НБФ-грамматика
Грамматикой называется формальное описание синтаксиса языка программирования.
Грамматика определяется набором правил (называемых иногда правилами подстановки), определяющих формирование из лексем достоверных программ.
Формальная грамматика использует строгую систему обозначений. Существуют различные типы грамматик. НБФ-грамматика является контекстно-свободной грамматикой. Эта грамматика использует НБФ-нотации, предложенные Джоном Бэкусом в конце 50-х годов для описания синтаксиса языка ALGOL.
Простая НБФ-нотация позволяет описывать все достоверные конструкции языка программирования, используя следующие символы:
символ ::= имеет значение "определяется как" и предшествует указанию всех допустимых значений описываемой синтаксической единицы; символ | имеет значение "или" и используется для перечисления альтернативных вариантов; пара символов < > ограничивает имя синтаксической единицы, называемой также нетерминальным символом или синтаксической категорией.
Значения, указываемые вне скобок < >, называются терминальными символами.
НБФ-грамматика состоит из набора правил (называемых иногда металингвистическими формулами или продукциями), записываемых при помощи НБФ-нотации.
Например:
<цифра>::= 0|1|2|3|4|5|6|7|8|9 <целочисленное значение> ::= цифра | цифра < целочисленное значение>
В данном примере символы 0, 1, 2, 3 и т.д. являются терминальными символами.
При построении грамматики, описывающей язык программирования, выделяется начальный нетерминальный символ, определяющий конструкцию "программа".
Существуют порождающие и распознающие грамматики. Порождающая грамматика генерирует множество цепочек терминальных символов из начального символа, а распознающая грамматика используется для построения по цепочке символов дерева грамматического разбора, ведущего к начальному символу.
Можно сказать, что грамматика состоит из множества терминальных и нетерминальных символов, начального нетерминального символа и набора правил.
В 1959 году Ноам Хомский предложил следующую классификацию грамматик:
регулярные грамматики, используемые для построения лексических анализаторов; контекстно-свободные грамматики, используемые для построения дерева грамматического разбора. К этому типу относятся НБФ-грамматики; контекстно-зависимые грамматики, представляемые набором правил типа x->y, в которых х может быть любой цепочкой нетерминальных символов, а y – цепочкой терминальных и нетерминальных символов. Этот тип грамматик намного сложнее контекстно-свободных грамматик и не имеет столь широкого применения при моделировании языков программирования; грамматики с фразовой структурой, реализуемые набором правил типа x->y, в которых х может быть любой цепочкой нетерминальных символов, а y – цепочкой терминальных и нетерминальных символов (при этом нет никаких ограничений на длину получаемых цепочек символов). Большинство таких грамматик являются неразрешимыми и не имеют практического интереса.
Процесс трансляции
Программу, написанную на языке программирования высокого уровня, называют исходной программой, а каждую самостоятельную программную единицу, образующую данную программу, - программным модулем. Для преобразования исходной программы в ее выполняемую форму (выполнимый файл) транслятор выполняет некоторую последовательность действий. Эта последовательность зависит как от языка программирования, так и от конкретной реализации самого транслятора. В ходе трансляции важно не просто откомпилировать программу, а получить при этом достаточно эффективный код.
В процессе трансляции выполняется анализ исходной программы, а затем синтез выполнимой формы данной программы. В зависимости от числа просмотров исходной программы, выполняемых компилятором, трансляторы разделяются на однопроходные, двухпроходные и трансляторы, использующие более двух проходов.
К достоинствам однопроходного компилятора можно отнести высокую скорость компиляции, а к недостаткам - получение, как правило, не самого эффективного кода.
Широкое распространение получили двухпроходные компиляторы. Они позволяют при первом проходе выполнить анализ программы и построить информационные таблицы, используемые при втором проходе для формирования объектного кода.
На рисунке 2.1 представлены основные этапы, выполняемые в процессе трансляции исходной программы.

Рис. 2.1. Основные этапы трансляции программы
Фаза анализа программы состоит из:
лексического анализа; синтаксического анализа; семантического анализа.
При анализе исходной программы транслятор последовательно просматривает текст программы, представимой как набор символов, выполняя разбор структуры программы.
На этапе лексического анализа выполняется выделение основных составляющих программы – лексем. Лексемами являются ключевые слова, идентификаторы, символы операций, комментарии, пробелы и разделители. Лексический анализатор не только выделяет лексемы, но и определяет тип каждой лексемы. При этом на этапе лексического анализа составляется таблица символов, в которой каждому идентификатору сопоставлен свой адрес.
Это позволяет при дальнейшем анализе вместо конкретного значения (строки символов) использовать его адрес в таблице символов.
Процесс выделения лексем достаточно трудоемок и требует применения сложных контекстно-зависимых алгоритмов.
На этапе синтаксического анализа выполняется разбор полученных лексем с целью получения семантически понятных синтаксических единиц, которые затем обрабатываются семантическим анализатором. Так, синтаксическими единицами выступают выражения, объявление, оператор языка программирования, вызов функции.
На этапе семантического анализа выполняется обработка синтаксических единиц и создание промежуточного кода. В зависимости от наличия или отсутствия фазы оптимизации результатом семантического анализа может быть оптимизируемый далее промежуточный код или готовый объектный модуль.
К наиболее общим задачам, решаемым семантическим анализатором, относятся:
обнаружение ошибок времени компиляции; заполнение таблицы символов, созданной на этапе лексического анализа, конкретными значениями, определяющими дополнительную информацию о каждом элементе таблицы; замена макросов их определениями; выполнение директив времени компиляции.
Макросом называется некоторый предварительно определенный код, который на этапе компиляции вставляется в программу во всех местах указания вызова данного макроса.
На фазе синтеза программы производится:
генерация кода;редактирование связей.
Процесс генерации кода состоит из преобразования промежуточного кода (или оптимизированного кода) в объектный код. При этом в зависимости от языка программирования получаемый объектный код может быть представлен в выполнимой форме или как объектный модуль, подлежащий дальнейшей обработке редактором связей.
Так, процесс генерации кода является неотъемлемой частью фазы синтеза программы, а необходимость выполнения редактора связей зависит от конкретного языка программирования. Следует учесть, что на практике термин "генерация кода" часто применяют ко всем действиям фазы синтеза программы, ведущим к получению выполнимой формы программы.
Редактор связей приводит в соответствие адреса фрагментов кода, расположенных в отдельных объектных модулях: определяются адреса вызываемых внешних функций, адреса внешних переменных, адреса функций и методов каждого модуля. Для редактирования адресов редактор связей использует специальные, создаваемые на этапе трансляции, таблицы загрузчика. После обработки объектных модулей редактором связей генерируется выполнимая форма программы.
Расширенная НБФ-нотация
При описании правил НБФ-грамматики с применением стандартной НБФ-нотации синтаксические конструкции, имеющие необязательные или альтернативные элементы, выглядят при всей их простоте достаточно громоздко. Расширенная НБФ-нотация вводит ряд дополнительных элементов, позволяющих значительно улучшить наглядность представления правил НБФ-грамматики.
Расширенная НБФ-нотация вводит следующие дополнительные элементы:
необязательные элементы указываются заключенными в квадратные скобки; альтернативные элементы, указываемые через символ вертикальной черты, также могут являться необязательными элементами, заключаемыми в квадратные скобки; последовательность нескольких однотипных элементов обозначается заключением элемента в фигурные скобки, за которыми указывается символ звездочка ({<целое>}*).

Трансляторы
Программа, написанная на языке высокого уровня, перед исполнением должна быть преобразована в программу на "машинном языке". Такой процесс называется трансляцией, или компиляцией. По типу выходных данных различают два основных вида трансляторов:
компилирующие окончательный выполнимый код;компилирующие интерпретируемый код, для выполнения которого требуется дополнительное программное обеспечение.
Окончательным выполнимым кодом являются приложения, реализованные как EXE-файлы, DLL-библиотеки, COM-компоненты. К интерпретируемому коду можно отнести байт-код JAVA-программ, выполняемый посредством виртуальной машины JVM.
Языки, формирующие окончательный выполнимый код, называются компилируемыми языками. К ним относятся языки С, C++, FORTRAN, Pascal. Языки, реализующие интерпретируемый код, называются интерпретируемыми языками. К таким языкам относятся язык Java, LISP, Perl, Prolog.
В большинстве случаев код, получаемый в результате процесса трансляции, формируется из нескольких программных модулей. Программным модулем называется определенным образом оформленный код на языке высокого уровня. Процесс трансляции в этом случае может выполняться как единое целое – компиляция и редактирование связей, или как два отдельных этапа – сначала компиляция объектных модулей, а затем вызов редактора связей, создающего окончательный код. Последний подход более удобен для разработки программ. Он реализован в трансляторах языков С и С++.
Объектный код, создаваемый компилятором, представляет собой область данных и область машинных команд, имеющих адреса, которые в дальнейшем "согласуются" редактором связи (иногда называемым загрузчиком). Редактор связи размещает в едином адресном пространстве все по отдельности откомпилированные объектные модули и статически подключаемые библиотеки.
Будем называть выполнимой формой программы код, получаемый в результате трансляции исходной программы.
Операции
При вычислении выражений учитывается приоритет операций: сначала выполняются операции с более высоким приоритетом.
Вычисление выражений, имеющих операции с одинаковым приоритетом, производится в соответствии с правилом сочетательности, которое определяет порядок выполнения таких операций. В языке С сочетательность операций применяется как слева направо, так и справа налево (как и при вычислении возведения в степень). Порядок вычисления справа налево означает, что выражение x** 2**4 трактуется как x**(2**4).
В следующей таблице приведены в убывающем порядке уровни приоритета операций языка С.
| Скобки | ( ), [ ] | слева направо |
| Индексы, вызов функций | x[i], fun() | слева направо |
| Постфиксный инкремент и декремент | ++, -- | слева направо |
| Префиксный инкремент и декремент | ++, -- | слева направо |
| Унарный минус | - | слева направо |
| Поразрядное отрицание (NOT) | ~ | слева направо |
| Размер объекта | sizeof | слева направо |
| Логическое отрицание | ! | слева направо |
| Получение адреса и разименование | &, * | справа налево |
| Явное приведение типа | (any_type) | слева направо |
| Умножение, деление, деление по модулю | *, / , % | слева направо |
| Сложение, вычитание | +, - | слева направо |
| Сдвиг влево, сдвиг вправо | <<, >> | слева направо |
| Сравнение (меньше, больше, меньше или равно, больше или равно) | <, >, <=, >= | слева направо |
| Сравнение (тождественное равенство, неравенство) | ==, != | слева направо |
| Поразрядное логическое И | & | слева направо |
| Поразрядное исключающее ИЛИ (XOR) | ^ | слева направо |
| Поразрядное логическое ИЛИ | | | слева направо |
| Логическое И (AND) | && | слева направо |
| Логическое ИЛИ (OR) | || | слева направо |
| Условная операция | ?: | справа налево |
| Операция перед присваиванием | =, +=, -=, *=, /=, %=, <<=, >>=, &=, ^=, |= | справа налево |
Операции AND, OR, NOT и XOR относятся к логическим операциям. Следующая таблица показывает результаты применения логических операций.
| 0 (false) | 0 (false) | 0 | 0 | 1 | 0 |
| 0 (false) | 1 (true) | 0 | 1 | 1 | 1 |
| 1 (true) | 0 (false) | 0 | 1 | 0 | 1 |
| 1 (true) | 1 (true) | 1 | 1 | 0 | 0 |
Единственной операцией, имеющей три операнда, является операция "условие" (называемая также условной операцией).
