А Последовательность команд в
Рисунок 5.9, а. Последовательность команд в конвейере и ускоренная пересылка данных
(data forwarding, data bypassing, short circuiting)
| ADD | R1,R2,R3 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R | W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SUB | R4,R1,R5 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R | W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AND | R6,R1,R7 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R | W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OR | R8,R1,R9 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R | W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| XOR | R10,R1,R11 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| R | W | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Адресная очередь
Адресная очередь
Очередь адресных команд выдает команды в устройство загрузки/записи и содержит 16 строк. Очередь организована в виде циклического буфера FIFO (first-in first-out). Команды могут выдаваться в произвольном порядке, но должны записываться в очередь и изыматься из нее строго последовательно. В каждом такте в очередь могут поступать до 4 команд. Буфер FIFO поддерживает первоначальную последовательность команд, что упрощает обнаружение зависимостей по адресам. Выполнение выданной команды может не закончиться при обнаружении зависимости по адресам, кэш-промаха или конфликта по ресурсам. В этих случаях адресная очередь должна заново повторять выдачу команды до тех пор, пока ее выполнение не завершится.
Альтернативные протоколы
Альтернативные протоколы
Имеются две методики поддержания описанной выше когерентности. Один из методов заключается в том, чтобы гарантировать, что процессор должен получить исключительные права доступа к элементу данных перед выполнением записи в этот элемент данных. Этот тип протоколов называется протоколом записи с аннулированием (write ivalidate protocol),
поскольку при выполнении записи он аннулирует другие копии. Это наиболее часто используемый протокол как в схемах на основе справочников, так и в схемах наблюдения. Исключительное право доступа гарантирует, что во время выполнения записи не существует никаких других копий элемента данных, в которые можно писать или из которых можно читать: все другие кэшированные копии элемента данных аннулированы. Чтобы увидеть, как такой протокол обеспечивает когерентность, рассмотрим операцию записи, вслед за которой следует операция чтения другим процессором. Поскольку запись требует исключительного права доступа, любая копия, поддерживаемая читающим процессором должна быть аннулирована (в соответствии с названием протокола). Таким образом, когда возникает операция чтения, произойдет промах кэш-памяти, который вынуждает выполнить выборку новой копии данных. Для выполнения операции записи мы можем потребовать, чтобы процессор имел достоверную (valid)
копию данных в своей кэш-памяти прежде, чем выполнять в нее запись. Таким образом, если оба процессора попытаются записать в один и тот же элемент данных одновременно, один из них выиграет состязание у второго (мы вскоре увидим, как принять решение, кто из них выиграет) и вызывает аннулирование его копии. Другой процессор для завершения своей операции записи должен сначала получить новую копию данных, которая теперь уже должна содержать обновленное значение.
Альтернативой протоколу записи с аннулированием является обновление всех копий элемента данных в случае записи в этот элемент данных. Этот тип протокола называется протоколом записи с обновлением (write update protocol) или протоколом записи с трансляцией (write broadcast protocol). Обычно в этом протоколе для снижения требований к полосе пропускания полезно отслеживать, является ли слово в кэш-памяти разделяемым объектом, или нет, а именно, содержится ли оно в других кэшах.
Если нет, то нет никакой необходимости обновлять другой кэш или транслировать в него обновленные данные.
Разница в производительности между протоколами записи с обновлением и с аннулированием определяется тремя характеристиками:
Несколько последовательных операций записи в одно и то же слово, не перемежающихся операциями чтения, требуют нескольких операций трансляции при использовании протокола записи с обновлением, но только одной начальной операции аннулирования при использовании протокола записи с аннулированием.
При наличии многословных блоков в кэш-памяти каждое слово, записываемое в блок кэша, требует трансляции при использовании протокола записи с обновлением, в то время как только первая запись в любое слово блока нуждается в генерации операции аннулирования при использовании протокола записи с аннулированием. Протокол записи с аннулированием работает на уровне блоков кэш-памяти, в то время как протокол записи с обновлением должен работать на уровне отдельных слов (или байтов, если выполняется запись байта).
Задержка между записью слова в одном процессоре и чтением записанного значения другим процессором обычно меньше при использовании схемы записи с обновлением, поскольку записанные данные немедленно транслируются в процессор, выполняющий чтение (предполагается, что этот процессор имеет копию данных). Для сравнения, при использовании протокола записи с аннулированием в процессоре, выполняющим чтение, сначала произойдет аннулирование его копии, затем будет производиться чтение данных и его приостановка до тех пор, пока обновленная копия блока не станет доступной и не вернется в процессор.
Эти две схемы во многом похожи на схемы работы кэш-памяти со сквозной записью и с записью с обратным копированием. Также как и схема задержанной записи с обратным копированием требует меньшей полосы пропускания памяти, так как она использует преимущества операций над целым блоком, протокол записи с аннулированием обычно требует менее тяжелого трафика, чем протокол записи с обновлением, поскольку несколько записей в один и тот же блок кэш-памяти не требуют трансляции каждой записи.При сквозной записи память обновляется почти мгновенно после записи (возможно с некоторой задержкой в буфере записи). Подобным образом при использовании протокола записи с обновлением другие копии обновляются так быстро, насколько это возможно. Наиболее важное отличие в производительности протоколов записи с аннулированием и с обновлением связано с характеристиками прикладных программ и с выбором размера блока.
АЛУ с цепями обхода и ускоренной пересылки
Рисунок 5.10. АЛУ с цепями обхода и ускоренной пересылки
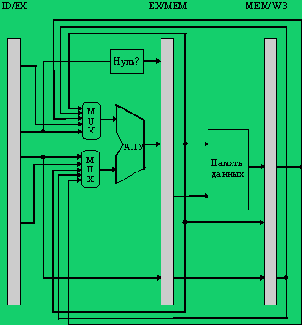
Эта техника "обходов" может быть обобщена для того, чтобы включить передачу результата прямо в то функциональное устройство, которое в нем нуждается: результат с выхода одного устройства "пересылается" на вход другого, а не с выхода некоторого устройства только на его вход.
Аппаратное прогнозирование направления переходов и снижение потерь на организацию переходов
Аппаратное прогнозирование направления переходов и снижение потерь на организацию переходов
Аппаратные средства поддержки большой степени распараллеливания
Аппаратные средства поддержки большой степени распараллеливания
Методы, подобные разворачиванию циклов и планированию трасс, могут использоваться для увеличения степени доступного параллелизма, когда поведение условных переходов достаточно предсказуемо во время компиляции. Если же поведение переходов не известно, одной техники компиляторов может оказаться не достаточно для выявления большей степени параллелизма уровня команд. В этом разделе представлены два метода, которые могут помочь преодолеть подобные ограничения. Первый метод заключается в расширении набора команд условными или предикатными командами. Такие команды могут использоваться для ликвидации условных переходов и помогают компилятору перемещать команды через точки условных переходов. Условные команды увеличивают степень параллелизма уровня команд, но имеют существенные ограничения. Для использования большей степени параллелизма разработчики исследовали идею, которая называется "выполнением по предположению" (speculation), и позволяет выполнить команду еще до того, как процессор узнает, что она должна выполняться (т.е. этот метод позволяет избежать приостановок конвейера, связанных с зависимостями по управлению).
Архитектура машин с длинным командным словом
Архитектура машин с длинным командным словом
Архитектура машин с очень длинным командным словом (VLIW - Very Long Instruction Word) позволяет сократить объем оборудования, требуемого для реализации параллельной выдачи нескольких команд, и потенциально чем большее количество команд выдается параллельно, тем больше эта экономия. Например, суперскалярная машина, обеспечивающая параллельную выдачу двух команд, требует параллельного анализа двух кодов операций, шести полей номеров регистров, а также того, чтобы динамически анализировалась возможность выдачи одной или двух команд и выполнялось распределение этих команд по функциональным устройствам. Хотя требования по объему аппаратуры для параллельной выдачи двух команд остаются достаточно умеренными, и можно даже увеличить степень распараллеливания до четырех (что применяется в современных микропроцессорах), дальнейшее увеличение количества выдаваемых параллельно для выполнения команд приводит к нарастанию сложности реализации из-за необходимости определения порядка следования команд и существующих между ними зависимостей.
Архитектура VLIW базируется на множестве независимых функциональных устройств. Вместо того, чтобы пытаться параллельно выдавать в эти устройства независимые команды, в таких машинах несколько операций упаковываются в одну очень длинную команду. При этом ответственность за выбор параллельно выдаваемых для выполнения операций полностью ложится на компилятор, а аппаратные средства, необходимые для реализации суперскалярной обработки, просто отсутствуют.
WLIW-команда может включать, например, две целочисленные операции, две операции с плавающей точкой, две операции обращения к памяти и операцию перехода. Такая команда будет иметь набор полей для каждого функционального устройства, возможно от 16 до 24 бит на устройство, что приводит к команде длиною от 112 до 168 бит.
Рассмотрим работу цикла инкрементирования элементов вектора на подобного рода машине в предположении, что одновременно могут выдаваться две операции обращения к памяти, две операции с плавающей точкой и одна целочисленная операция либо одна команда перехода.
На рисунке 5. 33 показан код для реализации этого цикла. Цикл был развернут семь раз, что позволило устранить все возможные приостановки конвейера. Один проход по циклу осуществляется за 9 тактов и вырабатывает 7 результатов. Таким образом, на вычисление каждого результата расходуется 1.28 такта (в нашем примере для суперскалярной машины на вычисление каждого результата расходовалось 2.4 такта).
Для машин с VLIW-архитектурой был разработан новый метод планирования выдачи команд, названный "трассировочным планированием". При использовании этого метода из последовательности исходной программы генерируются длинные команды путем просмотра программы за пределами базовых блоков. Как уже отмечалось, базовый блок - это линейный участок программы без ветвлений.
| Обращение к памяти 1 |
Обращение к памяти 2 |
Операция ПТ 1 | Операция ПТ 2 | Целочисленная операция/переход |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD F0,0(R1) LD F10,-16(R1) LD F18,-32(R1) LD F26,-48(R1) SD 0(R1),F4 SD -16(R1),F12 SD -32(R1),F20 SD 0(R1),F28 |
LD F6,-8(R1) LD F14,-24(R1) LD F22,-40(R1) SD -8(R1),F8 SD -24(R1),F16 SD -40(R1),F24 |
ADDD F4,F0,F2 ADDD F12,F10,F2 ADDD F20,F18,F2 ADDD F28,F26,F2 |
ADDD F8,F6,F2 ADDD F16,F14,F2 ADDD F24,F22,F2 |
SUBI R1,R1,#48 BNEZ R1,Loop |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Архитектура POWER
Архитектура POWER
Архитектура POWER во многих отношениях представляет собой традиционную RISC-архитектуру. Она придерживается наиболее важных отличительных особенностей RISC: фиксированной длины команд, архитектуры регистр-регистр, простых способов адресации, простых (не требующих интерпретации) команд, большого регистрового файла и трехоперандного (неразрушительного) формата команд. Однако архитектура POWER имеет также несколько дополнительных свойств, которые отличают ее от других RISC-архитектур.
Во-первых, набор команд был основан на идее суперскалярной обработки. В базовой архитектуре команды распределяются по трем независимым исполнительным устройствам: устройству переходов, устройству с фиксированной точкой и устройству с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, где они могут выполняться одновременно и заканчиваться не в порядке поступления. Для увеличения уровня параллелизма, который может быть достигнут на практике, архитектура набора команд определяет для каждого из устройств независимый набор регистров. Это минимизирует связи и синхронизацию, требуемые между устройствами, позволяя тем самым исполнительным устройствам настраиваться на динамическую смесь команд. Любая связь по данным, требующаяся между устройствами, должна анализироваться компилятором, который может ее эффективно спланировать. Следует отметить, что это только концептуальная модель. Любой конкретный процессор с архитектурой POWER может рассматривать любое из концептуальных устройств как множество исполнительных устройств для поддержки дополнительного параллелизма команд. Но существование модели приводит к согласованной разработке набора команд, который естественно поддерживает степень параллелизма по крайней мере равную трем.
Во-вторых, архитектура POWER расширена несколькими "смешанными" командами для сокращения времен выполнения. Возможно единственным недостатком технологии RISC по сравнению с CISC, является то, что иногда она использует большее количество команд для выполнения одного и того же задания. Было обнаружено, что во многих случаях увеличения размера кода можно избежать путем небольшого расширения набора команд, которое вовсе не означает возврат к сложным командам, подобным командам CISC. Например, значительная часть увеличения программного кода была обнаружена в кодах пролога и эпилога, связанных с сохранением и восстановлением регистров во время вызова процедуры. Чтобы устранить этот фактор IBM ввела команды "групповой загрузки и записи", которые обеспечивают пересылку нескольких регистров в/из памяти с помощью единственной команды. Соглашения о связях, используемые компиляторами POWER, рассматривают задачи планирования, разделяемые библиотеки и динамическое связывание как простой, единый механизм. Это было сделано с помощью косвенной адресации посредством таблицы содержания (TOC - Table Of Contents), которая модифицируется во время загрузки. Команды групповой загрузки и записи были важным элементом этих соглашений о связях.
Другим примером смешанных команд является возможность модификации базового регистра вновь вычисленным эффективным адресом при выполнении операций загрузки или записи (аналог автоинкрементной адресации). Эти команды устраняют необходимость выполнения дополнительных команд сложения, которые в противном случае потребовались бы для инкрементирования индекса при обращениях к массивам. Хотя это смешанная операция, она не мешает работе традиционного RISC-конвейера, поскольку модифицированный адрес уже вычислен и порт записи регистрового файла во время ожидания операции с памятью свободен.
Архитектура POWER обеспечивает также несколько других способов сокращения времени выполнения команд такие как: обширный набор команд для манипуляции битовыми полями, смешанные команды умножения-сложения с плавающей точкой, установку регистра условий в качестве побочного эффекта нормального выполнения команды и команды загрузки и записи строк (которые работают с произвольно выровненными строками байтов).
