Верификация модели (оценка ее адекватности) (БКОСА-
Данный режим исполняется после синтеза модели. Верификация модели осуществляется путем копирования обучающей выборки в распознаваемую, пакетного распознавания и последующего анализа в режиме "Измерение валидности системы распознавания" подсистемы "Анализ". Он показывает средневзвешенную погрешность идентификации (интегральная валидность) и погрешность идентификации в разрезе по классам. При этом объект считается отнесенным к классу, с которым у него наибольшее сходство. Необходимо отметить, что остальные классы, находящиеся по уровню сходства на второй и последующих позициях не учитываются. Это обусловлено тем, что их учет привел бы к завышению оценки валидности модели.
Классы, по которым дифференциальная валидность неприемлемо низка считаются не сформированными. Причинами этого может быть очень высокая вариабельность объектов, отнесенных к данным классам (тогда имеет смысл разделить их на несколько), а также недостаток достоверной классификационной и описательной информации по этим классам (некорректная работа экспертов).
Внешняя дифференциальная и интегральная валидность
Под внешней валидностью понимается способность модели верно идентифицировать объекты, не входящие в обучающую выборку, но относящиеся к генеральной совокупности, по отношению к которой она репрезентативна.
Для измерения внешней валидности необходимо выполнить следующие действия:
1. В режиме измерения адекватности модели запустить режим измерения внешней валидности (нажав F8 Измерение внешней валидности) (рисунок 166).
2. Выбрать один из режимов удаления объектов обучающей выборки, приведенный на экранной форме (рисунок 167).
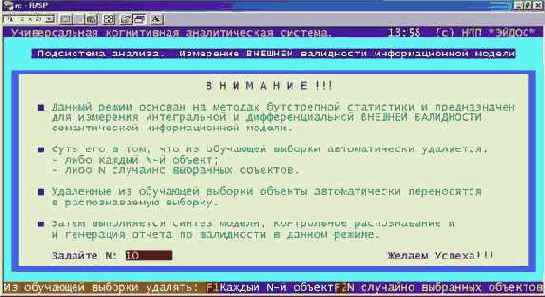 | |
| Рисунок 166. Режим переноса анкет обучающей выборки в распознаваемую для измерения внешней валидности |
Результат выполнения всех указанных на рисунке 166 действий приведен на рисунке 167.
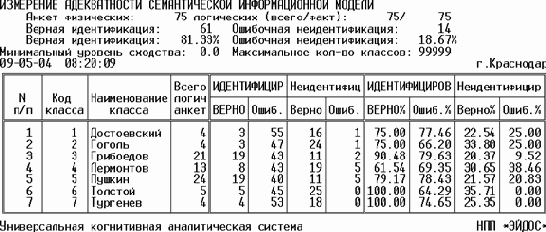 | |
| Рисунок 167. Выходная форма с результатами измерения внешней валидности методом бутстрепной статистики |
При этом исходная выборка была разделена на две:
– в обучающей выборке остались только нечетные анкеты;
– в распознаваемую выборку были включены только четные анкеты;
– при распознавании был использован 2-й интегральный критерий: сумма количества информации.
Анализ отчета по внешней валидности, приведенного на рисунке 167, позволяет сделать вывод о высокой степени адекватности семантической информационной модели. Это значит, что взаимосвязи между словами, использованными в текстах, и принадлежностью этих текстов различным авторам, выявленные по примерам обучающей выборки, оказались имеющими силу и для других фрагментов текстов, приведенных в распознаваемой выборке. Это означает, что они относятся к генеральной совокупности, по отношению к которой обучающая выборка репрезентативна.
Внутренняя дифференциальная и интегральная валидность
Под внутренней валидностью понимается способность модели верно идентифицировать объекты, входящие в обучающую выборку.
Для измерения адекватности модели необходимо выполнить следующие действия:
1. Скопировать обучающую выборку в распознаваемую (во 1-м режиме 2-й подсистемы нажав клавишу F5).
2. Выполнить пакетное распознавание (во 2-м режиме 4-й подсистемы, задав 1-й критерий сходства) (рисунок 161).
3. Измерить адекватность модели (во 2-м режиме 6-й подсистемы) (рисунки 162 и 163).
 | |
| Рисунок 161. Выход на режим пакетного распознавания |
 | |
| Рисунок 162. Выход на режим измерения адекватности модели |
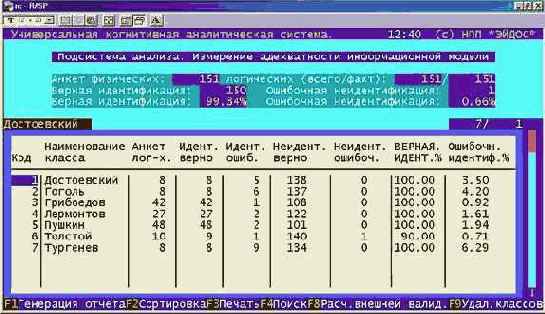 | |
| Рисунок 163. Экранная форма управления измерением адекватности модели и отображения результатов |
Эта форма может прокучиваться вправо-влево. В верхней части формы приведены показатели интегральной валидности (средневзвешенные по всей обучающей выборке), а в самой таблице – дифференциальной валидности, т.е. в разрезе по классам.
Кроме того, результаты измерения адекватности модели выводятся в форме файлов с именами ValidSys.txt (рисунок 164) и ValAnkSt.txt (рисунок165) стандарта "TXT-текст DOS" в поддиректории TXT. Первый файл имеет вид:
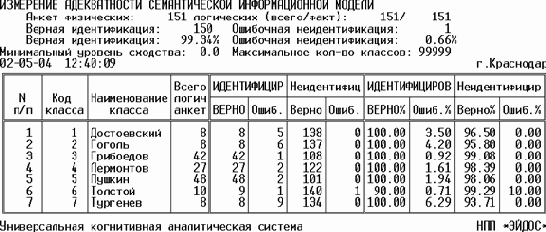 | |
| Рисунок 164. Выходная форма ValidSys.txt с результатами измерения адекватности модели и отображения результатов |
Рассмотрим, что означают графы этой выходной формы.
"Всего логических анкет" – это количество анкет (примеров текстов) в обучающей выборке, на основе которых формировался образ данного класса.
"Идентифицировано верно" – это количество анкет обучающей выборки, которые идентифицированы как классы, к которым они действительно относятся.
"Идентифицировано ошибочно"
– это количество анкет обучающей выборки, которые идентифицированы как классы, к которым они в действительности не относятся (ошибка идентификации).
"Неидентифицировано верно" – это количество анкет обучающей выборки, которые неидентифицированы как классы, к которым они действительно не относятся.
"Неидентифицировано ошибочно"
– это количество анкет обучающей выборки, которые неидентифицированы как классы, к которым они в действительности относятся (ошибка неидентфикации).
В правой части формы приведены те же показатели, но в процентом выражении:
– для анкет, идентифицированных верно и неидентифицированных ошибочно за 100% принимается количество логических анкет обучающей выборки по данному классу;
– для анкет, идентифицированных ошибочно и неидентифицированных верно за 100% принимается суммарное количество логических анкет обучающей выборки за вычетом логических анкет по данному классу.
 |
|
Рисунок 165. Фрагмент выходной формы ValAnkSt.txt с результатами измерения адекватности модели и отображения результатов |
Вопросы, относящиеся к дисциплине "ИИС", выносящиеся на государственный экзамен
1. Интеллектуальные информационные системы, как закономерный и неизбежный этап развития информационных систем.
2. Определение и критерии идентификации систем искусственного интеллекта. Тест Тьюринга.
3. Системы с интеллектуальной обратной связью.
4. Автоматизированные системы распознавания образов.
5. Системы поддержки принятия решений.
6. Экспертные системы.
7. Нейронные сети.
8. Генетические алгоритмы и моделирование эволюции.
9. Когнитивное моделирование.
10. Выявление знаний из опыта (эмпирических фактов) и интеллектуальный анализ данных (data mining).
11. Области применения систем искусственного интеллекта
12. Перспективы развития систем искусственного интеллекта, в т.ч. в Internet.
13. Абсолютная, относительная и аналитическая информация. Данные, информация, знания. Классификация СИИ.
14. Базы данных для поддержки принятия решений.
15. Автоматизированный системно-когнитивный анализ и универсальная когнитивная аналитическая система "Эйдос".
Вопросы, выносящиеся на экзамен по дисциплине
На экзамен выносятся вопросы, приведенные как контрольные вопросы к лекциям и лабораторным работам.
Возможность решения простых задач классификации непосредственно одним нейроном
Представим себе, что необходимо решать задачу определения пола студентов по их внешне наблюдаемым признакам.
Есть, конечно, и более надежные способы, но мы их рассматривать не будем, т.к. они требуют дополнительных затрат для получения исходной информации и превращают задачу в тривиальную.
Поэтому будем рассматривать такие описательные шкалы и градации:
1. Длина волос: длинные, средние, короткие.
2. Наличие брюк: да, нет.
3. Использование духов или одеколона:
да, нет.
Составим таблицу для определения весовых коэффициентов (таблица 33). Пусть столбцы этой таблицы соответствуют состояниям нейрона, а строки – дендритам, соединенным с соответствующими органами восприятия, которые способны устанавливать наличие или отсутствие соответствующего признака.
Тогда один из простейших способов определить значения весовых коэффициентов на дендритах будет заключаться в том, чтобы на пересечениях строк и столбцов просто проставить суммарное количество студентов в обучающей выборке, обладающих данным признаком.
Таблица 33 – ОПРЕДЕЛЕНИЕ ВЕСОВЫХ
КОЭФФИЦИЕНТОВ НЕЙРОНОВ НЕПОСРЕДСТВЕННО
НА ОСНОВЕ ЭМПИРИЧЕСКИХ ДАННЫХ
| Описательные шкалы и градации | Классификационные шкалы и градации | ||||
| Юноши | Девушки | ||||
| Длина волос: | |||||
| – длинные | 5 | 15 | |||
| – средние | 10 | 10 | |||
| – короткие | 15 | 5 | |||
| Наличие брюк: | |||||
| – да; | 30 | 10 | |||
| – нет | 0 | 20 | |||
| Использование духов или одеколона: | |||||
| – да; | 5 | 20 | |||
| – нет | 25 | 10 |
Если нейрон должен выдавать высокий выходной сигнал, когда на входе ему предъявляется юноша и низкий – когда девушка, то весовые коэффициенты на дендритах берутся из столбца: "Юноши". И наоборот, если нейрон должен выдавать высокий выходной сигнал, когда на входе ему предъявляется девушка и низкий – когда юноша, то весовые коэффициенты на дендритах берутся из столбца: "Девушки".
Можно представить себе сеть из двух нейронов, в которой весовые коэффициенты на дендритах взяты из столбцов: "Юноши" и "Девушки".
Большее количество нейронов для решения данной задачи будет избыточным. Его имеет смысл использовать в том случае, когда мы хотим повысить надежность идентификации объектов нейронной сетью и различные сходные по смыслу нейроны будут использовать независимые друг от друга рецепторы.
Например, если мы не только видим идентифицируемый объект, но можем его и обонять, и ощупывать, то это повышает надежность его идентификации. В этом состоит общепринятый в физике критерий реальности – принцип наблюдаемости, согласно которому объективное существование установлено для тех объектов и явлений, существование которых установлено несколькими, по крайней мере, двумя, независимыми способами.
В общем случае в нейронной сети каждому классу (градации классификационной шкалы) будет соответствовать один нейрон и объект, признаки которого будут измерены рецепторами на входе нейронной сети, будет идентифицирован сетью как класс, соответствующий нейрону с максимальным уровнем сигнала на выходе.
Психологические тесты обычно позволяют тестировать респондента сразу по нескольким шкалам. Очевидно, нейронные сети, реализующие эти тесты, будут иметь как минимум столько нейронов, сколько шкал в психологическом тесте.
Временные ряды
Временной ряд – это расположение во времени статистических показателей, которые в своих последовательных изменениях отражают ход развития изучаемых процессов.
Временные ряды исследуются с различными целями. В одном ряде случаях бывает достаточно получить описание характерных особенностей ряда, а в другом ряде случаев требуется не только предсказывать будущие значения временного ряда, но и управлять его поведением. Метод анализа временного ряда определяется, с одной стороны, целями анализа, а с другой стороны, вероятностной природой формирования его значений.
Спектральный анализ. Позволяет находить периодические составляющие временного ряда
Корреляционный анализ. Позволяет находить существенные периодические зависимости и соответствующие им задержки (лаги) как внутри одного ряда (автокорреляция), так и между несколькими рядами. (кросскорреляция)
Модели авторегрессии и скользящего среднего. Модели ориентированы на описание процессов, проявляющих однородные колебания, возбуждаемые случайными воздействиями. Позволяют предсказывать будущие значения ряда.
Время реакции системы на изменение факторов (ригидность)
Исследование, проведенное после разработки методики, показало, что наиболее сильное влияние на текущую ситуацию оказывают факторы, действующие неделю назад, а более поздние факторы практически не оказывают на нее никакого влияния. Это означает, что в ММВБ в 1995 году имела высокую "инерционность", "время реакции", "ригидность", составляющую примерно одну неделю. По некоторым данным аналогичный параметр для Лондонской биржи в этот же период времени составлял около 32 секунд.
Ввод-корректировка обучающей информации (БКОСА-
Данная подсистема обеспечивает ввод и корректировку обучающей выборки, управление ею, синтез и адаптацию модели на основе данных обучающей выборки, экспорт и импорт данных с других компьютеров.
Для ввода-корректировки обучающей выборки служит соответствующий режим, имеющий двухоконный интерфейс, позволяющий ввести в обучающую выборку двухвекторные описания объектов. Левое окно служит для ввода классификационной характеристики объекта. В этом окне каждому объекту соответствует одна строка с прокруткой. В правом окне вводится описательная характеристика объекта на языке признаков. Каждому объекту соответствует окно с прокруткой. Переход между окнами осуществляется по нажатию клавиши "TAB". Количество объектов в обучающей выборке не ограничено. Имеется практический опыт проведения расчетов с объемами обучающей выборки до 7000 объектов, суммарным количеством градаций описательных шкал до 3900 и количеством классов до 1500. Реализована также возможность автоматического формирования объектов обучающей выборки путем кодирования текстовых файлов.
В системе реализован ряд программных интерфейсов, обеспечивающих автоматическое формирование классификационных и описательных шкал и градаций, а также обучающей выборки:
– импорт данных из файлов стандарта "Текст DOS";
– импорт данных из DBF-файлов, стандарта проф. А.Н.Лебедева;
– импорт данных из транспонированных DBF-файлов, стандарта профессора А.Н.Лебедева;
– генерация случайной модели;
– генерация учебной модели для исследования свойств натуральных чисел.
Выбор единой интерпретируемой численной меры для классов и атрибутов
При построении модели объекта управления одной из принципиальных проблем является выбор формализованного представления для индикаторов, критериев и факторов (далее: факторов). Эта проблема распадается на две подпроблемы:
1. Выбор и обоснование смысла выбранной численной меры.
2. Выбор математической формы и способа определения (процедуры, алгоритма) количественного выражения для значений, отражающих степень взаимосвязи факторов и будущих состояний АОУ.
Рассмотрим требования к численной мере, определяемые существом подпроблем. Эти требования вытекают из необходимости совершать с численными значениями факторов математические операции (сложение, вычитание, умножение и деление), что в свою очередь необходимо для построения полноценной математической модели.
Требование 1: из формулировки 1-й подпроблемы следует, что все факторы должны быть приведены к некоторой общей и универсальной для всех факторов единице измерения, имеющей какой-то смысл, причем смысл, поддающийся единой сопоставимой в пространстве и времени интерпретации.
Традиционно в специальной литературе [10] рассматриваются следующие смысловые значения для факторов: стоимость (выигрыш-проигрыш или прибыль-убытки); полезность; риск; корреляционная или причинно-следственная взаимосвязь. Иногда предлагается использовать безразмерные меры для факторов, например эластичность, однако, этот вариант не является вполне удовлетворительным, т.к. не позволяет придать факторам содержательный и сопоставимый смысл и получить содержательную интерпретацию выводов, полученных на основе математической модели.
Таким образом, возникает ключевая при выборе численной меры проблема выбора смысла, т.е. по сути единиц измерения, для индикаторов, критериев и факторов.
Требование 2: высокая степень адекватности предметной области.
Требование 3: высокая скорость сходимости при увеличении объема обучающей выборки.
Требование 4: высокая независимость от артефактов.
Что касается конкретной математической формы и процедуры
определения числовых значений факторов в выбранных единицах измерения, то обычно применяется метод взвешивания экспертных оценок, при котором эксперты предлагают свои оценки, полученные как правило неформализованным путем.
При этом сами эксперты также обычно ранжированы по степени их компетентности. Фактически при таком подходе числовые значения факторов является не определяемой, искомой, а исходной величиной. Иначе обстоит дело в факторном анализе, но в этом методе, опять же на основе экспертных оценок важности факторов, требуется предварительно, т.е. перед проведением исследования, принять решение о том, какие факторы исследовать (из-за жестких ограничений на размерность задачи в факторном анализе). Таким образом оба эти подхода реализуемы при относительно небольших размерностях задачи, что с точки зрения достижения целей настоящего исследования, является недостатком этих подходов.
Поэтому самостоятельной и одной из ключевых проблем является обоснованный и удачный выбор математической формы для численной меры индикаторов и факторов.
Эта математическая форма с одной стороны должна удовлетворять предыдущим требованиям, прежде всего требованию 1, а также должна быть процедурно вычислимой, измеримой.
Выбор неметрической меры сходства объектов в семантических пространствах
Существует большое количество мер сходства, из которых можно было бы упомянуть скалярное произведение, ковариацию, корреляцию, евклидово расстояние, расстояние Махалонобиса и др.
