Администратор базы данных
Администратор базы данных – человек (или группа лиц), имеющий полное представление об одной или нескольких базах данных и контролирующий их проектирование и использование. Отвечает за состояние базы данных в организации (учреждении) на протяжении ее жизненного цикла. Функциями АБД являются [12, 17]:
– решение вопросов организации данных об объектах предметной области и установлении связей между этими данными с целью объединения информации о различных объектах; согласование представлений пользователей;
– координация всех действий по проектированию, реализации и ведению БД; учет перспективных и текущих требований пользователей;
– решение вопросов, связанных с расширением БД в связи с изменением границ предметной области;
– разработка и реализация мер по обеспечению защиты данных от некомпетентного использования, от сбоев технических средств, по обеспечению секретности определенной части данных и разграничению доступа к данным;
– выполнение работ по ведению словаря данных; контроль неизбыточности и непротиворечивости данных, их достоверности;
– обеспечение заданной производительности БД, чтобы обработка запросов выполнялась за приемлемое время;
– изменение при необходимости методов хранения данных, путей доступа к ним, связей между данными, форматов данных; определение степени влияния изменений на всю БД;
– координация вопросов технического обеспечения системы аппаратными средствами исходя из требований, предъявляемых БД к оборудованию;
– координация работы системных программистов разрабатывающих дополнительное программное обеспечение для улучшения эксплуатационных характеристик системы;
– координация работы прикладных программистов разрабатывающих новые пакеты программ и выполнение их проверки и включение в состав программного обеспечения системы.
Таким образом, при реализации достаточно сложных проектов, группа АБД может включать ряд специалистов, представленных на рис. 1.10 [17].

Рис. 1.10. Состав группы АБД
Аксиомы вывода функциональных зависимостей
Для отношения

Требуется выявить семейство F-зависимостей



Множество функциональных зависимостей, применимых к отношению
Если известны некоторые F-зависимости из
Множество F-зависимостей

Аксиома вывода – это правило, устанавливающее, что если отношение удовлетворяет определенным F-зависимостям, то оно должно удовлетворять и некоторым другим F-зависимостям.
Сформулировано шесть аксиом вывода F-зависимостей [10]. В этих формулировках используется обозначение r для отношения на




Fl. Рефлексивность.
F2. Пополнение.

F3. Аддитивность.

F4. Проективность.
F5. Транзитивность.

F6. Псевдотранзитивность.


Некоторые аксиомы вывода могут быть получены из других. Например, транзитивность F5 является частным случаем псевдотранзитивности F6 при

Приведенная система аксиом F1-F6 является полной. Это означает, что каждая F-зависимость, которая следует из множества Р, может быть выведена путем одно- или многократного применения к F этих аксиом.
Из аксиом Fl, F2 и F6 можно вывести остальные, а значит, они образуют полное подмножество для F1-F6. Аксиомы Fl, F2 и F6 являются также независимыми: ни одна из этих аксиом не может быть получена из двух других. Иногда эти три аксиомы называются аксиомами Армстронга.
Пусть

Из множества
Пример 2.5. Пусть


Тогда:




В свете новых знаний об F-зависимостях, следует уточнить понятия ключа и суперключа.
Для данной схемы отношения





Для некоторых допустимых отношений со схемой подмножество

Суперключ – это любая совокупность атрибутов, содержащая ключ.
Нормализация – формальный метод анализа отношений на основе их первичного ключа (или потенциальных ключей) и существующих функциональных зависимостей [2, 7,10].
Цель нормализации – получение такого проекта базы данных, в котором каждый факт хранится в одном месте, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных из-за их избыточности.
Нормальная форма представляет собой ограничение на схему базы данных (отношения), которое избавляет базу данных от некоторых нежелательных свойств.
Нормализация чаще всего выполняется в несколько последовательных этапов, результатом каждого из которых является некоторая нормальная форма с известными свойствами.
В теории реляционных баз данных разработано несколько нормальных форм (НФ), которые подчиняются правилу вложенности (рис. 2.25).


При реализации реляционной БД важно понимать, что только удовлетворение требований первой нормальной формы (1НФ) обязательно для создания отношений приемлемого качества. Все остальные формы могут использоваться по желанию проектировщика. Однако чтобы избежать аномалий обновления, описываемых ниже, нормализацию рекомендуется проводить как минимум до 3НФ.
Аксиомы вывода многозначных зависимостей
В разд. 2.4.3.2 определены аксиомы вывода функциональных зависимостей.
Первые шесть аксиом вывода, приведенные ниже, являются аналогами одноименных аксиом для F-зави-симостей, однако только первые три из них содержат похожие утверждения. Аксиома М7 не имеет аналога в F-зависимостях [10]. Пусть г – отношение со схемой R и W, X, У, Z – подмножества R.
Ml. Рефлексивность.
Отношение г удовлетворяет X

М2. Пополнение. Если r удовлетворяет X
МЗ. Аддитивность. Если r удовлетворяет Х
М4. Проективность. Если г удовлетворяет X

М5. Транзитивность. Если r удовлетворяет Х
M6. Псевдотранзитивность. Если r удовлетворяет X
M7. Дополнение. Если r удовлетворяет X
Система аксиом вывода Ml – М7 для MV-зависи-мостей является полной [10].
Обратимся к следствиям, которые можно вывести из множества F- и MV-зависимостей. Для их комбинации существуют только две аксиомы.
Пусть r – отношение со схемой R; W, X, Y, Z – подмножества R.
С1. Копирование. Если r удовлетворяет X
С2. Объединение. Если r удовлетворяет X

Системы аксиом F1 – F6, Ml – М7, С1 и С2 для множеств F- и MV-зависимостей являются полными [10].
Архитектура многопользовательских СУБД
В этом разделе приводятся различные типовые архитектурные решения, используемые при реализации многопользовательских СУБД, а именно схемы обычной телеобработки, файловый сервер и технология «клиент/сервер» [7].
Телеобработка
Традиционной архитектурой многопользовательских систем раньше считалась схема, получившая название «телеобработки», при которой один компьютер с единственным процессором был соединен с несколькими терминалами так. как показано на рис. 1.6 [7]. При этом вся обработка выполнялась в рамках единственного компьютера, а присоединенные к нему пользовательские терминалы были типичными «неинтеллектуальными» устройствами, не способными функционировать самостоятельно. С центральным процессором терминалы были связаны с помощью кабелей, по которым они посылали сообщения пользовательским приложениям (через подсистему управления обменом данными операционной системы). В свою очередь, пользовательские приложения обращались к необходимым службам СУБД. Таким же образом сообщения возвращались назад на пользовательский терминал. Недостатком является то, что при такой архитектуре основная и чрезвычайно большая нагрузка возлагалась на центральный компьютер, который должен был выполнять не только действия прикладных программ и СУБД, но и значительную работу по обслуживанию терминалов (например, форматирование данных, выводимых на экраны терминалов).

Рис. 1.6. Топология телеобработки
В последние годы был достигнут существенный прогресс в разработке высокопроизводительных персональных компьютеров и составленных из них сетей. При этом во всей индустрии наблюдается заметная тенденция к децентрализации (downsizing), т.е. замене дорогих мейнфреймов более эффективными, с точки зрения эксплуатационных затрат, сетями персональных компьютеров, позволяющими получить такие же результаты, если не лучше. Эта тенденция привела к появлению следующих двух типов архитектуры СУБД: технологии файлового сервера и технологии «клиент/сервер».
Файловый сервер
В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС).
Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и сама СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлам – как показано на рис. 1.7[7].

Рис. 1.7. Архитектура с использованием файлового сервера
Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск. СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файл-сервера. Такой подход характеризуется значительным сетевым графиком, что может привести к снижению производительности всей системы в целом.
Архитектура с использованием файлового сервера обладает следующими основными недостатками.
1. Большой объем сетевого графика.
2. На каждой рабочей станции должна находиться полная копия СУБД.
3. Управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
Технология «клиент/сервер»
Технология «клиент/сервер» была разработана с целью устранения недостатков, имеющихся в первых двух подходах. «Клиент/сервер» означает такой способ взаимодействия программных компонентов, при котором они образуют единую систему. Как видно из самого названия, существует некий клиентский
процесс, требующий определенных ресурсов, а также серверный процесс, который эти ресурсы предоставляет. При этом совсем необязательно, чтобы они находились на одном и том же компьютере. На практике принято размещать сервер на одном узле локальной сети, а клиенты – на других узлах. На рис. 1.8 показана архитектура типа «клиент/сервер» [7].

Рис. 1.8. Общая схема построения систем с архитектурой «клиент/сервер»
В контексте базы данных клиент управляет пользовательским интерфейсом и логикой приложения, Действуя как сложная рабочая станция, на которой выполняются приложения баз данных.
Клиент принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к базе данных на языке SQL или другом языке базы данных, который соответствует логике приложения. Затем он передает сообщение серверу, ожидает поступления ответа и форматирует полученные данные для представления их пользователю. Сервер принимает и обрабатывает запросы к базе данных, а затем передает полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также вы
полнение запроса и обновление данных. Помимо этого поддерживается управление параллельностью и восстановлением. Выполняемые клиентом и сервером операции приведены в табл. 1.1 [7].
Таблица 1.1
|
Клиент |
Сервер |
|
Управляет пользовательским интерфейсом |
Принимает и обрабатывает запросы к базе данных со стороны клиентов |
|
Принимает и проверяет синтаксис введенного пользователем запроса |
Проверяет полномочия пользователей |
|
Выполняет приложение |
Гарантирует соблюдение ограничений целостности |
|
Генерирует запрос к базе данных и передает его серверу |
Выполняет запросы/обновления и возвращает результаты клиенту |
|
Отображает полученные данные пользователю |
Поддерживает системный каталог |
|
Обеспечивает параллельный доступ к базе данных |
|
|
Обеспечивает управление восстановлением |
– Обеспечивается более широкий доступ к существующим базам данных.
– Повышается общая производительность системы. Поскольку клиенты и сервер находятся на разных компьютерах, их процессоры способны выполнять приложения параллельно. При этом настройка производительности компьютера с сервером упрощается, если на нем выполняется только работа с базой данных.
– Стоимость аппаратного обеспечения снижается. Достаточно мощный компьютер с большим устройством хранения нужен только серверу – для хранения и управления базой данных.
– Сокращаются коммуникационные расходы. Приложения выполняют часть операций на клиентских компьютерах и посылают через сеть только запросы к базе данных, что позволяет существенно сократить объем пересылаемых по сети данных.
– Повышается уровень непротиворечивости данных. Сервер может самостоятельно управлять проверкой целостности данных, поскольку все ограничения определяются и проверяются только в одном месте. При этом каждому приложению не придется выполнять собственную проверку.
– Эта архитектура весьма естественно отображается на архитектуру открытых систем.
Некоторые разработчики баз данных использовали эту архитектуру для организации средств работы с распределенными базами данных, т.е. с набором нескольких баз данных, логически связанных и распределенных в компьютерной сети. Однако, несмотря на то, что архитектура «клиент/сервер» вполне может быть использована для организации распределенной СУБД, сама по себе она не образует распределенную СУБД. Более подробно распределенные СУБД обсуждаются в главе 5.
Архитектура распределенных СУБД
Трехуровневая архитектура АЫ81-8РАЕС для СУБД, обсуждавшаяся в разделе 1.3, представляет собой типовое решение для централизованных СУБД. Однако распределенные СУБД имеют множество отличий, которые сложно отразить в некотором эквивалентном архитектурном решении, приемлемом для большинства случаев.
Один из примеров рекомендуемой архитектуры СУРБД представлен на рис. 5.3. Он включает следующие элементы [7]:
– набор глобальных внешних схем;
– глобальную концептуальную схему;
– схему фрагментации и схему распределения;
– набор схем для каждой локальной СУБД, отвечающих требованиям трехуровневой архитектуры АМ81-8РАКС.

Рис. 5.3. Рекомендуемая архитектура СУРБД
Соединительные линии на схеме представляют преобразования, выполняемые при переходе между схемами различных типов. В зависимости от поддерживаемого уровня прозрачности некоторые из уровней рекомендуемой архитектуры могут быть опущены.
Глобальная концептуальная схема
Глобальная концептуальная схема представляет собой логическое описание всей базы данных, представляющее ее так, как будто она не является распределенной. Этот уровень СУРБД соответствует концептуальному уровню архитектуры АЫ81-8РАЕС и содержит определения сущностей, связей, требований защиты и ограничений поддержки целостности информации. Он обеспечивает физическую независимость данных от распределенной среды. Логическую независимость данных обеспечивают глобальные внешние схемы.
Схемы фрагментации и распределения
Схема фрагментации содержит описание того, как данные должны логически распределяться по разделам. Схема распределения является описанием того, где расположены имеющиеся данные. Схема распределения учитывает все организованные в системе процессы репликации.
Локальные схемы
Каждая локальная СУБД имеет свой собственный набор схем. Локальная концептуальная и локальная внутренняя схемы полностью соответствуют эквивалентным уровням архитектуры АК81-8РАЕС.
Локальная схема отображения используется для отображения фрагментов в схеме распределения во внутренние объекты локальной базы данных. Эти элементы являются зависимыми от типа используемой СУБД и служат основой для построения гетерогенных СУРБД.
Независимо от рекомендованной общей архитектуры СУРБД компонентная архитектура СУРБД должна включать четыре следующих важнейших компонента (рис. 5.4) [7]:
1) локальную СУБД;
2) компонент передачи данных;
3) глобальный системный каталог;
4) распределенную СУБД (СУРБД).

Рис. 5.4. Компонентная архитектура распределенной СУБД
Локальная СУБД
Компонент локальной СУБД представляет собой стандартную СУБД, предназначенную для управления локальными данными на каждом из сайтов, входящих в состав распределенной базы данных. Локальная СУБД имеет свой собственный системный каталог, в котором содержится информация о данных, сохраняемых на этом сайте. В гомогенных системах на каждом из сайтов в качестве локальной СУБД используется один и тот же программный продукт. В гетерогенных системах существуют, по крайней мере, два сайта, использующих различные типы СУБД и/или различные типы вычислительных платформ.
Компонент передачи данных
Компонент передачи данных представляет собой программное обеспечение, позволяющее всем сайтам взаимодействовать между собой. Он содержит сведения о существующих сайтах и линиях связи между ними.
Глобальный системный каталог
Глобальный системный каталог имеет то же самое функциональное назначение, что и системный каталог в централизованных базах данных. Глобальный каталог содержит информацию, специфическую для распределенной природы системы, например схемы фрагментации и распределения. Этот каталог сам по себе может являться распределенной базой данных и поэтому подвергаться фрагментации и распределению, быть полностью реплицируемым или централизованным, как и любое другое отношение.
Что касается отношений, созданных на некотором сайте (сайте создания),
то ответственность за фиксацию описания каждого его фрагмента, каждой реплики, каждого фрагмента, а также хранение сведений о расположении этих фрагментов, возлагается на локальный каталог данного сайта. В случае если фрагмент или реплика перемещается в другое место, сведения в локальном каталоге сайта создания соответствующего отношения необходимым образом обновляются. Следовательно, для определения расположения фрагмента или реплики отношения необходимо получить доступ к каталогу его сайта создания. Сведения о сайте создания каждого глобального отношения должны фиксироваться в каждом локальном экземпляре глобального системного каталога.
Распределенная СУБД
Компонент распределенной СУБД является управляющим по отношению ко всей системе элементом. В предыдущем разделе описаны основные функциональные возможностями, которыми должен обладать этот компонент.
Бинарный поиск
Записи в файле можно упорядочить, например, по возрастанию или убыванию значения первичного ключа соответственно:

В этом случае можно построить более эффективные алгоритмы поиска, поскольку после сравнения значения



Методы поиска записей в упорядоченном файле различаются друг от друга стратегией выбора очередной записи из файла для выполнения операции сравнения ключа в соответствии с заданным условием Q. Метод бинарного поиска основан на делении интервала поиска пополам.
Поиск по равенству







Если



Процесс деления интервала пополам продолжается до тех пор, пока не будет найдена искомая запись (
Бинарный поиск можно выполнять, работая с блоками файла, а не с записями. При считывании блока в оперативную память поиск записи в блоке может быть последовательным. В этом случае в качестве характеристик блока используются граничные значения ключей записей, находящихся в блоке.
Поиск по интервалу значений