Третьим фактором, который отличает архитектуру POWER от многих других RISC-архитектур, является отсутствие механизма "задержанных переходов". Обычно этот механизм обеспечивает выполнение команды, следующей за командой условного перехода, перед выполнением самого перехода. Этот механизм эффективно работал в ранних RISC-машинах для заполнения "пузыря", появляющегося при оценке условий для выбора направления перехода и выборки нового потока команд. Однако в более продвинутых, суперскалярных машинах, этот механизм может оказаться неэффективным, поскольку один такт задержки команды перехода может привести к появлению нескольких "пузырей", которые не могут быть покрыты с помощью одного архитектурного слота задержки. Почти все такие машины, чтобы устранить влияние этих "пузырей", вынуждены вводить дополнительное оборудование (например, кэш-память адресов переходов). В таких машинах механизм задержанных переходов становится не только мало эффективным, но и привносит значительную сложность в логику обработки последовательности команд. Вместо этого архитектура переходов POWER была организована для поддержки методики "предварительного просмотра условных переходов" (branch-lockahead) и методики "свертывания переходов" (branch-folding).
Методика реализации условных переходов, используемая в архитектуре POWER, является четвертым уникальным свойством по сравнению с другими RISC-процессорами. Архитектура POWER определяет расширенные свойства регистра условий. Проблема архитектур с традиционным регистром условий заключается в том, что установка битов условий как побочного эффекта выполнения команды, ставит серьезные ограничения на возможность компилятора изменить порядок следования команд. Кроме того, регистр условий представляет собой единственный архитектурный ресурс, создающий серьезное узкое горло в машине, которая параллельно выполняет несколько команд или выполняет команды не в порядке их появления в программе. Некоторые RISC-архитектуры обходят эту проблему путем полного исключения из своего состава регистра условий и требуют установки кода условий с помощью команд сравнения в универсальный регистр, либо путем включения операции сравнения в саму команду перехода. Последний подход потенциально перегружает конвейер команд при выполнении перехода. Поэтому архитектура POWER вместо того, чтобы исправлять проблемы, связанные с традиционным подходом к регистру условий, предлагает: a) наличие специального бита в коде операции каждой команды, что делает модификацию регистра условий дополнительной возможностью, и тем самым восстанавливает способность компилятора реорганизовать код, и b) несколько (восемь) регистров условий для того, чтобы обойти проблему единственного ресурса и обеспечить большее число имен регистра условий так, что компилятор может разместить и распределить ресурсы регистра условий, как он это делает для универсальных регистров.
Другой причиной выбора модели расширенного регистра условий является то, что она согласуется с организацией машины в виде независимых исполнительных устройств. Концептуально регистр условий является локальным по отношению к устройству переходов. Следовательно, для оценки направления выполнения условного перехода не обязательно обращаться к универсальному регистровому файлу (который является локальным для устройства с фиксированной точкой). Для той степени, с которой компилятор может заранее спланировать модификацию кода условия (и/или загрузить заранее регистры адреса перехода), аппаратура может заранее просмотреть и свернуть условные переходы, выделяя их из потока команд. Это позволяет освободить в конвейере временной слот (такт) выдачи команды, обычно занятый командой перехода, и дает возможность диспетчеру команд создавать непрерывный линейный поток команд для вычислительных исполнительных устройств.
Первая реализация архитектуры POWER появилась на рынке в 1990 году. С тех пор компания IBM представила на рынок еще две версии процессоров POWER2 и POWER2+, обеспечивающих поддержку кэш-памяти второго уровня и имеющих расширенный набор команд.
По данным IBM процессор POWER требует менее одного такта для выполнении одной команды по сравнению с примерно 1.25 такта у процессора Motorola 68040, 1.45 такта у процессора SPARC, 1.8 такта у Intel i486DX и 1.8 такта Hewlett-Packard PA-RISC. Тактовая частота архитектурного ряда в зависимости от модели меняется от 25 МГц до 62 МГц.
Процессоры POWER работают на частоте 33, 41.6, 45, 50 и 62.5 МГЦ. Архитектура POWER включает раздельную кэш-память команд и данных (за исключением рабочих станций и серверов рабочих групп начального уровня, которые имеют однокристальную реализацию процессора POWER и общую кэш-память команд и данных), 64- или 128-битовую шину памяти и 52-битовый виртуальный адрес. Она также имеет интегрированный процессор плавающей точки и таким образом хорошо подходит для приложений с интенсивными вычислениями, типичными для технической среды, хотя текущая стратегия RS/6000 нацелена как на коммерческие, так и на технические приложения. RS/6000 показывает хорошую производительность на плавающей точке: 134.6 SPECp92 для POWERstation/Powerserver 580. Это меньше, чем уровень моделей Hewlett-Packard 9000 Series 800 G/H/I-50, которые достигают уровня 150 SPECfp92.
Для реализации быстрой обработки ввода/вывода в архитектуре POWER используется шина Micro Channel, имеющая пропускную способность 40 или 80 Мбайт/сек. Шина Micro Channel включает 64-битовую шину данных и обеспечивает поддержку работы нескольких главных адаптеров шины. Такая поддержка позволяет сетевым контроллерам, видеоадаптерам и другим интеллектуальным устройствам передавать информацию по шине независимо от основного процессора, что снижает нагрузку на процессор и соответственно увеличивает системную производительность.
Многокристальный набор POWER2 состоит из восьми полузаказных микросхем (устройств):
Блок кэш-памяти команд (ICU) - 32 Кбайт, имеет два порта с 128-битовыми шинами;
Блок устройств целочисленной арифметики (FXU) - содержит два целочисленных конвейера и два блока регистров общего назначения (по 32 32-битовых регистра). Выполняет все целочисленные и логические операции, а также все операции обращения к памяти;
Блок устройств плавающей точки (FPU) - содержит два конвейера для выполнения операций с плавающей точкой двойной точности, а также 54 64-битовых регистра плавающей точки;
Четыре блока кэш-памяти данных - максимальный объем кэш-памяти первого уровня составляет 256 Кбайт. Каждый блок имеет два порта. Устройство реализует также ряд функций обнаружения и коррекции ошибок при взаимодействии с системой памяти;
Блок управления памятью (MMU).
Набор кристаллов POWER2 содержит порядка 23 миллионов транзисторов на площади 1217 квадратных мм и изготовлен по технологии КМОП с проектными нормами 0.45 микрон. Рассеиваемая мощность на частоте 66.5 МГц составляет 65 Вт.
Производительность процессора POWER2 по сравнению с POWER значительно повышена: при тактовой частоте 71.5 МГц она достигает 131 SPECint92 и 274 SPECfp92.
Архитектура системы команд Классификация процессоров (CISC и RISC)
Архитектура системы команд. Классификация процессоров (CISC и RISC)
Термин "архитектура системы" часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле под архитектурой понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов. Следует отметить, что это наиболее частое употребление этого термина. В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера как систему памяти, структуру системной шины, организацию ввода/вывода и т.п.
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются архитектуры CISC и RISC. Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360, ядро которой используется с1964 года и дошло до наших дней, например, в таких современных мейнфреймах как IBM ES/9000.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно: сравнительно небольшое число регистров общего назначения; большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; большое количество методов адресации; большое количество форматов команд различной разрядности; преобладание двухадресного формата команд; наличие команд обработки типа регистр-память.
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC - Reduced Instruction Set Computer). Зачатки этой архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин.
Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Разработка экспериментального проекта компании IBM началась еще в конце 70-х годов, но его результаты никогда не публиковались и компьютер на его основе в промышленных масштабах не изготавливался. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины, которые получили названия RISC-I и RISC-II. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон. В 1981году Дж.Хеннесси со своими коллегами опубликовал описание стенфордской машины MIPS, основным аспектом разработки которой была эффективная реализация конвейерной обработки посредством тщательного планирования компилятором его загрузки.
Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата.
Среди других особенностей RISC-архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC-процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные.
Для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
Ко времени завершения университетских проектов (1983-1984 гг.) обозначился также прорыв в технологии изготовления сверхбольших интегральных схем. Простота архитектуры и ее эффективность, подтвержденная этими проектами, вызвали большой интерес в компьютерной индустрии и с 1986 года началась активная промышленная реализация архитектуры RISC. К настоящему времени эта архитектура прочно занимает лидирующие позиции на мировом компьютерном рынке рабочих станций и серверов.
Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих компиляторов. Именно современная техника компиляции позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC: реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд.
Следует отметить, что в последних разработках компании Intel (имеется в виду Pentium P54C и процессор следующего поколения P6), а также ее последователей-конкурентов (AMD R5, Cyrix M1, NexGen Nx586 и др.) широко используются идеи, реализованные в RISC-микропроцессорах, так что многие различия между CISC и RISC стираются. Однако сложность архитектуры и системы команд x86 остается и является главным фактором, ограничивающим производительность процессоров на ее основе.
Ашё 66 Блок-схема процессора
В процессоре UltraSPARC-1 применяется специальная подсистема ввода/вывода (MIU), которая обеспечивает управление всеми операциями ввода и вывода, которые осуществляются между локальными ресурсами: процессором, основной памятью, схемами управления и всеми внешними ресурсами системы. В частности, все системные транзакции, связанные с обработкой промахов кэш-памяти, прерываниями, наблюдением за когерентным состоянием кэш-памяти, операциями обратной записи и т.д., обрабатываются MIU. MIU взаимодействует с системой на частоте меньшей, чем частота UltraSPARC-1 в соотношении 1/2, или 1/3.
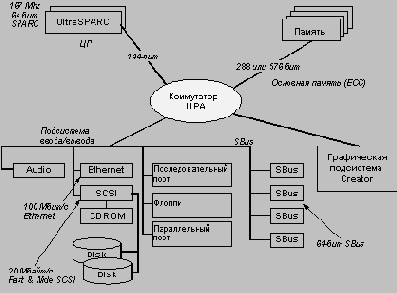
Архитектура компьютеров Ultra
ашё. 6.9. Архитектура компьютеров Ultra 1 и Ultra 2
Ашё67 Типовой процессорный
ашё. 6.8. Масштабируемая архитекутра UPA

В отличие от традиционных мультипроцессорных систем, которые поддерживают когерентное состояние кэш-памяти и разделяют глобально наблюдаемую адресную шину, архитектура межсоединений UPA основана на пакетной коммутации сообщений по принципу точка-точка. Поддержка когерентного состояния кэш-памяти системы для настольных рабочих станций, включающих от 1 до 4 процессоров, осуществляется централизованным системным контроллером, а для больших серверов - распределенным системным контроллером. UPA может поддерживать дублирование наборов тегов всех кэшей системы и позволяет для каждой когерентной транзакции выполнять параллельно просмотр дублированных тегов и обращение к основной памяти.
Отход от традиционных методов построения мультипроцессорных систем, основанных на наблюдаемой шине или на справочнике, позволяет существенно минимизировать задержки доступа к данным благодаря сокращению потерь на обработку промахов кэш-памяти. В итоге архитектура межсоединений UPA позволяет полностью использовать высокую пропускную способность процессора UltraSPARC-1. Максимальная скорость передачи данных составляет 1.3 Гбайт/с при работе UPA на тактовой частоте 83 МГц.
Разработчики архитектуры UPA многое сделали с целью минимизации задержек доступа к данным. Например, UPA поддерживает раздельные шины адреса и данных. Именно эти широкие шины (адресная шина имеет ширину 64 бит (в соответствии со спецификацией 64-битовой архитектуры V9), а шина данных - 144 бит (128 бит данных и 16 бит для контроля ошибок)) обеспечивают пиковую пропускную способность системы. Наличие отдельных шин позволяет устранить задержки, возникающие при переключении разделяемой шины между данными и адресом, а также возможные конфликты доступа к общей шине.
UPA не только поддерживает отдельные шины адреса и данных, но позволяет также иметь несколько шин с организацией соединений точка-точка. Обычно в большинстве систем имеются несколько интерфейсов для обеспечения работы подсистемы ввода/вывода, графической подсистемы и процессора.
В мультипроцессорных системах требуются также дополнительные интерфейсы для организации связи между несколькими ЦП. Вместо одного набора шин данных и адреса для всех этих интерфейсов UPA допускает создание неограниченного количества шин.
Подобная организация имеет ряд достоинств. Наличие нескольких наборов шин позволяет минимизировать количество циклов арбитража и уменьшает вероятность конфликтов. Системный контроллер несет ответственность за работу и взаимодействие различных шин и может параллельно обрабатывать запросы нескольких шин. Он позволяет также уменьшить задержки, связанные с захватом шины. По существу, наличие нескольких шин адреса и данных означает меньшее число потенциальных главных устройств на каждом наборе шин. Для обеспечения наименьшей возможной задержки захвата шины используется распределенный конвейеризованный протокол арбитража. Каждый порт UPA имеет собственные схемы арбитража, при этом каждый порт в системе видит запросы шины всех других портов. Такая схема также позволяет уменьшить задержку доступа и обеспечивает увеличение общей производительности системы.
Архитектура UPA легко адаптируется для работы почти с любой конфигурацией системы (от однопроцессорной до массивно-параллельной). Разработчиками были предприняты специальные усилия с целью ее оптимизации для систем, содержащих от 1 до 4 процессоров. В результате до четырех тесно связанных процессоров и системный контроллер могут разделять доступ к одной и той же системной адресной шине. Однако на базе богатого набора транзакций и протокола когерентности, которые поддерживаются устройством интерфейса памяти процессора UltraSPARC-1 могут быть построены мультипроцессорные системы с большим количеством процессоров. В архитектуре UPA применяется протокол когерентности, построенный на основе операций записи с аннулированием соответствующих копий блока в кэш-памяти других процессоров системы и использующий для наблюдения дублированные теги. Процессор UltraSPARC поддерживает переходы состояний блоков кэш-памяти, соответствующие протоколам MOESI, MOSI и MSI.
Следует отметить, что в основу архитектуры UPA положены настолько гибкие принципы, что она позволяет иметь в системе не только несколько шин (мультиплексированных или раздельных), но и в широких пределах варьировать разрядность шины данных для удовлетворения различных требований к отношению стоимость/производительность. При этом в различных частях системы в зависимости от конкретных требований может использоваться разная скорость передачи данных. Например, разрядность шины данных системы ввода/вывода вполне может быть ограничена 64 битами, но для согласования с интерфейсом процессора более предпочтительна разрядность в 128 бит. С другой стороны, разрядность шины данных оперативной памяти системы может быть еще более увеличена для обеспечения высокой пропускной способности при использовании более медленных, но более дешевых микросхем памяти (в младших моделях компьютеров на базе микропроцессора UltraSPARC-1 используется 256-битовая шина данных памяти, а в старших моделях - 512-битовая).
