Какой блок кэш-памяти должен быть замещен при промахе?
3. Какой блок кэш-памяти должен быть замещен при промахе?
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило для замещения блоков применяются две основных стратегии: случайная и LRU.
В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used).
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков для поддержания трассы увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным. На рисунке 5.37 показаны различия в долях промахов при использовании алгоритма замещения LRU и случайного алгоритма.
| Размер кэш-памяти | LRU Random | LRU Random | LRU Random | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 16 KB | 5.18% 5.69% | 4.67% 5.29% | 4.39% 4.96% | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 64 KB | 1.88% 2.01% | 1.54% 1.66% | 1.39% 1.53% | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 256 KB | 1.15% 1.17% | 1.13% 1.13% | 1.12% 1.12% | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Кэш-память данных (D-кэш) В процессоре
Кэш-память данных (D-кэш)
В процессоре UltraSPARC-1 используется кэш-память данных с прямым отображением емкостью 16 Кбайт, реализующая алгоритм сквозной записи. D-кэш организован в виде 512 строк, в каждой строке размещаются два 16-байтных подблока данных. С каждой строкой связан соответствующий адресный тег. D-кэш индексируется с помощью виртуального адреса, при этом теги также хранят соответствующую часть виртуального адреса. При возникновении промаха при обращении к кэшируемой ячейке памяти происходит загрузка 16-байтного подблока из основной памяти.
Поиск слова в D-кэше осуществляется с помощью виртуального адреса. Младшие разряды этого адреса обеспечивают доступ к строке кэш-памяти, содержащей требуемое слово (прямое отображение). Старшие разряды виртуального адреса сравниваются затем с битами соответствующего тега для определения попадания или промаха. Подобная схема гарантирует быстрое обнаружение промаха и обеспечивает преобразование виртуального адреса в физический только при наличии промаха.
Управление внешней кэш-памятью (E-кэшем)
Одной из важнейших проблем построения системы является согласование производительности процессора со скоростью основной памяти. Основными методами решения этой проблемы (помимо различных способов организации основной памяти и системы межсоединений) являются увеличение размеров и многоуровневая организация кэш-памяти. Устройство управления внешней кэш-памятью (ECU) процессора UltraSPARC-1 позволяет эффективно обрабатывать промахи кэш-памяти данных (D-кэша) и команд (Е-кэша). Все обращения к внешней кэш-памяти (E-кэшу) конвейеризованы, выполняются за 3 такта и осуществляют пересылку 16 байт команд или данных в каждом такте. Такая организация дает возможность эффективно планировать конвейерное выполнение программного кода, содержащего большой объем обрабатываемых данных, и минимизировать потери производительности, связанные с обработкой промахов в D-кэше. ECU позволяет наращивать объем внешней кэш-памяти от 512 Кбайт до 4 Мбайт.
ECU обеспечивает совмещенную во времени обработку промахов обращений по чтению данных из Е-кэша с операциями записи. Например, во время обработки промаха по загрузке ECU разрешает поступление запросов по записи данных в E-кэш. Кроме того, ECU поддерживает операции наблюдения (snoops), связанные с обеспечением когерентного состояния памяти системы.
Типовой процессорный модуль UltraSPARC-1
Типовой процессорный модуль (рисунок 6.7). UltraSPARC-1 состоит из собственно процессора UltraSPARC-1, микросхем синхронной статической памяти (SRAM), используемых для построения памяти тегов и данных внешнего кэша и двух кристаллов буферов системных данных (UDB). UDB изолируют внешний кэш процессора от остальной части системы и обеспечивают буферизацию данных для приходящих и исходящих системных транзакций, а также формирование, проверку контрольных разрядов и автоматическую коррекцию данных (с помощью ECC-кодов). Таким образом, UDB позволяет интерфейсу работать на тактовой частоте процессора (за счет снижения емкостной нагрузки).
Кэш-память данных первого уровня
Кэш-память данных первого уровня
Кэш-память данных первого уровня процессора R10000 имеет емкость 32 Кбайт и организована в виде двух одинаковых банков емкостью по 16 Кбайт, что обеспечивает двухкратное расслоение при выполнении обращений к этой кэш-памяти. Каждый банк представляет собой двухканальную множественно-ассоциативную кэш-память с размером строки (блока) в 32 байта. Кэш данных индексируется с помощью виртуального адреса и хранит теги физических адресов памяти. Такой метод индексации позволяет выбрать подмножество кэш-памяти в том же такте, в котором формируется виртуальный адрес. Однако для того, чтобы поддерживать когерентность с кэш-памятью второго уровня, в кэше первого уровня хранятся теги физических адресов памяти.
Массивы данных и тегов в каждом банке являются независимыми. Эти четыре массива работают под общим управлением очереди формирования адресов памяти и схем внешнего интерфейса кристалла. В очереди адресов могут одновременно находиться до 16 команд загрузки и записи, которые обрабатываются в четырех отдельных конвейерах. Команды из этой очереди динамически выдаются для выполнения в специальный конвейер, который обеспечивает вычисление исполнительного виртуального адреса и преобразование этого адреса в физический. Три других параллельно работающих конвейера могут одновременно выполнять проверку тегов, осуществлять пересылку данных для команд загрузки и завершать выполнение команд записи в память. Хотя команды выполняются в строгом порядке их расположения в памяти, вычисление адресов и пересылка данных для команд загрузки могут происходить неупорядоченно. Схемы внешнего интерфейса кристалла могут выполнять заполнение или обратное копирование строк кэш-памяти, либо операции просмотра тегов. Такая параллельная работа большинства устройств процессора позволяет R10000 эффективно выполнять реальные многопроцессорные приложения.
Работа конвейеров кэш-памяти данных тесно координирована. Например, команды загрузки могут выполнять проверку тегов и чтение данных в том же такте, что и преобразование адреса.
Команды записи сразу же начинают проверку тегов, чтобы в случае необходимости как можно раньше инициировать заполнение требуемой строки из кэш-памяти второго уровня, но непосредственная запись данных в кэш задерживается до тех пор, пока сама команда записи не станет самой старой командой в общей очереди выполняемых команд и ей будет позволено зафиксировать свой результат ("выпустится"). Промах при обращении к кэш-памяти данных первого уровня инициирует процесс заполнения строки из кэш-памяти второго уровня. При выполнении команд загрузки одновременно с заполнением строки кэш-памяти данные могут поступать по цепям обхода в регистровый файл.
При обнаружении промаха при обращении к кэш-памяти данных ее работа не блокируется, т.е. она может продолжать обслуживание следующих запросов. Это особенно полезно для уменьшения такого важного показателя качества реализованной архитектуры как среднее число тактов на команду (CPI - clock cycles per instruction). На рисунке 6.13 представлены результаты моделирования работы R10000 на нескольких программах тестового пакета SPEC. Для каждого теста даны два результата: с блокировкой кэш-памяти данных при обнаружении промаха (вверху) и действительное значение CPI R10000 (внизу). Выделенная более темным цветом правая область соответствует времени, потерянному из-за промахов кэш-памяти. Верхний результат отражает полную задержку в случае, если бы все операции по перезагрузке кэш-памяти выполнялись строго последовательно. Таким образом, стрелка представляет потери времени, которые возникают в блокируемом кэше. Эффект применения неблокируемой кэш-памяти сильно зависит характеристик самих программ. Для небольших тестов, рабочие наборы которых полностью помещаются в кэш-памяти первого уровня, этот эффект не велик. Однако для более реальных программ, подобных тесту tomcatv или тяжелому для кэш-памяти тесту compress, выигрыш оказывается существенным.
Кэш-память команд
Кэш-память команд
Объем внутренней двухканальной множественно-ассоциативной кэш-памяти команд составляет 32 Кбайт. В процессе ее загрузки команды частично декодируются. При этом к каждой команде добавляются 4 дополнительных бит, которые указывают исполнительное устройство, в котором она будет выполняться. Таким образом, в кэш-памяти команды хранятся в 36-битовом формате. Размер строки кэш-памяти команд составляет 64 байта.
Кэш-память второго уровня
Кэш-память второго уровня
Интерфейс кэш-памяти второго уровня процессора R10000 поддерживает 128-битовую магистраль данных, которая может работать с тактовой частотой до 200 МГц, обеспечивая скорость обмена до 3.2 Гбайт/с (для снижения требований к быстродействию микросхем памяти предусмотрена также возможность деления частоты с коэффициентами 1.5, 2, 2.5 и 3). Все стандартные синхронные сигналы управления статической памятью вырабатываются внутри процессора. Не требуется никаких внешних интерфейсных схем. Минимальный объем кэш-памяти второго уровня составляет 512 Кбайт, максимальный размер - 16 Мбайт. Размер строки этой кэш-памяти программируется и может составлять 64 или 128 байт.
Одним из методов улучшения временных показателей работы кэш-памяти является построение псевдо-множествнно-ассоциативной кэш-памяти. В такой кэш-памяти частота промахов находится на уровне частоты промахов множественно-ассоциативной памяти, а время выборки при попадании соответствует кэш-памяти с прямым отображением. Кэш-память R10000 организована именно таким способом, причем для ее реализации используются стандартные синхронные микросхемы памяти (SRAM). В одном наборе микросхем памяти находятся оба канала кэша. Информация о частоте использования этих каналов хранится в схемах управления кэшем на процессорном кристалле. Поэтому после обнаружения промаха в первичном кэше из наиболее часто используемого канала вторичного кэша считываются две четырехсловные строки. Их теги считываются вместе с первой четырехсловной строкой, а теги альтернативного канала читаются одновременно со второй четырехсловной строкой (это осуществляется простым инвертированием старшего разряда адреса).
При этом возможны три случая. Если происходит попадание по первому каналу, то данные доступны немедленно. Если происходит попадание по альтернативному каналу, происходит повторное чтение вторичного кэша. Если отсутствует попадание по обоим каналам, вторичный кэш должен перезаполняться из основной памяти.
Для обеспечения целостности данных в кэш-памяти большой емкости обычной практикой является использование кодов исправляющих одиночные ошибки (ECC-кодов). В R10000 с каждой четырехсловной строкой хранится 9-битовый ECC-код и бит четности. Дополнительный бит четности позволяет сократить задержку, поскольку проверка на четность может быть выполнена очень быстро, чтобы предотвратить использование некорректных данных. При этом, если обнаруживается корректируемая ошибка, то чтение повторяется через специальный двухтактный конвейер коррекции ошибок.
Классификация конфликтов по данным
Классификация конфликтов по данным
Конфликт возникает везде, где имеет место зависимость между командами, и они расположены по отношению друг к другу достаточно близко так, что совмещение операций, происходящее при конвейеризации, может привести к изменению порядка обращения к операндам. В нашем примере был проиллюстрирован конфликт, происходящий с регистровыми операндами, но для пары команд возможно появление зависимостей при записи или чтении одной и той же ячейки памяти. Однако, если все обращения к памяти выполняются в строгом порядке, то появление такого типа конфликтов предотвращается.
Известны три возможных конфликта по данным в зависимости от порядка операций чтения и записи. Рассмотрим две команды i и j, при этом i предшествует j. Возможны следующие конфликты:
RAW (чтение после записи) - j пытается прочитать операнд-источник данных прежде, чем i туда запишет. Таким образом, j может некорректно получить старое значение. Это наиболее общий тип конфликтов, способ их преодоления с помощью механизма "обходов" рассмотрен ранее.
WAR (запись после чтения) - j пытается записать результат в приемник прежде, чем он считывается оттуда командой i, так что i может некорректно получить новое значение. Этот тип конфликтов как правило не возникает в системах с централизованным управлением потоком команд, обеспечивающих выполнение команд в порядке их поступления, так как последующая запись всегда выполняется позже, чем предшествующее считывание. Однако конфликты такого рода могут возникать в системах, допускающих выполнение команд не в порядке их расположения в программном коде.
WAW (запись после записи) - j пытается записать операнд прежде, чем будет записан результат команды i, т.е. записи заканчиваются в неверном порядке, оставляя в приемнике значение, записанное командой i, а не j. Этот тип конфликтов присутствует только в конвейерах, которые выполняют запись со многих ступеней (или позволяют команде выполняться даже в случае, когда предыдущая приостановлена).
Кластерные архитектуры
Кластерные архитектуры
Двумя основными проблемами построения вычислительных систем для критически важных приложений, связанных с обработкой транзакций, управлением базами данных и обслуживанием телекоммуникаций, являются обеспечение высокой производительности и продолжительного функционирования систем. Наиболее эффективный способ достижения заданного уровня производительности - применение параллельных масштабируемых архитектур. Задача обеспечения продолжительного функционирования системы имеет три составляющих: надежность, готовность и удобство обслуживания. Все эти три составляющих предполагают, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем трем направлениям, которые взаимосвязаны и применяются совместно.
Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Повышение уровня готовности предполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления вычислительного процесса после проявления неисправности, включая аппаратурную и программную избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Повышение готовности есть способ борьбы за снижение времени простоя системы. Основные эксплуатационные характеристики системы существенно зависят от удобства ее обслуживания, в частности от ремонтопригодности, контролепригодности и т.д.
В последние годы в литературе по вычислительной технике все чаще употребляется термин "системы высокой готовности" (High Availability Systems). Все типы систем высокой готовности имеют общую цель - минимизацию времени простоя. Имеется два типа времени простоя компьютера: плановое и неплановое. Минимизация каждого из них требует различной стратегии и технологии. Плановое время простоя обычно включает время, принятое руководством, для проведения работ по модернизации системы и для ее обслуживания. Неплановое время простоя является результатом отказа системы или компонента. Хотя системы высокой готовности возможно больше ассоциируются с минимизацией неплановых простоев, они оказываются также полезными для уменьшения планового времени простоя.
Существует несколько типов систем высокой готовности, отличающиеся своими функциональными возможностями и стоимостью. Следует отметить, что высокая готовность не дается бесплатно. Стоимость систем высокой готовности на много превышает стоимость обычных систем. Вероятно поэтому наибольшее распространение в мире получили кластерные системы, благодаря тому, что они обеспечивают достаточно высокий уровень готовности систем при относительно низких затратах. Термин "кластеризация" на сегодня в компьютерной промышленности имеет много различных значений. Строгое определение могло бы звучать так: "реализация объединения машин, представляющегося единым целым для операционной системы, системного программного обеспечения, прикладных программ и пользователей". Машины, кластеризованные вместе таким способом могут при отказе одного процессора очень быстро перераспределить работу на другие процессоры внутри кластера. Это, возможно, наиболее важная задача многих поставщиков систем высокой готовности.
Первой концепцию кластерной системы анонсировала компания DEC, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования. В настоящее время на смену VAX-кластерам приходят UNIX-кластеры. При этом VAX-кластеры предлагают проверенный набор решений, который устанавливает критерии для оценки подобных систем.
VAX-кластер обладает следующими свойствами:
Разделение ресурсов.
Компьютеры VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все компьютеры VAX в кластере могут обращаться к отдельным файлам данных как к локальным.
Высокая готовность. Если происходит отказ одного из VAX-компьютеров, задания его пользователей автоматически могут быть перенесены на другой компьютер кластера. Если в системе имеется несколько контроллеров внешних накопителей и один из них отказывает, другие контроллеры автоматически подхватывают его работу.
Высокая пропускная способность.
Ряд прикладных систем могут пользоваться возможностью параллельного выполнения заданий на нескольких компьютерах кластера.
Удобство обслуживания системы.
Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми компьютерами кластера.
Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных VAX-компьютеров. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех компьютеров, входящих в кластер.
Работа любой кластерной системы определяется двумя главными компонентами: высокоскоростным механизмом связи процессоров между собой и системным программным обеспечением, которое обеспечивает клиентам прозрачный доступ к системному сервису.
