественно измеряет степень сходства формы этих векторов.
Результат прогнозирования поведения АОУ, описанного данной системой факторов, представляет собой список состояний, в котором они расположены в порядке убывания суммарного количества информации о переходе АОУ в каждое из них.
Решение подзадачи 3.3: "Выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; снижение размерности модели при заданных ограничениях"
Естественно считать, что некоторый фактор является тем более ценным, чем больше среднее количество информации, содержащееся в этом факторе о поведении АОУ [64]. Но так как в предложенной модели количество информации может быть и отрицательным (если фактор уменьшает вероятность перехода АОУ в некоторое состояние), то простое среднее арифметическое информативностей может быть близко к нулю. При этом среднее будет равно нулю и в случае, когда все информативности равны нулю, и тогда, когда они будут велики по модулю, но с разными знаками. Следовательно, более адекватной оценкой полезности фактора является среднее модулей или, что наиболее точно, исправленное (несмещенное) среднеквадратичное отклонение информативностей по профилю признака.
Ценность фактора по сути дела определяется его полезностью для различения состояний АОУ, т.е. является его дифференцирующей способностью или селективностью.
Необходимо также отметить, что различные состояния АОУ обладают различной степенью обусловленности, т.е. в различной степени детерминированы факторами: некоторые слабо зависят от учтенных факторов, тогда как другие определяются ими практически однозначно. Количественно детерминируемость состояния АОУ предлагается оценивать стандартным отклонением информативностей вектора обобщенного образа данного состояния.
Предложено и реализовано несколько итерационных алгоритмов корректного удаления малозначимых факторов и слабодетерминированных состояний АОУ при заданных граничных условиях [64]. Решение задачи снижения размерности модели АОУ при заданных граничных условиях позволяет снизить эксплуатационные затраты и повысить эффективность РАСУ АО.
Решение подзадачи 3.4: " Сравнение влияния факторов. Сравнение состояний объекта управления"
Факторы могут сравниваться друг с другом по тому влиянию, которое они оказывают на поведение АОУ. Сами состояния могут сравниваться друг с другом по тем факторам, которые способствуют или препятствуют переходу АОУ в эти состояния. Это сравнение может содержать лишь результат, т.е. различные степени сходства/различия (в кластерном анализе), или содержать также причины этого сходства/различия (в когнитивных диаграммах).
Эти задачи играют важную роль в теории и практике РАСУ АО при необходимости замены одних управляющих воздействий другими, но аналогичными по эффекту, а также при изучении вопросов семантической устойчивости управления (различимости состояний АОУ по детерминирующим их факторам).
Этот анализ проводится над классами распознавания и над признаками. Он включает: информационный (ранговый) анализ; кластерный и конструктивный анализ, семантические сети; содержательное сравнение информационных портретов, когнитивные диаграммы.
Семантический информационный анализ
Предложенная математическая модель позволяет сформировать информационные портреты обобщенных эталонных образов классов распознавания и признаков.
Портреты классов распознавания представляют собой списки признаков в порядке убывания содержащегося в них количества информации о принадлежности к этим классам.
Информационный портрет класса распознавания показывает нам, каков информационный вклад каждого признака в общий объем информации, содержащейся в обобщенном образе этого класса.
В подходе к решению задач рефлексивных АСУ АО, основанном на применении методов распознавания образов, классам распознавания соответствуют, во–первых, исходные, а во–вторых, результирующие, в том числе целевые состояния объекта управления. Это значит, что в первом случае портреты классов используются для идентификации исходного состояния АОУ, потому что именно с ними сравнивается состояние объекта управления, а во втором – для выработки управляющего воздействия, так как его выбирают в форме суперпозиции неальтернативных факторов из информационного портрета целевого состояния, оказывающих наибольшее влияние на перевод АОУ в это состояние.
Портреты признаков представляют собой списки классов распознавания в порядке убывания количества информации о них, которое содержит данный признак. По своей сути информационный портрет признака раскрывает нам смысл данного признака, т.е. его семантическую нагрузку. В теории и практике рефлексивных АСУАО информационный портрет фактора является развернутой количественной характеристикой, содержащей информацию о силе и характере его влияния на перевод АОУ в каждое из возможных результирующих состояний, в том числе в целевые. Информационные портреты классов и признаков допускают наглядную графическую интерпретацию в виде двухмерных (2d) и трехмерных (3d) диаграмм.
Кластерно-конструктивный анализ и семантические сети
Кластеры представляют собой такие группы классов распознавания (или признаков), внутри которых эти классы наиболее схожи друг с другом, а между которыми наиболее различны [64]. В данной работе, в качестве классов распознавания рассматриваются как исходные, так и результирующие, в том числе целевые состояния объекта управления, а в качестве признаков – факторы, влияющие на переход АОУ в результирующие состояния.
Исходные состояния АОУ, объединенные в кластер, характеризуются общими или сходными методами перевода в целевые состояния. Результирующие состояния АОУ, объединенные в кластер, являются слаборазличимыми по факторам, детерминирующим перевод АОУ в эти состояния. Это означает, что одно и то же управляющее воздействие при одних и тех же предпосылках (исходном состоянии и предыстории объекта управления и среды) могут привести к переводу АОУ в одно из результирующих состояний, относящихся к одному кластеру. Поэтому кластерный анализ результирующих состояний АОУ является инструментом, позволяющим изучать вопросы устойчивости управления сложными объектами.
При выборе управляющего воздействия как суперпозиции неальтернативных факторов часто возникает вопрос о замене одних управляющих факторов другими, имеющими сходное влияние на перевод АОУ из данного текущего состояния в заданное целевое состояние.
Кластерный анализ факторов как раз и позволяет решить эту задачу: при невозможности применить некоторый управляющий фактор его можно заменить другим фактором из того же кластера.
При формировании кластеров используются матрицы сходства объектов и признаков, формируемые на основе матрицы информативностей.
В соответствии с предлагаемой математической моделью могут быть сформированы кластеры для заданного диапазона кодов классов распознавания (признаков) или заданных диапазонов уровней системной организации с различными критериями включения объекта (признака) в кластер.
Эти критерии могут быть сформированы автоматически либо заданы непосредственно. В последнем уровне кластеризации, в частности при задании одного уровня, в кластеры включаются не только похожие, но и все непохожие объекты (признаки), и, таким образом, формируются конструкты классов распознавания и признаков.
В данной работе под конструктом понимается система противоположных (наиболее сильно отличающихся) кластеров, которые называются "полюсами" конструкта, а также спектр промежуточных кластеров, к которым применима количественная шкала измерения степени их сходства или различия [64].
Понятия "кластер" и "конструкт" тесно взаимосвязаны:
– так как положительный и отрицательный полюса конструкта представляют собой кластеры, в наибольшей степени отличающиеся друг от друга, то конструкты могут быть получены как результат кластерного анализа кластеров;
– конструкт может рассматриваться как кластер с нечеткими границами, включающий в различной степени, причем не только в положительной, но и отрицательной, все классы (признаки).
В теории рефлексивных АСУ АО, конструктивный анализ позволяет решить такие задачи, как:
1. Определение в принципе совместимых и в принципе несовместимых целевых состояний АОУ. Совместимыми называются целевые состояния, для достижения которых необходимы сходные предпосылки и управляющие воздействия, а несовместимыми – для которых они должны быть диаметрально противоположными.
Например, обычно сложно совмещаются такие целевые состояния, как очень высокое качество продукции и очень большое ее количество.
2. Определение факторов, имеющих не только сходное (это возможно и на уровне кластерного анализа), но и совершенно противоположное влияние на поведение сложного объекта управления.
Современный интеллект имеет дуальную структуру и, по сути дела, мыслит в системе кластеров и конструктов. Поэтому инструмент автоматизированного кластерно–конструктивного анализа может быть успешно применен для рефлексивного управления активными объектами.
Необходимо отметить, что формирование кластеров затруднено из-за проблемы комбинаторного взрыва, так как требует полного перебора и проверки "из n по m" сочетаний элементов (классов или признаков) в кластеры. Конструкты же формируются непосредственно из матрицы сходства прямой выборкой и сортировкой, что значительно проще в вычислительном отношении, так как конструктов значительно меньше, чем кластеров (всего n2). Поэтому учитывая, что при формировании конструктов автоматически формируются и их полюса, т.е. кластеры, в предложенной математической модели реализован не кластерный анализ, а сразу конструктивный (как более простой в вычислительном отношении и более ценный по получаемым результатам).
Диаграммы смыслового сходства–различия классов (признаков) соответствуют определению семантических сетей [64], т.е. представляют собой ориентированные графы, в которых признаки соединены линиями, соответствующими их смысловому сходству–различию.
Когнитивные диаграммы классов и признаков
В предложенной в настоящем исследовании математической модели в обобщенной постановке реализована возможность содержательного сравнения обобщенных образов классов распознавания и признаков, т.е. построения когнитивных диаграмм [64].
В информационных портретах классов
распознавания мы видим, какое количество информации о принадлежности (или не принадлежности) к данному классу мы получаем, обнаружив у некоторого объекта признаки, содержащиеся в информационном портрете.
В кластерно- конструктивном анализе мы получаем результаты сравнения классов распознавания друг с другом, т.е. мы видим, насколько они сходны и насколько отличаются. Но мы не видим, какими признаками они похожи и какими отличаются, и какой вклад каждый признак вносит в сходство или различие некоторых двух классов.
Эту информацию мы могли бы получить, если бы проанализировали и сравнили два информационных портрета. Эту работу и осуществляет режим содержательного сравнения классов распознавания.
Аналогично, в информационных портретах признаков
мы видим, какое количество информации о принадлежности (или не принадлежности) к различным классам распознавания мы получаем, обнаружив у некоторого объекта данный признак. В кластерно-конструктивном анализе мы получаем результаты сравнения признаков друг с другом, т.е. мы видим, насколько они сходны и насколько отличаются. Но мы не видим, какими классами они похожи и какими отличаются, и какой вклад каждый класс вносит в смысловое сходство или различие некоторых двух признаков.
Эту информацию мы могли бы получить, если бы проанализировали и сравнили информационные портреты двух признаков. Эту работу и осуществляет режим содержательного (смыслового) сравнения признаков.
Содержательное (смысловое) сравнение классов
Обобщим математическую модель, предложенную и развиваемую в данной главе, на случай содержательного сравнения двух классов распознавания: J–го и L–го.
