Организация последовательного доступа в NFS с интенсивным использованием данных
Организация последовательного доступа в NFS с интенсивным использованием данных
Опыт показывает, что большинство обращений к файлам в среде с интенсивным использованием данных являются последовательными, даже на серверах, которые поставляют данные многим клиентам. При этом, как правило, операционная система выполняет большую работу по организации доступа к своим устройствам. Поэтому если необходимо обеспечить сервис для приложений с интенсивным использованием данных следует выбирать конфигурацию для работы в последовательной среде.
Например, в свое время диск емкостью 2.9 Гбайт был самым быстрым диском Sun для последовательных приложений. Он мог обеспечивать обмен данными через файловую систему со скоростью 4.25 Мбайт/с. Это был также самый емкий диск Sun и поэтому оказывался наиболее удобным для хранения больших объемов данных. Высокая скорость обмена данными по отношению к скорости шины SCSI (пиковая пропускная способность шины составляет 20 Мбайт/с) определяет оптимальную конфигурацию дисковой подсистемы: 4-5 активных дисков емкостью 2.9 Гбайт на один главный адаптер (DWI/S). Если требуется дополнительная емкость для хранения данных, то подключение большего числа дисков на каждый главный адаптер вполне допустимо, но это не даст увеличения производительности дисковой подсистемы.
Диски 2.9 Гбайт в системах Sun размещаются на устанавливаемых в стойку шасси (до 6 дисковых накопителей на шасси). Каждое шасси может быть подключено к двум независимым главными адаптерами SCSI. Такая возможность очень рекомендуется для конфигурирования серверов, обслуживающих клиентов, выполняющих интенсивные запросы к данным. Чтобы обеспечить максимальную емкость дисковой памяти до 12 дисков могут быть сконфигурированы на одном адаптере DWI/S. Однако максимальная производительность достигается только с 4-5 накопителями.
В среде с последовательным доступом достаточно просто подсчитать, сколько дисков потребуется для обслуживания пиковой нагрузки. Каждый полностью активный клиент может потребовать от дисковой подсистемы пропускной способности до 2.7 Мбайт/с. (Здесь предполагается использование высокоскоростных сетей со скоростью передачи в среде 100 Мбит/с и выше).
Хорошее первое приближение дает обеспечение одного 2.9 Гбайт диска для каждых трех полностью активных клиентов. Предлагается именно такое соотношение, хотя каждый диск может передавать данные со скоростью более 4 Мбайт/с, а клиенты запрашивают только 2.7 Мбайт/с, поскольку работа двух активных клиентов на одном диске будет вызывать постоянное перемещение каретки вперед и назад между группами цилиндров (или даже файловыми системами) и приводить к существенно более низкой пропускной способности. Чтобы сбалансировать работу дисков, а также ускорить некоторые типы пересылок данных можно использовать специальное программное обеспечение типа Online:DiskSuit 2.0 (разд. 4.3.4.3). Если в качестве сетевой среды применяется Ethernet или 16 Мбит Token Ring, то достаточно одного диска на каждого полностью активного пользователя. Если используется NFS+, это отношение сильно меняется, поскольку NFS+ обеспечивает индивидуальную пропускную способность в режиме клиент/сервер примерно на скорости сетевой среды.
Организация произвольного доступа в NFS с интенсивными запросами атрибутов
Организация произвольного доступа в NFS с интенсивными запросами атрибутов
В отличие от среды с интенсивным использованием данных, действительно все обращения к файлам в среде с интенсивным использованием атрибутов приводят к произвольному доступу к дискам. Когда файлы небольшие, в доступе к данным доминирует выборка строк каталогов, строк индексных дескрипторов и нескольких первых косвенных блоков (требуется позиционирование, чтобы получить действительно все куски мета-информации), а также каждого блока данных пользователя. В результате каретка диска тратит значительно больше времени "рыская" между различными кусками мета-информации файловой системы, чем на собственно выборку данных пользователя.
Как следствие, критерии выбора конфигурации для интенсивной по атрибутам NFS существенно отличаются от критериев для среды с интенсивным использованием данных. Поскольку в общем времени, которое требуется для выполнения операции произвольного ввода/вывода доминирует время позиционирования каретки диска, общая пропускная способность диска в этом режиме оказывается намного меньше, чем в режиме последовательного доступа. Например, типовой дисковый накопитель 1993 года выпуска способен работать со скоростью 3.5-4 Мбайт/с в последовательном режиме доступа, но обеспечивает выполнение только 60-72 операций произвольного доступа в секунду, что соответствует примерно скорости 500 Кбайт/с. При этих условиях шина SCSI оказывается гораздо меньше занятой, что позволяет сконфигурировать на ней намного больше дисков, прежде чем встанет вопрос о перегрузке шины.
Кроме того, одной из задач выбора конфигурации системы является обеспечение наибольшего разумного числа дисковых накопителей, поскольку именно оно определяет число дисковых кареток, которые представляют собой ограничивающий фактор в дисковой подсистеме. К счастью, сама природа интенсивных по атрибутам приложений предполагает, что требования к объему дисковой памяти сравнительно небольшие (по отношению к интенсивным по данным приложениями).
В этих условиях часто бывает полезно включать в конфигурацию системы вместо одного большого диска два или даже четыре диска меньшей емкости. Хотя такая конфигурация обойдется несколько дороже в пересчете на мегабайт памяти, ее производительность существенно повысится. Например, два диска емкостью 1.05 Гбайт стоят примерно на 15% дороже, чем один диск емкостью 2.1 Гбайт, но они обеспечивают более чем в два раза большую пропускную способность произвольного ввода/вывода. Примерно тоже самое отношение остается справедливым между дисками емкостью 535 Мбайт и диском 1.05 Гбайт (см. таблицу 4.2).
Таким образом, для интенсивной по атрибутам среды лучше конфигурировать большее число небольших дисков, подсоединенных к умеренному числу главных адаптеров SCSI. Диск емкостью 1.05 Гбайт имеет прекрасное фирменное программное обеспечение, которое сводит к минимуму загрузку шины SCSI. Диск емкостью 535 Мбайт имеет сходные характеристики. Рекомендуемая конфигурация - это 4-5 полностью активных 535 Мбайт или 1 Гбайт дисков на одну шину SCSI, хотя 6 или 7 дисков также могут работать не вызывая серьезных конфликтов на шине.
Организация ввода/вывода
Организация ввода/вывода
Вопросы организации ввода/вывода в вычислительной системе иногда оказываются вне внимания потребителей. Это привело к тому, что при оценке производительности системы часто используются только оценки производительности процессора, а оценкой системы ввода/вывода пренебрегают. Такое отношение к системам ввода/вывода, как к некоторым не очень важным понятиям, проистекает также из термина "периферия", который применяется к устройствам ввода/вывода.
Однако это противоречит здравому смыслу. Компьютер без устройств ввода/вывода - как автомобиль без колес - на таком автомобиле далеко не уедешь. Очевидно одной из наиболее правильных оценок производительности системы является время ответа (время между моментом ввода пользователем задания и получения им результата), которое учитывает все накладные расходы, связанные с выполнением задания в системе, включая ввод/вывод.
Кроме того, важность системы ввода/вывода определяется еще и тем, что быстрое увеличение производительности процессоров настолько изменило принципы классификации компьютеров, что именно по организации ввода/вывода мы можем как-то грубо их отличать: разница между мейнфреймом и миникомпьютером заключается в том, что мейнфрейм может поддерживать намного больше терминалов и дисков; разница между миникомпьютером и рабочей станцией заключается в том, что рабочая станция имеет экран, клавиатуру и мышь; разница между файл-сервером и рабочей станцией заключается в том, что файл-сервер имеет диски и ленточные устройства, а экран, клавиатура и мышь отсутствуют; разница между рабочей станцией и персональным компьютером заключается лишь в том, что рабочие станции всегда соединены друг с другом с помощью локальной сети.
Уже сейчас мы можем наблюдать, что в компьютерах различного ценового класса от рабочих станций до суперкомпьютеров (суперсерверов) используется один и тот же тип микропроцессора. Различия в стоимости и производительности определяются практически только организацией систем памяти и ввода/вывода (а также количеством процессоров).
Как уже отмечалось, производительность процессоров растет со скоростью 50-100% в год. Если одновременно не улучшались бы характеристики систем ввод/вывода, то, очевидно, разработка новых систем зашла бы в тупик. Важность оценки работы систем ввода/вывода была осознана многими пользователями компьютеров. Были разработаны специальные тестовые программы, позволяющие оценить эффективность систем ввода/вывода. В частности, такие тесты применяются для оценки суперкомпьютеров, систем обработки транзакций и файл-серверов.
Основная идея динамической оптимизации
Основная идея динамической оптимизации
Главным ограничением методов конвейерной обработки, которые мы рассматривали ранее, является выдача для выполнения команд строго в порядке, предписанном программой: если выполнение какой-либо команды в конвейере приостанавливалось, следующие за ней команды также приостанавливались. Таким образом, при наличии зависимости между двумя близко расположенными в конвейере командами возникала приостановка обработки многих команд. Но если имеется несколько функциональных устройств, многие из них могут оказаться незагруженными. Если команда j зависит от длинной команды i, выполняющейся в конвейере, то все команды, следующие за командой j должны приостановиться до тех пор, пока команда i не завершится и не начнет выполняться команда j. Например, рассмотрим следующую последовательность команд:
DIVD F0,F2,F4
ADDD F10,F0,F8
SUBD F8,F8,F14
Команда SUBD не может выполняться из-за того, что зависимость между командами DIVD и ADDD привела к приостановке конвейера. Однако команда SUBD не имеет никаких зависимостей от команд в конвейере. Это ограничение производительности, которое может быть устранено снятием требования о выполнении команд в строгом порядке.
В рассмотренном нами конвейере структурные конфликты и конфликты по данным проверялись во время стадии декодирования команды (ID). Если команда могла нормально выполняться, она выдавалась с этой ступени конвейера в следующие. Чтобы позволить начать выполнение команды SUBD из предыдущего примера, необходимо разделить процесс выдачи на две части: проверку наличия структурных конфликтов и ожидание отсутствия конфликта по данным. Когда мы выдаем команду для выполнения, мы можем осуществлять проверку наличия структурных конфликтов; таким образом, мы все еще используем упорядоченную выдачу команд. Однако мы хотим начать выполнение команды как только станут доступными ее операнды. Таким образом, конвейер будет осуществлять неупорядоченное выполнение команд, которое означает и неупорядоченное завершение команд.
Неупорядоченное завершение команд создает основные трудности при обработке исключительных ситуаций. В рассматриваемых в данном разделе машинах с динамическим планированием потока команд прерывания будут неточными, поскольку команды могут завершиться до того, как выполнение более ранней выданной команды вызовет исключительную ситуацию. Таким образом, очень трудно повторить запуск после прерывания. Вместо того, чтобы рассматривать эти проблемы в данном разделе, мы обсудим возможные решения для реализации точных прерываний позже в контексте машин, использующих планирование по предположению.
Чтобы реализовать неупорядоченное выполнение команд, мы расщепляем ступень ID на две ступени:
Выдача - декодирование команд, проверка структурных конфликтов.
Чтение операндов - ожидание отсутствия конфликтов по данным и последующее чтение операндов.
Затем, как и в рассмотренном нами конвейере, следует ступень EX. Поскольку выполнение команд ПТ может потребовать нескольких тактов в зависимости от типа операции, мы должны знать, когда команда начинает выполняться и когда заканчивается. Это позволяет нескольким командам выполняться в один и тот же момент времени. В дополнение к этим изменениям структуры конвейера мы изменим и структуру функциональных устройств, варьируя количество устройств, задержку операций и степень конвейеризации функциональных устройств так, чтобы лучше использовать эти методы конвейеризации.
Основные компоненты процессора Alpha 21066
Рисунок 6.16. Основные компоненты процессора Alpha 21066

Кэш-память команд представляет собой кэш прямого отображения емкостью 8 Кбайт. Команды, выбираемые из этой кэш-памяти, могут выдаваться попарно для выполнения в одно из исполнительных устройств. Кэш-память данных емкостью 8 Кбайт также реализует кэш с прямым отображением. При выполнении операций записи в память данные одновременно записываются в этот кэш и в буфер записи. Контроллер памяти или контроллер ввода/вывода шины PCI обрабатывают все обращения, которые проходят через расположенные на кристалле кэш-памяти первого уровня.
Контроллер памяти прежде всего проверяет содержимое внешней кэш-памяти второго уровня, которая построена на принципе прямого отображения и реализует алгоритм отложенного обратного копирования при выполнении операций записи. При обнаружении промаха контроллер обращается к основной памяти для перезагрузки соответствующих строк кэш-памяти. Контроллер ввода/вывода шины PCI обрабатывает весь трафик, связанный с вводом/выводом. Под управлением центрального процессора он выполняет операции программируемого ввода/вывода. Трафик прямого доступа к памяти шины PCI обрабатывается контроллером PCI совместно с контроллером памяти. При выполнении операций прямого доступа к памяти в режиме чтения и записи данные не размещаются в кэш-памяти второго уровня. Интерфейсы памяти и PCI были разработаны специально в расчете на однопроцессорные конфигурации и не поддерживают реализацию мультипроцессорной архитектуры.
На рисунке 6.17 показан пример системы, построенной на базе микропроцессора 21066. В представленной конфигурации контроллер памяти выполняет обращения как к статической памяти, с помощью которой реализована кэш-память второго уровня, так и к динамической памяти, на которой построена основная память. Для хранения тегов и данных в кэш-памяти второго уровня используются кристаллы статическая памяти с одинаковым временем доступа по чтению и записи.
Конструкция поддерживает до четырех банков динамической памяти, каждый из которых может управляться независимо, что дает определенную гибкость при организации памяти и ее модернизации. Один из банков может заполняться микросхемами видеопамяти (VRAM) для реализации дешевой графики. Контроллер памяти прямо работает с видеопамятью и поддерживает несколько простых графических операций.
Основные критерии разработки Как
Основные критерии разработки
Как известно, производительность любого процессора при выполнении заданной программы зависит от трех параметров: такта (или частоты) синхронизации, среднего количества команд, выполняемых за один такт, и общего количества выполняемых в программе команд. Изменить ни один из указанных параметров независимо от других невозможно, поскольку соответствующие базовые технологии взаимосвязаны: частота синхронизации определяется достигнутым уровнем технологии интегральных схем и функциональной организацией процессора, среднее количество тактов на команду зависит от функциональной организации и архитектуры системы команд, а количество выполняемых в программе команд определяется архитектурой системы команд и технологией компиляторов.
Из сказанного ясно, что создание нового высокопроизводительного процессора требует решения сложных вопросов во всех трех направлениях разработки. При этом эффективная с точки зрения стоимости конструкция не может полагаться только на увеличение тактовой частоты. Экономические соображения заставляют разработчиков принимать решения, основой которых является массовая технология. Системы UltraSPARC-1 обеспечивают высокую производительность при достаточно умеренной тактовой частоте (до 200 МГц) путем оптимизации среднего количества команд, выполняемых за один такт. Однако при таком подходе естественно встают вопросы эффективного управления конвейером команд и иерархией памяти системы. Для увеличения производительности необходимо по возможности уменьшить среднее время доступа к памяти и увеличить среднее количество команд, выдаваемых для выполнения в каждом такте, не превышая при этом разумного уровня сложности процессора.
При разработке суперскалярного процессора практически сразу необходимо "расшить" целый ряд узких мест, ограничивающих выдачу для выполнения нескольких команд в каждом такте. Такими узкими местами являются наличие в программном коде зависимостей по управлению и данным, аппаратные ограничения на количество портов в регистровых файлах процессора и устройствах, реализующих иерархию памяти, а также количество целочисленных конвейеров и конвейеров выполнения операций с плавающей точкой.
При создании своего нового процессора UltraSPARC-1 компания Sun решила добиться увеличения производительности процессора в тех направлениях, где это не противоречило экономическим соображениям. Чтобы сократить число потенциальных проблем, было принято несколько конструкторских решений, которые определили основные характеристики UltraSPARC-1:
Реализация на кристалле раздельной кэш-памяти команд и данных
Организация широкой выборки команд (128 бит)
Создание эффективных средств динамического прогнозирования направления переходов
Реализация девятиступенчатого конвейера, обеспечивающего выдачу для выполнения до четырех команд в каждом такте
Оптимизация конвейерных операций обращения к памяти
Реализация команд обмена данными между памятью и регистрами плавающей точки, позволяющая не приостанавливать диспетчеризацию команд обработки
Реализация на кристалле устройства управления памятью (MMU)
Расширение набора команд для поддержки графики и обработки изображений
Реализация новой архитектуры шины UPA
UltraSPARC-I
Процессор UltraSPARC-1 представляет собой высокопроизводительный, высокоинтегрированной суперскалярный процессор, реализующий 64-битовую архитектуру SPARC-V9. В его состав входят: устройство предварительной выборки и диспетчеризации команд, целочисленное исполнительное устройство, устройство плавающей точки с графическим устройством, устройство управления памятью, устройство загрузки/записи, устройство управления внешней кэш-памятью, устройство управления интерфейсом памяти и кэш-памяти команд и данных (рисунок 6.6).
Основные типы команд
Рисунок 5.3. Основные типы команд
Команды управления потоком команд
В английском языке для указания команд безусловного перехода, как правило, используется термин jump, а для команд условного перехода - термин branch, хотя разные поставщики необязательно придерживаются этой терминологии. Например компания Intel использует термин jump и для условных, и для безусловных переходов. Можно выделить четыре основных типа команд для управления потоком команд: условные переходы, безусловные переходы, вызовы процедур и возвраты из процедур.
Частота использования этих команд по статистике примерно следующая. В программах доминируют команды условного перехода. Среди указанных команд управления на разных программах частота их использования колеблется от 66 до 78%. Следующие по частоте использования - команды безусловного перехода (от 12 до 18%). Частота переходов на выполнение процедур и возврата из них составляет от 10 до 16%.
При этом примерно 90% команд безусловного перехода выполняются относительно счетчика команд. Для команд перехода адрес перехода должен быть всегда заранее известным. Это не относится к адресам возврата, которые не известны во время компиляции программы и должны определяться во время ее работы. Наиболее простой способ определения адреса перехода заключается в указании его положения относительно текущего значения счетчика команд (с помощью смещения в команде), и такие переходы называются переходами относительно счетчика команд. Преимуществом такого метода адресации является то, что адреса переходов, как правило, расположены недалеко от текущего адреса выполняемой команды и указание относительно текущего значения счетчика команд требует небольшого количества бит в смещении. Кроме того, использование адресации относительно счетчика команд позволяет программе выполняться в любом месте памяти, независимо от того, куда она была загружена. То есть этот метод адресации позволяет автоматически создавать перемещаемые программы.
Реализация возвратов и переходов по косвенному адресу, в которых адрес не известен во время компиляции программы, требует методов адресации, отличных от адресации относительно счетчика команд. В этом случае адрес перехода должен определяться динамически во время работы программы. Наиболее простой способ заключается в указании регистра для хранения адреса возврата, либо для перехода может разрешаться любой метод адресации для вычисления адреса перехода.
Одним из ключевых вопросов реализации команд перехода состоит в том, насколько далеко целевой адрес перехода находится от самой команды перехода? И на этот вопрос статистика использования команд дает ответ: в подавляющем большинстве случаев переход идет в пределах 3 - 7 команд относительно команды перехода, причем в 75% случаев выполняются переходы в направлении увеличения адреса, т.е. вперед по программе.
Поскольку большинство команд управления потоком команд составляют команды условного перехода, важным вопросом реализации архитектуры является определение условий перехода. Для этого используются три различных подхода. При первом из них в архитектуре процессора предусматривается специальный регистр, разряды которого соответствуют определенным кодам условий. Команды условного перехода проверяют эти условия в процессе своего выполнения. Преимуществом такого подхода является то, что иногда установка кода условия и переход по нему могут быть выполнены без дополнительных потерь времени, что, впрочем, бывает достаточно редко. А недостатками такого подхода является то, что, во-первых, появляются новые состояния машины, за которыми необходимо следить (упрятывать при прерывании и восстанавливать при возврате из него). Во-вторых, и что очень важно для современных высокоскоростных конвейерных архитектур, коды условий ограничивают порядок выполнения команд в потоке, поскольку их основное назначение заключается в передаче кода условия команде условного перехода.
Второй метод заключается в простом использовании произвольного регистра (возможно одного выделенного) общего назначения. В этом случае выполняется проверка состояния этого регистра, в который предварительно помещается результат операции сравнения. Недостатком этого подхода является необходимость выделения в программе для анализа кодов условий специального регистра.
Третий метод предполагает объединение команды сравнения и перехода в одной команде. Недостатком такого подхода является то, что эта объединенная команда довольно сложна для реализации (в одной команде надо указать и тип условия, и константу для сравнения и адрес перехода). Поэтому в таких машинах часто используется компромиссный вариант, когда для некоторых кодов условий используются такие команды, например, для сравнения с нулем, а для более сложных условий используется регистр условий. Часто для анализа результатов команд сравнения для целочисленных операций и для операций с плавающей точкой используется разная техника, хотя это можно объяснить и тем, что в программах количество переходов по условиям выполнения операций с плавающей точкой значительно меньше общего количества переходов, определяемых результатами работы целочисленной арифметики.
Одним из наиболее заметных свойств большинства программ является преобладание в них сравнений на условие равно/неравно и сравнений с нулем. Поэтому в ряде архитектур такие команды выделяются в отдельный поднабор, особенно при использовании команд типа "сравнить и перейти".
