Синтез семантической информационной модели
Синтез СИМ состоит в расчете ряда баз данных, главной из которых является матрица информативностей. Этот синтез осуществляется на основе информации, содержащейся в файлах, перечисленных в предыдущем разделе. Для этих целей используется режим: "Обучение – Синтез семантической информационной модели – Автоматическое выполнение 1-2-3-4" (рисунок 207):
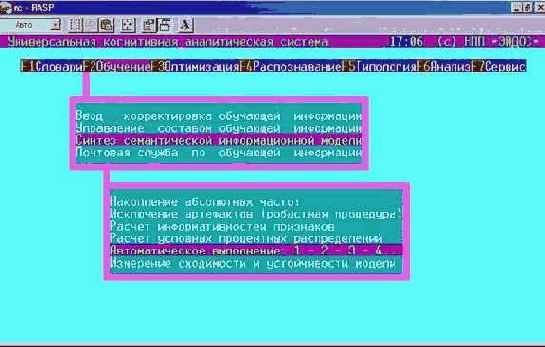 | |
| Рисунок 207. Режим: "Синтез СИМ" |
Синтез содержательной информационной модели предметной области
Синтез модели в СК-анализе осуществляется с применением подсистем: "Словари", "Обучение", "Оптимизация", "Распознавание" и "Анализ". Он включает следующие этапы:
1) формализация (когнитивная структуризация предметной области);
2) формирование исследуемой выборки и управление ею;
3) синтез или адаптация модели;
4) оптимизация модели;
5) измерение адекватности модели (внутренней и внешней, интегральной и дифференциальной валидности), ее скорости сходимости и семантической устойчивости.
Системно-когнитивный и факторный анализ. СК-анализ, как метод вариабельных контрольных групп
В науке широко известен "метод контрольных групп" (терм. авт.), позволяющий оценить влияние некоторого фактора на исследуемую группу по сравнению с контрольной, на которую он не влияет.
Обобщением метода контрольных групп является полный и дробный факторный анализ, при котором исследуется не одна контрольная группа, а столько, сколько факторов. При этом в каждой группе исследуется влияние одного фактора при остальных фиксированных. Таким образом факторный анализ можно было бы назвать "методом фиксированных контрольных групп". Факторный анализ требует проведения специально организованных экспериментов, что представляет собой проблему даже при нескольких факторах при большой длительности цикла управления (которая в АПК может составлять до десяти лет и более).
Например, для сбора исходных данных в факторном эксперименте при 3 факторах с 10 градациями каждый необходимо провести 103=1000 экспериментов. На практике это редко осуществимо.
Поэтому перед проведением факторного эксперимента обычно выбирают небольшое количество наиболее значимых или интересных факторов для исследования. Вопрос о том, какие факторы исследовать, решается самим исследователем на основе неформальных методов.
СК-анализ является обобщением метода факторного анализа в том смысле, что контрольные группы отличаются не значениями одного фактора при остальных фиксированных, а в общем случае различными комбинациями значений действующих факторов. СК-анализ позволяет выявлять и корректно исследовать влияние тысяч факторов на объект управления на основе непосредственно эмпирических данных, причем неполных и неупорядоченных, как в факторном эксперименте. При этом определяется и значимость факторов, что позволяет обоснованно выбрать из них небольшое количество наиболее значимых для последующего более детального исследования методом факторного анализа. Необходимо отметить, что СК-анализ является непараметрическим методом, в отличие от факторного анализа.
Системное обобщение формулы Хартли для количества информации
Классическая формула Хартли имеет вид:
 | (3. 1) |
Будем искать ее системное обобщение в виде:
 | (3. 2) |
где:
W – количество чистых (классических) состояний системы.
j – коэффициент эмерджентности Хартли (уровень системной организации объекта, имеющего W чистых состояний);
Учитывая, что возможны смешанные состояния, являющиеся нелинейной суперпозицией или одновременной реализацией чистых (классических) состояний "из W по m", всего возможно

 | (3. 3) |
где: W – количество элементов в системе альтернативных будущих состояний АОУ (количество чистых состояний); m – сложность смешанных состояний АОУ; M – максимальная сложность смешанных состояний АОУ.
Выражение (1) дает количество информации в активной системе, в которой чистые и смешанные состояния равновероятны. Смешанные состояния активных систем, возникающие под действием системы нелинейно-взаимодействующих факторов, считаются такими же измеримыми, как и чистые альтернативные состояния, возникающие под действием детерминистских факторов. Так как

Рассмотрим подробнее смысл выражения (3.3), представив сумму в виде ряда слагаемых:
 | (3. 4) |
Первое слагаемое в (3.4) дает количество информации по классической формуле Хартли, а остальные слагаемые – дополнительное количество информации, получаемое за счет системного эффекта, т.е. за счет наличия у системы иерархической структуры или смешанных состояний. По сути дела эта дополнительная информация является информацией об иерархической структуре системы, как состоящей из ряда подсистем различных уровней сложности.
Например, пусть система состоит из W пронумерованных элементов 1-го уровня иерархии. Тогда на 2-м уровне иерархии элементы соединены в подсистемы из 2 элементов 1-го уровня, на 3-м – из 3, и т.д.
Если выборка любого элемента равновероятна, то из факта выбора n-го элемента по классической формуле Хартли мы получаем количество информации согласно (3.1). Если же при этом известно, что данный элемент входит в определенную подсистему 2-го уровня, то это дает дополнительное количество информации, за счет учета второго слагаемого, поэтому общее количество получаемой при этом информации будет определяться выражением (3.4) уже с двумя слагаемыми (M=2). Если элемент одновременно входит в M подсистем разных уровней, то количество информации, получаемое о системе и ее подсистемах при выборке этого элемента определяется выражением (3.4). Так, если мы вытаскиваем кирпич из неструктурированной кучи, состоящей из 32 кирпичей, то получаем 5 бит информации, если же из этих кирпичей сложен дом, то при аналогичном действии мы получаем дополнительное количество информации о том, из каких части дома (подсистем различного уровня иерархии) вытащен этот кирпич. Действия каменщика, укладывающего кирпич на место, предусмотренное проектом, значительно выше по целесообразности, чем у грузчика, складывающего кирпичи в кучу. Учитывая, что при M=W:
 |
(3. 5) |
 |
(3. 6) |
Однако реально в любой системе осуществляются не все формально возможные сочетания элементов 1-го уровня иерархии, т.к. существуют различные правила запрета, различные для разных систем. Это означает, что возможно множество различных систем, состоящих из одинакового количества тождественных элементов, и отличающихся своей структурой, т.е. строением подсистем различных иерархических уровней. Эти различия систем как раз и возникают благодаря различию действующих для них этих правил запрета. По этой причине систему правил запрета предлагается назвать информационным проектом системы. Различные системы, состоящие из равного количества одинаковых элементов (например, дома, состоящие из 20000 кирпичей), отличаются друг от друга именно по причине различия своих информационных проектов.
Из выражения (3.5) очевидно, что I быстро стремится к W:
 |
(3. 7) |
|
Таблица 9 – ЗАВИСИМОСТЬ ПОГРЕШНОСТИ ВЫРАЖЕНИЯ (3.5) ОТ КОЛИЧЕСТВА КЛАССОВ W |
 |
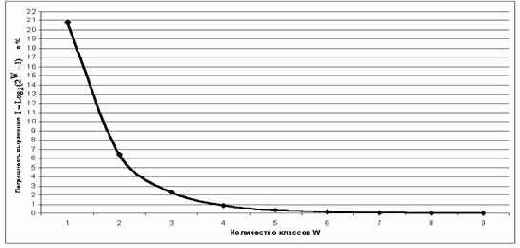 |
|
Рисунок 24. Зависимость погрешности приближенного выражения системного обобщения формулы Хартли от количества классов W |
 |
(3. 8) |
 |
(3. 9) |
С учетом выражения (3.9) выражение (3.2) примет вид:
 |
(3. 10) |
 |
(3. 11) |
Коэффициент эмерджентности Хартли представляет собой относительное превышение количества информации о системе при учете системных эффектов (смешанных состояний, иерархической структуры ее подсистем и т.п.) над количеством информации без учета системности, т.е. этот коэффициент является аналитическим выражением для уровня системности объекта. Таким образом, коэффициент эмерджентности Хартли отражает уровень системности объекта и изменяется от 1 (системность минимальна, т.е. отсутствует) до W/Log2W (системность максимальна). Очевидно, для каждого количества элементов системы существует свой максимальный уровень системности, который никогда реально не достигается из-за действия правил запрета
на реализацию в системе ряда подсистем различных уровней иерархии.
Например: из 32 букв русского алфавита может быть образовано не

Итак, в предложении сдержится значительно больше информации, чем в буквах, с помощью которых оно написано, т.к. кроме букв информацию содержат слова, сочетания слов, последовательность предложений и т.д.. Буквы образуют 1-й иерархический уровень языка, слова – 2-й, предложения – 3-й, абзацы – 4-й, параграфы – 5-й, главы – 6-й, произведения – 7-й. Теория Шеннона концентрирует основное внимание на рассмотрении 1-го уровня, т.е. рассматривает тексты, прежде всего, как последовательность символов. Но именно иерархическая организация, не учитываемая в теории Шеннона и отраженная в системной теории информации, обеспечивает языку его удивительную мощь, как средства отражения и моделирования реальности.
Аналогично и в генах, этих своеобразных "символах генома", содержится значительно больше информации о фенотипе, чем предполагается в классической генетике Менделя, т.к. гены образуют ансамбли различных уровней иерархии в зависимости от влияния среды и технологий управления (явление адаптивности системы "генотип-среда", Драгавцев В.А., 1993). Если ген уподобить букве алфавита, а смысл фразы – фенотипическому признаку, то можно сказать, что возможно очень большое количество фраз с одним и тем же смысловым содержанием (тогда как в классической генетике считалось, что признак соответствует гену, хотя есть и такие).
После расшифровки генома человека мы настолько же приблизились к его пониманию, как изучивший русскую или немецкую азбуку англичанин, не знающий этих языков, приблизился к чтению в оригинале и пониманию содержания "Войны и Мира" Льва Толстого или "Феноменологии Духа" Георга В.Ф.Гегеля.
На уровне слов верхняя оценка уровня системности русского языка с учетом (3.5) составляет огромную величину: 2616,48 (предполагается, что в русском языке 40000 слов и предложения могут иметь любую длину). Необходимо отметить, что правила запрета на порядок слов в русском языке значительно слабее, чем, например в английском, поэтому в русском языке возможно гораздо больше грамматически правильных и несущих различную информацию предложений из одних и тех же слов, чем в английском. Это значит, что уровень системности русского языка на уровне предложений, по-видимому, значительно превосходит уровень системности английского языка. При длине предложения до 2-х слов системность русского языка на уровне предложений согласно (3.9) составляет: 52330916.
Анализ выражения (3.9) показывает, что при М=1 оно преобразуется в (3.1), т.е. выполняется принцип соответствия. При М>1 количество информации в соответствии с системной теорией информации (СТИ) (3.9) будет превосходить количество информации, рассчитанное по классической теории информации (КТИ) (3.1). Непосредственно из выражения (3.2) получаем:
 |
(3. 12) |
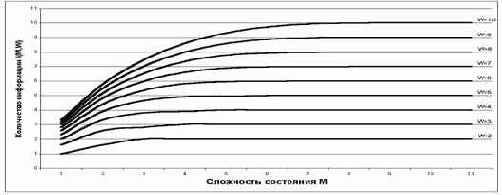
Представляет несомненный интерес исследование закономерностей изменения доли системной информации в поведении элемента системы в зависимости от количества классов W и сложности смешанных состоянийM.
В таблице 10 приведены результаты численных расчетов в соответствии с выражением (3.9). Сводные данные из таблицы 10 приведены в таблице 11, а в графическом виде они представлены на рисунке 25.
|
Таблица 10 – ЗАВИСИМОСТЬ I(W,M) ОТ КОЛИЧЕСТВА КЛАССОВ W И СЛОЖНОСТИ СМЕШАННЫХ СОСТОЯНИЙ М |
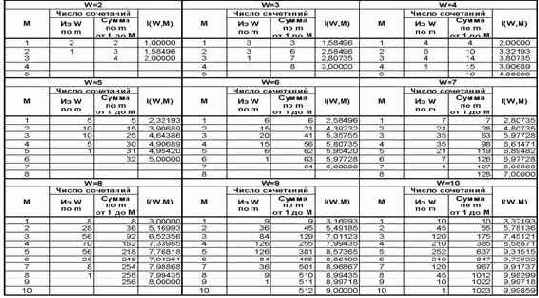 |
|
Таблица 11 – ЗАВИСИМОСТЬ КОЛИЧЕСТВА ИНФОРМАЦИИ I(W,M) ОТ СЛОЖНОСТИ СМЕШАННЫХ СОСТОЯНИЙ M ДЛЯ РАЗЛИЧНОГО КОЛИЧЕСТВА КЛАССОВ W |
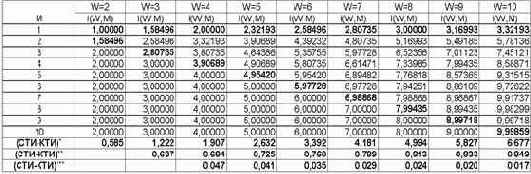 |
 |
|
Рисунок 25. Зависимость количества информации I(W,M) от сложности смешанных состояний M для разного количества классов W |
Фактически это означает, что в СТИ множество возможных состояний объекта рассматривается не как совокупность несвязанных друг с другом состояний, как в КТИ, а как система, уровень системности которой как раз и определяется коэффициентом эмерджентности Хартли j (3.9), являющегося монотонно возрастающей функцией сложности смешанных состояний M. Следовательно, дополнительная информация, которую мы получаем из поведения объекта в СТИ, по сути дела является информацией о системе всех возможных состояний объекта, элементом которой является объект в некотором данном состоянии.
Системное обобщение классической формулы Харкевича, как количественная мера знаний
Это обобщение представляет большой интерес, в связи с тем, что А.Харкевич впервые ввел в теорию информации понятие цели.
Он считал, что количество информации, сообщенное объекту, можно измерять по изменению вероятности достижения цели этим объектом за счет использования им этой информации.
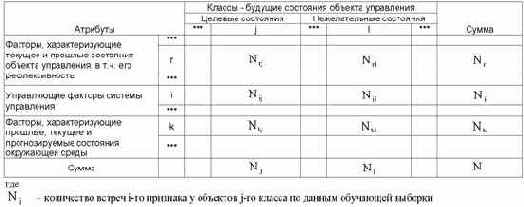
Рассмотрим таблицу 12, в которой столбцы соответствуют будущим состояниям АОУ (целевым и нежелательным), а строки факторам, характеризующим объект управления, управляющую систему и окружающую среду.
| Таблица 12 – МАТРИЦА АБСОЛЮТНЫХ ЧАСТОТ | |
 |
Классическая формула А.Харкевича имеет вид:
 | (3. 19) |
где:
– W – количество классов (мощность множества будущих состояний объекта управления)
– M – максимальный уровень сложности смешанных состояний объекта управления;
– индекс i обозначает фактор: 1£ i £ M;
– индекс j обозначает класс: 1£ j £ W;
– Pij – вероятность достижения объектом управления j-й цели при условии сообщения ему i-й информации;
– Pj – вероятность самопроизвольного достижения объектом управления j-й цели.
Ниже глобальные параметры модели W и M в выражениях для I опускаются, т.к. они являются константами для конкретной математической модели СК-анализа.
Однако: А.Харкевич в своем выражении для количества информации не ввел зависимости количества информации, от мощности пространства будущих состояний объекта управления, в т.ч. от количества его целевых состояний. Вместе с тем, один из возможных вариантов учета количества будущих состояний объекта управления обеспечивается классической и системной формулами Хартли (3.1) и (3.9); выражение (3.19) при подстановке в него реальных численных значений вероятностей Pij и Pj не дает количества информации в битах; для выражения (3.19) не выполняется принцип соответствия, считающийся обязательным для обобщающих теорий. Возможно, в этом состоит одна из причин слабого взаимодействия между классической теорией информации Шеннона и семантической теорией информации.
Чтобы снять эти вопросы, приближенно выразим вероятности Pij, Pi и Pj через частоты:
 |
(3. 20) |
Nij – суммарное количество наблюдений факта: "действовал i-й фактор и объект перешел в j-е состояние";
Nj – суммарное количество встреч различных факторов у объектов, перешедших в j-е состояние;
Ni – суммарное количество встреч i-го фактора у всех объектов;
N – суммарное количество встреч различных факторов у всех объектов.
Подставим в выражение (3.19) значения для Pij
и Pj из (3.20):
 |
(3. 21) |
 |
(3. 22) |
Известно, что классическая формула Шеннона для количества информации для неравновероятных событий преобразуется в формулу Хартли при условии, что события равновероятны, т.е. удовлетворяет фундаментальному принципу соответствия[64].