Признаки, которые есть по крайней мере в одном из классов, будем называть связями, так как благодаря тому, что они либо тождественны друг другу, либо между ними имеется определенное сходство или различие по смыслу, они вносят определенный вклад в отношения сходства/различия между классами.
Список выявленных связей сортируется в порядке убывания модуля силы связи, причем учитывается не более заданного количества связей.
Пусть, например:
у J–го класса обнаружен i–й признак,
у L–го класса обнаружен k–й признак.
Используем те же обозначения, что и в разделе 3.1.
На основе обучающей выборки системой рассчитывается матрица абсолютных частот встреч признаков по классам (таблица 15).
В разделе 3.1. получено выражение (3.28) для расчета количества информации в i–м признаке о принадлежности некоторого конкретного объекта к j–му классу (плотность информации), которое имеет вид:
 |
(3.28) |
Аналогично, формула для количества информации в k–м признаке о принадлежности к L–му классу имеет вид:
 |
(3. 42) |
Вклад некоторого признака i в сходство/различие двух классов j и l равен соответствующему слагаемому корреляции образов этих классов, т.е. просто произведению информативностей
 |
(3. 43) |
Классический коэффициент корреляции Пирсона, количественно определяющий степень сходства векторов двух классов: j и l, на основе учета вклада каждой связи, образованной i–м признаком, рассчитывается по формуле
 |
(3. 44) |
где:
 |
– средняя информативность признаков j–го класса; |
 |
– средняя информативность признаков L–го класса; |
 |
– среднеквадратичное отклонение информативностей признаков j–го класса; |
 |
– среднеквадратичное отклонение информативностей признаков L–го класса. |
Проанализируем, насколько классический коэффициент корреляции Пирсона (3.62) пригоден для решения важных задач:
– содержательного сравнения классов;
– изучения внутренней многоуровневой структуры класса.
Упростим анализ, считая, что средние информативности признаков по обоим классам близки к нулю, что при достаточно больших выборках (более 400 примеров в обучающей выборке) практически близко к истине.
Каждое слагаемое (3.43) суммы (3.44) отражает связь между классами, образованную одним i–м признаком. I–я связь существует в том и только в том случае, если i–й признак есть у обоих классов. Поэтому эти связи уместно называть одно–однозначными.
Этот подход можно назвать классическим для когнитивного анализа. Рассмотрим когнитивную диаграмму, приведенную на стр. 222 работы основной работы классика когнитивной психологии Р.Солсо (Когнитивная психология. /Пер. с англ. - М.: Тривола, 1996. - 600с.) (рисунок 31).
 |
|
Рисунок 31. Когнитивная диаграмма из классической работы Роберта Солсо. |
В приведенной когнитивной диаграмме наглядно в графической форме показано сравнение классов (обобщенных образов) "Малиновка" и "Птица" разных уровней общности по их атрибутам (признакам). Как видно из диаграммы, в ней:
1. Все атрибуты имеют одинаковый вес, т.е. не учитывается, что некоторые атрибуты более важны для идентификации класса, чем другие. Это соответствует предположению, что этот вес равен по модулю 1 для всех атрибутов.
2. Все признаки имеют одинаковый знак, т.е. они все характерны для классов и нет атрибутов нехарактерных. Это соответствует предположению, что вес всех признаков положительный, т.е. все признаки вносят вклад в сходство и нет признаков, вносящих вклад в различие.
3. Классы сравниваются только по тем атрибутам, которые есть одновременно у них обоих, т.е. признаки, имеющиеся у обоих классов вносят вклад в сходство классов, а признаки, которые есть только у одного из классов не вносят никакого вклада ни в сходство классов, ни в различие. Это соответствует предположению, что атрибуты ортонормированы, т.е. корреляция их друг с другом равна 0 (атрибуты семантически не связаны).
Каждое из этих трех допущений является довольно сильным и желательно их снять и, тем самым, обобщить принцип построения когнитивных диаграмм, приведенный в данном примере.
Но это означает, что данный подход не позволяет сравнивать классы, описанные различными, т.е. непересекающимися наборами признаков. Но даже если общие признаки и есть, то невозможность учета вклада остальных признаков является недостатком классического подхода, так как из содержательного анализа связей неконтролируемо исключается потенциально существенная информация. Таким образом, классический подход имеет ограниченную применимость при решении задачи №1. Для решения задачи №2 подход, основанный на формуле (3.44), вообще не применим, так как различные уровни системной организации классов образованы различными признаками и, следовательно, между уровнями не будет ни одной одно–однозначной связи.
Основываясь на этих соображениях, предлагается в общем случае учитывать вклад в сходство/различие двух классов, который вносят не только общие, но и остальные признаки. Логично предположить, что этот вклад (при прочих равных условиях) будет тем меньше, чем меньше корреляция между этими признаками.
Следовательно, для обобщения выражения для силы связи (3.43) необходимо умножить произведение информативностей признаков на коэффициент корреляции между ними, отражающий степень сходства или различия признаков по смыслу.
Таким образом, будем считать, что любые два признака (i,k) вносят определенный вклад в сходство/различие двух классов (j,l), определяемый сходством/различием признаков и количеством информации о принадлежности к этим классам, которое содержится в данных признаках:
 |
(3. 45) |
где:

 |
(3. 46) |
где
 |
– средняя информативность координат вектора i–го признака; |
 |
– средняя информативность координат вектора k–го признака; |
 |
– среднеквадратичное отклонение координат вектора i–го признака; |
 |
– среднеквадратичное отклонение координат вектора k–го признака. |
Коэффициент корреляции между признаками (3.46) рассчитывается на основе всей обучающей выборки, а не только объектов двух сравниваемых классов. Так как коэффициент корреляции между признаками (3.46) практически всегда не равен нулю, то каждый признак i образует связи со всеми признаками k, где k={1,...,A}, а каждый признак k в свою очередь связан со всеми остальными признаками. Это означает, что выражение (3.45) является обобщением (3.43) с учетом много-многозначных связей.
На основе этих представлений сформулируем выражение для обобщенного коэффициента корреляции Пирсона между двумя классами: j и l, учитывающего вклад в их сходство/различие не только одно–однозначных, но и много–многозначных связей, образуемых коррелирующими признаками.
Когнитивные диаграммы с много–многозначными связями предлагается называть обобщенными когнитивными диаграммами.
 |
(3. 47) |
где Kik определяется выражением (3.46).
Сравним классический (3.44) и обобщенный (3.47) коэффициенты корреляции Пирсона друг с другом. Очевидно, при i=k (3.47) преобразуется в (3.44), т.е. соблюдается принцип соответствия. Отметим, что модель позволяет задавать минимальный коэффициент корреляции (порог) между признаками, образующими учитываемые связи. При пороге 100% отображаются только одно–однозначные связи, учитываемые в классическом коэффициенте корреляции (3.44). Из выражений (3.47) и (3.44) видно, что
 |
(3. 48) |
так как в обобщенном коэффициенте корреляции учитываются связи между классами, образованные за счет учета корреляций между различными признаками. Ясно, что отношение
 |
(3. 49) |
отражает степень избыточности описания классов. В модели имеется возможность исключения из системы признаков наименее ценных из них для идентификации классов. При этом в первую очередь удаляются сильно коррелирующие друг с другом признаки. В результате степень избыточности системы признаков уменьшается, и она становится ближе к ортонормированной.
Рассмотрим вопрос о единицах измерения, в которых количественно выражаются связи между классами.
Сходство двух признаков

Максимальная теоретически возможная информативность признака в Bit выражается формулой
 |
(3. 50) |
Таким образом, учитывая выражения (3.45) и (3.50) получаем, что максимальная теоретически возможная сила связи Rmax
равна
 |
(3. 51) |
В разработанном инструментарии СК-анализа, реализующем данную модель (описанном в лекции 6), реализован режим отображения когнитивной графики, где фактическая сила связи (3.45) в когнитивных диаграммах выражается в процентах от максимальной теоретически возможной силы связи (3.50). На графической диаграмме (рисунок 32) отображается 8 наиболее сильных по модулю связей, рассчитанных согласно формулы (3.47), причем знак связи изображается цветом (красный +, синий – ), а величина – толщиной линии.
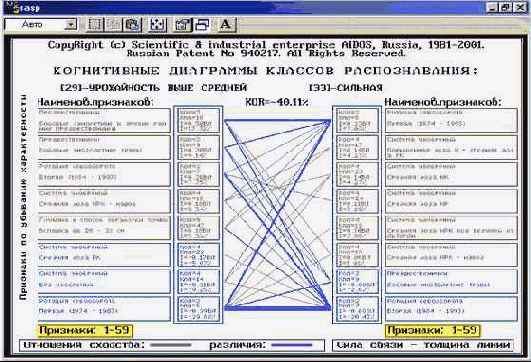 |
|
Рисунок 32. Когнитивная диаграмма конструкта классов "Качество-количество" |
Имеется возможность выводить диаграммы только с положительными или только с отрицательными связями (для не цветных принтеров).
Частным случаем предложенных в данной работе обобщенных когнитивных диаграмм являются известные диаграммы В.С.Мерлина (Очерк интегрального исследования индивидуальности. - М., 1986. - 187с.). Эти диаграммы представляют обобщенные когнитивные диаграммы, формируемые в соответствии с предложенной моделью при следующих граничных условиях:
1. Класс сравнивается сам с собой.
2. Фильтрация левого и правого информационных портретов выбрана по уровням системной организации признаков (в данном случае – уровням Мерлина, терм. авт.).
3. Левый класс отображается с фильтрацией по одному уровню системной организации, а правый – по другому.
4. Диалог задания вида диаграмм предоставляет пользователю возможность задать следующие параметры:
– способ нормирования толщины линий, отображающих связи: нормирование по текущей диаграмме или по всем диаграммам;
– способ фильтрации признаков в информационных портретах диаграммы: по диапазону признаков или по диапазону уровней системной организации (уровням Мерлина);
– сами диапазоны признаков или уровней для левого и правого информационных портретов;
– максимальное количество связей, отображаемых на диаграмме;
– уровень сходства признаков, образующих одну связь, отображаемую на диаграмме: от 0 до 100%. При уровне сходства 100% в диаграммах отображаются только связи, образованные теми признаками, которые есть в обоих портретах одновременно, т.е. взаимно–однозначные связи. При уровне сходства менее 100% вообще говоря связи становятся много–многозначными, так как каждый признак корреляционно связан со всеми остальными;
– уровень сходства классов, отображаемых на диаграмме.
