Распределенные файловые системы
Распределенные файловые системы
Появившаяся в 70-х годах возможность объединения компьютеров в единую сеть произвела революцию в компьютерной промышленности. Эта возможность прежде всего вызвала желание организовать разделение доступа к файлам между различными компьютерами. Первые достижения в этой области были ограничены возможностью копирования целых файлов из одной машины в другую. В качестве примера можно указать программу UNIX-to-UNIX copy (uucp) и File Transfer Protocol (ftp). Однако эти решения не позволяли даже близко подойти к реализации доступа к файлам на удаленной машине, по своим возможностям напоминающего доступ к файлам на локальных дисках.
Только в середине 80-х годов появилось несколько распределенных файловых систем, которые обеспечили прозрачный доступ по сети к удаленным файлам. Это были Network File System (NFS) компании Sun Microsystems (1985), Remote File Sharing system (RFS) компании AT&T (1986) и Andrew File System (AFS) университета Карнеги-Меллона (1995). Эти три системы резко отличались друг от друга по целям разработки, архитектуре и семантике, хотя все они пытались решить одну и ту же фундаментальную проблему. Сегодня RFS доступна практически на всех системах, базирующихся на UNIX System V. Разработка ASF перешла корпорации Transarc, в которой она была развита и превращена в Distributed File System (DFS) - компоненнт распределенной вычислительной среды DSE (Distributed Computing Environment) Open Software Foundation. Но наибольшее распространение получила NFS, которая поддерживается на всех UNIX и многих "не UNIX" системах.
Распространенные файловые системы
Распространенные файловые системы
Понятие файла является одним из наиболее важных для ОС UNIX. Все файлы, с которыми могут манипулировать пользователи, располагаются в файловой системе, представляющей собой дерево, промежуточные вершины которого соответствуют каталогам, и листья - файлам и пустым каталогам. Реально на каждом логическом диске (разделе физического дискового пакета) располагается отдельная иерархия каталогов и файлов. Для получения общего дерева в динамике используется "монтирование" отдельных иерархий к фиксированной корневой файловой системе.
Замечание: в мире ОС UNIX по историческим причинам термин "файловая система" является перегруженным, обозначая одновременно иерархию каталогов и файлов и часть ядра, которая управляет каталогами и файлами. Видимо, было бы правильнее называть иерархию каталогов и файлов архивом файлов, а термин "файловая система" использовать только во втором смысле. Однако, следуя традиции ОС UNIX, мы будем использовать этот термин в двух смыслах, различая значения по контексту.
Каждый каталог и файл файловой системы имеет уникальное полное имя (в ОС UNIX это имя принято называть full pathname - имя, задающее полный путь, посколько оно действительно задает полный путь от корня файловой системы через цепочку каталогов к соответствующему каталогу или файлу; мы будем использовать термин "полное имя", поскольку для pathname отсутствует благозвучный русский аналог). Каталог, являющийся корнем файловой системы (корневой каталог) в любой файловой системе имеет предопределенное имя "/" (слэш). Полное имя файла, например, /bin/sh означает, что в корневом каталоге должно содержаться имя каталога bin, а в каталоге bin должно содержаться имя файла sh. Коротким или относительным именем файла (relative pathname) называется имя (возможно, составное), задающее путь к файлу начиная от текущего рабочего каталога (существует команда и соответствующий системный вызов, позволяющие установить текущий рабочий каталог.
В каждом каталоге содержатся два специальных имени, имя ".", именующее сам этот каталог и имя "..", именующее "родительский" каталог данного каталога, т.е. каталог, непосредственно предшествующий данному в иерархии каталогов.
UNIX поддерживает многочисленные утилиты, позволяющие работать с файловой системой и доступные как команды командного интерпретатора. Вот некоторые из них (наиболее употребительные):
cp имя1 имя2 - копирование файла имя1 в файл имя2
rm имя1 - уничтожение файла имя1
mv имя1 имя2 - переименование файла имя1 в файл имя2
mkdir имя - создание нового каталога имя
rmdir имя - уничтожение каталога имя
ls имя - выдача содержимого каталога имя
cat имя - выдача на экран содержимого файла имя
chown имя режим - изменение режима доступа к файлу
Файловая система обычно размещается на дисках или других устройствах внешней памяти, имеющих блочную структуру. Кроме блоков, сохраняющих каталоги и файлы, во внешней памяти поддерживается еще несколько служебных областей.
В мире UNIX существует несколько разных видов файловых систем со своей структурой внешней памяти. Наиболее известны традиционная файловая система UNIX System V (s5) и файловая система семейства UNIX BSD (ufs). Файловая система s5 состоит из четырех секций (рисунок 6.1(a)). В файловой системе ufs на логическом диске (разделе реального диска) находится последовательность секций файловой системы.
Кратко опишем суть и назначение каждой области диска:
Boot-блок содержит программу раскрутки, которая служит для первоначального запуска ОС UNIX. В файловых системах s5 реально используется boot-блок только корневой файловой системы. В дополнительных файловых системах эта область присутствует, но не используется.
Расширение устройства ПТ средствами выполнения по предположению
Рисунок 5.35. Расширение устройства ПТ средствами выполнения по предположению

Каждая строка в буфере переупорядочивания содержит три поля: поле типа команды, поле места назначения (результата) и поле значения. Поле типа команды определяет, является ли команда условным переходом (для которого отсутствует место назначения результата), командой записи (которая в качестве места назначения результата использует адрес памяти) или регистровой операцией (команда АЛУ или команда загрузки, в которых местом назначения результата является регистр). Поле назначения обеспечивает хранение номера регистра (для команд загрузки и АЛУ) или адрес памяти (для команд записи), в который должен быть записан результат команды. Поле значения используется для хранения результата операции до момента фиксации результата команды. На рисунке 5.35 показана аппаратная структура машины с буфером переупорядочивания. Буфер переупорядочивания полностью заменяет буфера загрузки и записи. Хотя функция переименования станций резервирования заменена буфером переупорядочивания, нам все еще необходимо некоторое место для буферизации операций (и операндов) между моментом их выдачи и началом выполнения. Эту функцию выполняют регистровые станции резервирования. Поскольку каждая команда имеет позицию в буфере переупорядочивания до тех пор, пока она не будет зафиксирована (и результаты не будут отправлены в регистровый файл), результат тегируется посредством номера строки буфера переупорядочивания, а не номером станции резервирования. Это требует, чтобы номер строки буфера переупорядочивания, присвоенный команде, отслеживался станцией резервирования.
Ниже перечислены четыре этапа выполнение команды:
Выдача. Получает команду из очереди команд плавающей точки. Выдает команду для выполнения, если имеется свободная станция резервирования и свободная строка в буфере переупорядочивания; передает на станцию резервирования операнды, если они находятся в регистрах или в буфере переупорядочивания; и обновляет поля управления для индикации того, что буфера используются. Номер отведенной под результат строки буфера переупорядочивания также записывается в станцию резервирования, так что этот номер может использоваться для тегирования (пометки) результата, когда он помещается на CDB. Если все станции резервирования заполнены, или полон буфер переупорядочивания, выдача команды приостанавливается до тех пор, пока в обоих буферах не появится доступной строки.
Выполнение. Если один или несколько операндов еще не готовы (отсутствуют), осуществляется просмотр CDB (Common Data Bus) и происходит ожидание вычисления значения требуемого регистра. На этом шаге выполняется проверка наличия конфликтов типа RAW. Когда оба операнда оказываются на станции резервирования, происходит вычисление результата операции.
Запись результата. Когда результат вычислен и становится доступным, выполняется его запись на CDB (с посылкой тега буфера переупорядочивания, который был присвоен команде на этапе выдачи для выполнения) и из CDB в буфер переупорядочивания, а также в каждую станцию резервирования, ожидающую этот результат. (Можно было бы также читать результат из буфера переупорядочивания, а не из CDB, точно также, как централизованная схема управления (scoreboard) читает результаты из регистров, а не с шины завершения). Станция резервирования помечается как свободная.
Фиксация. Когда команда достигает головы буфера переупорядочивания и ее результат присутствует в буфере, соответствующий регистр обновляется значением результата (или выполняется запись в память, если операция - запись в память), и команда изымается из буфера переупорядочивания.
Когда команда фиксируется, соответствующая строка буфера переупорядочивания очищается, а место назначения результата (регистр или ячейка памяти) обновляется. Чтобы не менять номера строк буфера переупорядочивания после фиксации результата команды, буфер переупорядочивания реализуется в виде циклической очереди, так что позиции в буфере переупорядочивания меняются, только когда команда фиксируется. Если буфер переупорядочивания полностью заполнен, выдача команд останавливается до тех пор, пока не освободится очередная строка буфера.
Поскольку никакая запись в регистры или ячейки памяти не происходит до тех пор, пока команда не фиксируется, машина может просто ликвидировать все свои выполненные по предположению действия, если обнаруживается, что направление условного перехода было спрогнозировано не верно.
Исключительные ситуации в подобной машине не воспринимаются до тех пор, пока соответствующая команда не готова к фиксации. Если выполняемая по предположению команда вызывает исключительную ситуацию, эта исключительная ситуация записывается в буфер упорядочивания. Если обнаруживается неправильный прогноз направления условного перехода и выясняется, что команда не должна была выполняться, исключительная ситуация гасится вместе с командой, когда обнуляется буфер переупорядочивания. Если же команда достигает вершины буфера переупорядочивания, то мы знаем, что она более не является выполняемой по предположению (она уже стала безусловной), и исключительная ситуация должна действительно восприниматься.
Эту методику выполнения по предположению легко распространить и на целочисленные регистры и функциональные устройства. Действительно, выполнение по предположению может быть более полезно в целочисленных программах, поскольку именно такие программы имеют менее предсказуемое поведение переходов. Кроме того, эти методы могут быть расширены так, чтобы обеспечить работу в машинах с выдачей на выполнение и фиксацией результатов нескольких команд в каждом такте. Выполнение по предположению возможно является наиболее интересным методом именно для таких машин, поскольку менее амбициозные машины могут довольствоваться параллелизмом уровня команд внутри базовых блоков при соответствующей поддержке со стороны компилятора, использующего технологию разворачивания циклов.
Очевидно, все рассмотренные ранее методы не могут достичь большей степени распараллеливания, чем заложено в конкретной прикладной программе. Вопрос увеличения степени параллелизма прикладных систем в настоящее время является предметом интенсивных исследований, проводимых во всем мире.
Copyright © CIT
Сегментация памяти
Сегментация памяти
Другой подход к организации памяти опирается на тот факт, что программы обычно разделяются на отдельные области-сегменты. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается своя собственная нумерация слов, начиная с нуля.
Обычно в подобных системах обмен информацией между пользователями строится на базе сегментов. Поэтому сегменты являются отдельными логическими единицами информации, которые необходимо защищать, и именно на этом уровне вводятся различные режимы доступа к сегментам. Можно выделить два основных типа сегментов: программные сегменты и сегменты данных (сегменты стека являются частным случаем сегментов данных). Поскольку общие программы должны обладать свойством повторной входимости, то из программных сегментов допускается только выборка команд и чтение констант. Запись в программные сегменты может рассматриваться как незаконная и запрещаться системой. Выборка команд из сегментов данных также может считаться незаконной и любой сегмент данных может быть защищен от обращений по записи или по чтению.
Для реализации сегментации было предложено несколько схем, которые отличаются деталями реализации, но основаны на одних и тех же принципах.
В системах с сегментацией памяти каждое слово в адресном пространстве пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер сегмента, а младшие - как номер слова внутри сегмента. Наряду с сегментацией может также использоваться страничная организация памяти. В этом случае виртуальный адрес слова состоит из трех частей: старшие разряды адреса определяют номер сегмента, средние - номер страницы внутри сегмента, а младшие - номер слова внутри страницы.
Как и в случае страничной организации, необходимо обеспечить преобразование виртуального адреса в реальный физический адрес основной памяти. С этой целью для каждого пользователя операционная система должна сформировать таблицу сегментов. Каждый элемент таблицы сегментов содержит описатель (дескриптор) сегмента (поля базы, границы и индикаторов режима доступа). При отсутствии страничной организации поле базы определяет адрес начала сегмента в основной памяти, а граница - длину сегмента. При наличии страничной организации поле базы определяет адрес начала таблицы страниц данного сегмента, а граница - число страниц в сегменте. Поле индикаторов режима доступа представляет собой некоторую комбинацию признаков блокировки чтения, записи и выполнения.
Таблицы сегментов различных пользователей операционная система хранит в основной памяти. Для определения расположения таблицы сегментов выполняющейся программы используется специальный регистр защиты, который загружается операционной системой перед началом ее выполнения. Этот регистр содержит дескриптор таблицы сегментов (базу и границу), причем база содержит адрес начала таблицы сегментов выполняющейся программы, а граница - длину этой таблицы сегментов. Разряды номера сегмента виртуального адреса используются в качестве индекса для поиска в таблице сегментов. Таким образом, наличие базово-граничных пар в дескрипторе таблицы сегментов и элементах таблицы сегментов предотвращает возможность обращения программы пользователя к таблицам сегментов и страниц, с которыми она не связана. Наличие в элементах таблицы сегментов индикаторов режима доступа позволяет осуществить необходимый режим доступа к сегменту со стороны данной программы. Для повышения эффективности схемы используется ассоциативная кэш-память.
Отметим, что в описанной схеме сегментации таблица сегментов с индикаторами доступа предоставляет всем программам, являющимся частями некоторой задачи, одинаковые возможности доступа, т. е. она определяет единственную область (домен) защиты. Однако для создания защищенных подсистем в рамках одной задачи для того, чтобы изменять возможности доступа, когда точка выполнения переходит через различные программы, управляющие ее решением, необходимо связать с каждой задачей множество доменов защиты. Реализация защищенных подсистем требует разработки некоторых специальных аппаратных средств. Рассмотрение таких систем, которые включают в себя кольцевые схемы защиты, а также различного рода мандатные схемы защиты, выходит за рамки данного обзора.
Серверы
Серверы
Прикладные многопользовательские коммерческие и бизнес-системы, включающие системы управления базами данных и обработки транзакций, крупные издательские системы, сетевые приложения и системы обслуживания коммуникаций, разработку программного обеспечения и обработку изображений все более настойчиво требуют перехода к модели вычислений "клиент-сервер" и распределенной обработке. В распределенной модели "клиент-сервер" часть работы выполняет сервер, а часть пользовательский компьютер (в общем случае клиентская и пользовательская части могут работать и на одном компьютере). Существует несколько типов серверов, ориентированных на разные применения: файл-сервер, сервер базы данных, принт-сервер, вычислительный сервер, сервер приложений. Таким образом, тип сервера определяется видом ресурса, которым он владеет (файловая система, база данных, принтеры, процессоры или прикладные пакеты программ).
С другой стороны существует классификация серверов, определяющаяся масштабом сети, в которой они используются: сервер рабочей группы, сервер отдела или сервер масштаба предприятия (корпоративный сервер). Эта классификация весьма условна. Например, размер группы может меняться в диапазоне от нескольких человек до нескольких сотен человек, а сервер отдела обслуживать от 20 до 150 пользователей. Очевидно в зависимости от числа пользователей и характера решаемых ими задач требования к составу оборудования и программного обеспечения сервера, к его надежности и производительности сильно варьируются.
Файловые серверы небольших рабочих групп (не более 20-30 человек) проще всего реализуются на платформе персональных компьютеров и программном обеспечении Novell NetWare. Файл-сервер, в данном случае, выполняет роль центрального хранилища данных. Серверы прикладных систем и высокопроизводительные машины для среды "клиент-сервер" значительно отличаются требованиями к аппаратным и программным средствам.
Типичными для небольших файл-серверов являются: процессор 486DX2/66 или более быстродействующий, 32-Мбайт ОЗУ, 2 Гбайт дискового пространства и один адаптер Ethernet 10BaseT, имеющий быстродействие 10 Мбит/с. В состав таких серверов часто включаются флоппи-дисковод и дисковод компакт-дисков. Графика для большинства серверов несущественна, поэтому достаточно иметь обычный монохромный монитор с разрешением VGA.
Скорость процессора для серверов с интенсивным вводом/выводом некритична. Они должны быть оснащены достаточно мощными блоками питания для возможности установки дополнительных плат расширения и дисковых накопителей. Желательно применение устройства бесперебойного питания. Оперативная память обычно имеет объем не менее 32 Мбайт, что позволит операционной системе (например, NetWare) использовать большие дисковые кэши и увеличить производительность сервера. Как правило, для работы с многозадачными операционными системами такие серверы оснащаются интерфейсом SCSI (или Fast SCSI). Распределение данных по нескольким жестким дискам может значительно повысить производительность.
При наличии одного сегмента сети и 10-20 рабочих станций пиковая пропускная способность сервера ограничивается максимальной пропускной способностью сети. В этом случае замена процессоров или дисковых подсистем более мощными не увеличивают производительность, так как узким местом является сама сеть. Поэтому важно использовать хорошую плату сетевого интерфейса.
Хотя влияние более быстрого процессора явно на производительности не сказывается, оно заметно снижает коэффициент использования ЦП. Во многих серверах этого класса используются процессоры 486 и Pentium, microSPARC-II и PowerPC. Аналогично процессорам влияние типа системной шины (EISA со скоростью 33 Мбит/с или PCI со скоростью 132 Мбит/с) также минимально при таком режиме использования.
Однако для файл-серверов общего доступа, с которыми одновременно могут работать несколько десятков, а то и сотен человек, простой однопроцессорной платформы и программного обеспечения Novell может оказаться недостаточно. В этом случае используются мощные многопроцессорные серверы с возможностями наращивания оперативной памяти до нескольких гигабайт, дискового пространства до сотен гигабайт, быстрыми интерфейсами дискового обмена (типа Fast SCSI-2, Fast&Wide SCSI-2 и Fiber Channel) и несколькими сетевыми интерфейсами. Эти серверы используют операционную систему UNIX, сетевые протоколы TCP/IP и NFS. На базе многопроцессорных UNIX-серверов обычно строятся также серверы баз данных крупных информационных систем, так как на них ложится основная нагрузка по обработке информационных запросов. Подобного рода серверы получили название суперсерверов.
По уровню общесистемной производительности, функциональным возможностям отдельных компонентов, отказоустойчивости, а также в поддержке многопроцессорной обработки, системного администрирования и дисковых массивов большой емкости суперсерверы вышли в настоящее время на один уровень с мейнфреймами и мощными миникомпьютерами. Современные суперсерверы характеризуются:
наличием двух или более центральных процессоров RISC, либо Pentium, либо Intel 486;
многоуровневой шинной архитектурой, в которой запатентованная высокоскоростная системная шина связывает между собой несколько процессоров и оперативную память, а также множество стандартных шин ввода/вывода, размещенных в том же корпусе;
поддержкой технологии дисковых массивов RAID;
поддержкой режима симметричной многопроцессорной обработки, которая позволяет распределять задания по нескольким центральным процессорам или режима асимметричной многопроцессорной обработки, которая допускает выделение процессоров для выполнения конкретных задач.
Как правило, суперсерверы работают под управлением операционных систем UNIX, а в последнее время и Windows NT (на Digital 2100 Server Model A500MP), которые обеспечивают многопотоковую многопроцессорную и многозадачную обработку. Суперсерверы должны иметь достаточные возможности наращивания дискового пространства и вычислительной мощности, средства обеспечения надежности хранения данных и защиты от несанкционированного доступа. Кроме того, в условиях быстро растущей организации, важным условием является возможность наращивания и расширения уже существующей системы.
Сетевая файловая система NFS
Сетевая файловая система NFS
Компания Sun Microsystems представила NFS в 1985 году как средство обеспечения прозрачного доступа к удаленным файловым системам. Помимо публикации протокола Sun лицензировала его базовую реализацию, которая была использована различными поставщиками для портирования NFS на разные операционные системы. С тех пор NFS стала фактически промышленным стандартом, который поддерживается действительно всеми вариантами системы UNIX, а также некоторыми другими системами, например, VMS и MS-DOS.