Набор графических команд
UltraSPARC является первым универсальным процессором с 64-битовой архитектурой, обеспечивающий высокую пропускную способность, необходимую для реализации высокоскоростной графики и обработки видеоизображений в реальном масштабе времени. Расширенный набор команд UltraSPARC позволяет быстро (за один такт) выполнять достаточно сложные графические операции, для реализации которых обычно затрачивается несколько десятков тактов. При этом только три процента реальной площади кристалла было потрачено для реализации графических команд. Высокая производительность UltraSPARC и его способность выполнять декомпрессию и обработку видеоданных в реальном времени позволяют в ряде случае при построении системы обойтись без специальных дорогостоящих видеопроцессоров.
Высокоскоростная обработка графики и видеоизображений базируется на суперскалярной архитектуре процессора UltraSPARC. При этом для адресации данных (вычисления адресов команд загрузки и записи) широко используются целочисленные регистры, а для манипуляций с данными - регистры плавающей точки.
Такое функциональное разделение регистров существенно увеличивает пропускную способность процессора, обеспечивая приложению максимальное количество доступных регистров и параллельное выполнение команд.
Специальный набор видеокоманд UltraSPARC (VIS - Video Instruction Set) предоставляет широкие возможности обработки графических данных: команды упаковки и распаковки пикселей, команды параллельного сложения, умножения и сравнения данных, представленных в нескольких целочисленных форматах, команды выравнивания и слияния, обработки контуров изображений и адресации массивов. Эти графические команды оптимизированы для работы с малоразрядной целочисленной арифметикой, при использовании которой обычно возникают значительные накладные расходы из-за необходимости частого преобразования целочисленного формата в формат ПТ и обратно. Возможность увеличения разрядности промежуточных результатов обеспечивает дополнительную точность, необходимую для высококачественных графических изображений. Все операнды графических команд находятся в регистрах ПТ, что обеспечивает максимальное количество регистров для хранения промежуточных результатов вычислений и параллельное выполнение команд.
UltraSPARC поддерживает различные алгоритмы компрессии, используемые для разнообразных видеоприложений и обработки неподвижных изображений, включая H.261, MPEG-1, MPEG-2 и JPEG. Более того, он может обеспечивать скорости кодирования и декодирования, необходимые для организации видеоконференций в реальном времени.
Первые системы на базе нового процессора
В настоящее время Sun выпускает два типа настольных рабочих станций и серверов, оснащенных процессорами UltraSPARC: Ultra 1 и Ultra 2 (рисунок 6.9). В моделях Ultra 1 используются процессоры с тактовой частотой 143 и 167 МГц. При этом они комплектуются как стандартными видеоадаптерами TurboGX и TurboGXplus (модели 140 и 170), так и новыми мощными видеоподсистемами Creator и Creator3D (модель 170Е), позволяют наращивать объем оперативной памяти до 512 Мбайт, внутренних дисков до 4.2 Гбайт и устанавливать накопители на магнитной ленте, флоппи-дисководы и считывающие устройства с компакт-дисков.
Эти системы обеспечивают уровень производительности в 252 SPECint92 и 351 SPECfp92 при тактовой частоте 167 МГц. Модели 170Е оснащаются контроллерами Fast&Wide SCSI-2 и 100Base-T Ethernet.
Модели Ultra 2 - это однопроцессорные и двухпроцессорные системы на базе 200 МГц процессора UltraSPARC (332 SPECint92 и 505 SPECfp92), имеющие максимальный объем оперативной памяти 1 Гбайт. Появление следующих моделей, построенных на процессорах UltraSPARC II (420 SPECint92 и 660 SPECfp92), ожидается в середине 1996 года.
Таким образом, выпуск 64-битового процессора UltraSPARC и первых компьютеров на его основе ознаменовал собой новый этап в развитии Sun Microsystems. Компания планирует постепенно перевести на эти процессоры все свои изделия, включая рабочие станции и серверы начального уровня. Конечно для широкого внедрения новой концепции обработки данных, получившей название UltraComputing, понадобится некоторое время, но уже сейчас очевидно, что ориентация Sun на обеспечение высокой сбалансированной производительности для широкого класса прикладных систем, высокой пропускной способности передачи данных для сетевых приложений и построение эффективных средств визуализации и обработки видеоданных в реальном времени позволяет ей сохранять лидирующие позиции на современном рынке компьютеров для научно-технических и бизнес-приложений.
, Б
Рисунок 5.17, б
Статическое прогнозирование условных переходов: использование технологии
компиляторов
Имеются два основных метода, которые можно использовать для статического предсказания переходов: метод исследования структуры программы и метод использования информации о профиле выполнения программы, который собран в результате предварительных запусков программы. Использование структуры программы достаточно просто: в качестве исходной точки можно предположить, например, что все идущие назад по программе переходы являются выполняемыми, а идущие вперед по программе - невыполняемыми. Однако эта схема не очень эффективна для большинства программ. Основываясь только на структуре программы просто трудно сделать лучший прогноз.
Б Совмещение чтения и записи регистров в одном такте
Рисунок 5.9, б. Совмещение чтения и записи регистров в одном такте
В этом примере все команды, следующие за командой ADD, используют результат ее выполнения. Команда ADD записывает результат в регистр R1, а команда SUB читает это значение. Если не предпринять никаких мер для того, чтобы предотвратить этот конфликт, команда SUB прочитает неправильное значение и попытается его использовать. На самом деле значение, используемое командой SUB, является даже неопределенным: хотя логично предположить, что SUB всегда будет использовать значение R1, которое было присвоено какой-либо командой, предшествовавшей ADD, это не всегда так. Если произойдет прерывание между командами ADD и SUB, то команда ADD завершится, и значение R1 в этой точке будет соответствовать результату ADD. Такое непрогнозируемое поведение очевидно неприемлемо.
Проблема, поставленная в этом примере, может быть разрешена с помощью достаточно простой аппаратной техники, которая называется пересылкой или продвижением данных (data forwarding), обходом (data bypassing), иногда закороткой (short-circuiting). Эта аппаратура работает следующим образом. Результат операции АЛУ с его выходного регистра всегда снова подается назад на входы АЛУ. Если аппаратура обнаруживает, что предыдущая операция АЛУ записывает результат в регистр, соответствующий источнику операнда для следующей операции АЛУ, то логические схемы управления выбирают в качестве входа для АЛУ результат, поступающий по цепи "обхода" , а не значение, прочитанное из регистрового файла (рисунок 5.10).
Чтобы обеспечить столь высокий уровень
Рисунок 6.12. Блок-схема микропроцессора R10000

Чтобы обеспечить столь высокий уровень производительности в процессоре R10000 реализованы многие последние достижения в области технологии и архитектуры процессоров. На рисунке 6.12 показана блок-схема этого микропроцессора.
схема процессора, который включает пять
Рисунок 6.18. Блок-схема процессора Alpha 21164

На рисунке 6.18 представлена блок- схема процессора, который включает пять функциональных устройств: устройство управления потоком команд (IBOX), целочисленное устройство (EBOX), устройство плавающей точки (FBOX), устройство управления памятью (MBOX) и устройство управления кэш-памятью и интерфейсом шины (CBOX). На рисунке также показаны три расположенных на кристалле кэш-памяти. Кэш-память команд и кэш-память данных представляют собой первичные кэши, реализующие прямое отображение. Множественно-ассоциативная кэш-память второго уровня предназначена для хранения команд и данных. Длина конвейеров процессора 21164 варьируется от 7 ступеней для выполнения целочисленных команд и 9 ступеней для реализации команд с плавающей точкой до 12 ступеней при выполнении команд обращения к памяти в пределах кристалла и переменного числа ступеней при выполнении команд обращения к памяти за пределами кристалла.
Устройство управления потоком команд осуществляет выборку и декодирование команд из кэша команд и направляет их для выполнения в соответствующие исполнительные устройства после разрешения всех конфликтов по регистрам и функциональным устройствам. Оно управляет выполнением программы и всеми аспектами обработки исключительных ситуаций, ловушек и прерываний. Кроме того, оно обеспечивает управление всеми исполнительными устройствами, контролируя все цепи обхода данных и записи в регистровый файл. Устройство управления содержит 8 Кбайт кэш команд, схемы предварительной выборки команд и связанный с ними буфер перезагрузки, схемы прогнозирования направления условных переходов и буфер преобразования адресов команд (ITB).
Целочисленное исполнительное устройство выполняет целочисленные команды, вычисляет виртуальные адреса для всех команд загрузки и записи, выполняет целочисленные команды условного перехода и все другие команды управления. Оно включает в себя регистровый файл и несколько функциональных устройств, расположенных на четырех ступенях двух параллельных конвейеров. Первый конвейер содержит сумматор, устройство логических операций, сдвигатель и умножитель. Второй конвейер содержит сумматор, устройство логических операций и устройство выполнения команд управления.
Устройство плавающей точки состоит из двух конвейерных исполнительных устройств: конвейера сложения, который выполняет все команды плавающей точки, за исключением команд умножения, и конвейер умножения, который выполняет команды умножения с плавающей точкой. Два специальных конвейера загрузки и один конвейер записи данных позволяют командам загрузки/записи выполняться параллельно с выполнением операций с плавающей точкой. Аппаратно поддерживаются все режимы округления, предусмотренные стандартами IEEE и VAX.
Устройство управления памятью выполняет все команды загрузки, записи и барьерные операции синхронизации. Оно содержит полностью ассоциативный 64-строчный буфер преобразования адресов (DTB), 8 Кбайт кэш-память данных с прямым отображением, файл адресов промахов и буфер записи. Длина строки в кэше данных равна 32 байтам, он имеет два порта по чтению и реализован по принципу сквозной записи. Он индексируется разрядами физического адреса и в тегах хранятся физические адреса. В устройство управления памятью в каждом такте может поступать до двух виртуальных адресов из целочисленного устройства. DTB также имеет два порта, поэтому он может одновременно выполнять преобразование двух виртуальных адресов в физические. Команды загрузки обращаются к кэшу данных и возвращают результат в регистровый файл в случае попадания. При этом задержка составляет два такта. В случае промаха физические адреса направляются в файл адресов промахов, где они буферизуются и ожидают завершения обращения к кэш-памяти второго уровня. Команды записи записывают данные в кэш данных в случае попадания и всегда помещают данные в буфер записи, где они ожидают обращения к кэш-памяти второго уровня.
Отличительной особенностью микропроцессора 21164 является размещение на кристалле вторичного трехканального множественно-ассоциативного кэша, емкостью 96 Кбайт. Вторичный кэш резко снижает количество обращений к внешней шине микропроцессора. Кроме вторичного кэша на кристалле поддерживается работа с внешним кэшем третьего уровня.
Сочетание большого количества вычислительных устройств, более быстрого выполнения операций с плавающей точкой (четыре такта вместо шести), более быстрого доступа к первичному кэшу (два такта вместо трех) обеспечивают новому микропроцессору рекордные параметры производительности.
вывода посредством синхронной шины. Процессор
Рисунок 6.10. Блок-схема процессора PA 7100

Процессор подсоединяется к памяти и подсистеме ввода/ вывода посредством синхронной шины. Процессор может работать с тремя разными отношениями внутренней и внешней тактовой частоты в зависимости от частоты внешней шины: 1:1, 3:2 и 2:1. Это позволяет использовать в системах разные по скорости микросхемы памяти.
Конструктивно на кристалле PA-7100 размещены целочисленный процессор, процессор для обработки чисел с плавающей точкой, устройство управления кэшем, унифицированный буфер TLB, устройство управления, а также ряд интерфейсных схем. Целочисленный процессор включает АЛУ, устройство сдвига, сумматор команд перехода, схемы проверки кодов условий, схемы обхода, универсальный регистровый файл, регистры управления и регистры адресного конвейера. Устройство управления кэш-памятью содержит регистры, обеспечивающие перезагрузку кэш-памяти при возникновении промахов и контроль когерентного состояния памяти. Это устройство содержит также адресные регистры сегментов, буфер преобразования адреса TLB и аппаратуру хеширования, управляющую перезагрузкой TLB. В состав процессора плавающей точки входят устройство умножения, арифметико-логическое устройство, устройство деления и извлечения квадратного корня, регистровый файл и схемы "закоротки" результата. Интерфейсные устройства включают все необходимые схемы для связи с кэш-памятью команд и данных, а также с шиной данных. Обобщенный буфер TLB содержит 120 строк ассоциативной памяти фиксированного размера и 16 строк переменного размера.
Устройство плавающей точки (рисунок 6.11) реализует арифметику с одинарной и двойной точностью в стандарте IEEE 754. Его устройство умножения используется также для выполнения операций целочисленного умножения. Устройства деления и вычисления квадратного корня работают с удвоенной частотой процессора. Арифметико-логическое устройство выполняет операции сложения, вычитания и преобразования форматов данных. Регистровый файл состоит из 28 64-битовых регистров, каждый из которых может использоваться как два 32-битовых регистра для выполнения операций с плавающей точкой одинарной точности. Регистровый файл имеет пять портов чтения и три порта записи, которые обеспечивают одновременное выполнение операций умножения, сложения и загрузки/записи.
Большинство улучшений производительности процессора связано с увеличением тактовой частоты до 100 МГц по сравнению с 66 МГц у его предшественника.
схема процессора Power PC 604
Рисунок 6.20. Блок- схема процессора Power PC 604
Процессор 604 имеет 64-битовую внешнюю шину данных и 32-битовую шину адреса. Интерфейсный протокол процессора 604 позволяет нескольким главным устройствам шины конкурировать за системные ресурсы при наличии централизованного внешнего арбитра. Кроме того, внутренние логические схемы наблюдения за шиной поддерживают когерентность кэш-памяти в мультипроцессорных конфигурациях. Процессор 604 обеспечивает как одиночные, так и групповые пересылки данных при обращении к основной памяти.
Более мелкие файлы
Более мелкие файлы
Другой характерной чертой пользовательской базы ПК является то, что файлы, используемые этими клиентами, существенно меньше по размеру, чем аналогичные файлы, используемые на рабочих станциях. Об очень немногих приложениях ПК можно сказать, что они характеризуются "интенсивным использованием данных" (см. разд. 3.1.3) главным образом потому, что управление памятью в операционных системах ПК сложно и ограничено по возможностям. Сама природа такой среды, связанная с интенсивной работой с атрибутами, определяет выбор конфигурации системы для решения проблем организации произвольного доступа.