Проблема выбора меры сходства состоит в том, что при выбранной численной мере для координат классов и факторов она должна удовлетворять определенным критериям:
1. Обладать высокой степенью адекватности предметной области, т.е. высокой валидностью, при различных объемах выборки, как при очень малых, так и при средних и очень больших.
2. Иметь обоснованную, четкую, ясную и интуитивно понятную интерпретацию.
3. Быть нетрудоемкой в вычислительном отношении.
4. Обеспечивать корректное вычисление меры сходства для пространств с неортонормированным базисом.
Выбор в качестве базовой численной меры количества информации
Как было показано в лекции 2, системный анализ представляет собой теоретический метод познания, т.е. информационный процесс, в котором поток информации направлен от познаваемого объекта к познающему субъекту. Процесс труда, напротив, представляет собой процесс, в котором поток информации направлен от субъекта к объекту. При этом информация передается по каналу связи, представляющему собой средства труда, и записывается в носитель информации (предмет труда), который в ходе этого процесса преобразуется в заранее заданную форму, т.е. в продукт труда. Таким образом, процесс труда по сути дела представляет собой информационный процесс, обратный по направлению потока информации процессу познания. Управление представляет собой процесс, на различных этапах которого выполняются функции, сходные с процессами труда (управляющее воздействие) и познания (обратная связь). По мнению автора, информационный подход к управлению является наиболее общим. Поэтому в качестве количественной меры взаимосвязи факторов и будущих состояний АОУ целесообразно использовать количество информации. Более подробное обоснование целесообразности выбора в качестве численной меры количества информации приведено в работе автора[64].
Однако, известно много различных информационных мер и, следовательно, возникает задача выбора одной из них, оптимальной по выбранным критериям. Различные выражения классической теории информации для количества информации: Хартли, Шеннона, Харкевича и др., учитывают различные аспекты информационного моделирования объектов (таблице 8):
| Таблица 8 – СООТВЕТСТВИЕ ТРЕБОВАНИЯМ ВЫРАЖЕНИЙ ДЛЯ КОЛИЧЕСТВА ИНФОРМАЦИИ | |
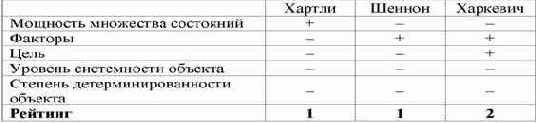 |
– формула Хартли учитывает количество классов (мощность множества состояний объекта управления) но никак не учитывает их признаков или факторов, переводящих объект в эти состояния, т.е. содержит интегральное описание объектов;
– формула Шеннона основывается на учете признаков, т.е. основывается на дискретном описании объектов;
– формула Харкевича учитывает понятие цели и также как формула Шеннона основана на статистике признаков, но не учитывает мощности множества будущих состояний объекта управления, включающего целевые и другие будущие состояния объекта управления и также как формула Шеннона основывается на дискретном описании объектов.
Как видно из таблицы 8, классическая формула Харкевича по учитываемым критериям имеет преимущества перед классическими формулами Хартли и Шеннона, т.к. учитывает как факторы, так и понятие цели, ключевое для системного анализа, теории и практики управления (в т.ч. АСУ). Поэтому именно выражение для семантической целесообразности информации Харкевича взято за основу при выводе обобщающего выражения, удовлетворяющего всем предъявляемым требованиям.
Выбор в условиях неопределенности
Выбор в условиях определенности – это частный случай выбора в условиях неопределенности (когда неопределенность близка к нулю).
Но неопределенность чего конкретно имеется в виду?
В современной теории выбора считается, что в задачах принятия решений существует три основных вида неопределенности:
1. Информационная (статистическая) неопределенность исходных данных для принятия решений.
2. Неопределенность последствий принятия решений (выбора).
3. Расплывчатость в описании компонент процесса принятия решений.
Рассмотрим их по порядку.
Выполнение и сдача лабораторной работы
Выполняются лабораторные работы, как правило, студентами индивидуально. В качестве исключения (при недостатке компьютеров в классе) допускается выполнение одной работы небольшими группами по 2-3 студента.
Сдаются лабораторные работы студентами только индивидуально в форме:
– демонстрации и объяснению преподавателю созданного ими приложения на компьютере непосредственно в среде используемой интеллектуальной информационной системы;
– предъявления и анализа сгенерированных в системе текстовых и графических выходных форм (в виде файлов);
– ответов на контрольные вопросы к данной лабораторной работе и на понимание базовых понятий.
Выполнить адаптацию модели и измерить, как изменилась ее адекватность
Под адаптацией модели понимается ее количественная модификация, осуществляемая путем включения в обучающую выборку дополнительных примеров реализации объектов, относящихся к тем же самым классам и описанным в той же системе признаков.
На первом этапе, для изучения адаптивности модели осуществим ее синтез на основе обучающей выборки, состоящей из нечетных анкет, которая использовалась в примере для измерения внешней валидности. Но в отличие от этого примера эту же выборку используем и как распознаваемую.
На втором этапе осуществим синтез модели на основе полной обучающей выборки, включающей как четные, так и нечетные анкеты.
Адаптация модели повышает точность идентификации объектов той же самой генеральной совокупности.
Выполнить формализацию предметной области.
Под формализацией предметной области понимается разработка классификационных и описательных шкал и градаций и ввод их в программную систему "Эйдос", являющуюся инструментарием СК-анализа.
2.1. Формирование классификационных шкал и градаций
В подсистеме "Классификационные шкалы и градации" введем классы, соответствующие следующим писателям: Ф.М. Достоевский; Н.В. Гоголь; А.С.Грибоедов; М.Ю. Лермонтов; А.С. Пушкин; Л.Н. Толстой; И.С. Тургенев (рисунок 152).
 | |
| Рисунок 152. Ввод классов |
2.1. Формирование описательных шкал и градаций
Для этого исходные файлы для формирования объекты обучающей выборки должны быть средствами Word представлены в виде текстовых файлов, стандарта "Текст DOS" (без разбиения на строки).
Затем каждый из этих файлов разбивается на столько файлов, сколько в нем строк, причем имена этих файлов должны иметь вид: ####SUBSTR(File_name,4).TXT, где #### – сквозной номер файлов, соответствующий будущему номеру анкеты обучающей выборки, SUBSTR(File_name,4) – первые 4 символа имени исходного файла.
Полученные файлы должны быть помещены в поддиректорию DOB системы "Эйдос", а исходные – удалены из нее.
Это осуществляется одним из трех способов:
1. Вручную.
2. С использованием специальной программы, текст которой приводится ниже (язык программирования xBase).
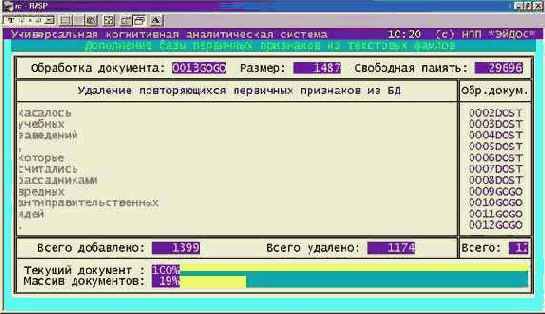
3. В режиме: "Словари – Программные интерфейсы для импорта данных – Импорт данных из TXT-файлов стандарта "Текст DOS", формируем описательные шкалы и градации (рисунок 153), причем в качестве признаков выбираем слова.
Исходный текст программы записи TXT-файлов с данными по строкам
**************************************************************************
********** Разбиение текстовых файлов DOS на нумерованные файлы по строкам
********** Луценко Е.В., 03/31/04 04:24pm
**************************************************************************
scr_start=SAVESCREEN(0,0,24,79)
SHOWTIME(0,58,.T.,"rb/n")
FOR j=0 TO 24
@j,0 SAY SPACE(80) COLOR "n/n"
NEXT
********** Удаление TXT-файлов, имена которых начинаются на 0
FILEDELETE("0*.TXT")
***** РЕКОГНОСЦИРОВКА
Count = ADIR("*.TXT") && Кол-во TXT-файлов
IF Count = 0
Mess = "В текущей директории TXT-файлов не обнаружено !!!"
@15,40-LEN(Mess)/2 SAY Mess COLOR "gr+/n"
INKEY(0)
RESTSCREEN(0,0,24,79,scr_start)
SHOWTIME()
QUIT
ENDIF
PRIVATE Name[Count],Size[Count] && Имена и размеры файлов
Count = ADIR("*.txt",Name,Size)
SortData(Name,Size,LEN(Name),1) && Сортировка файлов по алфавиту
CrLf = CHR(13)+CHR(10) && Конец строки (абзаца) (CrLf)
*** Загрузка TXT-файлов
Num_pp = 0 && Номера выходных файлов
FOR f = 1 TO Count && Начало цикла по TXT-файлам
****** Загрузка файла
Buffer = FILESTR(Name[f],.T.)
Buffer = CHARONE(" ",Buffer) && Удаление повторяющихся пробелов
Buffer = Buffer + CrLf
Len = AT(CrLf,Buffer)
DO WHILE Len > 0 .AND. LASTKEY() <> 27 && Цикл по строкам
Len = AT(CrLf,Buffer)
IF Len > 0
****** Запись фрагмента файла
Str_pr = ALLTRIM(SUBSTR(Buffer,1,Len-1))
Fn_out = STRTRAN(STR(++Num_pp,4)," ","0")+SUBSTR(Name[f],1,4)+".TXT"
STRFILE(Str_pr,Fn_out)
****** Исключение из буфера записанной строки
Buffer = ALLTRIM(SUBSTR(Buffer,Len+1))
ENDIF
ENDDO
NEXT
*** Удаление исходных TXT-файлов
FOR f=1 TO Count
FILEDELETE(Name[f])
NEXT
RESTSCREEN(0,0,24,79,scr_start)
SHOWTIME()
QUIT
 |
|
Рисунок 153. Выход на режим генерации справочников на основе текстовых файлов |
 |
|
Рисунок 154. Генерация описательных шкал и градаций на основе TXT-файлов |
Таблица 79 – КЛАССИФИКАЦИОННЫЕ
ШКАЛЫ И ГРАДАЦИИ
|
Код |
Наименование |
|
1 |
Достоевский |
|
2 |
Гоголь |
|
3 |
Грибоедов |
|
4 |
Лермонтов |
|
5 |
Пушкин |
|
6 |
Толстой |
|
7 |
Тургенев |
|
Код |
Наименование |
Код |
Наименование |
Код |
Наименование |
|
1 |
! |
41 |
Бедные |
81 |
Все |
|
2 |
( |
42 |
Без |
82 |
Вспомним |
|
3 |
(основной |
43 |
Бездушных |
83 |
Встреча |
|
4 |
) |
44 |
Безумным |
84 |
Всюду |
|
5 |
, |
45 |
Безумных |
85 |
Вы |
|
6 |
- |
46 |
Безухов |
86 |
Вызывают |
|
7 |
. |
47 |
Безухову |
87 |
Высокие |
|
8 |
1812 |
48 |
Белинский |
88 |
Высокопарные |
|
9 |
20- |
49 |
Бессильной |
89 |
Г |
|
10 |
30-е |
50 |
Бог |
90 |
Герой |
|
11 |
30-х |
51 |
Боже |
91 |
Главная |
|
12 |
60-х |
52 |
Болконский |
92 |
Глухость |
|
13 |
: |
53 |
Болконскому |
93 |
Говоря |
|
14 |
; |
54 |
Бордо |
94 |
Гоголь |
|
15 |
? |
55 |
Борис |
95 |
Гоголя |
|
16 |
Bcтает |
56 |
Бориса |
96 |
Годунов |
|
17 |
XIX |
57 |
Бородинским |
97 |
Горе |
|
18 |
А |
58 |
Бородинского |
98 |
Гости |
|
19 |
Автор |
59 |
Буянов |
99 |
Грибоедов |
|
20 |
Авторский |
60 |
Была |
100 |
Грибоедова |
|
21 |
Агрессивная |
61 |
В |
101 |
Гулливера |
|
22 |
Адама |
62 |
Ведь |
102 |
Да |
|
23 |
Александр |
63 |
Везде |
103 |
Даже |
|
24 |
Александра |
64 |
Век |
104 |
Дворянин-аристократ |
|
25 |
Алексевна |
65 |
Великий |
105 |
Действительно |
|
26 |
Алексеевна |
66 |
Великолепная |
106 |
Дельвигу |
|
27 |
Аммоса |
67 |
Вернулся |
107 |
Денисова |
|
28 |
Андреевич |
68 |
Взволнованный |
108 |
Дидло |
|
29 |
Андрей |
69 |
Взгляды |
109 |
Для |
|
30 |
Андрею |
70 |
Власы |
110 |
Дмитриевна |
|
31 |
Анной |
71 |
Вместе |
111 |
Добролюбова |
|
32 |
Архивам |
72 |
Внешней |
112 |
Достоевского |
|
33 |
Афанасьевича |
73 |
Внешние |
113 |
Драматична |
|
34 |
Ах |
74 |
Воды |
114 |
Друбецкого |
|
35 |
Базаров |
75 |
Возникает |
115 |
Другое |
|
36 |
Базарова |
76 |
Война |
116 |
Думы |
|
37 |
Базаровым |
77 |
Вообще |
117 |
Дуни |
|
38 |
Балы |
78 |
Вопрос |
118 |
Дуня |
|
39 |
Бегущим |
79 |
Вот |
119 |
Душа |
|
40 |
Бедность |
80 |
Время |
120 |
Евгений |
Выполнить кластерно-конструктивный анализ модели
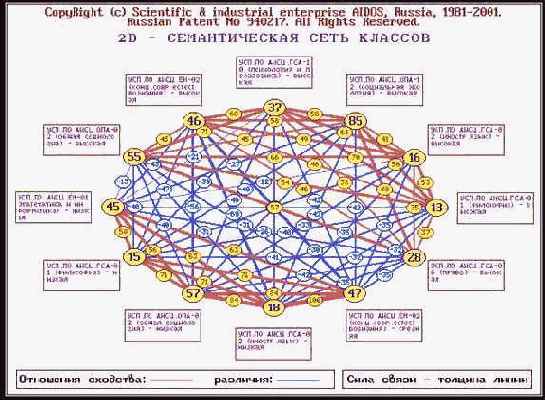
Кластерно-конструктивный анализ классов и признаков реализуется в 5-й подсистеме "Типология". В результате рассчитываются матрицы сходства классов и признаков, на основе которых генерируется и выводится ряд текстовых и графических форм. В данной работе мы приведем для примера лишь матрицу сходства классов (таблица 82 и отображающую ее в графической форме семантическую сеть классов (рисунок 170).