В настоящее время широкое распространение получила также технология параллельных баз данных. Эта технология позволяет множеству процессоров разделять доступ к единственной базе данных. Распределение заданий по множеству процессорных ресурсов и параллельное их выполнение позволяет достичь более высокого уровня пропускной способности транзакций, поддерживать большее число одновременно работающих пользователей и ускорить выполнение сложных запросов. Существуют три различных типа архитектуры, которые поддерживают параллельные базы данных:
Симметричная многопроцессорная архитектура с общей памятью (Shared Memory SMP Architecture). Эта архитектура поддерживает единую базу данных, работающую на многопроцессорном сервере под управлением одной операционной системы. Увеличение производительности таких систем обеспечивается наращиванием числа процессоров, устройств оперативной и внешней памяти.
Архитектура с общими (разделяемыми) дисками (Shared Disk Architecture). Это типичный случай построения кластерной системы. Эта архитектура поддерживает единую базу данных при работе с несколькими компьютерами, объединенными в кластер (обычно такие компьютеры называются узлами кластера), каждый из которых работает под управлением своей копии операционной системы. В таких системах все узлы разделяют доступ к общим дискам, на которых собственно и располагается единая база данных. Производительность таких систем может увеличиваться как путем наращивания числа процессоров и объемов оперативной памяти в каждом узле кластера, так и посредством увеличения количества самих узлов.
Архитектура без разделения ресурсов (Shared Nothing Architecture). Как и в архитектуре с общими дисками, в этой архитектуре поддерживается единый образ базы данных при работе с несколькими компьютерами, работающими под управлением своих копий операционной системы. Однако в этой архитектуре каждый узел системы имеет собственную оперативную память и собственные диски, которые не разделяются между отдельными узлами системы. Практически в таких системах разделяется только общий коммуникационный канал между узлами системы. Производительность таких систем может увеличиваться путем добавления процессоров, объемов оперативной и внешней (дисковой) памяти в каждом узле, а также путем наращивания количества таких узлов.
Таким образом, среда для работы параллельной базы данных обладает двумя важными свойствами: высокой готовностью и высокой производительностью. В случае кластерной организации несколько компьютеров или узлов кластера работают с единой базой данных. В случае отказа одного из таких узлов, оставшиеся узлы могут взять на себя задания, выполнявшиеся на отказавшем узле, не останавливая общий процесс работы с базой данных. Поскольку логически в каждом узле системы имеется образ базы данных, доступ к базе данных будет обеспечиваться до тех пор, пока в системе имеется по крайней мере один исправный узел. Производительность системы легко масштабируется, т.е. добавление дополнительных процессоров, объемов оперативной и дисковой памяти, и новых узлов в системе может выполняться в любое время, когда это действительно требуется.
Параллельные базы данных находят широкое применение в системах обработки транзакций в режиме on-line, системах поддержки принятия решений и часто используются при работе с критически важными для работы предприятий и организаций приложениями, которые эксплуатируются по 24 часа в сутки.
Компоненты NFS
Компоненты NFS
Реализация NFS состоит из нескольких компонент. Некоторые из них локализованы либо на сервере, либо на клиенте, а некоторые используются и тем и другим. Некоторые компоненты не требуются для обеспечения основных функциональных возможностеей, но составляют часть расширенного интерфейса NFS:
Протокол NFS определяет набор запросов (операций), которые могут быть направлены клиентом к серверу, а также набор аргументов и возвращаемые значения для каждого из этих запросов. Версия 1 этого протокола существовала только в недрах Sun Microsystems и никогда не была выпущена. Все реализации NFS (в том числе NFSv3) поддерживают версию 2 NFS (NFSv2), которая впервые была выпущена в 1985 году в SunOS 2.0. Версия 3 протокола была опубликована в 1993 году и реализована некоторыми фирмами-поставщиками. В таблице 3.1 приведен полный набор запросов NFS.
Протокол удаленного вызова процедур (RPC) определяет формат всех взаимодействий между клиентом и сервером. Каждый запрос NFS посылается как пакет RPC.
Расширенное представление данных (XDR - Extended Data Representation) обеспечивает машинно-независимый метод кодирования данных для пересылки через сеть. Все запросы RPC используют кодирование XDR для передачи данных. Следует отметить, что XDR и RPC используются для реализации многих других сервисов, помимо NFS.
Программный код сервера NFS отвечает за обработку всех запросов клиента и обеспечивает доступ к экспортируемым файловым системам.
Программный код клиента NFS реализует все обращения клиентской системы к удаленным файлам путем посылки серверу одного или нескольких запросов RPC.
Протокол монтирования определяет семантику монтирования и размонтирования файловых систем NFS.
NFS использует несколько фоновых процессов-демонов. На сервере набор демонов nfsd ожидают запросы клиентов NFS и отвечают на них. Демон mountd обрабатывает запросы монтирования. На клиенте набор демонов biod обрабатывает асинхронный ввод/вывод блоков файлов NFS.
Менеджер блокировок сети (NLM - Network Lock Manager) и монитор состояния сети (NSM - Network Status Monitor) вместе обеспечивают средства для блокировки файлов в сети. Эти средства, хотя формально не связаны с NFS, можно найти в большинстве реализаций NFS. Они обеспечивают сервисы не возможные в базовом протоколе. NLM и NSM реализуют функционирование сервера с помощью демонов lockd и statd соответственно.
Концепция виртуальной памяти
Концепция виртуальной памяти
Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем.
В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение.
Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти (на диске) и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью.
Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти.
Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами. Ниже рассмотрены оба типа организации виртуальной памяти.
Конфигурации дисковой подсистемы и балансировка нагрузки
Конфигурации дисковой подсистемы и балансировка нагрузки
Подобно конфигурации сети, конфигурация дисков определяется типом клиентов. Производительность дисковых накопителей меняется в широких пределах в зависимости от реализации требуемых от них методов доступа. Произвольный доступ по своей природе почти всегда некэшируем и требует, чтобы осуществлялось позиционирование дисковой каретки фактически для каждой операции ввода/вывода (механическое перемещение, которое существенно снижает производительность). При организации последовательного доступа, особенно последовательных обращений по чтению, требуется намного меньшее количество механических перемещений каретки диска на каждую операцию (обычно одно на цилиндр, примерно 1 Мбайт), что дает гораздо более высокую пропускную способность.
Конфигурация сети (локальной и глобальной)
Конфигурация сети (локальной и глобальной)
Возможно наиболее важным требованием к конфигурации NFS-сервера является обеспечение достаточной полосы пропускания и степени готовности сети. Это требование на практике трансформируется в необходимость создания конфигурации с соответствующим количеством и типом сетей и интерфейсов.
Конфликты по данным, остановы конвейера и реализация механизма обходов
Конфликты по данным, остановы конвейера и реализация механизма обходов
Одним из факторов, который оказывает существенное влияние на производительность конвейерных систем, являются межкомандные логические зависимости. Такие зависимости в большой степени ограничивают потенциальный параллелизм смежных операций, обеспечиваемый соответствующими аппаратными средствами обработки. Степень влияния этих зависимостей определяется как архитектурой процессора (в основном, структурой управления конвейером команд и параметрами функциональных устройств), так и характеристиками программ.
Конфликты по данным возникают в том случае, когда применение конвейерной обработки может изменить порядок обращений за операндами так, что этот порядок будет отличаться от порядка, который наблюдается при последовательном выполнении команд на неконвейерной машине. Рассмотрим конвейерное выполнение последовательности команд на рисунке 5.9.
| ADD | R1,R2,R3 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SUB | R4,R1,R5 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AND | R6,R1,R7 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OR | R8,R1,R9 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| XOR | R10,R1,R11 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Конфликты по данным, приводящие к приостановке конвейера
Конфликты по данным, приводящие к приостановке конвейера
К сожалению не все потенциальные конфликты по данным могут обрабатываться с помощью механизма "обходов". Рассмотрим следующую последовательность команд (рисунок 5.11):
| Команда | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LW R1,32(R6) | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADD R4,R1,R7 | IF | ID | stall | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SUB R5,R1,R8 | IF | stall | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| AND R6,R1,R7 | stall | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Контекст процесса
Контекст процесса
Каждому процессу соответствует контекст, в котором он выполняется. Этот контекст включает содержимое пользовательского адресного пространства - пользовательский контекст (т.е. содержимое сегментов программного кода, данных, стека, разделяемых сегментов и сегментов файлов, отображаемых в виртуальную память), содержимое аппаратных регистров - регистровый контекст (таких, как регистр счетчика команд, регистр состояния процессора, регистр указателя стека и регистров общего назначения), а также структуры данных ядра (контекст системного уровня), связанные с этим процессом. Контекст процесса системного уровня в ОС UNIX состоит из "статической" и "динамических" частей. У каждого процесса имеется одна статическая часть контекста системного уровня и переменное число динамических частей.
Статическая часть контекста процесса системного уровня включает следующее:
A.Описатель процесса, т.е. элемент таблицы описателей существующих в системе процессов. Описатель процесса включает, в частности, следующую информацию:
состояние процесса;
физический адрес в основной или внешней памяти u-области процесса;
идентификаторы пользователя, от имени которого запущен процесс;
идентификатор процесса;
прочую информацию, связанную с управлением процессом.
B. U-область (u-area), индивидуальная для каждого процесса область пространства ядра, обладающая тем свойством, что хотя u-область каждого процесса располагается в отдельном месте физической памяти, u-области всех процессов имеют один и тот же виртуальный адрес в адресном пространстве ядра. Именно это означает, что какая бы программа ядра не выполнялась, она всегда выполняется как ядерная часть некоторого пользовательского процесса, и именно того процесса, u-область которого является "видимой" для ядра в данный момент времени. U-область процесса содержит:
указатель на описатель процесса;
идентификаторы пользователя;
счетчик времени, которое процесс реально выполнялся (т.е. занимал процессор) в режиме пользователя и режиме ядра;
параметры системного вызова;
результаты системного вызова;
таблица дескрипторов открытых файлов;
предельные размеры адресного пространства процесса;
предельные размеры файла, в который процесс может писать;
и т.д.
Динамическая часть контекста процесса - это один или несколько стеков, которые используются процессом при его выполнении в режиме ядра. Число ядерных стеков процесса соответствует числу уровней прерывания, поддерживаемых конкретной аппаратурой.
Конвейер с дополнительными функциональными устройствами
Рисунок 5.20. Конвейер с дополнительными функциональными устройствами

Допустим, что в нашей реализации процессора имеются четыре отдельных функциональных устройства:
Основное целочисленное устройство.
Устройство умножения целочисленных операндов и операндов с плавающей точкой.
Устройство сложения с плавающей точкой.
Устройство деления целочисленных операндов и операндов с плавающей точкой.
Целочисленное устройство обрабатывает все команды загрузки и записи в память при работе с двумя наборами регистров (целочисленных и с плавающей точкой), все целочисленные операции (за исключением команд умножения и деления) и все команды переходов. Если предположить, что стадии выполнения других функциональных устройств неконвейерные, то рисунок 5.20 показывает структуру такого конвейера. Поскольку стадия EX является неконвейерной, никакая команда, использующая функциональное устройство, не может быть выдана для выполнения до тех пор, пока предыдущая команда не покинет ступень EX. Более того, если команда не может поступить на ступень EX, весь конвейер за этой командой будет приостановлен.
В действительности промежуточные результаты возможно не используются циклически ступенью EX, как это показано на рисунке 5.20, и ступень EX имеет задержки длительностью более одного такта. Мы можем обобщить структуру конвейера плавающей точки, допустив конвейеризацию некоторых ступеней и параллельное выполнение нескольких операций. Чтобы описать работу такого конвейера, мы должны определить задержки функциональных устройств, а также скорость инициаций или скорость повторения операций. Это скорость, с которой новые операции данного типа могут поступать в функциональное устройство. Например, предположим, что имеют место следующие задержки функциональных устройств и скорости повторения операций:
| Функциональное устройство | Задержка | Скорость повторения | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленное АЛУ | 1 | 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сложение с ПТ | 4 | 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Умножение с ПТ (и целочисленное) | 6 | 3 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Деление с ПТ (и целочисленное) | 15 | 15 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
На рисунке 5.21 представлена структура подобного конвейера. Ее реализация требует введения конвейерной регистровой станции EX1/EX2 и модификации связей между регистрами ID/EX и EX/MEM.
Конвейер с многоступенчатыми функциональными устройствами
Рисунок 5.21. Конвейер с многоступенчатыми функциональными устройствами

Конфликты и ускоренные пересылки в длинных конвейерах
Имеется несколько различных аспектов обнаружения конфликтов и организации ускоренной пересылки данных в конвейерах, подобных представленному на рисунке 5.21:
Поскольку устройства не являются полностью конвейерными, в данной схеме возможны структурные конфликты. Эти ситуации необходимо обнаруживать и приостанавливать выдачу команд.
Поскольку устройства имеют разные времена выполнения, количество записей в регистровый файл в каждом такте может быть больше 1.
Возможны конфликты типа WAW, поскольку команды больше не поступают на ступень WB в порядке их выдачи для выполнения. Заметим, что конфликты типа WAR невозможны, поскольку чтение регистров всегда осуществляется на ступени ID.
Команды могут завершаться не в том порядке, в котором они были выданы для выполнения, что вызывает проблемы с реализацией прерываний.
Прежде чем представить общее решение для реализации схем обнаружения конфликтов, рассмотрим вторую и третью проблемы.
Если предположить, что файл регистров с ПТ имеет только один порт записи, то последовательность операций с ПТ, а также операция загрузки ПТ совместно с операциями ПТ может вызвать конфликты по порту записи в регистровый файл. Рассмотрим последовательность команд, представленную на рисунке 5.22. В такте 10 все три команды достигнут ступени WB и должны произвести запись в регистровый файл. При наличии только одного порта записи в регистровый файл машина должна обеспечить последовательное завершение команд. Этот единственный регистровый порт является источником структурных конфликтов. Чтобы решить эту проблему, можно увеличить количество портов в регистровом файле, но такое решение может оказаться неприемлемым, поскольку эти дополнительные порты записи скорее всего будут редко использоваться. Однако в установившемся состоянии максимальное количество необходимых портов записи равно 1. Поэтому в реальных машинах разработчики предпочитают отслеживать обращения к порту записи в регистры и рассматривать одновременное к нему обращение как структурный конфликт.
| Команда | Номер такта | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MULTD F0,F4,F6 | IF | ID | EX11 | EX12 | EX13 | EX21 | EX22 | EX23 | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ... | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADDD F2,F4,F6 | IF | ID | EX11 | EX12 | EX21 | EX22 | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ... | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ... | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LD F8,0(R2) | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Конвейерное выполнение оператора А = В + С
Рисунок 5.12. Конвейерное выполнение оператора А = В + С
Очевидно, выполнение команды ADD должно быть приостановлено до тех пор, пока не станет доступным поступающий из памяти операнд C. Дополнительной задержки выполнения команды SW не произойдет в случае применения цепей обхода для пересылки результата операции АЛУ непосредственно в регистр данных памяти для последующей записи.
Для данного простого примера компилятор никак не может улучшить ситуацию, однако в ряде более общих случаев он может реорганизовать последовательность команд так, чтобы избежать приостановок конвейера. Эта техника, называемая планированием загрузки конвейера (pipeline scheduling) или планированием потока команд (instruction scheduling), использовалась начиная с 60-х годов и стала особой областью интереса в 80-х годах, когда конвейерные машины стали более распространенными.
Пусть, например, имеется последовательность операторов: a = b + c; d = e - f;
Как сгенерировать код, не вызывающий остановок конвейера? Предполагается, что задержка загрузки из памяти составляет один такт. Ответ очевиден (рисунок 5.13):
| Неоптимизированная последовательность команд |
Оптимизированная последовательность команд |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LW Rb,b | LW Rb,b | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LW Rc,c | LW Rc,c | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADD Ra,Rb,Rc | LW Re,e | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SW a,Ra | ADD Ra,Rb,Rc | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LW Re,e | LW Rf,f | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LW Rf,f | SW a,Ra | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SUB Rd,Re,Rf | SUB Rd,Re,Rf | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SW d,Rd | SW d,Rd | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Магнитные и магнитооптические диски
Магнитные и магнитооптические диски
В данном разделе мы кратко рассмотрим основную терминологию, применяемую при описании магнитных дисков и контроллеров, а затем приведем типовые характеристики нескольких современных дисковых подсистем.