Будущие тесты TPC
Будущие тесты TPC

Совсем недавно (см. ComputerWorld-Moscow, N15, 1995) TPC объявил об отмене тестов TPC-A и TPC-B. Отныне для оценки систем будут применяться существующий тестовый пакет TPC-C, новые тесты TPC-D и TPC-E, а также два еще полностью не разработанных теста. Представленный в первом квартале 1995 года тест TPC-D предназначен для оценки производительности систем принятия решений. Для оценки систем масштаба предприятия во втором квартале 1995 года TPC должен был представить тест TPC-E и его альтернативный вариант, не имеющий пока названия. Кроме того, TPC продолжает разработку тестовых пакетов для оценки баз данных и систем клиент/сервер. Первых результатов, полученных с помощью этих новых методов, следует ожидать не раньше середины 1996 года.
Буфер целевых адресов переходов
Рисунок 5.30. Буфер целевых адресов переходов

Каждая строка этого буфера включает программный адрес команды перехода, прогнозируемый адрес следующей команды и предысторию команды перехода (рисунок 5.30).
Биты предыстории представляют собой информацию о выполнении или невыполнении условий перехода данной команды в прошлом. Обращение к буферу целевых адресов перехода (сравнение с полями программных адресов команд перехода) производится с помощью текущего значения счетчика команд на этапе выборки очередной команды. Если обнаружено совпадение (попадание в терминах кэш-памяти), то по предыстории команды прогнозируется выполнение или невыполнение условий команды перехода, и немедленно производится выборка и дешифрация команд из прогнозируемой ветви программы. Считается, что предыстория перехода, содержащая информацию о двух предшествующих случаях выполнения этой команды, позволяет прогнозировать развитие событий с вполне достаточной вероятностью.
Существуют и некоторые вариации этого метода. Основной их смысл заключается в том, чтобы хранить в процессоре одну или несколько команд из прогнозируемой ветви перехода. Этот метод может применяться как в совокупности с буфером целевых адресов перехода, так и без него, и имеет два преимущества. Во-первых, он позволяет выполнять обращения к буферу целевых адресов перехода в течение более длительного времени, а не только в течение времени последовательной выборки команд. Это позволяет реализовать буфер большего объема. Во-вторых, буферизация самих целевых команд позволяет использовать дополнительный метод оптимизации, который называется свертыванием переходов (branch folding). Свертывание переходов может использоваться для реализации нулевого времени выполнения самих команд безусловного перехода, а в некоторых случаях и нулевого времени выполнения условных переходов. Рассмотрим буфер целевых адресов перехода, который буферизует команды из прогнозируемой ветви. Пусть к нему выполняется обращение по адресу команды безусловного перехода.
Единственной задачей этой команды безусловного перехода является замена текущего значения счетчика команд. В этом случае, когда буфер адресов регистрирует попадание и показывает, что переход безусловный, конвейер просто может заменить команду, которая выбирается из кэш-памяти (это и есть сама команда безусловного перехода), на команду из буфера. В некоторых случаях таким образом удается убрать потери для команд условного перехода, если код условия установлен заранее.
Еще одним методом уменьшения потерь на переходы является метод прогнозирования косвенных переходов, а именно переходов, адрес назначения которых меняется в процессе выполнения программы (в run-time). Компиляторы языков высокого уровня будут генерировать такие переходы для реализации косвенного вызова процедур, операторов select или case и вычисляемых операторов goto в Фортране. Однако подавляющее большинство косвенных переходов возникает в процессе выполнения программы при организации возврата из процедур. Например, для тестовых пакетов SPEC возвраты из процедур в среднем составляют 85% общего числа косвенных переходов.
Хотя возвраты из процедур могут прогнозироваться с помощью буфера целевых адресов переходов, точность такого метода прогнозирования может оказаться низкой, если процедура вызывается из нескольких мест программы или вызовы процедуры из одного места программы не локализуются по времени. Чтобы преодолеть эту проблему, была предложена концепция небольшого буфера адресов возврата, работающего как стек. Эта структура кэширует последние адреса возврата: во время вызова процедуры адрес возврата вталкивается в стек, а во время возврата он оттуда извлекается. Если этот кэш достаточно большой (например, настолько большой, чтобы обеспечить максимальную глубину вложенности вызовов), он будет прекрасно прогнозировать возвраты. На рисунке 5.31 показано исполнение такого буфера возвратов, содержащего от 1 до 16 строк (элементов) для нескольких тестов SPEC.
Точность прогноза в данном случае есть доля адресов возврата, предсказанных правильно.
Поскольку глубина вызовов процедур обычно не большая, за некоторыми исключениями даже небольшой буфер работает достаточно хорошо. В среднем возвраты составляют 81% общего числа косвенных переходов для этих шести тестов.
Схемы прогнозирования условных переходов ограничены как точностью прогноза, так и потерями в случае неправильного прогноза. Как мы видели, типичные схемы прогнозирования достигают точности прогноза в диапазоне от 80 до 95% в зависимости от типа программы и размера буфера. Кроме увеличения точности схемы прогнозирования, можно пытаться уменьшить потери при неверном прогнозе. Обычно это делается путем выборки команд по обоим ветвям (по предсказанному и по непредсказанному направлению). Это требует, чтобы система памяти была двухпортовой, включала кэш-память с расслоением, или осуществляла выборку по одному из направлений, а затем по другому (как это делается в IBM POWER-2). Хотя подобная организация увеличивает стоимость системы, возможно это единственный способ снижения потерь на условные переходы ниже определенного уровня. Другое альтернативное решение, которое используется в некоторых машинах, заключается в кэшировании адресов или команд из нескольких направлений (ветвей) в целевом буфере.
Буфер прогнозирования переходов (2,2)
Рисунок 5.29. Буфер прогнозирования переходов (2,2)

В этой реализации имеется тонкий эффект: поскольку буфер прогнозирования не является кэш-памятью, счетчики, индексируемые единственным значением глобальной схемы прогнозирования, могут в действительности в некоторый момент времени соответствовать разным командам перехода; это не отличается от того, что мы видели и раньше: прогноз может не соответствовать текущему переходу. На рисунке 5.29 с целью упрощения понимания буфер изображен как двумерный объект. В действительности он может быть реализован просто как линейный массив двухбитовой памяти; индексация выполняется путем конкатенации битов глобальной истории и соответствующим числом бит, требуемых от адреса перехода. Например, на рисунке 5.29 в буфере (2,2) с общим числом строк, равным 64, четыре младших разряда адреса команды перехода и два бита глобальной истории формируют 6-битовый индекс, который может использоваться для обращения к 64 счетчикам.
На рисунке 5.28 представлены результаты для сравнения простой двухбитовой схемы прогнозирования с 4К строками и схемы прогнозирования (2,2) с 1К строками. Как можно видеть, эта последняя схема прогнозирования не только превосходит простую двухбитовую схему прогнозирования с тем же самым количеством бит состояния, но часто превосходит даже двухбитовую схему прогнозирования с неограниченным (бесконечным) количеством строк. Имеется широкий спектр корреляционных схем прогнозирования, среди которых схемы (0,2) и (2,2) являются наиболее интересными.
Буфера прогнозирования условных переходов
Буфера прогнозирования условных переходов
Простейшей схемой динамического прогнозирования направления условных переходов является буфер прогнозирования условных переходов (branch-prediction buffer) или таблица "истории" условных переходов (branch history table). Буфер прогнозирования условных переходов представляет собой небольшую память, адресуемую с помощью младших разрядов адреса команды перехода. Каждая ячейка этой памяти содержит один бит, который говорит о том, был ли предыдущий переход выполняемым или нет. Это простейший вид такого рода буфера. В нем отсутствуют теги, и он оказывается полезным только для сокращения задержки перехода в случае, если эта задержка больше, чем время, необходимое для вычисления значения целевого адреса перехода. В действительности мы не знаем, является ли прогноз корректным (этот бит в соответствующую ячейку буфера могла установить совсем другая команда перехода, которая имела то же самое значение младших разрядов адреса). Но это не имеет значения. Прогноз - это только предположение, которое рассматривается как корректное, и выборка команд начинается по прогнозируемому направлению. Если же предположение окажется неверным, бит прогноза инвертируется. Конечно такой буфер можно рассматривать как кэш-память, каждое обращение к которой является попаданием, и производительность буфера зависит от того, насколько часто прогноз применялся и насколько он оказался точным.
Однако простая однобитовая схема прогноза имеет недостаточную производительность. Рассмотрим, например, команду условного перехода в цикле, которая являлась выполняемым переходом последовательно девять раз подряд, а затем однажды невыполняемым. Направление перехода будет неправильно предсказываться при первой и при последней итерации цикла. Неправильный прогноз последней итерации цикла неизбежен, поскольку бит прогноза будет говорить, что переход "выполняемый" (переход был девять раз подряд выполняемым). Неправильный прогноз на первой итерации происходит из-за того, что бит прогноза инвертируется при предыдущем выполнении последней итерации цикла, поскольку в этой итерации переход был невыполняемым. Таким образом, точность прогноза для перехода, который выполнялся в 90% случаев, составила только 80% (2 некорректных прогноза и 8 корректных). В общем случае, для команд условного перехода, используемых для организации циклов, переход является выполняемым много раз подряд, а затем один раз оказывается невыполняемым. Поэтому однобитовая схема прогнозирования будет неправильно предсказывать направление перехода дважды (при первой и при последней итерации).
Для исправления этого положения часто используется схема двухбитового прогноза. В двухбитовой схеме прогноз должен быть сделан неверно дважды, прежде чем он изменится на противоположное значение. На рисунке 5.27 представлена диаграмма состояний двухбитовой схемы прогнозирования направления перехода.
Цели разработки
Цели разработки
Первоначальная разработка NFS имела следующие цели:
NFS не должна ограничиваться операционной системой UNIX. Любая операционная система должна быть способной реализовать сервер и клиент NFS.
Протокол не должен зависеть от каких либо определенных аппаратных средств.
Должны быть реализованы простые механизмы восстановления в случае отказов сервера или клиента.
Приложения должны иметь прозрачный доступ к удаленным файлам без использования специальных путевых имен или библиотек и без перекомпиляции.
Для UNIX-клиентов должна поддерживаться семантика UNIX.
Производительность NFS должна быть сравнима с производительностью локальных дисков.
Реализация должна быть независимой от транспортных средств.
Целочисленные АЛУ
Целочисленные АЛУ
В микропроцессоре R10000 имеются два целочисленных АЛУ: АЛУ1 и АЛУ2. Время выполнения всех целочисленных операций АЛУ (за исключением операций умножения и деления) и частота повторений составляют один такт.
Оба АЛУ выполняют стандартные операции сложения, вычитания и логические операции. Эти операции завершаются за один такт. АЛУ1 обрабатывает все команды перехода, а также операции сдвига, а АЛУ2 - все операции умножения и деления с использованием итерационных алгоритмов. Целочисленные операции умножения и деления помещают свои результаты в регистры EntryHi и EntryLo.
Во время выполнения операций умножения в АЛУ2 могут выполняться другие однотактные команды, но сам умножитель оказывается занятым. Однако когда умножитель заканчивает свою работу, АЛУ2 оказывается занятым на два такта, чтобы обеспечить запись результата в два регистра. Во время выполнения операций деления, которые имеют очень большую задержку, АЛУ2 занято на все время выполнения операции.
Целочисленные операции умножения вырабатывают произведение с двойной точностью. Для операций с одинарной точностью происходит распространение знака результата до 64 бит прежде, чем он будет помещен в регистры EntryHi и EntryLo. Время выполнения операций с двойной точностью примерно в два раза превосходит время выполнения операций с одинарной точностью.
Централизованная схема управления
Рисунок 5.25. Централизованная схема управления

Машина CDC 6600 имела 16 отдельных функциональных устройств (4 устройства для операций с плавающей точкой, 5 устройств для организации обращений к основной памяти и 7 устройств для целочисленных операций). В нашем случае централизованная схема обнаружения конфликтов имеет смысл только для устройства плавающей точки. Предположим, что имеются два умножителя, один сложитель, одно устройство деления и одно целочисленное устройство для всех операций обращения к памяти, переходов и целочисленных операций. Хотя устройств в этом примере гораздо меньше, чем в CDC 6600, он достаточно мощный для демонстрации основных принципов работы. Поскольку как наша машина, так и CDC 6600 являются машинами с операциями регистр-регистр (операциями загрузки/записи), в обеих машинах методика практически одинаковая. На рисунке 5.25 показана подобная машина.
Каждая команда проходит через централизованную схему обнаружения конфликтов, которая определяет зависимости по данным; этот шаг соответствует стадии выдачи команд и заменяет часть стадии ID в нашем конвейере. Эти зависимости определяют затем моменты времени, когда команда может читать свои операнды и начинать выполнение операции. Если централизованная схема решает, что команда не может немедленно выполняться, она следит за всеми изменениями в аппаратуре и решает, когда команда сможет выполняться. Эта же централизованная схема определяет также когда команда может записать результат в свой регистр результата. Таким образом, все схемы обнаружения и разрешения конфликтов здесь выполняются устройством центрального управления.
Каждая команда проходит четыре стадии своего выполнения. (Поскольку в данный момент мы интересуемся операциями плавающей точки, мы не рассматриваем стадию обращения к памяти). Рассмотрим эти стадии сначала неформально, а затем детально рассмотрим как централизованная схема поддерживает необходимую информацию, которая определяет обработку при переходе с одной стадии на другую.
Следующие четыре стадии заменяют стадии ID, EX и WB в стандартном конвейере:
Выдача. Если функциональное устройство, необходимое для выполнения команды, свободно и никакая другая выполняющаяся команда не использует тот же самый регистр результата, централизованная схема выдает команду в функциональное устройство и обновляет свою внутреннюю структуру данных. Поскольку никакое другое работающее функциональное устройство не может записать результат в регистр результата нашей команды, мы гарантируем, что конфликты типа WAW не могут появляться. Если существует структурный конфликт или конфликт типа WAW, выдача команды блокируется и никакие следующие команды не будут выдаваться на выполнение до тех пор, пока эти конфликты существуют. Эта стадия заменяет часть стадии ID в нашем конвейере.
Чтение операндов.