Архитектура NFS базируется на модели клиент-сервер. Файл-сервер представляет собой машину, которая экспортирует некоторый набор файлов. Клиентами являются машины, которые имеют доступ к этим файлам. Одна машина может для различных файловых систем выступать как в качестве сервера, так и в качестве клиента. Однако программный код NFS разделен на две части, что позволяет иметь только клиентские или только серверные системы.
Клиенты и серверы взаимодействуют с помощью удаленных вызовов процедур (rpc - remote procedure call), которые работают как синхронные запросы. Когда приложение на клиенте пытается обратиться к удаленному файлу, ядро посылает запрос в сервер, а процесс клиента блокируется до получения ответа. Сервер ждет приходящие запросы, обрабатывает их и отсылает ответы назад клиентам.
Сетевая среда, определяемая профилем приложения
Сетевая среда, определяемая профилем приложения
Как отмечалось ранее, наиболее важным фактором, определяющим выбор конфигурации сети, является доминирующий тип операций NFS, используемых приложениями. Для приложений с интенсивной нагрузкой по данным требуется относительно небольшое количество сетей, но эти сети должны иметь большую полосу пропускания, как например, в сетях FDDI или CDDI. Эти требования могут удовлетворяться также с помощью сетей 100baseT (Ethernet 100 Мбит/с) или ATM (Asynchronous Transfer Mode 155 Мбит/с). Большинство интенсивных по атрибутам приложений работают и при наличии менее дорогой инфраструктуры, хотя может потребоваться большое количество сетей.
Принять решение по выбору типа сети сравнительно просто. Если для работы индивидуального клиента требуется агрегатированная скорость передачи данных, превышающая 1 Мбайт/с, или если для одновременной работы нескольких клиентов необходима полоса пропускания сети, превышающая 1 Мбайт/с, то такие приложения требуют применения высокоскоростных сетей. Реально эта цифра (1 Мбайт/с) искусственно завышена, поскольку она характеризует скорость передачи данных, которую вы гарантируете не превышать. Обычно более разумно рассматривать скорость сети Ethernet равной примерно 440 Кбайт/с, а не 1 Мбайт/с. (Обычно пользователи воспринимают Ethernet как "неотвечающую" уже примерно при 35% загрузке сети. Приведенная здесь цифра 440 Кбайт/с соответствует 35%-ной загрузке линии с пропускной способностью 1.25 Мбайт/с).
Если приложение в установившемся режиме работы не требует широкой полосы пропускания, то возможно будет достаточна менее скоростная сетевая среда типа Ethernet или TokenRing. Эта среда обеспечивает достаточную скорость передачи данных при выполнении операций lookup и getattr, которые доминируют в приложениях с интенсивным использованием атрибутов, а также относительно легкий трафик данных, связанный с таким использованием.
Симметричные мультипроцессорные архитектуры и проблема когерентности кэш-памяти
Симметричные мультипроцессорные архитектуры и проблема когерентности кэш-памяти
Требования, предъявляемые современными процессорами к полосе пропускания памяти можно существенно сократить путем применения больших многоуровневых кэшей. Тогда, если эти требования снижаются, то несколько процессоров смогут разделять доступ к одной и той же памяти. Начиная с 1980 года эта идея, подкрепленная широким распространением микропроцессоров, стимулировала многих разработчиков на создание небольших мультипроцессоров, в которых несколько процессоров разделяют одну физическую память, соединенную с ними с помощью разделяемой шины. Из-за малого размера процессоров и заметного сокращения требуемой полосы пропускания шины, достигнутого за счет возможности реализации достаточно большой кэш-памяти, такие машины стали исключительно эффективными по стоимости. В первых разработках подобного рода машин удавалось разместить весь процессор и кэш на одной плате, которая затем вставлялась в заднюю панель, с помощью которой реализовывалась шинная архитектура. Современные конструкции позволяют разместить до четырех процессоров на одной плате. На рисунке 5.40 показана схема именно такой машины.
В такой машине кэши могут содержать как разделяемые, так и частные данные. Частные данные - это данные, которые используются одним процессором, в то время как разделяемые данные используются многими процессорами, по существу обеспечивая обмен между ними. Когда кэшируется элемент частных данных, их значение переносится в кэш для сокращения среднего времени доступа, а также требуемой полосы пропускания. Поскольку никакой другой процессор не использует эти данные, этот процесс идентичен процессу для однопроцессорной машины с кэш-памятью. Если кэшируются разделяемые данные, то разделяемое значение реплицируется и может содержаться в нескольких кэшах. Кроме сокращения задержки доступа и требуемой полосы пропускания такая репликация данных способствует также общему сокращению количества обменов. Однако кэширование разделяемых данных вызывает новую проблему: когерентность кэш-памяти.
Системные и локальные шины
Системные и локальные шины
В вычислительной системе, состоящей из множества подсистем, необходим механизм для их взаимодействия. Эти подсистемы должны быстро и эффективно обмениваться данными. Например, процессор, с одной стороны, должен быть связан с памятью, с другой стороны, необходима связь процессора с устройствами ввода/вывода. Одним из простейших механизмов, позволяющих организовать взаимодействие различных подсистем, является единственная центральная шина, к которой подсоединяются все подсистемы. Доступ к такой шине разделяется между всеми подсистемами. Подобная организация имеет два основных преимущества: низкая стоимость и универсальность. Поскольку такая шина является единственным местом подсоединения для разных устройств, новые устройства могут быть легко добавлены, и одни и те же периферийные устройства можно даже применять в разных вычислительных системах, использующих однотипную шину. Стоимость такой организации получается достаточно низкой, поскольку для реализации множества путей передачи информации используется единственный набор линий шины, разделяемый множеством устройств.
Главным недостатком организации с единственной шиной является то, что шина создает узкое горло, ограничивая, возможно, максимальную пропускную способность ввода/вывода. Если весь поток ввода/вывода должен проходить через центральную шину, такое ограничение пропускной способности весьма реально. В коммерческих системах, где ввод/вывод осуществляется очень часто, а также в суперкомпьютерах, где необходимые скорости ввода/вывода очень высоки из-за высокой производительности процессора, одним из главных вопросов разработки является создание системы нескольких шин, способной удовлетворить все запросы.
Одна из причин больших трудностей, возникающих при разработке шин, заключается в том, что максимальная скорость шины главным образом лимитируется физическими факторами: длиной шины и количеством подсоединяемых устройств (и, следовательно, нагрузкой на шину). Эти физические ограничения не позволяют произвольно ускорять шины.
Требования быстродействия (малой задержки) системы ввода/ввывода и высокой пропускной способности являются противоречивыми. В современных крупных системах используется целый комплекс взаимосвязанных шин, каждая из которых обеспечивает упрощение взаимодействия различных подсистем, высокую пропускную способность, избыточность (для увеличения отказоустойчивости) и эффективность.
Традиционно шины делятся на шины, обеспечивающие организацию связи процессора с памятью, и шины ввода/вывода. Шины ввода/вывода могут иметь большую протяженность, поддерживать подсоединение многих типов устройств, и обычно следуют одному из шинных стандартов. Шины процессор-память, с другой стороны, сравнительно короткие, обычно высокоскоростные и соответствуют организации системы памяти для обеспечения максимальной пропускной способности канала память-процессор. На этапе разработки системы, для шины процессор-память заранее известны все типы и параметры устройств, которые должны соединяться между собой, в то время как разработчик шины ввода/вывода должен иметь дело с устройствами, различающимися по задержке и пропускной способности.
Как уже было отмечено, с целью снижения стоимости некоторые компьютеры имеют единственную шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Персональные компьютеры, как правило, строятся на основе одной системной шины в стандартах ISA, EISA или MCA. Необходимость сохранения баланса производительности по мере роста быстродействия микропроцессоров привела к двухуровневой организации шин в персональных компьютерах на основе локальной шины. Локальной шиной называется шина, электрически выходящая непосредственно на контакты микропроцессора. Она обычно объединяет процессор, память, схемы буферизации для системной шины и ее контроллер, а также некоторые вспомогательные схемы. Типичными примерами локальных шин являются VL-Bus и PCI.
Рассмотрим типичную транзакцию на шине. Шинная транзакция включает в себя две части: посылку адреса и прием (или посылку) данных.
Шинные транзакции обычно определяются характером взаимодействия с памятью: транзакция типа "Чтение" передает данные из памяти (либо в ЦП, либо в устройство ввода/вывода), транзакция типа "Запись" записывает данные в память. В транзакции типа "Чтение" по шине сначала посылается в память адрес вместе с соответствующими сигналами управления, индицирующими чтение. Память отвечает, возвращая на шину данные с соответствующими сигналами управления. Транзакция типа "Запись" требует, чтобы ЦП или устройство в/в послало в память адрес и данные и не ожидает возврата данных. Обычно ЦП вынужден простаивать во время интервала между посылкой адреса и получением данных при выполнении чтения, но часто он не ожидает завершения операции при записи данных в память.
Разработка шины связана с реализацией ряда дополнительных возможностей (рисунок 5.43). Решение о выборе той или иной возможности зависит от целевых параметров стоимости и производительности. Первые три возможности являются очевидными: раздельные линии адреса и данных, более широкие (имеющие большую разрядность) шины данных и режим групповых пересылок (пересылки нескольких слов) дают увеличение производительности за счет увеличения стоимости.
Следующий термин, указанный в таблице, - количество главных устройств шины (bus master). Главное устройство шины - это устройство, которое может инициировать транзакции чтения или записи. ЦП, например, всегда является главным устройством шины. Шина имеет несколько главных устройств, если имеется несколько ЦП или когда устройства ввода/вывода могут инициировать транзакции на шине. Если имеется несколько таких устройств, то требуется схема арбитража, чтобы решить, кто следующий захватит шину. Арбитраж часто основан либо на схеме с фиксированным приоритетом, либо на более "справедливой" схеме, которая случайным образом выбирает, какое главное устройство захватит шину.
В настоящее время используются два типа шин, отличающиеся способом коммутации: шины с коммутацией цепей (circuit-switched bus) и шины с коммутацией пакетов (packet-switched bus), получившие свои названия по аналогии со способами коммутации в сетях передачи данных.
Шина с коммутацией пакетов при наличии нескольких главных устройств шины обеспечивает значительно большую пропускную способность по сравнению с шиной с коммутацией цепей за счет разделения транзакции на две логические части: запроса шины и ответа. Такая методика получила название "расщепления" транзакций (split transaction). (В некоторых системах такая возможность называется шиной соединения/разъединения (connect/disconnect) или конвейерной шиной (pipelined bus). Транзакция чтения разбивается на транзакцию запроса чтения, которая содержит адрес, и транзакцию ответа памяти, которая содержит данные. Каждая транзакция теперь должна быть помечена (тегирована) соответствующим образом, чтобы ЦП и память могли сообщить что есть что.
Шина с коммутацией цепей не делает расщепления транзакций, любая транзакция на ней есть неделимая операция. Главное устройство запрашивает шину, после арбитража помещает на нее адрес и блокирует шину до окончания обслуживания запроса. Большая часть этого времени обслуживания при этом тратится не на выполнение операций на шине (например, на задержку выборки из памяти). Таким образом, в шинах с коммутацией цепей это время просто теряется. Расщепленные транзакции делают шину доступной для других главных устройств пока память читает слово по запрошенному адресу. Это, правда, также означает, что ЦП должен бороться за шину для посылки данных, а память должна бороться за шину, чтобы вернуть данные. Таким образом, шина с расщеплением транзакций имеет более высокую пропускную способность, но обычно она имеет и большую задержку, чем шина, которая захватывается на все время выполнения транзакции. Транзакция называется расщепленной, поскольку произвольное количество других пакетов или транзакций могут использовать шину между запросом и ответом.
Последний вопрос связан с выбором типа синхронизации и определяет является ли шина синхронной или асинхронной. Если шина синхронная, то она включает сигналы синхронизации, которые передаются по линиям управления шины, и фиксированный протокол, определяющий расположение сигналов адреса и данных относительно сигналов синхронизации.
Поскольку практически никакой дополнительной логики не требуется для того, чтобы решить, что делать в следующий момент времени, эти шины могут быть и быстрыми, и дешевыми. Однако они имеют два главных недостатка. Все на шине должно происходить с одной и той же частотой синхронизации, поэтому из-за проблемы перекоса синхросигналов, синхронные шины не могут быть длинными. Обычно шины процессор-память синхронные.
| Возможность | Высокая производительность | Низкая стоимость | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Общая разрядность шины | Отдельные линии адреса и данных | Мультиплексирование линий адреса и данных | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ширина (рязрядность) данных |
Чем шире, тем быстрее (например, 32 бит) | Чем уже, тем дешевле (например, 8 бит) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Размер пересылки | Пересылка нескольких слов имеет меньшие накладные расходы | Пересылка одного слова дешевле | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Главные устройства шины | Несколько (требуется арбитраж) | Одно (арбитраж не нужен) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Расщепленные транзакции? | Да - отдельные пакеты Запроса и Ответа дают большую полосу пропускания (нужно несколько главных устройств) | Нет - продолжающееся соединение дешевле и имеет меньшую задержку | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Тип синхронизации | Синхронные | Асинхронные | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Системный интерфейс
Системный интерфейс
Системный интерфейс процессора R10000 работает в качестве шлюза между самим процессором, связанным с ним кэшем второго уровня и остальной системой. Системный интерфейс работает с тактовой частотой внешней синхронизации (SysClk). Возможно программирование работы системного интерфейса на тактовой частоте 200, 133, 100, 80, 67, 57 и 50 МГц. Все выходы и входы системного интерфейса синхронизируются нарастающим фронтом сигнала SysClk, позволяя ему работать на максимально возможной тактовой частоте.
В большинстве микропроцессорных систем в каждый момент времени может происходить только одна системная транзакция.
Процессор R10000 поддерживает протокол расщепления транзакций, позволяющий осуществлять выдачу очередных запросов процессором или внешним абонентом шины, не дожидаясь ответа на предыдущий запрос. Максимально в любой момент времени поддерживается до четырех одновременных транзакций на шине.
Снижение потерь на выполнение
Снижение потерь на выполнение команд условного перехода
Имеется несколько методов сокращения приостановок конвейера, возникающих из-за задержек выполнения условных переходов. В данном разделе обсуждаются четыре простые схемы, используемые во время компиляции. В этих схемах прогнозирование направления перехода выполняется статически, т.е. прогнозируемое направление перехода фиксируется для каждой команды условного перехода на все время выполнения программы. После обсуждения этих схем мы исследуем вопрос о правильности предсказания направления перехода компиляторами, поскольку все эти схемы основаны на такой технологии. В следующей главе мы рассмотрим более мощные схемы, используемые компиляторами (такие, например, как разворачивание циклов), которые уменьшают частоту команд условных переходов при реализации циклов, а также динамические, аппаратно реализованные схемы прогнозирования.
Метод выжидания
Простейшая схема обработки команд условного перехода заключается в замораживании или подавлении операций в конвейере, путем блокировки выполнения любой команды, следующей за командой условного перехода, до тех пор, пока не станет известным направление перехода. Рисунок 5.14 отражал именно такой подход. Привлекательность такого решения заключается в его простоте.
Метод возврата
Более хорошая и не на много более сложная схема состоит в том, чтобы прогнозировать условный переход как невыполняемый. При этом аппаратура должна просто продолжать выполнение программы, как если бы условный переход вовсе не выполнялся. В этом случае необходимо позаботиться о том, чтобы не изменить состояние машины до тех пор, пока направление перехода не станет окончательно известным. В некоторых машинах эта схема с невыполняемыми по прогнозу условными переходами реализована путем продолжения выборки команд, как если бы условный переход был обычной командой. Поведение конвейера выглядит так, как будто ничего необычного не происходит. Однако, если условный переход на самом деле выполняется, то необходимо просто очистить конвейер от команд, выбранных вслед за командой условного перехода и заново повторить выборку команд (рисунок 5.16).
| Невыполняемый условный переход | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+1 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+2 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+3 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+4 | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Выполняемый условный переход |
IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда i+1/целевая команда | IF | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целевая команда +1 | stall | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целевая команда +2 | stall | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Целевая команда +3 | stall | IF | ID | EX | MEM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Сокращение потерь на выполнение команд перехода и минимизация конфликтов по управлению
Сокращение потерь на выполнение команд перехода и минимизация конфликтов по управлению
Конфликты по управлению могут вызывать даже большие потери производительности конвейера, чем конфликты по данным. Когда выполняется команда условного перехода, она может либо изменить, либо не изменить значение счетчика команд. Если команда условного перехода заменяет счетчик команд значением адреса, вычисленного в команде, то переход называется выполняемым; в противном случае, он называется невыполняемым.
Простейший метод работы с условными переходами заключается в приостановке конвейера как только обнаружена команда условного перехода до тех пор, пока она не достигнет ступени конвейера, которая вычисляет новое значение счетчика команд (рисунок 5.14). Такие приостановки конвейера из-за конфликтов по управлению должны реализовываться иначе, чем приостановки из-за конфликтов по данным, поскольку выборка команды, следующей за командой условного перехода, должна быть выполнена как можно быстрее, как только мы узнаем окончательное направление команды условного перехода.
Например, если конвейер будет приостановлен на три такта на каждой команде условного перехода, то это может существенно отразиться на производительности машины. При частоте команд условного перехода в программах, равной 30% и идеальном CPI, равным 1, машина с приостановками условных переходов достигает примерно только половины ускорения, получаемого за счет конвейерной организации. Таким образом, снижение потерь от условных переходов становится критическим вопросом. Число тактов, теряемых при приостановках из-за условных переходов, может быть уменьшено двумя способами:
Обнаружением является ли условный переход выполняемым или невыполняемым на более ранних ступенях конвейера.
Более ранним вычислением значения счетчика команд для выполняемого перехода (т.е. вычислением целевого адреса перехода).
| Команда перехода | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Следующая команда | IF | stall | stall | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Следующая команда +1 | stall | stall | stall | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Следующая команда +2 | stall | stall | stall | IF | ID | EX | MEM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Следующая команда +3 | stall | stall | stall | IF | ID | EX | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Следующая команда +4 | stall | stall | stall | IF | ID | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Следующая команда +5 | stall | stall | stall | IF | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Соотношение между реальными и
Рисунок 3.1. Соотношение между реальными и нормализованными операциями с плавающей точкой,
которым пользуются авторы "ливерморских циклов" для вычисления рейтинга MFLOPS
Наиболее часто MFLOPS, как единица измерения производительности, используется при проведении контрольных испытаний на тестовых пакетах "Ливерморские циклы" и LINPACK.
Ливерморские циклы - это набор фрагментов фортран-программ, каждый из которых взят из реальных программных систем, эксплуатируемых в Ливерморской национальной лаборатории им.Лоуренса (США). Обычно при проведении испытаний используется либо малый набор из 14 циклов, либо большой набор из 24 циклов.
Пакет Ливерморских циклов используется для оценки производительности вычислительных машин с середины 60-х годов. Ливерморские циклы считаются типичными фрагментами программ численных задач. Появление новых типов машин, в том числе векторных и параллельных, не уменьшило важности Ливерморских циклов, однако изменились значения производительности и величины разброса между разными циклами.
На векторной машине производительность зависит не только от элементной базы, но и от характера самого алгоритма, т.е. коэффициента векторизуемости. Среди Ливерморских циклов коэффициент векторизуемости колеблется от 0 до 100%, что еще раз подтверждает их ценность для оценки производительности векторных архитектур. Кроме характера алгоритма, на коэффициент векторизуемости влияет и качество векторизатора, встроенного в компилятор.
