Дополнительная литература
Как мы уже заявляли в начале главы, писать хороший код и просто хорошо писать по-английски — достаточно схожие понятия. "Элементы стиля" В. Странка и Э. Б. Уайта (W. Strunk, E. В. White. The Elements of Style. Allyn & Bacon) — самый хороший из небольших учебников письменного английского.
Эта глава во многом взята из книги Брайана Кернигана и П. Дж. Пла-угера "Элементы стиля программирования" (Brian Kernighan, P. J. Plau-ger. The Elements of Programming Style. McGraw-Hill, 1978). "Создание надежного кода" Стива Магьюира (Steve Maguire. Writing Solid Code. Microsoft Press, 1993) — идеальный источник советов по программированию. Кроме того, интересное обсуждение стиля имеется в книгах Мак-Коннелла "Все о коде" (Steve McConnell. Code Complete. Microsoft Press, 1993) и Питера ван дер Линдена "Профессиональное программирование на С: Секреты С" (Peter van der Linden. Expert С Programming: Deep С Secrets. Prentice Hall, 1994).
<
Имена
Что в имени? Имя переменной или функции помечает объект и содержит некоторую информацию о его назначении. Имя должно быть информативным, лаконичным, запоминающимся и, по возможности, произносимым. Многое становится ясным из контекста и области видимости переменной: чем больше область видимости, тем более информативным должно быть имя.
Используйте осмысленные имена для глобальных переменных и короткие — для локальных. Глобальные переменные по определению могут проявиться в любом месте программы, поэтому их имена должны быть достаточно длинными и информативными, чтобы напомнить читателю об их предназначении. Полезно описание каждой глобальной переменной снабжать коротким комментарием:
int npending = 0; // текущая длина очереди ввода
Глобальные функции, классы и структуры также должны иметь осмысленные имена, поясняющие их роль в программе.
Для локальных переменных, наоборот, лучше подходят короткие имена; для использования внутри функции вполне сойдет просто п, неплохо будет смотреться npoints, а вот numberO.f Points будет явным перебором.
Обычно используемые локальные переменные по соглашению могут иметь очень короткие имена. Так, употребление i и j для обозначения счетчиков цикла, р и q для указателей, s и t для строк стало настолько привычным, что применение более длинных имен не принесет никакой пользы, а наоборот, может даже навредить. Сравните
Комментарии должны
Комментарии должны помогать читать программу. Они не помогут, повторяя то, что и так понятно из кода или противореча коду или отвлекая читателя от сути типографскими ухищрениями. Лучший комментарий помогает понимать программу, кратко отмечая наиболее значимые детали или предоставляя укрупненную картину происходящего.
Не пишите об очевидном. Комментарии не должны содержать самоочевидной информации типа того, что оператор i++ увеличивает i. Ниже приведены некоторые из наших чемпионов бессмысленности:
Макрофункции
В среде программистов, давно пишущих на С, существует тенденция писать макросы вместо функций для очень коротких вычислений, которые будут часто вызываться: операции ввода-вывода, такие как getchar, и проверки символов вроде isdigit — это, так сказать, официально утвержденные примеры. Причина — в производительности: у макросов нет "накладных расходов", которые свойственны вызовам функций.
На самом деле этот аргумент был не слишком убедительным уже в те времена, когда С только появился, — в эпоху медленных машин и "дорогих" вызовов функций; теперь же он просто нелеп. Для современных машин и компиляторов недостатки макрофункций перевешивают их достоинства.
Избегайте макрофункций. В C++ встраиваемые (inline) функции делают использование макрофункций ненужным; в Java макросов вообще не существует. В С они больше проблем создают, чем решают.
Одна из наиболее серьезных проблем, связанных с макрофункциями: параметр, который появляется в определении более одного раза, может быть вычислен также более одного раза; если же аргумент вызова включает в себя выражение с побочными эффектами, то результатом будет трудно отлавливаемая ошибка. В приведенном коде сделана попытка самостоятельно реализовать одну из проверок символов из <ctype . h>:
? «define isupper(c) ((с) >= 'A' && (с) <= 'Z')
Обратите внимание на то, что параметр с дважды появляется в теле макроса. Если же наш макрос is up ре г вызывается в контексте вроде такого:
? while (isupper(c = getchar()))
?
то каждый раз, когда вводимый символ будет больше или равен А, он будет пропущен, и для сравнения с Z будет считан еще один символ. Стандарт С написан таким образом, чтобы функции, аналогичные isupper, можно было реализовать как макросы, но только если они гарантируют, что аргумент будет вычисляться лишь единожды, так что приведенная выше реализация не отвечает требованиям стандарта.
Всегда лучше использовать уже имеющиеся функции ctype, чем реализовывать их самостоятельно; кроме того, функции с побочными эффектами, типа getcha г, лучше не применять внутри составных выражений. Если разбить условие цикла на два выражения, то оно будет более понятно для читателя и, кроме того, даст возможность четко отследить конец файла:
while ((с = getcharO) != EOF && isupper(c))
Иногда многократные вычисления не несут в себе прямых ошибок, но снижают производительность. Рассмотрим такой пример:
Этот фрагмент тщательно написан, форматирован

Этот фрагмент тщательно написан, форматирован и комментирован, а программа, из которой он взят, работает предельно корректно; программисты, написавшие ее, по праву гордятся своим творением. Однако для постороннего глаза этот фрагмент все же представляется странноватым. По какому принципу объединены Сингапур, Бруней, Польша и Италия? И почему Италия не упомянута в комментариях? Код и комментарий не совпадают, так что один из них неверен. Не исключено, что неверны и оба. Правда, код все же исполнялся и тестировался, так что, скорее всего, он верен, а комментарий просто забыли обновить вместе с кодом. Комментарий не объясняет, что общего у перечисленных в нем стран, хотя эта информация будет просто необходима, если вам придется заниматься поддержкой этого кода.
Наша книга посвящена практике программирования — тому, как писать обычные программы. Мы хотим помочь вам писать программы, по крайней мере, не хуже той, откуда был взят пример, избегая беспокойных мест и слабостей. Мы расскажем, как с самого начала писать грамотный код и как улучшать его по мере его развития.
Начнем мы с непривычного — с обсуждения стиля в программировании. Чем лучше у вас стиль, тем проще читать ваши программы вам самим и другим программистам; хороший стиль просто необходим для хорошего программиста. Мы начинаем со стиля, чтобы в дальнейшем вы обращали на него внимание во всех примерах.
Написать программу — это больше чем добиться правильного синтаксиса, исправить ошибки и заставить ее выполняться достаточно быстро. Программы читаются не только компьютерами, но и программистами. А программу, написанную хорошо, куда проще понять, чем написанную плохо. Культура в написании кода поможет создавать программы, ошибок в которых будет гораздо меньше. К счастью, соблюдать дисциплину не трудно.
Принципы хорошего стиля программирования состоят вовсе не в наборе каких-то обязательных правил, а в здравом смысле, исходящем из опыта. Код должен быть прост и понятен: очевидная логика, естественные выражения, использование соглашений, принятых в языке разработки, осмысленные имена, аккуратное форматирование, развернутые комментарии, а также отсутствие хитрых трюков и необычных конструкций. Логичность и связность необходимы, потому что другим будет проще читать код, написанный вами, а вам, соответственно, — их код, если все будут использовать один и тот же стиль. Детали могут быть продиктованы местными соглашениями, требованиями менеджмента или самой программой, но даже если это не так, то лучше всего подчиняться наиболее распространенным соглашениям. Мы в своем повествовании будем придерживаться стиля, использованного в книге "Язык программирования С" с некоторыми поправками для C+ + и Java.
Правила, о которых пойдет речь, будут во множестве иллюстрироваться простыми примерами хорошего и плохого стиля, на контрасте все видно лучше. Кстати, примеры плохого стиля не придуманы специально; мы будем приводить куски кода из реальных программ, написанных самыми обычными программистами (даже нами самими), работавшими в обычной обстановке, когда работы много, а времени мало.
Некоторые куски будут несколько укорочены для большей выразительности, но не искажены. После "плохих" примеров мы будем приводить варианты, показывающие, как можно их улучшить. Так как все примеры взяты из реальных программ, со многими из РГИХ связано сразу несколько проблем. Обсуждение всех недостатков сразу уводило бы нас слишком далеко, так что некоторые примеры хорошего стиля будут по-прежнему таить в себе другие, неотмечаемые погрешности.
Для того чтобы вы могли без труда отличить хорошие примеры от плохих, мы будем начинать строки сомнительного кода со знака вопроса, как, например, в этом фрагменте (помните — все фрагменты взяты из реальных программ):