Цели и подходы к проектированию баз данных
Процесс проектирования БД представляет собой сложный процесс проектирования отображения [17]:
«Описание предметной области» ?? «схема внутренней модели базы данных».
Этот процесс представляется последовательностью более простых, обычно итеративных, процессов проектирования менее сложных отображений между промежуточными моделями данных, т.е. последовательностью проектирования моделей уровней абстрагирования. Основные уровни абстрагирования в БД [17]:
– информационный,
– внешний,
– концептуальный,
– внутренний.
В процессе проектирования БД разрабатываются схемы моделей названных уровней, проверяется возможность отображения объектов одной модели в объекты другой модели.
Только небольшие организации могут обобществить данные в одной полностью интегрированной базе данных. Чаще всего администратор баз данных (даже если это группа лиц) практически не в состоянии охватить и осмыслить все информационные требования сотрудников организации (т.е. будущих пользователей системы).
Наличие постоянных и разовых пользователей в автоматизированных информационных системах, и, следовательно, наличие потока регламентированных и произвольных по содержанию запросов требуют разработки специальных подходов к определению границ ПО и проектированию состава элементов информационной модели. Поэтому информационные системы больших организаций содержат несколько десятков БД, нередко распределенных между несколькими взаимосвязанными ЭВМ различных подразделений [5, 17]. (Так в больших городах создается не одна, а несколько овощных баз, расположенных в разных районах.)
Если бы в АИС существовал только поток регламентированных запросов и не ожидалось развитие системы, то можно было бы определить границы ПО и осуществить проектирование исходя из анализа содержания всей совокупности запросов пользователей – это так называемый подход к проектированию «от запросов пользователей» [17].
Основывая же проектирование БД на текущих и предвидимых приложениях, можно существенно ускорить создание высокоэффективной информационной системы, т.е. системы, структура которой учитывает наиболее часто встречающиеся пути доступа к данным. Поэтому прикладное проектирование до сих пор привлекает некоторых разработчиков. Однако по мере роста числа приложений таких информационных систем быстро увеличивается число прикладных БД, резко возрастает уровень дублирования данных и повышается стоимость их ведения. Таким образом, каждый из рассмотренных подходов к проектированию воздействует на результаты проектирования качественно по-разному.
Основная цель проектирования БД – это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте. Так называемый, «чистый» проект БД – «Каждый факт в одном месте» [5, 8].
При проектировании базы данных решаются две основных проблемы.
1. Каким образом отобразить объекты предметной области в абстрактные объекты модели данных, чтобы это отображение не противоречило семантике предметной области и было по возможности лучшим (эффективным, удобным и т.д.)? Часто эту проблему называют проблемой логического проектирования баз данных.
2. Как обеспечить эффективность выполнения запросов к базе данных, т.е. каким образом, имея в виду особенности конкретной СУБД, расположить данные во внешней памяти, создание каких дополнительных структур (например, индексов) потребовать и т.д.? Эту проблему называют проблемой физического проектирования баз данных [5, 8].
Четвертая нормальная форма
Известно, что каждое отношение r(R), удовлетворяющее MV-зависимости Х
MV-зависимость Х
Пусть F – множество F- и MV-зависимостей над U. Схема отношения R
Схема базы данных R находится в четвертой нормальной форме относительно F, если каждая входящая в нее схема отношения находится в четвертой нормальной форме относительно F.
Множество F из F-зависимостей и MV-зависимостей, аналогично тому как это делается для построения схем баз данных в ЗНФ, может быть использовано для построения декомпозиций схемы отношения R, находящихся в 4НФ. Для этого, начав с R, ищем выводимую из F нетривиальную MV-зависимость Х
Даталогические модели данных
Модель данных – фиксированная система понятий и правил для представления структуры данных, состояния и динамики проблемной области в базах данных [12]. Как правило, задается языком определения данных и языком манипулирования данными. Примерами модели данных, получившими широкое распространение, являются модели данных сетевая, иерархическая, реляционная и др.
Модель данных состоит из трех компонент [11].
1. Структура данных для представления точки зрения пользователя на базу данных.
2. Допустимые операции, выполняемые на структуре данных. Они составляют основу языка данных рассматриваемой модели данных. Одной лишь хорошей структуры данных недостаточно. Необходимо иметь возможность работать с этой структурой при помощи различных операций языка определения данных и языка манипулирования данными. Богатая структура данных ничего не стоит, если нет возможности оперировать ее содержимым.
3. Ограничения для контроля целостности. Модель данных должна быть обеспечена средствами, позволяющими сохранять ее целостность и защищать ее.
Схема – это средство, с помощью которого определяется модель данных приложения. В действительности схема содержит не только модель данных: в ней присутствует также некоторая семантическая информация, относящаяся к конкретному приложению. В модели данных можно определить, например, что база данных будет хранить информацию об организациях и служащих. Однако, тот факт, что данный служащий не может работать более чем в одной организации, отражает семантику приложения. Это семантическое ограничение должно выполняться для каждого отдельного экземпляра записи базы данных об этом служащем. Поддержка ограничений заданной модели данных в базе данных также является частью функций СУБД по обеспечению защиты и целостности.
Прежде, чем перейти к детальному и последовательному изучению реляционных систем БД, целесообразно ознакомиться с ранними СУБД [8]. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД. Подробный сравнительный анализ даталогических моделей приведен в прил. 3.
Достоинства и недостатки даталогических моделей
Сначала остановимся коротко на ранних (дореляционных) СУБД. Ограничимся рассмотрением только общих особенностей ранних систем, а именно, систем, основанных на иерархических и сетевых моделях [8].
1. Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
2. Все ранние системы не основывались на каких-либо абстрактных моделях. Как упоминалось, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков! у различных конкретных систем.
3. В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
4. Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
5. После появления реляционных систем большинство ранних систем было оснащено «реляционными» интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме (на низком физическом уровне).
Обобщая перечисленные особенности, можно сформулировать достоинства и недостатки ранних систем.
Достоинства:
– развитые средства управления данными во внешней памяти на низком уровне;
– возможность построения вручную эффективных прикладных программ;
– возможность экономии памяти.
Недостатки:
– сложность практического использования;
– необходимость знания физической организации данных;
– жесткая зависимость прикладных систем от физической организации данных;
– логика перегружена деталями организации доступа к БД.
По сравнению с ранними моделями, реляционный подход обладает следующими особенностями [2, 5, 8, 17].
Достоинства:
– наличие относительно небольшого набора абстракций;
– наличие простого, но мощного математического аппарата (в основе реляционного подхода – теория множеств);
– возможность ненавигационного манипулирования данными без знания их конкретной физической организации.
Недостатки:
– ограниченность использования в нетрадиционных предметных областях;
– относительно неполная адекватность отражения семантики предметной области.
В главе 4 рассматривается самая сильная сторона реляционного подхода - математический аппарат для выполнения операций над отношениями реляционной модели.
Наличие простого, но мощного математического аппарата сыграло решающую роль в повсеместном переходе разработчиков СУБД на реляционную модель.
Достоинства и недостатки СУБД
СУБД призваны решить недостатки файловых систем (см. прил.1), но при этом имеют и ряд специфических недостатков [7].
Достоинства СУБД
– Контроль за избыточностью данных.
– Непротиворечивость данных.
– Больше полезной информации при том же объеме хранимых данных.
– Совместное использование данных.
– Поддержка целостности данных.
– Повышенная безопасность.
– Применение стандартов.
– Повышение эффективности с ростом масштабов системы.
– Возможность нахождения компромисса при противоречивых требованиях.
– Повышение доступности данных.
– Улучшение показателей производительности.
– Упрощение сопровождения системы за счет независимости данных.
– Улучшенное управление параллельностью.
– Развитые службы резервного копирования и восстановления.
Контроль за избыточностью данных
Традиционные файловые системы неэкономно расходуют внешнюю память, сохраняя одни и те же данные с нескольких файлах. При использовании базы данных предпринимается попытка исключить избыточность данных за счет интеграции информации файлов, Однако реально полностью избыточность информации в базах данных не исключается, а лишь контролируется ее степень. В одних случаях ключевые элементы данных необходимо дублировать для моделирования связей, а в других случаях некоторые данные потребуется дублировать из соображений повышения производительности системы.
Непротиворечивость данных
Устранение избыточности данных или контроль над ней позволяют сократить риск возникновения противоречивых состояний. Если элемент данных хранится в базе только в одном месте, то для изменения его значения потребуется выполнить только одну операцию обновления, причем новое значение станет доступным сразу всем пользователям.
Если этот элемент данных с ведома системы хранится в базе данных в нескольких местах, то такая система сможет следить за тем, чтобы копии не противоречили друг другу.
Больше полезной информации при том же объеме хранимых данных
Благодаря интеграции рабочих данных организации на основе тех же данных можно получать дополнительную информацию.
Совместное использование данных
Файлы обычно принадлежат отдельным лицам или отделам, которые используют их в своей работе. База данных принадлежит всей организации в целом и может совместно использоваться всеми зарегистрированными пользователями. При такой организации работы большее количество пользователей может работать с большим объемом данных. Более того, при этом можно создавать новые приложения на основе уже хранящейся в базе данных информации и добавлять в нее только те данные, которые в настоящий момент еще не хранятся в ней, а не определять заново требования ко всем данным, необходимым новому приложению.
Поддержка целостности данных
Целостность базы данных означает корректность и непротиворечивость хранимых в ней данных. Целостность обычно описывается с помощью ограничений, т.е. правил поддержки непротиворечивости, которые не должны нарушаться в базе данных. Ограничения можно применять внутри одной записи или к связям между записями. Интеграция данных позволяет АБД задавать требования по поддержке целостности данных, а СУБД применять их.
Повышенная безопасность
Безопасность базы данных заключается в защите базы данных от несанкционированного доступа со стороны пользователей. Без привлечения соответствующих мер безопасности интегрированные данные становятся более уязвимыми, чем данные в файловой системе. Однако интеграция позволяет АБД определить требуемую систему безопасности базы данных, а СУБД привести ее в действие. Система обеспечения безопасности может быть выражена в форме учетных имен и паролей для идентификации пользователей, которые зарегистрированы в этой базе данных. Доступ к данным со стороны пользователя может быть ограничен только некоторыми операциями (добавлением, удалением данных).
Применение стандартов
Интеграция позволяет АБД определять и применять необходимые стандарты. Например, стандарты отдела и организации, государственные и международные стандарты могут регламентировать формат данных при обмене между системами, соглашения об именах, форму представления документации, процедуры обновления и правила доступа.
Повышение эффективности с ростом масштабов системы
Комбинируя все рабочие данные организации в одной базе данных, и создавая набор приложений, которые работают с одним источником данных, можно добиться существенной экономии средств. В этом случае бюджет, который обычно выделялся каждому отделу для разработки и поддержки собственных файловых систем, можно объединить с бюджетами других отделов, что позволит добиться повышения эффективности при росте масштабов производства.
Возможность нахождения компромисса при противоречивых требованиях
Потребности одних пользователей или отделов могут противоречить потребностям других пользователей. Поскольку база данных контролируется АБД, он может принимать решения о проектировании и способе использования базы данных, при которых имеющиеся ресурсы всей организации в целом будут использоваться наилучшим образом. Эти решения обеспечивают оптимальную производительность для самых важных приложений, причем чаще всего за счет менее критичных.
Повышение доступности данных
Данные, которые пересекают границы отдела, в результате интеграции становятся доступными конечным пользователям. Это повышает функциональность системы, что используется для более качественного обслуживания конечных пользователей.
Улучшение показателей производительности
В СУБД предусмотрено много стандартных функций, которые программист обычно должен самостоятельно реализовать в приложениях для файловых систем. На базовом уровне СУБД обеспечивает все низкоуровневые процедуры работы с файлами, которую обычно выполняют приложения. Наличие этих процедур дает возможность программисту сконцентрироваться на разработке специальных пользовательских функций, не заботясь о подробностях их воплощения на более низком уровне.
Упрощение сопровождения системы за счет независимости данных
В СУБД описания данных отделены от приложений, а потому приложения защищены от изменений в описаниях данных. Эта особенность называется независимостью данных. Наличие независимости данных от программ, использующих их, значительно упрощает обслуживание и сопровождение приложений, работающих с базой данных.
Улучшенное управление параллельностью
В некоторых файловых системах при одновременном доступе к одному и тому же файлу двух пользователей может возникнуть конфликт двух запросов, результатом которого будет потеря информации или утрата ее целостности. В СУБД предусмотрена возможность параллельного доступа к базе данных и гарантируется отсутствие подобных проблем.
Развитые службы резервного копирования и восстановления
Ответственность за обеспечение защитил данных от сбоев аппаратного и программного обеспечения в файловых системах возлагается на пользователя. В современных СУБД предусмотрены средства сокращения объема потерь информации от возникновения различных сбоев.
Недостатки СУБД
– Сложность.
– Размер.
– Стоимость.
– Дополнительные затраты на аппаратное обеспечение.
– Затраты на преобразование.
– Производительность.
– Серьезные последствия при выходе системы из строя.
Сложность
Обеспечение функциональности, которой должна обладать каждая хорошая СУБД, сопровождается значительным усложнением программного обеспечения СУБД. Чтобы воспользоваться всеми преимуществами СУБД разработчики и проектировщики баз данных, администраторы баз данных, а также конечные пользователи должны хорошо понимать функциональные возможности СУБД. Непонимание принципов работы системы может привести к неудачным результатам проектирования, что будет иметь серьезные последствия для всей организации.
Размер
Сложность и широта функциональных возможностей приводит к тому, что СУБД становится чрезвычайно сложным программным продуктом, который может занимать много места на диске и требовать большого объема оперативной памяти для эффективной работы.
Стоимость
В зависимости от имеющейся вычислительной среды и требуемых функциональных возможностей, стоимость СУБД варьирует в очень широких пределах. Кроме того, следует учитывать ежегодные расходы на сопровождение системы, которые составляют некоторой процент от ее общей стоимости.
Дополнительные затраты на аппаратное обеспечение
Для удовлетворения требований, предъявляемых к дисковым накопителям со стороны СУБД и базы данных, может понадобиться приобрести дополнительные устройства хранения информации. Более того, для достижения требуемой производительности может понадобиться более мощный компьютер.
Затраты на преобразование
В некоторых ситуациях стоимость СУБД и дополнительного аппаратного обеспечения может оказаться несущественной по сравнению со стоимостью преобразования существующих приложений для работы с новой СУБД и новым аппаратным обеспечением. Эти затраты также включают стоимость подготовки персонала для работы с новой системой, а также оплату услуг специалистов, которые будут оказывать помощь в преобразовании и запуске новой системы.
Производительность
Обычно файловая система создается для некоторых специализированных приложений, а потому ее производительность может быть высока. Однако СУБД предназначены для решения общих задач и обслуживания сразу нескольких приложений, что замедляет работу системы.
Серьезные последствия при выходе системы из строя
Централизация ресурсов повышает уязвимость системы. Поскольку работа всех пользователей и приложений зависит от готовности к работе СУБД, выход из строя одного из ее компонентов может привести к полному прекращению всей работы организации.
Фрагментация
Необходимость фрагментации вызывают следующие причины [7].
– Условия использования. Чаще всего приложения работают с некоторыми представлениями, а не с полными базовыми отношениями. Следовательно, с точки зрения распределения данных, целесообразнее организовать работу приложений с определенными фрагментами отношений, выступающими как распределяемые элементы.
– Эффективность.
Данные хранятся в тех местах в которых они чаще всего используются. Кроме того, исключается хранение данных, которые не используются локальными приложениями.
– Параллельность.
Поскольку фрагменты являются распределяемыми элементами, транзакции могут быть разделены на несколько подзапросов, обращающихся к различным фрагментам. Такой подход дает возможность повысить уровень параллельности обработки в системе, т.е. позволяет транзакциям, которые допускают это, безопасно выполняться в параллельном режиме.
– Защищенность.
Данные, не используемые локальными приложениями, не хранятся на сайтах, а значит, неавторизированные пользователи не смогут получить к ним доступ.
Механизму фрагментации свойственны два основных недостатка.
– Производительность.
Производительность приложений, требующих доступа к данным из нескольких фрагментов, расположенных на различных сайтах, может оказаться недостаточной.
– Целостность данных. Поддержка целостности данных может существенно осложняться, поскольку функционально зависимые данные могут оказаться фрагментированными и размещаться на различных сайтах.
При проведении фрагментации следует обязательно придерживаться трех следующих правил [7].
1. Полнота. Если экземпляр отношения К разбивается на фрагменты, например R1,R2, ..., Rn,
то каждый элемент данных, присутствующий в отношении К, должен присутствовать, по крайней мере, в одном из созданных фрагментов.
Выполнение этого правила гарантирует, что какие-либо данные не будут утрачены в результате выполнения фрагментации.
2. Восстановимость. Должна существовать операция реляционной алгебры, позволяющая восстановить отношение R из его фрагментов. Это правило гарантирует сохранение функциональных зависимостей.
3. Непересекаемость. Если элемент данных di присутствует во фрагменте Ri, то он не должен одновременно присутствовать в каком-либо ином фрагменте. Исключением из этого правила является операция вертикальной фрагментации, поскольку в этом случае в каждом фрагменте должны присутствовать атрибуты первичного ключа, необходимые для восстановления исходного отношения. Данное правило гарантирует минимальную избыточность данных во фрагментах.
В случае горизонтальной фрагментации элементом данных является кортеж, а в случае вертикальной фрагментации – атрибут.
Существуют два основных типа фрагментации (рис. 5.5, а,
б):
– горизонтальная,
– вертикальная.
Горизонтальные фрагменты представляют собой подмножества кортежей отношения, а вертикальные – подмножества атрибутов отношения.
Кроме того, различают смешанную (рис. 5.5, в,
г) и производную (вариант горизонтальной) фрагментации.

Рис. 5.5. Типы фрагментации: а) горизонтальная; б) вертикальная; в) горизонтально разделенные вертикальные фрагменты; г) вертикально разделенные горизонтальные фрагменты
Горизонтальный фрагмент - выделенный по горизонтали фрагмент отношения, состоящий из некоторого подмножества кортежей этого отношения.
Горизонтальный фрагмент создается посредством определения предиката, с помощью которого выполняется отбор кортежей из исходного отношения. Данный тип фрагмента определяется с помощью операции выборки (селекции) реляционной алгебры (см. гл. 4). Операция выборки позволяет выделить группу кортежей, обладающих некоторым общим для них свойством, – например, все кортежи, используемые одним из приложений, или все кортежи, применяемые на одном из сайтов.
В одних случаях целесообразность использования горизонтальной фрагментации вполне очевидна. Однако в других случаях потребуется выполнение детального анализа приложений. Этот анализ должен включать проверку предикатов (или условий) поиска, используемых в транзакциях или запросах, выполняемых в приложении. Предикаты могут быть простыми, включающими только по одному атрибуту, или сложными, включающими несколько атрибутов. Для каждого из используемых атрибутов предикат может содержать единственное значение или несколько значений. В последнем случае значения могут быть дискретными дли задавать диапазон значений.
Стратегия определения типа фрагментации предполагает поиск набора минимальных
(т.е. полных и релевантных) предикатов, которые можно будет использовать как основу для построения схемы фрагментации [7].
Набор предикатов является полным тогда и только тогда, когда вероятность обращения к любым двум кортежам одного и того же фрагмента со стороны любого приложения будет одинакова.
Предикат является релевантным, если существует, по крайней мере, одно приложение, которое по-разному обращается к выделенным с помощью этого предиката фрагментам.
Вертикальный фрагмент - выделенный по вертикали фрагмент отношения, состоящий из подмножества атрибутов этого отношения.
При вертикальной фрагментации в различные фрагменты объединяются атрибуты, используемые отдельными приложениями. Определение фрагментов в этом случае выполняется с помощью операции проекции реляционной алгебры (см. гл.4).
Вертикальные фрагменты определяются путем установки родственности
одного атрибута по отношению к другому. Один из способов решить эту задачу состоит в создании матрицы, содержащей количество обращений с выборкой каждой из пар атрибутов. Например, транзакция, которая осуществляет доступ к атрибутам А1, А2, и А4 отношения R, состоящего из набора атрибутов (А1, А2, А3, А4), может быть представлена следующей матрицей.

Эта матрица является треугольной, поскольку диагональ ее не заполняется, а нижняя часть является зеркальным отражением верхней части.
Единицы в матрице означают наличие доступа с обращением к соответствующей паре атрибутов и, в конечном счете, должны быть заменены числами, отражающими частоту выполнения транзакции. Подобная матрица составляется для каждой транзакции, после чего строится общая матрица, содержащая суммы всех показателей доступа к каждой из пар атрибутов. Пары атрибутов с высоким показателем родственности должны присутствовать в одном и том же вертикальном фрагменте. Пары с невысоким показателем родственности могут быть разнесены в разные вертикальные фрагменты. Очевидно, что обработка сведений об отдельных атрибутах для всех важнейших транзакций может потребовать немало времени и вычислений. Следователь но, если заранее известно о родственности определенных атрибутов, может оказаться целесообразным обработать сведения сразу о группах атрибутов.
Подобный подход носит название расщепления (splitting) и впервые был предложен группой разработчиков в 1984 году [7]. Он позволяет выделить неперекрывающихся фрагментов, которые гарантированно будут отвечать определенному выше правилу непересекаемости. Фактически требование непересе- каемости касается только атрибутов, не входящих в первичный ключ отношения. Атрибуты первичного ключа должны присутствовать в каждом из выделенных вертикальных фрагментов, а потому могут быть исключены из анализа.
В некоторых случаях применения только лишь горизонтальной и вертикальной фрагментации элементов схемы базы данных оказывается недостаточно для адекватного распределения данных между приложениями. В этом случае приходится прибегать к смешанной (или гибридной) фрагментации.
Смешанный фрагмент образуется либо посредством дополнительной вертикальной фрагментации созданных ранее горизонтальных фрагментов, либо за счет вторичной горизонтальной фрагментации предварительно определенных вертикальных фрагментов.
Смешанная фрагментация определяется с помощью операций выборки и проекции реляционной алгебры.
Некоторые приложения включают операции соединения двух или больше отношений.
Если отношения сохраняются в различных местах, то выполнение их соединения создаст очень большую дополнительную нагрузку на систему. В подобных случаях более приемлемым решением будет размещение соединяемых отношений или их фрагментов в одном и том же месте. Данная цель может быть достигнута за счет применения производной горизонтальной фрагментации.
Производный фрагмент – горизонтальный фрагмент отношения, созданный на основе горизонтального фрагмента родительского отношения.
Термин «дочернее» используется для ссылок на отношение, содержащее внешний ключ, а термин «родительское» – для ссылок на отношение с соответствующим первичным ключом. Определение производных фрагментов осуществляется с помощью операции полусоединения реляционной алгебры (см. гл. 4).
Если отношение включает больше одного внешнего ключа, то может потребоваться выбрать в качестве родительского только одно из связанных отношений. Выбор может быть сделан в соответствии с чаще всего используемым типом фрагментации или с целью достижения оптимальных характеристик соединения – например, соединения, которое включает более мелкие фрагменты или соединения, выполняемого с большей степенью распараллеливания.
Последний вариант возможной стратегии при разработке распределенных БД состоит в отказе от фрагментации отношения [7].
Функции распределенных СУБД
Очевидно, что типичная СУРБД должна обеспечивать, по крайней мере, тот же набор функциональных возможностей, который был определен для централизованных СУБД в главе 1.
Кроме того, СУРБД должна предоставлять следующий набор функциональных возможностей [7].
• Расширенные службы установки соединений должны обеспечивать доступ к удаленным сайтам и позволять передавать запросы и данные между сайтами, входящими в сеть.
• Расширенные средства ведения каталога, позволяющие сохранять сведения о распределении данных в сети.
• Средства обработки распределенных запросов, включая механизмы оптимизации запросов и организации удаленного доступа.
• Расширенные функции управления параллельностью, позволяющие поддерживать целостность реплицируемых данных.
• Расширенные функции восстановления, учитывающие возможность отказов в работе отдельных сайтов и отказов линий связи.
Функции службы репликации
В качестве базового уровня служба репликации распределенных данных должна быть способна копировать данные из одной базы данных в другую синхронно или асинхронно. Кроме того, существует множество других функций, которые должны поддерживаться, включая следующие [7].
– Масштабируемость.
Служба репликации должна эффективно обрабатывать как малые, так и большие объемы данных.
– Отображение и трансформация. Служба репликации должна поддерживать репликацию данных в гетерогенных системах, использующих несколько платформ. Это может быть связано с необходимостью отображения и преобразования данных из одной модели данных в другую или же для преобразования некоторого типа данных в соответствующий тип данных, но для среды другой СУБД.
– Репликация объектов. Должна существовать возможность реплицировать объекты, отличные от обычных данных. Например, в некоторых системах допускается репликация индексов и хранимых процедур (или триггеров).
– Средства определения схемы репликации. Система должна предоставлять механизм, позволяющий привилегированным пользователям задавать данные и объекты, подлежащие репликации.
– Механизм подписки. Система должна включать механизм, позволяющий привилегированным пользователям оформлять подписку на данные и другие подлежащие репликации объекты.
– Механизм инициализации. Система должна включать средства, обеспечивающие инициализацию вновь создаваемой реплики.
РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ И СУБД
Технология распределенных баз данных, получившая в настоящее время широкое распространение, способствует обратному переходу от централизованной обработки данных к децентрализованной. Создание технологии систем управления распределенными базами данных является одним самых больших достижений в области баз данных.
Иерархическая модель
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи [8].
Пример типа дерева (схемы иерархической БД) представлен на рис. 2.19.