На параллельной машине производительность существенно зависит от соответствия между структурой аппаратных связей вычислительных элементов и структурой вычислений в алгоритме. Важно, чтобы тестовый пакет представлял алгоритмы различных структур. В Ливерморских циклах встречаются последовательные, сеточные, конвейерные, волновые вычислительные алгоритмы, что подтверждает их пригодность и для параллельных машин. Однако обобщение результатов измерения производительности, полученных для одной параллельной машины, на другие параллельные машины или хотя бы некоторый подкласс параллельных машин, может дать неверный результат, ибо структуры аппаратных связей в таких машинах гораздо более разнообразны, чем, скажем, в векторных машинах.
LINPACK - это пакет фортран-программ для решения систем линейных алгебраических уравнений. Целью создания LINPACK отнюдь не было измерение производительности. Алгоритмы линейной алгебры весьма широко используются в самых разных задачах, и поэтому измерение производительности на LINPACK представляют интерес для многих пользователей. Сведения о производительности различных машин на пакете LINPACK публикуются сотрудником Аргоннской национальной лаборатории (США) Дж. Донгаррой и периодически обновляются.
В основе алгоритмов действующего варианта LINPACK лежит метод декомпозиции. Исходная матрица размером 100х100 элементов (в последнем варианте размером 1000х1000) сначала представляется в виде произведения двух матриц стандартной структуры, над которыми затем выполняется собственно алгоритм нахождения решения. Подпрограммы, входящие в LINPACK, структурированы. В стандартном варианте LINPACK выделен внутренний уровень базовых подпрограмм, каждая из которых выполняет элементарную операцию над векторами. Набор базовых подпрограмм называется BLAS (Basic Linear Algebra Subprograms). Например, в BLAS входят две простые подпрограммы SAXPY (умножение вектора на скаляр и сложение векторов) и SDOT (скалярное произведение векторов). Все операции выполняются над числами с плавающей точкой, представленными с двойной точностью. Результат измеряется в MFLOPS.
Использование результатов работы тестового пакета LINPACK с двойной точностью как основы для демонстрации рейтинга MFLOPS стало общепринятой практикой в компьютерной промышленности. При этом следует помнить, что при использовании исходной матрицы размером 100х100, она полностью может размещаться в кэш-памяти емкостью, например, 1 Мбайт. Если при проведении испытаний используется матрица размером 1000х1000, то емкости такого кэша уже недостаточно и некоторые обращения к памяти будут ускоряться благодаря наличию такого кэша, другие же будут приводить к промахам и потребуют большего времени на обработку обращений к памяти. Для многопроцессорных систем также имеются параллельные версии LINPACK и такие системы часто показывают линейное увеличение производительности с ростом числа процессоров.
Однако, как и любая другая единица измерения, рейтинг MFLOPS для отдельной программы не может быть обобщен на все случаи жизни, чтобы представлять единственную единицу измерения производительности компьютера, хотя очень соблазнительно характеризовать машину единственным рейтингом MIPS или MFLOPS без указания программы.
Сравнение долей промахов для
Рисунок 5.37. Сравнение долей промахов для алгоритма LRU и случайного алгоритма замещения
при нескольких размерах кэша и разных ассоциативностях при размере блока 16 байт
Сравнение качества 2-битового прогноза
Рисунок 5.28. Сравнение качества 2-битового прогноза
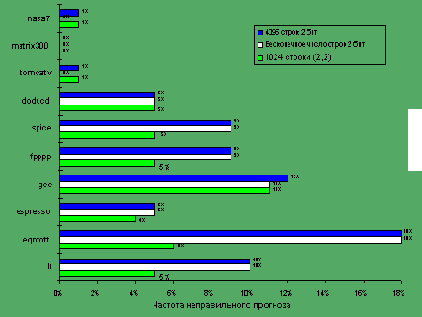
Какую точность можно ожидать от буфера прогнозирования переходов на реальных приложениях при использовании 2 бит на каждую строку буфера? Для набора оценочных тестов SPEC-89 буфер прогнозирования переходов с 4096 строками дает точность прогноза от 99% до 82%, т.е. процент неудачных прогнозов составляет от 1% до 18% (рисунок 5.28). Следует отметить, что буфер емкостью 4К строк считается очень большим. Буферы меньшего объема дадут худшие результаты.
Однако одного знания точности прогноза не достаточно для того, чтобы определить воздействие переходов на производительность машины, даже если известны время выполнения перехода и потери при неудачном прогнозе. Необходимо учитывать частоту переходов в программе, поскольку важность правильного прогноза больше в программах с большей частотой переходов. Например, целочисленные программы li, eqntott, expresso и gcc имеют большую частоту переходов, чем значительно более простые для прогнозирования программы плавающей точки nasa7, matrix300 и tomcatv.
Поскольку главной задачей является использование максимально доступной степени параллелизма программы, точность прогноза направления переходов становится очень важной. Как видно из рисунка 5.28, точность схемы прогнозирования для целочисленных программ, которые обычно имеют более высокую частоту переходов, меньше, чем для научных программ с плавающей точкой, в которых интенсивно используются циклы. Можно решать эту проблему двумя способами: увеличением размера буфера и увеличением точности схемы, которая используется для выполнения каждого отдельного прогноза. Буфер с 4К строками уже достаточно большой и, как показывает рисунок 5.28, работает практически также, что и буфер бесконечного размера. Из этого рисунка становится также ясно, что коэффициент попаданий буфера не является лимитирующим фактором. Как мы упоминали выше, увеличение числа бит в схеме прогноза также имеет малый эффект.
Рассмотренные двухбитовые схемы прогнозирования используют информацию о недавнем поведении команды условного перехода для прогноза будущего поведения этой команды.
Вероятно можно улучшить точность прогноза, если учитывать не только поведение того перехода, который мы пытаемся предсказать, но рассматривать также и недавнее поведение других команд перехода. Рассмотрим, например, небольшой фрагмент из текста программы eqntott тестового пакета SPEC92 (это наихудший случай для двухбитовой схемы прогноза):
i
f (aa==2)
aa=0;
if (bb==2)
bb=0;
if (aa!=bb) {
Ниже приведен текст сгенерированной программы (предполагается, что aa и bb размещены в регистрах R1 и R2):
SUBI R3,R1,#2
BNEZ R3,L1 ; переход b1 (aa!=2)
ADD R1,R0,R0 ; aa=0
L1: SUBI R3,R2,#2
BNEZ R3,L2 ; переход b2 (bb!=2)
ADD R2,R0,R0 ; bb=0
L2: SUB R3,R1,R2 ; R3=aa-bb
BEQZ R3,L3 ; branch b3 (aa==bb).
...
L3:
Пометим команды перехода как b1, b2 и b3. Можно заметить, что поведение перехода b3 коррелирует с переходами b1 и b2. Ясно, что если оба перехода b1 и b2 являются невыполняемыми (т.е. оба условия if оцениваются как истинные и обеим переменным aa и bb присвоено значение 0), то переход b3 будет выполняемым, поскольку aa и bb очевидно равны. Схема прогнозирования, которая для предсказания направления перехода использует только прошлое поведение того же перехода никогда этого не учтет.
Схемы прогнозирования, которые для предсказания направления перехода используют поведение других команд перехода, называются коррелированными или двухуровневыми схемами прогнозирования. Схема прогнозирования называется прогнозом (1,1), если она использует поведение одного последнего перехода для выбора из пары однобитовых схем прогнозирования на каждый переход. В общем случае схема прогнозирования (m,n) использует поведение последних m переходов для выбора из 2m
схем прогнозирования, каждая из которых представляет собой n-битовую схему прогнозирования для каждого отдельного перехода. Привлекательность такого типа коррелируемых схем прогнозирования переходов заключается в том, что они могут давать больший процент успешного прогнозирования, чем обычная двухбитовая схема, и требуют очень небольшого объема дополнительной аппаратуры.Простота аппаратной схемы определяется тем, что глобальная история последних m переходов может быть записана в m-битовом сдвиговом регистре, каждый разряд которого запоминает, был ли переход выполняемым или нет. Тогда буфер прогнозирования переходов может индексироваться конкатенацией (объединением) младших разрядов адреса перехода с m-битовой глобальной историей. Например, на рисунке 5.29 показана схема прогнозирования (2,2) и организация выборки битов прогноза.
Сравнение приложений с разными наборами операций NFS
Сравнение приложений с разными наборами операций NFS
В общем случае приложения, обращающиеся к множеству небольших файлов, могут характеризоваться как выполняющие интенсивные операции над атрибутами. Возможно наилучшим примером такого приложения является классическая система разработки программного обеспечения. Большие программные системы обычно состоят из тысяч небольших модулей. Каждый модуль обычно содержит файл включения (include file), файл исходного кода, объектный файл и некоторый тип файла управления архивом (подобный SCCS или RCS). Большинство файлов имеют небольшой размер, часто в пределах от 4 до 100 Кбайт. Поскольку обычно во время обслуживания транзакции NFS запросчик блокируется, время обработки в таких приложениях определяется скоростью обработки сервером легковесных запросов атрибутов. В общем числе операций операции над данными занимают менее 40%. В большинстве серверов с очень интенсивным выполнением операций с атрибутами требуется только умеренная пропускная способность сети: пропускная способность сети Ethernet (10 Мбит/с) обычно является адекватной.
Большинство серверов домашних каталогов (home directory) попадают в категорию интенсивного выполнения операций с атрибутами: большинство хранимых файлов небольшие. Кроме того, что эти файлы имеют небольшой размер по сравнению с размером атрибутов, они дают также возможность клиентской системе кэшировать данные файла, устраняя необходимость их повторного восстановления с сервера.
Приложения, работающие с очень большими файлами, попадают в категорию интенсивного выполнения операций с данными. К этой категории относятся, например, приложения из области геофизики, обработки изображений и электронных САПР. В этих приложениях обычный сценарий использования NFS рабочими станциями или вычислительными машинами включает: чтение очень большого файла, достаточно длительную обработку этого файла (минуты или даже часы) и, наконец, обратную запись меньшего по размерам файла результата. Файлы в этих прикладных областях часто достигают размера 1 Гбайт, а файлы размером более 200 Мбайт являются скорее правилом, чем исключением. При обработке больших файлов доминируют операции, связанные с обслуживанием запросов данных. Для приложений с интенсивным выполнением операций с данными наличие достаточной полосы пропускания сети всегда критично.
Например, считается, что скорость передачи данных в среде Ethernet составляет 10 Мбит/с. Такая скорость кажется достаточно высокой, однако 10 Мбит/с составляет всего 1.25 Мбайт/с, и даже эта скорость на практике не может быть достигнута из-за накладных расходов протокола обмена и ограниченной скорости обработки на каждой из взаимодействующих систем. В результате реальная предельная скорость Ethernet составляет примерно 1 Мбайт/с. Но даже эта скорость достижима только почти в идеальных условиях - при предоставлении всей полосы пропускания Ethernet для передачи данных только между двумя системами. К несчастью такая организация оказывается малопрактичной, хотя в действительности нередко случается, что только небольшое число клиентов сети запрашивают данные одновременно. При наличии множества активных клиентов максимальная загрузка сети составляет примерно 35%, что соответствует агрегатированной скорости передачи данных 440 Кбайт/с. Сама природа такого типа клиентов, характеризующихся интенсивным выполнением операций с данными, определяет процесс планирования конфигурации системы. Она обычно определяет выбор cетевой среды и часто диктует тип предполагаемого сервера. Во многих случаях освоение приложений с интенсивным выполнением операций с данными вызывает необходимость перепрокладки сетей.
В общем случае считается, что в среде с интенсивным выполнением операций с данными, примерно более половины операций NFS связаны с пересылкой пользовательских данных. В качестве представителя среды с интенсивным выполнением операций с атрибутами обычно берется классическая смесь Legato, в которой 22% всех операций составляют операции чтения (read) и 15% - операции записи (write).
Сравнительные характеристики современных аппаратных платформ
Сравнительные характеристики современных аппаратных платформ
Стандарты шин
Стандарты шин
Обычно количество и типы устройств ввода/вывода в вычислительных системах не фиксируются, что позволяет пользователю самому подобрать необходимую конфигурацию. Шина ввода/вывода компьютера может рассматриваться как шина расширения, обеспечивающая постепенное наращивание устройств ввода/вывода. Поэтому стандарты играют огромную роль, позволяя разработчикам компьютеров и устройств ввода/вывода работать независимо. Появление стандартов определяется разными обстоятельствами.
Иногда широкое распространение и популярность конкретных машин становятся причиной того, что их шина ввода/вывода становится стандартом де факто. Примерами таких шин могут служить PDP-11 Unibus и IBM PC-AT Bus. Иногда стандарты появляются также в результате определенных достижений по стандартизации в некотором секторе рынка устройств ввода/вывода. Интеллектуальный периферийный интерфейс (IPI - Intelligent Peripheral Interface) и Ethernet являются примерами стандартов, появившихся в результате кооперации производителей. Успех того или иного стандарта в значительной степени определяется его принятием такими организациями как ANSI (Национальный институт по стандартизации США) или IEEE (Институт инженеров по электротехнике и радиоэлектронике). Иногда стандарт шины может быть прямо разработан одним из комитетов по стандартизации: примером такого стандарта шины является FutureBus.
На рисунке 5.44 представлены характеристики нескольких стандартных шин. Заметим, что строки этой таблицы, касающиеся пропускной способности, не указаны в виде одной цифры для шин процессор-память (VME, FutureBus, MultibusII). Размер пересылки, из-за разных накладных расходов шины, сильно влияет на пропускную способность. Поскольку подобные шины обычно обеспечивают связь с памятью, то пропускная способность шины зависит также от быстродействия памяти. Например, в идеальном случае при бесконечном размере пересылки и бесконечно быстрой памяти (время доступа 0 нсек) шина FutureBus на 240% быстрее шины VME, но при пересылке одиночных слов из 150-нсекундной памяти шина FutureBus только примерно на 20% быстрее, чем шина VME.
| VME bus | FutureBus | Multibus II | IPI | SCSI | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ширина шины (кол-во сигналов) | 128 | 96 | 96 | 16 | 8 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Мультиплексирование адреса/данных | Нет | Да | Да | ( | ( | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Разрядность данных | 16/32 бит | 32 бит | 32 бит | 16 бит | 8 бит | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Размер пересылки (слов) | Одиночная или групповая | Одиночная или групповая | Одиночная или групповая | Одиночная или групповая | Одиночная или групповая | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Количество глав- ных устройств шины | Несколько | Несколько | Несколько | Одно | Несколько | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Расщепление транзакций | Нет | Доп. возможность | Доп. возможность | Доп. возможность | Доп. возможность | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Полоса пропускания (время доступа - 0 нс - 1 слово) | 25.9 Мб/c | 37.0 Мб/c | 20.0 Мб/c | 25.0 Мб/c | 5.0 Мб/c | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Полоса пропускания (время доступа - 150 нс - 1 слово) | 12.9 Мб/c | 15.5 Мб/c | 10.0 Мб/c | 25.0 Мб/c | 5.0 Мб/c | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Полоса пропускания (время доступа - 0 нс - неогр. размер блока) | 27.9 Мб/c | 95.2 Мб/c | 40.0 Мб/c | 25.0 Мб/c | 5.0 Мб/c | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Полоса пропускания (время доступа - 150 нс - неогр. размер блока) | 13.6 Мб/c | 20.8 Мб/c | 13.3 Мб/c | 25.0 Мб/c | 5.0 Мб/c | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Максимальное количество устройств | 21 | 20 | 21 | 8 | 7 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Максимальная длина шины | 0.5 м | 0.5 м | 0.5 м | 50 м | 25 м | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Стандарт | IEEE 1014 | IEEE 896.1 | ANSI/ IEEE 1296 | ANSI X3.129 | ANSI X3.131 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Страничная организация памяти
Страничная организация памяти
В системах со страничной организацией основная и внешняя память (главным образом дисковое пространство) делятся на блоки или страницы фиксированной длины. Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие - как номер слова (или байта) внутри страницы.
Управление различными уровнями памяти осуществляется программами ядра операционной системы, которые следят за распределением страниц и оптимизируют обмены между этими уровнями. При страничной организации памяти смежные виртуальные страницы не обязательно должны размещаться на смежных страницах основной физической памяти. Для указания соответствия между виртуальными страницами и страницами основной памяти операционная система должна сформировать таблицу страниц для каждой программы и разместить ее в основной памяти машины. При этом каждой странице программы, независимо от того находится ли она в основной памяти или нет, ставится в соответствие некоторый элемент таблицы страниц. Каждый элемент таблицы страниц содержит номер физической страницы основной памяти и специальный индикатор. Единичное состояние этого индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое состояние индикатора означает отсутствие страницы в оперативной памяти.
Для увеличения эффективности такого типа схем в процессорах используется специальная полностью ассоциативная кэш-память, которая также называется буфером преобразования адресов (TLB traнсlation-lookaside buffer). Хотя наличие TLB не меняет принципа построения схемы страничной организации, с точки зрения защиты памяти, необходимо предусмотреть возможность очистки его при переключении с одной программы на другую.
Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель (дескриптор) таблицы страниц или базово-граничную пару. База определяет адрес начала таблицы страниц в основной памяти, а граница - длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы.
Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц.
Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц.Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти. Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами.
Структура очередей команд
Структура очередей команд
Процессор R10000 содержит три очереди (буфера) команд (очередь целочисленных команд, очередь команд плавающей точки и адресную очередь). Эти три очереди осуществляют динамическую выдачу команд в соответствующие исполнительные устройства. С каждой командой в очереди хранится тег команды, который перемещается вместе с командой по ступеням конвейера. Каждая очередь осуществляет динамическое планирование потока команд и может определить моменты времени, когда становятся доступными операнды, необходимые для выполнения каждой команды. Кроме того, очередь определяет порядок выполнения команд на основе анализа состояния соответствующих исполнительных устройств. Как только ресурс оказывается свободным очередь выдает команду в соответствующее исполнительное устройство.
Структура устройства ПТ на основе алгоритма Томасуло
Рисунок 5.26. Структура устройства ПТ на основе алгоритма Томасуло

Хотя эти шаги в основном похожи на аналогичные шаги в централизованной схеме управления, имеются три важных отличия. Во-первых, отсутствует контроль конфликтов типа WAW и WAR - они устраняются как побочный эффект алгоритма. Во-вторых, для трансляции результатов используется CDB, а не схема ожидания готовности регистров. В-третьих, устройства загрузки и записи рассматриваются как основные функциональные устройства.
Структуры данных, используемые для обнаружения и устранения конфликтов, связаны со станциями резервирования, регистровым файлом и буферами загрузки и записи. Хотя с разными объектами связана разная информация, все устройства, за исключением буферов загрузки, содержат в каждой строке поле тега. Это поле тега представляет собой четырехбитовое значение, которое обозначает одну из пяти станций резервирования или один из шести буферов загрузки. Поле тега используется для описания того, какое функциональное устройства будет поставлять результат, нужный в качестве источника операнда. Неиспользуемые значения, такие как ноль, показывают что операнд уже доступен. Важно помнить, что теги в схеме Томасуло ссылаются на буфера или устройства, которые будут поставлять результат; когда команда выдается в станцию резервирования номера регистров исключаются из рассмотрения.
Большие преимущества схемы Томасуло заключаются в (1) распределении логики обнаружения конфликтов, и (2) устранение приостановок, связанных с конфликтами типа WAW и WAR. Первое преимущество возникает из-за наличия распределенных станций резервирования и использования CDB. Если несколько команд ожидают один и тот же результат и каждая команда уже имеет свой другой операнд, то команды могут выдаваться одновременно посредством трансляции по CDB. В централизованной схеме управления ожидающие команды должны читать свои операнды из регистров когда станут доступными регистровые шины. Конфликты типа WAW и WAR устраняются путем переименования регистров используя станции резервирования.
Эта динамическая схема может достигать очень высокой производительности при условии того, что стоимость переходов может поддерживаться небольшой. Этот вопрос мы будем рассматривать в следующем разделе. Главный недостаток этого подхода заключается в сложности схемы Томасуло, которая требует для своей реализации очень большого объема аппаратуры. Особенно это касается большого числа устройств ассоциативной памяти, которая должна работать с высокой скоростью, а также сложной логики управления. Наконец, увеличение производительности ограничивается наличием одной шины завершения (CDB). Хотя дополнительные шины CDB могут быть добавлены, каждая CDB должна взаимодействовать со всей аппаратурой конвейера, включая станции резервирования. В частности, аппаратуру ассоциативного сравнения необходимо дублировать на каждой станции для каждой CDB.