Говорят, что переход выполняется, если истинным является условие, которое проверяет команда условного перехода. В этом случае выполняется переход на адрес, заданный командой перехода. Поэтому все команды безусловного перехода всегда выполняемые. По статистике оказывается, что переходы назад по программе в большинстве случаев используются для организации циклов, причем примерно 60% из них составляют выполняемые переходы. В общем случае поведение команд условного перехода зависит от конкретной прикладной программы, однако иногда сказывается и зависимость от компилятора. Такие зависимости от компилятора возникают вследствие изменений потока управления, выполняемого оптимизирующими компиляторами для ускорения выполнения циклов.
Вызовы процедур и возвраты предполагают передачу управления и возможно сохранение некоторого состояния. Как минимум, необходимо уметь где-то сохранять адрес возврата. Некоторые архитектуры предлагают аппаратные механизмы для сохранения состояния регистров, в других случаях предполагается вставка в программу команд самим компилятором. Имеются два основных вида соглашений относительно сохранения состояния регистров. Сохранение вызывающей (caller saving) программой означает, что вызывающая процедура должна сохранять свои регистры, которые она хочет использовать после возврата в нее. Сохранение вызванной процедурой предполагает, что вызванная процедура должна сохранить регистры, которые она собирается использовать. Имеются случаи, когда должно использоваться сохранение вызывающей процедурой для обеспечения доступа к глобальным переменным, которые должны быть доступны для обеих процедур.
Типы и размеры операндов
Имеется два альтернативных метода определения типа операнда. В первом из них тип операнда может задаваться кодом операции в команде. Это наиболее употребительный способ задания типа операнда. Второй метод предполагает указание типа операнда с помощью тега, который хранится вместе с данными и интерпретируется аппаратурой во время выполнения операций над данными. Этот метод использовался, например, в машинах фирмы Burroughs, но в настоящее время он практически не применяется и все современные процессоры пользуются первым методом.
Обычно тип операнда (например, целый, вещественный с одинарной точностью или символ) определяет и его размер. Однако часто процессоры работают с целыми числами длиною 8, 16, 32 или 64 бит. Как правило целые числа представляются в дополнительном коде. Для задания символов (1 байт = 8 бит) в машинах компании IBM используется код EBCDIC, но в машинах других производителей почти повсеместно применяется кодировка ASCII. Еще до сравнительно недавнего времени каждый производитель процессоров пользовался своим собственным представлением вещественных чисел (чисел с плавающей точкой). Однако за последние несколько лет ситуация изменилась. Большинство поставщиков процессоров в настоящее время для представления вещественных чисел с одинарной и двойной точностью придерживаются стандарта IEEE 754.
В некоторых процессорах используются двоично кодированные десятичные числа, которые представляются в в упакованном и неупакованном форматах. Упакованный формат предполагает, что для кодирования цифр 0-9 используются 4 разряда и что две десятичные цифры упаковываются в каждый байт. В неупакованном формате байт содержит одну десятичную цифру, которая обычно изображается в символьном коде ASCII.
В большинстве процессоров, кроме того, реализуются операции над цепочками (строками) бит, байт, слов и двойных слов.
Основные типы устройств ввода/вывода
Основные типы устройств ввода/вывода
Как правило периферийные устройства компьютеров делятся на устройства ввода, устройства вывода и внешние запоминающие устройства (осуществляющие как ввод данных в машину, так и вывод данных из компьютера). Основной обобщающей характеристикой устройств ввода/вывода может служить скорость передачи данных (максимальная скорость, с которой данные могут передаваться между устройством ввода/вывода и основной памятью или процессором). На рисунке 5.45. представлены основные устройства ввода/вывода, применяемые в современных компьютерах, а также указаны примерные скорости обмена данными, обеспечиваемые этими устройствами.
| Тип устройства | Направление передачи данных |
Скорость передачи данных (Кбайт/с) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Клавиатура Мышь Голосовой ввод Сканер Голосовой вывод Строчный принтер Лазерный принтер Графический дисплей (ЦП (r) буфер кадра) Оптический диск Магнитная лента Магнитный диск |
Ввод Ввод Ввод Ввод Вывод Вывод Вывод Вывод Вывод ЗУ ЗУ ЗУ |
0.01 0.02 0.02 200.0 0.06 1.00 100.00 30000.00 200.0 500.00 2000.00 2000.00 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Основные возможности шин
Рисунок 5.43. Основные возможности шин
Асинхронная шина, с другой стороны, не тактируется. Вместо этого обычно используется старт-стопный режим передачи и протокол "рукопожатия" (handshaking) между источником и приемником данных на шине. Эта схема позволяет гораздо проще приспособить широкое разнообразие устройств и удлинить шину без беспокойства о перекосе сигналов синхронизации и о системе синхронизации. Если может использоваться синхронная шина, то она обычно быстрее, чем асинхронная, из-за отсутствия накладных расходов на синхронизацию шины для каждой транзакции. Выбор типа шины (синхронной или асинхронной) определяет не только пропускную способность, но также непосредственно влияет на емкость системы ввода/вывода в терминах физического расстояния и количества устройств, которые могут быть подсоединены к шине. Асинхронные шины по мере изменения технологии лучше масштабируются. Шины ввода/вывода обычно асинхронные.
Основы конфигурирования сетевых файловых систем (на примере NFS)
Основы конфигурирования сетевых файловых систем (на примере NFS)
Основы планирования загрузки конвейера и разворачивание циклов
Основы планирования загрузки конвейера и разворачивание циклов
Для поддержания максимальной загрузки конвейера должен использоваться параллелизм уровня команд, основанный на выявлении последовательностей несвязанных команд, которые могут выполняться в конвейере с совмещением. Чтобы избежать приостановки конвейера зависимая команда должна быть отделена от исходной команды на расстояние в тактах, равное задержке конвейера для этой исходной команды. Способность компилятора выполнять подобное планирование зависит как от степени параллелизма уровня команд, доступного в программе, так и от задержки функциональных устройств в конвейере. В рамках этой главы мы будем предполагать задержки, показанные на рисунке 5.24, если только явно не установлены другие задержки. Мы предполагаем, что условные переходы имеют задержку в один такт, так что команда следующая за командой перехода не может быть определена в течение одного такта после команды условного перехода. Мы предполагаем, что функциональные устройства полностью конвейеризованы или дублированы (столько раз, какова глубина конвейера), так что операция любого типа может выдаваться для выполнения в каждом такте и структурные конфликты отсутствуют.
| Команда, вырабатывающая результат | Команда, использующая результат |
Задержка в тактах | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Операция АЛУ с ПТ | Другая операция АЛУ с ПТ | 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Операция АЛУ с ПТ | Запись двойного слова | 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Загрузка двойного слова | Другая операция АЛУ с ПТ | 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Загрузка двойного слова | Запись двойного слова | 0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Основы реализации
Основы реализации
Ключевым моментом реализации в многопроцессорных системах с небольшим числом процессоров как схемы записи с аннулированием, так и схемы записи с обновлением данных, является использование для выполнения этих операций механизма шины. Для выполнения операции обновления или аннулирования процессор просто захватывает шину и транслирует по ней адрес, по которому должно производиться обновление или аннулирование данных. Все процессоры непрерывно наблюдают за шиной, контролируя появляющиеся на ней адреса. Процессоры проверяют не находится ли в их кэш-памяти адрес, появившийся на шине. Если это так, то соответствующие данные в кэше либо аннулируются, либо обновляются в зависимости от используемого протокола. Последовательный порядок обращений, присущий шине, обеспечивает также строго последовательное выполнение операций записи, поскольку когда два процессора конкурируют за выполнение записи в одну и ту же ячейку, один из них должен получить доступ к шине раньше другого. Один процессор, получив доступ к шине, вызовет необходимость обновления или аннулирования копий в других процессорах. В любом случае, все записи будут выполняться строго последовательно. Один из выводов, который следует сделать из анализа этой схемы заключается в том, что запись в разделяемый элемент данных не может закончиться до тех пор, пока она не захватит доступ к шине.
В дополнение к аннулированию или обновлению соответствующих копий блока кэш-памяти, в который производилась запись, мы должны также разместить элемент данных, если при записи происходит промах кэш-памяти. В кэш-памяти со сквозной записью последнее значение элемента данных найти легко, поскольку все записываемые данные всегда посылаются также и в память, из которой последнее записанное значение элемента данных может быть выбрано (наличие буферов записи может привести к некоторому усложнению).
Однако для кэш-памяти с обратным копированием задача нахождения последнего значения элемента данных сложнее, поскольку это значение скорее всего находится в кэше, а не в памяти.
В этом случае используется та же самая схема наблюдения, что и при записи: каждый процессор наблюдает и контролирует адреса, помещаемые на шину. Если процессор обнаруживает, что он имеет модифицированную ("грязную") копию блока кэш-памяти, то именно он должен обеспечить пересылку этого блока в ответ на запрос чтения и вызвать отмену обращения к основной памяти. Поскольку кэши с обратным копированием предъявляют меньшие требования к полосе пропускания памяти, они намного предпочтительнее в мультипроцессорах, несмотря на некоторое увеличение сложности. Поэтому далее мы рассмотрим вопросы реализации кэш-памяти с обратным копированием.
Для реализации процесса наблюдения могут быть использованы обычные теги кэша. Более того, упоминавшийся ранее бит достоверности (valid bit), позволяет легко реализовать аннулирование. Промахи операций чтения, вызванные либо аннулированием, либо каким-нибудь другим событием, также не сложны для понимания, поскольку они просто основаны на возможности наблюдения. Для операций записи мы хотели бы также знать, имеются ли другие кэшированные копии блока, поскольку в случае отсутствия таких копий, запись можно не посылать на шину, что сокращает время на выполнение записи, а также требуемую полосу пропускания.
Чтобы отследить, является ли блок разделяемым, мы можем ввести дополнительный бит состояния (shared), связанный с каждым блоком, точно также как это делалось для битов достоверности (valid) и модификации (modified или dirty) блока. Добавив бит состояния, определяющий является ли блок разделяемым, мы можем решить вопрос о том, должна ли запись генерировать операцию аннулирования в протоколе с аннулированием, или операцию трансляции при использовании протокола с обновлением. Если происходит запись в блок, находящийся в состоянии "разделяемый" при использовании протокола записи с аннулированием, кэш формирует на шине операцию аннулирования и помечает блок как частный (private). Никаких последующих операций аннулирования этого блока данный процессор посылать больше не будет.
Процессор с исключительной
(exclusive) копией блока кэш-памяти обычно называется "владельцем" (owner) блока кэш-памяти.
При использовании протокола записи с обновлением, если блок находится в состоянии "разделяемый", то каждая запись в этот блок должна транслироваться. В случае протокола с аннулированием, когда посылается операция аннулирования, состояние блока меняется с "разделяемый" на "неразделяемый" (или "частный"). Позже, если другой процессор запросит этот блок, состояние снова должно измениться на "разделяемый". Поскольку наш наблюдающий кэш видит также все промахи, он знает, когда этот блок кэша запрашивается другим процессором, и его состояние должно стать "разделяемый".
Поскольку любая транзакция на шине контролирует адресные теги кэша, потенциально это может приводить к конфликтам с обращениями к кэшу со стороны процессора. Число таких потенциальных конфликтов можно снизить применением одного из двух методов: дублированием тегов, или использованием многоуровневых кэшей с "охватом" (inclusion), в которых уровни, находящиеся ближе к процессору являются поднабором уровней, находящихся дальше от него. Если теги дублируются, то обращения процессора и наблюдение за шиной могут выполняться параллельно. Конечно, если при обращении процессора происходит промах, он должен будет выполнять арбитраж с механизмом наблюдения для обновления обоих наборов тегов. Точно также, если механизм наблюдения за шиной находит совпадающий тег, ему будет нужно проводить арбитраж и обращаться к обоим наборам тегов кэша (для выполнения аннулирования или обновления бита "разделяемый"), возможно также и к массиву данных в кэше, для нахождения копии блока. Таким образом, при использовании схемы дублирования тегов процессор должен приостановиться только в том случае, если он выполняет обращение к кэшу в тот же самый момент времени, когда механизм наблюдения обнаружил копию в кэше. Более того, активность механизма наблюдения задерживается только когда кэш имеет дело с промахом.
| Наименование | Тип протокола | Стратегия записи в память | Уникальные свойства |
Применение | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Одиночная запись | Запись с аннулированием | Обратное копирование при первой записи |
Первый описанный в литературе протокол наблюдения | - | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Synapse N+1 | Запись с аннулированием | Обратное копирование |
Точное состояние, где "вла-дельцем является память" | Машины Synapse Первые машины с когерентной кэш-памятью |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Berkely | Запись с аннулированием | Обратное копирование |
Состояние "разделяемый" | Машина SPUR университета Berkely | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Illinois | Запись с аннулированием | Обратное копирование |
Состояние "приватный"; может передавать данные из любого кэша | Серии Power и Challenge компании Silicon Graphics | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| "Firefly" | Запись с трансляцией | Обратное копирование для "приватных" блоков и сквозная запись для "разделяемых" | Обновление памяти во время трансляции | SPARCcenter 2000 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Особенности архитектуры Alpha компании DEC
Особенности архитектуры Alpha компании DEC
В настоящее время семейство микропроцессоров с архитектурой Alpha представлено несколькими кристаллами, имеющими различные диапазоны производительности, работающие с разной тактовой частотой и рассеивающие разную мощность.
Первым на рынке появился 64-разрядный микропроцессор Alpha (DECchip 21064) . Он представляет собой RISC-процессор в однокристальном исполнении, в состав которого входят устройства целочисленной и плавающей арифметики, а также кэш-память емкостью 16 Кб. Кристалл проектировался с учетом реализации передовых методов увеличения производительности, включая конвейерную организацию всех функциональных устройств, одновременную выдачу нескольких команд для выполнения, а также средства организации симметричной многопроцессорной обработки.
В кристалле имеются два регистровых файла по 32 64-битовых регистра: один для целых чисел, второй - для чисел с плавающей точкой. Для обеспечения совместимости с архитектурами MIPS и VAX архитектура Alpha поддерживает арифметику с одинарной и двойной точностью как в соответствии со стандартом IEEE 754, так и в соответствии с внутренним для компании стандартом арифметики VAX.
Самая мощная модель процессора 21064 работает на частоте 200 МГц. В конце 1993 года появилась модернизированная версия кристалла - модель 21064А, имеющая на кристалле кэш-память удвоенного объема и работающая с тактовой частотой 275 МГц.
Затем были выпущены модели 21066 и 21068, оперирующие на частоте 166 и 66 МГц. Отличительной особенностью этой ветви процессоров Alpha является реализация на кристалле шины PCI. Это существенно упрощает и удешевляет как проектирование, так и производство компьютеров. Отличительная особенность модели 21068 - низкая потребляемая мощность (около 8 ватт). Основное предназначение этих двух новых моделей - персональные компьютеры и одноплатные ЭВМ.
На рисунке 6.16 представлена блок-схема микропроцессора 21066. Основными компонентами этого процессора являются: кэш-память команд, целочисленное устройство, устройство плавающей точки, устройство выполнения команд загрузки/записи, кэш-память данных, а также контроллер памяти и контроллер ввода/вывода.
Особенности архитектуры MIPS компании MIPS Technology
Особенности архитектуры MIPS компании MIPS Technology
Архитектура MIPS была одной из первых RISC-архитектур, получившей признание со стороны промышленности. Она была анонсирована в 1986 году. Первоначально это была полностью 32-битовая архитектура, которая включала 32 регистра общего назначения, 16 регистров плавающей точки и специальную пару регистров для хранения результатов выполнения операций целочисленного умножения и деления. Размер команд составлял 32 бит, в ней поддерживался всего один метод адресации, и пользовательское адресное пространство также определялось 32 битами. Выполнение арифметических операций регламентировалось стандартом IEEE 754. В компьютерной промышленности широкую популярность приобрели 32-битовые процессоры R2000 и R3000, которые в течение достаточно длительного времени служили основой для построения рабочих станций и серверов компаний Silicon Graphics, Digital, Siemens Nixdorf и др. Процессоры R3000/R3010 работали на тактовой частоте 33 или 40 МГц и обеспечивали производительность на уровне 20 SPECint92 и 23 SPECfp92.
Затем на смену микропроцессорам семейства R3000 пришли новые 64-битовые микропроцессоры R4000 и R4400. (MIPS Technology была первой компанией выпустившей процессоры с 64-битовой архитектурой). Набор команд этих процессоров (спецификация MIPS II) был расширен командами загрузки и записи 64-разрядных чисел с плавающей точкой, командами вычисления квадратного корня с одинарной и двойной точностью, командами условных прерываний, а также атомарными операциями, необходимыми для поддержки мультипроцессорных конфигураций. В процессорах R4000 и R4400 реализованы 64-битовые шины данных и 64-битовые регистры. В этих процессорах применяется метод удвоения внутренней тактовой частоты.
Процессоры R2000 и R3000 имели стандартные пятиступенчатые конвейеры команд. В процессорах R4000 и R4400 применяются более длинные конвейеры (иногда их называют суперконвейерами). Количество ступеней в процессорах R4000 и R4400 увеличилось до восьми, что объясняется прежде всего увеличением тактовой частоты и необходимостью распределения логики для обеспечения заданной пропускной способности конвейера.
Процессор R4000 может работать с тактовой частотой 50/100 МГц и обеспечивает уровень производительности в 58 SPECint92 и 61 SPECfp92. Процессор R4400 может работать на частоте 50/100 МГц, или 75/150 МГц, показывая уровень производительности 94 SPECint92 и 105 SPECfp92.
Внутренняя кэш-память процессора R4000 имеет емкость 16 Кбайт. Она разделена на 8-Кб кэш команд и 8-Кб кэш данных. С точки зрения реализации кэш-памяти процессор R4400 имеет более развитые возможности. Он выпускается в трех модификациях: PC (Primary Cashe) - имеет внутренние кэши команд и данных емкостью по 16 Кбайт. Процессор в такой конфигурации предназначен главным образом для дешевых моделей рабочих станций. SC (Secondary Cashe) содержит логику управления кэш-памятью второго уровня. MC (Multiprocessor Cashe) - использует специальные алгоритмы обеспечения когерентности и согласованного состояния памяти для многопроцессорных конфигураций.
В середине 1994 года компания MIPS анонсировала процессор R8000, который прежде всего был ориентирован на научные прикладные задачи с интенсивным использованием операций с плавающей точкой. Этот процессор построен на двух кристаллах (выпускается в виде многокристальной сборки) и представляет собой первую суперскалярную реализацию архитектуры MIPS. Теоретическая пиковая производительность процессора для тактовой частоты 75 МГц составляет 300 MFLOPs (до четырех команд и шести операций с плавающей точкой в каждом такте). Реализация большой кэш-памяти данных емкостью 16 Мбайт, высокой пропускной способности доступа к данным (до 1.2 Гбайт/с) в сочетании с высокой скоростью выполнения операций позволяет R8000 достигать 75% теоретической производительности даже при решении больших задач типа LINPACK с размерами матриц 1000x1000 элементов. Аппаратные средства поддержки когерентного состояния кэш-памяти вместе со средствами распараллеливания компиляторов обеспечивают возможность построения высокопроизводительных симметричных многопроцессорных систем. Например, процессоры R8000 используются в системе Power Challenge компании Silicon Graphics, которая вполне может сравниться по производительности с известными суперкомпьютерами Cray Y-MP, имеет на порядок меньшую стоимость и предъявляет значительно меньшие требования к подсистемам питания и охлаждения.В однопроцессорном исполнении эта система обеспечивает производительность на уровне 310 SPECfp92 и 265 MFLOPs на пакете LINPACK (1000x1000).
В 1994 году MIPS Technology объявила также о создании своего нового суперскалярного процессора R10000, начало массовых поставок которого ожидалось в конце 1995 года. По заявлениям представителей MIPS Technology R10000 обеспечивает пиковую производительность в 800 MIPS при работе с внутренней тактовой частотой 200 МГц за счет обеспечения выдачи для выполнения четырех команд в каждом такте синхронизации. При этом он обеспечивает обмен данными с кэш-памятью второго уровня со скоростью 3.2 Гбайт/с.
Особенности архитектуры POWER компании IBM и PowerPC компаний Motorola, Apple и IBM
Особенности архитектуры POWER компании IBM и PowerPC компаний Motorola, Apple и IBM
Как уже было отмечено, одним из разработчиков фундаментальной концепции RISC-архитектуры был Джон Кук из Исследовательского центра IBM им. Уотсона, который в середине 70-х проводил исследования в этом направлении и построил миникомпьютер IBM 801, который так никогда и не появился на рынке. Дальнейшее развитие этих идей в компании IBM нашло отражение при разработке архитектуру POWER в конце 80-х. Архитектура POWER (и ее поднаправления POWER2 и PowerPC) в настоящее время являются основой семейства рабочих станций и серверов RISC System /6000 компании IBM.
Развитие архитектуры IBM 801 в направлении POWER шло в следующих направлениях: воплощение концепции суперскалярной обработки, улучшение архитектуры как целевого объекта компиляторов, сокращение длины конвейера и времени выполнения команд и, наконец, приоритетная ориентация на эффективное выполнение операций с плавающей точкой.
