КРАТКАЯ ИСТОРИЯ АЗВИТИЯ СУБД
Предшественницами СУБД были файловые системы, обладающие существенными недостатками (прил.1). Однако появление СУБД не привело к пол- ному исчезновению файловых систем. Для выполнения некоторых специализированных задач подобные файловые системы используются до сих пор. Считается, что развитие СУБД началось еще в 60-е годы, когда разрабатывался проект полета корабля Apollo на Луну. Этот проект был начат по инициативе президента США Дж.Ф.кеннеди, поставившего задачу вы- садить человека на Луну к концу десятилетия. В то время не существовало никаких систем, способных обрабатывать или как-либо управлять тем огромным количеством данных, которое было необходимо для реализации этого проекта [7].
В результате специалисты основного подрядчика – фирмы North American Aviation (теперь эта фирма называется Rockwell International) –. разработали программное обеспечение под названием GUAM (Generalized Update Access Method). Основная идея GUAM была построена на том, что малые компоненты объединяются вместе как части более крупных компонентов до тех пор, пока не будет собран воедино весь проект. Эта соответствующая инвертированному дереву структура часто называется иерархической структурой (hierarchical structure). В середине 60-х годов корпорация IBM присоединилась к фирме NAA для совместной работы над GUAM, в результате чего была создана система IMS (Information Management System). Причина, по которой корпорация IBM ограничила функциональные возможности IMS только управлением иерархиями записей, заключалась в том, что необходимо было обеспечить работу с устройствами хранения с последовательным доступом, а именно с магнитными лентами, которые были основным типом носителя в то время. Спустя некоторое время это ограничение удалось преодолеть. Несмотря на то, что IMS является самой первой из всех коммерческих СУБД, она до сих пор остается основной иерархической СУБД, используемой на большинстве крупных мейнфреймов [7].
Следующим заметным достижением середины 60-х годов было появление системы ПЭ8 (Integrated Data Store) фирмы General Electric.
Несмотря на то, что этот отчет официально не был одобрен Национальным Институтом Стандартизации США (American National Standards Institute – ANSI), большое количество систем было разработано в полном соответствии с этими предложениями группы DBTG. Теперь они называются CODASYL-системами, или DBTG-системами. СОРА8'Л -системы и системы на основе иерархических подходов представляют собой СУБД первого поколения. Однако этим двум моделям присущи приведенные ниже недостатки.
– Даже для выполнения простых запросов с использованием переходов и доступом к определенным записям необходимо создавать достаточно сложные про- граммы.
– Независимость от данных существует лишь в минимальной степени.
– Отсутствие общепризнанных теоретических основ.
В 1970 году Э.Ф.Кодд (Е.F.Codd), работавший в исследовательской лаборатории корпорации IBM, опубликовал очень важную и весьма своевременную статью о реляционной модели данных, позволявшей устранить недостатки прежних моделей. Вслед за этим появилось множество экспериментальных реляционных СУБД, а первые коммерческие продукты появились в конце 70-х - начале 80-х годов. Особенно следует отметить проект System В, разработанный в исследовательской лаборатории корпорации IBM, расположенной в городе Сан-Хосе, штат Калифорния, созданный в конце 70-х годов (Astrahan et al., 1976). Этот проект был задуман с целью доказать практичность реляционной модели, что достигалось посредством реализации предусмотренных ею структур данных и требуемых функциональных возможностей. На основе этого проекта были получены важнейшие результаты.
– Был разработан структурированный язык запросов SQL, который с тех пор стал стандартным языком любых реляционных СУБД.
– В 80-х годах были созданы различные коммерческие реляционные СУБД – например, DB2 или SQL/DS корпорации IBM или Oracle корпорации Oracle Corporation.
В настоящее время существует несколько сотен раз- личных реляционных СУБД для мейнфреймов и микрокомпьютеров, хотя для многих из них определение реляционной модели носит несколько преувеличенный характер. В качестве примера многопользовательских СУБД может служить система СА-OpenIngres фирмы Computer Associates и систему Informix фирмы Informix Software, Inc. Примерами реляционных СУБД для персональных компьютеров являются Access и FoxPro фирмы Microsoft, Paradox и Visual dBase фирмы Borland, а также R:Base фирмы Microrim. Реляционные СУБД относятся к СУБД второго поколения. Однако реляционная модель также обладает некоторыми недостатками – в частности, ограниченными возможностями моделирования сложных предметных областей. Для решения этой проблемы был выполнен большой объем исследовательской работы. В 1976 году Чен предложил модель <сущность-связь» (Entity-Relationship model – ER-модель), которая в настоящее время стала самой распространенной технологией проектирования баз данных.
В 1979 году Кодд сделал попытку устранить недостатки собственной основополагающей работы и опубликовал расширенную версию реляционной модели – RM/Т (1979), затем еще одну версию – RM/V2 (1990). Попытки создания модели данных, позволяющей более точно описывать реальный мир, нестрого называют семантическим моделированием данных (semantic data modeling).
В ответ на все возрастающую сложность приложений баз данных появились две новые системы: объектно-ориентированные СУБД, или ООСУБД (Object-Oriented DBMS – OODBMS), и объектно-реляционные СУБД, или ОРСУБД (Object-Relational DBMS - ORDBMS). Однако, в отличие от предыдущих моделей, действительная структура этих моделей не совсем ясна. Попытки реализации подобных моделей представляют собой СУБД третьего поколения.
КРАТКИЙ ТОЛКОВЫЙ СЛОВАРЬ
Автоматизированная информационная система (АИС) – информационная система, использующая ЭВМ на этапах ввода, обработки и выдачи информации по различным запросам потребителей. Представляя собой развитие информационно-поисковых систем, обеспечивающих выполнение лишь одной функции поиска информационного с помощью прикладных программ, АИС характеризуется преимуществами системного направления развития ЭВМ. многофункциональностью, т.е. способностью решать разнообразные задачи; одноразовостью подготовки и ввода данных; независимостью процесса сбора и обновления (актуализации) данных от процесса их использования прикладными программами; независимостью прикладных программ от физической организации базы данных; развитыми средствами лингвистического обеспечения. Для полного решения какой-либо информационной задачи в этих системах необходимо, чтобы ЭВМ понимала смысл текста, написанного на естественном языке, что тесно связано с проблемой искусственного интеллекта. АИС подразделяют на автоматизированные информационные системы документографические и автоматизированные информационные системы фактографическое.
Автоматизированные системы управления (АСУ) – человеко-машинные системы, основанные на комплексном использовании экономико-математических методов и технических средств обработки информации для решения задач управления. Внедрение АСУ обусловлено необходимостью совершенствования системы планирования и управления народным хозяйством и повышения эффективности производства. Основной предпосылкой создания АСУ является возможность автоматизации информационных процессов. АСУ характеризуется применением развитого комплекса технических средств, предназначенных для выполнения основных процессов сбора и обработки информации в ходе решения задач управления в соответствии с технологией планово-экономических работ. Используя технические средства, включая ЭВМ, выполняют определенные операции в общем информационном процессе и осуществляют следующие операции: фиксацию или сбор первичных данных в местах их возникновения, формирование первичной документации, передачу данных между пунктами их возникновения и использования, хранение данных обработку данных, предоставление сведений, формирование документов для специалистов аппарата управления.
Функционирование АСУ повышает эффективность управленческого труда, дает возможность в короткие сроки и с высокой степенью достоверности обрабатывать большие объемы информации, необходимой для управления. АСУ подразделяют на три основные группы: автоматизированные системы управления предприятием (АСУП), отраслевые автоматизированные системы управления (ОАСУ) и специализированные АСУ.
Администратор базы данных (АБД) – человек или группа лиц имеющий полное представление об одной или нескольких базах данных и контролирующий их проектирование и использование. Отвечает за состояние базы данных в организации (учреждении) на протяжении ее жизненного цикла. Функциями АБД являются: изучение потребностей пользователя, описание схемы базы данных и загрузка в нее первоначальных значений данных. АБД может иметь полномочия по контролю, защите, обеспечению целостности и высоких эксплуатационных характеристик базы данных.
Актуализация данных – обновление базы данных (добавление, удаление или изменение записей), связанное с развитием науки (появлением новых терминов, старением прежних, изменением в трактовке смысла термина) или с необходимостью решать новые задачи.
Алгоритм - совокупность правил, определяющих эффективную процедуру решения любой задачи из некоторого заданного класса задач. Понятие алгоритма использовалось в математике давно, но как математический объект исследуется в связи с решением ряда проблем оснований математики с 30-х гг. 20 века. Тогда же были разработаны основные понятия теории алгоритмов. В связи с развитием ЭВМ и их широким применением понятие алгоритма стало одним из центральных в прикладной математике. Уточнения понятия алгоритма, основанные, например, на понятиях частично-рекурсивной функции или машин Тьюринга, успешно использовались при решении принципиальных вопросов теории алгоритмов (таких, как существование алгоритмически неразрешимых проблем и др.), но оказались мало пригодными для практического применения в ЭВМ. Вместо них широкое распространение получили алгоритмические языки, которые можно рассматривать как современное уточнение понятия алгоритма.
В этом случае алгоритм трактуется как текст, записанный в алгоритмическом языке. Семантика такого языка определяет для каждого алгоритма (программы), записанного в языке, некоторую совокупность процессов вычислений, которые реализуются в зависимости от состояния информации, перерабатываемой алгоритмом. Если процесс вычислений оканчивается, то алгоритм дает их результат. Эффективность процессов вычислений, порождаемых алгоритмом, означает реализуемость этих процессов на вычислительной машине.
Атрибут – элементарное данное, описывающее свойство сущности. В записи данных представлен типом элемента данных и может использоваться в качестве первичного ключа (элемента данных, который однозначно идентифицирует запись), вторичного ключа (неоднозначно идентифицирует запись) или их составного элемента. Атрибут функционально зависит от группы других атрибутов, если его значение однозначно определяется совокупностью значений атрибутов этой группы. Существуют понятия первичного атрибута – атрибута, который входит в состав некоторого ключа, составляя весь первичный ключ или его часть, и вторичного атрибута – атрибута, используемого для индексирования записей в составе вторичного ключа.
База данных (БД) – именованная совокупность данных, отображающих состояние объектов и их отношений в рассматриваемой предметной области. Организуется так, что данные собираются однажды и централизованно хранятся (и модифицируются) в виде, доступном всем специалистам или системам программирования, которые могут их использовать. Особенности организации данных в БД обеспечивают использование одних и тех же данных в различных приложениях, позволяют решать различные задачи планирования, исследования и управления. БД сводят к минимуму дублирование данных, прибегая к дублированию только для ускорения доступа к данным или для обеспечения восстановления БД при ее разрушении. Одна из важных черт БД – независимость данных от особенностей прикладных программ, которые их используют, а также возможность создания этих программ в такой форме, что изменение особенностей хранения, логической структуры или значений данных не требует изменения программ их обработки.
Другой важной чертой БД является возможность изменения физических особенностей хранения данных без изменения их логической структуры. Функционирование БД обеспечивается совокупностью языковых и программных средств, называемых системой управления базами данных (СУБД). СУБД обеспечивают:
а) определение данных, подлежащих хранению в БД (определение логических свойств данных, соответствующих представлениям пользователя и называемых структурами данных в БД, а также физическая организация хранения данных, называемая структурами хранения БД);
б) первоначальную загрузку данных в БД – так называемое создание БД;
в) обновление данных;
г) доступ к данным по различным запросам пользователя, отбор и извлечение некоторой части БД, редактирование извлеченных данных и выдачу их пользователю.
Перечисленные действия принято называть процессом получения справок из БД. Специальные средства СУБД обеспечивают секретность данных, т.е. защиту данных от неправомочного воздействия, и целостность данных – защиту от непредсказуемого взаимодействия конкурирующих процессов, приводящих к случайному или преднамеренному разрушению данных, а также от отказов оборудования. Большинство современных БД работают под надзором администратора БД. Важным аспектом БД, обусловливающим спектр возможных использований, является допустимый в ней класс структур данных, задаваемый определением типов используемых структур и способами композиции структур. Для большинства современных СУБД можно выделить ряд базовых или порождающих типов структур, из которых по определенным правилам композиции могут конструироваться остальные используемые в БД структуры. Определение структуры данных называется схемой данных. Схема составляется на языке определения данных и обычно соотносит данным имена и свойства, устанавливает отношения между ними и др. обработка данных, извлекаемых по запросам пользователей, обычно производится с помощью языков программирования. Взаимодействие языка программирования с БД осуществляется с помощью специально включаемых в него средств, называемых языком манипулирования данными, позволяющих обращаться к БД в терминах используемого языка.
Многие БД допускают взаимодействие с прикладными программами, написанными на одном из множества допустимых языков программирования, причем каждая область использования БД устанавливает так называемую подсхему данных – определение используемой части БД с точки зрения использующего ее приложения. Современные идеи в построении БД сконцентрированы в трех наиболее известных моделях данных- иерархической, сетевой и реляционной.
Ведение базы данных – деятельность по обновлению и перестройке структуры базы данных с целью обеспечения ее целостности, сохранности и эффективности использования. Понятие «ведение» можно отнести и к отдельному файлу базы данных – это реорганизация файла для обеспечения лучшей обработки добавленных, изменяемых или удаляемых элементов данных.
Включающий язык (базовый язык) – язык программирования в СУБД, для которого строятся расширения, обеспечивающие взаимодействие программы на включающем языке с системой управления базой данных. Эти расширения получили название языка манипулирования данными.
Восстановление баз данных – процесс, приводящий в базах данных к восстановлению данных, поврежденных в результате ошибок персонала, неправильной работы оборудования или операционной системы.
Время доступа – промежуток времени между выдачей команды, содержащей обращение к некоторым данным, и фактическим получением данных для обработки.
Время отклика на запрос – промежуток времени между вводом запроса к базе данных в ЭВМ и завершением обработки запроса с предоставлением результатов.
Время поиска – промежуток времени между началом поиска записи с конкретным значением или некоторой комбинацией конкретных значений и его окончанием.
Данные – факты и идеи, представленные в формализованном виде, позволяющем передавать или обрабатывать их при помощи некоторого процесса (и соответствующих технических средств).
Данных структура в базе данных – представление пользователя о данных, не зависящее от способа их хранения в базе данных. Характеризует возможности системы по структурированию данных, определяя их типы и правила композиции, с которыми может работать пользователь базы данных.
Тип данных определяет множество значений, которые могут принимать соответствующие ему данные. Примерами свойств типа могут быть имя данного, категория значения (число, строка литер, дата или географическая координата), замок защиты для управления доступом к данному и др. База данных составляется из структур или элементов различного типа, причем структуры одного типа могут состоять или конструироваться из структур других типов. Класс структур данных, допустимых в конкретной базе данных, можно задать определением типов допустимых в нем структур и способов их композиции. Описание каждой структуры в терминах свойств, присущих всем данным, принадлежащим к структуре данного типа, составляет схему данных. Допустимые структуры можно представить как композиции пяти порождающих типов структур: элемента, группы, группового отношения, записи (или статьи) и файла. Для каждого из этих типов можно рассматривать свойства, присущие его схеме, и свойства отдельных экземпляров. Элемент представляет собой логически неделимую структуру данных, из которых в конечном итоге составляются структуры всех остальных типов. Схема элемента может определять его имя, категорию его значения, особенности представления значения (с плавающей запятой, в закодированном виде и т.д.), синтаксис его значения (задаваемый, например, шаблоном, длиной, диапазоном и т.д.) и др. правила проверки достоверности значения, способы редактирования значения при выдаче и т.д. В экземплярах элемента указываются: степень достоверности значения дата или источник его поступления и др. Группа есть именованная совокупность элементов и/или других групп. Соответственно схема группы состоит из схем ее составляющих - схем элементов и/или схем групп. Схема группы может быть повторяющейся - в каждом экземпляре объемлющей ее структуры может появляться несколько экземпляров повторяющейся группы. В схеме группы может указываться ее имя, число повторений или упорядоченность экземпляров повторяющейся группы, замки защиты для управления доступом к содержащимся в группе значениям элементов и др.
Групповое отношение есть соответствие или бинарное отношение между двумя множествами групп - множеством так называемых родительских групп и множеством так называемых зависимых групп. Групповое отношение позволяет установить связи между группами и, следовательно, отразить связи между объектами в конкретных приложениях. Схема группового отношения может указывать его имя, упорядоченность зависимых групп, замки защиты, критерии размещения и др. Статья или запись логическая есть именованная совокупность групп и групповых отношений, в которых имеется единственная группа, не содержащаяся в другой группе и не являющаяся зависимой по отношению к ней, - так называемая группа, определяющая статью. Статья обычно представляет некоторый информационный объект, свойства которого представляются элементами, образующими статью. Совокупность статей, имеющих общую область использования, образует файл. Совокупность файлов, представляющая модель некоторой предметной области, составляет базу данных.
Домен (от франц. domaine – владение) 1) область значений некоторого данного; 2) область значений атрибута в модели данных реляционной.
Доступ к базе данных санкционированный – доступ с установлением процедуры полномочий пользователя. Накладывает ограничения на использование операций, производимых над базой данных, в целях ее защиты от непреднамеренных или умышленных действий по раскрытию, изменению или разрушению. Установление санкционированного доступа к базе данных для различных категорий пользователей является одной из функций администратора базы данных.
Доступ к базе данных удаленный – доступ к базе данных одного или более пользователей, работающих за удаленным терминалом или на удаленной ЭВМ. Терминалы или ЭВМ считаются удаленными по отношению к БД, если требуется применение средств дистанционной связи. Удаленный доступ использует способность БД обслуживать более одного пользователя одновременно (коллективный доступ к БД).
Доступ к данным – предоставление данных пользователю в процессе его работы или принятие от него порции данных посредством последовательности операций поиска, чтения или записи.
Вызывается обращением пользователя с запросом к базе данных на языке манипулирования данными. Доступ к данным реализуется либо с помощью выборки или размещения данных непосредственно по их адресу на запоминающем устройстве (прямой доступ к данным), либо с помощью последовательной обработки записей файла (последовательный доступ к данным).
Замок защиты – механизм проверки паролей при обращении к базе данных. Обычно замок защиты бывает реализован в виде значения некоторой переменной или специальной системной процедуры. Замок защиты может учреждаться не уровне отдельных компонент структур данных (для файлов, для отдельных записей файла, для отдельных компонент записей и др.) и ограничивать отдельные действия с данными (чтение, изменение, передачу из схемы в подсхему и т.д.).
Записи поле – наименьшая единица поименованных данных. Может служить для формирования условий поиска записи, а также для указания ее элементов при чтении или модификации.
Запрос информационный – обращение к базе данных, содержащее задание на поиск, чтение в базе данных согласно некоторому условию и выдачу информации пользователю в требуемом виде, возможно, после некоторой обработки. Составляется на языке запросов.
Защита данных – возможность системы управления базой данных контролировать правомочность доступа пользователей к определенным порциям хранимых данных и способы использования этих данных. Механизм защиты данных обычно устраняет также возможность одновременного обновления одной и той же порции данных несколькими пользователями, параллельно обратившимися в базу данных. Для проверки прав программ пользователей на доступ к данным и (или) их обработку обычно вводятся так называемые замки защиты. Замки защиты данных учреждаются администратором базы данных, который сообщает введенные пароли пользователям, имеющим право обращаться к соответствующим данным. При обращении в базу данных пользователь сообщает соответствующие пароли – так называемые ключи защиты – в форме, определенной конкретной СУБД.
Инкапсуляция данных – способ работы с данными в языках программирования, не требующий знания структуры данных при их использовании; определены лишь процедуры, в которых они участвуют.
Интеграция баз данных – представление нескольких баз данных как логически единой базы данных. Позволяет пользователю или прикладной программе применять глобальные операции, которые транслируются в последовательность эквивалентных операций над локальными базами данных.
Информационное обеспечение – поддержка процессов управления, технологии, обучения, научных исследований и др. средствами систем баз данных и знаний. Качество информационного обеспечения обеспечивается за счет концентрации информации в базах данных, повышения интеллектуального информационных систем за счет средств баз знаний. Информационное обеспечение повышает производительность труда в десятки раз, изменяет характер многих видов информационной и трудовой деятельности. Информационное обеспечение является основой создания систем социально-культурно-бытового назначения для общественного использования.
Информационные системы – системы обработки данных о какой-либо предметной области со средствами накопления, хранения, обновления, поиска и выдачи данных. По средствам выполнения информационной задачи различают информационные системы ручные, механизированные и автоматизированные; по выполняемой функции - информационно - поисковые, управляющие, моделирующие, обучающие, экзаменующие и др.; по области применения - медицинские, финансовые, лингвистические и др.
Информация – (лат. informatio – разъяснение, осведомление) – одно из основных понятий кибернетики. Первоначально означало сообщение данных, сведений, осведомление и т.п. Кибернетика вывела понятие информации за пределы человеческой речи и других форм коммуникации между людьми, связала его с целенаправленными системами любой природы – биологическими, техническими, социальными. Информация выступает в трех формах: биологической (биотоки в организмах, связи в генетических механизмах), машинной (сигналы в электронных цепях) и социальной (движение человеческих знаний в общественных системах).
С общей стороны информация – связь в любых целенаправленных системах, определяющая их целостность, устойчивость, уровень функционирования. Информацию можно выразить математически и измерять с помощью информационной единицы – бита. Как отражение явлений реального мира, понятие информации раскрывается указанием действий, в которых она участвует: передачи, преобразования и хранения. Хранение информации предполагает наличие носителя информации. Передача информации предполагает наличие передатчика, приемника и канала связи, способного отображать состояние передатчика в состояние приемника. Обработка информации – выполнение любого алгоритма, исходные данные для которого отождествляются с состоянием того или другого носителя. Различают дискретную и непрерывную форму информации. Как в естественных, так и в искусственных процессах, в которых участвует информация, одни ее формы переходят в другие. Изучение общих свойств информации независимо от ее смыслового содержания является предметом теории информации.
Кардинальное число – (от лат. cardinalis - главный, основной) – обобщение понятия числа элементов на случай произвольных множеств. Пусть существует взаимно однозначное соответствие между двумя множествами. Тогда говорят, что они эквивалентны, равномощны, имеют одинаковую мощность, имеют одно и то же кардинальное число. Кардинальное число множества А определяют часто как класс Card А всех множеств, эквивалентных множеству А, иногда же в качестве кардинального числа эквивалентных между собой множеств берут некоторое одно из них. Пусть