Централизованная схема следит за возможностью выборки источников операндов для соответствующей команды. Операнд-источник доступен, если отсутствует выполняющаяся команда, которая записывает результат в этот регистр или если в данный момент времени в регистр, содержащий операнд, выполняется запись из работающего функционального устройства. Если операнды-источники доступны, централизованная схема сообщает функциональному устройству о необходимости чтения операндов из регистров и начале выполнения операции. Централизованная схема разрешает конфликты RAW на этой стадии динамически и команды могут посылаться для выполнения не в порядке, предписанном программой. Эта стадия, совместно со стадией выдачи, завершает работу стадии ID простого конвейера.
Выполнение. Функциональное устройство начинает выполнение операции после получения операндов. Когда результат готов оно уведомляет централизованную схему управления о том, что оно завершило выполнение операции. Эта стадия заменяет стадию EX и занимает несколько тактов в рассмотренном ранее конвейере.
Запись результата. Когда централизованная схема управления узнает о том, что функциональное устройство завершило выполнение операции, она проверяет существование конфликта типа WAR.
Конфликт типа WAR существует, если имеется последовательность команд, аналогичная представленной в нашем примере с командами ADDF и SUBF. В том примере мы имели следующую последовательность команд:
DIVF F0,F2,F4
ADDF F10,F0,F8
SUBF F8,F8,F14
Команда ADDF имеет операнд-источник F8, который является тем же самым регистром, что и регистр результата команды SUBF. Но в действительности команда ADDF зависит от предыдущей команды. Централизованная схема управления будет блокировать выдачу команды SUBF до тех пор, пока команда ADDF не прочитает свои операнды. Тогда в общем случае завершающейся команде не разрешается записывать свои результаты если:
имеется команда, которая не прочитала свои операнды,
один из операндов является регистром результата завершающейся команды.
Если этот конфликт типа WAR не существует, централизованная схема управления сообщает функциональному устройству о необходимости записи результата в регистр назначения. Эта стадия заменяет стадию WB в простом конвейере.
Основываясь на своей собственной структуре данных, централизованная схема управления управляет продвижением команды с одной ступени на другую взаимодействуя с функциональными устройствами. Но имеется небольшое усложнение: в регистровом файле имеется только ограниченное число магистралей для операндов-источников и магистралей для записи результата. Централизованная схема управления должна гарантировать, что количество функциональных устройств, которым разрешено продолжать работу на ступенях 2 и 4 не превышает числа доступных шин. Мы не будем вдаваться в дальнейшие подробности и упомянем лишь, что CDC 6600 решала эту проблему путем объединения 16 функциональных устройств друг с другом в четыре группы и поддержки для каждой группы устройств набора шин, называемых магистралями данных (data trunks). Только одно устройство в группе могло читать операнды или записывать свой результат в течение одного такта.
Интересным вопросом является стоимость и преимущества централизованного управления.
Разработчики CDC 6600 оценивают улучшение производительности для программ на Фортране в 1.7 раза, а для вручную запрограммированных на языке ассемблера программ в 2.5 раза. Однако эти оценки делались в то время, когда отсутствовали программные средства планирования загрузки конвейера, полупроводниковая основная память и кэш-память (с малым временем доступа). Централизованная схема управления CDC 6600 имела примерно столько же логических схем, что и одно из функциональных устройств, что на удивление мало. Основная стоимость определялась большим количеством шин (магистралей) - примерно в четыре раза больше по сравнению с машиной, которая выполняла бы команды в строгом порядке, заданном программой.
Централизованная схема управления не обрабатывает несколько ситуаций. Например, когда команда записывает свой результат, зависимая команда в конвейере должна дожидаться разрешения обращения к регистровому файлу, поскольку все результаты всегда записываются в регистровый файл и никогда не используется методика "ускоренной пересылки". Это увеличивает задержку и ограничивает возможность инициирования нескольких команд, ожидающих результата. Что касается CDC 6600, то конфликты типа WAW являются очень редкими, так что приостановки, которые они вызывают, возможно не являются существенными. Однако в следующем разделе мы увидим, что динамическое планирование дает возможность совмещенного выполнения нескольких итераций цикла. Чтобы это делать эффективно, требуется схема обработки конфликтов типа WAW, которые вероятно увеличиваются по частоте при совмещении выполнения нескольких итераций.
Частота использования различных методов адресации на программах TeX, Spice, GCC
Рисунок 5.2. Частота использования различных методов адресации на программах TeX, Spice, GCC

Этот же вопрос важен и для непосредственной адресации. Непосредственная адресация используется при выполнении арифметических операций, операций сравнения, а также для загрузки констант в регистры. Результаты анализа статистики показывают, что в подавляющем числе случаев 16 разрядов оказывается вполне достаточно (хотя для вычисления адресов намного реже используются и более длинные константы).
Важным вопросом построения любой системы команд является оптимальное кодирование команд. Оно определяется количеством регистров и применяемых методов адресации, а также сложностью аппаратуры, необходимой для декодирования. Именно поэтому в современных RISC-архитектурах используются достаточно простые методы адресации, позволяющие резко упростить декодирование команд. Более сложные и редко встречающиеся в реальных программах методы адресации реализуются с помощью дополнительных команд, что вообще говоря приводит к увеличению размера программного кода. Однако такое увеличение длины программы с лихвой окупается возможностью простого увеличения тактовой частоты RISC-процессоров.
Типы команд
Команды традиционного машинного уровня можно разделить на несколько типов, которые показаны на рисунке 5.3.
| Тип операции | Примеры | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Арифметические и логические | Целочисленные арифметические и логические операции: сложение, вычитание, логическое сложение, логическое умножение и т.д. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Пересылки данных | Операции загрузки/записи | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Управление потоком команд | Безусловные и условные переходы, вызовы процедур и возвраты | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Системные операции | Системные вызовы, команды управления виртуальной памятью и т.д. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Операции с плавающей точкой |
Операции сложения, вычитания, умножения и деления над вещественными числами | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Десятичные операции | Десятичное сложение, умножение, преобразование форматов и т.д. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Операции над строками | Пересылки, сравнения и поиск строк | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Частота заполнения одного слота задержки условного перехода
Рисунок 5.18. Частота заполнения одного слота задержки условного перехода

Альтернативная техника для предсказания переходов основана на информации о профиле выполнения программы, собранной во время предыдущих прогонов. Ключевым моментом, который делает этот подход заслуживающим внимания, является то, что поведение переходов при выполнении программы часто повторяется, т.е. каждый отдельный переход в программе часто оказывается смещенным в одну из сторон: он либо выполняемый, либо невыполняемый. Проведенные многими авторами исследования показывают достаточно успешное предсказания переходов с использованием этой стратегии.
В следующей главе мы рассмотрим использование схем динамического прогнозирования, основанного на поведении программы во время ее работы. Мы также рассмотрим несколько методов планирования кода во время компиляции. Эта методика требует статического предсказания переходов, таким образом идеи этого раздела являются важными.
Что происходит во время записи?
4. Что происходит во время записи?
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тег. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности:
сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти.
Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Когда процессор ожидает завершения записи при выполнении сквозной записи, то говорят, что он приостанавливается для записи (write stall). Общий прием минимизации остановов по записи связан с использованием буфера записи (write buffer), который позволяет процессору продолжить выполнение команд во время обновления содержимого памяти. Следует отметить, что остановы по записи могут возникать и при наличии буфера записи.
| Метод | Доля промахов |
Потери при промахе |
Время обращения при попадании | Сложность аппаратуры | Примечания |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Увеличение размера блока | + | - | 0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Повышение степени ассоциативности | + | - | 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Кэш-память с вспомогательным кэшем | + | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Псевдоассоциативные кэши | + | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Аппаратная предварительная выборка команд и данных | + | 2 | Предварительная выборка данных затруднена | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Предварительная выборка под управлением компилятора | + | 3 | Требует также неблокируемой кэш-памяти | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Специальные методы для уменьшения промахов | + | 0 | Вопрос ПО | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Установка приоритетов промахов по чтению над записями | + | 1 | Просто для однопроцессорных систем | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Использование подблоков | + | + | 1 | Сквозная запись + подблок на 1 слово помогают записям | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Пересылка требуемого слова первым | + | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Неблокируемые кэши | + | 3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Кэши второго уровня | + | 2 | Достаточно дорогое оборудование | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Простые кэши малого размера | - | + | 0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Обход преобразования адресов во время индексации кэш-памяти | + | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Конвейеризация операций записи для быстрого попадания при записи | + | 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Дальнейшее уменьшение приостановок по управлению: буфера целевых адресов переходов
Дальнейшее уменьшение приостановок по управлению: буфера целевых адресов переходов
Рассмотрим ситуацию, при которой на стадии выборки команд находится команда перехода (на следующей стадии будет осуществляться ее дешифрация). Тогда чтобы сократить потери, необходимо знать, по какому адресу выбирать следующую команду. Это означает, что нам как-то надо выяснить, что еще недешифрированная команда в самом деле является командой перехода, и чему равно следующее значение счетчика адресов команд. Если все это мы будем знать, то потери на команду перехода могут быть сведены к нулю. Специальный аппаратный кэш прогнозирования переходов, который хранит прогнозируемый адрес следующей команды, называется буфером целевых адресов переходов (branch-target buffer).
Диаграмма работы конвейера при структурном конфликте
Рисунок 5.8. Диаграмма работы конвейера при структурном конфликте
Диаграмма работы модернизированного
Рисунок 5.17, а. Требования к переставляемым командам при планировании задержанного перехода

Имеются небольшие дополнительные затраты аппаратуры на реализацию задержанных переходов. Из-за задержанного эффекта условных переходов, для корректного восстановления состояния в случае появления прерывания нужны несколько счетчиков команд (один плюс длина задержки).
| Рассматриваемый случай |
Требования | Когда увеличивается производительность |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (a) | Команда условного перехода не должна зависеть от переставляемой команды | Всегда | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (b) | Выполнение переставляемой команды должно быть корректным, даже если переход не выполняется Может потребоваться копирование команды |
Когда переход выполняется. Может увеличивать размер программы в случае копирования команды |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (c) | Выполнение переставляемой команды должно быть корректным, даже если переход выполняется | Когда переход не выполняется | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Диаграмма работы простейшего конвейера
Рисунок 5.6. Диаграмма работы простейшего конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
Тот факт, что время выполнения каждой команды в конвейере не уменьшается, накладывает некоторые ограничения на практическую длину конвейера. Кроме ограничений, связанных с задержкой конвейера, имеются также ограничения, возникающие в результате несбалансированности задержки на каждой его ступени и из-за накладных расходов на конвейеризацию. Частота синхронизации не может быть выше, а, следовательно, такт синхронизации не может быть меньше, чем время, необходимое для работы наиболее медленной ступени конвейера. Накладные расходы на организацию конвейера возникают из-за задержки сигналов в конвейерных регистрах (защелках) и из-за перекосов сигналов синхронизации. Конвейерные регистры к длительности такта добавляют время установки и задержку распространения сигналов. В предельном случае длительность такта можно уменьшить до суммы накладных расходов и перекоса сигналов синхронизации, однако при этом в такте не останется времени для выполнения полезной работы по преобразованию информации.
В качестве примера рассмотрим неконвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно (рисунок 5.7). Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. Тогда среднее время выполнения команды в неконвейерной машине будет равно 260 нс. Если же используется конвейерная организация, длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс.
Это время соответствует среднему времени выполнения команды в конвейере. Таким образом, ускорение, полученное в результате конвейеризации, будет равно:
| Среднее время выполнения команды в неконвейерном режиме | 260 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Среднее время выполнения команды в конвейерном режиме | = | 65 | = | 4 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Диаграмма состояния двухбитовой схемы прогнозирования
Рисунок 5.27. Диаграмма состояния двухбитовой схемы прогнозирования

Двухбитовая схема прогнозирования в действительности является частным случаем более общей схемы, которая в каждой строке буфера прогнозирования имеет n-битовый счетчик. Этот счетчик может принимать значения от 0 до 2n - 1. Тогда схема прогноза будет следующей:
Если значение счетчика больше или равно 2n-1 (точка на середине интервала), то переход прогнозируется как выполняемый. Если направление перехода предсказано правильно, к значению счетчика добавляется единица (если только оно не достигло максимальной величины); если прогноз был неверным, из значения счетчика вычитается единица.
Если значение счетчика меньше, чем 2n-1, то переход прогнозируется как невыполняемый. Если направление перехода предсказано правильно, из значения счетчика вычитается единица (если только не достигнуто значение 0); если прогноз был неверным, к значению счетчика добавляется единица.
Исследования n-битовых схем прогнозирования показали, что двухбитовая схема работает почти также хорошо, и поэтому в большинстве систем применяются двухбитовые схемы прогноза, а не n-битовые.
Буфер прогнозирования переходов может быть реализован в виде небольшой специальной кэш-памяти, доступ к которой осуществляется с помощью адреса команды во время стадии выборки команды в конвейере (IF), или как пара битов, связанных с каждым блоком кэш-памяти команд и выбираемых с каждой командой. Если команда декодируется как команда перехода, и если переход спрогнозирован как выполняемый, выборка команд начинается с целевого адреса как только станет известным новое значение счетчика команд. В противном случае продолжается последовательная выборка и выполнение команд. Если прогноз оказался неверным, значение битов прогноза меняется в соответствии с рисунком 5.27. Хотя эта схема полезна для большинства конвейеров, рассмотренный нами простейший конвейер выясняет примерно за одно и то же время оба вопроса: является ли переход выполняемым и каков целевой адрес перехода (предполагается отсутствие конфликта при обращении к регистру, определенному в команде условного перехода. Напомним, что для простейшего конвейера это справедливо, поскольку условный переход выполняет сравнение содержимого регистра с нулем во время стадии ID, во время которой вычисляется также и эффективный адрес). Таким образом, эта схема не помогает в случае простых конвейеров, подобных рассмотренному ранее.
Как уже упоминалось, точность двухбитовой схемы прогнозирования зависит от того, насколько часто прогноз каждого перехода является правильным и насколько часто строка в буфере прогнозирования соответствует выполняемой команде перехода. Если строка не соответствует данной команде перехода, прогноз в любом случае делается, поскольку все равно никакая другая информация не доступна. Даже если эта строка соответствует совсем другой команде перехода, прогноз может быть удачным.
Динамическая оптимизация с централизованной схемой обнаружения конфликтов
Динамическая оптимизация с централизованной схемой обнаружения конфликтов
В конвейере с динамическим планированием выполнения команд все команды проходят через ступень выдачи строго в порядке, предписанном программой (упоря-доченная выдача). Однако они могут приостанавливаться и обходить друг друга на второй ступени (ступени чтения операндов) и тем самым поступать на ступени выполнения неупорядочено. Централизованная схема обнаружения конфликтов представляет собой метод, допускающий неупорядоченное выполнение команд при наличии достаточных ресурсов и отсутствии зависимостей по данным. Впервые подобная схема была применена в компьютере CDC 6600.