Дисковый накопитель обычно состоит из набора пластин, представляющих собой металлические диски, покрытые магнитным материалом и соединенные между собой при помощи центрального шпинделя. Для записи данных используются обе поверхности пластины. В современных дисковых накопителях используется от 4 до 9 пластин. Шпиндель вращается с высокой постоянной скоростью (обычно 3600, 5400 или 7200 оборотов в минуту). Каждая пластина содержит набор концентрических записываемых дорожек. Обычно дорожки делятся на блоки данных объемом 512 байт, иногда называемые секторами. Количество блоков, записываемых на одну дорожку зависит от физических размеров пластины и плотности записи.
Данные записываются или считываются с пластин с помощью головок записи/считывания, по одной на каждую поверхность. Линейный двигатель представляет собой электро-механическое устройство, которое позиционирует головку над заданной дорожкой. Обычно головки крепятся на кронштейнах, которые приводятся в движение каретками. Цилиндр - это набор дорожек, соответствующих одному положению каретки. Накопитель на магнитных дисках (НМД) представляет собой набор пластин, магнитных головок, кареток, линейных двигателей плюс воздухонепроницаемый корпус. Дисковым устройством называется НМД с относящимися к нему электронными схемами.
Производительность диска является функцией времени обслуживания, которое включает в себя три основных компонента: время доступа, время ожидания и время передачи данных. Время доступа - это время, необходимое для позиционирования головок на соответствующую дорожку, содержащую искомые данные. Оно является функцией затрат на начальные действия по ускорению головки диска (порядка 6 мс), а также функцией числа дорожек, которые необходимо пересечь на пути к искомой дорожке. Характерные средние времена поиска - время, необходимое для перемещения головки между двумя случайно выбранными дорожками, лежат в диапазоне 10-20 мс. Время перехода с дорожки на дорожку меньше 10 мс и обычно составляет 2 мс.
Вторым компонентом времени обслуживания является время ожидания. Чтобы искомый сектор повернулся до совмещения с положением головки требуется некоторое время. После этого данные могут быть записаны или считаны. Для современных дисков время полного оборота лежит в диапазоне 8-16 мс, а среднее время ожидания составляет 4-8 мс.
Последним компонентом является время передачи данных, т.е. время, необходимое для физической передачи байтов. Время передачи данных является функцией от числа передаваемых байтов (размера блока), скорости вращения, плотности записи на дорожке и скорости электроники. Типичная скорость передачи равна 1-4 Мбайт/с.
В состав компьютеров часто входят специальные устройства, называемые дисковыми контроллерами. К каждому дисковому контроллеру может подключаться несколько дисковых накопителей. Между дисковым контроллером и основной памятью может быть целая иерархия контроллеров и магистралей данных, сложность которой определяется главным образом стоимостью компьютера. Поскольку время передачи часто составляет очень небольшую часть общего времени доступа к диску, контроллер в высокопроизводительной системе разъединяет магистрали данных от диска на время позиционирования так, что другие диски, подсоединенные к контроллеру, могут передавать свои данные в основную память. Поэтому время доступа к диску может увеличиваться на время, связанное с накладными расходами контроллера на организацию операции ввода/вывода.
Рассмотрим теперь основные составляющие времени доступа к диску в типичной подсистеме SCSI. Такая подсистема включает в себя четыре основных компонента: основной компьютер, главный адаптер SCSI, встроенный в дисковое устройство контроллер и собственно накопитель на магнитных дисках. Когда операционная система получает запрос от пользователя на выполнение операции ввода/вывода, она превращает этот запрос в набор команд SCSI. Запрашивающий процесс при этом блокируется и откладывается до завершения операции ввода/вывода (если только это был не запрос асинхронной передачи данных). Затем команды пересылаются по системе шин в главный адаптер SCSI, к которому подключен необходимый дисковый накопитель. После этого ответственность за выполнение взаимодействия с целевыми контроллерами и их устройствами ложится на главный адаптер.
Затем главный адаптер выбирает целевое устройство, устанавливая сигнал на линии управления шины SCSI (эта операция называется фазой выбора). Естественно, шина SCSI должна быть доступна для этой операции. Если целевое устройство возвращает ответ, то главный адаптер пересылает ему команду (это называется фазой команды). Если целевой контроллер может выполнить команду немедленно, то он пересылает в главный адаптер запрошенные данные или состояние. Команда может быть обслужена немедленно, только если это запрос состояния, или команда запрашивает данные, которые уже находятся в кэш-памяти целевого контроллера. Обычно же данные не доступны, и целевой контроллер выполняет разъединение, освобождая шину SCSI для других операций. Если выполняется операция записи, то за фазой команды на шине немедленно следует фаза данных, и данные помещаются в кэш-память целевого контроллера. Подтверждение записи обычно не происходит до тех пор, пока данные действительно не запишутся на поверхность диска.
После разъединения, целевой контроллер продолжает свою собственную работу. Если в нем не предусмотрены возможности буферизации команд (создание очереди команд), ему надо только выполнить одну команду. Однако, если создание очереди команд разрешено, то команда планируется в очереди работ целевого контроллера, при этом обрабатывается команда, обладающая наивысшим приоритетом в очереди. Когда запрос станет обладать наивысшим приоритетом, целевой контроллер должен вычислить физический адрес (или адреса), необходимый для обслуживания операции ввода/вывода. После этого становится доступным дисковый механизм: позиционируется каретка, подготавливается соответствующая головка записи/считывания и вычисляется момент появления данных под головкой. Наконец, данные физически считываются или записываются на дорожку. Считанные данные запоминаются в кэш-памяти целевого контроллера. Иногда целевой контроллер может выполнить считывание с просмотром вперед.
После завершения операции ввода/вывода целевой контроллер в случае свободы шины соединяется с главным адаптером, вслед за чем выполняется фаза данных (при передаче данных из целевого контроллера в главный адаптер) и фаза состояния для указания результата операции. Когда главный адаптер получает фазу состояния, он проверяет корректность завершения физической операции в целевом контроллере и соответствующим образом информирует операционную систему.
Одной из характеристик процесса ввода/вывода SCSI является большое количество шагов, которые обычно не видны пользователю. Обычно на шине SCSI происходит смена семи фаз (выбор, команда, разъединение, повторное соединение, данные, состояние, разъединение). Естественно каждая фаза выполняется за некоторое время, расходуемое на использование шины. Многие целевые контроллеры (особенно медленные устройства подобные магнитным лентам и компакт-дискам) потребляют значительную часть времени на реализацию фаз выбора, разъединения и повторного соединения.
Варианты применения высокопроизводительных подсистем ввода/вывода широко варьируются в зависимости от требований, которые к ним предъявляются. Они охватывают диапазон от обработки малого числа больших массивов данных, которые необходимо реализовать с минимальной задержкой (ввод/вывод суперкомпьютера), до большого числа простых заданий, которые оперируют с малыми объемами данных (обработка транзакций).
Запросы на ввод/вывод заданной рабочей нагрузки можно характеризовать в терминах трех метрик: производительность, время ожидания и пропускная способность. Производительность определяется числом запросов на обслуживание, получаемых в единицу времени. Время ожидания определяет время, необходимое на обслуживание индивидуального запроса. Пропускная способность определяет количество данных, передаваемых между устройствами, требующими обслуживания, и устройствами, выполняющими обслуживание.
Ввод/вывод суперкомпьютера почти полностью определяется последовательным механизмом. Обычно данные передаются с диска в память большими блоками, а результаты записываются обратно на диск. В таких применениях требуется высокая пропускная способность и минимальное время ожидания, однако они характеризуются низкой производительностью. В отличие от этого обработка транзакций характеризуется огромным числом случайных обращений, относительно небольшими отрезками работы и требует умеренного времени ожидания при очень высокой производительности.
Так как системы обработки транзакций тратят большую часть времени обслуживания на поиск и ожидание, технологические успехи, приводящие к сокращению времени передачи, не будут оказывать особого влияния на производительность таких систем. С другой стороны, в научных применениях на поиск данных и на их передачу затрачивается одинаковое время, и поэтому производительность таких систем оказывается очень чувствительной к любым усовершенствованиям в технологии изготовления дисков. Как будет показано ниже, можно организовать матрицу дисков таким образом, что будет обеспечена высокая производительность ввода/вывода для широкого спектра рабочих нагрузок.
В последние годы плотность записи на жестких магнитных дисках увеличивается на 60% в год при ежеквартальном снижении стоимости хранения одного Мегабайта на 12%. По данным фирмы Dataquest такая тенденция сохранится и в ближайшие два года. Сейчас на рынке представлен широкий ассортимент дисковых накопителей емкостью до 9.1 Гбайт. При этом среднее время доступа у самых быстрых моделей достигает 8 мс. Например, жесткий диск компании Seagate Technology имеет емкость 4.1 Гбайт и среднее время доступа 8 мс при скорости вращения 7200 оборот/мин. Улучшаются также характеристики дисковых контроллеров на базе новых стандартов Fast SCSI-2 и Enhanced IDE. Предполагается увеличение скорости передачи данных до 13 Мбайт/с. Надежность жестких дисков также постоянно улучшается. Например, некоторые модели дисков компаний Conner Peripherals Inc., Micropolis Corp. и Hewlett-Packard имеют время наработки на отказ от 500 тысяч до 1 миллиона часов. На такие диски предоставляется 5-летняя гарантия.
Дальнейшее повышение надежности и коэффициента готовности дисковых подсистем достигается построением избыточных дисковых массивов RAID, о которых речь пойдет в подразделе 5.6.3.
Другим направлением развития систем хранения информации являются магнитооптические диски. Запись на магнитооптические диски (МО-диски) выполняется при взаимодействии лазера и магнитной головки. Луч лазера разогревает до точки Кюри (температуры потери материалом магнитных свойств) микроскопическую область записывающего слоя, которая при при выходе из зоны действия лазера остывает, фиксируя магнитное поле, наведенное магнитной головкой. В результате данные, записанные на диск, не боятся сильных магнитных полей и колебаний температуры. Все функциональные свойства дисков сохраняются в диапазоне температур от -20 до +50 градусов Цельсия.
МО-диски уступают обычным жестким магнитным дискам лишь по времени доступа к данным. Предельное достигнутое МО-дисками время доступа составляет 19 мс. Магнитооптический принцип записи требует предварительного стирания данных перед записью, и соответственно, дополнительного оборота МО-диска. Однако завершенные недавно исследования в SONY и IBM показали, что это ограничение можно устранить, а плотность записи на МО-дисках можно увеличить в несколько раз. Во всех других отношениях МО-диски превосходят жесткие магнитные диски.
В магнитооптическом дисководе используются сменные диски, что обеспечивает практически неограниченную емкость. Стоимость хранения единицы данных на МО-дисках в несколько раз меньше стоимости хранения того же объема данных на жестких магнитных дисках.
Сегодня на рынке МО-дисков предлагается более 150 моделей различных фирм. Одно из лидирующих положений на этом рынке занимает компания Pinnacle Micro Inc. Для примера, ее дисковод Sierra 1.3 Гбайт обеспечивает среднее время доступа 19 мс и среднее время наработки на отказ 80000 часов. Для серверов локальных сетей и рабочих станций компания Pinnacle Micro предлагает целый спектр многодисковых систем емкостью 20, 40, 120, 186 Гбайт и даже 4 Тбайт. Для систем высокой готовности Pinnacle Micro выпускает дисковый массив Array Optical Disk System, который обеспечивает эффективное время доступа к данным не более 11 мс при скорости передачи данных до 10 Мбайт/с.
Мейнфреймы
Мейнфреймы
Мейнфрейм - это синоним понятия "большая универсальная ЭВМ". Мейнфреймы и до сегодняшнего дня остаются наиболее мощными (не считая суперкомпьютеров) вычислительными системами общего назначения, обеспечивающими непрерывный круглосуточный режим эксплуатации. Они могут включать один или несколько процессоров, каждый из которых, в свою очередь, может оснащаться векторными сопроцессорами (ускорителями операций с суперкомпьютерной производительностью). В нашем сознании мейнфреймы все еще ассоциируются с большими по габаритам машинами, требующими специально оборудованных помещений с системами водяного охлаждения и кондиционирования. Однако это не совсем так. Прогресс в области элементно-конструкторской базы позволил существенно сократить габариты основных устройств. Наряду со сверхмощными мейнфреймами, требующими организации двухконтурной водяной системы охлаждения, имеются менее мощные модели, для охлаждения которых достаточно принудительной воздушной вентиляции, и модели, построенные по блочно-модульному принципу и не требующие специальных помещений и кондиционеров.
Основными поставщиками мейнфреймов являются известные компьютерные компании IBM, Amdahl, ICL, Siemens Nixdorf и некоторые другие, но ведущая роль принадлежит безусловно компании IBM. Именно архитектура системы IBM/360, выпущенной в 1964 году, и ее последующие поколения стали образцом для подражания. В нашей стране в течение многих лет выпускались машины ряда ЕС ЭВМ, являвшиеся отечественным аналогом этой системы.
В архитектурном плане мейнфреймы представляют собой многопроцессорные системы, содержащие один или несколько центральных и периферийных процессоров с общей памятью, связанных между собой высокоскоростными магистралями передачи данных. При этом основная вычислительная нагрузка ложится на центральные процессоры, а периферийные процессоры (в терминологии IBM - селекторные, блок-мультиплексные, мультиплексные каналы и процессоры телеобработки) обеспечивают работу с широкой номенклатурой периферийных устройств.
Первоначально мейнфреймы ориентировались на централизованную модель вычислений, работали под управлением патентованных операционных систем и имели ограниченные возможности для объединения в единую систему оборудования различных фирм-поставщиков. Однако повышенный интерес потребителей к открытым системам, построенным на базе международных стандартов и позволяющим достаточно эффективно использовать все преимущества такого подхода, заставил поставщиков мейнфреймов существенно расширить возможности своих операционных систем в направлении совместимости. В настоящее время они демонстрирует свою "открытость", обеспечивая соответствие со спецификациями POSIX 1003.3, возможность использования протоколов межсоединений OSI и TCP/IP или предоставляя возможность работы на своих компьютерах под управлением операционной системы UNIX собственной разработки.
Стремительный рост производительности персональных компьютеров, рабочих станций и серверов создал тенденцию перехода с мейнфреймов на компьютеры менее дорогих классов: миникомпьютеры и многопроцессорные серверы. Эта тенденция получила название "разукрупнение" (downsizing). Однако этот процесс в самое последнее время несколько замедлился. Основной причиной возрождения интереса к мейнфреймам эксперты считают сложность перехода к распределенной архитектуре клиент-сервер, которая оказалась выше, чем предполагалось. Кроме того, многие пользователи считают, что распределенная среда не обладает достаточной надежностью для наиболее ответственных приложений, которой обладают мейнфреймы.
Очевидно выбор центральной машины (сервера) для построения информационной системы предприятия возможен только после глубокого анализа проблем, условий и требований конкретного заказчика и долгосрочного прогнозирования развития этой системы.
Главным недостатком мейнфреймов в настоящее время остается относительно низкое соотношение производительность/стоимость. Однако фирмами-поставщиками мейнфреймов предпринимаются значительные усилия по улучшению этого показателя.
Следует также помнить, что в мире существует огромная инсталлированная база мейнфреймов, на которой работают десятки тысяч прикладных программных систем. Отказаться от годами наработанного программного обеспечения просто не разумно. Поэтому в настоящее время ожидается рост продаж мейнфреймов по крайней мере до конца этого столетия. Эти системы, с одной стороны, позволят модернизировать существующие системы, обеспечив сокращение эксплуатационных расходов, с другой стороны, создадут новую базу для наиболее ответственных приложений.