Таким образом, в предлагаемой математической модели в общем виде реализована возможность содержательного сравнения обобщенных образов состояний АОУ и факторов, т.е.
построения когнитивных диаграмм [64], веса атрибутов определяются автоматически на основе исходных данных в соответствии с математической моделью и могут принимать различные по величине положительные и отрицательные значения. Кроме того на основе кластерного анализа атрибутов определяются корреляции между ними, которые учитываются при определении вклада атрибутов в сходство или различие классов. Поэтому отношения между атрибутами разных классов в когнитивной диаграмме не "один к одному", как в диаграмме на рисунке 31, а "многие ко многим" (рисунок 32).
В информационном портрете состояния АОУ показано, какое количество информации о принадлежности (не принадлежности) АОУ к данному состоянию, а также о переходе (не переходе) АОУ в данное состояние содержится в том факте, что на АОУ действуют факторы, содержащиеся в данном информационном портрете.
Кластерно-конструктивный анализ дает результат сравнения состояний АОУ друг с другом, т.е. показывает, насколько эти состояния сходны друг с другом и насколько отличаются друг от друга. Но он не показывает, какими факторами эти состояния АОУ похожи и какими отличаются, и какой вклад
каждый фактор вносит в сходство или различие каждых двух состояний. Чтобы получить эту информацию, необходимо проанализировать два информационных портрета, что и делается при содержательном сравнении состояний АОУ .
Смысл и значение диаграмм Мерлина применительно к проблематике АСУ состоит в том, что они наглядно представляют внутреннюю структуру детерминации состояний АОУ, т.е. показывают, каким образом связаны друг с другом факторы и будущие состояния АОУ.
Таким образом:
– для моделирования процессов принятия решений в рефлесивных АСУ активными системами целесообразно применение многокритериального подхода с аддитивным интегральным критерием, в котором в качестве частных критериев используется семантическая мера целесообразности информации (Харкевич, 1960);
– предложенная математическая модель обеспечивает эффективное решение следующих задач, возникающих при синтезе адаптивных АСУ АОУ: разработка абстрактной информационной модели АОУ; адаптация и конкретизация абстрактной модели на основе апостериорной информации о реальном поведении АОУ; расчет влияния факторов на переход АОУ в различные возможные состояния; прогнозирование поведения АОУ при конкретном управляющем воздействии и выработка многофакторного управляющего воздействия (основная задача АСУ); выявление факторов, вносящих основной вклад в детерминацию состояния АОУ; контролируемое удаление второстепенных факторов с низкой дифференцирующей способностью, т.е.
снижение размерности модели при заданных ограничениях; сравнение влияния факторов, сравнение целевых и других состояний АОУ.
Предложенная методология, основанная на теории информации, обеспечивает эффективное моделирование задач принятия решений в адаптивных АСУ сложными системами.
Содержательное (смысловое) сравнение признаков
Предложенная математическая модель позволяет осуществить содержательное сравнение информационных портретов двух признаков.
Выявляются классы, которые есть по крайней мере в одном из векторов. Такие классы называются связями, так как благодаря тому, что они либо тождественны друг другу, либо между ними имеется определенное сходство или различие, они вносят определенный вклад в отношения сходства/различия между признаками по смыслу.
Все связи между признаками сортируются в порядке убывания модуля, в соответствии с определенными ограничениями, связанными с тем, что нет необходимости учитывать очень слабые связи.
Для каждого класса известно, какое количество информации о принадлежности к нему содержит данный признак – это информативность. Здесь необходимо уточнить, что информативность признака – это не только количество информации в признаке о принадлежности к данному классу, но и количество информации в классе о том, что при нем наблюдается данный признак, т.е. это взаимная информация класса и признака.
Если бы классы были тождественны друг другу, т.е. это был бы один класс, то его вклад в сходство/различие двух признаков был бы просто равен соответствующему данному классу слагаемому корреляции этих признаков, т.е. просто произведению информативностей.
Но поскольку это в общем случае это могут быть различные классы, то, очевидно, необходимо умножить произведение информативностей на коэффициент корреляции между классами.
Таким образом, будем считать, что любые два класса (j,l) вносят определенный вклад в сходство/различие двух признаков (i,k), определяемый сходством/различием этих классов и количеством информации о принадлежности к ним, которое содержится в данных признаках
 |
(3. 52) |
Вывод формулы (3.52) обобщенного коэффициента корреляции Пирсона для двух признаков совершенно аналогичен выводу формулы (3.47), поэтому он здесь не приводится. Формулы для всех входящих в (3.52) величин приведены выше в предыдущем разделе.
Так же, как и в режиме содержательного сравнения классов, в данном режиме сила связи выражается в процентах от максимальной теоретически–возможной силы связи. На диаграммах отображается 16 наиболее значимых связей, рассчитанных согласно этой формуле, причем знак связи изображается цветом (красный +, синий –), а величина – толщиной линии. Имеется возможность вывода диаграмм только с положительными или только с отрицательными связями.
Математическая модель позволяет получить обобщенные инвертированные когнитивные диаграммы для любых двух заданных признаков, для пар наиболее похожих и непохожих признаков, для всех их возможных сочетаний, а также инвертированные диаграммы Мерлина.
Необходимо отметить, что понятия, соответствующие по смыслу терминам "обобщенная инвертированная когнитивная диаграмма" и "инвертированная диаграмма Мерлина" не упоминаются даже в фундаментальных руководствах по когнитивной психологии и впервые предложены в [92]. Эти диаграммы представляют собой частный случай обобщенных когнитивных диаграмм признаков, формируемых в соответствии с предложенной математической моделью при следующих ограничениях:
1. Признак сравнивается сам с собой.
2. Выбрана фильтрация левого и правого вектора по уровням системной организации классов (аналог уровней Мерлина для свойств).
3. Левый вектор отображается с фильтрацией по одному уровню системной организации классов, а правый – по другому.
Обоснование сопоставимости частных критериев Iij
Применение этого метода корректно, если можно сравнивать суммарное количество информации о переходе АОУ в различные состояния, рассчитанное в соответствии с выражением (3.44), т.е. если они сопоставимы друг с другом.
Будем считать, что величины сопоставимы тогда и только тогда, когда одновременно выполняются следующие три условия:
1. Сопоставимы индивидуальные количества информации, содержащейся в признаках о принадлежности к классам.
2. Сопоставимы величины, рассчитанные для одного объекта и разных классов.
3. Сопоставимы величины, рассчитанные для разных объектов и разных классов.
Очевидно, для решения всех этих вопросов необходимо дать точное и полное определение самого термина "сопоставимость".
Считается, что величины сопоставимы, если существует некоторая количественная шкала для измерения этих величин.
Таким образом, в нашем случае сопоставимость обеспечивается, если на шкале определены направление и единица измерения, а также есть абсолютный минимум (ноль) или максимум.
Докажем теоремы о выполнении условий сопоставимости для упрощенной и полной информационных моделей объектов и классов распознавания. Для этого рассмотрим вышеперечисленные необходимые и достаточные условия сопоставимости для упрощенной и полной информационных моделей.
Теорема-1: Индивидуальные количества информации, содержащейся в признаках объекта о принадлежности к классам, сопоставимы между собой.
В упрощенной информационной модели класса и информационной модели объекта принято, что все признаки имеют одинаковый вес, который равен 1, если признак есть у класса, и 0, если его нет. Уже одним этим обеспечивается сопоставимость индивидуальных количеств информации в упрощенной модели.
В полной модели количество информации рассчитывается в соответствии с модифицированной формулой Харкевича (3.28). Таким образом, в полной информационной модели класса для каждого признака известно, какое количество информации о принадлежности к данному классу он содержит. Это количество информации может быть положительным, нулевым и отрицательным, но не может превосходить некоторой максимальной величины, определяемой количеством классов распознавания: I=Log2W (мера Хартли), где W – количество классов распознавания. Следовательно, для полной информационной модели сопоставимость индивидуальных количеств информации также обеспечивается, так как для них применима шкала отношений.
Это означает, что индивидуальные количества информации можно суммировать и ввести интегральный критерий как аддитивную меру от индивидуальных количеств информации, что и требовалось доказать.
Теорема-2: Величины суммарной информации, рассчитанные для одного объекта и разных классов, сопоставимы друг с другом.
В упрощенной информационной модели вариант расстояния Хэмминга Hj, в котором учитываются только совпадения единиц (т.е. существующих признаков), для кодовых слов объекта и класса равно:
 |
(3. 53) |
где


Li – кодовое слово (профиль, массив–локатор) объекта.

Пусть длина кодового слова (количество признаков) равна А. Длины кодовых слов объекта и классов одинаковы. Признаки могут принимать значения {0,1}. Тогда из этих условий и выражения (3.53) следует:
 |
(3. 54) |
Но выражение (3.54) является математическим определением шкалы отношений, что означает полную сопоставимость предложенной меры сходства для упрощенной информационной модели одного объекта и многих классов. Для обобщенной информационной модели этот вывод сохраняет силу, т.к. в этой модели информация в соответствии с выражением (3.28) измеряется в единицах измерения – битах, определенных на шкале измерения информации, и на этой шкале имеется 0 и теоретический максимум, определяемый в соответствии с выражением Хартли. В полной информационной модели мера сходства объекта с классом

Очевидно, величина
 |
(3. 55) |
что и доказывает применимость шкалы отношений и полную сопоставимость меры сходства для полной информационной модели одного объекта и многих классов.
Это значит, что можно сравнивать меры сходства данного объекта с каждым из классов и ранжировать классы в порядке убывания сходства с данным объектом , что и требовалось доказать.
Теорема-3: Величины суммарной информации, рассчитанные для разных объектов и разных классов, а также классов и классов, признаков и признаков, взаимно-сопоставимы.
Очевидно, величина

 |
(3. 56) |
что и доказывает применимость шкалы отношений и полную сопоставимость мер сходства для полной информационной модели многих объектов и многих классов.
Это значит, что можно сравнивать меры сходства различных объектов с классами распознавания и делать выводы о том, что одни объекты распознаются лучше, а другие хуже на данном наборе классов и признаков, что и т.д.
Аналогичные рассуждения верны и для сравнения векторов классов друг с другом, а также векторов признаков друг с другом, что позволяет применить модели кластерно-конструктивного анализа и алгоритмы построения семантических сетей, что и требовалось доказать.
Теорема-4: Неметрический интегральный критерий сходства, основанный на модифицированной формуле А.Харкевича и обобщенной лемме Неймана-Пирсона, аддитивен.