Особенности процессоров с архитектурой SPARC компании Sun Microsystems
Особенности процессоров с архитектурой SPARC компании Sun Microsystems
Масштабируемая процессорная архитектура SPARC (Scalable Processor Architecture) компании Sun Microsystems является наиболее широко распространенной RISC-архитектурой, отражающей доминирующее положение компании на рынке UNIX рабочих станций и серверов. Процессоры с архитектурой SPARC лицензированы и изготавливаются по спецификациям Sun несколькими производителями, среди которых следует отметить компании Texas Instruments, Fujitsu, LSI Logic, Bipolar International Technology, Philips, Cypress Semiconductor и Ross Technologies. Эти компании осуществляют поставки процессоров SPARC не только самой Sun Microsystems, но и другим известным производителям вычислительных систем, например, Solbourne, Toshiba, Matsushita, Tatung и Cray Research.
Первоначально архитектура SPARC была разработана с целью упрощения реализации 32-битового процессора. В последствии, по мере улучшения технологии изготовления интегральных схем, она постепенно развивалось и в настоящее время имеется 64-битовая версия этой архитектуры (SPARC-V9), которая положена в основу новых микропроцессоров, получивших название UltraSPARC.
Первый процессор SPARC был изготовлен компанией Fujitsu на базе вентильной матрицы, работающей на частоте 16.67 МГц. На основе этого процессора была разработана первая рабочая станция Sun-4 с производительностью 10 MIPS, объявленная осенью 1987 года (до этого времени компания Sun использовала в своих изделиях микропроцессоры Motorola 680X0). В марте 1988 года Fujitsu увеличила тактовую частоту до 25 МГц создав процессор с производительностью 15 MIPS.
Позднее компания Sun умело использовала конкуренцию среди компаний-поставщиков интегральных схем, выбирая наиболее удачные разработки для реализации своих изделий SPARCstation 1, 1+, IPC, ELC, IPX, 2 и серверов серий 4xx и 6xx. Тактовая частота процессоров SPARC была повышена до 40 МГц, а производительность - до 28 MIPS.
Дальнейшее увеличение производительности процессоров с архитектурой SPARC было достигнуто за счет реализации в кристаллах принципов суперскалярной обработки компаниями Texas Instruments и Cypress.
Процессор SuperSPARC компании Texas Instruments стал основой серии рабочих станций и серверов SPARCstation/SPARCserver 10 и 20. В зависимости от смеси команд он обеспечивает выдачу до трех команд за один машинный такт. Процессор SuperSPARC имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кб (20 Кб - кэш команд и 16 Кб - кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS.
Компания Texas Instruments разработала также 50 МГц процессор MicroSPARC с встроенным кэшем емкостью 6 Кб, который ранее широко использовался в дешевых моделях рабочих станций SPARCclassic и LX. Затем Sun совместно с Fujitsu создали новую версию кристалла MicroSPARC II с встроенным кэшем емкостью 24 Кб. На его основе построены рабочие станции и серверы SPARCstation/SPARCserver 4 и 5, работающие на частоте 70, 85 и 110 МГц.
Хотя архитектура SPARC в течение длительного времени оставалась доминирующей на рынке процессоров RISC, особенно в секторе рабочих станций, повышение тактовой частоты процессоров в 1992-1994 годах происходило более медленными темпами по сравнению с повышением тактовой частоты конкурирующих архитектур процессоров. Чтобы ликвидировать это отставание, а также в ответ на появление на рынке 64-битовых процессоров компания Sun разработала и проводит в жизнь пятилетнюю программу модернизации. В соответствии с этой программой Sun планировала довести тактовую частоту процессоров MicroSPARC до 100 МГц в 1994 году (процессор MicroSPARC II с тактовой частотой 110 МГц используется в рабочих станциях и серверах SPARCstation 4 и 5). В конце 1994 и в течение 1995 года на рынке появились микропроцессоры hyperSPARC и однопроцессорные и многопроцессорные рабочие станции SPARCstation 20 с тактовой частотой процессора 100, 125 и 150 МГц. К середине 1995 года тактовая частота процессоров SuperSPARC была доведена до 85 МГц (60, 75 и 85 МГц версии этого процессора в настоящее время применяются в рабочих станциях и серверах SPARCstation 20, SPARCserver 1000 и SPARCcenter 2000 компании Sun и 64-процессорном сервере компании Cray Research).Наконец, в ноябре 1995 года, появились 64-битовые процессоры UltraSPARC-I с тактовой частотой 143, 167 и 200 МГц, и были объявлены процессоры UltraSPARC-II с тактовой частотой от 250 до 300 МГц, серийное производство которых должно начаться в середине 1996 года. В дальнейшем планируется выпуск процессоров UltraSPARC-III с частотой до 500 МГц.
Таким образом, компания Sun Microsystems в настоящее время обладает широчайшим спектром процессоров, способных удовлетворить нужды практически любого пользователя, как с точки зрения производительности выпускаемых ею рабочих станций и серверов, так и в отношении их стоимости, и судя по всему не собирается уступать своих позиций на быстро меняющемся компьютерном рынке.
Отсутствие сохранения состояния
Отсутствие сохранения состояния
Возможно наиболее важной характеристикой протокола NFS является то, что сервер, чтобы работать корректно, не запоминает состояний и не нуждается ни в какой информации о своих клиентах. Каждый запрос является полностью независимым от других запросов и содержит всю необходимую информацию для его обработки. Серверу не нужно поддерживать никаких записей о прошлых запросах клиентов, за исключением необязательных возможностей, которые могут использоваться с целью кэширования данных или для сбора статистики.
Например, в протоколе NFS отсутствуют запросы по открыванию и закрыванию файлов, поскольку они создали бы информацию о состоянии, которая должна запоминаться сервером. По этой же причине, запросы read и write передают в качестве параметра начальное смещение, в отличие от операций read и write с локальными файлами, которые получают смещение из объекта "открытый файл".
Протокол без сохранения состояний упрощает восстановление после краха системы. Если отказывает клиентская система, никакого восстановления не требуется, поскольку сервер не поддерживает никакой устойчивой информации о клиенте. Если клиент перезагрузился, он может перемонтировать файловые системы и запустить приложения, которые обращаются к удаленным файлам. Серверу не нужно ни знать, ни беспокоиться об отказе клиента.
Если отказывает сервер, то клиент увидит, что на свои запросы он не получает ответы. Тогда он продолжает повторно посылать запросы до тех пор, пока сервер не перезагрузится. (Это справедливо только в случае жесткого монтирования (которое выполняется по умолчанию). При мягком монтировании клиент спустя некоторое время прекращает посылку запросов и возвращает приложению сообщение об ошибке). С этого момента времени сервер начнет получать запросы и может их обрабатывать, поскольку запросы не зависят ни от какой более ранней информации о состоянии. Когда наконец сервер ответит на запросы, клиент перестанет их повторно посылать. У клиента нет никаких средств определить, действительно ли сервер отказал и был перезагружен, или просто медленно выполняет операции.
Протоколы с сохранением состояния требуют реализации сложных механизмов восстановления после отказа. Сервер должен обнаруживать отказы клиента и ликвидировать все состояния, связанные с этим клиентом. Если отказывает и перезагружается сервер, он должен уведомить клиентов так, чтобы они могли заново создать свое состояние на сервере.
Главная проблема работы без сохранения состояния заключается в том, что сервер должен зафиксировать все изменения в стабильной памяти до посылки ответа на запрос. Это означает, что не только данные файла, но и все метаданные, такие как индексные дескрипторы или косвенные блоки должны быть сброшены на диск до возвращения результатов. В противном случае сервер может потерять данные, о которых клиент уверен, что они успешно записались на диск. (Отказ системы может привести к потере данных даже в локальной файловой системе, но в таких случаях пользователи знают об отказе и о возможности потерять данные). Работа без сохранения состояния связана также с другими недостатками. Она требует отдельного протокола (NLM) для обеспечения блокировки файлов. Кроме того, чтобы решить проблемы производительности операций синхронной записи большинство клиентов кэшируют данные и метаданные локально. Но это противоречит гарантиям протокола о соблюдении согласованного состояния.
RISC является внекристальная реализация кэша,
PA 7100
Особенностью архитектуры PA- RISC является внекристальная реализация кэша, что позволяет реализовать различные объемы кэш-памяти и оптимизировать конструкцию в зависимости от условий применения (рисунок 6.10). Хранение команд и данных осуществляется в раздельных кэшах, причем процессор соединяется с ними с помощью высокоскоростных 64-битовых шин. Кэш-память реализуется на высокоскоростных кристаллах статической памяти (SRAM), синхронизация которых осуществляется непосредственно на тактовой частоте процессора. При тактовой частоте 100 МГц каждый кэш имеет полосу пропускания 800 Мбайт/с при выполнении операций считывания и 400 Мбайт/с при выполнении операций записи. Микропроцессор аппаратно поддерживает различный объем кэш-памяти: кэш команд может иметь объем от 4 Кбайт до 1 Мбайт, кэш данных - от 4 Кбайт до 2 Мбайт. Чтобы снизить коэффициент промахов применяется механизм хеширования адреса. В обоих кэшах для повышения надежности применяются дополнительные контрольные разряды, причем ошибки кэша команд корректируются аппаратными средствами.
Процессор PA 7200 имеет ряд
PA 7200
Процессор PA 7200 имеет ряд архитектурных усовершенствований по сравнению с PA 7100, главными из которых являются добавление второго целочисленного конвейера, построение внутрикристального вспомогательного кэша данных и реализация нового 64-битового интерфейса с шиной памяти.
Процессор PA 7200, как и его предшественник, обеспечивает суперскалярный режим работы с одновременной выдачей до двух команд в одном такте. Все команды процессора можно разделить на три группы: целочисленные операции, операции загрузки/записи и операции с плавающей точкой. PA 7200 осуществляет одновременную выдачу двух команд, принадлежащим разным группам, или двух целочисленных команд (благодаря наличию второго целочисленного конвейера с АЛУ и дополнительных портов чтения и записи в регистровом файле). Команды перехода выполняются в целочисленном конвейере, причем эти переходы могут составлять пару для одновременной выдачи на выполнение только с предшествующей командой.
Повышение тактовой частоты процессора требует упрощения декодирования команд на этапе выдачи. С этой целью предварительная дешифрация потока команд осуществляется еще на этапе загрузки кэш-памяти. Для каждого двойного слова кэш-память команд включает 6 дополнительных бит, которые содержат информацию о наличии зависимостей по данным и конфликтов ресурсов, что существенно упрощает выдачу команд в суперскалярном режиме.
В процессоре PA 7200 реализован эффективный алгоритм предварительной выборки команд, хорошо работающий и на линейных участках программ.
Как и в PA 7100 в процессоре реализован интерфейс с внешней кэш-памятью данных, работающей на тактовой частоте процессора с однотактным временем ожидания. Внешняя кэш-память данных построена по принципу прямого отображения. Кроме того, для повышения эффективности на кристалле процессора реализован небольшой вспомогательный кэш емкостью в 64 строки. Формирование, преобразование адреса и обращение к основной и вспомогательной кэш-памяти данных выполняется на двух ступенях конвейера.
Максимальная задержка при обнаружении попадания равна одному такту.
Вспомогательный внутренний кэш содержит 64 32-байтовые строки. При обращении к кэш-памяти осуществляется проверка 65 тегов: 64-х тегов вспомогательного кэша и одного тега внешнего кэша данных. При обнаружении совпадения данные направляются в требуемое функциональное устройство.
При отсутствии необходимой строки в кэш-памяти производится ее загрузка из основной памяти. При этом строка поступает во вспомогательный кэш, что в ряде случаев позволяет сократить количество перезагрузок внешней кэш-памяти, организованной по принципу прямого отображения. Архитектурой нового процессора для команд загрузки/записи предусмотрено кодирование специального признака локального размещения данных ("spatial locality only"). При выполнении команд загрузки, помеченных этим признаком, происходит обычное заполнение строки вспомогательного кэша. Однако последующая запись строки осуществляется непосредственно в основную память минуя внешний кэш данных, что значительно повышает эффективность работы с большими массивами данных, для которых размера строки кэш-памяти с прямым отображением оказывается недостаточно.
Расширенный набор команд процессора позволяет реализовать средства автоиндексации для повышения эффективности работы с массивами, а также осуществлять предварительную выборку команд, которые помещаются во вспомогательный внутренний кэш. Этот вспомогательный кэш обеспечивает динамическое расширение степени ассоциативности основной кэш-памяти, построенной на принципе прямого отображения, и является более простым альтернативным решением по сравнению с множественно-ассоциативной организацией.
Процессор PA 7200 включает интерфейс новой 64-битовой мультиплексной системной шины Runway, реализующей расщепление транзакций и поддержку протокола когерентности памяти. Этот интерфейс включает буфера транзакций, схемы арбитража и схемы управления соотношениями внешних и внутренних тактовых частот.
в марте 1995 года на
PA-8000
Процессор PA-8000 был анонсирован в марте 1995 года на конференции COMPCON 95. Было объявлено, что показатели его производительности будут достигать 8.6 единиц SPECint95 и 15 единиц SPECfp95 для операций целочисленной и вещественной арифметики соответственно. В настоящее время этот очень высокий уровень производительности подтвержден испытаниями рабочих станций и серверов, построенных на базе этого процессора.
Процессор PA-8000 вобрал в себя все известные методы ускорения выполнения команд. В его основе лежит концепция "интеллектуального выполнения", которая базируется на принципе внеочередного выполнения команд. Это свойство позволяет PA-8000 достигать пиковой суперскалярной производительности благодаря широкому использованию механизмов автоматического разрешения конфликтов по данным и управлению аппаратными средствами. Эти средства хорошо дополняют другие архитектурные компоненты, заложенные в структуру кристалла: большое число исполнительных функциональных устройств, средства прогнозирования направления переходов и выполнения команд по предположению, оптимизированная организация кэш-памяти и высокопроизводительный шинный интерфейс.
Высокая производительность PA-8000 во многом определяется наличием большого набора функциональных устройств, который включает в себя 10 исполнительных устройств: два арифметико-логических устройства (АЛУ) для выполнения целочисленных операций, два устройства для выполнения операций сдвига/слияния данных, два устройства для выполнения умножения/сложения чисел с плавающей точкой, два устройства деления/вычисления квадратного корня и два устройства выполнения операций загрузки/записи.
Средства внеочередного выполнения команд процессора PA-8000 обеспечивают аппаратное планирование загрузки конвейеров и лучшее использование функциональных устройств. В каждом такте на выполнение могут выдаваться до четырех команд, которые поступают в 56-строчный буфер переупорядочивания. Этот буфер позволяет поддерживать постоянную занятость функциональных устройств и обеспечивает эффективную минимизацию конфликтов по ресурсам. Кристалл может анализировать все 56 командных строк одновременно и выдавать в каждом такте по 4 готовых для выполнения команды в функциональные устройства. Это позволяет процессору автоматически выявлять параллелизм уровня выполнения команд.
Суперскалярный процессор PA-8000 обеспечивает полный набор средств выполнения 64-битовых операций, включая адресную арифметику, а также арифметику с фиксированной и плавающей точкой. При этом кристалл полностью сохраняет совместимость с 32-битовыми приложениями. Это первый процессор, в котором реализована 64-битовая архитектура PA-RISC. Он сохраняет полную совместимость с предыдущими и будущими реализациями PA-RISC.
Кристалл изготовлен по 0.5-микронной КМОП технологии с напряжением питания 3.3 В и можно рассчитывать на дальнейшее уменьшение размеров элементов в будущем.
Память с расслоением
Память с расслоением
Наличие в системе множества микросхем памяти позволяет использовать потенциальный параллелизм, заложенный в такой организации. Для этого микросхемы памяти часто объединяются в банки или модули, содержащие фиксированное число слов, причем только к одному из этих слов банка возможно обращение в каждый момент времени. Как уже отмечалось, в реальных системах имеющаяся скорость доступа к таким банкам памяти редко оказывается достаточной . Следовательно, чтобы получить большую скорость доступа, нужно осуществлять одновременный доступ ко многим банкам памяти. Одна из общих методик, используемых для этого, называется расслоением памяти. При расслоении банки памяти обычно упорядочиваются так, чтобы N последовательных адресов памяти i, i+1, i+2, ..., i+ N-1 приходились на N различных банков. В i-том банке памяти находятся только слова, адреса которых имеют вид kN + i (где 0 ( k ( M-1, а M число слов в одном банке). Можно достичь в N раз большей скорости доступа к памяти в целом, чем у отдельного ее банка, если обеспечить при каждом доступе обращение к данным в каждом из банков. Имеются разные способы реализации таких расслоенных структур. Большинство из них напоминают конвейеры, обеспечивающие рассылку адресов в различные банки и мультиплексирующие поступающие из банков данные. Таким образом, степень или коэффициент расслоения определяют распределение адресов по банкам памяти. Такие системы оптимизируют обращения по последовательным адресам памяти, что является характерным при подкачке информации в кэш-память при чтении, а также при записи, в случае использования кэш-памятью механизмов обратного копирования. Однако, если требуется доступ к непоследовательно расположенным словам памяти, производительность расслоенной памяти может значительно снижаться.
Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контроллеров памяти позволяют банкам памяти (или группам расслоенных банков памяти) работать независимо.
Если система памяти разработана для поддержки множества независимых запросов (как это имеет место при работе с кэш-памятью, при реализации многопроцессорной и векторной обработки), эффективность системы будет в значительной степени зависеть от частоты поступления независимых запросов к разным банкам. Обращения по последовательным адресам, или в более общем случае обращения по адресам, отличающимся на нечетное число, хорошо обрабатываются традиционными схемами расслоенной памяти. Проблемы возникают, если разница в адресах последовательных обращений четная. Одно из решений, используемое в больших компьютерах, заключается в том, чтобы статистически уменьшить вероятность подобных обращений путем значительного увеличения количества банков памяти. Например, в суперкомпьютере NEC SX/3 используются 128 банков памяти.
Подобные проблемы могут быть решены как программными, так и аппаратными средствами.
Параллелизм на уровне выполнения
Параллелизм на уровне выполнения команд, планирование загрузки конвейера и методика разворачивания циклов
В предыдущем разделе мы рассмотрели средства конвейеризации, которые обеспечивают совмещенный режим выполнения команд, когда они являются независимыми друг от друга. Это потенциальное совмещение выполнения команд называется параллелизмом на уровне команд. В данном разделе мы рассмотрим ряд методов развития идей конвейеризации, основанных на увеличении степени параллелизма, используемой при выполнении команд. Мы начнем с рассмотрения методов, позволяющих снизить влияние конфликтов по данным и по управлению, а затем вернемся к теме расширения возможностей процессора по использованию параллелизма, заложенного в программах.
Для начала запишем выражение, определяющее среднее количество тактов для выполнения команды в конвейере:
CPI конвейера = CPI идеального конвейера +
+ Приостановки из-за структурных конфликтов +
+ Приостановки из-за конфликтов типа RAW +
+ Приостановки из-за конфликтов типа WAR +
+ Приостановки из-за конфликтов типа WAW +
+ Приостановки из-за конфликтов по управлению
CPI идеального конвейера есть не что иное, как максимальная пропускная способность, достижимая при реализации. Уменьшая каждое из слагаемых в правой части выражения, мы минимизируем общий CPI конвейера и таким образом увеличиваем пропускную способность команд. Это выражение позволяет также охарактеризовать различные методы, которые будут рассмотрены в этой главе, по тому компоненту общего CPI, который соответствующий метод уменьшает. На рисунке 5.23 показаны некоторые методы, которые будут рассмотрены, и их воздействие на величину CPI.
Прежде, чем начать рассмотрение этих методов, необходимо определить концепции, на которых эти методы построены.
Параллелизм уровня команд: зависимости и конфликты по данным
Параллелизм уровня команд: зависимости и конфликты по данным
Все рассматриваемые в этой главе методы используют параллелизм, заложенный в последовательности команд. Как мы установили выше этот тип параллелизма называется параллелизмом уровня команд или ILP. Степень параллелизма, доступная внутри базового блока (линейной последовательности команд, переходы из вне которой разрешены только на ее вход, а переходы внутри которой разрешены только на ее выход) достаточно мала. Например, средняя частота переходов в целочисленных программах составляет около 16%. Это означает, что в среднем между двумя переходами выполняются примерно пять команд. Поскольку эти пять команд возможно взаимозависимые, то степень перекрытия, которую мы можем использовать внутри базового блока, возможно будет меньше чем пять. Чтобы получить существенное улучшение производительности, мы должны использовать параллелизм уровня команд одновременно для нескольких базовых блоков.
| Метод | Снижает | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Разворачивание циклов | Приостановки по управлению | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Базовое планирование конвейера | Приостановки RAW | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамической планирование с централизованной схемой управления | Приостановки RAW | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамическое планирование с переименованием регистров | Приостановки WAR и WAW | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамическое прогнозирование переходов | Приостановки по управлению | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Выдача нескольких команд в одном такте | Идеальный CPI | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Анализ зависимостей компилятором | Идеальный CPI и приостановки по данным | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Программная конвейеризация и планирование трасс | Идеальный CPI и приостановки по данным | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Выполнение по предположению | Все приостановки по данным и управлению | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Динамическое устранение неоднозначности памяти | Приостановки RAW, связанные с памятью | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Переименование регистров
Переименование регистров
Одним из аппаратных методов минимизации конфликтов по данным является метод переименования регистров (register renaming). Он получил свое название от широко применяющегося в компиляторах метода переименования - метода размещения данных, способствующего сокращению числа зависимостей и тем самым увеличению производительности при отображении необходимых исходной программе объектов (например, переменных) на аппаратные ресурсы (например, ячейки памяти и регистры).