Таблица 82 – МАТРИЦА СХОДСТВА КЛАССОВ
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |||||||||||||||||||
| 1 | 100,0 | -9,55 | -8,94 | -8,16 | -9,46 | 6,32 | -10,08 | 38,11 | -6,24 | 33,86 | -4,34 | 41,96 | -11,12 | -8,17 | 11,70 | -8,00 | -11,05 | ||||||||||||||||||
| 2 | -9,55 | 100,0 | -5,11 | -0,35 | -2,47 | -7,84 | -2,95 | -9,07 | -5,50 | -5,44 | -6,47 | 1,20 | -16,31 | -5,43 | -10,08 | -8,26 | 2,04 | ||||||||||||||||||
| 3 | -8,94 | -5,11 | 100,0 | -2,39 | 1,12 | -3,97 | -6,81 | -5,61 | -0,10 | -6,56 | -3,05 | -10,13 | -0,41 | -7,36 | -11,47 | -6,04 | -6,32 | ||||||||||||||||||
| 4 | -8,16 | -0,35 | -2,39 | 100,0 | 2,52 | 9,73 | 1,33 | -4,36 | -6,23 | -9,19 | -4,94 | -8,33 | -9,55 | -1,41 | -9,14 | -1,91 | 3,14 | ||||||||||||||||||
| 5 | -9,46 | -2,47 | 1,12 | 2,52 | 100,0 | -8,31 | -1,87 | -5,24 | -12,74 | -1,25 | -5,30 | -4,55 | -12,89 | -8,85 | -6,73 | -9,59 | -3,52 | ||||||||||||||||||
| 6 | 6,32 | -7,84 | -3,97 | 9,73 | -8,31 | 100,0 | -6,55 | -5,05 | -12,06 | 0,49 | -7,34 | -2,99 | -15,19 | -11,13 | 8,18 | -3,10 | -8,75 | ||||||||||||||||||
| 7 | -10,08 | -2,95 | -6,81 | 1,33 | -1,87 | -6,55 | 100,0 | -4,35 | -1,04 | -6,10 | -10,14 | -5,71 | -7,09 | -0,21 | -9,40 | -3,97 | 3,67 | ||||||||||||||||||
| 8 | 38,11 | -9,07 | -5,61 | -4,36 | -5,24 | -5,05 | -4,35 | 100,0 | -2,38 | 34,04 | -6,03 | 41,21 | -6,48 | -4,72 | 0,87 | -8,50 | -8,17 | ||||||||||||||||||
| 9 | -6,24 | -5,50 | -0,10 | -6,23 | -12,74 | -12,06 | -1,04 | -2,38 | 100,0 | -1,85 | -8,20 | -6,28 | -12,89 | -1,18 | -2,41 | 0,73 | -3,53 | ||||||||||||||||||
| 10 | 33,86 | -5,44 | -6,56 | -9,19 | -1,25 | 0,49 | -6,10 | 34,04 | -1,85 | 100,0 | -8,76 | 39,59 | -9,83 | -9,07 | -1,63 | -11,22 | -7,73 | ||||||||||||||||||
| 11 | -4,34 | -6,47 | -3,05 | -4,94 | -5,30 | -7,34 | -10,14 | -6,03 | -8,20 | -8,76 | 100,0 | -7,79 | 13,47 | -3,96 | -5,98 | -11,77 | -2,47 | ||||||||||||||||||
| 12 | 41,96 | 1,20 | -10,13 | -8,33 | -4,55 | -2,99 | -5,71 | 41,21 | -6,28 | 39,59 | -7,79 | 100,0 | -8,80 | -8,13 | 5,09 | -8,29 | -5,24 | ||||||||||||||||||
| 13 | -11,12 | -16,31 | -0,41 | -9,55 | -12,89 | -15,19 | -7,09 | -6,48 | -12,89 | -9,83 | 13,47 | -8,80 | 100,0 | -3,67 | -3,20 | -1,92 | 1,77 | ||||||||||||||||||
| 14 | -8,17 | -5,43 | -7,36 | -1,41 | -8,85 | -11,13 | -0,21 | -4,72 | -1,18 | -9,07 | -3,96 | -8,13 | -3,67 | 100,0 | -11,07 | -0,69 | -3,25 | ||||||||||||||||||
| 15 | 11,70 | -10,08 | -11,47 | -9,14 | -6,73 | 8,18 | -9,40 | 0,87 | -2,41 | -1,63 | -5,98 | 5,09 | -3,20 | -11,07 | 100,0 | -8,44 | -12,23 | ||||||||||||||||||
| 16 | -8,00 | -8,26 | -6,04 | -1,91 | -9,59 | -3,10 | -3,97 | -8,50 | 0,73 | -11,22 | -11,77 | -8,29 | -1,92 | -0,69 | -8,44 | 100,0 | -5,50 | ||||||||||||||||||
| 17 | -11,05 | 2,04 | -6,32 | 3,14 | -3,52 | -8,75 | 3,67 | -8,17 | -3,53 | -7,73 | -2,47 | -5,24 | 1,77 | -3,25 | -12,23 | -5,50 | 100,0 |
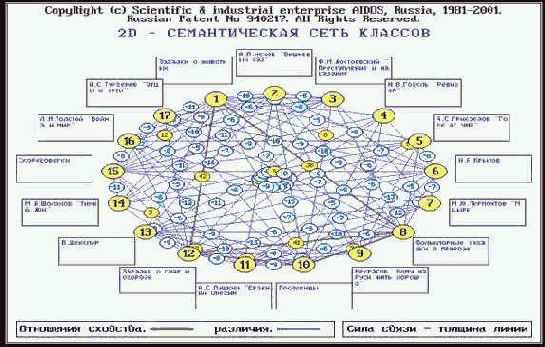 | |
| Рисунок 170. Отображение матрицы сходства классов в графической форме семантической сети классов (отображены связи значимостью более 5%) |
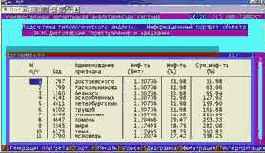
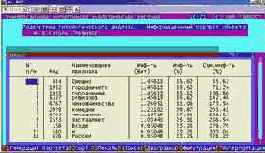
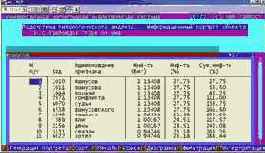
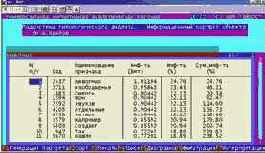
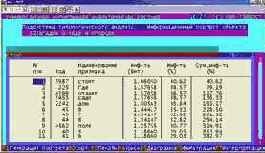
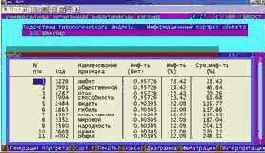
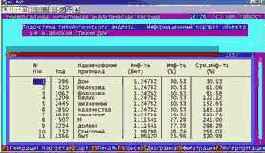
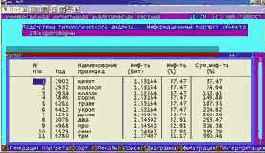
Вывести информационные портреты текстов и дать их интерпретацию
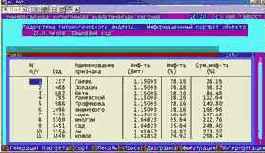
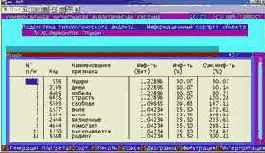
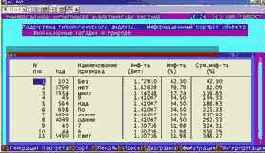
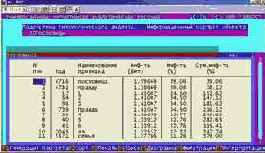
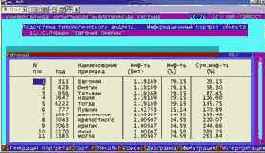
Информационный портрет класса представляет собой список признаков в порядке убывания количества информации, содержащегося в этих признаках о принадлежности к данному классу.
Генерируются они 1-м режиме 5-й подсистемы "Типология" (рисунок169). Информационные портреты классов отображаются системой "Эйдос" в виде экранных форм, круговых диаграмм и гистограмм, а также в распечатываются в форме таблиц в поддиректории TXT. Графические формы записываются в поддиректории PCX.
 |  | ||
 |  | ||
 |  | ||
 |  |
 |  | ||
 |  | ||
 |  | ||
 |  | ||
 |  | ||
| Рисунок 169. Информационные портреты классов |
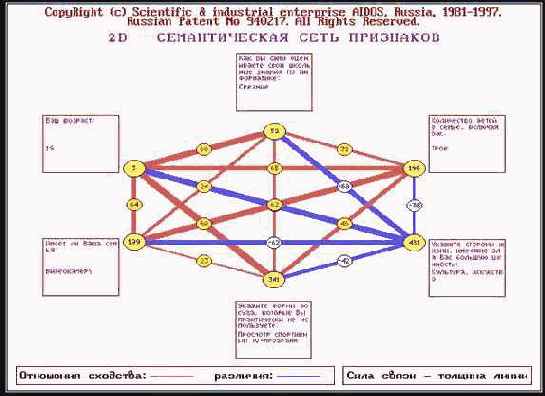
Вывод -семантических сетей атрибутов (БКОСА-.
Результаты кластерно-конструктивного анализа признаков отображаются для заданных признаков в наглядной графической форме семантических сетей.
Вывод -семантических сетей классов (БКОСА-.
В данном режиме пользователем в диалоге с системой "Эйдос" задаются коды от 3 до 12 классов (ограничение связано с тем, что больше классов не помещается на мониторе при используемом разрешении), а затем на основе данных матрицы сходства классов отображается ориентированный граф, в вершинах которого находятся классы, а ребра соответствуют знаку (красный – "+", синий – "-") и величине (толщина линии) сходства/различия между ними. Посередине каждой линии уровень сходства/различия соответствующих классов отображается в числовой форме (в процентах). Такие графы в данной работе называются 2d-семантическими сетями классов (2d означает "двухмерные").
Интервальные оценки сводят анализ чисел
Интервальные оценки сводят анализ чисел к анализу фактов и позволяют обрабатывать количественные величины как нечисловые данные. Это ограничивает возможности обработки количественных величин методами обработки нечисловых данных. В математической модели СК-анализа, основанной на системной теории информации, наоборот, качественным, нечисловым данным, сопоставляются количественные величины. Это позволяет использовать все возможности количественных методов для исследования нечисловых данных.
Таким образом, в СК-анализе числовые и нечисловые данные обрабатываются единообразно на основе единой математической модели как числовые данные.
Рассматривается связь метода измерения адекватности модели в СК-анализе с бутстрепными методами.
Описывается робастная процедура выявления и устранения артефактов в СК-анализе.
Таким образом, вербальные описания объектов реальности на естественном языке с полным основанием могут рассматриваются как их иерархические лингвистические модели. Предложены методика и автоматизированная технология, основанные на универсальной когнитивной аналитической системе "Эйдос", которые обеспечивают:
– автоматизированную формализацию предметной области на основе вербального описания ее объектов;
– автоматизированное формирование описательных шкал и градаций;
– автоматизированную генерацию обучающей выборки;
– синтез семантической информационной модели, ее оптимизацию, проверку адекватности и анализ.
Предлагаемые технологии обеспечивают значительную экономию труда и времени по сравнению с традиционным подходом.
Необходимо отметить также, что в системе "Эйдос" реализована полнофункциональная интеллектуальная информационно-поисковая система, обеспечивающая работу по приведенной в работе технологии с объектами, описанными на естественном языке.
На основе вышеизложенного можно сделать вывод о том, что для надежной и достоверной идентификации слов (по крайней мере при сравнительно небольшом их количестве) вполне достаточно информации о входящих в них буквах, и для этого нет особой необходимости привлекать дополнительную информацию о последовательности букв и их сочетаний. Продемонстрирована устойчивость модели от неполноты и зашумленности информации. Приведено более 30 графических форм, генерируемых системой "Эйдос", в т.ч. новые формы – классическая и интегральная когнитивные карты.
Продемонстрирована возможность и эффективность применения технологии и инструментария системно- когнитивного анализа для решения ряда задач атрибуции текстов.
Приведен подробный численный пример (с большим количеством конкретных иллюстративных материалов) реализации всех этапов СК-анализа при атрибуции текстов: когнитивной структуризации и формализации предметной области; формирования обучающей выборки; синтеза семантической информационной модели; оптимизации и измерения адекватности модели; адаптации и пересинтеза модели; типологического и кластерно-конструктивного анализа модели.
Взаимосвязь системной меры целесообразности
Статистика c2 представляет собой сумму вероятностей совместного наблюдения признаков и объектов по всей корреляционной матрице или определенным ее подматрицам (т.е. сумму относительных отклонений частот совместного наблюдения признаков и объектов от среднего):
 | (3. 57) |
где:
– Nij – фактическое количество встреч i-го признака у объектов j-го класса;
– t – ожидаемое количество встреч i-го признака у объектов j-го класса.
 | (3. 58) |
Отметим, что статистика c2 математически связана с количеством информации в системе признаков о классе распознавания, в соответствии с системным обобщением формулы Харкевича для плотности информации(3.28)
 | (3. 59) |
а именно из (3.58) и (3.59) получаем:
 | (3. 60) |
Из (3.60) очевидно:
 | (3. 61) |
Сравнивая выражения (3.57) и (3.61), видим, что числитель в выражении (3.57) под знаком суммы отличается от выражения (3.61) только тем, что в выражении (3.61) вместо значений Nij и t взяты их логарифмы. Так как логарифм является монотонно возрастающей функцией аргумента, то введение логарифма не меняет общего характера поведения функции.
Фактически это означает, что:
 | (3. 62) |
Если фактическая вероятность наблюдения i–го признака при предъявлении объекта j–го класса равна ожидаемой (средней), то наблюдение этого признака не несет никакой информации о принадлежности объекта к данному классу. Если же она выше средней – то это говорит в пользу того, что предъявлен объект данного класса, если же ниже – то другого.
Поэтому наличие статистической связи (информации) между признаками и классами распознавания, т.е. отличие вероятностей их совместных наблюдений от предсказываемого в соответствии со случайным нормальным распределением, приводит к увеличению фактической статистики c2 по сравнению с теоретической величиной.
Из этого следует возможность использования в качестве количественной меры степени выраженности закономерностей в предметной области не матрицы абсолютных частот и меры c2, а новой меры H, основанной на матрице информативностей и системном обобщении формулы Харкевича для количества информации:
средняя информативность признаков по матрице
 |
(3. 63) |
 |
– средняя информативность признаков по матрице информативностей. |
Значение данной меры показывает среднее отличие количества информации в факторах о будущих состояниях активного объекта управления от среднего количества информации в факторе (которое при больших выборках близко к 0). По своей математической форме эта мера сходна с мерами для значимости факторов и степени сформированности образов классов и коррелирует с объемом пространства классов и пространства атрибутов.
Описанная выше математическая модель обеспечивает инвариантность результатов ее синтеза относительно следующих параметров обучающей выборки: суммарное количество и порядок ввода анкет обучающей выборки; количество анкет обучающей выборки по каждому классу распознавания; суммарное количество признаков во всех анкетах обучающей выборки; суммарное количество признаков по эталонным описаниям различных классов распознавания; количество признаков и их порядок в отдельных анкетах обучающей выборки.
Это обеспечивает высокое качество решения задач системой распознавания на неполных и разнородных (в вышеперечисленных аспектах) данных как обучающей, так и распознаваемой выборки, т.е. при таких статистических характеристиках потоков этих данных, которые чаще всего и встречается на практике и которыми невозможно или очень сложно управлять.
и обучающую выборку на основе
1. Формализовать задачу, создав классификационные и описательные шкалы (с использованием таблицы 42) и обучающую выборку на основе рисунка 93.
2. Осуществить синтез и верификацию модели.
3. Провести анализ модели, сформулировав правила для прогнозирования направления движения составов (в режиме: "Типология", "Информационные портреты классов").
4. Оценить ценность признаков для прогнозирования. Выделить признаки, наиболее существенные для решения поставленной задачи.
5. Сравнить составы по степени "типичности" для своих кластеров ("Идущие на запад", "Идущие на восток"). Вывести в графической форме семантические сети составов, построить классические когнитивные карты для составов, идущих на запад и на восток.
с использованием исходных данных, приведенных
1. Создать стандартизированные ( с использованием исходных данных, приведенных на рисунке 93) текстовые описания составов в виде отдельных файлов стандарта DOS-текст с концами строк, записать их в поддиректорию DOB в виде: ####-zap.txt и ####-vos.txt.
2. Сгенерировать классификационные и описательные шкалы в режиме: "Автоввод первичных признаков и TXT-файлов", "Признаки – слова".
3. Сгенерировать обучающую выборку с использованием режима: "Ввод – корректировка обучающей выборки", "F7 InpTXT", "F6 Ввод из всех файлов". Дополнить анкеты, соответствующие составам, кодами принадлежности к обобщенным образам классов: "Идущие на запад", "Идущие на восток".
4. Осуществить синтез и верификацию семантической информационной модели.
5. Провести анализ модели, сформулировав правила для прогнозирования направления движения составов (в режиме: "Типология", "Информационные портеры классов").
6. Оценить ценность признаков для прогнозирования. Выделить признаки, наиболее существенные для решения поставленной задачи.
7. Сравнить составы по степени "типичности" для своих кластеров ("Идущие на запад", "Идущие на восток"). Отобразить в графической форме семантические сети составов, построить классические когнитивные карты для составов, идущих на запад и на восток.
Задачи формализации базовых когнитивных операций системного анализа
Для решения задачи формализации БКОСА необходимо решить следующие задачи:
1. Выбор единой интерпретируемой численной меры для классов и атрибутов.
2. Выбор неметрической меры сходства объектов в семантических пространствах.
4. Определение идентификационной и прогностической ценности атрибутов.
5. Ортонормирование семантических пространств классов и атрибутов (Парето-оптимизация).
Выбор единой интерпретируемой численной меры для классов и атрибутов
При построении модели объекта управления одной из принципиальных проблем является выбор формализованного представления для индикаторов, критериев и факторов (далее: факторов). Эта проблема распадается на две подпроблемы:
1. Выбор и обоснование смысла выбранной численной меры.
2. Выбор математической формы и способа определения (процедуры, алгоритма) количественного выражения для значений, отражающих степень взаимосвязи факторов и будущих состояний АОУ.
Рассмотрим требования к численной мере, определяемые существом подпроблем. Эти требования вытекают из необходимости совершать с численными значениями факторов математические операции (сложение, вычитание, умножение и деление), что в свою очередь необходимо для построения полноценной математической модели.
Требование 1: из формулировки 1-й подпроблемы следует, что все факторы должны быть приведены к некоторой общей и универсальной для всех факторов единице измерения, имеющей какой-то смысл, причем смысл, поддающийся единой сопоставимой в пространстве и времени интерпретации.
Традиционно в специальной литературе [10] рассматриваются следующие смысловые значения для факторов: стоимость (выигрыш-проигрыш или прибыль-убытки); полезность; риск; корреляционная или причинно-следственная взаимосвязь. Иногда предлагается использовать безразмерные меры для факторов, например эластичность, однако, этот вариант не является вполне удовлетворительным, т.к. не позволяет придать факторам содержательный и сопоставимый смысл и получить содержательную интерпретацию выводов, полученных на основе математической модели.
Для решения задачи формализации БКОСА необходимо решить следующие задачи:
1. Выбор единой интерпретируемой численной меры для классов и атрибутов.
2. Выбор неметрической меры сходства объектов в семантических пространствах.
4. Определение идентификационной и прогностической ценности атрибутов.
5. Ортонормирование семантических пространств классов и атрибутов (Парето-оптимизация).
Таким образом, возникает ключевая при выборе численной меры проблема выбора смысла, т.е. по сути единиц измерения, для индикаторов, критериев и факторов.
Требование 2: высокая степень адекватности предметной области.
Требование 3: высокая скорость сходимости при увеличении объема обучающей выборки.
Требование 4: высокая независимость от артефактов.
Что касается конкретной математической формы и процедуры определения числовых значений факторов в выбранных единицах измерения, то обычно применяется метод взвешивания экспертных оценок, при котором эксперты предлагают свои оценки, полученные как правило неформализованным путем. При этом сами эксперты также обычно ранжированы по степени их компетентности. Фактически при таком подходе числовые значения факторов является не определяемой, искомой, а исходной величиной. Иначе обстоит дело в факторном анализе, но в этом методе, опять же на основе экспертных оценок важности факторов, требуется предварительно, т.е. перед проведением исследования, принять решение о том, какие факторы исследовать (из-за жестких ограничений на размерность задачи в факторном анализе). Таким образом оба эти подхода реализуемы при относительно небольших размерностях задачи, что с точки зрения достижения целей настоящего исследования, является недостатком этих подходов.