Прежде чем начать обсуждение возможности применения подобных схем, важно заметить, что конфликты типа WAR, отсутствующие в простых конвейерах, могут появиться при неупорядоченном выполнении команд. В ранее приведенном примере регистром результата для команды SUBD является регистр R8, который одновременно является источником операнда для команды ADDD. Поэтому здесь между командами ADDD и SUBD имеет место антизависимость: если конвейер выполнит команду SUBD раньше команды ADDD, он нарушит эту антизависимость. Этот конфликт WAR можно обойти, если выполнить два правила: (1) читать регистры только во время стадии чтения операндов и (2) поставить в очередь операцию ADDD вместе с копией ее операндов. Чтобы избежать нарушений зависимостей по выходу конфликты типа WAW (например, это могло произойти, если бы регистром результата команды SUBD была бы регистр F10) все еще должны обнаруживаться. Конфликты типа WAW могут быть устранены с помощью приостановки выдачи команды, регистр результата которой совпадает с уже используемым в конвейере.
Задачей централизованной схемы обнаружения конфликтов является поддержание выполнения команд со скоростью одна команда за такт (при отсутствии структурных конфликтов) посредством как можно более раннего начала выполнения команд. Таким образом, когда команда в начале очереди приостанавливается, другие команды могут выдаваться и выполняться, если они не зависят от уже выполняющейся или приостановленной команды. Централизованная схема несет полную ответственность за выдачу и выполнение команд, включая обнаружение конфликтов. Подобное неупорядоченное выполнение команд требует одновременного нахождения нескольких команд на стадии выполнения. Этого можно достигнуть двумя способами: реализацией в процессоре либо множества неконвейерных функциональных устройств, либо путем конвейеризации всех функциональных устройств. Обе эти возможности по сути эквивалентны с точки зрения организации управления. Поэтому предположим, что в машине имеется несколько неконвейерных функциональных устройств.
Дисковые массивы и уровни RAID
Дисковые массивы и уровни RAID
Одним из способов повышения производительности ввода/вывода является использование параллелизма путем объединения нескольких физических дисков в матрицу (группу) с организацией их работы аналогично одному логическому диску. К сожалению, надежность матрицы любых устройств падает при увеличении числа устройств. Полагая интенсивность отказов постоянной, т.е. при экспоненциальном законе распределения наработки на отказ, а также при условии, что отказы независимы, получим, что среднее время безотказной работы (mean time to failure - MTTF) матрицы дисков будет равно:
MTTF одного диска / Число дисков в матрице
Для достижения повышенного уровня отказоустойчивости приходится жертвовать пропускной способностью ввода/вывода или емкостью памяти. Необходимо использовать дополнительные диски, содержащие избыточную информацию, позволяющую восстановить исходные данные при отказе диска. Отсюда получают акроним для избыточных матриц недорогих дисков RAID (redundant array of inexpensive disks). Существует несколько способов объединения дисков RAID. Каждый уровень представляет свой компромисс между пропускной способностью ввода/вывода и емкостью диска, предназначенной для хранения избыточной информации.
Когда какой-либо диск отказывает, предполагается, что в течение короткого интервала времени он будет заменен и информация будет восстановлена на новом диске с использованием избыточной информации. Это время называется средним временем восстановления (mean time to repair - MTTR). Этот показатель можно уменьшить, если в систему входят дополнительные диски в качестве "горячего резерва": при отказе диска резервный диск подключается аппаратно-программными средствами. Периодически оператор вручную заменяет все отказавшие диски. Четыре основных этапа этого процесса состоят в следующем:
определение отказавшего диска,
устранение отказа без останова обработки;
восстановление потерянных данных на резервном диске;
периодическая замена отказавших дисков на новые.
Другой подход к динамическому планированию - алгоритм Томасуло
Другой подход к динамическому планированию - алгоритм Томасуло
Другой подход к параллельному выполнению команд при наличии конфликтов был использован в устройстве плавающей точки в машине IBM 360/91. Эта схема приписывается Р. Томасуло и названа его именем. Разработка IBM 360/91 была завершена спустя три года после выпуска CDC 6600, прежде чем кэш-память появилась в коммерческих машинах. Задачей IBM было достижение высокой производительности на операциях с плавающей точкой, используя набор команд и компиляторы, разработанные для всего семейства 360, а не только для приложений с интенсивным использованием плавающей точки. Архитектура 360 предусматривала только четыре регистра плавающей точки двойной точности, что ограничивало эффективность планирования кода компилятором. Этот факт был другой мотивацией подхода Томасуло. Наконец, машина IBM 360/91 имела большое время обращения к памяти и большие задержки выполнения операций плавающей точки, преодолеть которые и был призван разработанный Томасуло алгоритм. В конце раздела мы увидим, что алгоритм Томасуло может также поддерживать совмещенное выполнение нескольких итераций цикла.
Мы поясним этот алгоритма на примере устройства ПТ. Основное различие между нашим конвейером ПТ и конвейером машины IBM/360 заключается в наличии в последней машине команд типа регистр-память. Поскольку алгоритм Томасуло использует функциональное устройство загрузки, не требуется значительных изменений, чтобы добавить режимы адресации регистр-память; основное добавление - другая шина. IBM 360/91 имела также конвейерные функциональные устройства, а не несколько функциональных устройств. Единственное отличие между ними заключается в том, что конвейерное функциональное устройство может начинать выполнение только одной операции в каждом такте. Поскольку реально отсутствуют фундаментальные отличия, мы описываем алгоритм, как если бы имели место несколько функциональных устройств. IBM 360/91 могла выполнять одновременно три операции сложения ПТ и две операции умножения ПТ.
Кроме того, в процессе выполнения могли находиться до 6 операций загрузки ПТ, или обращений к памяти, и до трех операций записи ПТ. Для реализации этих функций использовались буфера данных загрузки и буфера данных записи. Хотя мы не будем обсуждать устройства загрузки и записи, необходимо добавить буфера для операндов.
Схема Томасуло имеет много общего со схемой централизованного управления CDC 6600, однако имеются и существенные отличия. Во-первых, обнаружение конфликтов и управление выполнением являются распределенными - станции резервирования (reservation stations) в каждом функциональном устройстве определяют, когда команда может начать выполняться в данном функциональном устройстве. В CDC 6600 эта функция централизована. Во-вторых, результаты операций посылаются прямо в функциональные устройства, а не проходят через регистры. В IBM 360/91 имеется общая шина результатов операций (которая называется общей шиной данных (common data bus - CDB)), которая позволяет производить одновременную загрузку всех устройств, ожидающих операнда. CDC 6600 записывает результаты в регистры, за которые ожидающие функциональные устройства могут соперничать. Кроме того, CDC 6600 имеет несколько шин завершения операций (две в устройстве ПТ), а IBM 360/91 - только одну.
На рисунке 5.26 представлена основная структура устройства ПТ на базе алгоритма Томасуло. Никаких таблиц управления выполнением не показано. Станции резервирования хранят команды, которые выданы и ожидают выполнения в соответствующем функциональном устройстве, а также информацию, требующуюся для управления командой, когда ее выполнение началось в функциональном устройстве. Буфера загрузки и записи хранят данные поступающие из памяти и записываемые в память. Регистры ПТ соединены с функциональными устройствами парой шин и одной шиной с буферами записи. Все результаты из функциональных устройств и из памяти посылаются на общую шину данных, которая связана со входами всех устройств за исключением буфера загрузки. Все буфера и станции резервирования имеют поля тегов, используемых для управления конфликтами.
Прежде чем описывать детали станций резервирования и алгоритм, рассмотрим все стадии выполнения команды. В отличие от централизованной схемы управления, имеется всего три стадии:
Выдача - Берет команду из очереди команд ПТ. Если операция является операцией ПТ, выдает ее при наличии свободной станции резервирования и посылает операнды на станцию резервирования, если они находятся в регистрах. Если операция является операцией загрузки или записи, она может выдаваться при наличии свободного буфера. При отсутствии свободной станции резервирования или свободного буфера возникает структурный конфликт и команда приостанавливается до тех пор, пока не освободится станция резервирования или буфер.
Выполнение - Если один или более операндов команды не доступны по каким либо причинам, контролируется состояние CDB и ожидается завершение вычисления значений нужного регистра. На этой стадии выполняется контроль конфликтов типа RAW. Когда оба операнда доступны, выполняется операция.
Запись результата - Когда становится доступным результат, он записывается на CDB и оттуда в регистры и любое функциональное устройство, ожидающее этот результат.
Файловая система с репликацией данных (CFS)
Файловая система с репликацией данных (CFS)
Начиная с версии Solaris 2.3 Sun предлагает новую возможность, называемую файловой системой с репликацией данных или кэширующей файловой системой (CFS - Cashed File System). В соответствии со стандартным протоколом NFS файлы выбираются блок за блоком прямо с сервера в память клиента и все манипуляции с ними происходят прямо в этой памяти. Данные записываются обратно на диск сервера. Программное обеспечение CFS располагается между кодом клиента NFS и методами доступа сервера NFS. Когда блоки данных получены кодом клиента NFS, они кэшируются в выделенной области на локальном диске. Локальная копия называется файлом переднего плана (front file), а копия сервера - файлом заднего плана (back file). Любое последующее обращение к кэшированному файлу выполняется к его копии на локальном диске, а не к копии, находящейся на сервере. По очевидным причинам такая организация может существенно уменьшить нагрузку на сервер.
К сожалению, CFS - это не исчерпывающее средство для снижения нагрузки на сервер. Во-первых, поскольку она действительно создает копии блоков данных, система должна обеспечивать определенные мероприятия для поддержания согласованного состояния этих копий. В частности, подсистема CFS периодически проверяет атрибуты файла заднего плана (периодичность такой проверки устанавливается пользователем). Если файл заднего плана был модифицирован, файл переднего плана вычищается из кэша и последующее обращение к (логическому) файлу приведет к тому, что он заново будет выбран с сервера и кэширован. К сожалению, большинство прикладных программ продолжают работать с целым файлом, а не с определенными блоками данных. Например, программы vi, 1-2-3 и ProEngineer читают и записывают свои файлы данных целиком, независимо от действительных целей пользователя. (Вообще говоря, программы, использующие для доступа к файлам команду mmap(2), не обращаются к файлу в целом, в то время как, программы, использующие команды read(2) и write(2), обычно это делают). Как следствие, CFS обычно кэширует весь файл. В результате файловые системы NFS, подвергающиеся частым изменениям, оказываются не очень хорошими кандидатами для CFS: файлы будут постоянно кэшироваться и очищаться, что в конце концов приводит к увеличению общего сетевого трафика, по сравнению с простой работой через NFS.
Проблема поддержания согласованного состояния кэшированных данных между клиентами и сервером приводит также к другой проблеме: когда клиент модифицирует файл, файл переднего плана аннулируется, а файл заднего плана соответствующим образом обновляется. Последующее обращение по чтению к этому файлу будет выбирать и снова кэшировать файл. Если обновление файлов является обычной практикой, этот процесс приводит к большему трафику, чем при работе стандартной NFS.
Поскольку CSF является относительно новой возможностью, к сожалению было сделано очень мало измерений ее поведения при действительном использовании. Однако, сама идея протокола CSF приводит к следующим рекомендациям:
CSF следует использовать для файловых систем, из которых главным образом осуществляется чтение данных, например, для файловых систем разделяемых кодов приложений.
CSF особенно полезна для разделения данных между относительно медленными сетями, например WAN, соединенных с помощью линий связи уровня менее чем Т1.
CSF полезна и для высокоскоростных сетей, соединенных между собой маршрутизаторами, которые вносят задержку.
Файловые системы с журнализацией
Файловые системы с журнализацией
Одним из наиболее существенных недостатков традиционных файловых систем является трудность восстановления согласованного состояния файлов после сбоев, в результате которых теряется содержимое основной памяти. Это связано с тем, что для повышения эффективности работа с внешней памятью производится через буфера основной памяти, в которых в момент сбоя могут находиться как данные (содержимое блоков файла), так и метаданные (например, содержимое i-узлов). Обычным приемом восстановления файловой системы после сбоя является применение утилиты fsck, которая, работая на уровне логического диска, обходит всю файловую систему и, по мере возможности, находит и исправляет ошибочные ситуации. Естественно, если используются большие диски, то эта работа занимает много времени, приводя к серьезным задержкам в использовании компьютера. Для устранения этого недостатка все чаще применяются файловые системы с журнализацией.
Как и в случае журнализации изменений в системах управления базами данных, основным принципом журнализующих файловых систем является поддержание специального файла-журнала, в который в последовательном и только последовательном режиме записывается информация обо всех изменениях файловой системы. Запись, как правило, производится порциями большого объема, что обеспечивает высокий уровень полезного использования дисковой памяти и высокую эффективность. При восстановлении после сбоя требуется использовать только "хвост" журнала, что позволяет производить восстановление быстро и надежно.
Файловые системы с журнализацией разделяются на две категории: системы, производящие журнализацию всех изменений, и системы, журнализующие только изменения метаданных. Среди систем второй категории выделяются те, которые журнализуют только некоторую выделенную информацию (например, не помещают в журнал информацию о смене владельца файла).
Различаются подходы с журнализацией операций и журнализацией результатов операций. Если, например, журнализуется операция изменения таблицы распределения памяти на диске, то выгоднее поместить в журнал информацию о самой операции (поскольку она изменяет только несколько бит информации на диске). В случае же журнализации операции записи блока данных выгоднее занести в журнал все содержимое блока до его изменения.
Среди файловых систем с журнализацией выделяются такие, в которых журнал используется как вспомогательное средство, а структура самой файловой системы не меняется (в частности, как и в традиционных файловых системах, поддерживаются структуры i-узлов и суперблоков). Другой класс журнализующих файловых систем составляют те, в которых журнал является единственным средством представления файлов на магнитном диске.