Менее требовательные клиенты
Менее требовательные клиенты
Хотя наиболее быстрые ПК в настоящее время по производительности ЦП вполне могут оспорить превосходство рабочих станций начального уровня, типовой ПК оказывается значительно менее требовательным сетевым клиентом, чем типичная рабочая станция. Частично это происходит из-за того, что подавляющее большинство существующих ПК все еще базируются на более медленных процессорах 386 (и даже 286), а более медленные процессоры как правило работают с менее требовательными приложениями и пользователями. Более того, эти более медленные процессоры, работающие даже на полной скорости, просто генерируют запросы менее быстро, чем рабочие станции, поскольку внутренние шины и сетевые адаптеры таких ПК не настолько хорошо оптимизированы по сравнению с соответствующими устройствами систем большего размера. Например типовые адаптеры Ethernet ISA, доступные в 1991 году были способны поддерживать скорость передачи данных только на уровне 700 Кбайт/с (по сравнению со скоростью более 1 Мбайт/с, которая достигалась во всех рабочих станциях 1991 года), а некоторые достаточно распространенные интерфейсные платы были способны обеспечивать скорость только на уровне примерно 400 Кбайт/с. Ряд ПК, в частности портативные, используют интерфейсы "Ethernet", которые реально подключаются через параллельный порт. Хотя такое подключение позволяет сэкономить слот шины и достаточно удобно, однако такой интерфейс Ethernet оказывается одним из самых медленных, поскольку многие реализации параллельного порта ограничены скоростью передачи данных 500-800 Кбит/с (60-100 Кбайт/с). Конечно когда в пользовательской базе стали превалировать ПК на базе процессора 486, оснащенные 32-битовыми сетевыми адаптерами DMA, эти различия постепенно стерлись, но полезно помнить, что подавляющее большинство клиентов PC-NFS (особенно в нашей стране) попадают в более старую, менее требовательную категорию. Возможности ПК на базе процессора 33 МГц 486DX, оснащенного 32-битовым интерфейсом Ethernet, продемонстрирована на рисунке 4.2.
Методика планирования компилятора для устранения конфликтов по данным
Методика планирования компилятора для устранения конфликтов по данным
Многие типы приостановок конвейера могут происходить достаточно часто. Например, для оператора А = B + С компилятор скорее всего сгенерирует следующую последовательность команд (рисунок 5.12):
| LW R1,В | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| LW R2,С | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ADD R3,R1,R2 | IF | ID | stall | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SW A,R3 | IF | stall | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Методология применения легковесных процессов
Методология применения легковесных процессов
Мы проследили достоинства разных видов легковесных процессов и можем перейти к краткому анализу их недостатков. Многие программисты (включая автора статьи) испытали эти недостатки на себе. При программировании с явным использованием техники легковесных процессов возникает потребность в явной синхронизации по отношению к общим ресурсам. В современных вариантах ОС UNIX имеется несколько разновидностей средств синхронизации: блокировки, семафоры, условные переменные. Но в любом случае, механизм синхронизации является явным, оторванным от ресурса, для доступа к которому производится синхронизация. Если у легковесных процессов одного пользовательского процесса общих ресурсов немного, то такую программу написать и отладить сравнительно несложно. Но при наличии большого количества общих ресурсов отладка программы становится очень сложным делом (даже при использовании только пользовательских нитей).
Основной проблемой является недетерминированность поведения программы, поскольку время выполнения каждого легковесного процесса, вообще говоря, различно при каждом запуске программы. При использовании явных примитивов для синхронизации набора легковесных процессов наиболее распространенной ошибочной ситуацией является возникновение синхронизационных тупиков. Если при отладке параллельной программы возник тупик, нужно исследовать ситуацию, установить причину ее возникновения (как правило, эта причина состоит в несогласованном выполнении синхронизационных примитивов в разных легковесных процессах) и устранить причину тупика. Но по причине недетерминированности поведения программы тупики могут возникать при одном из ста запуске программы, и никогда нельзя быть полностью уверенным, что при некотором сочетании временных характеристик тупик все-таки не проявится. Заметим, что это относится и к LWP, и к пользовательским нитям.
Трудно также согласиться с тем, что использование явных средств распараллеливания улучшает структурность программы. Человеку свойственно последовательное мышление. Для программиста наиболее естественна модель фон Неймана. С другой стороны, было бы странно не использовать возможности мультипроцессоров для повышения скорости выполнения программ. В настоящее время явное использование пользовательских LWP является единственным доступным решением.
Конечно, появление в современных операционных системах механизма процессов, работающих на общей памяти, не является слишком прогрессивным явлением. Традиционный UNIX стимулировал простое и понятное программирование. Современный UNIX провоцирует сложное, запутанное и опасное программирование.
С другой стороны, системные программисты с успехом используют новые средства. При наличии большого желания, времени и денег параллельную программу можно надежно отладить, что демонстрирует большинство компаний, разрабатывающих программное обеспечение баз данных. При этом используются и LWP, поддерживаемые операционной системой, и пользовательские нити. Как кажется (это мнение не только автора), использование LWP безусловно оправдано, если сервер БД конфигурируется в расчете на работу на симметричном мультипроцессоре. На сегодняшний день это единственная возможность реально распараллелить работу сервера. Но совершенно неочевидно, что применение пользовательских нитей при разработке сервера в целях его структуризации (а это делается во многих серверах), является лучшим решением. Известны другие методы структуризации, которые, по меньшей мере, не менее удобны.
Методы адресации
Рисунок 5.1. Методы адресации
Использование сложных методов адресации позволяет существенно сократить количество команд в программе, но при этом значительно увеличивается сложность аппаратуры. Возникает вопрос, а как часто эти методы адресации используются в реальных программах? На рисунке 5.2 представлены результаты измерений частоты использования различных методов адресации на примере трех популярных программ (компилятора с языка Си GCC, текстового редактора TeX и САПР Spice), выполненных на компьютере VAX.
Из этого рисунка видно, что непосредственная адресация и базовая со смещением доминируют.
При этом основной вопрос, который возникает для метода базовой адресации со смещением, связан с длиной (разрядностью) смещения. Выбор длины смещения в конечном счете определяет длину команды. Результаты измерений показали, что в подавляющем большинстве случаев длина смещения не превышает 16 разрядов.
Методы адресации и типы данных
Методы адресации и типы данных
Методы адресации
В машинах к регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда, может задавать константу, регистр или ячейку памяти. Для обращения к ячейке памяти процессор прежде всего должен вычислить действительный или эффективный адрес памяти, который определяется заданным в команде методом адресации.
На рисунке 5.1 представлены все основные методы адресации операндов, которые реализованы в компьютерах, рассмотренных в настоящем обзоре. Адресация непосредственных данных и литеральных констант обычно рассматривается как один из методов адресации памяти (хотя значения данных, к которым в этом случае производятся обращения, являются частью самой команды и обрабатываются в общем потоке команд). Адресация регистров, как правило, рассматривается отдельно. В данном разделе методы адресации, связанные со счетчиком команд (адресация относительно счетчика команд) рассматриваются отдельно. Этот вид адресации используется главным образом для определения программных адресов в командах передачи управления.
На рисунке 5.1 на примере команды сложения (Add) приведены наиболее употребительные названия методов адресации, хотя при описании архитектуры в документации разные производители используют разные названия для этих методов. На этом рисунке знак "(" используется для обозначения оператора присваивания, а буква М обозначает память (Memory). Таким образом, M[R1] обозначает содержимое ячейки памяти, адрес которой определяется содержимым регистра R1.
| Метод адресации | Пример команды | Смысл команды метода | Использование | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Регистровая | Add R4,R3 | R4<--R4+R5 | Требуемое значение в регистре | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Непосредственная или литеральная | Add R4,#3 | R4<--R4+3 | Для задания констант | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Базовая со смещением | Add R4,100(R1) | R4<--R4+M[100+R1] | Для обращения к локальным переменным | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Косвенная регистровая | Add R4,(R1) | R4<--R4+M[R1] | Для обращения по указателю или вычисленному адресу | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Индексная | Add R3,(R1+R2) | R3<--R3+M[R1+R2] | Иногда полезна при работе с массивами: R1 - база, R3 - индекс | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Прямая или абсолютная |
Add R1,(1000) | R1<--R1+M[1000] | Иногда полезна для обращения к статическим данным | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Косвенная | Add R1,@(R3) | R1<--R1+M[M[R3]] | Если R3-адрес указателя p, то выбирается значение по этому указателю | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Автоинкрементная | Add R1,(R2)+ | R1<--R1+M[R2] R2<--R2+d |
Полезна для прохода в цикле по массиву с шагом: R2 - начало массива В каждом цикле R2 получает приращение d |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Автодекрементная | Add R1,(R2)- | R2<--R2-d R1<--R1+M[R2] |
Аналогична предыдущей Обе могут использоваться для реализации стека |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Базовая индексная со смещением и масштабированием | Add R1,100(R2)[R3] | R1<--R1+M[100]+R2+R3*d | Для индексации массивов | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
MFLOPS
MFLOPS
Измерение производительности компьютеров при решении научно-технических задач, в которых существенно используется арифметика с плавающей точкой, всегда вызывало особый интерес. Именно для таких вычислений впервые встал вопрос об измерении производительности, а по достигнутым показателям часто делались выводы об общем уровне разработок компьютеров. Обычно для научно-технических задач производительность процессора оценивается в MFLOPS (миллионах чисел-результатов вычислений с плавающей точкой в секунду, или миллионах элементарных арифметических операций над числами с плавающей точкой, выполненных в секунду).
Как единица измерения, MFLOPS, предназначена для оценки производительности только операций с плавающей точкой, и поэтому не применима вне этой ограниченной области. Например, программы компиляторов имеют рейтинг MFLOPS близкий к нулю вне зависимости от того, насколько быстра машина, поскольку компиляторы редко используют арифметику с плавающей точкой.
Ясно, что рейтинг MFLOPS зависит от машины и от программы. Этот термин менее безобидный, чем MIPS. Он базируется на количестве выполняемых операций, а не на количестве выполняемых команд. По мнению многих программистов, одна и та же программа, работающая на различных компьютерах, будет выполнять различное количество команд, но одно и то же количество операций с плавающей точкой. Именно поэтому рейтинг MFLOPS предназначался для справедливого сравнения различных машин между собой.
Однако и с MFLOPS не все обстоит так безоблачно. Прежде всего, это связано с тем, что наборы операций с плавающей точкой не совместимы на различных компьютерах. Например, в суперкомпьютерах фирмы Cray Research отсутствует команда деления (имеется, правда, операция вычисления обратной величины числа с плавающей точкой, а операция деления может быть реализована с помощью умножения делимого на обратную величину делителя). В то же время многие современные микропроцессоры имеют команды деления, вычисления квадратного корня, синуса и косинуса.
Другая, осознаваемая всеми, проблема заключается в том, что рейтинг MFLOPS меняется не только на смеси целочисленных операций и операций с плавающей точкой, но и на смеси быстрых и медленных операций с плавающей точкой. Например, программа со 100% операций сложения будет иметь более высокий рейтинг, чем программа со 100% операций деления.
Решение обеих проблем заключается в том, чтобы взять "каноническое" или "нормализованное" число операций с плавающей точкой из исходного текста программы и затем поделить его на время выполнения. На рисунке 2.1 показано, каким образом авторы тестового пакета "Ливерморские циклы", о котором речь пойдет ниже, вычисляют для программы количество нормализованных операций с плавающей точкой в соответствии с операциями, действительно находящимися в ее исходном тексте. Таким образом, рейтинг реальных MFLOPS отличается от рейтинга нормализованных MFLOPS, который часто приводится в литературе по суперкомпьютерам.
| Реальные операции с ПТ | Нормализованные операции с ПТ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сложение, вычитание, сравнение, умножение | 1 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Деление, квадратный корень | 4 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Экспонента, синус, ... | 8 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
MicroSPARC-II
MicroSPARC-II
Эффективная с точки зрения стоимости конструкция не может полагаться только на увеличение тактовой частоты. Экономические соображения заставляют принимать решения, основой которых является массовая технология. Системы microSPARC обеспечивают высокую производительность при умеренной тактовой частоте путем оптимизации среднего количества команд, выполняемых за один такт. Это ставит вопросы эффективного управления конвейером и иерархией памяти. Среднее время обращения к памяти должно сокращаться, либо должно возрастать среднее количество команд, выдаваемых для выполнения в каждом такте, увеличивая производительность на основе компромиссов в конструкции процессора.

Рисунок 6.5. Блок-схема процессора micro Sparc-II
MicroSPARC-II (рисунок 6.5) является одним из сравнительно недавно появившихся процессоров семейства SPARC. Основное его назначение - однопроцессорные низкостоимостные системы. Он представляет собой высокоинтегрированную микросхему, содержащую целочисленное устройство, устройство управления памятью, устройство плавающей точки, раздельную кэш-память команд и данных, контроллер управления микросхемами динамической памяти и контроллер шины SBus.
Основными свойствами целочисленного устройства microSPARC-II являются:
пятиступенчатый конвейер команд;
предварительная обработка команд переходов;
поддержка потокового режима работы кэш-памяти команд и данных;
регистровый файл емкостью 136 регистров (8 регистровых окон);
интерфейс с устройством плавающей точки;
предварительная выборка команд с очередью на четыре команды.
Целочисленное устройство использует пятиступенчатый конвейер команд с одновременным запуском до двух команд. Устройство плавающей точки обеспечивает выполнение операций в соответствии со стандартом IEEE 754.
Устройство управления памятью выполняет четыре основных функции. Во-первых, оно обеспечивает формирование и преобразование виртуального адреса в физический. Эта функция реализуется с помощью ассоциативного буфера TLB. Кроме того, устройство управления памятью реализует механизмы защиты памяти. И, наконец, оно выполняет арбитраж обращений к памяти со стороны ввода/вывода, кэша данных, кэша команд и TLB.
Процессор microSPARC II имеет 64-битовую шину данных для связи с памятью и поддерживает оперативную память емкостью до 256 Мбайт. В процессоре интегрирован контроллер шины SBus, обеспечивающий эффективную с точки зрения стоимости реализацию ввода/вывода.
MIPS
MIPS
Одной из альтернативных единиц измерения производительности процессора (по отношению к времени выполнения) является MIPS - (миллион команд в секунду). Имеется несколько различных вариантов интерпретации определения MIPS.
В общем случае MIPS есть скорость операций в единицу времени, т.е. для любой данной программы MIPS есть просто отношение количества команд в программе к времени ее выполнения. Таким образом, производительность может быть определена как обратная к времени выполнения величина, причем более быстрые машины при этом будут иметь более высокий рейтинг MIPS.
Положительными сторонами MIPS является то, что эту характеристику легко понять, особенно покупателю, и что более быстрая машина характеризуется большим числом MIPS, что соответствует нашим интуитивным представлениям. Однако использование MIPS в качестве метрики для сравнения наталкивается на три проблемы. Во-первых, MIPS зависит от набора команд процессора, что затрудняет сравнение по MIPS компьютеров, имеющих разные системы команд. Во-вторых, MIPS даже на одном и том же компьютере меняется от программы к программе. В-третьих, MIPS может меняться по отношению к производительности в противоположенную сторону.
Классическим примером для последнего случая является рейтинг MIPS для машины, в состав которой входит сопроцессор плавающей точки. Поскольку в общем случае на каждую команду с плавающей точкой требуется большее количество тактов синхронизации, чем на целочисленную команду, то программы, используя сопроцессор плавающей точки вместо соответствующих подпрограмм из состава программного обеспечения, выполняются за меньшее время, но имеют меньший рейтинг MIPS. При отсутствии сопроцессора операции над числами с плавающей точкой реализуются с помощью подпрограмм, использующих более простые команды целочисленной арифметики и, как следствие, такие машины имеют более высокий рейтинг MIPS, но выполняют настолько большее количество команд, что общее время выполнения значительно увеличивается. Подобные аномалии наблюдаются и при использовании оптимизирующих компиляторов, когда в результате оптимизации сокращается количество выполняемых в программе команд, рейтинг MIPS уменьшается, а производительность увеличивается.