Условная операция имеет следующий формальный синтаксис:
(expr_log) ? expr1:expr2.
Если выражение expr_log принимает значение true, то условная операция возвращает значение expr1, а если false, то значение expr2.
Например:
// x примет значение 1, если y>z. x=(y>z)? 1:0;
Операции сдвига целочисленного значения выполняют сдвиг всех битов операнда, указанного слева, на число позиций, заданных операндом, указанным справа, а вместо сдвинутых битов записываются нули. Операции сдвига имеют следующий формальный синтаксис:
value<<count_of_position value>>count_of_position.
Например, выражение 9<<2 вычисляется следующим образом: число 9 имеет в двоичном представлении значение 001001 (118) и при сдвиге его на два разряда влево получается значение 100100 (448).
Операции инкремента и декремента соответственно увеличивают или уменьшают значение операнда на 1. Различают постфиксный и префиксный инкремент и декремент. Например, выражение x++ возвращает значение переменной х, а затем увеличивает его на 1, а выражение ++x увеличивает значение x на 1 и возвращает его.
Операция присваивания в различных языках имеет разное обозначение. Так, в языках С, C++, Java операция присваивания обозначается символом =. Например, x=y+z;. Язык С позволяет в одном операторе указывать несколько операций присваивания. Например: x1=x2=y+z;. В языках Pascal и ALGOL операция присваивания указывается символами :=. Например: x:=y+z;. В языке LISP операция присваивания обозначается функцией SETQ (например, (SETQ x (PLUS y z))).
Операторы цикла
Операторы цикла наряду с механизмом рекурсии выражают форму повторения последовательности действий.
Языки программирования, как правило, имеют несколько форм оператора цикла.
В языке С++ предусмотрено три формы оператора цикла:
for dowhile.
Цикл for выполняется заданное число раз, а проверка условия принадлежности счетчика цикла заданному диапазону производится до выполнения операторов, указанных в цикле.
Оператор do выполняется до тех пор, пока условие цикла остается истинным, а проверка условия цикла производится после выполнения операторов, указанных в цикле.
Оператор while выполняется до тех пор, пока условие цикла остается истинным, а проверка условия цикла производится до выполнения операторов, указанных в цикле.
Принято считать, что любой оператор цикла состоит из двух частей:
заголовка цикла, определяющего число выполнений цикла; тела цикла, содержащего последовательность выполняемых операторов (в большинстве случаев указываемую как один составной оператор).
Реализация операторов цикла с конечным числом повторений отличается от реализации циклов с бесконечным повторением или повторением, основанным на некоторых данных. При реализации цикла с конечным числом повторений выделяется специальная область памяти для хранения этого значения. Цикл for также может относиться как к циклам с конечным числом повторений ( for (i=1; i<50; i++){cout<<i<<endl;}), так и к циклам с бесконечным повторением (for (;;){j=i+j;}).
Операторы исключений
Некоторые языки программирования позволяют реализовывать обработку ошибок, называемых исключениями, используя операторы исключений. Код, который может инициировать исключение, заключается в специальный оператор try-catch. При этом ключевое слово catch определяет действия, выполняемые в случае возникновения определенного исключения. Исключение может инициироваться программно или оператором throw (бросок исключения). Некоторые языки программирования позволяют передавать обработку исключения вызывающему методу (так, в языке Java в сигнатуре метода можно ключевым словом throws указать список исключений, при возникновении которых управление будет возвращено вызывающей программе).
Операторы перехода
Для выхода из бесконечных циклов или подпрограмм используются операторы перехода. В языке C++ реализованы четыре оператора перехода:
break – прерывает выполнение цикла, завершая его; continue – завершает текущую итерацию выполнения цикла; return – определяет выход из функции; goto – оператор безусловного перехода на метку.
Операторы выбора
К операторам выбора относятся:
if – условный оператор; switch – переключатель.
Операторы выбора осуществляют ветвление. Оператор if в зависимости от значения выражения-условия позволяет выполнить только одну из двух указанных последовательностей операторов (в большинстве языков программирования такая последовательность операторов указывается как один составной оператор). Существуют формы оператора if, позволяющие задавать вместо второй выполняемой последовательности операторов условие (if-elseif-then- elseif-then).
Оператор switch в зависимости от значения вычисляемого выражения позволяет выполнить одну из нескольких указанных последовательностей операторов.
Например:
switch (i): { case 0: case 1: // последовательность операторов break; case 2: // последовательность операторов break; default: }
Реализация оператора if достаточно проста: как правило, процессор поддерживает команды перехода и ветвления.
Реализация оператора switch может быть выполнена в виде таблицы перехода, состоящей из команд безусловного перехода на соответствующие фрагменты кода. Вычисляемое выражение оператора switch в этом случае преобразовывается в значение сдвига по таблице перехода, определяющее выполняемую команду.
Определение последовательности действий в выражениях
Выражение состоит из операций, операндов и функций (функции можно рассматривать как особый тип операции). Операндами могут выступать переменные и константы. Операторы, определяющие операции, могут быть унарными и бинарными.
Унарный оператор действует только на один операнд, а бинарный оператор – на два операнда.
Синтаксис выражения можно представить в виде дерева: вершиной дерева является последняя выполняемая операция, узлы описывают промежуточные операции, а листья указывают данные (переменные или константы).
На рисунке 3.1 показано древовидное представление вычисления выражения (x*y)-x*(-(x**2)+(y-0.3)).
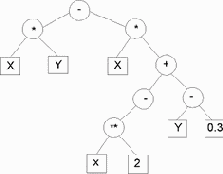
Рис. 3.1. Древовидное представление выражения
Для представления выражения в линейной форме применяются следующие формы записи:
префиксная запись; постфиксная запись; инфиксная запись.
В префиксной записи, называемой также польской префиксной записью, сначала записывается символ операции, а затем по порядку слева направо записываются операнды. Так, выражение (z+2)*(x+y) в префиксной записи будет иметь следующий вид: * + z 2 + x y. Польская префиксная запись не содержит скобок и позволяет однозначно определять порядок вычисления выражения.
Язык LISP для представления выражений использует префиксный тип записи, называемый кембриджской польской записью. Такая запись в отличие от польской записи содержит скобки, ограничивающие операнды, на которые действует операция. Таким образом, в кембриджской польской записи выражение представляет собой множество вложенных подвыражений, ограниченных скобками.
Например:
* (+ (z 2) +(x y))
В постфиксной записи, называемой также обратной польской записью или суффиксной записью, символ операции записывается после операндов. Выражение (z+2)*(x+y) в постфиксной записи будет иметь следующий вид: z 2 + x y + *.
Третьим типом записи выражений является инфиксная запись, используемая для представления выражений как в математике, так и в языках программирования. Инфиксная запись - это стандартный способ записи выражений, при котором символ операции указывается между операндами. Однако инфиксная запись не позволяет представлять унарные операции.
Наиболее простым представлением выражения с точки зрения процесса трансляции является постфиксная запись. Однако префиксная запись более удобно обеспечивает обработку функций. Кроме того, префиксная запись позволяет вычислить выражение за один просмотр транслятора, но существенным недостатком при этом является то, что для каждой операции требуется предварительно знать число обрабатываемых ею операндов (унарная, бинарная, функция).
Составные операторы
Каждая из основных форм управления последовательностью действий имеет в различных языках программирования свои, в значительной степени синтаксически схожие, операторы языка программирования.
Для создания сложных управляющих композиций иногда последовательность операторов необходимо указывать как один оператор. Для этой цели служит составной оператор. Синтаксически составной оператор может быть указан ключевыми словами begin end (язык Pascal) или фигурными скобками {} (языки C++, Java, Perl).
Структурное программирование
Первоначально все разрабатываемые универсальные языки программирования имели оператор безусловного перехода goto. В настоящее время разработчики языков большей частью придерживаются парадигмы структурного программирования (программирования без goto).
К основным достоинствам структурного программирования следует отнести:
иерархическое построение программы, включающее только три основные формы управления последовательностью действий: композиция (последовательное выполнение), ветвление (альтернативное выполнение) и повторение (циклическое выполнение); представление программы как набора блоков управляющих конструкций с одним входом и одним выходом.
Алгоритм выполнения структурированной программы может быть представлен в виде блок-схемы. Такая блок-схема может содержать три типа узлов:
функциональные узлы; узлы вычисления условия; узлы соединения ветвей.
Изображение этих узлов представлено на следующей схеме.
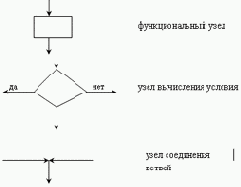
Рис. 3.2. Типы узлов и соответствующие блок-схемы
Правильная структурированная программа представляется блок-схемой, в которой существует только одна входящая и одна исходящая дуга, в любой узел можно попасть от входящей дуги и из любого узла можно попасть к выходящей дуге.
Управляющие структуры
Управление последовательностью действий в языках программирования может быть представлено некоторой управляющей структурой. Такая структура называется неявным управлением в том случае, если последовательность действий определяется естественным образом (например, выполнение программы идет с первого оператора и т.д.). Управляющая структура представляет собой явное управление в том случае, если для изменения порядка выполнения действий используются какие-либо операторы или иные синтаксические конструкции. Основными управляющими структурами принято считать:
операторы; выражения; подпрограммы.
В языках логического программирования управляющие структуры могут представляться несколько иначе. Так, в языке Prolog модель управления последовательностью действий вместо операторов использует такие категории, как факты, правила и запросы.
Определение и активация подпрограмм
Программу можно рассматривать как некоторую иерархическую структуру, состоящую из одной главной программы и множества произвольным образом вызываемых подпрограмм. Точка вызова подпрограммы является и точкой возврата из подпрограммы.
Для выполнения любого выражения транслятор преобразует его в некоторый код, который или может быть сразу аппаратно интерпретируем (машинный язык) или программно интерпретируем (использование интерпретатора).
Для выполнения подпрограммы производится ее активация, в результате чего создаются:
сегмент кода, содержащий выполняемый код и константы;сегмент данных, называемый также записью активации, содержащей локальные переменные и параметры.
Сегмент кода представляет собой неизменяемую часть, статически сохраняемую в памяти, а сегмент данных создается заново при каждом выполнении подпрограммы.
Каждая активация подпрограммы использует один единожды созданный сегмент кода.
Подпрограмма может быть реализована как процедура или функция. Процедура - это подпрограмма, выполняющая определенные действия и завершающаяся без возврата значения определенного типа.
Результатом выполнения функции всегда является возврат некоторого значения.
При выполнении программы текущая выполняемая команда идентифицируется двумя указателями:
CIP-указатель (current instruction pointer) является указателем текущей команды сегмента кода;CEP-указатель (current environment pointer) является указателем текущей записи активации. CEP-указатель иногда также называется указателем текущей среды, так как определяет среду всех объектов данных, используемых подпрограммой.
При выполнении программы интерпретатор выбирает команду по CIP-указателю, увеличивает значение этого указателя и выполняет выбранную команду. Если при выполнении команды был выполнен безусловный переход или вызов подпрограммы, то значение CIP-указателя опять изменяется. Значение переменной, используемой в подпрограмме, определяется по CEP-указателю, идентифицирующему конкретную запись активации.
Последовательный вызов подпрограмм
Запись активации для главной программы создается или перед началом выполнения программы или в процессе трансляции одновременно с формированием сегмента кода.
Перед переходом на подпрограмму текущие значения CIP- и CEP-указателей сохраняются. Выполнение программы начинается с присваивания CEP-указателю адреса записи активации, а CIP-указателю - ссылки на первую команду сегмента кода главной программы. При каждом вызове подпрограммы создается новая запись активации этой подпрограммы, и значение CEP-указателя устанавливается на эту запись активации, а значение CIP-указателя - на первую команду фрагмента кода подпрограммы.
При возврате из подпрограммы восстанавливаются сохраненные значения CIP- и CEP-указателей и удаляется запись активации.
Место сохранения значений CIP-указателя и CEP-указателя иногда называют точкой возврата. Точка возврата представляет собой системный объект, сохраняемый, как правило, в записи активации.
При последовательном вызове подпрограммы (реализуемом иногда как копирование подпрограммы) в процессе выполнения может создаваться множество записей активации подпрограммы, но в каждый отдельный момент времени хранится и используется только одна запись активации, т.е. перед созданием новой записи активации прежняя запись активации должна быть удалена.
Иногда в реализациях для достижения наибольшего быстродействия жертвуют некоторым количеством требуемой памяти: место под запись активации выделяется статически при компиляции (в фрагменте кода) и при каждом вызове происходит только повторная инициализация записи активации. В этом случае никакая подпрограмма не может одновременно иметь более одной записи активации, что значительно сужает возможности программиста. Такая модель выполнения присуща большинству трансляторов языка FORTRAN.
Для аппаратной реализации вызова подпрограммы с заранее фиксированной записью активации достаточно только CIP-указателя, сохраняемого командой перехода с возвратом.
Если место для записи активации должно выделяться динамически, то это, как правило, реализуется с помощью стека.
Стек создается в свободной области памяти. При вызове подпрограммы созданная запись активации помещается в стек. При этом значение указателя стека увеличивается с учетом размера выделяемого пространства. При удалении записи активации значение указателя стека уменьшается с учетом освобождаемого пространства. Выделение и освобождение памяти в стеке происходит с одного конца и фиксируется указателем стека.
Такая реализация позволяет создавать для одной подпрограммы несколько записей активации, которые будут последовательно заноситься в стек.
На рисунке 4.1 представлена организация памяти, используемая при выполнении программы на языке С.
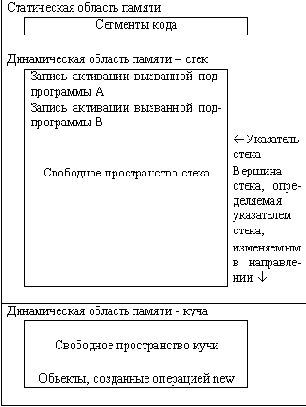
Рис. 4.1. Организация памяти, используемая при выполнении программы на языке С.
Вся память программы делится на статическую, определяемую при трансляции, и динамическую, содержание которой формируется в процессе выполнения. Стек располагается в динамической области памяти.
Также в динамической области памяти располагается куча, пространство которой используется под динамически создаваемые объекты.
Рекурсивный вызов подпрограмм
Применение стека для хранения записей активации позволяет реализовывать не только последовательный вызов подпрограмм, но и рекурсивный вызов.
Рекурсивным вызовом подпрограммы называется вызов подпрограммы из самой себя. При n вызовах подпрограммы A в стек будет последовательно добавлено n записей активации этой подпрограммы. Последний вызов подпрограммы A будет завершен первым, и его запись активации будет первой удалена из стека.
Примером использования рекурсии может служить программа вычисления факториала n! =(n*(n-1)!), 0!=1.
Пример подпрограммы на языке С:
int factoria(int n) { if (n) return n* factoria(n-1); else return 1; }
В некоторых случаях без применения рекурсии задачу решить практически невозможно. Хорошо известен пример программирования алгоритма ханойских башен. Условия задачи состоят в следующем: есть три башни, первая башня состоит из колец, диаметр которых увеличивается сверху вниз. Задача заключается в программировании алгоритма, обеспечивающего перемещение колец с первой башни на вторую по одному с возможным использованием вспомогательной третьей башни таким образом, чтобы все кольца оказались на второй башне и их диаметр увеличивается сверху вниз. Алгоритм решения этой задачи посредством рекурсии состоит в предположении, что эта задача решена для n-1 кольца. Тогда, если при n=1 решение задачи очевидно, то есть решение и для n колец.
Пример подпрограммы на языке С++, реализующей алгоритм ханойских башен:
#include "stdafx.h" #include <iostream> void tower_3(int n, int m, int k); int main(int argc, _TCHAR* argv[]) { tower_3 (3,1,3); return 0; }
void tower_3(int n, int m, int k){ /* n - число перемещаемых колец m - башня, с которой выполняется перемещение k - башня, на которую выполняется перемещение */
if (n==1) { //Последнее очевидное перемещение return ;}
tower_3(n-1,m,6-m-k); /* 6-m-k определяет номер вспомогательной башни, m - номер башни, с которой выполняется перемещение */
std::cout<<" from "<< m << " to "<< k << " n= "<<n-1<<std::endl; tower_3(n-1,6-m-k,k); /* 6-m-k- номер башни, с которой выполняется перемещение */ }
На рисунке 4.2 приведен пример выполнения алгоритма ханойских башен для трех колец (n указывает количество перекладываемых колец).
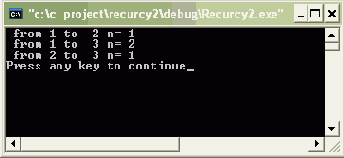
Рис. 4.2. Результат рекурсивного вызова процедуры.
Одним из первых языков программирования, допускавших рекурсию, являлся ALGOL 60. Раньше принципы реализации записей активации трансляторами языка FORTRAN не позволяли применять рекурсию, но последняя версия компилятора языка FORTRAN 90 это допускает.
Подпрограммы A и B называются взаимно рекурсивными, если подпрограмма A вызывает B, а подпрограмма B вызывает A.
Языки программирования, для которых традиционно используются однопроходные компиляторы, для реализации взаимной рекурсии должны вводить предварительное определение подпрограммы. Это объясняется тем, что при взаимно рекурсивном вызове подпрограмм A и B, в момент вызова B из A подпрограмма B должна быть уже определена, а в момент вызова A из B подпрограмма A должна быть определена. Такой механизм используется в языках Pascal и Ada.
Язык Pascal не требует указания сигнатуры функции или процедуры в том случае, если ее определение расположено в коде программы до ее вызова. В противном случае используется предварительное определение, указываемое ключевым словом forward.
На рисунке 4.3 приведен код модуля на языке Pascal (созданного в среде Delphi), иллюстрирующий предварительное объявление функции A.
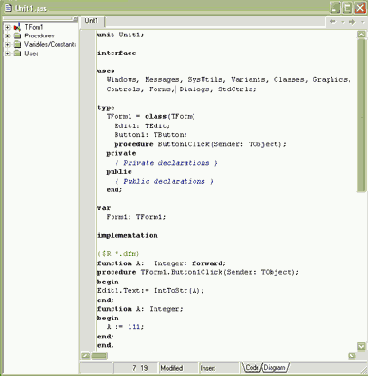
Рис. 4.3. Предварительное объявление функции.
Следует отметить, что компиляция программ, удовлетворяющих стандарту языка программирования, различными трансляторами может создавать различный выполнимый код. При этом очень часто компиляторы несколько "расширяют" диапазон возможностей, предоставляемых стандартом языка программирования. Такая ситуация будет приводить к ограничению использования "расширенного" синтаксиса программы с другими компиляторами.
Блочно-структурированные языки программирования
В блочно-структурированных языках программирования программа записывается как множество иерархически вложенных блоков определенной структуры.
Блочно-структурированные языки программирования можно подразделить на строго блочно-структурированные языки и просто блочно-структурированные языки.
В строго блочно-структурированных языках в начале каждого блока располагается область объявлений, а за ней следует фрагмент кода. Иначе говоря, в строго блочно-структурированных языках программирования не допускается объявление переменных в любом месте фрагмента кода.
К строго блочно-структурированным языкам программирования относятся языки ALGOL 60, Pascal, PL/I.
Каждый блок в блочно-структурированном языке программирования вводит новую среду локальных ссылок.
Следующий пример иллюстрирует блочную структуру программы на языке Pascal.
program Project1; procedure P1(); procedure P2(); {Вложенная процедура} var i:Integer; begin end; begin {Код процедуры P1} end; begin {Код главной программы Project1} end.
В языке Object Pascal по умолчанию приложения создаются как набор модулей, подключаемых ключевым словом uses. Следующий пример иллюстрирует блочную структуру программы на языке Object Pascal, представленную в виде одного модуля.
program Project2; {Начало программы} uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls; {$R *.res} {$R *.dfm} {Имя DFM-файла должно совпадать с именем модуля (блока). } {Для получения единого модуля на языке Object Pascal при автоматическом создании приложения в среде Delphi файл Unit1.dfm следует переименовать в Project2.dfm, а код модуля Unit1.pas перенести в модуль Project2.pas}
type {Объявление нового типа окна формы TForm1 } TForm1 = class(TForm) Button1: TButton; Button2: TButton; ListBox1: TListBox; Edit1: TEdit; procedure Button1Click(Sender: TObject); procedure Button2Click(Sender: TObject); procedure ListBox1Click(Sender: TObject); private { Private declarations } public { Public declarations } end; var {Начало области объявлений } Form1: TForm1; i: Integer; procedure TForm1.Button1Click(Sender: TObject); begin Edit1.Text:='Button1'; end; procedure TForm1.Button2Click(Sender: TObject); var i:Integer; procedure P1(); {Вложенная процедура} var i:Integer; begin i:=5; Edit1.Text:= Edit1.Text+' i= ' + IntToStr(i); end; begin Edit1.Text:='Button2'; i:=0; P1 (); end; procedure TForm1.ListBox1Click(Sender: TObject); begin Edit1.Text:='ListBox1'; end; begin {Начало выполнения программы} Application.Initialize; Application.CreateForm(TForm1, Form1); Application.Run; end.
Пример 5.1. Блочная структура программы на языке Object Pascal
На рисунке 5.1 отображен результат выполнения приведенной выше программы (сделан щелчок мышью на кнопке Button2, инициирующий выполнение процедуры TForm1.Button2Click и вложенной процедуры P1).
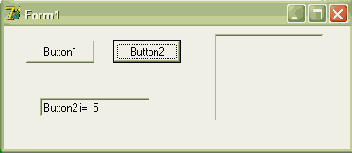
Рис. 5.1. Окно формы
К простым блочно-структурированным языкам относятся такие языки, как C и Java, позволяющие формировать область объявления переменных в любом месте блока.
Современные языки программирования, такие как C++, Java, Object Pascal, относятся к блочно-структурированным языкам программирования, и при этом программы на этих языках могут состоять из нескольких блоков (программных модулей), расположенных на верхнем уровне иерархии.
Блочная структура организации программ делает "прозрачной" для программиста статическую область видимости, определяя правила объявления идентификаторов. Так, если во вложенном блоке объявляется идентификатор с уже существующим именем, то это "перекрывает" ссылку на одноименный идентификатор во внешнем блоке (без квалификации внешнего идентификатора, когда это позволяет синтаксис языка программирования). Все идентификаторы, объявленные во вложенном блоке, недоступны во внешнем блоке.
Блок может представлять собой:
программу (например, program end.),фрагмент кода, заключенный в скобки блока (такие как begin end) подпрограмму (например, procedure begin end;).
Начало программы} uses Windows, Messages,
|
program Project2; { Начало программы} uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, StdCtrls; {$R *.res} {$R *.dfm} {Имя DFM-файла должно совпадать с именем модуля (блока). } {Для получения единого модуля на языке Object Pascal при автоматическом создании приложения в среде Delphi файл Unit1.dfm следует переименовать в Project2.dfm, а код модуля Unit1.pas перенести в модуль Project2.pas} type {Объявление нового типа окна формы TForm1 } TForm1 = class(TForm) Button1: TButton; Button2: TButton; ListBox1: TListBox; Edit1: TEdit; procedure Button1Click(Sender: TObject); procedure Button2Click(Sender: TObject); procedure ListBox1Click(Sender: TObject); private { Private declarations } public { Public declarations } end; var {Начало области объявлений } Form1: TForm1; i: Integer; procedure TForm1.Button1Click(Sender: TObject); begin Edit1.Text:='Button1'; end; procedure TForm1.Button2Click(Sender: TObject); var i:Integer; procedure P1(); {Вложенная процедура} var i:Integer; begin i:=5; Edit1.Text:= Edit1.Text+' i= ' + IntToStr(i); end; begin Edit1.Text:='Button2'; i:=0; P1 (); end; procedure TForm1.ListBox1Click(Sender: TObject); begin Edit1.Text:='ListBox1'; end; begin {Начало выполнения программы} Application.Initialize; Application.CreateForm(TForm1, Form1); Application.Run; end. |
| Пример 5.1. Блочная структура программы на языке Object Pascal |
| Закрыть окно |
program Project2; {Начало программы}
uses
Windows, Messages, SysUtils, Variants,
Classes, Graphics, Controls, Forms,
Dialogs, StdCtrls;
{$R *.res}
{$R *.dfm} {Имя DFM-файла должно совпадать
с именем модуля (блока). }
{ Для получения единого модуля на языке Object Pascal
при автоматическом создании приложения в среде Delphi
файл Unit1.dfm следует переименовать в Project2.dfm,
а код модуля Unit1.pas перенести в модуль Project2.pas}
type {Объявление нового типа окна формы TForm1 }
TForm1 = class(TForm)
Button1: TButton;
Button2: TButton;
ListBox1: TListBox;
Edit1: TEdit;
procedure Button1Click(Sender: TObject);
procedure Button2Click(Sender: TObject);
procedure ListBox1Click(Sender: TObject);
private
{ Private declarations }
public
{ Public declarations }
end;
var {Начало области объявлений }
Form1: TForm1;
i: Integer;
procedure TForm1.Button1Click(Sender: TObject);
begin
Edit1.Text:='Button1';
end;
procedure TForm1.Button2Click(Sender: TObject);
var i:Integer;
procedure P1(); {Вложенная процедура}
var i:Integer;
begin
i:=5;
Edit1.Text:= Edit1.Text+' i= ' + IntToStr(i);
end;
begin
Edit1.Text:='Button2';
i:=0;
P1 ();
end;
procedure TForm1.ListBox1Click(Sender: TObject);
begin
Edit1.Text:='ListBox1';
end;
begin {Начало выполнения программы}
Application.Initialize;
Application.CreateForm(TForm1, Form1);
Application.Run;
end.
Функции и процедуры
Как уже было сказано в предыдущей лекции, подпрограмма в большинстве языков программирования может быть реализована двумя способами: как функция и как процедура.
Если подпрограмма реализуется как функция, то она при завершении должна возвращать значение определенного типа (например, return 0;). Подпрограмма-функция может указываться в выражениях.
Подпрограмма-функция также может быть передана подпрограмме в качестве фактического параметра, например,
(procedure P1 (i: integer; function P2(j:integer):integer);).
Помимо использования глобальных переменных, некоторые языки программирования позволяют делать локальные переменные подпрограмм доступными для других подпрограмм, выполняющихся вне текущей записи активации данной подпрограммы. Это может быть реализовано как экспорт данных (externs в языке С, uses в языке Pascal), и в таком случае экспортируемая локальная переменная должна быть доступна вне записи активации. Поэтому ее, как правило, размещают в сегменте кода подпрограммы.
К способам реализации совместного использования данных относится и механизм явно организуемой общей среды. Все объекты данных, которые предполагается использовать в ряде подпрограмм, могут быть помещены в такую общую среду. Этот механизм реализуется в таких языках программирования, как С (переменные помечаются как extern), Ada (переменные указываются в пакете), FORTRAN (переменные задаются в блоке COMMON). В объектно-ориентированных языках программирования совместное использование данных может быть реализовано через модификаторы доступа переменных членов классов.
Другие языки программирования (LISP, APL) для реализации совместного использования данных применяют механизм динамической области видимости, при котором выполняется восходящий поиск ассоциации для переменной (ассоциация для нелокальной переменной подпрограммы последовательно ищется во всех средах ссылок выполняемых ранее подпрограмм).
Передача параметров
Внешние данные в подпрограмме могут использоваться, если они являются глобальными объектами для данной подпрограммы или переданы ей в качестве параметров. В описании подпрограммы указываются формальные параметры, а в точке вызова подпрограммы задаются фактические параметры. Формальный параметр определяет тип передаваемого фактического параметра. Фактический параметр представляет собой выражение соответствующего типа.
Различаются следующие способы передачи параметров: по ссылке, по имени, по значению, по значению-результату, по результату, по значению-константе. Набор допустимых способов передачи параметров зависит от конкретного языка программирования.
При передаче параметров по ссылке в записи активации, создаваемой при выполнении подпрограммы, ассоциация для фактического параметра может формироваться в нелокальной среде ссылок (в зависимости от реализации компилятора). Так, при вызове подпрограммы для параметров, передаваемых по ссылке, формируются указатели, доступные как из вызывающей, так и из вызываемой подпрограммы. Таким образом, при изменении в вызываемой подпрограмме значения фактического параметра, переданного по ссылке, в вызывающей программе объект, соответствующий фактическому параметру, также будет изменен.
При передаче параметров по имени в вызываемой подпрограмме до ее выполнения происходит замена формальных параметров на фактические. При этом значения фактических параметров вычисляются внутри вызываемой подпрограммы.
При передаче параметров по значению в вызываемой подпрограмме создается псевдоним фактического параметра (копия фактического параметра), значение которого присваивается формальному параметру подпрограммы. При таком способе передачи параметров изменения, произведенные в вызванной процедуре над значением фактического параметра, будут не видны далее в вызывающей подпрограмме.
При передаче параметров по значению-результату измененное значение фактического параметра возвращается вызывающей подпрограмме. Однако, в отличие от передачи параметров по ссылке, при данном способе сначала в момент вызова подпрограммы значение фактического параметра присваивается соответствующему формальному параметру вызываемой подпрограммы, и все изменения выполняются над формальным параметром, а не над ссылкой на фактический параметр.
При завершении вызываемой подпрограммы текущее значение формального параметра присваивается обратно фактическому параметру. Такой тип передачи параметров был применен в языке ALGOL-W.
При передаче параметров по результату текущее значение формального параметра присваивается обратно фактическому параметру при завершении вызываемой подпрограммы, но первоначальное значение фактического параметра вызываемой подпрограмме не передается. Формальный параметр подпрограммы должен быть инициирован подпрограммой (реализация может позволять инициализацию по умолчанию в соответствии с типом данных параметра).
При передаче параметров по значению-константе значение фактического параметра не может быть изменено. Такой способ передачи параметров может быть реализован и как частный случай передачи параметра по значению, и как передача параметра по ссылке на константное выражение, что однозначно гарантирует неизменность фактического параметра вызывающей подпрограммы.
В большинстве случаев языки программирования используют один или два способа передачи параметров. Так, язык программирования С позволяет только передачу параметров по значению (ссылка реализуется как значение указателя). В языке программирования Pascal допускается два способа передачи параметров: по значению и по ссылке.
В следующей таблице приведены фрагменты кода, иллюстрирующие способы передачи параметров в языках программирования С и Pascal.
| Передача параметров по значению | procedure P1(i: integer); begin i:=0; end; | // Передача значения void P1(int i) {i=0; } //Вызов подпрограммы i=10; P1(i); |
| Передача параметров по ссылке | procedure P1(var i: integer); begin i:=0; end; | // Передача указателя на значение void P1(int *i) { *i=*i+1;} //Вызов подпрограммы i=10; P1(&i); |
Управление данными
При интерпретации выполняемого выражения, содержащего данные, компилятор должен однозначно "понимать" указываемые идентификаторами операнды выражения. Так, один и тот же идентификатор может в различных частях программы использоваться для обозначения разных данных. Идентификатор может быть меткой или именем подпрограммы. В первом случае при трансляции выражения компилятор должен инициировать сообщение об ошибке компиляции. В зависимости от того, указывает ли идентификатор на переменную или на константу компилятор также должен предпринимать различные действия.
Имя в программе может быть простым или составным. К простым именам относятся имена переменных, имена подпрограмм, имена пользовательских типов данных. Составное имя ссылается на элемент некоторой структуры и записывается как простое имя и следующие за ним операции квалификации или индексации имени. Например, выражение array1[3] ссылается на третий элемент массива, а выражение record1.field2 ссылается на значение поля field2 структуры record1.
Для управления данными конкретные идентификаторы подпрограммы должны быть сопоставлены конкретным объектам данных. Такое сопоставление иногда называется ассоциацией. В момент создания записи активации устанавливается множество ассоциаций, сопоставляющих идентификаторы с текущими объектами данных. Такое множество ассоциаций определяет среду ссылок подпрограммы.
Среда ссылок подпрограммы включает среду глобальных ссылок, среду локальных ссылок, среду нелокальных ссылок и среду предопределенных ссылок.
Среда локальных ссылок образуется локальными переменными, формальными параметрами, а также подпрограммами, определенными внутри текущей подпрограммы.
Среда глобальных ссылок формируется ассоциациями, которые созданы при активации главной программы. Среда нелокальных ссылок содержит как среду глобальных ссылок, так и множество ассоциаций, сформированных для доступных далее в программе, но еще не созданных переменных.
Область видимости ассоциации в подпрограмме определяется включением этой ассоциации в среду ссылок подпрограммы.
При этом если имело место переопределение глобального идентификатора локальным идентификатором, то ассоциация для глобального идентификатора исключаются из среды глобальных ссылок подпрограммы.
Динамическая область видимости каждой ассоциации определяется совокупностью записей активации подпрограмм, включающих данную ассоциацию в среду ссылок подпрограммы.
На один и тот же объект данных можно ссылаться посредством различных имен - например, если в подпрограмме доступен идентификатор глобальной переменной и эта же переменная передается по ссылке как формальный параметр подпрограммы. Различные идентификаторы, существующие в среде ссылок для ассоциации с одним и тем же объектом данных, иногда называются псевдонимами.
Использование псевдонимов может приводить к различным ошибочным ситуациям. К тому же, наличие в подпрограмме псевдонимов осложняет процесс оптимизации кода, выполняемый компилятором. Например, если при выполнении последовательности двух операторов
int1=5*x; int2=8*y;
значение переменной int1 нигде в программе не используется, то при оптимизации программы первый оператор может быть упразднен. Но если переменная int1 является псевдонимом переменной y, то такая оптимизация приведет к ошибке вычисления, и, следовательно, потребуются дополнительные проверки.
Под статической областью видимости понимается фрагмент кода программы, в котором идентификатор ссылается на конкретный объект.
Статическая область видимости определяет объект, на который ссылается идентификатор в коде программы, а динамическая область видимости формируется ассоциациями, созданными во время выполнения программы.
Константы в языке Object Pascal
Объявление переменных выполняется в секции, начинающейся с ключевого слова var. Ключевое слово const предназначено для объявления констант.
Константами могут быть простые значения или значения типа записи, массива, функции и указателя.
При объявлении константного указателя его сразу необходимо инициализировать.
Инициализация константного указателя может быть выполнена тремя способами:
определением адреса глобальной переменной с использованием оператора @;указанием адреса равного nil;заданием значения константы типа PChar или PWideChar.
Например:
const PI: ^Integer = @i1; { i1 - переменная типа Integer} const StrNew: PChar = 'NewConst'; const PFunc: Pointer = @MyFunc;
Объявление объектов данных
Перед использованием в программе любой объект данных должен быть объявлен. Однако некоторые языки допускают неявное объявление. Так, в языке FORTRAN компилятор определяет тип используемой, но предварительно не объявленной переменной по первому символу имени, а в языке Perl неявное объявление переменной происходит при присваивании ей начального значения. Некоторые языки выполняют неявное объявление переменных, используемых в качестве счетчиков циклов.
Оператор объявления сообщает компилятору информацию об идентификаторах и типах данных, назначаемых объектам данных, и о предполагаемом времени жизни этих объектов (глобальная или локальная переменная, переменная - член класса, статическая переменная и т.п.).
При объявлении объекта данных в зависимости от типа этого объекта и языка программирования возможно выделение памяти под этот объект при объявлении или при последующем создании этого объекта.
В языке C++ для объявления новых имен в текущей области видимости предназначаются операторы объявления.
Например: int i, j; float m, n;
Оператор объявления в языке C++ может указываться в любом допустимом месте программы.
В языке C++ каждый оператор объявления завершается символом конца оператора (точка с запятой). В операторе объявления может объявляться несколько объектов данных одного типа, перечисляемых через запятую. Любой оператор объявления начинается с ключевого слова или идентификатора, указывающего тип объявляемого объекта.
Объявляемыми объектами данных могут быть названия типов и имена объектов.
Объявление определяет имя внутри области видимости. Имя, объявляемое внутри блока, класса, функции или пространства имен, является локальным. Блок в языке C++ заключается в фигурные скобки. Если вне блока существуют глобальные имена, обозначаемые теми же идентификаторами, то они становятся скрыты внутри блока и к ним следует обращаться, используя оператор разрешения области видимости ::.
Например:
int i1; // Объявление глобальной // переменной void metod1() { int i1; // Объявление локальной // переменной i1=22; // Доступ к локальной // переменной метода ::i1=44; // Доступ к глобальной // переменной { int i1; // Объявление локальной // переменной i1=33; // Доступ к локальной // переменной блока } i1=44; // Доступ к глобальной // переменной }
В языке C++ объявления применяются для создания нового имени, используемого в приложении (имя может указывать не только объект данных). Объявления позволяют:
специфицировать класс памяти, тип и область действия объекта;инициализировать объект начальным значением;назначать имена константе (при объявлении перечислимого типа);объявлять новый тип (class, struct и union);определять синоним существующего типа (typedef);специфицировать шаблон классов или функций (template);специфицировать пространство имен (namespace);специфицировать класс памяти, тип и область действия подпрограммы.
Отметим, что термин объявление означает только указание, каким образом объявляемое имя будет интерпретироваться компилятором.
В языке C++ при каждом объявлении локального объекта под него выделяется память.
Например:
// Объявление и инициализация // локального объекта в цикле
do { char char1 = _getch(); if( char1 == NULL ) continue; return (char1); } while( 1 );
Удаление объекта, который был объявлен в цикле, происходит после каждой итерации, при выходе из блока или при передаче управления в точку, расположенную выше объявления этого объекта.
Процедура удаления объекта в языке C++ может включать не только удаление объекта из памяти (освобождение памяти), но и выполнение деструкторов (для объектов типа класса).
В языке Java объявления переменной могут указываться в любом допустимом месте программы.
Например:
boolean b1=true; // Оператор присваивания // задается символом = char c1='N'; int int1=123;
Имена могут иметь следующие элементы языка Java:
пакет, определяемый оператором package;тип, вводимый определением класса или интерфейса;поле, являющееся переменной типа класса или типа интерфейса; группа методов типа класса или типа интерфейса;переменная, являющаяся формальным параметром метода;переменная, являющаяся локальной переменной блока;метка оператора.
Если имя или выражение означает переменную или значение простого типа, тогда тип этой переменной или значения называется типом имени или выражения.
В языке Object Pascal оператор объявления может указываться только в области объявлений, определяемой ключевым словом var.
Например:
var ch1: Char; {Оператор объявления в языке Object Pascal} begin ch1 := Chr(65); { Оператор присваивания задается символами :=} end;
Переменные и константы
Будем называть объектом данных один или несколько однотипных элементов данных, рассматриваемых программой как одно простое или составное целое.
Объекту данных присущи такие атрибуты, как тип, адрес памяти, присвоенное значение, имя.
Переменные и константы - это объекты данных. При создании переменной или константы им назначается имя, называемое иногда идентификатором. В отличие от переменной, атрибут "значение" объекта данных "константа" не может быть изменен в процессе выполнения программы.
Представление целых и вещественных типов данных
Представление целочисленных и вещественных значений в памяти компьютера в большинстве случаев реализуется аппаратным способом с учетом возможностей конкретного процессора. Также аппаратно реализуется примитивный набор операций над этими значениями. Применение операций, реализуемых аппаратно, значительно более эффективно, чем использование программно реализуемых операций. Поэтому компиляторы по возможности формируют код, в котором применяется аппаратная реализация примитивных операций (таких, как сложение, вычитание, умножение и деление).
Целочисленное значение типа integer, записанное как "signed 32-bit", может иметь в памяти компьютера следующее представление:
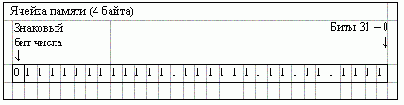
Рис. 6.1. Битовая структура типа integer
Целочисленное значение типа shortint, записанное как " signed 8-bit ", может иметь в памяти компьютера следующее представление:
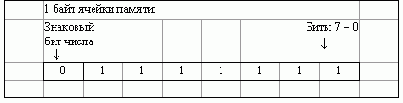
Рис. 6.2. Битовая структура типа shortint
Максимально допустимое значение, которое можно записать в 7 бит - это восьмеричное число 177, которое в десятичном исчислении равно 127 (1778=1*82+7*81+7*80=12710).
Таким образом, диапазон допустимых значений для каждого целочисленного типа данных определяется как стандартом языка, так и возможностями аппаратуры.
В некоторых языках программирования представление целочисленного значения включает еще и хранение дескриптора этого значения. При этом дескриптор может храниться как в одной ячейке со значением, так и в различных ячейках. В первом случае наличие дескриптора значительно уменьшает диапазон допустимых значений, а также, как правило, замедляет процесс выполнения арифметических операций (операции над частью ячейки памяти не поддерживаются аппаратно).
При хранении дескриптора и значения в разных ячейках (этот способ представления используется для языка LISP) одновременно с дескриптором хранится и указатель физического расположения значения.
Вещественные типы аппаратно могут иметь два представления: вещественные числа с фиксированной точкой и вещественные числа с плавающей точкой. Как правило, по умолчанию компиляторы преобразуют вещественные значения в экспоненциальный формат (формат с плавающей точкой), если синтаксис языка явно не указывает применение формата с фиксированной точкой.
Вещественное значение с плавающей точкой может иметь в памяти компьютера следующее представление:
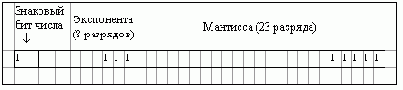
Рис. 6.3. Битовая структура типа float
Для представления вещественных чисел с плавающей точкой и вещественных чисел двойной точности с плавающей точкой стандартом IEEE 754 определены 32- и 64-битовые представления соответственно.
В разряды мантиссы записываются значащие цифры, а в разряды экспоненты заносится показатель степени. Положительные значения содержат в знаковом бите числа - 0, а отрицательные значения - 1.
При обозначении чисел с плавающей точкой приняты следующие соглашения: знаковый разряд обозначается буквой s, экспонента - e, а мантисса - m.
В языке Java значения с плавающей точкой могут объявляться следующими базовыми типами:
float диапазон значений от +3.40282347E+28 до +1.40239846E-45 (32 бита)double диапазон значений от +1.79769313486231579E+308 до +4.9406545841246544E-324 (64 бита).
Полной ненулевой формой значения типа float является форма s·m·2e, где s это +1 или -1 (знаковый бит числа), m является положительным значением, меньшим, чем 224 (мантисса), и e является целым в пределах от -149 до 104 включительно (экспонента).
Полной ненулевой формой значения типа double является форма s·m·2e, где s это +1 или -1, m является положительным значением, меньшим, чем 253, и e является целым в пределах от -1045 до 1000 включительно.
Положительным нулевым значением и отрицательным нулевым значением являются 0.0 и -0.0 (0.0 == -0.0 дает в результате true), но некоторые операторы различают эти "эквивалентные" значения, например, 1.0/0.0 равно положительной бесконечности, а 1.01/-0.0 - отрицательной бесконечности.
В языке Java приняты следующие правила приведения вещественных типов:
любые значения любого типа с плавающей точкой могут быть приведены к любому другому значению числового типа;любые значения любого типа с плавающей точкой могут быть приведены к значению типа char и наоборот;приведение невозможно между значениями типа boolean и значениями с плавающей точкой.
Если оба операнда имеют тип float, или один имеет тип float, а другой - целый тип, то результат будет иметь тип float.
Если же хотя бы один из операндов имеет тип double (устанавливаемый по умолчанию), то другой операнд также приводится к типу double и результат будет иметь тип double.
Операции со значениями с плавающей точкой не выдают исключений.
При вычислениях значений с плавающей точкой следует учитывать правила округления. Так например, для значений с плавающей точкой выражение1.0*10 не равно значению 10. Это иллюстрирует следующий пример на языке Java:
public class MyFloatSumma { public static void main(String[] args) { float f1 = (float) 1.0; // Число с плавающей точкой float fSum = 0; // Переменная для записи результата final static float myDeltaFloat = (float) 0.00001; // Дельта для "усечения" // мусора мантиссы
// Способ вычисления - простое // суммирование и сравнение for (byte i=0; i<10; i++) fSum = fSum + (float) 0.1; // Цикл от 0 до 10
if (f1 == fSum) // Сравнение (float) 1.0 и // полученной суммы System.out.println("Числа равны"); else System.out.println("Числа различны"); // Правильный способ вычисления - // с "усечением" мусора мантиссы fSum = 0; for (byte i=0; i<10; i++) fSum = fSum + (float) 0.1; if (Math.abs(fSum - f2) < myDeltaFloat) System.out. println("Числа одинаковы"); else System.out. println("Числа различны"); } }
Преобразование типов в языке C++
Язык C++ позволяет выполнять преобразование значения одного типа в значение другого типа. Преобразование типа может быть явным и неявным. Явное преобразование называется приведением типов.
Для явного приведения типов можно использовать две формы записи:
без указания дополнительной информации для преобразования типа (перед преобразуемой переменной в скобках указывается имя типа, к которому она приводится).
Например:
std::cout <<"strlen="<<(long)strlen(pArr1);
с указанием дополнительной информации для преобразования типа (используются операторы static_cast, dynamic_cast, reinterpret_cast и const_cast).
Например:
std::cout <<"strlen="<<static_cast<long>( strlen(pArr2));
Вторая форма явного преобразования типов более предпочтительна, поскольку несет в себе дополнительную информацию, позволяющую сократить число возможных ошибок.
Дополнительная информация о приводимом типе может быть указана следующими операторами:
static_cast - выполняет преобразование родственных типов;const_cast - выполняет приведение константных выражений;dynamic_cast - используется для динамического преобразования типа, реализуемого на этапе выполнения;reinterpret_cast - выполняет преобразование не связанных между собой типов.
Преобразование типов выполняется для значений переменных при вычислении выражений и оказывает влияние на тип результата. Преобразование типов не изменяет типа самих переменных, участвующих в выражении.
Типы данных
Тип данных назначается объекту данных при его объявлении и определяет: значения, которые может принимать объект данного типа; операции, которые используются для манипуляции над объектами заданного типа.
Современные языки программирования, как правило, могут иметь набор простых типов, являющихся встроенными в данный язык программирования, и средства для создания производных типов.
Объектно-ориентированные языки программирования позволяют определять типы класса.
Реализация простых типов данных заключается в способе представления значений данного типа в компьютере и в наборе операций, поддерживаемых для данного типа.
Типы данных языка C++
Тип данных определяет размер памяти, выделяемой под переменную данного типа при ее создании.
C++ поддерживает следующие типы данных:
базовые типы. Базовые типы указываются зарезервированными ключевыми словами, и их не надо определять.производные типы. Переменные этих типов создаются как с использованием базовых типов, так и типов классов. Это структуры, объединения, указатели, массивы.типы класса. Экземпляры этих типов называются объектами.
Базовые типы языка C++ можно подразделить на две группы: целочисленные и вещественные. Существует еще ключевое слово void, которое используется для описания типа подпрограмм, не имеющих возвращаемого значения, или при указании параметров подпрограмм неизвестного типа.
|
char signed char |
Символьный тип. Диапазон значений от -128 до 127. Содержит один символ или строку символов. Каждый символ представляется одним байтом. Компилятор различает как отдельные следующие типы: char, signed char и unsigned char. | ||
| unsigned char |
Символьный тип. Диапазон значений от 0 до 255. Каждый символ представляется одним байтом (значение в диапазоне от 0 до 255). | ||
|
short signed short |
Целый тип. Диапазон значений от -32768 до 32767. Сокращенное обозначение типа short int. Длина этого типа вне зависимости от используемого компилятора всегда больше или равна длине значения типа char и меньше или равна длине значения типа int. | ||
| unsigned short | Беззнаковый целый тип. Диапазон значений от 0 до 65535. | ||
|
int signed int |
Целый тип. Диапазон значений от -2147483648 до 2147483647. Длина этого типа вне зависимости от используемого компилятора всегда больше или равна длине значения типа short int. В общем случае размер типа int языка C++ зависит от конкретной реализации. | ||
| unsigned int | Беззнаковый целый тип. Диапазон значений от 0 до 4294967295. | ||
| __intn | Целый тип, размер в битах которого определяется значением n, и может быть равным 8, 16, 32 или 64 битам. | ||
|
long signed long |
Целый тип. Диапазон значений от -2147483648 до 2147483647. Сокращенное обозначение типа long int. | ||
| unsigned long | Беззнаковый целый тип. Диапазон значений от 0 до 4294967259 | ||
| float | Тип данных с плавающей точкой. Диапазон значений от 3.4Е-38 до 3.4Е+38. | ||
| double |
Тип данных с плавающей точкой двойной точности. Диапазон значений от 1.7Е-308 до 1.7Е+308. Длина типа double вне зависимости от используемого компилятора всегда больше или равна длине типа float и короче или равна длине типа long double. | ||
| long double |
Тип данных с плавающей точкой двойной точности, длина которого равна длине значений типа double. Типы double и long double имеют одинаковое представление, но компилятор трактует их как различные типы. |
Размер памяти, выделяемой под каждый тип данных языка C\C++, в некотором смысле зависит от используемой платформы и компилятора. Однако все компиляторы гарантируют, что для типа short памяти всегда выделяется меньше или столько же, сколько и для типа int, а тип long всегда "длиннее" или равен типу int.
Символьные типы char и unsigned char представляют значение символа, реализуемое одним байтом. Для использования символов в кодировке Unicode язык C++ предоставляет тип wchar_t, в котором под каждый символ отводятся два байта.
Ключевое слово typedef языка C++ позволяет объявить новое имя существующего типа.
Например:
typedef int my_integer; my_integer i1=0;
Создание псевдонима для типа значительно облегчает процесс изменения типа переменных в уже отлаженном коде.
Символьным литералом или символьной константой называется символ, заключенный в одинарные кавычки. Целые литералы представляют целочисленные константы в десятичном, восьмеричном или шестнадцатеричном виде.
Восьмеричные литералы начинаются с символа 0, а шестнадцатеричные - с символов 0x.
После литерала может быть указан суффикс, определяющий его тип: U - unsigned int, L - long int.
Например:
00 // Восьмеричное значение, равное 0 oxffff // Шестнадцатеричное значение, // равное 65535 10L // Значение типа long int
При записи шестнадцатеричных литералов каждый знак может принимать значение от 0 до 15. Для записи значений от 10 до 15 принято использовать следующие символы: a - 10, b - 11, c - 12, d - 13, e - 14 и f - 15.
Литералы с плавающей точкой могут записываться в двух формах: вещественной и экспоненциальной.
Например:
1.53 32.24e-12 // Экспоненциальная форма записи литерала
Литералы с плавающей точкой могут использоваться для инициализации значений переменных вещественного типа (float, double или long double).
Типы данных языка Java
Java - это язык со строгой типизацией. Это означает, что типы данных должны быть определены уже на этапе компиляции.
Все типы данных в Java можно подразделить на две группы:
простые типы;ссылочные типы.
Язык Java позволяет использовать следующие простые типы:
числовые типы
целые типы:
byte (8-битовое значение) диапазон значений от -128 до 127short (16-битовое значение) диапазон значений от -32768 до 32767.int (32-битовое значение) диапазон значений от -2147483648 до 2147483647long (64-битовое значение) диапазон значений от -9223372036854775808 до 9223372036854775807
типы значений с плавающей точкой:
float (32-битовое значение)double (64- битовое значение)
символьный тип
char (16-битовое значение Unicode)
логический тип
boolean (значение true или false)
Например:
// Объявление переменных boolean b1=true; float fN1=74.3F; float fN2=(float)(fN1+2); double dN1=14573.74; double dN2= 81.2E-2;
Значение одного целого типа может быть приведено к значению другого целого типа.
Приведение целых типов к логическому и обратно выполнять нельзя.
Язык Java предусматривает для целочисленных значений следующие операторы:
операторы сравнения = равно!= не равно
операторы отношения < меньше<= меньше или равно> больше>= больше или равно
унарные операторы + положительное значение- отрицательное значение
бинарные операторы + и += сложение (x=x+y эквивалентно записи x+=y)- и -= вычитание (x=x-y эквивалентно записи x-=y)* и *= умножение (x=x*y эквивалентно записи x*=y)/ и /= деление (x=x/y эквивалентно записи x/=y)% и %= остаток от деления
префиксный и постфиксный оператор приращения и декремента ++ приращение (увеличение значения на 1 до вычисления выражения (++x) или после (x++))-- декремент
операторы сдвига << сдвиг влево>> сдвиг вправо с распространением знака>>> сдвиг вправо без учета знака (слева происходит заполнение нулями)
унарный логический оператор ~ отрицание (побитовое дополнение)
бинарные логические операторы & логическое И (AND)| логическое ИЛИ (OR)^ логическое исключающее ИЛИ (XOR)
Если оба операнда имеют целочисленный тип, то операция рассматривается как целочисленная. Если один из операндов имеет тип long, то операция выполняется с использованием 64-битового представления: при этом любой другой операнд будет расширен до типа long и результат будет также иметь тип long. В противном случае операции выполняются, используя 32-битовое представление (любой операнд, не являющийся int, первоначально расширяется до типа int) и результат будет иметь тип int.
Логические значения представляются одним битом и обозначаются константами true и false
В языке Java нельзя прямо выполнить приведение типа int к типу boolean, но можно конвертировать значение int, используя следующий синтаксис языка: int x != 0, где любое не нулевое значение x даст в результате true, а нулевое значение даст false. Для преобразования значения типа boolean в целое следует выполнить условный оператор: bool x ? 1:0.
Для логических значений в языке Java предусмотрены следующие операторы:
== и !=!, &, |, и ^&& и ||.
Типы данных языка Object Pascal
Все переменные и константы, используемые в программе, всегда принадлежат какому-либо типу. Вызов функции также возвращает значение определенного типа.
Типы данных языка Object Pascal можно разбить на следующие группы:
базовые типы данных: целочисленный тип;действительный тип;логический тип;символьный тип;строковый тип;
производные типы данных;простые типы данных: порядковый тип;перечислимый тип;
структурированные типы данных: множества;массивы;записи;файлы;объектный тип (тип класса);тип ссылки на класс;
указатели;процедурный тип данных.
В язык Object Pascal включены следующие базовые типы данных:
Целочисленные типы
| Integer | -2147483648..2147483647 | signed 32-bit |
| Cardinal | 0..4294967295 | unsigned 32-bit |
| Shortint | -128..127 | signed 8-bit |
| Smallint | -32768..32767 | signed 16-bit |
| Longint | -2147483648..2147483647 | signed 32-bit |
| Int64 | -263..263-1 | signed 64-bit |
| Byte | 0..255 | unsigned 8-bit |
| Word | 0..65535 | unsigned 16-bit |
| Longword | 0..4294967295 | unsigned 32-bit |
Действительные типы
| Real | 5.0 * 10-324 .. 1.7 * 10308 | 8 |
| Real48 | 2.9 * 10-39 .. 1.7 * 1038 | 6 |
| Single | 1.5 * 10-45 .. 3.4 * 1038 | 4 |
| Double | 5.0 * 10-324 .. 1.7 * 10308 | 8 |
| Extended | 3.6 * 10-4951 .. 1.1 * 104932 | 10 |
| Comp | -263+1 .. 263 -1 | 8 |
| Currency | -922337203685477.5808.. 922337203685477.5807 | 8 |
Для указания значения действительного типа можно использовать экспоненциальный формат (например, значение 1.3Е-5 эквивалентно 1.3*10-5).
Логические типы
| Boolean | True или False | 1 |
| ByteBool | True или False | 1 |
| WordBool | True или False | 2 |
| LongBool | True или False | 4 |
Символьные типы
| Char | ANSI-символ | 1 |
| AnsiChar | ANSI-символ | 1 |
| WideChar | Unicode-символ | 2 |
Строковые типы
| string | Определяется директивой компилятора $H | |
| ShortString | 255 символов | От 2 до 256 байт |
| AnsiString (длинная строка) | ~231 символов | От 4 байт до 2 Гбайт |
| WideString (Символы Unicode) | ~230 символов | От 4 байт до 2 Гбайт |
Для строковых переменных выполняются следующие правила:
строки могут быть постоянной или переменной длины: при объявлении строки можно указать только идентификатор или идентификатор и в квадратных скобках длину строки;значение строки указывается в одинарных кавычках или как последовательность ASCII-символов, перед каждым из которых ставится знак #;доступ к символу строки можно выполнять по индексу, указываемому в квадратных скобках (например, MyString[7] := 'n';).
Например:
var S1: string; {Объявление строковой переменной произвольной длины} S2: string[2]; {Объявление строковой переменной длиной 2 символа}
Строки типа AnsiString также называют длинными строками (long string), представляющими динамически размещаемые строки, длина которых ограничена только доступной памятью. Такие строки используют 1-байтовое представление ANSI-символов.
Реально переменная типа AnsiString является указателем, состоящим из 4 байт. Если строка пустая (ее длина равна 0), то указатель равен nil и для хранения строки никакой памяти не выделяется. Если строка не является пустой, то данная переменная указывает на динамически размещаемый блок памяти, содержащий значение строки, на 32-битовое значение длины строки и на 32 битовое значение счетчика ссылок на строку.
Несколько идентификаторов строк могут ссылаться на одну строку. При этом им не будет выделяться дополнительная память, а только будет выполняться увеличение счетчика ссылок.
Элементы массива
Доступ к элементам массива может выполняться:
по указателю на массив и индексу элемента, задаваемого в квадратных скобках: первый элемент массива имеет индекс 0;по указателю на элемент массива.
Для получения адреса элемента массива применяется оператор &.
Имя массива является адресом массива и эквивалентно следующему выражению: &имя_массива[0].
Для определения размерности массива в байтах можно использовать функцию sizeof(имя_массива).
Например:
arrayOfInteger[0]=1; // Присваивание значения // первому элементу массива iInt1=arrayOfInteger[1]=13; // Групповое присваивание iInt2=&arrayOfInteger[4]; // Получение адреса пятого // элемента массива
Константные указатели
Значение указателя на константу можно изменять, а значение константного указателя является константой и не подлежит изменению.
Например:
char str1[]="123"; const char* pstr1= str1; // pstr1 можно изменять, // а *pstr1 - нельзя.
Задание ключевого слова const перед объявлением указателя создает этот указатель как указатель на константу (при этом само значение, доступное не через данный указатель, остается изменяемым).
Для того чтобы создать константный указатель, вместо оператора * используется *const.
Например:
const char *const pstr1= str1;
Объявление массивов
Массив переменных или объектов состоит из определенного числа однотипных данных, называемых элементами массива. Все элементы массива индексируются последовательно, начиная с нуля.
Размещение элементов массива в памяти выполняется последовательно.
Количество элементов в массиве определяет размер массива и является константным выражением. Для создания динамических массивов стандартная библиотека C++ предусматривает тип vector.
Имя массива определяет адрес первого элемента массива.
Имя массива в отличие от имени вектора нельзя указывать в левой части оператора присваивания.
Объявление массива может иметь следующее формальное описание:
// Объявление одномерного массива тип имя_массива[размерность_N]; // Объявление одномерного массива с // одновременной инициализацией тип имя_массива[размерность_N]= {значение0, значение1, ..., значение_N-1}; // Объявление безразмерного массива с // одновременной инициализацией: // размерность определяется количеством // значений, указанных в списке инициализации тип имя_массива[]={значение0, значение1, ..., значение_N-1}; // Объявление многомерного массива тип имя_массива[размерность_1N]... [размерность_MN]; // Объявление многомерного массива с // одновременной инициализацией тип имя_массива [размерность_N]... [размерность_M] = { {значение0, значение1, ..., значение_M-1}, ... {значение0N, значение1N, ..., значение_NM-1}};
Размерность массива может:
указываться любым константным выражением целого типа;автоматически определяться компилятором по списку значений инициализации массива (если размерность не указана явно).
Например:
int arrayOfInteger[17]; // Массив из 17 переменных типа int char arrayOfChar_3[3]={'L','M','N'}; // Объявление и инициализация // символьного массива char arrayOfChar_0[]={"Array of char. \n"}; int arrayOfInteger_6[2][3]= { {1,2,3}, {11,12,13}}; // Объявление и инициализация // двумерного массива
Если ни размерность массива, ни список значений инициализации не указаны, то будет создан массив нулевой длины.
Объявление многомерных массивов выполняется по следующим правилам:
список значений инициализации можно указывать как в единых фигурных скобках, так и в общих фигурных скобках, включающих через запятую списки по каждому левому индексу в отдельных фигурных скобках;при использовании общих фигурных скобок сначала следует указывать значения для неизменяемого самого левого индекса;можно не указывать только самую левую размерность массива, получая ее значение из списка значений инициализации.
Инициализацию массива можно выполнить одним из следующих способов:
указать во время объявления массива в фигурных скобках значения инициализации (начиная с нулевого элемента и первого столбца);присвоить значение элементам массива во время выполнения программы;объявить массив как глобальный или статический, инициализируемый по умолчанию (для числовых значений выполняется инициализация нулями, а для указателей - значением null). Глобальный массив объявляется вне всех функций, а статический массив объявляется с модификатором static.
Если количество значений инициализации больше, чем объявленная размерность массива, то компилятор Visual C++ инициирует ошибку.
Если количество значений инициализации меньше, чем объявленная размерность массива, то оставшиеся значения автоматически инициализируются нулями.
Преобразование типа указателя
Преобразование типа указателя происходит при различных операциях, таких как вызов процедуры, присваивание, инициализация и т.п.
Указатель типа void может быть преобразован к указателю любого другого типа только явным приведением типа. Но указатель любого типа может быть неявно преобразован к указателю типа void.
Это применяется для передачи параметров функции, если тип формального параметра не очевиден (он может быть указателем типа int * или типа float *). В этом случае в прототипе функции вместо явного задания типа записывается тип void.
Например:
Fx(void *px); // Прототип функции Fx(pi); // Вызов функции для int * pi Fx(pf); // Вызов функции для float * pf
В теле функции для работы с указателем следует использовать явное преобразование типа.
Например: (int *)px.
Производные типы
Производные типы можно условно подразделить на две группы:
Непосредственно производные типы. Эти типы являются производными от некоторых существующих типов, реализуя типы указателей, ссылки, функции преобразования типов. В группу непосредственно производных типов входят: массивыуказателиссылкиперечисленияуказатели на члены класса.
Составные производные типы. В группу составных производных типов входят: классы структурыобъединения
Размещение массива в памяти
При создании массива память под все его элементы выделяется последовательно для каждого элемента в зависимости от типа массива. Для многомерных массивов в первую очередь изменяются значения самого правого индекса.
Например, для массива char aCh[2][4] будет выделено восемь байтов памяти, в которых в следующем порядке будут размещены элементы массива:
| aCh[0][0] | aCh[0][1] | aCh[0][2] | aCh[0][3] | aCh[1][0] | aCh[1][1] | aCh[1][2] | aCh[1][3] |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
Двухмерные массивы можно рассматривать как матрицу, в которой первый индекс определяет строку, а второй индекс - столбец. Порядок расположения элементов матрицы в памяти - по строкам.
При размещении трехмерного массива char aCh[3][2][5] память под элементы этого массива будет выделяться последовательно в соответствии со следующими значениями индексов:
Рис. 7.1.
Общий объем выделяемой под массив памяти определяется как произведение всех размерностей массива (общее число элементов), умноженное на длину типа данных массива.
Символьные массивы и строки
Синтаксис языка не имеет простого строкового типа (стандартная библиотека содержит тип string, но переменные данного типа не являются массивами символов). Поэтому для работы со строками удобно использовать массивы символов. Объявить массив символов - строку можно двумя способами:
указать посимвольно каждый элемент массива, включая символ конца строки;указать в двойных кавычках при инициализации массива значение строки (символ конца строки будет добавлен автоматически).
Символом конца строки служит null-символ \0. При подсчете числа символов в строке учитывается общее число символов плюс символ конца строки.
Например:
char arrayOfChar[6]; arrayOfChar[0]='A'; // Доступ через указатель // на массив и индекс char * ph = arrayOfChar; // Создание указателя на элемент массива ph++; // Переход к следующему элементу массива
Префиксный оператор * называется оператором разыменования. Если ph указывает на элемент массива, то *ph является значением этого элемента.
Любое выражение, имеющее тип массива, может быть преобразовано к указателю того же типа: результатом будет указатель на первый элемент массива.
Например:
char cStr[_MAX_PATH]; // Массив типа char char *pStr = cStr; // Указатель на массив: // эквивалентно выражению &cStr[0]
Ссылки
Ссылка вводит для доступа к переменной второе имя и является константным указателем на объект. Значение переменной-ссылки изменить нельзя. При объявлении ссылки перед именем переменной ставится символ &. Ссылка при объявлении всегда должна быть проинициализирована.
Например:
int iV=12; int &sV=iV; // sV - ссылка cout<< sV; // sV равно 12 sV=22; // значение iV // стало равно 22 sV++; // sV и iV стало равно 23 int *pV= &sV; // указатель на sV и iV
Типы, определяемые в пространствах имен
Пространство имен позволяет именовать группу переменных и методов.
Создание пространства имен указывается ключевым словом namespace.
Пример:
namespace S // Пространство имен S { int i; } void main() { S::i++; // Обращение к переменной // i из пространства имен S }
В языке C++ объявляемые пространства имен могут быть иерархически вложены друг в друга.
Например:
namespace Outer { int iOuter1= 111; int func(int j); namespace Inner { int iInner1 = 222; } }
Для традиционных приложений можно использовать стандартную библиотеку C++, которая определяет дополнительный набор типов. Пространство имен стандартной библиотеки обозначается идентификатором std.
Для того чтобы иметь возможность обращаться к переменным или методам из пространства имен, можно использовать один из следующих способов:
имя соответствующей переменной или метода должно быть квалифицировано названием пространства имен (пространство имен указывается перед именем через два символа двоеточия). Например:
std::string s="Это строка";
имя библиотеки должно быть установлено как доступное оператором using. Например:
using namespace std; // ... string s1="Строка s1";
Оператор using можно указывать как до метода main, так и внутри метода main (в этом случае переменные и методы пространства имен будут доступны без квалификации их имени сразу после выполнения оператора using).
Для управляемых расширений используются библиотеки среды NET Framework, реализованные как пространства имен. Пространство имен System предоставляет большой набор типов, реализованных как классы или структуры.
Указатели на массивы
И указатель, и массив содержат адрес. Поэтому указателю может быть присвоен адрес первого элемента массива или имя массива. Но адресу массива нельзя присвоить значение указателя.
Например:
float fArray[3]; // Массив float* pArray; pArray=fArray; // Эквивалентно оператору // pArray=&fArray[0]; pArray++; // Указывает на второй // элемент массива float* pArray2; pArray2=&fArray[1]; // Указывает на второй //элемент массива
Указатели на переменные
Указатель на переменную содержит адрес памяти расположения этой переменной.
Объявление указателя имеет следующее формальное описание:
тип_переменной *имя_переменной_адреса;
Инициализация указателя выполняется следующим образом:
тип_переменной имя_переменной_содержания; имя_переменной_адреса = &имя_переменной_содержания;
Объявление указателя может быть выполнено с одновременной инициализацией:
тип_переменной *имя_переменной_адреса = &имя_переменной_содержания;
Доступ к значению переменной по указателю имеет следующее формальное описание:
имя_переменной_содержания1=*имя_переменной_адреса;
При работе с указателями действуют следующие правила:
при объявлении переменной-указателя перед именем переменной указывается операция *;если одним оператором объявляется несколько переменных-указателей, то перед каждой такой переменной следует указывать операцию *;после объявления указателя его следует инициализировать адресом значения того же типа, что и тип указателя;для получения адреса переменной перед ее именем указывается операция взятия адреса &;для получения значения переменной по указателю на нее перед указателем ставится операция разыменования * (называемая иногда операцией взятия значения);указатель строки содержит адрес первого символа строки;при увеличении указателя на единицу значение, содержащееся в переменной-указателе, увеличивается на число байт, которое отведено под переменную данного типа.
Операцию разыменования & нельзя использовать:
для регистровых переменных (register r1; pReg=&r1;);с константами (pAdr1=&444;);с арифметическими выражениями (int i=1234; pAdr1=&(i+3);).
Например:
int iVar; int* pInt; // Указатель pInt=&iVar; // Эквивалентно оператору // int *pInt=&iVar; *pInt=20; // Эквивалентно оператору // iVar=20; char* pStr="The string"; iVar=strlen(pStr); // Определение длины строки
Указателю может быть присвоено значение другого указателя: в этом случае следует использовать операцию *. Компилятор Visual C++ отслеживает некорректные присваивания - указателю значения или наоборот, и выдает предупреждение о различных уровнях адресации.
На следующей схеме иллюстрируется соотношение указателя и значения.
| Адреса ячеек памяти | 2000 | 2001 | 3000 | 3020 | ||||
| Операции: | Содержание ячеек: | |||||||
| A='w'; | w | |||||||
| pA=&A; //адрес переменной А | 2000 | |||||||
| B=*pA; //значение переменной А | w | |||||||
| *pA='я'; //изменение значения | я | |||||||
| pB=pA; //адрес переменной А | 2000 | |||||||
| pB=&A; //адрес переменной А | 2000 | |||||||
Выполнять вычитание можно только над указателями одного типа. Результатом вычитания указателей является целое число, указывающее разность адресов памяти.
Над указателями одного типа можно выполнять операцию сравнения, возвращающую логическое значение.
Так же как и при работе с массивами, компилятор Visual C++ не выполняет для указателей проверку на предельные значения.
Указатели на указатели
Объявление указателя на указатель имеет следующее формальное описание:
тип **имя_указателя_на_указатель;
При объявлении указателя на указатели уровнем вложенности указателей служит число звездочек перед именем переменной.
Для получения значения по указателю на указатели перед именем указателя надо записать количество звездочек, равное уровню вложенности указателя.
Например:
int iV, jV; int* pV=&iV; // pV - это адрес, //а *pV - значение int** ppV=&pV; int*** pppV=&ppV; iV=77; // Эквивалентно **ppV=77; jV=*pV; // Эквивалентно jV=**ppV; // или jV=***pppV;
Доступ к элементам структуры
Элементы структуры могут иметь модификаторы доступа: public, private и protected. По умолчанию все элементы структуры объявляются как общедоступные (public). Забегая вперед, следует сказать, что все члены класса по умолчанию объявляются как защищенные (private).
Для обращения к отдельным элементам структуры используются операторы: . и ->.
Доступ к элементам структуры может иметь следующее формальное описание:
переменная_структурного_типа.элемент_структуры=значение; имя_структурного_типа *указатель_структуры= & переменная_структурного_типа; указатель_структуры->элемент_структуры=значение;
Например:
struct structA { char c1; char s1[4]; float f1;} aS1, // aS1 - переменная структурного типа *prtaS1=&aS1; // prtaS1 - указатель на структуру aS1 struct structB { struct structA aS2; // Вложенная структура } bS1,*prtbS1=&bS1; aS1.c1= 'Е'; // Доступ к элементу c1 структуры aS1 prtaS1->c1= 'Е'; // Доступ к элементу c1 через // указатель prtaS1 (*prtaS1).c1= 'Е'; // Доступ к элементу c1 (prtbS1->aS2).c1='Е'; // Доступ к элементу вложенной структуры
Доступ к элементу массива структурного типа имеет следующий формальный синтаксис:
имя_массива[индекс_элемента_массива].элемент_структуры
При использовании указателей на массив структур следует сначала присвоить указателю адрес первого элемента массива, а затем реализовывать доступ к элементам массива, изменяя этот указатель адреса.
Например:
struct structA { int i; char c;} sA[4], *psA; psA=&sA[0]; … cout<<psA->i; // Доступ к первому элементу массива // структур // Переход ко второму элементу массива psA++; // Эквивалентно записи: psA=&sA[1]; cout<<psA->i;
Объединения
Объединение позволяет размещать в одном месте памяти данные, доступ к которым реализуется через переменные разных типов.
Использование объединений значительно экономит память, выделяемую под объекты.
При создании переменной типа объединение память под все элементы объединения выделяется исходя из размера наибольшего его элемента. В каждый отдельный момент времени объединение используется для доступа только к одному элементу данных, входящих в объединение.
Так, компилятор Visual C++ выделит 4 байта под следующее объединение:
union unionA { char ch1; float f1;} a1;
| char ch1 | |||
| 1 | |||
| float f1 | |||
| 1 | 2 | 3 | 4 |
Объединения, как и структуры, могут содержать битовые поля.
Инициализировать объединение при его объявлении можно только заданием значения первого элемента объединения.
Например:
union unionA { char ch1; float f1;} a1={ 'M' };
Доступ к элементам объединения, аналогично доступу к элементам структур, выполняется с помощью операторов . и ->.
Например:
union TypeNum { int i; long l; float f; }; union TypeNum vNum = { 1 }; // Инициализация первого элемента объединения i = 1 cout<< vNum.i; vNum.f = 4.13; cout<< vNum.f;
Элементы объединения не могут иметь модификаторов доступа и всегда реализуются как общедоступные (public).
Объявление структуры
Структуры языка C++ представляют поименованную совокупность компонентов, называемых полями, или элементами структуры. Элементом структуры может быть:
переменная любого допустимого типа;битовое поле;функция.
Объявление структуры имеет следующее формальное описание:
struct [имя_структуры] { тип_элемента_структуры имя_ элемента1; тип_элемента_структуры имя_ элемента2; ... тип_элемента_структуры имя_ элементаN; } [список_объявляемых_переменных];
Объявление структуры с битовыми полями имеет следующее формальное описание:
struct [имя_структуры] { тип_элемента_структуры [имя_ элемента1] : число_бит; тип_элемента_структуры [имя_ элемента2] : число_бит; ... тип_элемента_структуры [имя_ элементаN] : число_бит; } [список_объявляемых_переменных];
Возможно неполное объявление структуры, имеющее следующее формальное описание:
struct имя_структуры;
При отсутствии имени объявляемой структуры создается анонимная структура. При создании анонимной структуры обычно указывается список объявляемых переменных.
Список объявляемых переменных типа данной структуры может содержать:
имена переменных;имена массивов;указатели.
Например: struct sA {char a[2], int i;} struA, struB[10], *struC;
Для использования указателя на структуру ему необходимо присвоить адрес переменной типа структуры.
Размер структуры с битовыми полями всегда кратен байту. Битовые поля можно определять для целочисленных переменных типа int, unsigned int, char и unsigned char. Одна структура одновременно может содержать и переменные, и битовые поля. Если для битового поля не задано имя элемента, то доступ к такому полю не разрешен, но количество указанных бит в структуре размещается.
Типом элемента структуры может быть:
другой структурный тип (допускаются вложенные структуры);указатель на данный структурный тип;неполно объявленный структурный тип;любой другой базовый или производный тип, не ссылающийся рекурсивно на объявляемый структурный тип.
Например:
struct sA {char a[2], sA* this_struct;}; // Корректное объявление структуры struct sB; // Неполное объявление структуры struct sA {char a[2], sB* this_struct;}; // Корректное объявление структуры struct sA {char a[2], sA this_struct;}; // Ошибочное объявление
Структура не может содержать в качестве вложенной структуры саму себя, но она может содержать элемент, являющийся указателем на объявляемую структуру.
Например:
struct structA { struct structA *pA; int iA; } sA; // pA указатель на структуру
При одновременном объявлении структурного типа, объявлении переменной данного типа и ее инициализации список значений указывается в фигурных скобках в последовательности, соответствующей последовательности определения элементов структуры.
Например:
struct POINT // Объявление структурного // типа POINT { int x; // Объявление элементов x и y int y; } p_screen = { 50, 100 }; // Эквивалентно записи p_screen.x = 50; // и p_screen.y = 100;
Перечисления
Перечисление, или перечислимый тип определяет множество, состоящее из значений, указанных через запятую в фигурных скобках.
Перечисление задает для каждого мнемонического названия в указываемом множестве свой индекс.
Перечисление может иметь следующее формальное описание:
enum имя_типа {список_значений} список_объявляемых_переменных; enum имя_типа список_объявляемых_переменных; enum (список_элемент=значение);
Перечислимый тип описывает множество, состоящее из элементов-констант, иногда называемых нумераторами или именованными константами.
Значение каждого нумератора определяется как значение типа int. По умолчанию первый нумератор определяется значением 0, второй - значением 1 и т.д. Для инициализации значений нумератора не с 0, а с другого целочисленного значения, следует присвоить это значение первому элементу списка значений перечислимого типа.
Например:
// Создание перечисления enum eDay{sn, mn, ts, wd, th, fr, st} day1; // переменная day1 будет принимать // значения в диапазоне от 0 до 6 day1=st; // day1 - переменная перечислимого типа int i1=sn; // i1 будет равно 0 day1= eDay(0); // eDay(0) равно значению sn enum(color1=255); // Объявление перечисления, определяющего // именованную целую константу color1 int icolor=color1; enum eDay2{sn=1, mn, ts, wd, th, fr, st} day2; // переменная day2 будет принимать // значения в диапазоне от 1 до 7
Для перечислимого типа существует понятие диапазона значений, определяемого как диапазон целочисленных значений, которые может принимать переменная данного перечислимого типа.
Для перечислимого типа можно создавать указатели.
Передача структур в качестве параметров
Переменные структурного типа и элементы структуры можно передавать в функции в качестве параметров.
Передача параметров может выполняться:
по ссылке или указателю;по значению.
При передаче параметра по указателю передается только указатель на структуру, при передаче по значению в стек копируется все содержание структуры.
Например:
struct structA { int i; char c;} sA, *psA=&sA; void F1(struct structA sA); // Передача параметров по значению void F2(struct structA *psA); // Передача параметров по указателю void F3(struct structA &sA); // Передача параметров по ссылке … void F2(struct structA *psA) { psA->i =10; } // Доступ к элементу структуры
При большой вложенности вызовов и использовании большого числа структур или их значительных размерах вызов по значению может привести к переполнению стека.
Функция может возвращать значение структурного типа или типа указателя на структуру.
Например:
struct structA { int i; char с;}; struct structA Function3(void); // Функция возвращает значение // структурного типа struct structA *Function4(void); // Функция возвращает указатель // на структуру
Выделение памяти
При создании переменной типа структуры:
память под все элементы структуры выделяется последовательно для каждого элемента;для битовых полей память выделяется, начиная с младших разрядов;память, выделяемая под битовые поля, кратна байту;общая выделяемая память может быть больше, чем сумма размеров полей структуры.
Рассмотрим пример выделения памяти под структуру
struct structA { char cA; char sA[2]; float fA;};
При создании переменной структурного типа:
structA s1;
будет выделено 7 байтов. Элементы структуры будут размещены в памяти в следующем порядке:
| char cA | char sA[2] | float fA | ||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
Рассмотрим пример выделения памяти под структуру
struct structB { int i1:2; int i2:3; int :6; unsigned int i3:4;};
При создании переменной структурного типа:
structB s2;
будет выделено 2 байта. Элементы структуры будут размещены в памяти в следующем порядке:

Рис. 8.1.
Для целочисленных значений, предусматривающих наличие знакового разряда (например, int), старший левый бит из общего числа битов, выделяемых под данное битовое поле, интерпретируется как знак. Например, битовое значение 11 для поля i1 будет восприниматься как -1, а значение 11 для поля i3 - как 3.