В схеме Томасуло комбинируются две различных методики: методика переименования регистров и буферизация операндов-источников из регистрового файла. Буферизация источников операндов разрешает конфликты типа WAR, которые возникают когда операнды доступны в регистрах. Как мы увидим позже, возможно также устранять конфликты типа WAR посредством переименования регистра вместе с буферизацией результата до тех пор, пока остаются обращения к старой версии регистра; этот подход будет использоваться, когда мы будем обсуждать аппаратное выполнение по предположению.
Схема Томасуло является привлекательной, если разработчик вынужден делать конвейерную архитектуру, для которой трудно выполнить планирование кода или реализовать большое хранилище регистров. С другой стороны, преимущество подхода Томасуло возможно ощущается меньше, чем увеличение стоимости реализации, по сравнению с методами планирования загрузки конвейера средствами компилятора в машинах, ориентированных на выдачу для выполнения только одной команды в такте. Однако по мере того, как машины становятся все более агрессивными в своих возможностях выдачи команд и разработчики сталкиваются с вопросами производительности кода, который трудно планировать (большинство кодов для нечисловых расчетов), методика типа переименования регистров и динамического планирования будет становиться все более важной.Позже в этой главе мы увидим, что эти методы являются одним из важных компонентов большинства схем для реализации аппаратного выполнения по предположению.
Ключевыми компонентами увеличения параллелизма уровня команд в алгоритме Томасуло являются динамическое планирование, переименование регистров и динамическое устранение неоднозначности обращений к памяти. Трудно оценить значение каждого из этих свойств по отдельности.
Динамической аппаратной технике планирования загрузки конвейера при наличии зависимостей по данным соответствует и динамическая техника для эффективной обработки переходов. Эта техника используется для двух целей: для прогнозирования того, будет ли переход выполняемым, и для возможно более раннего нахождения целевой команды перехода. Эта техника называется аппаратным прогнозированием переходов.
Структурные конфликты и способы их минимизации
Структурные конфликты и способы их минимизации
Совмещенный режим выполнения команд в общем случае требует конвейеризации функциональных устройств и дублирования ресурсов для разрешения всех возможных комбинаций команд в конвейере. Если какая-нибудь комбинация команд не может быть принята из-за конфликта по ресурсам, то говорят, что в машине имеется структурный конфликт. Наиболее типичным примером машин, в которых возможно появление структурных конфликтов, являются машины с не полностью конвейерными функциональными устройствами. Время работы такого устройства может составлять несколько тактов синхронизации конвейера. В этом случае последовательные команды, которые используют данное функциональное устройство, не могут поступать в него в каждом такте. Другая возможность появления структурных конфликтов связана с недостаточным дублированием некоторых ресурсов, что препятствует выполнению произвольной последовательности команд в конвейере без его приостановки. Например, машина может иметь только один порт записи в регистровый файл, но при определенных обстоятельствах конвейеру может потребоваться выполнить две записи в регистровый файл в одном такте. Это также приведет к структурному конфликту. Когда последовательность команд наталкивается на такой конфликт, конвейер приостанавливает выполнение одной из команд до тех пор, пока не станет доступным требуемое устройство.
Структурные конфликты возникают, например, и в машинах, в которых имеется единственный конвейер памяти для команд и данных (рисунок 5.8). В этом случае, когда одна команда содержит обращение к памяти за данными, оно будет конфликтовать с выборкой более поздней команды из памяти. Чтобы разрешить эту ситуацию, можно просто приостановить конвейер на один такт, когда происходит обращение к памяти за данными. Подобная приостановка часто называются "конвейерным пузырем" (pipeline bubble) или просто пузырем, поскольку пузырь проходит по конвейеру, занимая место, но не выполняя никакой полезной работы.
При всех прочих обстоятельствах, машина без структурных конфликтов будет всегда иметь более низкий CPI (среднее число тактов на выдачу команды). Возникает вопрос: почему разработчики допускают наличие структурных конфликтов? Для этого имеются две причины: снижение стоимости и уменьшение задержки устройства. Конвейеризация всех функциональных устройств может оказаться слишком дорогой. Машины, допускающие два обращения к памяти в одном такте, должны иметь удвоенную пропускную способность памяти, например, путем организации раздельных кэшей для команд и данных. Аналогично, полностью конвейерное устройство деления с плавающей точкой требует огромного количества вентилей. Если структурные конфликты не будут возникать слишком часто, то может быть и не стоит платить за то, чтобы их обойти. Как правило, можно разработать неконвейерное, или не полностью конвейерное устройство, имеющее меньшую общую задержку, чем полностью конвейерное. Например, разработчики устройств с плавающей точкой компьютеров CDC7600 и MIPS R2010 предпочли иметь меньшую задержку выполнения операций вместо полной их конвейеризации.
| Команда | Номер такта |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда загрузки | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда 1 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда 2 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда 3 | stall | IF | ID | EX | MEM | WB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда 4 | IF | ID | EX | MEM | WB | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда 5 | IF | ID | EX | MEM | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Команда 6 | IF | ID | EX | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
SuperSPARC
SuperSPARC
Имеется несколько версий этого процессора, позволяющего в зависимости от смеси команд обрабатывать до трех команд за один машинный такт, отличающихся тактовой частотой (50, 60, 75 и 85 МГц). Процессор SuperSPARC (рисунок 6.2) имеет сбалансированную производительность на операциях с фиксированной и плавающей точкой. Он имеет внутренний кэш емкостью 36 Кб (20 Кб - кэш команд и 16 Кб - кэш данных), раздельные конвейеры целочисленной и вещественной арифметики и при тактовой частоте 75 МГц обеспечивает производительность около 205 MIPS. Процессор SuperSPARC применяется также в серверах SPARCserver 1000 и SPARCcenter 2000 компании Sun.
Конструктивно кристалл монтируется на взаимозаменяемых процессорных модулях трех типов, отличающихся наличием и объемом кэш-памяти второго уровня и тактовой частотой. Модуль M-bus SuperSPARC, используемый в модели 50 содержит 50-МГц SuperSPARC процессор с внутренним кэшем емкостью 36 Кб (20 Кб кэш команд и 16 Кб кэш данных). Модули M-bus SuperSPARC в моделях 51, 61 и 71 содержат по одному SuperSPARC процессору, работающему на частоте 50, 60 и 75 МГц соответственно, одному кристаллу кэш-контроллера (так называемому SuperCache), а также внешний кэш емкостью 1 Мб. Модули M-bus в моделях 502, 612, 712 и 514 содержат два SuperSPARC процессора и два кэш-контроллера каждый, а последние три модели и по одному 1 Мб внешнему кэшу на каждый процессор. Использование кэш-памяти позволяет модулям CPU работать с тактовой частотой, отличной от тактовой частоты материнской платы; пользователи всех моделей поэтому могут улучшить производительность своих систем заменой существующих модулей CPU вместо того, чтобы производить upgrade всей материнской платы.
Операции NFS
Таблица 4.1. Операции NFS
| Операция | Назначение операции | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| getattr | Получает атрибуты файла такие как тип, размер, права доступа и даты модификации | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| setattr | Изменяет значения атрибутов файла/каталога | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| root | Выбирает корень удаленной файловой системы в настоящее время не используется) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| lookup | Разыскивает файл в каталоге и возвращает расширенный дескриптор файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| readlink | Следует символической связи на сервере | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| read | Читает блок данных размером 8 Кбайт | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| wrcache | Записывает блок данных размером 8 Кбайт в удаленный кэш (в настоящее время не используется) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| write | Записывает блок данных размером 8 Кбайт | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| create | Создает индексный дескриптор файловой системы; может быть файлом или символической связью | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| remove | Удаляет индексный дескриптор файловой системы | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rename | Изменяет строку имени каталога файла | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| link | Создает жесткую связь в удаленной файловой системе | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| symlink | Создает символическую связь в удаленной файловой системе | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| mkdir | Создает каталог | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| rmdir | Удаляет каталог | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| readdir | Читает строку каталога | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| fsstat | Выбирает динамическую информацию файловой системы | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| null | Ничего не делает; используется для тестирования и хронометража ответа сервера | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
В каждой строке каталога файловой системы имеется некоторое количество характеристик, которые описывают файл или доступ к нему, такие как тип строки (файл, символическая связь, каталог), размер, даты обращений, права доступа и т.п. Большинство операций NFS связано с манипулированием этими атрибутами файла.
Характеристики некоторых дисковых накопителей
Таблица 4.2. Характеристики некоторых дисковых накопителей
| Емкость диска |
Время ожидания |
Среднее время позиционирования |
Количество операций в секунду, Мбайт/с | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Произвольный доступ |
Последовательный доступ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 535 Мб | 5.56 мс | 12 мс | 57, 0.456 | 451, 3.6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1.05 Гб | 5.56 мс | 11 мс | 67, 0.536 | 480, 3.8 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2.1 Гб | 5.56 мс | 11 мс | 62, 0.496 | 494, 4.0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2.9 Гб | 5.56 мс | 10.5 мс | 72, 0.576 | 521, 4.2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
В очень больших системах с интенсивным использованием атрибутов, которые требуют использования дисков емкостью 2.9 Гбайт (по причинам конструкции сервера или объема данных), оптимальная производительность достигается при 8 полностью активных дисках на шине fast/wide SCSI, хотя могут быть установлены и 9 или 10 дисковых накопителей только с небольшой деградацией времени ответа ввода/вывода. Как и в интенсивных по данным системах, конфигурирование большего числа накопителей на шине SCSI обеспечивает дополнительную емкость памяти, но не дает дополнительных результатов производительности.
Сложно дать какие-либо специальные рекомендации по числу дисковых кареток, которые требуются в интенсивной по атрибутам среде, поскольку нагрузки меняются в широких пределах. В такой среде время ответа сервера зависит от того, насколько быстро атрибуты могут быть найдены и переданы клиенту. Опыт показывает, что часто оказывается полезно конфигурировать по крайней мере один дисковый накопитель на каждых двух полностью активных клиентов, чтобы минимизировать задержки выполнения этих операций, но задержка может быть сокращена и с помощью установки дополнительной основной памяти, позволяющей кэшировать часто используемые атрибуты. По этой причине диски меньшей емкости часто оказываются более предпочтительны. Например, лучше использовать 8 дисков емкостью 535 Мбайт вместо двух дисков емкостью 2.1 Гбайт.
Показатели LADDIS
Таблица 4.3. Показатели LADDIS для различных NFS-серверов Sun под управлением Solaris 2.3. Немного (на 5%) более высокие скорости достижимы при использовании FDDI,
немного меньшие скорости - при использовании 16 Мбит Token Ring.
| Платформа | Результат на LADDIS |
Примечания по конфигурации | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCclassic | 236 оп/с, 50 мс | 64 Мб RAM, 4 диска на 2 FSBE/S, 2 сети | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCstation 10 Model 40 |
411 оп/с, 49 мс | 128 Мб RAM, 8 дисков на 4 FSBE/S, 2 сети | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCstation 10 Model 402 |
520 оп/с, 46 мс | 128 Мб RAM, 8 дисков на 4 FSBE/S, 2 сети | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCstation 10 Model 51 |
472 оп/с, 49 мс | 128 Мб RAM, 12 дисков на 4 FSBE/S, 3 сети | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCstation 10 Model 512 |
741 оп/с, 48 мс | 128 Мб RAM, 12 дисков на 4 FSBE/S, 3 сети | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCserver 1000 Model 1104 |
1410 оп/с, 41 мс | 256 Мб RAM, 4 Мб NVSIMM, 24 диска на 4 DWI/S, 6 сетей на 2 SQEC/C | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCserver 1000 Model 1108 |
1928 оп/с, 42 мс | 480 Мб RAM, 4 Мб NVSIMM, 24 диска на 4 DWI/S, 8 сетей на 2 SQEC/C | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCcenter 2000 Model 2208 |
2080 оп/с, 32 мс | 448 Мб RAM, 8 Мб NVSIMM, 48 дисков на 8 DWI/S, 12 сетей на 3 SQEC/C | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SPARCcenter 2000 Model 2208 |
2575 оп/с, 49 мс | 512 Мб RAM, 60 дисков на 8 DWI/S, 12 сетей на 2 SQEC/C | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последняя возможность: использование похожей нагрузки
Если отсутствует система для проведения измерений и поведение приложения не очень хорошо понятно, можно сделать оценку базируясь на похожей прикладной нагрузке, показанной в таблицах 4.4 - 4.6. Эти данные дают некоторое представление и примеры измеренных нагрузок NFS. Это не означает, что они дают определенную картину того, какую нагрузку следует ожидать от определенных задач. В частности, заметим, что приведенные в этих таблицах данные представляют собой максимальные предполагаемые нагрузки от реальных клиентов, поскольку эти цифры отражают только тот период времени, когда система активно выполняет NFS-запросы. Как отмечено выше в разд. 3.1.4, системы почти никогда не бывают полностью активными все время. Примечательным исключением из этого правила являются вычислительные серверы, которые в действительности представляют собой непрерывно работающие пакетные машины. Например, работа системы 486/33, выполняющей 1-2-3, показана в таблице 4.2 и на Рисунок 4.2. Хотя представленная в таблице пиковая нагрузка равна 80 ops/sec, из рисунка ясно, что общая нагрузка составляет меньше 10% этой скорости и что средняя за пять минут нагрузка значительно меньше 10 ops/sec. При усреднении за более длительный период времени, нагрузка ПК примерно равна 0.1 ops/sec. Большинство рабочих станций класса SPARCstation2 или SPARCstation ELC дают в среднем 1 op/sec, а большинство разумных эквивалентов клиентов SPARCstation 10 Model 51, Model 512, HP 9000/735 или RS6000/375 - 1-2 ops/sec. Конечно эти цифры существенно меняются в зависимости от индивидуальности пользователя и приложения.
Оценка нагрузки полностью
Таблица 4.4. Оценка нагрузки полностью активных клиентов NFS на бизнес-приложениях (операция/с и продолжительность этапов)
| Тип плат-формы | Тип сети | 1-2-3 (электронная таблица 800 Кб) |
Interleaf (Документ 50 Кб) |
Копирование дерева 10 Мб |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Старт | Загру-зка | Сохра-нение | Старт | Открытие документа | Сохранение документа | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 486/33 | Ethernet | 80/30 | 50/25 | 13/60 | 40/125 | 25/3 | 14/8 | 15/60 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SS10-40 | Ethernet | 101/17 | 48/20 | 13/60 | 55/33 | 25/3 | 25/3 | 45/19 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| IBM 560 | Ethernet | - | 40/30 | 25/3 | 25/3 | 38/23 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HP 847 | Ethernet | - | 57/27 | 21/3 | 19/5 | 40/22 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Оценка нагрузки полностью
Таблица 4.5. Оценка нагрузки полностью активных клиентов NFS на приложениях САПР (операция/с и продолжительность этапов)
| Тип платформы |
Тип сети | Verilog (50K вентилей) | Журнал Pro/E | Журнал SDRC Ideas | AutoCAD Site-3D | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SS10-41 | Ethernet | 5.1/602 | 3.22/749 | 17.9/354 | 8/180 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| IBM 375 | Ethernet | 6.8/390 | - | 18.5/535 | 11/167 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HP 730 | Ethernet | 7.2/444 | 3.05/860 | 21.5/295 | 10.5/170 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SGI Crim | Ethernet | - | 3.25/780 | 22.8/280 | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Оценка нагрузки полностью
Таблица 4.6. Оценка нагрузки полностью активных клиентов NFS на приложениях разработки ПО (операция/с и продолжительность этапов)
| Тип платформы |
Тип сети | "make bigproject" |
find /tree- name thing | cp -pr tree remote | dump 8MB core | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SS10-40 | Ethernet | 43/190 | 122/431 | 127/62 | 24/41 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SS10-40 | FDDI | 58/177 | 139/378 | 135/58 | 26/37 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SS2000 12cpu | Ethernet | 211/22 | - | - | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| IBM 560 | Ethernet | 65/317 | 112/475 | 58/158 | 8/3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HP 847 | Ethernet | 53/173 | 145/363 | 180/43 | 14/71 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
В лучшем случае такой суперскалярный
Таблица 5.1.
| Целочисленная команда | Команда ПТ | Номер такта |
| Loop: LD F0,0(R1) LD F8,-8(R1) LD F10,-16(R1) LD F14,-24(R1) LD F18,-32(R1) SD 0(R1),F4 SD -8(R1),F8 SD -16(R1),F12 SD -24(R1),F16 SUBI R1,R1,#40 BNEZ R1,Loop SD -32(R1),F20 |
ADDD F4,F0,F2 ADDD F8,F6,F2 ADDD F12,F10,F2 ADDD F16,F14,F2 ADDD F20,F18,F2 |
1 2 3 4 5 6 7 8 9 10 11 12 |
В лучшем случае такой суперскалярный конвейер позволит выбирать две команды и выдавать их на выполнение, если первая из них является целочисленной, а вторая - с плавающей точкой. Если это условие не соблюдается, что легко проверить, то команды выдаются последовательно. Это показывает два главных преимущества суперскалярной машины по сравнению с WLIW-машиной. Во-первых, малое воздействие на плотность кода, поскольку машина сама определяет, может ли быть выдана следующая команда, и нам не надо следить за тем, чтобы команды соответствовали возможностям выдачи. Во-вторых, на таких машинах могут работать неоптимизированные программы, или программы, откомпилированные в расчете на более старую реализацию. Конечно такие программы не могут работать очень хорошо. Один из способов улучшить ситуацию заключается в использовании аппаратных средств динамической оптимизации.
В общем случае в суперскалярной системе команды могут выполняться параллельно и возможно не в порядке, предписанном программой. Если не предпринимать никаких мер, такое неупорядоченное выполнение команд и наличие множества функциональных устройств с разными временами выполнения операций могут приводить к дополнительным трудностям. Например, при выполнении некоторой длинной команды с плавающей точкой (команды деления или вычисления квадратного корня) может возникнуть исключительная ситуация уже после того, как завершилось выполнение более быстрой операции, выданной после этой длинной команды. Для того, чтобы поддерживать модель точных прерываний, аппаратура должна гарантировать корректное состояние процессора при прерывании для организации последующего возврата.
Обычно в машинах с неупорядоченным выполнением команд предусматриваются дополнительные буферные схемы, гарантирующие завершение выполнения команд в строгом порядке, предписанном программой. Такие схемы представляют собой некоторый буфер "истории", т.е. аппаратную очередь, в которую при выдаче попадают команды и текущие значения регистров результата этих команд в заданном программой порядке.
В момент выдачи команды на выполнение она помещается в конец этой очереди, организованной в виде буфера FIFO (первый вошел - первый вышел). Единственный способ для команды достичь головы этой очереди - завершение выполнения всех предшествующих ей операций. При неупорядоченном выполнении некоторая команда может завершить свое выполнение, но все еще будет находиться в середине очереди. Команда покидает очередь, когда она достигает головы очереди и ее выполнение завершается в соответствующем функциональном устройстве. Если команда находится в голове очереди, но ее выполнение в функциональном устройстве не закончено, она очередь не покидает. Такой механизм может поддерживать модель точных прерываний, поскольку вся необходимая информация хранится в буфере и позволяет скорректировать состояние процессора в любой момент времени.