Что может быть спорным в этих макроопределениях? А вы представьте себе изменения, которые необходимо будет внести в программу, если массив из TWENTY (двадцати) элементов понадобится увеличить. Нужно по меньшей мере заменить все имена на более осмысленные, указывающие на роль данного значения в программе:

что программисты используют длинные имена

Бывает, что программисты используют длинные имена независимо от контекста. Это ошибка: ясность часто достигается краткостью.
Существует множество соглашений и местных традиций именования. К наиболее распространенным правилам относятся использование для указателей имен, начинающихся или заканчивающихся на р (от pointer, указатель), например nodep, а также заглавных букв в начале имен Глобальных переменных и всех заглавных — в именах КОНСТАНТ. Некоторые программистские фирмы придерживаются более радикальных правил, таких как отображение в имени переменной информации об ее типе и способе использования. Например, реп будет означать указатель на символьный тип (pointer to char), a st rFrom и strTo — строки для ввода и вывода, соответственно. Что же касается собственно напи-. сания имен, то.использование npending, numPending или num_pending зависит от личных пристрастий, и принципиальной разницы нет. Главное — соблюдать основные смысловые соглашения; все, что не выходит за их рамки, уже не так важно.
Использование соглашений облегчит вам понимание как вашего собственного кода, так и кода, написанного другими программистами. Кроме того, вам будет гораздо проще придумывать имена для новых переменных, появляющихся в программе. Чем больше размер вашего кода, тем важнее использовать информативные, систематизированные имена.
Пространства имен (namespaces) в C++ и пакеты (packages) в Java позволяют разграничивать области видимости переменных и тем самым помогают сохранить ясность кода без использования чрезмерно длинных имен.
Будьте последовательны. Сходным объектам давайте сходные имена, которые бы показывали их сходство и подчеркивали различия между ними.
Вот пример на языке Java, где имена членов класса не только слишком длинны, но и абсолютно непоследовательны:
в названиях как Q, Queue

Слово "queue" (очередь) используется в названиях как Q, Queue и queue. Однако, поскольку доступ к очереди может быть получен только через переменную типа UserQueue, в именах членов класса упоминание слова "queue" вообще не нужно — все будет понятно из контекста. Так, двойное упоминание очереди
? queue. queueCapacity
избыточно.Класс лучше описать так:
и понятны. Последняя версия тоже

поскольку выражения вроде
queue.capacity+++;
n=queue.nusers()
вполне ясны и понятны. Последняя версия тоже еще не идеальна: термины "items" и "users" обозначают одно и то же, так что для одного понятия следовало бы использовать только один термин.
Используйте активные имена для функций. Имя функции должно базироваться на активном глаголе (в действительном залоге), за которым может следовать существительное:
now = date.getTime();
putchar( "\n-);
Функции, которые возвращают логическое значение (истина или ложь — t rue или false), нужно называть так, чтобы их смысл не вызывал сомнений. Так, из вызова
? if (checkoctal(c)) ...
непонятно, когда будет возвращаться t rue, а когда false, а вот вызов
if (isoctal(c)) ...
не оставляет сомнений в том, что результат будет истиной, если аргумент — восьмеричное число, и ложью — в противном случае.
Будьте точны. Как мы уже решили, имя не только обозначает объект, но и предоставляет читателю некоторую информацию о нем. Неверно подобранное имя может стать причиной совершенно таинственных ошибок.
Один из нас написал и не один год распространял макрос, называемый isoctal, имеющий некорректную реализацию:
«define isoctal(c) ((с) >= '0' && (с) <= '8')?
вместо правильного
«define isoctal(c) ((c)>= '0' && (с) <= '7')
В этом случае имя было правильным, а реализация ошибочной; правильное имя облегчило раскрытие ошибки.
В следующем примере имя и код находятся в полнейшем противоречии:
? public boolean inTable(Object obj) {
? int j = this.getlndex(ob]);
? return (j == nTable);
? }
Функция getlndex возвращает значение от 0 до nTable-1 в случае, если объект найден, и nTable, если объект не найден. Таким образом, возвращаемое логическое значение будет прямо противоположно тому, что подразумевается в имени функции. Во время написания кода это, может быть, не страшно, но, если программа будет дорабатываться позднее, да еще другим программистом, подобное неправильное имя наверняка станет причиной затруднений.
с поддержкой синтаксиса уменьшает вероятность

