Фонд свободного программного обеспечения и проект GNU
Фонд свободного программного обеспечения (FSF - Free Software Foundation) представляет собой
очень интересное и во многих отношениях исключительное явление в современном мире
программирования. Многим отечественным программистам приходилось иметь дело с
программами из FSF (особенно хорошо известна система программирования GCC), однако
недостаточное количество публикаций на русском языке затрудняет понимание идеологии и целей
FSF, а также усложняет оценку имеющегося задела. Одной из целей доклада является хотя бы
частичное устранение этого пробела.
FSF - это программистская организация, основанная и возглавляемая Ричардом Столлманом
(Richard Stallman). В самой общей постановке задачей FSF является устранение ограничений по
копированию, распространению, изучению и модификации программ для компьютеров. Для
достижения этой общей задачи FSF стимулирует разработку и использование свободного
программного обеспечения, ориентированного на широкий класс применений.
В своем "Манифесте GNU" [1], написанном еще в 1985 г., Р. Столлман в качестве основной идеи,
приведшей к возникновению FSF и проекта GNU, выдвигает свое неприятие права собственности
на программы. Особенности взаимоотношений в сообществе программистов часто ставят людей
перед выбором следования естественному чувству дружбы и взаимопомощи или подчинения
препятствующего этому закону о собственности. При использовании свободного программного
обеспечения необходимость такого обременительного выбора исчезает.
Создание интегрированной свободной программной системы позволяет избежать дублирующей
работы программистов (которая часто требуется только по причине наличия программ в чьей-
либо собственности). Свободное распространение исходных текстов программ облегчает их
сопровождение и приспособление к нуждам конкретного пользователя (не требуется прибегать к
услугам только компаний - владельцев лицензий на исходные тексты). Появляется дополнительная
и очень важная возможность использования хорошего программного обеспечения в учебных
целях.
Как утверждает Р. Столлман, при переходе к свободному программному обеспечению
программисты не вымрут от голода (хотя, видимо, будут зарабатывать несколько меньше).
Ограничение на копирование программ - это не единственный способ зарабатывать деньги.
Основная идея Столлмана состоит в том, что нужно продавать не программы, а труд
программиста. В частности, источником дохода может быть сопровождение программных систем
или их настройка для использования на новых компьютерах и/или в новых условиях, преподавание
и т.д.
"Манифест" Столлмана написан очень эмоционально и местами слишком утопичен. Тем не менее,
как кажется, идеи свободного программного обеспечения исторически близки традиционным (за
исключением самых последних лет) отношениям в среде советских программистов. Возможно,
именно линия FSF - наиболее естественный путь к глубокой интеграции отечественного и
мирового сообществ программистов.
Более конкретно, FSF ведет разработку программ в рамках проекта GNU (аббревиатура GNU
раскрывается рекурсивно - GNU's Not Unix). Целью проекта GNU является создание полной
интегрированной программной системы, средства которой совместимы с возможностями среды
ОС Unix (как правило, возможности программ GNU шире возможностей аналогов среды Unix).
Программное обеспечение FSF является "свободным" в двух смыслах. Во-первых, любую
программу можно свободно копировать и передавать кому угодно. Во-вторых, наличие исходных
текстов программ обеспечивает возможность свободного изучения программ, их улучшения и
распространения доработанных вариантов.
Подобно тому, как права обычных компаний, производящих программное обеспечение,
охраняются их знаком авторских прав (copyright), "свобода" программных систем FSF защищается
"copyleft" - комбинацией copyright и присутствующим во всех текстах FSF документом с
заголовком "GNU General Public License" [2]. В этом документе говорится о правах, которыми
располагает любой текущий владелец данного текста, и о невозможности изъятия этих прав у
любого другого субъекта.
Основная деятельность FSF состоит в разработке новых составляющих свободного программного
обеспечения в рамках проекта GNU. Большей частью проект GNU развивается плановым
образом, но FSF принимает для свободного распространения и программы, разработанные
фирмами и частными лицами по собственной инициативе. Кроме того, FSF занимается
производством и продажей лент со свободным программным обеспечением, подготовкой,
публикацией и распространением руководств по различным компонентам программного
обеспечения GNU, а также поддерживает и распространяет справочник услуг - список фирм и
частных лиц, которые оказывают платные услуги пользователям программ и систем GNU.
Финансовой основой FSF является продажа магнитных лент и компактных дисков с текстами
программ GNU, документации в электронной и бумажной форме, а также спонсорство
коммерческих фирм и частных лиц.
В настоящее время готовы почти все компоненты программного обеспечения проекта GNU. FSF
распространяет много программ, часть которых написана непосредственно программистами FSF,
а часть передана в FSF для свободного распространения другими организациями и лицами.
Коротко охарактеризуем наиболее интересные программные продукты, распространяемые FSF [3].
Emacs - расширяемый, настраиваемый на разные типы терминалов и потребности пользователей
редактор. Расширяемость редактора основана на использовании встроенного в редактор
интерпретатора языка Лисп (диалекта Common Lisp). Одновременно с исходными текстами
редактора распространяются руководство по использованию Emacs и справочное руководство по
программированию на языке Лисп в среде Emacs. Основной версией Emacs, поставляемой и
поддерживаемой в настоящее время FSF, является Emacs V.19. Эта версия редактора сохраняет
свойства всех предыдущих версий, включая возможность использования на самых простых
алфавитно-цифровых терминалах. Однако Emacs V.19 очень хорошо работает на графических X-
терминалах. На самом деле, только после перехода к использованию Emacs на X-терминалах
можно по- настоящему оценить возможности этого редактора.
Некоторое время тому назад существовала непростая проблема локализации Emacs
применительно к особенностям национального языка. Скорее всего, найдутся люди, которые
помнят, сколько хлопот принесла работа по первой русификации Emacs. Несколько лет назад
внезапно активизировавшиеся японцы создали собственную версию редактора Emacs под
названием MULE (MULtilingual Enhancement to GNU Emacs - не подумайте чего плохого). В этой
версии используется расширенная многобайтовая кодировка символов, позволяющая в одном
сеансе редактирования употреблять символы разных алфавитов (в частности, японский,
китайский, арабский, русский, греческий и т.д.). В настоящее время MULE интегрирован в Emacs,
и серьезные проблемы локализации отсутствуют. Видимо, сегодня Emacs является лучшим
текстовым процессором, работающим в среде Unix (в действительности, эта программа
представляет собой гораздо большее, чем простой текстовый процессор).
Bison - замена стандартного генератора синтаксических анализаторов Yacc с некоторыми
расширениями. Руководство также распространяется. Люди, которые использовали Bison при
разработке компиляторов, очень хвалят программу. В последнее время FSF ослабил требования к
использованию Bison, позволив легально его применять при разработке коммерческих продуктов.
Имеются две реализации упрощенного диалекта языка Лисп - Scheme: одна из MIT (написана на
языке Си), вторая из университета г. Yale (написана на Scheme).
Поставляется набор утилит texiinfo, генерирующих печатные и гипертекстовые документы, в виде
которых в основном поставляется документация проекта GNU.
GCC - переносимый оптимизирующий компилятор. Начиная со второй версии компилятор
поддерживает языки Си (ANSI C, традиционный Си, расширенный диалект GNU C), Си++ и
Objective C. Среди оптимизаций, выполняемых GCC, содержится автоматическое распределение
регистров, выявление общих подвыражений, вынесение инвариантных выражений из тела цикла и
т.д. Компилятор содержит средства полуавтоматического построения генераторов кода для новых
компьютеров.
Доступен целый ряд библиотек функций для языка Си и библиотек классов для Си++ и Objective
C.
Отладчик GDB может быть использован для отладки программ, написанных на языках Си, Си++ и
Фортран.
Для работы с версиями программ в больших программных проектах поддерживаются системы
RCS (Revision Control System) и CVS (Concurrent Version System).
Распространяется громадное количество программ X11, реализация MIT X-Windows (версия 11,
релиз 6). Объем доклада не позволяет остановиться на этом более подробно.
В основном все программы, распространяемые FSF, рассчитаны на работу в среде Unix и
используются с различными вариантами этой системы, но имеются версии некоторых программ
для работы с ОС VMS, Windows NT и даже MS-DOS.
Одним из особенно важным, но еще незавершенным проектом FSF является проект Hurd. Это
свободная реализация UNIX-совместимой операционной системы, основанная на свободно
распространяемом варианте микроядра Mach, разработанного в университете Карнеги-Меллон. В
соответствии с технологией Mach разработан ряд серверов, воспроизводящих базовые функции
ядра ОС UNIX. Интерфейс системных вызовов UNIX воспроизводится с помощью специально
разработанной библиотеки Си-функций. Серверы Hurd и библиотечные функции первоначально
были разработаны на платформе PC 396, но легко переносятся на другие аппаратные платформы.
Основной текущей проблемой является массовый перенос Mach на различные платформы.
Среди программ GNU находится большое число других продуктов, которые заслуживают
внимания, но мы не будем обсуждать их в этом докладе.
Основные этапы развития языка
Первые версии языка программирования Си++ (тогда он назывался "Си с классами") были
разработаны в начале 80-х годов Бьярном Страуструпом, сотрудником знаменитой AT&T Bell
Labs, где ранее были разработаны такие шедевры программирования, как операционная система
UNIX и язык программирования Си.
По признанию самого автора языка, Си++ никогда не разрабатывался на бумаге.
Проектирование, реализация и документирование новых возможностей происходили фактически
одновременно. Единственной целью разработки было создание языка, на котором было бы удобно
программировать автору и его друзьям. Если вспомнить историю создания языка Си, то
прослеживаются явные аналогии.
За основу был взят популярный в среде профессиональных разработчиков язык программирования
Си. Первыми средствами, которыми был расширен Си, стали средства поддержки абстракций
данных и объектно-ориентированного программирования.
Как это принято в AT&T, описание нового языка не было опубликовано сразу. Первыми его
пользователями стали сами сотрудники Bell Labs. В 1993 впервые была реализована коммерческий
транслятор, и сам язык был назван "С++", что можно (имея в виду операцию инкрементирования
языка Си) трактовать как увеличенный или расширенный язык Си.
Первым транслятором языка был препроцессор cfront, транслирующий программу на Си++ в
эквивалентную программу на Си. И только в конце 80-х годов были реализованы прямые
трансляторы, не использующие Си в качестве промежуточного языка. Пионером среди таких
трансляторов стал GNU CC.
Если не считать документацию к транслятору cfront, первой книгой с описанием языка стала "The
C++ Programming Language" (Addison-Wesley, 1985), переведенная на русский язык и изданная в
1991 году (Страуструп Б. Язык программирования С++. М.: Радио и Связь, 1991).
С этого момента началось его бурное распространение и создание многочисленных
реализаций.
Модель реализации ООП была частично позаимствована из языка программирования Simula67 и
ориентировалась в основном на возможность эффективной реализации на вычислительных
машинах со стандартной архитектурой. Некоторые возможности языка Simula были отклонены,
так как, по мнению автора Си++, подталкивали разработчика к плохому стилю
программирования. Так, в первых версиях Си++ полностью отсутствовала возможность
динамической идентификации типа объекта (run-time type identification, rtti). Основные концепции
поддержки ООП в Си++ были изложены Страуструпом в статье "What is Object Oriented
Programming".
C 1985 года в язык были введены новые возможности: множественное и виртуальное наследование,
шаблоны функций и классов, обработка исключительных ситуаций. Кардинально изменена
семантика совместного использования оператора new, изменен синтаксис для вложенных
классов.
С момента опубликования и до настоящего момента язык постоянно усовершенствовался и
расширялся. Важным этапом в его развитии стала публикация в 1990 году подробного и
достаточно строгого описания языка [3]. Сокращенно эту книгу часто называют ARM. Фактически
одновременно с этим началась стандартизация языка.
Инициатором стандартизации выступил не автор языка. Более того, Страуструп всегда довольно
прохладно относился к попытке его полной стандартизации и выступал за реализации, в которых
базовые возможности языка расширялись бы средствами и библиотеками, характерными только
для данной реализации.
В настоящее время одним из
В настоящее время одним из перспективных и экономически оправданных подходов к развитию
информационной индустрии является создание информационных технологий (ИТ) и реализующих
их систем (ИТ-систем) на принципах открытости. Основными свойствам открытых систем
являются переносимость (программ, данных, пользовательских окружений), интероперабельность
(сетевая взаимосвязь и совместное использование ресурсов и данных компонентами
распределенных систем), масштабируемость (эффективность функционирования в широких
диапазонах характеристик производительности и ресурсов). Достижимость этих качеств возможна
лишь на основе высокого уровня стандартизованности интерфейсов ИТ-систем и поддерживающих
их платформ.
В настоящее время в обеспечение этого подхода создан мощный методический базис, включающий
в качестве концептуальной основы (метауровень) эталонные модели важнейших разделов области
ИТ (в первую очередь модели: OSI - для сетевого взаимодействия, ODP - для открытой
распределенной обработки, POSIX - для окружений открытых систем, DM - для управления
данными, CG - для компьютерной графики), а также обширный набор стандартов или базовых
спецификаций, регламентирующих процесс создания ИТ-систем или их компонент на принципах
открытости. Также в последние годы создан эффективный и гибкий инструмент комплексирования
ИТ - (функциональное) профилирование ИТ, значительно продвинуто решение проблемы
аттестации реализаций ИТ (ИТ-систем) на соответствие исходным спецификациям. Огромное
значение для технологии создания открытых ИТ-систем приобрела разработка единой таксономии
ИТ.
При всем кажущемся благополучии в области построения открытых ИТ-систем узким местом
остается, казалось бы давно решенная проблема, - стандартизация языков программирования и их
библиотечных окружений, составляющих основную часть прикладного интерфейса (в
терминологии международных стандартов - интерфейса на границе прикладной платформы и
прикладной программы или API).
В эру объектно-ориентированных технологий основным инструментальным языком построения
открытых ИТ-систем становится язык Си++. С целью обеспечения высокого уровня переносимости
программ, поддержки объектно-ориентированной технологии проектирования ИТ-систем,
бесшовной интеграции языков программирования с языками баз данных следующего поколения, в
настоящее время в рамках ИСО (подкомитет 22) осуществляется интенсивная работа по развитию
и стандартизации базового языка объектно-ориентированного программирования Си++, а также
набора объектно-ориентированных шаблонных библиотек. Данную работу планируется
завершить в 1998 г. (срок окончания работ неоднократно переносился). В настоящее время
опорными точками процесса формирования стандарта данного языка являются соответствующие
проекты стандарта, издаваемые указанным выше комитетом с периодичностью две-три версии в
год.
Следует отметить, что создание ведущими фирмами-разработчиками компиляторов,
соответствующих текущим проектам стандарта, значительно отстает от темпов развития языка и
его библиотечного окружения. Аттестация компиляторов ведущих фирм-поставщиков (таких как
Borland, Symantec, Microsoft) показывает наличие в них большого количества ошибок и
отклонений от стандарта. По существу, каждая из фирм, реализуя собственные диалекты языка,
включает нестандартные конструкции и возможности, не поддерживаемые другими фирмами-
разработчиками компиляторов.
Помимо некачественности зарубежных компиляторов, несоответствия их стандартным
спецификациям, в последнее время наблюдается тенденция значительного повышения цен на
компиляторы, особенно заметное для пользователей, работающих на более мощных, чем обычные
персональные компьютеры, системах - рабочих станциях. Помимо материальных потерь, которые
несет Россия ежегодно на массовых покупках этого вида продукта, большая опасность
монополизации данного рынка малым числом зарубежных фирм представляется, в частности, для
организаций, ответственных за решение задач, имеющих стратегическое значение. Зависимость от
зарубежных поставщиков, невозможность переноса их компиляторов на оригинальные
отечественные образцы вычислительной техники, делает неконкурентными отечественные
разработки, отрицательно сказывается на уровне технологий, в частности, кросс-технологий,
применяемых при создании многих технических систем. Таким образом, отсутствие качественных
отечественных компиляторов, соответствующих стандартному определению языка Си++,
оснащенных стандартным набором шаблонных библиотек, и предусматривающих переносимость
их и/или адаптацию на широкий спектр машинных архитектур в значительной степени сдерживает
развитие отечественной вычислительной техники и прикладных технологий, делает их
неконкурентноспособными на международном рынке.
В то же время отечественная школа разработчиков компиляторов богата своими традициями.
Сильными школами специалистов в этой области славились: ИПМ, ИТМиВТ, ВЦАН, НФ
ИТМиВТ, ЛГУ, РГУ, МГУ и др. Поэтому возрождение этих традиций, создание
высококачественных отечественных компиляторов, представляется важной стратегической задачей
в области ИТ.
Представляемый проект нацелен на разработку перспективной методологии систем
программирования тройного стандарта, оригинальных методов и алгоритмов построения
переносимой и адаптируемой к машинным архитектурам системы программирования тройного
стандарта (ТСС++) для объектно-ориентированного языка Си++, реализующей стандарт языка
Си++, полный набор стандартных шаблонных библиотек, технологический аттестационный
комплекс для проверки на соответствие стандарту компилятора системы и его версий. Таким
образом, система ТСС++ обеспечит высокий уровень переносимости (на уровне исходного текста)
создаваемого программного обеспечения открытых систем.
Основные задачи проекта можно сформулировать следующим образом:
Разработать концепцию создания и сопровождения систем
программирования тройного стандарта, обеспечивающих реализацию
стандарта входного языка и стандарта его библиотечного окружения, а также
содержащих аппарат аттестации систем программирования на соответствие их
языковому стандарту.
Данный аппарат обеспечивает устойчивость систем
тройного стандарта в условиях развития стандарта языка.
Исследовать и разработать высокоэффективные алгоритмы и структуры
данных для реализации на их основе переносимого компилятора объектно-
ориентированного языка Си++ (с адаптируемой кодогенерацией),
соответствующего полному стандарту языка. Создать базовый компилятор
объектно-ориентированного языка Си++, соответствующего стандарту языка,
удовлетворяющий требованию параметризации кодогенерации для настройки
его на широкий спектр машинных архитектур, а также требованию
переносимости компилятора (на уровне исходного текста) на различные
платформы;
Исследовать и разработать высокоэффективные алгоритмы и структуры
данных для реализации на их основе объектно-ориентированных шаблонных
библиотек, входящих в стандартное описание языка Си++. Создать полный
набор объектно-ориентированных шаблонных библиотек, входящих в
стандартное описание языка Си++.
Исследовать и разработать методы, высокоэффективные алгоритмы и
структуры данных, вспомогательные инструментальные средства для
реализации на их основе пакета программ для аттестации компиляторов языка
Си++ на их соответствие стандарту. Создать пакет программ для аттестации
компиляторов языка Си++ на их соответствие стандарту.
В настоящее время в НИВЦ МГУ завершается реализация действующего прототипа компилятора
языка Си++ для операционных сред SunOS и Solaris. Входной язык компилятора соответствует
последней к настоящему времени версии проекта стандарта от 28 мая 1996 г. Благодаря
оригинальным структурным решениям и алгоритмам созданный компилятор обладает
производственными характеристиками, сравнимыми с имеющимися на этой платформе
зарубежными компиляторами.
Кроме этого, разворачивается работа по реализации некоторых компонент Стандартной
Библиотеки Си++. Предполагается переносимость реализации
Наконец, проведена разработка первой версии пакета программ для аттестации компилятора на
соответствие исходному описанию.Реализация пакета основывалась на оригинальном подходе и
методах, разработанных сотрудниками НИВЦ МГУ, и подтвердила практичность предложенных
методов аттестации компиляторов. Созданная тестовая система обеспечила достаточно полное
покрытие языкового многообразия и позволила как протестировать разрабатываемый
компилятор, так и выявить многочисленные ошибки в существующих компиляторах.
Другие наиболее распространенные продукты Public Domain
Наверное, самым популярным на сегодня программным продуктом Public Domain является UNIX-
совместимая ОС Linux, созданная молодым финским программистом Линусом Торвалдсом и
поддерживаемая с помощью Internet тысячами энтузиастов. ОС Linux основана на традиционных
принципах построения ядра ОС UNIX, что не помешало энтузиастам перенести ее на несколько
популярных аппаратных платформ.
Linux является одной из наиболее подходящих операционных систем для домашнего компьютера,
если человек не собирается использовать его только для написания текстов и лазания в Internet. По
отзывам практиков, программа, аккуратно написанная в среде Linux безо всяких проблем
переносится в среду любого другого варианта ОС UNIX (если, конечно, этот вариант
соответствует стандартам). С другой стороны, известны примеры промышленного использования
Linux, в частности, в телекоммуникационных системах.
Альтернативой Linux является ОС Free BSD, разработанная и распространяемая университетом
Беркли. Это одна из ветвей BSD UNIX, проекта, в течение многих лет разрабатываемого в
университете Беркли. Free BSD - это эффективная и экономичная операционная система,
единственным недостатком которой можно считать ее абсолютную ориентацию на Intel-
платформы. Я знаю многих людей, которые предпочитают использовать дома Free BSD, а не
Linux.
В том же университете Беркли разработан замечательный пакет Tcl/Tk - средство для разработки
графических пользовательских интерфейсов. Это свободно распространяемый продукт, прекрасно
документированный и очень легко осваиваемый. Известны многие реальные проекты,
выполненные с использованием Tcl/Tk, например, основанный на графическом интерфейсе пакет
администрирования Linux.
Как говорилось в начале доклада, тема свободно распространяемого программного обеспечения