При аппаратной реализации метода переименования регистров выделяются логические регистры, обращение к которым выполняется с помощью соответствующих полей команды, и физические регистры, которые размещаются в аппаратном регистровом файле процессора. Номера логических регистров динамически отображаются на номера физических регистров посредством таблиц отображения, которые обновляются после декодирования каждой команды. Каждый новый результат записывается в новый физический регистр. Однако предыдущее значение каждого логического регистра сохраняется и может быть восстановлено в случае, если выполнение команды должно быть прервано из-за возникновения исключительной ситуации или неправильного предсказания направления условного перехода.
В процессе выполнения программы генерируется множество временных регистровых результатов. Эти временные значения записываются в регистровые файлы вместе с постоянными значениями. Временное значение становится новым постоянным значением, когда завершается выполнение команды (фиксируется ее результат). В свою очередь, завершение выполнения команды происходит когда все предыдущие команды успешно завершились в заданном программой порядке. Программист (или компилятор) имеет дело только с логическими регистрами. Реализация физических регистров от него скрыта.
Таким образом, аппаратный метод переименования регистров, используемый в процессоре R10000, имеет три основных достоинства. Во-первых, результаты "выполняемых по предположению" команд могут прямо записываться в регистровый файл.
Во-вторых, этот метод устраняет все конфликты типа "запись после чтения" и "запись после записи", которые часто возникают при неупорядоченном выполнении команд. И, наконец, метод переименования регистров упрощает контроль зависимостей по данным. Поскольку процессор обеспечивает выдачу для выполнения до четырех команд в каждом такте, в процессе переименования регистров их логические номера сравниваются для определения зависимостей между четырьмя командами, декодированными в одном и том же такте.
Реализованная в микропроцессоре R10000 схема отображения команд состоит из двух таблиц отображения, списка активных команд и двух списков свободных регистров (для целочисленных команд и команд плавающей точки имеются отдельные таблицы отображения и списки свободных регистров). Чтобы поддерживать последовательный порядок завершения выполнения команд, существует только один список активных команд, который содержит как целочисленные команды, так и команды плавающей точки.
Микропроцессор R10000 содержит по 64 физических регистра (целочисленных и плавающей точки). В любой момент времени значение физического регистра содержится в одном из указанных выше списков. На рисунке 6.14 показана упрощенная блок-схема отображения целочисленных команд.
Персональные компьютеры и рабочие станции
Персональные компьютеры и рабочие станции
Персональные компьютеры (ПК)
появились в результате эволюции миникомпьютеров при переходе элементной базы машин с малой и средней степенью интеграции на большие и сверхбольшие интегральные схемы. ПК, благодаря своей низкой стоимости, очень быстро завоевали хорошие позиции на компьютерном рынке и создали предпосылки для разработки новых программных средств, ориентированных на конечного пользователя. Это прежде всего - "дружественные пользовательские интерфейсы", а также проблемно-ориентированные среды и инструментальные средства для автоматизации разработки прикладных программ.
Миникомпьютеры стали прародителями и другого направления развития современных систем - 32-разрядных машин. Создание RISC-процессоров и микросхем памяти емкостью более 1 Мбит привело к окончательному оформлению настольных систем высокой производительности, которые сегодня известны как рабочие станции. Первоначальная ориентация рабочих станций на профессиональных пользователей (в отличие от ПК, которые в начале ориентировались на самого широкого потребителя непрофессионала) привела к тому, что рабочие станции - это хорошо сбалансированные системы, в которых высокое быстродействие сочетается с большим объемом оперативной и внешней памяти, высокопроизводительными внутренними магистралями, высококачественной и быстродействующей графической подсистемой и разнообразными устройствами ввода/вывода. Это свойство выгодно отличает рабочие станции среднего и высокого класса от ПК и сегодня.
Тем не менее быстрый рост производительности ПК на базе новейших микропроцессоров Intel в сочетании с резким снижением цен на эти изделия и развитием технологии локальных шин (VESA и PCI), позволяющей устранить многие "узкие места" в архитектуре ПК, делают современные персональные компьютеры весьма привлекательной альтернативой рабочим станциям. В свою очередь производители рабочих станций создали изделия так называемого "начального уровня", которые по стоимостным характеристикам близки к высокопроизводительным ПК, но все еще сохраняют лидерство по производительности и возможностям наращивания. Насколько успешно удаться ПК на базе процессоров Pentium бороться против рабочих станций UNIX, покажет будущее, но уже в настоящее время появилось понятие "персональной рабочей станции", которое объединяет оба направления.
Современный рынок "персональных рабочих станций" не просто определить. По сути он представляет собой совокупность архитектурных платформ персональных компьютеров и рабочих станций, которые появились в настоящее время, поскольку поставщики компьютерного оборудования уделяют все большее внимание рынку продуктов для коммерции и бизнеса. Этот рынок традиционно считался вотчиной миникомпьютеров и мейнфреймов, которые поддерживали работу настольных терминалов с ограниченным интеллектом. В прошлом персональные компьютеры не были достаточно мощными и не располагали достаточными функциональными возможностями, чтобы служить адекватной заменой подключенных к главной машине терминалов. С другой стороны, рабочие станции на платформе UNIX были очень сильны в научном, техническом и инженерном секторах и были почти также неудобны, как и ПК для того чтобы выполнять серьезные офисные приложения. С тех пор ситуация изменилась коренным образом. Персональные компьютеры в настоящее время имеют достаточную производительность, а рабочие станции на базе UNIX имеют программное обеспечение, способное выполнять большинство функций, которые стали ассоциироваться с понятием "персональной рабочей станции". Вероятно оба этих направления могут серьезно рассматриваться в качестве сетевого ресурса для систем масштаба предприятия. В результате этих изменений практически ушли со сцены старомодные миникомпьютеры с их патентованной архитектурой и использованием присоединяемых к главной машине терминалов. По мере продолжения процесса разукрупнения (downsizing) и увеличения производительности платформы Intel наиболее мощные ПК (но все же чаще открытые системы на базе UNIX) стали использоваться в качестве серверов, постепенно заменяя миникомпьютеры.
Среди других факторов, способствующих этому процессу, следует выделить:
Применение ПК стало более разнообразным. Помимо обычных для этого класса систем текстовых процессоров, даже средний пользователь ПК может теперь работать сразу с несколькими прикладными пакетами, включая электронные таблицы, базы данных и высококачественную графику.
Адаптация графических пользовательских интерфейсов существенно увеличила требования пользователей ПК к соотношению производительность/стоимость. И хотя оболочка MS Windows может работать на моделях ПК 386SX с 2 Мбайтами оперативной памяти, реальные пользователи хотели бы использовать все преимущества подобных систем, включая возможность комбинирования и эффективного использования различных пакетов.
Широкое распространение систем мультимедиа прямо зависит от возможности использования высокопроизводительных ПК и рабочих станций с адеквантными аудио- и графическими средствами, и объемами оперативной и внешней памяти.
Слишком высокая стоимость мейнфреймов и даже систем среднего класса помогла сместить многие разработки в область распределенных систем и систем клиент-сервер, которые многим представляются вполне оправданной по экономическим соображениям альтернативой. Эти системы прямо базируются на высоконадежных и мощных рабочих станциях и серверах.
В начале представлялось, что необходимость сосредоточения высокой мощности на каждом рабочем месте приведет к переходу многих потребителей ПК на UNIX-станции. Это определялось частично тем, что RISC-процессоры, использовавшиеся в рабочих станциях на базе UNIX, были намного более производительными по сравнению с CISC-процессорами, применявшимися в ПК, а частично мощностью системы UNIX по сравнению с MS-DOS и даже OS/2.
Производители рабочих станций быстро отреагировали на потребность в низкостоимостных моделях для рынка коммерческих приложений. Потребность в высокой мощности на рабочем столе, объединенная с желанием поставщиков UNIX-систем продавать как можно больше своих изделий, привела такие компании как Sun Microsystems и Hewlett Packard на рынок рабочих станций для коммерческих приложений. И хотя значительная часть систем этих фирм все еще ориентирована на технические приложения, наблюдается беспрецедентный рост продаж продукции этих компаний для работы с коммерческими приложениями, требующими все большей и большей мощности для реализации сложных, сетевых прикладных систем, включая системы мультимедиа.
Острая конкуренция со стороны производителей UNIX-систем и потребности в повышении производительности огромной уже инсталлированной базы ПК, заставили компанию Intel форсировать разработку высокопроизводительных процессоров семейства 486 и Pentium. Процессоры 486 и Pentium, при разработке которого были использованы многие подходы, применявшиеся ранее только в RISC-процессорах, а также использование других технологических усовершенствований, таких как архитектура локальной шины, позволили снабдить ПК достаточной мощностью, чтобы составить конкуренцию рабочим станциям во многих направлениях рынка коммерческих приложений. Правда для многих других приложений, в частности, в области сложного графического моделирования, ПК все еще отстают.
Поддержка многопроцессорной организации
Поддержка многопроцессорной организации
Процессор R10000 допускает два способа организации многопроцессорной системы. Один из способов связан с созданием специального внешнего интерфейса (агента) для каждого процессора системы. Этот интерфейс обычно реализуется с помощью заказной интегральной схемы, которая организует шлюз к основной памяти и подсистеме ввода/вывода. При таком типе соединений процессоры не связаны друг с другом непосредственно, а взаимодействуют через этот специальный интерфейс. Хотя такая реализация общепринята, ее стоимость, а также общая сложность системы достаточно высоки.(поскольку по крайней мере один внешний агент должен сопровождать каждый процессор.
Второй способ предназначен для достижения максимальной производительности минимальными затратами. Он подразумевает использование от двух до четырех процессоров, объединенных шиной Claster Bus. В этом случае необходим только один внешний интерфейс для взаимодействия с другими ресурсами системы. Все процессоры связаны с одним и тем же внешним агентом. Реализация кластерной шины не только снижает сложность, но и количество заказных интегральных схем, а следовательно и стоимость системы, требуя только одного внешнего агента на каждые четыре процессора.
В дополнение к 64-битовой мультиплексированной шины адреса/данных имеется двухбитовая шина состояний, которая используется для выдачи ответов о состоянии процессорной когерентности. Кроме того, используется 5-битовая шина системных ответов внешним агентом для выдачи внешних ответов подтверждения. На рисунке 6.15 показана блок-схема конфигурации кластерной шины.
Поддержка точных прерываний
Поддержка точных прерываний
Другая проблема, связанная с реализацией команд с большим временем выполнения, может быть проиллюстрирована с помощью следующей последовательности команд:
DIVF F0,F2,F4
ADDF F10,F10,F8
SUBF F12,F12,F14
Эта последовательность команд выглядит очень просто. В ней отсутствуют какие-либо зависимости. Однако она приводит к появлению новых проблем из-за того, что выданная раньше команда может завершиться после команды, выданной для выполнения позже. В данном примере можно ожидать, что команды ADDF и SUBF завершаться раньше, чем завершится команда DIVF. Этот эффект является типичным для конвейеров команд с большим временем выполнения и называется внеочередным завершением команд (out-of-order completion). Тогда, например, если команда DIVF вызовет арифметическое прерывание после завершения команды ADDF, мы не сможем реализовать точное прерывание на уровне аппаратуры. В действительности, поскольку команда ADDF меняет значение одного из своих операндов, невозможно даже с помощью программных средств восстановить состояние, которое было перед выполнением команды DIVF.
Имеются четыре возможных подхода для работы в условиях внеочередного завершения команд. Первый из них просто игнорирует проблему и предлагает механизмы неточного прерывания. Этот подход использовался в 60-х и 70-х годах и все еще применяется в некоторых суперкомпьютерах, в которых некоторые классы прерываний запрещены или обрабатываются аппаратурой без остановки конвейера. Такой подход трудно использовать в современных машинах при наличии концепции виртуальной памяти и стандарта на операции с плавающей точкой IEEE, которые требуют реализации точного прерывания путем комбинации аппаратных и программных средств. В некоторых машинах эта проблема решается путем введения двух режимов выполнения команд: быстрого, но с возможно не точными прерываниями, и медленного, гарантирующего реализацию точных прерываний.
Второй подход заключается в буферизации результатов операции до момента завершения выполнения всех команд, предшествовавших данной. В некоторых машинах используется этот подход, но он становится все более дорогостоящим, если отличия во времени выполнения разных команд велики, поскольку становится большим количество результатов, которые необходимо буферизовать. Более того, результаты из этой буферизованной очереди необходимо пересылать для обеспечения продолжения выдачи новых команд. Это требует большого количества схем сравнения и многовходовых мультиплексоров. Имеются две вариации этого основного подхода. Первая называется буфером истории (history file), использовавшемся в машине CYBER 180/990. Буфер истории отслеживает первоначальные значения регистров. Если возникает прерывание и состояние машины необходимо откатить назад до точки, предшествовавшей некоторым завершившимся вне очереди командам, то первоначальное значение регистров может быть восстановлено из этого буфера истории. Подобная методика использовалась также при реализации автоинкрементной и автодекрементной адресации в машинах типа VAX. Другой подход называется буфером будущего (future file). Этот буфер хранит новые значения регистров. Когда все предшествующие команды завершены, основной регистровый файл обновляется значениями из этого буфера. При прерывании основной регистровый файл хранит точные значения регистров, что упрощает организацию прерывания. В следующей главе будут рассмотрены некоторые расширения этой идеи.
Третий используемый метод заключается в том, чтобы разрешить в ряде случаев неточные прерывания, но при этом сохранить достаточно информации, чтобы подпрограмма обработки прерывания могла выполнить точную последовательность прерывания. Это предполагает наличие информации о находившихся в конвейере командах и их адресов. Тогда после обработки прерывания, программное обеспечение завершает выполнение всех команд, предшествовавших последней завершившейся команде, а затем последовательность может быть запущена заново. Рассмотрим следующий наихудший случай:
Команда 1 - длинная команда, которая в конце концов вызывает прерывание
Команда 2, ... , Команда n-1 - последовательность команд, выполнение которых не завершилось
Команда n - команда, выполнение которой завершилось
Имея значения адресов всех команд в конвейере и адрес возврата из прерывания, программное обеспечение может определить состояние команды 1 и команды n. Поскольку команда n завершила выполнение, хотелось бы продолжить выполнение с команды n+1. После обработки прерывания программное обеспечение должно смоделировать выполнение команд с 1 по n-1. Тогда можно осуществить возврат из прерывания на команду n+1. Наибольшая неприятность такого подхода связана с усложнением подпрограммы обработки прерывания. Но для простых конвейеров, подобных рассмотренному нами, имеются и упрощения. Если команды с 2 по n все являются целочисленными, то мы просто знаем, что в случае завершения выполнения команды n, все команды с 2 по n-1 также завершили выполнение. Таким образом, необходимо обрабатывать только операцию с плавающей точкой. Чтобы сделать эту схему работающей, количество операций ПТ, выполняющихся с совмещением, может быть ограничено. Например, если допускается совмещение только двух операций, то только прерванная команда должна завершаться программными средствами. Это ограничение может снизить потенциальную пропускную способность, если конвейеры плавающей точки являются достаточно длинными или если имеется значительное количество функциональных устройств. Такой подход использовался в архитектуре SPARC, позволяющей совмещать выполнение целочисленных операций с операциями плавающей точки.
Четвертый метод представляет собой гибридную схему, которая позволяет продолжать выдачу команд только если известно, что все команды, предшествовавшие выдаваемой, будут завершены без прерывания. Это гарантирует, что в случае возникновения прерывания ни одна следующая за ней команда не будет завершена, а все предшествующие будут завершены. Иногда это означает необходимость приостановки машины для поддержки точных прерываний. Чтобы эта схема работала, необходимо, чтобы функциональные устройства плавающей точки определяли возможность появления прерывания на самой ранней стадии выполнения команд так, чтобы предотвратить завершение выполнения следующих команд. Такая схема используется, например, в микропроцессорах R2000/R3000 и R4000 компании MIPS.
"Полностью активные" клиенты
"Полностью активные" клиенты
Все остальное время клиенты генерируют либо небольшое число запросов, либо вообще обходятся без них. Везде далее по тексту мы будем называть клиента, который активно выполняет запросы, полностью активным клиентом. По разным причинам многие клиенты (в ряде случаев таковыми оказывается подавляющее большинство клиентов) часто оказываются не очень занятыми, тем самым не очень нагружая, либо вообще не нагружая свой сервер. Например, некоторые клиенты работают на достаточно мощных системах и могут кэшировать большинство, либо все свои данные. Другие системы используются только часть рабочего времени, и даже интенсивно используемые клиенты часто остаются полностью свободными в то время, когда их владельцы обедают или находятся на совещаниях.
Пользовательские легковесные процессы
Пользовательские легковесные процессы
Видимо, следующим по важности классом легковесных процессов являются пользовательские LWP (LightWeight Processes). Механизмы этого рода позволяют пользователям организовать несколько потоков управления в одном адресном пространстве. Все LWP одного пользовательского процесса совместно используют все ресурсы процесса. При поступлении процессу сигнала на этот сигнал реагируют все LWP в соответствии со своими собственными установками. С другой стороны, каждый LWP обладает своим собственным контекстом, включающим, как и в случае ядерных нитей, стек и регистровое окружение (в частности, содержимое индивидуального счетчика команд). Любому LWP пользовательского процесса соответствует отдельная ядерная нить. Это означает, что каждый LWP может отдельно планироваться (и поэтому LWP одного пользовательского процесса могут параллельно выполняться на разных процессорах симметричного мультипроцессорного компьютера), и системные вызовы и прерывания LWP могут обрабатываться независимо. Основным преимуществом использования LWP является возможность достижения реального распараллеливания программы при ее выполнении на симметричном мультипроцессоре (на недостатках мы остановимся ниже).
Пользовательские нити
Пользовательские нити
Наконец, к третьему классу легковесных процессов относятся пользовательские нити. Они называются пользовательскими, поскольку реализуются не ядром ОС, а с помощью специальной библиотеки функций (поэтому, например, в ОС Mach их называют C-Threads). Это тоже очень старая идея, к использованию которой неоднократно прибегали все опытные программисты (здесь уже даже не важно, в среде какой операционной системы выполняется программа). Суть идеи состоит в том, что вся программа пользователя строится в виде набора сопрограмм (coroutine), которые выполняются под управлением общего монитора. Естественно, что в мониторе поддерживаются контексты всех сопрограмм, но и монитор, и сопрограммы являются составляющими одного пользовательского процесса, которому соответствует одна ядерная нить. Конечно, с использованием пользовательских нитей невозможно достичь реального распараллеливания программы. Единственный реальный эффект, которого можно добиться, состоит в возможности распараллеливания обменов при использовании асинхронного режима системных вызовов. Как считают некоторые специалисты (к числу которых не относится автор этой части курса), основное достоинство использования пользовательских нитей состоит в лучшей структуризации программы.
Последовательность команд с приостановкой конвейера
Рисунок 5.11. Последовательность команд с приостановкой конвейера
Этот случай отличается от последовательности подряд идущих команд АЛУ. Команда загрузки (LW) регистра R1 из памяти имеет задержку, которая не может быть устранена обычной "пересылкой". Вместо этого нам нужна дополнительная аппаратура, называемая аппаратурой внутренних блокировок конвейера (pipeline interlook), чтобы обеспечить корректное выполнение примера. Вообще такого рода аппаратура обнаруживает конфликты и приостанавливает конвейер до тех пор, пока существует конфликт. В этом случае эта аппаратура приостанавливает конвейер начиная с команды, которая хочет использовать данные в то время, когда предыдущая команда, результат которой является операндом для нашей, вырабатывает этот результат. Эта аппаратура вызывает приостановку конвейера или появление "пузыря" точно также, как и в случае структурных конфликтов.
Построение многопроцессорной системы на базе кластерной шины
Рисунок 6.15. Построение многопроцессорной системы на базе кластерной шины
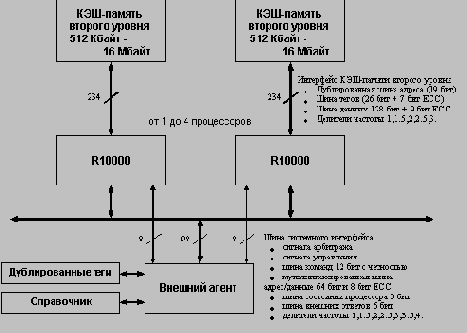
Потребление процессорных ресурсов
Потребление процессорных ресурсов
Поскольку многие компьютеры представляют собой универсальные системы, которые допускают достаточно большое расширение количества подключенным к ним периферийных устройств, почти всегда существует возможность сконфигурировать систему так, что основным ограничивающим фактором станет процессор. В среде NFS мощность процессора расходуется непосредственно для обработки протоколов IP, UDP, RPC и NFS, а также для управления устройствами (дисками и сетевыми адаптерами) и манипуляциями с файловой системой (грубо можно считать, что потребление процессорного времени нарастает пропорционально в соответствии с указанным здесь порядком).
Например, компания Sun рекомендует следующие эмпирические правила для конфигурирования NFS-серверов:
Если у заказчика преобладает интенсивная по атрибутам среда и имеется менее 4-6 сетей Ethernet или Token Ring, то для работы в качестве NFS-сервера вполне достаточно однопроцессорной системы. Для систем меньшего размера с одной-двумя сетями достаточно процессорной мощности машины начального уровня SPARCserver 4. Для очень большой интенсивной по атрибутам среды со многими сетями рекомендуются двухпроцессорные системы подобные SPARCstation 20 Мodel 502 или двухпроцессорные конфигурации SPARCserver 1000 или SPARCcenter 2000.