Поэтому самостоятельной и одной из ключевых проблем является обоснованный и удачный выбор математической формы для численной меры индикаторов и факторов.
Эта математическая форма с одной стороны должна удовлетворять предыдущим требованиям, прежде всего требованию 1, а также должна быть процедурно вычислимой, измеримой.
Выбор неметрической меры сходства объектов в семантических пространствах
Существует большое количество мер сходства, из которых можно было бы упомянуть скалярное произведение, ковариацию, корреляцию, евклидово расстояние, расстояние Махалонобиса и др.
Проблема выбора меры сходства состоит в том, что при выбранной численной мере для координат классов и факторов она должна удовлетворять определенным критериям:
1. Обладать высокой степенью адекватности предметной области, т.е. высокой валидностью, при различных объемах выборки, как при очень малых, так и при средних и очень больших.
2. Иметь обоснованную, четкую, ясную и интуитивно понятную интерпретацию.
3. Быть нетрудоемкой в вычислительном отношении.
4. Обеспечивать корректное вычисление меры сходства для пространств с неортонормированным базисом.
5. Обеспечивать высокую достоверность и устойчивость идентификации при неполных (фрагментарных) и зашумленных данных.
Определение идентификационной и прогностической ценности атрибутов
Не все факторы имеют одинаковую ценность для решения задач идентификации, прогнозирования и управления. Традиционно считается, что факторы имеют одинаковую ценность только в тех случаях (обычно в психологии), когда определить их действительную ценность не представляется возможным по каким-либо причинам.
Для достижения целей, поставленных в данном исследовании, необходимо решить проблему определения ценности факторов, т.е. разработать математическую модель и алгоритм, которые допускают программную реализацию и обеспечивают на практике определение идентификационной и прогностической ценности факторов.
Ортонормирование семантических пространств классов и атрибутов (Парето-оптимизация)
Если не все факторы имеют одинаковую ценность для решения задач идентификации, прогнозирования и управления, то возникает проблема исключения из системы факторов тех из них, которые не представляют особой ценности.
Удаление малоценных факторов вполне оправданно и целесообразно, т.к. сбор и обработка информации по ним в среднем связана с такими же затратами времени, вычислительных и информационных ресурсов, как и при обработке ценных факторов. В этом состоит идея Парето-оптимизации.
Однако это удаление должно осуществляться при вполне определенных граничных условиях, характеризующих результирующую систему:
– адекватность модели;
– количество признаков на класс;
– суммарное количество градаций признаков в описательных шкалах.
В противном случае удаление факторов может отрицательно сказываться на качестве решения задач. На практике проблема реализации Парето-оптимизации состоит в том, что факторы вообще говоря коррелируют друг с другом и поэтому их ценность может изменяться при удалении любого из них, в том числе и наименее ценного. Поэтому просто взять и удалить наименее ценные факторы не представляется возможным и необходимо разработать корректный итерационный вычислительный алгоритм обеспечивающий решение этой проблемы при заданных граничных условиях.
Оценить ценность признаков для прогнозирования.
1. Формализовать задачу:
– создать классификационные и описательные шкалы;
– собрать исходную фактографическую информацию и ввести в систему обучающую выборку.
2. Осуществить синтез и верификацию модели.
3. Оценить ценность признаков для прогнозирования. Выделить признаки, наиболее существенные для решения поставленной задачи.
4. Провести анализ модели, дав ответы на следующие вопросы:
– как посещаемость занятий по системам искусственного интеллекта влияет на успеваемость по этой дисциплине?
– как сказывается пол на посещаемости?
– как выглядят конструкты "Пол", "Город-деревня", "Учебная группа", "Успеваемость", "Посещаемость"?
– какие студенты являются "типичными представителями" для своих учебных групп, а какие обладают своеобразием и выраженной индивидуальностью;
Результаты анализа отобразить в графической форме нелокальных нейронов и семантических сетей признаков. На их основе построить классические когнитивные карты для хорошо и плохо успевающих студентов.
1. Формализовать задачу.
1.1. Сконструировать классификационные шкалы и градации, выбрав в качестве классов – различные уровни учебных достижений по различным дисциплинам, перечень которых взять из зачетной книжки.
1.2. В качестве описательных шкал и градаций использовать характеристики подчерка.
1.3. Обучающую выборку заполнить на основе данных по учащимся своей группы и дополнить данными параллельной группы.
2. Осуществить синтез и верификацию (измерение адекватности) семантической информационной модели.
3. Провести системно-когнитивный анализ модели:
3.1. Решить задачи идентификации и прогнозирования (для себя).
3.2. Сгенерировать информационные портреты классов и факторов, т.е. решить обратную задачу прогнозирования (результаты отобразить в графической форме двухмерных и трехмерных профилей классов и факторов).
3.3. Провести кластерно-конструктивный анализ классов и факторов (результаты отобразить в форме семантических сетей классов и факторов).
3.4. Осуществить содержательное сравнение классов и факторов (результаты отобразить в форме когнитивных диаграмм классов и факторов).
3.5. Построить нелокальные нейроны и интерпретируемые нейронные сети.
3.6. Построить классические когнитивные модели (отобразить в форме когнитивных карт).
3.7. Построить интегральные когнитивные модели (отобразить в форме интегральных когнитивных карт).
1. Формализовать задачу.
1.1. Сконструировать классификационные шкалы и градации, выбрав в качестве классов – различные уровни учебных достижений по различным дисциплинам, перечень которых взять из зачетной книжки.
1.2. В качестве описательных шкал и градаций использовать предлагаемую анкету.
1.3. Обучающую выборку заполнить на основе данных по учащимся своей группы и дополнить данными параллельной группы.
2. Осуществить синтез и верификацию (измерение адекватности) семантической информационной модели.
3. Провести системно-когнитивный анализ модели:
3.1. Решить задачи идентификации и прогнозирования (для себя).
3.2. Сгенерировать информационные портреты классов и факторов, т.е. решить обратную задачу прогнозирования (результаты отобразить в графической форме двухмерных и трехмерных профилей классов и факторов).
3.3. Провести кластерно-конструктивный анализ классов и факторов (результаты отобразить в форме семантических сетей классов и факторов).
3.4. Осуществить содержательное сравнение классов и факторов (результаты отобразить в форме когнитивных диаграмм классов и факторов).
3.5. Построить нелокальные нейроны и интерпретируемые нейронные сети.
3.6. Построить классические когнитивные модели (отобразить в форме когнитивных карт).
3.7. Построить интегральные когнитивные модели (отобразить в форме интегральных когнитивных карт).
1. Создать файл в стандарте DOS-текст с концами строк, записать его в поддиректорию DOB.
2. Сгенерировать классификационные и описательные шкалы и градации, а также обучающую выборку.
3. Осуществить синтез и верификацию модели.
4. Провести анализ устойчивости модели к неполноте информации и наличию шума.
5. Проверить способность модели правильно идентифицировать классы, один из которых является подмножеством другого.
6. Оценить ценность букв для идентификации слов. Сравнить суммарную ценность для этой цели гласных и согласных букв.
7. Выполнить кластерно-конструктивный анализ слов и букв, вывести информационные и семантические портреты слов и букв, построить их профили.
8. Вывести в графической форме семантические сети и когнитивные диаграммы слов и букв, а также классическую и интегральную когнитивные карты.
1. Формализовать задачу.
1.1. Сконструировать классификационные шкалы и градации.
1.2. Сконструировать описательные шкалы и градации.
1.3. Сгенерировать обучающую выборку.
2. Осуществить синтез и верификацию (измерение адекватности) семантической информационной модели.
3. Провести системно-когнитивный анализ модели:
3.1. Решить задачи идентификации и прогнозирования.
3.2. Сгенерировать информационные портреты классов и факторов, т.е. решить обратную задачу прогнозирования (результаты отобразить в графической форме двухмерных и трехмерных профилей классов и факторов).
3.3. Провести кластерно-конструктивный анализ классов и факторов (результаты отобразить в форме семантических сетей классов и факторов).
3.4. Осуществить содержательное сравнение классов и факторов (результаты отобразить в форме когнитивных диаграмм классов и факторов).
3.5. Построить нелокальные нейроны и интерпретируемые нейронные сети.
3.6. Построить классические когнитивные модели (отобразить в форме когнитивных карт).
3.7. Построить интегральные когнитивные модели (отобразить в форме интегральных когнитивных карт).
1. Формализовать задачу.
1.1. Сконструировать классификационные шкалы и градации.
1.2. Сконструировать описательные шкалы и градации.
1.3. Сгенерировать обучающую выборку.
2. Осуществить синтез и верификацию (измерение адекватности) семантической информационной модели.
3. Провести системно-когнитивный анализ модели:
3.1. Решить задачи идентификации и прогнозирования.
3.2. Сгенерировать информационные портреты классов и факторов, т.е. решить обратную задачу прогнозирования (результаты отобразить в графической форме двухмерных и трехмерных профилей классов и факторов).
3.3. Провести кластерно-конструктивный анализ классов и факторов (результаты отобразить в форме семантических сетей классов и факторов).
3.4. Осуществить содержательное сравнение классов и факторов (результаты отобразить в форме когнитивных диаграмм классов и факторов).
3.5. Построить нелокальные нейроны и интерпретируемые нейронные сети.
3.6. Построить классические когнитивные модели (отобразить в форме когнитивных карт).
3.7. Построить интегральные когнитивные модели (отобразить в форме интегральных когнитивных карт).
На основе предложенной технологии АСК- анализа разработать конкретное приложение системы "Эйдос", обеспечивающее управление урожайностью и качеством сельскохозяйственных культур путем выбора и применения оптимальной агротехнологии в зависимости от поставленной цели и вида почв, культуры–предшественника, а также ряда других параметров объекта управления и окружающей среды, например, таких как: нормы высева, виды и нормы внесения удобрений, методы вспашки, ротация и др.
1. Исследовать зависимость интегральной валидности семантической информационной модели в зависимости от объема обучающей выборки при различном количестве классов и признаков.
2. Построить графики в Excel и дать их интерпретацию.
Задание Обучающую выборку заполнить
Чтобы собрать информацию для обучающей выборки, студенты на доске рисуют и заполняют таблицу, аналогичную таблице 61. Каждый заполняет строку по себе, и все учащиеся переписывают таблицу целиком к себе в тетрадь. Затем, когда таблица в тетради заполнена – она заносится в систему "Эйдос" в 1-м режиме 2-й подсистемы.
Таблица 61 – ОБУЧАЮЩАЯ ВЫБОРКА
| Код | Наименование | Коды классов | Коды признаков | ||||||||||||||||||||||||||
| 2 | Воробьева ПИ-51 | 2 | 5 | 10 | 12 | 13 | 16 | 4 | 7 | 10 | 14 | 17 | 21 | 23 | |||||||||||||||
| 3 | Гура ПИ-51 | 1 | 13 | 17 | 0 | 0 | 0 | 3 | 7 | 11 | 15 | 17 | 21 | 24 | |||||||||||||||
| 5 | Дыбова ПИ-51 | 2 | 13 | 19 | 0 | 0 | 0 | ||||||||||||||||||||||
| 6 | Жеребятьев ПИ51 | 1 | 5 | 8 | 12 | 13 | 20 | ||||||||||||||||||||||
| 8 | Иванова ПИ-51 | 2 | 3 | 7 | 12 | 13 | 22 | 3 | 6 | 7 | 12 | 14 | 17 | 19 | |||||||||||||||
| 9 | Котенко ПИ-51 | 2 | 4 | 7 | 12 | 13 | 23 | 3 | 7 | 10 | 14 | 17 | 21 | 23 | |||||||||||||||
| 10 | Кузина О. ПИ-51 | 2 | 3 | 8 | 12 | 13 | 24 | 3 | 7 | 12 | 14 | 17 | 21 | 22 | |||||||||||||||
| 11 | Кузина Я. ПИ-51 | 2 | 3 | 8 | 12 | 13 | 25 | 3 | 7 | 11 | 14 | 17 | 21 | 22 | |||||||||||||||
| 12 | Лях ПИ-51 | 1 | 3 | 8 | 12 | 13 | 26 | 2 | 6 | 11 | 14 | 16 | 20 | 24 | |||||||||||||||
| 13 | Мясников ПИ-51 | 1 | 3 | 9 | 12 | 13 | 27 | 3 | 7 | 10 | 14 | 17 | 21 | 22 | |||||||||||||||
| 14 | Нагапетян ПИ-51 | 1 | 4 | 9 | 12 | 13 | 28 | 3 | 8 | 12 | 13 | 18 | 19 | 23 | |||||||||||||||
| 15 | Полонская ПИ-51 | 2 | 13 | 29 | 0 | 0 | 0 | ||||||||||||||||||||||
| 16 | Трунина ПИ-51 | 2 | 13 | 30 | 0 | 0 | 0 | 3 | 7 | 12 | 13 | 18 | 19 | 23 | |||||||||||||||
| 17 | Черкашина ПИ-51 | 2 | 4 | 10 | 12 | 13 | 31 | 3 | 7 | 12 | 14 | 17 | 19 | 23 | |||||||||||||||
| 18 | Чепурченко ПИ51 | 1 | 13 | 32 | 0 | 0 | 0 | 3 | 8 | 12 | 13 | 16 | 19 | 23 | |||||||||||||||
| 19 | Чушкин ПИ-51 | 1 | 13 | 33 | 0 | 0 | 0 | 3 | 6 | 11 | 14 | 17 | 20 | 23 | |||||||||||||||
| 20 | Шульгин ПИ-51 | 1 | 5 | 8 | 12 | 13 | 34 | ||||||||||||||||||||||
| 21 | Арушунян ПИ-52 | 1 | 14 | 35 | 0 | 0 | 0 | ||||||||||||||||||||||
| 22 | Быченок ПИ-52 | 1 | 14 | 36 | 0 | 0 | 0 | ||||||||||||||||||||||
| 23 | Веревкина ПИ-52 | 2 | 3 | 9 | 12 | 14 | 37 | ||||||||||||||||||||||
| 24 | Григорьева ПИ52 | 2 | 4 | 8 | 12 | 14 | 38 | ||||||||||||||||||||||
| 25 | Давыдич ПИ-52 | 2 | 14 | 39 | 0 | 0 | 0 | ||||||||||||||||||||||
| 26 | Дронова ПИ-52 | 2 | 14 | 40 | 0 | 0 | 0 | 3 | 7 | 11 | 14 | 17 | 20 | 23 | |||||||||||||||
| 27 | Еременко ПИ-52 | 2 | 4 | 8 | 12 | 14 | 41 | ||||||||||||||||||||||
| 28 | Жмурко ПИ-52 | 1 | 14 | 42 | 0 | 0 | 0 | 3 | 7 | 10 | 14 | 17 | 21 | 23 | |||||||||||||||
| 29 | Иванова ПИ-52 | 2 | 3 | 9 | 12 | 14 | 43 | ||||||||||||||||||||||
| 30 | Костенко ПИ-52 | 2 | 14 | 44 | 0 | 0 | 0 | ||||||||||||||||||||||
| 31 | Крейс ПИ-52 | 2 | 4 | 8 | 12 | 14 | 45 | ||||||||||||||||||||||
| 32 | Куркина ПИ-52 | 2 | 3 | 8 | 12 | 14 | 46 | ||||||||||||||||||||||
| 33 | Люлик ПИ-52 | 2 | 5 | 8 | 12 | 14 | 47 | ||||||||||||||||||||||
| 34 | Максимов ПИ-52 | 1 | 14 | 48 | 0 | 0 | 0 | ||||||||||||||||||||||
| 35 | Мануйлов ПИ-52 | 1 | 3 | 7 | 12 | 14 | 49 | ||||||||||||||||||||||
| 36 | Нарижний ПИ-52 | 1 | 3 | 7 | 12 | 14 | 50 | ||||||||||||||||||||||
| 37 | Ольховская ПИ52 | 2 | 14 | 51 | 0 | 0 | 0 | ||||||||||||||||||||||
| 38 | Паршакова ПИ-52 | 2 | 6 | 8 | 12 | 14 | 52 | ||||||||||||||||||||||
| 39 | Силенко ПИ-52 | 1 | 3 | 7 | 12 | 14 | 53 | 3 | 5 | 11 | 14 | 17 | 21 | 23 | |||||||||||||||
| 40 | Соколова ПИ-52 | 2 | 4 | 8 | 12 | 14 | 54 | ||||||||||||||||||||||
| 41 | Турбин ПИ-52 | 1 | 14 | 55 | 0 | 0 | 0 | 3 | 7 | 11 | 14 | 17 | 21 | 23 | |||||||||||||||
| 42 | Цисарь ПИ-52 | 2 | 5 | 9 | 12 | 14 | 56 | 3 | 9 | 10 | 14 | 17 | 21 | 23 | |||||||||||||||
| 43 | Бабенко ПИ-51 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 7 | 11 | 14 | 17 | 21 | 24 |
Так как по ряду студентов данных нет, то пример выполнения заданий 2 и 3 не приводится и они выполняются студентами самостоятельно.
Для этих целей каждый учащийся заполняет данными о себе "Карточку респондента", имеющую вид, представленный на таблице 64:
Таблица 64 – КАРТОЧКА РЕСПОНДЕНТА № _____
| Учебная группа: | |||||||||||||||
| Фамилия, имя, отчество: | |||||||||||||||
| Коды классов, к которым он принадлежит: | |||||||||||||||
| Коды признаков, которыми он характеризуется: | |||||||||||||||
При необходимости строки с кодами добавляются. На каждой карточке имеется номер студента по списку группы, который затем используется как номер анкеты в обучающей выборке. Необходимо сначала ввести пустые анкеты обучающей выборки по списку группы, а затем заполнить их, используя карточки. Учащиеся передают друг другу карточки передавать по компьютерному классу. В графе "Наим.физ.источника" указываются полностью: фамилия, и сокращенно: имя и отчество студента. Аналогично поступаем с карточками студентов 2-й группы, за исключением того, что для определения номера анкеты в обучающей выборке к списочному номеру студента 2-й группы прибавляется номер последнего студента 1-й группы.