Другое определение MIPS связано с очень популярным когда-то компьютером VAX 11/780 компании DEC. Именно этот компьютер был принят в качестве эталона для сравнения производительности различных машин. Считалось, что производительность VAX 11/780 равна 1MIPS (одному миллиону команд в секунду).
В то время широкое распространение получил синтетический тест Dhrystone, который позволял оценивать эффективность процессоров и компиляторов с языка C для программ нечисловой обработки. Он представлял собой тестовую смесь, 53% которой составляли операторы присваивания, 32% - операторы управления и 15% - вызовы функций. Это был очень короткий тест: общее число команд равнялось 100. Скорость выполнения программы из этих 100 команд измерялась в Dhrystone в секунду. Быстродействие VAX 11/780 на этом синтетическом тесте составляло 1757Dhrystone в секунду. Таким образом 1MIPS равен 1757 Dhrystone в секунду.
Следует отметить, что в настоящее время тест Dhrystone практически не применяется. Малый объем позволяет разместить все команды теста в кэш-памяти первого уровня современного микропроцессора и он не позволяет даже оценить эффект наличия кэш-памяти второго уровня, хотя может хорошо отражать эффект увеличения тактовой частоты.
Третье определение MIPS связано с IBM RS/6000 MIPS. Дело в том, что ряд производителей и пользователей (последователей фирмы IBM) предпочитают сравнивать производительность своих компьютеров с производительностью современных компьютеров IBM, а не со старой машиной компании DEC. Соотношение между VAX MIPS и RS/6000 MIPS никогда широко не публиковались, но 1 RS/6000 MIPS примерно равен 1.6 VAX 11/780 MIPS.
Моделирование работы R10000 на нескольких компонентах пакета SPEC
Рисунок 6.13. Моделирование работы R10000 на нескольких компонентах пакета SPEC

Монтирование файловых систем NFS
Рисунок 4.1. Монтирование файловых систем NFS

Все четыре операции монтирования будут успешно выполнены. На клиенте поддерево /usr отражает полное поддерево /usr на nfssrv, поскольку клиент также смонтировал /usr/local. Поддерево /u1 на клиенте отображает поддерево /usr/u1 на nfssrv. Этот пример иллюстрирует, что вполне законно можно монтировать подкаталог экспортированной файловой стстемы (это позволяют не все реализации). Наконец, поддерево /users на клиенте отображает только ту часть поддерева /usr сервера, которая размещена на диске 0. Файловая система диска 1 под /users/local не видна.
Мультипроцессорная когерентность кэш-памяти
Мультипроцессорная когерентность кэш-памяти
Проблема, о которой идет речь, возникает из-за того, что значение элемента данных в памяти, хранящееся в двух разных процессорах, доступно этим процессорам только через их индивидуальные кэши. На рисунке 5.41 показан простой пример, иллюстрирующий эту проблему.
Набор кристаллов процессора hyperSPARC
Рисунок 6.3. Набор кристаллов процессора hyperSPARC

Процессор hyperSPARC реализован в виде многокристальной микросборки (рисунок 6.3), в состав которой входит суперскалярная конвейерная часть и тесно связанная с ней кэш-память второго уровня. В набор кристаллов входят RT620 (CPU) - центральный процессор, RT625 (CMTU) - контроллер кэш-памяти, устройство управления памятью и устройство тегов и четыре RT627 (CDU) кэш-память данных для реализации кэш-памяти второго уровня емкостью 256 Кбайт. RT625 обеспечивает также интерфейс с MBus.
Центральный процессор RT620 (рисунок 6.4) состоит из целочисленного устройства, устройства с плавающей точкой, устройства загрузки/записи, устройства переходов и двухканальной множественно-ассоциативной памяти команд емкостью 8 Кбайт. Целочисленное устройство включает АЛУ и отдельный тракт данных для операций загрузки/записи, которые представляют собой два из четырех исполнительных устройств процессора. Устройство переходов обрабатывает команды передачи управления, а устройство плавающей точки, реально состоит из двух независимых конвейеров - сложения и умножения чисел с плавающей точкой. Для увеличения пропускной способности процессора команды плавающей точки, проходя через целочисленный конвейер, поступают в очередь, где они ожидают запуска в одном из конвейеров плавающей точки. В каждом такте выбираются две команды. В общем случае, до тех пор, пока эти две команды требуют для своего выполнения различных исполнительных устройств при отсутствии зависимостей по данным, они могут запускаться одновременно. RT620 содержит два регистровых файла: 136 целочисленных регистров, сконфигурированных в виде восьми регистровых окон, и 32 отдельных регистра плавающей точки, расположенных в устройстве плавающей точки.
Кэш-память второго уровня в процессоре hyperSPARC строится на базе RT625 CMTU, который представляет собой комбинированный кристалл, включающий контроллер кэш-памяти и устройство управления памятью, которое поддерживает разделяемую внешнюю память и симметричную многопроцессорную обработку.
Контроллер кэш- памяти поддерживает кэш емкостью 256 Кбайт, состоящий из четырех RT627 CDU. Кэш-память имеет прямое отображение и 4К тегов. Теги в кэш-памяти содержат физические адреса, поэтому логические схемы для соблюдения когерентности кэш-памяти в многопроцессорной системе, имеющиеся в RT625, могут быстро определить попадания или промахи при просмотре со стороны внешней шины без приостановки обращений к кэш-памяти со стороны центрального процессора. Поддерживается как режим сквозной записи, так и режим обратного копирования.
Устройство управления памятью содержит в своем составе полностью ассоциативную кэш-память преобразования виртуальных адресов в физические (TLB), состоящую из 64 строк, которая поддерживает 4096 контекстов. RT625 содержит буфер чтения емкостью 32 байта, используемый для загрузки, и буфер записи емкостью 64 байта, используемый для разгрузки кэш-памяти второго уровня. Размер строки кэш-памяти составляет 32 байта. Кроме того, в RT625 имеются логические схемы синхронизации, которые обеспечивают интерфейс между внутренней шиной процессора и SPARC MBus при выполнении асинхронных операций.
RT627 представляет собой статическую память 16К ( 32, специально разработанную для удовлетворения требований hyperSPARC. Она организована как четырехканальная статическая память в виде четырех массивов с логикой побайтной записи и входными и выходными регистрами-защелками. RT627 для ЦП является кэш-памятью с нулевым состоянием ожидания без потерь (т.е. приостановок) на конвейеризацию для всех операций загрузки и записи, которые попадают в кэш-память. RT627 был разработан специально для процессора hyperSPARC, таким образом для соединения с RT620 и RT625 не нужны никакие дополнительные схемы.
Набор кристаллов позволяет использовать преимущества тесной связи процессора с кэш-памятью. Конструкция RT620 допускает потерю одного такта в случае промаха в кэш-памяти первого уровня. Для доступа к кэш-памяти второго уровня в RT620 отведена специальная ступень конвейера.
Если происходит промах в кэш-памяти первого уровня, а в кэш- памяти второго уровня имеет место попадание, то центральный процессор не останавливается.
Команды загрузки и записи одновременно генерируют два обращения: одно к кэш-памяти команд первого уровня емкостью 8 Кбайт и другое к кэш-памяти второго уровня. Если адрес команды найден в кэш-памяти первого уровня, то обращение к кэш-памяти второго уровня отменяется и команда становится доступной на стадии декодирования конвейера. Если же во внутренней кэш-памяти произошел промах, а в кэш-памяти второго уровня обнаружено попадание, то команда станет доступной с потерей одного такта, который встроен в конвейер. Такая возможность позволяет конвейеру продолжать непрерывную работу до тех пор, пока имеют место попадания в кэш-память либо первого, либо второго уровня, которые составляют 90% и 98% соответственно для типовых прикладных задач рабочей станции. С целью достижения архитектурного баланса и упрощения обработки исключительных ситуаций целочисленный конвейер и конвейер плавающей точки имеют по пять стадий выполнения операций. Такая конструкция позволяет RT620 обеспечить максимальную пропускную способность, не достижимую в противном случае.
Нагрузка клиента NFS, генерируемая
Рисунок 4.3. Нагрузка клиента NFS, генерируемая бездисковой рабочей станцией 16 Mb SPARC station ELC, работающей под управлением SunOS 4.1.3 и выполняющей инструментальные средства
OpenWindowsDescSet, 1-2-3 и Interleaf.
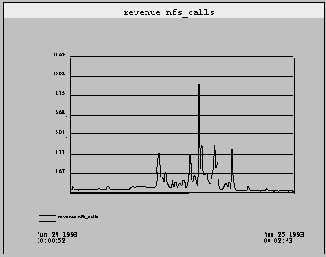
Рисунок 4.3 показывает фрагмент журнала SunNetManager для бездискового клиента - SPARCstation ELC с 16 Мбайт памяти, выполняющей различные инструментальные программы автоматизации офисной деятельности. Относительно ровная нагрузка, отраженная на этом графике, является типичной для большинства клиентов (Lotus 1-2-3, Interleaf 5.3, OpenWindows DeskSet, электронной почты с очень большими файлами). Хотя имеются несколько случаев, когда требуется скорость 40-50 операций в секунду, все они имеют небольшую продолжительность (1-5 секунд). Усредненная по времени результирующая общая нагрузка намного ниже: в данном случае существенно ниже 1 операции в секунду, даже если не учитывать свободные ночные часы. На этом графике интервал измерений составляет 10 минут. Заметим, что это бездисковая система с относительно небольшой памятью. Нагрузка от клиентов, оснащенных дисками и большой оперативной памятью будет еще меньше.
Наконец, рисунок 4.4 показывает, как случайная природа работы различных клиентов приводит к эффекту сглаживания нагрузки на сервер. График показывает нагрузку на сервер двадцати бездисковых клиентов с памятью 16 Мбайт в течение десяти дней.
в течение 10 дней. Этот
Рисунок 4.4. Нагрузка NFS сервера SPARCserver10 в течение 10 дней. Этот сервер обслуживает
20 бездисковых клиентов, в том числе клиента, показанного на рисунке 4.3.

Нестандартные требования к памяти
Нестандартные требования к памяти
Поскольку во многих UNIX-системах (например, в Solaris) реализовано кэширование файлов в виртуальной памяти, большинство пользователей склонны конфигурировать серверы NFS очень большой подсистемой основной памяти. Однако примеры типичного использования файлов клиентами NFS показывают, что данные восстанавливаются из буферного кэша в действительности относительно редко и дополнительная основная память обычно не обязательна.
В типичных серверах предоставляемое клиентам пространство на диске намного превышает размер основной памяти системы. Повторные запросы к блоками данных удовлетворяются скорее путем чтения из памяти, а не с диска. К сожалению, большинство клиентов работает со своими собственными файлами и редко пользуются общими разделяемыми файлами. Более того, большинство приложений обычно читают файл данных целиком в память, а затем закрывают его. В результате клиент редко обращается к первоначальному файлу снова. Если никто из других клиентов не воспользуется тем же самый файлом прежде, чем произойдет перезапись данных в кэш, то это означает, что кэшированные данные никогда снова не используются. Правда какие-либо дополнительные накладные расходы, связанные с кэшированием этих данных и последующим их неиспользованием, отсутствуют. Если требуется память для кэширования других страниц данных, в соответствующие страницы просто происходит запись новых данных. Не обязательно сбрасывать страницу на диск, поскольку представление памяти, которое предстоит сохранить, уже находится на диске. Конечно мало пользы от хранения в памяти старой страницы, которая повторно не используется. Когда объем свободной памяти снижается ниже уровня 1/16 всего объема памяти, страницы, неиспользованные в недавнем прошлом, становятся доступными для повторного использования.
Самым большим исключением из этих эмпирических правил является временный рабочий файл, который часто открывается в начале и закрывается в конце работы. Поскольку файл остается для клиента открытым, страницы данных, связанные с этим файлом, остаются отображенными (и кэшированными) в памяти клиента. Подсистема виртуальной памяти клиента использует сервер в качестве резервного хранилища временного файла. Если клиент не имеет достаточного объема физической памяти для хранения этих страниц в собственном кэше, некоторые или все страницы данных будут откачены или заменены новым содержимым при выполнении последующих операций, а повторные обращения к этим данным будут приводить к выдаче операции чтения NFS для восстановления этих данных. В этом случае способность сервера кэшировать такие данные является определенным преимуществом.
Операции записи не могут использовать все преимущества механизма кэширования UNIX на сервере, поскольку протокол NFS требует, чтобы любая операция записи на удаленный диск выполнялась полностью синхронно, чтобы гарантировать согласованное состояние даже в случае выхода сервера из строя. Операция записи называется синхронной в этом смысле, поскольку логическая операция с диском в целом полностью завершается прежде, чем она будет подтверждена. Хотя данные кэшированы, операции записи NFS не выигрывают от буферизации и откладывания момента записи, которые обычно выполняются при реализации операций записи UNIX. Заметим, что клиент может и обычно выполняет операции записи в кэш точно таким же способом, что и любую другую операцию дискового ввода/вывода. Клиент в любом случае способен контролировать когда результаты операции записи сбрасываются на "диск" независимо от того, является ли диск локальным или удаленным.
Возможно самым простым и наиболее полезным является эмпирическое правило, которое называется "правилом пяти минут". Это правило широко используется при конфигурировании серверов баз данных, значительно большая сложность которых делает очень трудным определение размера кэша. Существующее в настоящее время соотношение между ценами подсистемы памяти и дисковой подсистемы показывает, что экономически целесообразно кэшировать данные, к которым осуществляются обращения более одного раза каждые пять минут.
В заключении приведем несколько простых эмпирических правил, которые позволяют выбрать конфигурацию памяти в серверах NFS:
Если сервер в основном обеспечивает пользовательскими данными многих клиентов, следует конфигурировать относительно минимальную память. Для небольших коллективов обычно ее объем составляет 32 Мбайта, а для больших коллективов - примерно 128 Мбайт. В мультипроцессорных конфигурациях всегда необходимо предусматривать по крайней мере 64 Мбайт на каждый процессор. Приложения с интенсивным использованием атрибутов обычно выигрывают от увеличенного объема памяти несколько больше, чем приложения с интенсивным использованием данных.
Если на сервере выделяется пространство для хранения временных файлов приложений, которые очень интенсивно работают с этими файлами (хорошим примером является Verilog фирмы Cadence), следует конфигурировать память сервера равной примерно сумме размеров активных временных файлов, используемых на сервере. Например, если размер временного файла клиента составляет примерно 5 Мбайт и предполагается, что сервер будет обслуживать 20 полностью активных клиентов, следует установить (20 клиентов х 5 Мбайт) = 100 Мбайт дополнительной памяти (конечно 128 Мбайт представляет собой наиболее удобную цифру, которую легко конфигурировать). Однако часто этот временный файл может быть размещен в локальном справочнике типа /tmp, что приведет к значительно более высокой производительности клиента, а также к существенному уменьшению сетевого трафика.
Если главной задачей сервера является хранение только выполняемых файлов, следует конфигурировать память сервера примерно равной суммарному объему интенсивно используемых двоичных файлов. При этом нельзя забывать о библиотеках! Например, сервер предполагающийся для хранения /usr/openwin для некоторого коллектива сотрудников должен иметь достаточно памяти, чтобы кэшировать Xsun, cmdtool, libX11.so, libxwiew.so и libXt.so. Это приложение NFS значительно отличается от более типового сервера тем, что оно все время поставляет одни и те же файлы всем своим клиентам, а потому способно эффективно кэшировать эти данные. Обычно клиенты не используют каждую страницу всех двоичных кодов, а потому разумно в конфигурации сервера предусмотреть только такой объем памяти, которого достаточно для размещения часто используемых программ и библиотек.