Рис. 2.19. Пример схемы иерархической БД
На рис. 2.19 ОТДЕЛ является предком для НАЧАЛЬНИК и СОТРУДНИКИ, а НАЧАЛЬНИК и СОТРУДНИКИ - потомки ОТДЕЛ. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (рис. 2.20, показан один экземпляр дерева) [8].

Рис. 2.20. Реализация иерархической БД
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие [8].
– Найти указанное дерево БД (например, отдел 42).
– Перейти от одного дерева к другому.
– Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику).
– Перейти от одной записи к другой в порядке обхода иерархии.
– Вставить новую запись в указанную позицию.
– Удалить текущую запись.
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается.
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии.
Примером представления приведенной выше БД может быть следующая иерархия (рис. 2.21) [8].

Рис. 2.21. Пример схемы иерархической БД
Экземпляр дерева базы данных не обязательно должен содержать все свои сегменты. При необходимости можно добавлять или удалять экземпляры типов записей в соответствии с требованиями приложения.
Иерархическая структура реализует отношение ОДИН-КО-МНОГИМ между исходным и порожденным типами записей. Это отображение полностью функционально, т.к. дерево не может содержать порожденный узел без исходного узла (за исключением «корня»). Следовательно, отображения ОДИН-К-ОДНОМУ и ОДИН-КО-МНОГИМ могут непосредственно представляться иерархическими структурами. Однако для представления отображения МНОГИЕ-КО-МНОГИМ необходимо дублирование деревьев, а значит, реализация сложных связей требует больших затрат памяти.
Другой проблемой иерархий является невозможность хранения в БД порожденного узла без соответствующего исходного, т.е. в этом случае необходимо ввести пустой исходный узел. Соответственно удаление данного исходного узла влечет удаление всех порожденных узлов (поддеревьев), связанных в ним. Эти ограничения создают проблемы применения иерархической модели для некоторых приложений.
Индекс - «бинарное дерево»
Любой бинарный алгоритм поиска в упорядоченном файле БД можно представить с помощью соответствующего бинарного дерева [17]. Это бинарное дерево можно реализовать в виде самостоятельного файла (или индекса). При этом операции поиска будут освобождены от необходимости каждый раз вычислять адреса записей (они будут сформированы один раз при начальной загрузке файла БД и при последующих добавлениях в файл новых записей).
На рис. 3.8 представлено бинарное дерево, построенное для файла из 15 записей [17]. Запись бинарного дерева состоит из поля ключа записи и двух полей указателей. Один указатель для левого поддерева, другой – для правого поддерева. Листовые записи бинарного дерева содержат указатели на блоки файла основных записей (файла данных). Для уменьшения количества операций обмена с внешней памятью при выполнении поиска соседние записи в бинарном дереве объединяются в блоки. На слайде объединяемые в один блок записи бинарного дерева очерчены штриховой линией.
Записи бинарного дерева обычно меньше по объему памяти записей основного файла


Рис. 3.8. Пример бинарного дерева
Реализация бинарного дерева позволяет сократить время поиска данных по сравнению с бинарным поиском, однако возрастает требуемый объем внешней памяти [17].
Инфологическое проектирование базы данных
Все этапы проектирования БД подразумевают создание моделей данных об интересующей предметной области. Моделирование данных упрощает понимание смысла элементов данных, способствует более плодотворному общению пользователей и разработчиков.
Исходя из важности адекватного отображения предметной области, к моделям данных предъявляют ряд требований, и выдвигают комплекс критериев для оценки их эффективности (оптимальности) (табл. 2.1).
Инфологическое (концептуальное) проектирование – процесс создания внешней (инфологической) модели данных о предметной области, не зависящее от любых физических аспектов ее представления.
На этом этапе используется информация, объединяющая требования пользователей. Инфологическое проектирование базы данных не зависит от таких подробностей ее реализации, как тип выбранной СУБД, набор создаваемых прикладных программ, используемые языки программирования, тип вычислительной системы и т.п. При разработке инфологическая модель постоянно подвергается критической оценке, проверке на соответствие требованиям пользователей, и при необходимости модифицируется. От качества созданной инфологической модели в определяющей степени зависит эффективность конечной базы данных.
Таблица 2.1
| Критерий | Пояснение | ||
| Структурная достоверность | Соответствие способу определения и организации информации в данной предметной области | ||
| Простота | Легкость понимания модели разработчиками и пользователями информационной системы | ||
| Выразительность | Способность представлять отличия между разными типами данных, связи между данными и ограничения | ||
| Отсутствие избыточности | Исключение излишней информации, т.е. любая часть данных должна быть представлена только в одном месте | ||
| Готовность к совместному использованию | Отсутствие принадлежности к какому-то особому приложению или технологии | ||
| Расширяемость | Способность эволюционировать с целью включения новых требований с минимальным влиянием на существующих пользователей | ||
| Целостность | Согласованность по способам использования и управления информацией | ||
| Представление в виде диаграмм | Способность представления модели с помощью понятных широкому кругу пользователей обозначений |
Инвертированный файл
В рассмотренных выше способах индексирования данных расчет делался на поиск по значению ключевого поля. Но часто требуется осуществить выборку данных по значениям неключевых полей. В этом случае неключевые поля также должны быть проиндексированы (т.е. для каждого из них строится особый индекс). Индексы, построенные для неключевых полей используются при организации многоаспектного поиска. Широко распространены на практике методы многоаспектного поиска по инвертированным файлам. Пусть имеется основной файл

1) записи файла


2) записи файла
Построенный дополнительный файл

Рассмотренный способ организации инвертированного файла предполагает использование записей переменной длины. Инвертированный файл можно организовать и с помощью записей фиксированной длины, если в каждой записи инвертированного файла выделять фиксированное число полей для указателей

Этапы проектирования баз данных
На рис. 2.2 приведены основные этапы проектирования баз данных. Так, весь сложный процесс создания БД может быть разбит на инфологическое и даталогическое проектирование. Последнее подразделяется на логическое и физическое проектирование. В зависимости от этапов проектирования различают: концептуальную инфологическую модель и концептуальную даталогическую модель, внешнюю инфологическую модель и внешнюю даталогическую модель [17].
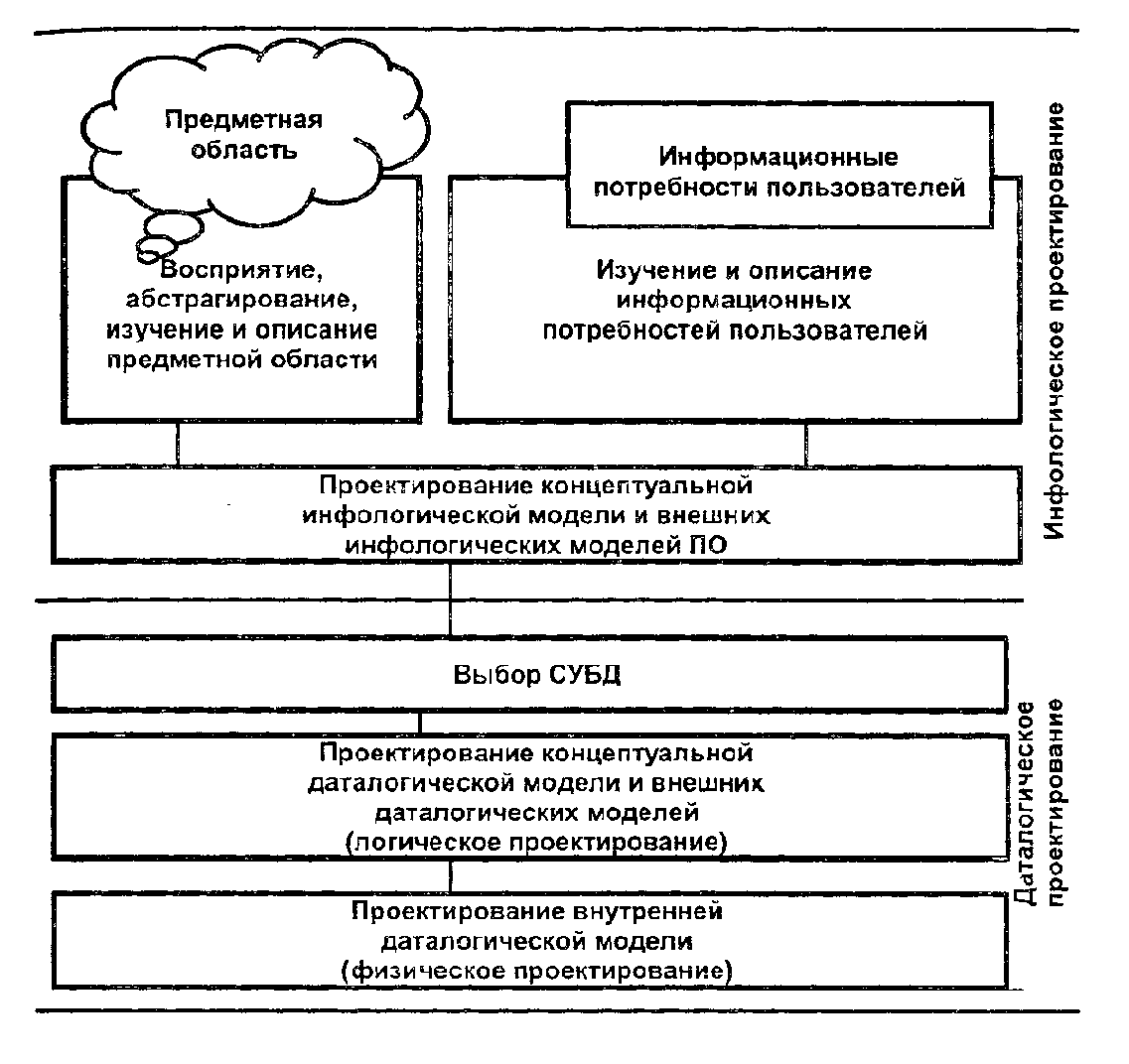
Рис. 2.2. Этапы проектирования базы данных
Задача инфологического моделирования базы данных - получение семантических (смысловых) моделей, отражающих информационное содержание конкретной ПО. На этом этапе выполняется восприятие реальной действительности, абстрагирование, изучение и описание предметной области. Вначале выделяется из воспринимаемой реальности ПО, определяются ее границы, происходит абстрагирование от несущественных частей для данного конкретного применения базы данных. В результате этих действий определяются объекты, их свойства и связи, которые будут существенны для будущих пользователей системы.
После этого изучается предметная область, накапливаются знания о ней. Эти знания представляются в какой-либо языковой системе, обычно это неформализованное описание с использованием естественного языка, математических формул, диаграмм, связей и т.д. Выполняется структуризация знаний о предметной области: выделяются и классифицируются множества составляющих ПО, стандартизуется терминология.
Затем компонуется концептуальная инфологическая модель, основное значение при этом имеют потребности пользователей. Описывается информация, требуемая каждому конкретному пользователю, т.е. описываются запросы к БД. Каждый запрос соотносится с определенным фрагментом предметной области. Формируются описания внешних инфологических моделей, их взаимная увязка с концептуальной инфологической моделью. Полученные описания инфологических моделей отражают составляющие (сущности) предметной области, связи между ними, но эти описания не должны зависеть от методов представления данных в конкретной СУБД.
Концептуальная инфологическая модель призвана обеспечить прочную и долговременную работу всей системы, выдерживать замену одной используемой СУБД на другую.
Задача логического этапа проектирования – организация данных, выделенных на предыдущем этапе проектирования в форму, принятую в выбранной конкретной СУБД. Иными словами, требуется разработать схему концептуальной модели и схемы внешних моделей данных о предметной области, пользуясь только теми типами моделей данных и их особенностями, которые поддерживаются этой СУБД. На этом этапе проектирования обычно не прорабатываются вопросы, связанные с организацией хранения и доступа к данным на внутреннем уровне. Но целесообразно уже здесь получить вполне определенные рекомендации по выбору методов доступа.
Задача физического этапа проектирования – выбор рациональной структуры хранения данных и методов доступа к ним, исходя из арсенала методов и средств, который предоставляется разработчику системой управления базами данных.
Классификация сущностей, расширение ER-модели
Один из активных разработчиков реляционной модели К. Дейт [2] выделил три основные класса сущностей: стержневые, ассоциативные и характеристические, а также подкласс ассоциативных сущностей – обозначения.
Стержневая сущность (стержень) – это независимая сущность.
В рассмотренных ранее примерах стержни - это-
СТУДЕНТ, КВАРТИРА, МУЖЧИНА, ПРЕПОДАВА-ГТЕЛЬ, и другие, названия которых помещены в прямоугольники.
Ассоциативная сущность (ассоциация) - это связь? вида МНОГИЕ-КО-МНОГИМ (-КО-МНОГИМ и т.д.) между двумя или более сущностями или экземпляра- Ч ми сущности. Ассоциации рассматриваются как полноправные сущности:
– могут участвовать в других ассоциациях и обозначениях точно так же, как стержневые сущности;
– могут обладать свойствами, т.е. иметь не только набор ключевых атрибутов, необходимых для указания связей, но и любое число других атрибутов, характеризующих связь.
Характеристическая сущность (характеристика) - это связь вида МНОГИЕ-К-ОДНОМУ или ОДИН-КОД НОМУ между двумя сущностями (частный случай ассоциации). Единственная цель характеристики в рамках рассматриваемой предметной области состоит в описании или уточнении некоторой другой сущности. Необходимость в них возникает в связи с тем, что сущности реального мира имеют иногда многозначные свойства. Муж может иметь несколько жен (пример 2.1), книга – несколько характеристик переиздания (исправленное, дополненное, переработанное, ...) и т.д.
Существование характеристики полностью зависит, от характеризуемой сущности: женщины лишают статуса жен, если умирает их муж.
Для описания характеристики используется новое предложение ЯИМ, имеющее в общем случае вид:
(ХАРАКТЕРИСТИКА (атрибут 1, атрибут 2, ...)
{СПИСОК ХАРАКТЕРИЗУЕМЫХ СУЩНОСТЕЙ}.
Часто используют расширенный язык ER-диаграмм {5, 7] (Enhanced ER-диаграммы), в котором для изображения характеристики используют трапецию (рис. 2.10).

Рис. 2.10. Элементы расширенного языка ER-диаграмм
Обозначающая сущность или обозначение - это связь вида МНОГИЕ-К-ОДНОМУ или ОДИН-К-ОДНОМУ между двумя сущностями и отличается от характеристики тем, что не зависит от обозначаемой сущности.
Обозначения используют для хранения повторяющихся значений больших текстовых атрибутов: кодификаторов изучаемых студентами дисциплин, наименований организаций и их отделов, перечней товаров и т.п.
Описание обозначения внешне отличается от описания характеристики только тем, что обозначаемые сущности заключается не в фигурные скобки, а в квадратике:
ОБОЗНАЧЕНИЕ (атрибут 1, атрибут 2, )[СПИСОК ОБОЗНАЧАЕМЫХ СУЩНОСТЕЙ]
Обозначения и характеристики не являются полностью независимыми сущностями, поскольку они предполагают наличие некоторой другой сущности, которая будет «обозначаться» или «характеризоваться». Однако они все же представляют собой частные случаи сущности и могут, конечно, иметь свойства, могут участвовать в ассоциациях, обозначениях и иметь свои собственные (более низкого уровня) характеристики. Все экземпляры характеристики должны быть обязательно связаны с каким-либо экземпляром характеризуемой сущности. Однако допускается, чтобы некоторые экземпляры характеризуемой сущности не имели связей. Правда, если это касается браков, то сущность «Мужья» должна быть заменена сущностью «Мужчины» (нет мужа без жены).
Теперь можно переопределить стержневую сущность как сущность, которая не является ни ассоциацией, ни обозначением, ни характеристикой. Такие сущности имеют независимое существование [5].
Литература
1. Веттинг Д. Novell NetWare... для пользователя: Пер. с нем. К., BHV, 1993.
2. Дейт К. Введение в системы баз данных. М., Наука, 1980.
3. Денисов АА., Колесников Д.Н. Теория больших систем управления: Учеб. пособие для вузов. Л., Энергоиздат, Ленингр. отдние, 1982.
4. Джексон Г. Проектирование реляционных баз данных для использования с микроЭВМ. М., Мир, 1991.
5. Кириллов В. В. Основы проектирования реляционных баз данных: Учеб. пособие: http://www.citmgu.ru.
6. Кириллов В.В. Структуризованный язык запросов (SQL). СПб., ИТМО, 1994.
7. Коннолли Т., Бегг К., Страчан А. Базы данных: проектирование, реализация и сопровождение. Теория и практика, 2-е изд.. Пер. с англ.: Учебное пособие. М., Вильяме, 2000.
8. Кузнецов С. Д. Основы современных баз данных: Курс лекций: http://www.citmgu.ru.
9. Мартин Дж. Планирование развития автоматизированных систем. М.: Финансы и статистика, 1984.
10. Мейер М, Теория реляционных баз данных. М., Мир, 1987.
11. Озкарахан Э. Машины баз данных и управление базами данных: Пер. с англ. М., Мир, 1989.
12. Словарь по кибернетике: Св. 2000ст. /Под ред. В.С.Михалевича. 2-е изд. К., Гл. ред. УСЭ им.М.П.Бажана, 1989.
13. Тиори Т., Фрай Дж. Проектирование структур баз данных. В 2 кн. М., Мир, 1985.
14. Ульман Дж. Основы систем баз данных. М., Финансы и статистика, 1983.
15. Хаббард Дж. Автоматизированное проектирование баз данных. М., Мир, 1984.
16. Цикритизис Д., Лоховски Ф.
Модели данных. М.: Финансы и статистика, 1985.
17. Четвериков В.Н. и др. Базы и банки данных: Учеб. для вузов по спец. «АСУ» /В.Н.Четвериков, Г.И.Ревунков, Э.Н.Самохвалов; Под ред. В.Н.Четверикова. М., Высш. шк., 1987.
Предисловие. 2
Введение. 5
Глава 1. ИФОРМАЦИОННЫЕ СИСТЕМЫ НА БАЗАХ ДАННЫХ.. 7
1.1. Понятие информационной системы, информационное обеспечение. 7
1.2. Понятие базы данных. 8
1.3. Понятие системы управления базами данных. 9
1.3.1. Обобщенная архитектура СУБД.. 10
1.3.2. Достоинства и недостатки СУБД.. 18
1.3.3. Архитектура многопользовательских СУБД.. 22
1.4. Понятие независимости данных. 26
1.5. Категории пользователей базой данных. 27
1.5.1. Общая классификация пользователей БД.. 27
1.5.2. Администратор базы данных. 29
1.5.3. Разделение функций администрирования. 30
1.6. Средства администрирования баз данных. 32
Глава 2. ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ.. 37
2.1. Жизненный цикл информационной системы.. 37
2.2. Подходы и этапы проектирования баз данных. 40
2.2.1. Цели и подходы к проектированию баз данных. 40
2.2.2. Этапы проектирования баз данных. 42
2.3. Инфологическое проектирование базы данных. 43
2.3.1 Модель «сущность-связь». 44
2.3.2. Классификация сущностей, расширение ER-модели. 51
2.3.3. Проблемы ER-моделирования. 53
2.4. Логическое проектирование. 57
2.4.1. Выбор СУБД.. 57
2.4.1.1. Метод ранжировки. 59
2.4.1.2. Метод непосредственных оценок. 60
2.4.1.3. Метод последовательных предпочтений. 61
2.4.1.4. Оценка результатов экспертного анализа. 62
2.4.2. Даталогические модели данных. 66
2.4.2.1. Иерархическая модель. 67
2.4.2.2. Сетевая модель. 69
2.4.2.3. Реляционная модель. 70
2.4.2.4. Достоинства и недостатки даталогических моделей. 75
2.4.3. Нормализация. 76
2.4.3.1. Понятие функциональной зависимости. 76
2.4.3.2. Аксиомы вывода функциональных зависимостей. 77
2.4.3.3. Первая нормальная форма. 80
2.4.3.4. Вторая нормальная форма. 83
2.4.3.5.Третья нормальная форма. 83
2.4.3.6. Нормализация через декомпозицию.. 85
2.4.3.7. Недостатки нормализации посредством декомпозиции. 88
2.4.3.8. Нормальная форма Бойса–Кодда (НФБК) 90
2.4.3.9. Многозначные зависимости. 91
2.4.3.10. Аксиомы вывода многозначных зависимостей. 93
2.4.3.11. Четвертая нормальная форма. 93
2.4.3.12. Зависимости соединения. 94
2.4.3.13. Пятая нормальная форма. 95
2.4.3.14. Обобщение этапов нормализации. 96
Метод непосредственных оценок
В основу этого метода положена менее жесткая гипотеза об убывающей (но необязательно линейной) зависимости между рангом и относительной ценностью критерия. Вначале каждый j-й эксперт производит упорядочение всех критериев в соответствии с вышерассмотренной процедурой. После этого он эвристическим путем дает численную оценку относительной полезности каждого критерия по сравнению с самым главным, которому присваивается значение, равное единице. Всем неразличимым критериям присваиваются одинаковые значения Сij. В результате каждому критерию в упорядоченном ряду вместо рангов сразу присваиваются числа Сij, совокупность которых должна образовать невозрастающую последовательность. При использовании метода непосредственных оценок возникает возможность более дифференцированно подходить к оценке важности отдельных критериев, но при этом понижается достоверность полученной информации.
Метод последовательных предпочтений
Алгоритм последовательных предпочтений предназначен для повышения достоверности информации, полученной от экспертов методом непосредственных оценок. Он позволяет каждому эксперту провести самоконтроль суждений на основе сопоставления трех подходов: ранжирования критериев, числовой оценки их ценности и сравнения п–2 пар специально подобранных абстрактных объектов.
Последняя процедура, отражающая сущность метода последовательных предпочтений, основана на следующей гипотезе. Если ценность i-го критерия объекта некоторого класса для j-го эксперта есть Сij, то ценность объекта по всем критериям определяется