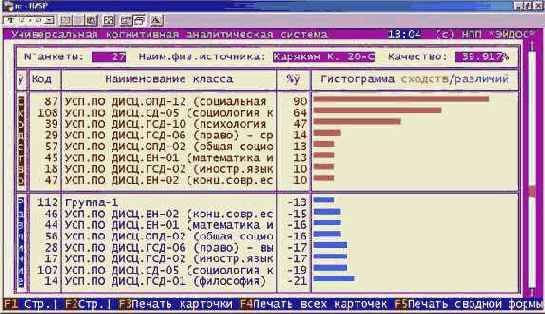
Осуществить синтез и верификацию
Синтез и верификация модели осуществляется в соответствующих подсистемах системы "Эйдос". Результаты верификации представлены в таблице 65.
Таблица 65 – РЕЗУЛЬТАТЫ ВЕРИФИКАЦИИ СЕМАНТИЧЕСКОЙ ИНФОРМАЦИОННОЙ МОДЕЛИ
| № | Код | Наименование класса | Ко-во
лог. анк. | % верной
идентификации | |||||
| ВЫСОКАЯ адекватность модели | |||||||||
| 1 | 87 | УСП.ПО ДИСЦ.ОПД-12 (социальная экология) - низкая | 1 | 100,00 | |||||
| 2 | 106 | УСП.ПО ДИСЦ.СД-05 (социология культуры) - высокая | 27 | 88,89 | |||||
| 3 | 46 | УСП.ПО ДИСЦ.ЕН-02 (конц.совр.естествознания) - высокая | 35 | 88,57 | |||||
| 4 | 55 | УСП.ПО ДИСЦ.ОПД-02 (общая социология) - высокая | 26 | 88,46 | |||||
| 5 | 45 | УСП.ПО ДИСЦ.ЕН-01 (математика и информатика) - низкая | 8 | 87,50 | |||||
| 6 | 85 | УСП.ПО ДИСЦ.ОПД-12 (социальная экология) - высокая | 24 | 87,50 | |||||
| 7 | 13 | УСП.ПО ДИСЦ.ГСД-01 (философия) - высокая | 23 | 86,96 | |||||
| 8 | 28 | УСП.ПО ДИСЦ.ГСД-06 (право) - высокая | 35 | 85,71 | |||||
| 9 | 37 | УСП.ПО ДИСЦ.ГСД-10 (психология и педагогика) - высокая | 26 | 84,62 | |||||
| 10 | 14 | УСП.ПО ДИСЦ.ГСД-01 (философия) - средняя | 6 | 83,33 | |||||
| 11 | 16 | УСП.ПО ДИСЦ.ГСД-02 (иностр.язык) - высокая | 24 | 83,33 | |||||
| 12 | 18 | УСП.ПО ДИСЦ.ГСД-02 (иностр.язык) - низкая | 6 | 83,33 | |||||
| СРЕДНЯЯ адекватность модели | |||||||||
| 13 | 24 | УСП.ПО ДИСЦ.ГСД-04 (история) - низкая | 9 | 77,78 | |||||
| 14 | 22 | УСП.ПО ДИСЦ.ГСД-04 (история) - высокая | 17 | 76,47 | |||||
| 15 | 17 | УСП.ПО ДИСЦ.ГСД-02 (иностр.язык) - средняя | 12 | 75,00 | |||||
| 16 | 56 | УСП.ПО ДИСЦ.ОПД-02 (общая социология) - средняя | 8 | 75,00 | |||||
| 17 | 57 | УСП.ПО ДИСЦ.ОПД-02 (общая социология) - низкая | 8 | 75,00 | |||||
| 18 | 43 | УСП.ПО ДИСЦ.ЕН-01 (математика и информатика) - высокая | 15 | 73,33 | |||||
| 19 | 29 | УСП.ПО ДИСЦ.ГСД-06 (право) - средняя | 7 | 71,43 | |||||
| 20 | 47 | УСП.ПО ДИСЦ.ЕН-02 (конц.совр.естествознания) - средняя | 7 | 71,43 | |||||
| НИЗКАЯ адекватность модели | |||||||||
| 21 | 113 | Группа-2 | 23 | 69,57 | |||||
| 22 | 23 | УСП.ПО ДИСЦ.ГСД-04 (история) - средняя | 16 | 68,75 | |||||
| 23 | 44 | УСП.ПО ДИСЦ.ЕН-01 (математика и информатика) - средняя | 19 | 68,42 | |||||
| 24 | 39 | УСП.ПО ДИСЦ.ГСД-10 (психология и педагогика) - низкая | 3 | 66,67 | |||||
| 25 | 112 | Группа-1 | 19 | 63,16 | |||||
| 26 | 15 | УСП.ПО ДИСЦ.ГСД-01 (философия) - низкая | 13 | 61,54 | |||||
| ОЧЕНЬ НИЗКАЯ адекватность модели | |||||||||
| 27 | 107 | УСП.ПО ДИСЦ.СД-05 (социология культуры) - средняя | 11 | 54,55 | |||||
| 28 | 38 | УСП.ПО ДИСЦ.ГСД-10 (психология и педагогика) - средняя | 13 | 53,85 | |||||
| 29 | 86 | УСП.ПО ДИСЦ.ОПД-12 (социальная экология) - средняя | 17 | 52,94 | |||||
| 30 | 108 | УСП.ПО ДИСЦ.СД-05 (социология культуры) - низкая | 4 | 50,00 |
Из таблицы 65 видно, что:
– из 113 классов сформированными оказались лишь 30, т.к. по остальным в обучающей выборке просто не было данных;
– если исключить из модели не сформированные классы, а также классы с дифференциальной валидностью (% верной идентификации) меньше 70% (строки с 21 по 30), то получившаяся в результате модель по 20 классам модель будет иметь среднюю адекватность не ниже 70%. Для автоматизации
этой операции в системе "Эйдос" в подсистеме измерения адекватности имеется специальный режим. Необходимо отметить, что этот прием аналогичен исключению из рассмотрения результатов обработки с низким доверительным интервалом, что широко используется в дискриминантом анализе.
Осуществить содержательное
Для этого в 3-й функции 1-го режиме 5-й подсистемы системы "Эйдос" зададим коды классов 13 и 15 (высокая и низкая успеваемость по философии) и фильтр по факторам для обоих портретов от 347 до 373 (влияние образовательного уровня отца). В результате получим когнитивную диаграмму, представленную на рисунке 118.
 | |
| Рисунок 118. Когнитивная диаграмма, показывающая результаты содержательного сравнения двух классов по системам их детерминации |
Проинтерпретировать данную когнитивную диаграмму студенты должны самостоятельно.
Построить интегральные
В 7-м режиме 6-й подсистемы системы "Эйдос" при задании диапазона кода классов {13, 15} и диапазона кодов факторов {1, 11} генерируется следующая классическая когнитивная карта (рисунок 120), которая, по сути, является суперпозицией нескольких классических когнитивных карт.
Из этого рисунка видно, что факторы с кодами 3, 5, 11 сходны по влиянию на учебные достижения по философии:
– они все препятствуют достижению результата с кодом 13;
– они все способствуют достижению результата с кодом 15;
– результаты с кодами 13 и 15 детерминируются несовместимыми системами факторов и одновременно недостижимы, на что указывает антикорреляция между ними в семантической сети классов;
– фактор 3 способствует результату 14 и препятствует результату 13, а фактор 2, наоборот, препятствует 14 и способствует 13, и факторы 2 и 3 имеют различное влияние на поведение объекта управления, на что указывает антикорреляция между ними в семантической сети факторов.
Насколько известно, система "Эйдос" на данный момент является единственной системой, обеспечивающей автоматический синтез непосредственно на основе эмпирических данных и отображение в графической форме классических и интегральных когнитивных карт (интегральные когнитивные карты впервые предложены автором).
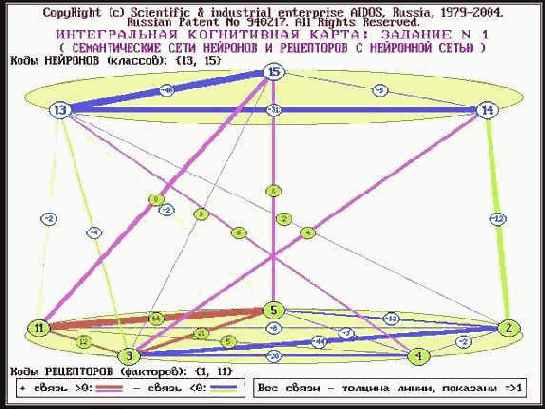 | |
| Рисунок 120. Пример интегральной когнитивной карты |
Построить классические когнитивные модели (отобразить в форме когнитивных карт).
В 7-м режиме 6-й подсистемы системы "Эйдос" при задании кода класса13 и диапазона кодов факторов 1 – 11 генерируется следующая классическая когнитивная карта (рисунок 119).
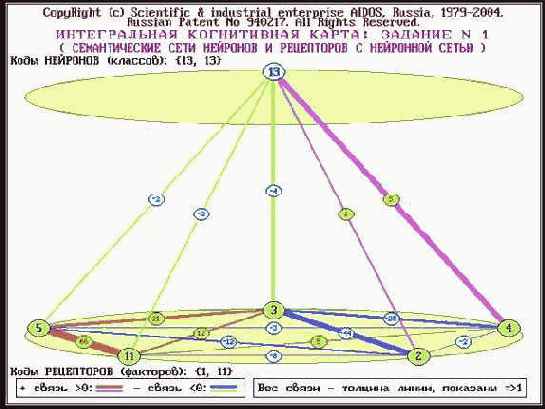 | |
| Рисунок 119. Пример классической когнитивной карты |
Построить нелокальные нейроны и интерпретируемые нейронные сети.
Это задание предлагается выполнить самостоятельно. При этом использовать 6-й режим 6-й подсистемы системы "Эйдос".
Провести кластерно-конструктивный
В 5-й подсистеме системы "Эйдос" получены следующие семантические сети классов, отражающие степень их сходства по детерминирующим их факторам (рисунок 116), и факторов, отражающие, их сходство и различие по влиянию на уровень учебных достижений учащихся (рисунок117).
 | |
| Рисунок 116. Пример семантической сети классов | |
 | |
| Рисунок 117. Пример семантической сети факторов |
Решить задачи идентификации и прогнозирования (для себя).
Эти операции выполняются в 4-й подсистеме системы "Эйдос". Результаты выводятся в двух разрезах:
– индивидуальная универсальная характеристика конкретного респондента (рисунок 113);
– выборка респондентов, имеющих наивысшие сходство с заданным классом (рисунок 114).
Анализ карточек прогноза успеваемости показывает, что вариабельность внутри группы успевающих студентов гораздо выше, чем в группе неуспевающих. В результате в среднем уровень сходства конкретных респондентов с обобщенными образами классов, соответствующих высоким уровням успеваемости, гораздо ниже, чем с классами, соответствующими низким уровням успеваемости.
Это дает основание предложить гипотезу, что высокая успеваемость детерминируется менее жестко, чем низкая, т.е. существуют конкретные факторы, фактически предопределяющие
низкую успеваемость, тогда как для высокой успеваемости можно говорить лишь о системе факторов, способствующих высокой успеваемости.
Конечно, чтобы подобные выводы имели достаточную научную достоверность необходима значительно большая статистика, чем использованная в данном учебном примере. Например, если бы подобное исследование было проведено хотя бы в масштабах КубГАУ (более 17000 студентов), то тогда уже с достаточной уверенностью можно было бы говорить о реально обнаруженных закономерностях.
 | |
| Рисунок 113. Прогноз успеваемости по различным предметам для конкретного студента |
 | |
| Рисунок 114. Список респондентов в порядке убывания сходства с заданным классом |
Формы, подобные представленной на рисунке 113, могут интересовать потенциальных работодателей, а также приемную комиссию вуза в качестве дополнительной информации для принятия решения.
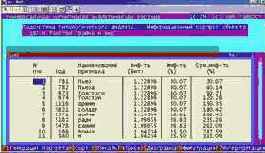
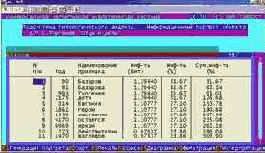
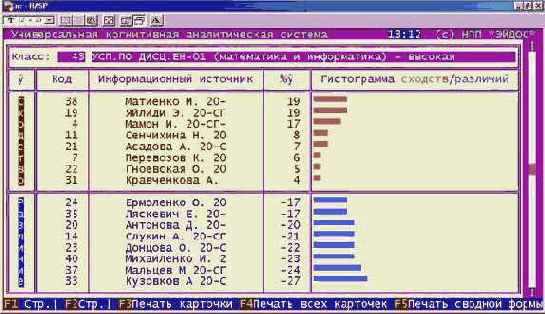
Сгенерировать информационные
Определим, как влияют "ФОРМЫ ДОСУГА, КОТОРЫЕ ВЫ ИСПОЛЬЗУЕТЕ ПО ВОЗМОЖНОСТИ" на успеваемость по философии. Для этого в 1-м режиме 5-й подсистемы системы "Эйдос" получим информационный портрет класса с кодом 13: УСП.ПО ДИСЦ.ГСД-01 (философия) – высокая и нажав клавишу F6 зададим фильтр по диапазону градаций названной шкалы с кодом 50: {347, 373}. В результате получим информационный портрет данного класса, представленный в таблице 66.
| Таблица 66 – ИНФОРМАЦИОННЫЙ ПОРТРЕТ КЛАССА, КОД: 13 | |
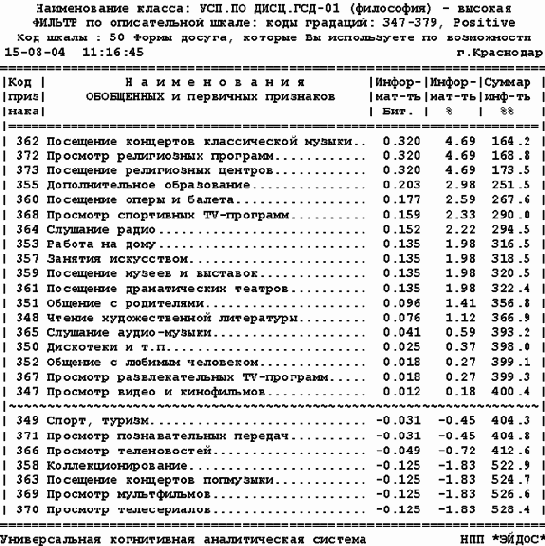 |
Профиль класса в разрезе по диапазону факторов можно получить в 4-м режиме 6-й подсистемы системы "Эйдос" (рисунок 115).
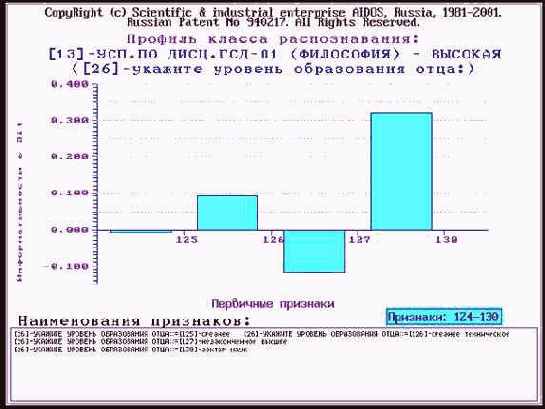 | |
| Рисунок 115. Профиль влияния образовательного уровня отца на отличную успеваемость студента по философии |
Из этого рисунка видно, что на отличную успеваемость студента по философии наиболее положительно сказывается если его отец – доктор наук.
В этой связи позволим себе немного повеселить читателей следующей историей. Профессор спрашивает абитуриента на вступительном экзамене:
– из каких соображений Вы выбрали для поступления именно наш вуз и именно эту специальность?
– не задавай глупых вопросов, папа!
отвечает абитуриент.
Оставшуюся часть задания студентам предлагается выполнить самостоятельно.
Сконструировать классификационные
Пример формирования классификационных шкалы и градаций приведен в таблице 59.