Естественно потребовать, чтобы и обобщенная формула Харкевича также удовлетворяла аналогичному принципу соответствия, т.е. преобразовывалась в формулу Хартли в предельном случае, когда каждому классу (состоянию объекта) соответствует один признак (фактор), и каждому признаку – один класс, и эти классы (а, значит и признаки), равновероятны. Иначе говоря факторов столько же, сколько и будущих состояний объекта управления, все факторы детерминистские, а состояния объекта управления – альтернативные, т.е. каждый фактор однозначно определяет переход объекта управления в определенное состояние.
В этом предельном случае отпадает необходимость двухвекторного описания объектов, при котором 1-й вектор (классификационный) содержит интегральное описание объекта, как принадлежащего к определенным классам, а 2-й вектор (описательный) – дискретное его описание, как имеющего определенные атрибуты. Соответственно, двухвекторная модель, предложенная в данной работе, преобразуется в "вырожденный" частный случай – стандартную статистическую модель.
В этом случае количество информации, содержащейся в признаке о принадлежности объекта к классу является максимальным
и равным количеству информации, вычисляемому по системной формуле Хартли (3.9).
Таким образом при взаимно-однозначном соответствии классов и признаков:
 |
(3. 23) |
 |
(3. 24) |
 |
(3. 25) |
 |
(3. 26) |
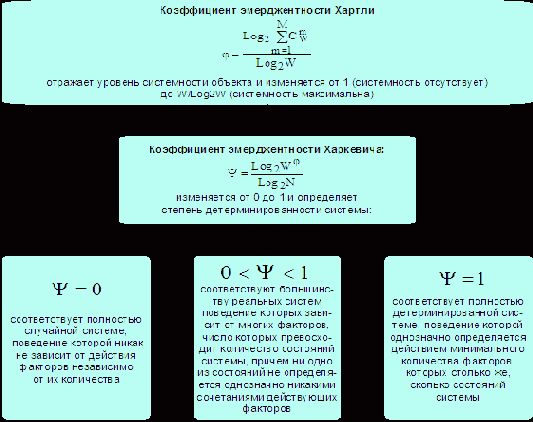
Таким образом, коэффициент эмерджентности Харкевича Y изменяется от 0 до 1 и определяет степень детерминированности системы:
– Y=1 соответствует полностью детерминированной системе, поведение которой однозначно определяется действием минимального количества факторов, которых столько же, сколько состояний системы;
– Y=0 соответствует полностью случайной системе, поведение которой никак не зависит действия факторов независимо от их количества;
– 0<Y<1 соответствуют большинству реальных систем поведение которых зависит от многих факторов, число которых превосходит количество состояний системы, причем ни одно из состояний не определяется однозначно никакими сочетаниями действующих факторов (рисунок 29):
 |
|
Рисунок 29. Интерпретация коэффициентов эмерджентности СТИ |
M=1, коэффициент эмерджентности А.Харкевича приобретает вид:
 |
(3. 27) |
 |
 |
(3. 28) |
Например: управлять толпой из 1000 человек значительно сложнее, чем воздушно-десантным полком той же численности. Процесс превращения 1000 новобранцев в воздушно-десантный полк это и есть процесс повышения уровня системности и степени детерминированности системы. Этот процесс включает процесс иерархического структурирования (на отделения, взвода, роты, батальоны), а также процесс повышения степени детерминированности команд, путем повышения "степени беспрекословности" их исполнения. Оркестр, настраивающий инструменты, также весьма существенно отличается от оркестра, исполняющего произведение под управлением дирижера.
Необходимо отметить, что при повторном использовании той же самой обучающей выборки степень детерминированности модели уменьшается. Очевидно, с формальной математической точки зрения этого явления можно избежать, если перед расчетом информативностей признаков делить абсолютные частоты на количество объектов обучающей выборки.
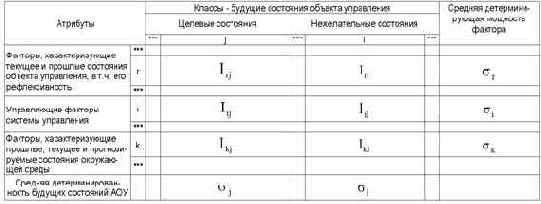
С использованием выражения (3.28) непосредственно из матрицы абсолютных частот (таблица 12) рассчитывается матрица информативностей (таблица 13), содержащая связи между факторами и будущими состояниями АОУ и имеющая много различных интерпретаций и играющая основополагающую роль в данном исследовании.
|
Таблица 13 – МАТРИЦА ИНФОРМАТИВНОСТЕЙ |
 |
1. При выполнении условий взаимно-однозначного соответствия классов и признаков (3.23) первое слагаемое в выражении (3.28) обращается в ноль и при всех реальных значениях входящих в него переменных оно отрицательно.
2. Выражение (3.28) является нелинейной суперпозицией двух выражений: системного общения формулы Хартли (второе слагаемое), и первого слагаемого, которое имеет вид формулы Шеннона для плотности информации и отличается от него тем, что выражение под логарифмом находится в степени, которая совпадает с коэффициентом эмерджентности Харкевича, а также способом взаимосвязи входящих в него абсолютных частот с вероятностями.
Это дает основание предположить, что первое слагаемое в выражении (3.28) является одной из форм системного обобщения выражения Шеннона для плотности информации:
 |
(3. 29) |
Системы с дистанционным телекинетическим интерфейсом
В 1981 году Л.А.Бакурадзе и Е.В.Луценко были оформлены заявки на изобретение компьютерной системы, выполняющей все трудовые функции физического тела, обеспечивающую управление с использованием дистанционного мысленного воздействия, т.е. микротелекинеза.
По мнению автора телекинез представляет собой управление физическими объектами путем воздействия на них непосредственно с высших планов без использования физического тела, т.е. тем же способом, с помощью которого любой человек, осознает он это или нет, управляет своим физическим телом.
Были предложены технические и программные решения и инженерно – психологические методики. Система предлагалась адаптивной, т.е. автоматически настраивающейся на индивидуальные особенности, "почерк" оператора и его состояние сознания, с плавным переключением на дистанционные каналы при повышении их надежности (которая измерялась автоматически) и могла одновременно с выполнением основной работы выступать в качестве тренажера для овладения высшими формами сознания.
Человек, начиная работу с системой в обычной форме сознания с использованием традиционных каналов (интерфейса), имея мгновенную адекватную по форме и содержанию обратную связь об эффективности своего телекинетического воздействия, должен быстро переходить в одну из высших форм сознания, оптимальную для использования телекинеза в качестве управляющего воздействия.
Системы с семантическим резонансом
Системами с семантическим резонансом будем называть системы, поведение которых зависит от состояния сознания пользователя и его психологической реакции на смысловые стимулы.
Это означает, что в состав систем с семантическим резонансом, также как и систем с БОС, в качестве подсистем входят информационно-измерительные системы и системы искусственного интеллекта, аналогично осуществляется и съем информации о состоянии пользователя.
Различие между системами с БОС и с семантическим резонансом состоит в том, что в первом случае набор снимаемых параметров и методы их математической обработки определяются необходимостью идентификации биологического состояния пользователя, тогда как во втором – его реакции на смысловые стимулы (раздражители).
В частности, имеется возможность по наличию в электроэнцефалограмме так называемых вызванных потенциалов [221] установить реакцию человека на стимул: заинтересовался он или нет.
Здесь принципиально важно, что вызванные потенциалы после предъявления стимула по времени возникают гораздо раньше, чем его осознание.
Из этого следует ряд важных выводов:
1. Если это осознание не наступает по каким-либо причинам, то вызванные потенциалы все равно с очень высокой достоверностью позволяют прогнозировать ту реакцию, которая была бы у человека, если бы информация о стимуле проникла в его сознание (причинами, по которым зрительный образ стимула может не успеть сформироваться и проникнуть в сознание пользователя, могут быть, например, его очень сильную зашумленность, фрагментарность или слишком короткое время его предъявления).
2. Реакция на стимул на уровне вызванных потенциалов не подвергается критическому анализу и корректировке на уровне сознания, т.е. является гораздо более "искренней" и "откровенной", адекватной и достоверной, чем сознательные ответы на опросник с тем же самым стимульным материалом (сознательные ответы зависят от мотивации, коньюктуры и массы других обстоятельств).
3. Для получения информации о подсознательной реакции пользователя на стимульный материал он может предъявляться в значительно более высоком темпе, чем при сознательном тестировании.
4. При подсознательном тестировании пользователь может даже не знать о том, что оно проводится.
Все это в совокупности означает, что системы с семантическим резонансом позволяют получить и вывести на уровень сознания обычно ранее не осознаваемую адекватную информацию о состоянии своего сознания, систем мотивации, целеполагания, ценностей и т.д., т.е. расширить область осознаваемого. Это позволяет создать качественно более благоприятные условия для управления состоянием сознания, чем ранее, что является важным эволюционным достижением технократической цивилизации.
Системы с семантическим резонансом могут эффективно использоваться в ряде направлений:
– психологическое и профессиональное тестирование, подбор персонала, в т.ч. для действий в специальных условиях и в измененных формах сознания;
– модификация сознания, систем мотиваций, целеполагания, ценностей и др. (компьютерное нейролингвистическое программирование: "компьютерные НЛП-технологии");
– компьютерные игры с системами семантической обратной связи.
СК-анализ, как системный анализ, структурированный до уровня базовых когнитивных операций
В предложенной схеме системного анализа (рисунок 11) наглядно прослеживается сходство с когнитивным анализом (рисунок 9). Это естественно, т.к. системный анализ рассматриваться многими авторами, как одна из форм теоретического познания. Учитывая это и с целью создания благоприятных условий для дальнейшей декомпозиции системного анализа до уровня, достаточного для разработки алгоритмов и программной реализации, предлагается структурировать системный анализ до уровня базовых когнитивных операций. Предлагается рассматривать системный анализ, структурированный до уровня базовых когнитивных операций, как системно-когнитивный анализ (СК-анализ). Насколько известно впервые понятие "СК-анализ" предложено в 1995 году А.Е.Кибрик и Е.А.Богдановой. Однако этими авторами данное понятие было введено в другой предметной области, ими не ставилась и не решалась задача автоматизации СК-анализа.
В связи с тем, что СК-анализ структурируется нами до уровня БКОСА, его алгоритмизация и последующая автоматизация становится практически решаемой задачей, в отличие от автоматизация непосредственно системного анализа или детализированного системного анализа.
Отсюда органично вытекает возможность структурирования системного анализа до уровня базовых когнитивных (познавательных) операций.
Учитывая структуру когнитивного конфигуратора (таблица 4) конкретизируем обобщенную схему этапов системного анализа, ориентированного на интеграцию с когнитивными технологиями (рисунок 11), в результате чего получим обобщенную схему этапов СК-анализа (рисунок14).
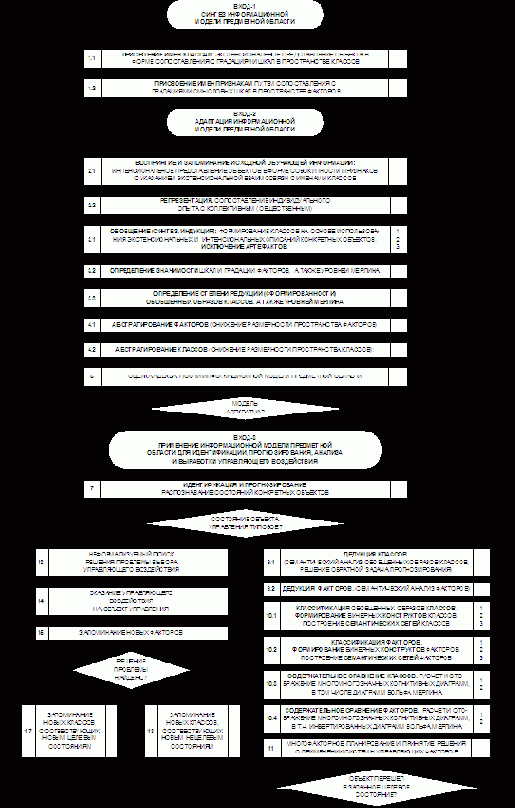 | |
| Рисунок 14. Обобщенная схема этапов СК-анализа |
Предложенная схема представляет собой схему системного анализа, структурированного до уровня базовых когнитивных операций, который предлагается называть "Системно-когнитивным анализом (СК-анализ). Нумерация блоков на рисунке 14 соответствует этапам СА на рисунке 11.
Схема, СК-анализа, представленная на рисунке 14, определяет место каждой базовой когнитивной операции в системном анализе.
Сконструировать классификационные шкалы и градации.
Выберем в качестве классов натуральные числа от 1 до 30 (вместо 30 может быть взято другое число). В результате получим 30 классов с кодами от 1 до 30, наименования которых совпадают с их кодом. Приводить здесь эту элементарную таблицу не имеет смысла.
Так как задачей является идентификация формы тела, то в качестве классов выберем для исследования простые и широко известные формы: шар, тетраэдр, куб, конус, пирамиду, призму и цилиндр, а также их наблюдения по две ортогональные проекции, которые будем обозначать числами 11, 12, 23, и одно наблюдение сразу трех проекций: 123 (таблица 84). Одновременно или последовательно наблюдаются проекции, в данном случае неважно.
Таблица 84 – КЛАССИФИКАЦИОННЫЕ
ШКАЛЫ И ГРАДАЦИИ
| Код | Наимено-
вание | Код | Наимено-вание | Код | Наимено-
вание | Код | Наимено-вание | ||||||||
| 1 | Шар | 11 | Куб | 21 | Пирамида | 31 | Призма | ||||||||
| 2 | Шар-11 | 12 | Куб-11 | 22 | Пирамида-11 | 32 | Призма-11 | ||||||||
| 3 | Шар-12 | 13 | Куб-12 | 23 | Пирамида-12 | 33 | Призма-12 | ||||||||
| 4 | Шар-22 | 14 | Куб-23 | 24 | Пирамида-23 | 34 | Призма-23 | ||||||||
| 5 | Шар-123 | 15 | Куб-123 | 25 | Пирамида-123 | 35 | Призма-123 | ||||||||
| 6 | Тетраэдр | 16 | Конус | 26 | Цилиндр | ||||||||||
| 7 | Тетраэдр-11 | 17 | Конус-11 | 27 | Цилиндр-11 | ||||||||||
| 8 | Тетраэдр-12 | 18 | Конус-12 | 28 | Цилиндр-12 | ||||||||||
| 9 | Тетраэдр-23 | 19 | Конус-23 | 29 | Цилиндр-23 | ||||||||||
| 10 | Тетраэдр-123 | 20 | Конус-123 | 30 | Цилиндр-123 |
Сконструировать описательные шкалы и градации.
В качестве описательных шкал и градаций используем простейшие свойства натуральных чисел, такие как: делители, неделители, количество делителей (таблица 83). Могут быть использованы и более сложные свойства, изучаемые в теории чисел, но суть задачи от этого не изменится.