Этот же буфер "истории" позволяет реализовать и условное (speculative) выполнение команд (выполнение по предположению), следующих за командами условного перехода. Это особенно важно для повышения производительности суперскалярных архитектур. Статистика показывает, что на каждые шесть обычных команд в программах приходится в среднем одна команда перехода. Если задерживать выполнение следующих за командой перехода команд, потери на конвейеризацию могут оказаться просто неприемлемыми. Например, при выдаче четырех команд в одном такте в среднем в каждом втором такте выполняется команда перехода. Механизм условного выполнения команд, следующих за командой перехода, позволяет решить эту проблему. Это условное выполнение обычно связано с последовательным выполнением команд из заранее предсказанной ветви команды перехода.Устройство управления выдает команду условного перехода, прогнозирует направление перехода и продолжает выдавать команды из этой предсказанной ветви программы.
Если прогноз оказался верным, выдача команд так и будет продолжаться без приостановок. Однако если прогноз был ошибочным, устройство управления приостанавливает выполнение условно выданных команд и, если необходимо, использует информацию из буфера истории для ликвидации всех последствий выполнения условно выданных команд. Затем начинается выборка команд из правильной ветви программы. Таким образом, аппаратура, подобная буферу, истории позволяет не только решить проблемы с реализацией точного прерывания, но и обеспечивает увеличение производительности суперскалярных архитектур.
Тест TPC-A
Тест TPC-A
Выпущенный в ноябре 1989 года, тест TCP-A предназначался для оценки производительности систем, работающих в среде интенсивно обновляемых баз данных, типичной для приложений интерактивной обработки данных (OLDP - on-line data processing). Такая среда характеризуется:
множеством терминальных сессий в режиме on-line
значительным объемом ввода/вывода при работе с дисками
умеренным временем работы системы и приложений
целостностью транзакций.
Практически при выполнении теста эмулируется типичная вычислительная среда банка, включающая сервер базы данных, терминалы и линии связи. Этот тест использует одиночные, простые транзакции, интенсивно обновляющие базу данных. Одиночная транзакция (подобная обычной операции обновления счета клиента) обеспечивает простую, повторяемую единицу работы, которая проверяет ключевые компоненты системы OLTP.
Тест TPC-A определяет пропускную способность системы, измеряемую количеством транзакций в секунду (tps A), которые система может выполнить при работе с множеством терминалов. Хотя спецификация TPC-A не определяет точное количество терминалов, компании-поставщики систем должны увеличивать или уменьшать их количество в соответствии с нормой пропускной способности. Тест TPC-A может выполняться в локальных или региональных вычислительных сетях. В этом случае его результаты определяют либо "локальную" пропускную способность(TPC-A-local Throughput), либо "региональную" пропускную способность (TPC-A wide Throughput). Очевидно, эти два тестовых показателя нельзя непосредственно сравнивать. Спецификация теста TPC-A требует, чтобы все компании полностью раскрывали детали работы своего теста, свою конфигурацию системы и ее стоимость (с учетом пятилетнего срока обслуживания). Это позволяет определить нормализованную стоимость системы ($/tpsA).
Тест TPC-B
Тест TPC-B
В августе 1990 года TPC одобрил TPC-B, интенсивный тест базы данных, характеризующийся следующими элементами:
значительный объем дискового ввода/вывода
умеренное время работы системы и приложений
целостность транзакций.
TPC-B измеряет пропускную способность системы в транзакциях в секунду (tpsB). Поскольку имеются существенные различия между двумя тестами TPC-A и TPC-B (в частности, в TPC-B не выполняется эмуляция терминалов и линий связи), их нельзя прямо сравнивать. На рисунке 3.2 показаны взаимоотношения между TPC-A и TPC-B.
Тест TPC-C
Тест TPC-C
Тестовый пакет TPC-C моделирует прикладную задачу обработки заказов. Он моделирует достаточно сложную систему OLTP, которая должна управлять приемом заказов, управлением учетом товаров и распространением товаров и услуг. Тест TPC-C осуществляет тестирование всех основных компонентов системы: терминалов, линий связи, ЦП, дискового в/в и базы данных.
TPC-C требует, чтобы выполнялись пять типов транзакций:
новый заказ, вводимый с помощью сложной экранной формы
простое обновление базы данных, связанное с платежом
простое обновление базы данных, связанное с поставкой
справка о состоянии заказов
справка по учету товаров
Среди этих пяти типов транзакций по крайней мере 43%должны составлять платежи. Транзакции, связанные со справками о состоянии заказов, состоянии поставки и учета, должны составлять по 4%. Затем измеряется скорость транзакций по новым заказам, обрабатываемых совместно со смесью других транзакций, выполняющихся в фоновом режиме.
База данных TPC-C основана на модели оптового поставщика с удаленными районами и товарными складами. База данных содержит девять таблиц: товарные склады, район, покупатель, заказ, порядок заказов, новый заказ, статья счета, складские запасы и история.
Обычно публикуются два результата (таблица 3.1.). Один из них, tpm-C, представляет пиковую скорость выполнения транзакций (выражается в количестве транзакций в минуту). Второй результат, $/tpm-C, представляет собой нормализованную стоимость системы. Стоимость системы включает все аппаратные средства и программное обеспечение, используемые в тесте, плюс стоимость обслуживания в течение пяти лет.
Тесты AIM
Тесты AIM
Одной из независимых организаций, осуществляющей оценку производительности вычислительных систем, является частная компания AIM Technology, которая была основана в 1981 году. Компания разрабатывает и поставляет программное обеспечение для измерения производительности систем, а также оказывает услуги по тестированию систем конечным пользователям и поставщикам вычислительных систем и сетей, которые используют промышленные стандартные операционные системы, такие как UNIX и OS/2.
За время своего существования компания разработала специальное программное обеспечение, позволяющее легко создавать различные рабочие нагрузки, соответствующие уровню тестируемой системы и требованиям по ее использованию. Это программное обеспечение состоит из двух основных частей: генератора тестовых пакетов (Benchmark Generator) и нагрузочных смесей (Load Mixes) прикладных задач.
Генератор тестовых пакетов представляет собой программную систему, которая обеспечивает одновременное выполнение множества программ. Он содержит большое число отдельных тестов, которые потребляют определенные ресурсы системы, и тем самым акцентируют внимание на определенных компонентах, из которых складывается ее общая производительность. При каждом запуске генератора могут выполняться любые отдельные или все доступные тесты в любом порядке и при любом количестве проходов, позволяя тем самым создавать для системы практически любую необходимую рабочую нагрузку. Все это дает возможность тестовому пакету моделировать любой тип смеси при постоянной смене акцентов (для лучшего представления реальной окружающей обстановки) и при обеспечении высокой степени конфигурирования.
Каждая нагрузочная смесь представляют собой формулу, которая определяет компоненты требуемой нагрузки. Эта формула задается в терминах количества различных доступных тестов, которые должны выполняться одновременно для моделирования рабочей нагрузки.
Используя эти две части программного обеспечения AIM, можно действительно создать для тестируемой системы любую рабочую нагрузку, определяя компоненты нагрузки в терминах тестов, которые должны выполняться генератором тестовых пакетов. Если некоторые требуемые тесты отсутствуют в составе генератора тестовых пакетов, то они могут быть легко туда добавлены.
Генератор тестовых пакетов во время своей работы "масштабирует" или увеличивает нагрузку на систему. Первоначально он выполняет и хронометрирует одну копию нагрузочной смеси. Затем одновременно выполняет и хронометрирует три копии нагрузочной смеси и т.д. По мере увеличения нагрузки, на основе оценки производительности системы, выбираются различные уровни увеличения нагрузки. В конце концов может быть нарисована кривая пропускной способности, показывающая возможности системы по обработке нагрузочной смеси в зависимости от числа моделируемых нагрузок. Это позволяет с достаточной достоверностью дать заключение о возможностях работы системы при данной нагрузке или при изменении нагрузки.
Очевидно, что сам по себе процесс моделирования рабочей нагрузки мало что дал бы для сравнения различных машин между собой при отсутствии у AIM набора хорошо подобранных смесей, которые представляют собой ряд важных для пользователя прикладных задач.
Все смеси AIM могут быть разделены на две категории: стандартные и заказные. Заказные смеси создаются для точного моделирования особенностей среды конечного пользователя или поставщика оборудования. Заказная смесь может быть тесно связана с определенными тестами, добавляемыми к генератору тестовых пакетов. В качестве альтернативы заказная смесь может быть связана с очень специфическим приложением, которое создает для системы необычную нагрузку. В общем случае заказные смеси разрабатываются на основе одной из стандартных смесей AIM путем ее "подгонки" для более точного представления определенной ситуации. Обычно заказные смеси разрабатываются заказчиком совместно с AIM Technology, что позволяет использовать многолетний опыт AIM по созданию и моделированию нагрузочных смесей.
К настоящему времени AIM создала восемь стандартных смесей, которые представляют собой обычную среду прикладных задач. В состав этих стандартных смесей входят:
Универсальная смесь для рабочих станций (General Workstation Mix) - моделирует работу рабочей станции в среде разработки программного обеспечения.
Смесь для механического САПР (Mechanical CAD Mix) моделирует рабочую станцию, используемую для трехмерного моделирования и среды системы автоматизации проектирования в механике.
Смесь для геоинформационных систем (GIS Mix) - моделирует рабочую станцию, используемую для обработки изображений и в приложениях геоинформацинных систем.
Смесь универсальных деловых приложений (General Business) - моделирует рабочую станцию, используемую для выполнения таких стандартных инструментальных средств, как электронная почта, электронные таблицы, база данных, текстовый процессор и т.д.
Многопользовательская смесь (Shared/Multiuser Mix) моделирует многопользовательскую систему, обеспечивающую обслуживание приложений для множества работающих в ней пользователей.
Смесь для вычислительного (счетного) сервера (ComputeServer Mix) - моделирует систему, используемую для выполнения заданий с большим объемом вычислений, таких как маршрутизация PCB, гидростатическое моделирование, вычислительная химия, взламывание кодов и т.д.
Смесь для файл-сервера (File Server Mix) - моделирует запросы, поступающие в систему, используемую в качестве централизованного файлового сервера, включая ввод/вывод и вычислительные мощности для других услуг по запросу.
Смесь СУБД (RBMS Mix) - моделирует систему, выполняющую ответственные приложения управления базой данных.
Одним из видов деятельность AIM Technology является выпуск сертифицированных отчетов по результатам тестирования различных систем. В качестве примера рассмотрим форму отчета AIM Performance Report II - независимое сертифицированное заключение о производительности системы.
Ключевыми частями этого отчета являются:
стоимость системы,
детали конфигурации системы,
результаты измерения производительности, показанные на трех тестовых пакетах AIM.
Используются следующие три тестовых пакета:
многопользовательский тестовый пакет AIM (набор III),
тестовый пакет утилит AIM (Milestone),
тестовый пакет для оценки различных подсистем (набор II).
В частности, набор III, разработанный компанией AIM Technology, используется в различных формах уже более 10 лет. Он представляет собой пакет тестов для системы UNIX, который пытается оценить все аспекты производительности системы, включая все основные аппаратные средства, используемые в многопрограммной среде. Этот тестовый пакет моделирует многопользовательскую работу в среде разделения времени путем генерации возрастающих уровней нагрузки на ЦП, подсистему ввода/вывода, переключение контекста и измеряет производительность системы при работе с множеством процессов.
Для оценки и сравнения систем в AIM Performance Report II используются следующие критерии:
Пиковая производительность (рейтинг производительности по AIM)
Максимальная пользовательская нагрузка
Индекс производительности утилит
Пропускная способность системы
Рейтинг производительности по AIM - стандартная единица измерения пиковой производительности, установленная AIM Technology. Этот рейтинг определяет наивысший уровень производительности системы, который достигается при оптимальном использовании ЦП, операций с плавающей точкой и кэширования диска. Рейтинг вездесущей машины VAX 11/780 обычно составляет 1 AIM. В отчетах AIM представлен широкий ряд UNIX-систем, которые можно сравнивать по этому параметру.
Максимальная пользовательская нагрузка - определяет "емкость" (capacity) системы, т.е. такую точку, начиная с которой производительность системы падает ниже приемлемого уровня для N-го пользователя (меньше чем одно задание в минуту на одного пользователя).
Индекс производительности утилит - определяет количество пользовательских нагрузок пакета Milestone, которые данная система выполняет в течение одного часа. Набор тестов Milestone многократно выполняет выбранные утилиты UNIX в качестве основных и фоновых заданий при умеренных пользовательских нагрузках. Этот параметр показывает возможности системы по выполнению универсальных утилит UNIX.
Максимальная пропускная способность - определяет пиковую производительность мультипрограммной системы, измеряемую количеством выполненных заданий в минуту. Приводящийся в отчете график пропускной способности системы показывает, как она работает при различных нагрузках.
Отчет по производительности разработан с использованием набора тестов AIM собственной разработки. В отличие от многих популярных тестовых пакетов, которые измеряют только производительность ЦП в однозадачном режиме и/или на операциях с плавающей точкой, тестовые пакеты AIM проверяют итоговую производительность системы и всех ее основных компонентов в многозадачной среде, включая ЦП, плавающую точку, память, диски, системные и библиотечные вызовы.
Синтетические ядра и натуральные тесты не могут служить в качестве настоящих тестовых пакетов для оценки систем: они не могут моделировать точно среду конечного пользователя и оценивать производительность всех относящихся к делу компонентов системы. Без такой гарантии результаты измерения производительности остаются под вопросом.
Тесты SPEC
Тесты SPEC
Важность создания пакетов тестов, базирующихся на реальных прикладных программах широкого круга пользователей и обеспечивающих эффективную оценку производительности процессоров, была осознана большинством крупнейших производителей компьютерного оборудования, которые в 1988 году учредили бесприбыльную корпорацию SPEC (Standard Performance Evaluation Corporation). Основной целью этой организации является разработка и поддержка стандартизованного набора специально подобранных тестовых программ для оценки производительности новейших поколений высокопроизводительных компьютеров. Членом SPEC может стать любая организация, уплатившая вступительный взнос.
Главными видами деятельности SPEC являются:
Разработка и публикация наборов тестов, предназначенных для измерения производительности компьютеров. Перед публикацией объектные коды этих наборов вместе с исходными текстами и инструментальными средствами интенсивно проверяются на предмет возможности импортирования на разные платформы. Они доступны для широкого круга пользователей за плату, покрывающую расходы на разработку и административные издержки. Специальное лицензионное соглашение регулирует вопросы выполнения тестирования и публикации результатов в соответствии с документацией на каждый тестовый набор.
SPEC публикует ежеквартальный отчет о новостях SPEC и результатах тестирования: "The SPEC Newsletter", что обеспечивает централизованный источник информации для результатов тестирования на тестах SPEC.
Основным результатом работы SPEC являются наборы тестов. Эти наборы разрабатываются SPEC с использованием кодов, поступающих из разных источников. SPEC работает над импортированием этих кодов на разные платформы, а также создает инструментальные средства для формирования из кодов, выбранных в качестве тестов, осмысленных рабочих нагрузок. Поэтому тесты SPEC отличаются от свободно распространяемых программ. Хотя они могут существовать под похожими или теми же самыми именами, время их выполнения в общем случае будет отличаться.
В настоящее время имеется два базовых набора тестов SPEC, ориентированных на интенсивные расчеты и измеряющих производительность процессора, системы памяти, а также эффективность генерации кода компилятором. Как правило, эти тесты ориентированы на операционную систему UNIX, но они также импортированы и на другие платформы. Процент времени, расходуемого на работу операционной системы и функции ввода/вывода, в общем случае ничтожно мал.
Набор тестов CINT92, измеряющий производительность процессора при обработке целых чисел, состоит из шести программ, написанных на языке Си и выбранных из различных прикладных областей: теория цепей, интерпретатор языка Лисп, разработка логических схем, упаковка текстовых файлов, электронные таблицы и компиляция программ.
Набор тестов CFP92, измеряющий производительность процессора при обработке чисел с плавающей точкой, состоит из 14 программ, также выбранных из различных прикладных областей: разработка аналоговых схем, моделирование методом Монте-Карло, квантовая химия, оптика, робототехника, квантовая физика, астрофизика, прогноз погоды и другие научные и инженерные задачи. Две программы из этого набора написаны на языке Си, а остальные 12 - на Фортране. В пяти программах используется одинарная, а в остальных - двойная точность.
Результаты прогона каждого индивидуального теста из этих двух наборов выражаются отношением времени выполнения одной копии теста на тестируемой машине к времени ее выполнения на эталонной машине. В качестве эталонной машины используется VAX 11/780. SPEC публикует результаты прогона каждого отдельного теста, а также две составные оценки: SPECint92 - среднее геометрическое 6 результатов индивидуальных тестов из набора CINT92 и SPECfp92 - среднее геометрическое 14 результатов индивидуальных тестов из набора CFP92.
Следует отметить, что результаты тестирования на наборах CINT92 и CFT92 сильно зависят от качества применяемых оптимизирующих компиляторов. Для более точного выяснения возможностей аппаратных средств с середины 1994 года SPEC ввел две дополнительные составные оценки: SPECbase_int92 и SPECbase_fp92, которые накладывает определенные ограничения на используемые компиляторы поставщиками компьютеров при проведении испытаний.
Составные оценки SPECint92 и SPECfp92 достаточно хорошо характеризуют производительность процессора и системы памяти при работе в однозадачном режиме, но они совершенно не подходят для оценки производительности многопроцессорных и однопроцессорных систем, работающих в многозадачном режиме. Для этого нужна оценка пропускной способности системы или ее емкости, показывающая количество заданий, которое система может выполнить в течение заданного интервала времени. Пропускная способность системы определяется прежде всего количеством ресурсов (числом процессоров, емкостью оперативной и кэш-памяти, пропускной способностью шины), которые система может предоставить в распоряжение пользователя в каждый момент времени. Именно такую оценку, названную SPECrate и заменившую ранее применявшуюся оценку SPECthruput89, SPEC предложила в качестве единицы измерения производительности многопроцессорных систем.
При этом для измерения выбран метод "однородной нагрузки" (homogenous capacity metod), заключающийся в том, что одновременно выполняются несколько копий одной и той же тестовой программы. Результаты этих тестов показывают, как много задач конкретного типа могут быть выполнены в указанное время, а их средние геометрические значения (SPECrate_int92 - на наборе тестов, измеряющих производительность целочисленных операций и SPECrate_fp92 - на наборе тестов, измеряющих производительность на операциях с плавающей точкой) наглядно отражают пропускную способность однопроцессорных и многопроцессорных конфигураций при работе в многозадачном режиме в системах коллективного пользования. В качестве тестовых программ для проведения испытаний на пропускную способность выбраны те же наборы CINT92 и CFT92.
При прогоне тестового пакета делаются независимые измерения по каждому отдельному тесту. Обычно такой параметр, как количество запускаемых копий каждого отдельного теста, выбирается исходя из соображений оптимального использования ресурсов, что зависит от архитектурных особенностей конкретной системы. Одной из очевидных возможностей является установка этого параметра равным количеству процессоров в системе. При этом все копии отдельной тестовой программы запускаются одновременно, и фиксируется время завершения последней из всех запущенных программ.
С середины 1994 года SPEC ввела две дополнительные составные оценки: SPECrate_base_int92 и SPECrate_base_fp92, которые накладывает ограничения на используемые компиляторы.
Следует отметить, что SPEC объявила о полном переходе с середины 1996 года на новый (третий) комплект тестов - CINT95, CFP95. Эти тесты удовлетворяют следующим ограничениям и требованиям:
размер кода и данных должен быть достаточно большим, чтобы он гарантированно не размещался целиком в кэш-памяти
время выполнения тестов должно быть увеличено с секунд до минут
используемые фрагменты программ должны быть реалистичными
применение усовершенствованного способа измерения времени
реализация более удобных инструментальных средств
стандартизация требований к компиляторам и методов вызова
Новый комплект тестов состоит из 8 целочисленных программ, написанных на языке Си и 10 программ вещественной арифметики, написанных на Фортране. Новые метрики получили соответствующие названия: SPECint95, SPECfp95, SPECint_base95, SPECfp_base95, SPECrate_int95, SPECrate_fp95, SPECrate_base_int95 и SPECrate_base_fp95.