Таблица 59 – КЛАССИФИКАЦИОННЫЕ ШКАЛЫ И ГРАДАЦИИ
| Код | Наименование класса | Код | Наименование класса | ||||
| 1 | ПОЛ - мужской | 29 | Полонская ПИ-51 | ||||
| 2 | ПОЛ - женский | 30 | Трунина ПИ-51 | ||||
| 3 | ОТКУДА РОДОМ - город-краевой центр | 31 | Черкашина ПИ-51 | ||||
| 4 | ОТКУДА РОДОМ - город-районный центр | 32 | Чепурченко ПИ-51 | ||||
| 5 | ОТКУДА РОДОМ - поселок городского типа | 33 | Чушкин ПИ-51 | ||||
| 6 | ОТКУДА РОДОМ - село | 34 | Шульгин ПИ-51 | ||||
| 7 | УСПЕВАЕМОСТЬ - "5" более 75% | 35 | Арушанян ПИ-52 | ||||
| 8 | УСПЕВАЕМОСТЬ - "5" более 50% но меньше 75% | 36 | Быченок ПИ-52 | ||||
| 9 | УСПЕВАЕМОСТЬ - "5" более 25% но меньше 50% | 37 | Веревкина ПИ-52 | ||||
| 10 | УСПЕВАЕМОСТЬ - "5" менее 25% | 38 | Григорьева ПИ-52 | ||||
| 11 | ФОРМА ОБУЧЕНИЯ - бюджетная | 39 | Давыдич ПИ-52 | ||||
| 12 | ФОРМА ОБУЧЕНИЯ - платная | 40 | Дронова ПИ-52 | ||||
| 13 | ГРУППА ПИ-51 | 41 | Еременко ПИ-52 | ||||
| 14 | ГРУППА ПИ-52 | 42 | Жмурко ПИ-52 | ||||
| 15 | Бабенко ПИ-51 | 43 | Иванова ПИ-52 | ||||
| 16 | Воробьева ПИ-51 | 44 | Костенко ПИ-52 | ||||
| 17 | Гура ПИ-51 | 45 | Крейс ПИ-52 | ||||
| 18 | Головнев ПИ-51 | 46 | Куркина ПИ-52 | ||||
| 19 | Дыбова ПИ-51 | 47 | Люлик ПИ-52 | ||||
| 20 | Жеребятьев ПИ-51 | 48 | Максимов ПИ-52 | ||||
| 21 | Заяц ПИ-51 | 49 | Мануйлов ПИ-52 | ||||
| 22 | Иванова ПИ-51 | 50 | Нарижний ПИ-52 | ||||
| 23 | Котенко ПИ-51 | 51 | Ольховская ПИ-52 | ||||
| 24 | Кузина О. ПИ-51 | 52 | Паршакова ПИ-52 | ||||
| 25 | Кузина Я. ПИ-51 | 53 | Силенко ПИ-52 | ||||
| 26 | Лях ПИ-51 | 54 | Соколова ПИ-52 | ||||
| 27 | Мясников ПИ-51 | 55 | Турбин ПИ-52 | ||||
| 28 | Нагапетян ПИ-51 | 56 | Цисарь ПИ-52 |
Продолжение таблицы 62
|
Код |
Наименование класса |
|
72 |
УСП.ПО ДИСЦ.ОПД-07 (социальная психология) – низкая |
|
73 |
УСП.ПО ДИСЦ.ОПД-08 (соц.труда и экон.соц.) - высокая |
|
74 |
УСП.ПО ДИСЦ.ОПД-08 (соц.труда и экон.соц.) - средняя |
|
75 |
УСП.ПО ДИСЦ.ОПД-08 (соц.труда и экон.соц.) - низкая |
|
76 |
УСП.ПО ДИСЦ.ОПД-09 (социология организаций) - высокая |
|
77 |
УСП.ПО ДИСЦ.ОПД-09 (социология организаций) - средняя |
|
78 |
УСП.ПО ДИСЦ.ОПД-09 (социология организаций) - низкая |
|
79 |
УСП.ПО ДИСЦ.ОПД-10 (социология коммуникаций) - высокая |
|
80 |
УСП.ПО ДИСЦ.ОПД-10 (социология коммуникаций) - средняя |
|
81 |
УСП.ПО ДИСЦ.ОПД-10 (социология коммуникаций) - низкая |
|
82 |
УСП.ПО ДИСЦ.ОПД-11 (основы менеджмента) - высокая |
|
83 |
УСП.ПО ДИСЦ.ОПД-11 (основы менеджмента) - средняя |
|
84 |
УСП.ПО ДИСЦ.ОПД-11 (основы менеджмента) - низкая |
|
85 |
УСП.ПО ДИСЦ.ОПД-12 (социальная экология) - высокая |
|
86 |
УСП.ПО ДИСЦ.ОПД-12 (социальная экология) - средняя |
|
87 |
УСП.ПО ДИСЦ.ОПД-12 (социальная экология) - низкая |
|
88 |
УСП.ПО ДИСЦ.ОПД-13 (социология религий) - высокая |
|
89 |
УСП.ПО ДИСЦ.ОПД-13 (социология религий) - средняя |
|
90 |
УСП.ПО ДИСЦ.ОПД-13 (социология религий) - низкая |
|
91 |
УСП.ПО ДИСЦ.ОПД-14 (дисц. и курсы по выбору) - высокая |
|
92 |
УСП.ПО ДИСЦ.ОПД-14 (дисц.и курсы по выбору) - средняя |
|
93 |
УСП.ПО ДИСЦ.ОПД-14 (дисц.и курсы по выбору) - низкая |
|
94 |
УСП.ПО ДИСЦ.СД-01 (соц.прогнозирование и проект.) - высокая |
|
95 |
УСП.ПО ДИСЦ.СД-01 (соц.прогнозирование и проект.) - средняя |
|
96 |
УСП.ПО ДИСЦ.СД-01 (соц.прогнозирование и проект.) - низкая |
|
97 |
УСП.ПО ДИСЦ.СД-02 (соц.проблемы изуч.общ.мнения) - высокая |
|
98 |
УСП.ПО ДИСЦ.СД-02 (соц.проблемы изуч.общ.мнения) - средняя |
|
99 |
УСП.ПО ДИСЦ.СД-02 (соц.проблемы изуч.общ.мнения) - низкая |
|
100 |
УСП.ПО ДИСЦ.СД-03 (соц.полит.процессов) - высокая |
|
101 |
УСП.ПО ДИСЦ.СД-03 (соц.полит.процессов) - средняя |
|
102 |
УСП.ПО ДИСЦ.СД-03 (соц.полит.процессов) - низкая |
|
103 |
УСП.ПО ДИСЦ.СД-04 (социология семьи) - высокая |
|
104 |
УСП.ПО ДИСЦ.СД-04 (социология семьи) - средняя |
|
105 |
УСП.ПО ДИСЦ.СД-04 (социология семьи) - низкая |
|
106 |
УСП.ПО ДИСЦ.СД-05 (социология культуры) - высокая |
|
107 |
УСП.ПО ДИСЦ.СД-05 (социология культуры) - средняя |
|
108 |
УСП.ПО ДИСЦ.СД-05 (социология культуры) - низкая |
|
109 |
УСП.ПО ДИСЦ.СД-06 (дисц.и курсы по выбору) - высокая |
|
110 |
УСП.ПО ДИСЦ.СД-06 (дисц.и кусры по выбору) - средняя |
|
111 |
УСП.ПО ДИСЦ.СД-06 (дисц.и курсы по выбору) - низкая |
|
112 |
Группа-1 |
|
113 |
Группа-2 |
В качестве описательных шкал и градаций использовать характеристики подчерка.
Существует много различных систем выявления признаков подчерка. Мы в учебных целях воспользуемся одной из самых простых из них, используемой на сайте: Альянс-медиа "Деловые тесты":
http://www.businesstest.ru/test.asp?test_id=155&topic_id=3
В таблице 60 эта система приведена в виде, преобразованном для удобства использования в системе "Эйдос".
Таблица 60 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
СПРАВОЧНИК НАИМЕНОВАНИЙ ШКАЛ И ГРАДАЦИЙ ПРИЗНАКОВ
06-09-04 10:39:45 г.Краснодар
==========================================================================
| N | Код | Наименование |
|========================================================================|
| |[ 1]|РАЗМЕР БУКВ: |
| 1| 1 |Очень мелкие................................................|
| 2| 2 |Мелкие......................................................|
| 3| 3 |Средние.....................................................|
| 4| 4 |Крупные.....................................................|
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| |[ 2]|НАКЛОН БУКВ: |
| 5| 5 |Влево.......................................................|
| 6| 6 |Легкий влево................................................|
| 7| 7 |Вправо......................................................|
| 8| 8 |Резкий вправо...............................................|
| 9| 9 |Прямое написание............................................|
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| |[ 3]|ФОРМА БУКВ: |
| 10| 10 |Округлые....................................................|
| 11| 11 |Бесформенные................................................|
| 12| 12 |Угловатые...................................................|
Анкета организаторов тестирования преобразована к виду, удобному для обработки в системе "Эйдос" (таблица 63).
Таблица 63 – ОПИСАТЕЛЬНЫЕ ШКАЛЫ И ГРАДАЦИИ
| Код | Наименования шкал и градаций признаков | ||
| [ 1] | ВАШ ВОЗРАСТ: | ||
| 1 | 17 | ||
| 2 | 18 | ||
| 3 | 19 | ||
| 4 | 20 | ||
| 5 | 21 | ||
| 6 | 22 | ||
| 7 | 23 | ||
| 8 | 24 | ||
| 9 | 25 или более | ||
| [ 2] | ВЫ РОДИЛИСЬ В РОССИИ? | ||
| 10 | Да | ||
| 11 | Нет | ||
| [ 3] | ЕСЛИ ВЫ РОДИЛИСЬ НЕ В РОССИИ, ТО ВО СКОЛЬКО ЛЕТ ВЫ СЮДА ПРИЕХАЛИ? | ||
| 12 | До 7 лет | ||
| 13 | От 7 до 17 лет | ||
| 14 | Больше 17 лет | ||
| [ 4] | КОЛИЧЕСТВО ЖИЛЫХ КОМНАТ У ВАС ДОМА: | ||
| 15 | 1 | ||
| 16 | 2 | ||
| 17 | 3 | ||
| 18 | 4 | ||
| 19 | 5 или более | ||
| [ 5] | СКОЛЬКО ВСЕГО ЧЕЛОВЕК ЖИВУТ У ВАС ДОМА? | ||
| 20 | 1 | ||
| 21 | 2 | ||
| 22 | 3 | ||
| 23 | 4 | ||
| 24 | 5 | ||
| 25 | 6 | ||
| 26 | 7 и более | ||
| [ 6] | ДОХОД НА ЧЛЕНА СЕМЬИ (В МЕСЯЦ): | ||
| 27 | Низкий | ||
| 28 | Средний | ||
| 29 | Высокий | ||
| [ 7] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО РУССКОМУ ЯЗЫКУ: | ||
| 30 | Отличные | ||
| 31 | Хорошие | ||
| 32 | Средние | ||
| 33 | Низкие | ||
| [ 8] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО АЛГЕБРЕ: | ||
| 34 | Отличные | ||
| 35 | Хорошие | ||
| 36 | Средние | ||
| 37 | Низкие | ||
| [ 9] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО ГЕОМЕТРИИ: | ||
| 38 | Отличные | ||
| 39 | Хорошие | ||
| 40 | Средние | ||
| 41 | Низкие | ||
| [ 10] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО ФИЗИКЕ: | ||
| 42 | Отличные | ||
| 43 | Хорошие | ||
| 44 | Средние | ||
| 45 | Низкие |
Продолжение таблицы 63
| Код | Наименования шкал и градаций признаков | ||
| [ 11] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО ХИМИИ: | ||
| 46 | Отличные | ||
| 47 | Хорошие | ||
| 48 | Средние | ||
| 49 | Низкие | ||
| [ 12] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО ИНФОРМАТИКЕ: | ||
| 50 | Отличные | ||
| 51 | Хорошие | ||
| 52 | Средние | ||
| [ 13] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО БИОЛОГИИ: | ||
| 54 | Отличные | ||
| 55 | Хорошие | ||
| 56 | Средние | ||
| 57 | Низкие | ||
| [ 14] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО ИСТОРИИ: | ||
| 58 | Отличные | ||
| 59 | Хорошие | ||
| 60 | Средние | ||
| 61 | Низкие | ||
| [ 15] | КАК ВЫ САМИ ОЦЕНИВАЕТЕ СВОИ ШКОЛЬНЫЕ ЗНАНИЯ ПО ИНОСТРАННОМУ ЯЗЫКУ | ||
| 62 | Отличные | ||
| 63 | Хорошие | ||
| 64 | Средние | ||
| 65 | Низкие | ||
| [ 16] | КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО РУССКОМУ ЯЗЫКУ: | ||
| 66 | Уроки в школе | ||
| 67 | Со знакомыми | ||
| 68 | С репетитором | ||
| 69 | Факультатив в школе | ||
| 70 | Курсы при ВУЗе | ||
| 71 | Заочно при ВУЗе | ||
| [ 17] | КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО АЛГЕБРЕ: | ||
| 72 | Уроки в школе | ||
| 73 | Со знакомыми | ||
| 74 | С репетитором | ||
| 75 | Факультатив в школе | ||
| 76 | Курсы при ВУЗе | ||
| 77 | Заочно при ВУЗе | ||
| [ 18] | КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО ГЕОМЕТРИИ: | ||
| 78 | Уроки в школе | ||
| 79 | Со знакомыми | ||
| 80 | С репетитором | ||
| 81 | Факультатив в школе | ||
| 82 | Курсы при ВУЗе | ||
| 83 | Заочно при ВУЗе | ||
| [ 19] | КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО ФИЗИКЕ: | ||
| 84 | Уроки в школе | ||
| 85 | Со знакомыми | ||
| 86 | С репетитором | ||
| 87 | Факультатив в школе | ||
| 88 | Курсы при ВУЗе | ||
| 89 | Заочно при ВУЗе | ||
| [ 20] | КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО ХИМИИ: | ||
| 90 | Уроки в школе | ||
| 91 | Со знакомыми | ||
| 92 | С репетитором | ||
| 93 | Факультатив в школе | ||
| 94 | Курсы при ВУЗе | ||
| 95 | Заочно при ВУЗе |
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| |[ 4]|НАПРАВЛЕНИЕ ПОЧЕРКА: |
| 13| 13 |Строчки "ползут" вверх......................................|
| 14| 14 |Строчки прямые..............................................|
| 15| 15 |Строчки "сползают" вниз.....................................|
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| |[ 5]|ИНТЕНСИВНОСТЬ ПОЧЕРКА И СИЛА НАЖИМА: |
| 16| 16 |Легкая......................................................|
| 17| 17 |Средняя.....................................................|
| 18| 18 |Сильная.....................................................|
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| |[ 6]|ХАРАКТЕР НАПИСАНИЯ СЛОВ: |
| 19| 19 |Склонность к соединению букв................................|
| 20| 20 |Склонность к отделению букв друг от друга...................|
| 21| 21 |Смешанный стиль.............................................|
|~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
| |[ 7]|ОБЩАЯ ОЦЕНКА ПОЧЕРКА: |
| 22| 22 |Почерк старательный, буквы аккуратные.......................|
| 23| 23 |Почерк неровный, одни слова видны, другие читаются с трудом.|
| 24| 24 |Буквы написаны кое-как, почерк неразборчивый и небрежный....|
==========================================================================
Универсальная когнитивная аналитическая система НПП *ЭЙДОС*
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
[ 21] |
КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО ИНФОРМАТИКЕ: |
|
96 |
Уроки в школе |
|
97 |
Со знакомыми |
|
98 |
С репетитором |
|
99 |
Факультатив в школе |
|
100 |
Курсы при ВУЗе |
|
101 |
Заочно при ВУЗе |
|
[ 22] |
КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО БИОЛОГИИ: |
|
102 |
Уроки в школе |
|
103 |
Со знакомыми |
|
104 |
С репетитором |
|
105 |
Факультатив в школе |
|
106 |
Курсы при ВУЗе |
|
107 |
Заочно при ВУЗе |
|
[ 23] |
КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО ИСТОРИИ: |
|
108 |
Уроки в школе |
|
109 |
Со знакомыми |
|
110 |
С репетитором |
|
111 |
Факультатив в школе |
|
112 |
Курсы при ВУЗе |
|
113 |
Заочно при ВУЗе |
|
[ 24] |
КАК ВЫ ГОТОВИЛИСЬ К ВСТУПИТЕЛЬНОМУ ЭКЗАМЕНУ ПО ИНОСТРАННОМУ ЯЗЫКУ |
|
114 |
Уроки в школе |
|
115 |
Со знакомыми |
|
116 |
С репетитором |
|
117 |
Факультатив в школе |
|
118 |
Курсы при ВУЗе |
|
119 |
Заочно при ВУЗе |
|
[ 25] |
СКОЛЬКО ВРЕМЕНИ СУММАРНО УХОДИТ У ВАС НА ВЫПОЛНЕНИЕ ДОМАШНИХ ЗАДАНИЙ? |
|
120 |
До 15 минут |
|
121 |
Около 30 минут |
|
122 |
1 - 2 часа |
|
123 |
Более 2-х часов |
|
[ 26] |
УКАЖИТЕ УРОВЕНЬ ОБРАЗОВАНИЯ ОТЦА: |
|
124 |
Неполное среднее |
|
125 |
Среднее |
|
126 |
Среднее техническое |
|
127 |
Незаконченное высшее |
|
128 |
Высшее |
|
129 |
Кандидат наук |
|
130 |
Доктор наук |
|
[ 27] |
УКАЖИТЕ УРОВЕНЬ ОБРАЗОВАНИЯ МАТЕРИ: |
|
131 |
Неполное среднее |
|
132 |
Среднее |
|
133 |
Среднее техническое |
|
134 |
Незаконченное высшее |
|
135 |
Высшее |
|
136 |
Кандидат наук |
|
137 |
Доктор наук |
|
[ 28] |
УКАЖИТЕ НАЦИОНАЛЬНОСТЬ ОТЦА: |
|
138 |
Русский |
|
139 |
Украинец |
|
140 |
Белорус |
|
141 |
Татарин |
|
142 |
Мордвин |
|
143 |
Удмурт |
|
144 |
Мари |
|
145 |