Имеется два типа журналов: журнал, ориентированный только на повторное выполнение операций (redo-only), и журнал, способный поддерживать как повторное выполнение операций, так и их обратное выполнение (undo-redo). В журнале "undo-redo" сохраняются как новые, так и старые значения данных. При использовании журнала типа "redo-only" операции восстановления упрощаются, но требуется ограничивать порядок записи метаданных в журнал и на место их постоянного хранения. Журнал "undo-redo" больше по объему и требует применения более сложного механизма журнализации, но использование этого типа журнализации допускает более высокий уровень параллельности.
Хотя имеются файловые системы, производящие архивизацию наиболее старых порций журнала, наиболее распространенным подходом является использование циклического файла-журнала конечного размера. Для поддержки такого журнала применятся специализированная процедура "сборки мусора", выявляющая "устарелые" порции журнальной информации. В некоторых системах эта процедура запускается на фоне работающей системы, в других - только при проведении профилактических работ.
Как упоминалось выше, для лучшего использования дисковой памяти и увеличения эффективности записи в журнал производятся порциями большого объема. В результате часто в одну физическую запись пакуются несколько логических записей об изменении файловой системы. Естественно, это снижает надежность файловой системы, поскольку в случае сбоя последний буфер с журнальной информацией будет утрачен. На практике приходится делать выбор между эффективностью и надежностью.
Наиболее известной файловой системой, основанной исключительно на журнализации и журнализующей все изменения, является BSD-LFS (UNIX BSD 4.4 Log-Structured File System). Среди файловых систем, поддерживающих журнализацию только метаданных, можно выделить Cedar, Calaveras и Veritas.
Где может размещаться блок в кэш-памяти?
1. Где может размещаться блок в кэш-памяти?
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped). Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е.
(адрес блока кэш-памяти) =
(адрес блока основной памяти) mod (число блоков в кэш-памяти)
Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative).
Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative). Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
(адрес множества кэш-памяти) =
(адрес блока основной памяти) mod (число множеств в кэш-памяти)
Далее, блок может размещаться на любом месте данного множества.
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с m блоками может быть названа m-канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
Характер рабочей нагрузки NFS
Характер рабочей нагрузки NFS
Если бы клиенты NFS постоянно выполняли запросы к серверам (или сетям), то в конфигурацию системы пришлось бы включить огромное число выделенных сетей Ethernet или большое число высокоскоростных сетей типа FDDI или FastEthernet. К счастью, обычно трафик NFS имеет достаточно взрывной характер. Клиенты могут выполнять интенсивные запросы к файл-серверам или сетям, но периоды такой интенсивной работы возникают довольно случайно и относительно не очень часто.
HyperSPARC
hyperSPARC
Одной из главных задач, стоявших перед разработчиками микропроцессора hyperSPARC, было повышение производительности, особенно при выполнении операций с плавающей точкой. Поэтому особое внимание разработчиков было уделено созданию простых и сбалансированных шестиступенчатых конвейеров целочисленной арифметики и плавающей точки. Логические схемы этих конвейеров тщательно разрабатывались, количество логических уровней вентилей между ступенями выравнивалось, чтобы упростить вопросы дальнейшего повышения тактовой частоты.
Производительность процессоров hyperSPARC может меняться независимо от скорости работы внешней шины (MBus). Набор кристаллов hyperSPARC обеспечивает как синхронные, так и асинхронные операции с помощью специальной логики кристалла RT625. Отделение внутренней шины процессора от внешней шины позволяет увеличивать тактовую частоту процессора независимо от частоты работы подсистем памяти и ввода/вывода. Это обеспечивает более длительный жизненный цикл, поскольку переход на более производительные модули hyperSPARC не требует переделки всей системы.
Процессорный набор hyperSPARC с тактовой частотой 100 МГц построен на основе технологического процесса КМОП с тремя уровнями металлизации и проектными нормами 0.5 микрон. Внутренняя логика работает с напряжением питания 3.3В.
Иерархия памяти
Иерархия памяти
При разработке процессора R10000 большое внимание было уделено эффективной реализации иерархии памяти. В нем обеспечиваются раннее обнаружение промахов кэш-памяти и параллельная перезагрузка строк с выполнением другой полезной работой. Реализованные на кристалле кэши поддерживают одновременную выборку команд, выполнение команд загрузки и записи данных в память, а также операций перезагрузки строк кэш-памяти. Заполнение строк кэш-памяти выполняется по принципу "запрошенное слово первым", что позволяет существенно сократить простои процессора из-за ожидания требуемой информации. Все кэши имеют двухканальную множественно-ассоциативную организацию с алгоритмом замещения LRU.
Иллюстрация проблемы когерентности кэш-памяти
Рисунок 5.41. Иллюстрация проблемы когерентности кэш-памяти

Проблема когерентности памяти для мультипроцессоров и устройств ввода/вывода имеет много аспектов. Обычно в малых мультипроцессорах используется аппаратный механизм, называемый протоколом, позволяющий решить эту проблему. Такие протоколы называются протоколами когерентности кэш-памяти. Существуют два класса таких протоколов:
Протоколы на основе справочника (directory based). Информация о состоянии блока физической памяти содержится только в одном месте, называемом справочником (физически справочник может быть распределен по узлам системы).
Протоколы наблюдения (snooping). Каждый кэш, который содержит копию данных некоторого блока физической памяти, имеет также соответствующую копию служебной информации о его состоянии. Централизованная система записей отсутствует. Обычно кэши расположены на общей (разделяемой) шине и контроллеры всех кэшей наблюдают за шиной (просматривают ее) для определения того, не содержат ли они копию соответствующего блока.
В мультипроцессорных системах, использующих микропроцессоры с кэш-памятью, подсоединенные к централизованной общей памяти, протоколы наблюдения приобрели популярность, поскольку для опроса состояния кэшей они могут использовать заранее существующее физическое соединение - шину памяти.
Неформально, проблема когерентности памяти состоит в необходимости гарантировать, что любое считывание элемента данных возвращает последнее по времени записанное в него значение. Это определение не совсем корректно, поскольку невозможно требовать, чтобы операция считывания мгновенно видела значение, записанное в этот элемент данных некоторым другим процессором. Если, например, операция записи на одном процессоре предшествует операции чтения той же ячейки на другом процессоре в пределах очень короткого интервала времени, то невозможно гарантировать, что чтение вернет записанное значение данных, поскольку в этот момент времени записываемые данные могут даже не покинуть процессор.
Вопрос о том, когда точно записываемое значение должно быть доступно процессору, выполняющему чтение, определяется выбранной моделью согласованного (непротиворечивого) состояния памяти и связан с реализацией синхронизации параллельных вычислений. Поэтому с целью упрощения предположим, что мы требуем только, чтобы записанное операцией записи значение было доступно операции чтения, возникшей немного позже записи и что операции записи данного процессора всегда видны в порядке их выполнения.
С этим простым определением согласованного состояния памяти мы можем гарантировать когерентность путем обеспечения двух свойств:
Операция чтения ячейки памяти одним процессором, которая следует за операцией записи в ту же ячейку памяти другим процессором получит записанное значение, если операции чтения и записи достаточно отделены друг от друга по времени.
Операции записи в одну и ту же ячейку памяти выполняются строго последовательно (иногда говорят, что они сериализованы): это означает, что две подряд идущие операции записи в одну и ту же ячейку памяти будут наблюдаться другими процессорами именно в том порядке, в котором они появляются в программе процессора, выполняющего эти операции записи.
Первое свойство очевидно связано с определением когерентного (согласованного) состояния памяти: если бы процессор всегда бы считывал только старое значение данных, мы сказали бы, что память некогерентна.
Необходимость строго последовательного выполнения операций записи является более тонким, но также очень важным свойством. Представим себе, что строго последовательное выполнение операций записи не соблюдается. Тогда процессор P1 может записать данные в ячейку, а затем в эту ячейку выполнит запись процессор P2. Строго последовательное выполнение операций записи гарантирует два важных следствия для этой последовательности операций записи. Во-первых, оно гарантирует, что каждый процессор в машине в некоторый момент времени будет наблюдать запись, выполняемую процессором P2. Если последовательность операций записи не соблюдается, то может возникнуть ситуация, когда какой-нибудь процессор будет наблюдать сначала операцию записи процессора P2, а затем операцию записи процессора P1, и будет хранить это записанное P1 значение неограниченно долго.
Более тонкая проблема возникает с поддержанием разумной модели порядка выполнения программ и когерентности памяти для пользователя: представьте, что третий процессор постоянно читает ту же самую ячейку памяти, в которую записывают процессоры P1 и P2; он должен наблюдать сначала значение, записанное P1, а затем значение, записанное P2. Возможно он никогда не сможет увидеть значения, записанного P1, поскольку запись от P2 возникла раньше чтения. Если он даже видит значение, записанное P1, он должен видеть значение, записанное P2, при последующем чтении. Подобным образом любой другой процессор, который может наблюдать за значениями, записываемыми как P1, так и P2, должен наблюдать идентичное поведение. Простейший способ добиться таких свойств заключается в строгом соблюдении порядка операций записи, чтобы все записи в одну и ту же ячейку могли наблюдаться в том же самом порядке. Это свойство называется последовательным выполнением (сериализацией) операций записи (write serialization). Вопрос о том, когда процессор должен увидеть значение, записанное другим процессором достаточно сложен и имеет заметное воздействие на производительность, особенно в больших машинах.
Интерфейс кэш-памяти второго уровня
Интерфейс кэш-памяти второго уровня
Внешняя кэш-память второго уровня управляется с помощью внутреннего контроллера, который имеет специальный порт для подсоединения кэш-памяти. Специальная магистраль данных шириной в 128 бит осуществляет пересылки данных на внутренней тактовой частоте процессора 200 МГц, обеспечивая максимальную скорость передачи данных кэш-памяти второго уровня 3.2 Гбайт/с. В процессоре имеется также 64-битовая шина данных системного интерфейса.
Кэш-память второго уровня имеет двухканальную множественно-ассоциативную организацию. Максимальный размер этой кэш-памяти - 16 Мбайт. Минимальный размер - 512 Кбайт. Пересылки осуществляются 128-битовыми порциями (4 32-битовых слова). Для пересылки больших блоков данных используются последовательные циклы шины:
Четырехсловные обращения (128 бит) используются для команд кэш-памяти (CASHE);
Восьмисловные обращения (256 бит) используются для перезагрузки первичного кэша данных;
Шестнадцатисловные обращения (512 бит) используются для перезагрузки первичного кэша команд;
Тридцатидвухсловные обращения (1024 бит) используются для перезагрузки кэш-памяти второго уровня.
Исходные предпосылки
Исходные предпосылки
Чтобы собрать достаточную и точную информацию для создания конфигурации сервера NFS необходимо ответить на следующие вопросы:
Является ли нагрузка интенсивной по атрибутам или интенсивной по данным?
Будут ли клиенты пользоваться кэширующей файловой системой для сокращения числа запросов?
Сколько в среднем будет полностью активных клиентов?
Какие типы клиентских систем предполагается использовать и под управлением каких операционных систем они работают?
Насколько большие файловые системы предполагается использовать в режиме разделения доступа?
Повторяются ли запросы разных клиентов к одним и тем же файлам (например, к файлам include), или они относятся к разным файлам?
Каковы количество и тип предполагаемых для эксплуатации сетей? Является ли существующая конфигурация сети подходящей для соответствующего типа трафика?
Достаточно ли в предполагаемой конфигурации сервера количество ЦП для управления трафиком, связанным с применяемыми сетями?
Если используются территориальные сети (WAN), имеют ли среда передачи данных и маршрутизаторы достаточно малую задержку и высокую пропускную способность, чтобы обеспечить практичность применения NFS?
Достаточно ли дисковых накопителей и главных адаптеров SCSI для достижения заданной производительности?
Требуется ли применение программных средств типа Online:DiskSuit для адекватного распределения нагрузки по доступу к дискам между всеми доступными дисковыми накопителями?
Если часто используются операции записи NFS, то имеются ли в конфигурации системы NVSIMM?
Соответствует ли предполагаемая стратегия резервного копирования типу, числу и размещению на шине SCSI устройств резервного копирования?
Исполнительные устройства
Исполнительные устройства
В процессоре R10000 имеются пять полностью независимых исполнительных устройств: два целочисленных АЛУ, два основных устройства плавающей точки с двумя вторичными устройствами плавающей точки, которые работают с длинными операциями деления и вычисления квадратного корня, а также устройство загрузки/записи.
Использование оптимальных зон диска
Использование оптимальных зон диска
Многие диски, которые сегодня поставляются компаниями-поставщиками компьютеров, пользуются механизмами кодирования, которые получили название "записи битовых зон - zone bit recording"). Этот тип кодирования позволяет использовать геометрические свойства вращающегося диска упаковывать больше данных на тех частях поверхности диска, которые находятся дальше от его центра. Практический эффект заключается в том, что количество адресов с меньшими номерами (которые соответствуют внешним цилиндрам диска) превосходят количество адресов с большими номерами. Обычно это в пределе составляет 50%. Такой способ кодирования в большей степени сказывается на производительности последовательного доступа к данным (например, для диска 2.1 Гбайт указывается диапазон скоростей передачи данных 3.5-5.1 Мбайт/с), но он также сказывается на производительности произвольного доступа к диску. Данные, расположенные на внешних цилиндрах диска, не только проходят быстрее под головками чтения/записи (поэтому и скорость передачи данных выше), но эти цилиндры также просто больше по размеру. Заданное количество данных можно распределить по меньшему числу больших цилиндров, что приведет к меньшему числу механических перемещений каретки.
Использование специфических свойств динамических ЗУПВ
Использование специфических свойств динамических ЗУПВ
Как упоминалось раньше, обращение к ДЗУПВ состоит из двух этапов: обращения к строке и обращения к столбцу. При этом внутри микросхемы осуществляется буферизация битов строки, прежде чем происходит обращение к столбцу. Размер строки обычно является корнем квадратным от емкости кристалла памяти: 1024 бита для 1Мбит, 2048 бит для 4 Мбит и т.д. С целью увеличения производительности все современные микросхемы памяти обеспечивают возможность подачи сигналов синхронизации, которые позволяют выполнять последовательные обращения к буферу без дополнительного времени обращения к строке. Имеются три способа подобной оптимизации:
блочный режим (nibble mode) - ДЗУВП может обеспечить выдачу четырех последовательных ячеек для каждого сигнала RAS.
страничный режим (page mode) - Буфер работает как статическое ЗУПВ; при изменении адреса столбца возможен доступ к произвольным битам в буфере до тех пор, пока не поступит новое обращение к строке или не наступит время регенерации.