Таблица 83 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
| Код | Наименование
признака | Код | Наименование
признака | Код | Наименование
признака | ||||||
| 1 | Делится на 1 | 31 | Не делится на 1 | 61 | Делителей: 1 | ||||||
| 2 | Делится на 2 | 32 | Не делится на 2 | 62 | Делителей: 2 | ||||||
| 3 | Делится на 3 | 33 | Не делится на 3 | 63 | Делителей: 3 | ||||||
| 4 | Делится на 4 | 34 | Не делится на 4 | 64 | Делителей: 4 | ||||||
| 5 | Делится на 5 | 35 | Не делится на 5 | 65 | Делителей: 5 | ||||||
| 6 | Делится на 6 | 36 | Не делится на 6 | 66 | Делителей: 6 | ||||||
| 7 | Делится на 7 | 37 | Не делится на 7 | 67 | Делителей: 7 | ||||||
| 8 | Делится на 8 | 38 | Не делится на 8 | 68 | Делителей: 8 | ||||||
| 9 | Делится на 9 | 39 | Не делится на 9 | 69 | Делителей: 9 | ||||||
| 10 | Делится на 10 | 40 | Не делится на 10 | 70 | Делителей: 10 | ||||||
| 11 | Делится на 11 | 41 | Не делится на 11 | 71 | Делителей: 11 | ||||||
| 12 | Делится на 12 | 42 | Не делится на 12 | 72 | Делителей: 12 | ||||||
| 13 | Делится на 13 | 43 | Не делится на 13 | 73 | Делителей: 13 | ||||||
| 14 | Делится на 14 | 44 | Не делится на 14 | 74 | Делителей: 14 | ||||||
| 15 | Делится на 15 | 45 | Не делится на 15 | 75 | Делителей: 15 | ||||||
| 16 | Делится на 16 | 46 | Не делится на 16 | 76 | Делителей: 16 | ||||||
| 17 | Делится на 17 | 47 | Не делится на 17 | 77 | Делителей: 17 | ||||||
| 18 | Делится на 18 | 48 | Не делится на 18 | 78 | Делителей: 18 | ||||||
| 19 | Делится на 19 | 49 | Не делится на 19 | 79 | Делителей: 19 | ||||||
| 20 | Делится на 20 | 50 | Не делится на 20 | 80 | Делителей: 20 | ||||||
| 21 | Делится на 21 | 51 | Не делится на 21 | 81 | Делителей: 21 | ||||||
| 22 | Делится на 22 | 52 | Не делится на 22 | 82 | Делителей: 22 | ||||||
| 23 | Делится на 23 | 53 | Не делится на 23 | 83 | Делителей: 23 | ||||||
| 24 | Делится на 24 | 54 | Не делится на 24 | 84 | Делителей: 24 | ||||||
| 25 | Делится на 25 | 55 | Не делится на 25 | 85 | Делителей: 25 | ||||||
| 26 | Делится на 26 | 56 | Не делится на 26 | 86 | Делителей: 26 | ||||||
| 27 | Делится на 27 | 57 | Не делится на 27 | 87 | Делителей: 27 | ||||||
| 28 | Делится на 28 | 58 | Не делится на 28 | 88 | Делителей: 28 | ||||||
| 29 | Делится на 29 | 59 | Не делится на 29 | 89 | Делителей: 29 | ||||||
| 30 | Делится на 30 | 60 | Не делится на 30 | 90 | Делителей: 30 |
Проекциями перечисленных трехмерных тел на взаимно-ортогональные плоскости являются двухмерные фигуры: круг, квадрат и треугольник. Соответственно, сконструируем и описательные шкалы и градации, чтобы они позволяли отразить все варианты проекций трехмерных тел (таблица 85).
Таблица 85 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
| Код | Наименование | ||
| [1] | ВИД СПЕРЕДИ: | ||
| 1 | Круг | ||
| 2 | Квадрат | ||
| 3 | Треугольник | ||
| [2] | ВИД СБОКУ: | ||
| 4 | Круг | ||
| 5 | Квадрат | ||
| 6 | Треугольник | ||
| [3] | ВИД СВЕРХУ: | ||
| 7 | Круг | ||
| 8 | Квадрат | ||
| 9 | Треугольник |
Социально–психологический мониторинг
Предлагаемая методология и технология обеспечивает сбор и обработку данных мониторинга по тем срезам социума, которые приняты как объекты постоянного контроля и управления: общественное и индивидуальное сознание; национально–этнические проблемы; культурно–религиозные проблемы; демографические проблемы; проблемы возрастных групп (молодежи, трудоспособного населения и пенсионеров); проблемы профессиональных групп; проблемы безработицы; проблемы групп населения с различным образовательным уровнем; классовые проблемы (профсоюзы, забастовки, приватизация и национализация, группы различного уровня достатка); политические ситуации; криминогенные ситуации; экономические ситуации; рейтинг политических лидеров, партий и движений.
Кроме того, может быть дан психологический анализ различных типов управленческого и вспомогательного персонала, разработаны фотороботы этих типов и автоматизированные методики их идентификации.
Социологические и политологические исследования
С применением предложенной методологии и технологии может быть выполнен ряд работ в области социологии и политологии:
– определение социальной базы (структуры электората) партий, их блоков и объединений, конкретных кандидатов в разрезах по краевому центру, городам и районам края (социальный, возрастной, профессиональный, национальный, образовательный, половой и т.п.;
– состав, поддерживающих и отвергающих программные лозунги предвыборной борьбы);
– изучение социальных запросов различных групп населения и формирование на этой основе предвыборной программы блока, партии, кандидата;
– выявление объективных союзников и оппозиции, как в среди партий, блоков и кандидатов, так и среди различных групп населения;
– изучение динамики и территориальных особенностей по всем этим аспектам.
Имеется положительный опыт исследований по данной проблематике, подтвержденный рядом актов (ДСП).
В настоящее время работы, проводящиеся различными группами и организациями по этим проблемам не основаны на использовании автоматизированных систем искусственного интеллекта, позволяющих разрабатывать и использовать оптимальные методики получения социологической информации и ее анализа. Обычно применяемое для компьютерной обработки результатов анкетирования программное обеспечение позволяет получить лишь простейшие характеристики исследуемой выборки, вроде процентного распределения голосов по районам или различным группам населения.
Рассмотрим подробнее вопросы применения АСК-анализа для выявления конфликтующих коалиций в сложных организационных системах.
В теории конфликтов традиционно считается, что конфликтующие стороны известны, т.е. заданы априорно, и, таким образом, вопрос об их обнаружении и выявлении в рамках этой теории не стоит.
Однако в ряде предметных областей, таких, например, как психология общения, социально-экономические и политологические системы, которые представляют собой сложные организационные системы, перед применением методов теории конфликтов часто бывает необходимо предварительно выявить сами конфликтующие стороны и их возможные коалиции, определить содержание и источники конфликтов, и уже только после этого конкретизировать типы конфликтов и применять стандартные методы их разрешения или компромиссного согласования интересов.
Более того, именно в обнаружении конфликтующих сторон, а не в дальнейшем анализе, зачастую и состоит основной смысл интеллектуальной обработки данных в этих предметных областях.
Таким образом проблема выявления конфликтующих сторон и коалиций является актуальной научно-технической проблемой, относящейся к области, непосредственно смежной с теорией конфликтов и как бы подготавливающей исходные данные для ее применения.
Авторы предлагают применить для выявления конфликтующих коалиций в сложных организационных системах методы кластерно-конструктивного анализа и теории информации, реализованные в адаптивной системе анализа и прогнозирования состояний сложных систем "Эйдос".
Теория конструктов возникла в 1955 году (Дж.Келли) в области когнитивной психологии. Конструктом называется понятие, имеющее семантические полюса и шкалу промежуточных смысловых значений (градаций). В частности, конструктом является и система из двух наиболее сильно отличающихся кластеров со спектром объектов, занимающих между этими полюсами промежуточные положения.
Более конкретно суть предлагаемой авторами технологии состоит в следующем.
Осуществляется формализация предметной области, которая состоит в том, что каждой относительно самостоятельной компоненте системы ставится в соответствие некоторая обобщенная категория и все компоненты описываются в одной системе свойств и качеств (атрибутов).
На основе описаний компонент формируются обобщенные образы категорий, которые соответствуют конфликтующим или вступающим в коалицию сторонам. Для этой цели применяются методы теории информации, в частности апостериорная семантическая мера информации А.А.Харкевича.
Каждый из обобщенных образов представляет собой список атрибутов, расположенных в порядке убывания их характерности для данной категории. Кроме того, каждый атрибут описывается количеством информации, которое он содержит о принадлежности обладающего данным атрибутом компонента системы к каждой из категорий.
Обобщенные образы непосредственно сравниваются между собой методами корреляционного анализа, на основе чего формируется матрица сходства, которая является непосредственной основной для расчета конструктов и кластеров.
Важно, что в предложенной математической модели при формировании конструктов одновременно формируются и кластеры, причем если для формирования кластеров по классическим алгоритмам необходимо произвести число операций, равное количеству сочетаний из "n по m", то для формирования конструктов, всего n2, т.е. в предложенной модели в данном случае снимается проблема комбинаторного взрыва.
Результаты кластерно-конструктивного анализа представляются в наглядной графической форме в виде семантических сетей, которые представляют собой ориентированные графы, в вершинах которых находятся обобщенные категории, а ребрами являются вектора, величина и направление которых соответствуют величине сходства или различия каждой пары категорий.
Конкретное содержание конфликтов и основа для коалиций раскрывается в форме когнитивных диаграмм, представляющих собой по сути дела графическое изображение обобщенных образов двух категорий в форме списков наиболее характерных и нехарактерных для них атрибутов с указанием в форме векторов вклада каждой пары атрибутов в сходство или различие данных категорий.
Таким образом, предложенные математические модели, основанные на теории информации, и конкретная технология интеллектуальной обработки информации, реализованная на базе адаптивной системы анализа и прогнозирования состояний сложных систем "Эйдос", обеспечивают успешное выявление конфликтующих коалиций в сложных организационных системах, в частности коллективах, социально-экономических и политологических системах.
Соотношение психографологии и атрибуции текстов
Таким образом, любой текст содержит не только ту информацию, для передачи которой его собственно и создавали, но и информацию о самом авторе этого текста и о технических средствах и технологии его создания.
Существует целая наука – "Психографология", которая ставит своей задачей получение максимального количества информации об авторах текстов на основе изучения индивидуальных особенностей их почерка [125].
В настоящее время в России действует институт графологии. На сайте этого института http://graphology.boom.ru можно познакомится с тем, что такое графология, с ее историей и задачами, которые она позволяет решать сегодня. Графологическое исследование имеет значительное преимущество перед простым тестированием или собеседованием, поскольку нет необходимости информировать человека, чей почерк подвергается изучению о производимых исследованиях.
Но текст представляет собой не просто совокупность букв, а сложную иерархическую структуру, в которой буквы образуют лишь фундамент пирамиды, а на более высоких ее уровнях находятся слова, предложения, и другие части текстов различных размеров, обладающие относительной целостностью и самостоятельностью (абзацы, параграфы, главы, части, книги).
Понятие почерка акцентирует внимание именно на начертании и динамике воспроизведения букв и слов. При этом в понятие почерка не входят индивидуальные особенности текстов, обнаруживаемые на более высоких уровнях иерархической организации текстов, например: частоты употребления тех или иных слов и словосочетаний, средние длины предложений и абзацев, и т.п. Но именно эти индивидуальные особенности текстов исследуются и используются при атрибуции анонимных и псевдонимных текстов (определении их вероятного авторства) и датировки.
Соответственно и текст может представлять для читателя интерес по крайней мере с трех точек зрения:
1. Как источник информации о том, о чем говорит автор, т.е. о предмете изложения.
2. Как источник информации о самом авторе.
3. Как источник информации о предмете изложения и об авторе.
В этом смысле читать Пушкина в рукописи может быть значительно интереснее, чем в взяв томик с полки. Это объясняется просто: в томике есть лишь сам результат работы поэта и выхолощена вся информация о процессе, т.е. о самом поэте, содержащаяся в почерке, способе размещения текста на листе, порядке и динамике его формирования, различных вариантах и ассоциациях, возникавших в процессе создания произведения.
Таким образом, система, оснащенная интеллектуальным интерфейсом, может вести по-разному в зависимости от результатов идентификации пользователя, его профессионального уровня и текущего психофизиологического состояния.
СООТВЕТСТВИЕ ЛАБОРАТОРНЫХ РАБОТ РАБОЧИМ ПРОГРАММАМ ПО СПЕЦИАЛЬНОСТЯМ
В соответствии с рабочими программами при обучении по специальностям:
– 351401 "Прикладная информатика в экономике";
– 351403 "Прикладная информатика в юриспруденции"
рекомендуется несколько различные наборы лабораторных работ, приведенные в таблицах 40 и 41.
Таблица 40 – ЛАБОРАТОРНЫЕ РАБОТЫ,
РЕКОМЕНДУЕМЫЕ ПО СПЕЦИАЛЬНОСТИ:
351401 – Прикладная информатика в экономике
| № п/п | Наименование | Часов | |||
| 1 | ЛР-1: "Прогнозирование вероятных пунктов назначения железнодорожных составов" | 8 | |||
| 2 | ЛР-2: "Прогнозирование учебных достижений студентов на основе их имеджевых фотороботов" | 4 | |||
| 3 | ЛР-5: "Идентификация слов по входящим в них буквам" | 4 | |||
| 4 | ЛР-7: "Идентификация и классификация натуральных чисел по их свойствам" | 4 | |||
| 5 | ЛР-8: "Идентификация трехмерных тел по их ортогональным проекциям" | 4 | |||
| 6 | ЛР-9: "Прогнозирование количественных и качественных результатов выращивания зерновых колосовых и поддержка принятия решений по выбору агротехнологий" | 4 | |||
| 7 | ЛР-10: "Исследование случайной семантической информационной модели при различных объемах выборки" | 4 | |||
| Всего: | 32 |
Таблица 41 – ЛАБОРАТОРНЫЕ РАБОТЫ,
РЕКОМЕНДУЕМЫЕ ПО СПЕЦИАЛЬНОСТИ:
351403 – Прикладная информатика в юриспруденции
| № п/п | Наименование | Часов | |||
| 1 | ЛР-1: "Прогнозирование вероятных пунктов назначения железнодорожных составов" | 8 | |||
| 2 | ЛР-2: "Прогнозирование учебных достижений студентов на основе их имеджевых фотороботов" | 4 | |||
| 3 | ЛР-3: "Прогнозирование учебных достижений студентов на основе особенностей их почерка" | 4 | |||
| 4 | ЛР-4: "Прогнозирование учебных достижений студентов на основе информации об их социальном статусе" | 4 | |||
| 5 | ЛР-6: "Атрибуция анонимных и псевдонимных текстов" | 4 | |||
| 6 | ЛР-9: "Прогнозирование количественных и качественных результатов выращивания зерновых колосовых и поддержка принятия решений по выбору агротехнологий" | 4 | |||
| 7 | ЛР-10: "Исследование случайной семантической информационной модели при различных объемах выборки" | 4 | |||
| Всего: | 32 |
На первую лабораторную работу отводится 8 часов, т.к. на ней у учащихся будут формироваться первичные умения по применению универсальной когнитивной аналитической системы "Эйдос", которые на последующих лабораторных работах должны быть развиты и доведены до уровня навыков.
По технологии выполнения лабораторные работы имеют много общего, не смотря на различное содержание заданий. Это позволяет освоить эту технологию в общем виде на таком уровне, который в принципе позволяет учащимся самостоятельно осуществить формальную постановку и решение прикладной задачи применения систем искусственного интеллекта, независимо от предметной области. Кроме того, при такой структуре занятий материал лучше усваивается теми учащимися, которые пропускали занятия, что является реальностью, которую также необходимо учитывать.
Соответствие основных терминов и понятий
Предлагается следующая система соответствий, позволяющая рассматривать термины и понятия из теории нейронных сетей и предложенной семантической информационной модели практически как синонимы. Нейрон – вектор обобщенного образа класса в матрице информативностей. Входные сигналы – факторы (признаки). Весовой коэффициент – системная мера целесообразности информации. Обучение сети – адаптация модели, т.е. перерасчет значений весовых коэффициентов дендридов для каждого нейрона (матрицы информативностей) и изменение вида активационной функции. Самоорганизация сети – синтез модели, т.е. изменение количества нейронов и дендридов, изменение количества нейронных слоев и структуры связей между факторами и классами, а затем адаптация (перерасчет матрицы информативностей). Таким образом, адаптация – это обучение сети на уровне изменения информационных весовых коэффициентов и активационной функции, а синтез – на уровне изменения размерности и структуры связей нейронов сети. 1-й (входной) слой нейронной сети – формирование обобщенных образов классов. Сети Хопфилда и Хэмминга – обучение с учителем, сопоставление описательной и классификационной информации, идентификация и прогнозирование. 2-й слой, сети Хебба и Кохонена – самообучение, анализ структуры данных без априорной классификационной информации, формирование кластеров классов и факторов. 3-й слой – формирование конструктов (в традиционных нейронных сетях не реализовано). Необходимо отметить, что любой слой нейронной сети является в предлагаемой модели не только обрабатывающим, но и выходным, т.е. с одной стороны дает результаты обработки информации, имеющие самостоятельное значение, а с другой – поставляет информацию для последующих слоев нейронной сети, т.е. более высоких уровней иерархии информационной системы (в полном соответствии с формализуемой когнитивной концепцией).
Состав системы "Эйдос"
Система "Эйдос" (текущей версии 12.5) включает базовую систему (система "Эйдос" в узком смысле слова), а также две системы окружения:
– систему комплексного психологического тестирования "Эйдос-Y", разработанную совместно с С.Д.Некрасовым [142, 169];
– систему анализа и прогнозирования ситуация на фондовом рынке "Эйдос-фонд", разработанную совместно с Б.Х.Шульман [146].
Данные системы окружения представляют собой программные интерфейсы базовой системы "Эйдос" с базами данных психологических тестов и биржевыми базами данных соответственно, а также выполняют ряд самостоятельных функций по предварительной обработке информации.
Специальное программное обеспечение
При выполнении лабораторных работ и заданий по самостоятельной работе студентов используется следующее специальное программное обеспечение:
– Универсальная когнитивная аналитическая система "Эйдос" версии 12.5 или выше.
– Нейросетевой пакет Neuro Office фирмы "АЛЬФА-СИСТЕМ" (C`Петербург).