Рассмотрим информационные модели распознаваемого объекта и классов распознавания, т.е. модели, основанные на теории кодирования – декодирования и расстоянии Хэмминга (кодовое расстояние) в качестве критерия сходства. Эта модель является упрощенной, но достаточно адекватной для решения вопроса об аддитивности меры сходства объектов и классов.
Информационная модель распознаваемого объекта представляет собой двоичное слово, каждый разряд которого соответствует определенному признаку. Если признак есть у распознаваемого объекта, то соответствующий разряд имеет значение 1, если нет – то 0. Двоичное слово с установленными в 1 разрядами, соответствующими признакам распознаваемого объекта, называется его кодовым словом.
Упрощенная информационная модель класса распознавания есть двоичное слово, каждый разряд которого соответствует определенному признаку. Соответствие между двоичными разрядами и признаками для классов то же самое, что и для распознаваемых объектов. Если признак есть у класса, то соответствующий разряд имеет значение 1, если нет – то 0. Двоичное слово с установленными в 1 разрядами, соответствующими признакам класса, называется его кодовым словом.
Такая модель класса является упрощенной, так как в ней принято, что все признаки имеют одинаковый вес равный 1, если он есть у класса, и 0, если его нет, тогда как в полной информационной модели класса для каждого признака известно, какое количество информации о принадлежности к данному классу он содержит. Это количество информации может быть положительным, нулевым и отрицательным, но не может превосходить некоторой максимальной величины, определяемой количеством классов распознавания: I=Log2W (мера Хартли), где W – количество классов.
Таким образом, в упрощенной информационной модели различные классы распознавания отличаются друг от друга только наборами признаков, которые им соответствуют.
При использовании этих упрощенных моделей задача распознавания объекта сводится к задаче декодирования, т.е. кодовые слова объектов рассматриваются как искаженные зашумленным каналом связи кодовые слова классов. Распознавание состоит в том, что по кодовому слову объекта определяется наиболее близкое ему в определенном смысле кодовое слово класса. При этом естественной и наиболее простой мерой сходства между распознаваемым объектом и классом является расстояние Хэмминга между их кодовыми словами, т.е. количество разрядов, которыми они отличаются друг от друга.
Рассмотрим теперь вопрос об аддитивности количества информации как частного критерия в интегральном критерии.
Известно [148], что существует всего два варианта формирования интегрального критерия из частных критериев: аддитивный и мультипликативный, поэтому задача сводится к выбору одного из этих вариантов.
Рассмотрим эти варианты. Пусть кодовое слово объекта состоит из N разрядов. Тогда добавление еще одного разряда, отображающего имеющийся (1) или отсутствующий (0) признак, приведет к различным результатам в случаях, когда интегральный критерий есть аддитивная и мультипликативная функция индивидуальных количеств информации в признаках (таблица 19).
|
Таблица 19 – СРАВНЕНИЕ АДДИТИВНОГО И МУЛЬТИПЛИКАТИВНОГО ВАРИАНТОВ ИНТЕГРАЛЬНОГО КРИТЕРИЯ |
||
|
Дополнительный признак |
Аддитивная функция:  |
Мультипликативная функция:  |
|
Есть (1) |
 |
 |
|
Нет (0) |
 |
 |
Здесь предполагается, что: I=f(n), f(1)=1, f(0)=0.
Итак, если функция аддитивна – добавление еще одного разряда увеличит количество информации в кодовом слове на 1 бит, если соответствующий признак есть, и не изменит этого количества, если его нет; если же функция мультипликативна, – то это не изменит количества информации в кодовом слове, если соответствующий признак есть, и сделает его равным нулю, если его нет.
Очевидно, мультипликативный вариант интегрального критерия не соответствует классическим представлениям о природе информации, тогда как аддитивный вариант полностью им соответствует: требование аддитивности самой меры информации было впервые обосновано Хартли в 1928 году, подтверждено Шенноном в 1948 году, и в последующем развитии теории информации никогда не подвергалось сомнению. На аддитивности частных критериев, имеющих смысл количества информации, основана известная лемма Неймана-Пирсона [148, стр.152].
Пусть по выборке (т.е. совокупности факторов) {x=x1,…, xN} требуется отдать предпочтение одной из конкурирующих гипотез (H1 или H0), т.е. определить в какое будущее состояние перейдет объект управления, если известны распределения наблюдений при каждой из них (по данным обучающей выборки), т.е. р(х|H0) и р(х|H1). Как обработать предпочтительную гипотезу? Из теории информации известно, что никакая обработка не может увеличить количества информации, содержащегося в выборке {х}. Следовательно, выборке {х} нужно поставить в соответствие число, содержащее всю полезную информацию, т.е. обработать выборку без потерь. Возникает мысль о у том, чтобы вычислить индивидуальные количества информации в выборке {х} о каждой из гипотез и сравнить их:
 |
Какой из гипотез отдать предпочтение, зависит теперь от величины Di и от того, какой порог сравнения мы назначим. Оптимальность данной статистической процедуры специально доказывается в математической статистике, – именно к этому сводится содержание фундаментальной Леммы Неймана-Пирсона, которая утверждает, что предпочтение следует отдавать той статистической гипотезе, о которой в выборке содержится больше информации.
Согласно описанной выше процедуре предполагается, что объект управления перейдет в то будущее состояние, о переходе в которое в системе факторов содержится большее суммарное количество информации.
Таким образом, аддитивность интегрального критерия, основанного на частных критериях, имеющих смысл количества информации, можно считать обоснованной, что и требовалось доказать.
Решение задачи "Синтез семантической информационной модели активного объекта управления"
Исходные данные для выявления взаимосвязей между факторами и состояниями объекта управления предлагается представить в виде корреляционной матрицы – матрицы абсолютных частот (таблица 15):
| Таблица 15 – МАТРИЦА АБСОЛЮТНЫХ ЧАСТОТ | |
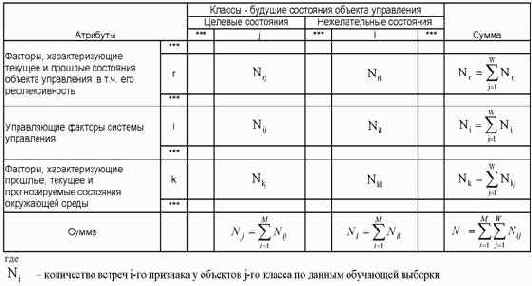 |
В этой матрице в качестве классов (столбцов) приняты будущие состояния объекта управления, как целевые, так и нежелательные, а в качестве атрибутов (строк) – факторы, которые разделены на три основных группы, математически обрабатываемые единообразно: факторы, характеризующие текущее и прошлые состояния объекта управления; управляющие факторы системы управления; факторы, характеризующие прошлые, текущее и прогнозируемые состояния окружающей среды. Отметим, что форма таблицы 15 является универсальной формой представления и обобщения фактов – эмпирических данных
в единстве их дискретного и интегрального представления (причины – следствия, факторы – результирующие состояния, признаки – обобщенные образы классов, образное – логическое и т.п.).
Управляющие факторы объединяются в группы, внутри каждой из которых они альтернативны (несовместны), а между которыми - нет (совместны). В этом случае внутри каждой группы выбирают одно из доступных управляющих воздействий с максимальным влиянием. Варианты содержательной информационной модели без учета прошлых состояний объекта управления и с их учетом, аналогичны, соответственно, простым и составным цепям Маркова, автоматам без памяти и с памятью.
В качестве количественной меры влияния факторов, предложено использовать обобщенную формулу А.Харкевича (3.28), полученную на основе предложенной эмерджентной теории информации. При этом по формуле (3.28) непосредственно из матрицы абсолютных частот (таблица 15) рассчитывается матрица информативностей (таблица 16), которая и представляет собой основу содержательной информационной модели предметной области.
| Таблица 16 – МАТРИЦА ИНФОРМАТИВНОСТЕЙ | |
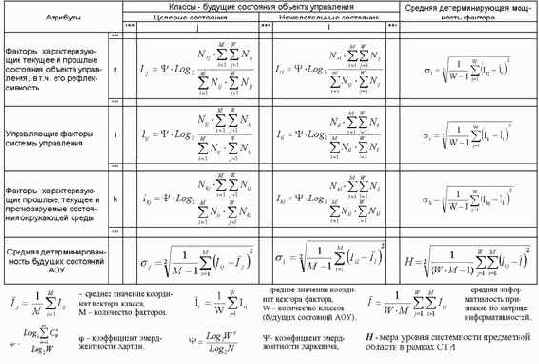 |
Весовые коэффициенты таблицы 3.28 непосредственно определяют, какое количество информации Iij система управления получает о наступлении события: "активный объект управления перейдет в j–е состояние", из сообщения: "на активный объект управления действует i–й фактор".
Принципиально важно, что эти весовые коэффициенты не определяются экспертами неформализуемым способом, а рассчитываются непосредственно
на основе эмпирических данных и удовлетворяют всем ранее сформулированным требованиям, т.е. являются сопоставимыми, содержательно интерпретируемыми, отражают понятия "достижение цели управления" и "мощность множества будущих состояний объекта управления" и т.д.
В данном исследовании обосновано, что предложенная информационная мера обеспечивает сопоставимость индивидуальных количеств информации, содержащейся в факторах о классах, а также сопоставимость интегральных критериев, рассчитанных для одного объекта и разных классов, для разных объектов и разных классов.
Когда количество информации Iij>0
– i–й фактор способствует переходу объекта управления в j–е
состояние, когда Iij<0 – препятствует этому переходу, когда же Iij=0 – никак не влияет на это. В векторе i–го
фактора (строка матрицы информативностей) отображается, какое количество информации о переходе объекта управления в каждое из будущих состояний содержится в том факте, что данный фактор действует. В векторе j–го состояния класса (столбец матрицы информативностей) отображается, какое количество информации о переходе объекта управления в соответствующее состояние содержится в каждом из факторов.
Таким образом, матрица информативностей (таблица 16) является обобщенной таблицей решений, в которой входы (факторы) и выходы (будущие состояния АОУ) связаны друг с другом не с помощью классических (Аристотелевских) импликаций, принимающих только значения: "Истина" и "Ложь", а различными значениями истинности, выраженными в битах
и принимающими значения от положительного теоретически-максимально-возможного ("Максимальная степень истинности"), до теоретически неограниченного отрицательного ("Степень ложности").