Применение средств редактирования с поддержкой синтаксиса уменьшает вероятность возникновения подобных ошибок.
В рассматриваемом примере даже после исправления отмеченной ошибки код трудно понять. В нем будет проще разобраться, если мы заведем переменную для хранения количества дней в феврале:
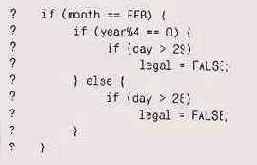
Код все еще неверен: 2000 год является високосным, а 1900-й и 2100-й — не високосные. Тем не менее такая структура уже значительно проще доводится до безупречной.
Кстати, если вы работаете над программой, которую писал кто-то другой, сохраняйте ее оригинальный стиль. При внесении изменений не применяйте свой стиль, даже если он вам больше нравится. Постоянство в форматировании программы гораздо важнее, чем ваше собственное, поскольку только оно сможет облегчить жизнь тем, кому придется вникать в способы функционирования этой программы.
Используйте идиомы для единства стиля. В языках программирования, как и в обычных языках, существуют свои идиомы — это устоявшиеся приемы, используемые опытными программистами для написания типичных фрагментов кода. Одна из центральных проблем, возникающих при изучении языка программирования, — необходимость привыкнуть к его идиомам.
Одной из наиболее типичных идиом является форма написания цикла. Рассмотрим код на С, C++ или Java для просмотра п элементов массива, например для их инициализации. Можно написать этот код так:
? 1 = 0;
? while (1 <= п-1)
? array[i++] =1.0;
или так:
? for (1=0; 1 < п; )
? аггау[1++] = 1.0;
или даже так:
for (i = n; --1 >~ 0; )
array[i] = 1.0;
Все три способа, в принципе, правильны, однако устоявшаяся, идиоматическая форма выглядит так:
for (1 = 0; i < n; i++)
array[i] = 1.0;
Выбор именно этой формы не случаен. При такой записи обходятся все п элементов массива, пронумерованные от 0 до n-1. Все управление циклом находится непосредственно в его заголовке; обход происходит в возрастающем порядке; для обновления переменной счетчика цикла используется типичная операция инкремента (++). После выхода индекс цикла имеет известное нам значение как раз за последним элементом массива. Те, для кого этот язык как родной, все понимают без пояснений и воспроизводят конструкцию не задумываясь.
В C++ и Java стандартный вариант включает еще и объявление переменной цикла:
for (int 1=0; i < n; i++)
array[i] = 1.0;
Вот как выглядит стандартный цикл для обхода списка в С:
for (р = list; р != NULL; р = p->next) .......
И опять все управляющие элементы цикла находятся непосредственно в выражении for.
Для бесконечного цикла мы предпочитаем конструкцию
for (;;)
однако популярна и конструкция
while (1)
........
Не используйте других форм, кроме двух приведенных.
Использование отступов также должно быть стандартным, можно сказать — идиоматичным. Вот такое необычное вертикальное расположение управляющих элементов цикла ухудшает читабельность кода, поскольку выглядит как три отдельных выражения, а не как единый заголовок цикла:
>
>
Прочитайте вслух следующее

Упражнение 1-3
Прочитайте вслух следующее выражение:
в отдельный оператор, тогда цикл

Еще лучше — перенести оператор присваивания в тело цикла и выделить инкремент (приращение) счетчика в отдельный оператор, тогда цикл примет более традиционный вид и, следовательно, можно будет быстрее догадаться о его смысле.
Используйте естественную форму выражений. Записывайте

Используйте естественную форму выражений. Записывайте выражения в том виде, в котором вы произносили бы их вслух. Условные выражения, содержащие отрицания, всегда трудно воспринять:
if (!(block_id < actblks) !(blocked >= unblocks))
Здесь каждая проверка используется с отрицанием, однако необходимости в этом нет никакой. Достаточно изменить знаки сравнения, и можно обойтись без отрицаний:
, if ((blocked >= actblks) (blockj.d < unblocks))
Теперь код читается вполне естественно.
Используйте скобки для устранения неясностей. Скобки подчеркивают смысловую группировку кода, и их можно использовать для упрощения понимания его структуры даже тогда, когда с точки зрения грамматики в их применении нет необходимости. Так, в предыдущем примере внутренние скобки не нужны, однако их применение как минимум ничему не мешает. Бывалый программист мог бы и опустить их, поскольку операторы сравнения (< <= == ! = >= >) имеют более низкий приоритет, чем логические операторы (&& и | |).
Все же, когда используются операторы с различным приоритетом, лучше применять скобки. В языке С и ему подобных существует ряд проблем с последовательностью выполнения операций, так что ошибку сделать совсем не сложно. Поскольку логические операции имеют более высокий приоритет, чем присваивание, употребление скобок обязательно для большинства выражений, использующих оба типа операций:
while ((с = getchar()) != EOF)
...
Побитовые операции & и | имеют более низкий приоритет, чем "обычные" операции сравнения типа ==, так что, несмотря на, казалось бы, очевидный порядок выполнения, выражение
if (x&MASK == BITS)
на самом деле выполнится как
? if (х & (MASK==BITS))
?
а это, очевидно, вовсе не то, что подразумевал программист. Поскольку используется комбинация операций сравнения и побитовых операций, скобки просто необходимы: if ((x&MASK) == BITS)
Даже если скобки в выражении не обязательны, они могут помочь сгруппировать операции так, чтобы фрагмент кода стал понятен с первого взгляда.
В следующем примере проверки високосности
В следующем примере проверки високосности года по его номеру в использовании скобок нет жесткой необходимости:
? lеар_уеаг = у % 4 == 0 && у % 100 ! = 0 | | у % 400 == 0;
но с ними фрагмент станет гораздо проще для понимания:
lеар_уеаг = ((у%4 == 0) && (у%100 != 0)) | (у%400 ==0);
Мы убрали здесь некоторые пробелы: группировка операций с самым высоким приоритетом помогает читателю быстрее разобраться в структуре программы.
Разбивайте сложные выражения. Языки С, C++ и Java имеют богатый и разнообразный синтаксис, поэтому многие увлекаются втискиванием всего подряд в одну конструкцию. Приведенное выражение весьма компактно, однако в нем содержится слишком много операторов:
*х += (*xp=(2*k < (n-m) ? c [k+1] : d[k--]));
Если разбить это выражение на несколько, оно станет гораздо более удобочитаемым:
if (2*k < n-m)
*хр = c[k+1j;
else
*xp = d[k--];
*x += *xp;
Будьте проще. Безудержная энергия программистов иногда направляется на то, чтобы написать наиболее краткий код или достичь результата самым хитрым и красивым способом. Иногда, впрочем, эти таланты тратятся впустую: настоящая задача в том, чтобы написать код попроще, а не похлеще. Вот, к примеру, что делает это замысловатое выражение?
? subkey = subkey » (bitoff - ((bitoff » 3) « 3));
Самое внутреннее выражение сдвигает bitoff на три бита вправо. Результат сдвигается обратно влево, при этом три сдвинутых бита замещаются нулями. Затем результат вычитается из первоначального значения, оставляя три младших бита bitoff, которые используются для сдвига subkey вправо.
Таким образом, приведенная конструкция эквивалентна
subkey = subkey » (bitoff & 0x7);
Над первой версией приходится гадать некоторое время, чтобы понять, что там происходит; со второй же все просто и ясно. Опытные программисты записали бы ее еще короче:
subkey »= bitoff & 0x7;
Некоторые конструкции кажутся специально созданными для того, чтобы сбить читателя с толку. Например, применение оператора ? : может привести к появлению абсолютно загадочного кода:
только разобрав все возможные варианты
? child=(!LC&&!RC)?0:(!LC?RC:LC);
Согласитесь, что, только разобрав все возможные варианты сравнений, можно догадаться, что же делает этот фрагмент. Приведенная ниже конструкция длиннее, но значительно проще, потому что возможные варианты видны сразу:
f (LC == 0 && RC == 0)
child = 0; else if (LC == 0)
child = RC; else
child = LC;
Операция ? : хороша только для коротких и простых выражений-, где она может заменить четыре строки if-else одной, как в следующем примере:
max = (а > b) ? а : b;
или даже в таком случае:
printf("The list has %d item%s\n", n, n==1 ? "" : "s");
однако подобная замена все же не является распространенной.
Ясность и краткость — не одно и то же. Часто более ясный код будет и более коротким (как в примере со сдвигом битов), однако он может быть и, наоборот, более длинным (как в примере с if-else). Главным критерием выбора должна служить простота восприятия.
Будьте осторожны с побочными эффектами. Операции типа ++ имеют побочные эффекты: они не только возвращают значение, но еще и изменяют операнд. Эти побочные эффекты иногда могут быть весьма удобны, но они же могут вызвать трудности из-за того, что получение значения и обновление переменной могут происходить не тогда, когда ожидается. В С и C++ порядок выполнения этих побочных эффектов вообще не определен, поэтому нижеприведенное множественное присваивание, скорее всего, будет выдавать неправильный ответ:
? str[i++] = str[i++] = ' ';
Смысл выражения — записать пробел в следующие две позиции строки str. Однако в зависимости от того, когда будет обновляться i, позиция в st r может быть пропущена, и в результате переменная 1 будет увеличена только на 1. Разбейте выражение на два:
str[i++] = ' ';
str[i++] =''.-"';
Даже если в вы ражении содержится только один инкремент, результат может быть неоднозначным:
? array[i++] = i;
Если изначально i имеет значение 3, то элемент массива может принять значение 3 либо 4.
Побочные эффекты есть не только у инкремента и декремента; ввод-вывод — еще один потенциальный источник возникновения закулисных действий.В следующем примере осуществляется попытка прочитать два взаимосвязанных числа из стандартного ввода:
scanf ("' &yr, &profit[yr]);
Выражение неверно, поскольку одна его часть изменяет уг, а другая использует ее. Значение prof it[yr] будет правильным только в том случае, если новое значение уг будет таким же, как и старое. Вы, наверное, думаете, что все дело в порядке вычисления аргументов, однако в действительности проблема здесь в том, что все аргументы scanf вычисляются до того, как эта операция вызывается на выполнение, так что &profit[yr] всегда будет вычисляться с использованием старого значения у г. Проблемы подобного рода могут возникнуть в любом языке программирования. Для исправления достаточно опять же разбить выражение на две части:
scanf("%d", &yr);
scanf("%d", &profit[yr]);
Будьте осторожны с любым выражением, вызывающим побочные эффекты.
с поддержкой синтаксиса уменьшает вероятность
Применение средств редактирования с поддержкой синтаксиса уменьшает вероятность возникновения подобных ошибок.
В рассматриваемом примере даже после исправления отмеченной ошибки код трудно понять. В нем будет проще разобраться, если мы заведем переменную для хранения количества дней в феврале:
Код все еще неверен: 2000 год является високосным, а 1900-й и 2100-й — не високосные. Тем не менее такая структура уже значительно проще доводится до безупречной.
Кстати, если вы работаете над программой, которую писал кто-то другой, сохраняйте ее оригинальный стиль. При внесении изменений не применяйте свой стиль, даже если он вам больше нравится. Постоянство в форматировании программы гораздо важнее, чем ваше собственное, поскольку только оно сможет облегчить жизнь тем, кому придется вникать в способы функционирования этой программы.
Используйте идиомы для единства стиля. В языках программирования, как и в обычных языках, существуют свои идиомы — это устоявшиеся приемы, используемые опытными программистами для написания типичных фрагментов кода. Одна из центральных проблем, возникающих при изучении языка программирования, — необходимость привыкнуть к его идиомам.
Одной из наиболее типичных идиом является форма написания цикла. Рассмотрим код на С, C++ или Java для просмотра п элементов массива, например для их инициализации. Можно написать этот код так:
? 1 = 0;
? while (1 <= п-1)
? array[i++] =1.0;
или так:
? for (1=0; 1 < п; )
? аггау[1++] = 1.0;
или даже так:
for (i = n; --1 >~ 0; )
array[i] = 1.0;
Все три способа, в принципе, правильны, однако устоявшаяся, идиоматическая форма выглядит так:
for (1 = 0; i < n; i++)
array[i] = 1.0;
Выбор именно этой формы не случаен. При такой записи обходятся все п элементов массива, пронумерованные от 0 до n-1. Все управление циклом находится непосредственно в его заголовке; обход происходит в возрастающем порядке; для обновления переменной счетчика цикла используется типичная операция инкремента (++). После выхода индекс цикла имеет известное нам значение как раз за последним элементом массива. Те, для кого этот язык как родной, все понимают без пояснений и воспроизводят конструкцию не задумываясь.
В C++ и Java стандартный вариант включает еще и объявление переменной цикла:
for (int 1=0; i < n; i++)
array[i] = 1.0;
Вот как выглядит стандартный цикл для обхода списка в С:
for (р = list; р != NULL; р = p->next) .......
И опять все управляющие элементы цикла находятся непосредственно в выражении for.
Для бесконечного цикла мы предпочитаем конструкцию
for (;;)
однако популярна и конструкция
while (1)
........
Не используйте других форм, кроме двух приведенных.
Использование отступов также должно быть стандартным, можно сказать — идиоматичным. Вот такое необычное вертикальное расположение управляющих элементов цикла ухудшает читабельность кода, поскольку выглядит как три отдельных выражения, а не как единый заголовок цикла:
>
>
Стандартную форму записи цикла воспринять