В результате будут получены (n– 2) условия:

Далее производится последовательная проверка каждого из этих условий, начиная с последнего, на соответствие ранее выбранным оценкам Сij и их ранжировке. При выявлении противоречий в i-м условии эксперт должен либо изменить знак отношения R, либо откорректировать значение величины Сij. В последнем случае он обязан убедиться в том, что не оказалась нарушенной первоначальная ранжировка критериев. При нарушении ее необходимо либо изменить порядок критериев, либо откорректировать значение Сij. После исправления последней оценки Сij ее значение может отличаться от единицы. Следует отметить, что в этом случае психологические ограничения не дают использовать метод последовательных предпочтений, когда число рассматриваемых критериев превышает семь [3]. Рассмотрим пример.
Пример 2.3. Пусть некоторый эксперт выставил следующий ряд коэффициентов Сi, отражающих его мнение об относительной ценности шести частных критериев некоторого объекта (табл. 2.4) [3].
Таблица 2.4
| i | 1 | 2 | 3 | 4 | 5 | 6 | |||||||
| Сij | 1,0 | 0,9 | 0,7 | 0,6 | 0,3 | 0,1 |
Для уточнения оценок коэффициентов Сi, эксперту предлагается сравнивать четыре пары абстрактных объектов. Каждому объекту соответствует вектор х=(x1, x2, ..., хi, ..., x6), где xi=(0; 1): 1 –учитывается полезность i-го критерия, 0 – не учитывается; тогда:
1) (100000) хуже (011111);
2) (010000) лучше (001111);
3) (001000) хуже (000111);
4) (000100) лучше (000011).
Эксперт вынес систему решений. Соотношение x(1) лучше x(2) соответствует большей предпочтительности для эксперта объекта х(1) по сравнению с объектом х(2).
Непротиворечивость принятых решений должна подтверждаться выполнением системы неравенств:

Проверка неравенств начинается с последнего (четвертого). Третье и четвертое неравенства выполняются, второе – нет; значит, необходимо скорректировать значения коэффициента С2. Примем значение С2=2. Однако одновременно необходимо изменить значение С1 таким образом, чтобы, во-первых, сохранился первоначальный порядок критериев, определенный экспертом, т. е. С1>С2, и, во-вторых, выполнялось первое неравенство. Принимаем, например, значение C1=2,5. В результате применения метода последовательных предпочтений получили непротиворечивый ряд оценок (табл. 2.5), которые в дальнейшем необходимо масштабировать.
Таблица 2.5
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
|
Ci |
2,5 |
2,0 |
0,7 |
0,6 |
0,3 |
1,0 |
Метод ранжировки
В соответствии с данным методом производится нумерация всех критериев полученного ряда, причем все неразличимые критерии, которые оказались на одном месте, нумеруются в произвольном порядке [3]. В результате данной процедуры каждый критерий получает свой номер. Ранг критерия определяется его номером, если на его месте в ряду отсутствуют какие-либо другие. Если на одном месте находится несколько неразличимых критериев, то ранг каждого из них равен среднему арифметическому их новых номеров.
Пример 2.2 ([3]). Пусть имеется следующий ряд упорядоченных критериев q1, q2, ..., q8 для j-го эксперта:

Ранги критериев, вычисленные в соответствии с вышеуказанной процедурой, сведены в табл. 2.2.
Таблица 2.2
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||||||||
| rij | 8,0 | 4,5 | 1,0 | 4,5 | 2,5 | 2,5 | 7,0 | 6,0 |
Переход от рангов к коэффициентам Сij. производится на основе гипотезы о линейной зависимости между рангом и относительной ценностью критерия. Чем ниже ранг, тем более важным является соответствующий критерий. Определение коэффициентов Сij для произвольного rij(1 < rij £ п) производится в соответствии со следующей формулой:

Для рассмотренного примера коэффициенты Сij сведены в табл. 2.3.
Таблица 2.3
| i | q1 | q2 | qз | q4 | q5 | q6 | q7 | q8 | |||||||||
| Cij | 0,125 | 0,433 | 1,000 | 0,433 | 0,812 | 0,812 | 0,250 | 0,375 |
Следует отметить, что гипотеза о линейной зависимости между рангом и относительной ценностью критерия делает оценки Сij весьма грубыми, но определяет их сравнительно высокую достоверность.
Методы поиска и индексирования данных
При рассмотрении последующего учебного материала используются модели, приведенные в разд. 3.1, 3.2.
Многозначные зависимости
Выше было показано, что присутствие функциональных зависимостей в реляционной схеме означает возможность декомпозиции схемы, уменьшающей избыточность и при этом сохраняющей информацию. Однако существование F-зависимостей не является необходимым условием такой декомпозиции. Рассмотрим состояние отношения Назначение табл. 2.8.
Кортеж

на самолёте типа p. В отношении не выполняются ни F-зависимость РЕЙС
Рассмотрим другое состояние отношения Назначение, задаваемое табл. 2.10. Если разложить это состояние на схемы (РЕЙС, ДЕНЬ-НЕДЕЛИ) и (РЕЙС, ТИП-САМОЛЁТА), то снова получится вариант из табл. 2.9. Однако соединение отношений табл. 2.9 не восстанавливает исходного отношения.
Таблица 2.8
| Назначение | РЕЙС | ДЕНЬ-НЕДЕЛИ | ТИП-САМОЛЁТА | ||||
| 106 | Понедельник | 747 | |||||
| 106 | Четверг | 747 | |||||
| 106 | Понедельник | 1011 | |||||
| 106 | Четверг | 1011 | |||||
| 204 | Среда | 707 | |||||
| 204 | Среда | 727 |
Таблица 2.9
| День назначения | РЕЙС | ДЕНЬ-НЕДЕЛИ | |||
| 106 | Понедельник | ||||
| 106 | Четверг | ||||
| 204 | Среда |
| Тип самолёта назначения | РЕЙС | ТИП-САМОЛЁТА | |||
| 106 | 747 | ||||
| 106 | 1011 | ||||
| 204 | 707 | ||||
| 204 | 727 |
Таблица 2.10
| Назначение | РЕЙС | ДЕНЬ-НЕДЕЛИ | ТИП-САМОЛЁТА | ||||
| 106 | Понедельник | 747 | |||||
| 106 | Четверг | 747 | |||||
| 106 | Четверг | 1011 | |||||
| 204 | Среда | 707 | |||||
| 204 | Среда | 727 |
Каковы же свойства первого состояния отношения Назначение, отсутствующие у второго, которые обеспечивают декомпозицию без потери информации? В первом случае, если самолет некоторого типа использован для выполнения маршрута в один день, он может быть использован для выполнения этого маршрута в любой другой день. Это свойство отсутствует во втором состоянии отношения Назначение, поскольку рейс №106 может использовать тип 1011 в четверг, но не в понедельник.
Отношение в первом состоянии следует подвергнуть декомпозиции, ибо при заданном рейсе ДЕНЬ-НЕДЕЛИ не содержит информации об атрибуте ТИП-САМОЛЕТА, и наоборот.
Сформулируем это свойство по-другому. Если в отношении Назначение существуют кортежи


Пусть R – реляционная схема, X и Y - непересекающиеся подмножества R, и пусть Z=R–(XY). Отношение r(R) удовлетворяет многозначной зависимости (MV-зависимости) X
Из симметрии определения относительно t1 и t2 следует, что в r
существует также t4 для которого
t4(X)=t1(X), t4(Y)=t1(Y), t4(Z)=t2(Z).
Пример 2.17. MV-зависимость РЕЙС
Модель «сущность-связь»
Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить на доступном широкому кругу пользователей и разработчиков языке. Известны следующие средства создания внешних моделей:
– семантические сети;
– язык инфологического моделирования;
– ЕR-диаграммы.
Наибольшую популярность из-за доступности, наглядности и компактности приобрел подход моделирования «сущность-связь».
Модель «сущность-связь» (Entity-Relationship model) разработана Ченом в 1976 году с целью упрощения концептуального проектирования баз данных.
Основными элементами этой модели являются:
– сущности;
– атрибуты;
– связи.
Сущность представляет собой различимое множество объектов (экземпляров сущности) реального мира с одинаковым набором атрибутов.
Сущность идентифицируется именем и списком свойств (атрибутов). База данных о сколько-нибудь значительной предметной области содержит много (несколько) сущностей. Каждый экземпляр сущности обладает уникальным набором значений атрибутов.
На ER-диаграммах сущность представляется прямоугольником с именем сущности внутри.
Атрибут – неотъемлемое свойство сущности или связи. Именно по значениям атрибутов можно идентифицировать экземпляр сущности. Значения атрибутов представляют основную часть сведений, хранящихся в БД.
На ER-диаграммах атрибут представляется овалом (эллипсом), соединенным с соответствующей сущностью линией и с именем атрибута внутри.
С понятием атрибута тесно связано понятие домена.
Домен – множество значений, которые может принимать атрибут. Разработчика не должен удивлять тот факт, что домены могут быть бесконечными (хотя и перечислимыми) множествами
Атрибуты делятся на:
– простые;
– составные;
– однозначные;
– многозначные;
– производные.
Простой атрибут состоит из одного компонента с независимым существованием.
Составной атрибут состоит из нескольких компонентов, каждый из которых характеризуется независимым существованием.
Однозначный атрибут содержит одно значение для одного экземпляра сущности.
Многозначный атрибут может содержать несколько значений для одного экземпляра сущности.
Производный атрибут представляет значение, производное (вычисляемое) от значения связанного с ним атрибута или некоторого множества атрибутов, принадлежащих некоторой сущности.
Вопрос однозначной идентификации экземпляров сущности связан с понятием ключа.
Ключ - минимальный набор атрибутов, по значениям которых можно идентифицировать экземпляр сущности.
В наборе атрибутов сущности можно выделить несколько потенциальных ключей. Потенциальный ключ, используемый реально для идентификации экземпляров сущности называется первичным ключом.
На ER-диаграммах имена атрибутов, выбранных в качестве первичного ключа, подчеркиваются.
Суперключом называется набор атрибутов, содержащий ключ.
Ассоциирование двух или более сущностей называется связью.
Связи, также как и сущности и атрибуты идентифицируют именем.
На ER-диаграммах связь изображается в виде ромба или шестиугольника, помеченного соответствующим именем. Соединение с ассоциированными сущностями производится линиями.
Пример ER-диаграммы с обозначениями сущностей, их атрибутов и связей представлен на рис. 2.3.

Рис. 2.3. Пример ER-диаграммы
Степень связи - количество сущностей, которые охвачены данной связью.
Если связь определена между двумя сущностями, то ее степень - 2, а называется такая связь бинарной. Связь между тремя сущностями называется тернарной, четырьмя сущностями – кватернарной и т.д.
В общем случае связь между п сущностями называется n - арной. Примеры различных связей представлены на рис. 2.4.

Рис. 2.4.Примеры связей: а) – бинарной; б) – тернарной; в) – кватернарной; г) – унарной (рекурсивной)
Рекурсивная связь – связь, в которой одни и те же сущности участвуют несколько раз в разных ролях.
Рекурсивная связь часто называют унарной. Пример такой связи представлен на рис. 2.4,2. В приведенном примере каждый студент из сущности СТУДЕНТ может исполнять обязанности дежурного по отношению к другим студентам той же сущности.
При построении инфологической модели, на сущности – участницы некоторых связей могут накладываться ограничения, отражающие семантику предметной области.
С этими ограничениями связано понятие показателя кардинальности связи.
Показатель кардинальности указывает количественное соотношение экземпляров сущностей для каждой связи [5, 7].
Классическими признаны бинарные связи с показателями кардинальности «ОДИН-К-ОДНОМУ», «ОДИН-КО-МНОГИМ», «МНОГИЕ-КО-МНОГИМ».
Пусть в предметной области выделены сущности А и В.
1. Связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому экземпляру сущности А соответствует не более одного экземпляра сущности В (рис. 2.5).

Рис. 2.5. Связь ОДИН-К-ОДНОМУ
Декан осуществляет свою деятельность на одном факультете вуза.
2. Связь ОДИН-КО-МНОГИМ (1:М): каждому экземпляру сущности А соответствуют О, 1 или несколько представителей сущности В (рис. 2.6).

Рис. 2.6. Связь ОДИН-КО-МНОГИМ
В квартире может проживать несколько жильцов.
3. Связь МНОГИЕ-КО-МНОГИМ (М:М): каждому экземпляру сущности А соответствуют 0, 1 или несколько представителей сущности В, каждому экземпляру сущности В соответствуют 0, 1 или несколько представителей сущности А (рис. 2.7).

Рис. 2.7. Связь МНОГИЕ-КО-МНОГИМ
Процесс обучения осуществляется множеством преподавателей с множеством студентов.
Пример 2.1. Если связь между сущностями МУЖЧИНЫ и ЖЕНЩИНЫ называется БРАК, то существует четыре возможных представления такой связи (рис. 2.8) [5].
Характер связей между сущностями может оказаться более сложным (рис. 2.9) [5, 7].
Рис. 2.8. Пример связи БРАК между сущностями МУЖЧИНЫ и ЖЕНЩИНЫ

Рис. 2.9. Пример множества связей между сущностями ПРЕПОДАВАТЕЛЬ и СТУДЕНТ
В приведенных примерах для повышения иллюстративности рассматриваемых связей не показаны атрибуты сущностей и ассоциаций во всех ER-диаграмах. Так, ввод лишь нескольких основных атрибутов в описание значительно усложняет ER-диаграмму. В связи с этим язык ER-диаграмм используется для построении небольших моделей и иллюстрации отдельных фрагментов больших. Для представления полных инфологических моделей предметной области применяется менее наглядный, но более содержательный язык инфологического моделирования (ЯИМ) [5], в котором сущности и ассоциации представляются предложениями вида:
СУЩНОСТЬ (атрибут 1, атрибут 2, ..., атрибут n)
Связь [СУЩНОСТЬ S1, СУЩНОСТЬ S2, ...]
(атрибут 1, атрибут 2, ..., атрибут n),
где S - степень связи, а атрибуты, входящие в ключ, должны быть отмечены с помощью подчеркивания.
Так, рассмотренный выше пример множества связей между сущностями, может быть описан на ЯИМ следующим образом.
ПРЕПОДАВАТЕЛЬ (УслНомерП,
Фамилия, Имя, Отчество, УчСтепень)
СТУДЕНТ (УслНомерС.
Фамилия, Имя, Отчество,
Адрес, Специальность, Пол)
Лектор [ПРЕПОДАВАТЕЛЬ 1, СТУДЕНТ М]
(УслНомерП, УслНомерС)
Консультант [ПРЕПОДАВАТЕЛЬ М, СТУДЕНТ Р]
(УслНомерП, УслНомерС).
Для определения связей между сущностями необходимо, как минимум, выделить в интересующей предметной области сами сущности. Но это непростая задача, так как в разных предметных областях один и тот же объект может быть сущностью, атрибутом или связью.
Модель внешней памяти
Данные хранятся во внешней памяти на магнитных дисках, магнитных лентах и т.д., а их обработка выполняется в оперативной памяти ЭВМ. Поэтому при обработке некоторые порции данных пересылаются из внешней памяти в оперативную либо наоборот [17].
При больших объемах данных в БД может потребоваться несколько томов внешней памяти. Однако обмен между внешней и оперативной памятью выполняется небольшими порциями данных – обычно объемом не более нескольких сотен байт. С этой целью внешняя память разбивается на части, называемые блоками или страницами. Данные пересылаются блоками. Операции пересылки еще называют обменом данными между внешней и оперативной памятью. Такой обмен называется чтением блока, а в обратном направлении - записью блока.
При чтении блока, последний помещается в оперативной памяти в специально отведенный (буферный) участок памяти. Может отводиться участок под несколько буферов (буферный пул). Чем больше буферный пул, тем эффективнее обработка данных. При считывании другого блока из внешней памяти в тот же самый буфер предыдущее содержимое буфера теряется. При внесении изменений в блок вначале блок считывается в буфер, затем выполняются изменения и далее блок записывается во внешнюю память.
Для организации каждого файла в зависимости от его размера во внешней памяти ему выделяется от одного до

Каждый байт в блоке пронумерован:

В качестве адресов записей файла во внешней памяти используют: машинный адрес, относительный адрес, ключ записи [17].
В качестве относительного адреса записи файла используют ее номер по порядку (внутрисистемный номер) в файле либо комбинацию таких составляющих адреса, как номер блока и относительный адрес в блоке, ибо номер блока и значение ключа.
В последнем случае, после считывания блока в буфер оперативной памяти, доступ к записи в буфере осуществляется с помощью какого-либо метода поиска записей в файле по значению ключа.
При чтении записи из блока, который уже находится в буфере, обмен с внешней памятью не выполняется. Во многих системах при вводе записи ей присваивается уникальный системный идентификатор – ключ базы данных.
Запись обычно состоит из:
1) служебных полей, в которых хранятся указатели, реализующие связи с другими записями, и другая информация, необходимая для организации управления файлом,
2) полей хранимых данных.
Записи могут быть фиксированной и переменной длинны. Записи размещаются в блоках плотно, без промежутков, последовательно одна за другой. В блоке часть памяти отводится для служебной информации о блоке: относительные адреса свободных участков памяти, указатели на следующий блок и т.д.
Если файл базы данных состоит из записей фиксированной длинны, то в одном блоке может разместиться


где



Однако обычно блоки заполняются не полностью, например, наполовину. Оставшаяся область блока остается некоторое время при работе системы незаполненной (зарезервированной). В дальнейшем эта область заполняется при расширении (увеличении) записей, хранящихся в блоке, или при поступлении в систему новых записей, которые в соответствии со значениями их ключей или по другим условиям необходимо поместить в одном блоке с уже хранящимися записями. По истечении некоторого времени блок заполняют полностью.
Для хранения поступающих данных, которые должны были бы попасть в этот блок, выделяется дополнительный блок памяти в области переполнения. Записи, которые должны были размещаться в одном блоке, связываются специальными указателями в одну цепь.
Процесс выделения дополнительных блоков в области переполнения можно было бы не ограничивать, если бы при этом не снижалась эффективность (по временному критерию) обработки хранимых данных.
Снижение эффективности обработки данных связано с тем, что система непроизводительно затрачивает время на поиск записей в области переполнения, что сказывается на увеличении общего времени поиска требуемых записей (по сравнению со случаем, когда область переполнения еще не была использована и все записи были размещены в основной области).
Поэтому периодически файл реорганизуется: при необходимости файлу добавляется требуемое количество блоков в основной области памяти и выполняется требуемая перекомпоновка записей. При этом исходят из расчета, чтобы можно было освободить область переполнения, а все записи разместить в блоках основной области, причем, в каждом блоке разместить записи последовательно и в таком количестве, чтобы


где

Считается, что все блоки каждого файла пронумерованы:


Среднее время выполнения операций обмена зависит от типа устройства внешней памяти (от его характеристик) и от размера блока:

где



Время поиска данных в файле:

где




Если
На скорость поиска данных в файле наибольшее влияние оказывают следующие характеристики файла и технических устройств внешней памяти, использованных для его организации [17]:
– объем блока;
– объем байта;
– количество записей в блоке файла

– количество записей в блоке индекса;
– количество блоков в файле данных

– доля резервируемой части блока

– длина поля, отведенного для указателя;
– количество записей в файле

– размер записи

– длина ключевого поля записи;
– число записей файла, удовлетворяющих условию поиска Q;
– среднее число блоков переполнения на один блок файла;
– среднее время обмена

На рис. 3.7 изображен файл со следующими характеристиками:



Моментальные снимки таблиц
Метод моментальных снимков таблиц позволяет асинхронно распространять результаты изменений, выполненных в отдельных таблицах, группах таблиц, представлениях или фрагментах таблиц в соответствии с заранее установленным графиком [7].
Общий подход к созданию моментальных снимков состоит в использовании файла журнала восстановления базы данных, который позволяет минимизировать уровень дополнительной нагрузки на систему. Основная идея состоит в том, что файл журнала является лучшим источником для получения сведений об изменениях в исходных данных. Достаточно иметь механизм, который будет обращаться к файлу журнала для выявления изменений в исходных данных, после чего распространять обнаруженные изменения на целевые базы данных, не оказывая никакого влияния на нормальное функционирование исходной системы. Различные СУБД реализуют подобный механизм по-разному:
в некоторых случаях данный процесс является частью самого сервера СУБД, тогда как в других случаях он Реализуется как независимый внешний сервер.
Для отправки сведений об изменениях на другие байты целесообразно применять метод организации очередей. Если произойдет отказ сетевого соединен! или целевого сайта, сведения об изменениях могут с храниться в очередях до тех пор, пока соединение I будет восстановлено. Для гарантии сохранения согласованности данных порядок доставки сведений на целевые сайты должен сохранять исходную очередное внесения изменений.
Недостатки нормализации посредством декомпозиции
При нормализации схемы отношения посредством декомпозиции возникает ряд проблем.
Во-первых, временная сложность процесса не ограничивается полиномиальной [10]. В терминах размера схемы отношения и заданного множества F-зависимостей схема отношения может обладать экспоненциальным числом ключей. Кроме того, проверка атрибута схемы на непервичность является NP-полной задачей.
Во-вторых, число порожденных процессом схем отношения может оказаться большим, чем в действительности необходимо для 3НФ.
Пример 2.13. Пусть заданы схема










Далее в





Окончательная схема базы данных в 3НФ имеет вид
R
Существует декомпозиция R в ЗНФ с двумя схемами отношений, а именно:



Третья проблема состоит в том, что при декомпозиции схемы отношения могут возникнуть частичные зависимости. Эти зависимости могут породить в окончательной схеме базы данных больше схем, чем это в действительности необходимо.
Пример 2.14. Для схемы отношения







Фактическим ключом





Схемы


Этих недостатков можно избежать, если при декомпозиции следить за тем, чтобы промежуточное множество атрибутов в разлагаемой транзитивной зависимости было минимальным. В примере 2.14 атрибут
Четвертая проблема состоит в том, что для построенной схемы базы данных заданное множество F-зависимостей может оказаться ненавязанным [10].
Пример 2.15. Пусть заданы схема







Множество


Наконец, пятая проблема. С помощью декомпозиции можно породить схемы со «скрытыми» транзитивными зависимостями.
Пример 2.16. Пусть заданы схема







Несмотря на то, что
Чтобы избежать проблем, возникающих при декомпозиции схем отношений, необходимо использовать другие методы получения третьей нормальной формы, например, метод синтеза 3НФ [10].
Неплотный индекс
Пусть основной файл



2) записи файла


Для осуществления последовательного поиска блоки первого уровня могут быть связаны в цепь по возрастанию значения ключа. Поиск в В-дереве выполняется так же, как и в неплотном индексе. Удачный и неудачный поиск записи в В-дереве требует

При поиске по интервалу значений


Нормализация через декомпозицию
Всегда можно начать с того, что, взяв некоторую схему отношения

Разложение схемы отношений означает разбиение схемы отношения на пару схем отношений
На самом деле процесс декомпозиции схемы не бесконечен. Каждый раз, когда разлагается схема отношения, обе получившиеся в результате схемы становятся меньше, а в схеме отношения, содержащей только два атрибута, не может быть никакой транзитивной зависимости [10].
Пример 2.12. Пусть
где I-КЛАСС и II -КЛАСС – количество посадочных мест в каждом салоне. Пусть множество выделенных ключей
К={РЕЙС, ПУНКТ-ОТПРАВЛЕНИЯ ПУНКТ-НАЗНАЧЕНИЯ ВРЕМЯ-ВЫЛЕТА, ПУНКТ-ОТПРАВЛЕНИЯ ПУНКТ-НАЗНАЧЕНИЯ ВРЕМЯ-ПРИБЫТИЯ}.
Предполагается, что в одно и то же время не может быть двух рейсов с одинаковыми пунктами отправления и назначения. Пусть все выделенные ключи действительно являются ключами, и пусть имеются также следующие F-зависимости в множестве
ТИП-САМОЛЕТА
ВРЕМЯ-ВЫЛЕТА ДЛИТЕЛЬНОСТЬ-ПОЛЕТА
ВРЕМЯ-ПРИБЫТИЯ ДЛИТЕЛЬНОСТЬ-ПОЛЕТА
I-КЛАСС II-КЛАСС
I-КЛАСС КОЛИЧЕСТВО-ПОСАДОЧНЫХ-МЕСТ-Ш-КЛАСС,
II-КЛАСС КОЛИЧЕСТВО-ПОСАДОЧНЫХ-МЕСТ
Казалось бы, ВРЕМЯ-ВЫЛЕТА ВРЕМЯ-ПРИБЫТИЯ
Сначала удалим транзитивную зависимость атрибута ПИТАНИЕ от РЕЙСА через ВРЕМЯ-ВЫЛЕТА ДЛИТЕЛЬНОСТЬ-ПОЛЕТА. Получим схему отношения
с выделенными ключами

и схему отношения
ПИТАНИЕ)
с выделенным ключом
Схема

с выделенными ключами

и схему

с выделенным ключом
К12={ТИП-САМОЛЕТА}.
Схема отношения

с выделенным ключом

и схему отношения

с выделенным ключом

Декомпозиция
R

находится в 3НФ.
Схема базы данных R не однозначна. Есть точки, в которых можно выбирать пути декомпозиции определенного отношения с целью удаления транзитивно зависимого атрибута. Так, на первом шаге можно было выбрать
так как ПИТАНИЕ также транзитивно зависит от РЕЙСА через ВРЕМЯ-ПРИБЫТИЯ ДЛИТЕЛЬНОСТЬ-ПОЛЕТА. На третьем шаге существует три варианта декомпозиции
Нормальная форма Бойса–Кодда (НФБК)
Схема отношения
Схема базы данных R находится в нормальной форте Бойса-Кодда (НФБК) относительно множества F-зависимостей

Схема отношения



Для схемы отношения, не находящейся в НФБК, можно всегда провести декомпозицию в схему базы данных в НФБК [10].
С одной стороны, НФБК в некотором смысле является более сильной, чем 3НФ, а значит, более желательной. Но, с другой стороны, НФБК имеет свои проблемы [10]. Из предыдущего изложения следует, что при заданном множестве F-зависимостей над
Пример 2.16. Пусть заданы схема






Несмотря на то чт R1, R2 формально находятся в ЗНФ, в Rl существует «скрытая» транзитивная зависимость С от AD.
Чтобы избежать проблем, возникающих при декомпозиции схем отношений, необходимо использовать другие методы получения третьей нормальной формы, например, метод синтеза ЗНФ [10].
2.4.3.8. Нормальная форма Бойса–Кодда (НФБК)
Схема отношения R находится в нормальной форме Бойса-Кодда
(НФБК) относительно множества F-зависимостей F, если она находится в 1НФ и никакой атрибут в Л не зависит транзитивно ни от одного ключа R [10].
Схема базы данных R находится в нормальной форме Бойса-Кодда
(НФБК) относительно множества F- зависимостей F, если каждая схема отношения

НФБК включает в себя 3НФ [10].
отношения R находится в нормальной форме Бойса-Кодда
(НФБК) относительно множества F-зависимостей F, если для каждого подмножества Y из R и каждого атрибута



нетривиально определяет произвольный атрибут из R, то Y
есть сверхключ R.
Для схемы отношения, не находящейся в НФБК, ложно всегда провести декомпозицию в схему базы данных в НФБК [10].
С одной стороны, НФБК в некотором смысле является более сильной, чем ЗНФ, а значит, более желательной. Но, с другой стороны, НФБК имеет свои проблемы [10]. Из предыдущего изложения следует, что при заданном множестве F-зависимостей над R можно найти схему базы данных в ЗНФ, полностью характеризующую F. Для НФБК это неверно. Множество F-зависимостей может не иметь полной НФБК схемы базы данных, кроме того, проверка свойства НФБК для заданной схемы базы данных является NP-полной задачей.
Обеспечение прозрачности
В определении РСУБД, приведенном в разд.5.1, утверждается, что система должна обеспечить прозрачность распределенного хранения данных для кон го пользователя. Под прозрачностью понимается сокрытие от пользователей деталей реализации системы. Например, в централизованной СУБД обеспечение независимости программ от данных также можно рассматривать как одну из форм прозрачности – в данном случае от пользователя скрываются изменения, происходящие в определении и организации хранения данных.
Распределенные СУБД могут обеспечивать различные уровни прозрачности. Однако в любом случае преследуется одна и та же цель: сделать работу с распределенной базой данных совершенно аналогичной работе с обычной централизованной СУБД. Выделяют четыре основных типа прозрачности, которые могут иметь место в системе с распределенной базой данных [7].
– Прозрачность распределенности.
– Прозрачность транзакций.
– Прозрачность выполнения.
– Прозрачность использования.
Следует отметить, что полная прозрачность не всегда принимается как одна из целевых установок. В [7] указывается, что приложения, написанные с учетом полной прозрачности доступа в географически распределенной базе данных, обычно характеризуются недостаточными управляемостью, модульностью и производительностью обработки сообщений.
Обобщение этапов нормализации
Упрощенная обобщенная схема этапов нормализации отношений с привязкой к известным нормальным формам, выполняемая на этапе логического проектирования базы данных, представлена на рис. 2.28.

Рис. 2.28. Обобщённая схема процесса нормализации
Глава 3. ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ ДАННЫХ В СУБД.. 2
3.1. Списковые структуры.. 2
3.1.1. Последовательное распределение памяти. 3
3.1.2. Связанное распределение памяти. 5
3.2. Модель внешней памяти. 9
3.3. Методы поиска и индексирования данных. 12
3.3.1 Последовательный поиск. 12
3.3.2. Бинарный поиск. 14
3.3.3. Индекс - «бинарное дерево». 14
3.3.4. Неплотный индекс. 16
3.3.5. Плотный индекс. 18
3.3.6. Инвертированный файл. 19
Глава 4. МАТЕМАТИЧЕСКИЕ ОСНОВЫ МАНИПУЛИРОВАНИЯ РЕЛЯЦИОННЫМИ ДАННЫМИ.. 21
4.1. Теоретические языки запросов. 21
4.1.1. Реляционная алгебра. 21
4.1.2. Реляционное исчисление кортежей. 27
4.1.3. Реляционное исчисление доменов. 32
4.1.4. Сравнение теоретических языков. 33
4.2. Определение реляционной полноты.. 34
Обобщенная архитектура СУБД
Основной интерес применения СУБД заключается в том, чтобы предложить пользователям (или прикладным процессам) абстрактное представление данных, скрыв особенности хранения и управления ими.
Обобщенная структура связей программ и данных при использовании СУБД представлена на рис. 1.1 [5].

Рис. 1.1. Связь программ и данных при использовании СУБД
СУБД должна предоставлять доступ к данным посредством прикладных программ любым пользователям, включая и тех, которые практически не имеют представления о:
– физическом размещении в памяти данных и их описаний;
– механизмах поиска запрашиваемых данных;
– проблемах, возникающих при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
– способах обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа;
– поддержании баз данных в актуальном состоянии и множестве других функций СУБД [5, 8, 17].
При выполнении основных из этих функций СУБД должна использовать различные описания данных. Очевидно, что в таких описаниях обязательно должны быть учтены:
– сущности
интересующей предметной области;
– атрибуты,
характеризующие неотъемлемые свойства каждой сущности;
– связи,
ассоциирующие выделенные сущности.
С самых общих позиций, в архитектуре современных СУБД выделяют три уровня абстракции, т.е. три уровня описания элементов хранимых данных. Эти уровни составляют трехуровневую архитектуру, представленную на рис. 1.2, которая охватывает внешний, концептуальный и внутренний уровни [7].

Рис. 1.2. Трехуровневая архитектура ANSI/SPARC
Представленный подход к описанию данных предложен комитетом ANSI/SPARC (Комитет Планирования Стандартов и Норм Национального Института Стандартизации США) и имеет целью отделение пользовательского представления о базе данных от ее физической организации.
Такое отделение обеспечивает независимость хранимых данных и желательно по следующим причинам.
– Каждый пользователь должен иметь возможность обращаться к данным, используя свое представление о них, изменять свое представление о данных без влияния на представления других пользователей.
– Пользователи не должны иметь дело с деталями физической организации данных, т.е. не должны зависеть от особенностей физического хранения данных.
– Администратор базы данных (АБД) должен иметь возможность изменять структуру хранения данных в базе так, чтобы эти изменения оставались «прозрачными» для остальных пользователей.
– Структура базы данных не должна зависеть от физических аспектов хранения, например, при переключении на новое устройство внешней памяти.
Внешний уровень - представление базы данных с точки зрения конкретных пользователей.
Указанный уровень может включать несколько различных представлений БД со стороны различных групп пользователей. При этом каждый пользователь имеет дело с представлением предметной области, выраженным в наиболее понятной и удобной для него форме. Такое представление содержит только те сущности, атрибуты и связи, которые интересны ему при решении профессиональных задач.
Различные представления на внешнем уровне могут пересекаться, т.е. использовать общие описания абстракций предметной области.
На внешнем уровне создается инфологическая модель БД (внешняя схема), полностью независимая от платформы (т.е. вычислительной системы, на которой будет использоваться). Инфологическая модель является человеко-ориентированной: средой ее хранения может быть память человека, а не ЭВМ. Инфологическая модель не изменяется до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Концептуальный уровень – обобщающее представление базы данных, описывающее то, какие данные хранятся в БД, а также связи, существующие между ними.
Концептуальный уровень является промежуточным в трехуровневой архитектуре. Содержит логическую структуру всей базы данных. Фактически, это полное представление требований к данным со стороны организации, которое не зависит от соображений относительно способа их хранения. На концептуальном уровне необходимо выделить:
– сущности, их атрибуты и связи;
– ограничения, накладываемые на данные;
– семантическую информацию о данных;
– информацию о мерах обеспечения безопасности.
Концептуальный уровень поддерживает каждое внешнее представление. Поэтому на этом уровне содержатся любые доступные пользователю данные, за исключением сведений о методах хранения этих данных.
На концептуальном уровне создается даталогическая модель
(концептуальная схема БД), представляющая собой описание инфологической модели (внешней схемы) на языке определения данных конкретной СУБД. Эта модель является компыотеро-ориентированной (зависит от применяемой на компьютере СУБД).
Внутренний уровень – физическое представление базы данных, описывающее методы их хранения в вычислительной системе.
Данный уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Содержит описания структур данных и отдельных файлов, используемых для хранения данных в запоминающих устройствах.
На внутреннем уровне осуществляется взаимодействие СУБД с методами доступа операционной системы с целью эффективного размещения данных на носителях, создания индексов и т.д. На этом уровне используется следующая информация:
– карта распределения дискового пространства для хранения данных и индексов;
– описание подробностей сохранения записей (с указанием реальных размеров сохраняемых элементов данных);
– сведения о размещении записей;
– сведения о возможном сжатии данных и выбранных методах их шифрования.
Реализация перечисленной информации производится на физическом уровне вычислительной системы, который контролируется операционной системой. В настоящее время функции СУБД и операционной системы на физическом уровне строго не разграничиваются. В одних СУБД используются все предусмотренные в данной операционной системе методы доступа, в других применяются только основные и реализована собственная файловая система.
На внутреннем уровне создается физическая модель БД (внутренняя схема), которая также является ком-пьютеро-ориентированной (зависит от СУБД и операционной системы). С ее помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным по именам, не заботясь об их физическом расположении. По этой модели СУБД отыскивает необходимые данные на внешних запоминающих устройствах.
Соответствующие трехуровневой архитектуре ANSI/ SPARC три уровня моделей данных для описания предметной области и реализации базы данных представлены на рис.1.3 [5].
Для реализации рекомендаций ANSI/SPARC и выполнения сервисных функций, СУБД строится по модульному принципу и является сложным программным продуктом. Конкретный состав модулей и их взаимосвязей в реальных СУБД сильно различается, но можно выделить ряд их обобщенных компонентов.
Основные программные компоненты СУБД представлены на рис. 1.4 [7].

Рис. 1.3. Уровни моделей данных

Рис. 1.4. Основные компоненты типичной СУБД
– Процессор запросов. Это основной компонент СУБД, который преобразует запросы в последовательность низкоуровневых инструкций для контроллера базы данных.
– Контроллер базы данных. Этот компонент взаимодействует с запущенными пользователями прикладными программами и запросами. Контроллер базы данных принимает запросы и проверяет внешние и концептуальные схемы для определения тех концептуальных записей, которые необходимы для удовлетворения требований запроса.
Затем контроллер базы данных вызывает контроллер файлов для выполнения поступившего запроса. Компоненты контроллера базы данных показаны на рис. 1.5 [7].
– Контроллер файлов манипулирует предназначенными для хранения данных файлами и отвечает за распределение доступного дискового пространства. Он создает и поддерживает список структур и индексов, определенных во внутренней схеме. Если используются хешированные файлы, то в его обязанности входит и вызов функций хеширования для генерации адресов записей. Однако контроллер файлов не управляет физическим вводом и выводом данных непосредственно, а лишь передает запросы соответствующим методам доступа, которые считывают данные в системные буферы или записывают их оттуда на диск.
– Препроцессор языка DML. Этот модуль преобразует внедренные в прикладные программы DML-операторы в вызовы стандартных функции базового языка. Для генерации соответствующего кода препроцессор языка DML должен взаимодействовать с процессором запросов.
– Компилятор языка DDL. Компилятор языка DDL преобразует DDL-команды в набор таблиц, содержащих метаданные. Затем эти таблицы сохраняются в системном каталоге, а управляющая информация - в заголовках файлов с данными.
– Контроллер словаря. Контроллер словаря управляет доступом к системному каталогу и обеспечивает работу с ним. Системный каталог доступен большинству компонентов СУБД.

Рис. 1.5. Компоненты контроллера БД
Ниже перечислены основные программные компоненты входящие в состав контроллера базы данных.
– Контроль прав доступа. Этот модуль проверяет наличие у данного пользователя полномочии для выполнения затребованной операции.
– Процессор команд. После проверки полномочии пользователя для выполнения затребованной операции управление передается процессору команд.
– Средства контроля целостности. В случае операций, которые изменяют содержимое базы данных, средства контроля целостности выполняют проверку того, удовлетворяет ли затребованная операция всем установленным ограничениям поддержки целостности данных (например, требованиям, установленным для ключей).
– Оптимизатор запросов. Этот модуль определяет оптимальную стратегию выполнения запроса.
– Контроллер транзакций. Этот модуль осуществляет требуемую обработку операций, поступающих в процессе выполнения транзакций.
– Планировщик.
Этот модуль отвечает за бесконфликтное выполнение параллельных операций с базой данных. Он управляет относительным порядком выполнения операций, затребованных в отдельных транзакциях.
– Контроллер восстановления. Этот модуль гарантирует восстановление базы данных до непротиворечивого состояния при возникновении сбоев. В частности, он отвечает за фиксацию и отмену результатов выполнения транзакций.
– Контроллер буферов. Этот модуль отвечает за перенос данных между оперативной памятью и вторичным запоминающим устройством – например, жестким диском или магнитной лентой. Контроллер восстановления и контроллер буферов иногда (в совокупности) называют контроллером данных.
Для воплощения базы данных на физическом уровне помимо перечисленных выше модулей нужны некоторые другие структуры данных. К ним относятся файлы данных и индексов, а также системный каталог (см. гл. З).
Общая классификация пользователей БД
Рассмотренные особенности СУБД позволяют создавать базы данных для обеспечения информационных потребностей пользователей. Одним из аспектов этой задачи является разработка системы, ориентированной на эффективное обслуживание запросов пользователей. Исходя из этого, целесообразно проанализировать типы и виды предъявляемых к БД запросов. Результаты та кого анализа представлены на рис. 1.9 [17].
Постоянные пользователи - такие, которые регулярно пользуются услугами БД и для которых можно заранее спрогнозировать типы запросов, определяющие круг их интересов. Постоянные пользователи могут обращаться к БД и с произвольными по содержанию запросами. Предварительное определение тематики запросов существенно помогает организовать эффективную обработку запросов.

Рис. 1.9. Категории пользователей БД
Разовые пользователи – те, которые не имеют постоянных запросов, но могут обращаться к системе с произвольными по содержанию запросами.
При разделении пользователей БД по уровню компетенции речь идет о защите определенной части данных от тех пользователей, которые по различным причинам не должны иметь возможность их получения или изменения. Следовательно, в архитектуре СУБД должны быть предусмотрены специальные средства для обеспечения санкционированного доступа пользователей к данным.
Пользователи-задачи обращаются к базе данных с регламентированными по форме и содержанию запросами. Выдаваемая им информация соответствующим образом обрабатывается и компонуется на основании принятых в системе формальных правил и соглашений.
Пользователи-люди обращаются к БД с произвольными либо с регламентированными по содержанию запросами. Выдаваемая им информация должна иметь удобную для человека форму представления: в виде текста на естественном языке, таблиц с пояснениями, графиков и т.п.
Пользователи – прикладные программисты – особая категория, которая выполняет работы по программированию функциональных задач.
Пользователи-непрограммисты – наиболее многочисленная группа лиц, для удовлетворения информационных потребностей которых создается база данных. Поэтому таких пользователей часто называют конечными пользователями. Это специалисты в своей области деятельности, которые обычно не имеют специальной подготовки по программированию.
Особо следует рассмотреть задачи и функции, выполняемые администратором базы данных.
Оценка результатов экспертного анализа
При использовании всех рассмотренных выше методов возникает естественный вопрос: насколько можно доверять результатам оценки коэффициентов Сij, полученным из субъективных мнений экспертов? Достоверность результатов экспертного анализа чаще всего характеризуется степенью согласованности данных ими оценок. Для количественной оценки степени согласованности часто используется коэффициент конкордации [3]:

где

гij – место, которое заняло i-е свойство в ранжировке j-м экспертом.
Коэффициент W позволяет оценить, насколько согласованы между собой ряды предпочтительности, построенные каждым экспертом. Его значение находится в пределах 0£W£1, причем W=0 означает полную противоположность, а W=1 - полное совпадение ранжировок. Практически достоверность считается хорошей, если W=0,7¸0,8.
На основе рассмотренных методов могут быть определены значения коэффициентов Сij (j=1, 2, ..., m; i=1, 2, ..., п), по которым будут вычислены коэффициенты b., линейной формы интегрального критерия. При использовании такого подхода к формированию интегрального критерия в дальнейшем считается, что единица измерения каждого свойства системы, отраженного в соответствующем частном критерии, выбрана по принципу «чем больше, тем лучше». Отсюда следует, что качество решения по выбору альтернативы тем лучше, чем больше значение показателя эффективности.
Так как критерии qi могут иметь различную размерность, то при использовании их в качестве аргументов функции Е необходимо провести нормирование, т. е. привести их к общей размерности, и в частности к безразмерному виду.
Для придания равномерности влияния каждого из критериев на значение интегрального критерия необходимо выровнять диапазоны изменения значений критериев путем масштабирования и сведения их к диапазону [0; 1].
Проведение преобразований типов нормирования и масштабирования требует, чтобы для каждого из критериев были определены понятия «негодного» и «идеального» объектов, а это означает, что должны быть заданы допустимые области изменений значений критериев qi, qiн<qi<qiв. В этом случае самым простым масштабирующим и нормирующим преобразованием является линейное преобразование следующего вида:

где qiотн, qiн, qiв - относительное, нижнее и верхнее значения критерия qi соответственно.
В случае такого преобразования чувствительность шкалы изменения qi во всем диапазоне изменений qi постоянна. Если же разработчика особенно интересуют альтернативы в окрестности некоторой точки qi*, то можно повысить разрешающую способность частного критерия в окрестности этой точки за счет использования соответствующих нелинейных преобразований [3].
После проведения операций нормирования и масштабирования область годных альтернатив окажется заданной в виде n-мерного единичного куба, причем
0 < qiотн £ 1, i=1, 2, ..., п.
В результате проведенных преобразований для каждой рассматриваемой альтернативы будет определен вектор qотн(а), причем а Î А, где А – множество возможных альтернатив. Оценка интегрального показателя решения по выбору альтернативы производится в соответствии со следующим соотношением:

Заканчивая рассмотрение вопросов, связанных с построением обобщенного критерия эффективности сложных систем на основе метода экспертных оценок, следует еще раз обратить внимание на то, что на многих этапах его построения приходится опираться на субъективные мнения специалистов при выборе:
– наиболее существенных частных критериев;
– процедуры и единицы измерения для критериев;
– «идеального» значения критерия;
– значения, дающего наибольшую разрешающую способность критерия;
– нормирующего и масштабирующего преобразований;
– структуры функции обобщенного критерия;
– значений весовых коэффициентов.
Поэтому решения на каждом из перечисленных этапов должны приниматься на основе усредненного мнения многих специалистов, что повышает объективное содержание критерия. Однако это не исключает таких ситуаций, когда оценки некоторых реальных объектов, полученные с помощью обобщенного критерия, противоречат мнению специалистов.
В подобных случаях следует не отказываться от дальнейшего использования данного подхода, а тщательна проанализировать и выявить конкретные причины расхождения, после чего внести соответствующие изменения в критерий.
Как указывалось выше, для оценки СУБД могут использоваться самые разнообразные параметры, которые могут быть сгруппированы следующим образом:
– параметры определения данных;
– физические параметры;
– параметры доступности;
– параметры обработки транзакций;
– утилиты;
– средства разработки... и т.д.
Рекомендуемые параметры (показатели) для оценки СУБД приведены в табл. 2.6 [7].
Таблица 2.6
|
Наименование группы |
Наименование параметра |
|
Определение данных |
Расширенная поддержка первичных ключей |
|
Определение внешних ключей |
|
|
Предусмотренные типы данных |
|
|
Расширяемость типов данных |
|
|
Определение доменов |
|
|
Простота реструктуризации |
|
|
Средства поддержки целостности данных |
|
|
Реализация механизма представлений |
|
|
Поддержка словаря данных |
|
|
Независимость данных |
|
|
Тип базовой модели организации данных |
|
|
Поддержка эволюции схемы |
|
|
Физические параметры |
Предусмотренные файловые структуры |
|
|
Поддержка определения файловых структур |
|
Простота реорганизации |
|
|
Средства индексирования |
|
|
Поля/записи с переменной длиной |
|
|
Сжатие данных |
|
|
Возможности шифрования |
|
|
Требования к памяти |
|
|
Требования к устройствам хранения данных |
|
|
Доступность |
Язык запросов: совместимость со стандартами SQL |
|
Интерфейс для других систем |
|
|
Интерфейс для языков третьего поколения |
|
|
Многопользовательский доступ |
|
|
Защита базы данных: управление доступом к данным, поддержка механизма авторизации |
|
|
Обработка транзакций |
Процедуры резервного копирования и восстановления |
|
Поддержка контрольных точек |
|
|
Средства ведения системного журнала |
|
|
Поддерживаемый уровень детализации параллельности |
|
|
Возможные стратегии разрешения тупиковых ситуаций |
|
|
Поддержка усовершенствованных моделей управления транзакциями |
|
|
Параллельная обработка запросов |
|
|
Утилиты |
Измерение производительности |
|
Настройка производительности базы данных |
|
|
Инструменты загрузки/выгрузки данных |
|
|
Контроль активности пользователей |
|
|
Поддержка процедур администрирования базы данных |
|
|
Средства разработки |
Инструменты, использующие языки четвертого и пятого поколений |
|
Case-инструменты |
|
|
Инструменты для работы с оконным инструментом |
|
|
Поддержка хранимых процедур, триггеров и правил |
|
|
Другие параметры |
Способность к модернизации |
|
Стабильность производителя СУБД |
|
|
База пользователей |
|
|
Обучение и поддержка пользователей |
|
|
Взаимодействие с другими СУБД и прочими системами |
|
|
Поддержка работы в Internet |
|
|
Утилиты репликации |
|
|
Возможности распределенной работы |
|
|
Качество и полнота документации |
|
|
`Наименование группы |
Наименование параметра |
|
Требуемая операционная система |
|
|
Стоимость |
|
|
Оперативная справочная система |
|
|
Используемые стандарты |
|
|
Управление версиями |
|
|
Расширенная оптимизация запросов |
|
|
Масштабируемость |
|
|
Переносимость |
|
|
Требуемое аппаратное обеспечение |
|
|
Поддержка работы в сети |
|
|
Объектно-ориентированные свойства |
|
|
Поддержка двух- или трехуровневой архитектуры «клиент/сервер» |
|
|
Производительность |
|
|
Пропускная способность при обработке транзакций |
|
|
Максимальное количество одновременно работающих пользователей |
Определение реляционной полноты
Пусть реляционная база данных содержит множество отношений R{R1, R2, …, Rп}, а множество C(R)
представляет собой множество отношений, полученных из R с помощью операций реляционной алгебры. Множество C(R) отражает все связи, имеющиеся в базе данных. Говорят, что язык обладает реляционной полнотой, если он может охватить все связи, представленные C(R). Это означает, что язык имеет такую же выразительную мощность, как реляционная алгебра и реляционное исчисление [11].
Для обеспечения реляционной полноты при реализации языка необходимы две следующие операции [11]:
1) операция присваивания, т.е. возможность создавать новые отношения для хранения результатов операций реляционной алгебры, являющихся также отношениями. R1 помещается во вновь созданное отношение R1; 2) операция транзитивного замыкания, допускающая рекурсию или вложенность операций реляционной алгебры для построения выражений произвольной сложности. Например, выражение R1<((R2[A, B]*R3)[B]*R4)[C] содержит вложенные выражения и присваивание, необходимые для получения результата. Основной причиной разработки систем, использующих базы данных, является стремление интегрировать все обрабатываемые в организации данные в единое Целое и обеспечить к ним контролируемый доступ. Хотя интеграция и предоставление контролируемого доступа могут способствовать централизации, последняя не является самоцелью. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный подход отражает организационную структуру компании, логически состоящую из отдельных подразделений, отделов, проектных групп и тому подобного, которые физически распределены по разным офисам, отделениям, предприятиям или филиалам, причем каждая отдельная единица имеет дело с собственным набором обрабатываемых данных [7, 9]. Разработка распределенных баз данных позволяет сделать данные, поддерживаемые каждым из существующих подразделений организации, общедоступными, обеспечив при этом их сохранение именно в тех местах, где они чаще всего используются. Подобный подход расширяет возможности совместного использования информации, одновременно повышая эффективность доступа к ней. Распределенные системы призваны разрешить проблему островов информации. Базы данных иногда рассматривают как некие электронные острова, представляющие собой отдельные и, в общем случае, труднодоступные места, подобные удаленным друг от друга островам. Данное положение может являться следствием географической разобщенности, несовместимости используемой компьютерной архитектуры, несовместимости используемых коммутационных протоколов и т.д. Интеграция отдельных баз данных в одно логическое целое способна изменить подобное положение дел. Распределенная база данных – набор логически связанных между собой разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети. Распределенная СУБД – программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя. Схема отношения
Основные определения, классификация распределенных систем
Система управления распределенными базами дан-яйХ (СУРБД) состоит из единой логической базы дан-яых, разделенной на некоторое количество фрагментов.
Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, которые соединены между собой линиями связи и каждый из которых работает под управлением отдельной СУБД. Любой из сайтов способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным (что создает определенную степень локальной автономии), а также способен обрабатывать данные, сохраняемые на других компьютерах сети.
Пользователи взаимодействуют с распределенной базой данных через приложения. Приложения могут быть классифицированы как те, которые не требуют доступа к данным на других сайтах (локальные приложения), и те, которые требуют подобного доступа (глобальные приложения). В распределенной СУБД должно существовать хотя бы одно глобальное приложение, поэтому любая СУРБД должна иметь следующие особенности [7].
– Набор логически связанных разделяемых данных.
– Сохраняемые данные разбиты на некоторое количество фрагментов.
– Между фрагментами может быть организована репликация данных.
– Фрагменты и их реплики распределены по различным сайтам.
– Сайты связаны между собой сетевыми соединениями.
– Работа с данными на каждом сайте управляется СУБД.
– СУБД на каждом сайте способна поддерживать автономную работу локальных приложений.
– СУБД каждого сайта поддерживает хотя бы одно глобальное приложение.
Нет необходимости в том, чтобы на каждом из сайтов системы существовала своя собственная локальная база данных, что и показано на примере топологии СУРБД, представленной на рис. 5.1.

Рис. 5.1. Топология системы управления распределенной базой данных
Из определения СУРБД следует, что для конечного пользователя распределенность системы должна быть совершенно прозрачна (невидима). Другими словами, от пользователей должен быть полностью скрыт тот факт, что распределенная база данных состоит из нескольких фрагментов, которые могут размещаться на различных компьютерах и для которых, возможно, организована служба репликации данных.
Назначение обеспечения прозрачности состоит в том, чтобы распределенная система внешне вела себя точно так, как и централизованная. В некоторых случаях требование называют основным принципом построения распределенных СУБД [7]. Данный принцип требует предоставления конечному пользователю существенного диапазона функциональных возможностей, но, к сожалению, одновременно ставит перед программным обеспечением СУРБД множество дополнительных задач.
Очень важно понимать различия, существующие между распределенными СУБД и распределенной обработкой данных.
распределенная обработка – обработка с использованием централизованной базы данных, доступ к которой может осуществляться с различных компьютеров сети.
Ключевым моментом в определении распределенной базы данных является утверждение, что система работает с данными, физически распределенными в сети. Если данные хранятся централизованно, то даже в том случае, когда доступ к ним обеспечивается для любого пользователя в сети, данная система просто поддерживает распределенную обработку, но не может рассматриваться как распределенная СУБД.
Кроме того, следует четко понимать различия, существующие между распределенными и параллельными СУБД.
Параллельная СУБД – система управления базой Данных, функционирующая с использованием нескольких процессоров и устройств жестких дисков, что позволяет ей (если это возможно) распараллеливать выполнение некоторых операций с целью повышения °б1цей производительности обработки.
Появление параллельных СУБД было вызвано тем Фактом, что системы с одним процессором оказались неспособны удовлетворять растущие требования к мас- штабируемости, надежности и производительности обработки данных.
Эффективной и экономически обоснованной альтернативой однопроцессорным СУБД стали параллельные СУБД, функционирующие одновременно на нескольких процессорах. Применение параллельных СУБД позволяет объединить несколько маломощных машин для получения того же самого уровня производительности, что и в случае одной, но более мощной машины, с дополнительным выигрышем в масштабируемости и надежности системы, по сравнению с однопроцессорными СУБД.
Для предоставления нескольким процессорам совместного доступа к одной и той же базе данных параллельная СУБД должна обеспечивать управление совместным доступом к ресурсам. Какие именно ресурсы разделяются и как это разделение реализовано на практике, непосредственно влияет на показатели производительности и масштабируемости создаваемой системы, что, в свою очередь, определяет пригодность конкретной СУБД к условиям заданной вычислительной среды и требованиям приложений. Три основных типа архитектуры параллельных СУБД представлены на рис. 5.2. К ним относятся:
– системы с разделением памяти;
– системы с разделением дисков;
– системы без разделения.

Рис. 5.2. Архитектура систем с параллельной обработкой: а) с разделением памяти; б) с разделением дисков; в) без разделения
Хотя схему без разделения в некоторых случаях относят к распределенным СУБД, в параллельных системах размещение данных диктуется исключительно соображениями производительности. Более того, узлы (сайты) распределенной СУБД обычно разделены географически, независимо администрируются и соединены между собой относительно медленными сетевыми соединениями, тогда как узлы параллельной СУБД чаще всего располагаются на одном и том же компьютере или в пределах одного и того же сайта [7].
Системы с разделением памяти состоят из тесно связанных между собой компонентов, в число которых входит несколько процессоров, разделяющих общую системную память. Иначе называемая симметричной многопроцессорной обработкой (СМП), эта архитектура в настоящее время приобрела большую популярность и применяется для самых разных вычислительных платформ, начиная от персональных рабочих станций, содержащих несколько параллельно работающих микропроцессоров, больших RISC-систем и вплоть до крупнейших мейнфреймов.
Данная архитектура обеспечивает быстрый доступ к данным для ограниченного числа процессоров, количество которых обычно не превосходит 64. В противном случае сетевые взаимодействия превращаются в узкое место,
ограничивающее производительность всей системы.
Системы, без разделения (эту архитектуру иначе называют массовой параллельной обработкой – ММП) используют схему, в которой каждый процессор, являющийся частью системы, имеет свою собственную оперативную и дисковую память. База данных распределена между всеми дисковыми устройствами, подключенным к отдельным, связанным с этой базой данных вычислительным подсистемам, в результате чего все данные прозрачно доступны пользователям каждой из этих подсистем. Данная архитектура обеспечивает более высокий уровень масштабируемости, чем системы с СМП, и позволяет легко организовать поддержку работы большого количества процессоров. Однако оптимальной производительности удается достичь только в том случае, если требуемые данные хранятся локально.
Системы с разделением дисков строятся из менее тесно связанных между собой компонентов. Они являются оптимальным вариантом для приложений, которые унаследовали высокую централизацию обработки и должны обеспечивать самые высокие показатели доступности и производительности. Каждый из процессоров имеет непосредственный доступ ко всем совместно используемым дисковым устройствам, но обладает собственной оперативной памятью. Как и в случае архитектуры без разделения, архитектура с разделением дисков исключает узкие места, связанные с совместно используемой памятью. Однако, в отличие от архитектуры без разделения, данная архитектура исключает упомянутые узкие места без внесения дополнительной нагрузки, связанной с физическим распределением данных по отдельным устройствам. Разделяемые дисковые системы в некоторых случаях называют кластерами.
Параллельные технологии обычно используются в случае исключительно больших баз данных, размеры которых могут достигать нескольких терабайт (1012 байт), или в системах, которые должны поддерживать выполнение тысяч транзакций в секунду.
Подобные системы нуждаются в доступе к большому объему данных и должны обеспечивать приемлемое время реакции на запрос. Параллельные СУБД могут использовать различные вспомогательные технологии, позволяющие повысить производительность обработки сложных запросов за счет применения методов распараллеливания операций сканирования, соединения и сортировки, что позволяет нескольким процессорным узлам автоматически распределять между собой текущую нагрузку [7].
Распределенные СУБД можно классифицировать как гомогенные и гетерогенные
[7].
В гомогенных системах все сайты используют один и тот же тип СУБД.
В гетерогенных системах на сайтах могут функционировать различные типы СУБД, использующие разные модели данных, т.е. гетерогенная система может включать сайты с реляционными, сетевыми, иерархическими или объектно-ориентированными СУБД.
Гомогенные системы значительно проще проектировать и сопровождать. Кроме того, подобный подход позволяет поэтапно наращивать размеры системы, последовательно добавляя новые сайты к уже существующей распределенной системе. Дополнительно появляется возможность повышать производительность системы за счет организации на различных сайтах параллельной обработки информации.
Гетерогенные системы обычно возникают в тех случаях, когда независимые сайты, уже эксплуатирующие свои собственные системы с базами данных, интегрируются во вновь создаваемую распределенную систему. В гетерогенных системах для организации взаимодействия между различными типами СУБД потребуется организовать трансляцию передаваемых сообщений. Для обеспечения прозрачности в отношении типа используемой СУБД пользователи каждого из сайтов должны иметь возможность вводить интересующие их запросы на языке той СУБД, которая используется на данном сайте. Система должна взять на себя локализацию требуемых данных и выполнение трансляции», передаваемых сообщений. В общем случае данные могут быть затребованы с другого сайта, который характеризуется такими особенностями, как:
– иной тип используемого оборудования;• иной тип используемой СУБД;
– иной тип применяемых оборудования и СУБД,
Если используется иной тип оборудования, однако да сайте установлен тот же самый тип СУБД, методы выполнения трансляции вполне очевидны и включают замену кодов и изменение длины слова. Если типы используемых на сайтах СУБД различны, процедура трансляции усложняется тем, что необходимо отображать структуры данных одной модели в соответствующие структуры данных другой модели. Например, отношения в реляционной модели данных должны быть преобразованы в записи и наборы, типичные для сетевой модели данных. Кроме того, потребуется транслировать текст запросов с одного используемого языка на другой (например, запросы с SQL-оператором STLECT потребуется преобразовать в запросы с операторами FIND и GET языка манипулирования данными сетевой СУБД). Если отличаются и тип используемого оборудования, и тип программного обеспечения, потребуется выполнять оба вида трансляции. Все изложенное выше чрезвычайно усложняет обработку данных в гетерогенных СУБД.
Дополнительные сложности возникают при попытках выработки единой концептуальной схемы, создаваемой путем интеграции независимых локальных концептуальных схем.
Типичное решение, применяемое в некоторых реляционных системах, состоит в том, что отдельные части гетерогенных распределенных систем должны использовать шлюзы, предназначенные для преобразования языка и модели данных каждого из используемых типов СУБД в язык и модель данных реляционной системы. Однако подходу с использованием шлюзов свойственны некоторые серьезные ограничения.
Во-первых, шлюзы не позволяют организовать систему управления транзакциями даже для отдельных пар систем. Другими словами, шлюз между двумя системами представляет собой не более чем транслятор запросов. Например, шлюзы не позволяют системе координировать управление параллельностью и процедурами восстановления транзакций, включающих обновление данных в обеих базах.
Во-вторых, использование шлюзов призвано лишь решить задачу трансляции запросов с языка одной СУБД на язык другой СУБД.
Поэтому они не позволяют справиться с проблемами, вызванными неоднородностью структур и представлением данных в различных схемах.
В настоящее время организована рабочая группа (Specification Working Group – 8ЛУО) для подготовки спецификаций, регламентирующих инфраструктуру среды базы данных, включающую следующие элементы [7].
1. Унифицированный и достаточно мощный интерфейс языка SQL (SQL API), позволяющий создавать клиентские приложения таким образом, чтобы они не были привязаны к конкретному типу используемой СУБД.
2. Унифицированный протокол доступа к базе данных, позволяющий СУБД одного типа непосредственно взаимодействовать с СУБД другого типа, без необходимости использования какого-либо шлюза.
3. Унифицированный сетевой протокол, позволяющий осуществлять взаимодействие СУБД различного типа.
Самой важной задачей этой группы следует считать отыскание способа, позволяющего в одной транзакции выполнять обработку данных, содержащихся в нескольких базах, управляемых СУБД различных типов, причем без необходимости использования каких-либо шлюзов.
Одной из разновидностей распределенных СУБД, являются мультибазовые системы.
Мулътибазовая система – распределенная система управления базами данных, в которой управление каждым из сайтов осуществляется совершенно автономно.
В последние годы заметно возрос интерес к мульти-базовым СУБД, в которых предпринимается попытка интеграции таких распределенных систем баз данных, в которых весь контроль над отдельными локальными системами целиком и полностью осуществляется их операторами. Одним из следствий полной автономии сайтов является отсутствие необходимости внесения каких-либо изменений в локальные СУБД. Следовательно, мультибазовые СУБД требуют создания поверх существующих локальных систем дополнительного уровня программного обеспечения, предназначенного для предоставления необходимой функциональности.
Мультибазовые системы позволяют конечным пользователям разных сайтов получать доступ и совместно использовать данные без необходимости физической интеграции существующих баз данных.
Они обеспечивают пользователям возможность управлять базами данных их собственных сайтов без какого-либо централизованного контроля, который обязательно присутствует в обычных типах СУРБД. Администратор локальной базы данных может разрешить доступ к определенной части своей базы данных посредством создания схемы, экспорта, определяющей, к каким элементам локальной базы данных смогут получать Доступ внешние пользователи. Различают нефедеральные (не имеющие локальных пользователей) и федеральные
мультибазовые системы. Федеральная система представляет собой некоторый гибрид распределенной и централизованной систем, поскольку она выглядят как распределенная система для удаленных пользователей и как централизованная система – для локальных.
Говоря простыми словами, мультибазовая СУБД является такой СУБД, которая прозрачным образом располагается поверх существующих баз данных и файловых систем, предоставляя их своим пользователям как некоторую единую базу данных. Мультибазовая СУБД поддерживает глобальную схему, на основании которой пользователи могут строить запросы и модифицировать данные. Мультибазовая СУБД работает только с глобальной схемой, тогда как локальные СУБД собственными силами обеспечивают поддержку данных всех их пользователей. Глобальная схема создается посредством интеграции схем локальных баз данных. Программное обеспечение мультибазовой СУБД предварительно транслирует глобальные запросы и превращает их в запросы и операторы модификации данных соответствующих локальных СУБД. Затем полученные после выполнения локальных запросов результаты сливаются в единый глобальный результат, предоставляемый пользователю. Кроме того, мультибазовая СУБД осуществляет контроль за выполнением фиксации или отката отдельных операций глобальных транзакций локальных СУБД, а также обеспечивает сохранение целостности данных в каждой из локальных баз данных. Программы мультибазовой СУБД управляют различными шлюзами, с помощью которых они контролируют работу локальных СУБД.
Первая нормальная форма

Схема базы данных R находится в первой нормальной форме, если каждая схема отношения в R
находится в 1НФ.
Определить понятие атомарности трудно: значение атомарное в одном приложении, может быть неатомарным в другом. Можно руководствоваться общим принципом, что значение неатомарно, если в приложении оно используется по частям.
Пример 2.6. Имеется отношение Сотрудники:
| Сотрудники | НОМЕР | ФИО | |||
| 23 | Вербов Александр Владимирович | ||||
| 24 | Фисенко Александр Сергеевич | ||||
| 25 | Фатхи Дмитрий Владимирович |
Если понадобится указать только фамилии сотрудников, то указанное отношение не находится в 1НФ, так как требуемые значения являются частью атрибута ФИО. Чтобы отношение в таких условиях находилось в 1НФ, атрибут ФИО должен быть разбит на части, как показано ниже.
| Сотрудники | НОМЕР | ФАМИЛИЯ | ИМЯ | ОТЧЕСТВО | |||||
| 23 | Вербов | Александр | Владимирович | ||||||
| 24 | Фисенко | Александр | Сергеевич | ||||||
| 25 | Фатхи | Дмитрий | Владимирович |
Пример 2.7. Отношение Род, представленное ниже, не находится в первой нормальной форме потому, что оно включает величины, являющиеся совокупностью атомарных значений.
| Род | ИМЯ | ПОЛ | |||
| Иван, Александр, Сергей | мужской | ||||
| Мария, Ирина | женский |
Чтобы отношение Род находилось в 1НФ, оно должно быть представлено следующим образом.
| Род | ИМЯ | ПОЛ | |||||
| Иван | мужской | ||||||
| Александр | мужской | ||||||
| Сергей | мужской | ||||||
| Мария | женский | ||||||
| Ирина | женский | ||||||
В чем преимущество применения 1НФ? В том, что 1НФ позволяет выражать F-зависимости с той степенью детализации, с какой требует приложение, что невозможно без 1НФ.
Но и 1НФ обладает рядом существенных недостатков [2, 7, 10]. На первых этапах проектирования базы данных, после анализа предметной области и определения состава информации для хранения в БД обычно формируется так называемое универсальное отношение.
Универсальное отношение – одна таблица, находящаяся в 1НФ, в которой может храниться вся информация об интересующей предметной области. Другими словами схему этого отношения образует весь перечень интересующих атрибутов предметной области [5].
При использовании универсального отношения возникают следующие проблемы [5, 10].
1. Избыточность. Данные многих столбцов многократно повторяются. Повторяются и некоторые наборы данных.
2. Аномалии обновления:
а) аномалии добавления;
б) аномалии изменения;
в) аномалии удаления.
Аномалии обновления являются нежелательным побочным эффектом, обусловленным избыточностью хранимых данных при внесении изменений в отношение.
Рассмотрим отношение График.
|
График |
РЕЙС |
ДАТА |
ПИЛОТ |
ГАЛЕРЕЯ |
|
112 |
6 июня |
Иванов |
7 |
|
|
112 |
7 июня |
Петров |
7 |
|
|
203 |
8 июня |
Иванов |
12 |
ИЗМЕНИТЬ (График; 112, 6 июня, ПИЛОТ=Иванов, ГАЛЕРЕЯ=8),
то отношение перестанет удовлетворять F-зависимости РЕЙС
С точки зрения как обновления, так и устранения избыточности лучше представить ту же информацию в виде базы данных из двух отношений Пилот-График и Галерея-График.
|
Пилот-График |
РЕЙС |
ДАТА |
ПИЛОТ |
|
112 |
6 июня |
Иванов |
|
|
112 |
7 июня |
Петров |
|
|
203 |
8 июня |
Иванов |
|
Галерея-График |
РЕЙС |
ГАЛЕРЕЯ |
|
112 |
6 июня |
|
|
112 |
7 июня |
|
|
203 |
8 июня |
Пятая нормальная форма
Целью поиска декомпозиций без потери информации является устранение избыточности из отношений. В терминах поиска декомпозиций без потерь 4НФ не является наилучшим решением.
J-зависимость *[R1, R2,..., Rp] над R называется тривиальной, если она удовлетворяется в любом отношении r(R) [10].
J-зависимость соединения *[R1, R2, ..., Rp] приложима к реляционной схеме, если R=R1R2...R.
Пусть R – схема отношения и F – множество F- и J-зависимостей над R. Схема R находится в пятой нормальной форме (5НФ) относительно F, если для каждой J-зависимости *[R1, R2, ..., R ], выводимой из F и приложимой к R, J-зависимость тривиальна или каждое Ri является сверхключом R [10].
Схема базы данных R находится в пятой нормальной форме относительно F, если в этой форме находится каждая схема R из R.
Приведем еще одно определение 5НФ [10].
Пусть R - схема отношения и F – множество F- и J-зависимостей. R находится в пятой нормальной форме (5НФ) относительно F, если для каждой J-зависимости *[R1, R2, ..., Rp], выводимой из F и приложимой к R, зависимость *[R1, R2, …, Rp ] выводима из ключевых F-зависимостей в R.
Плотный индекс
Пусть по каким-либо причинам невозможно упорядочить основной файл
1) записи файла
2) записи файла
Пример плотного индекса представлен на рис. 3.11. Над плотным индексом можно также построить В-дерево.

Рис. 3.11. Пример плотного индекса
Понятие базы данных
База данных (БД) – именованная совокупность данных, отображающих состояние объектов и их отношений в рассматриваемой предметной области. Организуется так, что данные собираются однажды и централизованно хранятся (и модифицируются) в виде, доступном всем специалистам или системам программирования, которые могут их использовать.
Особенности организации данных в БД по сравнению с файловыми системами обеспечивают использование одних и тех же данных в различных приложениях, позволяют решать различные задачи планирования, исследования и управления. БД сводят к минимуму дублирование данных, прибегая к дублированию только для ускорения доступа к данным или для обеспечения восстановления БД при ее разрушении. Одна из важных черт БД – независимость данных от особенностей прикладных программ, которые их используют, а также возможность создания этих программ в такой форме, что изменение особенностей хранения, логической структуры или значений данных не требует изменения программ их обработки. Другой важной чертой БД является возможность изменения физических особенностей хранения данных без изменения их логической структуры.
Можно четко сформулировать требования к БД со стороны внешних пользователей [17]. База данных должна:
1. удовлетворять актуальным информационным потребностям пользователей, обеспечивать возможность хранения и модификации больших объемов многоаспектной информации;
2. обеспечивать заданный уровень достоверности хранимой информации и ее непротиворечивость;
3. обеспечивать доступ к данным только пользователей с соответствующими полномочиями;
4. обеспечить возможность поиска информации по произвольной группе признаков;
5. удовлетворять заданным требованиям производительности при обработке запросов;
6. иметь возможность реорганизации и расширения при изменении границ предметной области;
7. обеспечивать выдачу информации пользователям в различной форме;
8. обеспечивать простоту и удобство обращения внешних пользователей за информацией;
9. обеспечивать возможность одновременного обслуживания большого числа внешних пользователей.
Соответственно двум понятиям – «информация» и «данные» – в базах данных различают два аспекта рассмотрения вопросов: инфологический и даталогический
[5, 17].
Инфологических аспект употребляется при рассмотрении вопросов, связанных со смысловым содержанием данных независимо от способов их представления в памяти системы.
Патологический аспект употребляется при рассмотрении вопросов представления данных в памяти информационной системы.
Данные соответствуют зарегистрированным фактам об объектах реального мира. Чтобы в дальнейшем использовать эти данные, требуется их смысловое содержание - семантика данных. Поэтому в информационной системе должны быть сформулированы правила смысловой интерпретации данных.
Основное средство представления семантики данных - естественный язык. Но существует возможность использовать формализованные языки, которые позволяют более эффективно организовать обработку данных на вычислительной технике и представить необходимую семантику данных, удовлетворяющую практическим потребностям целого ряда прикладных задач. К этому классу информационных систем (автоматизированных информационных систем) относятся и системы на основе баз данных.
Понятие функциональной зависимости
Создание баз данных преследует две основные цели [2, 10, 17]:
– понизить избыточность хранимых данных;
– повысить их надежность.
Любое априорное знание о различного рода ограничениях, накладываемых на совокупности данных, может принести большую пользу для достижения указанных целей.
Один из способов формализации этих знаний – установление зависимостей между элементами данных. Известно два основных типа таких зависимостей:
1) функциональные зависимости;
2) многозначные зависимости.
Функциональная зависимость является обобщением понятия ключа.
В табл. 2.7 представлено отношение График (ПИЛОТ, РЕЙС, ДАТА, ВРЕМЯ-ВЫЛЕТА). Это отношение показывает, какой пилот участвует в данном рейсе в данный день и каково время вылета самолета. Не любое сочетание значений атрибутов ПИЛОТ, РЕЙС, ДАТА и ВРЕМЯ-ВЫЛЕТА допустимо в таком расписании.
Таблица 2.7
| График | ПИЛОТ | РЕЙС | ДАТА | ВРЕМЯ-ВЫЛЕТА | |||||
| Мовчан | 83 | 9 августа | 10:15 | ||||||
| Мовчан | 116 | 10 августа | 13:25 | ||||||
| Синицын | 281 | 8 августа | 05:50 | ||||||
| Синицын | 301 | 12 августа | 18:35 | ||||||
| Синицын | 83 | 11 августа | 10:15 | ||||||
| Федотов | 83 | 13 августа | 10:15 | ||||||
| Федотов | 116 | 12 августа | 13:25 | ||||||
| Вишневский | 281 | 9 августа | 05:50 | ||||||
| Вишневский | 281 | 13 августа | 05:50 | ||||||
| Вишневский | 412 | 15 августа | 13:25 |
На табл. 2.7 накладываются следующие ограничения.
1. Для каждого рейса назначается только одно время вылета.
2. Для данного пилота, даты и времени вылета возможен только один рейс.
3. Для данного рейса и даты назначается только один пилот.
Эти ограничения являются примерами F-зависимостей (F-зависимость – функциональная зависимость между данными).
F-зависимость имеет место тогда, когда значения кортежа на одном множестве атрибутов единственным образом определяют эти значения на другом множестве атрибутов.
Указанные выше ограничения можно сформулировать следующим образом.
1. ВРЕМЯ функционально зависит от РЕЙСА.
2. РЕЙС функционально зависит от {ПИЛОТ, ДАТА, ВРЕМЯ}.
3. ПИЛОТ функционально зависит от {РЕЙС, ДАТА}. Порядок в этих последовательностях могут менять и говорить, что РЕЙС, ДАТА функционально определяют ПИЛОТ, или символически:
{РЕЙС, ДАТА}
Пусть r – отношение со схемой


для любых кортежей
В F-зависимости
Понятие информационной системы, информационное обеспечение
Информационные системы – системы обработки данных о какой-либо предметной области со средствами накопления, хранения, обновления, поиска и выдачи данных [12].
Данные – информация (факты и идеи), представленная в формализованном виде, позволяющем передавать или обрабатывать ее при помощи некоторого процесса (и соответствующих технических средств).
В последнем определении под «передачей» данных подразумевается и процесс их хранения, т.к. с теоретических позиций – хранение равносильно передаче данных, но не в пространстве, а во времени (соответственно схемы памяти рассматриваются как каналы передачи данных во времени).
В широком смысле под информацией понимают любые сведения о каком-либо событии, сущности, процессе и т.п., являющиеся объектом некоторых операций: восприятия, передачи, преобразования, хранения или использования.
Процесс осмысливания понятия информации и ее роли в жизни и деятельности человека продолжается. Понятие информации вместе с другими научными понятиями позволяет более глубоко познать законы развития материального мира. На современном этапе считается, что оно является общим для всех видов и форм движения материи и связывается с тем или иным неотъемлемым свойством или атрибутом материи [17].
Все многообразие информационных систем можно классифицировать по ряду признаков.
По средствам выполнения информационной задачи различают информационные системы ручные, механизированные и автоматизированные; по выполняемой функции – информационно-поисковые, управляющие, моделирующие, обучающие, экзаменующие и др.; по области применения – медицинские, финансовые, лингвистические и др.
Автоматизированная информационная система (АИС) – информационная система, использующая ЭВМ на этапах ввода, обработки и выдачи информации по различным запросам пользователей. Представляя собой развитие информационно-поисковых систем, обеспечивающих выполнение информационного поиска с помощью прикладных программ, АИС характеризуется преимуществами системного направления развития ЭВМ:
– многофункциональностью, т.е. способностью решать разнообразные задачи; одноразовостью подготовки и ввода данных;
– независимостью процесса сбора и обновления (актуализации) данных от процесса их использования прикладными программами;
– независимостью прикладных программ от физической организации базы данных;
– развитыми средствами лингвистического обеспечения.
Для полного решения какой-либо информационной задачи в этих системах необходимо, чтобы ЭВМ понимала смысл текста, написанного на естественном языке, что тесно связано с проблемой искусственного интеллекта [17].
Таким образом, информационные системы служат информационному обеспечению различных видов деятельности человека. Логично будет уточнить понятие информационного обеспечения на современном этапе развития информационных технологий [12].
Информационное обеспечение – поддержка процессов управления, технологии, обучения, научных исследований и др. средствами систем баз данных и знаний.
Качество информационного обеспечения гарантируется за счет концентрации информации в базах данных, повышения интеллектуального уровня информационных систем средствами баз знаний. Информационное обеспечение повышает производительность труда в десятки раз, изменяет характер многих видов информационной и трудовой деятельности.
Понятие независимости данных
Трехуровневая архитектура позволяет обеспечить независимость
хранимых данных от использующих их программ и пользователей [2, 5, 17]. АБД может при необходимости переписать хранимые данные на дру гие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель (внутреннюю схему) данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель (концептуальную схему). Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся «прозрачными» для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
Таким образом, различают два типа независимости данных – логическую
и физическую.
Логическая независимость данных – полная защищенность внешних схем (инфологической модели) от изменений, вносимых в концептуальную схему (даталогическую модель).
Физическая независимость данных – полная защищенность концептуальной схемы (даталогической модели) от изменений, вносимых во внутреннюю схему (физическую модель).
Структура СУБД определяется используемой моделью данных. В этом смысле для СУБД являются обязательными следующие функции [12]:
а) трансляция схемы, определяющей структуру хранимых данных, в некоторое внутреннее представление, используемое СУБД при дальнейшей работе с данными (схема обычно составляется администратором базы данных на основании требований предполагаемых пользователей и записывается на языке определения данных,
принятом в СУБД); б) загрузка данных в базу данных (создание БД), сопровождаемая максимально возможной проверкой их правильности;
в) реализация запросов пользователей (формулируемых на специальном языке, принятом в данной СУБД) на отбор и извлечение некоторой части базы данных по задаваемым ими критериям отбора; этот процесс может сопровождаться некоторыми процедурами редактирования и обработки отобранной информации;
г) обновление некоторых частей базы данных без изменения структуры данных; критерии определения обновляемой части обычно аналогичны критериям отбора данных и задаются пользователем.
Понятие системы управления базами данных
Функционирование БД обеспечивается совокупностью языковых и программных средств, называемых системой управления базами данных (СУБД).
Система управления базами данных – совокупность языковых и программных средств, предназначенных для создания, ведения и конкурентного использования базы данных многими пользователями [12].
Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры. Файлы, снабженные описанием хранимых в них данных и находящиеся под управлением СУБД, называются в свою очередь базами данных.
Создание и применение СУБД призвано к максимальному удовлетворению требований, предъявляемых к эффективным базам данных. Это приводит к необходимости решения вопроса централизованного управления данными.
Концепция централизованного управления данными имеет ряд неоспоримых преимуществ по сравнению с файловыми системами (см. прил.1).
1. Минимальная избыточность хранимых данных.
2. Непротиворечивость хранимых данных.
3. Многоаспектное использование данных.
4. Комплексная оптимизация.
5. Возможность стандартизации представления и обмена данными.
6. Возможность обеспечения санкционированного доступа к данным.
Но, предоставляя весомые преимущества, централизованное управление данными предъявляет к СУБД требование независимости данных от использующих их прикладных программ.
Современные СУБД реализуют централизованное управление данными и, кроме того, обеспечивают:
а) определение данных, подлежащих хранению в БД (определение логических свойств данных, соответствующих представлениям пользователя и называемых структурами данных в БД, а также физическая организация хранения данных, называемая структурами хранения БД);
б) первоначальную загрузку данных в БД – так называемое создание БД;
в) обновление данных;
г) доступ к данным по различным запросам пользователя, отбор и извлечение некоторой части БД, редактирование извлеченных данных и выдачу их пользователю. Перечисленные действия принято называть процессом получения справок из БД.
Специальные средства СУБД обеспечивают секретность данных, т.е. защиту данных от неправомочного воздействия, и целостность данных – защиту от непредсказуемого взаимодействия конкурирующих процессов, приводящих к случайному или преднамеренному разрушению данных, а также от отказов оборудования.
Последовательное распределение памяти
Последовательное распределение – простой и естественный способ хранения линейного списка. В этом случае узлы списка размещаются в последовательных элементах памяти (рис.3.1) [17].
При последовательном распределении вектор данных логически отделен от описания структуры хранимых данных. Например, если структура данных представляет собой линейный список (файл записей фиксированной длины), то описание структуры хранится в отдельной записи и содержит:

В случае линейного списка адресная функция состоит из операций смещения и масштабирования. Любые отношения, которые можно выразить на языке целых чисел, можно истолковать как отношения между элементами памяти, получая при этом всевозможные варианты структур.
В качестве примера (из [17]) рассмотрим реализацию с помощью линейного списка при последовательном распределении памяти для логической структуры типа регулярного двоичного дерева (рис. 3.2). Идея способа заключается в том, что начиная с элемента памяти ?(1), делают его корнем дерева, размещают там данные, соответствующие узлу У1. В элементах памяти ?(2) и ?(3) размещают непосредственных потомков узла У1
– узлы У2 и У3, и т.д. В общем случае, непосредственные потомки узла Ук размещаются по адресам: ?(2k) и ?(2k+1). Адресная функция имеет вид

где k – номер узла древовидной структуры; р – базовый адрес; т – размер элемента памяти, который требуется для хранения данных узлов дерева (каждый узел представляет собой запись фиксированной длины). По дереву, которое при этом получается, можно двигаться в обоих направлениях, так как от узла Ун можно перейти к его потомкам, удвоив k (или удвоив k и прибавив единицу).
Можно двигаться к узлу, являющемуся исходным для узла Ун, разделив k пополам и отбросив дробную часть. Адрес соответствующего узлу элемента памяти определяется по адресной функции.
Рассмотрим еще один способ реализации, который применим только для двоичных деревьев. Если для представления двоичного дерева используется вектор памяти от элемента i до элемента j включительно, то корень дерева размещается в элементе памяти с адресом

где

Рис. 3.2. Пример реализации структуры типа регулярного двоичного дерева с помощью линейного списка
Корень дерева размещается в середину вектора. В элементах памяти от г-то до (m-l)-ro включительно размещается левое поддерево. В элементах памяти от (m+1)-го до j-го включительно размещается правое поддерево. Аналогично процесс повторяется для размещения каждого поддерева. Приведенный способ позволяет реализовать двоичное сбалансированное дерево.
Существует ряд других способов представления древовидных структур [4, 13, 17]. С помощью приемов, основанных на свойствах целых чисел, можно с помощью последовательного распределения организовать в памяти некоторые сетевые структуры. Однако для представления сложных сетевых структур требуются более гибкие методы построения в памяти ЭВМ, которые невозможно получить с помощью последовательного распределения памяти. В этом случае используется связанное распределение памяти.
Последовательный поиск
Последовательный поиск заключается в последовательной проверке всех записей файла на их соответствие условию поиска Q [17]. Записи, значения полей которых удовлетворяют условию Q, выдаются в качестве результата поиска.

Если ключ

Поиск по интервалу значений ключа
Требуемое время на поиск:

Поиск по множеству значений






Основным достоинством последовательного поиска данных при последовательной организации файла является простота его реализации.
Использование информационных систем становится повсеместным,
Использование информационных систем становится повсеместным, и концепция баз данных является в настоящее время наиболее значимой в информационных технологиях. Вы можете быть пользователем (потенциальным пользователем) базы данных; человеком, который хочет (или должен) освоить принципы организации современных информационных систем в рамках учебной программы; или человеком, которому поручено спроектировать и реализовать проект базы данных в какой-либо предметной области. Эта книга поможет Вам эффективно решить поставленные задачи. Без основательного изучения организации баз данных в наше время невозможно быть не только квалифицированным программистом, но даже грамотным пользователем информационных систем.
Содержание учебного пособия соответствует Государственному образовательному стандарту высшего профессионального образования по направлению подготовки инженеров специальности 651900 «Автоматизация и управление»; в частности, образовательной программе 210100 «Управление и информатика в технических системах» и учебной программе дисциплины «Информационное обеспечение систем управления».
Кроме того, материал учебного пособия соответствует учебным программам дисциплин «Организация баз данных», «Базы данных», «Базы данных и банки данных», «Системы управления базами данных», «Структуры и алгоритмы обработки данных». Базовыми дисциплинами для изучения этого курса являются «Информационные технологии», «Алгоритмические языки и технологии программирования», «Операционные системы, системное программирование», «Электронно-вычислительные машины, микропроцессорные вычислительные средства, организация вычислительных систем».
В результате изучения данного курса студенты получают необходимые сведения об информационном обеспечении, информационных системах, базах данных, системах управления базами данных; знакомятся с жизненным циклом информационных систем; изучают основные этапы проектирования информационных систем, модель данных «сущность-связь», реляционную, сетевую и иерархическую модели данных; знакомятся с языками определения и манипулирования данными; получают представление о физической организации данных, методах доступа к данным, о перспективах развития информационных систем.
Основная цель данного учебного пособия – введение в технологии и методы, применяемые в современных базах данных и СУБД; в проблемы и идеи, возникающие при использовании иерархических, сетевых и реляционных моделей данных. В предлагаемом пособии нет жесткой привязки к какой-либо одной популярной СУБД, акцент сделан на теоретических основах организации больших, часто запрашиваемых массивов данных. Опыт всех упоминаемых в пособии авторов показывает, что без знания этих основ невозможно эффективно работать с конкретными автоматизированными информационными системами, как бы хорошо они не сопровождались и документировались.
Поэтому была предпринята попытка собрать и использовать в одном издании наиболее проработанный учебный материал лучших специалистов, осуществляющих свою деятельность в области обучения, научных исследований и практической реализации подходов, основанных на технологии баз данных.
Структура учебного пособия отличается от общепринятой по данной тематике. С самого начала рассматриваются общие вопросы по определению информационных систем на базах данных и систем управления базами данных как основных объектов изучения. Определяются общие этапы и подходы к проектированию эффективных баз данных.
Дальнейшее изложение связано с последовательным рассмотрением вопросов проектирования и реализации БД в соответствии с логикой этапов. Читатель знакомится с общими проблемами каждого этапа реализации проекта БД, изучает существующие методы их решения. При этом сам определяет степень детализации и необходимый уровень получаемых знаний.
В начале каждого раздела пособия в доступной широкому кругу читателей форме формулируется основная проблема этапа. Затем рассматриваются известные пути решения стоящих перед разработчиком задач с постепенным усложнением материала. Некоторые параграфы, предлагающие новые постановки задач и новые подходы к их решению, призваны стимулировать творческую направленность обучения и деятельности читателей, склонных к научным исследованиям.
Чтобы просто получить представление о проблематике современных информационных систем и концепции баз данных, нет необходимости штудировать весь объем учебного пособия – достаточно ознакомиться с содержанием основных параграфов каждой главы.
В первой главе учебного пособия даются определения информационной системы, базы данных, системы управления базами данных. Обсуждаются основные функции, и приводится типовая организация СУБД, классифицируются пользователи БД. Здесь же детализируется круг обязанностей администратора базы данных, рассматриваются основные средства администрирования.
Вторая глава учебного пособия содержит анализ жизненного цикла автоматизированной информационной системы, рассматриваются цели и подходы к проектированию баз данных, определяются этапы процесса проектирования. Рассматриваются способы создания инфологических моделей предметной области на примере языка ER-диаграмм. Вводится необходимый для дальнейшего изложения теоретический базис. Детально рассматривается сложный этап логического проектирования эффективных БД. Обсуждены достоинства и недостатки наиболее популярных моделей данных – иерархической, сетевой, реляционной. Особое внимание уделено восходящему пути проектирования – процессу нормализации отношений реляционной модели. Акцентированы недостатки универсального отношения, классифицированы зависимости атрибутов и даны обобщенные определения известным нормальным формам. Поставлена задача нормализации для целей практики.
В третьей главе рассмотрены принципы физической организации данных в современных СУБД. Построена модель внешней памяти и предложены некоторые методы исследования оптимальных способов физического хранения данных. Коротко приведены наиболее распространенные методы поиска и индексирования данных.
Четвертая глава посвящена математическим основам манипулирования реляционными данными. В главе обсуждаются особенности трех теоретических языков запросов, приведены теоремы об эквивалентности выразительной мощности реляционной алгебры и реляционного исчисления. Проведен сравнительный анализ теоретических языков запросов, обсуждены перспективы реальных языков запросов.
В пятой главе приведен обзор принципов построения и использования распределенных баз данных как наиболее перспективного направления в информационных технологиях.Обобщены концепции организации и работы компьютерных сетей, функции и архитектура распределенных баз данных. Обсуждена проблема прозрачности и сформулированы правила, при выполнении которых СУБД является распределенной.
В приложениях к учебному пособию помещены краткий толковый словарь по организации баз данных, примеры проектов баз данных, результаты сравнительного анализа даталогических моделей, принципы организации компьютерных сетей и правила реализации распределенных СУБД.
Авторы надеются, что предлагаемое учебное пособие поможет читателю освоить основы организации баз данных, а значит сделать важный шаг в становлении квалифицированного пользователя современных информационных систем и затребованным специалистом в перспективных предметных областях.
Преимущества и недостатки распределенных СУБД
Системы с распределенными базами данных имеют дополнительные преимущества перед традиционными централизованными системами баз данных [7]. Но эта технология не лишена и некоторых недостатков (табл. 5.1).
Комплексный учет всех предоставляемых выигрышей и проигрышей является сложной задачей, методология решения которой в настоящее время не определена. Ответственность за принятие решения по разработке и внедрению распределенной системы может взять на себя группа смелых специалистов.
Таблица 5.1
| Преимущества | Недостатки | ||
| Отражение структуры организации | Повышение сложности | ||
| Разделяемость и локальная автономность | Увеличение стоимости | ||
| Повышение доступности данных | Проблемы защиты | ||
| Повышение надежности | Усложнение контроля за целостностью данных | ||
| Повышение производительности | Отсутствие стандартов | ||
| Экономические выгоды | Недостаток опыта | ||
| Модульность системы | Усложнение процедуры разработки базы данных |
Преимущества
Отражение структуры организации
Крупные организации, как правило, имеют множество отделений, которые могут находиться в разных концах страны и даже за ее пределами. Вполне логично будет предположить, что используемые этими организациями базы данных должны быть распределены между отдельными офисами. В каждом отделении может поддерживаться своя база данных. В подобной базе данных персонал отделения сможет выполнять необходимые ему локальные запросы. Руководству компании может потребоваться выполнять глобальные запросы, предусматривающие получение доступа к данным, сохраняемым во всех существующих отделениях компании.
Разделяемостъ и локальная автономность
Географическая распределенность организации может быть отражена в распределении ее данных, причем пользователи одного сайта смогут получать доступ к данным, сохраняемым на других сайтах. Данные могут быть помещены на тот сайт, на котором зарегистрированы пользователи, которые их чаще всего используют. В результате заинтересованные пользователи получают локальный контроль над требуемыми им данными и могут устанавливать или регулировать локальные ограничения на их использование.
Администратор глобальной базы данных (АБД) отвечает за систему в целом. Как правило, часть этой ответственности делегируется на локальный уровень, благодаря чему АБД локального уровня получает возможность управлять локальной СУБД.
Повышение доступности данных
В централизованных СУБД отказ центрального компьютера вызывает прекращение функционирования всей СУБД. Однако отказ одного из сайтов СУРБД или линии связи между сайтами сделает недоступным лишь некоторые сайты, тогда как вся система в целом
сохранит свою работоспособность. Распределенные СУБД проектируются таким образом, чтобы обеспечивать продолжение функционирования системы, несмотря на подобные отказы. Если выходит из строя один из узлов, система сможет перенаправить запросы к отказавшему узлу в адрес другого сайта.
Повышение надежности
Если организована репликация данных, в результате чего данные и их копии будут размещены на более чем одном сайте, отказ отдельного узла или соединительной связи между узлами не приведет к недоступности данных в системе.
Повышение производительности
Если данные размещены на самом нагруженном сайте, который унаследовал от систем-предшественников высокий уровень параллельности обработки, то развертывание распределенной СУБД может способствовать повышению скорости доступа к базе данных (по сравнению с доступом к удаленной централизованной СУБД). Более того, поскольку каждый сайт работает только с частью базы данных, уровень использования центрального процессора и служб ввода/ вывода может оказаться ниже, чем в случае централизованной СУБД.
Экономические выгоды
В шестидесятые годы мощность вычислительной установки возрастала пропорционально квадрату стоимости ее оборудования, поэтому система, стоимость которой была втрое выше стоимости данной, превосходила ее по мощности в девять раз. Эта зависимость получила название закона Гроша [7]. Однако в настоящее время считается общепринятым положение, согласно которому намного дешевле собрать из небольших компьютеров систему, мощность которой будет эквивалентна мощности одного большого компьютера.
Оказывается, что намного выгоднее устанавливать в подразделениях организации собственные маломощные компьютеры, кроме того, гораздо дешевле добавить в сеть новые рабочие станции, чем модернизировать систему с мейнфреймом.
Второй потенциальный источник экономии имеет место в том случае, когда базы данных географически удалены друг от друга и приложения требуют осуществления доступа к распределенным данным. В этом случае из-за относительно высокой стоимости передаваемых по сети данных (по сравнению со стоимостью их локальной обработки) может оказаться экономически выгодным разделить приложение на соответствующие части и выполнять необходимую обработку на каждом из сайтов локально.
Модульность системы
В распределенной среде расширение существующей системы осуществляется намного проще. Добавление в сеть нового сайта не оказывает влияния на функционирование уже существующих. Подобная гибкость позволяет организации легко расширяться. Перегрузки из-за увеличения размера базы данных обычно устраняются путем добавления в сеть новых вычислительных мощностей и устройств дисковой памяти. В централизованных СУБД рост размера базы данных может потребовать замены и оборудования (более мощной системой), и используемого программного обеспечения (более мощной или более гибкой СУБД).
Недостатки
Повышение сложности
Распределенные СУБД, способные скрыть от конечных пользователей распределенную природу используемых ими данных и обеспечить необходимый уровень производительности, надежности и доступности, безусловно, являются более сложными программными комплексами, чем централизованные СУБД. Тот факт, что данные могут подвергаться репликации, также добавляет дополнительный уровень сложности в программное обеспечение СУРБД. Если репликация данных не будет поддерживаться на требуемом уровне, система будет иметь более низкий уровень доступности данных, надежности и производительности, чем централизованные системы, а все изложенные выше преимущества превратятся в недостатки.
Увеличение стоимости
Увеличение сложности означает и увеличение затрат на приобретение и сопровождение СУРБД (по сравнению с обычными централизованными СУБД). Разворачивание распределенной СУБД потребует дополнительного оборудования, необходимого для установки сетевых соединений между сайтами. Следует ожидать и роста расходов на оплату каналов связи, вызванных возрастанием сетевого графика. Кроме того, возрастают затраты на оплату труда персонала, который потребуется для обслуживания локальных СУБД и сетевых соединений.
Проблемы защиты
В централизованных системах доступ к данным легко контролируется. Однако в распределенных системах потребуется организовать контроль доступа не только к данным, реплицируемым на несколько различных сайтов, но и защиту сетевых соединений самих по себе. Раньше сети рассматривались как совершенно незащищенные каналы связи. Хотя это отчасти справедливо и для настоящего времени, тем не менее, в отношении защиты сетевых соединений достигнут весьма существенный прогресс.
Усложнение контроля за целостностью данных
Целостность базы данных означает корректность и согласованность сохраняемых в ней данных. Требования обеспечения целостности обычно формулируются в виде некоторых ограничений, выполнение которых будет гарантировать защиту информации в базе данных от разрушения. Реализация ограничений поддержки целостности обычно требует доступа к большому количеству данных, используемых при выполнении проверок, но не требует выполнения операций обновления. В распределенных СУБД повышенная стоимость передачи и обработки данных может препятствовать организации эффективной защиты от нарушений целостности данных.
Отсутствие стандартов
Хотя функционирование распределенных СУБД зависит от эффективности используемых каналов связи, только в последнее время стали вырисовываться контуры стандарта на каналы связи и протоколы доступа к данным. Отсутствие стандартов существенно ограничивает потенциальные возможности распределенных СУБД. Кроме того, не существует инструментальных средств и методологий, способных помочь пользователям в преобразовании централизованных систем в распределенные.
Недостаток опыта
В настоящее время в эксплуатации находится уже несколько систем-прототипов и распределенных СУБД специального назначения, что позволило уточнить требования к используемым протоколам и установить круг основных проблем. Однако на текущий момент распределенные системы общего назначения еще не получили широкого распространения. Соответственно, еще не накоплен необходимый опыт промышленной эксплуатации распределенных систем, сравнимый с опытом эксплуатации централизованных систем. Такое положение дел является серьезным сдерживающим фактором для многих потенциальных сторонников данной технологии.
Усложнение процедуры разработки базы данных
Разработка распределенных баз данных, помимо обычных трудностей, связанных с процессом проектирования централизованных баз данных, требует принятия решения о фрагментации данных, распределении фрагментов по отдельным сайтам и организации процедур репликации данных.