Фактически предложенная модель позволяет осуществить синтез обобщенных таблиц решений для различных предметных областей непосредственно на основе эмпирических исходных данных и продуцировать на их основе прямые и обратные правдоподобные (нечеткие) логические рассуждения по неклассическим схемам с различными расчетными значениями истинности, являющимся обобщением классических импликаций (таблица 17).
|
Таблица 17 – ПРЯМЫЕ И ОБРАТНЫЕ ПРАВДОПОДОБНЫЕ ЛОГИЧЕСКИЕ ВЫСКАЗЫВАНИЯ С РАСЧЕТНОЙ (В СООТВЕТСТВИИ С СТИ) СТЕПЕНЬЮ ИСТИННОСТИ ИМПЛИКАЦИЙ |
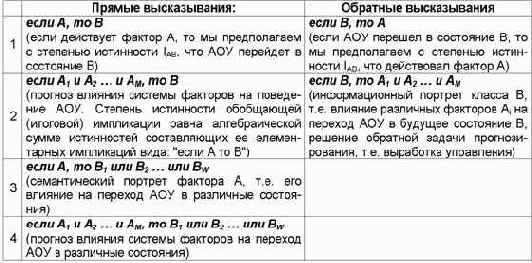 |
Приведем пример более сложного высказывания, которое может быть рассчитано непосредственно на основе матрицы информативностей – обобщенной таблицы решений (таблица 16):
Если A, со степенью истинности a(A,B) детерминирует B, и если С, со степенью истинности a(C,D) детерминирует D, и A совпадает по смыслу с C со степенью истинности a(A,C), то это вносит вклад в совпадение B с D, равный степени истинности a(B,D).
При этом в прямых рассуждениях как предпосылки рассматриваются факторы, а как заключение – будущие состояния АОУ, а в обратных – наоборот: как предпосылки – будущие состояния АОУ, а как заключение – факторы. Степень истинности i-й предпосылки – это просто количество информации Iij, содержащейся в ней о наступлении j-го будущего состояния АОУ. Если предпосылок несколько, то степень истинности наступления j-го состояния АОУ равна суммарному количеству информации, содержащемуся в них об этом. Количество информации в i-м факторе о наступлении j-го состояния АОУ, рассчитывается в соответствии с выражением (3.28) СТИ.
Прямые правдоподобные логические рассуждения позволяют прогнозировать степень достоверности наступления события по действующим факторам, а обратные – по заданному состоянию восстановить степень необходимости и степень нежелательности каждого фактора для наступления этого состояния, т.е. принимать решение по выбору управляющих воздействий на АОУ, оптимальных для перевода его в заданное целевое состояние.
Необходимо отметить, что предложенная модель, основывающаяся на теории информации, обеспечивает автоматизированное формирования системы нечетких правил по содержимому входных данных, как и комбинация нечеткой логики Заде-Коско с нейронными сетями Кохонена. Принципиально важно, что качественное изменение модели путем добавления в нее новых классов не уменьшает достоверности распознавания уже сформированных классов.
Кроме того, при сравнении распознаваемого объекта с каждым классом учитываются не только признаки, имеющиеся у объекта, но и отсутствующие у него, поэтому предложенной моделью правильно идентифицируются объекты, признаки которых образуют множества, одно из которых является подмножеством другого (как и в Неокогнитроне К.Фукушимы) [197].
Данная модель позволяет прогнозировать поведение АОУ при воздействии на него не только одного, но и целой системы факторов:
 |
(3. 35) |
В теории принятия решений скалярная функция Ij
векторного аргумента называется интегральным критерием. Основная проблема состоит в выборе такого аналитического вида функции интегрального критерия, который обеспечил бы эффективное решение сформулированной выше задачи АСУ.
Учитывая, что частные критерии (3.28) имеют смысл количества информации, а информация по определению является аддитивной функцией, предлагается ввести интегральный критерий, как аддитивную функцию от частных критериев в виде:
 |
(3. 36) |
В выражении (3.54) круглыми скобками обозначено скалярное произведение. В координатной форме это выражение имеет вид:
 |
(3. 37) |
где:



В реализованной модели значения координат вектора состояния ПО принимались равными либо 1 (фактор действует), либо 0 (фактор не действует).
Таким образом, интегральный критерий
представляет собой суммарное количество информации, содержащееся в системе факторов различной природы (т.е. факторах, характеризующих объект управления, управляющее воздействие и окружающую среду) о переходе активного объекта управления в будущее (в т.ч. целевое или нежелательное) состояние.
В многокритериальной постановке задача прогнозирования состояния объекта управления, при оказании на него заданного многофакторного управляющего воздействия Ij, сводится к максимизации интегрального критерия:
 |
(3. 38) |
т.е. к выбору такого состояния объекта управления, для которого интегральный критерий максимален.
Задача принятия решения о выборе наиболее эффективного управляющего воздействия является обратной задачей по отношению к задаче максимизации интегрального критерия (идентификации и прогнозирования), т.е. вместо того, чтобы по набору факторов прогнозировать будущее состояние АОУ, наоборот, по заданному (целевому) состоянию АОУ определяется такой набор факторов, который с наибольшей эффективностью перевел бы объект управления в это состояние.
Предлагается еще одно обобщение этой фундаментальной леммы, основанное на косвенном учете корреляций между информативностями в векторе состояний при использовании средних по векторам. Соответственно, вместо простой суммы количеств информации предлагается использовать корреляцию между векторами состояния и объекта управления, которая количественно измеряет степень сходства этих векторов:
 |
(3. 39) |
где:




Выражение (3.39) получается непосредственно из (3.37) после замены координат перемножаемых векторов их стандартизированными значениями:

Результат прогнозирования поведения объекта управления, описанного данной системой факторов, представляет собой список его возможных будущих состояний, в котором они расположены в порядке убывания суммарного количества информации о переходе объекта управления в каждое из них.
Сравнения результатов идентификации и прогнозирования с опытными данными, с использованием выражений (3.37) и (3.39), показали, что при малых выборках они практически не отличаются, но при увеличении объема выборки до 400 и более (независимо от предметной области) выражение (3.39) дает погрешность идентификации (прогнозирования) на 5% – 7% меньше, чем (3.37).
Поэтому в предлагаемой модели фактически используется не метрическая мера сходства (3.39).
В связи с тем, что в дальнейшем изложении широко применяются понятия теории АСУ, теории информации (связи), теории распознавания образов и методов принятия решений, приведем таблицу соответствия наиболее часто используемых нами терминов из этих научных направлений, имеющих сходный смысл (таблица 18):
|
Таблица 18 – СООТВЕТСТВИЕ ТЕРМИНОВ РАЗЛИЧНЫХ НАУЧНЫХ НАПРАВЛЕНИЙ |
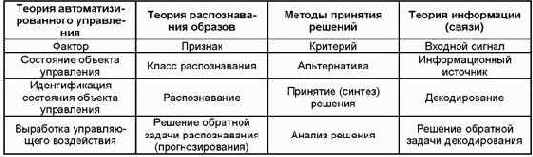 |
Вывод системного обобщения формулы Харкевича (3.28) приведен в разделе 3.1 данной работы. Чрезвычайно важное для данного исследования выражение (3.28) заслуживает специального комментария. Прежде всего нельзя не обратить внимания на то, что оно по своей математической форме, т.е. формально, ничем не отличается от выражения для превышения сигнала над помехой для информационного канала [196]. Из этого, на первый взгляд, внешнего совпадения следует интересная интерпретация выражения (3.28). А именно: можно считать, что обнаружив некоторый i–й признак у объекта, предъявленного на распознавание, мы тем самым получаем сигнал, содержащий некоторое количество информации

о том, что этот объект принадлежит к j–му классу. По–видимому, это так и есть, однако чтобы оценить насколько много или мало этой информации нами получено, ее необходимо с чем–то сравнить, т.е. необходимо иметь точку отсчета или базу для сравнения. В качестве такой базы естественно принять среднее по всем признакам количество информации, которое мы получаем, обнаружив этот j–й класс:

Иначе говоря, если при предъявлении какого–либо объекта на распознавание у него обнаружен i–й признак, то для того, чтобы сделать из этого факта обоснованный вывод о принадлежности этого объекта к тому или иному классу, необходимо знать и учесть, насколько часто вообще (т.е. в среднем) обнаруживается этот признак при предъявлении объектов данного класса.
Фактически это среднее количество информации можно рассматривать как некоторый "информационный шум", который имеется в данном признаке и не несет никакой полезной информации о принадлежности объектов к тем или иным классам.
Полезной же информацией является степень отличия от этого шума. Таким образом классическому выражению Харкевича (3.12) для семантической целесообразности информации может быть придан более привычный для теории связи вид:

который интерпретируется как вычитание шума из полезного сигнала. Эта операция является совершенно стандартной в системах шумоподавления.
Если полезный сигнал выше уровня шума, то его обнаружение несет информацию в пользу принадлежности объекта к данному классу, если нет – то, наоборот, в пользу не принадлежности.
Возвращаясь к выражению (3.12), необходимо отметить, что сам А.А.Харкевич рассматривал



Необходимо отметить также, что каждый признак объекта управления как канала связи может быть охарактеризован динамическим диапазоном, равным разности максимально возможного (допустимого) уровня сигнала в канале и уровня помех в логарифмическом масштабе:

Максимальное количество информации, которое может содержаться в признаке, полностью определяется количеством классов распознавания W и равно количеству информации по Хартли: I=Log2W.
Динамический диапазон признака является количественной мерой его полезности (ценности) для распознавания, но все же предпочтительней для этой цели является среднее количество полезной для классификации информации в признаке, т.е. исправленное выборочное среднеквадратичное отклонение информативностей:
 |
(3. 40) |
Очевидна близость этой меры к длине вектора признака в семантическом пространстве атрибутов:
 |
(3. 41) |
В сущности выражение (3.40) просто представляет собой нормированный вариант (3.41).
Решить задачи идентификации и прогнозирования.
Идентификация проводится во 2-м режиме 4-й подсистемы системы "Эйдос". Результаты идентификации выводятся в форме карточек в 1-й и 2-й функциях 3-го режима 4-й подсистемы системы "Эйдос" (примеры карточек на рисунке 172).