режим статического столбца (static column) - Очень похож на страничный режим за исключением того, что не обязательно переключать строб адреса столбца каждый раз для изменения адреса столбца.
Начиная с микросхем ДЗУПВ емкостью 1 Мбит, большинство ДЗУПВ допускают любой из этих режимов, причем выбор режима осуществляется на стадии установки кристалла в корпус путем выбора соответствующих соединений. Эти операции изменили определение длительности цикла памяти для ДЗУВП. На рисунке 5.39 показано традиционное время цикла и максимальная скорость между обращениями в оптимизированном режиме.
Преимуществом такой оптимизации является то, что она основана на внутренних схемах ДЗУПВ и незначительно увеличивает стоимость системы, позволяя практически учетверить пропускную способность памяти. Например, nibble mode был разработан для поддержки режимов, аналогичных расслоению памяти. Кристалл за один раз читает значения четырех бит и подает их наружу в течение четырех оптимизированных циклов. Если время пересылки по шине не превосходит время оптимизированного цикла, единственное усложнение для организации памяти с четырехкратным расслоением заключается в несколько усложненной схеме управления синхросигналами. Страничный режим и режим статического столбца также могут использоваться, обеспечивая даже большую степень расслоения при несколько более сложном управлении. Одной из тенденций в разработке ДЗУПВ является наличие в них буферов с тремя состояниями. Это предполагает, что для реализации традиционного расслоения с большим числом кристаллов памяти в системе должны быть предусмотрены буферные микросхемы для каждого банка памяти.
Новые поколения ДЗУВП разработаны с учетом возможности дальнейшей оптимизации интерфейса между ДЗУПВ и процессором. В качестве примера можно привести изделия компании RAMBUS. Эта компания берет стандартную начинку ДЗУПВ и обеспечивает новый интерфейс, делающий работу отдельной микросхемы более похожей на работу системы памяти, а не на работу отдельного ее компонента. RAMBUS отбросила сигналы RAS/CAS, заменив их шиной, которая допускает выполнение других обращений в интервале между посылкой адреса и приходом данных. (Такого рода шины называются шинами с пакетным переключением (packet-switched bus) или шинами с расщепленными транзакциями (split-traнсaction bus), которые будут рассмотрены в других главах. Такая шина позволяет работать кристаллу как отдельному банку памяти. Кристалл может вернуть переменное количество данных на один запрос и даже самостоятельно выполняет регенерацию. RAMBUS предлагает байтовый интерфейс и сигнал синхронизации, так что микросхема может тесно синхронизироваться с тактовой частотой процессора. После того, как адресный конвейер наполнен, отдельный кристалл может выдавать по байту каждые 2 нсек.
Большинство систем основной памяти используют методы, подобные страничному режиму ДЗУПВ, для уменьшения различий в производительности процессоров и микросхем памяти.
Использование высокоскоростных сетей для предотвращения перегрузки
Использование высокоскоростных сетей для предотвращения перегрузки
Высокоскоростные сети наиболее полезны для обслуживания больших групп клиентов с интенсивной нагрузкой по данным скорее из-за более низкой стоимости инфраструктуры, а не по причине обеспечения максимальной пропускной способности при взаимодействии одной системы с другой. Причиной этого является текущее состояние протокола NFS, который в настоящее время работает с блоками данных длиной 8 Кбайт и обеспечивает предварительную выборку только 8 Кбайт (т.е. в одной операции с сервером можно определить максимально 16 Кбайт данных).
Общий эффект такой организации проявляется в том, что максимальная скорость передачи данных между клиентом и сервером, которые взаимодействуют через кольцо FDDI, составляет примерно 2.7 Мбайт/с. (Эта скорость достигается только при добавлении в файл /etc/system на клиенте оператора set nfs: nfs_async_threads = 16. Клиенты SunOS 4.1.x должны запускать 12 демонов biod, а не 8, как это делается по умолчанию). Эта скорость всего в три раза превосходит максимальную скорость, которую обеспечивает Ethernet несмотря на то, что скорость среды FDDI в десять раз больше. (NFS представляет собой протокол прикладного уровня (уровня 7 в модели OSI). Протоколы более низких уровней, такие как TCP и UDP могут работать с гораздо более высокими скоростями, используя те же самые аппаратные средства. Большая часть времени тратится на ожидание ответов и другую обработку прикладного уровня. Другие протоколы прикладного уровня, которые не рассчитаны на немедленное получение ответа и/или подтверждения, также могут эффективно использовать значительно более высокую скорость среды). Пиковая скорость при использовании 16 Мбит/с Token Ring составляет примерно 1.4 Мбайт/с. Сравнительно недавно была анонсирована новая версия протокола NFS+, которая устраняет этот недостаток, разрешая работу с блоками значительно больших размеров. NFS+ допускает пересылку блоков данных почти произвольных размеров. Клиент и сервер договариваются о максимальном размере блока при каждом монтировании файловой системы.
При этом размер блока может увеличиваться до 4 Гбайт.
Главное преимущество 100-Мбитных сетей при работе с обычными версиями NFS заключается в том, что эти сети могут поддерживать много одновременных передач данных без деградации. Когда сервер пересылает по Ethernet данные клиенту со скоростью 1 Мбайт/с, то такая передача потребляет 100% доступной полосы пропускания сети. Попытки передачи по этой сети большего объема данных приводят к более низкой пропускной способности для всех пользователей. Те же самые клиент и сервер могут осуществлять пересылки данных со скоростью 2.7 Мбайт/с по кольцу FDDI, но в более высокоскоростной сети эта транзакция потребляет только 21% доступной полосы пропускания. Сеть может поддерживать пять или шесть пересылок одновременно без серьезной деградации.
Эту ситуацию лучше всего можно сравнить со скоростной магистралью. Когда движение небольшое (легкий трафик) скоростная магистраль с двумя полосами и ограничением скорости в 90 км в час почти так же хороша, как и восьмиполосная супермагистраль с ограничением скорости 120 км в час. Но когда движение очень интенсивное (тяжелый трафик) супермагистраль гораздо менее чувствительна к перегрузке.
Сеть FDDI также немного (примерно на 5%) более эффективна по сравнению с Ethernet и Token Ring в среде с интенсивной пересылкой данных, поскольку в ее пакете можно разместить больший объем полезных данных (4500 байт по сравнению с 1500 байт у Ethernet и 2048 байт у Token Ring). При пересылках данных объемом 8 Кбайт требуется обработать всего два пакета по сравнению с пятью-шестью для Token Ring или Ethernet. Но все эти рассуждения имеют смысл только для среды с интенсивной передачей данных, поскольку объем атрибутов при обработке соответствующих запросов настолько мал (по 80-128 байт), что для их передачи требуется только один пакет независимо от типа используемой сети. Если существующая на предприятии проводка сети заранее исключает возможность применения оптоволоконной среды FDDI, то существуют стандарты "FDDI по медным проводам" (CDDI), которые обеспечивают возможность предотвращения перегрузки сети при сохранении существующей разводки на основе витой пары.
Хотя ATM до сих пор не превратилась в повсеместно применяемую технологию, возможно в будущем она станет основным средством для среды с интенсивной пересылкой данных, поскольку она обеспечивает более высокую скорость передачи данных (в настоящее время определены скорости передачи данных 155 Мбит/с, 622 Мбит/с и 2.4 Гбит/с), а также использует топологию точка-точка, в которой каждое соединение клиент-хаб может работать со своей определенной скоростью среды.
Измерение существующих систем
Измерение существующих систем
Имеется много разнообразных механизмов для измерения существующих систем. Самый простой из них - это просто использовать команду nfsstat(8), которая дает информацию о смеси операций. Поскольку эти статистические данные могут быть заново устанавливаться в ноль посредством флага -z, команда nfsstat может также использоваться для измерения пропускной способности системы с помощью скрипта Shell, подобного показанному ниже.
#!/bin/sh
nfsstat -z >/dev/null #zero initial counters
while true
do
sleep 10
nfsstat - z -s #show the statistics
done
Выход показывает количество NFS-вызовов, которые были обслужены в заданном интервале и, следовательно, скорость, с которой обрабатываются операции NFS. Следует иметь в виду, что при тяжелых нагрузках команда sleep может в действительности "спать" намного больше, чем запрошенные 10 секунд, что приводит к неточности данных (т.е. переоценке количества запросов). В этих случаях должно использоваться какое-либо более точное средство. Имеется много таких средств, среди которых можно указать SunNetManager, NetMetrix от Metrix и SharpShooter от AIM Technologies. Все эти средства позволяют выяснить пропускную способность системы под действительной нагрузкой и смесь операций. Для вычисления средней пропускной способности обычно требуется некоторая последующая обработка данных. Для этого можно воспользоваться разнообразными средствами (awk(1), электронная таблица типа WingZ или 1-2-3).
Ядерные нити
Ядерные нити
Базовым классом являются ядерные нити. В мире UNIX это не новость. Когда в пользовательском процессе происходит системный вызов или прерывание, выполняется ядерная составляющая пользовательского процесса в своем собственном контексте, включающем набор ядерных стеков и регистровое окружение. Естественно, все ядерные составляющие пользовательских процессов работают в общем адресном пространстве с общим набором ресурсов ядра. Поэтому их вполне можно назвать ядерными легковесными процессами. Наличие ядерных нитей, в частности, облегчает обработку прерываний в режиме ядра. Как и в случае прерывания обычного пользовательского процесса, обработка прерывания ядерной нити производится в ее контексте, и после возврата из прерывания продолжается выполнение прерванной ядерной нити. Кроме того, каждая ядерная нить, вообще говоря, обладает собственным приоритетом по отношению к праву выполняться на процессоре (конечно, этот приоритет связан с приоритетом соответствующего пользовательского процесса). Это позволяет использовать гибкую политику планирования процессорных ресурсов для ядерных составляющих. Итак, ядерные нити должны существовать независимо от того, поддерживаются ли легковесные процессы в режиме пользователя. Наверное, трудно найти сегодня какую-либо многопользовательскую операционную систему, в ядре которой в каком-то виде не поддерживались бы нити.
Эффект конвейеризации при выполнении 3-х команд - четырехкратное ускорение
Рисунок 5.7. Эффект конвейеризации при выполнении 3-х команд - четырехкратное ускорение

При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Существуют три класса конфликтов:
Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Эффективное использование легковесных процессов в симметричных мультипроцессорах
Эффективное использование легковесных процессов в симметричных мультипроцессорах
Поддерживаемые в современных операционных системах (в частности, в ОС UNIX) понятия нити (thread), потока управления, или легковесного процесса на самом деле появились и получили реализацию около 30 лет тому назад. Наиболее известной операционной системой, ориентированной на поддержку множественных процессов, которые работают в общем адресном пространстве и с общими прочими ресурсами, была легендарная ОС Multics. Эта операционная система заслуживает длительного отдельного обсуждения, но, естественно не в данном курсе. Мы рассмотрим (в общих чертах) особенности легковесных процессов в современных вариантах операционной системы UNIX. По всей видимости, все или почти все содержимое этого раздела можно легко отнести к любой операционной системе, поддерживающей легковесные процессы. Несмотря на различия в терминологии, в различных реализациях легковесных процессов выделяются три класса. Но прежде, чем перейти к рассмотрению этих классов, обсудим общую природу процесса в ОС UNIX.
Эволюция архитектуры POWER в направлении архитектуры PowerPC
Эволюция архитектуры POWER в направлении архитектуры PowerPC
Компания IBM распространяет влияние архитектуры POWER в направлении малых систем с помощью платформы PowerPC. Архитектура POWER в этой форме может обеспечивать уровень производительности и масштабируемость, превышающие возможности современных персональных компьютеров. PowerPC базируется на платформе RS/6000 в дешевой конфигурации. В архитектурном плане основные отличия этих двух разработок заключаются лишь в том, что системы PowerPC используют однокристальную реализацию архитектуры POWER, изготавливаемую компанией Motorola, в то время как большинство систем RS/6000 используют многокристальную реализацию. Имеется несколько вариаций процессора PowerPC, обеспечивающих потребности портативных изделий и настольных рабочих станций, но это не исключает возможность применения этих процессоров в больших системах. Первым на рынке был объявлен процессор 601, предназначенный для использования в настольных рабочих станциях компаний IBM и Apple. За ним последовали кристаллы 603 для портативных и настольных систем начального уровня и 604 для высокопроизводительных настольных систем. Наконец, процессор 620 разработан специально для серверных конфигураций и ожидается, что со своей 64-битовой организацией он обеспечит исключительно высокий уровень производительности.
При разработке архитектуры PowerPC для удовлетворения потребностей трех различных компаний (Apple, IBM и Motorola) при сохранении совместимости с RS/6000, в архитектуре POWER было сделано несколько изменений в следующих направлениях:
упрощение архитектуры с целью ее приспособления ее для реализации дешевых однокристальных процессоров;
устранение команд, которые могут стать препятствием повышения тактовой частоты;
устранение архитектурных препятствий суперскалярной обработке и внеочередному выполнению команд;
добавление свойств, необходимых для поддержки симметричной многопроцессорной обработки;
добавление новых свойств, считающихся необходимыми для будущих прикладных программ;
ясное определение линии раздела между "архитектурой" и "реализацией";
обеспечение длительного времени жизни архитектуры путем ее расширения до 64-битовой.
Архитектура PowerPC поддерживает ту же самую базовую модель программирования и назначение кодов операций команд, что и архитектура POWER. В тех местах, где были сделаны изменения, которые могли потенциально препятствовать процессорам PowerPC выполнять существующие двоичные коды RS/6000, были расставлены "ловушки", обеспечивающие прерывание и эмуляцию с помощью программного обеспечения. Такие изменения вводились, естественно, только в тех случаях, если соответствующая возможность либо использовалась не очень часто в кодах прикладных программ, либо была изолирована в библиотечных программах, которые можно просто заменить.
Как найти блок, находящийся в кэш-памяти?
2. Как найти блок, находящийся в кэш-памяти?
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Кроме того, необходим способ определения того, что блок кэш-памяти содержит достоверную или пригодную для использования информацию. Наиболее общим способом решения этой проблемы является добавление к тегу так называемого бита достоверности (valid bit).
Адресация множественно-ассоциативной кэш-памяти осуществляется путем деления адреса, поступающего из процессора, на три части: поле смещения используется для выбора байта внутри блока кэш-памяти, поле индекса определяет номер множества, а поле тега используется для сравнения. Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тега.