поистине неисчерпаема. По этому поводу можно говорить бесконечно. Но лучше следить за
новыми программами самостоятельно.
[]
[]
[]
История стандартизации
Объединенный ANSI-ISO (ANSI X3J16; ISO WG21/N0836) комитет начал функционировать в
конце 1989 года. Целью его работы является создание единого стандарта для языка Си++ и его
библиотечных средств. За основу проекта стандарта было взято описание языка, данное в ARM, и
книга [4].
В работе объединенного комитета, функционирующего и по сей день, значительное место занимает
изучение (с последующим принятием или отказом от) возможных изменений текста проекта
стандарта, а также уточнение различных правил языка. Позволим себе напомнить, что
непосредственный предшественник Си++ - язык Си прошел успешно процесс стандартизации.
Работа по его стандартизации завершилась в 1989 году, и стандартизованный вариант сейчас
известен под именем ANSI Си.
Работа по стандартизации Си++ осложнялась тем, что язык долгое время был открыт для
расширений. Сами формулировки правил ARM были недостаточно строги и часто требовали
уточнения. Си++ стал довольно громоздким языком (сопоставимым разве что с языком Ada), и ни
один человек сейчас не в состоянии точно помнить все его детали и тонкости.
С момента начала стандартизации несколько изменилась и сама идеология Си++. Изначально
автор отвергал возможность использования в языке средств динамического определения типов
(rtti), однако в текущем проекте стандарта такие средства имеются. Аналогично, в Си++,
описанном в ARM, есть довольно жесткие ограничения на возможность определения виртуальных
функций, которые сейчас ослаблены. Характерно, что некоторые изменения, требующие
пересмотра самой идеологии языка, вносились самим Страуструпом [11]
Изначально планировалось, что окончательная редакция проекта стандарта будет опубликована в
1994 году. Эти сроки были безнадежно провалены. Можно сказать, что последние 3 года процесс
стандартизации постоянно находится в состоянии "2 года до завершения". Так, согласно текущему
расписанию международный стандарт Си++ должен быть опубликован в конце 1998 года, во что
авторы статьи не верят.
Даже теперешние, на редкость подробные и громоздкие формулировки
семантических правил и ограничений языка явно не дотягивают до математической строгости и
оставляют простор для различных трактований.
В ранних версиях проекта стандарта не было раздела, описывающего стандартные библиотеки. Не
было описаний библиотеки и в ARM. В то же время реализация библиотеки потокового
ввода/вывода, предложенная Andrew Koenig, была повторена в нескольких реализациях и стала
стандартом "де-факто". В 1993-1994 годах в проекте стандарта было введено около семи новых
разделов для описания библиотеки.
Принципиально важным событием в истории развития стандарта стандартной библиотеки стало
включение библиотеки STL (Standard Template Library) разработанной нашим бывшим
соотечественником, сотрудником Hewllet-Packard Александром Степановым. В своей статье об
истории STL он упоминает, что изначально стремился использовать в Си++ только возможности
шаблонов, аналогичные родовым (generic) пакетам и процедурам языка Ada, но после обсуждений
со Страуструпом существующих возможностей Си++ изменил свое мнение. Комитет по
стандартизации пошел навстречу этим двум гуру, вплоть до того, что в семантику шаблонов были
внесены изменения. Этим был создан интересный прецедент в истории языков программирования:
не библиотека написана для языка, а сам язык претерпел изменения под влиянием библиотеки,
причем разработанной не автором языка.
Согласно расписанию работы комитета по стандартизации, проект стандарта принятый в апреле
1995 года, был предложен для публичного обсуждения и сделан доступен пользователям Internet.
Утверждается, что с этого момента никаких серьезных изменений в текст стандарта вноситься не
будет. Предполагалось, что в сентябре 1996 года новая редакция проекта стандарта будет вынесена
на публичное обсуждение, но не так давно этот этап был перенесен на конец года.
Компилятор Си++
Важнейшей задачей при разработке компилятора с языка программирования Си++, предпринятой
в рамках проекта системы программирования тройного стандарта, являлось обеспечение
максимально полного соответствия его входного языка стандартному определению Си++.
Понятно, что эта задача является весьма и весьма тяжелой. Невозможно обеспечить полную
синхронизацию процесса разработки с независимо идущим процессом стандартизации, который
протекает весьма интенсивно (новые версии проекта стандарта появляются примерно один раз в
квартал) и сопровождается постоянными модификациями как синтаксиса, так и семантики
языка.
К сожалению, появление очередной версии стандарта не сопровождается указателем изменений по
отношению к предыдущей версии, поэтому контроль соответствия компилятора последней версии
превращается в отдельную весьма трудоемкую задачу, которая в весьма незначительной степени
может быть автоматизирована (например, путем использования процессоров сравнения
текстов).
В качестве примера радикального изменения языка можно привести главу 14 проекта стандарта
(Шаблоны). Первые версии определяли сравнительно простые средства параметризации периода
компиляции (правда, описание содержало большое количество неясных мест), которые допускали
простую модель реализации, основанную на "отложенной компиляции". Однако, в 1995 году
указанная глава подверглась кардинальной ревизии (ее объем увеличился в несколько раз) с
существенным расширением возможностей и усложнением синтаксиса и семантики. В основном это
было обусловлено стремлением поддержать возможности, заложенные в Стандартной Библиотеке
Шаблонов (Standard Template Library) Александра Степанова , которая в качестве составной
части вошла в проект стандарта. "Новые шаблоны" не допускали отложенную компиляцию, явно
требуя полного синтаксического и семантического контроля непосредственно в месте описания
шаблонов. Это привело не только к перепроектированию соответствующих компонент
компилятора, но затронуло очень многие, формально не связанные с шаблонами, его модули.
Можно сказать, что многие алгоритмы трансляции пришлось параметризовать, научив их
"понимать" те или иные случаи вхождения шаблонных конструкций. Подчеркнем, что это
относится к давно разработанным и протестированным фрагментам компилятора.
Компилятор в целом можно рассматривать как композицию следующих процессоров, каждый из
которых реализован в виде независимой программы:
Препроцессор Си++;
Компилятор переднего плана Си++ (front-end compiler);
Генератор объектного кода.
Построение компилятора в виде отдельных подсистем достаточно традиционно (в частности, в
среде UNIX). Помимо очевидного выигрыша по времени при одновременной разработке трех
компонент, а также упрощения тестирования и отладки, указанная структура обеспечивает более
легкую перенастраиваемость системы в целом, позволяя, например путем добавления новых
генераторов кода переносить компилятор на различные платформы.
Препроцессор. Данная компонента выполняет препроцессорную обработку исходного текста
согласно правилам соответствующей глава проекта стандарта Си++. Несмотря на значительную
семантическую независимость конструкций, обрабатываемых препроцессором, от самого языка
Си++, формально они являются частью определения языка. Именно по этой причине мы называем
данную компоненту "препроцессор Си++", хотя, очевидно, ее можно использовать для обработки
текстов любой природы.
Заметим, что в "минимальной" версии системы программирования могло бы и не быть реализации
препроцессора; в принципе, можно использовать аналогичный инструмент из любой Си-
ориентированной системы программирования. Наиболее существенным доводом в пользу
разработки собственной версии препроцессора было требование обеспечения полного
соответствия стандарту языка Си++, чего не обеспечивают многие препроцессоры известных
фирм-разработчиков.
Компилятор переднего плана. Эта компонента является центральной частью всего компилятора
Си++. Она воспринимает на входе текст программы на Си++ (в терминах стандарта - translation
unit), формируя на выходе файл с семантически эквивалентным представлением этой программы
на некотором промежуточном языке, который можно трактовать как "обобщенный
ассемблер".
Компилятор переднего плана построен по традиционной двухпроходной схеме. На первом проходе
осуществляется лексический и синтаксический анализ исходного текста, выполняется большой
массив семантических проверок, а также генерируется таблично-древовидное представление
программы.
Первичный лексический анализ (распознавание и кодирование лексем) выполняется по
традиционной схеме конечного автомата и для обеспечения большей эффективности реализован
без использования метасредств типа lex. Существенным моментом в схеме лексического разбора
компилятора является наличие дополнительной фазы - так называемого расширенного
лексического анализатора, функции которого заключаются, во-первых, в агрегации некоторых
"стандартных" последовательностей лексем в одну "суперлексему", и, во-вторых, в идентификации
имен везде, где это возможно; для этого используется ряд контекстных условий разбора, а также
привлекается информация из уже построенных семантических таблиц. Результатом этой функции
является подмена (уже на этапе лексического анализа) общего синтаксического понятия
"идентификатор" и соответствующей лексемы на более точное понятие, например, "объявляемое
имя", "имя типа", "имя-не-типа", "непосредственный базовый класс" и т.п. Для обозначения
подобных понятий используются соответствующие суперлексемы.
Синтаксический анализ реализован с использованием расширенного и оптимизирующего варианта
известного генератора YACC. Формальное описание языка Си++ основано на множестве лексем и
суперлексем (см. выше) и включает семантические действия, которые, как правило, сводятся к
вызовам функций обработки объявлений, генерации поддеревьев и вычислению контекстных
признаков. Свертка лексических последовательностей и ранняя идентификация имен, описанная
выше, привела к существенному (около 2- х раз) сокращению объема синтаксиса по сравнению с
аналогичным синтаксисом, используемым в свободно распространяемом компиляторе GNU
C++.
Совокупность семантических таблиц, организованная в соответствии со структурой областей
видимости исходной программы, содержит атрибуты всех программных сущностей, а дерево
программы отражает структуру исполняемых конструкций. Элементы семантических таблиц
("семантические слова") и узлы дерева связаны взаимными ссылками. Ссылки из дерева в таблицы
представляют, как правило, использующие вхождения объявленных сущностей. Обратные ссылки
обычно имеют характер атрибутов (например, ссылка из семантического слова переменной на
дерево выражения для инициализатора этой переменной).
Кроме того, на первом проходе практически полностью обрабатываются объявления шаблонов
функций и классов, а также настройки шаблонов классов (полная обработка вызовов функций-по-шаблону и некоторых других шаблонных конструкций откладывается до второго прохода).
Второй проход компилятора заключается в серии рекурсивных обходов дерева программы. При
этом выполняется довычисление атрибутов сущностей, необходимых для генерации
промежуточного кода (в частности, вычисляются размеры и смещения для стековых объектов),
производится частичное перестроение поддеревьев (например, формируются функциональные
эквиваленты операций преобразования типов, вставляются неявные вызовы деструкторов и т.п.),
специальным образом (в терминах стандарта - по алгоритму "best-matching" - поиска наилучшего
соответствия) обрабатываются вызовы функций, включая вызовы функций-по-шаблону. На
завершающей фазе второго прохода производится непосредственная генерация промежуточного
представления,
Генератор кода. В настоящее время в компиляторе используется фирменный генератор объектного
кода для платформ Sun и Sparc, полученный от компании-разработчика формата внутреннего
представления. Напомним, что генератор, как и другие компоненты компилятора, представляет
собой независимую программу, которая легко может быть заменена на эквивалентный по
интерфейсу генератор для некоторой другой платформы.
В настоящее время ведется разработка семейства оригинальных генераторов объектного кода для
нескольких аппаратных платформ, включая процессоры специального назначения.
Текущее состояние компилятора. В настоящее время разработка перешла в завершающую стадию.
Полностью реализован, отлажен и протестирован препроцессор. Компилятор переднего плана
практически полностью реализован; спроектированы все алгоритмы обработки "новых"
шаблонов, идет их реализация.
При тестировании компилятора переднего плана использовались средства аттестации,
создаваемые в рамках всего проекта (см. разд. 4). К началу октября 1996 г. компилятор успешно
обрабатывал около 97% тестов (используемый тестовый набор включает более 6000 тестов без
учета тестов на шаблонные конструкции). Проводились попытки сравнить степень соответствия
стандарту разрабатываемого компилятора с компиляторами известных фирм-производителей
инструментальных средств. Так, компилятор Watcom C++ версии 10.0 показал результат около
93%.
Специальные измерения производительности компилятора не проводились, однако эмпирически
можно утверждать, что его быстродействие сравнимо с быстродействием известных компиляторов
Си++, в частности, с GNU C++.
Современное состояние языка
Приведем беглое описание новых возможностей языка, введенных с момента публикации ARM и
до публикации проекта стандарта в апреле 1995г.
Ведены новые ключевые слова-синонимы для операций (and, and_eq, bitand, bitor, compl,
not, or, or_eq, xor, xor-equ).
В языке появился булевский тип данных bool и литералы этого типа true и false.
Появился механизм пространств имен (namespace), облегчающий совместную реализацию
проектов группами программистов и позволяющий избегать проблем при использовании
нескольких библиотек (ключевые слова namespace и using).
Новое ключевое слово explicit позволяет запретить нежелательное использование
конструкторов как функций преобразования типов.
Изменены синтаксис и семантика для изменения прав доступа к членам классов. Новый
механизм позволяет использовать единый синтаксис для использования членов пространств имен и
членов классов. При этом несколько изменились правила выбора наиболее подходящей из набора
совместно используемых функций (на основе использования ключевого слова using).
Добавлен механизм явного использования rtti (включающий операцию с ключевым словом
typeid и класс type_info стандартной библиотеки).
Добавлены новые и скорректированы старые способы явного преобразования типов
(static_cast, dynamic_cast, const_cast и reinterpret_cast).
Добавлена новая операция new[], парная к операции delete[]; для операций new и delete
изменена семантика выражения размещения с целью более безопасной обработки исключительных
ситуаций в конструкторах. Стандартная операция new теперь не может вернуть значение 0 в случае
нехватки памяти или ошибки, а генерирует исключительную ситуацию. Старый вариант,
возвращающий 0, доступен программисту только c явным указанием.
Объявления переменных теперь возможны не только в заголовке for-цикла, но и в операторах
if, while, do-while, switch.
Более точно определено время жизни временных объектов в выражении. Теперь время их
жизни ограниченно полным выражением, а не концом текущего блока, как сказано в ARM.
Полностью переработано определение шаблонов в Си++. Теперь уже нельзя сказать, что
шаблоны Си++ являются лишь слегка замаскированными синтаксическими подстановками. Для
них обязателен синтаксический разбор и контроль семантики (в максимально возможной степени).
Неоднозначности внутри тел шаблонов, вызываемые неизвестной природой типовых параметров,
явно разрешаются посредством ключевого словом typename.
Допускаются шаблонные функции-члены нешаблонных классов, вложенные шаблонные
классы и шаблоны - параметры шаблонов.
Виртуальные функции могут возвращать тип, отличный от типа подменяемой функции
базового класса, если эти типы являются указателями или ссылками на производный и базовый
класс.
Перечислимый тип (enum) окончательно утвердился как самостоятельный тип, не являющийся
ни одним из целочисленных типов. Теперь разрешено совместное использование функций,
основанное на этом различии; константа 0 перечислимого типа более не считается целочисленным
0, запрещено ее неявное преобразование к указательному типу.
Ослаблено ограничение на тип, возвращаемый операцией ->. Теперь это может быть
практически произвольный тип.
Добавлено (на редкость бессмысленное) ключевое слово mutable, позволяющее допускать
изменение членов объекта константного класса.
Более подробно некоторые из этих изменений рассмотрены в статье [6].
Стандартная библиотека Си++: принципы построения
Стандартная Библиотека языка Си++ (The Standard C++ Library) представляет собой весьма
значительную (как по объему, так и по "идеологической" насыщенности) часть готовящегося
стандарта языка Си++. Описание Библиотеки (главы 17-27) в совокупности составляет более
половины общего объема Предварительного Стандарта . Помимо внушительного размера,
предлагаемый стандартный комплекс библиотечных ресурсов языка Си++ воплощает большое
количество важных принципов и подходов, отражающих современное состояние программистской
теории и практики.
Как и язык в целом, Библиотека находится в состоянии разработки, причем интенсивность ее
модификаций от версии к версии в целом выше, нежели интенсивность модификаций описания
собственно языка. Тем не менее, базовый состав Библиотеки и многие ее существенные
особенности можно считать уже устоявшимися. Это позволяет кратко рассмотреть ее основные
черты.
Прежде всего необходимо отметить несколько существенных черт, свойственных проекту
Стандартной Библиотеки. Важным (и в то же время очевидным) моментом представляется
адекватная поддержка воплощенной в языке парадигмы объектно-ориентированного
программирования. Практически все библиотечные ресурсы спроектированы в виде иерархий
классов; используется понятие абстрактных классов и механизм виртуальных функций.
Другая особенность - активное использование шаблонов (templates) для повышения уровня
абстракции базовых алгоритмов. Следует специально отметить, что в последних версиях проекта
Си++ средства типовой (с ударением на "и") параметризации времени компиляции,
обеспечиваемые в языке понятием шаблона, весьма существенно усилились новыми
возможностями, и произошло это прежде всего под влиянием требований, возникавших в процессе
проектирования Стандартной Библиотеки.
Между прочим, техника применения шаблонов в библиотечных модулях может служить
прекрасным пособием для изучения этого средства языка по причине тщательной продуманности
структуры и иерархии библиотечных шаблонов.
Это тем более существенно, что сам по себе
данный языковой механизм спроектирован в Си++ явно не лучшим образом и теоретически может
приводить к невообразимо запутанным конструкциям.
Наконец, третья важная черта Библиотеки - использование механизма исключительных ситуаций
(exceptions). Практически все возможные "нештатные" эффекты в процессе выполнения
библиотечных функций специфицированы в виде исключительных ситуаций; в библиотеке
предусмотрена иерархия стандартных классов, предназначенных именно передачи значений при
возбуждении исключительных ситуаций.
Однако наиболее существенной идеологической концепцией, на основе которой строится
Стандартная Библиотека, является технология "generic programming" (обобщенного
программирования), впервые примененная для Си++ А.Степановым при разработке его Standard
Template Library (и вошедшей в качестве составной части в Стандартную Библиотеку). Как
результат, важнейшей особенностью Стандартной Библиотеки Си++ становится тенденция к
максимальному обобщению структур и алгоритмов при одновременном сохранении их
эффективности. Практически явное выделение понятийного ядра библиотеки позволило упростить
общую схему ее построения. Кроме того, произошел отказ от попыток создания замкнутой
системы классов и функций, предоставляющей пользователю фиксированный сервис. Наоборот,
основное внимание в библиотеке уделяется универсальным шаблонным средствам порождения
требуемого пользователю контекстно-ориентированного кода. С точки зрения классического
понимания слова "библиотека" С++ Standard Library скорее является средством быстрой
разработки контекстно-ориентированных библиотек, предоставляя программисту совокупность
понятий, в терминах которых он может проектировать собственные системы, и набор типовых
решений с использованием этих понятий.
Таким образом, общую структуру Стандартной Библиотеки Си++ можно представить как
объединение нескольких крупных компонент, каждая из которых предоставляет набор примитивов
и типовых решений, позволяющих достаточно легко построить набор конкретных классов и
функций для некоторой прикладной области.
Практически каждая компонента Библиотеки существенно использует возможности,
предоставляемые другими компонентами, за счет чего достигается максимальная гибкость,
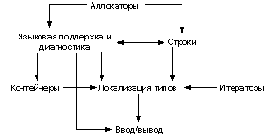
общность и эффективность. В качестве примера можно привести следующую схему, отражающую
взаимодействие компонент библиотеки, используемых при реализации ввода/вывода. Здесь связь
вида Компонента1-->Компонента2 отражает тот факт, что для построения второй компоненты
привлекаются понятия из первой компоненты.
Классическое объектно-ориентированное программирование использует единственный базовый
механизм - механизм наследования с последовательным увеличением детализации при переходе от
класса родителя к классу потомку. В случае Стандартной библиотеки Си++ активное
использование шаблонных структур - шаблонных алгоритмов и шаблонных иерархий классов
позволяет библиотеке, с одной стороны, сохранять высокий уровень абстрактизации, а с другой -
предоставлять разработчику реально действующий код. Кроме того, исходное построение
библиотеки в виде совокупности четко выделенных блоков не только позволяет достичь простоты
и единообразности интерфейсов, но дает пользователю большую широту в выборе способов их
взаимодействия.
Заметим, что идея создания библиотек повторно используемых программных компонент реально
не столь нова, как кажется на первый взгляд. Еще в 1976 году МакИлрой в своей статье (McIlroy
"Mass-Produced Software Components") аргументировал необходимость повторного использования
программного обеспечения, в том числе стандартизации и абстрактизации наиболее часто
используемых алгоритмов и структур данных, и, по всей видимости, единственным ограничением к
созданию подобного рода библиотек являлось отсутствие развитых средств абстрактизации у
большинства распространенных к тому времени языков программирования.
Подходя к проблеме эффективности библиотеки заметим, что абстрактизация компонент
библиотеки была достигнута без утраты эффективности по скорости. Как пример, можно привести
использование обобщенной функции sort, упорядочивающей натуральные числа по возрастанию,
для упорядочивания их по убыванию с привлечением понятия функционального объекта.
#include
#include
class IntGreater {
public:
bool operator()( int x, int y) const { return x>y; }
};
int main()
{
int x[1024];
............ // Инициализация
sort(&x[0],&x[1024]); // Обычное упорядочивание
sort(&x[0],&x[1024],IntGreater); // Упорядочивание по убыванию
}
При этом эффективность по скорости выполнения будет такой же, как и при написании
сортировки целых вручную, а реально может оказаться и выше за счет удачного выбора алгоритма
сортировки. Примеры использования средств STL можно найти в .
Стандартная Библиотека Си++ предоставляет:
Расширяемый набор классов и определений, необходимых для
поддержки понятий самого языка Си++ (Language Support Library).
Классы поддержки диагностики пользовательских приложений (Diagnostics
Library);
Утилиты общего назначения (General Utilities);
Контейнеры (Containers) и итераторы (Iterators);
Обобщенные алгоритмы (Algorithms);
Средства локализации программ (Locales);
Классы и функции для математических вычислений (Numeric Library);
Средства работы со строками (Strings Library);
Ввод/вывод (Input/Output Library).
Перспективы
Очень хочется, чтобы стандарт языка был наконец принят. Это может подстегнуть разработчиков
систем программирования для Си++ на максимально полную поддержку новых возможностей
языка, которые в настоящий момент не реализованы. Хочется, чтобы язык был наконец
зафиксирован, и в него не добавлялись новые средства, противоречащие старой идеологии.
И, наконец, несколько замечаний по поводу продолжительных дискуссий на темы вроде "Что
лучше - Си или Си++" или "Является ли Си++ языком ООП".
Си++ изначально не был "академическим" языком программирования. Его часто подвергали и
подвергают критике за неклассический подход к реализации поддержки ООП, даже за то, что его
непосредственным предшественником был язык Си, который явно не подходил на роль
"академического" языка, но очень популярен в среде профессиональных разработчиков.
Бесполезно критиковать Си++ за недостаточно неполную или "неправильную" поддержку ООП.
Си++ вполне укладывается в формулировку парадигмы ООП, данную Страуструпом. Си++ не
является единственным языком ООП и имеет право на свои недостатки и своеобразие.
Сейчас ООП явно поддерживается в нескольких языках программирования, во многих не так как
Си++, и разработчик имеет возможность выбора (так, превосходно спроектированный объектно-
ориентированный язык Ada95 уже стандартизован). Постоянные упреки в адрес Си++ за
"неправильное" понимание ООП кажутся абсолютно несуразными. Даже такие столпы ООП, как
Грэди Буч [9] и Роберт Мартин [10] признают, что Си++ является вполне подходящим и неплохим
инструментом ООП.
Благодаря своим корням Си++ был быстро воспринят разработчиками, уже имеющими опыт
программирования на Си, но не избалованными дорогими и малоэффективными языками
"чистого" объектно-ориентированного программирования.
Противопоставлять Си и Си++ тоже не стоит. Один из них ортогонально расширяет другой по
нескольким направлениям, которые могут быть использованы независимо.
Си++ допускает использование в нескольких вариантах. Во-первых, он содержит язык
программирования Си, точнее, его стандартизованный диалект ANSI C почти целиком. При этом
Си++ обладает более мощными и строгими правилами проверки типов. Программист волен
использовать лишь часть возможностей Си++, не сталкиваясь при этом с неприятностями,
связанными с неполным знанием языка (то есть воспринимать Си++ как "улучшенный" Си).
Можно использовать только механизм классов и наследования, не пользуясь возможностями
обобщенного (generic) программирования, основанного на шаблонах. Наконец, многим
разработчикам приглянулась возможность обработки исключительных ситуаций, не зависящая от
других механизмов языка. Взятые вместе, эти возможности предлагают разработчику
современный, достаточно гибкий и мощный язык программирования высокого уровня с
поддержкой ООП.
Думаем, Си не нуждается в защите. По крайней мере, последние 20 лет показали, что он является
исключительно гибким и продуктивным языком, годным как для системного программирования,
так и для создания приложений широкого спектра. Почему Си имеет такой успех ? Прежде всего
потому, что вместо создания "чистого" языка Керниган и Ричи создали язык, который можно
использовать. И в этом они преуспели.
Почему успешен Си++ ? По той же причине.
Дополнительная информация по языку Си++ см.:
Тестовый пакет
4.1. Основные принципы аттестации
Исходя из общих критериев качества и требований к пакетам тестов были выбраны следующие
принципы разработки пакета аттестационных тестов для проверки компиляторов Си++ на
соответствие стандарту:
Набор аттестационных тестов должен покрывать весь стандарт языка
C++.
Программы, входящие в пакет, должны быть независимыми в том смысле,
что результаты компиляции или запуска любой из них не должны влиять на
условия или результаты компиляции или запуска любой другой тестовой
программы.
Каждая тестовая программа необходима для проверки соответствия между
реализацией некоторой языковой конструкции и ее описанием в стандарте
языка C++.
4.2. Пакет тестов
Общая структура
Проблема реализации методов конформности языковых процессоров представляет собой
комплексную наукоемкую и весьма сложную в реализационном плане задачу. Аттестационный
пакет, разрабатываемый в рамках данного проекта, создавался с учетом научных результатов и
практического опыта, накопленных в МГУ .
Тестовый пакет построен иерархически в соответствии со структурой текста стандарта языка C++.
Тесты, содержащиеся в определенном каталоге (включая подкаталоги), должны тестировать
языковые ситуации, описанные в соответствующей части стандарта C++.
При этом подразумевался принцип независимости частей спецификации тестов (состоящих из
набора тестовых атрибутов, их значений, соответствующей таблицы решений и списка
ограничений), хотя он является лишь рекомендацией, а не требованием. Например, если
совместный список атрибутов и соответствующая таблица решений для более чем одной части
стандарта описывают сходную языковую конструкцию, то правильнее и удобнее будет создать
единый набор тестов для этих частей и расположить их в одном месте, а не разделять их или писать
несколько раз одинаковые тесты.
Группы тестов, соответствующие частям стандарта языка С++
Все тесты, содержащиеся в определенном каталоге, соответствующем части стандарта языка С++,
образуют группу тестов для этой части.
Основная цель каждой группы состоит в проверке
реализации некоторого требования, содержащегося или выводимого из текста соответствующей
части стандарта языка.
Каждая группа тестов разделяется на две подгруппы, состоящие из А-тестов и Б-тестов
соответственно. А-тесты это самопpовеpяющиеся правильные программы, проверяющие
правильность реализации некой языковой конструкции, а Б-тесты - программы, содержащие
ошибки, необходимые для проверки правильности реакции компилятора на данные ошибки.
Кроме этого, группы тестов разделяются на подгруппы в соответствии с целями тестирования и
тестовыми спецификациями. Каждая такая спецификация определяет некоторую конструкцию,
описанную в стандарте языка С++, которая должна быть запрограммирована, и эффект, который
должен быть получен при обработке этой конструкции проверяемой реализацией компилятора.
Каждой отдельной спецификации должен соответствовать ровно один тест.
Спецификации тестов: создание и реализация
Стандарт языка С++ является неформализованным (частично формализованной является лишь
синтаксическая часть языка). Это ведет к тому, что процесс создания тестов тоже является
частично формализованным. В этом случае одним из возможных путей создания тестов является
глубокое изучение стандарта языка С++, в ходе которого выявляются и фиксируются ограничения,
накладываемые на реализацию компилятора и языковые конструкции, появляющиеся в
программах и программных элементах языка С++.
Таким образом, при разработке тестовых спецификаций используется частично формализованная
запись и специальные методы создания и уточнения тестовых атрибутов.
Следующие три раздела описывают методы разработки спецификаций для А-тестов и Б-тестов, а
также методы выбора гипотез для ограничения и уточнения тестовых спецификаций.
Создание спецификаций А-тестов: атрибуты тестов и таблицы решений
Спецификации для А-тестов выражены в виде таблиц решений для наборов тестовых
атрибутов.
Метод создания таблиц решений основан на методе функциональных диаграмм, описанном в
книгах Майеpса . Однако, несмотря на кажущуюся простоту, явное использование методов
Майеpса оказалось непрактичным.
При применении метода функциональных диаграмм к спецификациям языков программирования,
как к внешним спецификациям тестируемой системы, набор ситуаций, эффектов и отношений
между ними в полной функциональной диаграмме становится безгранично большим. Поэтому
возникла необходимость применять специальные приемы для разграничения рассматриваемых
вариантов связей. Одна из таких технологий заключается в использовании неполных
функциональных диаграмм: ситуации и эффекты, используемые в полной диаграмме, разделяются
и образуют несколько диаграмм, которые в дальнейшем преобразуются в таблицу решений.
Но даже создание неполных диаграмм чаще всего является довольно сложной задачей, поэтому
члены команды тестирования собственными методами анализировали неполные диаграммы и
преобразовывали их в таблицы решений.
Несмотря на эти замечания, разработка спецификаций для А-тестов включает в себя следующие
четыре шага:
Определяется набор тестовых атрибутов. Атрибут теста - это любой атрибут или свойство
языковой конструкции или выражения, встречающиеся в рассматриваемой части стандарта, или
любое свойство контекста данной конструкции, которое может рассматриваться как предмет
отдельного тестирования.
Для каждого тестового атрибута определяется набор возможных значений. Каждое значение
должно удовлетворять следующим двум требованиям:
значение присутствует в стандарте,
значение определяет отдельную тестируемую сущность.
Определяется набор эффектов, получаемых при компиляции. Каждый эффект должен
удовлетворять следующим двум требованиям:
существует возможность определения наличия или отсутствие данного
эффекта,
данный эффект должен быть как можно проще.
Создаются таблица решений. Каждая строка или столбец, в зависимости от выбранного
представления таблицы, должны содержать спецификацию для определенного теста, которая
состоит из двух частей. Первая часть отвечает за набор значений атрибутов, которые должны
реализовываться программой, а вторая описывает набор эффектов, которые получаются при
выполнении данной программы и могут быть определены при помощи среды пакета
тестирования.
Создание спецификаций для Б-тестов: "Б-значения" и "Ограничения"
Спецификации для Б-тестов и методы их создания отличаются от соответствующих методов для А-
тестов. Каждая такая спецификация состоит из двух частей.
Первая часть, называемая "Б-значения", состоит из набора ошибочных значений тестовых
атрибутов, определенных в соответствующей спецификации А-тестов. Каждое из ошибочных
значений должно удовлетворять следующим свойствам:
значение присутствует в стандарте языка С++,
значение определять отдельную тестируемую сущность.
Вторая часть называется "Ограничения" и состоит из формулировок ограничений, накладываемых
на программы языка С++ и явно выделенных в соответствующей части стандарта или логически
следующих из ее текста. Для некоторых ограничений явно указывается пути их нарушения.
Каждое ограничение, накладываемое на программы языка С++, может быть отражено, как в части
"Б-значения", так и в части "Ограничения", но не в обеих сразу.
Спецификация Б-тестов не предполагала создания таблиц решений, и единственным их эффектом
являлась диагностика в процессе компиляции. Это означает, что Б-тесты являются тестами этапа
компиляции. По крайней мере один тест был создан для каждого неправильного значения
тестовых атрибутов. Аналогично, для каждого ограничения был создан по крайней мере один
тест.
Если для некоторого ограничения добавлен набор возможностей его нарушения, то
подразумевалось написание набора тестов, проверяющих каждое из этих нарушений.
Гипотезы
Так как стандарт языка C++ является неформализованным, оценка значимости тестовых
атрибутов, их значений и комбинаций этих значений также была неформализованной. Главной
целью этой оценки является систематическое уменьшение количества тестов.
С другой стороны, принципы и результаты оценки важности атрибутов должны быть хорошо
документированы, поскольку они напрямую связаны с полнотой пакета тестов.
Для того, чтобы объяснить способ, которым оценивалась величина важности значений атрибутов,
необходимо явно сформулировать гипотезы о тестируемых свойствах реализации языка С++. Одна
из таких гипотез, называемая "Гипотеза об относительной корректности реализации", относится
ко всему пакету тестов. Эта гипотеза, называемая в дальнейшем ГОКР, формулируется так: "Когда
проверяется взаимодействие между различными языковыми конструкциями, предполагается, что
каждая из этих конструкций реализована правильно. Отсюда вытекает, что конкретное
представление данных конструкций не важно".
Предполагалось, что ГОКР будет использоваться только для ограничения количества тестов в
потенциально-бесконечном наборе тестов, а не для ограничения их сложности. Другими словами,
конкретный выбор языковых конструкций производился в соответствии с ГОКР, но был
тривиальным.
Поддержка версий
Пакет тестов строится и изменяется методом "от версии к версии". Любая конечная версия пакета
тестов является результатом точного последовательного выполнения следующих шагов:
Строится и документиpуется список различий между стандартами C и C ++. Каждое
различие снабжается соответствующей ссылкой на стандарт языка C++.
Для каждого различия выполняется следующая последовательность шагов:
Каждое различие анализируется, чтобы определить может ли оно быть
основой для аттестационных тестов. Возможно, что некоторые различия
являются следствиями других различий или имеют информационное и
технологическое, а не нормативное значение.
Для каждого различия, отбираемого, как основа для аттестационного
тестирования, определяется набор разделов стандарта C++ соответствующий
рассматриваемой языковой ситуации.
Для каждого раздела стандарта C++ определяются атрибуты тестов и
соответствующие значения, а затем создается таблица решений. Эти действия
для различных разделов могут быть выполнены независимо.
Если в течение выполнения шага 2. найдены новые различия между C и C++, они
объединяются в отдельный список различий. Этот список может быть добавлен к первоначальному
списку различий и тогда процесс создания набора тестов должен быть повторно начат с шага 2.,
или он может сохраняться как отдельный список, который нужно использовать при создании
следующей версии набора тестов. Выбор между этими альтернативами зависит от большого
количества неформальных причин, включая доступные ресурсы и значимости данных различий.
На основе спецификаций, полученных в течение шага 3, создаются тесты. Для
дополнительного сокращения числа тестов могут использоваться формальные и неформальные
методы. (То есть тесты создаются только для выбранных, а не для всех спецификаций) Этот шаг
может быть повторен несколько раз для той же самой версии набора тестов (и, поэтому, для того
же самого набора спецификации); каждый раз невыбранные спецификации выбираются, чтобы
получить более полную версию пакета тестов.
4.3. Свойства тестов
Опишем подробнее свойства различных групп тестов и требования, предъявляемые к ним.
Классы тестов
Как уже неоднократно отмечалось, все тесты в пакете подразделены на два класса, в соответствии с
задачей тестирования и природой критериев успешного завершения или отказа:
А-тесты:
Тест относится к классу А-тестов, если он является правильной выполнимой (в соответствии со
стандартом языка C++) программой. А-тесты проверяют способность реализации обрабатывать
правильные с точки зрения стандарта программы правильным образом. А-тест считается успешно
завершенным, если его компиляция прошла успешно и вызов получившегося кода прошел без
ошибок. причем ошибками в последнем случае являются не только ошибки, выданные
соответствующей реализацией, но и сообщения самой программы о том, что данная реализация
обработала ее не соответствующем стандарту способом.
Б-тесты:
Тест относится к классу Б-тестов если он является неправильной (нарушающей требования
стандарта языка C++) программой.
Б-тест проверяет способность реализации обнаруживать
нарушения стандарта в компилируемой программе. Б-тест считается успешно завершенным, если
во время компиляции определены все ошибки, содержащиеся в нем.
Полученные тесты являются компиляционными тестами, содержащими нарушения стандарта,
проверяемые на этапе компиляции. Это ограничение основано на следующих допущениях:
Для любого ограничения, налагаемого стандартом языка C++, которое может быть
проверенно на этапе компиляции, и для любой реализации компилятора с языка C++, есть только
два случая: либо реализация способна обнаружить нарушения этого ограничения во время
компиляции, либо получается потенциально исполнимый код, содержащий это нарушение.
Последний случай считается несоответствием стандарту C++, даже если в процессе выполнения
программы появились сообщения об ошибках (ошибках исполнения кода программы). Ситуация,
при которой реализация проверяет данные ограничения в процессе выполнения программы,
кажется практически невероятной.
Даже если реализация сама способна исправить ошибки программы, она должна выдать
сообщения о них, и конечный код должен отличаться от кода, полученного в ситуации, когда
ошибок нет.
Все исключительные ситуации (как вызываемые так и обрабатываемые) могут быть проверены
с помощью А-тестов. Соответствующие тесты должны содержать соответствующую функцию
обработки исключительной ситуации, и во всем другом быть обычными А-тестами.
Для других ошибок этапа выполнения (которые не сводятся к обработке исключительных
ситуаций) стандарт языка C++ не содержит ограничений (касающихся поведения реализации),
которые позволяют написать аттестационные тесты.
Общие требования к тестам
Основные требования, предъявляемые к тестам, следующие:
Необходим отдельный тест для каждой спецификации. Однако, выяснено, что это
требование не может быть выполнено и, следовательно, должно стать целью. Основными
причинами этого стали:
На этапе проектирования пакета тестов трудно оценить человеческие и
компьютерные ресурсы, необходимые для следующего этапа, на котором
происходит написание тестов. Поэтому, на этапе написания тестов полезно и
даже необходимо исправление спецификаций.
Во время разработки спецификаций тестов, трудно проверить возможность
написания теста для каждой конкретной спецификации. Поэтому была
проведена лишь приблизительная оценка достижимости спецификаций. Все
явно недостижимые спецификации были удалены, но спорные были оставлены
в окончательном варианте набора тестовых спецификаций. При последующем
написании тестов появились спецификации, реализация которых
представляется сложной или технически невозможной. Эти спецификации тоже
удаляются из полного набора спецификаций. Данная практика является
общепринятой и будет продолжаться в процессе отладки пакета тестов.
Стандарты написания тестов должны ограничивать использование некоторых языковых
конструкций, во всех случаях кроме случая, когда данная конструкция является тестируемой.
Каждый тест должен быть написан как можно проще и короче.
Тесты должны быть просмотрены и отлажены для того, чтобы устранить ошибки и установить
соответствие между тестами и целями тестирования.
Специальные Требования к А-тестам
А-тесты могут быть разделены на две подгруппы. Первая состоит из тестов, которые производят
некоторые нетривиальные действия во время выполнения. Как правило, в течение этих действий
вычисляется некоторое значение, и затем оно сравнивается с эталонным значением. Спецификации
для этой подгруппы тестов могут содержать некоторые комбинация нетривиальных эффектов.
Другая подгруппа состоит из тестов которые проверяют правильность компиляции некоторой
комбинации языковых ситуаций. Спецификации для этой подгруппы обычно содержит только
один эффект типа "ситуация, содержащаяся в тесте, обрабатывается реализацией".
Различия между этими двумя подгруппами тестов существенны для проектировщиков и
разработчиков тестов, но они могут быть скрыты от конечного пользователя пакета тестов.
Поэтому, все А-тесты должны быть самопроверяющимися и сходно обрабатываться средой
тестирования.
Как было сказано выше, тесты, проверяющие обработку исключительных ситуаций, тоже могут
быть организованы как обычное А-тесты посредством выбора соответствующей структуры
обработки исключительной ситуации для каждого конкретного теста.
Специальные Требования к Б-тестам
Каждый Б-тест должен содержать ровно одну ошибку, соответствующую спецификации
теста.
Все Б-тесты в пакете тестов являются тестами процесса компиляции. (То есть, тест прошел если
его компиляция не удалась, и наоборот) Это предположение не полностью правильно, но оно
основано на общепринятой модели компилятора для языка фон Неймана и позволяет
организовывать естественную и удобную среду тестирования для B-tests.
AIM
AIM Technology
Генератор тестовых пакетов
Нагрузочные смеси (стандартные/заказные)
Сертифицированный отчет (для AIM Performance
Report II)
Стоимость системы
Детали конфигурации системы
Результаты измерений на трех тестовых пакетах:
многопользовательский тестовый пакет AIM (набор
III)
тестовый пакет утилит AIM (Milestone)
тестовый пакет для оценки различных систем (набор II)
Критерии:
Пиковая производительность (рейтинг VAX 11/780 = 1 AIM)
Максимальная пользовательская нагрузка (емкость системы)
Индекс производительности утилит (количество пользовательских
заданий пакета Milestone, выполненных за 1 час)
Пропускная способность системы (количество выполненных заданий
в минуту)
Архитектура машин с очень длинным командным словом
Пример с 7-кратным разворачиванием цикла:
| Обращение к памяти 1 | Обращение к памяти 2 | Операция ПТ 1 | Операция ПТ 2 | Целочисленная операция/переход |
| LD F0,0(R1) LD F10,-16(R1) LD F18,-32(R1) LD F26,-48(R1) SD 0(R1),F4 SD -16(R1),F12 SD -32(R1),F20 SD 0(R1),F28 | LD F6,-8(R1) LD F14,-24(R1) LD F22,-40(R1) SD -8(R1),F8 SD -24(R1),F16 SD -40(R1),F24 | ADDD F4,F0,F2 ADDD F12,F10,F2 ADDD F20,F18,F2 ADDD F28,F26,F2 | ADDD F8,F6,F2 ADDD F16,F14,F2 ADDD F24,F22,F2 | SUBI R1,R1,#48 BNEZ R1,Loop |
Скорость работы цикла: 1.28 такта на элемент
Архитектура MIPS
MIPS - 1986 г.
R2000/R3000: Silicon Graphics, Digital, Siemens Nixdorf
R3000/R3010 - 33/40 МГц, 20 SPECint 92, 23 SPECfp 92
R4000/R4400 (64-битовая архитектура)
R4000 50/100 МГц, 58 SPECint 92, 61 SPECfp 92
R4400 75/150 МГц, 94 SPECint 92, 105 SPECfp 92
R10000: 200 МГц, 800 MIPS4 команды за такт,Обмен данными - 3.2 Гбайт/с
Архитектура Alpha (64 бит)
DECchip 21064 - до 200 МГц
DECchip 21064А, 1993 г., 275 МГц
DECchip 21066, 166 МГц
DECchip 21068, 66 МГц, 8 Вт
DECchip 21066А, 100, 233 МГц
DECchip 21164:
1994 г.
300 МГц,
330 SPECint 92, 500 SPECfp 92
0,5 микрон КМОП
9,3 млн. транзисторов
POWER - 33, 41.6, 45, 50, 62.5 МГц - 134.6 SPECfp
92
POWER 2 - 66.5, 71.5 МГц, 65 Вт
23 млн. транзисторов
0.45 микрон
1217 кв. миллиметров
131 SPECint 92, 247 SPECfp 92
Состав многокристального набора:
Блок кэш-памяти команд (ICU) - 32 Кбайт, имеет
два порта с 128-битовыми шинами;
Блок устройств целочисленной арифметики (FXU) - содержит два
целочисленных конвейера и два блока регистров общего назначения
(по 32 32-битовых регистра). Выполняет все целочисленные и логические
операции, а также все операции обращения к памяти;
Блок устройств плавающей точки (FPU) - содержит два конвейера
для выполнения операций с плавающей точкой двойной точности, а
также 54 64-битовых регистра плавающей точки;
Четыре блока кэш-памяти данных - максимальный объем кэш-памяти
первого уровня составляет 256 Кбайт. Каждый блок имеет два порта.
Устройство реализует также ряд функций обнаружения и коррекции
ошибок при взаимодействии с системой памяти;
Блок управления памятью (MMU).
Эволюция в направлении Power PC:
упрощение архитектуры с целью ее приспособления
ее для реализации дешевых однокристальных процессоров;
устранение команд, которые могут стать препятствием
повышения тактовой частоты;
устранение архитектурных препятствий суперскалярной
обработке и внеочередному выполнению команд;
добавление свойств, необходимых для поддержки
симметричной многопроцессорной обработки;
добавление новых свойств, считающихся необходимыми
для будущих прикладных программ;
ясное определение линии раздела между "архитектурой"
и "реализацией";
обеспечение длительного времени жизни архитектуры
путем ее расширения до 64-битовой.
Микропроцессоры Power PC:
Power PC 601
Power PC 603
Power PC 604
Power PC 620, 133 МГц, 225 SPECint92, 300 SPECfp92
Архитектура системы
Архитектура разработанной системы представляет собой механизм взаимодействия клиент-сервер,
причем этот механизм реализуется на нескольких уровнях.
На глобальном уровне конечным клиентом является удаленный пользователь, получающий доступ
к системе посредством сети Internet, а конечным сервером является сервер СУБД Oracle. Далее эту
схему можно детализировать и разбить на следующие взаимодействия по схеме клиент-сервер:
Взаимодействия удаленный пользователь - WWW сервер Alibaba;
Взаимодействие обработчик, связанный с HTML документом - серверное приложение;
Серверное приложение - сервер СУБД.
Шлюз к базе данных состоит из двух частей: резидентной (серверной) и вызываемой WWW
сервером (клиентской).
Клиентская часть, указанная в HTML документе, передаваемом удаленному пользователю,
запускается при помощи вызова WinExec() WWW сервером Alibaba. Ей передаются данные,
введенные пользователем посредством диалогов в HTML документ, которые клиентское
приложение передает серверному. После выполнения серверным приложением SQL запроса,
клиентское приложение получает результаты от серверного приложения, производит их
декодирование и формирует на их основе HTML документ, направляемый WWW серверу для
последующей передачи его удаленному клиенту.
Серверная часть, называемая серверным приложением, устанавливает соединение с базой данных,
принимает данные, заданные пользователем в запросе, от клиентского приложения-обработчика,
формирует запрос к базе данных на языке SQL на основе данных, полученных от клиентского
приложения, исполняет этот запрос и передает результаты клиентскому приложению.
Хотя клиентских приложений может быть много, в каждый момент времени существует
единственное соединение (connection) с базой данных. Несмотря на то, что СУБД может
одновременно поддерживать несколько соединений, используемая схема позволяет работать с БД
во-первых, большему числу пользователей, во-вторых, уменьшает время обработки запроса, и, в-
третьих, экономит оперативную память, включая, в общем-то одинаковую для всех клиентских
приложений процедуру формирования и посылки SQL-запроса, в единое серверное
приложение.
Архитектурные спецификации
Имеюся следующие основные эталонные модели:
Эталонная модель взаимосвязи открытых систем
(Reference Model for Open Sysnems Interconnection - RM-OSI); -
ITU-T X.200 (1994); ISO/IEC 7498-1,2,3,4:1994
Руководство по окружению открытых систем POSIX
Portable Operaring System Interface for Computer Environments)
- ISO/IEC DTR 14252;
Эталонная модель для открытой распределенной
обработки
(RM-ODR) - ITU-T Rec. 902 ISO/IEC 10746-2:1995;
Эталонная модель управления данными (Reference
Model for Data Management - RMDF) - DIS 9075:1992 ;
Эталонная модель компьютерной графики (Reference
Model of Computer Graphics - RM CG);
Эталонная модель программной инженерии (ISO 9000
- ISO 9004, ISO8402:1988);
Эталонная модель текстовых и офисных систем (ISO/IEC
TROTSM-1), в частности, общая (general) модель распределенных
офисных систем (ISO/IEC 10031:1991).
Разрабатываются и близки к опубликованию:
Методы аттестации и аттестационное тестирование
(conformance and conformance test methods);
основы общей безопасности (generic security frameworks);
качества OSI-сервиса (Quality of Service for
OSI).
Архитектуры и технологии разработки интероперабельных систем
Л.Калиниченко, Институт проблем информатики РАН,
E-mail:
Автоматическая генерация С++ кода.
Rational Rose/C++ включает средства автоматической
генерации кодов программ на языке С++. Используя информацию, содержащуюся
в модели проекта, генератор кодов формирует файлы заголовков и
файлы реализаций классов.
Создаваемая структура программы может быть уточнена путем прямого
программирования на языке С++. При повторной генерации внесенные
изменения не теряются
Стиль структуры программы в коде С++ формируется настройкой свойств
(properties) проекта.
Ошибки, обнаруженные генератором кодов С++, представляются в специальном
Log файле.
Свойства генерации кода могут быть настроены как
для всего проекта, так и для отдельных его компонент.
Rational Rose/C++ генерирует С++ код стандарта ANSI.
Базируясь на выбранных свойствах генерации, Rational Rose генерирует
следующие элементы кода:
Для каждого модуля:
Заголовочный файл и файл реализации для модуля.
#include директивы, явно или неявно определенные
в моделе.
Для каждого класса:
Определение класса.
Объявление атрибутов, отношений включения и ассоциативных
отношений.
Get и Set функции для доступа к атрибутам.
Объявления для стандартных операций с заготовками
определений.
Объявления для операций, определенных пользователем.
Все поля документирования из спецификаций диаграмм
переносятся в код как комментарии.
Автоматическое преобразование нотаций
Ассоциативные связи позволяют документировать проектные
решения
Категории классов применяются
для разбиения приложения на отдельные группы взаимосвязанных
классов.
Категории классов образуют
иерархию, в которой классы являются терминальными узлами
Базовые спецификации
Базовые функции ОС; определяются
стандартами по окружению открытых систем POSIX (Portable Operaring
System Interface for Computer Environments) - ISO/IEC 9945:1990.
Функции управления базами данных;
включают язык баз данных SQL (Structured Query Language), информационную
справочную систему (Information Resource Dictionary System - IRDS),
протокол распределенных операций RDA (Remote Data base Access).
Функции пользовательского интерфейса;
включают следующие ИТ: MOTIF из OSF для графического пользовательского
интерфейса (GUI); система X Windows, охватывающая рпоцедуры GUI
и телекоммуникации; стандарты для виртуального терминала (Virtual
Terminal - VT), включая Telenet, определяющую процедуры для работы
VT в символьном режиме через транпортную службу TCP/IP; cтандарты
машинной графики GKS (Grafical Kernel System - ISO/IEC 7942),
PHIGS (Programmers Hierarchical Interactive Graphics System, а
также CGI (Computer Graphics Interface).
Функции взаимосвязи открытых систем,
включая спецификации сервиса и протоколов, разработанные в соответствии
с моделью OSI (рекомендации серии X 200); стандарта локальных
сетей (IEEE 802); спецификации сети Internet.
Функции распределенной обработки,
включая базовые спецификации OSI (Remote Procedure Call - RPC;
Commitment, Concurrency and Recovery - CCR; Distributed Transaction
Processing - TP; File Transfer, Access and Management (FTAM),
OSI Management, а также API для доступа к сервису Object Request
Broker (ORB) в архитектуре CORBA, API, определяющий базовые возможности
такого сервиса (Commom Object Services - COS 1), язык спецификации
интерфейсов объектов IDL (Interface Definition Language) и его
проекции на ООП.
Распределенные приложения,
включая, спецификации специальных сервисных элементов прикладного
уровня модели OSI, стандартов Internet, OMG, X/Open. В частности,
к ним относятся: система обработки сообщений MHS (Message Handling
System - X.400), служба справочника (The Directory - X.500) и
др.
Cтруктуры данных и документов,
в том, числе средства языка ASN.1 (Abstract Syntax Notation One
- ISO/IEC 8824:1990), предназначенного для спецификации прикладных
структур данных, т.е. абстрактного синтаксиса прикладных объектов;
спецификация структур учрежденческих документов (Office Document
Architecture (ODA) - T.411-T.418, T.421, T.502, T.505, T.506;
структура документов для производства - Standard Generalized Markup
Language (SGML - ISO/IEC 8876:1986); форматы метафайла для представления
графической информации: Computer Graphics Metafile (CGM); стандарт
на сообщения и элементы данных для электронного обмена данными
в управлении, коммерции и торговле (стандарт EDIFACT - Electronic
Data Interchange for Administration, Commence and Trade); языки
описания документов гипермалтимедиа: HyTime (ISO/IEC 10744:1992),
SMDL (Standard Music Description Language - ISO/IEC 1074:1992),
SMSL (Standard Multimedia/Hypermedia Scripting Language - ISO/SC1/WG8:1993),
SPDS (Standard Page Description Language - ISO/IEC 10180:1994),
DSSSL (Document Style Semantics and Specification Language - ISO/IEC
10179), HTML (HyperText Markup Language) и др.
Borland Delphi как инструмент корпоративного разработчика
С.Орлик, Borland
Может быть немало споров - они идут постоянно - по
поводу
механизма эволюции, но никто не оспаривает самого факта.
Айзек Азимов
"В
начале"
Говоря о том или ином средстве разработки приложений всегда хочется понять какие
тенденции приводят к его появлению. Borland Delphi не является исключением из правил. Итак,
что же мы имели к середине 90-х?
Одно направление - объектно-ориентированный подход, хорошо структурирующий
задачу, как таковую, так и ее решение в виде прикладной системы.
Другое направление, возникшее во многом благодаря объектной ориентации, - визуальные
средства быстрой разработки приложений (RAD - Rapid Application Development),
основанные на компонентной архитектуре.
Третья тенденция - использование компиляции, а не интерпретации. Это объясняется тем,
что скоростные характеристики компилируемых приложений в десятки раз лучше, чем у систем,
использующих интерпретатор. При этом повышается легкость отчуждаемости готовых систем, так
как отпадает необходимость "таскать за собой" сам интерпретатор (run-time), выполненный
обычно в виде динамической библиотеки и занимающий в лучшем случае несколько сотен
килобайт (а большинстве случаев - два-три мегабайта). Отсюда и меньшая ресурсоемкость у
скомпилированных систем.
Четвертая тенденция - возможность работы с базами данных универсальными
(единообразными) методами. Если мы попытаемся оценить процент систем, которые так или
иначе требуют обработки структурированной информации (как для внутрикорпоративного
использования, так и для коммерческого или иного распространения), то окажется, что цифра 60-
70% может представлять лишь нижнюю границу. Важным свойством средств обеспечения доступа
к базам данных является их масштабируемость, как возможность не только
количественного, но и качественного роста системы. Например, обеспечение перехода от
локальных ,в том числе, файл-серверных данных к архитектуре клиент-сервер или тем более к
многоуровневой N-tier схеме.
Delphi создавался как продукт, в полной мере реализующий описанные тенденции, с архитектурой,
открытой для расширения спектра поддерживаемых стандартов и подходов.
Быстрая и надежная разработка приложений с использованием PowerBuilder
А.Чибисов, фирма Метатехнология
PowerBuilder™ - это объектно-ориентированный инструмент для профессиональной разработки
приложений в среде клиент/сервер, позволяющий коллективам разработчиков легко и быстро создавать
графические приложения, которые имеют доступ к базам данных и другой корпоративной информации,
хранящейся локально или на сетевых серверах.
Цели OSE-профилей
В рассматриваемом документе свойства открытости систем,
являющимися и целями OSE-профилей, развиваются до следующего набора:
переносимость прикладного программного обеспечения
и переиспользуемость программного обеспечения на уровне исходного
кода
переносимость данных
интероперабельность прикладного программного обеспечения
интероперабельность управления и безопасности
переносимость пользователей
использование существующих стандартов и аккомодация к стандартам
перспективных технологий
легкая настраиваемость на новые технологии информационных
систем
масштабируемость прикладных платформ
масштабируемость распределенных систем
прозрачность реализаций
поддержка пользовательских требований
CPI-конвейера R4000 на тестах SPEC
| Тест | CPI - конвейера | Приостановки по загрузке | Приостановки по переходам | Приостановки по результатам операции ПТ | Приостановки по структурным конфликтам ПТ |
| eqntott | 1.88 | 0.27 | 0.61 | 0.00 | 0.00 |
| espresso | 1.42 | 0.07 | 0.35 | 0.00 | 0.00 |
| gcc | 1.56 | 0.13 | 0.43 | 0.00 | 0.00 |
| li | 1.64 | 0.18 | 0.46 | 0.00 | 0.00 |
| doduc | 2.84 | 0.01 | 0.22 | 1.39 | 0.22 |
| nasa7 | 1.83 | 0.00 | 0.08 | 0.65 | 0.10 |
| ora | 4.30 | 0.00 | 0.19 | 3.69 | 0.42 |
| spice2g6 | 1.91 | 0.30 | 0.29 | 0.26 | 0.06 |
| su2cor | 2.19 | 0.02 | 0.07 | 0.84 | 0.26 |
| tomcatv | 1.90 | 0.00 | 0.05 | 0.60 | 0.25 |
| Mean | 2.15 | 0.10 | 0.27 | 0.64 | 0.13 |
Диаграмма процессов
Изображаются процессоры и устройства, образующие физическую конфигурацию
прикладной системы
Диаграмма сценариев
Диаграммы сценариев - динамический взгляд на модель.
Диаграммы сценариев показывают основные объекты проекта и взаимодействия
между ними.
Имеется возможность задать последовательность обращений объектов
друг к другу.
Два типа сценарных диаграмм:
Диаграммы сценариев объектов
Диаграммы сценариев сообщений
Система включает средства автоматического взаимного
преобразования диаграмм сценариев.
Диаграмма состояний
Для каждого класса может быть создана диаграмма состояний.
На ней указывается начальное, конечное и промежуточные состояния,
а также события, определяющие переход из одного состояния в другое.
Имеется возможность гнездования состояний.
Диаграммы классов
Отображают логику построения прикладной системы.
На них отображают классы, категории классов и отношения между
ними.
Возможность отражения параметризованых классов.
Допускаются разнообразные отношения: ассоциации, включения, использования,
наследования.
Имеются простые и удобные средства просмотра иерархий диаграмм
классов.
Для каждого конкретного отношения можно задать имя
и основные его характеристики
Все диаграммы сопровождаются подробными спецификациями.
Диаграммы модулей
Диаграммы модулей - физическая модель системы.
Показывает подсистемы проектируемого приложения и основные модули
каждой из них.
Диаграммы модулей образуют иерархию.
Для каждого модуля можно отдельно показать на диаграмме его файл-заголовок
и файл реализации.
Диаграммы сценариев объектов
Диаграммы сценариев сообщений могут сопровождаться
структурированным текстом.
Дисковые массивы
RAID (Redundant Array of Inexpensive disks) - избыточный массив
недорогих дисков
4 этапа процесса обслуживания:
определение отказавшего диска,
устранение отказа без останова обработки;
восстановление потерянных данных на резервном диске;
периодическая замена отказавших дисков на новые.
Уровни RAID:
RAID 0: расслоение дисков (disk stripping)
RAID 1: зеркальные диски
RAID 2: матрица с поразрядным расслоением
RAID 3: аппаратное обнаружение ошибок и четность
RAID 4: внутригрупповой параллелизм
RAID 5: четность вращения для распараллеливания записей
RAID 6: двумерная четность
Доменная служба каталогов Windows NT
Домен - это объединение одного или нескольких серверов, обеспечивающее единую базу
учетных записей пользователей
Между доменами могут существовать доверительные отношения
Графические интерфейсы и средства их разработки
С.Клименко, Институт Системного Программирования РАН,
В.Уразметов, Московский Физико-Технический Институт
Групповая работа в Rational Rose/C++
Каждому разработчику может быть выделено собственное
рабочее пространство, чем устраняется неконтролируемое и асинхронное
распространение изменений.
Декомпозиция модели на категории и управляемые части (units)
позволяет наделить разработчика своим кругом ответственности.
Rational Rose/C++ интегрируется с системой управления версиями
(PVCS) или подобными ей.
Внутри выделенного рабочего пространства участники групповой
работы могут работать на различных платформах (UNIX или Windows)
и в дальнейшем собрать единую модель.
Документирование модели
Rational Rose/C++ включает средства документирования
модели:
Вывод на печать диаграмм и спецификаций непосредственно
из Rose/C++
Генерация документации модели в RTF формате для
последующего редактирования средствами мощных редакторов типа
MicroSoft Word
Создание шаблонов для генерации проектной документации
в соответствии с заданным стандартом с помощью средства автоматизированного
документирования SoDA.
Classes
Class name:
Environmental Controller
Documentation:
Контролирует поддержание заданных условий (температeра,
кислотность, влажность, освещенность и т.д.) в теплице, управляя
нагревателем, холодильником и т.п
Superclasses:
<none>
Roles/Associations:
<none>
Attributes:
Voltage : int = 220
напряжение питания
Has-A Relationships:
<unnamed> : Cooler
<unnamed> : Heater
<unnamed> : Light
Operations:
Define_climate( temperature : temp_range, humidity
: humid_range) : control_status
Задать климат
Terminate_climate( )
отменить заданный климат
Характеристики рабочих станций на базе процессора Alpha
| Система/ Характеристики | AlphaStation 200 4/100 | AlphaStation 200 4/166 и 200 4/233 | AlphaStation 250 4/266 | DEC 3000 модель 900 |
| Частота | 100 МГц | 200 4/166: 166 МГц 200 4/233: 233 МГц | 266 МГц | 275 МГц |
| Размер кэш | 512 Кб | 512 Кб | 2 Мб | 2 Мб |
| Макс. размер памяти | 192 Мб | 192 Мб | 512 Мб | 1 Гб |
| Макс. емкость дисков (внутренняя/ общая) | 3.15Гб / 29.4 Гб | 3.15 Гб / 29.4 Гб | 4.2Гб /29.4Гб | 8.4Гб/170 Гб |
| Макс. пропускная способность ввода/вывода | 132 Мб/с | 132 Мб/с | 132 Мб/с | 100 Мб/с |
| Графика и мультимедиа | DEC864 ATI Mach64 ATI Video Basic ZLXp-Es FullVideo Supreme Встроенная стерео-аудио система | DEC864 ATI Mach64 ZLXp-Es Встроеннаястерео-аудио система | DEC864 ZLXp-Es FullVideo Supreme Встроенная стерео-аудио система | ZLX-Es ZLX-L1 ZLX-M2 J300 Голосовая аудио-система |
| Слоты ввода/вывода | 1 PCI, 1 ISA, 1 PCI/ISA, встроенный Ethernet, FDDI, Token Ring | 2 PCI/ISA C, 1 ISA, SCSI-2, Ethernet, FDDI, Token Ring | 1 PCI, 1 ISA, 1 PCI/ISA, Fast SCSI-2, встроенныйEthernet, FDDI, Token Ring | 6 TURBOchannel, 12 Fast SCSI-2, Ethernet, FDDI, ISDN, Prestoserve, VME |
| Поддержка кластеров | Ethernet, FDDI | Ethernet, FDDI | Ethernet, FDDI | Ethernet, FDDI |
| Операционные системы | Digital UNIX, OpenVMS, Windows NT Workstation | Digital UNIX, OpenVMS, Windows NT Workstation | Digital UNIX, OpenVMS, Windows NT Workstation | Digital UNIX, OpenVMS |
unlimited users Solstice
| E3000 | K250 | K260 | |
| Processor | UltraSPARC | PA-8000 | PA-8000 |
| Clock Speed | 167MHz | 160MHz | 180MHz |
| Cache per CPU | 1MB per CPU | 1MB/1MB(I/D) | 1MB/1MB(I/D) |
| Max CPUs | 6 | 4 | 4 |
| estimated tpm | 6,660 (6) | 11,580 (4) | 12,320 (4) |
| SPECrate_int95 | 336 (6) | 390 (4) | 415 (4) |
| SPECrate_fp95 | 469 (6) | 380 (4) | 400 (4) |
| Min/Max Memory | 64MB-6GB | 128MB-3.75GB | 128MB-3.75GB |
| Max External Disk | >2TB | 3.8TB | 3.8TB |
| I/O Slots | 6 SBus | 4 HP-PB | 4 HP-PB |
| 1 HP-HSC | 1 HP-HSC | ||
| I/O Bandwidth | 1.2 GBps(peak) | 128 MBps(peak) | 128 MBps(peak) |
| Hot Plug Disks | 10 internal | no internal | no internal |
| Hot Plug Components | Power/Cooling Boards | no | no |
| Warranty | 1 yr, on-site | 1 yr, on-site | 1 yr, on-site |
| Basic OS | Solaris 2.5. 1 unlimited users Solstice Disk-Suite, Solstice Backup | HP-UX 10.20 2-user | HP-UX 10.202-user |
unlimited users Solstice Disk-
| E4000 | K450 | K460 | |
| Processor | UltraSPARC | PA-8000 | PA-8000 |
| Clock Speed | 167MHz | 160MHz | 180MHz |
| Cache per CPU | 1MB per CPU | 1MB/1MB(I/D) | 1MB/1MB(I/D) |
| Max CPUs | 14 | 4 | 4 |
| estimated tpm | 11,500 (12) | 11,580 (4) | 12,320 (4) |
| LADDIS (NFSops/s) | 15,674 (12) | na | 9,572 (4) |
| LADDIS (ms/op) | 21.1 (12) | na | 19.9 (4) |
| SPECrate_int95 | 660 (12) | 390 (4) | 415 (4) |
| SPECrate_fp95 | 887 (12) | 380 (4) | 400 (4) |
| Min/Max Memory | 64MB-14GB | 128MB-3.75GB | 128MB-3.75GB |
| Max External Disk | >4TB | 8.3TB | 8.3TB |
| I/O Slots | 21 SBus | 8 HP-PB | 8 HP-PB |
| 5 HP-HSC | 5 HP-HSC | ||
| I/O Bandwidth | 2.6 GBps(peak) | 288 MBps(peak) | 288 MBps(peak) |
| Hot Plug Disks | 10 internal | no internal | no internal |
| Hot Plug Components | Power/Cooling | no | no |
| Boards | |||
| Warranty | 1 yr, on-site | 1 yr, on-site | 1 yr, on-site |
| Basic OS | Solaris 2.5. 1 unlimited users Solstice Disk- Suite, Solstice Backup | HP-UX 10.20 2-user | HP-UX 10.202-user |
Arrays or4 Trays and
| E5000 | T520 | T600 | |
| Processor | UltraSPARC | PA-7150 | PA-8000 |
| Clock Speed | 167MHz | 120MHz | 180MHz |
| Cache per CPU | 1MB per CPU | 1MB/1MB(I/D) | 1MB/1MB(I/D) |
| Max CPUs | 14 | 14 | 12 |
| estimated tpm | 11,500 (12) | 7,000 (12) | 15,000 (12) |
| Min/Max Memory | 64MB-14GB | 256MB-3.75GB | na-3.75GB |
| Max External Disk | >6TB | 20TB | 30TB |
| I/O Slots | 21 SBus | 112 HP-PB | 168 HP-PB or |
| 24 HP-HSC | |||
| I/O Bandwidth | 2.6 GBps(peak) | 256 MBps(peak) | na |
| System Bus Throughput | 2.6 GBps(peak) | 960 MBps(peak) | 960 MBps(peak) |
| In-rack Devices | 3 Arrays or4 Trays and Tape Unit | no internal | no internal |
| Hot Plug Components | Power/Cooling Boards | no | no |
| Warranty | 1 yr, on-site | 1 yr, on-site | 1 yr, on-site |
| Basic OS | Solaris 2.5.1 unlimited users Solstice Disk-Suite, Solstice Backup | HP-UX 10.20 2-user | HP-UX 10.20 2-user |
| МОДЕЛЬ | G40 | J40 | |||||
| ЦП | |||||||
| Тип процессора | PowerPC604 | PowerPC604 | |||||
| Тактовая частота (Мгц) | 112 | 112 | 112 | 112 | 112 | 112 | 112 |
| Число процессоров | 1 | 2 | 4 | 2 | 4 | 6 | 8 |
| Системная шина (бит) | 64 | 64 | 64 | 64 | 64 | 64 | 64 |
| Размер кэша | |||||||
| L1 (команды/данные)(Кб) | 16/16 | 16/16 | 16/16 | 16/16 | 16/16 | 16/16 | 16/16 |
| L2 (Мб) | 0.5 | 0.5 | 0.5 | 1 | 1 | 1 | 1 |
| ПАМЯТЬ | |||||||
| Минимальный объем (Мб) | 64 | 64 | 64 | 128 | 128 | 128 | 128 |
| Максимальный объем (Мб) | 1024 | 1024 | 1024 | 2048 | 2048 | 2048 | 2048 |
| ВВОД/ВЫВОД | |||||||
| Количество слотов | 5MCA | 5MCA | 5MCA | 6MCA | 6MCA | 6MCA | 6MCA |
| Периферийные интерфейсы | Fast/Wide SCSI-2 | Fast/Wide SCSI-2 | |||||
| Максимальная емкость внутренних дисков (Гб) | 13.5 | 13.5 | 13.5 | 36 | 36 | 36 | 36 |
| Максимальная емкость дисковой памяти (Гб) | 350 | 350 | 350 | 99 | 99 | 99 | 99 |
| ПРОИЗВОДИТЕЛЬНОСТЬ | |||||||
| SPECint_rate95 | 33.6 | 66.5 | 122.0 | 71.9 | 138.0 | 205.0 | 258.0 |
| SPECfp_rate95 | 28.2 | 53.3 | - | 57.3 | 107.0 | 159.0 | 200.0 |
| SPECint_base_rate95 | 32.2 | 60.6 | 110.0 | 64.9 | 129.0 | 195.0 | 244.0 |
| SPECfp_Base_rate95 | 26.9 | 50.7 | - | 53.4 | 102.0 | 154.0 | 189.0 |
| tpmC | - | - | - | - | - | - | 5774 |
| $/tpmC | - | - | - | - | - | - | 243 |
Инструментальная среда PowerBuilder
Инструментальная среда разработки PowerBuilder состоит из ряда интегрированных графических
инструментов - художников, позволяющих коллективу разработчиков проектировать, создавать,
интерактивно тестировать и применять приложения клиент/сервер в режиме "укажи и щелкни
кнопкой мыши". Cреда разработки PowerBuilder может быть расширена для организации
непосредственного доступа к набору инструментальных средств разработки других фирм. Интерфейс
пользователя PowerBuilder MDI позволяет разработчикам открывать окна нескольких художников
одновременно, что дает возможность мгновенно получить доступ к нужному режиму работы.
Поддержка средой разработки правой кнопки мыши упрощает и ускоряет процесс создания сложных
приложений.

приложений (Application Painter)
Художник приложений определяет среду приложения, включая имя приложения и его
пиктограмму, установленные по умолчанию цвета и шрифты, программы обработки событий
приложений, список библиотеки, а также позволяет разработчику графически просматривать всю
иерархию объектов приложения. Как только все объекты приложения будут созданы,
откомпилированы и протестированы, Художник приложений создаст исполняемый файл
(.EXE).

Художник окон (Window Painter)
Художник окон создает окна (являющиеся основным элементом интерфейса приложений) и
элементы управления, которые могут быть частью окна. Элементами управления являются командные
кнопки, линейки прокрутки, списки выбора, открывающиеся списки выбора, радиокнопки,
альтернативы, элементы управления Окна данных (DataWindow) и многое другое.

Художник меню (Menu Painter)
Художник меню создает меню и линейки инструментов, которые можно связать с любым
окном как в процессе определения окна, так и динамически из программы, в ходе ее выполнения.

Художник Окна данных (DataWindow Painter)
Художник Окна данных создает интеллектуальный объект данных для просмотра,
манипулирования и обновления реляционных баз данных без необходимости программирования на
SQL. Художник Окна данных содержит множество параметров, предоставляемых в режиме
"укажи и щелкни кнопкой мыши", которые позволяют изменять оформление внешнего вида Окна
данных. Не прибегая к программированию, разработчики могут создавать деловую графику,
вычисляемые столбцы, автоматические сводки, а также осуществлять межтабличный анализ. Окна
данных могут быть динамическими и поддерживать изменения во время выполнения приложения
в виде незапланированных запросов и отчетов, чтобы удовлетворить самым специфическим
требованиям конечных пользователей.

Художник структур (Structure Painter)
Художник структур создает сложные структуры данных для использования их в
конструкциях языка PowerScript и для связи с внешними функциями. Структуры помогают
разработчику организовать переменные в программах и облегчают взаимодействие с внешними
функциями.

Художник настроек (Preferences Painter)
Художник настроек позволяет настраивать конфигурацию PowerBuilder в соответствии с
привычками и вкусом разработчика.

(Help)
PowerBuilder снабжен подробной контекстно-зависимой оперативной подсказкой (Online Help),
предоставляющей информацию из справочных руководств по PowerBuilder.

Художник баз данных (DataBase Painter)
Художник баз данных предоставляет интерактивные средства для создания и поддержки баз
данных SQL. Разработчики могут создавать таблицы и представления, определять первичные и
внешние ключи, запускать командные файлы баз данных, обеспечивать безопасность и
редактировать данные из базы данных.
Центральный репозиторий дизайна приложений (Central Application Design Repository) предоставляет
развитые возможности управления хранением расширенных атрибутов столбцов, таких как
заголовки, метки, форматы изображения, правила проверки и графические стили
редактирования.

Художник переноса данных (Data Pipeline Painter)
Художник переноса данных обеспечивает разработчикам доступ к данным и перенос данных без
программирования, даже если они находятся в различных базах данных.
Определения DataPipeline
могут быть сохранены в виде объектов и затем использованы в приложениях.

Художник запросов (Query Painter)
Художник запросов предоставляет графические средства для создания запросов к базам
данных и сохранения этих запросов в виде объектов. Объекты запросов можно использовать в
качестве источника информации для Окна данных и отчетов, обеспечивая еще более тесную
интеграцию с базами данных. Художник запросов полностью поддерживает графическое
рисование SQL как для таблиц, так и для представлений. Для дополнительной гибкости пользователи
при желании могут иметь полный доступ к оператору SQL Select.

Художник функций (Function Painter)
Художник функций позволяет разработчику создавать и поддерживать функции, которые
чаще всего представляют собой общие процедуры, неоднократно используемые в одном или
нескольких приложениях, сокращая при этом объем повторяющегося кода.

Художник проектов (Project Painter)
Художник проектов позволяет указывать порядок и параметры сборки различных
приложений из общего набора объектов в библиотеках PowerBuilder. Определения проектов
сохраняются в библиотеках и позволяют автоматизировать большинство действий по подготовке
готового приложения.

Художник библиотек (Library Painter)
Художник библиотек позволяет разработчикам совместно использовать все объекты
приложений, такие как окна, Окна данных, меню, структуры и Объекты пользователей
(User Objects). Эти объекты хранятся в одной или нескольких библиотеках, локализованных в одном
месте или распределенных в сети. Возможность проверки при выдаче и возврате объектов (check-
in/check-out) позволяет предотвратить одновременное обновление одного объекта несколькими
разработчиками. Предоставляются также возможности поиска в библиотеках, анализа взаимосвязи и
создания подробных отчетов для разработчиков по библиотекам и их компонентам.
Художник библиотек предлагает также прозрачный доступ ко множеству систем контроля
версий и систем управления конфигурацией, разработанных третьими фирмами.
Разработчики,
создающие крупные приложения, могут поддерживать несколько версий объектов и отслеживать, кто
и когда внес данное изменение.

Художник Объектов пользователей (User Object Painter)
Художник Объектов пользователей создает объекты, определенные пользователями, из
стандартных элементов управления Windows, предварительно определенных объектов пользователей
и элементов управления VBX. Художник Объектов пользователей может также создавать
невидимые объекты пользователя, обеспечивая полное использование объектно-ориентированной
техники разработки. Используя построитель классов C++ (C++ Class Builder), основанный на
технологии Watcom, объекты пользователя можно реализовывать на языке C++.

(Run)
Щелчок левой кнопкой мыши на пиктограмме Run (запуск) приведет к запуску текущего приложения
в среде разработки PowerBuilder для проверки его функциональности.

Отладка (Debug)
Отладчик выполняет приложение в режиме отладки для поиска ошибок в работе программ и
объектов. Отладчик позволяет разработчику устанавливать очки прерывания, осуществлять
выполнение по шагам, просматривать и изменять значения переменных, а также сохранять среду
сеанса отладки для использования в будущем.
Интеграция CORBA и WWW-технологий
Быстрое распространение всемирной паутины (WWW) происходило в тот период, когда
распределенные объектные системы, в особенности архитектура CORBA, проходили стадию
стабилизации и созревания. Принятие стандарта CORBA 2.0 позволяет
обеспечить поддержку глобального объектного пространства в масштабе Internet.
Существенное различие назначений WWW и CORBA заключается в том, что WWW облегчает
жизнь поставщиков и потребителей информации, а CORBA облегчает задачу разработчиков
систем и фирм-поставщиков инструментальных средств. Поэтому роли WWW и CORBA являются
взаимно дополняющими, и в этой связи требуются специальные технологии, обеспечивающие их
сопряжение. Такое сопряжение сулит очевидные преимущества. Разработчики программных
продуктов, использующие CORBA, получают доступ к быстро растущему рынку на основе WWW,
а мир WWW получает доступ к услугам, обеспечиваемым на основе возможностей CORBA,
значительно более мощным, чем реализуемая WWW простая модель обмена HTML-страницами.
Интеграция двух миров приведет к наилучшему использованию этих двух стандартов.
Известны два основных подхода к интеграции CORBA и WWW. Первый из них основан на
построении шлюзов между мирами WWW и CORBA, служащих для трансформации HTTP
в протокол CORBA 2.0 IIOP . Другой подход заключается во
встраивании функций CORBA в состав клиентов WWW (программ просмотра) и серверов.
Реализация второго подхода возможна либо на основе новых WWW клиентов и серверов со
встроенным IIOP, либо при помощи подгрузки (downloading) из сети модуля поддержки IIOP в
клиенте или сервере.
В новом поколении WWW клиентов и серверов, поддерживающих Java, модуль поддержки IIOP
реализуется на Java. Достоинства этого подхода заключаются в обеспечении динамической
"раскрутки" функций по отношению к CORBA. Так, для любого ресурса, доступного посредством
CORBA, может быть разработан пользовательский интерфейс как апплет Java. Этот апплет
использует модуль IIOP для взаимодействия с сервером CORBA. При первом доступе пользователя
к какой-либо услуге, программа просмотра автоматически загружает и инсталлирует апплет
пользовательского интерфейса. После этого пользователь имеет доступ к этой услуге посредством
собственного апплета.
Таким образом, услуги объектов-серверов оказываются доступными широчайшей аудитории,
независимо от применяемых пользователями платформ и при сохранении для разработчика
возможности усовершенствования реализации услуг и их интерфейсов.
Интеграция СУБД в глобальную сеть Internet
Интеграция информационных ресурсов библиотеки организована путем создания на основе WWW
(World Wide Web) - технологии серверов в основных библиотеках и информационных центрах
страны с обеспечением средств доступа к ним на основе протокола TCP/IP.
Таким образом, одной из задач проекта является обеспечение стыковки базы данных СУБД
ORACLE с Internet протоколами и разработка удобного пользовательского интерфейса
позволяющего осуществлять поиск интересующей пользователя литературы. WWW - это
гипертекстовая система, использующая для общения клиента с сервером собственный протокол
HTTP (HyperText Transfer Protocol), а также поддерживающий массу различных протоколов
обмена приложений Internet. Для создания и использования гипертекстовых документов определен
язык HTML (HyperText Markup Language). Для указания ресурсов используется технология URL
(Universal Resource Locator). С помощью данной технологии реализуется взаимодействие WWW-
сервера с базами данных ORACLE. Суть такого взаимодействия заключается в том, что
программа-сервер (Alibaba) WWW способна организовать взаимодействие с классом программ
класса CGI (Common Gateway Interface). Один из вариантов использования CGI - исполнение SQL-
запросов к базе данных.
Целью работы является создание программного комплекса, предоставляющего удаленному
пользователю, связавшемуся с WWW сервером библиотечной системы, удобного интерфейса для
формирования запросов для поиска литературы в базе данных, осуществление этого поиска и
выдача результатов в удобном для пользователя представлении.
Программа должна перефразировать запрос пользователя в SQL запрос к базе данных и получать
результаты его выполнения, а также диагностировать возникающие ошибки.
Инструментальными средствами решения этой задачи являются C, SQL и HTML, а также пакет
разработчика ODBC SDK.
Обмен данными производится на основе архитектуры клиент-сервер. Для обмена данными
используются документы MIME (Multipurpose Internet Mail Extensions) стандарта, который
включает в себя описание различных типов документов от простого текста до анимации.
Интерпретация полученных документов возлагается на средства просмотра документов
работающие на стороне клиента такие, как Modzilla, Netscape, Mozaic и им подобные,
объединяемые названием WWW browsers.
WWW сервер постоянно находится в режиме ожидания запросов на соединение от удаленных
пользователей. После установления сеанса связи с клиентским приложением просмотра
документов клиенту пересылается либо указанный им документ, либо стандартный документ-
заставка (home page) сервера.
Интегрированный подход к разработке крупных программных систем управления реального времени
В.Крюков, А.Петренко, Институт прикладной математики
им. М.В.Келдыша
РАН
Данный доклад посвящен обзору основных результатов исследований и разработок средств
поддержки разработки ПО для крупных управляющих систем реального времени, в которых
участвовал Институт прикладной математики (ИПМ) им. М.В.Келдыша РАН в содружестве с
другими научными центрами на протяжении последних 14 лет.
Начало этих работ было положено проектом Системы Автоматизации разработки Программного
Обеспечения (САПО) ПРОЛОГ для космического корабля "Буран". Второй этап этой деятельности
состоял в развитии САПО ПРОЛОГ в целях расширения сферы приложения методики разработки
систем реального времени (СРВ) и языка реального времени ПРОЛ2 за счет перехода на новые
программно/аппаратные платформы и за счет более широкого охвата фаз жизненного цикла,
начиная от эскизного проектирования, кончая тестированием. Третий этап определяется
привлечением качественно новых подходов к методам разработки и созданием инструментов,
поддерживающих эти методы. В основе этих подходов лежит идея систематизации, а там, где это
возможно, даже формализации процесса разработки, формального описания структуры
разрабатываемого программного продукта с учетом его эволюции и вариантности и формального
описания поведения, которое открывает возможности автоматизации сопоставления поведения
программной системы с ее спецификацией.
На каждом из этапов приходилось заново переоценивать приоритеты проблем, менялись
ограничения на ресурсы, эволюционировали требования пользователей программного продукта.
По мере накопления опыта менялись наши представления о проблемах создания систем реального
времени, о том, что собственно нуждается в автоматизации или хотя бы в машинной поддержке, и
о возможностях повышения уровня разработки программного обеспечения (ПО).
Надеясь, что читателю будет интересно проследить эволюцию наших представлений, мы
построили доклад в соответствии с хронологией наших работ.
При создании программного обеспечения многоразовой космической системы (МКС) "БУРАН"
разработчики встретились с обычными трудностями разработки и отладки программного
обеспечения, однако, помноженные на большой объем и на большое количество разработчиков
разнообразных систем и алгоритмов, эти трудности приобрели особую остроту.
Наибольшее количество ошибок при создании программного обеспечения возникает:
на стыке между алгоритмистом и программистом, когда они по разному
понимают алгоритм, написанный на бумаге;
при кодировании информационных посылок из ЭВМ в аппаратуру;
при организации взаимодействия различных алгоритмов между собой.
Для устранения первого источника ошибок для разработки ПО МКС "БУРАН" был создан
проблемно-ориентированный язык высокого уровня для описания алгоритмов управления
бортовыми системами ПРОЛ2. Используя ПРОЛОГ алгоритмисты и разработчики бортовых
систем описывали алгоритмы, вводили их в ЭВМ и, далее, с помощью системы автоматизации
программирования автоматически получали исполняемые программы для управления бортовыми
системами.
Второй источник ошибок, возникающих при кодировании большим количеством программистов
кодовых посылок из ЭВМ во внешнюю аппаратуру, устранялся тем, что эти кодовые посылки
формировались автоматически и помещались в специализированную базу данных, из которой
трансляторы выбирали их при компиляции исполняемых программ.
Ошибки взаимодействия различных алгоритмов между собой устранялись при отладке алгоритмов
на инструментальной ЭВМ и на комплексном моделирующем стенде, где штатные алгоритмы
управления, исполняемые на штатной ЭВМ взаимодействовали в замкнутой схеме с
математическими моделями движения и бортовых систем, реализованных на универсальной
ЭВМ.
Таким образом, интегрированный комплекс для разработки программных систем позволял:
описывать и вводить в ЭВМ алгоритмы процессов управления и
испытаний в удобном и понятном разработчикам бортовых систем виде;
описывать алгоритмы математических моделей этих бортовых систем ;
отлаживать автономно и комплексно взаимодействие алгоритмов в
замкнутой схеме ;
получать загрузочные модули для специализированной управляющей ЭВМ;
отлаживать полный комплекс программного обеспечения, загружаемый в
специализированную ЭВМ и взаимодействующий с математическими
моделями бортовых систем, функционирующих в универсальной ЭВМ.
Интегрированные комплекс для разработки программного обеспечения включает большой набор
сервисных средств, позволяющих:
проводить статический контроль программного обеспечения по
формальным описаниям алгоритмов, переменных, входным и выходным
воздействиям и т.д.
при отладке задавать условия испытаний программного обеспечения
управлять процессом сбора, отображения и анализа всей необходимой
информации для каждого конкретного разработчика; в ходе автономной
отладки обеспечивался контроль выполнения требований жесткого реального
времени.
Благодаря использованию интегрированного комплекса при разработке программного
обеспечения МКС "БУРАН" за 4 года было создано и отработано ПО для управления системами
МКС "БУРАН" и необходимая инфраструктура объемом свыше миллиона операторов.
В рамках второго этапа работ были разработаны язык СИПРОЛ, который является упрощенным
вариантом языка ПРОЛ2, и интегрированная система проектирования и разработки СИПРОЛ-
программ .
В ходе этих работ решались следующие проблемы:
проблема разработки языка и пользовательского интерфейса, который
позволял бы более активно участвовать в процессе проектирования систем
управления специалистам в области аппаратуры и технологам;
проблема ускорения технологического микроцикла разработки, состоящего
в редактировании и отладке, в стиле "Турбо-систем";
проблема интеграции различных инструментов, поддерживающих
проектирование, кодирование, отладку и тестирование систем управления.
Все перечисленные проблемы были решены. Реализованная система СИПРОЛ была разработана
для IBM-совместимых платформ в качестве инструментальной ЭВМ. Для расширения спектра
целевых ЭВМ генератор кода позволял получать исполнимый код в форме С-программ.
Это
позволяло переносить разработанные системы управления практически на все современные
ЭВМ.
Отличительной особенностью системы СИПРОЛ явились графический редактор и отладчик,
которые были интегрированы в единую "турбо-систему". Наряду с графическим диалектом язык
СИПРОЛ имеет и текстовый диалект, поэтому разработку систем можно вести как средствами
графического, так и обычного (тестового) программирования.
Третий этап работ преимущественно был посвящен вопросам повышения качества как собственно
создаваемого ПО, так и качества процесса разработки ПО.
Как известно на западе в последние 3-4 года очень серьезное внимание уделяется "уровню
зрелости" (maturity level) процесса разработки. Это внимание обусловлено пониманием того факта,
что главным фактором, определяющим уверенность пользователя (покупателя или заказчика)
программного обеспечения в его качестве, не может являться какая-либо однократная проверка
качества, будь то тестирование, инспекция кода или нечто подобное. Гарантию качества дает
только совокупность мер по организации взаимодействия разработчиков, совместного
использования и разработки программ, документов и др. что в целом и определяет уровень
зрелости организации- и группы-производителя ПО. В качестве стартовой точки в систематизации
процесса разработки всеми признано введение организационных процедур и средств управления
конфигурациями ПО. В русскоязычных публикациях конфигурационное управление (КУ) часто
называется управлением версиями, хотя, в действительности, оно охватывает проблемы
структуризации и хранения программных материалов существенно шире, чем простое хранение
версий.
В ИПМ был разработан подход иерархического конфигурационного управления (ИКУ). Данный
подход позволил на единой основе решить следующие задачи:
разработать языково-независимое иерархическое представление
структуры программного материала, позволяющее явно описывать связи и
зависимости между отдельными компонентами ПО, их вариантами,
отличающимися функционально, и поколениями, которые отражают эволюцию
компонента, вызванную коррекцией ошибок, модернизацией и т.п.;
обеспечить поддержку откатов и ретроспективного анализа процесса
разработки, за счет интегрирования системы хранения поколений и описаний-
изменений;
автоматизировать поддержку сборки согласованных версий
(конфигураций);
обеспечить целостность контролируемых версий.
На основе предложенного подхода была разработана система управления конфигурациями для
IDM PC. Концепция иерархического конфигурационного управления описана в
Как известно, одной из главных проблем разработки СРВ является проблема надежности. К
средствам повышения надежности ПО, которые развивались в рамках третьего этапа относятся
методика и средства поддержки формальных спецификаций и автоматизации тестирования на
основе таких спецификаций.
Данная методика была апробирована в ходе верификации ядра реальной операционной системы
(объем около 200 тыс. строк языка высокого уровня). Формальные спецификации строились по
результатам реверс-инженеринга. В качестве языка спецификаций использовался язык RAISE
(Rigorous Approach to Industrial Software Engineering) . По разработанным
спецификациям при помощи наших инструментов были сгенерированы тесты. Уровень
автоматизации (отношение объемов автоматически сгенерированных частей тестовых программ к
объемам программ тестовой системы, написанным вручную) лежит в диапазоне 10/1-30/1. Причем,
количество тестовых вариантов (test cases) для каждой из тестируемых процедур легко варьируется
в широком диапазоне (вплоть до миллионов и большего числа вариантов). Заметим, что методика
автоматической генерации нацелена не столько на достижение большого числа тестовых
вариантов, сколько на селекцию так называемых "интересных" тестовых ситуаций, поэтому оценка
эффективности тестирования только через число тестовых вариантов не является главной и
определяющей.
Результативность предложенного подхода была продемонстрирована при тестирования
упомянутой операционной системы. Верификация группы подсистем, составляющей примерно
треть ядра ОС (этот результат отражает текущее состояние данного проекта), позволила выявить
более тридцати скрытых до сих пор ошибок. Важно, что данная ОС уже несколько лет находится в
эксплуатации.
Важной особенностью предложенного метода верификации является независимость спецификаций
от реализации целевой (тестируемой ) системы. За счет этого тестовые наборы, которые
получаются в результате генерации также не зависят от реализации, они определяются только
интерфейсами целевой системы, ее поведением. Это позволяет широко использовать данный
подход для проверки сохранения интерфейсов программных систем при переносе на новые
программные и аппаратные платформы.
При изменении интерфейсов тестируемой системы для создания нового комплекта тестов
необходимо скорректировать спецификации изменившихся интерфейсов, после чего заново
выполняется генерация тестов. В результате, в общем случае, все старые тесты могут оказаться
негодными, однако, вместо них генерируются новые и это выполняется автоматически.
Таковы основные результаты, которые были получены в ходе исследований и разработок средств
поддержки разработки ПО для крупных управляющих систем реального времени, в которых
участвовали авторы доклада.
Интерфейс общения с пользователем посредством Internet
Основными функциями интерфейса для работы с удаленным пользователем являются построение
пользователем запроса на поиск информации о требуемой литературе в базе данных и
преобразование результатов поиска к удобному для восприятия пользователем
представлению.
Реализация интерфейса пользователя проводится на стандартизированном языке WWW серверов
HTML версии 2.0. Данный язык позволяет организовывать гипертекстовые и гипермедиа
документы , в узлах которых могут находиться документы одного из стандартных MIME типов.
Второй уровень HTML позволяет встраивать в документы, передаваемые пользователю ,
стандартные объекты диалога. Данные, введенные пользователем, посредством CGI интерфейса
передаются приложению-обработчику. При построении интерфейса конструирования запросов к
базе данных было принято предположение о том, что пользователь может для запроса
использовать логическое выражение любой конструкции.
При построении указанного выражения из атомов допускается использование логических
операций NOT, AND, OR и скобок для задания порядка вычисления выражений. Данный подход
является серьезным обобщением стандартного конструирования логических выражений,
используемого в большинстве программных средств. Атомы представляются следующим образом:
.
На основе проведенного статистического анализа запросов в библиотеках и консультаций со
специалистами в области библиотечного дела были выделены следующие критерии поиска:
автор,
коллективный автор,
тематический рубрикатор,
название
фрагмент названия
год издания,
ISSN.
При отсутствии выражения для соответствующего критерия считается , что данный критерий
следует не учитывать в этой части запроса. После формирования указанной части выражения
пользователю предоставляется возможность либо сразу выполнить запрос, либо продолжить его
конструирование. При продолжении конструирования предыдущая часть запроса предоставляется
пользователю в качестве восьмого атома для конструирования (наряду с теми же семью
стандартными критериями). Пользователь может уточнять запрос как за счет использования семи
стандартных критериев поиска, так и за счет модификации предыдущей части запроса путем
добавления в нее новых атомов, модификации и удаления старых. Данный процесс продолжается
итеративно до получения пользователем требуемого запроса, которые пользователь и отсылает
для исполнения.
Для перехода от одного бланка к следующему в процессе уточнения запроса согласно стандарту
CGI используются приложения-обработчики, которые и генерируют новые формы для ввода
данных с учетом ранее введенных пользователем данных.
Получаемые из базы данных результаты запроса приложения формируют в цепочку HTML
документов MIME типа "text/html" и передают их пользователю посредством WWW сервера.
Internet Information Server - составная часть Windows NT Server
Работа в качестве сервера Internet
WWW Server
FTP server
Gopher server
Консоль управления
Защита
Высокая производительность
Работа в качестве клиента
Встроены Telnet и FTP
Microsoft Internet Explorer
Использование Windows NT для построения глобальных сетей
Объединение нескольких локальных сетей в одну большую
Объединение нескольких локальных сетей с использованием линий связи
ISDN, X.25, Frame Relay, PPP
PPTP
RAS Multilink
Автодозвон
ИТОЛОГИЯ - наука об информационных технологиях
В. Сухомлин, НИВЦ МГУ, учебные материалы конференции ,
В последнее десятилетие произошло становление новой
науки - науки об информационных технологиях (ИТ-науки) или итологии,
основными характерными чертами которой являются:
фундаментальное значение для развития по существу
всех областей знания и видов деятельности, как эффективного метода
познания и инструмента, усиливающего интеллектуальные возможности
человека;
целевая направленность на преображение человеческой практики
и бытия, способность прокникновения во все аспекты жизни и деятельности
человека;
междисциплинарная роль как общезначимой дисциплины (аналогично
математике и философии), обусловленная прежде всего ее методологическим
значением, благодаря наличию развитого концептуального базиса,
универсальных в применении парадигм, методов, языков для формализации,
анализа и синтеза прикладных знаний.
Предмет итологии - информационные технологии
(ИТ), а также процессы, связанные с их созданием и применением.
Основными методами итологии являются:
Создание основ научного знания в виде методологичекого
ядра (метазнаний), представляющего собой целостную систему эталонных
моделей важнейших разделов ИТ, осуществляющего структуризацию
научного знания в целом. Данный метод получил название архитектурной
спецификации.
Представление ИТ в виде спецификаций поведения
реализаций ИТ, т.е. ИТ-систем, которое может наблюдаться на интерфейсах
(границах) этих систем. Данный метод называют также функциональной
спецификацией.
Стандартизация спецификаций ИТ и управление их
жизненным циклом, осуществляемая системой специализированных международных
организаций на основе строго регламентированной деятельности.
Данный процесс обеспечивает накопление базовых сертифицированных
научных знаний, служит основой создания открытых технологий.
Аппарат (концепция и методология) проверки соответствия
(аттестации) реализаций ИТ (т.е. ИТ-систем) ИТ-спецификациям,
на основе которых данные ИТ-системы были разработаны (по существу
данный аппарат играет такую же роль в пространстве информационных
технологий, как и эпсилон-дельта аппарат в математическом анализе).
Профилирование ИТ или разработка функциональных
профилей ИТ - метод построения спецификаций комплексных технологий
посредством комбинирования базовых и производных от них (представленных
в стандартизованном виде) спецификаций с соответствующей параметрической
настройкой этих спецификаций (по существу профилирование является
композиционным оператором в пространстве ИТ с базисом, в качестве
которого выступают базовые, т.е. стандартные спецификации).
Таксономия (классификационная система) профилей
ИТ, обеспечивающая уникальность идентификации в пространстве ИТ,
явное отражение взаимосвязей ИТ между собой.
Разнообразные методы формализации и алгоритмизации
знаний, методы конструирования прикладных информационных технологий
(пара-дигмы, языки программирования, базовые открытые технологии,
функциональное профилирование ИТ и т.п.).
Язык программирования Си++: этапы эволюции и современное состояние
В.Сухомлин, Научно-исследовательский Вычислительный центр
МГУ им.
М.В.Ломоносова
Эффект конвейеризации при выполнении трех команд - четырехкратное ускорение

Типы конфликтов в конвейере:
Структурные конфликты (конфликты по ресурсам)
Конфликты по данным (зависимость команды от результатов выполнения
предыдущих команд)
Конфликты по управлению (зависимость от направления условного
перехода и других команд, меняющих значение счетчика команд)
Эволюции продуктной линии SKIP
Хотя SKIP пока не является стандартом Internet, на основе этого протокола, на правах открытого
индустриального стандарта, разработали программные продукты, по меньшей мере, три
организации: Sun Microsystems, Swiss Federal Institute of Technology и АО ЭЛВИС+. Заявили о
работе над продуктами на основе этого протокола такие организации, как Check Point Software,
Toshiba Corporation, и две небольших калифорнийских фирмы - VPNet Technology и IRE.
Уже в июле 1995 года на 33 сессии IETF разработчиками были представлены реализации
протоколов и проверена их совместимость. Тогда эти программы были достаточно далеки от
состояния, которое можно было бы характеризовать как "программный продукт".
На сегодняшний день картина изменилась, и мы имеем масштабируемый ряд продуктов защиты
информации на основе спецификации SKIP. В разработке этого ряда приняли участие, по
существу, все три из упомянутых организаций, однако на деятельности каждой из них сказалась
внутренняя специфика каждой из них. Sun Microsystems использовала SKIP, как базовое средство
защиты трафика в устройстве SunScreen - продукте, который получил признание, в частности, как
продукт 1996 года по категории firewall в журнале LAN Magazine. Продукт SunScreen анонсирован
в мае 1995 года и с тех пор находится в эксплуатации. Кроме устройства SunScreen, Sun предлагает
программную реализацию SKIP для ОС Solaris. В Швейцарии выпущена public domain версия
протокола SKIP. Разработка продуктных предложений, видимо, вследствие некоммерческой
ориентации Swiss Federal Institute of Technology, не анонсировалась. АО ЭЛВИС+, ориентируясь
на специфику российского рынка, пошел по пути разработки недорогих программных реализаций
SKIP для распространенных платформ UNIX и Windows. Помимо платформного деления, АО
ЭЛВИС+ предлагаются версии продукта с различной функциональностью: от простой программы
для защиты трафика оконечного устройства, работающего с одним выделенным сервером, до
полнофункционального продукта защиты станции в корпоративной сети, который обеспечивает
учет топологии сети и индивидуальную настройку дисциплины взаимодействия с различными ее
узлами. Кроме того, нами разработано и предлагается в виде готового продукта устройство для
коллективной защиты локальных сетей SKIPbridge. Это - аппаратно-программный комплекс на
основе SPARCserver 5, который устанавливается на интерфейсе LAN/WAN и обеспечивает
решение двух задач: SKIP-защиту входящего и исходящего трафика и реализацию заданной
политики безопасности на интерфейсе LAN/WAN путем расширенной пакетной фильтрации. На
текущий момент оттестирована совместимость всех продуктов АО ЭЛВИС+ и Sun Microsystems, и
мы можем говорить о едином, широко масштабируемом по функциональности и стоимости, ряде
продуктов. Разработка целого продуктного ряда потребовала от нас решения ряда
технологических проблем разработки ПО - от традиционных, связанных, например, с
переносимостью с платформы на платформу - до достаточно необычных, таких, как обеспечение
совместимости с продуктами других, независимо работающих, групп разработчиков и
отслеживание версионности продуктов в условиях достаточно быстро меняющейся спецификации
базового протокола. Большая часть этих проблем этапа разработки продуктов решена, что,
впрочем, не позволяет нам расслабиться, поскольку следом за проблемами разработки ПО
неизбежно встают проблемы его внедрения и сопровождения.
Сергей Дмитриевич Рябко, руководитель проектов АО ЭЛВИС+
Sergei D. Ryabko, ELVIS+ project manager
tel. (095) 531-1754
fax 531-2403
[]
[]
[]
Эволюции спецификации SKIP
Текущая версия эскизных материалов IETF по стандарту SKIP от 14 августа 1996 года имеет ряд
отличий от первой версии, опубликованной 15 мая 1994 года.
Суммировать изменения, вносившиеся в спецификацию за время рассмотрения этого протокола в
рабочей группе IETF, можно следующим образом.
Усовершенствована и стандартизована логика инкапсуляции в SKIP (туннелирования) в
соответствии со стандартом RFC 1827.
Повышена стойкость защиты системы и за счет введения временно- зависимого механизма защиты
пакетного ключа.
Появился функционально набор проектов стандартов, превращающих SKIP из отдельного
протокола в комплексное технологическое решение. Специальный документ выпущен авторами
спецификации протокола SKIP для использования сертификатов в формате X.509. Описана
процедура обмена информацией о поддерживаемых алгоритмах шифрования для данного узла.
Опуская ряд идейно более мелких коррекций спецификации, следует отметить проработку в новой
спецификации вопросов совместимости SKIP и со следующей (пока повсеместно не внедренной)
версией протокола IP (IPv6).
Кластерные архитектуры
Три составляющих:
Надежность
Готовность
Удобство обслуживания
Свойства VAX-кластеров:
Разделение ресурсов
Высокая готовность
Высокая пропускная способность
Удобство обслуживания системы
Расширяемость
Технологии параллельных баз данных:
Симметричная многопроцессорная архитектура с
общей памятью (Shared Memory SMP Architecture)
Архитектура с общими дисками (Shared Disk Architecture)
Архитектура без разделения ресурсов (Shared Nothing Architecture)
SPEC (Standard Performance Evaluation Corporation):
Разработка и публикация наборов тестов
Публикация ежеквартального отчета
Два базовых набора:
CINT92 (6 программ на Си):
теория цепей
интепретатор ЛИСП
разработка логических схем
упаковка текстовых файлов
электронные таблицы
компиляция программ
CFP92 (14 программ, из них: 2 на Си, 12 на
Фортране)
разработка аналоговых схем
моделирование методом Монте-Карло
квантовая химия
оптика
робототехника
квантовая физика
астрофизика
прогноз погоды
и др.
Типовая среда обработки транзакций
и соответствующие оценочные тесты TPC

Тест ТРС-С: единицы измерения tpm-С и $/tpm-С
Пять типов транзакций:
новый заказ, вводимый с помощью экранной формы - 45%
простое обновление базы данных, связанное с платежом - 43%
простое обновление базы данных, связанное с поставкой - 4%
справка о состоянии заказов - 4%
справка о состоянии склада - 4%
База данных компании:
Товарные склады
Район
Покупатель
Заказ
Порядок заказов
Новый заказ
Статья счета (наименование товара)
Складские запасы
История
Новые тесты: TPC-D и TPC-E
Компоненты архитектуры
Брокер Объектных Заявок. Брокер Объектных Заявок обеспечивает механизмы, позволяющие
объектам посылать или принимать заявки, отвечать на них и получать результаты, не заботясь о
положении в распределенной среде и способе реализации взаимодействующих с ними объектов.
ORB отвечает за поиск реализации объекта, участвующего в заявке, подготовку объектной
реализации к приему заявки и передачу данных, являющихся результатом заявки. Интерфейс
клиента полностью независим от расположения вызываемого объекта, языка программирования,
на котором он реализован, и любых других аспектов, не отраженных в интерфейсе вызываемого
объекта. На основании совместных предложений ряда ведущих компаний OMG был разработан
стандарт Общей Архитектуры Брокера Объектных Заявок (Common Object Request Broker
Architecture (CORBA)) . CORBA определяет среду для различных реализаций
ORB, поддерживающих общие сервисы и интерфейсы. Это обеспечивает переносимость клиентов и
реализаций объектов между различными ORB.
В настоящее время существует ряд промышленных реализаций ORB, соответствующих стандарту
CORBA . CORBA непрерывно совершенствуется OMG. Текущий уровень
стандарта -- CORBA 2.0.
Объектные Службы. Объектные Службы представляют собой набор услуг (интерфейсов и
объектов), которые обеспечивают базовые функции, необходимые для реализации других
объектов. Операции, предоставляемые Объектными Службами, выступают в качестве базовых
"строительных" блоков для Общих Средств и прикладных объектов. В настоящее время OMG
приняты, или наxодятся в процессе формирования спецификации следующиx служб:
Служба Уведомления Объектов о Событии (Event Notification Service).
Служба Жизненного Цикла Объектов (Object Lifecycle Service).
Служба Именования Объектов (Name Service).
Служба Долговременного Хранения Объектов (Persistent Object Service).
Служба Управления Конкурентым Доступом (Concurrency Control Service).
Служба Внешнего Представления Объектов (Externalization Service).
Служба Объектных Связей (Relationships Service).
Служба Транзакций (Transaction Service).
Служба Изменения Объектов (Change Management Service).
Служба Лицензирования (Licensing Service)/
Служба Объектных Свойств (Properties Service).
Служба Объектных Запросов (Object Query Service).
Служба Безопасности Объектов (Object Security Service).
Служба Объектного Времени (Time Service).
Функции СУБД в информационной арxитектуре. Следуя принципам модульности и
ортогональности компонентов информационной архитектуры, OMG представляет функции
управления базами данных рядом таких служб, как долговременное хранение объектов,
управление конкурентным доступом к объектам, служба транзакций, службы объектных связей,
объектных запросов, изменений объектов и т.п. Эти и другие службы, взятые вместе, реализуют
функции как объектных так и реляционных СУБД.
Спецификация служб формируется на основе опыта промышленных корпораций, входящих в
состав OMG. Существенное влияние на архитектурные решения оказывают также исследования и
разработки, воплощенные в согласованном стандарте интерфейсов объектных СУБД
Management Group). Эта группа включает представителей основных компаний - производителей
объектных СУБД.
Общие Средства. Общие Средства заполняют концептуальное пространство между ORB и
объектными службами с одной стороны, и прикладными объектами с другой. Таким образом, ORB
обеспечивает базовую инфраструктуру, Объектные Службы -- фундаментальные объектные
интерфейсы, а задача Общих Средств -- поддержка интерфейсов сервисов высокого уровня. Общие
Средства подразделяются на две категории: "горизонтальные" и "вертикальные" наборы средств.
"Горизонтальный" набор средств определяет операции, используемые во многих системах, и не
зависящие от конкретных прикладных систем. "Вертикальный" набор средств представляет
технологию поддержки конкретной прикладной системы (вертикального сегмента рынка), такого,
как здравоохранение, производство, управление финансовой деятельностью, САПР и т.д.
Ниже кратко рассматривается состав первоначальных компонентов спецификации архитектуры
Общих Средств OMG .
Средства поддержки пользовательского интерфейса (User Interface Common
Facilities)
Средства управления информацией (Information Management Common Facilities)
Средства управления системой (System Management Common Facilities)
Средства управления задачами (Task Management Common Facilities)
Вертикальные общие средства (Vertical Common Facilities)
Вертикальные общие средства предназначены для использования в качестве стандартных для
обеспечения интероперабельности в специфических прикладных областях.
Поддержка интероперабельности брокеров в стандарте CORBA 2.0
Интероперабельность брокеров поддерживается Универсальным Межброкерным
Протоколом (General Inter-ORB Protocol, сокращенно GIOP). GIOP
является универсальным, поскольку он не зависит от конкретной сетевой транспортной среды и
может быть отображен в любой транспортный протокол, поддерживающий виртуальные
соединения. Одно из таких отображений - отображение GIOP в протокол TCP/IP - определено
CORBA 2.0 в качестве Межброкерного Протокола Internet (Internet Inter-ORB Protocol,
сокращенно IIOP). Назначение протокола GIOP/IIOP заключается в том, чтобы поддержать сети
брокеров в рамках Internet и за ее пределами.
Согласно GIOP, внутренняя архитектура брокеров предполагается неизвестной. Подход, который
может быть выбран конкретным брокером для поддержки GIOP/IIOP, не определяется. Все, что
требуется для согласованного включения брокера в компьютерную сеть, - это существование
связанных с ним компонентов, способных посылать и принимать сообщения IIOP.
Спецификация GIOP включает:
Определение Общего представления данных (Common Data
Representation - CDR), являющегося, по существу, коммуникационным
синтаксисом, отображающим значения типов данных OMG IDL в формат
передачи данных между брокерами и межброкерными мостами (агентами);
Форматы передаваемых между агентами сообщений GIOP, которые
введены для поддержки объектных заявок, установления местоположения
реализаций объектов и управления транспортными соединениями.
Определение ограничений на допустимый сетевой транспорт GIOP.
Протокол IIOP, который можно считать специализацией GIOP, определяет дополнительно, как
агенты открывают соединения TCP/IP и используют их для передачи сообщений GIOP.