Если среда интенсивная по данным, то рекомендуется конфигурировать по два процессора SuperSPARC с SuperCashe на каждую высокоскоростную сеть (подобную FDDI). Если существующие ограничения по организации кабельной проводки диктуют использование в такой среде Ethernet, то рекомендуется конфигурировать один процессор SuperSPARC на каждые 4 сети Ethernet или Token Ring.
Первый микропроцессор PowerPC, PowerPC 601,
PowerPC 601
Первый микропроцессор PowerPC, PowerPC 601, в настоящее время выпускается как компанией IBM, так и компанией Motorola. Он представляет собой процессор среднего класса и предназначен для использования в настольных вычислительных системах малой и средней стоимости. Он был разработан в качестве переходной модели от архитектуры POWER к архитектуре PowerPC и реализует возможности обеих архитектур. При этом двоичные коды RS/6000 выполняются на нем без изменений, что дало дополнительное время разработчикам компиляторов для освоения архитектуры PowerPC, а также разработчикам прикладных систем, которые должны перекомпилировать свои программы, чтобы полностью использовать возможности архитектуры PowerPC.
Процессор 601 базировался на однокристальном процессоре IBM, который был разработан к моменту создания альянса трех ведущих фирм. Но по сравнению со своим предшественником, PowerPC 601 претерпел серьезные изменения в сторону повышения производительности и снижения стоимости. Например, в его состав было включено более сложное устройство переходов, расширенные возможностями мультипроцессорной работы, включая интерфейс шины высокопроизводительного процессора 88110 компании Motorola. В Power 601 реализована суперскалярная обработка, позволяющая выдавать на выполнение в каждом такте 3 команды, возможно не в порядке их расположения в программном коде.
Суперскалярный процессор PowerPC 604 обеспечивает
PowerPC 604
Суперскалярный процессор PowerPC 604 обеспечивает одновременную выдачу до четырех команд. При этом параллельно в каждом такте может завершаться выполнение до шести команд. На рисунке 6.20 представлена блок-схема процессора 604. Процессор включает шесть исполнительных устройств, которые могут работать параллельно:
устройство плавающей точки (FPU);
устройство выполнения переходов (BPU);
устройство загрузки/записи (LSU);
три целочисленных устройства (IU):
два однотактных целочисленных устройства (SCIU);
одно многотактное целочисленное устройство (MCIU).
Такая параллельная конструкция в сочетании со спецификацией команд PowerPC, допускающей реализацию ускоренного выполнения команд, обеспечивает высокую эффективность и большую пропускную способность процессора. Применяемые в процессоре 604 буфера переименования регистров, буферные станции резервирования, динамическое прогнозирование направления условных переходов и устройство завершения выполнения команд существенно увеличивают пропускную способность системы, гарантируют завершение выполнения команд в порядке, предписанном программой, и обеспечивают реализацию модели точного прерывания.
В процессоре 604 имеются отдельные устройства управления памятью и отдельные по 16 Кбайт внутренние кэши для команд и данных. В нем реализованы два буфера преобразования виртуальных адресов в физические TLB (отдельно для команд и для данных), содержащие по 128 строк. Оба буфера являются двухканальными множественно-ассоциативными и обеспечивают переменный размер страниц виртуальной памяти. Кэш-памяти и буфера TLB используют для замещения блоков алгоритм LRU.
К концу 1995 года ожидается
PowerPC 620
К концу 1995 года ожидается появление нового процессора PowerPC 620. В отличие от своих предшественников это будет полностью 64-битовый процессор. При работе на тактовой частоте 133 МГц его производительность оценивается в 225 единиц SPECint92 и 300 единиц SPECfp92, что соответственно на 40 и 100% больше показателей процессора PowerPC 604.
Подобно другим 64-битовым процессорам, PowerPC 620 содержит 64-битовые регистры общего назначения и плавающей точки и обеспечивает формирование 64-битовых виртуальных адресов. При этом сохраняется совместимость с 32-битовым режимом работы, реализованным в других моделях семейства PowerPC.
В процессоре имеется кэш-память данных и команд общей емкостью 64 Кбайт, интерфейсные схемы управления кэш-памятью второго уровня, 128-битовая шина данных между процессором и основной памятью, а также логические схемы поддержания когерентного состояния памяти при организации многопроцессорной системы.
Процессор PowerPC 620 нацелен на рынок высокопроизводительных рабочих станций и серверов.
В заключении отметим, что в иллюстрациях к курсу приведены основные характеристики некоторых современных систем, построенных на рассмотренных в данном разделе процессорах.
Предварительная оценка рабочей нагрузки
Предварительная оценка рабочей нагрузки
Проведение работ по оценке нагрузки на будущую систему оказывается не очень точным, но часто вполне хорошим приближением, которое пользователь может получить заранее. Для этого используются два основных подхода. Более предпочтительный метод заключается в измерении параметров существующей системы. Этот метод обеспечивает некоторую уверенность в точности оценки нагрузки по крайней мере на текущий момент времени, хотя нельзя конечно гарантировать, что нагрузка при эксплуатации системы в будущем останется эквивалентной существующей. Альтернативным методом является грубый расчет. Он полезен, когда в распоряжении пользователя отсутствуют необходимые для измерения системы.
Чтобы создать достаточно точную конфигурацию системы необходимо знать две вещи: смесь операций NFS и общую пропускную способность системы. Смесь операций NFS позволяет показать, является ли система интенсивной по атрибутам или по данным.
PrestoServe/NVSIMM
PrestoServe/NVSIMM
Дисковые операции по своей природе связаны с механическими перемещениями головок диска, поэтому они выполняются медленно. Обычно UNIX буферизует операции записи в основной памяти и позволяет выдавшему их процессу продолжаться, в то время как на операционную систему ложится задача физической записи данных на диск. Синхронный принцип операций записи в NFS означает, что они обычно выполняются очень медленно (значительно медленнее, чем операции записи на локальный диск). Если клиент выдает запрос записи, требуется, чтобы сервер обновил на диске сами данные, а также все связанные с ними метаданные файловой системы. Для типичного файла необходимо выполнить до 4 записей на диск: каждая операция должна обновить сами данные, информацию в каталоге файла, индицирующую дату последней модификации, и косвенный блок; если файл большой, то потребуется также обновить второй косвенный блок. Прежде, чем подтвердить завершение запроса записи NFS, сервер должен выполнить все эти обновления и гарантировать, что они действительно находятся на диске. Операция записи NFS часто может продолжаться в течение 150-200 миллисекунд (три или четыре синхронных записи, больше чем по 40 миллисекунд каждая), по сравнению с обычными 15-20 миллисекундами для записи на локальный диск.
Для того чтобы существенно ускорить операции записи NFS, серверы могут использовать стабильную память (non-volatile RAM - NVRAM). Эта дополнительная возможность опирается на тот факт, что протокол NFS просто требует, чтобы данные операции записи NFS были бы зафиксированы в стабильной памяти вместо их фиксации на диске. До тех пор, пока сервер возвращает данные, которые подтверждены предыдущими операциями записи, он может сохранять эти данные любым доступным способом.
PrestoServe и NVRAM в точности реализуют эту семантику. При установке этих устройств в сервер драйвер устройства NVRAM перехватывает запросы синхронных операций записи на диск. Данные не посылаются прямо в дисковое устройство. Вместо этого, результаты операций записи фиксируются в стабильной памяти и подтверждаются как завершенные. Это намного быстрее, чем ожидание окончания механической операции записи данных на диск. Спустя некоторое время данные фиксируются на диске.
Поскольку одна логическая операция записи NFS выполняет три или четыре синхронные дисковые операции, использование NVRAM существенно ускоряет пропускную способность операций записи NFS. В зависимости от условий (состояния файловой системы, наличия других запросов к диску, размера и месторасположения записи и т.п.) использование NVRAM ускоряет операции записи NFS в 2-4 раза. Например, типичная пропускная способность при выполнении операций записи NFS под управлением ОС Solaris 2 составляет примерно 450 Кбайт/с. При использовании NVRAM скорость повышается примерно до 950 Кбайт/с и даже несколько выше, если используется сетевая среда более быстрая, чем Ethernet. Никаких улучшений времени выполнения операций чтения NVRAM не дает.
С точки зрения дисковой подсистемы или клиентов NFS дополнительные возможности PrestoServe и NVSIMM функционально эквивалентны. Основная разница заключается в том, что NVSIMM более эффективны, поскольку они требуют меньше манипуляций с данными. Поскольку плата PrestoServe физически размещается на шине SBus, требуется, чтобы данные копировались на нее через периферийную шину. В отличие от этого, NVSIMM размещаются прямо в основной памяти. Записываемые на диск данные не копируются в NVSIMM через периферийную шину. Такое копирование может быть выполнено очень быстро с помощью операций память-память. По этим причинам NVSIMM оказываются предпочтительными в ситуациях, когда обе возможности NVSIMM и PrestoServe оказываются доступными.
В связи с важностью получаемого ускорения Sun рекомендует использование NVRAM действительно во всех своих системах, которые обеспечивают универсальный сервис NFS. Единственным исключением из этого правила являются серверы, которые обеспечивают только сервис по чтению файлов. Наиболее характерным примером такого использования являются серверы, хранящие двоичные коды программ для большого коллектива клиентов. (В Sun он известен как сервер /usr/dist или softdist).
Поскольку драйвер устройства NVSIMM/PrestoServe должен находится на диске в корневой файловой системе, ускорение с помощью NVRAM не может быть получено для работы с самой корневой файловой системы. Драйвер NVRAM должен успевать откачивать модифицированные буфера на диск прежде, чем станет активным любой другой процесс. Если бы и корневая файловая система была ускорена, она могла бы оказаться "грязной" (модифицированной) после краха системы, и драйвер NVRAM не мог бы загрузиться.
Еще одно важное соображение при сравнении серверов, которые оборудованы NVRAM и без него, заключается в том, что использование такого ускорения обычно снижает максимальную пропускную способность системы примерно на 10%. (Системы, использующие NVRAM, должны управлять кэшем NVRAM и поддерживать в согласованном состоянии копии в кэше и на диске). Однако время ответа системы существенно улучшается (примерно на 40%). Например, максимальная пропускная способность SPARCserver 1000 на тесте LADDIS без NVSIMM составляет 2108 операций в секунду с временем ответа 49.4 мс. Таже система с NVSIMM может выполнять только примерно 1928 операций в секунду, но среднее время ответа сокращается примерно до 32 мс. Это означает, что клиенты NFS воспринимают сервер, оборудованный NVRAM, гораздо более быстрым, чем сервер без NVRAM, хотя общая пропускная способность системы несколько сократилась. К счастью, величина 10% редко оказывается проблемой, поскольку возможности максимальной пропускной способности большинства систем намного превышают типовые нагрузки, которые вообще находятся в диапазоне 10-150 операций в секунду на сеть.
Причины прерываний в простейшем конвейере
Рисунок 5.19. Причины прерываний в простейшем конвейере
Пример конфликта по записи в регистровый файл
Рисунок 5.22. Пример конфликта по записи в регистровый файл
Имеется два способа для обхода этого конфликта. Первый заключается в отслеживании использования порта записи на ступени ID конвейера и приостановке выдачи команды как при структурном конфликте. Схема обнаружения такого конфликта обычно реализуется с помощью сдвигового регистра. Альтернативная схема предполагает приостановку конфликтующей команды, когда она пытается попасть на ступень MEM конвейера. Преимуществом такой схемы является то, что она не требует обнаружения конфликта до входа на ступень MEM, где это легче сделать. Однако подобная реализация усложняет управление конвейером, поскольку приостановки в этом случае могут возникать в двух разных местах конвейера.
Другой проблемой является возможность конфликтов типа WAW. Можно рассмотреть тот же пример, что и на рисунке 5.22. Если бы команда LD была выдана на один такт раньше и имела в качестве месторасположения результата регистр F2, то возник бы конфликт типа WAW, поскольку эта команда выполняла бы запись в регистр F2 на один такт раньше команды ADDD. Имеются два способа обработки этого конфликта типа WAW. Первый подход заключается в задержке выдачи команды загрузки до момента передачи команды ADDD на ступень MEM. Второй подход заключается в подавлении результата операции сложения при обнаружении конфликта и изменении управления таким образом, чтобы команда сложения не записывала свой результат. Тогда команда LD может выдаваться для выполнения сразу же. Поскольку такой конфликт является редким, обе схемы будут работать достаточно хорошо. В любом случае конфликт может быть обнаружен на ранней стадии ID, когда команда LD выдается для выполнения. Тогда приостановка команды LD или установка блокировки записи результата командой ADDD реализуются достаточно просто.
Таким образом, для обнаружения возможных конфликтов необходимо рассматривать конфликты между командами ПТ, а также конфликты между командами ПТ и целочисленными командами. За исключением команд загрузки/записи с ПТ и команд пересылки данных между регистрами ПТ и целочисленными регистрами, команды ПТ и целочисленные команды достаточно хорошо разделены, и все целочисленные команды работают с целочисленными регистрами, а команды ПТ - с регистрами ПТ.
Таким образом, для обнаружения конфликтов между целочисленными командами и командами ПТ необходимо рассматривать только команды загрузки/записи с ПТ и команды пересылки регистров ПТ. Это упрощение управления конвейером является дополнительным преимуществом поддержания отдельных регистровых файлов для хранения целочисленных данных и данных с ПТ. (Главное преимущество заключается в удвоении общего количества регистров и увеличении пропускной способности без увеличения числа портов в каждом наборе). Если предположить, что конвейер выполняет обнаружение всех конфликтов на стадии ID, перед выдачей команды для выполнения в функциональные устройства должны быть выполнены три проверки:
Проверка наличия структурных конфликтов. Ожидание освобождения функционального устройства и порта записи в регистры, если он потребуется.
Проверка наличия конфликтов по данным типа RAW. Ожидание до тех пор, пока регистры-источники операндов указаны в качестве регистров результата на конвейерных станциях ID/EX (которая соответствует команде, выданной в предыдущем такте), EX1/EX2 или EX/MEM.
Проверка наличия конфликтов типа WAW. Проверка того, что команды, находящиеся на конвейерных станциях EX1 и EX2, не имеют в качестве месторасположения результата регистр результата выдаваемой для выполнения команды. В противном случае выдача команды, находящейся на ступени ID, приостанавливается.
Хотя логика обнаружения конфликтов для многотактных операций ПТ несколько более сложная, концептуально она не отличается от такой же логики для целочисленного конвейера. То же самое касается логики для ускоренной пересылки данных. Логика ускоренной пересылки данных может быть реализована с помощью проверки того, что указанный на конвейерных станциях EX/MEM и MEM/WB регистр результата является регистром операнда команды ПТ. Если происходит такое совпадение, для пересылки данных разрешается прием по соответствующему входу мультиплексора. Многотактные операции ПТ создают также новые проблемы для механизма прерывания.
Пример построения системы на базе
Рисунок 6.17. Пример построения системы на базе микропроцессора Alpha 21066

Высокоскоростная шина PCI имеет ряд привлекательных свойств. Помимо возможности работы с прямым доступом к памяти и программируемым вводом/выводом она допускает специальные конфигурационные циклы, расширяемость до 64 бит, компоненты, работающие с питающими напряжениями 3.3 и 5 В, а также более быстрое тактирование. Базовая реализация шины PCI поддерживает мультиплексирование адреса и данных и работает на частоте 33 МГц, обеспечивая максимальную скорость передачи данных 132 Мбайт/с. Шина PCI непосредственно управляется микропроцессором. На рисунке 6.17 показаны некоторые высокоскоростные периферийные устройства: графические адаптеры, контроллеры SCSI и сетевые адаптеры, подключенные непосредственно к шине PCI. Мостовая микросхема интерфейса ISA позволяет подключить к системе низкоскоростные устройства типа модема, флоппи-дисковода и т.д.
В настоящее время выпущена модернизированная версия этого микропроцессора. Как и его предшественник, новый кристалл Alpha 21066A помимо интерфейса PCI содержит на кристалле интегрированный контроллер памяти и графический акселератор. Эти характеристики позволяют значительно снизить стоимость реализации систем, базирующихся на Alpha 21066A, и обеспечивают простой и дешевый доступ к внешней памяти и периферийным устройствам. Alpha 21066A имеет две модификации в соответствии с частотой: 100 МГц и 233 МГц. Модель с 233 МГц обеспечивает производительность 94 и 100 единиц, соответственно, по тестам SPECint92 и SPECfp92.
Новейший микропроцессор Alpha 21164 представляет собой вторую полностью новую реализацию архитектуры Alpha. Микропроцессор 21164, представленный в сентябре 1994 года, обеспечивает производительность 330 и 500 единиц, соответственно, по шкалам SPECint92 и SPECfp92 или около 1200 MIPS и выполняет до четырех инструкций за такт. На кристалле микропроцессора 21164 размещено около 9,3 миллиона транзисторов, большинство из которых образуют кэш. Кристалл построен на базе 0.5 микронной КМОП технологии компании DEC.
Он собирается в 499-контактные корпуса PGA ( при этом 205 контактов отводятся под разводку питания и земли) и рассеивает 50 Вт при питающем напряжении 3.3 В на частоте 300 МГц.
Переход в 1996 году на 0.35 микронную КМОП технологию привел к возможности дальнейшего увеличения тактовой частоты и производительности процессора. В настоящее время процессоры 21164 выпускаются с тактовой частотой 366 МГц (11.3 SPECint95, 15.4 SPECfp95) и 433 МГц (13.3 SPECint95, 18.3 SPECfp95). В конце 1996 года начнутся массовые поставки 21164 с тактовой частотой 500 МГц (15.4 SPECint95, 21.1 SPECfp95). Таким образом, компания DEC в настоящее время имеет самые мощные процессоры, пиковая производительность которых составляет 2 миллиарда операций в секунду.
Ключевыми моментами для реализации высокой производительности является суперскалярный режим работы процессора, обеспечивающий выдачу для выполнения до четырех команд в каждом такте, высокопроизводительная неблокируемая подсистема памяти с быстродействующей кэш-памятью первого уровня, большая, размещенная на кристалле, кэш-память второго уровня и уменьшенная задержка выполнения операций во всех функциональных устройствах.
Пример устранения конфликтов компилятором
Рисунок 5.13. Пример устранения конфликтов компилятором
В результате устранены обе блокировки (командой LW Rc,c команды ADD Ra,Rb,Rc
и командой LW Rf,f команды SUB Rd,Re,Rf). Имеется зависимость между операцией АЛУ и операцией записи в память, но структура конвейера допускает пересылку результата с помощью цепей "обхода". Заметим, что использование разных регистров для первого и второго операторов было достаточно важным для реализации такого правильного планирования. В частности, если переменная e была бы загружена в тот же самый регистр, что b или c, такое планирование не было бы корректным. В общем случае планирование конвейера может требовать увеличенного количества регистров. Такое увеличение может оказаться особенно существенным для машин, которые могут выдавать на выполнение несколько команд в одном такте.
Многие современные компиляторы используют технику планирования команд для улучшения производительности конвейера. В простейшем алгоритме компилятор просто планирует распределение команд в одном и том же базовом блоке. Базовый блок представляет собой линейный участок последовательности программного кода, в котором отсутствуют команды перехода, за исключением начала и конца участка (переходы внутрь этого участка тоже должны отсутствовать). Планирование такой последовательности команд осуществляется достаточно просто, поскольку компилятор знает, что каждая команда в блоке будет выполняться, если выполняется первая из них, и можно просто построить граф зависимостей этих команд и упорядочить их так, чтобы минимизировать приостановки конвейера. Для простых конвейеров стратегия планирования на основе базовых блоков вполне удовлетворительна. Однако когда конвейеризация становится более интенсивной и действительные задержки конвейера растут, требуются более сложные алгоритмы планирования.
К счастью, существуют аппаратные методы, позволяющие изменить порядок выполнения команд программы так, чтобы минимизировать приостановки конвейера. Эти методы получили общее название методов динамической оптимизации (в англоязычной литературе в последнее время часто применяются также термины "out-of-order execution" - неупорядоченное выполнение и "out-of-order issue" - неупорядоченная выдача).
Каждый новый результат записывается в новый физический регистр. Однако предыдущее значение каждого логического регистра сохраняется и может быть восстановлено в случае, если выполнение команды должно быть прервано из-за возникновения исключительной ситуации или неправильного предсказания направления условного перехода.
В процессе выполнения программы генерируется множество временных регистровых результатов. Эти временные значения записываются в регистровые файлы вместе с постоянными значениями. Временное значение становится новым постоянным значением, когда завершается выполнение команды (фиксируется ее результат). В свою очередь, завершение выполнения команды происходит, когда все предыдущие команды успешно завершились в заданном программой порядке.
Программист имеет дело только с логическими регистрами. Реализация физических регистров от него скрыта. Как уже отмечалось, номера логических регистров ставятся в соответствие номерам физических регистров. Отображение реализуется с помощью таблиц отображения, которые обновляются после декодирования каждой команды. Каждый новый результат записывается в физический регистр. Однако до тех пор, пока не завершится выполнение соответствующей команды, значение в этом физическом регистре рассматривается как временное.