Специальный программный инструментарий СК-анализа – система "Эйдос"
На таблице 26 показана обобщенная схема когнитивной аналитической системы "Эйдос", которая реализует математическую модель и численный метод системно-когнитивного анализа и, таким образом, является его инструментарием.
В состав данной системы входит 7 подсистем.
Первые 3 подсистемы являются инструментальными, т.е. позволяют осуществлять синтез и адаптацию модели.
Остальные 4 подсистемы обеспечивают идентификацию, прогнозирование и кластерно-конструктивный анализ модели, в т.ч. верификацию модели и выработку управляющих воздействий.
Система "Эйдос" является довольно большой системой: распечатка ее исходных текстов 6-м шрифтом составляет около 800 листов, она генерирует 54 графических формы (двумерные и трехмерные) и 50 текстовых форм. На данную систему и системы окружения получено 8 свидетельств РосПатента РФ.
Таблица 26 – ОБОБЩЕННАЯ СТРУКТУРА УНИВЕРСАЛЬНОЙ
КОГНИТИВНОЙ АНАЛИТИЧЕСКОЙ СИСТЕМЫ "ЭЙДОС"
| Подсистема | Режим | Функция | Операция | ||||
| 1.
Словари | 1. Классификационные шкалы и градации | ||||||
| 2. Описательные шкалы (и градации) | |||||||
| 3. Градации описательных шкал (признаки) | |||||||
| 4. Иерархические уровни систем | 1. Уровни классов | ||||||
| 2. Уровни признаков | |||||||
| 5. Программные интерфейсы для импорта данных | 1. Импорт данных из TXT-фалов стандарта DOS-текст | ||||||
| 2. Импорт данных из DBF-файлов стандарта проф. А.Н.Лебедева | |||||||
| 3. Импорт из транспонированных DBF-файлов проф. А.Н.Лебедева | |||||||
| 4. Генерация шкал и обучающей выборки RND-модели | |||||||
| 5. Генерация шкал и обучающей выборки для исследования чисел | |||||||
| 6. Транспонирование DBF-матриц исходных данных | |||||||
| 6. Почтовая служба по НСИ | 1. Обмен по классам | ||||||
| 2. Обмен по обобщенным признакам | |||||||
| 3. Обмен по первичным признакам | |||||||
| 7. Печать анкеты | |||||||
| 2.
Обучение | 1. Ввод–корректировка обучающей выборки | ||||||
| 2. Управление обучающей выборкой | 1. Параметрическое задание объектов для обработки | ||||||
| 2. Статистическая характеристика, ручной ремонт | |||||||
| 3. Автоматический ремонт обучающей выборки | |||||||
| 3. Пакетное обучение системы распознавания | 1. Накопление абсолютных частот | ||||||
| 2. Исключение артефактов (робастная процедура) | |||||||
| 3. Расчет информативностей признаков | |||||||
| 4. Расчет условных процентных распределений | |||||||
| 5. Автоматическое выполнение режимов 1–2–3–4 | |||||||
| 6. Измерение сходимости и устойчивости модели | 1. Сходимость и устойчивость СИМ | ||||||
| 2. Зависимость валидности модели от объема обучающей выборки | |||||||
| 4. Почтовая служба по обучающей информации | |||||||
| 3.
Оптимизация | 1. Формирование ортонормированного базиса классов | ||||||
| 2. Исключение признаков с низкой селективной силой | |||||||
| 3. Удаление классов и признаков, по которым недостаточно данных | |||||||
| 4.
Распознавание | 1. Ввод–корректировка распознаваемой выборки | ||||||
| 2. Пакетное распознавание | |||||||
| 3. Вывод результатов распознавания | 1. Разрез: один объект – много классов | ||||||
| 2. Разрез: один класс – много объектов | |||||||
| 4. Почтовая служба по распознаваемой выборке | |||||||
| 5.
Типология | 1. Типологический анализ классов распознавания | 1. Информационные (ранговые) портреты (классов) | |||||
| 2. Кластерный и конструктивный анализ классов | 1 Расчет матрицы сходства образов классов | ||||||
| 2. Генерация кластеров и конструктов классов | |||||||
| 3. Просмотр и печать кластеров и конструктов | |||||||
| 4. Автоматическое выполнение режимов: 1,2,3 | |||||||
| 5. Вывод 2d семантических сетей классов | |||||||
| 3. Когнитивные диаграммы классов | |||||||
| 2. Типологический анализ первичных признаков | 1. Информационные (ранговые) портреты признаков | ||||||
| 2. Кластерный и конструктивный анализ признаков | 1. Расчет матрицы сходства образов признаков | ||||||
| 2. Генерация кластеров и конструктов признаков | |||||||
| 3. Просмотр и печать кластеров и конструктов | |||||||
| 4. Автоматическое выполнение режимов: 1,2,3 | |||||||
| 5. Вывод 2d семантических сетей признаков | |||||||
| 3. Когнитивные диаграммы признаков | |||||||
| 6. Анализ | 1. Оценка достоверности заполнения объектов | ||||||
| 2. Измерение адекватности семантической информационной модели | |||||||
| 3. Измерение независимости классов и признаков | |||||||
| 4. Просмотр профилей классов и признаков | |||||||
| 5. Графическое отображение нелокальных нейронов | |||||||
| 6. Отображение Паретто-подмножеств нейронной сети | |||||||
| 7. Классические и интегральные когнитивные карты |
Продолжение таблицы 26
|
Подсистема |
Режим |
Функция |
Операция |
|
7. Сервис |
1. Генерация (сброс) БД |
1. Все базы данных |
|
|
2. НСИ |
1. Всех баз данных |
||
|
2. БД классов |
|||
|
3. БД первичных признаков |
|||
|
4. БД обобщенных признаков |
|||
|
3. Обучающая выборка |
|||
|
4. Распознаваемая выборка |
|||
|
5. Базы данных статистики |
|||
|
2. Переиндексация всех баз данных |
|||
|
3. Печать БД абсолютных частот |
|||
|
4. Печать БД условных процентных распределений |
|||
|
5. Печать БД информативностей |
|||
|
6. Интеллектуальная дескрипторная информационно–поисковая система |
Сравнение, идентификация и прогнозирование
В разделе 3.2.3 были введены неметрические интегральные критерии сходства объекта, описанного массивом-локатором Li с обобщенными образами классов Iij
(выражения 3.35 – 3.37)
 | (3. 64) |
В выражении (3.64) круглыми скобками обозначено скалярное произведение. В координатной форме это выражение имеет вид:
 | (3. 65) |
где:

состояния объекта управления;


Для непрерывного случая выражение (3.65) принимает вид:
 | (3. 66) |
Таким образом, выражение (3.66) представляет собой вариант выражения (3.65) интегрального критерия сходства объекта и класса для непрерывного случая в координатной форме.
Интересно и очень важно отметить, что коэффициенты ряда Фурье по своей математической форме и смыслу сходны с ненормированными коэффициентами корреляции, т.е. по сути скалярными произведениями для непрерывных функций в координатной форме: выражение (3.66), между разлагаемой в ряд кривой f(x) и функциями Sin и Сos различных частот и амплитуд на отрезке [–L, L] [3]:
 | (3. 67) |
где: n={1, 2, 3,…} – натуральное число.
Из сравнения выражений (3.66) и (3.67) следует вывод, что процесс идентификации и прогнозирования (распознавания), реализованный в предложенной математической модели, может рассматриваться как разложение вектора-локатора распознаваемого объекта в ряд по векторам информативностей классов распознавания (которые представляют собой произвольные функции, сформированные при синтезе модели на основе эмпирических данных).
Например, при результатах идентификации, представленных на рисунке 36.
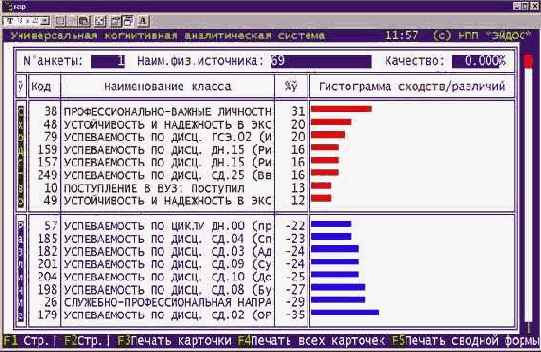 | |
| Рисунок 36. Пример разложения профиля курсанта усл.№69 в ряд по обобщенным образам классов |
Продолжая развивать аналогию с разложением в ряд, данный результат идентификации можно представить в векторной аналитической форме:
 |
Или в координатной форме, более удобной для численных расчетов:
 |
(3. 68) |
I(j) – интегральный критерий сходства массива-локатора, описывающего состояние объекта, и j- го класса, рассчитываемый согласно выражения (3.39):
 |
(3.39) |
 |
(3.28) |
При дальнейшем развитии данной аналогии естественно возникают вопросы: о полноте, избыточности и ортонормированности системы векторов классов как функций, по которым будет вестись разложение вектора объекта; о сходимости, т.е. вообще возможности и корректности такого разложения.
В общем случае вектор объекта совершенно не обязательно должен разлагаться в ряд по векторам классов таким образом, что сумма ряда во всех точках точно совпадала со значениям исходной функции. Это означает, что система векторов классов может быть неполна по отношению к профилю распознаваемого объекта, и, тем более, всех возможных объектов.
Предлагается считать не разлагаемые в ряд, т.е. плохо распознаваемые объекты, суперпозицией хорошо распознаваемых объектов ("похожих" на те, которые использовались для формирования обобщенных образов классов), и объектов, которые и не должны распознаваться, так как объекты этого типа не встречались в обучающей выборке и не использовались для формирования обобщенных образов классов, а также не относятся к представляемой обучающей выборкой генеральной совокупности.
Нераспознаваемую компоненту можно рассматривать либо как шум, либо считать ее полезным сигналом, несущим ценную информацию о еще не исследованных объектах интересующей нас предметной области (в зависимости от целей и тезауруса исследователей). Первый вариант не приводит к осложнениям, так как примененный в математической модели алгоритм сравнения векторов объектов и классов, основанный на вычислении нормированной корреляции Пирсона (сумма произведений), является весьма устойчивым к наличию белого шума в идентифицируемом сигнале.
Во втором варианте необходимо дообучить систему распознаванию объектов, несущих такую компоненту (в этой возможности и заключается адаптивность модели). Технически этот вопрос решается просто копированием описаний плохо распознавшихся объектов из распознаваемой выборки в обучающую, их идентификацией экспертами и дообучением системы. Кроме того, может быть целесообразным расширить справочник классов распознавания новыми классами, соответствующими этим объектам.
Но на практике гораздо чаще наблюдается противоположная ситуация (можно даже сказать, что она типична), когда система векторов избыточна, т.е. в системе классов распознавания есть очень похожие классы (между которыми имеет место высокая корреляция, наблюдаемая в режиме: "кластерно-конструктивный анализ"). Практически это означает, что в системе сформировано несколько практически одинаковых образов с разными наименованиями. Для исследователя это само по себе является очень ценной информацией. Однако, если исходить только из потребности разложения распознаваемого объекта в ряд по векторам классов (чтобы определить суперпозицией каких образов он является, т.е. "разложить его на компоненты"), то наличие сильно коррелирующих друг с другом векторов представляется неоправданным, так как просто увеличивает размерности данных, внося в них мало нового по существу. Поэтому возникает задача исключения избыточности системы классов распознавания, т.е. выбора из всей системы классов распознавания такого минимального их набора, в котором профили классов минимально коррелируют друг с другом, т.е. ортогональны в фазовом пространстве признаков. Это условие в теории рядов называется "ортонормируемостью" системы базовых функций, а в факторном анализе связано с идеей выделения "главных компонент".
В предлагаемой математической модели релизованы два варианта выхода из данной ситуации:
1) исключение неформирующихся, расплывчатых классов;
2) объединение почти идентичных по содержанию (дублирующих друг друга) классов.
Но выбрать нужный вариант и реализовать его, используя соответствующие режимы, пользователь технологии АСК-анализа должен сам. Вся необходимая и достаточная информация для принятия соответствующих решений предоставляется пользователю инструментария АСК-анализа.
Если считать, что функции образов составляют формально–логическую систему, к которой применима теорема Геделя, то можно сформулировать эту теорему для данного случая следующим образом: "Для любой системы базисных функций в принципе всегда может существовать по крайней мере одна такая функция, что она не может быть разложена в ряд по данной системе базисных функций, т.е. функция, которая является ортонормированной ко всей системе
базисных функций в целом".
Очевидно, не взаимосвязанными друг с другом могут быть только четко оформленные, детерминистские образы, т.е. образы с высокой степенью редукции ("степень сформированности конструкта"). Поэтому в процессе выявления взаимно–ортогональных базисных образов в первую очередь будут выброшены аморфные "расплывчатые" образы, которые связаны практически со всеми остальными образами.
В некоторых случаях результат такого процесса представляет интерес и это делает оправданным его реализацию. Однако можно предположить, что и наличие расплывчатых образов в системе является оправданным, так как в этом случае система образов не будет формальной и подчиняющейся теореме Геделя, следовательно, система распознавания будет более полна в том смысле, что повысится вероятность идентификации любого объекта, предъявленного ей на распознавание. Конечно, уровень сходства с аморфным образом не может быть столь же высоким, как с четко оформленным, поэтому в этом случае может быть более уместно применить термин "ассоциация" или нечеткая, расплывчатая идентификация, чем "однозначная идентификация".
Итак, можно сделать следующий вывод: допустимость в математической модели СК-анализа не только четко оформленных (детерминистских) образов, но и образов аморфных, нечетких, расплывчатых является важным достоинством данной модели.
Это обусловлено тем, что данная модель обеспечивает корректные результаты анализа, идентификации и прогнозирования даже в тех случаях, когда модели идентификации и информационно–поисковые системы детерминистского типа традиционных АСУ практически неработоспособны. В этих условиях данная модель СК-анализа работает как система ассоциативной (нечеткой) идентификации.
Таким образом, в предложенной семантической информационной модели при идентификации и прогнозировании по сути дела осуществляется разложение векторов идентифицируемых объектов по векторам классов распознавания, т.е. осуществляется "объектный анализ" (по аналогии с спектральным, гармоническим или Фурье–анализом), что позволяет рассматривать идентифицируемые объекты как суперпозицию обобщенных образов классов различного типа с различными амплитудами (3.68). При этом вектора обобщенных образов классов с математической точки зрения представляют собой произвольные функции, и не обязательно образуют полную и не избыточную (ортонормированную) систему функций.
Для любого объекта всегда существует такая система базисных функций, что вектор объекта может быть представлен в форме линейной суперпозиции (суммы) этих базисных функций с различными амплитудами. Это утверждение, по-видимому, является одним из следствий фундаментальной теоремы А.Н.Колмогорова, доказанной им в 1957 году (О представлении непрерывных функций нескольких переменных в виде суперпозиций непрерывных функций одного переменного и сложения // Докл. АН СССР, том 114, с. 953-956, 1957).
Теорема Колмогорова: Любая непрерывная функция от n переменных F(x1, x2, ..., xn)
может быть представлена в виде:
 |
– непрерывные функции, причем hij не зависят от функции F.
Эта теорема означает, что для реализации функций многих переменных достаточно операций суммирования и композиции функций одной переменной. Удивительно, что в этом представлении лишь функции gj зависят от представляемой функции F, а функции hij универсальны. Необходимо отметить, что терема Колмогорова является обобщением теоремы В.И.Арнольда (1957), которая дает решение 13-й проблемы Гильберта.
К сожалению определение вида функций hij
и gj для данной функции F представляет собой математическую проблему, для которой пока не найдено общего строгого решения.
В данной работе предлагается рассматривать предлагаемую семантическую информационную модель как один из вариантов решения этой проблемы. В этом контексте функция F интерпретируется как образ идентифицируемого объекта, функция hij – как образ j-го класса, а функция gj – как мера сходства образа объекта с образом класса.
Старение информации и периоды эргодичности процессов в предметной области
В то же время при исследовании зависимости валидности методики от продолжительности предстоящего периода, в течение которого учитывается действие факторов, было обнаружено, что при увеличении этого периода валидность методики сначала возрастает, а затем начинает плавно, а иногда и скачком снижаться. Рост валидности объясняется увеличением статистики базы примеров, что повышает ее представительность и адекватность. Последующее уменьшение валидности может быть объяснено тем, что закономерности в предметной области изменяются с течением времени, и, поэтому, очень старые данные основаны на иных закономерностях, чем действующие в настоящее время, и значит они уже не повышают адекватность методики, а снижают ее, по сути искажают картину.
Периоды времени, в течение которых закономерности в предметной области существенно не меняются, называются периодами эргодичности. Именно на эр годичных периодах неадаптивные АСУ сохраняют свою адекватность. Эргодичность процессов нарушается либо в результате длительного действия эволюционных изменений в предметной области, которые в конце концов приводят к ее качественному изменению, или в результате действия кратковременных революционных (качественных, скачкообразных) изменений.