Размер памяти может быть выбран исходя из правила пяти минут: 16 Мбайт для ОС плюс объем памяти для кэширования данных, к которым будут происходить обращения чаще, чем один раз в пять минут.
Поскольку серверы NFS не выполняют пользовательских процессов, большого пространства подкачки (swap) не нужно. Для таких серверов пространства подкачки объемом примерно 50% от размера основной памяти более чем достаточно. Заметим, что большинство этих правил прямо противоположены тому, что все ожидают.
NFS и глобальные сети
NFS и глобальные сети
В реальной жизни часто возникают ситуации, когда клиенты и серверы NFS могут располагаться в разных сетях, объединенных маршрутизаторами. Топология сети может существенно отразиться на ощущаемой пользователем производительности сервера NFS и обеспечиваемого им сервиса. Эффективность обеспечения NFS-сервиса через комплексные сети должна тщательно анализироваться. Но по крайней мере известно, что можно успешно сконфигурировать сети и приложения в глобальных (wide-area) топологиях NFS.
Возможно наиболее важным вопросом в этой ситуации является задержка выполнения операций: время, которое проходит между выдачей запроса и получением ответа. Задержка выполнения операций в локальных сетях не столь критична, поскольку связанные с такими сетями сравнительно короткие расстояния не могут вызвать значительных задержек в среде передачи данных. В глобальных сетях задержки выполнения операций могут происходить просто при транспортировке пакетов из одного пункта в другой. Задержка передачи пакетов складывается из нескольких составляющих:
Задержка маршрутизатора: маршрутизаторы затрачивают некоторое конечное (и часто существенное) время на выполнение собственно маршрутизации пакетов из одной сети в другую. Заметим, что при построении большинства глобальных сетей (даже при прокладке линий между двумя соседними зданиями) используются по крайней мере два маршрутизатора. На рисунке 4.6 представлена топология типичного университетского кампуса, в котором обычно между клиентом и сервером устанавливаются три или даже четыре маршрутизатора.
Задержка передачи по сети: физическая среда, используемая для передачи пакетов через глобальные сети, часто может вносить свою собственную существенную задержку, превосходящую по величине задержку маршрутизаторов. Например, организация спутниковых мостов часто связана с появлением очень больших задержек.
Ошибочные передачи: глобальные сети возможно на порядок величины более восприимчивы к ошибкам передачи, чем большинство локальных сетей.
Эти ошибки вызывают значительный объем повторных пересылок данных, что приводит как к увеличению задержки выполнения операций, так и к снижению эффективной пропускной способности сети. Для сетей, сильно подверженных ошибкам передачи, размер блока данных NFS часто устанавливается равным 1 Кбайт, вместо нормальных 8 Кбайт. Это позволяет сократить объем данных, которые должны повторно передаваться в случае появления ошибки.
Если обеспечивается приемлемый уровень безошибочных передач данных, файловый сервис по глобальным сетям вполне возможен. Наиболее часто в конфигурации таких сетей используются высокоскоростные синхронные последовательные линии связи точка-точка, которые подсоединяются к одной или нескольким локальным сетям на каждом конце. В США такие последовательные линии связи обычно имеют скорость передачи данных 1.544 Мбит/с (линия T1) или 56 Кбит/с. Европейские коммуникационные компании предлагают немного большие скорости: 2.048 Мбит/с (линия E1) или 64 Кбит/с соответственно. Доступны даже более высокоскоростные линии передачи данных. Эти арендуемые линии, известные под названием T3, обеспечивают скорость передачи до 45 Мбит/с (5.3 Мбайт/с). На сегодня большинство линий T3 частично используются для передачи данных.
NFS и клиентские ПК
NFS и клиентские ПК
В отличие от рабочих станций, которые работают под управлением UNIX или VMS, наиболее распространенные операционные системы персональных компьютеров MS-DOS и Windows 3.x не используют одноуровневую виртуальную память для выполнения операций с диском или виртуальных операций дискового ввода/вывода. Системы с одноуровневой виртуальной памятью, подобные Solaris, рассматривают все диски и виртуальный дисковый ввод/вывод как расширение памяти. В результате имеет место тенденция откладывать обращение к диску или сети до тех пор, пока это не окажется абсолютно необходимым. Обычно эта стратегия приводит к более равномерному распределению требований ввода/вывода. В системах с небольшой памятью это иногда приводит к большей активности ввода/вывода, хотя в системах с типовым размером памяти такая стратегия обеспечивает в среднем значительно меньшую общую активность ввода/вывода.
Новые возможности операционных систем
Новые возможности операционных систем
В этой части курса будут рассмотрены некоторые вопросы, актуальные в операционных системах современных аппаратных платформ. Мы обсудим проблемы, связанные с эффективным использованием симметричных мультипроцессорных архитектур, а также состояние и перспективы развития систем управления файлами во внешней памяти.
Обеспечение резервного копирования и устойчивости к неисправностям
Обеспечение резервного копирования и устойчивости к неисправностям
Проблемы резервного копирование файловых систем и обеспечения устойчивости к неисправностям для NFS сервера совпадают с аналогичными проблемами, возникающими при эксплуатации любой другой системы. Некоторые рекомендации по организации резервного копирования и обеспечению устойчивости к неисправностям можно обобщить следующим образом:
Простые, сравнительно небольшие резервные копии могут изготавливаться с помощью одного или двух ленточных накопителей. Местоположение этих накопителей на шине SCSI не имеет особого значения, если они не активны в течение рабочих часов системы.
Создание полностью согласованных резервных копий требует блокировки файловой системы для предотвращения ее модификации. Для выполнения таких операций необходимы специальные программные средства, подобные продукту Online:Backup 2.0. Как и в предыдущем случае, местоположение устройств резервного копирования на шинах SCSI не имеет особого значения, если само копирование выполняется вне рабочего времени.
Зеркалированные файловые системы дают возможность пережить полные отказы дисков и, кроме того, обеспечивают возможность непрерывного доступа к системе даже во время создания полностью согласованных резервных копий. Зеркалирование приводит к очень небольшим потерям пропускной способности дисков на операциях записи (максимально на 7-8% при произвольном, и на 15-20% при последовательном доступе; в системах с большим числом пользователей, каковыми являются большинство серверов, можно надеяться, что эти цифры уменьшатся вдвое). Зеркалирование автоматически улучшает пропускную способность при выполнении операций чтения.
При создании зеркалированных файловых систем каждое зеркало должно конфигурироваться на отдельной шине SCSI.
Если резервное копирование должно выполняться в течение обычных рабочих часов системы, то устройство копирования должно конфигурироваться либо на своей собственной шине SCSI, либо на той же шине SCSI, что и выключенное из работы зеркало (отдельное и неактивное), чтобы обойти ряд проблем с обеспечением заданного времени ответа.
Когда требуется быстрое восстановление файловой системы в среде с интенсивным использованием атрибутов следует предусмотреть в конфигурации NVRAM.
В среде с интенсивным использованием данных необходимо исследовать возможность применения высокоскоростных механических устройств типа стэккеров лент и устройств массовой памяти.
Обобщение методов оптимизации кэш-памяти
Рисунок 5.38. Обобщение методов оптимизации кэш-памяти
При промахе во время записи имеются две дополнительные возможности:
разместить запись в кэш-памяти (write allocate) (называется также выборкой при записи (fetch on write)). Блок загружается в кэш-память, вслед за чем выполняются действия аналогичные выполняющимся при выполнении записи с попаданием. Это похоже на промах при чтении.
не размещать запись в кэш-памяти (называется также записью в окружение (write around)). Блок модифицируется на более низком уровне и не загружается в кэш-память.
Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Обработка команд перехода
Обработка команд перехода
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Одним из типов конфликтов, с которыми приходится иметь дело разработчикам высокопроизводительных процессоров, являются конфликты по управлению, которые возникают при конвейеризации команд перехода и других команд, изменяющих значение счетчика команд.
Конфликты по управлению могут вызывать даже большие потери производительности суперскалярного процессора, чем конфликты по данным. По статистике среди команд управления, меняющих значение счетчика команд, преобладают команды условного перехода. Таким образом, снижение потерь от условных переходов становится критически важным вопросом. Имеется несколько методов сокращения приостановок конвейера, возникающих из-за задержек выполнения условных переходов. В процессоре R10000 используются два наиболее мощных метода динамической оптимизации выполнения условных переходов: аппаратное прогнозирование направления условных переходов и "выполнение по предположению" (speculation).
Устройство переходов процессора R10000 может декодировать и выполнять только по одной команде перехода в каждом такте. Поскольку за каждой командой перехода следует слот задержки, максимально могут быть одновременно выбраны две команды перехода, но только одна более ранняя команда перехода может декодироваться в данный момент времени. Во время декодирования команд к каждой команде добавляется бит признака перехода. Эти биты используются для пометки команд перехода в конвейере выборки команд.
Направление условного перехода прогнозируется с помощью специальной памяти (branch history table) емкостью 512 строк, которая хранит историю выполнения переходов в прошлом. Обращение к этой таблице осуществляется с помощью адреса команды во время ее выборки.
Двухбитовый код прогноза в этой памяти обновляется каждый раз, когда принято окончательное решение о направлении перехода. Моделирование показало, что точность двухбитовой схемы прогнозирования для тестового пакета программ SPEC составляет 87%.
Все команды, выбранные вслед за командой условного перехода, считаются выполняемыми по предположению (условно). Это означает, что в момент их выборки заранее не известно, будет ли завершено их выполнение. Процессор допускает предварительную обработку и прогнозирование направления четырех команд условного перехода, которые могут разрешаться в произвольном порядке. При этом для каждой выполняемой по предположению команды условного перехода в специальный стек переходов записывается информация, необходимая для восстановления состояния процессора в случае, если направление перехода было предсказано неверно. Стек переходов имеет глубину в 4 элемента и позволяет в случае необходимости быстро и эффективно (за один такт) восстановить конвейер.
Обработка многотактных операций и механизмы обходов в длинных конвейерах
Обработка многотактных операций и механизмы обходов в длинных конвейерах
В рассмотренном нами конвейере стадия выполнения команды (EX) составляла всего один такт, что вполне приемлемо для целочисленных операций. Однако для большинства операций плавающей точки было бы непрактично требовать, чтобы все они выполнялись за один или даже за два такта. Это привело бы к существенному увеличению такта синхронизации конвейера, либо к сверхмерному увеличению количества оборудования (объема логических схем) для реализации устройств плавающей точки. Проще всего представить, что команды плавающей точки используют тот же самый конвейер, что и целочисленные команды, но с двумя важными изменениями. Во-первых, такт EX может повторяться многократно столько раз, сколько необходимо для выполнения операции. Во-вторых, в процессоре может быть несколько функциональных устройств, реализующих операции плавающей точки. При этом могут возникать приостановки конвейера, если выданная для выполнения команда либо вызывает структурный конфликт по функциональному устройству, которое она использует, либо существует конфликт по данным.
Общие положения
Общие положения
Основная память представляет собой следующий уровень иерархии памяти. Основная память удовлетворяет запросы кэш-памяти и служит в качестве интерфейса ввода/вывода, поскольку является местом назначения для ввода и источником для вывода. Для оценки производительности основной памяти используются два основных параметра: задержка и полоса пропускания. Традиционно задержка основной памяти имеет отношение к кэш-памяти, а полоса пропускания или пропускная способность относится к вводу/выводу. В связи с ростом популярности кэш-памяти второго уровня и увеличением размеров блоков у такой кэш-памяти, полоса пропускания основной памяти становится важной также и для кэш-памяти.
Задержка памяти традиционно оценивается двумя параметрами: временем доступа (access time) и длительностью цикла памяти (cycle time). Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Основная память современных компьютеров реализуется на микросхемах статических и динамических ЗУПВ (Запоминающее Устройство с Произвольной Выборкой). Микросхемы статических ЗУВП (СЗУПВ) имеют меньшее время доступа и не требуют циклов регенерации. Микросхемы динамических ЗУПВ (ДЗУПВ) характеризуются большей емкостью и меньшей стоимостью, но требуют схем регенерации и имеют значительно большее время доступа.
В процессе развития ДЗУВП с ростом их емкости основным вопросом стоимости таких микросхем был вопрос о количестве адресных линий и стоимости соответствующего корпуса. В те годы было принято решение о необходимости мультиплексирования адресных линий, позволившее сократить наполовину количество контактов корпуса, необходимых для передачи адреса. Поэтому обращение к ДЗУВП обычно происходит в два этапа: первый этап начинается с выдачи сигнала RAS - row-access strobe (строб адреса строки), который фиксирует в микросхеме поступивший адрес строки, второй этап включает переключение адреса для указания адреса столбца и подачу сигнала CAS - column-access stobe (строб адреса столбца), который фиксирует этот адрес и разрешает работу выходных буферов микросхемы.
Названия этих сигналов связаны с внутренней организацией микросхемы, которая как правило представляет собой прямоугольную матрицу, к элементам которой можно адресоваться с помощью указания адреса строки и адреса столбца.
Дополнительным требованием организации ДЗУВП является необходимость периодической регенерации ее состояния. При этом все биты в строке могут регенерироваться одновременно, например, путем чтения этой строки. Поэтому ко всем строкам всех микросхем ДЗУПВ основной памяти компьютера должны прозводиться периодические обращения в пределах определенного временного интервала порядка 8 миллисекунд.
Это требование кроме всего прочего означает, что система основной памяти компьютера оказывается иногда недоступной процессору, так как она вынуждена рассылать сигналы регенерации каждой микросхеме. Разработчики ДЗУПВ стараются поддерживать время, затрачиваемое на регенерацию, на уровне менее 5% общего времени. Обычно контроллеры памяти включают в свой состав аппаратуру для периодической регенерации ДЗУПВ.
В отличие от динамических, статические ЗУПВ не требуют регенерации и время доступа к ним совпадает с длительностью цикла. Для микросхем, использующих примерно одну и ту же технологию, емкость ДЗУВП по грубым оценкам в 4 - 8 раз превышает емкость СЗУПВ, но последние имеют в 8 - 16 раз меньшую длительность цикла и большую стоимость. По этим причинам в основной памяти практически любого компьютера, проданного после 1975 года, использовались полупроводниковые микросхемы ДЗУПВ (для построения кэш-памяти при этом применялись СЗУПВ). Естественно были и исключения, например, в оперативной памяти суперкомпьютеров компании Cray Research использовались микросхемы СЗУПВ.
Для обеспечения сбалансированности системы с ростом скорости процессоров должна линейно расти и емкость основной памяти. В последние годы емкость микросхем динамической памяти учетверялась каждые три года, увеличиваясь примерно на 60% в год. К сожалению скорость этих схем за этот же период росла гораздо меньшими темпами (примерно на 7% в год).
В то же время производительность процессоров начиная с 1987 года практически увеличивалась на 50% в год. На рисунке 5.39 представлены основные временные параметры различных поколений ДЗУПВ.