Метод переименования регистров упрощает контроль зависимостей по данным. В машине, которая может выполнять команды не в порядке их расположения в программе, номера логических регистров могут стать двусмысленными, поскольку один и тот же регистр может быть назначен последовательно для хранения различных значений. Но поскольку номера физических регистров уникально идентифицируют каждый результат, все неоднозначности устраняются.
Примеры протоколов наблюдения
Рисунок 5.42. Примеры протоколов наблюдения
Если процессор использует многоуровневый кэш со свойствами охвата, тогда каждая строка в основном кэше имеется и во вторичном кэше. Таким образом, активность по наблюдению может быть связана с кэшем второго уровня, в то время как большинство активностей процессора могут быть связаны с первичным кэшем. Если механизм наблюдения получает попадание во вторичный кэш, тогда он должен выполнять арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Такое решение было принято во многих современных системах, поскольку многоуровневый кэш позволяет существенно снизить требований к полосе пропускания. Иногда может быть даже полезно дублировать теги во вторичном кэше, чтобы еще больше сократить количество конфликтов между активностями процессора и механизма наблюдения.
В реальных системах существует много вариаций схем когерентности кэша, в зависимости от того используется ли схема на основе аннулирования или обновления, построена ли кэш-память на принципах сквозной или обратной записи, когда происходит обновление, а также имеет ли место состояние "владения" и как оно реализуется. На рисунке 5.42 представлены несколько протоколов с наблюдением и некоторые машины , которые используют эти протоколы.
Примеры стандартных шин
Рисунок 5.44. Примеры стандартных шин
Одной из популярных шин персональных компьютеров была системная шина IBM PC/XT, обеспечивавшая передачу 8 бит данных. Кроме того, эта шина включала 20 адресных линий, которые ограничивали адресное пространство пределом в 1 Мбайт. Для работы с внешними устройствами в этой шине были предусмотрены также 4 линии аппаратных прерываний (IRQ) и 4 линии для требования внешними устройствами прямого доступа к памяти (DMA). Для подключения плат расширения использовались специальные 62-контактные разъемы. При этом системная шина и микропроцессор синхронизировались от одного тактового генератора с частотой 4.77 МГц. Таким образом теоретическая скорость передачи данных могла достигать немногим более 4 Мбайт/с.
Системная шина ISA (Industry Standard Architecture) впервые стала применяться в персональных компьютерах IBM PC/AT на базе процессора i286. Эта системная шина отличалась наличием второго, 36-контактного дополнительного разъема для соответствующих плат расширения. За счет этого количество адресных линий было увеличено на 4, а данных - на 8, что позволило передавать параллельно 16 бит данных и обращаться к 16 Мбайт системной памяти. Количество линий аппаратных прерываний в этой шине было увеличено до 15, а каналов прямого доступа - до 7. Системная шина ISA полностью включала в себя возможности старой 8-разрядной шины. Шина ISA позволяет синхронизировать работу процессора и шины с разными тактовыми частотами. Она работает на частоте 8 МГц, что соответствует максимальной скорости передачи 16 Мбайт/с.
С появлением процессоров i386, i486 и Pentium шина ISA стала узким местом персональных компьютеров на их основе. Новая системная шина EISA (Extended Industry Standard Architecture),
появившаяся в конце 1988 года, обеспечивает адресное пространство в 4 Гбайта, 32-битовую передачу данных (в том числе и в режиме DMA), улучшенную систему прерываний и арбитраж DMA, автоматическую конфигурацию системы и плат расширения. Устройства шины ISA могут работать на шине EISA.
Шина EISA предусматривает централизованное управление доступом к шине за счет наличия специального устройства - арбитра шины. Поэтому к ней может подключаться несколько главных устройств шины. Улучшенная система прерываний позволяет подключать к каждой физической линии запроса на прерывание несколько устройств, что снимает проблему количества линий прерывания. Шина EISA тактируется частотой около 8 МГц и имеет максимальную теоретическую скорость передачи данных 33 Мбайт/с.
Шина MCA также обеспечивает 32-разрядную передачу данных, тактируется частотой 10 МГц, имеет средства автоматического конфигурирования и арбитража запросов. В отличие от EISA она не совместима с шиной ISA и используется только в компьютерах компании IBM.
Шина VL-bus, предложенная ассоциацией VESA (Video Electronics Standard Association), предназначалась для увеличения быстродействия видеоадаптеров и контроллеров дисковых накопителей для того, чтобы они могли работать с тактовой частотой до 40 МГц. Шина VL-bus имеет 32 линии данных и позволяет подключать до трех периферийных устройств, в качестве которых наряду с видеоадаптерами и дисковыми контроллерами могут выступать и сетевые адаптеры. Максимальная скорость передачи данных по шине VL-bus может составлять около 130 Мбайт/с. После появления процессора Pentium ассоциация VESA приступила к работе над новым стандартом VL-bus версии 2, который предусматривает использование 64-битовой шины данных и увеличение количества разъемов расширения. Ожидаемая скорость передачи данных - до 400 Мбайт/с.
Шина PCI (Peripheral Component Interconnect) также, как и шина VL-bus, поддерживает 32-битовый канал передачи данных между процессором и периферийными устройствами, работает на тактовой частоте 33 МГц и имеет максимальную пропускную способность 120 Мбайт/с. При работе с процессорами i486 шина PCI дает примерно те же показатели производительности, что и шина VL-bus. Однако, в отличие от последней, шина PCI является процессорно независимой (шина VL-bus подключается непосредственно к процессору i486 и только к нему). Ee легко подключить к различным центральным процессорам. В их числе Pentium, Alpha, R4400 и PowerPC.
Шина VME приобрела большую популярность как шина ввода/вывода в рабочих станциях и серверах на базе RISC-процессоров. Эта шина высоко стандартизована, имеется несколько версий этого стандарта. В частности, VME32 - 32-битовая шина с производительностью 30 Мбайт/с, а VME64 - 64-битовая шина с производительностью 160 Мбайт/с.
В однопроцессорных и многопроцессорных рабочих станциях и серверах на основе микропроцессоров SPARC одновременно используются несколько типов шин: SBus, MBus и XDBus, причем шина SBus применяется в качестве шины ввода/вывода, а MBus и XDBus - в качестве шин для объединения большого числа процессоров и памяти.
Шина SBus (известная также как стандарт IEEE-1496) имеет 32-битовую и 64-битовую реализацию, работает на частоте 20 и 25 МГц и имеет максимальную скорость передачи данных в 32-битовом режиме равную соответственно 80 или 100 Мбайт/с. Шина предусматривает режим групповой пересылки данных с максимальным размером пересылки до 128 байт. Она может работать в двух режимах передачи данных: режиме программируемого ввода/вывода и в режиме прямого доступа к виртуальной памяти (DVMA). Последний режим особенно эффективен при передаче больших блоков данных.
Шина MBus работает на тактовой частоте 50 МГц в синхронном режиме с мультиплексированием адреса и данных. Общее число сигналов шины равно 100, а разрядность шины данных составляет 64 бит. По шине передаются 36-битовые физические адреса. Шина обеспечивает протокол поддержания когерентного состояния кэш-памяти нескольких (до четырех) процессоров, имеет максимальную пропускную способность в 400 Мбайт/с, а типовая скорость передачи составляет 125 Мбайт/с. Отличительными свойствами шины MBus являются: возможность увеличения числа процессорных модулей, поддержка симметричной мультипроцессорной обработки, высокая пропускная способность при обмене с памятью и подсистемой ввода/вывода, открытые (непатентованные) спецификации интерфейсов.
Шина MBus была разработана для относительно небольших систем (ее длина ограничивается десятью дюймами, что позволяет объединить до четырех процессоров с кэш-памятью второго уровня и основной памятью). Для построения систем с большим числом процессоров нужна большая масштабируемость шины. Одна из подобного рода шин - XDBus, используется в серверах SPARCserver 1000 (до 8 процессоров) и SPARCcenter 2000 (до 20 процессоров) компании Sun Microsystems и SuperServer 6400 компании Cray Research (до 64 процессоров). XDBus представляет собой шину, работающую в режиме расщепления транзакций. Это позволяет ей, имея пиковую производительность в 400 Мбайт/с, поддерживать типовую скорость передачи на уровне более 310 Мбайт/с.
В современных компьютерах часто применяются и фирменные (запатентованные) шины, обеспечивающие очень высокую пропускную способность для построения многопроцессорных серверов. Одной из подобных шин является системная шина POWERpath-2, которая применяется в суперсервере Chellenge компании Silicon Graphics. Она способна поддерживать эффективную работу до 36 процессоров MIPS R4400 (9 процессорных плат с четырьмя 150 МГц процессорами на каждой плате) с общей расслоенной памятью объемом до 16 Гбайт (коэффициент расслоения памяти равен восьми). POWERpath-2 имеет разрядность данных 256 бит, разрядность адреса 40 бит, и работает на частоте 50 МГц с пониженным напряжением питания. Она поддерживает методику расщепления транзакций, причем может иметь до восьми отложенных транзакций чтения одновременно. При этом арбитраж шины адреса и шины данных выполняется независимо. POWERpath-2 поддерживает протокол когерентного состояния кэш-памяти каждого процессора в системе.
Одной из наиболее популярных шин ввода-вывода в настоящее время является шина SCSI.
Под термином SCSI - Small Computer System Interface (Интерфейс малых вычислительных систем) обычно понимается набор стандартов, разработанных Национальным институтом стандартов США (ANSI) и определяющих механизм реализации магистрали передачи данных между системной шиной компьютера и периферийными устройствами. На сегодняшний день приняты два стандарта (SCSI-1 и SCSI-2). Стандарт SCSI-3 находится в процессе доработки.
Начальный стандарт 1986 года, известный теперь под названием SCSI-1, определял рабочие спецификации протокола шины, набор команд и электрические параметры. В 1992 году этот стандарт был пересмотрен с целью устранения недостатков первоначальной спецификации (особенно в части синхронного режима передачи данных) и добавления новых возможностей повышения производительности, таких как "быстрый режим" (fast mode), "широкий режим" (wide mode) и помеченные очереди. Этот пересмотренный стандарт получил название SCSI-2 и в настоящее время используется большинством поставщиков вычислительных систем.
Первоначально SCSI предназначался для использования в небольших дешевых системах и поэтому был ориентирован на достижение хороших результатов при низкой стоимости. Характерной его чертой является простота, особенно в части обеспечения гибкости конфигурирования периферийных устройств без изменения организации основного процессора. Главной особенностью подсистемы SCSI является размещение в периферийном оборудовании интеллектуального контроллера.
Для достижения требуемого высокого уровня независимости от типов периферийных устройств в операционной системе основной машины, устройства SCSI представляются имеющими очень простую архитектуру. Например, геометрия дискового накопителя представляется в виде линейной последовательности одинаковых блоков, хотя в действительности любой диск имеет более сложную многомерную геометрию, содержащую поверхности, цилиндры, дорожки, характеристики плотности, таблицу дефектных блоков и множество других деталей. В этом случае само устройство или его контроллер несут ответственность за преобразование упрощенной SCSI модели в данные для реального устройства.
Стандарт SCSI-2 определяет в частности различные режимы: Wide SCSI, Fast SCSI и Fast-and-Wide SCSI. Стандарт SCSI-1 определяет построение периферийной шины на основе 50-жильного экранированного кабеля, описывает методы адресации и электрические характеристики сигналов. Шина данных SCSI-1 имеет разрядность 8 бит, а максимальная скорость передачи составляет 5 Мбайт/сек. Fast SCSI сохраняет 8-битовую шину данных и тем самым может использовать те же самые физические кабели, что и SCSI-1. Он отличается только тем, что допускает передачи со скоростью 10 Мбайт/сек в синхронном режиме. Wide SCSI удваивает либо учетверяет разрядность шины данных (либо 16, либо 32 бит), допуская соответственно передачи со скоростью либо 10, либо 20 Мбайт/сек. В комбинации Fast-and-Wide SCSI возможно достижение скоростей передачи 20 и 40 Мбайт/сек соответственно.
Однако поскольку в обычном 50-жильном кабеле просто не хватает жил, комитет SCSI решил расширить спецификацию вторым 66-жильным кабелем (так называемый B-кабель). B-кабель имеет дополнительные линии данных и ряд других сигнальных линий, позволяющие реализовать режим Fast-and-Wide.
В реализации режима Wide SCSI предложена также расширенная адресация, допускающая подсоединение к шине до 16 устройств (вместо стандартных восьми). Это значительно увеличивает гибкость подсистемы SCSI, правда приводит к появлению дополнительных проблем, связанных с эффективностью ее использования.
Реализация режимов Wide-SCSI и Fast-and-Wide SCSI до 1994 года редко использовалась, поскольку эффективность их применения не была достаточно высокой. Однако широкое распространение дисковых массивов и дисковых накопителей со скоростью вращения 7200 оборотов в минуту делают эту технологию весьма актуальной.
Следует отметить некоторую путаницу в терминологии. Часто стандартный 50-контактный разъем также называют разъемом SCSI-1, а более новый микроразъем - разъемом SCSI-2. Стандарт SCSI определяет только количество жил в кабеле, и вообще не определяет тип разъема.
Примеры устройств ввода/вывода
Рисунок 5.45. Примеры устройств ввода/вывода
В рамках данного обзора мы рассмотрим наиболее быстрые из этих устройств: магнитные и магнитооптические диски, а также магнитные ленты.
Принципы организации основной памяти в современных компьютерах
Принципы организации основной памяти в современных компьютерах
Приостановка конвейера при выполнении команды условного перехода
Рисунок 5.14. Приостановка конвейера при выполнении команды условного перехода
Реализация этих условий требует модернизации исходной схемы конвейера (рисунок 5.15).
В некоторых машинах конфликты из-за условных переходов являются даже еще более дорогостоящими по количеству тактов, чем в нашем примере, поскольку время на оценку условия перехода и вычисление адреса перехода может быть даже большим. Например, машина с раздельными ступенями декодирования и выборки регистров возможно будет иметь задержку условного перехода (длительность конфликта по управлению), которая по крайней мере на один такт длиннее. Многие компьютеры VAX имеют задержки условных переходов в четыре и более тактов, а большие машины с глубокими конвейерами имеют потери по условным переходам, равные шести или семи тактам. В общем случае, чем глубина конвейера больше, тем больше потери на командах условного перехода, исчисляемые в тактах. Конечно эффект снижения относительной производительности при этом зависит от общего CPI машины. Машины с высоким CPI могут иметь условные переходы большей длительности, поскольку процент производительности машины, которая будет потеряна из-за условных переходов, меньше.
Проблемы реализации точного прерывания в конвейере
Проблемы реализации точного прерывания в конвейере
Обработка прерываний в конвейерной машине оказывается более сложной из-за того, что совмещенное выполнение команд затрудняет определение возможности безопасного изменения состояния машины произвольной командой. В конвейерной машине команда выполняется по этапам, и ее завершение осуществляется через несколько тактов после выдачи для выполнения. Еще в процессе выполнения отдельных этапов команда может изменить состояние машины. Тем временем возникшее прерывание может вынудить машину прервать выполнение еще не завершенных команд.
Как и в неконвейерных машинах двумя основными проблемами при реализации прерываний являются: (1) прерывания возникают в процессе выполнения некоторой команды; (2) необходим механизм возврата из прерывания для продолжения выполнения программы. Например, для нашего простейшего конвейера прерывание по отсутствию страницы виртуальной памяти при выборке данных не может произойти до этапа выборки из памяти (MEM). В момент возникновения этого прерывания в процессе обработки уже будут находиться несколько команд. Поскольку подобное прерывание должно обеспечить возврат для продолжения программы и требует переключения на другой процесс (операционную систему), необходимо надежно очистить конвейер и сохранить состояние машины таким, чтобы повторное выполнение команды после возврата из прерывания осуществлялось при корректном состоянии машины. Обычно это реализуется путем сохранения адреса команды (PC), вызвавшей прерывание. Если выбранная после возврата из прерывания команда не является командой перехода, то сохраняется обычная последовательность выборки и обработки команд в конвейере. Если же это команда перехода, то мы должны оценить условие перехода и в зависимости от выбранного направления начать выборку либо по целевому адресу команды перехода, либо следующей за переходом команды. Когда происходит прерывание, для корректного сохранения состояния машины необходимо выполнить следующие шаги:
В последовательность команд, поступающих на обработку в конвейер, принудительно вставить команду перехода на прерывание.
Пока выполняется команда перехода на прерывание, погасить все требования записи, выставленные командой, вызвавшей прерывание, а также всеми следующими за ней в конвейере командами. Эти действия позволяют предотвратить все изменения состояния машины командами, которые не завершились к моменту начала обработки прерывания.
После передачи управления подпрограмме обработки прерываний операционной системы, она немедленно должна сохранить значение адреса команды (PC), вызвавшей прерывание. Это значение будет использоваться позже для организации возврата из прерывания.
Если используются механизмы задержанных переходов, состояние машины уже невозможно восстановить с помощью одного счетчика команд, поскольку в процессе восстановления команды в конвейере могут оказаться вовсе не последовательными. В частности, если команда, вызвавшая прерывание, находилась в слоте задержки перехода и переход был выполненным, то необходимо заново повторить выполнение команд из слота задержки плюс команду, находящуюся по целевому адресу команды перехода. Сама команда перехода уже выполнилась и ее повторения не требуется. При этом адреса команд из слота задержки перехода и целевой адрес команды перехода естественно не являются последовательными. Поэтому необходимо сохранять и восстанавливать несколько счетчиков команд, число которых на единицу превышает длину слота задержки. Это выполняется на третьем шаге обработки прерывания.
После обработки прерывания специальные команды осуществляют возврат из прерывания путем перезагрузки счетчиков команд и инициализации потока команд. Если конвейер может быть остановлен так, что команды, непосредственно предшествовавшие вызвавшей прерывание команде, завершаются, а следовавшие за ней могут быть заново запущены для выполнения, то говорят, что конвейер обеспечивает точное прерывание. В идеале команда, вызывающая прерывание, не должна менять состояние машины, и для корректной обработки некоторых типов прерываний требуется, чтобы команда, вызывающая прерывание, не имела никаких побочных эффектов.
Для других типов прерываний, например, для прерываний по исключительным ситуациям плавающей точки, вызывающая прерывание команда на некоторых машинах записывает свои результаты еще до того момента, когда прерывание может быть обработано. В этих случаях аппаратура должна быть готовой для восстановления операндов-источников, даже если местоположение результата команды совпадает с местоположением одного из операндов-источников.
Поддержка точных прерываний во многих системах является обязательным требованием, а в некоторых системах была бы весьма желательной, поскольку она упрощает интерфейс операционной системы. Как минимум в машинах со страничной организацией памяти или с реализацией арифметической обработки в соответствии со стандартом IEEE средства обработки прерываний должны обеспечивать точное прерывание либо целиком с помощью аппаратуры, либо с помощью некоторой поддержки со стороны программных средств.
Необходимость реализации в машине точных прерываний иногда оспаривается из-за некоторых проблем, которые осложняют повторный запуск команд. Повторный запуск сложен из-за того, что команды могут изменить состояние машины еще до того, как они гарантировано завершают свое выполнение (иногда гарантированное завершение команды называется фиксацией команды или фиксацией результатов выполнения команды). Поскольку команды в конвейере могут быть взаимозависимыми, блокировка изменения состояния машины может оказаться непрактичной, если конвейер продолжает работать. Таким образом, по мере увеличения степени конвейеризации машины возникает необходимость отката любого изменения состояния, выполненного до фиксации команды. К счастью, в простых конвейерах, подобных рассмотренному, эти проблемы не возникают. На рисунке 5.19 показаны ступени рассмотренного конвейера и причины прерываний, которые могут возникнуть на соответствующих ступенях при выполнении команд.
| Ступень конвейера | Причина прерывания | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| IF | Ошибка при обращении к странице памяти при выборке команды; невыровненное обращение к памяти; нарушение защиты памяти | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ID | Неопределенный или запрещенный код операции | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| EX | Арифметическое прерывание | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| MEM | Ошибка при обращении к странице памяти при выборке данных; невыровненное обращение к памяти; нарушение защиты памяти | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| WB | Отсутствует | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Проблемы выбора аппаратно-программной платформы, соответствующей потребностям прикладной области
Проблемы выбора аппаратно-программной платформы, соответствующей потребностям прикладной области
Выбор аппаратной платформы и конфигурации системы представляет собой чрезвычайно сложную задачу. Это связано, в частности, с характером прикладных систем, который в значительной степени может определять рабочую нагрузку вычислительного комплекса в целом. Однако часто оказывается просто трудно с достаточной точностью предсказать саму нагрузку, особенно в случае, если система должна обслуживать несколько групп разнородных по своим потребностям пользователей. Например, иногда даже бессмысленно говорить, что для каждых N пользователей необходимо в конфигурации сервера иметь один процессор, поскольку для некоторых прикладных систем, в частности, для систем из области механических и электронных САПР, может потребоваться 2-4 процессора для обеспечения запросов одного пользователя. С другой стороны, даже одного процессора может вполне хватить для поддержки 15-40 пользователей, работающих с прикладным пакетом Oracle*Financial. Другие прикладные системы могут оказаться еще менее требовательными. Но следует помнить, что даже если рабочую нагрузку удается описать с достаточной точностью, обычно скорее можно только выяснить, какая конфигурация не справится с данной нагрузкой, чем с уверенностью сказать, что данная конфигурация системы будет обрабатывать заданную нагрузку, если только отсутствует определенный опыт работы с приложением.