Для каждой методики должны быть определены периоды эргодичности, т.к. при выходе за эти периоды необходима адаптация старой или разработка новой методики.
Стоимость и амортизация систем искусственного интеллекта и баз знаний
Любая программная система представляет собой виртуальное средство труда работающее на базе универсального компьютера. Эти информационные средства труда, так же как и обычные "физические", могут быть предназначены либо для непосредственного потребления пользователем (группа "Б"), или для создания других подобных средств труда ("группа "А").
Вопрос о стоимости программных систем – это вопрос о стоимости средств труда, начисто лишенных своего "физического тела". В их создание вложен огромный высококвалифицированный труд, наукоемкие технологии, но тиражируются такие средства очень просто: путем перезаписи на магнитный носитель. Это своего рода "психосинтез", и если бы нечто аналогичное стало возможным с физическими объектами, то наступил бы настоящий "золотой век", по крайней мере в плане материальном (гибкие роботизированные комплексы уже приближают их к этому).
Следовательно, в соответствии с информационной теорией стоимости программные продукты имеют высокую потребительную стоимость и практически никакой меновой стоимости.
Меновая стоимость программных продуктов определяется практически затратами на поиск места, где они уже есть, и на доставку потребителю. С появлением Internet практически решены вопросы и поиска, и доставки программного обеспечения и других "информационных товаров".
Чтобы повысить меновую стоимость программных систем их разработчики стараются затруднить их так называемое "свободное тиражирование" или попросту говоря – воровство, вводя необходимость инсталляции и "привязывая" систему к конкретному компьютеру (имеются также другие способы). Но, во-первых, против этого также есть свои средства, а во-вторых, такая привязка снижает функциональную ценность программной системы, т.к. делает ее более уязвимой при технических авариях, модернизации компьютера и т.п., что в общем делает ее просто менее удобной для пользователя.
Что касается износа программных систем, этих "нематериальных активов", то физический износ у них вообще отсутствует, а моральный может быть весьма значительным: после появления новой версии программного продукта старой уже никто не хочет пользоваться (хотя иногда появляется "сырая" и "не очень работающая" новая версия, а старая хорошо отработана и идеально выполняет свои функции). Итак, с появлением новой версии старая может "в один момент" потерять всю свою стоимость (в том числе и балансовую – в результате переоценки).
Иначе обстоит дело с базами данных и интеллектуальными системами, которые накапливают и структурируют информацию, обрабатывают ее по более или менее сложным алгоритмам, в результате чего их стоимость непрерывно возрастает. Стоимость баз данных, находящихся на банковском сервере, может в десятки миллионов раз превышать стоимость самого компьютера и в процессе работы это соотношение все больше увеличивается в пользу информации. Естественно, такую ценную информацию необходимо защищать, чтобы даже если сервер будет похищен, злоумышленники не смогли извлечь из него ни одно бита интересующей их информации.
Страховой бизнес
Страховые компании накапливают значительные объемы подробнейшей информации о клиентах, используемых ими услугах, страховых премиях и выплатах. Технологии data mining позволяют использовать накопившиеся данные для решения следующих задач:
Классификация и кластеризация клиентов. Система интеллектуального анализа данных позволяет страховой компании проводить эффективную тарифную политику, основанную на индивидуальных предпочтениях различных категорий клиентов.
Разработка нового товара. Технологии data mining являются инструментом, с помощью которого можно спрогнозировать спрос на услугу, оценить страховые выплаты и сформировать политику в отношении взимаемых страховых премий.
Структура лабораторной работы
Лабораторные работы имеют типовую структуру, включающую следующие разделы:
– краткая теория;
– одно или несколько заданий;
– пример решения;
– контрольные вопросы;
– литература по данной лабораторной работе.
В разделе "Краткая теория"
излагается минимум теоретических понятий, необходимых для осмысленного выполнения студентом данной работы.
В разделе "Задание" ставится цель лабораторной работы и формулируются этапы ее достижения.
В разделе "Пример решения" приводятся примеры выполнения некоторых этапов сформулированных заданий. Примеры выполнения служат для пояснения наиболее сложных этапов выполнения работы и не должны тождественно повторяться студентами в своих лабораторных работах.
Контрольные вопросы по лабораторной работе служат для проверки качества усвоения и понимания материала, могут быть заданы преподавателем при защите лабораторной работы и включены в экзаменационные билеты.
В разделе "Литература" приводятся конкретные литературные источники, использованные при разработке данной лабораторной работы.
Структура типовой АСУ
Цель применения АСУ обычно можно представить в виде некоторой суперпозиции трех подцелей:
1) стабилизация состояния объекта управления в динамичной или агрессивной внешней среде;
2) перевод объекта в некоторое конечное (целевое) состояние, в котором он приобретает определенные заранее заданные свойства;
3) повышение качества функционирования АСУ (синтез новых моделей и их адаптация).
Обычно АСУ рассматривается как система, состоящая из двух основных подсистем: управляющей и управляемой, т.е. из субъекта и объекта управления (рисунок15).
Как правило, АСУ действует в определенной окружающей среде, которая является общей и для субъекта, и для объекта управления.
Граница между
тем, что считается окружающей средой, и тем, что считается объектом
управления относительна и определяется возможностью управляющей системы оказывать на них воздействие: на объект управления управляющее воздействие может быть оказано, а на среду нет.
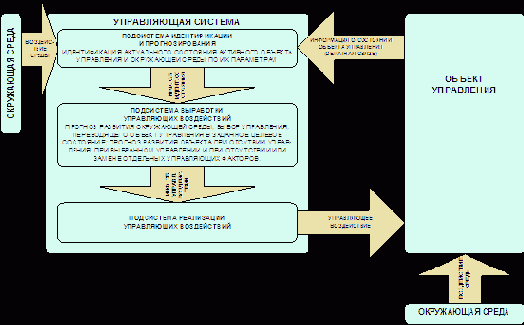 | |
| Рисунок 15. Структура типовой АСУ |
Суть концепции смысла Шенка-Абельсона
Согласно Л.Г. Васильеву [10] суть концепции смысла Шенка-Абельсона состоит в том, что факты рассматриваются как причины
и их смысл считается известным, если известны последствия данного факта. Таким образом, понимание смысла определенных конкретных событий заключается в выявлении причинно-следственных взаимосвязей между этими событиями и другими.
По нашему мнению, данная концепция смысла является одной из наиболее интуитивно убедительных и хорошо обоснованных, поэтому она в целом принята нами за основу.
Естественно, в этой концепции одним из ключевых моментов является определение способа выявления силы и направленности влияния причинно-следственных взаимосвязей и их количественной оценки (меры).
На наш взгляд слабым местом концепции смысла Шенка-Абельсона является сложность корректного и обоснованного выбора количественной меры силы и направленности причинно-следственных связей, а также конкретного способа определения численной величины этой меры в каждом конкретном случае (т.е. для каждого факта), причем непосредственно на основе эмпирических данных.
Проблема в том, что в общественном сознании продолжает господствовать упрощенческая точка зрения, состоящая в том, что корреляция является мерой причинно-следственных связей. И это имеет место не смотря на многочисленные разъяснения в специальной литературе о том, что это не так, точнее не совсем так.
Поэтому одной из целей данной работы будет обоснована другой меры силы и направленности причинно-следственных взаимодействий.
Связь количества и качества информации с меновой и потребительной стоимостью
Информационная теория стоимости разработана автором в 1979 – 1981 годах и опубликована в специальных материалах, а также в сокращенном виде в работах[64, 92].
Эта теория базируется на двух положениях, имеющих очень высокую степень достоверности:
1. Стоимость товара определяется временем, необходимым в обществе на его производство.
2. Создание продукта труда есть информационный процесс воплощения информационного образа этого продукта в предмете труда.
Рассмотрим рисунок 3.
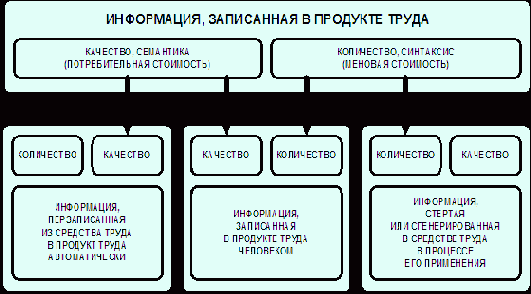 | |
| Рисунок 3. Схема образования потребительной стоимости и стоимости в процессе труда с позиций информационной теории стоимости |
Информация записанная в структуре продукта труда непосредственно человеком создает и потребительную, и меновую стоимость. Информация же записанная в структуре продукта средствами труда, т.е. без участия человека, автоматически, не увеличивает стоимость этого продукта, хотя и создает его потребительную стоимость.
При этом совершенно неважно, каким образом записана эта информация в самих средствах труда: непосредственно человеком или также с помощью средств труда. Неважно также записана эта информация непосредственно в механической или другой консервативной структуре средств труда жестко один раз и навсегда, или в некотором мобильном устройстве памяти с возможностью его перепрограммирования (как в компьютерах, на гибких автоматизированных линиях и роботизированных комплексах).
Напротив информация стертая в средстве труда в процессе создания данного продукта (износ средства труда) переноситься на него и увеличивает его стоимость, хотя и не создает никакой потребительной стоимости. Но в процессе труда информация в средстве труда может не только стираться, но и накапливаться: это происходит, например, в интеллектуальных автоматизированных системах, как обучающихся с учителем, так и самообучающихся (поэтому их называют генераторами информации). В этом случае стоимость средств труда в процессе их использования не уменьшается, а возрастает, и стоимость продукта, созданного с их помощью соответственно уменьшается, а не увеличивается.
Итак, потребительная стоимость продукта труда определяется КАЧЕСТВОМ (смыслом, содержанием) связанной информации, записанной в физической форме и структуре того продукта непосредственно человеком или его средствами труда.
Абстрактная себестоимость продукта труда определяется алгебраической суммой КОЛИЧЕСТВА связанной информации, записанной в структуре физической формы продукта труда человеком и КОЛИЧЕСТВА связанной информации стертой или записанной в структуре физической формы средств труда в процессе производства данного продукта, причем последняя берется со знаком "+", если она стерта (износ средств труда), и со знаком "-", если она записана (генерация информации).
Производительность человеческого труда тем выше, чем большее количество функций тела человека передано его средствам труда, а также чем выше степень использования функциональных возможностей этих средств труда человеком. Чем выше производительность труда, тем большая доля информации записывается в продукте труда средствами труда автоматически, т.е. без участия человека. Таким образом, в конечном счете производительность труда определяется прежде всего уровнем развития сознания человека.
В отличие от производительности труда изменение его интенсивности не влияет на функциональный уровень технологии, а значит и на соотношение между количеством информации, записанной в продукт труда человеком и средствами труда. Поэтому только уменьшение рабочего времени, необходимого на производство данного продукта, достигнутое за счет увеличения производительности человеческого труда уменьшает абстрактную себестоимость этого продукта и может служить адекватной мерой изменения этой себестоимости. Так гениальные произведения искусства, содержащие колоссальную информацию, записанную в них непосредственно человеком-творцом практически без использования средств труда, всегда будут иметь наивысшую стоимость, значительно превосходящую стоимость самых качественных репродукций.
До сих пор мы использовали термин и понятие "время" без его специального анализа и определения в каком-то обыденно-экономическом значении.
Теперь же основываясь на общности основных законов информационных взаимодействий проведем аналогию (а может быть и больше чем аналогию) между "временем физическим", "психофизиологическим" и "экономическим", естественно, насколько это возможно в рамках данной работы.
Из физики известно, что редукция виртуального объекта происходит при сообщении ему энергии, необходимой для образования его массы покоя. Очевидно, редуцируемый объект представляет собой канал взаимодействия классического и виртуального уровней Реальности и этот канал обеспечивает передачу энергии с первого уровня на второй. Однако для возникновения структуры редуцированной формы объекта одной энергии явно недостаточно: для этого необходима также и информация об этой структуре. Эта информация существовала еще до редукции на виртуальном уровне строения редуцируемого объекта и была передана по тому же каналу, но в направлении обратном энергетическому потоку.
Таким образом, в физике виртуальная сущность объекта выступает как источник информации, сам объект как информационно-энергетический канал взаимодействия виртуального и редуцированного уровней Реальности, а редуцированная форма объекта – как носитель информации, изменяющий свою структуру по мере записи соответствующей информации в структуре среды.
Чем выше уровень развития (сложность) объекта, тем более отдаленные друг от друга качественно различные уровни Реальности он соединяет как информационно-энергетический канал, тем выше пропускная способность (мощность) этого канала, тем большее разнообразие форм энергии и языковых форм представления информации он обеспечивает, и, наконец, тем выше информационная емкость его формы, т.е. тем большее количество информации может быть записано в структуре его формы до момента начала повышения ее энтропии.
Здесь уместным является пример с магнитофонной лентой на которую мы пытаемся записать как можно больше информации на единицу длины путем уменьшения скорости протяжки. Если при постоянном информационном потоке записи эту скорость уменьшать линейно, то первоначально плотность информации будет возрастать также практически линейно (а энтропия соответственно уменьшаться), однако скоро мы заметим, что плотность информации стала возрастать медленнее, т.к.
возросли шумы (уменьшилось отношение сигнал/шум). Если продолжать и дальше уменьшать скорость протяжки, то конце концов это приведет к тому, что качественный записывающий сигнал будет восприниматься лентой практически как стирающий, т.е. на нее будет записываться один шум.
Таким образом, можно сделать по крайней мере следующие выводы:
Процесс труда можно рассматривать как процесс редукции образа продукта труда в структуре физической среды, что становится непосредственно очевидным при развитии интеллектуальных информационных технологий.
Человеческая Душа с ее неисчерпаемым творческим потенциалом является единственным источником всякой собственности и стоимости в этом мире. Поэтому даже в чисто экономическом, в общем-то достаточно "приземленном" смысле, нет ничего более ценного в мире, чем человеческая Душа.
Примечание: Согласно теории "Естественного права" (Сократ, Платон, Фома Аквинский) наиболее глубоким источником права является природа самого человека. Одним из основных правовых отношений является отношение собственности. На этом основании автор выдвигает (в качестве гипотезы, конечно) "Естественную теорию собственности":
1. Человеческая Душа является единственным и наиболее глубоким источником всех форм собственности и их фундаментом;
2. В зависимости от формы сознания
человеческая душа отождествляет себя с различными "телами проявления" и, таким образом, возникает первая производная форма собственности: - собственность на свое тело и право на жизнь (при физической форме сознания – это собственность на физическое тело и физическую жизнь).
3. Из "Естественного права" собственности на свое тело возникает право собственности на все, что произведено непосредственно и исключительно с применением своего тела: прежде всего сам живой (собственный) труд, средства и продукты труда (физического и "умственного").
4. Право собственности на свой труд и средства труда приводят к праву собственности на продукты своего труда, произведенные с использованием собственных средств труда, а также к отсутствию права собственности на продукты труда, произведенные с использованием чужих средств труда (наемный труд).
Темп времени является величиной индивидуальной для каждого объекта и определяется мощностью информационно-энергетического канала, связывающего физическую форму объекта с его более глубокими структурными уровнями.
Связь принятия решений и распознавания образов
Распознавание образов есть решение задачи идентификации состояния объекта или системы, отнесение его к той или иной классификационной категории.
Распознавание образов и принятие решений тесно взаимосвязаны:
– само распознавание безусловно представляет собой принятие решения об отнесении состояния системы к той или иной категории;
– от того, к какой категории отнесено состояние системы самым непосредственным образом зависят и решения по управлению этой системой;
– математический аппарат распознавания образов и принятия решений имеет очень много аналогий, а иногда и просто является тождественным (например, сведение многокритериальной задачи к однокритериальной).
Связь семантической информационной модели с нейронными сетями
В 1943 году Дж. Маккалоки и У. Питт предложили формальную модель биологического нейрона как устройства, имеющего несколько входов (входные синапсы – дендриты), и один выход (выходной синапс – аксон). Дендриты получают информацию от источников информации (рецепторов) Li, в качестве которых могут выступать и нейроны. Набор входных сигналов {Li} характеризует объект или ситуацию, обрабатываемую нейроном. Каждому i-му входу j-го нейрона ставится в соответствие некоторый весовой коэффициент Iij, характеризующий степень влияния сигнала с этого входа на аргумент передаточной (активационной) функции, определяющей сигнал Yj на выходе нейрона. В нейроне происходит взвешенное суммирование входных сигналов, и далее это значение используется как аргумент активационной (передаточной) функции нейрона. На рисунке 37 данная модель приведена в обозначениях, принятых в настоящей работе.
 | |
| Рисунок 37. Классическая модель нейрона Дж. Маккалоки и У. Питта (1943)
в обозначениях системной теории информации |
Свойства эластичности
Рассмотрим некоторые свойства эластичности, которые, как мы заметили, удивительным образом полностью или частично совпадают со свойствами логарифма (таблица 21).