Тесты TPC
Тесты TPC
По мере расширения использования компьютеров при обработке транзакций в сфере бизнеса все более важной становится возможность справедливого сравнения систем между собой. С этой целью в 1988 году был создан Совет по оценке производительности обработки транзакций (TPC - Transaction Processing Performance Council), который представляет собой бесприбыльную организацию. Любая компания или организация может стать членом TPC после уплаты соответствующего взноса. На сегодня членами TPC являются практически все крупнейшие производители аппаратных платформ и программного обеспечения для автоматизации коммерческой деятельности. К настоящему времени TPC создал три тестовых пакета для обеспечения объективного сравнения различных систем обработки транзакций и планирует создать новые оценочные тесты.
В компьютерной индустрии термин транзакция (transaction) может означать почти любой вид взаимодействия или обмена информацией. Однако в мире бизнеса "транзакция" имеет вполне определенный смысл: коммерческий обмен товарами, услугами или деньгами. В настоящее время практически все бизнес-транзакции выполняются с помощью компьютеров. Наиболее характерными примерами систем обработки транзакций являются системы управления учетом, системы резервирования авиабилетов и банковские системы. Таким образом, необходимость стандартов и тестовых пакетов для оценки таких систем все больше усиливается.
До 1988 года отсутствовало общее согласие относительно методики оценки систем обработки транзакций. Широко использовались два тестовых пакета: Дебет/Кредит и TPI. Однако эти пакеты не позволяли осуществлять адекватную оценку систем: они не имели полных, основательных спецификаций; не давали объективных, проверяемых результатов; не содержали полного описания конфигурации системы, ее стоимости и методологии тестирования; не обеспечивали объективного, беспристрастного сравнения одной системы с другой.
Чтобы решить эти проблемы, и была создана организация TPC, основной задачей которой является точное определение тестовых пакетов для оценки систем обработки транзакций и баз данных, а также для распространения объективных, проверяемых данных в промышленности.
TPC публикует спецификации тестовых пакетов, которые регулируют вопросы, связанные с работой тестов. Эти спецификации гарантируют, что покупатели имеют объективные значения данных для сравнения производительности различных вычислительных систем. Хотя реализация спецификаций оценочных тестов оставлена на усмотрение индивидуальных спонсоров тестов, сами спонсоры, объявляя результаты TPC, должны представить TPC детальные отчеты, документирующие соответствие всем спецификациям. Эти отчеты, в частности, включают конфигурацию системы, методику калькуляции цены, диаграммы значений производительности и документацию, показывающую, что тест соответствует требованиям атомарности, согласованности, изолированности и долговечности
(ACID - atomicity, consistency, isolation, and durability), которые гарантируют, что все транзакции из оценочного теста обрабатываются должным образом.
Работой TPC руководит Совет Полного Состава (Full Council), который принимает все решения; каждая компания-участник имеет один голос, а для того, чтобы провести какое-либо решение требуется две трети голосов. Управляющий Комитет (Steering Committee), состоящий из пяти представителей и избираемый ежегодно, надзирает за работой администрации TPC, поддерживает и обеспечивает все направления и рекомендации для членов Совета Полного Состава и Управляющего Комитета.
В составе TPC имеются два типа подкомитетов: постоянные подкомитеты, которые управляют администрацией TPC, осуществляют связи с общественностью и обеспечивают выпуск документации; и технические подкомитеты, которые формируются для разработки предложений по оценочным тестам и распускаются после того, как их работа по разработке завершена.
Типичная топология сети при организации связи между зданиями
Рисунок 4.6. Типичная топология сети при организации связи между зданиями

На первый взгляд кажется, что эти линии значительно более медленные по сравнению с локальными сетями, к которым они подсоединяются. Однако в действительности быстрые последовательные линии (Т1) обеспечивают пропускную способность гораздо более близкую к реальной пропускной способности локальных сетей. Это происходит потому, что последовательные линии могут использоваться почти со 100% загрузкой без чрезмерных накладных расходов, в то время как сети Ethernet обычно насыщаются уже примерно при 440 Кбайт/с (3.5 Мбит/с), что всего примерно вдвое превышает пропускную способность линии Т1. По этой причине файловый сервис по высокоскоростным последовательным линиям связи возможен и позволяет передавать данные с приемлемыми скоростями. В частности, такая организация оказывается полезной при передаче данных между удаленными офисами. В приложениях с интенсивной обработкой атрибутов работа NFS по глобальным сетям может быть успешной, если задержка выполнения операций не является критичной. В глобальной сети короткие пакеты передаются через каждый сегмент достаточно быстро (при высокой пропускной способности), хотя задержки маршрутизации и самой среды часто вызывают значительную задержку выполнения операций.
Выводы:
Для реализации глобальных сервисов NFS подходят последовательные линии Т1, Е1 или Т3.
Для большинства применений NFS линии со скоростями передачи 56 и 64 Кбит/с обычно оказываются недостаточно быстрыми.
При организации NFS через глобальные сети существуют проблемы с задержками сети и маршрутизации. Пропускная способность сети обычно не вызывает проблем.
Для существенного сокращения трафика по глобальной сети, можно использовать на клиентских системах кэширующую файловую систему (CFS), если только в этом трафике не доминируют операции записи NFS.
Типовая архитектура мультипроцессорной системы с общей памятью
Рисунок 5.40. Типовая архитектура мультипроцессорной системы с общей памятью

Типовая среда обработки транзакций и соответствующие оценочные тесты TPC
Рисунок 3.2. Типовая среда обработки транзакций и соответствующие оценочные тесты TPC

Типовой пример использования NFS
Типовой пример использования NFS
В конце концов примеры использования большинства приложений показывают, что клиенты нагружают сервер очень неравномерно. Рассмотрим работу с типичным приложением. Обычно пользователь должен прежде всего считать двоичный код приложения, выполнить ту часть кода, которая отвечает за организацию диалога с пользователем, который должен определить необходимый для работы набор данных. Затем приложение читает набор данных с диска (возможно удаленного). Далее пользователь взаимодействует с приложением манипулируя представлением данных в основной памяти. Эта фаза продолжается большую части времени работы приложения до тех пор, пока в конце концов модифицированный набор данных не запишется на диск. Большинство (но не все) приложения следуют этой универсальной схеме работы, часто с повторяющимися фазами. Приведенные ниже рисунки иллюстрирую типичную нагрузку NFS.
Типовые значения ключевых параметров для кэш-памяти рабочих станций и серверов
Рисунок 5.36. Типовые значения ключевых параметров для кэш-памяти рабочих станций и серверов
Все термины, которые были определены раньше могут быть использованы и для кэш-памяти, хотя слово "строка" (line) часто употребляется вместо слова "блок" (block).
На рисунке 5.36 представлен типичный набор параметров, который используется для описания кэш-памяти.
Рассмотрим организацию кэш-памяти более детально, отвечая на четыре вопроса об иерархии памяти.
Точность прогноза для адресов возврата
Рисунок 5.31. Точность прогноза для адресов возврата

Управление командами плавающей точки
Рисунок 6.11. Управление командами плавающей точки

Конвейер целочисленного устройства включает шесть ступеней: Чтение из кэша команд (IR), Чтение операндов (OR), Выполнение/Чтение из кэша данных (DR), Завершение чтения кэша данных (DRC), Запись в регистры (RW) и Запись в кэш данных (DW). На ступени ID выполняется выборка команд. Реализация механизма выдачи двух команд требует небольшого буфера предварительной выборки, который обеспечивает предварительную выборку команд за два такта до начала работы ступени IR. Во время выполнения на ступени OR все исполнительные устройства декодируют поля операндов в команде и начинают вычислять результат операции. На ступени DR целочисленное устройство завершает свою работу. Кроме того, кэш-память данных выполняет чтение, но данные не поступают до момента завершения работы ступени DRC. Результаты операций сложения (ADD) и умножения (MULTIPLY) также становятся достоверными в конце ступени DRC. Запись в универсальные регистры и регистры плавающей точки производится на ступени RW. Запись в кэш данных командами записи (STORE) требует двух тактов. Наиболее раннее двухтактное окно команды STORE возникает на ступенях RW и DW. Однако это окно может сдвигаться, поскольку записи в кэш данных происходят только когда появляется следующая команда записи. Операции деления и вычисления квадратного корня для чисел с плавающей точкой заканчиваются на много тактов позже ступени DW.
Конвейер проектировался с целью максимального увеличения времени, необходимого для выполнения чтения внешних кристаллов SRAM кэш-памяти данных. Это позволяет максимизировать частоту процессора при заданной скорости SRAM. Все команды загрузки (LOAD) выполняются за один такт и требуют только одного такта полосы пропускания кэш-памяти данных. Поскольку кэши команд и данных размещены на разных шинах, в конвейере отсутствуют какие-либо потери, связанные с конфликтами по обращениям в кэш данных и кэш команд.
Процессор может в каждом такте выдавать на выполнение одну целочисленную команду и одну команду плавающей точки.
Полоса пропускания кэша команд достаточна для поддержания непрерывной выдачи двух команд в каждом такте. Отсутствуют какие-либо ограничения по выравниванию или порядку следования пары команд, которые выполняются вместе. Кроме того, отсутствуют потери тактов, связанных с переключением с выполнения двух команд на выполнение одной команды. Специальное внимание было уделено тому, чтобы выдача двух команд в одном такте не приводила к ограничению тактовой частоты. Чтобы добиться этого, в кэше команд был реализован специально предназначенный для этого заранее декодируемый бит, чтобы отделить команды целочисленного устройства от команд устройства плавающей точки. Этот бит предварительного декодирования команд минимизирует время, необходимое для правильного разделения команд.
Потери, связанные с зависимостями по данным и управлению, в этом конвейере минимальны. Команды загрузки выполняются за один такт, за исключением случая, когда последующая команда пользуется регистром-приемником команды LOAD. Как правило компилятор позволяет обойти подобные потери одного такта. Для уменьшения потерь, связанных с командами условного перехода, в процессоре используется алгоритм прогнозирования направления передачи управления. Для оптимизации производительности циклов передачи управления вперед по программе прогнозируются как невыполняемые переходы, а передачи управления назад по программе - как выполняемые переходы. Правильно спрогнозированные условные переходы выполняются за один такт.
Количество тактов, необходимое для записи слова или двойного слова командой STORE уменьшено с трех до двух тактов. В более ранних реализациях архитектуры PA-RISC был необходим один дополнительный такт для чтения тега кэша, чтобы гарантировать попадание, а также для того, чтобы объединить старые данные строки кэш-памяти данных с записываемыми данными. PA 7100 использует отдельную шину адресного тега, чтобы совместить по времени чтение тега с записью данных предыдущей команды STORE. Кроме того, наличие отдельных сигналов разрешения записи для каждого слова строки кэш-памяти устраняет необходимость объединения старых данных с новыми, поступающими при выполнении команд записи слова или двойного слова.
Этот алгоритм требует, чтобы запись в микросхемы SRAM происходила только после того, когда будет определено, что данная запись сопровождается попаданием в кэш и не вызывает прерывания. Это требует дополнительной ступени конвейера между чтением тега и записью данных. Такая конвейеризация не приводит к дополнительным потерям тактов, поскольку в процессоре реализованы специальные цепи обхода, позволяющие направить отложенные данные команды записи последующим командам загрузки или командам STORE, записывающим только часть слова. Для данного процессора потери конвейера для команд записи слова или двойного слова сведены к нулю, если непосредственно последующая команда не является командой загрузки или записи. В противном случае потери равны одному такту. Потери на запись части слова могут составлять от нуля до двух тактов. Моделирование показывает, что подавляющее большинство команд записи в действительности работают с однословным или двухсловным форматом.
Все операции с плавающей точкой, за исключением команд деления и вычисления квадратного корня, полностью конвейеризованы и имеют двухтактную задержку выполнения как в режиме с одинарной, так и с двойной точностью. Процессор может выдавать на выполнение независимые команды с плавающей точкой в каждом такте при отсутствии каких-либо потерь. Последовательные операции с зависимостями по регистрам приводят к потере одного такта. Команды деления и вычисления квадратного корня выполняются за 8 тактов при одиночной и за 15 тактов при двойной точности. Выполнение команд не останавливается из-за команд деления/вычисления квадратного корня до тех пор, пока не потребуется регистр результата или не будет выдаваться следующая команда деления/вычисления квадратного корня.
Процессор может выполнять параллельно одну целочисленную команду и одну команду с плавающей точкой. При этом "целочисленными командами" считаются и команды загрузки и записи регистров плавающей точки, а "команды плавающей точки" включают команды FMPYADD и FMPYSUB.
Эти последние команды объединяют операцию умножения с операциями сложения или вычитания соответственно, которые выполняются параллельно. Пиковая производительность составляет 200 MFLOPS для последовательности команд FMPYADD, в которых смежные команды независимы по регистрам.
Потери для операций плавающей точки, использующих предварительную загрузку операнда командой LOAD, составляют один такт, если команды загрузки и плавающей арифметики являются смежными, и два такта, если они выдаются для выполнения одновременно. Для команды записи, использующей результат операции с плавающей точкой, потери отсутствуют, даже если они выполняются параллельно.
Потери, возникающие при промахах в кэше данных, минимизируются посредством применения четырех разных методов: "попадание при промахе" для команд LOAD и STORE, потоковый режим работы с кэшем данных, специальная кодировка команд записи, позволяющая избежать копирования строки, в которой произошел промах, и семафорные операции в кэш-памяти. Первое свойство позволяет во время обработки промаха в кэше данных выполнять любые типы других команд. Для промахов, возникающих при выполнении команды LOAD, обработка последующих команд может продолжаться до тех пор, пока регистр результата команды LOAD не потребуется в качестве регистра операнда для другой команды. Компилятор может использовать это свойство для предварительной выборки в кэш необходимых данных задолго до того момента, когда они действительно потребуются. Для промахов, возникающих при выполнении команды STORE, обработка последующих команд загрузки или операций записи в части одного слова продолжается до тех пор, пока не возникает обращений к строке, в которой произошел промах. Компилятор может использовать это свойство для выполнения команд на фоне записи результатов предыдущих вычислений. Во время задержки, связанной с обработкой промаха, другие команды LOAD и STORE, для которых происходит попадание в кэш данных, могут выполняться как и другие команды целочисленной арифметики и плавающей точки.
В течение всего времени обработки промаха команды STORE, другие команды записи в ту же строку кэш-памяти могут происходить без дополнительных потерь времени. Для каждого слова в строке кэш-памяти процессор имеет специальный индикационный бит, предотвращающий копирование из памяти тех слов строки, которые были записаны командами STORE. Эта возможность применяется к целочисленным и плавающим операциям LOAD и STORE.
Выполнение команд останавливается, когда регистр-приемник команды LOAD, выполняющейся с промахом, требуется в качестве операнда другой команды. Свойство "потоковости" позволяет продолжить выполнение как только нужное слово или двойное слово возвращается из памяти. Таким образом, выполнение команд может продолжаться как во время задержки, связанной с обработкой промаха, так и во время заполнения соответствующей строки при промахе.
При выполнении блочного копирования данных в ряде случаев компилятор заранее знает, что запись должна осуществляться в полную строку кэш-памяти. Для оптимизации обработки таких ситуаций архитектура PA-RISC 1.1 определяет специальную кодировку команд записи ("блочное копирование"), которая показывает, что аппаратуре не нужно осуществлять выборку из памяти строки, при обращении к которой может произойти промах кэш-памяти. В этом случае время обращения к кэшу данных складывается из времени, которое требуется для копирования в память старой строки кэш-памяти по тому же адресу в кэше (если он "грязный") и времени, необходимого для записи нового тега кэша. В процессоре PA 7100 такая возможность реализована как для привилегированных, так и для непривилегированных команд.
Последнее улучшение управления кэшем данных связано с реализацией семафорных операций "загрузки с обнулением" непосредственно в кэш-памяти. Если семафорная операция выполняется в кэше, то потери времени при ее выполнении не превышают потерь обычных операций записи. Это не только сокращает конвейерные потери, но и снижает трафик шины памяти.
В архитектуре PA-RISC 1. 1 предусмотрен также другой тип специального кодирования команд, который устраняет требование синхронизации семафорных операций с устройствами ввода/вывода.
Управление кэш-памятью команд позволяет при промахе продолжить выполнение команд сразу же после поступления отсутствующей в кэше команды из памяти. 64-битовая магистраль данных, используемая для заполнения блоков кэша команд, соответствует максимальной полосе пропускания внешней шины памяти 400 Мбайт/с при тактовой частоте 100 МГц.
В процессоре предусмотрен также ряд мер по минимизации потерь, связанных с преобразованиями виртуальных адресов в физические.
Конструкция процессора обеспечивает реализацию двух способов построения многопроцессорных систем. При первом способе каждый процессор подсоединяется к интерфейсному кристаллу, который наблюдает за всеми транзакциями на шине основной памяти. В такой системе все функции по поддержанию когерентного состояния кэш-памяти возложены на интерфейсный кристалл, который посылает процессору соответствующие транзакции. Кэш данных построен на принципах отложенного обратного копирования и для каждого блока кэш-памяти поддерживаются биты состояния "частный" (private), "грязный" (dirty) и "достоверный" (valid), значения которых меняются в соответствии с транзакциями, которые выдает или принимает процессор.
Второй способ организации многопроцессорной системы позволяет объединить два процессора и контроллер памяти и ввода-вывода на одной и той же локальной шине памяти. В такой конфигурации не требуется дополнительных интерфейсных кристаллов и она совместима с существующей системой памяти. Когерентность кэш-памяти обеспечивается наблюдением за локальной шиной памяти. Пересылки строк между кэшами выполняются без участия контроллера памяти и ввода-вывода. Такая конфигурация обеспечивает возможность построения очень дешевых высокопроизводительных многопроцессорных систем.
Процессор поддерживает ряд операций, необходимых для улучшения графической производительности рабочих станций серии 700: блочные пересылки, Z-буфери-зацию, интерполяцию цветов и команды пересылки данных с плавающей точкой для обмена с пространством ввода/вывода.
Процессор построен на базе технологического процесса КМОП с проектными нормами 0.8 микрон, что обеспечивает тактовую частоту 100 МГц.
Упрощенная блок-схема отображения целочисленных команд
Рисунок 6.14. Упрощенная блок-схема отображения целочисленных команд

Команды выбираются из кэша команд и помещаются в таблицу отображения. В любой момент времени каждый из 64 номеров физических регистров находится в одном из трех указанных на рисунке блоков.
Список активных команд длиною 32 элемента может хранить упорядоченную в соответствии с программой последовательность команд, которые могут находиться в обработке в любой данный момент времени. Команды из очереди целочисленных команд могут выполняться неупорядочено и записывать результаты в физические регистры, но порядок их окончательного завершения определяется списком активных команд.
Каждая команда может уникально идентифицироваться своим положением в списке активных команд. Поэтому каждую команду в очереди и в соответствующем исполнительном устройстве сопровождает 5-битовая метка, называемая тегом команды. Этот тег и определяет положение команды в списке активных команд. Когда в исполнительном устройстве заканчивается выполнение команды, тег позволяет очень просто ее отыскать в списке активных команд и пометить как выполненную. Когда результат операции из исполнительного устройства записывается в физический регистр, номер этого физического регистра становится больше не нужным и может быть затем возвращен в список свободных регистров, а соответствующая команда перестает быть активной.
Когда в процессе переименования из списка свободных регистров выбирается очередной номер физического регистра, он передается в таблицу отображения, которая обновляется. При этом старый номер регистра, соответствующий определенному в команде логическому регистру результата, помещается из таблицы отображения в список активных команд. Этот номер остается в списке активных команд до тех пор, пока соответствующая команда не "выпустится" (graduate), т.е. завершится в заданном программой порядке. Команда может "выпуститься" только после того, как успешно завершится выполнение всех предыдущих команд.
Микропроцессор R10000 содержит 64 физических и 32 логических целочисленных регистра. Список активных команд может содержать максимально 32 элемента. Список свободных регистров также может максимально содержать 32 значения. Если список активных команд полон, то могут быть 32 "зафиксированных" и 32 временных значения. Отсюда потребность в 64 регистрах.