Башкир |
|
146 |
Чуваш |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
147 |
Еврей |
|
148 |
Калмык |
|
149 |
Бурят |
|
150 |
Коми |
|
151 |
Грузин |
|
152 |
Армянин |
|
153 |
Азербайджанец |
|
154 |
Другая |
|
[ 29] |
УКАЖИТЕ НАЦИОНАЛЬНОСТЬ МАТЕРИ: |
|
155 |
Русский |
|
156 |
Украинец |
|
157 |
Белорус |
|
158 |
Татарин |
|
159 |
Мордвин |
|
160 |
Удмурт |
|
161 |
Мари |
|
162 |
Башкир |
|
163 |
Чуваш |
|
164 |
Еврей |
|
165 |
Калмык |
|
166 |
Бурят |
|
167 |
Коми |
|
168 |
Грузин |
|
169 |
Армянин |
|
170 |
Азербайджанец |
|
171 |
Другая |
|
[ 30] |
ВЫ ПОСТОЯННО ЖИВЕТЕ В ДАННОМ МЕСТЕ ИЛИ ПЕРЕЕХАЛИ СЮДА ИЗ ДРУГОЙ МЕСТНОСТИ? |
|
172 |
Родился и живу здесь постоянно |
|
173 |
Приехал сюда из другого города России |
|
174 |
Приехал из сельской местности России |
|
175 |
Приехал из бывших республик СССР |
|
[ 31] |
ВЫ ПРОЖИВАЕТЕ: |
|
176 |
Москве |
|
177 |
Санкт-Петербурге |
|
178 |
В областном (краевом) центре или столице республики |
|
179 |
В крупном городе |
|
180 |
В среднем городе |
|
181 |
В малом городе |
|
182 |
В поселке, деревне, селе, хуторе и т.п. |
|
[ 32] |
КАК ЧАСТО ВЫ ДОМА РАЗГОВАРИВАЕТЕ НА РУССКОМ ЯЗЫКЕ? |
|
183 |
Всегда |
|
184 |
Почти всегда |
|
185 |
Иногда |
|
186 |
Очень редко |
|
187 |
Никогда |
|
[ 33] |
ВМЕСТЕ С ВАМИ ПОСТОЯННО ПРОЖИВАЮТ: |
|
188 |
Мать |
|
189 |
Отец |
|
190 |
Отчим/мачеха |
|
191 |
Братья/сестры |
|
192 |
Бабушки/дедушки |
|
193 |
Другие родственники |
|
[ 34] |
КОЛИЧЕСТВО ДЕТЕЙ В СЕМЬЕ, ВКЛЮЧАЯ ВАС: |
|
194 |
Один |
|
195 |
Двое |
|
196 |
Трое |
|
197 |
Четверо или более |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
[ 35] |
ИМЕЕТ ЛИ ВАША СЕМЬЯ: |
|
198 |
Видеомагнитофон |
|
199 |
Видеокамеру |
|
200 |
Несколько цветных телевизоров |
|
201 |
Компьютер |
|
202 |
Отечественную автомашину |
|
203 |
Несколько отечественных автомашин или иномарку |
|
[ 36] |
ЕСЛИ ВЫ ИМЕЕТЕ КОМПЬЮТЕР ДОМА, ТО КАК ВЫ ЕГО ИСПОЛЬЗУЕТЕ? |
|
204 |
Для игр |
|
205 |
Для изучения учебных предметов (например, иностранных языков) |
|
206 |
Для обмена информацией с помощью модема, в т.ч. в Internet |
|
207 |
Для оплачиваемой работы |
|
[ 37] |
СКОЛЬКО ПРИМЕРНО КНИГ У ВАС В СЕМЬЕ (НЕ СЧИТАЯ УЧЕБНИКОВ И УЧЕБНЫХ ПОСОБИЙ)? |
|
208 |
Менее 50 |
|
209 |
Около 100 |
|
210 |
Несколько сотен |
|
211 |
Более тысячи |
|
[ 38] |
ВАШЕ ОТНОШЕНИЕ К ПЕРИОДИЧЕСКОЙ ПЕЧАТИ: |
|
212 |
Выписываем на дом |
|
213 |
Покупаем ежедневно |
|
214 |
Покупаем еженедельно |
|
215 |
Почти не читаем |
|
[ 39] |
ЖИЛИЩНЫЕ УСЛОВИЯ ВАШЕЙ СЕМЬИ: |
|
216 |
Комната в коммунальной квартире |
|
217 |
1-комнатная квартира |
|
218 |
2-комнатная квартира |
|
219 |
Квартира из 3-х или более комнат |
|
220 |
Обычный дом в сельской местности |
|
221 |
Дом повышенной комфортности (особняк) |
|
[ 40] |
ПРИ СОСТАВЛЕНИИ ПЛАНОВ НА БУДУЩЕЕ ЧЬЕ МНЕНИЕ ВЫ УЧИТЫВАЕТЕ В ПЕРВУЮ ОЧЕРЕДЬ (ВЫБЕРИТЕ ТОЛЬКО ОДИН ОТВЕТ): |
|
222 |
Родителей |
|
223 |
Учителей |
|
224 |
Сверстников (друзей) |
|
225 |
Средств массовой информации |
|
226 |
Свое собственное |
|
[ 41] |
ГДЕ ВЫ ОБЫЧНО ПРОВОДИТЕ ЕЖЕГОДНЫЙ ОТПУСК (КАНИКУЛЫ): |
|
227 |
Дома |
|
228 |
На собственной даче |
|
229 |
В другом городе или на даче у родственников или знакомых |
|
230 |
В туристическом походе |
|
231 |
На Черном море в России |
|
232 |
В бывших республиках СССР |
|
233 |
За рубежом |
|
234 |
Другое |
|
[ 42] |
ВЫ ЗАКОНЧИЛИ ВЫПУСКНОЙ КЛАСС: |
|
235 |
Общеобразовательный |
|
236 |
Профилированный на ВУЗ |
|
237 |
Гимназический или лицейский |
|
238 |
другой (экономический, юридический и др.) |
|
[ 43] |
ВЫ ЗАКОНЧИЛИ ВЫПУСКНОЙ КЛАСС С УГЛУБЛЕННЫМ ИЗУЧЕНИЕМ: |
|
239 |
Математики |
|
240 |
Физики |
|
241 |
Биологии |
|
242 |
Химии |
|
243 |
Географии |
|
244 |
Информатики |
|
245 |
Истории, обществоведения |
|
246 |
Русского языка, литературы |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
247 |
Иностранных языков |
|
[ 44] |
ВЫБЕРИТЕ ПРЕДМЕТЫ, КОТОРЫЕ ВАМ НРАВЯТСЯ: |
|
248 |
Русский язык |
|
249 |
Математика |
|
250 |
Физика |
|
251 |
Химия |
|
252 |
Информатика |
|
253 |
Биология |
|
254 |
История |
|
255 |
Иностранный язык |
|
256 |
География |
|
[ 45] |
ЧЕМ ВАМ НРАВИТСЯ ШКОЛА, КОТОРУЮ ВЫ ЗАКОНЧИЛИ? |
|
257 |
Хорошие отношения со сверстниками |
|
258 |
Хорошие учителя |
|
259 |
Хорошая подготовка к поступлению в ВУЗ |
|
260 |
Расположена рядом с домом |
|
261 |
Ничем не нравится |
|
262 |
Другое |
|
[ 46] |
ОБЛАСТЬ ПРОФЕССИОНАЛЬНОЙ ДЕЯТЕЛЬНОСТИ ОТЦА: |
|
263 |
Промышленность (тяжелая) |
|
264 |
Промышленность (легкая) |
|
265 |
Строительство |
|
266 |
Сельское хозяйство |
|
267 |
Транспорт |
|
268 |
Коммерция, торговля, сфера бытового обслуживания |
|
269 |
Экономика |
|
270 |
Частный бизнес, предпринимательство |
|
271 |
Государственная служба |
|
272 |
Служба в силовых структурах |
|
273 |
Выборные органы власти |
|
274 |
Образование |
|
275 |
Здравоохранение, медицина |
|
276 |
Культура, искусство |
|
277 |
Наука |
|
278 |
Юриспруденция |
|
279 |
Спорт |
|
280 |
Религия |
|
281 |
Другое |
|
[ 47] |
ОБЛАСТЬ ПРОФЕССИОНАЛЬНОЙ ДЕЯТЕЛЬНОСТИ МАТЕРИ: |
|
282 |
Промышленность (тяжелая) |
|
283 |
Промышленность (легкая) |
|
284 |
Строительство |
|
285 |
Сельское хозяйство |
|
286 |
Транспорт |
|
287 |
Коммерция, торговля, сфера бытового обслуживания |
|
288 |
Экономика |
|
289 |
Частный бизнес, предпринимательство |
|
290 |
Государственная служба |
|
291 |
Служба в силовых структурах |
|
292 |
Выборные органы власти |
|
293 |
Образование |
|
294 |
Здравоохранение, медицина |
|
295 |
Культура, искусство |
|
296 |
Наука |
|
297 |
Юриспруденция |
|
298 |
Спорт |
|
299 |
Религия |
|
300 |
Другое |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
[ 48] |
ОБЛАСТЬ ПРОФЕССИОНАЛЬНОЙ ДЕЯТЕЛЬНОСТИ, НАИБОЛЕЕ ПРИВЛЕКАЮЩАЯ МЕНЯ |
|
301 |
Промышленность (тяжелая) |
|
302 |
Промышленность (легкая) |
|
303 |
Строительство |
|
304 |
Сельское хозяйство |
|
305 |
Транспорт |
|
306 |
Коммерция, торговля, сфера бытового обслуживания |
|
307 |
Экономика |
|
308 |
Частный бизнес, предпринимательство |
|
309 |
Государственная служба |
|
310 |
Служба в силовых структурах |
|
311 |
Выборные органы власти |
|
312 |
Образование |
|
313 |
Здравоохранение, медицина |
|
314 |
Культура, искусство |
|
315 |
Наука |
|
316 |
Юриспруденция |
|
317 |
Спорт |
|
318 |
Религия |
|
319 |
Другое |
|
[ 49] |
УКАЖИТЕ ФОРМЫ ДОСУГА, КОТОРЫЕ ВЫ ПРАКТИЧЕСКИ НЕ ИСПОЛЬЗУЕТЕ: |
|
320 |
Просмотр видео и кинофильмов |
|
321 |
Чтение художественной литературы |
|
322 |
Спорт, туризм |
|
323 |
Дискотеки и т.п. |
|
324 |
Общение с родителями |
|
325 |
Общение с любимым человеком |
|
326 |
Работа на дому |
|
327 |
Оплачиваемая работа |
|
328 |
Дополнительное образование |
|
329 |
Техническое творчество |
|
330 |
Занятия искусством |
|
331 |
Коллекционирование |
|
332 |
Посещение музеев и выставок |
|
333 |
Посещение оперы и балета |
|
334 |
Посещение драматических театров |
|
335 |
Посещение концертов классической музыки |
|
336 |
Посещение концертов попмузыки |
|
337 |
Слушание радио |
|
338 |
Слушание аудио-музыки |
|
339 |
Просмотр теленовостей |
|
340 |
Просмотр развлекательных TV-программ |
|
341 |
Просмотр спортивных TV-программ |
|
342 |
Просмотр мультфильмов |
|
343 |
Просмотр телесериалов |
|
344 |
Просмотр познавательных передач |
|
345 |
Просмотр религиозных программ |
|
346 |
Посещение религиозных центров |
|
[ 50] |
УКАЖИТЕ ФОРМЫ ДОСУГА, КОТОРЫЕ ВЫ ИСПОЛЬЗУЕТЕ ПО ВОЗМОЖНОСТИ: |
|
347 |
Просмотр видео и кинофильмов |
|
348 |
Чтение художественной литературы |
|
349 |
Спорт, туризм |
|
350 |
Дискотеки и т.п. |
|
351 |
Общение с родителями |
|
352 |
Общение с любимым человеком |
|
353 |
Работа на дому |
|
354 |
Оплачиваемая работа |
|
355 |
Дополнительное образование |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
356 |
Техническое творчество |
|
357 |
Занятия искусством |
|
358 |
Коллекционирование |
|
359 |
Посещение музеев и выставок |
|
360 |
Посещение оперы и балета |
|
361 |
Посещение драматических театров |
|
362 |
Посещение концертов классической музыки |
|
363 |
Посещение концертов попмузыки |
|
364 |
Слушание радио |
|
365 |
Слушание аудио-музыки |
|
366 |
Просмотр теленовостей |
|
367 |
Просмотр развлекательных TV-программ |
|
368 |
Просмотр спортивных TV-программ |
|
369 |
Просмотр мультфильмов |
|
370 |
Просмотр телесериалов |
|
371 |
Просмотр познавательных передач |
|
372 |
Просмотр религиозных программ |
|
373 |
Посещение религиозных центров |
|
[ 51] |
УКАЖИТЕ ФОРМЫ ДОСУГА, КОТОРЫЕ ВЫ ЧАСТО ИСПОЛЬЗУЕТЕ: |
|
374 |
Просмотр видео и кинофильмов |
|
375 |
Чтение художественной литературы |
|
376 |
Спорт, туризм |
|
377 |
Дискотеки и т.п. |
|
378 |
Общение с родителями |
|
379 |
Общение с любимым человеком |
|
380 |
Работа на дому |
|
381 |
Оплачиваемая работа |
|
382 |
Дополнительное образование |
|
383 |
Техническое творчество |
|
384 |
Занятия искусством |
|
385 |
Коллекционирование |
|
386 |
Посещение музеев и выставок |
|
387 |
Посещение оперы и балета |
|
388 |
Посещение драматических театров |
|
389 |
Посещение концертов классической музыки |
|
390 |
Посещение концертов попмузыки |
|
391 |
Слушание радио |
|
392 |
Слушание аудио-музыки |
|
393 |
Просмотр теленовостей |
|
394 |
Просмотр развлекательных TV-программ |
|
395 |
Просмотр спортивных TV-программ |
|
396 |
Просмотр мультфильмов |
|
397 |
Просмотр телесериалов |
|
398 |
Просмотр познавательных передач |
|
399 |
Просмотр религиозных программ |
|
400 |
Посещение религиозных центров |
|
[ 52] |
УКАЖИТЕ ФОРМЫ ДОСУГА, КОТОРЫЕ ВЫ ИСПОЛЬЗУЕТЕ ПРАКТИЧЕСКИ ВСЕГДА: |
|
401 |
Просмотр видео и кинофильмов |
|
402 |
Чтение художественной литературы |
|
403 |
Спорт, туризм |
|
404 |
Дискотеки и т.п. |
|
405 |
Общение с родителями |
|
406 |
Общение с любимым человеком |
|
407 |
Работа на дому |
|
408 |
Оплачиваемая работа |
|
409 |
Дополнительное образование |
|
410 |
Техническое творчество |
|
411 |
Занятия искусством |
|
412 |
Коллекционирование |
|
413 |
Посещение музеев и выставок |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
414 |
Посещение оперы и балета |
|
415 |
Посещение драматических театров |
|
416 |
Посещение концертов классической музыки |
|
417 |
Посещение концертов попмузыки |
|
418 |
Слушание радио |
|
419 |
Слушание аудио-музыки |
|
420 |
Просмотр теленовостей |
|
421 |
Просмотр развлекательных TV-программ |
|
422 |
Просмотр спортивных TV-программ |
|
423 |
Просмотр мультфильмов |
|
424 |
Просмотр телесериалов |
|
425 |
Просмотр познавательных передач |
|
426 |
Просмотр религиозных программ |
|
427 |
Посещение религиозных центров |
|
[ 53] |
УКАЖИТЕ СТОРОНЫ ЖИЗНИ, ИМЕЮЩИЕ ДЛЯ ВАС МАЛУЮ ЦЕННОСТЬ: |
|
428 |
Общение с друзьями |
|
429 |
Общение с родителями |
|
430 |
Наличие вещей, имеющих продуктивную работу и учебу |
|
431 |
Наличие престижных вещей |
|
432 |
Наличие вещей, обеспечивающих комфортные условия жизни |
|
433 |
Возможность влияния на ход важных событий в семье |
|
434 |
Материальная независимость |
|
435 |
Свобода высказываться и публиковаться |
|
436 |
Свобода религии |
|
437 |
Удовольствия, развлечения |
|
438 |
Работа и учеба как творчество |
|
439 |
Работа на благо общества |
|
440 |
Работа как средство заработка |
|
441 |
Счастливая семья |
|
442 |
Любовь |
|
443 |
Красота человека |
|
444 |
Природа |
|
445 |
Культура, искусство |
|
[ 54] |
УКАЖИТЕ СТОРОНЫ ЖИЗНИ, ИМЕЮЩИЕ ДЛЯ ВАС НЕКОТОРУЮ ЦЕННОСТЬ: |
|
446 |
Общение с друзьями |
|
447 |
Общение с родителями |
|
448 |
Наличие вещей, имеющих продуктивную работу и учебу |
|
449 |
Наличие престижных вещей |
|
450 |
Наличие вещей, обеспечивающих комфортные условия жизни |
|
451 |
Возможность влияния на ход важных событий в семье |
|
452 |
Материальная независимость |
|
453 |
Свобода высказываться и публиковаться |
|
454 |
Свобода религии |
|
455 |
Удовольствия, развлечения |
|
456 |
Работа и учеба как творчество |
|
457 |
Работа на благо общества |
|
458 |
Работа как средство заработка |
|
459 |
Счастливая семья |
|
460 |
Любовь |
|
461 |
Красота человека |
|
462 |
Природа |
|
463 |
Культура, искусство |
|
[ 55] |
УКАЖИТЕ СТОРОНЫ ЖИЗНИ, ИМЕЮЩИЕ ДЛЯ ВАС БОЛЬШУЮ ЦЕННОСТЬ: |
|
464 |
Общение с друзьями |
|
465 |
Общение с родителями |
|
466 |
Наличие вещей, имеющих продуктивную работу и учебу |
|
467 |
Наличие престижных вещей |
|
468 |
Наличие вещей, обеспечивающих комфортные условия жизни |
|
469 |
Возможность влияния на ход важных событий в семье |
Продолжение таблицы 63
|
Код |
Наименования шкал и градаций признаков |
|
470 |
Материальная независимость |
|
471 |
Свобода высказываться и публиковаться |
|
472 |
Свобода религии |
|
473 |
Удовольствия, развлечения |
|
474 |
Работа и учеба как творчество |
|
475 |
Работа на благо общества |
|
476 |
Работа как средство заработка |
|
477 |
Счастливая семья |
|
478 |
Любовь |
|
479 |
Красота человека |
|
480 |
Природа |
|
481 |
Культура, искусство |
Проверить семантическую информационную модель на
Следуя логике Системно-когнитивного анализа выполнить следующие работы.