Обычно рабочая нагрузка существенно определяется "типом использования" системы. Например, можно выделить серверы NFS, серверы управления базами данных и системы, работающие в режиме разделения времени. Эти категории систем перечислены в порядке увеличения их сложности. Как правило серверы СУБД значительно более сложны, чем серверы NFS, а серверы разделения времени, особенно обслуживающие различные категории пользователей, являются наиболее сложными для оценки. К счастью, существует ряд упрощающих факторов. Во-первых, как правило нагрузка на систему в среднем сглаживается особенно при наличии большого коллектива пользователей (хотя почти всегда имеют место предсказуемые пики). Например, известно, что нагрузка на систему достигает пиковых значений через 1-1.5 часа после начала рабочего дня или окончания обеденного перерыва и резко падает во время обеденного перерыва. С большой вероятностью нагрузка будет нарастать к концу месяца, квартала или года.
Во-вторых, универсальный характер большинства наиболее сложных для оценки систем - систем разделения времени, предполагает и большое разнообразие, выполняемых на них приложений, которые в свою очередь как правило стараются загрузить различные части системы. Далеко не все приложения интенсивно используют процессорные ресурсы, и не все из них связаны с интенсивным вводом/выводом. Поэтому смесь таких приложений на одной системе может обеспечить достаточно равномерную загрузку всех ресурсов. Естественно неправильно подобранная смесь может дать совсем противоположенный эффект.
Все, кто сталкивается с задачей выбора конфигурации системы, должны начинать с определения ответов на два главных вопроса: какой сервис должен обеспечиваться системой и какой уровень сервиса может обеспечить данная конфигурация. Имея набор целевых показателей производительности конечного пользователя и стоимостных ограничений, необходимо спрогнозировать возможности определенного набора компонентов, которые включаются в конфигурацию системы. Любой, кто попробовал это сделать, знает, что подобная оценка сложна и связана с неточностью. Почему оценка конфигурации системы так сложна? Некоторое из причин перечислены ниже:
Подобная оценка прогнозирует будущее: предполагаемую комбинацию устройств, будущее использование программного обеспечения, будущих пользователей.
Сами конфигурации аппаратных и программных средств сложны, связаны с определением множества разнородных по своей сути компонентов системы, в результате чего сложность быстро увеличивается. Несколько лет назад существовала только одна вычислительная парадигма: мейнфрейм с терминалами. В настоящее время по выбору пользователя могут использоваться несколько вычислительных парадигм с широким разнообразием возможных конфигураций системы для каждой из них. Каждое новое поколение аппаратных и программных средств обеспечивает настолько больше возможностей, чем их предшественники, что относительно новые представления об их работе постоянно разрушаются.
Скорость технологических усовершенствований во всех направлениях разработки компьютерной техники (аппаратных средствах, функциональной организации систем, операционных системах, ПО СУБД, ПО "среднего" слоя (middleware) уже очень высокая и постоянно растет. Ко времени, когда какое-либо изделие широко используется и хорошо изучено, оно часто рассматривается уже как устаревшее.
Доступная потребителю информация о самих системах, операционных системах, программном обеспечении инфраструктуры (СУБД и мониторы обработки транзакций) как правило носит очень общий характер. Структура аппаратных средств, на базе которых работают программные системы, стала настолько сложной, что эксперты в одной области редко являются таковыми в другой.
Информация о реальном использовании систем редко является точной. Более того, пользователи всегда находят новые способы использования вычислительных систем как только становятся доступными новые возможности.
При стольких неопределенностях просто удивительно, что многие конфигурации систем работают достаточно хорошо. Оценка конфигурации все еще остается некоторым видом искусства, но к ней можно подойти с научных позиций. Намного проще решить, что определенная конфигурация не сможет обрабатывать определенные виды нагрузки, чем определить с уверенностью, что нагрузка может обрабатываться внутри определенных ограничений производительности. Более того, реальное использование систем показывает, что имеет место тенденция заполнения всех доступных ресурсов. Как следствие, системы, даже имеющие некоторые избыточные ресурсы, со временем не будут воспринимать дополнительную нагрузку.
Для выполнения анализа конфигурации, система (под которой понимается весь комплекс компьютеров, периферийных устройств, сетей и программного обеспечения) должна рассматриваться как ряд соединенных друг с другом компонентов. Например, сети состоят из клиентов, серверов и сетевой инфраструктуры. Сетевая инфраструктура включает среду (часто нескольких типов) вместе с мостами, маршрутизаторами и системой сетевого управления, поддерживающей ее работу. В состав клиентских систем и серверов входят центральные процессоры, иерархия памяти, шин, периферийных устройств и ПО. Ограничения производительности некоторой конфигурации по любому направлению (например, в части организации дискового ввода/вывода) обычно могут быть предсказаны исходя из анализа наиболее слабых компонентов.
Поскольку современные комплексы почти всегда включают несколько работающих совместно систем, точная оценка полной конфигурации требует ее рассмотрения как на макроскопическом уровне (уровне сети), так и на микроскопическом уровне (уровне компонент или подсистем).
Эта же методология может быть использована для настройки системы после ее инсталляции: настройка системы и сети выполняются как правило после предварительной оценки и анализа узких мест. Более точно, настройка конфигурации представляет собой процесс определения наиболее слабых компонентов в системе и устранения этих узких мест.
Следует отметить, что выбор той или иной аппаратной платформы и конфигурации определяется и рядом общих требований, которые предъявляются к характеристикам современных вычислительных систем. К ним относятся:
отношение стоимость/производительность
надежность и отказоустойчивость
масштабируемость
совместимость и мобильность программного обеспечения.
Отношение стоимость/производительность. Появление любого нового направления в вычислительной технике определяется требованиями компьютерного рынка. Поэтому у разработчиков компьютеров нет одной единственной цели. Большая универсальная вычислительная машина (мейнфрейм) или суперкомпьютер стоят дорого. Для достижения поставленных целей при проектировании высокопроизводительных конструкций приходится игнорировать стоимостные характеристики. Суперкомпьютеры фирмы Cray Research и высокопроизводительные мейнфреймы компании IBM относятся именно к этой категории компьютеров. Другим крайним примером может служить низкостоимостная конструкция, где производительность принесена в жертву для достижения низкой стоимости. К этому направлению относятся персональные компьютеры различных клонов IBM PC. Между этими двумя крайними направлениями находятся конструкции, основанные на отношении стоимость/производительность, в которых разработчики находят баланс между стоимостными параметрами и производительностью. Типичными примерами такого рода компьютеров являются миникомпьютеры и рабочие станции.
Для сравнения различных компьютеров между собой обычно используются стандартные методики измерения производительности. Эти методики позволяют разработчикам и пользователям использовать полученные в результате испытаний количественные показатели для оценки тех или иных технических решений, и в конце концов именно производительность и стоимость дают пользователю рациональную основу для решения вопроса, какой компьютер выбрать.
Надежность и отказоустойчивость. Важнейшей характеристикой вычислительных
систем является надежность. Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры.
Отказоустойчивость - это такое свойство вычислительной системы, которое обеспечивает ей, как логической машине, возможность продолжения действий, заданных программой, после возникновения неисправностей. Введение отказоустойчивости требует избыточного аппаратного и программного обеспечения. Направления, связанные с предотвращением неисправностей и с отказоустойчивостью, - основные в проблеме надежности. Концепции параллельности и отказоустойчивости вычислительных систем естественным образом связаны между собой, поскольку в обоих случаях требуются дополнительные функциональные компоненты. Поэтому, собственно, на параллельных вычислительных системах достигается как наиболее высокая производительность, так и, во многих случаях, очень высокая надежность. Имеющиеся ресурсы избыточности в параллельных системах могут гибко использоваться как для повышения производительности, так и для повышения надежности. Структура многопроцессорных и многомашинных систем приспособлена к автоматической реконфигурации и обеспечивает возможность продолжения работы системы после возникновения неисправностей.
Следует помнить, что понятие надежности включает не только аппаратные средства, но и программное обеспечение. Главной целью повышения надежности систем является целостность хранимых в них данных.
Масштабируемость. Масштабируемость представляет собой возможность наращивания числа и мощности процессоров, объемов оперативной и внешней памяти и других ресурсов вычислительной системы. Масштабируемость должна обеспечиваться архитектурой и конструкцией компьютера, а также соответствующими средствами программного обеспечения.
Добавление каждого нового процессора в действительно масштабируемой системе должно давать прогнозируемое увеличение производительности и пропускной способности при приемлемых затратах. Одной из основных задач при построении масштабируемых систем является минимизация стоимости расширения компьютера и упрощение планирования. В идеале добавление процессоров к системе должно приводить к линейному росту ее производительности. Однако это не всегда так. Потери производительности могут возникать, например, при недостаточной пропускной способности шин из-за возрастания трафика между процессорами и основной памятью, а также между памятью и устройствами ввода/вывода. В действительности реальное увеличение производительности трудно оценить заранее, поскольку оно в значительной степени зависит от динамики поведения прикладных задач.
Возможность масштабирования системы определяется не только архитектурой аппаратных средств, но зависит от заложенных свойств программного обеспечения. Масштабируемость программного обеспечения затрагивает все его уровни от простых механизмов передачи сообщений до работы с такими сложными объектами как мониторы транзакций и вся среда прикладной системы. В частности, программное обеспечение должно минимизировать трафик межпроцессорного обмена, который может препятствовать линейному росту производительности системы. Аппаратные средства (процессоры, шины и устройства ввода/вывода) являются только частью масштабируемой архитектуры, на которой программное обеспечение может обеспечить предсказуемый рост производительности. Важно понимать, что простой переход, например, на более мощный процессор может привести к перегрузке других компонентов системы. Это означает, что действительно масштабируемая система должна быть сбалансирована по всем параметрам.
Совместимость и мобильность программного обеспечения. Концепция программной совместимости впервые в широких масштабах была применена разработчиками системы IBM/360. Основная задача при проектировании всего ряда моделей этой системы заключалась в создании такой архитектуры, которая была бы одинаковой с точки зрения пользователя для всех моделей системы независимо от цены и производительности каждой из них. Огромные преимущества такого подхода, позволяющего сохранять существующий задел программного обеспечения при переходе на новые (как правило, более производительные) модели были быстро оценены как производителями компьютеров, так и пользователями и начиная с этого времени практически все фирмы-поставщики компьютерного оборудования взяли на вооружение эти принципы, поставляя серии совместимых компьютеров. Следует заметить однако, что со временем даже самая передовая архитектура неизбежно устаревает и возникает потребность внесения радикальных изменений архитектуру и способы организации вычислительных систем.
В настоящее время одним из наиболее важных факторов, определяющих современные тенденции в развитии информационных технологий, является ориентация компаний-поставщиков компьютерного оборудования на рынок прикладных программных средств. Это объясняется прежде всего тем, что для конечного пользователя в конце концов важно программное обеспечение, позволяющее решить его задачи, а не выбор той или иной аппаратной платформы. Переход от однородных сетей программно совместимых компьютеров к построению неоднородных сетей, включающих компьютеры разных фирм-производителей, в корне изменил и точку зрения на саму сеть: из сравнительно простого средства обмена информацией она превратилась в средство интеграции отдельных ресурсов - мощную распределенную вычислительную систему, каждый элемент которой (сервер или рабочая станция) лучше всего соответствует требованиям конкретной прикладной задачи.
Этот переход выдвинул ряд новых требований. Прежде всего такая вычислительная среда должна позволять гибко менять количество и состав аппаратных средств и программного обеспечения в соответствии с меняющимися требованиями решаемых задач. Во-вторых, она должна обеспечивать возможность запуска одних и тех же программных систем на различных аппаратных платформах, т.е. обеспечивать мобильность программного обеспечения. В третьих, эта среда должна гарантировать возможность применения одних и тех же человеко-машинных интерфейсов на всех компьютерах, входящих в неоднородную сеть. В условиях жесткой конкуренции производителей аппаратных платформ и программного обеспечения сформировалась концепция открытых систем, представляющая собой совокупность стандартов на различные компоненты вычислительной среды, предназначенных для обеспечения мобильности программных средств в рамках неоднородной, распределенной вычислительной системы.
Одним из вариантов моделей открытой среды является модель OSE (Open System Environment), предложенная комитетом IEEE POSIX. На основе этой модели национальный институт стандартов и технологии США выпустил документ "Application Portability Profile (APP). The U.S. Government's Open System Environment Profile OSE/1 Version 2.0", который определяет рекомендуемые для федеральных учреждений США спецификации в области информационных технологий, обеспечивающие мобильность системного и прикладного программного обеспечения. Все ведущие производители компьютеров и программного обеспечения в США в настоящее время придерживаются требований этого документа.
PowerPC 603 является первым микропроцессором
Процессор PowerPC 603
PowerPC 603 является первым микропроцессором в семействе PowerPC, который полностью поддерживает архитектуру PowerPC (рисунок 6.19). Он включает пять функциональных устройств: устройство переходов, целочисленное устройство, устройство плавающей точки, устройство загрузки/записи и устройство системных регистров, а также две, расположенных на кристалле кэш-памяти для команд и данных, емкостью по 8 Кбайт. Поскольку PowerPC 603 - суперскалярный микропроцессор, он может выдавать в эти исполнительные устройства и завершать выполнение до трех команд в каждом такте. Для увеличения производительности PowerPC 603 допускает внеочередное выполнение команд. Кроме того он обеспечивает программируемые режимы снижения потребляемой мощности, которые дают разработчикам систем гибкость реализации различных технологий управления питанием.
При обработке в процессоре команды распределяются по пяти исполнительным устройствам в заданном программой порядке. Если отсутствуют зависимости по операндам, выполнение происходит немедленно. Целочисленное устройство выполняет большинство команд за один такт. Устройство плавающей точки имеет конвейерную организацию и выполняет операции с плавающей точкой как с одинарной, так и с двойной точностью. Команды условных переходов обрабатывается в устройстве переходов. Если условия перехода доступны, то решение о направлении перехода принимается немедленно, в противном случае выполнение последующих команд продолжается по предположению (спекулятивно). Команды, модифицирующие состояние регистров управления процессором, выполняются устройством системных регистров. Наконец, пересылки данных между кэш-памятью данных, с одной стороны, и регистрами общего назначения и регистрами плавающей точки, с другой стороны, обрабатываются устройством загрузки/записи.
В случае промаха при обращении к кэш-памяти, обращение к основной памяти осуществляется с помощью 64-битовой высокопроизводительной шины, подобной шине микропроцессора MC88110. Для максимизации пропускной способности и, как следствие, увеличения общей производительности кэш-память взаимодействует с основной памятью главным образом посредством групповых операций, которые позволяют заполнить строку кэш-памяти за одну транзакцию.
После окончания выполнения команды в исполнительном устройстве ее результаты направляются в буфер завершения команд (completion buffer) и затем последовательно записываются в соответствующий регистровый файл по мере изъятия команд из буфера завершения. Для минимизации конфликтов по регистрам, в процессоре PowerPC 603 предусмотрены отдельные наборы из 32 целочисленных регистров общего назначения и 32 регистров плавающей точки.
Процессоры PA-RISC компании Hewlett-Packard
Процессоры PA-RISC компании Hewlett-Packard
Основой разработки современных изделий Hewlett-Packard является архитектура PA-RISC. Она была разработана компанией в 1986 году и с тех пор прошла несколько стадий своего развития благодаря успехам интегральной технологии от многокристального до однокристального исполнения. В сентябре 1992 года компания Hewlett-Packard объявила о создании своего суперскалярного процессора PA-7100, который с тех пор стал основой построения семейства рабочих станций HP 9000 Series 700 и семейства бизнес-серверов HP 9000 Series 800. В настоящее время имеются 33-, 50- и 99 МГц реализации кристалла PA-7100. Кроме того выпущены модифицированные, улучшенные по многим параметрам кристаллы PA-7100LC с тактовой частотой 64, 80 и 100 МГц, и PA-7150 с тактовой частотой 125 МГц, а также PA-7200 с тактовой частотой 90 и 100 МГц. Компания активно разрабатывает процессор следующего поколения HP 8000, которые будет работать с тактовой частотой 200 МГц и обеспечивать уровень 360 единиц SPECint92 и 550 единиц SPECfp92. Появление этого кристалла ожидается в 1996 году. Кроме того, Hewlett-Packard в сотрудничестве с Intel планируют создать новый процессор с очень длинным командным словом (VLIW-архитектура), который будет совместим как с семейством Intel x86, так и семейством PA-RISC. Выпуск этого процессора планируется на 1998 год.
Процессоры с архитектурой 80x86 и Pentium
Процессоры с архитектурой 80x86 и Pentium
Обычно, когда новая архитектура создается одним архитектором или группой архитекторов, ее отдельные части очень хорошо подогнаны друг к другу и вся архитектура может быть описана достаточно связано. Этого нельзя сказать об архитектуре 80x86, поскольку это продукт нескольких независимых групп разработчиков, которые развивали эту архитектуру более 15 лет, добавляя новые возможности к первоначальному набору команд.
В 1978 году была анонсирована архитектура Intel 8086 как совместимое вверх расширение в то время успешного 8-бит микропроцессора 8080. 8086 представляет собой 16-битовую архитектуру со всеми внутренними регистрами, имеющими 16-битовую разрядность. Микропроцессор 8080 был просто построен на базе накапливающего сумматора (аккумулятора), но архитектура 8086 была расширена дополнительными регистрами. Поскольку почти каждый регистр в этой архитектуре имеет определенное назначение, 8086 по классификации частично можно отнести к машинам с накапливающим сумматором, а частично - к машинам с регистрами общего назначения, и его можно назвать расширенной машиной с накапливающим сумматором. Микропроцессор 8086 (точнее его версия 8088 с 8-битовой внешней шиной) стал основой завоевавшей в последствии весь мир серии компьютеров IBM PC, работающих под управлением операционной системы MS-DOS.
В 1980 году был анонсирован сопроцессор плавающей точки 8087. Эта архитектура расширила 8086 почти на 60 команд плавающей точки. Ее архитекторы отказались от расширенных накапливающих сумматоров для того, чтобы создать некий гибрид стеков и регистров, по сути расширенную стековую архитектуру. Полный набор стековых команд дополнен ограниченным набором команд типа регистр-память.
Анонсированный в 1982 году микропроцессор 80286, еще дальше расширил архитектуру 8086. Была создана сложная модель распределения и защиты памяти, расширено адресное пространство до 24 разрядов, а также добавлено небольшое число дополнительных команд. Поскольку очень важно было обеспечить выполнение без изменений программ, разработанных для 8086, в 80286 был предусмотрен режим реальных адресов, позволяющий машине выглядеть почти как 8086.
В 1984 году компания IBM объявила об использовании этого процессора в своей новой серии персональных компьютеров IBM PC/AT.
В 1987 году появился микропроцессор 80386, который расширил архитектуру 80286 до 32 бит. В дополнение к 32-битовой архитектуре с 32-битовыми регистрами и 32-битовым адресным пространством, в микропроцессоре 80386 появились новые режимы адресации и дополнительные операции. Все эти расширения превратили 80386 в машину, по идеологии близкую к машинам с регистрами общего назначения. В дополнение к механизмам сегментации памяти, в микропроцессор 80386 была добавлена также поддержка страничной организации памяти. Также как и 80286, микропроцессор 80386 имеет режим выполнения программ, написанных для 8086. Хотя в то время базовой операционной системой для этих микропроцессоров оставалась MS-DOS, 32-разрядная архитектура и страничная организация памяти послужили основой для переноса на эту платформу операционной системы UNIX. Следует отметить, что для процессора 80286 была создана операционная система XENIX (сильно урезанный вариант системы UNIX).
Эта история иллюстрирует эффект, вызванный необходимостью обеспечения совместимости с 80x86, поскольку существовавшая база программного обеспечения на каждом шаге была слишком важной. К счастью, последующие процессоры (80486 в 1989 и Pentium в 1993 году) были нацелены на увеличение производительности и добавили к видимому пользователем набору команд только три новые команды, облегчающие организацию многопроцессорной работы.
Что бы ни говорилось о неудобствах архитектуры 80x86, следует иметь в виду, что она преобладает в мире персональных компьютеров. Почти 80% установленных малых систем базируются именно на этой архитектуре. Споры относительно преимуществ CISC и RISC архитектур постепенно стихают, поскольку современные микропроцессоры стараются вобрать в себя наилучшие свойства обоих подходов.
Современное семейство процессоров i486 (i486SX, i486DX, i486DX2 и i486DX4), в котором сохранились система команд и методы адресации процессора i386, уже имеет некоторые свойства RISC-микропроцессоров.
Например, наиболее употребительные команды выполняются за один такт. Компания Intel для оценки производительности своих процессоров ввела в употребление специальную характеристику, которая называется рейтингом iCOMP. Компания надеется, что эта характеристика станет стандартной тестовой оценкой и будет применяться другими производителями микропроцессоров, однако последние с понятной осторожностью относятся к системе измерений производительности, введенной компанией Intel. Ниже в таблице приведены сравнительные характеристики некоторых процессоров компании Intel на базе рейтинга iCOMP.
| Процессор | Тактовая частота (МГц) | Рейтинг iCOMP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 386SX 386SL 386DX 386DX i486SX i486SX i486SX i486DX i486DX2 i486DX i486DX2 i486DX4 i486DX4 Pentium Pentium Pentium Pentium Pentium Pentium |
25 25 25 33 20 25 33 33 50 50 66 75 100 60 66 90 100 120 133 |
39 41 49 68 78 100 136 166 231 249 297 319 435 510 567 735 815 1000 1200 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Процессоры Intel OverDrive и i486DX2 практически идентичны. Однако кристалл OverDrive имеет корпус, который может устанавливаться в гнездо расширения сопроцессора i487SX, применяемое в ПК на базе i486SX. В процессорах OverDrive и i486DX2 применяется технология удвоения внутренней тактовой частоты, что позволяет увеличить производительность процессора почти на 70%. Процессор i486DX4/100 использует технологию утроения тактовой частоты. Он работает с внутренней тактовой частотой 99 МГц, в то время как внешняя тактовая частота (частота, на которой работает внешняя шина) составляет 33 МГц.