Упрощенная блок схема процессора Pentium
Рисунок 6.1. Упрощенная блок схема процессора Pentium

Следует отметить, что возросшая производительность процессора Pentium требует и соответствующей организации системы на его основе. Компания Intel разработала и поставляет все необходимые для этого наборы микросхем. Прежде всего для согласования скорости с динамической основной памятью необходима кэш-память второго уровня. Контроллер кэш-памяти 82496 и микросхемы статической памяти 82491 обеспечивают построение такой кэш-памяти объемом 256 Кбайт и работу процессора без тактов ожидания. Для эффективной организации систем Intel разработала стандарт на высокопроизводительную локальную шину PCI. Выпускаются наборы микросхем для построения мощных компьютеров на ее основе.
В настоящее время компания Intel разработалаи выпустила новый процессор, продолжающий архитектурную линию x86. Этот процессор получил название P6 или PentiumPro. Он работает с тактовыми частотами 150: 166: 180 и 200 МГц. PentiumPro обеспечивает полную совместимость с процессорами предыдущих поколений. Он предназначен главным образом для поддержки высокопроизводительных 32-битовых вычислений в области САПР, трехмерной графики и мультимедиа: а также широкого круга коммерческих приложений баз данных. По результатам испытаний на тестах SPEC (8.58 SPECint95 и 6.48 SPECfp95) процессор PentiumPro по производительности целочисленных операций в текущий момент времени вышел на третье место в мировой классификации, уступая только 180 МГц HP PA-8000 и 400 МГц DEC Alpha. Для достижения такой производительности необходимо использование технических решений, широко применяющихся при построении RISC-процессоров:
выполнение команд не в предписанной программой последовательности, что устраняет во многих случаях приостановку конвейеров из-за ожидания операндов операций;
использование методики переименования регистров, позволяющей увеличивать эффективный размер регистрового файла (малое количество регистров - одно из самых узких мест архитектуры x86);
расширение суперскалярных возможностей по отношению к процессору Pentium, в котором обеспечивается одновременная выдача только двух команд с достаточно жесткими ограничениями на их комбинации.
Кроме того, в борьбу за новое поколение процессоров x86 включились компании, ранее занимавшиеся изготовлением Intel-совместимых процессоров. Это компании Advanced Micro Devices (AMD), Cyrix Corp и NexGen. С точки зрения микроархитектуры наиболее близок к Pentium процессор М1 компании Cyrix, который должен появиться на рынке в ближайшее время. Также как и Pentium он имеет два конвейера и может выполнять до двух команд в одном такте. Однако в процессоре М1 число случаев, когда операции могут выполняться попарно, значительно увеличено. Кроме того в нем применяется методика обходов и ускорения пересылки данных, позволяющая устранить приостановку конвейеров во многих ситуациях, с которыми не справляется Pentium. Процессор содержит 32 физических регистра (вместо 8 логических, предусмотренных архитектурой x86) и применяет методику переименования регистров для устранения зависимостей по данным. Как и Pentium, процессор M1 для прогнозирования направления перехода использует буфер целевых адресов перехода емкостью 256 элементов, но кроме того поддерживает специальный стек возвратов, отслеживающий вызовы процедур и последующие возвраты.
Процессоры К5 компании AMD и Nx586 компании NexGen используют в корне другой подход. Основа их процессоров - очень быстрое RISC-ядро, выполняющее высокорегулярные операции в суперскалярном режиме. Внутренние форматы команд (ROP у компании AMD и RISC86 у компании NexGen) соответствуют традиционным системам команд RISC-процессоров. Все команды имеют одинаковую длину и кодируются в регулярном формате. Обращения к памяти выполняются специальными командами загрузки и записи. Как известно, архитектура x86 имеет очень сложную для декодирования систему команд. В процессорах K5 и Nx586 осуществляется аппаратная трансляция команд x86 в команды внутреннего формата, что дает лучшие условия для распараллеливания вычислений. В процессоре К5 имеются 40, а в процессоре Nx586 22 физических регистра, которые реализуют методику переименования. В процессоре К5 информация, необходимая для прогнозирования направления перехода, записывается прямо в кэш команд и хранится вместе с каждой строкой кэш-памяти. В процессоре Nx586 для этих целей используется кэш-память адресов переходов на 96 элементов.
Таким образом, компания Intel больше не обладает монополией на методы конструирования высокопроизводительных процессоров x86, и можно ожидать появления новых процессоров, не только не уступающих, но и возможно превосходящих по производительности процессоры компании, стоявшей у истоков этой архитектуры. Следует отметить, что сама компания Intel заключила стратегическое соглашение с компанией Hewlett-Packard на разработку следующего поколения микропроцессоров, в которых архитектура x86 будет сочетаться с архитектурой очень длинного командного слова (VLIW -архитектурой). Появление этих микропроцессоров не ожидается до конца 1998 года.
Условные команды
Условные команды
Концепция, лежащая в основе условных команд, достаточно проста: команда обращается к некоторому условию, оценка которого является частью выполнения команды. Если условие истинно, то команда выполняется нормально; если условие ложно, то выполнение команды осуществляется, как если бы это была пустая команда. Многие новейшие архитектуры включают в себя ту или иную форму условных команд. Наиболее общим примером такой команды является команда условной пересылки, которая выполняет пересылку значения одного регистра в другой, если условие истинно. Такая команда может использоваться для полного устранения условных переходов в простых последовательностях программного кода.
Например, рассмотрим следующий оператор:
if (A=0) {S=T;};
Предполагая, что регистры R1, R2 и R3 хранят значения A, S и T соответственно, представим код этого оператора с командой условного перехода и с командой условной пересылки.
Код с использованием команды условного перехода будет иметь следующий вид:
BEQZ R1,L
MOV R2,R3
L:
Используя команду условной пересылки, которая выполняет пересылку только если ее третий операнд равен нулю, мы можем реализовать этот оператор с помощью одной команды:
CMOVZ R2,R3,R1
Условная команда позволяет преобразовать зависимость по управлению, присутствующую в коде с командой условного перехода, в зависимость по данным. (Это преобразование используется также в векторных машинах, в которых оно называется if-преобразованием (if-convertion)). Для конвейерной машины такое преобразование позволяет перенести точку, в которой должна разрешаться зависимость, от начала конвейера, где она разрешается для условных переходов, в конец конвейера, где происходит запись в регистр.
Одним из примеров использования команд условной пересылки является реализация функции вычисления абсолютного значения: A = abs (B), которая реализуется оператором
if (B<0) {A=-B} else {A=B}.
Этот оператор if может быть реализован парой команд условных пересылок или командой безусловной пересылки (A=B), за которой следует команда условной пересылки (A=-B).
Условные команды могут использоваться также для улучшения планирования в суперскалярных или VLIW-процессорах. Ниже приведен пример кодовой последовательности для суперскалярной машины с одновременной выдачей для выполнения не более двух команд. При этом в каждом такте может выдаваться комбинация одной команды обращения к памяти и одной команды АЛУ или только одна команда условного перехода:
LW R1,40(R2) ADD R3,R4,R5
ADD R6,R3,R7
BEQZ R10,L
LW R8,20(R10)
LW R9,0(R8)
Эта последовательность теряет слот операции обращения к памяти во втором такте и приостанавливается из-за зависимости по данным, если переход невыполняемый, поскольку вторая команда LW после перехода зависит от предыдущей команды загрузки. Если доступна условная версия команды LW, то команда LW, немедленно следующая за переходом (LW R8,20(R10)), может быть перенесена во второй слот выдачи. Это улучшает время выполнения на несколько тактов, поскольку устраняет один слот выдачи команды и сокращает приостановку конвейера для последней команды последовательности.
Для успешного использования условных команд в примерах, подобных этому, семантика команды должна определять команду таким образом, чтобы не было никакого побочного эффекта, если условие не выполняется. Это означает, что если условие не выполняется, команда не должна записывать результат по месту назначения, а также не должна вызывать исключительную ситуацию. Как показывает вышеприведенный пример, способность не вызывать исключительную ситуацию достаточно важна: если регистр R10 содержит нуль, команда LW R8,20(R10), выполненная безусловно, возможно вызовет исключительную ситуацию по защите памяти, а эта исключительная ситуация не должна возникать. Именно эта вероятность возникновения исключительной ситуации не дает возможность компилятору просто перенести команду загрузки R8 через команду условного перехода. Конечно, если условие удовлетворено, команда LW все еще может вызвать исключительную ситуацию (например, ошибку страницы), и аппаратура должна воспринять эту исключительную ситуацию, поскольку она знает, что управляющее условие истинно.
Условные команды определенно полезны для реализации коротких альтернативных потоков управления. Тем не менее полезность условных команд существенно ограничивается несколькими факторами:
Аннулируемые условные команды (т.е. команды, условие которых является ложным) все же отнимают определенное время выполнения. Поэтому перенос команды через команду условного перехода и превращение ее в условную будет замедлять программу всякий раз, когда перенесенная команда не будет нормально выполняться. Важное исключение из этого правила возникает, когда такты, используемые перенесенной невыполняемой командой, были бы в любом случае холостыми (как в вышеприведенном примере с суперскалярной обработкой). Перенос команды через команду условного перехода существенно базируется на предположении о направлении перехода. Условные команды упрощают реализацию такого переноса, но не устраняют время выполнения, которое будет затрачено при неправильном предположении.
Условные команды наиболее полезны, когда условие может быть вычислено заранее. Если условие и условный переход не могут быть отделены друг от друга (из-за зависимости по данным при определении условия), то условная команда не поможет, хотя все еще может оказаться полезной, поскольку она задерживает момент времени, когда условие должно стать известным, почти до конца конвейера.
Использование условных команд ограничено, когда в поток управления вовлечено больше одной простой альтернативной последовательности команд. Например, при переносе команды через пару команд условного перехода необходимо, чтобы она оставалась зависимой от обоих условий, что требует либо спецификации в команде сразу двух условий (маловероятная возможность), либо вставки дополнительных команд для вычисления конъюнкции условий.
Условные команды могут давать некоторые потери скорости по сравнению с безусловными командами. Это может проявиться либо в большем количестве тактов, необходимых для выполнения таких команд, либо в уменьшении общей частоты синхронизации машины.
Если условные команды являются более дорогими с точки зрения скорости выполнения, то их следует использовать осмысленно.
По этим причинам во многих современных архитектурах используется небольшое число условных команд (наиболее популярными являются команды условных пересылок), хотя некоторые из них включают условные версии большинства команд (рисунок 5.34).
| Alpha | HP-PA | MIPS | PowerPC | SPARC | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Условная пересылка |
Любая команда типа регистр-регистр может аннулировать следующую команду, делая ее условной | Условная пересылка |
Условная пересылка |
Условная пересылка |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Условные команды в современных архитектурах
Рисунок 5.34. Условные команды в современных архитектурах
Устранение зависимостей по данным и механизмы динамического планирования
Устранение зависимостей по данным и механизмы динамического планирования
Устройства архивирования информации
Устройства архивирования информации
В качестве носителя для резервного копирования информации обычно используется магнитная лента. Резервное копирование предполагает использование различных стратегий и различных конфигураций оборудования в зависимости от требований пользователя. При планировании и создании системы этим вопросам приходится уделять большое внимание, так как обычно требования к системе резервного копирования выходят далеко за рамки простого обеспечения емкости носителя, превышающей емкость дисковой памяти системы, или выбора скорости операций копирования на магнитную ленту. Среди этих вопросов следует выделить, например, такие как определение количества клиентов, копирование данных которых должно осуществляться одновременно; цикличность операций копирования, т.е. по каким дням и в какие часы такое копирование должно осуществляться, а также уровень копирования (полное, частичное или смешанное); определение устройств на которых должно выполняться резервное копирование и т.д.
В настоящее время в большинстве систем накопители на магнитных лентах (НМЛ) обычно подсоединяются к компьютеру с помощью шины SCSI. Очень часто к этой же шине подсоединяются и дисковые накопители. К сожалению, высокий коэффициент использования шины SCSI практически всеми применяемыми в настоящее время типами НМЛ становится критическим фактором при организации резервного копирования и восстановления информации особенно в больших серверах с высокой степенью готовности. В таблице 5.1 приведены типичные параметры НМЛ. Очевидно такая высокая загрузка шины SCSI (до 20 - 65 % пропускной способности шины) при работе НМЛ накладывает определенные ограничения как на конфигурацию и типы применяемых НМЛ, так и на организацию самого резервного копирования.
Устройства плавающей точки
Устройства плавающей точки
В микропроцессоре R10000 реализованы два основных устройства плавающей точки. Устройство сложения обрабатывает операции сложения, а устройство умножения - операции умножения. Кроме того, существуют два вторичных устройства плавающей точки, которые обрабатывают длинные операции деления и вычисления квадратного корня.
Время выполнения команд сложения, вычитания и преобразования типов равно двум тактам, а скорость их поступления в устройство составляет 1 команда/такт. Эти команды обрабатываются в устройстве сложения. Команды преобразования целочисленных значений в значения с плавающей точкой с однократной точностью имеют задержку в 4 такта, поскольку они должны пройти через устройство сложения дважды.
В устройстве умножения обрабатываются все операции умножения с плавающей точкой. Время их выполнения составляет два такта, а скорость поступления - 1 команда/такт. Устройства деления и вычисления квадратного корня выполняют операции с использованием итерационных алгоритмов. Эти устройства не конвейеризованы и не могут начать выполнение следующей операции до тех пор, пока не завершилось выполнение текущей команды. Таким образом, скорость повторения этих операций примерно равна задержке их выполнения. Порты умножителя являются общими и для устройств деления и вычисления квадратного корня. В начале и в конце операции теряется по одному такту (для выборки операндов и для записи результата).
Операция с плавающей точкой "умножить-сложить", которая в вычислительных программах возникает достаточно часто, выполняется с использованием двух отдельных операций: операции умножения и операции сложения. Команда "умножить-сложить" (MADD) имеет задержку 4 такта и скорость повторения 1 команда/ такт. Эта составная команда увеличивает производительность за счет устранения выборки и декодирования дополнительной команды.
Устройства деления и вычисления квадратного корня используют раздельные цепи и могут работать одновременно. Однако очередь команд плавающей точки не может выдать для выполнения обе команды в одном и том же такте.
Устройство загрузки/записи и TLB
Устройство загрузки/записи и TLB
Устройство загрузки/записи содержит очередь адресов, устройство вычисления адреса, устройство преобразования виртуальных адресов в физические (TLB), стек адресов, буфер записи и кэш-память данных первого уровня. Устройство загрузки/записи выполняет команды загрузки, записи, предварительной выборки, а также команды работы с кэш-памятью.
Выполнение всех команд загрузки и записи начинается с трехтактной последовательности, во время которой осуществляется выдача команды, вычисление виртуального адреса и его преобразование в физический. Преобразование адреса осуществляется во время выполнения команды только однажды. Производится обращение к кэш-памяти данных, и пересылка требуемых данных завершается при наличии данных в кэш-памяти первого уровня.
В случае промаха, или в случае занятости разделяемого порта регистрового файла, обращение к кэшу данных и к тегу должно быть повторено после получения данных либо из кэш-памяти второго уровня, либо из основной памяти.
TLB содержит 64 строки и выполняет преобразование виртуального адреса в физический. Виртуальный адрес для преобразования поступает либо из устройства вычисления адреса, либо из счетчика команд.
Увеличение производительности кэш-памяти
Увеличение производительности кэш-памяти
Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом:
Среднее время доступа = Время обращения при попадании + Доля промахов x Потери при промахе
Эта формула наглядно показывает пути оптимизации работы кэш-памяти: сокращение доли промахов, сокращение потерь при промахе, а также сокращение времени обращения к кэш-памяти при попадании. На рисунке 5.38 кратко представлены различные методы, которые используются в настоящее время для увеличения производительности кэш-памяти. Использование тех или иных методов определяется прежде всего целью разработки, при этом конструкторы современных компьютеров заботятся о том, чтобы система оказалась сбалансированной по всем параметрам.
Увеличение разрядности основной памяти
Увеличение разрядности основной памяти
Кэш-память первого уровня во многих случаях имеет физическую ширину шин данных соответствующую количеству разрядов в слове, поскольку большинство компьютеров выполняют обращения именно к этой единице информации. В системах без кэш-памяти второго уровня ширина шин данных основной памяти часто соответствует ширине шин данных кэш-памяти. Удвоение или учетверение ширины шин кэш-памяти и основной памяти удваивает или учетверяет соответственно полосу пропускания системы памяти.
Реализация более широких шин вызывает необходимость мультиплексирования данных между кэш-памятью и процессором, поскольку основной единицей обработки данных в процессоре все еще остается слово. Эти мультиплексоры оказываются на критическом пути поступления информации в процессор. Кэш-память второго уровня несколько смягчает эту проблему, т.к. в этом случае мультиплексоры могут располагаться между двумя уровнями кэш-памяти, т.е. вносимая ими задержка не столь критична. Другая проблема, связанная с увеличением разрядности памяти, определяется необходимостью определения минимального объема (инкремента) для поэтапного расширения памяти, которое часто выполняется самими пользователями на месте эксплуатации системы. Удвоение или учетверение ширины памяти приводит к удвоению или учетверению этого минимального инкремента. Наконец, имеются проблемы и с организацией коррекции ошибок в системах с широкой памятью.
Примером организации широкой основной памяти является система Alpha AXP 21064, в которой кэш второго уровня, шина памяти и сама память имеют разрядность в 256 бит.
Вопросы разработки
Вопросы разработки
Имеется несколько важных вопросов, которые рассматриваются при разработке распределенных файловых систем. Они касаются функциональных возможностей, семантики и производительности системы. Различные файловые системы можно сравнивать между собой, выясняя как они решают эти вопросы:
Пространство имен - Некоторые распределенные файловые системы обеспечивают однородное пространство имен такое, что каждый клиент использует одно и то же путевое имя для доступа к данному файлу. Другие системы позволяют клиенту создавать свое пространство имен путем монтирования разделяемых поддеревьев к произвольным каталогам в иерархии файлов. Оба метода имеют свою привлекательность.
Операции с сохранением и без сохранения состояний - Сервер сохраняющий состояния обеспечивает хранение информации об операциях клиента между запросами и использует эту информацию о состоянии для корректного обслуживания последующих запросов. Такие запросы как open или seek связаны с изменением состояний, так как кто-то должен запомнить информацию о том, какие файлы открыл клиент, а также все смещения в открытых файлах. В системе без сохранения состояний каждый запрос является "самодостаточным" и сервер не поддерживает устойчивых состояний о клиентах. Например, вместо того, чтобы поддерживать информацию о смещении в открытом файле сервер может требовать от клиента указания смещения в каждой операции чтения или записи. Серверы с сохранением состояний работают быстрее, поскольку они могут использовать знания о состоянии клиента для существенного уменьшения сетевого трафика. Однако они должны иметь и целый комплекс механизмов поддержания согласованного состояния системы и восстановления после ее отказа. Серверы без сохранения состояний более просты в разработке и реализации, но не дают такой высокой производительности.
Семантика разделения - Распределенная файловая система должна определить семантику, которая применяется когда несколько клиентов одновременно обращаются к одному файлу. Семантика UNIX требует, чтобы все изменения, сделанные одним клиентом, были бы видны другим клиентам, когда они выдают следующий системный вызов read или write. Некоторые файловые системы обеспечивают "семантику сессии" (session semantics), при которой изменения становятся доступными другим клиентам на основе гранулированности системных вызовов open и close. А некоторые системы дают даже еще более слабые гарантии, например, интервал времени, который должен пройти прежде, чем изменения наверняка попадут к другим клиентам.