Таблица 21 – СВОЙСТВА ЭЛАСТИЧНОСТИ И ЛОГАРИФМА
| № | ЭЛАСТИЧНОСТЬ | ЛОГАРИФМ | Примечание | ||||
| 1 | Эластичность взаимно-обратной функции взаимно-обратна:
 | Логарифм взаимно-обратной функции равен той же функции с обратным знаком:
 | Совпадает по модулю (с точностью до знака) | ||||
| 2 | Эластичность произведения двух функций одного аргумента равна сумме эластичностей функций:
 | Логарифм произведения двух функций одного аргумента равна сумме логарифмов функций:
 | Полностью совпадает | ||||
| 3 | Эластичность частного двух функций одного аргумента равна разности эластичностей функций:
 | Логарифм частного двух функций одного аргумента равна разности логарифмов функций:
 | Полностью совпадает | ||||
| 4 | Эластичность показательной функции   | Логарифм показательной функции  | Полностью совпадает | ||||
| 5 | Область значений эластичности:
  | Область значений логарифма:
| Полностью совпадает |
Необходимо отметить, что ряд других свойств эластичности, таких как эластичность суммы функций, эластичность линейной функции и др., не совпадают со свойствами логарифма. Итак, учитывая свойства эластичности 2-5 (таблица 21) мы видим, что большинство свойств эластичности совпадают со свойствами логарифмической функции. Это позволяет высказать гипотезу, что свойства эластичности Ex(y) схожи со свойствами количества информации I, т.к. во все выражения для количества информации Хартли-Найквиста-Больцмана, Шеннона и Харкевича входит логарифмическая функция.
Какая же из этих мер информации в наибольшей степени соответствует понятию эластичности? Ключевым в решении этого вопроса является свойство 5 (таблица 21):
– область значений мер Хартли-Найквиста-Больцмана и Шеннона изменяется от 0 до

– область значений меры Харкевича, как и эластичности, изменяется от
Однако классическая мера семантической целесообразности информации мера Харкевича не удовлетворяет принципу соответствия с мерой Хартли в детерминистском случае, поэтому автором данной работы в [64] предложена системная мера целесообразности информации (СМЦИ) – Iij(W,M). В отличие от эластичности Ex(y), которая определена для однозначной функции одного аргумента, Iij(W,M) определена для многозначной функции многих аргументов.
Таким образом, системная мера целесообразности информации, предложенная в настоящем исследовании, имеет математические свойства сходные со свойствами эластичности многозначной функции многих аргументов.
Технология применения программного инструментария
Эта технология включает следующие этапы:
1) формализация предметной области;
2) сбор и ввод исходных данных в систему;
3) синтез информационной модели;
4) оптимизация информационной модели;
5) оценка адекватности информационной модели;
6) если модель адекватна – переход на п.7, иначе – на п.1.;
7) эксплуатация информационной модели для прогнозирования и управления в режиме адаптации и периодического синтеза модели.
Темы состоятельной работы студентов:
СР-1-Ю. Идентификация изображений местности по их вербальным описаниям.
СР-2-Ю. Оценка рисков правонарушений по признакам почерка (психографология).
СР-3-ЭЮ.
Оценка рисков страхования и кредитования предприятий по их вербальным описаниям.
СР-4-Ю. Прогнозирование рисков совершения ДТП (дорожно-транспортных происшествий) по видам и времени на основе данных о владельце и автомобиле.
СР-5-Э. Прогнозирование успешности деятельности фирмы на основе оценки ее персонала.
СР-6-Ю. Прогнозирование продолжительности жизни пациентов, перенесших сердечный приступ, по данным эхокардиограммы на основе базы данных репозитария UCI.
СР-7. Классификация животных по внешним признакам на основе базы данных репозитария UCI.
СР-8. Диагностика фитопатологии по симптоматике и выработку рекомендаций по плану лечения на основе информации, содержащейся в учебниках.
СР-9-Ю. Идентификация изображений различных мест на территории КубГАУ по вербальным описаниям их фотографий (изображения взять с сайта КубГАУ: http://kubagro.ru, фотогалерея). СК-анализ семантической информационной модели.
СР-10. Прогнозирование успеваемости по ИИС на основе данных по социальному статусу студентов и их родителей.
СР-11. Прогнозирование направления деятельности фирмы на основе данных о расположении и внешнем виде ее офиса. СК-анализ семантической информационной модели.
СР-12. Выбор автомобиля для приобретения по его признакам (обучающую выборку взять на автомобильном рынке). СК-анализ семантической информационной модели.
СР-13. Выбор вариантов приобретения жилья по его признакам. СК-анализ семантической информационной модели.
СР-14-Э. Оценка важности различных видов городского транспорта и различных маршрутов в разрезе по остановкам. СК-анализ семантической информационной модели.
СР-15. Исследование систем: FineReader, Cunie Form и других систем ввода текстов со сканера. Исследовать зависимость качества распознавания текста от разрешения сканирования для разных систем. Оценку качества производить по количеству ошибок распознавания на одном и том же тексте.
Составить рейтинг систем и версий, дать рекомендации. Оценить тоже самое, после использования After Scan.
СР-16. Исследование систем Stylus (Promt), Сократ, и других систем автоматизированного перевода. Сравнить качество автоматизированного перевода с русского языка на английский язык и обратно для текстов различной направленности (юридические, технические, художественные, стихи) и с различной длиной и сложностью предложений (статистика). Составить рейтинг систем и версий, дать рекомендации. Оценку качества перевода осуществлять путем обобщения экспертных оценок экспертов с разным уровнем компетентности (студенты).
СР-17. Исследовать реальную систему распознавание образов, идентификации и прогнозирования при решении задач лабораторных работ.
СР-18. Исследовать реальную систему поддержки принятия решений при решении задач лабораторных работ.
СР-19. Исследовать реальную экспертную систему при решении задач лабораторных работ.
СР-20. Исследовать реальную систему класса: "Нейронная сеть" на примере пакета NeuroOffice при решении задач лабораторных работ.
СР-21. Исследовать реальную систему, реализующую генетические алгоритмы при решении задач лабораторных работ.
СР-22. Исследовать реальную систему когнитивного моделирования при решении задач лабораторных работ.
СР-23. Исследовать реальную систему выявления знаний из опыта (эмпирических фактов) и интеллектуального анализа данных при решении задач лабораторных работ.
СР-23+. Решение задач идентификации и прогнозирования на основе данных репозитория UCI по следующим направлениям:
Abalone, Adult, Annealing, Anonymous Microsoft Web Data, Arrhythmia, Artificial Characters, Audiologys, Auto-Mpg, Automobile, Badges, Balance Scale, Balloons, Breast Cancer, Wisconsin Breast Cancers, Pittsburgh Bridges, Car Evaluation, Census Income, Chesss, Bach Chorales (time-series), Connect-4 Opening, Credit Screenings, Computer Hardware, Contraceptive Method Choice, Covertype data, Cylinder Bands, Dermatology, Diabetes Data, The Second Data Generation Program - DGP/2, Document Understanding, EBL Domain Theories and Examples, Echocardiogram, Ecoli, Flags,Function Findings, Glass Identification, Haberman's Survival Data, Hayes-Roth, Heart Diseases, Hepatitis, Horse Colic, Housing (Boston), ICU Data, Image segmentation, Internet Advertisements, Ionosphere, Iris Plant, Isolet Spoken Letter Recognition, Kinship, Labor relations, LED Display Domains, Lenses, Letter Recognition, Liver-disorders, Logic-theorist, Lung Cancer, Lymphography, Mechanical Analysis Data, Meta-data, Mobile Robots, Molecular Biologys, MONK's Problems, Moral Reasoner, Multiple Features, Mushrooms, MUSKs, Nursery, Othello Domain Theory, Page Blocks Classification, Pima Indians Diabetes, Optical Recognition of Handwritten Digits, Pen-Based Recognition of Handwritten Digits, Postoperative Patient, Primary Tumor, Qualitative Structure Activity Relationships (QSARs), Quadraped Animals Data Generator, Servo, Shuttle Landing Control, Solar Flares, Soybeans, Challenger USA Space Shuttle O-Rings, Low Resolution Spectrometer, Spambase, SPECT and SPECTF hearts, Sponge, Statlog Projects, Student Loan Relational, Teaching Assistant Evaluation, Tic-Tac-Toe Endgame, Thyroid Disease, Trains, University, Congressional Voting Records, Water Treatement Plant, Waveform Data Generator, Wine Recognition, Yeast, Zoo, Undocumenteds.
Тест Тьюринга и критерии "интеллектуальности"
В 1950 году в статье "Вычислительные машины и разум" (Computing machinery and intelligence) выдающийся английский математики и философ Алан Тьюринг предложил тест, чтобы заменить бессмысленный, по его мнению, вопрос "может ли машина мыслить?" на более определённый.
Вместо того, чтобы отвлеченно спорить о критериях, позволяющих отличить живое мыслящее существо от машины, выглядящей как живая и мыслящая, он предложил реализуемый на практике способ установить это.
Судья-человек ограниченное время, например, 5 минут, переписывается в чате (в оригинале – по телеграфу) на естественном языке с двумя собеседниками, один из которых – человек, а другой – компьютер. Если судья за предоставленное время не сможет надёжно определить, кто есть кто, то компьютер прошёл тест.
Предполагается, что каждый из собеседников стремится, чтобы человеком признали его. С целью сделать тест простым и универсальным, переписка сводится к обмену текстовыми сообщениями.
Переписка должна производиться через контролируемые промежутки времени, чтобы судья не мог делать заключения исходя из скорости ответов. (Тьюринг ввел это правило потому, что в его времена компьютеры реагировали гораздо медленнее человека. Сегодня же это правило необходимо, наоборот, потому что они реагируют гораздо быстрее, чем человек).
Идею Тьюринга поддержал Джо Вайзенбаум, написавший в 1966 году первую "беседующую" программу "Элиза". Программа всего в 200 строк лишь повторяла фразы собеседника в форме вопросов и составляла новые фразы из уже использованных в беседе слов. Тем ни менее этого оказалось достаточно, чтобы поразить воображение тысяч людей.
А.Тьюринг считал, что компьютеры в конечном счёте пройдут его тест, т.е. на вопрос: "Может ли машина мыслить?" он отвечал утвердительно, но в будущем времени: "Да, смогут!"
Алан Тьюринг был не только выдающимся ученым, но и настоящим пророком компьютерной эры. Достаточно сказать, что в 1950 году (!!!), когда он писал, что к 2000 году, на столе у миллионов людей будут стоять компьютеры, имеющие оперативную память 1 миллиард бит (около 119 Мб) и оказался в этом абсолютно прав.
Когда он писал это, все компьютеры мира вместе взятые едва ли имели такую память. Он также предсказал, что обучение будет играть важную роль в создании мощных интеллектуальных систем, что сегодня совершенно очевидно для всех специалистов по СИИ. Вот его слова: "Пытаясь имитировать интеллект взрослого человека, мы вынуждены много размышлять о том процессе, в результате которого человеческий мозг достиг своего настоящего состояния… Почему бы нам вместо того, чтобы пытаться создать программу, имитирующую интеллект взрослого человека, не попытаться создать программу, которая имитировала бы интеллект ребенка? Ведь если интеллект ребенка получает соответствующее воспитание, он становится интеллектом взрослого человека… Наш расчет состоит в том, что устройство, ему подобное, может быть легко запрограммировано… Таким образом, мы расчленим нашу проблему на две части: на задачу построения "программы-ребенка" и задачу "воспитания" этой программы".
Именно этот путь и используют практически все системы ИИ. Кроме того, именно на этом пути появляются и другие признаки интеллектуальной деятельности: накопление опыта, адаптация и т. д.
Против теста Тьюринга было выдвинуто несколько возражений.
1. Машина, прошедшая тест, может не быть разумной, а просто следовать какому-то хитроумному набору правил.
На что Тьюринг не без юмора отвечал: "А откуда мы знаем, что человек, который искренне считает, что он мыслит, на самом деле не следует какому-то хитроумному набору правил?"
2. Машина может быть разумной и не умея разговаривать, как человек, ведь и не все люди, которым мы не отказываем в разумности, умеют писать.
Могут быть разработаны варианты теста Тьюринга для неграмотных машин и судей.
3. Если тест Тьюринга и проверяет наличие разума, то он не проверяет сознание
(consciousness) и свободу воли (intentionality), тем самым не улавливая весьма существенных различий между разумными людьми и разумными машинами.
Сегодня уже существуют многочисленные варианты интеллектуальных систем, которые не имеют цели, но имеют критерии поведения: генетические алгоритмы и имитационное моделирование эволюции.
Поведение этих систем выглядит таким образом, как будто они имеют различные цели и добиваются их.
Ежегодно производится соревнование между разговаривающими программами, и наиболее человекоподобной, по мнению судей, присуждается приз Лебнера (Loebner).
Существует также приз для программы, которая, по мнению судей, пройдёт тест Тьюринга. Этот приз ещё ни разу не присуждался.
В заключение отметим, что и сегодня тест Тьюринга не потерял своей фундаментальности и актуальности, более того – приобрел новое звучание в связи с возникновением Internet, общением людей в чатах и на форумах под условными никами и появлением почтовых и других программ-роботов, которые рассылают спам (некорректную навязчивую рекламу и другую невостребованную информацию), взламывают пароли систем и пытаются выступать от имени их зарегистрированных пользователей и совершают другие неправомерные действия.
Таким образом, возникает задачи:
– идентификации пола и других параметров собеседника (на эту возможность применения своего теста указывал и сам Тьюринг);
– выявления писем, написанных и посланных не людьми, а также такого автоматического написания писем, чтобы отличить их от написанных людьми было невозможно. Так что антиспамовый фильтр на электронной почте тоже представляет собой что-то вроде теста Тьюринга.
Не исключено, что скоро подобные проблемы (идентификации: человек или программа) могут возникнуть и в чатах. Что мешает сделать сетевых роботов типа программы "Элиза", но значительно более совершенных (все же сейчас не 1966, а 2004 год), которые будут сами регистрироваться в чатах и форумах участвовать в них с использованием слов и модифицированных предложений других участников? Простейший вариант – дублирование тем с других форумов и перенос их с форума на форум без изменений, что мы уже иногда наблюдаем в Internet (например: сквозная тема про "Чакра-муни").
На практике чтобы на входе системы определить, кто в нее входит, человек или робот, достаточно при входе предъявить для решения простенькую для человека, но требующую огромных вычислительных ресурсов и системы типа неокогнитрона Фукушимы, задачку распознавания случайных наборов символов, представленных в нестандартных начертаниях, масштабах и поворотах на фоне шума (Vladimir Maximenko).Решил, – значит стучится человек-пользователь, не решил, – значит на входе робот, лазающий по мировой сети с неизвестными, чаще всего неблаговидными целями.
Источники информации:
1. Свободная энциклопедия: http://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D1%81%D1%82_%D0%A2%D1%8C%D1%8E%D1%80%D0%B8%D0%BD%D0%B3%D0%B0
2. Сотник С.Л. Конспект лекций по курсу "Основы проектирования систем искусственного интеллекта": (1997-1998), http://neuroschool.narod.ru/books/sotnik.html.
3. Vladimir Maximenko. Реализация теста Тьюринга на Perl (ввод цифр изображенных на картинке) (perl image auth web cgi): http://www.opennet.ru/base/dev/turing_test.txt.html
4. Captcha (http://en.wikipedia.org/wiki/Captcha) – полностью автоматизированные открытые тесты Тьюринга по разделению людей и машин (Completely Automated Public Turing tests to tell Computers and Humans Apart).
5. Сайт: http://www.opennet.ru/opennews/art.shtml?num=4105
Типы выявляемых закономерностей
Успех применения систем data mining
основан на том, что эти технологии обеспечивают исследование эмпирических данных и выявление в них скрытых закономерностей различных видов.
Ассоциация (идентификация). Если некоторый факт-1 является частью определенного события, то с расчетной вероятностью и другой факт-2, связанный с первым, будет частью того же события.
Последовательность (прогнозирование). Если свершилось некоторое событие-1, то с расчетной вероятностью через определенный период времени свершится другое событие-2, связанное с первым.
Классификация. На основании информации о свойствах объекта ему присваивается определенное дискретное значение показателя, по которому проводится классификация (идентификатор).
Кластеризация. Наиболее сходные по своим признакам объекты объединяются в группы (кластеры) таким образом, что в разных кластерах оказываются наиболее сильно отличающиеся друг от друга объекты. Кластеризация аналогична классификации, но в отличие от последней классы – кластеры объектов заранее не известны, а формируются в процессе кластеризации.