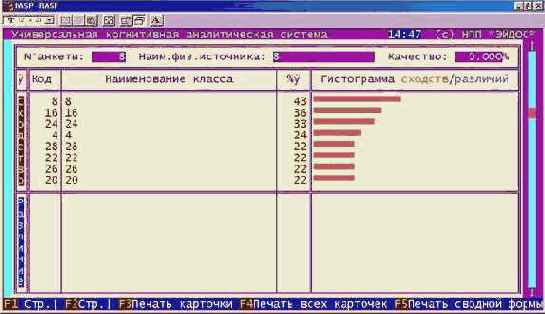 | |
| Рисунок 172. Пример карточки идентификации объекта с классами |
После выполнения 2-го режима 4-й подсистемы "Распознавание" в 1-й функции 3-го режима 4-й подсистемы получаем итоговую форму по результатам идентификации (таблица 88).
Таблица 88 – ИТОГОВЫЕ РЕЗУЛЬТАТЫ ИДЕНТИФИКАЦИИ
| Объект | Класс | Сходство | |||||||
| Код | Наименован. | Код | Наименован. | ||||||
| 1 | Шар | 1 | Шар | 94,083 | |||||
| 2 | Шар-11 | 1 | Шар | 76,819 | |||||
| 3 | Шар-12 | 1 | Шар | 76,819 | |||||
| 4 | Шар-23 | 1 | Шар | 76,819 | |||||
| 5 | Шар-123 | 1 | Шар | 54,319 | |||||
| 6 | Тетраэдр | 6 | Тетраэдр | 94,257 | |||||
| 7 | Тетраэдр-11 | 6 | Тетраэдр | 76,960 | |||||
| 8 | Тетраэдр-12 | 6 | Тетраэдр | 76,960 | |||||
| 9 | Тетраэдр-23 | 6 | Тетраэдр | 76,960 | |||||
| 10 | Тетраэдр-123 | 6 | Тетраэдр | 54,419 | |||||
| 11 | Куб | 11 | Куб | 94,189 | |||||
| 12 | Куб-11 | 11 | Куб | 76,905 | |||||
| 13 | Куб-12 | 11 | Куб | 76,905 | |||||
| 14 | Куб-23 | 11 | Куб | 76,905 | |||||
| 15 | Куб-123 | 11 | Куб | 54,380 | |||||
| 16 | Конус | 16 | Конус | 92,171 | |||||
| 17 | Конус-11 | 17 | Конус-11 | 75,941 | |||||
| 18 | Конус-12 | 20 | Конус-123 | 77,354 | |||||
| 19 | Конус-23 | 20 | Конус-123 | 82,367 | |||||
| 20 | Конус-123 | 20 | Конус-123 | 69,532 |
Продолжение таблицы 88
| Объект | Класс | Сходство | |||||||
| Код | Наименован. | Код | Наименован. | ||||||
| 21 | Пирамида | 21 | Пирамида | 94,257 | |||||
| 22 | Пирамида-11 | 22 | Пирамида-11 | 66,725 | |||||
| 23 | Пирамида-12 | 23 | Пирамида-12 | 64,571 | |||||
| 24 | Пирамида-23 | 24 | Пирамида-23 | 62,412 | |||||
| 25 | Пирамида-123 | 32 | Призма-11 | 44,934 | |||||
| 26 | Цилиндр | 26 | Цилиндр | 92,128 | |||||
| 27 | Цилиндр-11 | 27 | Цилиндр-11 | 77,694 | |||||
| 28 | Цилиндр-12 | 27 | Цилиндр-11 | 77,694 | |||||
| 29 | Цилиндр-23 | 30 | Цилиндр-123 | 82,136 | |||||
| 30 | Цилиндр-123 | 30 | Цилиндр-123 | 69,328 | |||||
| 31 | Призма | 31 | Призма | 94,189 | |||||
| 32 | Призма-11 | 32 | Призма-11 | 67,933 | |||||
| 33 | Призма-12 | 33 | Призма-12 | 63,420 | |||||
| 34 | Призма-23 | 34 | Призма-23 | 62,412 | |||||
| 35 | Призма-123 | 32 | Призма-11 | 44,934 |
Из таблицы 88 видно, что объект "Пирамида-123" неверно идентифицирован как класс "Призма-11". В остальных случаях тип объекта идентифицирован верно, что не исключает в ряде случаев неверной идентификации вида проекции (что, конечно, не имеет отношения к телам Платона – первым трем классам). Карточка, дающая расшифровку результатов идентификации 25-го объекта "Пирамида-123", представлена на рисунке 182.
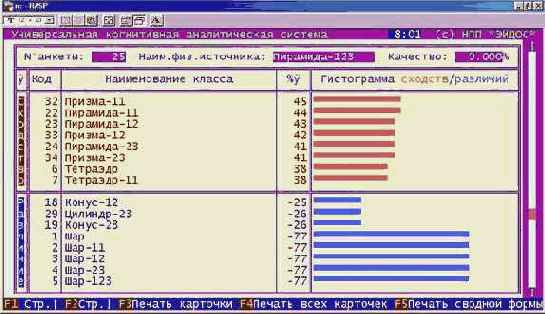 |
|
Рисунок 182. Карточка результатов идентификации объекта 25. |
С целью поиска путей автоматизации
1. С целью поиска путей автоматизации системного анализа проанализированы различные его варианты, предложенные ведущими учеными в этой области. Показана несостоятельность мнения о том, что автоматизацию системного анализа осуществить тем проще, чем более он детализирован. Отмечена не системность самой этой идеи, противоречащая духу системного анализа.
2. Предложена альтернативная идея поиска путей автоматизации системного анализа на пути его интеграции с когнитивными технологиями. В рамках этой идеи предложено структурировать системный анализ до уровня базовых когнитивных операций, достаточно элементарных, чтобы их было возможно автоматизировать при современном уровне развития науки и техники.
3. Для выявления базовых когнитивных операций разработана формализуемая когнитивная концепция. В ней процесс познания рассматривается как многоуровневая иерархическая система обработки информации, в которой когнитивные структуры каждого последующий уровня является результатом интеграции структур предыдущего уровня:
на 1-м уровне этой системы находятся дискретные элементы потока чувственного восприятия, которые получаются непосредственно от органов чувств и рассматриваются как исходная информация о реальности;
на 2-м уровне дискретные элементы потока чувственного восприятия интегрируются в чувственные образы конкретных объектов и факторов, которым присваиваются конкретные имена;
на 3-м уровне конкретные чувственные образы объектов и факторов интегрируются в обобщенные образы классов и факторов, которым присваиваются обобщенные и символические имена (обобщение и абстрагирование);
на 4-м уровне обобщенные образы классов и факторов сравниваются друг с другом и классифицируются в кластеры;
на 5-м уровне кластеры классов и факторов сравниваются друг с другом и образуют бинарные и многополюсные конструкты;
на 6-м уровне конструкты классов и факторов образуют текущую парадигму реальности, формулируется гипотеза о том, что человек познает мир путем синтеза и применения конструктов;
Результаты и перспективы
Таким образом, предлагаемый подход позволяет решить следующие задачи:
1) разработка выводов о состоянии и динамике объекта управления на основе сбора и анализа информации;
2) разработка рекомендаций по способам и содержанию управляющих воздействий на объект управления;
3) подготовка регламентных тематических и сводных аналитических отчетов (ежедневных, недельных, месячных, квартальных и годовых отчетов), а также заказных отчетов по ранее проведенным исследованиям.
Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью технологий data mining в сфере розничной торговли:
Анализ покупательской корзины предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.
Исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа «Если сегодня покупатель приобрел видеокамеру, то, через какое время он вероятнее всего купит новые батарейки и пленку?»
Создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
Семантическая информационная модель, как нелокальная нейронная сеть
Учитывая большое количество содержательных параллелей между семантической информационной моделью и нейронными сетями предлагается рассматривать данную модель как нейросетевую модель, основанную на системной теории информации. В данной модели предлагается вариант решения важных нейросетевых проблем интерпретируемости и ограничения размерности за счет введения меры целесообразности информации (системное обобщение формулы Харкевича), обеспечивающей прямой расчет интерпретируемых весовых коэффициентов на основе непосредственно эмпирических данных. Итак, в данной работе предлагается новый класс нейронных сетей, основанных на семантической информационной модели и информационном подходе. Для этих сетей предлагается полное наименование: "Нелокальные интерпретируемые нейронные сети прямого счета" и сокращенное наименование: "Нелокальные нейронные сети".
Нелокальная нейронная сеть является системой нелокальных нейронов, обладающей качественно новыми (системными, эмерджентными) свойствами, не сводящимися к сумме свойств нейронов. В такой сети поведение нейронов определяется как их собственными свойствами и поступающими на них входными сигналами, так и свойствами нейронной сети в целом, т.е. поведение нейронов в нелокальной нейронной сети согласовано друг с другом не только за счет их прямого и опосредованного синаптического взаимодействия (как в традиционных нейронных сетях), но за счет общего информационного поля весовых коэффициентов всех нейронов данной сети.
Семантическая информационная модель СК-анализа
Основная проблема, решаемая в аналитической модели: выбор способа вычисления весовых коэффициентов, отражающих степень и характер влияния факторов на переход активного объекта управления в различные состояния.
Основное отличие предлагаемого подхода от методов обобщения экспертных оценок состоит в том, что в предлагаемом подходе от экспертов требуется лишь само решение, а весовые коэффициенты автоматически подбираются в соответствии с моделью таким образом, что в сходных случаях будут приниматься решения, аналогичные предлагаемым экспертами. В традиционных подходах от экспертов требуют либо самих весовых коэффициентов, либо правил принятия решения (продукций).
Семантическая устойчивость модели
Под семантической устойчивостью модели [64] нами понимается ее свойство давать малое различие в прогнозе при замене одних факторов, другими, мало отличающимися по смыслу (т.е. сходными по их влиянию на поведение АОУ). Проведенные автором исследования численные эксперименты в течение 1987 – 2003 годов показали, что разработанная математическая модель обладает очень высокой семантической устойчивостью.
Семантические портреты атрибутов (БКОСА-
В данном режиме обеспечивается формирование семантического портрета заданного признака и его отображение в текстовой и графической формах. Окно для просмотра текстового отчета имеет прокрутку вправо, что позволяет отобразить количественные характеристики. Графическая диаграмма выводится по нажатию клавиши F5, и может быть непосредственно распечатана или записана в виде графического файла в соответствующую поддиректорию.
Кластерный и конструктивный анализ атрибутов
обеспечивает: расчет матрицы сходства признаков; генерация кластеров и конструктов признаков: просмотр и печать результатов кластерно-конструктивного анализа; автоматическое выполнение перечисленных режимов; отображение результатов кластерно-конструктивного анализа в форме семантических сетей и когнитивных диаграмм.