Методы удаленного доступа - В простой модели клиент-сервер используется метод удаленного обслуживания, при котором каждое действие инициируется клиентом, а сервер просто представляет собой агента, который выполняет заявки клиента. Во многих распределенных системах, особенно в системах, сохраняющих состояние, сервер играет гораздо более активную роль. Он не только обслуживает запросы клиентов, но и участвует в работе механизма обеспечения когерентности, уведомляя клиентов о всех случаях, когда кэшированные в нем данные становятся недостоверными.
Временные параметры ДЗУПВ (в последней строке приведены ожидаемые параметры)
Рисунок 5.39. Временные параметры ДЗУПВ (в последней строке приведены ожидаемые параметры)
Хотя для организации кэш-памяти в большей степени важно уменьшение задержки памяти, чем увеличение полосы пропускания. Однако при увеличении полосы пропускания памяти возможно увеличение размера блоков кэш-памяти без заметного увеличения потерь при промахах.
Основными методами увеличения полосы пропускания памяти являются: увеличение разрядности или "ширины" памяти, использование расслоения памяти, использование независимых банков памяти, обеспечение режима бесконфликтного обращения к банкам памяти, использование специальных режимов работы динамических микросхем памяти.
Выбор типа сети и количества клиентов
Выбор типа сети и количества клиентов
Учитывая вышеизложенные соображения, для определения надлежащего типа и числа сетей могут быть использованы следующие эмпирические правила:
Если в приложении доминируют операции с данными, следует выбрать сеть FDDI или какую-нибудь другую высокоскоростную сеть. Если по материально-техническим причинам прокладка оптоволоконных кабелей не представляется возможной, следует рассмотреть возможность реализации FDDI на витых парах. При создании новой системы следует иметь в виду, что для сетей ATM используются те же самые кабели, что и для FDDI.
В конфигурации сети необходимо предусмотреть одно кольцо FDDI для каждых 5-7 клиентов, одновременно полностью активных в смысле NFS и интенсивно работающих с данными. Следует помнить, что очень немногие интенсивные по данным приложения непрерывно генерируют запросы к серверу NFS. В типичных интенсивных по данным приложениях автоматизации проектирования электронных устройств и системах исследования земных ресурсов это часто позволяет иметь до 25-40 клиентов на кольцо.
В системах с интенсивным использованием данных, где существующая система кабелей вынуждает использовать Ethernet, следует предусмотреть отдельную сеть Ethernet для каждых двух активных клиентов и максимально 4-6 клиентов на одну сеть.
Если приложение связано с интенсивной обработкой атрибутов, то вполне достаточно построения сетей Ethernet или Token Ring.
В среде с интенсивным использованием атрибутов следует иметь одну сеть Ethernet на 8-10 полностью активных клиентов. Неблагоразумно превышать уровень 20-25 клиентов на Ethernet независимо от требований из-за резкой деградации, возникающей в случае активности многих клиентов. В качестве контрольной точки с точки зрения здравого смысла можно считать, что Ethernet способен поддерживать 250-300 NFS-операций в секунду на тесте SPECsfs_97 (LADDIS) даже с высоким уровнем коллизий. Неразумно превышать уровень 200 операций NFS в секунду в установившемся режиме.
Следует конфигурировать одну сеть TokenRing для каждых 10-15 полностью активных клиентов в среде с интенсивным использованием атрибутов. Если необходимо, к сети Token Ring можно подключать 50-80 клиентов благодаря превосходным характеристикам этого типа сети по устойчивости к деградации при тяжелой нагрузке (по сравнению с Ethernet).
Для систем, которые обеспечивают сервис нескольким классам пользователей имеют смысл смешанные конфигурации сетей. Например, и FDDI, и Token Ring подходят для сервера, который поддерживает как приложения, связанные с отображением документов (интенсивные по данным), так и группу ПК, выполняющих приложение финансового анализа (возможно интенсивное по атрибутам).
Выполнение по предположению (speculation)
Выполнение по предположению (speculation)
Поддерживаемое аппаратурой выполнение по предположению позволяет выполнить команду до момента определения направления условного перехода, от которого данная команда зависит. Это снижает потери, которые возникают при наличии в программе зависимостей по управлению. Чтобы понять, почему выполнение по предположению оказывается полезным, рассмотрим следующий простой пример программного кода, который реализует проход по связанному списку и инкрементирование каждого элемента этого списка:
for (p=head; p <> nil; *p=*p.next) {
*p.value = *p.value+1;
}
Подобно циклам for, с которыми мы встречались в более ранних разделах, разворачивание этого цикла не увеличит степени доступного параллелизма уровня команд. Действительно, каждая развернутая итерация будет содержать оператор if и выход из цикла. Ниже приведена последовательность команд в предположении, что значение head находится в регистре R4, который используется для хранения p, и что каждый элемент списка состоит из поля значения и следующего за ним поля указателя. Проверка размещается внизу так, что на каждой итерации цикла выполняется только один переход.
J looptest
start: LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
looptest: BNEZ R4,start
Развернув цикл однажды можно видеть, что разворачивание в данном случае не помогает:
J looptest
start: LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
BNEZ R4,end
LW R5,0(R4)
ADDI R5,R5,#1
SW 0(R4),R5
LW R4,4(R4)
looptest: BNEZ R4,start
end:
Даже прогнозируя направление перехода мы не можем выполнять с перекрытием команды из двух разных итераций цикла, и условные команды в любом случае здесь не помогут. Имеются несколько сложных моментов для выявления параллелизма из этого развернутого цикла:
Первая команда в итерации цикла (LW R5,0(R4)) зависит по управлению от обоих условных переходов. Таким образом, команда не может выполняться успешно (и безопасно) до тех пор, пока мы не узнаем исходы команд перехода.
Вторая и третья команды в итерации цикла зависят по данным от первой команды цикла.
Четвертая команда в каждой итерации цикла (LW R4,4(R4)) зависит по управлению от обоих переходов и антизависит от непосредственно предшествующей ей команды SW.
Последняя команда итерации цикла зависит от четвертой.
Вместе эти условия означают, что мы не можем совмещать выполнение никаких команд между последовательными итерациями цикла! Имеется небольшая возможность совмещения посредством переименования регистров либо аппаратными, либо программными средствами, если цикл развернут, так что вторая загрузка более не антизависит от SW и может быть перенесена выше.
В альтернативном варианте, при выполнении по предположению, что переход не будет выполняться, мы можем попытаться совместить выполнение последовательных итераций цикла. Действительно, это в точности то, что делает компилятор с планированием трасс. Когда направление переходов может прогнозироваться во время компиляции, и компилятор может найти команды, которые он может безопасно перенести на место перед точкой перехода, решение, базирующееся на технологии компилятора, идеально. Эти два условия являются ключевыми ограничениями для выявления параллелизма уровня команд статически с помощью компилятора. Рассмотрим развернутый выше цикл. Переход просто трудно прогнозируем, поскольку частота, с которой он является выполняемым, зависит от длины списка, по которому осуществляется проход. Кроме того, мы не можем безопасно перенести команду загрузки через переход, поскольку, если содержимое R4 равно nil, то команда загрузки слова, которая использует R4 как базовый регистр, гарантированно приведет к ошибке и обычно сгенерирует исключительную ситуацию по защите. Во многих системах значение nil реализуется с помощью указателя на неиспользуемую страницу виртуальной памяти, что обеспечивает ловушку (trap) при обращении по нему. Такое решение хорошо для универсальной схемы обнаружения указателей на nil, но в данном случае это не очень помогает, поскольку мы можем регулярно генерировать эту исключительную ситуацию, и стоимость обработки исключительной ситуации плюс уничтожения результатов выполнения по предположению будет огромной.
Чтобы преодолеть эти сложности, машина может иметь в своем составе специальные аппаратные средства поддержки выполнения по предположению. Эта методика позволяет машине выполнять команду, которая может быть зависимой по управлению, и избежать любых последствий выполнения этой команды (включая исключительные ситуации), если окажется, что в действительности команда не должна выполняться. Таким образом выполнение по предположению, подобно условным командам, позволяет преодолеть два сложных момента, которые могут возникнуть при более раннем выполнении команд: возможность появления исключительной ситуации и ненужное изменение состояния машины, вызванное выполнением команды. Кроме того, механизмы выполнения по предположению позволяют выполнять команду даже до момента оценки условия командой условного перехода, что невозможно при условных командах. Конечно, аппаратная поддержка выполнения по предположению достаточно сложна и требует значительных аппаратных ресурсов.
Один из подходов, который был хорошо исследован во множестве исследовательских проектов и используется в той или иной степени в машинах, которые разработаны или находятся на стадии разработки в настоящее время, заключается в объединении аппаратных средств динамического планирования и выполнения по предположению. В определенной степени подобную работу делала и IBM 360/91, поскольку она могла использовать средства прогнозирования направления переходов для выборки команд и назначения этих команд на станции резервирования. Механизмы, допускающие выполнение по предположению, идут дальше и позволяют действительно выполнять эти команды, а также другие команды, зависящие от команд, выполняющихся по предположению. Как и для алгоритма Томасуло, поясним аппаратное выполнение по предположению на примере устройства плавающей точки, но все идеи естественно применимы и для целочисленного устройства.
Аппаратура, реализующая алгоритм Томасуло, может быть расширена для обеспечения поддержки выполнения по предположению. С этой целью необходимо отделить средства пересылки результатов команд, которые требуются для выполнения по предположению некоторой команды, от механизма действительного завершения команды.
Имея такое разделение функций, мы можем допустить выполнение команды и пересылать ее результаты другим командам, не позволяя ей однако делать никакие обновления состояния машины, которые не могут быть ликвидированы, до тех пор, пока мы не узнаем, что команда должна безусловно выполниться. Использование цепей ускоренной пересылки также подобно выполнению по предположению чтения регистра, поскольку мы не знаем, обеспечивает ли команда, формирующая значение регистра-источника, корректный результат до тех пор, пока ее выполнение не станет безусловным. Если команда, выполняемая по предположению, становится безусловной, ей разрешается обновить регистровый файл или память. Этот дополнительный этап выполнения команд обычно называется стадией фиксации результатов команды (instruction commit).
Главная идея, лежащая в основе реализации выполнения по предположению, заключается в разрешении неупорядоченного выполнения команд, но в строгом соблюдении порядка фиксации результатов и предотвращением любого безвозвратного действия (например, обновления состояния или приема исключительной ситуации) до тех пор, пока результат команды не фиксируется. В простом конвейере с выдачей одиночных команд мы могли бы гарантировать, что команда фиксируется в порядке, предписанном программой, и только после проверки отсутствия исключительной ситуации, вырабатываемой этой командой, просто посредством переноса этапа записи результата в конец конвейера. Когда мы добавляем механизм выполнения по предположению, мы должны отделить процесс фиксации команды, поскольку он может произойти намного позже, чем в простом конвейере. Добавление к последовательности выполнения команды этой фазы фиксации требует некоторых изменений в последовательности действий, а также в дополнительного набора аппаратных буферов, которые хранят результаты команд, которые завершили выполнение, но результаты которых еще не зафиксированы. Этот аппаратный буфер, который можно назвать буфером переупорядочивания, используется также для передачи результатов между командами, которые могут выполняться по предположению.
Буфер переупорядочивания предоставляет дополнительные виртуальные регистры точно так же, как станции резервирования в алгоритме Томасуло расширяют набор регистров. Буфер переупорядочивания хранит результат некоторой операции в промежутке времени от момента завершения операции, связанной с этой командой, до момента фиксации результатов команды. Поэтому буфер переупорядочивания является источником операндов для команд, точно также как станции резервирования обеспечивают промежуточное хранение и передачу операндов в алгоритме Томасуло. Основная разница заключается в том, что когда в алгоритме Томасуло команда записывает свой результат, любая последующая выдаваемая команда будет выбирать этот результат из регистрового файла. При выполнении по предположению регистровый файл не обновляется до тех пор, пока команда не фиксируется (и мы знаем определенно, что команда должна выполняться); таким образом, буфер переупорядочивания поставляет операнды в интервале между завершением выполнения и фиксацией результатов команды. Буфер переупорядочивания не похож на буфер записи в алгоритме Томасуло, и в нашем примере функции буфера записи интегрированы с буфером переупорядочивания только с целью упрощения. Поскольку буфер переупорядочивания отвечает за хранение результатов до момента их записи в регистры, он также выполняет функции буфера загрузки.
Взаимодействие между приложением, файловой системой виртуальной памяти и NFS
Рисунок 4.5. Взаимодействие между приложением, файловой системой виртуальной памяти и NFS

Работа механизмов кэширования системы виртуальной памяти задерживает, а иногда и полностью отменяет работу NFS. Например, рассмотрим бездисковую рабочую станцию, выполняющую 1-2-3. Если и данные, и двоичные коды приложения размещаются удаленно, система должна будет, как и требуется, загрузить в страницы памяти выполняемые двоичные коды 1-2-3 с помощью NFS. Затем с помощью NFS в память будут загружены данные. Для большинства файлов 1-2-3 на типично сконфигурированной рабочей станции данные будут кэшироваться в памяти и оставаться там в течение значительного времени (скорее минуты, а не секунды). Если открывается и остается открытым временный файл, то само открытие файла выполняется немедленно как на клиенте, так и на сервере, но все обновления содержимого файла обычно кэшируются на некоторое время в клиенте перед передачей на сервер. В соответствии с семантикой UNIX-файла, когда файл закрывается все изменения должны быть записаны на внешнее запоминающее устройство, в данном случае на сервер NFS. В альтернативном варианте кэшированные записи могут записываться на внешнее запоминающее устройство с помощью демонов fsflush (Solaris 2.x) или udpated (Solaris 1.x). Как и в случае обычного дискового ввода/вывода, кэшированные данные ввода/вывода NFS остаются в памяти до тех пор, пока память не потребуется для каких-либо других целей.
Когда операция записи выдана в сервер, он должен зафиксировать эти данные в стабильной памяти перед последующей передачей. Однако на клиенте все происходит несколько иначе. Если снова происходит обращение к кэшированным данным, например, если в нашем примере снова обрабатываются некоторые текстовые страницы 1-2-3, то вместо выдачи запросов к серверу, обращение удовлетворяется прямо из виртуальной памяти клиента. Конечно когда клиенту не хватает памяти, для того чтобы выделить пространство для новых данных модифицированные страницы быстро записываются обратно на сервер, а немодифицированные страницы просто исключаются.
Взаимодействие с системой виртуальной памяти
Взаимодействие с системой виртуальной памяти
В базирующихся на UNIX системах, подобных Solaris, работа подсистемы клиента NFS эквивалентна работе дисковой подсистемы, а именно, она обеспечивает сервис менеджеру виртуальной памяти и, в частности, файловой системе на той же самой основе, что и дисковый сервис, за исключением того, что этот сервис осуществляется с привлечением сети. Это может показаться очевидным, но имеет определенное воздействие на работу системы NFS клиент/сервер. В частности, менеджер виртуальной памяти располагается между приложениями и клиентом NFS. Выполняемые приложениями обращения к файловой системе кэшируются системой виртуальной памяти клиента, сокращая требования клиента к вводу/выводу. Это можно увидеть на рисунке 4.5. Для большинства приложений больший объем памяти на клиенте приводит к меньшей нагрузке на сервер и более высокой общей (т.е. клиент/сервер) производительности системы. Это особенно справедливо для бездисковых клиентов, которые вынуждены использовать NFS в качестве внешнего запоминающего устройства для анонимной памяти.
Взгляд со стороны пользователя
Взгляд со стороны пользователя
Сервер NFS экспортирует одну или несколько файловых систем. Каждая экспортируемая файловая система может быть либо целым разделом диска либо его поддеревом. (Различные варианты UNIX имеют свои собственные правила дробления экспортируемых систем. Некоторые из них могут, например, разрешать экспортировать только файловую систему целиком, другие - только одно одно поддерево в каждой файловой системе). Сервер может определить, обычно посредством строк в файле /etc/exports, какие клиенты могут иметь доступ к каждой экспортируемой файловой системе, а также разрешенный режим доступа к ней: "только чтение" или "чтение и запись".
Затем клиентские машины могут подмонтировать такую файловую систему или ее поддерево к любому каталогу в своей существующей иерархии файлов, точно так же, как они смогли бы смонтировать любую локальную файловую систему. Клиент может монтировать каталог с режимом "только чтение", даже если сервер экспортирует его в режиме "чтение и запись". NFS поддерживает два типа монтирования: жесткое и мякгое. От типа монтирования зависит поведение клиента в случае, если сервер не отвечает на запрос. Если файловая система смонтирована жестко, клиент продолжает повторные запросы до получения ответа. В случае мягкого монтирования клиент спустя некоторое время отказывается от повторных запросов и получает ошибку. Когда монтирование произведено, клиент может обращаться к файлам в удаленной файловой системе, используя те же самые операции, которые применяются к локальным файлам. Некоторые системы поддерживают также такой тип монтирования, поведение которого соответствует жесткому монтированию при организации повторных попыток смонтировать файловую систему, но оказывается мягким для последующих операций ввода/вывода.
Операции монтирования NFS менее ограничены по сравнению с операциями монтирования локальных файловых систем. Протокол не требует, чтобы вызывающий операцию монтирования пользователь был привилегированным, хотя большинству пользователей навязываются эти требования. (Например, ULTRIX компании Digital позволяет любому пользователю монтировать файловую систему NFS до тех пор, пока этот пользователь имеет права доступа по записи в каталог точки монтирования. Пользователь может монтировать ту же самую файловую систему к нескольким точкам дерева каталогов, даже к своему подкаталогу. Сервер может экспортировать только свои локальные файловые системы и не может пересекать свои собственные точки монтирования во время прохода по путевому имени. Таким образом, чтобы увидеть все файлы сервера, клиент должен смонтировать все его файловые системы.
На рисунке 4.1 приведен пример. Серверная система nfssrv имеет два диска. Она смонтировала диск 1 к каталогу /usr/local диска 0 и экспортировала каталоги /usr и /usr/local. Предположим, что клиент выполняет следующие четыре операции mount:
mount -t nfs nfssrv:/usr /usr
mount -t nfs nfssrv:/usr/u1 /u1
mount -t nfs nfssrv:/usr /users
mount -t nfs nfssrv:/usr/local /usr/local
Заключительные рекомендации по конфигурированию дисков
Заключительные рекомендации по конфигурированию дисков
Основные правила по конфигурированию дисков можно обобщить следующим образом:
В среде с интенсивным использованием данных следует конфигурировать от 3 до 5 полностью активных 2.9 Гбайт дисков на каждый главный адаптер fast/wide SCSI. Необходимо предусматривать по крайней мере 3 дисковых накопителя на каждого активного клиента при использовании сети FDDI, или один дисковод для каждого активного клиента в сетях Ethernet или Token Ring.
В среде с интенсивным использованием атрибутов следует конфигурировать примерно по 4-5 полностью активных 1.05 Гбайт или 535 Мбайт дисков на каждый главный адаптер SCSI. Необходимо предусматривать по крайней мере один дисковод для каждых двух полностью активных клиентов (в любой сетевой среде).
К каждому главному адаптеру могут подключаться дополнительные накопители без существенной деградации производительности до тех пор, пока количество обычно активных накопителей на шине SCSI не превысит указаний, приведенных выше.
Для распределения нагрузки доступа по многим дискам можно рекомендовать использование программного обеспечения типа Online:DiskSuit 2.0.
Если это возможно, следует пользоваться наиболее быстрыми зонами на диске.
в Sun Net Manager для
Рисунок 4.2. Журнал трафика NFS в Sun Net Manager для клиента на базе 486/33 PC,
использующего Lotus 1-2-3

На рисунке 4.2 показан фрагмент журнала SunNetManager для ПК 486/33, работающих под управлением MS-DOS. Взрывной характер нагрузки клиентов проявляется очень отчетливо: в короткие промежутки времени видны пики, достигающие 100 операций в секунду, но средняя нагрузка невелика - 7 операций в секунду, а типичная нагрузка возможно составляет около 1 операции в секунду. Этот график снимался с интервалом измерений в одну секунду, чтобы просмотреть скорость транзакций при мелкой грануляции.