Стандартную форму записи цикла воспринять гораздо проще:
for (ар = агг; ар < агг+128; ар++)
*ар = 0;
Небрежно выбранное расположение отступов растянет код на несколько экранов или страниц, что также не улучшает его восприятие.
Еще.один стандартный прием — вставлять присваивание внутрь условия цикла:
while ((с = getchar()) != EOF)
putchar(c);
Выражение do-while используется гораздо реже, чем for и while, поскольку при его применении тело цикла исполняется как минимум один раз вне зависимости от условий, которые проверяются не в начале цикла, а в конце. Во многих случаях это становится причиной появления ошибки, ждущей своего часа, как, например, в следующем варианте цикла для getchar:
Стандартную форму записи цикла воспринять
Стандартную форму записи цикла воспринять гораздо проще:
for (ар = агг; ар < агг+128; ар++)
*ар = 0;
Небрежно выбранное расположение отступов растянет код на несколько экранов или страниц, что также не улучшает его восприятие.
Еще.один стандартный прием — вставлять присваивание внутрь условия цикла:
while ((с = getchar()) != EOF)
putchar(c);
Выражение do-while используется гораздо реже, чем for и while, поскольку при его применении тело цикла исполняется как минимум один раз вне зависимости от условий, которые проверяются не в начале цикла, а в конце. Во многих случаях это становится причиной появления ошибки, ждущей своего часа, как, например, в следующем варианте цикла для getchar:
в переменную будет записано мусорное

В этом случае в переменную будет записано мусорное значение, поскольку проверка производится уже после вызова putchar. Цикл do-while стоит применять только в тех случаях, когда тело цикла обязательно должно быть выполнено хотя бы один раз; некоторые примеры подобных ситуаций мы рассмотрим несколько позже.
Одно из преимуществ последовательного применения идиом состоит в том, что любой нестандартный цикл, потенциальный источник ошибок, сразу же привлечет внимание. Например:
в переменную будет записано мусорное
В этом случае в переменную будет записано мусорное значение, поскольку проверка производится уже после вызова putchar. Цикл do-while стоит применять только в тех случаях, когда тело цикла обязательно должно быть выполнено хотя бы один раз; некоторые примеры подобных ситуаций мы рассмотрим несколько позже.
Одно из преимуществ последовательного применения идиом состоит в том, что любой нестандартный цикл, потенциальный источник ошибок, сразу же привлечет внимание. Например:
в памяти выделяется для элементов