1. Осуществить когнитивную структуризацию предметной области.
2. Выполнить формализацию предметной области.
3. Сформировать обучающую выборку.
4. Осуществить синтез семантической информационной модели.
5. Оптимизировать семантическую информационную модель.
6. Проверить семантическую информационную модель на адекватность, измерить внутреннюю и внешнюю, дифференциальную и интегральную валидность.
7. Выполнить адаптацию модели и измерить, как изменилась ее адекватность.
8. Осуществить пересинтез модели и измерить, как изменилась ее адекватность.
9. Вывести информационные портреты текстов и дать их интерпретацию.
10. Выполнить кластерно-конструктивный анализ модели.
В заключение хотелось бы отметить,
В заключение хотелось бы отметить, что данное учебное пособие основано на материалах печати, Internet, а также на научных материалах кандидатской и докторской диссертаций автора, его научных работах, учебно-методических материалах, разработанных в ходе преподавания дисциплины "Интеллектуальные информационные системы" в течение 2002-2003 учебного года на факультете прикладной информатики КубГАУ и опыте, полученном в ходе преподавания этой и других дисциплин. Таким образом, это 1-е издание.
Объем учебного пособия по ряду лекций оказался превышен и в будущем безусловно будет сокращен. Мы надеемся, что студенты сами обнаружат эти лекции и, прочитав их "по диагонали", смогут извлечь из них самую суть и в краткой форме донести ее до экзамена, способность к чему они уже не раз успешно демонстрировали.
Мы надеемся, что в дальнейшем данное учебное пособие будет совершенствоваться, как и универсальная когнитивная аналитическая система "Эйдос" и методология и технология системно-когнитивного анализа, на которых оно основано. Все критические замечания и пожелания, направленные на совершенствование данного учебного пособия, будут с благодарностью приняты.
Автор
Краснодар. 22.08.2004.
Закон перераспределения функций между человеком и средствами труда
Развитие средств труда происходит путем последовательной передачи им трудовых функций человеческого организма в результате чего они начинают выполняться средствами труда вне естественных ограничений организма человека, а человек выполняет оставшиеся функции вне ограничений, связанных с необходимостью выполнения переданных функций.
Физический организм выполняет следующие функции, трудовые функции, последовательно передаваемые средствам труда:
1. Функция контакта с физической средой.
2. Функция трансмиссии (передачи и перераспределения энергии).
3. Рабочая функция (преобразование простого движения в сложное и выполняющее работу).
4. Функция двигателя (преобразование формы энергии).
5. Функция преобразования формы информации.
Другие структурные уровни организма человека поддерживают еще ряд функций, связанных с чувственно-эмоциональной и интеллектуальной обработкой информации. Рассмотрение этих функций выходит за рамки данного учебного пособия.
Когда средствам передается очередная трудовая функция – происходит технологическая революция, которая с неизбежностью вызывает революцию экономическую и социальную, а значит переход к новой общественно–экономической формации и соответствующему состоянию сознания (этапу общественного познания). Так формулируется закон перераспределения трудовых функций в системе "человек–машина", т.е. закон количественного повышения базиса.
Закон повышения качества базиса
Формулировка закона повышения качества базиса.
Развитие любой системы происходит путем разрешения противоречий между системой и средой в наинизшем качественном уровне системы, в котором они еще не разрешены. Этот уровень называется базисом (базисным). Разрешение противоречия в базисном уровне осуществляется поэтапно, путем перераспределения функций по преобразованию формы информации между внешним и внутренним.
Это перераспределение может осуществляться в двух формах:
1) в форме внешнего отчуждения (развитие средств труда и технологии);
2) путем внутреннего отчуждения (развитие сознания).
Причем развитие технологии детерминирует соответствующее развитие сознания, а уровень сознания определяет функциональный уровень технологии.
При отчуждении каждой очередной функции базисного уровня (передаче ее средствам труда или осознания ее как "не-Я") происходит количественное изменение системы. При отчуждении всех функций некоторого базисного уровня происходит качественное изменение системы и она переходит к развитию путем разрешения противоречий в следующем, более глубоком чем предыдущий уровне, который и становится базисным.
Когда средствам труда полностью и в массовом масштабе передается последняя функция некоторого относительно автономного уровня организации организма человека, то это вызывает переход к следующей группе общественно–экономических формаций и к следующему типу сознания. При этом человек как объективное начинает осознавать соответствующий качественно новый уровень Реальности и постепенно начинает действовать на нем как человек используя принцип свободы воли, в частности: сначала пользоваться тем, что "лежит на поверхности и ждет когда его возьмут", а затем трудиться и производить для потребления то, чего "на поверхности" не оказалось, и, наконец, производить средства производства. Таким образом при переходе к следующей группе формаций технологический базис общества повышается качественно, т.е. включает в себя средства труда, созданные на тех уровнях Реальности, которые ранее осознавались основной массой людей как субъективные.
Так формулируется закон повышения качества базиса.
Таким образом, в процессе развития технологии создаются технические системы, в состав которых входят уровни Реальности, поддерживающие так называемые субъективные функции (чувственно–эмоциональное восприятие и формально–логическое мышление), которые на предыдущих этапах эволюции общества осознавались как субъективные и относились не к базису, а к надстройке. В результате этого изменяется положение границы между базисом и надстройкой и соответственно изменяется содержание этих понятий, хотя их соотношение остается тем же что и раньше. Конечно, в этой связи изменяется и содержание таких понятий, как "производственная сфера" и "непроизводственная сфера", под которыми ранее понимались соответственно "сфера материального производства" и сфера производства самого человека, т.е. в основном культура, наука, образование и медицина. Становится вполне очевидным, что главной производительной силой является сам человек.
Законы развития техники
На любом этапе развития общества технологический базис общества основан на тех уровнях Реальности, которые осознаются как объективное при соответствующей данному этапу форме сознания. Технологический прогресс состоит в последовательной передаче трудовых функций организма человека средствам труда.
Зависимость адекватности модели от ее ортонормированности
Модель изучалась методом численного эксперимента. При этом были получены следующие результаты.
На 1-м этапе ортонормирования
адекватность модели (ее внутренняя дифференциальная и интегральная валидность) возрастает. Это можно объяснить тем, что, во-первых, уменьшается количество ошибок идентификации с близкими, т.е. коррелирующими классами, и, во-вторых, удаление из модели малоинформативных признаков по сути улучшает отношение "сигнал/шум" модели, т.е. качество идентификации.
На 2-м этапе ортонормирования
адекватность модели стабилизируется и незначительно колеблется около максимума. Это объясняется тем, что атрибуты, удаляемые на этом этапе, не являются критическим для адекватности модели.
На 3-м этапе ортонормирования
адекватность модели начинает уменьшаться, т.к. дальнейшее удаление атрибутов не позволяет адекватно описать предметную область.
При приближении процесса ортонормирования к 3-му этапу или его наступлении этот процесс должен быть остановлен.
Зависимость адекватности семантической
При экспериментальном исследовании свойств предлагаемой математической модели было установлено следующее (рисунок 35).
 | |
| Рисунок 35. Зависимость адекватности модели от объема обучающей выборки |
1. При малых выборках адекватность модели (внутренняя интегральная и дифференциальная валидность) равна 100% (рисунок 35, диапазон "А"). Это можно объяснить тем, что при малых объемах выборки все выявленные закономерности имеют детерминистский характер.
2. При увеличении объема исследуемой выборки происходит понижение адекватности модели (переход: А®В) и стабилизация ее адекватности на некотором уровне около 95-98% (рисунок 35, диапазон "В").
3. Учет в модели объектов обучающей выборки, отражающих закономерности, качественно отличающиеся от ранее выявленных, приводит к понижению адекватности модели (переход: В®С) и ее стабилизации на уровне от 80 до 90% (рисунок 35, диапазон "С").
4. Внутри диапазона "В" вариабельность объектов обучающей выборки по закономерностям "атрибут®класс" меньше, чем в диапазоне "С", т.е. объекты обучающей выборки диапазона "В" более однородны, чем "С".
Выявленные в модели причинно-следственные закономерности имеют силу для определенного подмножества обучающей выборки, например, отражающих определенный период времени, который соответствует детерминистскому периоду развития предметной области. При качественном изменении закономерностей устаревшие данные могут даже на некоторое время (пока модель не сойдется к новым закономерностям) нарушать ее адекватность.
В многочисленных проведенных практических исследованных модель показала высокую скорость сходимости и высокую адекватность на малых выборках. На больших выборках (т.е. охватывающих несколько детерминистских и бифуркационных состояний предметной области) закономерности с коротким периодом "причина-следствие" переформировываются заново, а с длительным (охватывающим несколько детерминистских и бифуркационных состояний) – автоматически становятся незначимыми и не ухудшают адекватность модели, если процесс апериодический, или сохраняют силу, если они имеют фундаментальный характер.
Выявленные закономерности сходимости модели позволяют сформулировать следующий критерий остановки процесса обучения:
если в модели ничего существенно не меняется при добавлении в обучающую выборку все новых и новых данных, то это означает, что модель адекватно отображает генеральную совокупность, к которой относятся эти данные, и продолжать процесс обучения нецелесообразно.
Здесь уместно рассмотреть ответ на следующий вопрос. Если для формирования образов классов распознавания предъявлено настолько малое количество обучающих объектов, что говорить об обобщении и статистике не приходится, то как это может повлиять на качество формирования модели и ее адекватность? При большой статистике, как показывает опыт, около 95% объектов, формирующих образ некоторого класса оказывается типичными для него, а остальные не типичными. Следовательно, если этот образ формируется на основе буквально одного - двух объектов, то вероятнее всего (т.е. с вероятностью около 95%) они являются типичными, и, следовательно, образ будет сформирован практически таким же, как и при большой статистике, т.е. правильным. При увеличении статистики в этом случае информативности признаков, составляющих образ практически не меняются). Но есть некоторая, сравнительно незначительная вероятность (около 5%), что попадется нетипичная анкета. Тогда при увеличении статистики образ быстро качественно изменится и "быстро сойдется" к адекватному, "нетипичная" анкета будет идентифицирована и ее данные либо будут удалены из модели, либо для нее специально будет создан свой класс.
При незначительной статистике относительный вклад каждого объекта в обобщенный образ некоторого класса, сформированный с его применением, будет достаточно велик. Поэтому в этом случае при распознавании модель уверенно относит объект к этому классу. При большой статистике модель также уверенно относит типичные объекты к классам, сформированным с их применением. Незначительное количество нетипичных объектов могут быть распознаны ошибочно, т.е.не отнесены моделью к тем классам, к которым их отнесли эксперты.
Наличие в системе очень сходных классов также может формально уменьшать валидность модели. Однако фактически эти очень сходные классы целесообразно объединить в один, т.к. по-видимому, их разделение объективно ничем не оправдано, т.е. не соответствует действительности. Для осуществления данной операции в математической модели целесообразно использовать режим: "Получение статистической характеристики обучающей выборки и объединение классов (ручной ремонт обучающей выборки)".
Зависимость информативностей факторов от объема обучающей выборки
При учете в модели апостериорной информации, содержащейся в очередном объекте обучающей выборки, осуществляется перерасчет значений информативностей всех атрибутов. При этом изменяется количество информации, содержащейся в факте обнаружения у объекта данного атрибута о принадлежности объекта к определенному классу.
В этом процессе пересчета информативностей атрибута их значения "сходятся" к некоторому пределу в соответствии с двумя "сценариями":
1) процесс "последовательных приближений", напоминающего по своей форме "затухающие колебания" (рисунок33);
2) относительно "плавное" возрастание или убывание с небольшими временными отклонениями от этой тенденции (рисунок 34).
 | |
| Рисунок 33. Зависимость количества информации, содержащегося в атрибуте №1 о принадлежности идентифицируемого объекта (обладающего этим атрибутом) к классу №4 от объема обучающей выборки |
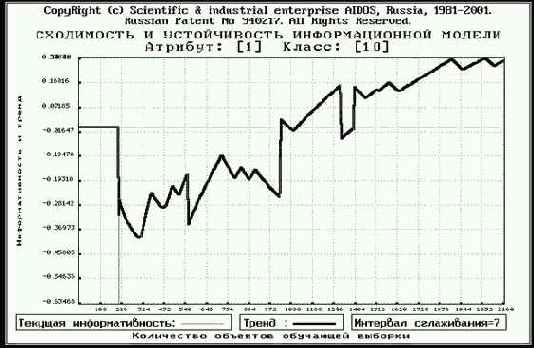 | |
| Рисунок 34. Зависимость количества информации, содержащегося в атрибуте №1 о принадлежности идентифицируемого объекта (обладающего этим атрибутом) к классу №10 от объема обучающей выборки |
Как показали численные эксперименты и специально проведенные исследования, других сценариев на практике не наблюдается.
В любом случае при накоплении достаточно большой статистики и сохранении закономерностей предметной области, отражаемых обучающей выборкой, модель стабилизируется в том смысле, что значения информативностей атрибутов перестают существенно изменяться.
Это дает основание утверждать, что при достижении этого состояния добавление новых примеров из обучающей выборки не вносит в модель ничего нового в модель и процесс обучения продолжать нецелесообразно. Это и является одним из критериев для принятия решения об остановке процесса обучения.
Зависимость некоторых параметров модели от ее ортонормированности
Изучим зависимость уровня системности, степени детерминированности и адекватности модели от ее ортонормированности. В связи с тем, что соответствующий научно-исследовательский режим, позволяющий изучить эти зависимости методом численного эксперимента, на момент написания данной работы находится в стадии разработки, получим интересующие нас зависимости путем анализа выражений (3.9) и (3.25).
При этом будем различать ортонормированность модели по классам и ортонормированность по атрибутам.
Зависимость степени детерминированности модели от ее ортонормированности
Рассмотрим выражение (3.25):
 | (3.25) |
Так как каждый класс как правило описан более чем одним признаком, то при ортонормировании классов и удалении некоторых из них из модели суммарное количество признаков N будет уменьшаться быстрее, чем количество классов W, поэтому степень детерминированности будет возрастать.
При ортонормировании атрибутов числитель выражения (3.25) не изменяется, а знаменатель уменьшается, поэтому и в этом случае степень детерминированности возрастает.
Таким образом, ортонормирование модели приводит к увеличению степени ее детерминированности.
По этой причине предлагается считать "детерменированностью" и "системностью" модели не их значения в текущем состоянии модели, а тот предел, к которому стремятся эти величины при корректном ортонормировании модели при достижении ею точки максимума адекватности.
Зависимость уровня системности модели от ее ортонормированности
Рассмотрим выражение (3.9):
 | (3.9) |
При выполнении операции ортонормирования по классам из модели последовательно удаляются те из них, которые наиболее сильно корреляционно связаны друг с другом. В результате в модели остаются классы практически не коррелирующие, т.е. ортонормированные. Поэтому можно предположить, что в результате ортонормирования правила запрета на образование подсистем классов становятся более жесткими, и уровень системности модели уменьшается.
Жизненный цикл системы искусственного интеллекта и критерии перехода между этапами этого цикла
Жизненный цикл систем искусственного интеллекта сходен с жизненным циклом другого программного обеспечения и включает этапы и критерии перехода между ними, представленные в таблице 2.
Таблица 2 – ЭТАПЫ ЖИЗНЕННОГО ЦИКЛА СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА И КРИТЕРИИ ПЕРЕХОДА МЕЖДУ НИМИ
| № | Наименование
этапа | Критерии перехода
к следующему этапу | |||
| 1 | Разработка идеи и концепции системы | Появление (в результате проведения маркетинговых и рекламных мероприятий) заказчика или спонсора, заинтересовавшегося системой | |||
| 2 | Разработка теоретических основ системы | Обоснование выбора математической модели по критериям или обоснование необходимости разработки новой модели | |||
| 3 | Разработка математической модели системы | Детальная разработка математической модели | |||
| 4 | Разработка методики численных расчетов в системе: | ||||
| 4.1 | – разработка структур данных | детальная разработка структур входных, промежуточных и выходных данных | |||
| 4.2 | – разработка алгоритмов обработки данных | разработка обобщенных и детальных алгоритмов, реализующих на разработанных структурах данных математическую модель | |||
| 5 | Разработка структуры системы и экранных форм интерфейса | Разработка иерархической системы управления системой, структуры меню, экранных форм и средств управления на экранных формах | |||
| 6 | Разработка программной реализации системы | Разработка исходного текста программы системы, его компиляция и линковка. Исправление синтаксических ошибок в исходных текстах | |||
| 7 | Отладка системы | Поиск и исправление логических ошибок в исходных текстах на контрольных примерах. На контрольных примерах новые ошибки не обнаруживаются. | |||
| 8 | Экспериментальная эксплуатация | Поиск и исправление логических ошибок в исходных текстах на реальных данных без применения результатов работы системы на практике. На реальных данных новые ошибки практически не обнаруживаются, но считаются в принципе возможными. | |||
| 9 | Опытная эксплуатация | Поиск и исправление логических ошибок в исходных текстах на реальных данных с применением результатов работы системы на практике. На реальных данных новые ошибки не обнаруживаются и считаются недопустимыми. | |||
| 10 | Промышленная эксплуатация | Основной по длительности период, который продолжается до тех пор, пока система функционально устраивает Заказчика. У Заказчика появляется необходимость внесения количественных (косметических) изменений в систему на уровне п.5 (т.е. без изменения математической модели, структур данных и алгоритмов) | |||
| 11 | Заказные модификации системы | У Заказчика формируется потребность внесения качественных (принципиальных) изменений в систему на уровне п.3 и п.4, т.е. с изменениями в математической модели, структурах данных и алгоритмах | |||
| 12 | Разработка новых версий системы | Выясняется техническая невозможность или финансовая нецелесообразность разработки новых версий системы | |||
| 13 | Снятие системы с эксплуатации |