Прогнозирование. Прошлые фактические значения величин используются для прогнозирования будущих значений тех же или других величин на основании на основании знания зависимостей между ними, трендов и статистики.
Традиционные подходы к решению
Существуют два основных подхода к решению сформулированной выше проблемы:
– фундаментальный, основанный на выявлении взаимосвязей между внутренними и внешними по отношению к предприятию факторами и (событиями) и уровнем целесообразности инвестиций в данное предприятие;
– технический, основанный на анализе временных рядов различных параметров предприятия и его окружения средствами регрессионного анализа и математической статистики.
Фундаментальный подход оперирует средствами многомерного факторного анализа и содержательным аналитическим аппаратом математической экономики. Технический подход основан на статистических феноменологических моделях, отражающих внешнюю сторону явлений. Первое выглядит более обоснованным, однако наталкивается на технические трудности сбора и подготовки исходной информации. Технический подход более технологичен в плане сбора информации и ее обработки, но является более поверхностным в ее анализе и дает менее качественные прогнозы.
Традиционные пути решения
Традиционно проблема районирования сортов решалась путем обобщения фактических результатов выращивания тех или иных сортов в различных регионах за длительный исторический период. В этом подходе, однако, есть следующие недостатки. Традиционные ареалы выращивания сортов обусловлены не только объективными ландшафтно-климатическим факторами, но и традициями этносов, а также путями и исторически сложившимися зонами их расселения. Это означает, что, с одной стороны, в ряде случаев сорта возделываются там, где это не вполне оправданно по объективным условиям, а с другой стороны, наоборот, они могут не возделываться там, где для этого существуют наилучшие природные условия. Традиционный подход не позволяет на количественном уровне оценить степень соответствия объективных условий в той или иной точке для выращивания заданного сорта, и таким образом, не соответствует критериям строгости, принятым в современной науке.
Еще в 1935 г. Всесоюзной Академией сельскохозяйственных наук бывшего Советского Союза перед Государственной системой испытания сельскохозяйственных культур была поставлена задача проведения их районирования.
Однако, эта задача не решена в полной мере до сих пор, особенно по многолетним культурам. И это понятно, т.к. государственное испытание проводит изучение плодовых в конкретных точках, которые привязываются чаще всего к крупным плодовым хозяйствам иногда без возможности проводить испытание всего набора культур.
Например, в Краснодарском крае нет ни одного
сортоучастка, где абрикос давал бы более 4-х урожаев за 10 лет. Госсортосеть рекомендует к закладке садов сорта по данным эмпирического испытания, без учета и анализа их адаптивного потенциала и природно-ресурсного потенциала конкретного пункта. Эти рекомендации с аналогичными данными НИИ используются при разработке проектов закладки садов проектными организациями, например, по Краснодарскому краю ОАО "Краснодарагроспецпроект".
Традиционные пути решения проблемы
Традиционно при необходимости проведения подобных исследований реализуется один из двух вариантов, т.е. либо изучается подмножество однородных по своей природе данных, измеряемых в одних единицах измерения; либо перед исследованием данные приводятся к сопоставимому виду, например, широко используются процентные или другие относительные величины, реже – стандартизированные значения.
Ясно, что первый вариант является не решением проблемы, а лишь ее вынужденным обходом, обусловленным ограничениями реально имеющегося в распоряжении исследователей инструментария.
Второй вариант лишь частично решает проблему, т.к. хотя и снимает различие в единицах измерения, но не преодолевает принципиального различия между количественными и качественными (нечисловыми) величинами и не позволяет обрабатывать их совместно в рамках единой модели.
В последние годы развивается ряд новых методов статистики, полный обзор которых дан в работах А. И. Орлова [http://antorlov.chat.ru]. Прежде всего, это интервальная статистика, статистика объектов нечисловой природы, робастные, бутстрепные и непараметрические методы.
В частности методы интервальной статистики, позволяют сводить числовые величины к фактам попадания их значений в определенные интервалы, т.е. к событиям. При этом преодолевается проблема различия в размерности числовых величин. Это обеспечивает также обработку числовых величин, как событий совместно с информацией о других событиях, связанных с объектами нечисловой природы. Таким образом, интервальные методы сводят обработку числовых величин к методам обработки нечисловой информации
и позволяет обрабатывать их единообразно по одной методике. И это является очень важным достижением.
Требования к математической модели и численной мере
Для практической реализации идеи решения проблемы необходимо сформулировать требования к математической модели и численной мере, вытекающие из когнитивной концепции и специфических свойств активного объекта управления в АПК (слабодетерминированность, многофакторность, активность).
Требования к математической модели предусматривают: содержательную интерпретируемость; эффективную вычислимость на основе непосредственно эмпирических данных (наличие эффективного численного метода); универсальность; адекватность; сходимость; семантическую устойчивость; сопоставимость результатов моделирования в пространстве и времени; непараметричность; формализацию базовых когнитивных операций системного анализа (прежде всего таких, как обобщение, абстрагирование, сравнение, классификация и др.); корректность работы на фрагментарных, неточных и зашумленных данных; возможность обработки данных очень больших размерностей (тысячи факторов и будущих состояний объекта управления); математическую и алгоритмическую ясность и простоту, эффективность программной реализации.
Требования к численной мере. Ключевым при построении математических моделей является выбор количественной меры, обеспечивающей учет степени причинно-следственной взаимосвязи исследуемых параметров. Эта мера должна удовлетворять следующим требованиям: 1) обеспечивать эффективную вычислимость на основе эмпирических данных, полученных непосредственно из опыта; 2)обладать универсальностью, т.е. независимостью от предметной области; 3) подчиняться единому для различных предметных областей принципу содержательной интерпретации; 4) количественно измеряться в единых единицах измерения а количественной шкале (шкала с естественным нулем, максимумом или минимумом); 5) учитывать понятия: "цели объекта управления", "цели управления"; "мощность множества будущих состояний объекта управления"; уровень системности объекта управления; степень детерминированности объекта управления; 6) обладать сопоставимостью в пространстве и во времени; 7) обеспечивать возможность введения метрики или неметрической функции принадлежности на базе выбранной количественной меры.
Для того, чтобы выбрать тип (класс) модели, удовлетворяющей сформулированным требованиям, необходимо решить на какой форме информации эта модель будет основана: абсолютной, относительной или аналитической.
Требования к системам координат
В качестве осей координат пространства атрибутов целесообразно выбрать вектора атрибутов, обладающие следующими свойствами:
1. Их должно быть минимальное количество, достаточное для полного описания предметной области.
2. Эти вектора должны пересекаться в одной точке.
3. Значения координат вектора должны измеряться в одной единице измерения, т.е. должны быть сопоставимы.
Для выполнения первого требования необходимо, чтобы математическая форма и смысл весовых коэффициентов были выбраны таким образом, чтобы модули векторов атрибутов в пространстве классов были пропорциональны их значимости для решения задач идентификации, прогнозирования и управления. Причем наиболее значимые вектора атрибутов не должны коррелировать друг с другом, т.е. должны быть ортонормированны. В этом случае при удалении векторов с минимальными модулями автоматически останутся наиболее значимые практически ортонормированные вектора, которые можно принять за базисные, т.е. в качестве осей системы координат.
Второе требование означает, что минимальное расстояние между этими векторами в пространстве классов должно быть равно нулю.
Третье требование предполагает соответствующий выбор математической формы для значений координат.
Эти идеальные требования практически никогда не будут соблюдаться на практике с абсолютной точностью. Однако этого и не требуется. Достаточно, чтобы реально выбранные в качестве базисных атрибуты отображались в пространстве классов векторами, для которых эти требования выполняются с точностью, достаточной для применения соответствующих математических моделей и математического аппарата на практике.
Аналогично обстоит дело и с минимизацией размерности пространства классов. В качестве базисных могут выбраны вектора классов, имеющие максимальную длину и взаимно (попарно) ортонормированные.
Очевидно, задача выбора базисных векторов имеет не единственное решение, т.е. может существовать несколько систем таких векторов, которые можно рассматривать как результат действия преобразований системы координат, состоящих из смещений и поворотов.
Учебные вопросы:
1. Основные положения информационно-функциональной теории развития техники
2. Информационная теория стоимости
3. Интеллектуализация – генеральное направление и развития информационных технологий
1. Данные, информация, знания. Системно-когнитивный анализ как развитие концепции смысла Шенка-Абельсона.
2. Понятие: "Система искусственного интеллекта", место СИИ в классификации информационных систем.
3. Определение и классификация систем искусственного интеллекта, цели и пути их создания.
4. Информационная модель деятельности специалиста и место систем искусственного интеллекта в этой деятельности.
5. Жизненный цикл системы искусственного интеллекта и критерии перехода между этапами этого цикла.
1. Системный анализ, как метод познания.
2. Когнитивная концепция и синтез когнитивного конфигуратора.
3. СК-анализ, как системный анализ, структурированный до уровня базовых когнитивных операций.
4. Место и роль СК-анализа в структуре управления.
1. Теоретические основы системной теории информации.
2. Семантическая информационная модель СК-анализа.
3. Некоторые свойства математической модели (сходимость, адекватность, устойчивость и др.).
4. Взаимосвязь математической модели СК-анализа с другими моделями.
1. Принципы формализации предметной области и подготовки эмпирических данных.
2. Иерархическая структура данных и последовательность численных расчетов в СК-анализе.
3. Обобщенное описание алгоритмов СК-анализа.
4. Детальные алгоритмы СК-анализа.
1. Назначение и состав системы "ЭЙДОС".
2. Пользовательский интерфейс, технология разработки и эксплуатации приложений в системе "ЭЙДОС".
3. Технические характеристики и обеспечение эксплуатации системы "ЭЙДОС" (версии 12.5).
4. АСК-анализ, как технология синтеза и эксплуатации рефлексивных АСУ активными объектами.
В данной лекции рассматривается инструментарий автоматизации СК-анализа в качестве которого выступает универсальная когнитивная аналитическая система "Эйдос". Данная система является одним из вариантов программной реализации предложенной математической модели и численного метода СК-анализа. Наличие данного инструментария, автоматизирующего СК-анализ, позволяет ввести в новый термин: автоматизированный системно-когнитивный анализ (АСК-анализ), под которым понимается СК-анализ, оснащенный математическим методом, методикой численных расчетов и реализующим их программным инструментарием.
1. Интеллектуальные интерфейсы. Использование биометрической информации о пользователе в управлении системами.
2. Системы с биологической обратной связью.
3. Системы с семантическим резонансом. Компьютерные (Y-технологии и интеллектуальный подсознательный интерфейс.
4. Системы виртуальной реальности и критерии реальности. Эффекты присутствия, деперсонализации и модификация сознания пользователя.
5. Системы с дистанционным телекинетическим интерфейсом.
1. Основные понятия и определения, связанные с системами распознавания образов.
2. Проблема распознавания образов.
3. Классификация методов распознавания образов.
4. Применение распознавания образов для идентификации и прогнозирования. Сходство и различие в содержании понятий "идентификация" и "прогнозирование".
5. Роль и место распознавания образов в автоматизации управления сложными системами.
6. Методы кластерного анализа.
1. Многообразие задач принятия решений.
2. Языки описания методов принятия решений.
3. Выбор в условиях неопределенности.
4. Решение как компромисс и баланс различных интересов. О некоторых ограничениях оптимизационного подхода.
5. Экспертные методы выбора.
6. Юридическая ответственность за решения, принятые с применением систем поддержки принятия решений.
7. Условия корректности использования систем поддержки принятия решений.
8. Хранилища данных для принятия решений.
1. Экспертные системы, базовые понятия.
2. Экспертные системы, методика построения.
3. Этап-1 синтеза ЭС: "Идентификация".
4. Этап-2 синтеза ЭС: "Концептуализация".
5. Этап-3 синтеза ЭС: "Формализация".
6. Этап-4 синтеза ЭС: "Разработка прототипа".
7. Этап-5 синтеза ЭС: "Экспериментальная эксплуатация".
8. Этап-6 синтеза ЭС: "Разработка продукта".
9. Этап-7 синтеза ЭС: "Промышленная эксплуатация".
Данный раздел основан на конспекте лекций по курсу "Основы проектирования систем искусственного интеллекта": Сотник С.Л. (1997-1998), который несложно найти Internet, например, по адресу: http://neuroschool.narod.ru/books/sotnik.html [191].
1. Биологический нейрон и формальная модель нейрона Маккалоки и Питтса.
2. Возможность решения простых задач классификации непосредственно одним нейроном.
3. Однослойная нейронная сеть и персептрон Розенблата.
4. Линейная разделимость и персептронная представляемость.
5. Многослойные нейронные сети.
6. Проблемы и перспективы нейронных сетей.
7. Модель нелокального нейрона и нелокальные интерпретируемые нейронные сети прямого счета.
В разделах 1.3.5.1 и 1.3.5.3 широко использованы материалы лекций по теории и приложениям искусственных нейронных сетей, размещенные в Internet Сергеем А. Тереховым, Лаборатория Искусственных Нейронных Сетей НТО-2, ВНИИТФ, Снежинск (http://alife.narod.ru/lectures/neural/Neu_index.htm) [197].
1. Основные понятия, принципы и предпосылки генетических алгоритмов.
2. Пример работы простого генетического алгоритма.
3. Достоинства и недостатки генетических алгоритмов.
4. Примеры применения генетических алгоритмов.
1. Определение основных понятий: "Когнитивное моделирование" и "Классическая когнитивная карта", их связь с когнитивной психологией и гносеологией.
2. Когнитивная (познавательно-целевая) структуризация знаний об исследуемом объекте и внешней для него среды на основе PEST-анализа и SWOT-анализа.
3. Разработка программы реализации стратегии развития исследуемого объекта на основе динамического имитационного моделирования (при поддержке программного пакета Ithink).
1. Интеллектуальный анализ данных (data mining)
2. Типы выявляемых закономерностей data mining.
3. Математический аппарат data mining.
4. Области применения технологий интеллектуального анализа данных.
5. Автоматизированные системы для интеллектуального анализа данных.
Данная лекция основана на работе В. Дюк, А. Самойленко. Data Mining: учебный курс (+ CD-ROM). 2001 г. Издательство: Питер. Серия: Учебный курс. – 368с., а также материалах сайта компании BI Partner: http://www.bipartner.ru/services/dm.html.
1. Обзор опыта применения АСК-анализа для управления и исследования социально-экономических систем.
2. Поддержка принятия решений по выбору агротехнологий, культур и пунктов выращивания.
3. Прогнозирование динамики сегмента рынка.
4. Анализ динамики макроэкономических состояний городов и районов на уровне субъекта Федерации в ходе экономической реформы (на примере Краснодарского края) и прогнозирование уровня безработицы (на примере Ярославской области).
1. Ограничения АСК-анализа и обоснованное расширение области его применения на основе научной индукции.
2. Перспективы применения АСК-анализа в управлении.
3. Развитие АСК-анализа.
4. Другие перспективные области применения АСК-анализа и систем искусственного интеллекта.
Удаление классов и признаков, по которым недостаточно данных
В данном режиме реализована возможность удаления из модели всех классов и признаков, по которым или вообще нет данных, или их недостаточно в соответствии с заданным критерием. Этот режим сходен с режимом выявления и исключения артефактов.
Углубленный анализ содержательной информационной модели предметной области
Этот анализ выполняется в подсистеме "Типология", которая включает:
1. Информационный и семантический анализ классов и признаков.
2. Кластерно-конструктивный анализ классов распознавания и признаков, включая визуализацию результатов анализа в оригинальной графической форме когнитивной графики (семантические сети классов и признаков).
3. Когнитивный анализ классов и признаков (когнитивные диаграммы и диаграммы Вольфа Мерлина).
Управление фондовым рынком на детерминистских участках траектории
Из факторов, существенно влияющих на динамику курса доллара США лишь некоторые зависят от решений крупных финансовых негосударственных руководителей, да и то, если они будут действовать скоординировано. Прежде всего это количество банков, участвующих в торгах, а также объем первоначального спроса и предложения. На второй параметр может оказывать существенное влияние Центральный банк, путем крупных интервенций или закупок доллара США.
Управление фондовым рынком в точках бифуркации
Однако, в точках бифуркации обычные закономерности фондового рынка нарушаются или практически теряют силу, в игру вступают совсем другие факторы, которые имеют в основном не экономическую, а психологическую природу. Изучение этих факторов и разработка тактики оперативных действий требует прогнозирования динамики курса в течение суток буквально по часам. Такая работа была проведена совместно с Б.Х.Шульман (США). На первом этапе автором была разработана универсальная формальная классификация, включающая очень большое (заранее избыточное) количество вариантов суточной динамики курса доллара США, которая генерировалась автоматически. Затем было изучено влияние факторов, действующих на фондовом рынке в течение предшествующего месяца. Проведенная работа показала, что: не все теоретически-возможные варианты суточной динамики курса фактически реализуются; существует возможность надежного прогнозирования суточной динамики курса доллара не только в детерминистские периоды, но и в точках бифуркации. Это позволяет участникам рынка сознательно и спокойно принимать ответственные решения не только заблаговременно, но и точно привязываясь к времени в течение дня.