Место в памяти выделяется для элементов в количестве nmemb — от iArray[0] до iArray[nmemb-1 ], но, поскольку в условии цикла проверка производится на "меньше или равно" (<=), цикл вылезет за границу массива и испортит новой записью то, что хранится за пределами выделенной памяти. К сожалению, ошибки подобного типа нередко можно обнаружить только после того, как данные уже разрушены.
В С и C++ есть также идиомы для выделения места под строки и для работы с ними, а код, который их не использует, зачастую таит в себе ошибку:
в памяти выделяется для элементов
Место в памяти выделяется для элементов в количестве nmemb — от iArray[0] до iArray[nmemb-1 ], но, поскольку в условии цикла проверка производится на "меньше или равно" (<=), цикл вылезет за границу массива и испортит новой записью то, что хранится за пределами выделенной памяти. К сожалению, ошибки подобного типа нередко можно обнаружить только после того, как данные уже разрушены.
В С и C++ есть также идиомы для выделения места под строки и для работы с ними, а код, который их не использует, зачастую таит в себе ошибку:
Никогда не следует употреблять gets,

Никогда не следует употреблять gets, поскольку не существует способа ограничить размер вводимой информации. Это ведет к проблемам, связанным с безопасностью, к которым мы вернемся в главе 6; там мы увидим, что всегда лучше использовать fgets. Однако существует и еще одна проблема: функция strlen вычисляет размер строки, не учитывая завершающего строку символа ' \0', а функция st rcpy его копирует. Таким образом, выделяется недостаточно места, и st rcpy пишет за пределами выделенной памяти. Стандартной формой является следующая:
р = malloc(strlen(buf)+1);
strcpy(p, buf);
или
р = new char[strlen(buf)+1];
strcpy(p, buf);
в C++. Таким образом, если вы не видите +1, то стоит проверить все еще раз.
В Java такой проблемы нет, поскольку строки там не представляются в виде массивов, оканчивающихся на 0. Кроме того, индексы массивов проверяются, так что в Java выйти за границы массива невозможно.
В большинстве сред С и C++ предусмотрена библиотечная функция strdup, которая создает копию строки, используя для этого malloc и st rcpy, что гарантирует от обсуждавшейся чуть выше ошибки. К сожалению, st rdup не входит в стандарт ANSI С.
Кстати говоря, ни в первой, ни в окончательной версии не проверяется значение, возвращаемое функцией malloc. Мы опустили эту проверку для того, чтобы сфокусировать ваше внимание на теме данного раздела, однако в настоящей программе значения, возвращаемые функциями malloc, realloc, strdup, а также другими функциями, выделяющими память, должны в обязательном порядке проверяться.
Используйте цепочки else-if для многовариантных ветвлений. Стандартной формой записи многовариантного ветвления является последовательность операторов if. . .else if...else:
Никогда не следует употреблять gets,
Никогда не следует употреблять gets, поскольку не существует способа ограничить размер вводимой информации. Это ведет к проблемам, связанным с безопасностью, к которым мы вернемся в главе 6; там мы увидим, что всегда лучше использовать fgets. Однако существует и еще одна проблема: функция strlen вычисляет размер строки, не учитывая завершающего строку символа ' \0', а функция st rcpy его копирует. Таким образом, выделяется недостаточно места, и st rcpy пишет за пределами выделенной памяти. Стандартной формой является следующая:
р = malloc(strlen(buf)+1);
strcpy(p, buf);
или
р = new char[strlen(buf)+1];
strcpy(p, buf);
в C++. Таким образом, если вы не видите +1, то стоит проверить все еще раз.
В Java такой проблемы нет, поскольку строки там не представляются в виде массивов, оканчивающихся на 0. Кроме того, индексы массивов проверяются, так что в Java выйти за границы массива невозможно.
В большинстве сред С и C++ предусмотрена библиотечная функция strdup, которая создает копию строки, используя для этого malloc и st rcpy, что гарантирует от обсуждавшейся чуть выше ошибки. К сожалению, st rdup не входит в стандарт ANSI С.
Кстати говоря, ни в первой, ни в окончательной версии не проверяется значение, возвращаемое функцией malloc. Мы опустили эту проверку для того, чтобы сфокусировать ваше внимание на теме данного раздела, однако в настоящей программе значения, возвращаемые функциями malloc, realloc, strdup, а также другими функциями, выделяющими память, должны в обязательном порядке проверяться.
Используйте цепочки else-if для многовариантных ветвлений. Стандартной формой записи многовариантного ветвления является последовательность операторов if. . .else if...else:
Условия читаются сверху вниз; по

Условия читаются сверху вниз; по достижении первого условия, которое оказалось верным, выполняется следующее за ним выражение, после чего оставшаяся часть конструкции пропускается. Под выражением мы, естественно, понимаем здесь либо одно выражение, либо группу выражений, заключенную в фигурные скобки. Последнее else обрабатывает ситуацию "по умолчанию" — когда ни одна из перечисленных альтернатив не была выбрана. Это замыкающее else может быть опущено, если не предусматривается никаких действий "по умолчанию", однако и в таком случае полезно оставить эту часть с сообщением об ошибке, чтобы отловить условия, которых "не может быть никогда".
Все операторы else стоит выровнять по вертикали, вместо того чтобы устанавливать каждое else на одном уровне с соответствующим ему if. Вертикальное выравнивание означает, что проверки производятся последовательно; кроме того, предотвращается выползание кода за правый край страницы.
Последовательность вложенных выражений if —. предвестник трудно читаемого кода, если не заведомых ошибок:
Условия читаются сверху вниз; по
Условия читаются сверху вниз; по достижении первого условия, которое оказалось верным, выполняется следующее за ним выражение, после чего оставшаяся часть конструкции пропускается. Под выражением мы, естественно, понимаем здесь либо одно выражение, либо группу выражений, заключенную в фигурные скобки. Последнее else обрабатывает ситуацию "по умолчанию" — когда ни одна из перечисленных альтернатив не была выбрана. Это замыкающее else может быть опущено, если не предусматривается никаких действий "по умолчанию", однако и в таком случае полезно оставить эту часть с сообщением об ошибке, чтобы отловить условия, которых "не может быть никогда".
Все операторы else стоит выровнять по вертикали, вместо того чтобы устанавливать каждое else на одном уровне с соответствующим ему if. Вертикальное выравнивание означает, что проверки производятся последовательно; кроме того, предотвращается выползание кода за правый край страницы.
Последовательность вложенных выражений if —. предвестник трудно читаемого кода, если не заведомых ошибок:
Последовательность условных операторов заставляет нас