Ключ базы данных – элемент данных, значение которого используется для поиска отдельных совокупностей данных (чаще всего записей или сегментов) в базе данных.
Ключ защиты – пароль, позволяющий пользователям обращаться к базе данных.
Ключ поиска – информация в записи, являющаяся признаком, по которому данная запись может разыскиваться программами поиска, в частности программами, реализующими индексно-последовательный метод доступа. Для эффективного поиска множество записей упорядочивается по значениям ключа поиска.
Ключ сортировки – элемент данного, определяющий упорядоченность данных (например, записей в файлах или наборах).
Кодда модель базы данных – модель данных реляционная.
Кортеж – элемент прямого (декартова) произведения множеств. В отличие от вектора компоненты кортежа на обязательно числа. Ими могут быть также ранги, символы, имена и т.п. В модели данных реляционной кортеж представляет собой строку таблицы (отношения).
QBE (англ. Query by Example – запрос на примере) – язык запросов к базам данных в модели данных реляционной и модели данных иерархической. Разработан в 1975 году М. Злуфом (США). Основан на исчислении предикатов, где в запросах требуемое множество кортежей определяется путем спецификации предиката, которому должны удовлетворять эти кортежи, запрос формулируется посредством экрана видеотерминала, на котором пользователю показывается так называемый макет отношения – заголовки столбцов таблицы, под которыми можно задать параметры своего запроса. Если в столбец помещается какое-либо значение атрибута, это означает, что требуется найти кортеж с заданным значением атрибута. Если значение атрибута отмечается подчеркиванием (или другим способом), это значит, что приведен только пример значения атрибута, который нас интересует. Специальные буквы, указанные в столбце перед значением атрибута, определяют требуемые манипуляции для атрибута: выдачу на печать, замену, исключение или добавление. QBE позволяет строить сложные запросы, является реляционно полным языком, удобен для любых пользователей.
Манипулирование данными – действия по извлечению или изменению данных в базе данных. Описываются не языке манипулирования данными модели базы данных.
Манипулирование данными может приводить к изменению состояния базы данных и нарушению ее целостности; поэтому оно ограничено рамками санкционированного доступа к базе данных.
Машина баз данных – специализированная вычислительная система для параллельной или аппаратно-программной реализации функций системы управления базами данных. По сфере применения различают машины для управления формализованными базами данных и машины для поиска и просмотра текстовых баз данных. В настоящее время проекты машин баз данных характерны многочисленностью используемых архитектурных решений и многообразием действующих образцов.
Меню – способ взаимодействия с пользователем в диалоговых системах программирования, при котором пользователю предлагается (обычно на экране видеотерминала) перечень возможных действий, из которых он может выбрать и отметить (напри мер, посредством клавиши или курсора) одно, подлежащее выполнению. Использование меню позволяет определять требуемые действия программы на удобном для пользователя языке его профессиональной деятельности, экономить его усилия по формулировке задачи; меню широко применяется в массовых системах взаимодействия с ЭВМ (например, автоматизированных обучающих системах).
Метаданные – вспомогательные данные, представляющие характеристики, размещение, режимы использования, семантику и т.п. сведения об основных данных, относящихся непосредственно к объектам и связям предметной области процесса. Фиксируются в описании схем баз данных, а также в форме поддерживающих их словарей-справочников. Примерами метаданных могут быть описания логических структур данных, типы и длины значений данных и др.
Модель – физическая система либо математическое описание, отображающие существенные свойства или характеристики изучаемого объекта, процесса или явления.
Модель данных – фиксированная система понятий и правил для представления структуры данных, состояния и динамики проблемной области в базах данных. Как правило, задается языком определения данных и языком манипулирования данными.
Примерами модели данных, получившими широкое распространение, являются модели данных сетевая, бинарная, иерархическая, реляционная и др.
Модель данных бинарная – представление о проблемной области в виде бинарных отношений, характеризуемых триадой (объект, атрибут, значение). Используется в области искусственного интеллекта.
Модель данных иерархическая – представление о проблемной области в виде иерархий или деревьев объектов, когда каждый объект может иметь несколько «подчиненных» объектов, но только один «старший». Соответственно, язык манипулирования данными иерархической модели обладает средствами манипулирования объектами в терминах их иерархических связей. Иерархическая модель реализована в ряде широко распространенных СУБД.
Модель данных инфологическая – формализованное описание информационного содержания проблемной области независимо от структур баз данных, используемых СУБД. Обычно такое описание производится в терминах информационный объектов, их свойств (атрибутов) и взаимных связей.
Модель данных кодасиловская – модель данных сетевая, разработанная рабочей группой по базам данных при комитете CODASYL (США). Цель модели – создание интегральной многоцелевой базы данных, доступной для многих приложений, использующих различные языки программирования. Данные, централизованно хранящиеся в базе данных, логически описываются схемой данных, для записи которой предлагается язык определения данных высокого уровня, обеспечивающий независимость данных от способов их использования и языка манипулирования данными. Функции составления и поддержания схемы выполняются администратором базы данных. Для отдельных областей применения базы данных конструируются подсхемы данных. Язык описания подсхемы позволяет задавать подмножество базы данных, используемое в соответствующей области, в терминах языка программирования, ориентированного на эту область. Язык манипулирования данными, включаемый в этот язык программирования, используется для организации передач данных между базой данных и рабочей областью задачи.
Подсхемы могут составляться и транслироваться независимо друг от друга, определяемые ими данные могут частично совпадать. Понятия схемы и подсхемы, их разделение, а также разделение языков определения данных и манипулирования данными являются фундаментальными концепциями модели. Язык определения описывает базу данных в терминах имен и характеристик следующих элементов структуры данных: элементов данных, называемых агрегатами, записей данных, иерархических групповых отношений, организованных в виде наборов записей, именованных областей памяти базы данных и базы данных, состоящей из всех экземпляров (конкретных значений) записей, наборов и областей, описанных и управляемых конкретной схемой. Посредством наборов можно строить универсальные структуры данных, в том числе и сетевые. Набор представляет собой именованную упорядоченную совокупность записей, из которых единственная запись объявляется владельцем набора, а остальные – его членами. Записи в наборах связаны в структуры, аналогичные списковым структурам, причем указателями следующего элемента служат ключи базы данных. Каждый тип записей может быть объявлен владельцем произвольного числа типов наборов и/или членом произвольного числа типов наборов, отличных от первых. Схема определяет особенности связи записей в наборе и логическую упорядоченность записей-членов, а также правила включения записей в наборы, идентификацию и методы размещения записей внутри набора; последние определяют механизмы доступа к записям набора при выполнении операторов языка манипулирования данными. При включении в подсхему допускается переименование и перегруппировка данных базы данных внутри записей, изменение характеристик элементов данных, исключение некоторых типов данных или исключение записей, принадлежащих определенным областям, изменение способа выбора экземпляра набора. Язык манипулирования данными позволяет указать режим использования областей: открыть (подготовить к работе) или закрыть область, занести в базу данных новый экземпляр записи и связать ее с теми наборами, членом которых она объявлена; модифицировать значение записи; определить некоторую запись, заданную поисковым выражением, как текущую запись задачи, набора или области; передать текущую запись в рабочую область задачи; исключить ее из набора или вставить в набор; изменить логический порядок членов набора.
Кодасиловская модель предусматривает средства защиты данных. Кодасиловская модель является существенным вкладом в развитие программного обеспечения банков данных. Она реализована во многих широко используемых СУБД.
Модель данных реляционная – модель данных, предложенная в 1970 году американским ученым Е.Ф.Коддом. Основана на представлении данных в виде отношений между ними, при этом представление этих отношений подвергается нормализации – пошаговому процессу приведения их к двумерной табличной форме с полным сохранением информации о них. К двумерной табличной форме могут быть приведены и отношения, имеющие структуру дерева, и наиболее общий вид отношений – сетевые, которые могут быть сведены к нескольким деревьям. Представление данных в виде двумерных таблиц является естественным и легкодоступным для пользователей. Под таблицами понимают прямоугольные массивы, обладающие следующими свойствами: элементу данных соответствует единственный вход в таблицу; в каждой из колонок таблицы располагаются элементы некоторого вида, каждой колонке присваивается имя; не допускаются строки таблиц с совпадающими значениями всех колонок; колонки и строки таблиц могут просматриваться в любой последовательности. Отношения в реляционной модели представлены таблицами, в которых каждая из строк содержит значения свойств (или атрибутов), которыми обладает некоторый объект данного типа; каждый из столбцов соответствует множеству значений, которые принимает некоторый атрибут этого типа, т.е. отношение есть множество векторов из n элементов – кортежей (

...






Возможны три уровня сопряжения пользователя с базой данных: на высшем уровне пользователь формулирует свои запросы в терминах реляционного исчисления, определяя, какие новые отношения он желает образовать из существующих; на среднем уровне запрос формулируется как последовательность операций реляционной алгебры, выполняемых над отношениями; на самом низком уровне пользователь определяет шаги получения некоторого кортежа отношения, т.е. полностью управляет поиском данных в базе данных. Реляционная модель основана на представлениях пользователя о данных и не касается физического представления структур хранения. Таким образом, пользователь освобождается от знания деталей физического представления данных и особенностей программирования, что существенно облегчает процесс обучения. Отношения базы данных трактуются как множества, чьи упорядоченность, организация и физическое представление не известны большинству пользователей и изменяются без предупреждения. Однако пользователь может определить упорядоченность получения элементов, передаваемых из его рабочего поля в базу данных. Гибкий аппарат получения файлов для различных областей использования данных с помощью просто реализуемых операций над отношениями единой базы данных позволяет обеспечить независимость данных. Язык манипулирования данными реляционной модели послужил основой ряда популярных языков запросов (SQL, QBE и др.).
Модель данных сетевая – представление о проблемной области в виде объектов, связанных бинарными отношениями «многие-ко-многим», т.е. каждый объект может иметь несколько «подчиненных» и несколько «старших», благодаря чему сетевая модель может быть представлена ориентированным графом. Наиболее известной сетевой моделью является модель данных кодасиловская.
Модель данных «сущность-связь» - представление о проблемной области в виде объектов (называемых сущностями), между которыми фиксируются связи. Для каждой связи устанавливается число связываемых ею объектов. Модель «сущность-связь» имеет наглядное графическое представление: сущности изображаются прямоугольниками, связи – ромбами, число связываемых объектов указывается на линии соединения объекта связью.
Модель информационная - система данных об объекте, которую формируют в задачах при системном направлении развития ЭВМ. Вводится в ЭВМ один раз, и это позволяет любым прикладным программам использовать необходимые для них данные из этой базы данных.
Набор данных - представление группового отношения в кодасиловской модели данных.
Независимость данных в базах данных - возможность осуществлять реорганизацию баз данных (физическая независимость) или их реструктурирование (логическая независимость), не меняя при этом программ их обработки.
Неизбыточность базы данных - состояние базы данных, при котором в ней не содержатся дубликаты значений данных и их отношений, или данные, значения которых могут быть получены как производные значений других данных, также хранимых в базе данных.
Ограничения целостности – совокупность правил и зависимостей в базах данных, соблюдение которых защищает от занесения в них искаженных данных.
Организация данных - представление данных и управление ими в соответствии с определенными соглашениями. Логическая организация данных учитывает конструкции данных и операции над теми данными, которые находятся в распоряжении программы, физическая - размещение и связь данных в среде хранения.
Откат в системах управления транзакциями – возврат базы данных и взаимодействующего с ней процесса к состоянию, которое они имели до начала выполнения транзакции. Необходим в нерегулярных ситуациях, например, при возникновении тупика или при отказе одного из узлов вычислительной сети, на котором также выполнялась одна из ветвей данной транзакции. Благодаря откату аннулируется начавшая выполняться транзакция, но база данных остается в целостном состоянии. В отличие от этого, если прекратить выполнение некоторой транзакции до ее окончания и не делать откат, то целостность БД может быть нарушена. Откат производится путем выполнения над базой данных действий, обратных тем, которые были произведены транзакцией. Возможность отката характеризуется тем, что вся информация, необходимая для выполнения, хранится в стабильной памяти до завершения транзакции.
Откат может быть реализован также на основе периодического запоминания контрольной точки. Наиболее сложным для реализации отката является случай, когда БД считывалась и изменялась несколькими транзакциями. В этом случае один отказ компонента системы может вызвать необходимость отката нескольких баз данных и процессов (эффект домино). Этот случай характерен для транзакций, функционирующих в вычислительной сети.
Подсхема данных – определение структуры некоторой части базы данных, используемой в соответствующей прикладной области. Язык определения данных для подсхемы данных обычно отличается от языка задания схемы и оперирует с данными в терминах языка программирования, используемого в соответствующем приложении; вместе с тем, множество данных определяемых подсхемой, должно быть согласующимся логическим подмножеством данных, определяемых схемой данных. На уровне подсхемы данных может обеспечиваться переименование элементов данных, изменение их свойств, исключение неиспользуемых данных, переупорядочение и изменение средств защиты данных от неправомочного использования и др. Использование подсхемы данных повышает удобство программирования и степень защиты данных в базе данных в базе данных, полностью исключая обращение к данным, не включенным в подсхему.
Предметная область – часть реального мира, представляющая собой среду определения и реализации конкретного автоматизируемого процесса или группы процессов. На концептуальном уровне представляется выделяемыми в ней типами объектов, атрибутами этих типов объектов и связями между ними.
Представление данных – обобщенная характеристика, выражающая правила кодирования элементов и образование конструкций данных на конкретном уровне рассмотрения в вычислительной системе или базе данных. Представление данных в среде хранения и пути доступа к данным определяются внутренней схемой базы данных. Для представления данных различной структуры предназначены модели данных иерархическая, сетевая и реляционная.
Проектирование баз данных – разработка схемы данных для некоторой проблемной области.
Цель проектирования – получение баз данных, позволяющих эффективно решать соответствующие задачи. На основе анализа проблемной области выявляются информационные объекты и связи между ними (иногда в терминах некоторой инфологической модели данных), выбирается адекватная им модель данных, в терминах которой представляется логическая или концептуальная данных структура, затем выбирается подходящая СУБД и физическая структура хранения баз данных. Основными критериями, которым должна удовлетворять спроектированная структура баз данных, являются обеспечение функциональных требований приложений и высокая производительность системы. Плохо спроектированная база данных может привести к структурному конфликту, что существенно затруднит программирование прикладных задач. Проектирование должно обеспечить целостность (исключение случайных потерь или искажения данных) и согласованность обновления данных, защиту данных от несанкционированного доступа. База данных должна обладать способностью адаптации к изменяющимся условиям ее использования. Разработаны методы автоматической поддержки процесса проектирования баз данных.
Разрушение данных – процесс, приводящий базу данных в состояние, при котором невозможен доступ к порциям данных, хранимых в ней. Разрушение данных в базе данных может произойти в результате некорректных операций над данными и сбоев технических средств, а также в результате преднамеренных действий при отсутствии средств защиты данных от несанкционированного доступа.
Редактирование данных – преобразование формы представления данных к виду, удобному для использования. Обычно редактирование данных осуществляется при выдаче данных на печать. Типичными действиями редактирования являются устранение ведущих (незначащих) нулей в числе, вставка обозначений денежных единиц или специальных разделителей (например, пробелов или знаков препинания), изменение формата числа и т.д. Редактирование данных обычно осуществляется с помощью специальных средств, имеющихся во многих языках программирования.
Реляционная алгебра (от лат. relatio – отнесение, перенесение) – алгебра отношений, принятая в реляционной модели данных как один из уровней языка манипулирования данными. Операции реляционной алгебры позволяют вырезать отдельные домены из отношения, уменьшая его степень, объединять отношения, получая отношения более высокой степени, причем в результирующем отношении исключаются совпадающие строки, и др. Эти операции применяются к отношению в целом, а не к отдельным его записям и аналогичны характерным операторам обработки файлов в автоматизированной обработке данных.
Реляционно полный язык – язык манипулирования данными, средства которого позволяют выразить любую операцию реляционной алгебры.
Реляционное исчисление – исчисление предикатов, используемое как один из уровней языка манипулирования данными в реляционной модели данных. С помощью реляционного исчисления пользователь определяет отношение, которое он желает получить из существующих в базе данных отношений, не определяя процедурных шагов достижения поставленной цели. Реляционное исчисление позволяет формулировать запросы пользователей в терминах свойств, которыми должны обладать данные, подлежащие извлечению из базы данных или занесению в нее.
Реорганизация данных – процесс изменения концептуальной, логической или физической структуры данных. Логическую реорганизацию данных принять называть реструктуризацией, физическую - реформатированием данных.
Связь данных – свойство данных, отражающее функциональную, статистическую, логическую и т.п. зависимость между ними. Наряду с сущностью является основным понятием в модели предметной области (модель данных «сущность-связь»). Может рассматриваться как одна из форм сущности, однако чаще этого не делают для большей наглядности модели.
Сегмент данных – единица данных, участвующая в обмене между прикладными программами и базами данных. В большинстве современных СУБД такой единицей обмена является запись.
Система баз данных – совокупность общесистемного и прикладного программного обеспечения, баз данных, операционной системы и технических средств вычислительной техники.
Используется с целью информационного обеспечения пользователей. Системное программное обеспечение, как правило, включает СУБД и средства ее окружения, средства администратора баз данных или средства ведения файловых систем. Прикладное программное обеспечение обычно включает проблемно-ориентированные пакеты программ анализа информации и решения прикладных задач.
Система управления базами данных (СУБД) – совокупность языковых и программных средств, предназначенных для создания, ведения и конкурентного использования базы данных многими пользователями. Структура СУБД определяется используемой моделью данных. Основными функциями СУБД являются:
а) трансляция схемы, определяющей структуру хранимых данных, в некоторое внутреннее представление, используемое СУБД при дальнейшей работе с данными (схема обычно составляется администратором базы данных на основании требований предполагаемых пользователей и записывается на языке определения данных, принятом в СУБД);
б) загрузка данных в базу данных (создание БД), сопровождаемая максимально возможной проверкой их правильности;
в) реализация запросов пользователей (формулируемых на специальном языке, принятом в данной СУБД) на отбор и извлечение некоторой части базы данных по задаваемым ими критериям отбора; этот процесс может сопровождаться некоторыми процедурами редактирования и обработки отобранной информации;
г) обновление некоторых частей базы данных без изменения структуры данных; критерии определения обновляемой части обычно аналогичны критериям отбора данных и задаются пользователем.
Важным аспектом, характеризующим СУБД, является обеспечиваемые ими структуры данных, их базовые компоненты и способы композиции. Современные СУБД различают логические структуры, отражающие представление пользователя о данных безотносительно к деталям методов их хранения, и структуры хранения, определяющие способы запоминания данных в физических блоках базы данных. В функции СУБД входит также обеспечение защиты данных от неправомочного доступа и разрушений.
В зависимости от ориентации пользователей СУБД можно условно разделить на системы с включающим языком, обслуживающие программистов, которые обращаются к БД в терминах языка программирования высокого уровня – включающего языка, расширенного средствами сопряжения с СУБД, называемыми языком манипулирования данными, и системы с замкнутыми возможностями, обслуживающие непрограммирующих пользователей, решающий узкий круг профессиональных проблем, для которых можно предложить язык запросов, близкий по терминологии к характеру решаемых задач и нацеленный на осуществление определенного замкнутого набора функций над базой данных без использования традиционного процедурного программирования. Этот набор составляется из функций высокого уровня, которые приходится многократно программировать. Многолетний опыт использования таких функций показывает, что они могут быть обобщены, т.е. один раз запрограммированы с возможностью настройки по задаваемым пользователем параметрам. К таким функциям чаще всего относятся функции создания и обновления базы данных и так называемая функция получения справок – извлечение данных из базы данных на основе задаваемых пользователем критериев выборки и некоторая типизированная их обработка (сортировка, усреднение, суммирование и др.).
Система управления транзакциями – программных комплекс, управляющий последовательностью выполнения в информационно-вычислительной системе элементарных работ (транзакций) над базой данных. Для повышения производительности система управления транзакциями должна обеспечивать параллельное протекание процессов выполнения транзакций. Параллелизм может быть кажущимся (в однопроцессорной системе) и истинным (в многопроцессорной системе или вычислительной сети). Свойство плана параллельного выполнения транзакций, гарантирующее то, что по окончании выполнения плана база данных остается целостной, называется сериализуемостью. Система управления транзакциями должна обеспечить достаточную отказоустойчивость информационно-вычислительной системы.
Это достигается механизмом отката, гарантирующим атомарность каждой транзакции в случае отказа компонентов системы.
SQL, SEQUEL (от англ. Structured English Query Language – структурный английский язык запросов) – язык запросов, базирующийся на реляционной алгебре. Разработан в начале 70-х гг. в США. Центральным оператором языка является так называемое отображение исходных отношений на некое производное отношение, образованное из отдельных атрибутов исходных отношений при соблюдении для них заданных условий. Имеются средства композиции отображений, в том числе отображения могут быть вложенными, к ним можно применять теоретико-множественные операции, можно именовать кортежи производных отношений, к совокупности значений некоторого атрибута в отношении можно применять функции вычисления числа таких значений, их суммы, среднего, минимального и максимального значения. SQL является реляционно полным языком. Широко распространен, ведутся работы по его стандартизации.
Совместимость базы данных – свойство, характеризующее способность базы данных к интеграции баз данных. Является необходимым, но недостаточным условием для интегрированного представления базы данных. Выделяют совместимость по моделям данных и соответствие типу СУБД, по физическому представлению базы данных (текстовая и графическая) и др.
Сортировка данных – переупорядочение элементов информации, в результате которого они располагаются в последовательности, определяемой значениями некоторых признаков (элементов), называемых ключевыми признаками, или ключами сортировки.
Справочник данных – совокупность программных и организационных средств СУБД, обеспечивающая возможность получения справок по определению и смыслу данных. Иногда функциями справочника данных являются также сбор статистики использования данных, генерация процедур проверки их правильности и пр.
Структура хранения базы данных – представление структур данных на физических носителях информации. Определяется обычно администратором базы данных, пользователи базы данных избавлены от необходимости определять ее.
В современных базах данных допускается изменение структуры хранения без изменения логической структуры данных – так называемый принцип физической независимости данных. Определение структуры хранения состоит в определении правил соотнесения с экземплярами компонентов структуры данных (элементов, групп, записей, файлов, наборов) физических единиц памяти и методов доступа к хранимой информации.
Сущность – элемент модели предметной области, означающий объект, предмет, понятие и т.п.
Схема данных – определение структуры данных, хранящихся и используемых в базе данных. В схеме данных обычно устанавливаются соответствие имен и значений данных, свойства, присущие всем представителям определенных типов данных (так называемые схемные свойства), правила композиции структур данных, отношения между данными, правила, ограничивающие доступ к данным и др. Для задания схемы данных используются специальные формальные языки, называемые языками определения данных (ЯОД). Описание схемы данных на ЯОД в большинстве БД является функцией администратора баз данных. Схема данных характеризует хранимые в базе данные с точки зрения администратора базы данных, т.е. в форме, независимой от прикладных программ и лиц, которые могут использовать данные. Наряду со схемой данных, некоторая часть БД может определяться как подсхема данных, указывающая характеристики данных в терминах использующего их приложения.
Транзакция – единица работы в СУБД. Формируется так, чтобы, начав работать с целостной БД, оставить ее после своего завершения также целостной. Указанное свойство обеспечивается правильным программированием транзакций программистом, а также системой управления транзакциями, обеспечивающей атомарность транзакции, т.е. либо доведение транзакции до завершения, либо аннулирование всех действий начавшейся транзакции. Последнее необходимо для повышения отказоустойчивости информационной вычислительной системы.
Указатель в программировании – элемент данных, указывающий расположение некоторого данного.
Файл (англ. file – досье, картотека) в языках программирования – рассматриваемая как единое целое совокупность однотипных по структуре и способу использования записей, относящихся к определенному этапу управленческих работ. Как правило, файл содержит большие объемы информации и размещается на внешних носителях памяти ЭВМ. При обработке файла его записи поочередно вызываются в оперативную память. Кроме записей, файл обычно содержит некоторые сведения, позволяющие отличить один файл от другого, определить последнюю запись файла и т.д.
Целостность данных в базах данных – автоматически обеспечиваемая защита данных от отказов оборудования или воздействия отдельных процессов взаимодействия пользователей с базой данных, приводящих к случайному или преднамеренному разрушению данных.
Язык запросов – совокупность языковых средств, позволяющих удовлетворить информационные потребности пользователей баз данных без дополнительного программирования. Одним из примеров языка запросов является язык QBE.
Язык манипулирования данными (ЯМД) – совокупность языковых средств для организации доступа к данным в некоторой модели данных и в соответствующих ей СУБД. Может выступать в роли языка запросов, прямо обеспечивающего информационное обслуживание пользователей баз данных, или быть расширением некоторого языка программирования, называемого включающим языком, с конструкциями и понятиями которого ЯМД должен быть согласован. Операторы ЯМД позволяют извлекать данные из баз данных, создавать или модифицировать последние.
Язык определения данных (ЯОД) – формальный закон, используемый в некоторой модели данных для определения структуры баз данных. Посредством ЯОД обычно определяются подразделения данных, типовые структуры и правила их композиции, присваиваются имена данным, определяются типы элементов данных посредством задания присущих им свойств, учреждаются ключи базы данных, а также определяются отношения между данными, упорядоченность данных внутри их совокупностей, правила проверки достоверности данных и замки защиты от неправомочного использования их.Обычно в ЯОД не определяются техника запоминания или поиска данных на физических носителях и др. особенности физической их организации, что обусловлено одной из основных концепций базы данных – независимостью логической структуры данных от физических особенностей их хранения. ЯОД обычно полностью независим от языка манипулирования данными. Следовательно, определение данных в базах данных независимо от программ обработки, что является второй важной концепцией использования баз данных.
НЕДОСТАТКИ ФАЙЛОВЫХ СИСТЕМ
Ограничения файловых систем, закрывающие перспективы их использования при обработке значительных объемов информации большим количеством кон- курирующих пользователей следующие [7, 1Ц.
1. Разделение и изоляция данных.
2. Дублирование данных.
3. Зависимость данных.
4. Несовместимость форматов файлов.
5. Фиксированный набор запросов, быстрое увеличение количества приложений.
1. Разделение и изоляция данных
Данные изолированы в отдельных файлах, доступ к ним затруднен. Например, для создания списка всех домов, отвечающих требованиям потенциальных арендаторов, предварительно нужно создать временный файл со списком арендаторов, желающих арендовать недвижимость типа «дом». Затем в соответствующих файлах следует осуществить поиск объектов недвижимости типа «дом» с арендной платой ниже установленного арендатором максимума. Выполнять подобную об- работку данных в файловых системах достаточно сложно. Для извлечения соответствующей поставленным условиям информации программист должен организовать синхронную обработку двух файлов. Трудности существенно возрастают, когда необходимо извлечь данные из более чем двух файлов.
2. Дублирование данных
Из-за децентрализованной работы с данными про- водимой в каждом отделе организации независимо от других отделов, в файловой системе фактически поощряется бесконтрольное дублирование данных, что, в принципе, неизбежно. Бесконтрольное дублирование данных нежелательно по двум причинам:
1) дублирование данных сопровождается неэкономным расходованием ресурсов. Во многих случаях дублирования данных можно избежать за счет совместного использования файлов;
2) дублирование данных может привести к нарушению их целостности, данные из разных файлов могут стать противоречивыми. Поскольку не существует ни- какого автоматического способа обновления данных одновременно и в нескольких файлах, подобные противоречия с какой-то вероятностью будут возникать.
3. Зависимость данных
Физическая структура и способ хранения записей файлов данных жестко зафиксированы в коде программ приложений. Это значит, что изменить существующую структуру данных достаточно сложно. Для этого придется создать одноразовую программу специального назначения, которая выполняется один раз.
Помимо этого, все обращающиеся к файлу данных программы должны быть изменены с целью соответствия новой структуре этого файла. Причем таких программ может быть очень много. Следовательно, программист должен прежде всего выявить такие программы, а затем перепроверить их и изменить. Ясно, что выполнение всех этих действий требует больших затрат времени и может явиться причиной появления ошибок. Данная особенность файловых систем называется зависимостью от программ и данных.
4. Несовместимость форматов файлов
Поскольку структура файлов определяется кодом приложений, она также зависит от языка программирования этого приложения. Например, структура файла, созданного программой на языке COBOL, может совершенно отличаться от структуры файла, создаваемого программой на языке С. Прямая несовместимость таких файлов затрудняет процесс их совместной обработки.
5. Фиксированный набор запросов, быстрое увеличение количества приложений
С точки зрения пользователя возможности файловых систем намного превосходят возможности ручных картотек. Соответственно возрастают и их требования к реализации новых или модифицированных запросов. Однако файловые системы во многом зависят от программиста, потому что все требуемые запросы и отчеты должны быть созданы именно им. В результате события обычно развивались по одному из сценариев. Во многих организациях типы создаваемых запросов и отчетов имели фиксированную форму, и не было никаких инструментов создания незапланированных или произвольных (ad Ьос) запросов как к самим данным, так и к сведениям о том, какие типы данных доступны.
В других организациях наблюдалось быстрое увеличение количества файлов и приложений. В конечном счете наступал момент, когда сотрудники отдела по обработке данных были просто не в состоянии справиться со всей этой работой с помощью имеющихся ресурсов.В этом случае программное обеспечение переставало адекватно отвечать запросам пользователей, эффективность его падала, а недостаточность документирования имела следствием дополнительное усложнение сопровождения программ. При этом часто игнорировались меры по обеспечению безопасности или целостности данных; средства восстановления в случае сбоя аппаратного или программного обеспечения были крайне ограничены или вообще отсутствовали. Доступ к файлам часто ограничивался одним пользователем, т.е. не предусматривалось их совместное использование даже сотрудниками одного и того же отдела.
Все перечисленные ограничения файловых систем являются следствием двух факторов.
1. Определение данных содержится внутри приложений, а не хранятся отдельно и независимо от них.
2. Помимо приложений не предусмотрено никаких других инструментов доступа к данным и их обработки.
ОБОБЩЕННАЯ МЕТОДИКА ПРОЕКТИРОВАНИЯ РЕЛЯЦИОННЫХ БАЗ ДАННЫХ
Процесс разработки баз данных включает три фазы:
1. концептуальное (инфологическое) проектирование;
2. логическое проектирование;
3. физическое проектирование [7, 17].
ЭТАП 1
Создание локальной концептуальное модели данных исходя из представлений о предметной области каждого из типов пользователей
Построение локальной концептуальной модели данных организации с точки зрения представления о функционировании организации каждого из существующих типов пользователей.
1.1. Определение типов сущностей
Определение основных типов сущностей, присутствующих в представлении данного пользователя о предметной области приложения. Документирование выделенных типов сущностей.
1.2. Определение типов связей
Определение важнейших типов связей, существующих между сущностями, выделенными на предыдущем этапе. Определение кардинальности связей и ограничений участия их членов. Документирование типов связей. При необходимости могут использоваться диаграммы «сущность-связь» (ER-диаграммы).
1.3. Определение атрибутов и связывание их с типами сущностей и связей
Связывание атрибутов с соответствующими типами сущностей или связей. Идентификация простых и составных атрибутов. Документирование сведений об атрибутах.
1.4. Определение доменов атрибутов
Определение доменов для всех атрибутов в каждой локальной концептуальной модели данных. Документирование сведений о доменах атрибутов.
1.5. Определение атрибутов, являющихся потенциальными и первичными ключами
Определение потенциального ключа для каждого типа сущности; если таких ключей окажется несколько, выбор среди них первичного ключа. Документирование сведений о первичных и альтернативных ключах для каждой сильной сущности.
1.6. Специализация или генерализация типов сущностей (необязательно)
Определение суперклассов и подклассов для типов сущностей (при необходимости).
1.7. Создание диаграммы «сущность-связь»
Разработка диаграмм ~сущность-связь» (KR-диаграмм), содержащих концептуальное отражение представлений пользователей о предметной области приложения.
1.8. Обсуждение локальных концептуальных моделей данных с конечными пользователями
Обсуждение локальных концептуальных моделей данных с конечными пользователями для получения подтверждений того, что данная модель корректно отражает представления пользователей о приложении и организации.
ЭТАП 2
Построение и проверка локальной логической модели данных на основе представлений о предметной области каждого из типов пользователей
Построение логической модели .данных на основе концептуальной модели данных, отражающей представление отдельного пользователя о предметной области приложения, проверка полученной модели с помощью методов нормализации и контроля возможности выполнения транзакций.
2.1. Преобразование локальной концептуальной модели данных в локальную логическую
модель Доработка локальных концептуальных моделей с целью удаления из них нежелательных элементов и преобразование полученных моделей в локальные логические модели данных. Удаление связей типа М:N, сложных связей, рекурсивных связей, множественных атрибутов, связей с атрибутами и избыточных связей. Перепроверка связей типа 1:1.
2.2. Определение набора отношений исходя из структуры локальной логической модели данных
Определение на основе локальных логических моделей данных набора отношений, необходимого для представления сущностей и связей, входящих в представления отдельных пользователей о предметной области приложения. Документирование сведений о новых первичных или потенциальных ключах, которые были определены в процессе создания отношений на основе логической модели данных.
2.3. Проверка модели с помощью правил нормализации
Проверка локальной логической модели данных с использованием технологии нормализации. Целью выполнения этого этапа является получение гарантий того, что каждое из отношений, созданных на основе логической модели данных, отвечает, по крайней мере, требованиям НФБК (нормальной формы Бойса-Кодда).
2.4. Проверка модели в отношении транзакций пользователей
Цель выполнения этого этапа – убедиться в том, что локальная логическая модель данных позволяет выполнить все транзакции, предусмотренные данным представлением пользователя. 2.5.
Создание диаграмм «сущность-связь» Создание диаграмм «сущность-связь» (ER-диаграмм), являющихся локальным логическим представлением данных, используемых отдельными пользователями приложения.
2.6. Определение требований поддержания целостности данных
Определение ограничений, налагаемых на отдельные элементы представлений пользователей требованиями сохранения целостности данных. Сюда относятся определение обязательности наличия данных, установление ограничений для доменов атрибутов, определение требований сохранения целостности сущностей и поддержки ссылочной целостности данных, а также учет требований (бизнес правил) данной организации. Документирование всех установленных ограничений.
2.7. Обсуждение разработанных локальных логических моделей данных с конечными пользователями
Назначение данного этапа – убедиться в том, что созданные локальные модели данных точно отражают представления пользователей о предметной области приложения.
ЭТАП 3
Создание и проверка глобальной логической модели данных
Объединение отдельных локальных логических моделей данных в единую глобальную логическую модель данных, представляющую ту часть организации, которая охватывается данным приложением.
3.1. Слияние локальных логических моделей данных в единую глобальную модель данных
Объединение отдельных локальных логических моделей данных в единую глобальную логическую модель данных организации. В круг решаемых при этом задач включены следующие:
– анализ имен сущностей и их первичных ключей
– анализ имен связей;
– слияние общих сущностей из отдельных локальных моделей;
– включение (без слияния) сущностей, уникальных для каждого локального представления;
– слияние общих связей из отдельных локальных моделей;
– включение (без слияния) связей, уникальных для каждого локального представления;
– проверка на наличие пропущенных сущностей и связей;
– проверка корректности внешних ключей;
– проверка соблюдения ограничений целостности;
– выполнение чертежа глобальной логической модели данных;
– обновление документации.
3.2. Проверка глобальной логической модели данных
Проверка глобальной логической модели данных с помощью методов нормализации и контроль возможности выполнения требуемых транзакций. На этом этапе выполняются действия, аналогичные тем, которые производились на этапах 2.3 и 2.4 при проверке каждой из локальных логических моделей данных.
3.3. Проверка возможностей расширения модели в будущем
Определение вероятности внесения каких-либо существенных изменений в созданную модель данных в обозримом будущем и оценка того, насколько данная модель приспособлена для внесения подобных изменений.
3.4. Создание окончательного варианта диаграммы «сущность-связь»
Создание окончательного варианта диаграммы «сущность-связь», представляющей глобальную логическую модель данных организации.
3.5. Обсуждение глобальной логической модели данных с пользователями
Цель данного этапа – убедиться в том, что созданная глобальная логическая модель данных адекватно отражает моделируемую часть информационной структуры организации.
ЭТАП 4
Перенос глобальной логической модели данных в среду целевой СУБД
Создание базовой функциональной схемы реляционной базы данных на основе глобальной логической модели данных.
4.1. Проектирование таблиц базы данных в среде целевой СУБД.
Определение способа представления всех выделенных в глобальной логической модели данных отношений в виде таблиц целевой СУБД. Документирование результатов проектирования таблиц.
4.2. Реализация бизнес правил организации в среде целевой СУБД
Реализация бизнес правил организации в среде целевой СУБД. Документирование полученных результатов разработки.
ЭТАП 5
Проектирование физического представления базы данных
Определение файловой структуры и методов доступа, которые будут использоваться для представления таблиц базы данных. Другими словами, определение способа хранения таблиц и их строк во вторичной памяти.
5.1. Анализ транзакций
Определение функциональных характеристик транзакций, которые будут выполняться в проектируемой базе данных, выделение наиболее важных из них.
5.2. Выбор файловой структуры
Определение самого эффективного файлового представления для каждой из таблиц базы данных.
5.3. Определение вторичных индексов
Определение того, будет ли добавление вторичных индексов способствовать повышению производительности системы.
5.4. Анализ необходимости введения контролируемой избыточности данных
Определение того, будет ли внесение контролируемой избыточности данных (за счет снижения требований к уровню их нормализации) способствовать повышению производительности системы.
5.5. Определение требований к дисковой памяти
Определение объема дискового пространства, необходимого для размещения базы данных.
ЭТАП б
Разработка механизмов защиты
Разработка механизмов защиты базы данных в соответствии с требованиями пользователей.
6.1. Разработка пользовательских представлений (видов)
Разработка пользовательских представлений (видов), которые были выделены на первом этапе концептуального проектирования базы данных.
6.2. Определение прав доступа
Определение прав доступа к таблицам базы данных для каждого из представлений пользователей. Документирование результатов разработки средств защиты и прав представлений пользователей.
ЭТАП 7
Организация мониторинга и настройка функционирования системы
Мониторинг функционирования операционной системы и достигнутого уровня производительности базы данных с целью устранений ошибочных проектных решений или отображения изменения требований к системе.
ПРАВИЛА РАСПРЕДЕЛЕННЫХ СУБД
Двенадцать правил (или целей) были сформулированы Дейтом для типичной РСУБД. Основой для построения всех этих правил является то, что распределенная СУБД должна восприниматься конечным пользователем точно так же, как и централизованная СУБД. Данные правила сходны с двенадцатью правилами Кодда для реляционных систем, представленными в [7].
Правило 1
Основной принцип. Локальная автономность
С точки зрения конечного пользователя распределенная система должна выглядеть в точности так, как и обычная, нераспределенная система.
Сайты в распределенной системе должны быть автономными. В данном контексте автономность означает следующее:
– локальные данные принадлежат локальным владельцам и сопровождаются локально;
– все локальные процессы остаются чисто локальными;
– все процессы на заданном сайте контролируются только этим сайтом.
Правило 2
Отсутствие опоры на центральный сайт
В системе не должно быть ни одного сайта, без которого система не сможет функционировать. Это означает, что в системе не должно существовать центральных серверов таких служб, как управление транзакциями, выявление взаимных блокировок, оптимизация запросов и управление глобальным системным каталогом.
Правило 3
Непрерывное функционирование
В идеале, в системе никогда не должна возникать потребность в плановом останове ее функционирования для выполнения таких операций, как:
– добавление или удаление сайта из системы;
– динамическое создание или удаление фрагментов из одного или нескольких сайтов.
Правило 4
Независимость от расположения
Независимость от расположения эквивалентна прозрачности расположения. Пользователь должен получать доступ к базе данных с любого из сайтов. Более того, пользователь должен получать доступ к любым данным так, как если бы они хранились на его сайте, независимо от того, где они физически сохраняются.
Правило 5
Независимость от фрагментации
Пользователь должен получать доступ к данным независимо от способа их фрагментации.
Правило 6
Независимость от репликации
Пользователь не должен нуждаться в сведениях о наличии репликации данных.
Это значит, что пользователь не будет иметь средств для получения прямого доступа к конкретной копии элемента данных, а также не должен заботиться об обновлении всех имеющихся копий элемента данных.
Правило 7
Обработка распределенных запросов
Система должна поддерживать обработку запросов, ссылающихся на данные, расположенные на более чем одном сайте.
Правило 8
Обработка распределенных транзакций
Система должна поддерживать выполнение транзакций, как единицы восстановления.
Система должна гарантировать, что выполнение как глобальных, так и локальных транзакций будет происходить с сохранением четырех основных свойств транзакций, а именно: атомарности, согласованности, изолированности и продолжительности.
Правило 9
Независимость от типа оборудования
СУРБД должна быть способна функционировать на оборудовании с различными вычислительными платформами.
Правило 10
Независимость от операционной системы
Прямым следствием предыдущего правила является требование, согласно которому СУРБД должна быть способна функционировать под управлением различных операционных систем.
Правило 11
Независимость от сетевой архитектуры
СУРБД должна быть способна функционировать в сетях с различной архитектурой и типами носителя.
Правило 12
Независимость от типа СУБД
СУРБД должна быть способна функционировать поверх различных локальных СУБД, возможно, с разным типом используемой модели данных. Другими словами, СУРБД должна поддерживать гетерогенность.
ПРИМЕР ИНФОЛОГИЧЕСКОГО ПРОЕКТА БАЗЫ ДАННЫХ
В [5] приведен отличный («классический») пример построения инфологической модели базы данных «Питание», где должна храниться информация о блюдах (рис.П.4.1), их ежедневном потреблении, продуктах, из которых приготавливаются эти блюда, и поставщиках этих продуктов. Информация предназначена для использования поваром и руководителем небольшого предприятия общественного питания, а также его посетителями.
| 1. Лобио по грузински
Ломаную очищенную фасоль, нашинкованный лук посолить, посыпать перцем и припустить в масле с небольшим количеством бульона; добавить кинзу, зелень петрушки, рейган (базилик) и довести до готовности. Затем запечь в духовке. Фасоль стручковая (свежая или консервированная) 200, Лук зеленый 40, Масло сливочное 30, Зелень 10. Выход 210. Калорий 725. |
Рис. П.4.1 Пример кулинарного рецепта
С помощью потенциальных пользователей выделены следующие объекты и характеристики проектируемой базы данных.
1. Блюда, для описания которых нужны данные, входящие в их кулинарные рецепты: номер блюда (например, из книги кулинарных рецептов), название блюда, вид блюда (закуска, суп, горячее и т. п.), рецепт (технология приготовления блюда), выход (вес порции), название, калорийность и вес каждого продукта, входящего в блюдо.
2. Для каждого поставщика продуктов: наименование, адрес, название поставляемого продукта, дата поставки и цена на момент поставки.
3. Ежедневное потребление блюд (расход): блюдо, количество порций, дата.
Анализ объектов позволяет выделить:
– стержни Блюда, Продукты и Города;
– ассоциации Состав (связывает Блюда с Продуктами) и Поставки (связывает Поставщиков с Продуктами);
– обозначение Поставщики;
– характеристики Рецепты и Расход.
ER-диаграмма модели показана на рис. П.4.2 а модель на языке ЯИМ имеет следующий вид.
БЛЮДА (БЛ, Блюдо, Вид)
ПРОДУКТЫ (ПР, Продукт, Калорийность)
Поставщики (ПОС, Город, Поставщик) [ГородА]
Состав [Блюда М, Продукты N] (БЛ, IIP, Вес (г))
Поставки [Поставщики М, Продукты И] (ПЯС, ПР, Дата П, Цена, Вес (кг))
ГОРОДА (Город, Страна)
Рецепты (БЛ, Рецепт) {Блюда}
Расход (БЛ, Лата Р, Порций) {Блюда}
В этих моделях Блюдо, Продукт и Поставщик – наименования, а БЛ, ПР и ПОС – цифровые коды блюд, продуктов и организаций, поставляющих эти продукты.

Рис. П.4.2. Инфологическая модель базы данных «Питание»
ПРИНЦИПЫ ОРГАНИЗАЦИИ КОМПЬЮТЕРНЫХ СЕТЕЙ
Компьютерная сеть – множество автономных компьютеров, соединенных между собой и способных обмениваться информацией [1]. Компьютерные сети представляют собой сложную и интенсивно развивающуюся область компьютерной индустрии, однако определенные знания в этой области совершенно необходимы для понимания принципов построения распределенных СУБД. За последних несколько десятилетий был пройден путь от использования полностью автономных отдельных компьютеров до современного состояния, когда сети компьютером, получили повсеместное распространение. Размеры компьютерных сетей варьируются от нескольких соединенных между собой персональных компьютеров до сетей глобального масштаба, насчитывающих тысячи машин и сотни тысяч пользователей. В нашем конкретном случае распределенные СУБД устанавливаются поверх компьютерной сети таким образом, что работа последней оказывается полностью скрыта от конечного пользователя.
Локальная вычислительная сеть (ЛВС) – совместное подключение нескольких компьютерных рабочих мест (рабочих станций) к единому каналу передачи данных.
ЛВС – географически ограниченная (территориально или производственно) аппаратно-программная реализация, в которой несколько компьютерных систем связанны друг с другом последовательностью соответствующих средств коммутации. Благодаря такому со
единению пользователь может взаимодействовать с другими рабочими местами, подключенными к этой ЛВС. Посредством ЛВС в систему объединяются ПК, расположенные на многих удаленных рабочих местах, которые используют совместное оборудование, программные средства и информацию. Преимущества сетевого объединения следующие [1].
1. Разделение ресурсов: позволяет экономично использовать ресурсы, управлять периферийными устройствами, такими как лазерные печатающие устройства, со всех присоединенных рабочих станций.
2. Разделение данных: предоставляет возможность доступа и управления БД с периферийных рабочих мест, нуждающихся в информации.
3. Разделение программных средств: предоставляет возможность одновременного использования централизованных, ранее установленных программных средств.
4. Разделение ресурсов процессора: дает возможность использовать вычислительные мощности для обработки данных двумя системами, входящими в сеть. Эта возможность заключается в том, что на имеющиеся ресурсы не «набрасываются» моментально, а только лишь через специальный процессор, доступный каждой станции.
5. Многопользовательский режим: содействует одновременному использованию централизованных прикладных программных средств, ранее установленных и управляемых, например, если пользователь системы работает с другим заданием, то текущая выполняемая работа отодвигается на задний план.
6. Электронная почта: с ее помощью происходит интерактивный обмен информацией между рабочими станциями сети, а также с другими устройствами в ВС.
Отличие ЛВС от систем на основе мини-ЭВМ
Основными структурами в используемых ЛВС считаются ВС с расположенной в центре мини-ЭВМ. Однако более перспективны ВС на основе ПК. Объясняется это следующим [1].
1. Система с мини-ЭВМ располагает одним процессорным устройством. производительность такой системы определяется при проектировании. Дополнительно увеличить производительность очень дорого.
2. К мини-ЭВМ подключают терминалы, являющиеся «глупыми» рабочими местами. Поэтому необходимо распределить вычислительные мощности между такими рабочими местами.
3. Локальные терминалы в такой системе зависят от центрального процессора и применяемого программного обеспечения.
4. Локальные рабочие места в ЛВС обладают собственным интеллектом. Это увеличивает производительность вычислительной сети. Производительность возрастает при подключении к системе новых РМ и наоборот.
5. Локальные РМ обладают и собственными внешними носителями данных. Поэтому облегчается внешний обмен данными.
6. Если центральный процессор перегружен, то сеть должна уметь быстро перестраиваться. ЦП может быть заменен на более производительную систему при сохранении всех программных приложений.
7. ЛВС просто и недорого соединяется с другим ЛВС.
8. Для ПК существует необозримое множество приложений ПО и аппаратных решений (самые гибкие системы).
9. Производительность ПК сравнима с производительностью мини-ЭВМ. В ЛВС аккумулируется производительность всех присоединенных ПК.
10. ПК, подключенный как РМ в системе с ЦП не использует свои «интеллектуальные» возможности. Из-за этого теряются вычислительные мощности РМ, и в особенности, возможность передачи данных между ПК РМ и централизованными накопителями данных – файловыми серверами.
При использовании ЛВС, можно утверждать, что прикладные программы практически не влияют на; эффективность функционирования системы в целом. Обработка выполняется в рабочей станции на локальном уровне и не зависит от производительности ЦП сервера. Многотерминальная система с небольшим количеством РМ является более быстродействующей и производительной по сравнению с ЛВС.
Топология ВС
Под топологией ВС понимают конфигурацию физических соединений компонентов ВС.
Тип топологии определяет производительность и надежность сети РМ, для которой имеет значение время обращения к серверу.
1. Топология типа «звезда»
Вся информация между двумя РМ проходит через центральный узел ВС (рис. П.6.1). Пропускная способность сети определяется вычислительной мощностью узла и гарантируется для каждой рабочей станции. Коллизий (столкновений) данных не возникает. Кабельное соединение простое. Затраты на прокладку высокие. Расширение дорогое. Является наиболее быстродействующей. Частота запросов передачи информации от одной станции к другой невысокая.

Рис. П.6.1. Топология типа «звезда»
В случае выхода из строя центрального узла нарушается работа всей сети. Центральный узел управления – сервер может реализовать оптимальный механизм защиты против несанкционированного доступа к информации. Вся ВС может управляться из ее центра.
2. Кольцо
Коммуникационная связь замыкается в кольцо (рис.П.6.2). Прокладка может быть дорогой. Пересылка очень эффективна. Продолжительность передачи информации пропорциональна количеству РМ.

Рис. П.6.2. Топология типа «кольцо»
Основная проблема – каждая рабочая станция должна активно участвовать в пересылке информации, и в случае выхода из строя хотя бы одной, вся сеть парализуется.
Неисправности локализируются легко.
Подключение нового РМ требует кратковременного отключения сети. Ограничения на протяженность не существуют, так как определяется расстоянием между .соседними РМ.
Специальной формой кольцевой топологии является логическая кольцевая сеть (рис. П.6.3). Физически это соединение звездных топологий. Отдельные звезды включаются специальными коммутаторами (концентраторами).
Активные концентраторы (АК) содержат усилители для подключения от 4-х до 16-ти РМ.
Пассивные концентраторы (ПК) – разветвительное устройство (mах – 3 РМ).

Рис. П.6.3. Топология типа «логическое кольцо»
Управление отдельными РМ такое же, как и в обычной кольцевой. Каждой рабочей станции присваивается соответствующий адрес, по которому передается управление (от старшего к младшему, и от самого младшего к самому старшему). Разрыв соединения происходит только для нижерасположенного ближайшего) узла ВС, так что лишь в редких случаях может нарушиться работа всей сети.
3. Шинная топология
При данной топологии среда передачи информации представляется в форме коммуникационного пути, доступного для всех РМ, к которым они все должны быть подключены (рис.П.6.4). Все РМ могут вступить в контакт с любым РМ, имеющимся в сети.

Рис. П.6.4. Топология типа «шина»
РМ в любое время, без прерывания работы всей ВС, могут быть подключены к ней или отключены. Функционирование ВС не зависит от состояния отдельной РМ. Очень легко прослушивать информацию. В ЛВС с прямой (немодулированной) передачей данных всегда может существовать только одна передающая станция. В ЛВС с модулируемой широкополосной передачей каждой станции присваивается своя частота, на которой они принимают и отправляют информацию. Одновременно транспортируется большой объем информации.
4. Древовидная структура ЛВС
На практике применяются и комбинированные структуры, например, древовидная (рис.П.6.5). Она образуется в виде комбинации вышеназванных топологий. Основание дерева ВС располагается в точке (корень), в которой собираются коммутационные линии (ветви дерева).
Древовидная структура применяется там, где невозможно применение чистой базовой топологии.

Рис. П.6.5. Древовидная структура
Объединение ВС
Классификация региональных соединений следующая[1].
GAN - глобальная сеть, общепланетное соединение ВС.
WAN – широкомасштабная, континентальное на уровне государства объединение ВС.
MAN – междугородная сеть, междугороднее и областное объединение сетей.
LAN (ЛВС) -локальная, функционирует в пределах нескольких зданий, территории предприятия.
Соединение ВС будет лишь тогда гибким и широко используемым, если различные системы, которые в обычных условиях не могут взаимодействовать (Macintosh и MS-DOS) находят взаимопонимание посредством пересылки информации друг другу.
Объединение таких ВС осуществляется через мосты (bridges) или межсетевые шлюзы (gateways).
Скорость передачи данных в глобальных сетях обычно находится в пределах от 2 до 2000 Убит/с. Скорость передачи данных в локальных сетях намного больше и составляет от 10 до 100 Мбит/с, а надежность установленных соединений существенно выше. Очевидно, что распределенные системы, построенные на основе локальных сетей, будут обеспечивать меньшее время реакции' системы, чем системы, использующие глобальные сети.
Если классифицировать сети на основе метода выбора пути (или маршрутизации), то их можно разделить на широковещательные и одноадресные.
В случае одноадресной сети при необходимости разослать сообщения всем узлам сети потребуется отправить несколько отдельных сообщений.
В случае широковещательной сети все узлы получают все сообщения, однако в каждом из сообщений присутствует префикс, идентифицирующий узел-получатель, а все остальные узлы сети просто проигнорируют поступившее сообщение.
Глобальные сети обычно строятся по одноадресному принципу, тогда как в локальных сетях, как правило, используется широковещательный принцип. Сводка типичных характеристик глобальных и локальных сетей представлена в табл. П.6.1.
Таблица П.6.1
|
Глобальные сети |
Локальные сети |
|
Удаленность узлов до тысяч километров |
Удаленность узлов до нескольких километров |
|
Связывают автономные компьютеры |
Связывает компьютеры, совместно использующие распределенные приложения |
|
Сеть управляется независимой организацией (используются телефонные или спутниковые каналы связи) |
Сеть управляется ее пользователями (используются собственные кабельные соединения) |
|
Скорость передачи данных до 2 Мбит/с (линии T1) или до 45 Мбит/с (линии T3) |
Скорость передачи данных до 100 Мбит/с |
|
Сложные протоколы |
Более простые протоколы |
|
Используется одноадресная маршрутизация |
Используется широковещательная маршрутизация |
|
Используется нерегулярная топология |
Используется топология шины или звезды |
|
Вероятность ошибки порядка 1:105 |
Вероятность ошибки порядка 1:109 |
Международная организация стандартов (ISO) установила набор правил (или протоколов), регламентирующих способы взаимодействия систем [7]. Выбранный подход состоит в разделении сетевого аппаратного и программного обеспечения на несколько уровней, каждый из которых предоставляет определенные услуги расположенным выше уровням, одновременно скрывая от них все подробности реализации нижних уровней. Протокол, получивший название «модель OSI» (Open System Interconnection), предусматривает использование семи уровней, логически не зависящих от изготовителя оборудования или программ. Отдельные уровни отвечают за передачу последовательностей битов информации по сети, за установку соединений и
контроль наличия ошибок, маршрутизацию и устранение заторов в сети, организацию сеансов связи между отдельными машинами и устранение различий в формате и способе представления данных в компьютерах различных платформ. Модель OSI является международным стандартом для передачи данных. Модель содержит семь отдельных уровней.
Уровень 1: физический – битовые протоколы передачи информации.
Уровень 2: канальный – формирование кадров, управление доступом к среде.
Уровень 3: сетевой – маршрутизация, управление потоком данных.
Уровень 4: транспортный – обеспечение взаимодействия удаленных процессов.
Уровень 5: сеансовый – поддержка, диалога между удаленными процессами.
Уровень 6: представления данных – интерпретация передаваемых данных.
Уровень 7: прикладной – пользовательское управление данными.
Основная идея этой модели в том, что каждому уровню отводится конкретная роль. Благодаря этому общая задача передачи данных расчленяется на отдельные легкообозримые задачи. Необходимые соглашения для связи одного уровня с выше- и нижестоящими называют протоколом.
Так как пользователи нуждаются в эффективном управлении, система вычислительной сети представляется как комплексное строение, которое координирует взаимодействие задач пользователей.
Отдельные. уровни базовой модели. проходят в направлении вниз от источника данных (от уровня 7 к уровню 1).
Пользовательские данные передаются в нижерасположенный уровень вместе со специфическим для уровня заголовком до тех пор, пока не будет достигнут последний уровень.
На приемной стороне поступающие данные анализируются и, по мере надобности, передаются далее в вышерасположенный уровень пока информация не будет передана в пользовательский прикладной уровень.
Уровень 1. Физический
На этом уровне определяются электрические,, механические, функциональные и процедурные параметры для физической связи в системах. Физическая связь и неразрывная с ней эксплуатационная готовность являются основной функцией 1-го уровня.
В качестве среды передачи используют трехжильный медный провод (экранированная витая пара), коаксиальный кабель, оптоволоконный проводник и радиорелейную линию.
Уровень 2. Канальный
Канальный уровень формирует из данных, передаваемых 1-ым уровнем, так называемые «кадры» или последовательности кадров. На этом уровне осуществляется управление доступом к передающей среде, используемой несколькими ЭВМ, синхронизация, обнаружение и исправление ошибок.
Уровень 3. Сетевой
Сетевой уровень устанавливает связь в ВС между двумя абонентами. Соединение происходит благодаря функциям маршрутизации, которые требуют наличие сетевого адреса в пакете. Сетевой уровень так же должен обеспечивать обработку ошибок, мультиплексирование, управление потоками данных.
Уровень 4. Транспортный
Поддерживает непрерывную передачу данных между двумя взаимодействующими друг с другом пользовательскими процессами. Качество транспортировки, безошибочность передачи, независимость ВС, сервис транспортировки из конца в конец, минимизация затрат и адресация связи гарантируют непрерывную и безошибочную передачу данных.
Уровень 5. Сеансовый
Координирует прием, передачу и выдачу одного сеанса связи. Для координации необходимы контроль рабочих параметров, управление потоками данных промежуточных накопителей и диалоговый контроль, гарантирующий передачу, имеющихся в распоряжении данных. Кроме того, сеансовый уровень содержит дополнительные функции управления паролями, подсчета платы за пользование ресурсами сети, управления диалогом, синхронизации и отмене связи в сеансе передачи после сбоя вследствие ошибок в нижерасположенных уровнях.
Уровень 6. Представления данных
Предназначается для интерпретации данных, а также для подготовки данных для пользовательского уровня. На этом уровне происходит преобразование данных из кадров, используемых для передачи данных в экранный формат или формат для печатающих устройств оконечной системы.
Уровень 7. Прикладной
На этом уровне необходимо предоставить в распоряжение пользователей уже переработанную информацию. С этим может справиться системное и пользовательское прикладное программное обеспечение. Для передачи информации по коммутационным ЛС данные преобразуются в цепочку друг за другом следующих битов («0» и «1»).
Передаваемые знаки представляются с помощью битовых комбинаций. Битовые комбинации располагают в определенной кодовой таблице, содержащей 4-х, 5-и, 6-и, 7-и или 8-и битовые коды.
На международном уровне передача символьной информации осуществляется с помощью 7-и битового кодирования, позволяющего закодировать заглавные и строчные буквы английского алфавита и некоторые специальные символы. Национальные и специальные знаки с помощью 7-ми битового кодирования закодировать нельзя. Для этих целей применяется 8-ми битовый код.
Для правильной и безошибочной передачи данных необходимо придерживаться согласованных и установленных правил. Все они оговариваются в протоколе передачи данных.
Протокол передачи данных требует определения следующих аспектов обмена информацией [1].
1. Синхронизация – механизм распознавания начала блока данных и его конца.
2. Инициализация – установление соединения между взаимодействующими процессами.
3. Блокирование – разбиение передаваемой информации на блоки данных строго определенной длины.
4. Адресация – идентификация различного используемого оборудования данных, которое обменивается друг с другом информацией.
5. Обнаружение ошибок – установка битов четности и вычисление контрольных битов.
6. Нумерация блоков – позволяет установить ошибочно передаваемую или терявшуюся информацию.
7. Управление потоком данных – для распределения и синхронизации информационных потоков. Так, например, если не хватает места в буфере устройства данных или данные недостаточно быстро обрабатываются в периферийных устройствах (например, принтерах), сообщения и/или запросы накапливаются.
8. Методы восстановления – используются после прерывания процесса передачи данных, чтобы вернуться к определенному положению для повторной передачи информации.
9. Разрешение доступа – для распределения, контроля и управления разграничением доступа к данным. Вменяется в обязанность пункта разрешения доступа.
Международный консультативный комитет по телеграфии и телефонии (CCITT) разработал стандарт, получивший название Х.25 и охватывающий три нижних уровня описанной выше модели. Большинство распределенных СУБД было разработано с целью использования поверх протокола Х.25. Однако позже были выпущены новые стандарты, охватывающие более высокие уровни модели и способные предоставить СУРБД полезные дополнительные функциональные возможности. К ним можно отнести протоколы RDA (Remote Database Access – ISO, 9579) и DTP (Distribution Transaction Processing – IS0, 10026).
Время передачи
Время, необходимое для доставки сообщения, зависит от размеров посылаемого сообщения и типа используемого сетевого соединения. Оно может быть определено по следующей формуле:
 |
|||||
|
где |
 |
– |
время передачи; |
||
 |
– |
затраты времени на инициацию сообщения, называемые задержкой доступа; |
|||
 |
– |
количество бит сообщения; |
|||
 |
– |
скорость передачи. |
|||
СРАВНИТЕЛЬНАЯ ХАРАКТЕРИСТИКА ДАТАЛОГИЧЕСКИХ МОДЕЛЕЙ
Сетевая модель данных
– Непосредственно поддерживает бинарные связи и связи более высоких степеней типа 1:1 и 1:М.
– Поддержание бинарных связей и связей более высоких степеней типа М:N с помощью декомпозиции.
– Поддерживает рекурсивные связи с помощью декомпозиции.
– Типы записи непосредственно связаны друг с другом с помощью конструкции «тип набора».
– Целостность на уровне ссылок поддерживается за счёт конструкций «тип набора».
– Обладает ограниченной гибкостью по отношению к изменению требований к данным и методам доступа.
– Доступ к типам записей осуществляется путем «перемещения» (навигации) по структуре. В зависимости от конкретного расположения типа записи по отношению к начальной точке в структуре, для доступа к данным могут использоваться различные специальные команды.
Иерархическая модель данных
– Непосредственно поддерживает бинарные связи и связи более высоких степеней типа 1:1 и 1:М.
– Бинарные связи более высоких степеней типа М:N поддерживаются только с помощью декомпозиции и дублирования данных в разных иерархиях.
– Рекурсивные связи поддерживаются только с помощью декомпозиции и дублирования данных.
– Типы записей непосредственно связаны между собой с помощью иерархической структуры.
– Целостность на уровне ссылок поддерживается в тех случаях, когда зависимый дочерний тип записи полностью участвует в связи со своим родительским типом записи.
– Не обладает гибкостью по отношению к изменению требований к данным и методам доступа.
– Доступ к типам записей осуществляется путем «перемещения» (навигации) от корневого типа записи к типам записи более низкого уровня в данной иерархии при ее прямом или обратном обходе.
Реляционная модель данных
– Непосредственно поддерживает бинарные связи и связи более высоких степеней типа 1:1 и 1:М, а также рекурсивные связи типа 1:1 и 1:М.
– Бинарные связи более высоких степеней типа М:N поддерживаются с помощью декомпозиции.
– Рекурсивные связи типа М:N поддерживаются с помощью декомпозиции и Типы записей связанны друг с другом символически с помощью конструкции «первичный/внешний ключ».
– В реляционной модели поддерживается целостность на уровне ссылок.
– Обладает гибкостью по отношению к изменению требований к данным и методам доступа
– Доступ к типам записей осуществляется с помощью команд реляционной алгебры или реляционного исчисления. Эти команды могут быть вложенными, что позволяет создавать сложные запросы.
Сводная характеристика систем баз данных
|
Критерий |
CODASYL (сетевая система) |
IMS (иерархическая система) |
Реляционная система |
|
Период создания |
1960-1970 годы |
1960-1970 годы |
1960-настоящее время |
|
Над чем ведется работа сейчас |
Разделение физических и логических концепций |
Обеспечение взаимодействия с другими системами и типами СУБД |
Повышение производительности, обеспечение совместимости с SQL2, а также добавление объектно-ориентированных компонентов |
|
Реализация |
Записи и указатели |
Обычно записи и указатели, но могут быть и просто физически смежные записи |
Записи со значениями, которые могут использоваться как логические указатели |
|
Базовая физическая структура данных |
Сеть, в которой записи связаны друг с другом в один набор с помощью указателей. Могут содержать встроенные в них указатели |
Обобщенная древовидная структура, в которой один тип записи образует корень, а все другие типы записей - зависимые от корня узлы |
Двумерная таблица |
|
Общая структура файлов и методы доступа к ним |
Прямые методы доступа и индексно-последовательные методы доступа (включая метод VSAM) |
Методы доступа HIDAM, HDAM, HISAM, HSA М. Варианты прямого доступа и индексно-последователь-ных методов доступа (включая метод VSAM) |
Разные методы доступа от последовательных файлов с индексами и методов прямого доступа вплоть до сложных древовидных поисковых структур |
|
Логическая структура данных |
Набор, в котором один тип записи-владельца может быть связан со многими типами записей-членов. Сложные сети создаются с помощью типов наборов |
Обобщенная древовидная структура |
Набор двумерных таблиц |
|
Поддерживаемые типы связей |
Связи типа 1:1 и 1:М.Связи типа M:N и рекурсивные связи поддерживаются с помощью декомпозиции. С ними проще всего работать в иерархической системе |
Связи типа 1:1и 1:М. Связи типа M:N обычно поддерживаются с помощью логических указателей, которые связывают разные физические структуры данных. Рекурсивные связи поддерживаются с помощью декомпозиции и дублирования |
Связи типа 1:1 и 1:М.Связи типа M:N и рекурсивные поддерживаются с помощью декомпозиции |
|
Поддержка целостности на уровне ссылок для связей типа «родитель-потомок» |
Обеспечивается средствами СУБД с использованием правил вставки и сохранения для структуры наборов. Если записи-члены закреплены за записью-владельцем, то удаление записи-владельца приводит к каскадному удалению записей-членов. Если записи-члены не обязательно являются частью набора, то удаление записи-владельца эквивалентно заданию неопределенной связи (NULL). Можно запрограммировать и другие варианты действий. Обычно внешние ключи в типах записей не требуются |
Обеспечивается средствами СУБД с использованием зависимостей в древовидной структуре. То есть при удалении корня дерева (или поддерева)будут удалены все зависящие от него узлы, что эквивалентно каскадному удалению. Обычно в типах записей внешние ключи не нужны. Сложности могут возникнуть в случаях,когда связи M:N представляются с помощью логических указателей |
Поддержка варьируется от разработки процедур, правил или триггеров, используемых непосредственно средствами СУБД, вплоть до процедур, реализуемых в прикладных программах. Стандарт SQL92 требует реализации этой функции механизмами самой СУБД |
|
Логическая независимость от данных |
Концептуальная схема моет быть расширена без изменения подсхем. При перестройке или удалении из концептуальной схемы типов записи, поля набора потребуется ввести поправки только в те представления, в которых они используются |
Полностью аналогична CODASYL-системам |
Полностью аналогична CODASYL-системам |
|
Физическая независимость от данных |
Концептуальная схема должна быть изменена в соответствии с изменениями структуры хранения в тех местах схемы, в которых описаны детали физического хранения. Это может вызвать необходимость изменения прикладных программ. Следовательно, реализация макета базы данных может значительно усложниться |
При изменении структуры хранения может потребоваться изменить концептуальную схему (ОБД) и внести поправку в логику обработки данных в приложениях. Для упрощения процесса изменения структур хранения предусмотрены специальные утилиты |
В тех случаях когда не допускается выбор из нескольких возможных физических структур данных, некоторые СУБД при необходимости позволяют определять различные структуры файлов и вторичных индексов |
|
Гибкость при изменении приложений |
Новые или изменённые приложения могут не обладать достаточной производительностью, потому что база данных структурирована для существовавших ранее приложений. Поэтому может оказаться не возможным эффектно поддерживать все требуемые приложения |
Новые или изменённые приложения могут быть неэффективны, потому что базовые структуры подогнаны под исходные приложения. Изменить базовую структуру так, чтобы обеспечить удовлетворительную работу базы данных со всеми требуемыми приложениями,достаточно сложно или даже вообще не возможно. Вероятно, для этого потребуется создать дополнительные структуры |
Настройка для работы с новыми или изменёнными приложениями может быть выполнена без особых затруднений. В СУБД, "" поддерживающей выбор структуры файлов,для разных таблиц могут быть выбраны самые подходящие структуры данных |
|
Простота проектирования |
Вероятно, потребуется квалифицированная помощь, особенно при определении необходимых структур данных и при разработке связанных с ними прикладных программ |
Проектирование могут выполнить только опытные специалисты-эксперты |
Большинство пользователей (включая конечных пользователей) легко поймут логическую структуру данных,а потому смогут спроектировать базу данных и отобразить её на физические структуры. К сожалению, недостаточное знание методов проектирования баз данных может привести к созданию слабых, неэффективных и негибких макетов |
|
Доступ к базе данных |
Стандартные методы доступа посредством API: приложение содержит встроенные вызовы процедур для работы с СУБД, команды обрабатывают записи последовательно, по одной, хотя потенциально они могут оказывать влияние и на другие записи. Дополнительные программные конструкции необходимы для навигации по базе данных и обработки наборов записей |
Здесь также доступ осуществляется исключительно посредством API. Команды обрабатывают записи по одной, но при этом они могут влиять и на зависимые записи. Благодаря использованию специальных команд навигации по базе данных пользователь может перемещаться к разным местам иерархической структуры. Для обработки наборов записей могут потребоваться специальные программные конструкции |
Доступ может варьироваться от использования API до таких интерактивных языков, как SQL или QBE. Языки запросов позволяют конечным пользователям опрашивать базу данных в произвольной манере. Кроме того, SQL-команды могут внедряться в прикладные программы |
|
Стандарты |
Для CODASYL-совместимой модели данных существует набор стандартных концепций,хотя между разными реализациями есть некоторые различия |
Для иерархической модели данных не существует строгого набора стандартных концепций, а реализации этой модели не соответствуют какому-либо особому стандарту |
Для реляционных моделей данных существует набор стандартных концепций, хотя между разными реализациями есть некоторые различия |
Проблемы ER-моделирования
В процессе создания инфологической модели на языке ER-диаграмм, могут возникать нежелательные ситуации, которые в литературе называются ловушками соединения. Причины этих проблем кроются в неправильной интерпретации семантики предметной области, в том числе смысла некоторых связей между выделенными сущностями. Очень важно своевременно выявлять в модели данных ловушки соединения, иначе • они могут привести к неадекватному описанию пред-, меткой области и необходимости перестройки всей концептуальной модели [7].
Наиболее распространенными являются два вида
ловушек соединения:
– ловушки разветвления;
– ловушки разрыва.
Ловушка разветвления имеет место в том случае, если модель отображает связь между сущностями, но путь между отдельными экземплярами этих сущностей однозначно не определяется.
Ловушка разветвления возникает в случае, когда две или больше связей ОДИН-КО-МНОГИМ разветвляются из одной сущности. Потенциальная ловушка разветвления показана на рис. 2.11, где две связи типа 1:М выходят из одной и той же сущности ФАКУЛЬТЕТ. Проанализировав модель, можно сделать вывод, что на одном факультете осуществляется обучение по нескольким специальностям, и на факультете учится множество студентов. Проблема может возникнуть при попытке выяснить, по какой специальности обучается каждый из студентов факультета.
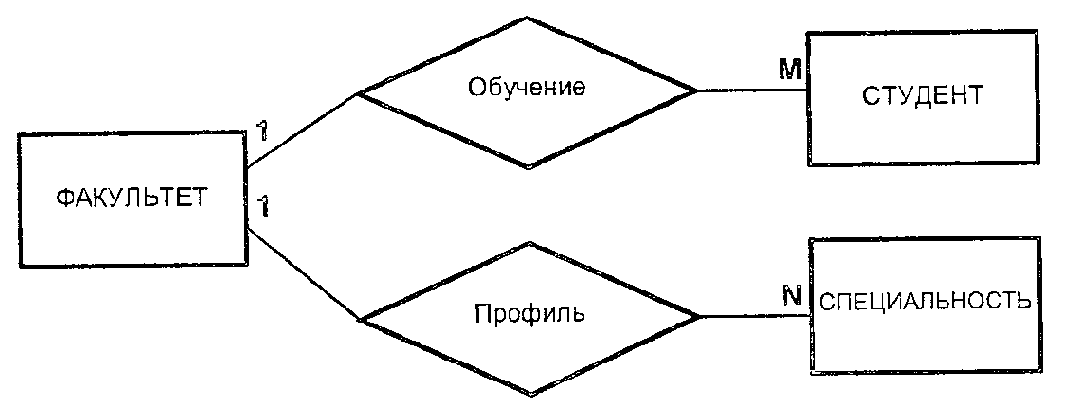
Рис. 2.11. Пример ловушки разветвления
Для обнаружения этой проблемы удобно пользоваться семантическими сетями – (рис, 2.12). С помощью семантической сетевой модели на конкретном примере невозможно дать однозначный ответ на вопрос: «По какой специальности обучается студент Гаврюхов?» -это ловушка разветвления» Эта неприятность произошла из-за неправильной трактовки связей между сущностями ФАКУЛЬТЕТ, СПЕЦИАЛЬНОСТЬ, СТУДЕНТ. Устранить такой дефект можно только путем перестройки исходной модели.
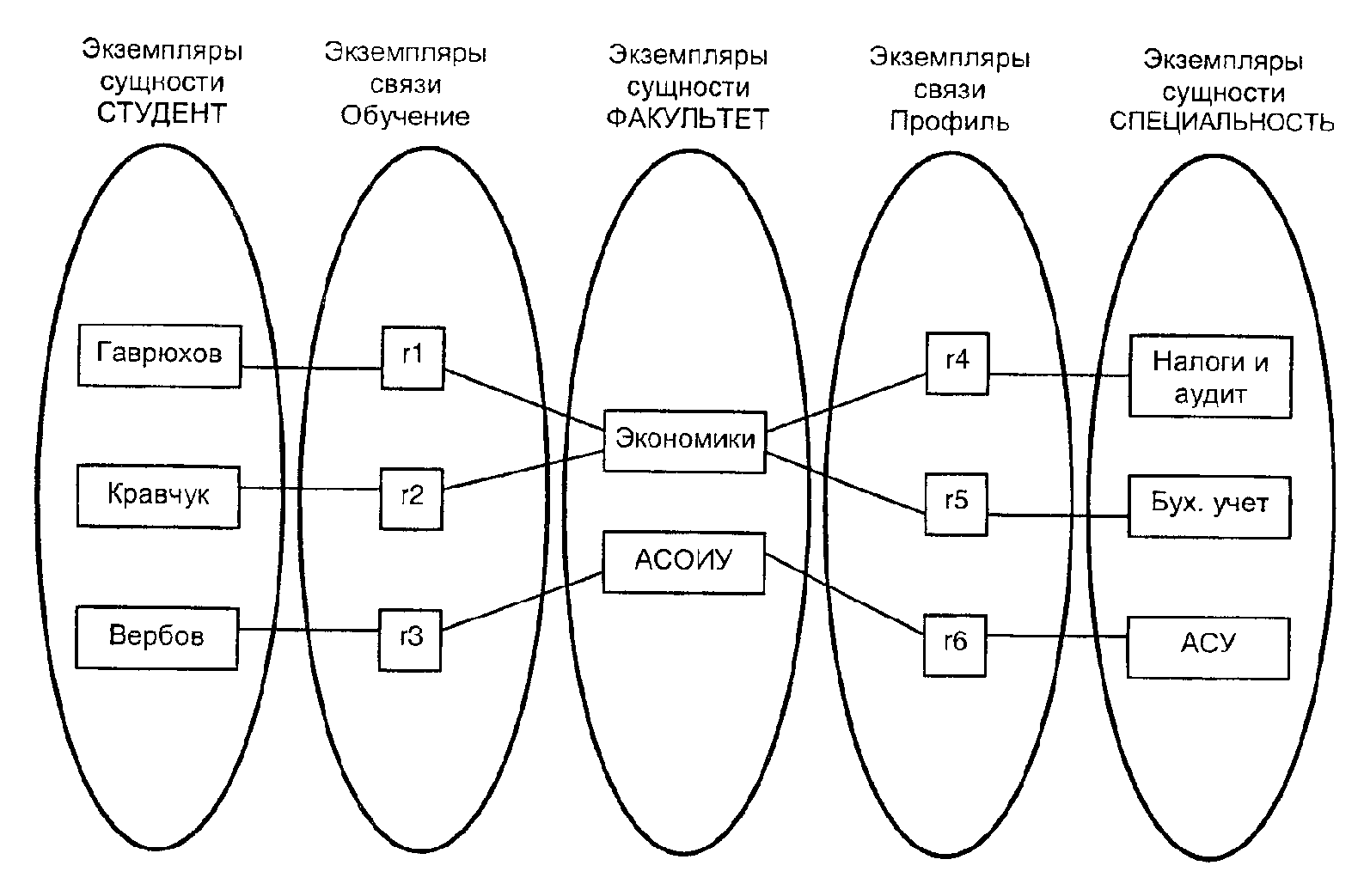
Рис. 2.12. Семантическая сеть ER-модели с ловушкой разветвления
Результат адекватного преобразования модели представлен на рис. 2.13.
В таком варианте легко определяется, что студент Гаврюхов учится на экономическом факультете по специальности «Налоговая работа и аудиторский контроль».
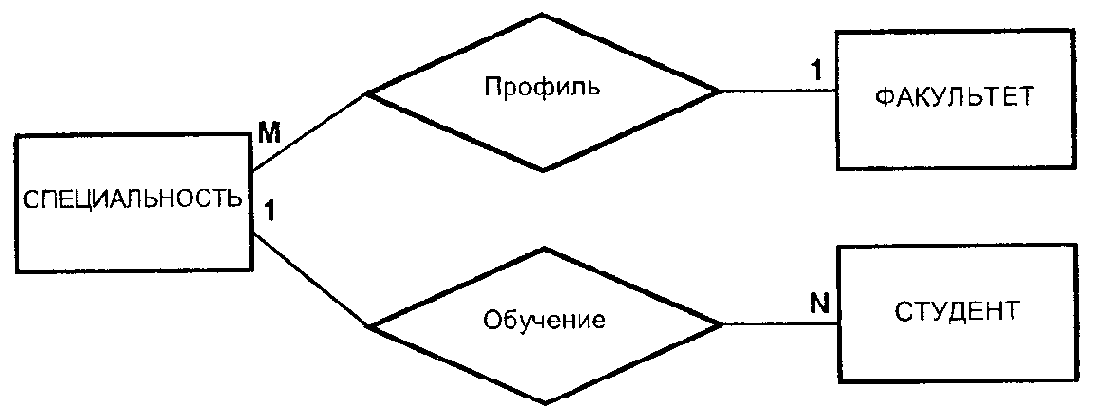
Рис. 2.13. Преобразованная ER-модель
Если проверить полученную структуру на уровне отдельных экземпляров сущностей (как показано на рис. 2.14), можно убедиться, что по преобразованной модели легко дать однозначный ответ на поставленный выше вопрос.

Рис. 2.14. Семантическая сеть преобразованной ER-моделт
Ловушка разрыва появляется в том случае, если в модели предполагается наличие связи между сущностями, но не существует пути между отдельными экземплярами этих сущностей.
Ловушка разрыва возникает при наличии связи, образующей часть пути между связанными сущностями.
На рис. 2.15 потенциальная ловушка разрыва показана на примере связей между сущностями ОБЩЕЖИТИЕ, СТУДЕНТ и КОМНАТА.

Рис. 2.15. Пример ловушки-разрыва
С помощью семантической сети ER-модели с рис. 2.15 (представлена на рис. 2.16), невозможно дать ответ на вопрос: «В каком общежитии находится комната под условным номером 703?». Это причина проявления ловушки разрыва, возникающей из-за неправильной интерпретации связей между сущностями ОБЩЕЖИТИЕ, СТУДЕНТ и КОМНАТА.

Рис. 2.16. Преобразованная ER-модель
Устранить эту проблему можно только путем перестройки ER-модели для представления правильного взаимоотношения между этими сущностями. Преобразованная ЕR-модель показана на рис. 2.17. В модель добавлена связь Размещение между сущностями ОБЩЕЖИТИЕ и КОМНАТА.