Семантические портреты и профили букв
Выход на режим генерации семантических портретов признаков (букв) показан на рисунке 140. Один таких портретов, а именно портрет буквы "Й", приведен на рисунке 144, а ее профиль – на рисунке 145.
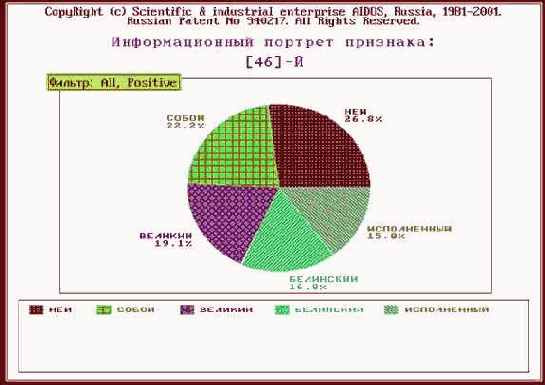 | |
| Рисунок 144. Информационный портрет буквы "Й" |
 | |
| Рисунок 145. Профиль буквы "Й" |
Семантические пространства классов и атрибутов
Наглядно модель данных целесообразно представить себе в виде двух взаимосвязанных фазовых (т.е. абстрактных) пространств, в первом из которых осями координат служат шкалы атрибутов (пространство атрибутов), а во втором – шкалы классов (пространство классов).
В пространстве атрибутов векторами являются объекты обучающей выборки и обобщенные образы классов. Вектор класса представляет собой массив координат в фазовом пространстве, каждый элемент массива, т.е. координата, соответствует определенному атрибуту, а значение этой координаты – весовому коэффициенту, отражающему количество информации, содержащееся в факте наблюдения данного атрибута у объекта о принадлежности этого объекта к данному классу.
В пространстве классов векторами являются атрибуты. Вектор атрибута представляет собой массив координат в фазовом пространстве, каждый элемент массива, т.е. координата, соответствует определенному классу, а значение этой координаты – весовому коэффициенту, отражающему количество информации, содержащееся в факте наблюдения объекта данного класса о том, что у этого объекта будет определенный атрибут.
Таким образом, выбор смысла и математической формы значений весовых коэффициентов в виде количества информации вводит метрику
в этих фазовых пространствах. Поэтому данные пространства являются нелинейными самосогласованными пространствами. Ясно, что линейная разделяющая функция в нелинейном пространстве является нелинейной функцией в линейном пространстве. Самосогласованность семантических пространств означает, что любое изменение одной координаты в общем случае связано с изменением всех остальных. Нелинейность и самосогласованность самым существенным образом отличает предложенные семантические информационные пространства классов и атрибутов от линейного семантического пространства, используемого в основном в психодиагностике [32], в котором осями являются признаки (шкалы), а значениями координат по осям являются непосредственно градации признаков.
Однако этого недостаточно. Чтобы над векторами в фазовых пространствах можно было корректно выполнять стандартные операции сложения, вычитания, скалярного и векторного умножения, выполнять преобразования системы координат, переход от одной системы координат к другой, и вообще применять аппарат линейной алгебры и аналитической геометрии, что представляет большой научный и практический интерес и является очень актуальным, необходимо корректно ввести в этих пространствах системы координат т.е. системы отсчета, удовлетворяющие определенным требованиям.
Сформировать обучающую выборку
Обучающая выборка представляет собой фрагменты текстов различных авторов, используемые в качестве примеров для формирования семантической информационной модели. На основе анализа этих примеров выявляются взаимосвязи между теми или иными словами и принадлежностью текстов разным авторам.
Для генерации обучающей выборки используется 1-й режим 2-й подсистемы, функция F7InpTXT – F6Ввод из всех файлов. При этом в качестве признаков, также как при формировании описательных шкал и градаций, выбираются слова (рисунок 155).
 | |
| Рисунок 155. Генерация обучающей выборки из TXT-файлов |
В результате формируется обучающая выборка, состоящая из 151 примера фрагментов текстов различных авторов. Остается лишь проставить в каждом примере (анкете) код писателя, о котором данный текст, т.е. код класса (в левом окне).
Сгенерировать информационные портреты
Информационные портреты классов генерируются и отображаются в 1-й функции 1-го режима 5-й подсистемы системы "Эйдос" (рисунок 173).
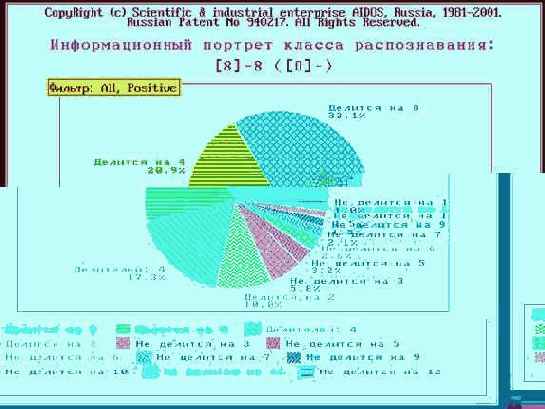 | |
| Рисунок 173. Пример информационного портрета класса в форме круговой диаграммы |
Двухмерные и трехмерные профили классов и признаков генерируются и отображаются в 4-м режиме 6-й подсистемы системы "Эйдос" (рисунок 174).
Информационные портреты признаков (факторов) генерируются и отображаются в 1-й функции 2-го режима 5-й подсистемы системы "Эйдос" (рисунок 175). Размеры секторов в круговой диаграмме соответствуют относительному вкладу признаков в общее количество информации, содержащейся в информационном портрете.
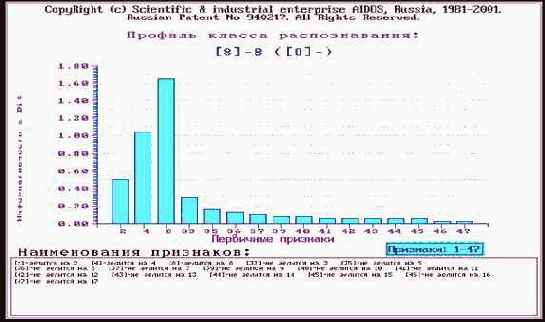 | |
| Рисунок 174. Пример профиля класса |
 | |
| Рисунок 175. Экранная форма информационного портрета фактора в форме таблицы |
Из рисунка 148 видно, что система способна выявить простые числа по признаку: "Число делителей 2".
В 1-й функции 1-го режима 5-й подсистемы системы "Эйдос" получим информационный портрет класса, а в 1-й функции 2-го режима той же подсистемы – информационный портрет признака (рисунок 183).
 | |
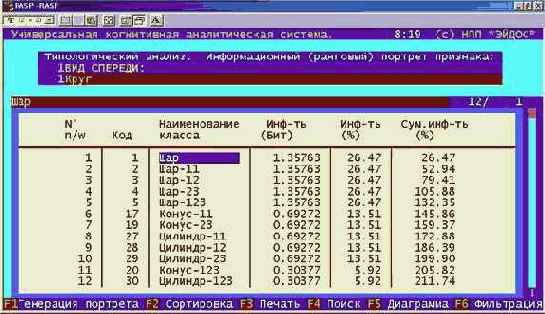 | |
| Рисунок 183. Примеры информационных портретов классов и признаков |
Сгенерировать обучающую выборку.
Чтобы сгенерировать обучающую выборку составим таблицу 86, в которой в наглядной форме изобразим проекции выбранных нами тел на ортогональные плоскости.
Таблица 86 – КОДИРОВАНИЕ ПРОЕКЦИЙ ТЕЛ
ДЛЯ ОБУЧАЮЩЕЙ ВЫБОРКИ
| Код | Тело | Проекции | 1-я проекция
X«Y вращение вокруг Z 1 | 2-я проекция
X«Z вращение вокруг Y 2 | 3-я проекция
Y«Z вращение вокруг X 3 | ||||||||||||||||||
| X | Y | Z | X | Y | Z | X | Y | Z | |||||||||||||||
| 1 | Шар | Вид | O | O | O | O | O | O | O | O | O | ||||||||||||
| Код | 1 | 4 | 7 | 1 | 4 | 7 | 1 | 4 | 7 | ||||||||||||||
| 2 | Тетраэдр | Вид |  | | | | | | | | | ||||||||||||
| Код | 3 | 6 | 9 | 3 | 6 | 9 | 3 | 6 | 9 | ||||||||||||||
| 3 | Куб | Вид | | | | | | | | | | ||||||||||||
| Код | 2 | 5 | 8 | 2 | 5 | 8 | 2 | 5 | 8 | ||||||||||||||
| 4 | Конус | Вид | | | O | O | | | | O | | ||||||||||||
| Код | 3 | 6 | 7 | 1 | 6 | 9 | 3 | 4 | 9 | ||||||||||||||
| 5 | Пирамида | Вид | | | | | | | | | | ||||||||||||
| Код | 3 | 6 | 8 | 2 | 6 | 9 | 3 | 5 | 9 | ||||||||||||||
| 6 | Цилиндр | Вид | | | O | O | | | | O | | ||||||||||||
| Код | 2 | 5 | 7 | 1 | 5 | 8 | 2 | 4 | 8 | ||||||||||||||
| 7 | Призма | Вид | | | | | | | | | | ||||||||||||
| Код | 2 | 5 | 9 | 3 | 5 | 8 | 2 | 6 | 8 |
С использованием таблицы 86 составим таблицу 87 с обучающей выборкой.