Последовательность условных операторов заставляет нас напрягаться, запоминая, какие тесты в каком порядке следуют, с тем чтобы в нужной точке вставить соответствующее событие (если мы еще в состоянии его вспомнить). Там, где должно быть произведено хотя бы одно действие, лучше использовать else if. Изменение порядка, в котором производятся проверки, ведет к тому, что код становится более понятным, кроме того, мы избавляемся от утечки ресурса, которая присутствовала в первой версии (файлы остались незакрытыми):
Последовательность условных операторов заставляет нас
Последовательность условных операторов заставляет нас напрягаться, запоминая, какие тесты в каком порядке следуют, с тем чтобы в нужной точке вставить соответствующее событие (если мы еще в состоянии его вспомнить). Там, где должно быть произведено хотя бы одно действие, лучше использовать else if. Изменение порядка, в котором производятся проверки, ведет к тому, что код становится более понятным, кроме того, мы избавляемся от утечки ресурса, которая присутствовала в первой версии (файлы остались незакрытыми):
Мы производим проверки до тех

Мы производим проверки до тех пор, пока не находим первое выполненное условие, совершаем соответствующее действие и опускаем все последующие проверки. Правило тут такое: каждое действие должно быть расположено как можно ближе к той проверке, с которой связано. Другими словами, каждый раз, произведя проверку, совершите что-нибудь.
Попытки повторного использования уже написанных блоков кода ведут к появлению программ, похожих на затянутые узлы:
Мы производим проверки до тех
Мы производим проверки до тех пор, пока не находим первое выполненное условие, совершаем соответствующее действие и опускаем все последующие проверки. Правило тут такое: каждое действие должно быть расположено как можно ближе к той проверке, с которой связано. Другими словами, каждый раз, произведя проверку, совершите что-нибудь.
Попытки повторного использования уже написанных блоков кода ведут к появлению программ, похожих на затянутые узлы:
В данном фрагменте выравнивание выполнено
В данном фрагменте выравнивание выполнено неправильно, поскольку ia самом деле else относится к строке
if (day > 29)
и весь код работает неверно. Когда один if следует сразу за другим всегда используйте фигурные скобки:
Здесь используется замысловатая последовательность перескоков

Здесь используется замысловатая последовательность перескоков в выражении-переключателе, а все для того, чтобы избежать дублирования одной строки кода! В стандартной, идиоматической форме каждый вариант должен оканчиваться выходом (break), с редкими и обязательно откомментированными исключениями. Традиционную структуру проще воспринимать, хотя она и получается несколько длиннее:
с лихвой окупается увеличением ясности.

Некоторое удлинение кода с лихвой окупается увеличением ясности. В данной конкретной ситуации, однако, применение последовательности выражений else-if будет даже более понятным:
В этом примере фигурные скобки

В этом примере фигурные скобки вокруг блока из одной строки подчеркивают, что структура выражения параллельна.
Использование перескоков оправдано в случае, когда несколько условий имеют одинаковый код. Тогда их размещают таким образом:
в этом фрагменте кода на

Упражнение 1-8
Найдите ошибки в этом фрагменте кода на языке Java и исправьте их, переписав цикл в стандартной форме:
Вычисление квадратного корня будет производиться

Вычисление квадратного корня будет производиться в два раза чаще, чем требуется (он передается как аргумент, который дважды участвует в вычислении). Даже при задании простого аргумента сложное выражение вроде ROUND_TO__INT преобразуется во множество машинных команд, которые лучше хранить в одной функции, вызываемой при необходимости. Обращения к макросу увеличивают размер скомпилированной программы. (Встраиваемые (inline) функции в C++ имеют тот же недостаток.)
Заключайте тело макроса и аргументы в скобки. Если вы все же решили использовать макрофункции, будьте с ними осторожны. Макрос работает за счет простой подстановки текста: параметры в описании заменяются аргументами вызова, и результат (текст!) замещает собой текст вызова. В этом состоит важное отличие макросов от функций, делающее макросы столь ненадежными. Так, выражение
1 / square(x)
будет работать отлично, если square — это функция, однако если это макрос вроде следующего:
? «define square(x) (x) * (х)
то выражение будет преобразовано в ошибочное:
? 1 / (х) * (х)
Этот макрос надо переписать так:
«define square(x) ((x) * (х))
Скобки здесь необходимы, однако даже грамотная расстановка скобок не спасет макрос от его главной беды — многократного вычисления аргументов. Если операция настолько сложна или настолько часто повторяется, что ее стоит вынести в отдельный блок, используйте для этого функцию.
В C++ встраиваемые (inline) функции позволяют избежать синтаксических проблем, сохраняя при этом высокую производительность, присущую макросам. Они хорошо подходят для коротких функций, которые получают или устанавливают только одно значение.
в коде присутствуют числа 20,

Наряду с другими в коде присутствуют числа 20, 21, 22, 23 и 27. Они как-то тесно связаны... или нет? На самом деле есть только три критических числа, существенных для программы: 24 — число строк экрана; 80 — число столбцов экрана и, наконец, 26 — количество букв в английском алфавите. Однако, как мы видим, ни одно из этих чиеел в коде не встречается, отчего числа, используемые в коде, становятся еще более загадочными.
Присвоив имена числам, имеющим принципиальное значение, мы облегчим понимание кода. Например, станет понятно, что число 3 берется из арифметического выражения (80-1)/26, а массив let должен иметь 26 элементов, а не 27 (иначе возможна ошибка его переполнения на единицу — из-за того, что экранные координаты индексируются, начиная с 1). Сделав еще пару усовершенствований, мы придем к следующему результату:
Теперь стало гораздо понятнее, что