Управление как задача, обратная идентификации и прогнозированию
Кратко рассмотрим вопрос о применении систем распознавания образов для принятия решений об управляющем воздействии. Очевидно, что применение систем распознавания для прогнозирования результатов управления при различных сочетаниях управляющих факторов позволяет рассмотреть и сравнить различные варианты управления и выбрать наилучшие из них по определенным критериям. Однако, этот подход на практике малоэффективен, особенно если факторов много, т.к. в этом случае количество сочетаний их значений может быть чрезвычайно большим.
Если в качестве классов распознавания взять целевые и иные будущие состояния объекта управления, а в качестве признаков – факторы, влияющие на него, то в модели распознавания образов может быть сформирована количественная мера причинно-следственной связи факторов и состояний.
Это позволяет по заданному целевому состоянию объекта управления получить информацию о силе и направлении влияния факторов, способствующих или препятствующих переходу объекта в это состояние, и, на этой основе, выработать решение об управляющем воздействии.
Задача выбора факторов по состоянию является обратной задачей прогнозирования, т.к. при прогнозировании, наоборот, определяется состояние по факторам.
Факторы могут быть разделены на следующие группы:
– характеризующие предысторию объекта управления и его актуальное состояние управления;
– технологические (управляющие) факторы;
– факторы окружающей среды;
Таким образом, системы распознавания образов могут быть применены в составе АСУ в подсистемах:
– идентификации состояния объекта управления;
– выработки управляющих воздействий.
Это целесообразно в случае, когда объект управления представляет собой сложную или активную систему.
Управление составом обучающей информации (БКОСА-
Данный режим предназначен для управления обучающей выборкой путем параметрического задания подмножеств анкет для обработки, объединения классов, автоматического ремонта обучающей выборки ("ремонт или взвешивание данных"). Параметрическое выделение подмножества анкет для обработки может осуществляться логически и физически (рекомендуется 2-й вариант), это осуществляется путем сравнения с анкетой-маской. В ней задаются коды тех классов и признаков, которые обязательно должны присутствовать во всех анкетах обрабатываемого подмножества. Режим: "Статистическая характеристика обучающей выборки. Ручной ремонт" предназначен для выявления слабо представленных классов (по которым недостаточно данных) и объединения нескольких классов в один. При этом производится переформирование справочника классов и автоматическое перекодирование анкет обучающей выборки. В режиме "Автоматический ремонт обучающей выборки (ремонт или взвешивание данных)" реализуется БКОСА-2.2: задается частотное распределение объектов по категориям, характерное для генеральной совокупности (или другое), затем автоматически осуществляется формирование последовательных подмножеств анкет обучающей выборки (с увеличивающимся числом анкет), на каждом этапе максимально соответствующих заданному частотному распределению генеральной совокупности. При этом используется метод последовательных приближений по минимаксному критерию: максимизация корреляции и минимизация максимального отклонения. Соответствующие графики представлены на рисунке69.
Система рекомендует оптимальное (по этим двум критериям) подмножество и позволяет исключить остальные анкеты из рассмотрения. На рисунке 70 приведены графики частотных распределений объектов генеральной совокупности и выбранного подмножества обучающей выборки по категориям (классам), а также отклонение между этими распределениями.
 | |
| Рисунок 69. Автоматический ремонт обучающей выборки (диагр.1) (БКОСА-2.2) |
 | |
| Рисунок 70. Автоматический ремонт обучающей выборки (диагр.2) (БКОСА-2.2) |
При достижении минимакса можно говорить об обеспечении структурной репрезентативности [64].
Условия корректности использования систем поддержки принятия решений
Этих условий три:
1. Само решение о выборе той или иной конкретной системы поддержки принятия решений должно приниматься лицом, принимающим решения, который и будет пользоваться ее рекомендациями, либо подчиненными ему компетентными специалистами по его личному поручению.
2. Сам выбор системы поддержки принятия решений должен осуществляться, как правило, не по их специальным, или, тем более, рекламным описаниям и литературным данным, а по результатам сравнительных испытаний на реальных примерах из практики работы организации.
3. Выбранная система должна быть официально принятой для решения тех задач, для решения которых она будет использоваться, т.е. должна быть сертифицирована.
Под сертификацией понимается:
– апробация системы поддержки принятия решений и оценка адекватности рекомендуемых ей решений на ряде реальных задач, которые возникали в прошлом или возникают в течение определенного периода экспериментальной эксплуатации;
– придание системе поддержки принятия решений юридического статуса, который предписывает и лицам принимающим решения "принимать к сведению" рекомендации системы.
Для сертификации системы создается соответствующая компетентная и полномочная комиссия, которая в течение определенного времени изучает систему и выдаваемые ею рекомендации на предмет адекватности складывающимся ситуациям. Результаты работы комиссии оформляются в форме юридического документа, имеющего силу в ведомстве или организации, в которых будет применяться система.
В этом документе описывается круг задач, для решения которых применяется система, инфраструктура и технология ее применения, а также определяются обязанности и персональная ответственность специалистов по эксплуатации системы.
Если система не сертифицирована, то ее применение некорректно с юридической точки зрения. На практике это происходит гораздо чаще, чем многие представляют, например, с системами бухгалтерского учета или психологическими тестами, которые распространяются на пиратских компакт-дисках, не локализованы для регионов и организаций применения, не адаптированы для решения задач, для решения которых они фактически применяются.
Устойчивость модели к наличию шума
Шум можно рассматривать как сочетание неполноты информации (т.к. некоторые значащие символы исчезают из описаний объектов), и дезинформации (т.к. в описание включаются ложные символы).
Поэтому замену символов в словах на символы, которые не встречаются по обучающей выборке можно считать неполнотой информации. Этот случай мы рассматривать не будем, т.к. по сути уже рассмотрели его в предыдущем пункте.
Рассмотрим пример, в котором одно слово заменой букв преобразуется в другое слово, например, слово "критик" преобразуется в слово "окорок". Каждой замене будет соответствовать одна анкета распознаваемой выборки (таблица 73):
Таблица 73 – ВАРИАНТЫ КОДИРОВАНИЯ ОБЪЕКТА ОБУЧАЮЩЕЙ ВЫБОРКИ, ОТЛИЧАЮЩИЕСЯ УРОВНЕМ ШУМА
| № | Класс | Коды признаков | |||||||||||||||||||||||||||||
| 1 | КРИТИК | 47 | 53 | 45 | 55 | 45 | 47 | ||||||||||||||||||||||||
| 2 | КРОТИК | 47 | 53 | 51 | 55 | 45 | 47 | ||||||||||||||||||||||||
| 3 | КРОТОК | 47 | 53 | 51 | 55 | 51 | 47 | ||||||||||||||||||||||||
| 4 | ОКОРОК | 47 | 53 | 51 | 51 | 51 | 47 |
Результаты идентификации представлены на рисунке 135:
 |
 |
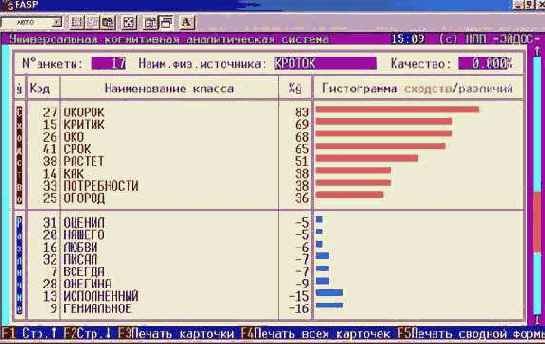 |
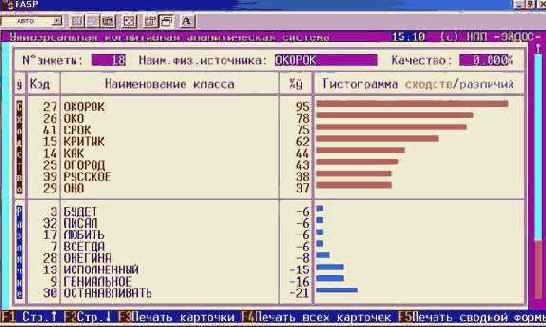 | |
| Рисунок 135. Результаты идентификации в условиях шума в системе "Эйдос" |
Видим, что модель обладает определенной устойчивостью и к шуму.
Устойчивость модели к неполноте информации
Подготовим распознаваемую выборку, состоящую из идентифицируемых слов с отсутствующими буквами.
Для этого выполним следующую последовательность шагов:
Шаг 1.
Сбросим распознаваемую выборку в режиме "F7 Сервис – Генерация (сброс) баз данных – Распознаваемые анкеты" (рисунок 129):
 | |
| Рисунок 129. Режим "Сброс распознаваемой выборки" системы "Эйдос" |
Шаг 2. Скопируем, например, первую анкету из обучающей выборки в распознаваемую, используя возможности режима "F2 Обучение – Ввод-корректировка обучающей выборки" (рисунок 124);
Шаг 3. Выберем режим "F4 Распознавание – Ввод-корректировка распознаваемой выборки" (рисунок 130):
 | |
| Рисунок 130. Выбор режима "Ввод-корректировка распознаваемой выборки" системы "Эйдос" |
Выбор режима осуществляется нажатием клавиши Enter.
Шаг 4. Перейдем в правое окно, в котором задаются коды признаков, нажав клавишу "TAB".
Шаг 5. Удаляем последний код признака и дублируем анкету, нажав клавишу "F5 Дублирование анкеты".
Повторяем шаги 4 и 5 до тех пор, пока в описании слова останется одна буква. В результате получится видеограмма, представленная на рисунке 131.
Студенты при выполнении этого этапа работы могут взять несколько анкет на выбор. При этом набор анкет должен отличаться у разных студентов.
Обучающая выборка в этом случае будет иметь вид, представленный на таблице 72:
Таблица 72 – ВАРИАНТЫ КОДИРОВАНИЯ ОБЪЕКТА ОБУЧАЮЩЕЙ ВЫБОРКИ, ОТЛИЧАЮЩИЕСЯ СТЕПЕНЬЮ НЕПОЛНОТЫ ИНФОРМАЦИИ
| № | Класс | Коды признаков | |||||||||||||||||||||||||||||
| 1 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | 47 | 45 | 46 | |||||||||||||||||||||
| 2 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | 47 | 45 | ||||||||||||||||||||||
| 3 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | 47 | |||||||||||||||||||||||
| 4 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | 54 | ||||||||||||||||||||||||
| 5 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | 50 | |||||||||||||||||||||||||
| 6 | БЕЛИНСКИЙ | 38 | 42 | 48 | 45 | ||||||||||||||||||||||||||
| 7 | БЕЛИНСКИЙ | 38 | 42 | 48 | |||||||||||||||||||||||||||
| 8 | БЕЛИНСКИЙ | 38 | 42 | ||||||||||||||||||||||||||||
| 9 | БЕЛИНСКИЙ | 38 |
Жирным шрифтом выделены символы, коды которых есть в анкете.
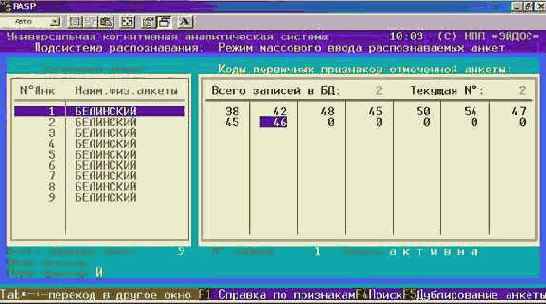 |
|
Рисунок 131. Выполнение режима "Ввод-корректировка распознаваемой выборки" системы "Эйдос" |
Шаг 7. Затем выберем и выполним режим "F4 Распознавание – Вывод результатов распознавания" (рисунок 132):
 |
|
Рисунок 132. Выбор режима "Вывод результатов распознавания" системы "Эйдос" |
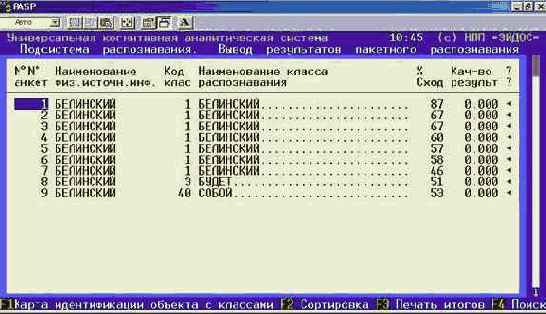 |
|
Рисунок 133. Обобщенная форма по результатам выполнения режима "Вывод результатов распознавания" системы "Эйдос" |
Шаг 9. Нажав клавишу "F1 Карта идентификации объекта с классами" получим более подробные результаты идентификации, представленные в карточках распознавания на рисунке 134:
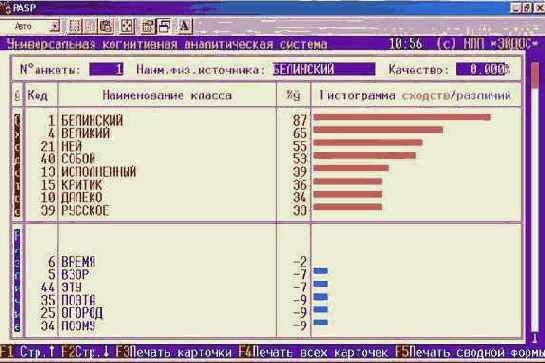 |
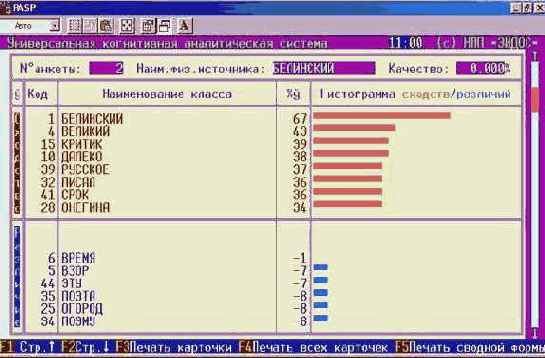 |
 |
 |
 |
|
Рисунок 134. Идентификация в условиях неполноты информации в системе "Эйдос" |
Варианты постановки задачи распознавания клавиатурного почерка
Аутентификация – это проверка, действительно ли пользователь является тем, за кого себя выдает. При этом пользователь должен предварительно сообщить о себе идентификационную информацию: свое имя и пароль, соответствующий названному имени.
Идентификация – это установление его личности.
И идентификация, и аутентификация являются типичными задачами распознавания образов, которое может проводиться по заранее определенной или произвольной последовательности нажатий клавиш.
Верификация, адаптация и синтез модели
Как только произнесено или написано слово "модель", сразу неизбежно возникает вопрос о степени ее адекватности.
Верификация модели – это операция установления степени ее адекватности (валидности) путем сравнения результатов идентификации конкретных объектов с их фактической принадлежностью к обобщенным образам классов.
Различают внутреннюю и внешнюю, интегральную и дифференциальную валидность.
Внутренняя валидность – это способность модели верно идентифицировать объекты обучающей выборки.
Если модель имеет низкую внутреннюю валидность, то модель нельзя считать удачно сформированной.
Внешняя валидность – это способность модели верно идентифицировать объекты, не входящие в обучающую выборку.
Интегральная валидность – это средневзвешенная достоверность идентификации по всем классам и распознаваемым объектам.
Дифференциальная валидность – это способность модели верно идентифицировать объекты в разрезе по классам.
Адаптация модели – это учет в модели объектов, не входящих в обучающую выборку, но входящих в генеральную совокупность, по отношению к которой данная обучающая выборка репрезентативна.
Если моделью верно идентифицируются объекты, не входящие в обучающую выборку, то это означает, что эти объекты входят в генеральную совокупность, по отношению к которой данная обучающая выборка репрезентативна. Следовательно, на основе обучающей выборки удалось выявить закономерности взаимосвязей между признаками и принадлежностью объектов к классам, которые действуют не только в обучающей выборке, но имеют силу и для генеральной совокупности.
Адаптация модели не требует изменения классификационных и описательных шкал и градаций, а лишь объема обучающей выборки, и приводит к количественному изменению модели.
Синтез (или повторный синтез – пересинтез) модели – это учет в модели объектов, не входящих ни в обучающую выборку, ни в генеральную совокупность, по отношению к которой данная обучающая выборка репрезентативна.
Это объекты с новыми, ранее неизвестными закономерностями взаимосвязей признаков с принадлежностью этих объектов к тем или иным классам. Причем и признаки, и классы, могут быть как те, которые уже были отражены в модели ранее, так и новые. Пересинтез модели приводит к ее качественному изменению.