Таблица 87 – ФОРМА ДЛЯ ВВОДА ОБУЧАЮЩЕЙ ВЫБОРКИ
| Код | Наименование | Классы | Признаки | ||||||||||||||||||||||||
| 1 | 2 | 3 | Проекция-1 | Проекция-2 | Проекция-3 | ||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||||||||||
| 1 | Шар | 1 | 1 | 4 | 7 | ||||||||||||||||||||||
| 2 | Шар-11 | 2 | 1 | 4 | 7 | 1 | 4 | 7 | |||||||||||||||||||
| 3 | Шар-12 | 3 | 1 | 4 | 7 | 1 | 4 | 7 | |||||||||||||||||||
| 4 | Шар-22 | 4 | 1 | 4 | 7 | 1 | 4 | 7 | |||||||||||||||||||
| 5 | Шар-123 | 5 | 1 | 4 | 7 | 1 | 4 | 7 | 1 | 4 | 7 | ||||||||||||||||
| 6 | Тетраэдр | 6 | 3 | 6 | 9 | ||||||||||||||||||||||
| 7 | Тетраэдр-11 | 7 | 3 | 6 | 9 | 3 | 6 | 9 | |||||||||||||||||||
| 8 | Тетраэдр-12 | 8 | 3 | 6 | 9 | 3 | 6 | 9 | |||||||||||||||||||
| 9 | Тетраэдр-23 | 9 | 3 | 6 | 9 | 3 | 6 | 9 | |||||||||||||||||||
| 10 | Тетраэдр-123 | 10 | 3 | 6 | 9 | 3 | 6 | 9 | 3 | 6 | 9 |
Продолжение таблицы 87
|
Код |
Наименование |
Классы |
Признаки |
||||||||||
|
1 |
2 |
3 |
Проекция-1 |
Проекция-2 |
Проекция-3 |
||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|||||
|
11 |
Куб |
11 |
2 |
5 |
8 |
||||||||
|
12 |
Куб-11 |
12 |
2 |
5 |
8 |
2 |
5 |
8 |
|||||
|
13 |
Куб-12 |
13 |
2 |
5 |
8 |
2 |
5 |
8 |
|||||
|
14 |
Куб-23 |
14 |
2 |
5 |
8 |
2 |
5 |
8 |
|||||
|
15 |
Куб-123 |
15 |
2 |
5 |
8 |
2 |
5 |
8 |
2 |
5 |
8 |
||
|
16 |
Конус |
16 |
3 |
6 |
7 |
||||||||
|
17 |
Конус-11 |
17 |
3 |
6 |
7 |
1 |
6 |
9 |
|||||
|
18 |
Конус-12 |
18 |
3 |
6 |
7 |
3 |
4 |
9 |
|||||
|
19 |
Конус-23 |
19 |
1 |
6 |
9 |
3 |
4 |
9 |
|||||
|
20 |
Конус-123 |
20 |
3 |
6 |
7 |
1 |
6 |
9 |
3 |
4 |
9 |
||
|
21 |
Пирамида |
21 |
3 |
6 |
8 |
||||||||
|
22 |
Пирамида-11 |
22 |
3 |
6 |
8 |
2 |
6 |
9 |
|||||
|
23 |
Пирамида-12 |
23 |
3 |
6 |
8 |
3 |
5 |
9 |
|||||
|
24 |
Пирамида-23 |
24 |
2 |
6 |
9 |
3 |
5 |
9 |
|||||
|
25 |
Пирамида-123 |
25 |
3 |
6 |
8 |
2 |
6 |
9 |
3 |
5 |
9 |
||
|
26 |
Цилиндр |
26 |
2 |
5 |
7 |
||||||||
|
27 |
Цилиндр-11 |
27 |
2 |
5 |
7 |
1 |
5 |
8 |
|||||
|
28 |
Цилиндр-12 |
28 |
2 |
5 |
7 |
2 |
4 |
8 |
|||||
|
29 |
Цилиндр-23 |
29 |
1 |
5 |
8 |
2 |
4 |
8 |
|||||
|
30 |
Цилиндр-123 |
30 |
2 |
5 |
7 |
1 |
5 |
8 |
2 |
4 |
8 |
||
|
31 |
Призма |
31 |
2 |
5 |
9 |
||||||||
|
32 |
Призма-11 |
32 |
2 |
5 |
9 |
3 |
5 |
8 |
|||||
|
33 |
Призма-12 |
33 |
2 |
5 |
9 |
2 |
6 |
8 |
|||||
|
34 |
Призма-23 |
34 |
3 |
5 |
8 |
2 |
6 |
8 |
|||||
|
35 |
Призма-123 |
35 |
2 |
5 |
9 |
3 |
5 |
8 |
2 |
6 |
8 |
Сгенерируем обучающую выборку.
Обучающая выборка генерируется автоматически вместе с шкалами и градациями и здесь не приводится из-за ее большого объема.
Шкалы атрибутов (описательные шкалы)
Конкретные объекты, предъявляемые на входе модели в качестве примеров или реализаций некоторых обобщенных классов (прецедентов), описываются на языке атрибутов, т.е. признаков.
Признаки могут иметь любую природу, в частности: объективную - физическую, химическую и др. (вес, температура, рост); социально-экономическую (меновую и потребительную стоимость, степень амортизации, процент дивидендов); эмоционально-психологическую (привлекательный, предупредительный, исполнительный, конфликтный и т.п.).
Система признаков двухуровневая, что позволяет формализовать (шкалировать) не только качественные (да/нет), но и количественные (числовые) признаки, а также позволяет обрабатывать вопросы со многими, в том числе и неальтернативными вариантами ответов. Вопрос с вариантами ответов можно рассматривать как шкалу с градациями. Такое понимание позволяет "ввести в оборот" хорошо разработанную теорию шкалирования, что является весьма ценным. В предлагаемой модели нет ограничений на тип и количество шкал, а также на количество градаций в них (за исключением суммарного общего количества градаций. Нет в предлагаемой модели и таких искусственных ограничений, как, например, необходимость одинакового количества градаций во всех шкалах, или необходимость использовать только шкалы только одного какого-либо типа, и т.п., которые, как правило, встречаются в других системах.
В принципе могут быть сконструированы системы признаков, представляемые деревьями трех и более уровней, однако программно реализовывать их нецелесообразно, т.к. они все сводятся к двухуровневым деревьям (вопросы с вариантами ответов).
Шкалы классов (классификационные шкалы)
Плодотворным является представление классов, как некоторых областей в фазовом пространстве, в котором в качестве осей координат выступают некоторые шкалы классов меньшего уровня общности или признаков. Классы распознавания могут рассматриваться, также, как градации (конкретные значения, заданные с некоторой точностью, или диапазоны – зоны), заданные на этих шкалах. Количество шкал, тип шкал и количество градаций на них в предлагаемой модели задает сам пользователь.
Если представить эти шкалы как оси координат, то, очевидно, наиболее обобщенным классам распознавания соответствуют зоны на самих осях. Кроме того возможны варианты сочетаний по 2 оси, соответствующие областям на координатных плоскостях. Существуют также области в фазовом пространстве, образованные сочетаниями градаций сразу n-го количества шкал, где n <= N, где N - размерность фазового пространства. Естественно, пользователь может исследовать только те классы, которые его интересуют, сознательно принимая решение не рассматривать остальных. Но он должен знать, что и остальные классы также могут быть сформированы и исследованы, а для этого нужно иметь их классификацию, принцип разработки которой мы только что рассмотрели.
Конкретными реализациями обобщенных категорий могут быть объекты, их состояния или ситуации (но применять мы, как правило, будем термин "объекты", всегда имея в виду и остальные возможные варианты). Синонимами понятия "класс" являются применяющиеся в специальной литературе термины "объекты", "категории", "образы", "эталоны", "типы", "профили", "вектора". В данной работе объекты рассматриваются как конкретные реализации классов, а классы – как обобщенные образы объектов определенной категории.
Когда классы распознавания сформированы с ними могут осуществляться три основные операции: сравнение конкретных объектов, их состояний или ситуаций с классами; сравнение классов друг с другом; вывод информации о содержании обобщенного образа класса в форме таблиц или графических диаграмм.
Синтез и решение задач управления качеством подготовки специалистов
Данное исследование проведено совместно с В.Н.Лаптевым и В.Г.Третьяком [62, 104 – 107, 111, 185, 206]. Наиболее подробно технология проведения работ и полученные результаты приведены в работе [64], в которой есть специальный большой раздел, посвященный этому исследованию, а также приложение 5, которое содержит видеограммы интерфейса системы "Эйдос", полученные на основе данного приложения. На основе данных по абитуриентам и учащимся Краснодарского юридического института МВД РФ (КЮИ МВД РФ) за 1995 – 2002 годы (7-летний лонгитюд) с помощью системы "Эйдос" был осуществлен синтез семантической информационной модели, отражающей информационные взаимосвязи между индивидуальными личностными особенностями учащихся и их учебными и профессиональными достижениями. Размерность модели составила: 318 прогнозируемых состояний учащихся и выпускников КЮИ МВД РФ, 129 градаций факторов, 69 прецедентов в обучающей выборке, 76128 фактов. С помощью модели решены следующие задачи прогнозирования, входящие в состав рефлексивной АСУ качеством подготовки специалистов:
1) поступление в вуз;
2) успешность обучения в вузе по различным дисциплинам и циклам дисциплин;
3) успешность окончания вуза;
4) причины отчисления;
5) успешность профессиональной деятельности после окончания вуза;
6) продолжительность профессиональной деятельности по специальности, полученной в вузе;
7) причины ухода из ОВД (средневзвешенная достоверность прогнозирования составила 83%).
Система "Эйдос", как специальное программное средство (инструментарий интеллектуальной обработки информации), продемонстрировала возможность решения задач выбора оптимальной педагогической технологии для перевода учащегося из текущего состояния в заданное целевое состояние. Технология применения системы "Эйдос", разработанная автором для КЮИ МВД РФ, позволяет заблаговременно принимать обоснованные решения о целесообразности обучения конкретных курсантов по тем или иным специальностям. Перспективно применение данного инструментария и технологии в адаптивном режиме на систематической основе на выборках значительно большего и постоянно увеличивающегося объема по широкому спектру специальностей, в том числе и на межвузовском и межведомственном уровне. Развитие данного направления исследований и разработок целесообразно осуществить за счет включения в модель данных, характеризующих динамику личностных свойств учащихся, т.е. путем учета данных, полученных в процессе обучения, а не только перед его началом (как в проведенном исследовании), а также путем более детального учета влияния педагогических технологий, учебной, бытовой и профессиональной среды.
Описанная технология АСК-анализа может быть успешно применена для решения задач профотбора, подготовки и переподготовки кадров среднего и высшего звена управления АПК в вузах сельскохозяйственного профиля.
Синтез модели: пакетное обучение системы распознавания (подсистема "Обучение") (БКОСА-
Данный режим обеспечивает: расчет матрицы абсолютных частот, поиск и исключение из дальнейшего анализа артефактов, расчет матрицы информативностей, расчет матрицы условных процентных распределений, пакетный режим автоматического выполнения вышеперечисленных 4-х режимов, а также исследовательский режим, обеспечивающий измерение скорости сходимости и семантической устойчивости сформированной содержательной информационной модели.