Очевидно, согласование производительности современных процессоров со скоростью основной памяти вычислительных систем остается на сегодняшний день одной из важнейших проблем. Приведенные в предыдущем разделе методы повышения производительности за счет увеличения размеров кэш-памяти и введения многоуровневой организации кэш-памяти могут оказаться не достаточно эффективными с точки зрения стоимости систем. Поэтому важным направлением современных разработок являются методы повышения полосы пропускания или пропускной способности памяти за счет ее организации, включая специальные методы организации ДЗУПВ.
| Год появления | Емкость кристалла |
Длительность RAS | Длительность CAS | Время цикла | Оптими-зированный режим |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| max | min | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1980 1983 1986 1989 1992 1995? |
64 Кбит 256 Кбит 1 Мбит 4 Мбит 16 Мбит 64 Мбит |
180 нс 150 нс 120 нс 100 нс 80 нс 65 нс |
150 нс 120 нс 100 нс 80 нс 60 нс 45 нс |
75 нс 50 нс 25 нс 20 нс 15 нс 10 нс |
250 нс 220 нс 190 нс 165 нс 120 нс 100 нс |
150 нс 100 нс 50 нс 40 нс 30 нс 20 нс |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Общие сведения о работе и нагрузке NFS
Общие сведения о работе и нагрузке NFS
По крайней мере на системах Sun чистые серверы NFS представляют собой наиболее простые для конфигурирования широкомасштабные серверы, главным образом потому, что они работают с одним и тем же кодом операционной системы (имеется только одна реализация сервера NFS, которую можно найти на Sun, поскольку она представляет собой связанный с операционной системой продукт). Более того, сами по себе сервисы NFS относительно просты, так как NFS выполняет всего 18 операций, которые своей семантикой ограничены размещением удаленных файлов и обеспечением к ним доступа. Они намного менее сложны, например, по сравнению с сервисами реляционной базы данных, где имеются более 75 операций, определенных стандартом SQL, причем эти операции применяются к сложному набору единиц данных, которые включают структурные отношения. NFS решает только часть этих проблем и поэтому гораздо проще.
Ниже в таблице 3.1 представлены 18 операций NFS. Шесть из них являются основными и представляют громадное большинство реально выполняемых операций как по количеству, так и по потреблению ресурсов: getattr, setattr, lookup, readlink, read и write. Эти операции реализуют поиск и модификацию атрибутов файла, поиск имени файла, разрешение символических связей, а также чтение и запись данных соответственно. Можно явно выделить два принципиально разных набора операций: в частности, операции read и write манипулируют действительным содержимым файла, в то время как другие операции манипулируют атрибутами файлов. Отличия между этими наборами операций определяются прежде всего типом нагрузки, которая ложится при выполнении соответствующего запроса на серверные и сетевые ресурсы системы.
Общие свойства распределенных файловых систем
Общие свойства распределенных файловых систем
Традиционная централизованная файловая система позволяет множеству пользователей, работающих на одной системе, разделять доступ к файлам, хранящихся локально на этой машине. Распределенная файловая система расширяет эти возможности, позволяя разделять доступ к файлам пользователям на разных машинах, объединенных между собой с помощью сети. В основе распределенных файловых систем лежит модель клиент-сервер. В данном случае под клиентом понимается машина, которая обращается к некоторому файлу, а под сервером - машина, хранящая файлы и обеспечивающая к ним доступ. Некоторые системы требуют, чтобы клиенты и серверы были разными машинами, в то время как другие допускают, чтобы одна машина работала и как клиент, и как сервер.
Важно отметить различие между распределенными файловыми системами и распределенными операционными системами. Распределенная операционная система, подобная V или Amoeba, для пользователя выглядит как централизованная операционная система, но работает одновременно на нескольких машинах. Она может иметь файловую систему, которая разделяется всеми машинами системы. В отличие от них, распределенная файловая система представляет собой определенный слой программного обеспечения, который управляет связью между традиционными операционными системами и файловыми системами. Этот слой программных средств интегрируется с операционными системами мащин-хостов сети и обеспечивает сервис распределенного доступа к файлам для систем, которые имеют централизованное ядро.
Распределенные файловые системы имеют ряд важных свойств. Каждая конкретная система может обладать всеми или частью этих свойств. Это как раз и создает основу для сравнения различных архитектур между собой.
Сетевая прозрачность - Клиенты должны иметь возможность обращаться к удаленным файлам пользуясь теми же самыми операциями, что и для доступа к локальным файлам.
Прозрачность размещения - Имя файла не должно определять его местоположения в сети.
Независимость размещения - Имя файла не должно меняться при изменении его физического меторасположения.
Мобильность пользователя - Пользователи должны иметь возможность обращаться к разделяемым файлам из любого узла сети.
Устойчивость к сбоям - Система должна продолжать функционировать при неисправности отдельного компонента (сервера или сегмента сети). Однако это может приводить к деградации производительности или к исключению доступа к некоторой части файловой системы.
Масштабируемость - Система должна обладать возможностью масштабирования в случае увеличения нагрузки. Кроме того, должна существовать возможность постепенного наращивания системы путем добавления отдельных компонентов.
Мобильность файлов - Должна быть возможность перемещения файлов из одного месторасположения в другое на работающей системе.
Общие замечания
Общие замечания
Основу для сравнения различных типов компьютеров между собой дают стандартные методики измерения производительности. В процессе развития вычислительной техники появилось несколько таких стандартных методик. Они позволяют разработчикам и пользователям осуществлять выбор между альтернативами на основе количественных показателей, что дает возможность постоянного прогресса в данной области.
Единицей измерения производительности компьютера является время: компьютер, выполняющий тот же объем работы за меньшее время является более быстрым. Время выполнения любой программы измеряется в секундах. Часто производительность измеряется как скорость появления некоторого числа событий в секунду, так что меньшее время подразумевает большую производительность.
Однако в зависимости от того, что мы считаем, время может быть определено различными способами. Наиболее простой способ определения времени называется астрономическим временем, временем ответа (response time), временем выполнения(execution time) или прошедшим временем (elapsed time). Это задержка выполнения задания, включающая буквально все: работу процессора, обращения к диску, обращения к памяти, ввод/вывод и накладные расходы операционной системы. Однако при работе в мультипрограммном режиме во время ожидания ввода/вывода для одной программы, процессор может выполнять другую программу, и система не обязательно будет минимизировать время выполнения данной конкретной программы.
Для измерения времени работы процессора на данной программе используется специальный параметр - время ЦП (CPU time), которое не включает время ожидания ввода/вывода или время выполнения другой программы. Очевидно, что время ответа, видимое пользователем, является полным временем выполнения программы, а не временем ЦП. Время ЦП может далее делиться на время, потраченное ЦП непосредственно на выполнение программы пользователя и называемое пользовательским временем ЦП, и время ЦП, затраченное операционной системой на выполнение заданий, затребованных программой, и называемое системным временем ЦП.
В ряде случаев системное время ЦП игнорируется из-за возможной неточности измерений, выполняемых самой операционной системой, а также из-за проблем, связанных со сравнением производительности машин с разными операционными системами. С другой стороны, системный код на некоторых машинах является пользовательским кодом на других и, кроме того, практически никакая программа не может работать без некоторой операционной системы. Поэтому при измерениях производительности процессора часто используется сумма пользовательского и системного времени ЦП.
В большинстве современных процессоров скорость протекания процессов взаимодействия внутренних функциональных устройств определяется не естественными задержками в этих устройствах, а задается единой системой синхросигналов, вырабатываемых некоторым генератором тактовых импульсов, как правило, работающим с постоянной скоростью. Дискретные временные события называются тактами синхронизации (clock ticks), просто тактами (ticks), периодами синхронизации (clock periods), циклами (cycles) или циклами синхронизации (clock cycles).Разработчики компьютеров обычно говорят о периоде синхронизации, который определяется либо своей длительностью (например, 10 наносекунд), либо частотой (например, 100 МГц). Длительность периода синхронизации есть величина, обратная к частоте синхронизации.
Таким образом, время ЦП для некоторой программы может быть выражено двумя способами: количеством тактов синхронизации для данной программы, умноженным на длительность такта синхронизации, либо количеством тактов синхронизации для данной программы, деленным на частоту синхронизации.
Важной характеристикой, часто публикуемой в отчетах по процессорам, является среднее количество тактов синхронизации на одну команду - CPI (clock cycles per instruction). При известном количестве выполняемых команд в программе этот параметр позволяет быстро оценить время ЦП для данной программы.
Таким образом, производительность ЦП зависит от трех параметров: такта (или частоты) синхронизации, среднего количества тактов на команду и количества выполняемых команд. Невозможно изменить ни один из указанных параметров изолированно от другого, поскольку базовые технологии, используемые для изменения каждого из этих параметров, взаимосвязаны: частота синхронизации определяется технологией аппаратных средств и функциональной организацией процессора; среднее количество тактов на команду зависит от функциональной организации и архитектуры системы команд; а количество выполняемых в программе команд определяется архитектурой системы команд и технологией компиляторов. Когда сравниваются две машины, необходимо рассматривать все три компоненты, чтобы понять относительную производительность.
В процессе поиска стандартной единицы измерения производительности компьютеров было принято несколько популярных единиц измерения, вследствие чего несколько безвредных терминов были искусственно вырваны из их хорошо определенного контекста и использованы там, для чего они никогда не предназначались. В действительности единственной подходящей и надежной единицей измерения производительности является время выполнения реальных программ, и все предлагаемые замены этого времени в качестве единицы измерения или замены реальных программ в качестве объектов измерения на синтетические программы только вводят в заблуждение.
Опасности некоторых популярных альтернативных единиц измерения (MIPS и MFLOPS) будут рассмотрены в соответствующих подразделах.
Оценка нагрузки в отсутствие системы
Оценка нагрузки в отсутствие системы
Если для проведения измерений существующая система не доступна, часто оказывается возможной примерная оценка, основанная на предполагаемом использовании системы. Выполнение такой оценки требует понимания того, каким объемом данных будет манипулировать клиент. Этот метод достаточно точен, если приложение попадает в категорию систем с интенсивным использованием данных. Некоторая разумная оценка обычно может быть также сделана и для среды с интенсивным использованием атрибутов, но множество факторов делает такую оценку несколько менее точной.
Оценка среды с интенсивным использованием атрибутов
Оценка среды с интенсивным использованием атрибутов
В предыдущем примере предполагалось, что нагрузка NFS от операций с атрибутами была пренебрежимо мала по сравнению с операциями с данными. Если же это не так, например, в среде разработки программного обеспечения, необходимо сделать некоторые предположения относительно предполагаемой смеси команд NFS. В отсутствии другой информации, в качестве образца можно принять, например, так называемую смесь Legato. В тесте SPECsfs_097 (известной также под названием LADDIS) используется именно эта смесь, в которой операции с данными включают 22% операций чтения и 15% операций записи.
Рассмотрим клиентскую рабочую станцию, наиболее интенсивная работа которой связана с перекомпиляцией программной системы, состоящей из исходного кода объемом 25 Мбайт. Известно, что рабочие станции могут скомпилировать систему примерно за 30 минут. В процессе компиляции генерируется примерно 18 Мбайт промежуточного объектного кода и двоичные коды. Из этой информации мы можем заключить, что клиентская система будет записывать на сервер 18 Мбайт и читать по крайней мере 25 Мбайт (возможно больше, поскольку почти треть исходного кода состоит из файлов заголовков, которые включены посредством множества исходных модулей). Для предотвращения повторного чтения этих файлов включений может использоваться кэширующая файловая система. Предположим, что используется CFS. Во время "конструирования" необходимо передать 33 Мбайт действительных данных, или 33 Мb х 125 ops/Mb = 4125 операций с данными за 30 минут (1800 секунд), что примерно соответствует скорости 2.3 ops/sec. (Здесь предполагается, что каждая операция выполняется с данными объемом 8 Kb, поэтому для пересылки 1 Mb данных требуется 125 операций). Поскольку эта работа связана с интенсивным использованием атрибутов, необходимо оценить существенное количество промахивающихся операций с атрибутами. Предположив, что смесь операций соответствует смеси Legato, общая скорость будет примерно равна:
Объем читаемых данных * 125
NFSops/sec = или
22%
Объем записываемых данных * 125
NFSops/sec = .
15%
В данном случае скорость равна: (25 Мb по чтению х 125ops/Mb) / 22% / 1800 секунд, или 7.89 ops/sec. Для проверки мы также имеем (18 Мb по записи х 125 ops/Mb) / 15% / 1800 секунд, или 8.33 ops/sec. В данном случае соотношение операций чтения и записи очень похоже на смесь Legato, но это может быть и не так, например, если были открыты файлы программы просмотра исходного текста (размер файлов программы просмотра исходного текста (source brouser files) часто в 4-6 раз превосходит размер исходного кода). В этом случае у нас нет способа оценки пиковой нагрузки.
Если имеются двадцать рабочих станций, работающие в описанном выше режиме, мы можем составить следующие заключения:
Даже при совершенно невероятном условии, когда все двадцать рабочих станций полностью активны все время, общая скорость запросов составляет 8.33 ops/sec x 20 клиентов, или 166 ops/sec, т.е. ниже максимума в 200 ops/sec, который поддерживает Ethernet. Осторожные люди сконфигурируют для такой нагрузки две сети, но если материально-технические соображения заранее это исключают, то и одной сети вероятно будет достаточно.
Поскольку нагрузка относительно легкая, система SPARCstation 10 Model 40 оказывается более, чем адекватной. (Даже в самом плохом случае, имеются только две сети). Процессорной мощности системы SPARCclassic также обычно вполне достаточно.
Хотя общее количество данных очень невелико (25 Мбайт исходного кода и 18 Мбайт объектного кода; даже двадцать полных копий составляют только 660 Мбайт), то в рекомендуемую конфигурацию дисков можно включить два диска по 535 Мбайт. В предположении, что используется CFS, может быть достаточно и одного диска, поскольку файлы заголовков не будут часто читаться с сервера (они будут кэшироваться клиентами).
При одном или двух дисках данных одной шины SCSI полностью достаточно.
Объем данных очень маленький и большинство из них будут читаться и пересылаться многим клиентам многократно, поэтому конечно стоит сконфигурировать достаточно памяти, чтобы все эти данные кэшировать: 16 Мбайт базовой памяти под ОС, плюс 25 Мбайт для кэширования исходных кодов в конфигурации 48-64 Мбайт.
Поскольку в этой среде операции записи достаточно часты, NVSIMM или PrestoServe являются существенными.
Для окончательного варианта системы можно выбрать либо станцию начального уровня SPARCstation 10, либо хорошо сконфигурированную станцию SPARCclassic. Для контроля с точки зрения здравого смысла заметим, что максимальная скорость запросов в 166 ops/sec на 75% меньше показателей SPARCclassic (236 ops/sec) на тесте LADDIS (вспомните, что скорость 166 ops/sec предполагала, что все 20 клиентов полностью активны все время, хотя реальные журналы использования систем показывают, что этого никогда не бывает); Максимальная требуемая нагрузка наполовину меньше той, которую показывает SPARCstation 10 Model 40 на тесте LADDIS (411 ops/sec). Сравнение с показателем LADDIS соответствует ситуациям с интенсивным использованием атрибутов, поскольку результаты LADDIS используют интенсивную по атрибутам смесь операций.
Оценка среды с интенсивным использованием данных
Оценка среды с интенсивным использованием данных
Первый шаг для получения такой оценки заключается в определении полностью активного запроса типового клиента. Для этого необходимо понимание поведения клиента. Если нагрузка интенсивная по данным, то имеет смысл просто просуммировать количество предполагаемых операций чтения и записи и взять это число в качестве нагрузки для каждого клиента. Операции с атрибутами обычно являются несущественными для рабочей нагрузки, в которой доминируют операции с данными (с одной стороны, они составляют лишь небольшой процент всех операций, а с другой стороны, эти операции задают серверу минимальное количество работы по сравнению с объемом работы, который необходимо выполнить для выборки данных).
Например, рассмотрим клиентскую рабочую станцию, выполняющую приложение, которое осуществляет поиск областей с заданной температурой в некотором объеме жидкости. Типовой набор данных для решения этой задачи составляет 400 Мбайт. Обычно он читается порциями по 50 Мбайт. Каждая порция проходит полную обработку прежде, чем приложение переходит к следующей. Обработка каждого сегмента занимает примерно 5 минут времени ЦП, а результирующие файлы, которые записываются на диск имеют размер около 1 Мбайта. Предположим, что в качестве сетевой среды используется FDDI. Максимальная нагрузка на NFS будет возникать, когда клиент читает каждую порцию объемом 50 Мбайт. При максимальной скорости 2.5 Мбайт/с клиент будет полностью активным примерно в течение двадцати секунд, выполняя 320 операций чтения в секунду. Поскольку каждый запуск программы занимает примерно 40 минут (или 2400 секунд) времени, и на один прогон требуется (400 + 1) Мb х 125 ops/Mb = 50,125 ops, средняя скорость равна примерно 20 ops/sec. Сервер должен будет обеспечивать обслуживание пиковой скорости запросов (320 ops/sec) в течение примерно 20 секунд из каждых 5 минут, или примерно в течение 7% времени. Из этого упражнения можно извлечь три порции полезной информации: среднюю скорость активных запросов (20 ops/sec), пиковую скорость запросов (320 ops/sec) и вероятность того, что пиковая скорость требуется.
На базе этой информации может быть сформирована оценка общей скорости запросов. Если в конфигурации системы будет 10 клиентов, то средняя скорость запросов составит 200 ops/sec. (Эту скорость не следует сравнивать с результатами теста LADDIS, поскольку в данном случае смеси операций очень отличаются). Вероятность того, что два клиента будут требовать работы с пиковой скоростью одновременно составляет примерно 0.07 х 0.07 = 0.049, или примерно 5%, а три клиента будут требовать пикового обслуживания только в течение 0.034% времени. Таким образом, из этой информации разумно вывести следующие заключения:
Поскольку вероятность того, что три клиента будут одновременно активными, намного меньше 1%, максимальная нагрузка будет превышать индивидуальную пиковую нагрузку в 2-3 раза.
Требуется только одна сеть, поскольку максимальная предполагаемая нагрузка составляет только 3 х 2.5 Mb/sec = 7.5 MB/s, т.е. намного ниже максимальной полосы пропускания сети FDDI (12.5 MB/sec).
Поскольку в любой момент времени полностью активными будут только два или три клиента, требуется по крайней мере от 3 до 6 дисковых накопителей (хотя для типовых файлов размером по 400 MB очень вероятно, что потребуется более 6 дисков просто для хранения данных).
Требуется по крайней мере два главных адаптера SCSI.
Поскольку в состав системы входит одна высокоскоростная сеть, то рекомендуется использовать сервер с двумя процессорами SuperSPARC/SuperCashe.
Поскольку маловероятно, что очень большой кэш файлов окажется полезным для работы такого сервера, требуется минимальный объем основной памяти - 128 Мбайт вполне достаточно.
Если требуется сравнительно небольшая ферма дисков, например, объемом около 16 Гбайт, то система SPARCstation 10 Model 512 очень хорошо сможет справиться с этой задачей, поскольку один слот SBus требуется для интерфейса FDDI, а оставшиеся три слота могут использоваться для установки главных адаптеров SCSI, чтобы обеспечить в общей сложности 4 интерфейса FSBE/S, к каждому из которых подключается дисковые накопители общей емкостью по 4.2 Гбайт.
Однако для этого приложения может лучше подойти система SPARCserver 1000, которая обеспечит большую емкость памяти: система с двумя системными платами позволяет создать конфигурацию с семью главными адаптерами SCSI и емкостью дисковой памяти более 28 Гбайт (по одному многодисковому устройству емкостью 4.2 Гбайт на каждую плату FSBE/S, не считая четырех встроенных дисков емкостью по 535 Мбайт). В случае, если потребуется большая емкость дисков, можно сконфигурировать систему SPARCcenter 2000 с двумя системными платами, чтобы обеспечить реализацию шести интерфейсов DWI/S и до 12 шасси с дисками емкостью по 2.9 Гбайт - примерно 208 Гбайт памяти.
Во все предлагаемые системы можно установить NVSIMM без использования слотов SBus, и все они легко поддерживают установку двух требуемых процессоров. Использование NVSIMM вообще не очень важно, поскольку пропорция операций записи слишком мала (меньше, чем 1:400, или 0.25%).
Заметим, что при выборе конфигурации системы для приложений с интенсивным использованием данных вообще говоря не очень полезно сравнивать предполагаемые скорости запросов с рейтингом предполагаемого сервера по SPECsfs_097, поскольку смеси операций отличаются настолько, что нагрузки нельзя сравнивать. К счастью, такая оценка обычно оказывается достаточно точной.
Очередь целочисленных команд
Очередь целочисленных команд
Очередь целочисленных команд содержит 16 строк и выдает команды в два арифметико-логических устройства. Целочисленные команды поступают в свободные строки этой очереди, причем в каждом такте в нее могут записываться до 4 команд. Целочисленные команды остаются в очереди до тех пор, пока они не будут выданы в одно из АЛУ.
Очередь команд плавающей точки
Очередь команд плавающей точки
Очередь команд плавающей точки также содержит 16 строк и выдает команды в исполнительные устройства сложения и умножения с плавающей точкой. Команды плавающей точки поступают в свободные строки очереди, причем в каждом такте в нее могут записываться до 4 команд. Команды остаются в очереди до тех пор, пока они не будут выданы в одно из исполнительных устройств. Очередь команд плавающей точки содержит также логику управления команд типа "умножить-сложить". Эта команда сначала направляется в устройство умножения, а затем прямо в устройство сложения.
Одновременная выдача нескольких команд для выполнения и динамическое планирование
Одновременная выдача нескольких команд для выполнения и динамическое планирование
Методы минимизации приостановок работы конвейера из-за наличия в программах логических зависимостей по данным и по управлению, рассмотренные в предыдущих разделах, были нацелены на достижение идеального CPI (среднего количества тактов на выполнение команды в конвейере), равного 1. Чтобы еще больше повысить производительность процессора необходимо сделать CPI меньшим, чем 1. Однако этого нельзя добиться, если в одном такте выдается на выполнение только одна команда. Следовательно необходима параллельная выдача нескольких команд в каждом такте. Существуют два типа подобного рода машин: суперскалярные машины и VLIW-машины (машины с очень длинным командным словом). Суперскалярные машины могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. В отличие от суперскалярных машин, VLIW-машины выдают на выполнение фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором.
Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств. Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд, прогнозирование переходов, кэши целевых адресов переходов и условное (по предположению) выполнение команд. Возросшая сложность, реализуемая этими механизмами, создает также проблемы реализации точного прерывания.
В типичной суперскалярной машине аппаратура может осуществлять выдачу от одной до восьми команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти.
Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор, а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд.
Предположим, что машина может выдавать на выполнение две команды в одном такте. Одной из таких команд может быть команда загрузки регистров из памяти, записи регистров в память, команда переходов, операции целочисленного АЛУ, а другой может быть любая операция плавающей точки. Параллельная выдача целочисленной операции и операции с плавающей точкой намного проще, чем выдача двух произвольных команд. В реальных системах (например, в микропроцессорах PA7100, hyperSPARC, Pentium и др.) применяется именно такой подход. В более мощных микропроцессорах (например, MIPS R10000, UltraSPARC, PowerPC 620 и др.) реализована выдача до четырех команд в одном такте.
Выдача двух команд в каждом такте требует одновременной выборки и декодирования по крайней мере 64 бит. Чтобы упростить декодирование можно потребовать, чтобы команды располагались в памяти парами и были выровнены по 64-битовым границам. В противном случае необходимо анализировать команды в процессе выборки и, возможно, менять их местами в момент пересылки в целочисленное устройство и в устройство ПТ. При этом возникают дополнительные требования к схемам обнаружения конфликтов. В любом случае вторая команда может выдаваться, только если может быть выдана на выполнение первая команда. Аппаратура принимает такие решения в динамике, обеспечивая выдачу только первой команды, если условия для одновременной выдачи двух команд не соблюдаются. На рисунке 5.32 представлена диаграмма работы подобного конвейера в идеальном случае, когда в каждом такте на выполнение выдается пара команд.
Такой конвейер позволяет существенно увеличить скорость выдачи команд. Однако чтобы он смог так работать, необходимо иметь либо полностью конвейеризованные устройства плавающей точки, либо соответствующее число независимых функциональных устройств. В противном случае устройство плавающей точки станет узким горлом и эффект, достигнутый за счет выдачи в каждом такте пары команд, сведется к минимуму.
| Тип команды | Ступень конвейера | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда ПТ | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| КомандаПТ | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда ПТ | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целочисленная команда | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда ПТ | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ограничения традиционных файловых систем
Ограничения традиционных файловых систем
При работе с внешней памятью мы по-прежнему в основном имеем дело с магнитными дисками с подвижными головками. Если несколько лет тому назад казалось, что это временное явление, и что наступит такое время, когда электро-механические задержки доступа к внешней памяти скоро исчезнут, то теперь уже понятна устойчивость таких устройств, сопровождаемая постоянным снижением их стоимости. В чем состоит проблема?
На практике наиболее распространена последовательная работа с файлами. Если требуется произвести последовательный просмотр файла, хранящегося на магнитном диске с подвижными головками, то основные задержки создают именно электро-механическом действия, связанные с перемещением магнитных головок. Известно, что в среднем время движения головок на два порядка превышает время двух последующих актов - ожидания подкрутки диска до нужного блока (тоже долго, но не так) и собственно выполнения обмена (это как раз достаточно быстро, и чем дальше, тем быстрее по мере развития технологии магнитных носителей; к сожалению заставить быстро двигаться пакеты магнитных головок не так легко).
Основной неприятностью традиционных файловых систем являлось хаотическое распределение внешней памяти. Один блок внешней памяти файла мог отстоять на произвольное количество цилиндров, т.е. элементов передвижения головок. Коренной перелом произошел в так называемой "быстрой файловой системе", разработанной Кирком МакКусиком в рамках проекта BSD 4.3. МакКусик решил, что лучше головкам магнитного диска двигаться не слишком сильно. Поэтому было введено понятие группы магнитных цилиндров, в пределах которых должен располагаться файл. Вместо произвольного передвижения магнитных головок в масштабе всей поверхности диска для последовательного чтения файла требуется ограниченное смещение головок в выделенной группе цилиндров. Но это не решает всех проблем.
Появились устройства с магнитными дисками, предъявляющие внешнему миру интерфейс с 24 магнитными головками в то время, когда на самом деле (физически) их было 15. И что же теперь оптимизируется? Аппаратура и встроенное программное обеспечение контроллеров магнитных дисков сами производят собственную оптимизацию, а файловая система считает, что все уже оптимизировано. Еще хуже дела стали с появлением дисковых массивов, особенно начиная с пятого уровня организации. RAID обеспечивает надежное хранение данных с 90-процентной гарантией и разделенное хранение блока данных на всех дисках, входящих в массив. Что же теперь оптимизируют операционная система по отношению к доступу к файлам? Это одна из основных проблем современных файловых систем; она не решена, и не ясно, будет ли решена в ближайшее время. Тем не менее, файловые системы развиваются, и мы далее приведем обзор наиболее интересных существующих файловых систем (из мира UNIX) и некоторые примеры перспективных файловых систем.
Операции с атрибутами
Операции с атрибутами
Операции с атрибутами создают для системы намного меньшую нагрузку, чем операции с данными. Поскольку размер атрибутов файла очень мал (пара сотен байтов на файл), большинство атрибутов файловой системы, связанных с активными файлами, будет буферизоваться (кэшироваться) в основной памяти сервера. Даже если атрибуты файла не кэшируются, они просто отыскиваются и читаются с диска. После того как атрибуты файла выбраны сервером для какого-либо клиента, обслуживание любого запроса к этим атрибутам заключается лишь в манипулировании битами кэшированных атрибутов и выполнении обычного сетевого протокола. Накладные расходы, связанные с сетевой обработкой этих операций сравнительно высоки, поскольку относительное количество полезных байтов данных в реально передаваемом пакете невелико. Атрибуты пересылаются небольшими пакетами (большинство имеют размер 64-128 байт). В результате операции с атрибутами потребляют относительно небольшую полосу пропускания сети.
Операции с данными
Операции с данными
В отличие от операций с атрибутами, операции с данными по определению имеют размер 8 Кбайт. (Это размер блока данных, определенный NFS. Сравнительно недавно анонсированная версия протокола NFS+ допускает блоки данных размером до 4 Гбайт. Однако это существенно не меняет саму природу операций с данными). Кроме того, в то время как для каждого файла имеется только один набор атрибутов, количество блоков данных размером по 8 Кбайт в одном файле может быть большим (потенциально может достигать несколько миллионов). Для большинства типов NFS-серверов блоки данных обычно не кэшируются и, таким образом, обслуживание соответствующих запросов связано с существенным потреблением ресурсов системы. В частности, для выполнения операций с данными требуется значительно большая полоса пропускания сети: каждая операция с данными включает пересылку шести больших пакетов по Ethernet (двух по FDDI). В результате вероятность перегрузки сети представляет собой гораздо более важный фактор при рассмотрении операций с данными.
Как это ни удивительно, но в большинстве существующих систем доминируют операции с атрибутами, а не операции с данными. Если клиентская система NFS хочет использовать файл, хранящийся на удаленном файл-сервере, она выдает последовательность операций поиска (lookup) для определения размещения файла в удаленной иерархии каталогов, за которой следует операция getattr для получения маски прав доступа и других атрибутов файла; наконец, операция чтения извлекает первые 8 Кбайт данных. Для типичного файла, который находится на глубине четырех или пяти уровней подкаталогов удаленной иерархии, простое открывание файла требует пяти-шести операций NFS. Поскольку большинство файлов достаточно короткие (в среднем для большинства систем менее 16 Кбайт) для чтения всего файла требуется меньше операций, чем для его поиска и открывания. Последние исследования компании Sun обнаружили, что со времен операционной системы BSD 4.1 средний размер файла существенно увеличился от примерно 1 Кбайт до немногим более 8 Кбайт.
Для определения корректной конфигурации сервера NFS прежде всего необходимо отнести систему к одному из двух классов в соответствии с доминирующей рабочей нагрузкой для предполагаемых сервисов NFS: с интенсивными операциями над атрибутами или с интенсивными операциями над данными.
Операционные системы реальной памяти
Операционные системы реальной памяти
Операционные системы персональных компьютеров используют более простую двухуровневую модель ввода/вывода, в которой основная память и ввод/вывод файлов управляются раздельно. На практике это приводит даже к еще меньшей нагрузке на подсистему ввода/вывода. Например, когда ПК под Windows вызывает для выполнения Lotus 1-2-3, весь 123.exe копируются в основную память системы. При этом в основную память копируется полный код объемом 1.5 Мбайт, даже если пользователь вслед за этим выполнит команду quit без выполнения любой другой функции. Во время выполнения приложения этот клиент не будет выдавать никаких дополнительных запросов на ввод/вывод этого файла, поскольку весь двоичный код находится резидентно в памяти. Даже если этот код свопируется Windows, он будет откачиваться на локальный диск, что приводит к отсутствию сетевого трафика.
В отличие от этого системы, базирующиеся на Solaris, при вызове приложения копируют в память функцию quit и только те функции, которые необходимы для выполнения его инициализации. Другие функции загружаются в страницы памяти позже, при действительном использовании, что дает существенную начальную экономию, а также распределяет во времени нагрузку на подсистему ввода/вывода. Если клиенту не хватает памяти, соответствующие страницы могут быть уничтожены и затем восстановлены с первоначального источника кодов программ (сетевого сервера), но это приводит к дополнительной нагрузке на сервер. В итоге, нагрузка на подсистему ввода/вывода сервера от ПК-клиентов носит гораздо более взрывной характер, чем для клиентов рабочих станций, выполняющих одни и те же приложения.
Организация кэш-памяти
Организация кэш-памяти
Концепция кэш-памяти возникла раньше чем архитектура IBM/360, и сегодня кэш-память имеется практически в любом классе компьютеров, а в некоторых компьютерах - во множественном числе.
| Размер блока (строки) | 4-128 байт | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Время попадания (hit time) | 1-4 такта синхронизации (обычно 1 такт) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Потери при промахе (miss penalty) (Время доступа - access time) (Время пересылки - transfer time) |
8-32 такта синхронизации (6-10 тактов синхронизации) (2-22 такта синхронизации) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Доля промахов (miss rate) | 1%-20% | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Размер кэш-памяти | 4 Кбайт - 16 Мбайт | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||