Этот процессор практически обеспечивает равные возможности с машинами класса 60 МГц Pentium, являясь их полноценной и доступной по цене альтернативой.
Появившийся в 1993 году процессор Pentium ознаменовал собой новый этап в развитии архитектуры x86, связанный с адаптацией многих свойств процессоров с архитектурой RISC. Он изготовлен по 0.8 микронной БиКМОП технологии и содержит 3.1 миллиона транзисторов. Первоначальная реализация была рассчитана на работу с тактовой частотой 60 и 66 МГц. В настоящее время имеются также процессоры Pentium, работающие с тактовой частотой 75, 90, 100, 120, 133, 150 и 200 МГц. Процессор Pentium по сравнению со своими предшественниками обладает целым рядом улучшенных характеристик. Главными его особенностями являются:
двухпотоковая суперскалярная организация, допускающая параллельное выполнение пары простых команд;
наличие двух независимых двухканальных множественно-ассоциативных кэшей для команд и для данных, обеспечивающих выборку данных для двух операций в каждом такте;
динамическое прогнозирование переходов;
конвейерная организация устройства плавающей точки с 8 ступенями;
двоичная совместимость с существующими процессорами семейства 80x86.
Блок-схема процессора Pentium представлена на рисунке 6.1. Прежде всего новая микроархитектура этого процессора базируется на идее суперскалярной обработки (правда с некоторыми ограничениями). Основные команды распределяются по двум независимым исполнительным устройствам (конвейерам U и V). Конвейер U может выполнять любые команды семейства x86, включая целочисленные команды и команды с плавающей точкой. Конвейер V предназначен для выполнения простых целочисленных команд и некоторых команд с плавающей точкой. Команды могут направляться в каждое из этих устройств одновременно, причем при выдаче устройством управления в одном такте пары команд более сложная команда поступает в конвейер U, а менее сложная - в конвейер V. Такая попарная выдача команд возможна правда только для ограниченного подмножества целочисленных команд.
Команды арифметики с плавающей точкой не могут запускаться в паре с целочисленными командами. Одновременная выдача двух команд возможна только при отсутствии зависимостей по регистрам. При остановке команды по любой причине в одном конвейере, как правило останавливается и второй конвейер.
Остальные устройства процессора предназначены для снабжения конвейеров необходимыми командами и данными. В отличие от процессоров i486 в процессоре Pentium используется раздельная кэш-память команд и данных емкостью по 8 Кбайт, что обеспечивает независимость обращений. За один такт из каждой кэш-памяти могут считываться два слова. При этом кэш-память данных построена на принципах двухкратного расслоения, что обеспечивает одновременное считывание двух слов, принадлежащих одной строке кэш-памяти. Кэш-память команд хранит сразу три копии тегов, что позволяет в одном такте считывать два командных слова, принадлежащих либо одной строке, либо смежным строкам для обеспечения попарной выдачи команд, при этом третья копия тегов используется для организации протокола наблюдения за когерентностью состояния кэш-памяти. Для повышения эффективности перезагрузки кэш-памяти в процессоре применяется 64-битовая внешняя шина данных.
В процессоре предусмотрен механизм динамического прогнозирования направления переходов. С этой целью на кристалле размещена небольшая кэш-память, которая называется буфером целевых адресов переходов (BTB), и две независимые пары буферов предварительной выборки команд (по два 32-битовых буфера на каждый конвейер). Буфер целевых адресов переходов хранит адреса команд, которые находятся в буферах предварительной выборки. Работа буферов предварительной выборки организована таким образом, что в каждый момент времени осуществляется выборка команд только в один из буферов соответствующей пары. При обнаружении в потоке команд операции перехода вычисленный адрес перехода сравнивается с адресами, хранящимися в буфере BTB. В случае совпадения предсказывается, что переход будет выполнен, и разрешается работа другого буфера предварительной выборки, который начинает выдавать команды для выполнения в соответствующий конвейер.При несовпадении считается, что переход выполняться не будет и буфер предварительной выборки не переключается, продолжая обычный порядок выдачи команд. Это позволяет избежать простоев конвейеров при правильном прогнозе направления перехода. Окончательное решение о направлении перехода естественно принимается на основании анализа кода условия. При неправильно сделанном прогнозе содержимое конвейеров аннулируется и выдача команд начинается с необходимого адреса. Неправильный прогноз приводит к приостановке работы конвейеров на 3-4 такта.
Простейшая организация конвейера и оценка его производительности
Простейшая организация конвейера и оценка его производительности
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Для иллюстрации основных принципов построения процессоров мы будем использовать простейшую архитектуру, содержащую 32 целочисленных регистра общего назначения (R0,...,R31), 32 регистра плавающей точки (F0,...,F31) и счетчик команд PC. Будем считать, что набор команд нашего процессора включает типичные арифметические и логические операции, операции с плавающей точкой, операции пересылки данных, операции управления потоком команд и системные операции. В арифметических командах используется трехадресный формат, типичный для RISC-процессоров, а для обращения к памяти используются операции загрузки и записи содержимого регистров в память.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды - IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
На рисунке 5.4 представлена схема простейшего процессора, выполняющего указанные выше этапы выполнения команд без совмещения. Чтобы конвейеризовать эту схему, мы можем просто разбить выполнение команд на указанные выше этапы, отведя для выполнения каждого этапа один такт синхронизации, и начинать в каждом такте выполнение новой команды. Естественно, для хранения промежуточных результатов каждого этапа необходимо использовать регистровые станции. На рисунке 5.5 показана схема процессора с промежуточными регистровыми станциями, которые обеспечивают передачу данных и управляющих сигналов с одной ступени конвейера на следующую. Хотя общее время выполнения одной команды в таком конвейере будет составлять пять тактов, в каждом такте аппаратура будет выполнять в совмещенном режиме пять различных команд.
Работу конвейера можно условно представить в видевременные диаграммы (рисунок 5.6), на которых обычно изображаются выполняемые команды, номера тактов и этапы выполнения команд.
| Номер команды | Номер такта |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+1 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+2 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+3 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+4 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Работа суперскалярного конвейера
Рисунок 5.32. Работа суперскалярного конвейера
При параллельной выдаче двух операций (одной целочисленной команды и одной команды ПТ) потребность в дополнительной аппаратуре, помимо обычной логики обнаружения конфликтов, минимальна: целочисленные операции и операции ПТ используют разные наборы регистров и разные функциональные устройства. Более того, усиление ограничений на выдачу команд, которые можно рассматривать как специфические структурные конфликты (поскольку выдаваться на выполнение могут только определенные пары команд), обнаружение которых требует только анализа кодов операций. Единственная сложность возникает, только если команды представляют собой команды загрузки, записи и пересылки чисел с плавающей точкой. Эти команды создают конфликты по портам регистров ПТ, а также могут приводить к новым конфликтам типа RAW, когда операция ПТ, которая могла бы быть выдана в том же такте, является зависимой от первой команды в паре.
Проблема регистровых портов может быть решена, например, путем реализации отдельной выдачи команд загрузки, записи и пересылки с ПТ. В случае составления ими пары с обычной операцией ПТ ситуацию можно рассматривать как структурный конфликт. Такую схему легко реализовать, но она будет иметь существенное воздействие на общую производительность. Конфликт подобного типа может быть устранен посредством реализации в регистровом файле двух дополнительных портов (для выборки и записи).
Если пара команд состоит из одной команды загрузки с ПТ и одной операции с ПТ, которая от нее зависит, необходимо обнаруживать подобный конфликт и блокировать выдачу операции с ПТ. За исключением этого случая, все другие конфликты естественно могут возникать, как и в обычной машине, обеспечивающей выдачу одной команды в каждом такте. Для предотвращения ненужных приостановок могут, правда потребоваться дополнительные цепи обхода.
Другой проблемой, которая может ограничить эффективность суперскалярной обработки, является задержка загрузки данных из памяти. В нашем примере простого конвейера команды загрузки имели задержку в один такт, что не позволяло следующей команде воспользоваться результатом команды загрузки без приостановки.
В суперскалярном конвейере результат команды загрузки не может быть использован в том же самом и в следующем такте. Это означает, что следующие три команды не могут использовать результат команды загрузки без приостановки. Задержка перехода также становится длиною в три команды, поскольку команда перехода должна быть первой в паре команд. Чтобы эффективно использовать параллелизм, доступный на суперскалярной машине, нужны более сложные методы планирования потока команд, используемые компилятором или аппаратными средствами, а также более сложные схемы декодирования команд.
Рассмотрим, например, что дает разворачивание циклов и планирование потока команд для суперскалярного конвейера. Ниже представлен цикл, который мы уже разворачивали и планировали его выполнение на простом конвейере.
Loop: LD F0,0(R1) ;F0=элемент вектора
ADDD F4,F0,F2 ;добавление скалярной величины из F2
SD 0(R1),F4 ;запись результата
SUBI R1,R1,#8 ;декрементирование указателя
;8 байт на двойное слово
BNEZ R1,Loop ;переход R1!=нулю
Чтобы спланировать этот цикл для работы без задержек, необходимо его развернуть и сделать пять копий тела цикла. После такого разворачивания цикл будет содержать по пять команд LD, ADDD, и SD, а также одну команду SUBI и один условный переход BNEZ. Развернутая и оптимизированная программа этого цикла приведена в таблице 5.1.
Этот развернутый суперскалярный цикл теперь работает со скоростью 12 тактов на итерацию, или 2.4 такта на один элемент (по сравнению с 3.5 тактами для оптимизированного развернутого цикла на обычном конвейере. В этом примере производительность суперскалярного конвейера ограничена существующим соотношением целочисленных операций и операций ПТ, но команд ПТ не достаточно для поддержания полной загрузки конвейера ПТ. Первоначальный оптимизированный неразвернутый цикл выполнялся со скоростью 6 тактов на итерацию, вычисляющую один элемент. Мы получили таким образом ускорение в 2.5 раза, больше половины которого произошло за счет разворачивания цикла.Чистое ускорение за счет суперскалярной обработки дало улучшение примерно в 1.5 раза.
RAID 2: матрица с поразрядным расслоением
RAID 2: матрица с поразрядным расслоением
Один из путей достижения надежности при снижении потерь емкости памяти может быть подсказан организацией основной памяти, в которой для исправления одиночных и обнаружения двойных ошибок используются избыточные контрольные разряды. Такое решение можно повторить путем поразрядного расслоения данных и записи их на диски группы, дополненной достаточным количеством контрольных дисков для обнаружения и исправления одиночных ошибок. Один диск контроля четности позволяет обнаружить одиночную ошибку, но для ее исправления требуется больше дисков.
Такая организация обеспечивает лишь один поток ввода/вывода для каждой группы независимо от ее размера. Группы большого размера приводят к снижению избыточной емкости, идущей на обеспечение отказоустойчивости, тогда как при организации меньшего числа групп наблюдается снижение операций ввода/вывода, которые могут выполняться матрицей параллельно.
При записи больших массивов данных системы уровня 2 имеют такую же производительность, что и системы уровня 1, хотя в них используется меньше контрольных дисков и, таким образом, по этому показателю они превосходят системы уровня 1. При передаче небольших порций данных производительность теряется, так как требуется записать либо считать группу целиком, независимо от конкретных потребностей. Таким образом, RAID уровня 2 предпочтительны для суперкомпьютеров, но не подходят для обработки транзакций. Компания Thinking Machine использовала RAID уровня 2 в ЭВМ Connection Machine при 32 дисках данных и 10 контрольных дисках, включая 3 диска горячего резерва.
RAID 3: аппаратное обнаружение ошибок и четность
RAID 3: аппаратное обнаружение ошибок и четность
Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Эти диски становятся полностью избыточными, так как большинство контроллеров в состоянии определить, когда диск отказал при помощи специальных сигналов, поддерживаемых дисковым интерфейсом, либо при помощи дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев. По существу, если контроллер может определить положение ошибочного разряда, то для восстановления данных требуется лишь один бит четности. Уменьшение числа контрольных дисков до одного на группу снижает избыточность емкости до вполне разумных размеров. Часто количество дисков в группе равно 5 (4 диска данных плюс 1 контрольный). Подобные устройства выпускаются, например, фирмами Maxtor и Micropolis. Каждое из таких устройств воспринимается машиной как отдельный логический диск с учетверенной пропускной способностью, учетверенной емкостью и значительно более высокой надежностью.
RAID 4: внутригрупповой параллелизм
RAID 4: внутригрупповой параллелизм
RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу к группе в единицу времени. Логические блоки передачи в данном случае не распределяются между отдельными дисками, вместо этого каждый индивидуальный блок попадает на отдельный диск.
Достоинство поразрядного расслоения состоит в простоте вычисления кода Хэмминга, что необходимо для обнаружения и исправления ошибок в системах уровня 2. В RAID уровня 3 обнаружение ошибок диска с точностью до сектора осуществляется дисковым контроллером. Следовательно, если записывать отдельный блок передачи в отдельный сектор, то можно обнаружить ошибки отдельного считывания без доступа к дополнительным дискам. Главное отличие между системами уровня 3 и 4 состоит в том, что в последних расслоение выполняется на уровне сектора, а не на уровне битов или байтов.
В системах уровня 4 обновление контрольной информации реализовано достаточно просто. Для вычисления нового значения четности требуются лишь старый блок данных, старый блок четности и новый блок данных:
новая четность = (старые данные xor новые данные) xor старая четность
В системах уровня 4 для записи небольших массивов данных используются два диска, которые выполняют четыре выборки (чтение данных плюс четности, запись данных плюс четности). Производительность групповых операций записи и считывания остается прежней, но при небольших (на один диск) записях и считываниях производительность существенно улучшается. К сожалению, улучшение производительности оказывается недостаточной для того, чтобы этот метод мог занять место системы уровня 1.
RAID 5: четность вращения для распараллеливания записей
RAID 5: четность вращения для распараллеливания записей
RAID уровня 4 позволяли добиться параллелизма при считывании отдельных дисков, но запись по-прежнему ограничена возможностью выполнения одной операции на группу, так как при каждой операции должны выполняться запись и чтение контрольного диска. Система уровня 5 улучшает возможности системы уровня 4 посредством распределения контрольной информации между всеми дисками группы.
Это небольшое изменение оказывает огромное влияние на производительность записи небольших массивов информации. Если операции записи могут быть спланированы так, чтобы обращаться за данными и соответствующими им блоками четности к разным дискам, появляется возможность параллельного выполнения N/2 записей, где N - число дисков в группе. Данная организация имеет одинаково высокую производительность при записи и при считывании как небольших, так и больших объемов информации, что делает ее наиболее привлекательной в случаях смешанных применений.
RAID 6: Двумерная четность для обеспечения большей надежности
RAID 6: Двумерная четность для обеспечения большей надежности
Этот пункт можно рассмотреть в контексте соотношения отказоустойчивость/пропускная способность. RAID 5 предлагают, по существу, лишь одно измерение дисковой матрицы, вторым измерением которой являются секторы. Теперь рассмотрим объединение дисков в двумерный массив таким образом, чтобы секторы являлись третьим измерением. Мы можем иметь контроль четности по строкам, как в системах уровня 5, а также по столбцам, которые, в свою очередь. могут расслаиваться для обеспечения возможности параллельной записи. При такой организации можно преодолеть любые отказы двух дисков и многие отказы трех дисков. Однако при выполнении логической записи реально происходит шесть обращений к диску: за старыми данными, за четностью по строкам и по столбцам, а также для записи новых данных и новых значений четности. Для некоторых применений с очень высокими требованиями к отказоустойчивости такая избыточность может оказаться приемлемой, однако для традиционных суперкомпьютеров и для обработки транзакций данный метод не подойдет.
В общем случае, если доминируют короткие записи и считывания и стоимость емкости памяти не является определяющей, наилучшую производительность демонстрируют системы RAID уровня 1. Однако если стоимость емкости памяти существенна, либо если можно снизить вероятность появления коротких записей (например, при высоком коэффициенте отношения числа считываний к числу записей, при эффективной буферизации последовательностей считывания-модификации-записи, либо при приведении коротких записей к длинным с использованием стратегии кэширования файлов), RAID уровня 5 могут обеспечить очень высокую производительность, особенно в терминах отношения стоимость/производительность.
RAID1: Зеркальные диски
RAID1: Зеркальные диски
Зеркальные диски представляют традиционный способ повышения надежности магнитных дисков. Это наиболее дорогостоящий из рассматриваемых способов, так как все диски дублируются и при каждой записи информация записывается также и на проверочный диск. Таким образом, приходится идти на некоторые жертвы в пропускной способности ввода/вывода и емкости памяти ради получения более высокой надежности. Зеркальные диски широко применяются многими фирмами. В частности компания Tandem Computers применяет зеркальные диски, а также дублирует контроллеры и магистрали ввода/вывода с целью повышения отказоустойчивости. Эта версия зеркальных дисков поддерживает параллельное считывание.
Контроллер HSC-70, используемый в VAX-кластерах компании DEC, выполнен по методу зеркальных дисков, называемому методом двойников. Содержимое отдельного диска распределяется между членами его группы двойников. Если группа состоит из двух двойников, мы получаем вариант зеркальных дисков. Заданный сектор может быть прочитан с любого из устройств группы двойников. После того как некоторый сектор записан, необходимо обновить информацию на всех дисках-двойниках. Контроллер имеет возможность предсказывать ожидаемые отказы некоторого диска и выделять горячий резерв для создания копии и сохранения ее на время работы механизма создания группы двойников. Затем отказавший диск может быть выключен.
Дублирование всех дисков может означать удвоение стоимости всей системы или, иначе, использование лишь 50% емкости диска для хранения данных. Повышение емкости, на которое приходится идти, составляет 100%. Такая низкая экономичность привела к появлению следующего уровня RAID.
Распределение нагрузки по доступу к дискам с помощью программного обеспечения типа Online:DiskSuit
Распределение нагрузки по доступу к дискам с помощью программного обеспечения типа Online:DiskSuit
Одной из общих проблем серверов NFS является плохая балансировка нагрузки между дисковыми накопителями и дисковыми контроллерами. Например, для поддержки некоторого числа бездисковых клиентов часто используется конфигурация системы с тремя дисками. Первый диск содержит операционную систему сервера и двоичные коды приложений; второй диск - файловые системы root и swap для всех бездисковых клиентов, а третий диск - домашние каталоги пользователей бездисковых клиентов. Такая конфигурация сбалансирована скорее по логическому принципу, а не по реальной физической нагрузке на диски. В такой среде диск, хранящий область подкачки (swap) для бездисковых клиентов, обычно оказывается намного более загруженным, чем любой из двух других дисков: этот диск почти все время будет загружен на 100%, а другие два в среднем на 5%. Подобные принципы распределения часто применяются также и для работы в другой среде.
Для обеспечения прозрачного распределения доступа по нескольким дисковым накопителям с успехом можно использовать функции расщепления и/или зеркалирования, которые поддерживаются специальным программным обеспечением типа Online:DiskSuit. (Конкатенация дисков достигает минимальной степени балансировки нагрузки, но только когда диски являются относительно полными). В среде с интенсивным использованием данных расщепление с небольшим перекрытием обеспечивает увеличение пропускной способности дисков, а также распределение нагрузки обслуживания. Расщепление дисков существенно улучшает также производительность операций последовательного чтения и записи. Хорошим начальным приближением для определения величины перекрытия является отношение 64 Кбайт/число дисков в полосе. В среде с интенсивным использованием атрибутов, для которых характерен произвольный доступ, установленное по умолчанию перекрытие (один цилиндр диска) является наиболее подходящим.
Хотя функция зеркалирования дисков в DiskSuit прежде всего разработана для обеспечения устойчивости к отказам, побочным эффектом ее использования является улучшение времени доступа и уменьшение нагрузки на диски за счет предоставления доступа к двум или трем копиям одних и тех же данных.
Это особенно справедливо для среды, в которой доминируют операции чтения. Операции записи на зеркальных дисках обычно выполняются более медленно, поскольку для каждой запрошенной логической операции в действительности необходимо выполнить две или три операции записи.
В настоящее время в компьютерной промышленности рекомендуется максимальная степень загрузки каждого дискового накопителя на уровне 60-65%. (Степень загрузки диска можно выяснить с помощью команды iostat(1)). Обычно на практике не удается заранее спланировать распределение данных так, чтобы обеспечить этот рекомендованный уровень загрузки дисков. Для этого необходимо выполнить несколько итераций, которые включают съем статистики и соответствующую реорганизацию данных. Более того, следует отметить, что типовое распределение нагрузки на диски со временем меняется, причем иногда радикально. Поэтому распределение данных, которое обеспечивало даже очень хорошую работу системы во время инсталляции, может давать очень слабые результаты год спустя. При оптимизации распределения данных на существующем наборе дисковых накопителей имеется множество других соображений второго порядка.