Теперь стало гораздо понятнее, что же делает основной цикл: в нем используется стандартный идиоматический цикл от 0 до NLET-1, то есть по всем элементам данных. Вызовы функции d raw также стали более понятны — названия вроде MAXROW и MINCOL дают четкое представление об аргументе. Главное же — программу теперь можно без труда адаптировать к другому разрешению экрана или другому алфавиту: с чисел и с кода снята завеса таинственности.
Определяйте числа как константы, а не как макросы. Программисты, пишущие на С, традиционно использовали для определения загадочных чисел директиву #def те. Однако препроцессор С — мощный, но несколько туповатый инструмент, а макросы — вообще довольно опасная вещь, поскольку они изменяют лексическую структуру программы. Пусть лучше язык делает свойственную ему работу. В С и C++ целые (integer) константы можно определять с помощью выражения en urn (которое мы и использовали в предыдущем примере). В C++ любые константы можно определять с помощью ключевого слова const:
const int MAXROW = 24, MAXCOL = 80;
В Java для этого служит слово final:
static final int MAXROW = 24, MAXCOL = 80;
В С также можно определять значения с помощью ключевого слова const, но эти значения нельзя использовать как границы массива, так что зачастую придется прибегать все к тому же enum.
Используйте символьные, а не целые константы. Для проверки свойств символов должны использоваться функции из <ctype. h> или их эквиваленты. Если проверку организовать так:
? if (с >= 65 && с <= 90)
?....
то ее результат будет всецело зависеть от представления символов на конкретной машине. Лучше использовать
if (с >= 'А' с <= 'Z')
?...
но и это может не принести желаемого результата, если буквы в имеющейся кодировке идут не по порядку или если в алфавите есть и другие буквы. Лучшее решение — привлечь на помощь библиотеку:
if (isupper(c))
в С и C++ или
if (Character. isllpperCase(c))
в Java.
Сходный вопрос — использование в программе числа 0. Оно используется очень часто и в различных контекстах. Компилятор преобразует этр число в соответствующий тип, однако читателю гораздо проще понять роль каждого конкретного 0, если тип этого числа каждый раз обозначен явным образом. Так, например, стоит использовать (void * )0 или NULL для обозначения нулевого указателя в С, а ' \0' вместо просто 0 — для обозначения нулевого байта в конце строки. Другими словами, не пишите
Мы рекомендуем использовать различные явные
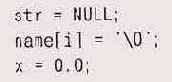
Мы рекомендуем использовать различные явные константы, оставив О для простого целого нуля, — такие константы обозначат цель использования данного значения. Надо отметить, правда, что в C++ для обозначения нулевого указателя принято использовать все же 0, а не NULL. Лучше всего проблема решена в Java — там ключевое слово null определено как ссылка на объект, которая ни к чему не относится.
Используйте средства языка для определения размера объекта. Не используйте явно заданного размера ни для каких типов данных — так, например, используйте sizeof (int) вместо прямого указания числа 2,4 и т.п. По сходным причинам лучше использовать sizeof(array[OJ) вместо sizeof (int) — меньше придется исправлять при изменении типа массива.
Использование оператора sizeof избавит вас от необходимости выдумывать имена для чисел, обозначающих размер массива. Например, если написать
char buf[1024];
fgets(buf, sizeof(buf), stdin);
то размер буфера хоть и станет "загадочным числом", от которого мы предостерегали ранее, но зато оно появится только один раз — непосредственно в описании. Может быть, и не стоит прилагать слишком большие усилия, чтобы придумать имя для размера локального массива, но определенно стоит постараться и написать код, который не нужно переписывать при изменении размера или типа:
У массивов в Java есть поле length, которое содержит количество элементов:
char buf[] = new char[1024];
for (int 1=0; i < but.length; i++)
.....
В С и C++ нет эквивалента этому полю, но для массива (не указателя), описание которого является видимым, количество элементов можно вычислить с помощью следующего макроса:
таки размер массива задается лишь

Здесь опять- таки размер массива задается лишь в одном месте, и при его изменении весь остальной код менять не придется.
В данном макросе нет проблем с многократным вычислением аргумента, поскольку в нем нет никаких побочных эффектов, и на самом деле все вычисление происходит во время компиляции. Это пример грамотного использования макроса — здесь он делает то, чего не может сделать функция: вычисляет размер массива исходя из его описания.
Все эти комментарии надо удалить,

Все эти комментарии надо удалить, они лишь мешают.
В комментариях должна содержаться информация, не вытекающая из кода, или же информация, относящаяся к большому фрагменту кода и собранная в одно место. Когда в коде происходит что-то трудноуловимое, комментарий должен уточнять происходящее, но если все действия и так очевидны, описывать их еще раз в словах просто бессмысленно:
Эти комментарии также стоит удалить,

Эти комментарии также стоит удалить, поскольку грамотно подобранные имена уже содержат всю необходимую информацию.
Комментируйте функции и глобальные данные. Конечно же, комментарии могут и должны быть полезны. Мы советуем комментировать функции, глобальные переменные, определения констант, поля в структурах и классах и вообще все элементы, в понимании сути которых может помочь краткое резюме.
Глобальные переменные имеют тенденцию появляться в разных местах программы, поэтому иногда их стоит сопроводить комментарием с напоминанием об их роли. В качестве примера мы выбрали отрывок программы, приведенной в главе 3 этой книги:
Иногда код действительно сложен, возможно,

Иногда код действительно сложен, возможно, из-за сложного алгоритма или замысловатых структур данных. В таком случае читателю может помочь комментарий, указывающий на источник, в котором описан данный алгоритм или структура. В него можно также включить пояснения, касающиеся того, почему были приняты те или иные конкретные решения. Ниже приведен комментарий, предваряющий весьма эффективную реализацию обратного дискретного косинус-преобразования (discrete cosine transform - DCT), используемого в декодере изображений в формате JPEG:
В этом содержательном комментарии имеется

В этом содержательном комментарии имеется ссылка на описание алгоритма, кратко представлены используемые данные, обозначена производительность алгоритма и показано, когда и для чего была произведена модификация кода.
Не комментируйте плохой код, а передишите его. Все необычное или потенциально смущающее стоит комментировать, но когда комментарий по своему размеру приближается к коду, то, скорее всего, код стоит подправить. В приводимом примере используются длинный, путаный комментарий и условно компилируемое выражение для распечатки отладочной информации — и все это для пояснения всего лишь одного выражения:
В отрицаниях всегда легко запутаться,

В отрицаниях всегда легко запутаться, и поэтому лучше обойтись без них. В рассмотренном примере проблема во многом заключается в неграмотном выборе имени для переменной — result. Лучше выбрать более информативное имя — matchfound (совпадение найдено), тогда комментарий станет вообще не нужен и печатаемое при отладке сообщение будет более понятным:
He противоречьте коду. Как правило,

He противоречьте коду. Как правило, все комментарии согласуются с кодом, когда он пишется, но по мере устранения ошибок и развития программы комментарии часто остаются без изменений и перестают соответствовать коду. Скорее всего, именно из-за этого и возникли проблемы во фрагменте, приведенном в самом начале этой главы.
В чем бы ни крылась причина несоответствия, комментарий, противоречащий коду, сильно сбивает читателя с толку. Страшно представить, сколько времени и сил было потрачено на отладку программ впустую только из-за того, что некорректный или устаревший комментарий принимался на веру. Поэтому запомните: каждый раз, изменив код, убедитесь в том, что комментарии ему соответствуют.
Комментарии должны не только соответствовать коду, но и. поддерживать его. В следующем примере комментарий помещен грамотно — он поясняет назначение следующих за ним строк, но противоречит коду, поскольку в нем говорится о переводе строки, в то время как код относится к пробелам:
что надо сделать, это переписать

Первое, что надо сделать, это переписать код в более привычном идиоматическом виде:
и комментарий соответствуют друг другу,

Теперь код и комментарий соответствуют друг другу, но и тот и другой можно улучшить, сделав их более прямолинейными. Задача фрагмента — удалить символ перевода строки, который функция ctime помещает в конец возвращаемой ею строки. Собственно, это комментарий и должен сообщить, а код сделать:
идиома языка С, предназначенная для

Последнее выражение — идиома языка С, предназначенная для удаления последнего символа из строки. Теперь наш код стал коротким, стандартизованным и понятным, а комментарий поясняет причину, по которой в этом коде возникла необходимость.
Вносите ясность, а не сумятицу. Комментарии предназначены для того, чтобы помочь читателю разобраться в критических местах кода, а не для того, чтобы создавать дополнительные препятствия. В следующем примере выполнены наши рекомендации по комментированию функций и разъяснению необычных участков кода; однако речь идет о функции strcmp, и все такие необычные участки не имеют никакого отношения к тому, что на самом деле нужно сделать — реализовать стандартный и всем привычный интерфейс:
Если нескольких слов недостаточно для