Рис. 2.17. Семантическая сеть ER-модели с ловушкой разрыва
Если исследовать новую структуру на уровне отдельных сущностей (как показано на рис. 2.18), то можно дать ответ на поставленный вопрос: «Комната с условным номером 703 находится в общежитии №1».

Рис. 2.18. Семантическая сеть преобразованной ER-модели
Прозрачность использования
Прозрачность использования СУБД позволяет скрыть от пользователя тот факт, что на разных сайтах могут функционировать различные локальные СУБД. Данный тип прозрачности является самым сложным, и применим только для гетерогенных распределенных систем.
Таким образом, концепция прозрачности не может быть отнесена к типу «все или ничего, так как может быть организована на нескольких различных уровнях. Каждый из уровней подразумевает определенный на- бор соглашений между сайтами системы. Так, при полной прозрачности сайты должны следовать общему соглашению по вопросам модели данных, интерпретации схем, представления данных и т.п. В непрозрачных системах единственным соглашением является формат обмена данными и набор функциональных возможностей, предоставляемых каждым сайтом в системе.
С точки зрения конечного пользователя полная прозрачность желательна. Но с точки зрения АБД локальной базы полностью прозрачный доступ связан с трудностями осуществления контроля. Традиционный способ работы с представлениями, используемый для построения защитного механизма, в такой ситуации может оказаться неэффективным. Например, механизм работы с представлениями языка SQL позволяет ограничивать доступ к базовым таблицам или подмножеству данных базовой таблицы и разрешать его только конкретным пользователям. Однако он не позволяет также легко ограничивать доступ к данным на основе набора критериев, отличных от имени пользователя.
Проще обеспечить подобный тип функциональности с помощью процедур, которые будут запускаться удаленным пользователем. В этом случае локальной пользователи смогут работать с данными так же, как они работали прежде, при использовании стандартного механизма защиты СУБД. Однако удаленные пользователи смогут получать только такой тип доступа в данным, который реализован в предоставленном наборе процедур, подобно тому, как это делается в объектно-ориентированных системах. Подобный тип федеральной архитектуры реализовать проще, чем обеспечить полную прозрачность системы, к тому же он предоставляет более высокий уровень локальной автономности.
В приложении 7 сведены правила, при выполнении которых СУБД может считаться распределенной.
Прозрачность распределенности
Прозрачность распределенности базы данных позволяет конечным пользователям воспринимать базу данных как единое логическое целое. Если СУРБД обеспечивает прозрачность распределенности, то пользователю не требуется каких-либо знаний о фрагментации Данных (прозрачность фрагментации) или их размещении (прозрачность расположения).
Если пользователю необходимо иметь сведения о фрагментации данных и расположении фрагментов, то этот тип прозрачности называют прозрачностью локального отображения.
Прозрачность фрагментации является самым высоким уровнем прозрачности распределенности. Если СУРБД обеспечивает прозрачность фрагментации, то пользователю не требуется знать, как именно фрагментированы данные. В этом случае доступ к данным осуществляется на основе глобальной схемы и пользователю нет необходимости указывать имена фрагментов или расположение данных.
Пользователь применяет те же самые SQL-операторы, которые потребовалось бы ввести для получения необходимых результатов в централизованной системе.
Прозрачность расположения представляет собой средний уровень прозрачности распределенности. В этом случае пользователь должен иметь сведения о способах фрагментации данных в системе, но не нуждается в сведениях о расположении данных. При наличии в системе прозрачности расположения в запросах следует указывать имена используемых фрагментов.
Кроме того, дополнительно необходимо воспользоваться операциями соединения (или подзапросами), поскольку некоторые атрибуты могут находиться в разных фрагментах. Основное преимущество прозрачности расположения состоит в том, что база данных может быть подвергнута физической реорганизации и это не окажет никакого влияния на программы приложений, осуществляющих к ней доступ.
С прозрачностью расположения очень тесно связан еще один тип прозрачности – прозрачность репликации. Он означает, что пользователю не требуется иметь сведения о существующей репликации фрагментов. Под прозрачностью репликации подразумевается прозрачность расположения реплик.
Однако могут существовать системы, которые не обеспечивают прозрачности расположения, но поддерживают прозрачность репликации.
Прозрачность локального отображения - самый низкий уровень прозрачности распределенности. При наличии в системе прозрачности локального отображения пользователю необходимо указывать как имена используемых фрагментов, так и расположение соответствующих элементов данных.
Очевидно, что в данном случае запрос имеет более сложный вид и на его подготовку потребуется больше времени, чем в двух предыдущих случаях. Маловероятно, чтобы система, предоставляющая только такой уровень прозрачности распределенности, была приемлема для конечного пользователя.
Прямым следствием обсуждавшихся выше вариантов прозрачности распределенности является требование наличия прозрачности именования. Как и в случае централизованной базы данных, каждый элемент распределенной базы данных должен иметь уникальное имя. Следовательно, СУРБД должна гарантировать, что никакие два сайта системы не смогут создать некоторый объект базы данных, имеющий одно и то же имя.
Одним из вариантов решения этой проблемы является создание центрального сервера имен, который будет нести ответственность за полную уникальность всех существующих в системе имен. Однако подобному подходу свойственны такие недостатки, как:
– утрата определенной части локальной автономии;
– появление проблем с производительностью (поскольку центральный сайт превращается в узкое место всей системы);
– снижение доступности – если центральный сайт по какой- либо причине станет недоступным, все остальные сайты системы не смогут создавать никаких новых объектов базы данных [7].
Альтернативное решение состоит в использовании префиксов, помещаемых в имена объектов в качестве идентификатора сайта, создавшего этот объект
[7]. Аналогичным образом, необходимо иметь возможность идентифицировать каждый фрагмент и каждую его копию.Однако подобный подход приводит к утрате прозрачности распределенности.
Подход, который позволяет преодолеть недостатки, свойственные обоим упомянутым методам, состоит в использовании алиасов, создаваемых для каждого из объектов базы данных [7]. Задача преобразования алиаса в истинное имя соответствующего объекта базы данных возлагается на СУРБД.
Прозрачность транзакций
Прозрачность транзакций в среде распределенных СУБД означает, что при выполнении любых распределенных транзакций гарантируется сохранение целостности и согласованности распределенной базы данных.
Распределенная транзакция осуществляет доступ к данным, сохраняемым более чем в одном местоположении. Каждая из транзакций разделяется на несколько субтранзакций – по одной для каждого сайта, к данным которого осуществляется доступ. На удаленных сайтах субтранзакции представляются агентами.
Неделимость остается фундаментальной концепцией понятия транзакции и в случае распределенных транзакций, однако дополнительно СУРБД должна гарантировать неделимость и каждой из ее субтранзакцпй [7]. Следовательно, СУРБД должна гарантировать не только синхронизацию субтранзакций с другими локальными транзакциями, выполняющимися параллельно с ними на одном сайте, но и обеспечить синхронизацию субтранзакций с глобальными транзакциями, выполняющимися одновременно с ними на этом и других сайтах системы. Прозрачность транзакций в распределенных СУБД дополнительно усложняется за счет наличия фрагментации, распределения данных и использования репликации. Существуют два дополнительных аспекта прозрачности транзакций, таких как прозрачность параллельности и прозрачность отказов.
Прозрачность параллельности обеспечивается СУБРД в том случае, если результаты всех параллельно выполняемых транзакций (как распределенных, так и нераспределенных) генерируются независимо и являются логически согласующимися с результатами, которые были бы получены в, том случае, если бы все эти транзакции выполнялись последовательно в некотором произвольном порядке, по одной в каждый момент времени. В случае распределенных СУБД имеют место дополнительные усложнения, связанные с необходимостью гарантировать, что как глобальные, так и локальные транзакции не могут оказывать влияния друг на друга. Кроме того, СУРБД должны гарантировать согласованность всех субтранзакций каждой глобальной транзакции.
Наличие в системе репликации еще более усложняет проблему организации параллельной обработки в системе.
Если одна из копий реплицируемых данных подвергается обновлению, сведения об этом в конечном счете должны быть представлены в каждой из существующих копий. В данном случае наиболее очевидная стратегия – сделать распространение сведений об изменении частью исходной транзакции, оформив его как еще одну атомарную операцию. Однако, если один из содержащих копию измененных данных сайтов окажется в момент внесения изменения недоступным из-за отказа на самом сайте или в канале связи, то выполнение транзакции будет отложено до тех пор, пока этот сайт вновь не станет доступным.
Если существует большое количество копий данных, .то вероятность успешного завершения транзакции уменьшается в экспоненциальной зависимости от их числа. Альтернативной стратегией является ограничение распространения сведений об изменении только теми сайтами, которые в данный момент доступны. На остальные сайты сведения об изменении поступят, как только они вновь станут доступными.
Дополнительной стратегией могла бы быть выдача разрешения обновлять копии асинхронно, через некоторое время после внесения исходного обновления. За- держка в восстановлении целостности может варьироваться от нескольких секунд до нескольких часов [7].
Любая централизованная СУБД должна включать механизм восстановления, который в подверженной различным сбоям и отказам среде будет гарантировать атомарность выполнения транзакций – либо все операции транзакции будут завершены, либо ни одна из них. Если транзакция выполнена, внесенные ею изменения приобретают длительный характер. Среди отказов централизованных СУБД выделяют: сбои системы, отказ носителей, ошибки в программах, небрежность персонала, стихийные бедствия и действия злоумышленников. В распределенных СУБД необходимо дополнительно учитывать следующее:
– возможность потери сообщения;
– возможность отказа линии связи;
– аварийный останов одного из сайтов;
– расчленение сетевых соединений.
СУРБД должна гарантировать атомарность глобальных транзакций, т.е. должна синхронизировать выполнение глобальной транзакции так, чтобы все ее субтранзакции были успешно завершены до финальной операции фиксации результатов глобальной транзакции.
Прозрачность выполнения
Прозрачность выполнения требует, чтобы работа в среде СУРБД выполнялась аналогично работе в централизованной СУБД. В распределенной среде не должно быть видно снижение производительности из-за наличия медленных сетевых соединений и т.д. Прозрачность выполнения требует также, чтобы СУРБД могла находить наиболее эффективные стратегии выполнения запросов.
В централизованной СУБД обработчик запросов оценивает каждый запрос на доступ к данным и находит оптимальную стратегию его выполнения в виде упорядоченной последовательности операций с базой данных. В распределенной среде обработчик запросов отображает запрос на доступ к данным в упорядоченную последовательность операций с локальными базами данных. При этом дополнительная сложность возникает из-за необходимости учитывать наличие фрагментации, репликации и определенной схемы размещения данных.
Обработчик распределенных запросов должен знать:
– к какому фрагменту следует обратиться;
– какую копию фрагмента использовать, если его данные реплицируются;
– какое из местоположении должно использоваться [7].
Обработчик распределенных запросов вырабатывает стратегию выполнения, которая является оптимальной с точки зрения некоторой стоимостной функции. Обычно используются следующие показатели:
– время доступа, включающее физический доступ к данным на диске;
– время работы центрального процессора, затрачиваемое на обработку данных в первичной памяти;
– время, необходимое для передачи данных по сетевым соединениям.
Первые два фактора аналогичны тем, которые учитываются в централизованных системах для оптимизации выполнения запросов. Но в СУРБД доминирующую роль играет время передачи данных по сетевым соединениям, что особенно актуально для глобальных сетей. Скорость передачи в таких каналах может составлять лишь несколько Кбайт в секунду. В подобных ситуациях при оптимизации можно игнорировать затраты на ввод/вывод и использование ЦП. Однако некоторые сетевые соединения имеют скорость пере- дачи данных, сравнимую со скоростью доступа к дискам (в локальных сетях). В этом случае целесообразно учитывать все три указанных показателя.
Распределение данных
Существуют четыре альтернативные стратегии размещения данных в системе
[7]:
1) централизованное;
2) раздельное (фрагментированное);
3) размещение с полной репликацией;
4) размещение с выборочной репликацией.
Централизованное размещение
Данная стратегия предусматривает создание на одном из сайтов единственной базы данных под управлением СУБД, доступ к которой будут иметь все пользователи сети («распределенная обработка»). В этом случае локальность ссылок минимальна для всех сайтов, за исключением центрального, поскольку для получения любого доступа к данным требуется установка сетевого соединения. Соответственно уровень затрат на передачу данных будет высок. Уровень надежности и доступности в системе низок, поскольку отказ на центральном сайте вызовет паралич работы всей системы.
Раздельное (фрагментированное) размещение
В этом случае база данных разбивается на непересекающиеся фрагменты, каждый из которых размещается на одном из сайтов системы. Если элемент данных будет размещен на том сайте, на котором он чаще всего используется, полученный уровень локальности ссылок будет высок. При отсутствии репликации стоимость хранения данных будет минимальна, но при этом будет невысок также уровень надежности и доступности данных в системе. Однако он будет выше, чем в предыдущем варианте, поскольку отказ на любом из сайтов вызовет утрату доступа только к той части данных, которая на нем хранилась. При правильно выбранном способе распределения данных уровень производительности в системе будет относительно высоким, а уровень затрат на передачу данных – низким.
Размещение с полной репликацией
Эта стратегия предусматривает размещение полной копии всей базы данных на каждом из сайтов системы. Следовательно, локальность ссылок, надежность и доступность данных, а также уровень производительности системы будут максимальны. Однако стоимость устройств хранения данных и уровень затрат на передачу данных в этом случае также будут самыми высокими.
Для преодоления части этих проблем в некоторых случаях используется технология моментальных снимков. Моментальный снимок представляет собой копию базы данных в определенный момент времени. Эти копии обновляются через некоторый установленный интервал времени – например, один раз в час или в неделю, – а потому они не всегда будут актуальными в текущий момент. Иногда в распределенных системах моментальные снимки используются для реализации представлений, что позволяет улучшить время выполнения в базе данных операций с представлениями.
Размещение с выборочной репликацией
Данная стратегия представляет собой комбинацию методов фрагментации, репликации и централизации. Одни массивы данных разделяются на фрагменты, что позволяет добиться для них высокой локальности ссылок, тогда как другие, используемые на многих сай-тах, но не подверженные частым обновлениям, подвергаются репликации. Все остальные данные хранятся централизованно. Целью применения данной стратегии является объединение всех преимуществ, существующих в остальных, моделях, с одновременным исключением свойственных им недостатков. Благодаря своей гибкости именно эта стратегия используется чаще всего.
Сводные характеристики всех рассмотренных выше стратегий приведены в табл. 5.2.
Таблица 5.2
|
Локальность ссылок |
Надежность и доступность |
Производительность |
Стоимость устройств хранения данных |
Затраты на передачу |
|
|
Централизованное |
Самая низкая |
Самая низкая |
Неудовлетворительная |
Самая низкая |
Самая высокая |
|
Фрагментированное |
Высокая |
Низкая для отдельных элементов; высокая для системы в целом |
Удовлетворительная |
Самая низкая |
Низкая |
|
Полная репликация |
Самая высокая |
Самая высокая |
Хорошая для операций чтения |
Самая высокая |
Высокая для операций обновления, низкая для операций чтения |
|
Выборочная репликация |
Высокая |
Низкая для отдельных элементов; высокая для системы |
Удовлетворительная |
Средняя |
Низкая |
Разделение функций администрирования
В некоторых очень сложных предметных областях функции администрирования автоматизированной информационной системы могут быть распределены между администратором данных (АД) и администратором базы данных (АБД).
Специфика обязанностей АД и АБД на этапах жиз-ненного цикла автоматизированной информационной системы представлена в табл. 1.2 [7].
Таблица 1.2
| Этап | Основная роль | Вспомогательная роль | |||
| Планирование разработки базы данных | АД | АБД | |||
| Определение требований к системе | АД | АБД | |||
| Сбор и анализ требований пользователей | АД | АБД | |||
| Концептуальное проектирование базы данных | АД | АБД | |||
| Выбор целевой СУБД | АБД | АД | |||
| Логическое проектирование базы данных | АБД | АД | |||
| Разработка приложений | АБД | АД | |||
| Физическое проектирование базы данных | АБД | АД | |||
| Создание прототипов | АБД | АД | |||
| Реализация | АБД | АД | |||
| Конвертирование и первичная загрузка данных | АБД | АД | |||
| Тестирование | АБД | АД | |||
| Эксплуатация и сопровождение | АБД | АД |
При таком делении функций администрирования к задачам администрирования данных относятся следующие.
– Разработка стратегии построения информационной системы.
– Предварительная оценка осуществимости и планирование процесса создания базы данных.
– Разработка корпоративной модели данных.
– Определение требований организации к используемым данным.
– Определение стандартов сбора данных и выбор формата их представления.
– Оценка объемов данных и вероятности их роста.
– Определение способов и интенсивности использования данных.
– Определение правил доступа к данным и мер безопасности соответствующих правовым нормам и внутренним требованиям организации.
– Концептуальное проектирование базы данных.
– Взаимодействие с АБД и разработчиками приложений.
– Обучение пользователей существующим стандартам обработки данных и юридической ответственности за их некорректное применение.
– Постоянная модернизация используемых информационных систем и технологий.
– Обеспечение полноты всей требуемой документации.
– Поддержка словаря данных.
– Взаимодействие с конечными пользователями для определения новых требований и разрешения проблем, связанных с доступом к данным и недостаточной производительностью их обработки.
Деятельность АДБ по сравнению с АД является в большей мере технической. Основные задачи администратора БД при наличии АД следующие [7].
– Оценка и выбор целевой СУБД.
– Логическое и физическое проектирование базы данных.
– Реализация физического проекта базы данных в среде целевой СУБД.
– Определение требований защиты и поддержки целостности данных.
– Взаимодействие с разработчиками приложений баз данных.
– Разработка стратегии тестирования.
– Обучение пользователей.
– Ответственность за сдачу в эксплуатацию готового приложения базы данных.
– Контроль текущей производительности системы и соответствующая настройка базы данных.
– Регулярное резервное копирование.
– Разработка требуемых механизмов и процедур восстановления.
– Обеспечение полноты используемой документации, включая материалы, разработанные внутри организации.
– Поддержка актуальности используемого программного и аппаратного обеспечения, включая заказ и установку пакетов обновлений в случае необходимости.
Результаты сравнительного анализа задач администрирования данных и администрирования базы данных представлены в табл. 1.3 [7], из которой видно, что работа АД является в большей степени управленческой, а работа АБД - технической.
Таблица 1.3
|
Администрирование данных |
Администрирование базы данных |
|
Участвует в стратегическом планировании информационной системы организации |
Оценивает новые СУБД |
|
Определяет долгосрочные цели |
Выполняет планы достижения целей |
|
Применяет стандарты, политики и процедуры |
Применяет стандарты, политики и процедуры |
|
Определяет требования к данным |
Реализует требования к данным |
|
Выполняет концептуальное проектирование базы данных |
Выполняет логическое и физическое проектирование базы данных |
|
Разрабатывает и сопровождает корпоративную модель данных |
Реализует физический проект базы данных |
|
Координирует разработку системы |
Выполняет текущий контроль и управление базой данных |
|
Управленческая направленность |
Техническая направленность |
|
Работа не зависит от типа целевой СУБД |
Работа зависит от типа целевой СУБД |
Разработка распределенных реляционных баз данных
В главе 2 была приведена методология концептуального и логического проектирования централизованных реляционных баз данных. В данном разделе рассматриваются следующие дополнительные факторы, которые должны приниматься во внимание при разработке распределенных реляционных баз данных [7].
– Фрагментация.
Любое отношение может быть разделено на некоторое количество частей, называемых фрагментами, которые затем распределяются по различным сайгам. Существуют два основных типа фрагментов: горизонтальные и вертикальные.
Горизонтальные фрагменты представляют собой подмножества кортежей, а вертикальные – подмножества атрибутов.
– Распределение.
Каждый фрагмент сохраняется на сайте, выбранном с учетом «оптимальной» схемы их размещения.
– Репликация.
СУРБД может поддерживать актуальную копию некоторого фрагмента на нескольких различных сайтах.
Определение и размещение фрагментов должно проводиться с учетом особенностей использования базы данных. Это подразумевает выполнение анализа приложений. Как правило, провести анализ всех приложений не представляется возможным, поэтому следует сосредоточить усилия на самых важных из них.
Проектирование должно выполняться на основе как количественных, так и качественных показателей. Количественная информация используется в качестве основы для распределения, тогда как качественная служит базой при создании схемы фрагментации. Количественная информация включает такие показатели:
– частота запуска приложения на выполнение;
– сайт, на котором запускается приложение;
– требования к производительности транзакций и
приложений.
Качественная информация может включать перечень выполняемых в приложении транзакций, используемые отношения, атрибуты и кортежи, к которым осуществляется доступ, тип доступа (чтение или запись), предикаты, используемые в операциях чтения.
Определение и размещение фрагментов по сайтам выполняется для достижения следующих стратегических целей.
– Локальность ссылок. Везде, где только это возможно, данные должны храниться как можно ближе к местам их использования. Если фрагмент используется на нескольких сайтах, может оказаться целесообразным разместить на этих сайтах его копии.
– Повышение надежности и доступности. Надежность и доступность данных повышаются за счет использования механизма репликации. В случае отказа одного из сайтов всегда будет существовать копия фрагмента, сохраняемая на другом сайте.
– Приемлемый уровень производительности. Неверное распределение данных будет иметь следствием возникновение в системе узких мест. В этом случае некоторый сайт оказывается просто завален запросами со стороны других сайтов, что может вызвать существенное снижение производительности всей системы. В то же время неправильное распределение может иметь следствием неэффективное использование ресурсов системы.
– Баланс между емкостью и стоимостью внешней памяти. Обязательно следует учитывать доступность и стоимость устройств хранения данных, имеющихся на каждом из сайтов системы. Везде, где только это, возможно, рекомендуется использовать более дешевые устройства массовой памяти. Это требование должно быть сбалансировано с требованием поддержки локальности ссылок.
– Минимизация расходов на передачу данных. Следует тщательно учитывать стоимость выполнения в системе удаленных запросов. Затраты на выборку будут минимальны при обеспечении максимальной локальности ссылок, т.е. когда каждый сайт будет иметь собственную копию данных. Однако при обновлении реплицируемых данных внесенные изменения потребуется распространить на все сайты, имеющие копию обновленного отношения, что вызовет увеличение затрат на передачу данных.
Реляционная алгебра
В этом разделе на ряде примеров рассматриваются операции реляционной алгебры [11]. Для представления каждой операции будем использовать терминологию как алгебры, так и исчисления. Последняя базируется на системе понятий, использованной Коддом. Пять операций являются основными:
– проекция;
– объединение;
– разность;
– декартово произведение;
– селекция.
Другие часто используемые операции пересечения, соединения и деления можно выразить через пять основных операций. Ниже представлены отношения, используемые в примерах [11].
| P(D 1 | D2, | D3) | Q(D4 | D5) | R(M, | P, | Q, | T) | S(A, | B) | |||||||||||
| 1 | 11 | x | x | 1 | x | 101 | 5 | a | 5 | a | |||||||||||
| 2 | 11 | у | x | 2 | y | 105 | 3 | a | 10 | b | |||||||||||
| 3 | 11 | z | y | 1 | z | 500 | 9 | a | 15 | c | |||||||||||
| 4 | 12 | x | w | 50 | 1 | b | 2 | d | |||||||||||||
| w | 10 | 2 | b | 6 | a | ||||||||||||||||
| w | 300 | 4 | b | 1 | b | ||||||||||||||||
Описание каждого отношения состоит из имени отношения, за которым в круглых скобках следует список атрибутов (это описание называется интенсионалом или схемой отношения). Под описанием приведено некоторое заполнение кортежей отношения (экстенсинал отношения). В последующих примерах буквы R и S
используются для обозначения отношений, а буквы A и B – для обозначения списка атрибутов (для простоты можно считать, что список состоит из единственного атрибута).
Проекция
| Алгебра | Исчисление | ||
| R[A] | {t[A] t ?R} |
Операция проекции представляет собой выборку из каждого кортежа отношения значений атрибутов, входящих в A, и удаление из полученного отношения повторяющихся строк. В исчислении t обозначает «кортежную» переменную, значениями которой являются кортежи исходного отношения R, a t[A] – часть кортежа R с атрибутами из A.
В соответствии с определением отношения неявно предполагается удаление дубликатов кортежей результирующего отношения.
Пример


Объединение
|
Алгебра |
Исчисление |
R  |
{t| t ?R ?t ?S} |
Пример


Разность
|
Алгебра |
Исчисление |
|
R –S |
{t| t ?R ?t ?S} |


Пример


Декартово произведение
|
Алгебра |
Исчисление |
R  |
{(r||s) | r ?R ?r ?S} |
Степень(R
Мощность(R
Отсюда следует, что результирующее отношение может иметь очень большие размеры. (На практике используется ограниченны вариант этой операции, называемый соединением.) Пусть
RA=R[M,T] и RB=R[Q,T]

т.е.

Тогда

Степень результирующего отношения равна 4(2+2), а мощность – 8 (2×4).
Селекция (Ограничение)
|
Алгебра |
Исчисление |
|
(a) R[A?v] |
{t| t ?R ?(t[A]?v)} |
|
(б) R[A?B] |
{t| t ?R ?(t[A]?t[B])} |
используется для обозначения одной из операций сравнения (<, ?, =, ?, ?, >).
Примеры
P[D1>D2]=Ø (пустое множество) поскольку в отношении отсутствуют кортежи, где D1>D2.

Пересечение
|
Алгебра |
Исчисление |
|
R |
{t| t ?R ?t ?S} |
Пример


Соединение
|
Алгебра |
Исчисление |
|
R[A?B]S |
{(r||s) | r ?R ?s ?S ?(r[A]?s[B])} |
Имеется несколько вариантов операции соединения:
а) тета- и эквисоединение. При этой операции A и B являются совместимыми атрибутами соединения, а степень результирующего отношения равна сумме степеней отношений-операндов. Такое соединение называется ?-соединением (тета-соединением). В случае сравнения на равенство соединение называется экви-соединение;
б) естественное соединение. В этом случае атрибуты соединения имеют общие (одинаковые) домены, и после соединения один из атрибутов отбрасывается. Степень результирующего отношения на единицу меньше суммы степеней отношений-операндов;
в) композиция. Это соединение отличается от естественного тем, что из результирующего отношения удаляются оба атрибута соединения. Поэтому степень результирующего отношения на две единицы меньше суммы степеней отношений-операндов.
Примеры
Тета-соединение R[Q>A]S
При выполнении соединения необходимо для каждого кортежа из R взять значение атрибута Q и сравнить его со значением атрибута A из каждого кортежа S. В результате получим

Следует отметить, что кортеж <w 50 1 b> отношения R не вошел в результирующее отношение.
Естественное соединение P[D3 =D4]Q


Деление
|
Алгебра |
Исчисление |
|
R[A÷B]S |
{r[  |
B являются совместимыми и/или общими атрибутами деления. Для упрощения объяснения можно считать R бинарным отношением, состоящим из A и дополнения A, которое обозначается

• выбрать допустимые строки кортежей r[
из R[
• в результирующее отношение входят кортежи r, для которых выполняется S[B]HgR(r[
Примеры
Р[D3>÷D4]=Ø (пустое множество), так как




Следовательно, подходящие

Реляционная модель
В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных даталогических моделей данных, т.е. возможности использования привычных и естественных способов представления данных. Наиболее значительной из них была статья сотрудника фирмы IBM д-ра Э.Кодда (Codd E.F. A Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), где, вероятно, впервые был применен термин «реляционная модель данных».
Будучи математиком по образованию Э.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.) [2, 5, 7, 10].
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
Доменом называется множество атомарных значений одного и того же типа. Так, на рис. 2.23 домен пунктов отправления (назначения) – множество названий населенных пунктов, а домен номеров рейса – множество целых положительных чисел.
Смысл доменов состоит в следующем. Если значения двух атрибутов берутся из одного и того же домена, то, вероятно, имеют смысл сравнения, использующие эти два атрибута (например, для организации транзитного рейса можно дать запрос «Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву»), Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета?
Отношение на доменах D1, D2, ..., Dп (не обязательно, чтобы все они были различны) состоит из заголовка и тела. На рис. 2.23 приведен пример отношения для расписания движения самолетов.
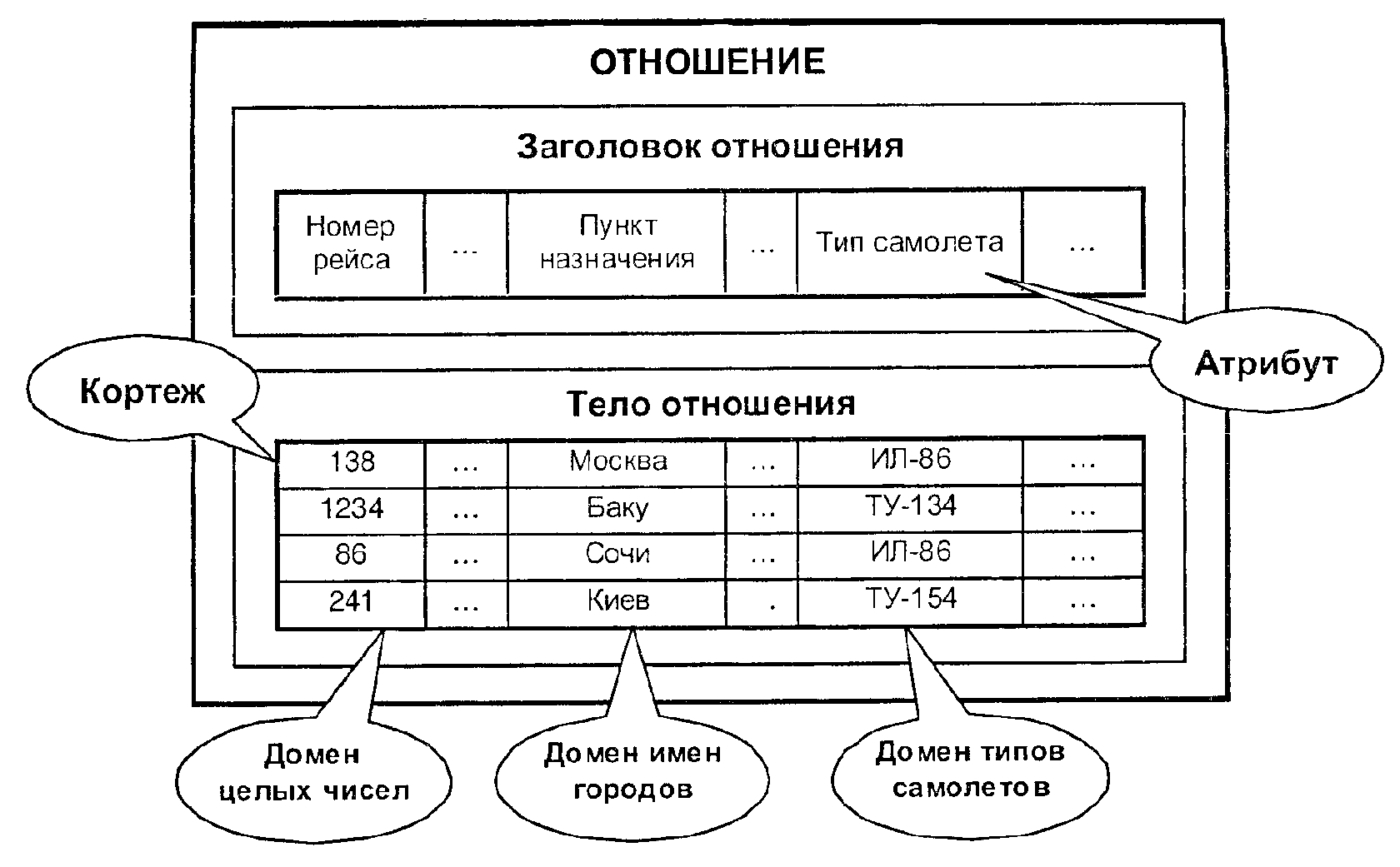
Рис. 2.23. Отношение в реляционной модели
Заголовок состоит из такого фиксированного множества атрибутов А1, А2, ..., Ап, что существует взаимно однозначное соответствие между этими атрибутами Аi и определяющими их доменами Di
= (i=1, 2, ..., n).
Тело состоит из меняющегося во времени множества кортежей, где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Аi:Vi), (i=1, 2, ..., n), по одной такой паре для каждого атрибута Аi в заголовке. Для любой заданной пары атрибут-значение (Аi:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Аi.
Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два - бинарным, степени три – тернарным, ..., а степени n – n-арным,
Кардинальное число или мощность отношения
– это число его кортежей. Кардинальное число отношения изменяется во времени в отличие от его степени.
Изменение кардинального числа отношения связано с изменением состояния отношения.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Пусть R – отношение с атрибутами А1, А2, ..., Ап. Говорят, что множество атрибутов К=(Аi, Аj, ..., Аk) отношения R является возможным ключом R тогда и только тогда, когда удовлетворяются два независимых от времени условия [5].
1. Уникальность: в произвольный заданный момент времени никакие два различных кортежа R не имеют одного и того же значения для Аi, Аj, ..., Аk
2. Минимальность: ни один из атрибутов Аi, Аj, ..., Аk не может быть исключен из К без нарушения уникальности.
Каждое отношение обладает хотя бы одним возможным ключом, поскольку, по меньшей мере, комбинация всех его атрибутов удовлетворяет условию уникальности. Один из возможных ключей (выбранный произвольным образом) принимается за его первичный ключ. Остальные возможные ключи, если они есть, называются альтернативными ключами.
Вышеупомянутые и некоторые другие математические понятия явились теоретической базой для создания реляционных СУБД, разработки соответствующих языковых средств и программных систем, обеспечивающих их высокую производительность, и создания основ теории проектирования баз данных.
Однако для массового пользователя реляционных СУБД можно использовать неформальные эквиваленты этих понятий:
Отношение – Таблица (иногда Файл),
Кортеж – Строка (иногда Запись),
Атрибут - Столбец, Поле.
При этом принимается, что «запись» означает «экземпляр записи», а «поле» означает «имя и тип поля».
Математическое определение реляционной модели приводится в [10, 17].
Отношение рассматривается как подмножество декартова произведения доменов.
Декартовым произведение доменов D1, D2, ..., Dk

где



Пример 2.4. Если D1{А2, 2}, D2={B, С}, D3={4, 5, D}, то k=3 и соответственно декартово произведение:
D= D1 X D2 X D2 ={(А, B, 4), (А, В, 5), (А, B, D), (А, С,4), (А, С, 5), (А, С, D), (2, B, 4), (2, B, 5), (2, Б, D), (2, С, 4), (2, С, 5), (2, С, D}.
Декартово произведение позволяет получить все возможные комбинации элементов исходных множеств – элементов рассматриваемых доменов.
Отношением К на множествах D1, D2, ..., Dk называется подмножество декартова произведения D=D1 х D2 х ...х DK. Отношение R, определенное на множествах D1,D2, ..., DK (причем не обязательно, чтобы эти множества были различными), есть некоторое множество кортежей арности k: (d1.i1, d2.i2, …, di,ik), таких, что d1.i1 принадлежит D1, d2.i2 - D2 и т.д.:
Элементами отношения являются кортежи. Арность кортежа определяет арность отношения. Поскольку отношение есть множество, то в нем не должны встречаться одинаковые кортежи и порядок кортежей в отношении несуществен.
Отношение может использоваться двояко [17]:
1) для представления набора объектов;
2) для представления связей между наборами объектов.
Для представления набора объектов атрибуты интерпретируются столбцами отношения. Множество допустимых значений атрибута интерпретируется соответствующим доменом. Каждый кортеж отношения выполняет роль описания отдельного объекта из набора.
Отношение выполняет роль описания всего набора объектов.
Отношение также используется для представления связей между наборами объектов. В этом случае кортеж в отношении К связь между объектами. Чтобы реализовать такую ситуацию, каждому столбцу отношения ставится в соответствие ключевой атрибут соответствующего набора объектов.
Список имен атрибутов отношения называется схемой отношения. Если отношение называется R и его схема имеет атрибуты с именами А1, А2, ..., Аk, то схема отношения
R(A1, А2, ..., Аk).
Реляционная база данных – это набор экземпляров конечных отношений. Схему реляционной БД можно представить в виде совокупности схем отношений

Другими словами - реляционная база данных - это совокупность отношений, содержащих всю информацию, которая должна храниться в БД. Однако пользователи могут воспринимать такую базу данных как совокупность таблиц. Так на рис. 2.24 показаны таблицы базы данных, построенные по инфологической модели базы данных «Питание» (прил. 4) [5].
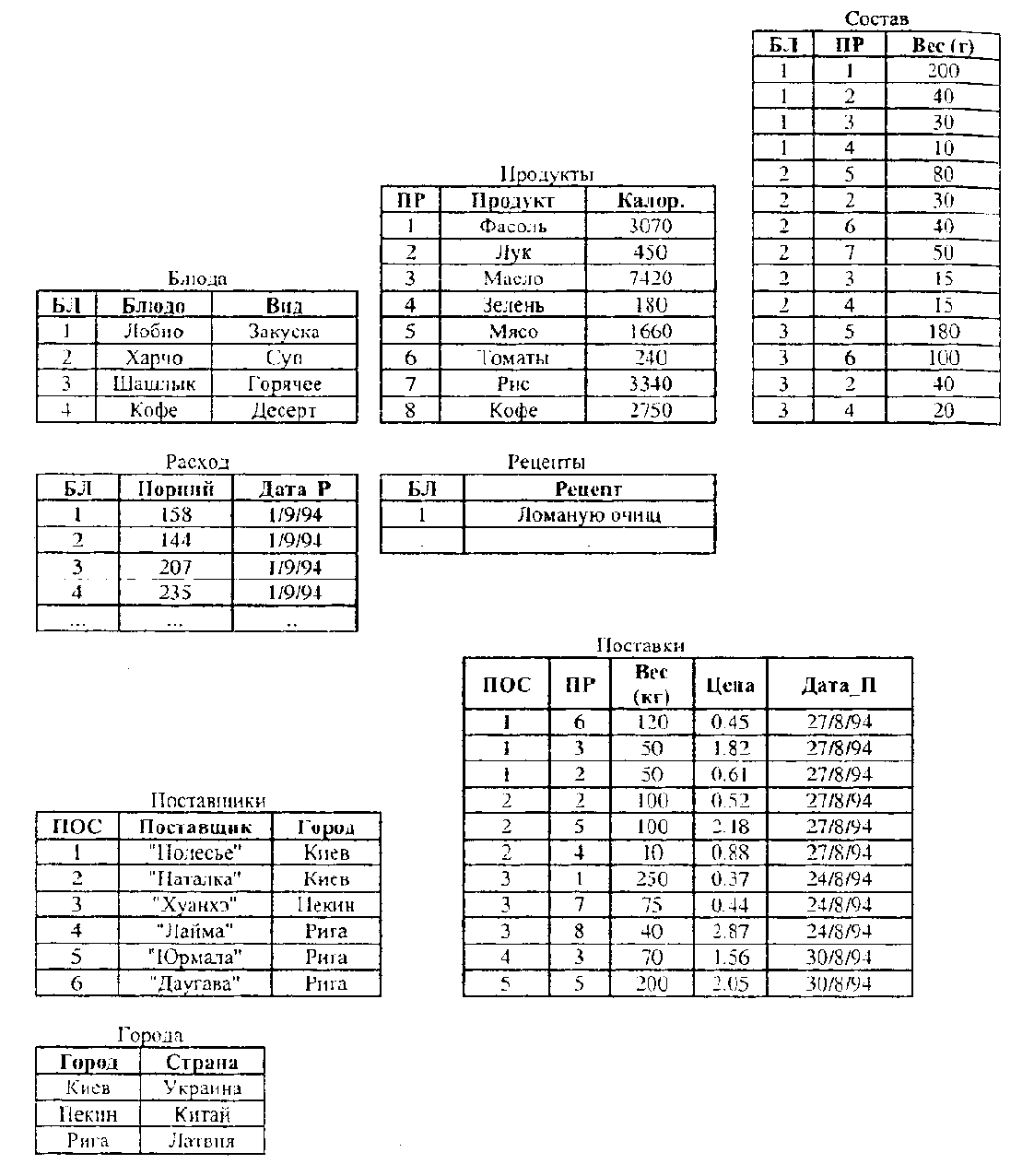
Рис. 2.24. База данных «Питание» (см. прил. 4)
1. Каждая таблица состоит из однотипных строк и имеет уникальное имя.
2. Строки имеют фиксированное число полей (столбцов) и значений (множественные поля и повторяющиеся группы недопустимы). Иначе говоря, в каждой позиции таблицы на пересечении строки и столбца всегда имеется в точности одно атомарное значение или ничего.
3. Строки таблицы обязательно отличаются друг от друга хотя бы единственным значением, что позволяет однозначно идентифицировать любую строку такой таблицы.
4. Столбцам таблицы однозначно присваиваются имена, и в каждом из них размещаются однородные значения данных (даты, фамилии, целые числа или денежные суммы).
5. Полное информационное содержание базы данных представляется в виде явных значений данных, и такой метод представления является единственным. В частности, не существует каких-либо специальных «связей» или указателей, соединяющих одну таблицу с другой.Так, связи между строкой с БЛ=2 таблицы «Блюда» на рис. 2.24 и строкой с ПР=7 таблицы продукты (для приготовления Харчо нужен Рис), представляется не с помощью указателей, а благодаря существованию в таблице «Состав» строки, в которой номер блюда равен 2, а номер продукта - 7.
6. При выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию. Этому способствует наличие имен таблиц и их столбцов, а также возможность выделения любой их строки или любого набора строк с указанными признаками.
Реляционное исчисление доменов
В реляционном исчислении с переменными на доменах используются те же операторы, что и в реляционном исчислении с переменными-кортежами.
Атомы формул могут быть двух типов [11, 17].
1. R(x1x2…xk),
где R - k-арное отношение; xi - константа или переменная на некотором домене.
Атом R(x1x2…xk)
указывает, что значения тех xi, которые являются переменными, должны быть выбраны так, чтобы (x1x2…xk) было кортежем отношения R.
2. x

Атом x
Формулы в реляционном исчислении с переменными на доменах также используют логические связки ?, ?, ¬ и кванторы (


Реляционное исчисление с переменными на доменах имеет вид
{x1x2…xk | ?(x1 , x2 ,…, xk)},
где ? – формула, обладающая тем свойством, что только ее свободные переменные на доменах являются различными переменными x1 , x2 ,…, xk. Например, выражение
{x1x2 | R1(x1x2) ?(
имеет место для бинарных отношений R1
и R2 и означает множество кортежей в R1, таких, что ни один из их компонентов не является первым компонентом какого-либо кортежа отношения R2.
С целью учета ограничения – конечности реальных отношений – аналогично вводятся безопасные выражения.
Реляционное исчисление с переменными на доменах называется безопасным, если выполняются следующие условия:
1) из истинности ?(x1 , x2 ,…, xk) следует, что xi принадлежит –D(?);
2) если (
3) если (
Выражение исчисления с переменными на доменах, эквивалентное заданному выражению исчисления с переменными-кортежами {t| ?(t) строится следующим образом:
1) если t является кортежем арности k, то вводится k новых переменных на доменах t1, t2, …, tk;
2) атомы R(t) заменяются атомами R(t1, t2, …, tk);
3) каждое свободное вхождение t[i] заменяется на ti;
4) для каждого квантора (
где m – арность кортежа u. В области действия этой квантификации выполняются замены:
R(u) на R(u1u2…um),
u[i] заменяется на ui,
(
(
5) выполняется построение выражения
{t1t2…tk | ?'(t1, t2, …, tk)},
где ?' – это ?, в которой выполнены соответствующие замены.
Например, {t| R1(t) ?R2(t)} перепишется так:
В реляционном исчислении с переменными на доменах существуют следующие две теоремы.
Теорема 4.2. Для каждого безопасного выражения реляционного исчисления с переменными-кортежами существует эквивалентное безопасное выражение реляционного исчисления с переменными на доменах [17].
Теорема 4.3. Для каждого безопасного выражения реляционного исчисления с переменными на доменах существует эквивалентное ему выражение реляционной алгебры [17].
Примером реального языка запросов, реализующего реляционное исчисление с переменными на доменах, является QBE. Это графический язык, предоставляющий пользователю графическое отображение структуры отношения. Пользователь создает некий образец желаемого результата, а система возвращает затребованные данные в указанном формате.
Реляционное исчисление кортежей
В выражениях реляционной алгебры всегда явно задается некий порядок выполнения запроса. В реляционном же исчислении указывается что необходимо извлечь, а не как.
Реляционное исчисление никак не связано с дифференциальным и интегральным исчислениями в математике, а его название произошло от части символьной логики, которая называется логикой предикатов.
В логике первого порядка или теории исчисления предикатов под предикатом подразумевается истинностная функция с аргументами. При подстановке вместо аргументов значений, функция становится выражением, называемым суждением, которое может быть истинным или ложным. Например, предложения «студент Шепе-лявцев учится на третьем курсе вуза» и «средний балл успеваемости студента Шепелявцева выше, чем у студента Мамаева» являются суждениями, поскольку можно определить их истинность или ложность. В первом случае функция «учится на третьем курсе вуза» имеет один аргумент («студент Шепелявцев»), а во втором случае функция «средний балл выше» имеет два аргумента («студент Шепелявцев» и «студент Мамаев»).
Если предикат содержит переменную, например в виде «x учится на третьем курсе вуза», то у этой переменной должна быть область определения. При подстановке вместо переменной x одних значений из ее области определения данное суждение может оказаться истинным, а при подстановке других – ложным.
Если P – предикат, то множество всех значений переменной x, при которых суждение Р становится истинным, можно символически записать следующим образом:
{x| P(x)}.
Предикаты могут соединяться с помощью логических операторов ?, ?, ¬ с образованием составных предикатов.
В реляционном исчислении кортежей задача состоит в нахождении таких кортежей, для которых предикат является истинным.
Выражение реляционного исчисления с переменными-кортежами записывается в виде [17]
{t| ?(t)},
где t – свободная переменная-кортеж, обозначающая кортеж фиксированной длины (если необходимо указать арность кортежа, то используют запись t(i); i-арность кортежа t); ? – некоторая формула, построенная по специальным правилам.
Например, выражение {t| R1(t) ?R2(t)}, где в качестве формулы выступает конструкция R1(t) ?R2(t), означает, что необходимо получить множество всех кортежей t, причем таких кортежей, которые принадлежат отношениям R1 или R2. Формула (R1(t) ?R2(t))) имеет смысл только тогда, когда отношения R1 и R2 имеют одинаковую арность, поскольку переменная-кортеж t задана как переменная фиксированной длины. Выражение { t| R1(t) ?R2(t)} эквивалентно операции объединения (R1
реляционной алгебры.
Формулы в реляционном исчислении строятся из атомов и совокупности арифметических и логических операторов.
Атомы формул могут быть трех типов [17]:
1) R(t), где R – имя отношения. Этот атом означает, что t – это кортеж в отношении R;
2) s[i]?u[j], где s и u - переменные-кортежи; ? – арифметический оператор (<, >, =, ?, ?, ?); i, j – номера или имена необходимых компонентов (столбцов) в соответствующих кортежах; s[i] – i-тый компонент в кортеже-переменной s; u[j] - j-тый компонент в кортеже-переменной и. Например, атом (s[3] ? u[5]) означает, что третий компонент переменной s больше или равен пятому компоненту переменной u;
3) s[i]?a или a?s[i], где a – константа. Например, атом (s[4]=70), означает, что четвертая компонента переменной-кортежа s
равна 70.
При записи формул используется понятие свободных и связанных переменных-кортежей, что определяется характером использования в формуле кванторов;
Вхождение переменной t в формулу ? связано, если в ? оно находится в подформуле, начинающейся квантором

все вхождения переменной x связаны, первое и последнее вхождения y свободны, остальные вхождения переменной y связаны, все вхождения переменной z свободны, единственное вхождение переменной r связано.
Кванторы в реляционном исчислении играют ту же роль, что декларации в языке программирования. Понятие свободной переменной аналогично понятию глобальной переменной, описанной вне текущей процедуры. Понятие связанной переменной аналогично понятию локальной переменной, описанной в текущей процедуре.
Аналогично тому, как не все возможные комбинации букв алфавита образуют правильные слова, так и в реляционном исчислении не каждая последовательность формул является допустимой. Допустимыми формулами могут быть только недвусмысленные и небессмысленные последовательности.
Правильно построенные формулы определяются рекурсивно следующим образом [11, 17].
1. Каждый атом – это формула. Все вхождения переменных-кортежей, упомянутые в атоме, являются свободными.
2. Если ?1 и ?2 - формулы, то выражения ?1 ??2
(утверждает, что ?1 и ?2 истинны), ?1
??2
(утверждает, что ?1 или ?2, или обе истинны), ¬?1 (утверждает, что ?1 не истинна), также являются формулами.
Экземпляры переменных-кортежей – свободные или связанные в формулах (?1 ??
2), (?1 ??
2) и (¬?1) так же, как и в ?1 и ?2. Таким образом, свободными (связанными) являются те и только те вхождения переменных, которые происходят от свободных (связанных) вхождений переменных ?1 и ?2. Некоторое вхождение переменной может быть связанным в ?1 например, в то время как другое – свободным в ?2 и т.п.
3. Если ? – формула, то (
в формуле ? становятся связанными квантором (
4. Если ? – формула, то (
в формулу ? эта формула становится истинной.
Например, формула (
5. Формулы могут при необходимости заключаться в скобки. Используется следующий порядок старшинства:
§ арифметические операторы сравнения;
§ кванторы
§ ?, ?, ¬.
6. Ничто иное не является формулой.
В качестве примера можно записать выражение реляционного исчисления на переменных-кортежах, соответствующее операции проекции в реляционной алгебре:

Введем ограничения на конечность реальных отношений в БД, чтобы исключить возможность формирования выражений типа {t|-R(t)}, не имеющих смысла. Это выражение обозначает все возможные, не принадлежащие R кортежи, арность которых согласуется с t.
С этой целью в реляционном исчислении рассматривают только безопасные выражения {t|?(t)}, для которых выполняется условие, что каждый компонент (элемент столбца) любого кортежа t, удовлетворяющего ?(t) является элементом некоторого множества элементов D(?). Множество D(?) определяется как функция фактических отношений, которые указываются в ?(t), и констант, присутствующих в формуле ?(t) и элементов кортежей тех отношений, которые указаны в ?(t). Так как все отношения в БД предполагаются конечными, то и множество D(?) – конечно:
D(?)={a1.?}
где a1.?, a2.?, ..., an.? – константы, встретившиеся в формуле ?(t); ?1(R1), …, ?k(Rn) – проекции кортежей фактических отношений R1, ..., Rn, встретившихся в формуле ?(t) (в данном случае – компоненты кортежей).
При таком определении множества D(?) справедливо следующее:
D(?1(t) ??2(t))= D(?1)
D(?1(t) ??2(t))= D(?1)
D(?1(t) ?¬?2(t))= D(?1)
Например, если задано выражение {t|c ?R(t)}, где R – бинарное отношение, то
D(?)={c}
Реляционное исчисление является безопасным, если выполнятся следующие условия:
1) из истинности ?(t) следует, что каждый компонент кортежа t принадлежит – D(?);
2) для любой подформулы вида (

3) для любой подформулы вида (

При выполнении этих условий выражение {t|?(t)} является безопасным. Выражению (
На основании вышеизложенного можно утверждать, что если формула ?(t) такова, что любая ее подформула вида (
{t|R(t) ??(t)}. Действительно, любой кортеж, удовлетворяющий формуле (R(t) ??(t)), принадлежит в соответствии с этой формулой отношению R. Следовательно, каждый из его компонентов будет принадлежать также и множеству элементов D(R(t) ??(t)). Тогда в силу выполнения условия 1 (выполнение условий 2 и 3 задано как исходная предпосылка) выражение { t|R(t) ??(t)} – безопасное. Если в ?(t) найдется хотя бы одна из подформул вида (
Например, если ?(t)=¬R2(t) то получим безопасное выражение {t|R1(t) ?¬R2(t)} соответствующее операции разности отношений в реляционной алгебре (R1–R2).
Безопасным является также выражение {t|R(t)}, соответствующее выражению R (точнее – переменной R, обозначающей отношение).
В реляционном исчислении на переменных- кортежах доказана теорема, устанавливающая эквивалентность безопасных выражений в исчислении операциям реляционной алгебры.
Теорема 4.1. Если E - выражение реляционной алгебры, то существует эквивалентное ему безопасное выражение в реляционном исчислении с переменными-кортежами [17].
Для основных операций реляционной алгебры укажем следующие соответствующие выражения реляционного исчисления на переменных-кортежах.
1. Операции объединения (R1
соответствует выражение
соответствует выражение
{t|R1(t) ?R2(t)}.
2. Операции разности (R1-R2) соответствует выражение
соответствует выражение
{t|R1(t) ?¬R2(t)}.
Рассматривается все множество кортежей t, таких, что t принадлежит R1 и не принадлежит R2.
3. Операции декартова произведения (R1
{t(k+m)|(
=u[k] ?t[k+1]=v[1] ?… ?t[k+m]=v[m])}.
Рассматривается все множество кортежей t арности (k+m), таких, что существует кортеж u, принадлежащий R1, и существует кортеж v, принадлежащий R2, причем k первых компонентов кортежа t образуют компоненты кортежа и, а следующие m компонентов кортежа t образуют компоненты кортежа v.
4. Операции проекции соответствует выражение
{t(k)|(
?t[1]=u[i1] ?… ?t[k]= u[ik])}
5. Операции селекции соответствует выражение {t|R(t) ?F'}, где F' – это выражение F, в котором каждый операнд, обозначающий компонент i, заменен на t[i].
Несмотря на то, что реляционное исчисление является достаточно сложным с точки зрения освоения и использования, тем не менее, его непроцедурная природа считается весьма перспективной и это стимулирует поиск других, более простых в употреблении непроцедурных методов. Подобные исследования привели к появлению двух категорий реальных реляционных языков:
– языков на основе преобразований;
– графических языков.
Языки на основе преобразований являются классом непроцедурных языков, которые используют отношения для преобразования исходных данных к требуемому виду. Эти языки предоставляют простые в употреблении структуры для получения результата. Примером реального языка на основе преобразований, реализующего реляционное исчисление с переменными-кортежами, является язык запросов SQL.
Репликация
Репликацию можно определить как процесс генерации и воспроизведения нескольких копий данных, размещаемых на одном или нескольких сайтах.
Механизм репликации очень важен, поскольку позволяет организации обеспечивать доступ пользователям к актуальным данным там и тогда, когда они в этом нуждаются. Использование репликации позволяет достичь многих преимуществ, включая повышение производительности (в тех случаях, когда централизованный ресурс оказывается перегруженным), надежности хранения и доступности данных, наличие «горячей» резервной копии на случай восстановления, а также возможность поддержки мобильных пользователей и хранилищ данных.
Сетевая модель
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. С точки зрения теории графов сетевой модели соответствует произвольный граф (возможно имеющий циклы и петли). В узлах графа помещаются типы записей, а ребра интерпретируются как связи между типами записей.
Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи [8].
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка Р и типом записи потомка С должны выполняться следующие два условия:
– каждый экземпляр типа Р является предком только в одном экземпляре L;
– каждый экземпляр С является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации [8].
А. Тип записи потомка в одном типе связи L1 может
быть типом записи предка в другом типе связи L2
(как в иерархии).
В. Данный тип записи Р может быть типом записи предка в любом числе типов связи.
С. Данный тип записи Р может быть типом записи потомка в любом числе типов связи.
D. Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 - два типа связи с одним и тем же типом записи предка Р и одним и тем же типом записи потомка С, то правила, по которым образуется родство, в разных связях могут различаться.
Е. Типы записи X и У могут быть предком и потомком в одной связи и потомком и предком - в другой.
F. Предок и потомок могут быть одного типа записи.
Простой пример сетевой схемы БД приведен на рис. 2.22.

Рис. 2.22. Пример схемы сетевой БД
Примерный набор операций при использовании сетевой модели может быть следующим [8].
– Найти конкретную запись в наборе однотипных записей (инженера Петрова).
– Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 42).
– Перейти к следующему потомку в некоторой связи (от Петрова к Иванову).
– Перейти от потомка к предку по некоторой связи (найти отдел Петрова).
– Создать новую запись.
– Уничтожить запись,
– Модифицировать запись.
– Включить в связь.
– Исключить из связи.
– Переставить в другую связь и т. д.
Схемы владения данными
Владение данными определяет, какому из сайтов будет предоставлена привилегия обновления данных Основными типами схем владения являются [7]:
– «ведущий/ведомый»;
– «рабочий поток»;
– «повсеместное обновление».
Последний вариант иногда называют одноранговой, или симметричной репликацией.
При организации владения данными по схеме «ведущий/ведомый» асинхронно реплицируемые данные принадлежат одному из сайтов, называемому ведущим, или первичным, и могут обновляться только на нем. Здесь можно провести аналогию между издателем и подписчиками. Издатель (ведущий сайт) публикует свои данные. Все остальные сайты только лишь подписываются на данные, принадлежащие ведущему сайту, т.е. имеют собственные локальные копии, доступные им только для чтения. Потенциально каждый из сайтов может играть роль ведущего для различных, не перекрывающихся наборов данных. Однако в системе может существовать только один сайт, на котором располагается ведущая обновляемая копия каждого конкретного набора данных, а это означает, что конфликты обновления данных в системе полностью исключены. Ниже приводится несколько примеров возможных вариантов использования этой схемы репликации.
– Системы, поддержки принятия решений (ППР). Данные из одной или более распределенных баз данных могут выгружаться в отдельную, локальную систему ППР, где они будут только считываться при выполнении различных видов анализа.
– Централизованное распределение или распространение информации. Распространение данных имеет место в тех случаях, когда данные обновляются только в центральном звене системы, после чего реплицируются их копии, доступные только для чтения. Этот вариант репликации данных показан на рис.5.6,а.
– Консолидация удаленной информации. Консолидация данных имеет место в тех случаях, когда обновление данных выполняется локально, поле чего их копии, доступные только для чтения, отсылаются в общее хранилище.
В этой схеме каждый из сайтов автономно владеет некоторой частью данных. Этот вариант репликации данных показан на рис. 5.6, б.
– Поддержка мобильных пользователей. Поддержка работы мобильных пользователей получила в последние годы очень широкое распространение. Сотрудники многих организаций вынуждены постоянно перемещаться с места на место и работать за пределами офисов. Разработано несколько методов предоставления необходимых данных мобильным пользователям. Одним из них и является репликация. В этом случае по требованию пользователя данные загружаются с локального сервера его рабочей группы. Обновления, выполненные клиентом для данных рабочей группы или центрального сайта, обрабатываются сходным образом.

Рис. 5.6. Владение данными по схеме «ведущий/ведомый»: а) распределение данных; б) консолидация данных
Ведущий сайт может владеть данными всей таблицы, и в этом случае все остальные сайты являются лишь подписчиками на копии этой таблицы, доступные только для чтения. В альтернативном варианте многие сайты владеют отдельными фрагментами таблицы, а остальные сайты могут выступать как подписчики копий каждого из этих фрагментов, доступных им только для чтения. Этот тип репликации называют асимметричной репликацией.
Как и в случае схемы «ведущий/ведомый», в модели «рабочий поток»
удается избежать появления конфликтов обновления, хотя данной модели свойствен больший динамизм. Схема владения «рабочий поток» позволяет передавать право обновления реплицируемых данных от одного сайта другому. Однако в каждый конкретный момент времени существует только один сайт, имеющий право обновлять некоторый конкретный набор данных. Типичным примером использования схемы рабочего потока является система обработки заказов, в которой работа с каждым заказом выполняется в несколько этапов, например оформление заказа, контроль кредитоспособности, выписка счета, доставка и т. д.
Централизованные системы позволяют приложениям, выполняющим отдельные этапы обработки, получать доступ и обновлять данные в одной интегрированной базе данных.
Каждое приложение обновляет данные о заказе по очереди тогда и только тогда, когда состояние заказа указывает, что предыдущий этап обработки уже завершен. В модели владения «рабочий поток» приложения могут быть распределены по различным сайтам, и когда данные реплицируются и пересылаются на следующий сайт в цепочке, вместе с ними передается и право на их обновление, как показано на рис. 5.7.

Рис. 5.7. Схема владения «рабочий поток»
У двух предыдущих моделей есть одно общее свойство: в любой заданный момент времени только один сайт имеет право обновлять данные. Всем остальным сайтам доступ к репликам данным будет разрешен только для чтения. В некоторых случаях это ограничение оказывается слишком жестким.
Схема владения с повсеместным обновлением создает равноправную среду, в которой множество сайтов имеют одинаковые права на обновление реплицируемых данных. В результате локальные сайты получают возможность работать автономно, даже в тех случаях, когда другие сайты недоступны.
Разделение права владения может вызвать возникновение в системе конфликтов, поэтому служба репликации в этой схеме должна использовать тот или иной метод выявления и разрешения конфликтов.
Сохранение целостности транзакций
Первые попытки реализации механизма репликации по самой своей сути не предусматривали сохранения целостности транзакций [7]. Данные копировались без сохранения свойства атомарности транзакций, что потенциально могло привести к утрате целостности Распределенных данных. Этот подход проиллюстрирован на рис. 5.8, а.
В данном случае транзакция, состоящая на исходном сайте из нескольких операций обновления данных в различных таблицах, в процессе репликации преобразовывалась в серию отдельных транзакций, каждая из которых обновляла данные в одной из таблиц. Если часть этих транзакций на целевом сайте завершалась успешно, а остальная часть – нет, то согласованность информации между двумя базами данных утрачивалась.
В противоположность этому, на рис. 5.8, б показан пример репликации с сохранением структуры транзакции в исходной базе данных.

Рис. 5.8. Репликация транзакций: а) без соблюдения свойства атомарности; б) с соблюдением атомарности транзакций
Списковые структуры
В системах обработки данных в качестве данных выступают описания (представления) фактов и понятий рассматриваемой предметной области на точном и формализованном входном языке системы - языке описания данных [17]. С помощью входного языка при описании фактов и понятий ПО между элементами данных конструируются логические структурные отношения. В качестве логических структур (см. гл.2) используют либо таблицы, представляющие собой двумерный или re-мерный массив данных, либо древовидные иерархически структуры, либо сетевые структуры, представляющие собой сложную многосвязную структуру с большим количеством взаимных соединений и т.п. Чтобы правильно использовать вычислительную машину, необходимо хорошо представлять себе структурные отношения между данными, знать способы представления таких структур в памяти машины и методы работы с ними. Структура данных и представление этой структуры в памяти ЭВМ – два важных, но Различных между собой понятия [17]. Так, например, некоторая логическая структура данных типа «дерево» может быть представлена в памяти ЭВМ несколькими различными способами.
Таким образом, любое представление структуры данных в памяти ЭВМ должно включать в себя как сами данные, так и задаваемые взаимосвязи, которые и определяют логическое структурирование.
Форма представления структур данных в памяти ЭВМ зависит от предполагаемого использования данных, поскольку для различных типов структур эффективность выполнения тех или иных операций обработки данных различна. Основное различие форм представления структур данных в памяти ЭВМ определяются в первую очередь тем, как адресуются элементы структуры данных в памяти машины – по месту или по содержимому. В первом случае указываются логические или физические адреса данных, определяющие местоположение данных в памяти машины. Во втором случае размещение данных и их выборка осуществляются по известному значению ключа, т.е. определяются содержимым самих данных [4].
Наиболее простой формой хранения данных в памяти ЭВМ является одномерный линейный список.
Линейный список – это множество n>0 объектов (узлов) Х[1], Х[2], ..., Х[п], структурные свойства которого связаны только с линейным (одномерным) относительным расположением узлов. Если п>0, то Х[1] является первым узлом; для 1<i<n узел Х[i-1] предшествует узлу X[i], а узел X[i+l] следует за ним, Х[п] является последним узлом, т.е. линейный список реализует структуру, которую можно определить как линейное упорядочение элементов данных [17].
Линейный список X рассматривают как последовательность Х[1], Х[2], ..., Х[i], ..., Х[п], компоненты которой идентифицированы порядковым номером, указывающим их относительное расположение в X.
Одномерный линейный список, используемый для хранения данных в памяти машины, называют еще вектором данных или физической структурой хранения данных. Использование линейного списка в качестве физической структуры хранения данных определяется свойствами памяти вычислительной машины. Так, оперативная память ЭВМ представляет вектор, в котором байты упорядочены по возрастанию их адресов от 0 до наивысшего, т.е. проидентифицирова-ны адресом.
Проблема представления логических структур данных в памяти ЭВМ заключается в нахождении эффективных методов отображения логической структуры данных на физическую структуру хранения. Такое отображение называют адресной функцией.
При реализации адресной функции используют два основных метода [17]:
– последовательное распределение памяти;
– в связанное распределение памяти.
Сравнение теоретических языков
Рассмотренные выше три абстрактных языка запросов служат основой реальных языков манипулирования данными реляционных систем.
Каждый из трех рассмотренных языков эквивалентен по своей выразительности двум другим. Однако языки исчисления – это непроцедурные языки, поскольку их средствами можно выразить все, что необходимо и не обязательно указывать, как это получить (выражение в исчислении описывает лишь свойства желаемого результата, фактически не указывая, как его получить). Выражение реляционной алгебры, напротив, специфицируют конкретный порядок выполнения операций.
В первом случае определение наиболее эффективного порядка вычисления для реализации запроса пользователя выполняется транслятором или интерпретатором. Во втором случае пользователь обычно сам должен выполнить оптимизацию своего запроса при его формулировке. Однако, например, в соответствии с теоремой 1 транслятор на первом шаге трансляции запроса может выполнить преобразование алгебраического выражения в эквивалентное выражение исчисления и далее определить эффективный порядок вычислений [7, 17].
В общем случае языки манипулирования данными выходят за рамки теоретических языков, поскольку для обработки данных требуются операции, выходящие за рамки возможностей реляционного исчисления. Это прежде всего следующие команды: включить данные; модифицировать данные; удалить данные. Кроме этих операций обычно представляются следующие дополнительные возможности:
– арифметические вычисления и сравнения могут включаться в формулы селекции реляционных алгебраических выражений или в атомы в выражениях реляционного исчисления;
– команды печати;
– агрегатные функции – функции, применяемые к столбцам отношений, в результате выполнения которых вычисляется одна-единственная величина, например максимальное или минимальное значение, сумма, среднее.
Так как реальные языки могут реализовывать функции, не имеющие аналогов ни в реляционной алгебре, ни в реляционном исчислении, то в действительности они являются более чем полными. Причем, полным считается язык, в котором реализуются все возможности реляционного исчисления или реляционной алгебры.
Перспективной категорией языков запросов являются языки четвертого поколения (4-generation languages – 4GL), которые позволяют создавать полностью готовое и соответствующее требованиям заказчика прикладное приложение с помощью ограниченного набора команд и в то же время предоставляют дружественную по отношению к пользователю среду разработки, чаще всего построенную на использовании команд меню. В некоторых системах даже используются некоторые разновидности естественного языка, т.е. ограниченной версии обычного английского языка, который иногда называется языком пятого поколения (5GL) [7].
Средства администрирования баз данных
Учитывая сложность и важность функций АБД, легко предположить, что для их успешного выполнения, У администратора должны быть специальные средства администрирования
К основным из таких средств администрирования можно отнести:
1) язык определения данных;
2) язык манипулирования данными,
3) словарь данных (системный каталог)
Вкратце остановимся на назначении перечисленных средств.
Для работы с данными в СУБД предусмотрен внутренний язык, состоящий из двух частей: языка определения данных (Data Definition Language - DDL) и языка манипулирования данными (Data Manipulation Language - DML).
Эти языки еще называются подъязыками данных, т. к. в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы на языках высокого уровня. В этом случае язык высокого уровня принято называть базовым или включающим языком.
Язык определения данных (ЯОД, DDL) - формальный закон, используемый в некоторой модели данных для определения структуры баз данных [12].
Результат компиляции операторов ЯОД - набор таблиц хранимых в особых файлах, называемых словарями данных или системными каталогами.
Посредством ЯОД обычно определяются подразделения данных, типовые структуры и правила их композиции, присваиваются имена данным, определяются типы элементов данных посредством задания присущих им свойств, учреждаются ключи базы данных, а также определяются отношения между данными, упорядоченность данных внутри их совокупностей, правила проверки достоверности данных и замки защиты от неправомочного использования их.
Обычно в ЯОД не определяются техника запоминания или поиска данных на физических носителях и другие особенности их физической организации, что обусловлено одной из основных концепций базы данных - независимостью логической структуры данных от физических особенностей их хранения.
ЯОД обычно полностью независим от языка манипулирования данными. Следовательно, определение Данных в базах данных независимо от программ обра-отки, что является второй важной концепцией использования баз данных.
Язык манипулирования данными (ЯМД, DML) - совокупность языковых средств для организации доступа к данным в некоторой модели данных и в соответствующих ей СУБД [12].
Может выступать в роли языка запросов, прямо обеспечивающего информационное обслуживание пользователей баз данных, или быть расширением некоторого языка программирования, называемого базовым (включающим) языком, с конструкциями и понятиями которого ЯМД должен быть согласован. Операторы ЯМД позволяют извлекать данные из баз данных, создавать или модифицировать последние.
К основным операциям манипулирования данными относятся:
– вставка в БД новых сведений;
– модификация сведений, хранимых в БД;
– извлечение сведений, содержащихся в БД;
– удаление сведений из БД.
ЯМД отличаются базовыми конструкциями манипулирования данными. Отличают два их типа:
а) процедурные ЯМД;
б) непроцедурные (декларативные) ЯМД.
С помощью процедурного языка пользователь (программист) указывает на то, как можно получить необходимые данные из определенного набора данных. Т.е. пользователь должен определить все операции доступа к данным, чтобы получить результат. При этом предполагается знание пользователем деталей внутренней организации структур данных в БД.
С помощью непроцедурных языков пользователь указывает какие
данные ему нужны, без определения способа их получения. Данный подход освобождает пользователя от необходимости знать подробности внутренней организации БД. Работа пользователя обретает некоторую независимость от данных.
В общем случае язык запросов – часть ЯМД, высокоуровневый узкоспециализированный язык, предназначенный для удовлетворения различных требований по выборке данных из БД.
СУБД должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных.
Словарь данных (системный каталог) - специальная система в составе БД, содержащая информацию обо всех ресурсах системы (см. рис. 1.11).
В словаре данных (системном каталоге) интегрированы метаданные - данные об объектах базы данных, позволяющие упростить способ доступа к ним и управление ими. Перед доступом к реальным данным СУБД обращается к системному каталогу.
Ключевой особенностью архитектуры ANSI/SPARC является наличие интегрированного системного каталога с данными о схемах, пользователях, приложениях и т.д. Предполагается, что каталог доступен как пользователям, так и функциям СУБД. В зависимости от типа используемой СУБД количество информации и способ ее применения могут варьироваться. Обычно в системном каталоге хранятся следующие сведения:
– имена, типы и размеры элементов данных;
– имена связей;
– накладываемые на данные ограничения поддержки целостности;
– имена зарегистрированных пользователей, которым предоставлено право доступа к данным;
– внешняя, концептуальная и внутренняя схемы и отображения между ними;
– статистические данные, например частота транзакций и счетчики обращений к объектам базы данных.
|
СТРУКТУРА СЛОВАРЯ ДАННЫХ 1. БАЗА ДАННЫХ – полное название базы и имя файла Описание назначения и общего содержания БД, а также лиц, которые могут ею пользоваться. Список приложений, работающих с базой, информация о других БД, использующих данные из этой базы. Если имеются, то сюда же включаются диаграммы БД. А. ОБЛАСТЬ ДАННЫХ - название группы, к которой принадлежат таблицы Если таблицы классифицируются по группам, то включается описание каждой группы. 1. ТАБЛИЦА- таблицы, входящие в область данных а) ДОСТУП - права пользователей на доступ к таблице б) ЗАПИСЬ - общее определение элементов данных (1) ПЕРВИЧНЫЙ КЛЮЧ - поле (поля) первичного ключа (а) ИНДЕКС - описание индекса первичного ключа (2) ВНЕШНИЕ КЛЮЧИ - внешние ключевые поля (а) ИНДЕКС - индексы внешних ключей |
Рис. 1.11. Примерная структура словаря данных
Системный каталог позволяет достичь определенных
преимуществ, перечисленных ниже.
– Информация о данных может быть централизованно собрана и сохранена, что позволит контролировать доступ к этим данным, как и к любому
– другому ресурсу.
– Можно определить смысл данных, что поможет другим пользователям понять их предназначение.
– Упрощается сообщение, так как сохраняются точные определения смысла данных. В системном каталоге также могут быть указаны один или несколько пользователей, которые являются владельцами данных или обладают правом доступа к ним.
– Благодаря централизованному хранению избыточность и противоречивость описания отдельных элементов данных могут быть легко обнаружены.
– Внесенные в базу данных изменения могут быть запротоколированы.
– Последствия любых изменений могут быть определены еще до их внесения, поскольку в системном каталоге зафиксированы все существующие элементы данных, установленные между ними связи, а также все их пользователи.
– Меры обеспечения безопасности могут быть дополнительно усилены.
– Появляются новые возможности организации поддержки целостности данных.
– Может выполняться аудит сохраняемой информации.
Системный каталог СУБД является одним из фундаментальных компонентов системы. Многие перечаленные в разд.1.3 [7] программные компоненты стройся на использовании данных, хранящихся в системном каталоге. Например, модуль контроля прав доступа использует системный каталог для проверки наличия у пользователя полномочий, необходимых для выполнения запрошенных им операций. Для проведения подобной проверки системный каталог должен включать следующие компоненты:
– имена пользователей, для которых разрешен доступ к базе данных;
– имена элементов данных в базе данных;
– элементы данных, к которым каждый пользователь имеет право доступа, и разрешенные типы доступа к ним - для вставки, обновления, удаления или чтения.
Другим примером могут служить средства проверки целостности данных, которые используют системный каталог для проверки того, удовлетворяет ли запрошенная операция всем установленным ограничениям поддержки целостности данных. Для выполнения этой проверки в системном каталоге должны храниться такие сведения:
– имена элементов данных из базы данных;
– типы и размеры элементов данных;
– ограничения, установленные для каждого из элементов данных.
Термин «словарь данных» часто используется для программного обеспечения более общего типа, чем просто каталог СУБД. Система словаря данных может быть либо пассивной, либо активной. Активная система всегда согласуется со структурой базы данных, поскольку она автоматически поддерживается этой системой. Пассивная система может противоречить состоянию базы данных из-за инициируемых пользователями изменений. Если словарь данных является частью базы данных, то он называется интегрированным словарем данных. Изолированный словарь данных обладает своей собственной специализированной СУБД. Его предпочтительно использовать на начальных этапах проектирования базы данных для некоторой организации, когда требуется отложить на какое-то время привязку к конкретной СУБД. Однако недостаток этого подхода заключается в том, что после выбора СУБД и воплощения базы данных изолированный словарь данных значительно труднее поддерживать в согласии с состоянием базы данных.
Эту проблему можно было бы свести к минимуму, если преобразовать использовавшийся при проектировании словарь данных непосредственно в каталог СУБД.
Связанное распределение памяти
Связанное представление линейного списка называется связанным списком. При связанном распределении памяти для построения структуры необходимо задать отношения следования и предшествования элементов с помощью указателей. Указателями служат адреса, хранимые в записях данных. В отличие от последовательного распределения памяти, при котором с помощью адресной функции вычисляется адрес следующего элемента, при связанном распределении памяти значение адресной функции можно получить только путем просмотра хранящихся указателей. Такой метод распределения памяти позволяет расширить либо сократить структуру без перемещения самих данных в памяти ЭВМ, однако при этом требуется больше памяти для хранения структуры по сравнению с последовательным распределением [16, 17].
Связанное распределение - более сложный, но и более гибкий способ хранения линейного списка. Каждый узел содержит указатель на следующий узел списка, т.е. адрес следующего узла списка (рис. 3.3). При связанном распределении не требуется, чтобы список хранился в последовательных элементах памяти. Наличие адресов связи в данном способе хранения позволяет размещать узлы списка произвольно в любом свободном участке памяти. При этом линейная структура списка обеспечивается указателями.
Структура линейного списка, представленная с помощью связанного распределения, называется также Цепной структурой или цепью.
Для достижения большей гибкости при работе с линейными списками в каждый узел X[i] вводятся два Указателя. Один из указателей реализует связь рас сматриваемого узла с узлом Х[М], а другой - с узлом X[i+l] (рис. 3.4).

Рис. 3.3. Примеры связанных линейных списков: а) – однонаправленный список; б) – тот же список после удаления узла 4 и включения узлов 2а и 5
Связанные списки - удобная форма представления динамически изменяющихся линейных структур. Любое произвольное изменение порядка записей, сокращение или расширение вектора данных в какой-либо записи не требуют перемещения записей в памяти ЭВМ.
Для выполнения этих операций достаточно лишь изменить значения полей связи.
Однако доступ к конкретному узлу может оказаться намного длительнее, чем при последовательном распределении памяти. Чтобы получить доступ к данным, хранящимся в узле X[i], необходимо сделать i итераций, используя указатели и поля связи в узлах X[k], где k=1, 2, ..., i, т.е. последовательно просмотреть все предшествующие узлы списка. Этот недостаток можно устранить различными способами.

Число групп


Для связанных линейных одно- или двунаправленных списков в ряде случаев целесообразно создать специальный узел – голову списка – и хранить его в специальной фиксированной ячейке памяти по адресу ?.
В этот узел помещается указатель на первый узел списка.
В голове списка можно хранить различную слу-ясебную информацию, необходимую при обработке списка (идентификатор списка, количество узлов в списке и т. п.).
Важной разновидностью представления в памяти линейного списка является циклический список. Циклически связанный линейный список обладает той особенностью, что связь от последнего узла идет к первому узлу списка (рис. 3.6). Циклический список позволяет получить доступ к любому узлу списка, отправляясь от любого заданного узла. Циклические списки называются также кольцевыми структурами или кольцами.

Рис. 3.6. Пример однонаправленного циклического списка
Наряду с однонаправленными используются двунаправленные циклические списки. В ряде случаев удобно использовать циклический список с указателями на голову списка из каждого узла, за исключением последнего узла, поскольку используется прямой указатель на голову списка [17].
Базируясь на использовании способов представления связанных линейных списков, можно реализовать в памяти ЭВМ сложные нелинейные структуры, например древовидные или сетевые. Такие представления структур называются многосвязанными списками. Для построения многосвязанного списка требуется иметь в узлах достаточное количество указателей. Наличие большого числа указателей в многосвязанной структуре в ряде случаев повышает эффективность обработки.
Таким образом, основой построения связанных списковых структур являются указатели.
При практической реализации на ЭВМ можно использовать три типа указателей (адресов записей):
– машинный (действительный);
– относительный;
– символический (идентификатор).
Первый тип указателей - действительный адрес -используется тогда, когда необходимо получить наибольшую скорость обработки данных, организованных в связанные списковые структуры. Этот тип указателей имеет серьезный недостаток - жесткую привязку записей к конкретному месту расположения в памяти.
Если возникнет необходимость переместить список на новое место в памяти ЭВМ, то потребуется выполнить работу изменению указателей во всех записях.
Второй тип указателей – относительный адрес – позволяет размещать записи в любом месте памяти и на различных внешних устройствах без изменения значений указателей, при этом относительное расположение в памяти узлов списка между собой должно оставаться постоянным. При перемещении списка ука затели в записях не изменяются, а изменяется базовый адрес при вычислении действительных машинных адресов. Относительные адреса в качестве указателей применяются при страничной организации памяти. Скорость доступа к узлам при использовании относительных адресов несколько замедляется по сравнению со случаем машинных адресов, однако появляется возможность размещать список в любом свободном месте памяти подходящего размера.
Третий тип указателей – символический адрес (идентификатор) – позволяет перемещать отдельные записи относительно друг друга, включать или удалять записи в список без изменения указателей во всех остальных записях списка. Однако при работе с символическими указателями скорость доступа меньше, чем при работе с машинными или относительными адресами. Идентификаторы в качестве указателей удобно использовать для интенсивно изменяющихся файлов. Преобразование идентификатора в машинный адрес при выполнении операций обращения к узлам списка выполняется с помощью специального алгоритма в соответствии с выбранным методом адресации.
С точки зрения организации структуры данных различают два типа указателей [17]:
– встроенные указатели;
– справочник указателей.
Если указатели образуют часть записи, то они называются встроенными. Если указатели хранятся отдельно от записей, то они образуют справочник.
Указатели имеют следующие возможные пути использования [17]:
1) определяют направление доступа (можно двигаться только в тех направлениях, которые заданы указателями);
2) соединяют вместе связанные по смыслу данные;
3) отображают ориентированные ребра в древовидных или сетевых структурах;
4) связывают память на дисках и организуют цепочки дисковых страниц и т. п.
Применение многосвязанных списков – это основной механизм, позволяющий разработчикам СУБД реализовывать сложные нелинейные структуры. Однако следует избегать слишком большого количества указателей, поскольку на них тратится память и время на переходы по указателям. Кроме того, при большом количестве указателей основная структура, представляемая в памяти ЭВМ, теряет четкость, и могут возникнуть связи, которые в отображаемой структуре отсутствуют.
Теоретические языки запросов

1) реляционная алгебра;
2) реляционное исчисление с переменными-кортежами;
3) реляционное исчисление с переменными-доменами.
Языки запросов первого типа – алгебраические языки – позволяют выражать запросы средствами специализированных операторов, применяемых к отношениям.
Языки запросов второго и третьего типов – языки исчисления – позволяют выражать запросы путем спецификации предиката, которому должны удовлетворять требуемые кортежи или домены.
Теоретические языки служат эталоном для оценки существующих реальных языков запросов [17]. Они были предложены Коддом для представления минимальных возможностей любого разумного языка запросов для реляционной модели данных. По своей выразительности все три языка оказались эквивалентными между собой.
Третья нормальная форма
Рассмотрим другое отношение График, представленное ниже. Предположим, что это отношение имеет ключ РЕЙС ДЕНЬ и к тому же удовлетворяет функциональным зависимостям КОД-ПИЛОТА

Если выполнить операцию обновления
ИЗМЕНИТЬ (График; 112, 6 июня,
КОД-ПИЛОТА=31039, ИМЯ=Иванов),
то изменяется функциональная зависимость ИМЯ
Проблема здесь не из-за частичной зависимости непервичного атрибута, хотя решение получается то же самое.
Это отношение можно представить в виде базы данных следующим образом.
| Пилот-График | РЕЙС | ДАТА | КОД-ПИЛОТА | ||||
| 112 | 6 июня | 31174 | |||||
| 112 | 7 июня | 30046 | |||||
| 203 | 9 июня | 31174 |
| Код | КОД-ПИЛОТА | ИМЯ | |||
| 31174 | Иванов | ||||
| 30046 | Петров |
Возможность восстановления первоначального отношения сохраняется.
Перед определением третьей нормальной формы характеризуется транзитивная зависимость атрибутов.
Для данной схемы отношения









Пример 2.10. Пусть
Атрибут ИМЯ является транзитивно зависимым от РЕЙС ДАТА, так как РЕЙС ДАТА® КОД-ПИЛОТА, КОД-ПИЛОТА не определяет функционально РЕЙС ДАТА и КОД-ПИЛОТА®ИМЯ.
Схема отношения
Схема базы данных R находится в третьей нормальной форме относительно
Пример 2.11. Пусть
Схема базы данных R не находится в 3НФ относительно
Если R={(PEЙC, ДАТА, КОД-ПИЛОТА); (КОД-ПИЛОТА, ИМЯ)}, то R находится в 3НФ относительно
Следует заметить, что любая схема отношения, находящаяся в 3НФ относительно
Триггеры базы данных
Альтернативный подход заключается в предоставлении пользователям возможности создавать собственные приложения, выполняющие репликацию данных с использованием механизма триггеров базы данных.
В этом случае на пользователей возлагается ответственность за написание тех триггерных процедур, которые будут вызываться при возникновении соответствующих событий, например при создании новых записей или обновлении уже существующих. Хотя подобный подход предоставляет большую гибкость, чем механизм создания моментального снимка, ему также присущи определенные недостатки.
– Отслеживание запуска и выполнение триггерных процедур создает дополнительную нагрузку на систему.
– Триггеры выполняются при каждом изменении строки в ведущей таблице. Если ведущая таблица подвержена частым обновлениям, вызов триггерных процедур может создать существенную дополнительную нагрузку на приложения и сетевые соединения. В противоположность этому, при использовании моментальных снимков все выполненные изменения пересылаются за одну операцию.
– Триггеры не могут выполняться в соответствии с некоторым графиком. Они выполняются в тот момент, когда происходит обновление данных в ведущей таблице. Моментальные снимки могут создаваться в соответствии с установленным графиком или даже вручную. В любом случае это позволяет исключить дополнительную нагрузку от репликации данных в периоды пиковой нагрузки на систему.
– Если реплицируется несколько связанных таблиц, синхронизация их репликации может быть достигнута за счет использования механизма групповых обновлений. Решить эту задачу с помощью триггеров существенно сложнее.
– Аннулирование результатов выполнения триггер-ной процедуры в случае отмены или отката транзакции – достаточно сложная задача.
Виды репликации
Протоколы обновления реплицируемых данных, построены на допущении, что обновления всех копий данных выполняются как часть самой транзакции обновления. Другими словами, все копии реплицируемых данных обновляются одновременно с изменением исходной копии и, как правило, с помощью протокола двухфазной фиксации транзакций [7]. Такой вариант репликации называется синхронной репликацией.
Хотя этот механизм может быть просто необходим для некоторого класса систем, в которых все копии данных требуется поддерживать в абсолютно синхронном состоянии (например, в случае финансовых операций), ему свойственны определенные недостатки. В частности, транзакция не сможет быть завершена, если один из сайтов с копией реплицируемых данных окажется недоступным. Кроме того, множество сообщений, необходимых для координации процесса синхронизации данных, создают существенную дополнительную нагрузку на корпоративную сеть.
Многие коммерческие распределенные СУБД предоставляют другой механизм репликации, получивший название асинхронного. Он предусматривает обновление целевых баз данных после выполнения обновления исходной базы данных. Задержка в восстановлении согласованности данных может варьироваться от нескольких секунд до нескольких часов или даже дней. Однако рано или поздно данные во всех копиях будут приведены в синхронное состояние. Хотя такой подход нарушает принцип независимости распределенных данных, он вполне может пониматься как приемлемый компромисс между целостностью данных и их доступностью, причем последнее может быть важнее для организаций, чья деятельность допускает работу с копией данных, необязательно точно синхронизованной на текущий момент.
Вторая нормальная форма
Для данной схемы отношения

Ключи в этом определении не следует путать с выделенными ключами для
Пример 2.8.
Пусть
Атрибуты РЕЙС и ДАТА являются первичными, ПИЛОТ и ГАЛЕРЕЯ – непервичными. (Допустимо, чтобы один пилот имел два рейса в день, так что ПИЛОТ ДАТА ключом не является.)
Схема отношения
Схема базы данных R имеет вторую нормальную форму относительно
Пример 2.9. Пусть
Схема не находится в 2НФ, так как ГАЛЕРЕЯ частично зависит от РЕЙС ДАТА. Если положить R={(PEЙC, ДАТА, ПИЛОТ); (РЕЙС, ГАЛЕРЕЯ)}, тогда схема будет находиться во второй нормальной форме. РЕЙС теперь является ключом для схемы отношения (РЕЙС, ГАЛЕРЕЯ).
Предметом настоящего учебного пособия являются
Предметом настоящего учебного пособия являются информационные системы, базы данных и системы управления базами данных. Это очень важная область, определяющая характер революции в информационных системах.
Границы применения вычислительной техники в различных сферах человеческой деятельности с каждым годом определить все сложнее – они становятся необъятными. Это объясняется рядом объективных причин [2, 5, 7, 8, 17]. Так, неоспоримы успехи в областях технического и математического обеспечения ЭВМ, в развитии электроники и интегральной схемо-техники. Современные вычислительные машины и системы достигли высочайшего уровня развития.
Повсеместное применение средств вычислительной техники связано и с информационным взрывом [1, 11, 14, 15], сущность которого состоит в лавинообразном росте количества информации, которое должно воспринимать и перерабатывать человечество (экспоненциальный закон роста количества информации). Это касается всех сфер человеческой деятельности. Информация, данные все чаще рассматриваются как стратегические национальные ресурсы, которые должны быть организованы так, чтобы ценность их была максимальной.
Революционный рост объемов перерабатываемой информации и накопленный опыт использования электронно-вычислительной техники в различных областях привели в 60-70-х годах XX века к необходимости пересмотреть такую традиционную область обработки информации, как управление данными. Новый подход к обработке информации нашел наиболее яркое отражение в концепции баз данных [17]. Автоматизированные информационные системы на основе баз данных позволили обеспечить устранение излишней избыточности хранимых данных, предоставили возможности многоаспектного поиска во взаимосвязанной совокупности именованных данных. Теперь круг решаемых в информационной системе задач не ограничивается кругом задач, сформулированных при разработке, если она основана на технологии баз данных.
С начала развития вычислительной техники образовались два основных направления ее использования [2, 5, 9].
Первое направление – применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах [17]. В самом широком смысле информационная система представляет собой программный комплекс, предназначенный для надежного хранения информации, выполнения специфических для данного приложения преобразований информации и вычислений, предоставлении
пользователям удобного и легко осваиваемого (дружелюбного) интерфейса. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Классическими примерами информационных систем в гражданской сфере являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т.д.
Второе направление объективно возникло позже первого. Это связано с тем, что на заре вычислительной техники компьютеры обладали ограниченными возможностями в отношении объемов памяти. Очевидно, что указанное ограничение не очень существенно для численных расчетов. Даже если программа должна обработать большой объем информации, при программировании можно продумать расположение этой информации во внешней памяти, чтобы программа работала как можно быстрее, а алгоритм был выполнен.
С другой стороны, к информационным системам, в которых потребность в текущих данных определяется пользователями, естественными требованиями являются высокая скорость выполнения запросов и максимальный объем памяти.
С появлением магнитных дисков началась история систем управления данными во внешней памяти.
До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла операции обмена между оперативной и внешней памятью с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволял или очень затруднял поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти [6, 9].
Для обеспечения гибкости использования данных необходимо учитывать два аспекта разработки баз данных:
во-первых, данные должны быть независимы от использующих их программ, чтобы данные можно было добавлять или перестраивать без изменения программ;
во-вторых, должна быть обеспечена возможность запрашивать и отыскивать информацию в базе данных без трудоемкого написания программ на обычном языке программирования.
Таким образом, проектирование баз данных основывается на вполне определенной системе положений – четко сформулированной концепции [5].
Концепция баз данных стала определяющим фактором при создании эффективных систем автоматизированной обработки информации [5, 17]. Поэтому проектирование автоматизированных систем управления различного назначения должно включать в себя и проектирование информационных систем, основанных на технологии баз данных.
Выбор СУБД
Важным этапом жизненного цикла информационной системы и, в частности, проектирования базы данных, является выбор целевой СУБД.
Предлагаемые в разделе методы пригодны и к оценке новых продуктов, поступающих на рынок.
Основная цель при подборе СУБД – выбор системы, удовлетворяющей текущим и прогнозируемым требованиям организации при оптимальном уровне затрат.
Затраты могут включать расходы на приобретение СУБД и дополнительного аппаратного и программного обеспечения, а также расходы, связанные с переходом к новой системе и необходимостью переобучения персонала.
Сложность и комплексность проблем, возникающих при проектировании сложных систем, в том числе и информационных систем, основанных на базах данных, привели к тому, что вопросы формирования критериев для анализа и синтеза систем перестали быть только искусством, основанным на инженерной интуиции, а превратились в серьезное научное направление, важность которого возрастает с каждым днем [3].
Если раньше выбор инструментальных средств (в том числе СУБД) производился исходя из предпочтений разработчика вне зависимости от специфики предметной области и перспектив использования базы данных, то на современном этапе развития программного обеспечения, когда на рынке предлагается необозримое количество СУБД, выбор средства реализации БД становится сложной задачей. Принятие строго оптимального решения в таких условиях желательно, но затруднено.
В общем виде процесс выбора СУБД включает следующие этапы:
1) определение списка показателей; по которым будут оцениваться СУБД;
2) определение списка сравниваемых СУБД;
3) оценка продуктов по выбранным показателям;
4) принятие обоснованного решения, подготовка отчета.
Современные СУБД имеют множество основных и дополнительных функций, предоставляющих разработчику мощный инструментарий для реализации, поддержки и ведения баз данных. Какую из них выбрать в каждом конкретном случае?
Известны математические методы для решения задач оптимизации.
В частности при выборе СУБД по множеству показателей очевидно применение методов линейного или целочисленного программирования. К числу сходных задач относится, например, задача о наименьшем покрытии, а универсальный метод для решения таких задач – метод ветвей и границ. Но эти задачи относятся к классу NР-полных, а значит, сложность их решения может сравниться (или превзойти) сложную многоэтапную задачу проектирования информационной системы.
В таких условиях при выборе СУБД целесообразно использовать методы построения обобщенных критериев.
Общая постановка задачи принятия решений выглядит следующим образом [3].
А. Имеется некоторое множество альтернатив (в рассматриваемом случае – СУБД) А, причем каждая альтернатива а
характеризуется определенной совокупностью свойств a1, а2, ..., аn.
Б. Имеется совокупность критериев q = (q1, q2, ..., qi, ..., qп), отражающих количественно множество свойств системы, т.е. каждая альтернатива характеризуется вектором q(а) = [q1(а), q2(а), ..., qi(а), ..., qn(а)].
В. Необходимо принять решение о выборе одной из альтернатив (СУБД), причем решение называется простым, если выбор производится по одному критерию, и сложным, если выбранная альтернатива не является наилучшей по какому-то одному критерию, но может оказаться наиболее приемлемой для всей их совокупности.
Г. Задача принятия решения по выбору альтернативы на множестве критериев формально сводится к отысканию отображения j, которое каждому вектору q ставит в соответствие действительное число
E=j(q)=j(q1,q2,…,qn)
определяющее степень предпочтительности данного решения.
Оператор j называют интегральным (обобщенным) критерием. Интегральный критерий присваивает каждому решению по выбору альтернативы соответствующее значение эффективности Е. Это позволяет упорядочить множество решений по степени предпочтительности.
В данном разделе предлагается использовать аддитивное преобразование при построении обобщенного показателя эффективности, известное из теории полезности [3]:

Однако в этом случае значения коэффициентов bi отражают полезность (ценность) критерия qi при принятии сложного решения о выборе альтернативы. Определение их значений производится в результате предварительного опроса группы из т экспертов (специалистов в данной области). Один из возможных путей получения этих значений заключается в следующем. Каждый j-й эксперт вначале определяет набор чисел Сij, отражающих его мнение об относительной ценности i-го критерия, причем числа Сij, записаны в произвольном масштабе. Затем они масштабируются, в результате получают

Окончательные значения коэффициентов bi, вычисляются в результате осреднения значений bij (j =1, 2, ..., m), получаемых от всех экспертов. Если компетентность экспертов в группе считается одинаковой, то

Если же компетентность j-го эксперта оценивается числом


Ниже рассматриваются основные методы формирования коэффициентов Сij, отражающих мнение j-го эксперта о ценности i-го критерия. В дальнейшем предполагается, что вначале каждый эксперт провел ранжировку всех критериев, т.е. упорядочил их в соответствии с относительной ценностью так, что на первом месте находится самый главный критерий.
Выявление и разрешение конфликтов
Когда несколько сайтов могут независимо вносить изменения в реплицируемые данные, необходимо использовать некоторый механизм, позволяющий выявлять конфликтующие обновления данных и восстанавливать согласованность информации в базе. Простейший механизм обнаружения конфликтов в отдельной таблице состоит в рассылке исходным сайтом как новых, так и исходных значений измененных данных Для каждой строки, которая была обновлена с момента последней синхронизации копий. На целевом сайте сервер репликации должен сравнить с полученными эвачениями каждую строку в целевой базе данных, которая была локально изменена за данный период. Однако этот метод требует установки дополнительных Оглашении для обнаружения других типов конфликтов, например нарушения ссылочной целостности между двумя таблицами.
Было предложено несколько различных механизмов разрешения конфликтов, однако чаще всего применяются следующие [7].
– Самая ранняя или самая поздняя временная отметка. Изменяются соответственно данные с самой ранней или самой поздней временной отметкой.
– Приоритеты сайтов. Применяется обновление, поступившее с сайта с наибольшим приоритетом.
– Дополняющие и усредненные обновления. Введенные изменения обобщаются. Этот вариант разрешения конфликтов может использоваться в тех случаях, когда обновление атрибута выполняется операциями, записанными в форме отклонений.
– Минимальное или максимальное значение. Применяются обновления, соответствующие столбцу с минимальным или максимальным значением.
– По решению пользователя. АБД создает собственную процедуру разрешения конфликта. Для устранения различных типов конфликтов могут быть подготовлены различные процедуры.
– Сохранение информации для принятия решения вручную. Сведения о конфликте записываются в журнал ошибок для последующего анализа и устранения администратором базы данных вручную.
и сети. Следовательно, симбиоз этих
Наиболее перспективные направления в развитии информационных технологий – это базы данных и сети. Следовательно, симбиоз этих концепций – применение распределенных баз данных, как основы систем искусственного интеллекта (экспертных систем), перерастание баз данных в базы знаний, доступные широким массам общества, будет определять дальнейший ход революции в электронно-вычислительной технике и информационной технологии.
Учебный материал, собранный в данном учебном пособии, в целом представляет основной спектр проблем и подходов, существующих в современной организации баз данных. Особую роль в разработке структуры и содержания учебного пособия сыграли источники [5, 7, 8, 17].
Читатель, имевший терпение прочесть данное издание, несомненно, серьезно отнесется к процессу проектирования и реализации баз данных в интересующих его предметных областях. А серьезный, научно- обоснованный подход – это подход профессионала.
Целесообразно было включить в качестве приложения краткий толковый словарь по организации баз данных. Знание единой терминологии снимает проблему «языкового барьера», способствует пониманию новых идей.
Остается пожелать успехов в применении полученных знаний в полезных предметных областях.
Зависимости соединения
Многозначные зависимости представляют собой попытку выделения декомпозиций без потери информации, сохраняющих это свойство для всех отношений с заданной схемой. Однако MV-зависимости не полностью в этом смысле адекватны. Отношение может иметь нетривиальную декомпозицию без потерь на три схемы, но не обладать таким свойством для любых двух из них.
В Пример 2.18. Отношение r со схемой ABC на рис. 2.26 разлагается без потерь на схемы АВ, АС и БС (рис.2.27). Однако r не удовлетворяет никаким нетривиальным MV-зависимостям и, следовательно, не имеет декомпозиций без потери информации на пары R1, R2, такие, что R1


Для J-зависимости можно привести определение, аналогичное определению MV-зависимости [10]. Пусть r удовлетворяет зависимости *[R1,R2, ..., Rp]. Если r содержит кортежи t1, t2, ..., t , такие, что для всех i, j
ti(Ri
то r содержит кортеж t, такой, что t(Ri) = ti(Ri),1<i<p.
Жизненный цикл информационной системы
Рассмотрение вопросов проектирования эффективных баз данных целесообразно начать с обзора жизненного цикла автоматизированных информационных систем.
Типичная автоматизированная информационная система включает следующие компоненты [7].
– База данных.
– Программное обеспечение базы данных.
– Прикладное программное обеспечение.
– Аппаратное обеспечение, в том числе устройства хранения.
– Персонал, использующий и разрабатывающий систему.
База данных является фундаментальным компонентом информационной системы, а ее разработку и использование следует рассматривать с точки зрения самых широких требований организации. Таким образом, жизненный цикл ИС неотъемлемо связан с жизненным циклом лежащей в основе базы данных. I
Жизненный цикл любой сложной системы и, безусловно, ИС, основанной на базе данных, обычно состоит из нескольких этапов:
1) планирование;
2) сбор и анализ требований к системе;
3) проектирование системы (в том числе проектирование базы данных);
4) создание прототипа;
5) реализация;
6) тестирование;
7) преобразование;
8) сопровождение.
Учитывая специфику разработки приложения базы данных, можно специфицировать этапы, представленные на рис.2.1 [7]. Общепризнанным является тот факт, что указанные этапы не являются строго последовательными, а подразумевают повторы предыдущих этапов с помощью циклов обратной связи. Процесс разработки БД является итеративным, предполагает многократные возвраты и анализ полученных результатов с целью максимально адекватного описания предметной области. На рис.2.1 показаны наиболее очевидные циклы обратной связи, и их множество не является окончательным.

Рис. 2.1. Жизненный цикл информационной системы
Вкратце следует остановиться на действиях, выполняемых на каждом из указанных этапов жизненного цикла приложения базы данных.
Планирование разработки базы данных
Планирование самого эффективного способа реализации этапов жизненного цикла системы.
Определение требований в системе
Определение диапазона действия и границ приложения базы данных, состава его пользователей и областей применения.
Сбор и анализ требований пользователей
На этом этапе производится сбор и анализ требований пользователей из всех возможных областей применения БД.
Проектирование базы данных
Полный цикл разработки включает концептуальное, логическое и физическое проектирование базы данных.
Выбор целевой СУБД
Выполняется подбор наиболее подходящей СУБД для приложения базы данных.
Разработка приложений
Определение пользовательского интерфейса и прикладных программ, которые используют и обрабатывают базу данных.
Создание прототипа (необязательно) Создается рабочая модель приложения базы данных, которая дает возможность разработчикам и пользователям представить и оценить окончательный вид и способы функционирования системы.
Реализация
Создание внешнего, концептуального и внутреннего определений базы данных и прикладных программ.
Конвертирование и загрузка данных (первичное наполнение)
Преобразование и загрузка данных (и прикладных программ) из старой системы в новую.
Тестирование
Приложение базы данных тестируется с Целью обнаружения ошибок, а также его проверки на соответствие всем требованиям, выдвинутым пользователем.
Эксплуатация и сопровождение
База данных считается полностью разработанной и реализованной. Система наблюдается и поддерживается. При этом по необходимости в приложение вносятся изменения, отвечающие новым требованиям. Реализация изменений производится посредством повторного выполнения некоторых вышеперечисленных этапов.
Сложность жизненного цикла зависит от сложности рассматриваемой системы, от количества пользователей, приложений и запросов к базе данных.
В последующих разделах подробно рассматриваются проблемные вопросы проектирования баз данных.