Если нескольких слов недостаточно для пояснения происходящего, то скорее всего код стоит переписать. В рассматриваемом примере код, наверное, можно несколько улучшить, но главная беда кроется все же в комментарии, который почти того же размера, что и вся реализация, да к тому же еще и не совсем понятен (что значит "выше", например?). Мы так подробно разбираем этот пример, чтобы подчеркнуть: если во фрагменте реализуется стандартная функция, комментарий должен лишь обобщать сведения о ее поведении и сообщать, откуда взялось ее определение, вот и все:
Студентам внушают, что комментировать надо

Студентам внушают, что комментировать надо все подряд; профессиональным программистам часто вменяется в обязанность комментировать весь созданный ими код. Однако если слепо следовать правилам, то смысл написания комментариев может потеряться. Комментарии должны помогать читателю разобраться в тех частях программы, смысл и назначение которых нельзя (или просто трудно) понять из самого кода. Всюду, где это возможно, старайтесь писать код, который было бы просто понять; чем лучше вам это удастся, тем меньше комментариев вам потребуется. Хороший код меньше нуждается в комментариях, чем плохой.
Стиль
Есть старое наблюдение, что лучшие писатели иногда пренебрегают правилами риторики. Однако, когда они это делают, читатель обычно находит в тексте какие-то компенсирующие достоинства, достигнутые ценой этого нарушения. Пока кто-то не уверен, что он сможет сделать то же самое, ему, вероятно, лучше всего следовать правилам.
Вильям Странк, Элвин Б. Уайт. Элементы стиля
Приводимый фрагмент кода взят из большой программы, написанной много лет назад:
Стилевое единство и идиомы
Чем логичнее и последовательнее оформлена программа, тем она лучше. Если форматирование кода меняется непредсказуемым образом: цикл просматривает массив то по возрастанию, то по убыванию, строки копируются то с помощью strcpy, то с помощью цикла for — все перечисленные вариации сбивают читателя с толку, и ему трудно понять, что в действительности происходит. Но если одни и те же вычисления всегда выполняются одинаково, то каждое отклонение от обычного стиля будет указывать на действительное различие, заслуживающее быть отмеченным.
Будьте последовательны в применении отступов и фигурных скобок.
Отступы помогают воспринять структуру кода, но какой стиль расположения лучше? Следует располагать открывающую фигурную скобку на той же строке, что if, или на следующей? Программисты ведут нескончаемые споры о наилучшем расположении текста кода, однако выбор конкретного стиля гораздо менее важен, чем логичность и последовательность его применения во всем приложении. Выберите себе раз и навсегда один стиль — лучше всего, конечно, наш — и используйте его всегда, не тратьте времени на споры.
Стоит ли вставлять фигурные скобки, когда необходимости в них нет? Как и обычные скобки, дополнительные фигурные скобки могут разрешить неясные моменты и облегчить понимание структуры кода. Многие опытные программисты во имя все того же постоянства всегда заключают в фигурные скобки тела циклов и условных операторов. Однако если тело состоит лишь из одной строки, то скобки явно не нужны, и мы бы посоветовали их опустить. Впрочем, не забудьте вставить их в тех случаях, когда они помогут разрешить неясности с "висящим else", — подобная неопределенность хорошо иллюстрируется следующим примером:
Стоит ли так беспокоиться?
В этой главе мы поговорили об основных составляющих хорошего стиля программирования: информативных именах, ясности в выражениях, прозрачной логике, читабельности кода и комментариев, а также обсудили важность использования соглашений и идиоматических блоков для достижения всего вышеперечисленного.
Однако стоит ли так беспокоиться о стиле? Кому какая разница, как программа выглядит изнутри, если она работает? Не слишком ли много времени придется тратить на ее "причесывание"? Не слишком ли расплывчаты рекомендуемые правила?
Ответ на эти вопросы состоит в следующем: хорошо и красиво написанный код проще читать и воспринимать; в нем, без сомнения, содержится меньше ошибок, и он почти наверняка будет короче, чем код, бездумно скомпонованный и оставленный без улучшений. Когда программа пишется в спешке, когда и так трудно успеть к установленным срокам, кажется вполне естественным не обращать внимания на стиль, оставив заботы о нем на потом. Однако подобное решение может оказаться весьма накладным. Некоторые примеры из этой главы уже дали вам представление о том, что может случиться, если пренебрегать хорошим стилем. Небрежно оформленный код — плохой код, и не только потому, что выглядит он некрасиво и читать его трудно; как правило, в таком коде содержатся и ошибки.
Основная мысль состоит в том, что хороший стиль должен просто войти в привычку. Если вы будете задумываться о стиле при написании кода, если вы будете выкраивать время для того, чтобы проверять и улучшать его стиль, вы выработаете у себя очень полезную привычку. После того как все это вы будете проделывать автоматически, ваше подсознание позаботится о многих деталях, и даже код, который вы будете писать в спешке, станет гораздо лучше.
<
Составьте комментарий, объясняющий принцип выбора
Составьте комментарий, объясняющий принцип выбора имен и значений в следующем примере:
Перечислите все возможные варианты, которые
Перечислите все возможные варианты, которые выдаст приведенное выражение в зависимости от порядка вычислений:
? n=1
? printf(."%d %d\n", n++, n++);
Попробуйте пропустить это выражение через разные компиляторы и посмотрите, что получается на практике. <
Перепишите выражения
Перепишите выражения C/C++ более понятным образом:
Определите все проблемы, связанные
Определите все проблемы, связанные с приведенным описанием макроса:
? «define ISDIGIT(c) ((с >= '0') && (с <= '9')) ?
1 : О
<
Как бы вы переписали приведенные
Как бы вы переписали приведенные определения, чтобы уменьшить число потенциальных ошибок?
Выражения
Итак, имена надо подбирать так, чтобы максимально облегчить жизнь читателю; точно так же и выражения следует писать так, чтобы их смысл был предельно ясен. Пишите самый ясный код, какой только возможен. Вставляйте пробелы вокруг операторов для логической группировки выражений; вообще, форматируйте выражения так, чтобы сделать их наиболее удобочитаемыми. Идея тривиальна, но очень полезна: совсем как мысль о том, что чем аккуратнее убран ваш рабочий стол, тем проще на нем найти необходимую вещь. Правда, в отличие от рабочего стола в вашей программе могут копаться и посторонние — и им тоже должно быть удобно.
Форматируйте код, подчеркивая его структуру. Форматирование кода логично выбранными отступами — самый простой способ добиться того, чтобы структура программы стала самоочевидна. Приведенный фрагмент плохо отформатирован:
? for(n++;n<100;field[n++]='\(O');
? *i = \О'; return( '\n);
Проведя простейшее форматирование, мы несколько улучшим его:
Загадочные числа
Загадочные числа — это константы, размеры массивов, позиции символов и другие числовые значения, появляющиеся в программе непосредственно, как "буквальные константы".
Давайте имена загадочным числам. В принципе нужно считать, что любое встречающееся в программе число, отличное от 0 и 1, является загадочным и должно получить собственное имя. Просто "сырые" числа в тексте программы не дают представления об их происхождении и назначении, затрудняя понимание и изменение программы. Вот отрывок из программы, которая печатает гистограмму частот букв на терминале с разрешением 24 X 80. Этот отрывок неоправданно запутан из-за целого сонма непонятных чисел: