Алгоритмы и структуры данных
В конце концов, только знание инструментов и технологий обеспечит правильное решение поставленной задачи, и только определенный уровень опыта обеспечит устойчиво профессиональные результаты.
Реймонд Филдинг. Технология специальных эффектов в кинематографе
Исследование алгоритмов и структур данных является одной из основ программирования, а также богатым полем элегантных технологий и сложных математических изысканий. И это — что-то большее, чем развлечение для теоретически подготовленных: хороший алгоритм или структура данных могут позволить решить в течение нескольких секунд проблему, которая без них решалась бы годы.
В таких специальных областях, как графика, базы данных, синтаксический разбор, цифровой анализ и моделирование, возможность решения задачи целиком и полностью зависит от наличия специальных алгоритмов и структур данных. Если вы разрабатываете программы в новых для вас областях программирования, то вы должны выяснить, какие наработки уже существуют, иначе вы потратите свое время впустую в попытках плохо сделать то, что уже кем-то было сделано хорошо.
Каждая программа зависит от алгоритмов и структур данных, но редко бывает нужно изобретать новые алгоритмы. Даже в сложной программе, например в компиляторе или Web-браузере, структуры данных по большей части являются массивами, списками, деревьями и хэш-таб-лицами. Когда программе нужна более изощренная структура, она, скорее всего, будет основываться на этих более простых структурах. Соответственно, задача программиста — знать, какие алгоритмы и структуры доступны, а также понимать, как выбрать среди них нужные.
Такова, вкратце, ситуация. Есть лишь горстка основных алгоритмов, которые применяются практически в каждой программе, — это, прежде всего, поиск и сортировка, и даже эти алгоритмы зачастую включены в библиотеки. Почти все структуры данных также сделаны на основе нескольких фундаментальных структур. Поэтому материал данной главы знаком почти всем программистам. Мы написали работающие версии программ, чтобы дискуссия была более конкретной, и при желании вы можете обратиться непосредственно к исходному коду, но делайте это, только если вы разобрались в том, что вам могут предложить ваш язык программирования и его библиотеки.
<
Библиотеки
В стандартные библиотеки языков С и C++ входят функции сортировки, которые устойчивы к неблагоприятным входным данным и настроены на предельно быструю работу.
Библиотечные функции написаны так, что они могут сортировать данные любого типа, но мы в свою очередь должны адаптироваться к их интерфейсу, что может быть несколько сложнее, чем в рассмотренном выше примере. В языке С библиотечная функция называется qso rt, и ей нужно предоставлять функцию сравнения двух значений. Поскольку значения могут быть любых типов, то функции сравнения передаются два нетипизированных указателя (void *) на сравниваемые значения. Функция преобразует указатели к нужному типу, извлекает значения данных, сравнивает их и возвращает результат (отрицательный, нуль или положительный в зависимости от того, меньше ли первый элемент, равен ли второму или больше его).
Рассмотрим реализацию функции сравнения для сортировки массива строк, случая, встречающегося довольно часто. Мы написали функцию scmp, которая -преобразует параметры к другому типу и затем вызывает st rcmp для выполнения самого сравнения:
Быстрая сортировка на языке Java
В Java ситуация другая. В ранних версиях не было стандартной функции сортировки, поэтому приходилось писать собственную. В последних версиях появилась такая функция, работающая с классами, реализующими интерфейс Comparable, поэтому теперь мы можем просить библиотеку сортировать то, что нам потребуется. Но поскольку используемые технологии полезны и в других ситуациях, в данном разделе мы опишем все детали реализации быстрой сортировки в Java.
Адаптировать быструю сортировку для каждого конкретного типа данных легко; однако же более поучительно написать обобщенную функцию для сортировки объектов любых типов, что больше похоже на интерфейс qsort.
Одно из крупных отличий от С и C++ заключается в том, что в Java мы не можем передать функцию сравнения в другую функцию — здесь не существует указателей на функции. Вместо этого мы создаем интерфейс (interface), единственным содержимым которого будет функция, сравнивающая два объекта типа Object. Далее для каждого сортируемого типа данных мы создаем класс с функцией (методом), которая реализует интерфейс для этого типа данных. Мы передаем экземпляр класса в функцию сортировки, которая в свою очередь использует функцию сравнения из этого класса для сравнения элементов.
Сначала опишем интерфейс Стр, который определяет единственную функцию стр, сравнивающую два значения типа Object:
interface Cmp {
int cmp(0bject x, Object y);
}
Теперь мы можем написать функции сравнения, которые реализуют этот интерфейс; например, следующий класс определяет функцию, сравнивающую объекты типа Integer:
Деревья
Дерево — иерархическая структура данных, хранящая набор элементов. Каждый элемент имеет значение и может указывать на ноль или более других элементов. На каждый элемент указывает только один другой элемент. Единственным исключением является корень дерева, на который не указывает ни один элемент. Входящие в дерево элементы называются его вершинами.
Есть много типов деревьев, которые отражают сложные структуры, например деревья синтаксического разбора (parse trees), хранящие синтаксис предложения или программы, либо генеалогические деревья, описывающие родственные связи. Мы продемонстрируем основные принципы на деревьях двоичного поиска, в которых каждая вершина (node) имеет по две связи. Они наиболее просто реализуются и демонстрируют наиболее важные свойства деревьев. Вершина в двоичном дереве имеет значение и два указателя, left и right, которые показывают на его дочерние вершины. Эти указатели могут быть равны null, если у вершины меньше двух дочерних вершин. Структуру двоичного дерева поиска определяют значения в его вершинах: все дочерние вершины, расположенные левее данной, имеют меньшие значения, а все дочерние вершины правее — большие. Благодаря этому свойству мы можем использовать разновидность двоичного поиска для быстрого поиска значения по дереву или определения, что такого значения нет.
Вариант структуры Nameval для дерева пишется сразу:
Динамически расширяемые массивы
Массивы, использованные в нескольких предыдущих разделах, были статическими, их размер и содержимое задавались во время компиляции. Если потребовать, чтобы некоторую таблицу слов или символов HTML можно было изменять во время выполнения, то хэш-таблица была бы для этой цели более подходящей структурой. Вставка в отсортированный массив п элементов по одному занимает О(n2), чего стоит избегать при больших n.
Однако часто нам нужно работать с переменным, но небольшим числом значений, и тогда массивы по-прежнему могут применяться. Для уменьшения потерь при перераспределении памяти изменение размера должно происходить блоками, и для простоты массив должен храниться вместе с информацией, необходимой для управления им^ В C++ и Java это делается с помощью классов из стандартных библиотек, а в С мы можем добиться похожего результата с помощью структур.
Следующий код определяет расширяемый массив с элементами типа Nameval: новые элементы добавляются в хвост массива, который удлиняется при необходимости. Доступ к каждому элементу по его индексу происходит за константное время. Эта конструкция аналогична векторным классам из библиотек C++ и Java.
Дополнительная литература
Серия книг "Алгоритмы" Боба Седжвика (Bob Sedgewick. Algorithms. Addison-Wesley) содержит доступные сведения о большом числе полезных алгоритмов. В третьем издании "Алгоритмов на C++" (Algorithms in C++, 1998) идет неплохое обсуждение хэш-функций и размеров хэш-таблиц. "Искусство программирования" Дона Кнута (Don Knuth. The Art of Computer Programming. Addison-Wesley) — первейший источник для строгого анализа многих алгоритмов; в третьем томе (2nd ed., 19981) рассматриваются поиск и сортировка.
Программа Supertrace описана в книге Джерарда Холзманна "Дизайн и проверка протоколов" (Gerard Holzmann. Design and Validation of Computer Protocols. Prentice Hall, 1991).
Ион Бентли и Дуг Мак-Илрой описывают создание скоростной и устойчивой версии быстрой сортировки в статье "Конструирование функции сортировки" (Jon Bentley, Doug Mcllroy. Engineering a sort function. Software - Practice and Experience, 23, 1, p. 1249-1265, 1993).
<
Хэш-таблицы
Хэш-таблицы (hash tables) — одно из величайших изобретений информатики. Сочетание массивов и списков с небольшой добавкой математики позволило создать эффективную структуру для хранения и* получения динамических данных. Типичное применение хэш-таблиц -символьная таблица, которая ассоциирует некоторое значение (данные) с каждым членом динамического набора строк (ключей). Ваш любимый компилятор практически наверняка использует хэш-таблицу для управления информацией о переменных в вашей программе. Ваш web-браузер наверняка использует хэш-таблицу для хранения адресов страниц, которые вы недавно посещали, а при соединении вашего компьютера с Интернетом, вероятно, она применяется для оперативного хранения (cache — кэширования) недавно использованных доменных имен и их IP-адресов.
Идея состоит в том, чтобы пропустить ключ через хэш-функцию (hash function) для получения хэш-значения (hash value), которое было бы равномерно распределено по диапазону целых чисел приемлемого размера. Это хэш-значение используется как индекс в таблице, где хранится информация. Java предоставляет стандартный интерфейс к хэш-таб-лицам. В С и C++ обычно с каждым хэш-значением (или "bucket" -"корзиной") ассоциируется список элементов, которые обладают этим значением, как показано на следующем рисунке:
"О большое"
Мы описывали трудоемкость алгоритма в зависимости от п, количества входных элементов. Поиск в неотсортированных данных занимает время, пропорциональное п; при использовании двоичного поиска по отсортированным данным время будет пропорционально log п. Время сортировки пропорционально n2 или n logn.
Нам нужно как-то уточнить эти высказывания, при этом абстрагируясь от таких деталей, как скорость процессора и качество компилятора (и программиста). Хотелось бы сравнивать время работы и затраты памяти алгоритмов вне зависимости от языка программирования, компилятора, архитектуры компьютера, скорости процессора, загруженности системы и других сложных факторов.
Для этой цели существует стандартная форма записи, которая называется "О большое". Основной параметр этой записи — п, размер входных данных, а сложность или время работы алгоритма выражается как функция от п. "О" — от английского order, то есть порядок. Например, фраза "Двоичный поиск имеет сложность 0(log n)" означает, что для поиска в массиве из п элементов требуется порядка log n действий. Запись О(f(n)) предусматривает, что при достаточно больших п время выполнения пропорционально f(n), не быстрее, например, О(n2) или 0(n log n). Асимптотические оценки вроде этой полезны при теоретическом анализе и грубом сравнении алгоритмов, однако на практике разница в деталях может иметь большое значение. Например, алгоритм класса 0(n2) с малым количеством дополнительных вычислений для малых п может работать быстрее, чем сложный алгоритм класса О(n logn), однако при достаточно большом п алгоритм с медленнее возрастающей функцией поведения неизбежно будет работать быстрее.
Нам нужно различать также случаи наихудшего и ожидаемого поведения. Трудно строго определить, что такое "ожидаемое" поведение, потому что определение зависит от наших предположений о возможных входных данных. Обычно мы можем точно указать самый плохой случай, хотя иногда и здесь можно ошибиться. Для quicksort в самом плохом случае время работы растет как О(n2), а среднее ("ожидаемое") время — как О(n log n).
Если каждый раз аккуратно выбирать
Если каждый раз аккуратно выбирать элемент-разделитель, то мы можем свести вероятность квадратичного (то есть 0(n2)) поведения практически к нулю; хорошо реализованная quicksort действительно обычно ведет себя как О(n log n).
Вот основные случаи:
| Запись | Название времени | Пример |
| 0(1) | Константное | Индексирование массива |
| 0(log n) | Логарифмическое | Двоичный поиск |
| 0(n) | Линейное | Сравнение строк |
| 0(n log n) | n logn | Quicksort |
| 0(n2) | Квадратичное | Простые методы сортировки |
| О(n3) | Кубическое | Перемножение матриц |
| 0(2n) | Экспоненциальное | Перебор всех подмножеств |
Традиционный алгоритм перемножения двух квадратных матриц порядка п занимает О(и!), поскольку каждый элемент получается в результате перемножения и пар чисел и суммирования результатов, а всего элементов n2.
Экспоненциальное время работы алгоритма обычно является результатом перебора всех вариантов: у множества из п элементов — 2"различных подмножеств, поэтому алгоритм, которому надо пройтись по всем подмножествам, будет выполняться за время 0(2"), то есть будет экспоненциальным. Экспоненциальные алгоритмы обычно слишком долго работают, если только п не очень мало, поскольку добавление одного элемента удваивает время работы алгоритма. К сожалению, существует много задач, таких как, например, знаменитая "задача коммивояжера", для которых известны только экспоненциальные решения. Когда задача такова, часто вместо точных решений берут алгоритмы, находящие некоторое приближение к ответу.
Поиск
Ничто не сравнится с массивом, если нам нужно хранить статические табличные данные. Инициализация во время компиляции делает задачу конструирования таких массивов простой и легкой. (В Java инициализация происходит во время выполнения, но это можно считать незначительной деталью реализации, пока массивы не слишком велики.) В программе для распознания слов, слишком часто употребляемых в плохой прозе, мы можем написать:
Функция поиска должна знать, сколько

Функция поиска должна знать, сколько в массиве элементов. Один из способов сообщить ей это — передать длину массива в виде аргумента; второй способ, использованный здесь, — поместить в конце массива элемент-маркер NULL:
в качестве параметра массив строк

В С и C++ для передачи в качестве параметра массив строк можно описать как char *array[] или char **array. Эти две формы эквивалентны, но в первой сразу видно, как будет использоваться параметр.
Предлагаемый поисковый алгоритм называется последовательным, поиском, потому что он просматривает по очереди все элементы, сравнивая их с искомым. Когда данных немного, последовательный поиск работает достаточно быстро. Есть стандартные библиотечные функции, которые выполняют последовательный поиск для определенных типов данных. Например, в языках С и C++ функции st rch г и st rst r ищут первое вхождение заданного символа или подстроки в строку, в Java у класса String есть метод indexOf, а обобщенные функции поиска в C++ find применимы к большинству типов данных. Если такая функция существует для нужного вам типа данных, то используйте ее.
Последовательный поиск достаточно прост, но время его работы прямо пропорционально количеству данных, которые нужно просмотреть; удвоение количества элементов приведет к удвоению времени на поиск, если искомого элемента в массиве нет. Это линейное соотношение (время выполнения является линейной функцией от размера данных), поэтому такой метод также называется линейным поиском.
Вот пример массива более реалистичного размера из программы, выполняющей синтаксический разбор текста, написанного на HTML, где определены имена более чем сотни отдельных символов:

Для объемистого массива вроде этого

Для объемистого массива вроде этого более эффективно было бы использовать двоичный поиск. Алгоритм двоичного поиска является систематизированной версией поиска слова в словаре. Проверяем средний элемент. Если это значение больше, чем нужное, то ищем далее в первой части; в противном случае ищем во второй части. Повторяем до тех пор, пока не найдем нужный элемент или не убедимся, что его в массиве нет.
Для двоичного поиска таблица должна быть отсортирована, как в данном случае (в любом случае это полезно; люди тоже быстрее находят требуемое в отсортированных таблицах), а также должно быть известно, сколько элементов в таблице. Здесь может помочь макрофункция NELEMS из первой главы:
printf("Ta6лица HTML содержит %d слов\n", NELEMS(htmlchars));
Функция двоичного поиска для этой таблицы могла бы выглядеть так:
Объединяя все это вместе, мы

Объединяя все это вместе, мы можем написать:
half = lookup("frac12", htmlchars, NElEMS(htmlchars));
для определения индекса, под которым символ 1/2 (одна вторая) стоит в массиве htmlchars.
Двоичный поиск отбрасывает за каждый шаг половину данных, поэтому количество шагов пропорционально тому, сколько раз мы можем поделить п на 2, пока у нас не останется один элемент. Без учета округления это число равно Iog2 п. Если у нас в массиве 100"0 элементов, то линейный поиск займет до 1000 шагов, в то время как двоичный — только около 10; при миллионе элементов линейный поиск займет миллион шагов, а двоичный — 20. Очевидно, чем больше число элементов, тем больше преимущество двоичного поиска. Начиная с некоторого зависящего от реализации размера данных, двоичный поиск работает быстрее, чем линейный. <
Операция swap, которая меняет местами

Операция swap, которая меняет местами два элемента, встречается в quicksort трижды, поэтому лучше всего вынести ее в отдельную функцию:
При разделении прежде всего случайным

При разделении прежде всего случайным образом выбирается элемент-разделитель, который временно переставляется в начало массива, затем просматриваются остальные. Элементы, меньшие разделителя ("маленькие" элементы), перемещаются ближе к началу массива (на позицию last), а "большие" элементы — в сторону конца массива (на позицию i). В начале процесса, сразу после перемещения разделителя в начало, last = 0 и элементы с i = 1 по п-1 еще не исследованы:

В начале 1-й итерации элементы с первого по last строго меньше разделителя, элементы с last+1 no i-1 больше или равны разделителю, а элементы с i по п-1 еще не рассмотрены. Пока не выполнилось первый раз условие v[i] >='v[0], алгоритм будет переставлять элемент v[i] сам с собой; это, конечно, занимает дополнительное время, но не столь страшно.
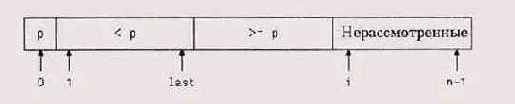
Когда все элементы просмотрены, нулевой элемент переставляется на позицию last, чтобы разделитель занял свою окончательную позицию; тогда порядок элементов будет правильным. Теперь массив выглядит так:

Та же самая операция применяется к левой и правой частям массива; после окончания этого процесса весь массив будет отсортирован.
Насколько быстро работает быстрая сортировка? В наилучшем случае
первый проход делит массив из п элементов на две группы примерно по п/2 элементов;
второй проход разделяет две группы по п/2 элементов на 4 группы, в каждой из которых примерно по п/4 элементов;
на следующем проходе четыре группы по п/4 делятся на восемь групп по (примерно) п/8 элементов;
и т. д.
Данный процесс продолжается примерно Iog2 n раз, поэтому общее время работы в лучшем случае пропорционально п + 2 X и/2 + 4 х и/4 + + 8 X п/8 ... (Iog2 и слагаемых), что равно п log? п. В среднем алгоритм работает совсем не намного дольше. Обычно принято использовать именно двоичные логарифмы, поэтому мы можем сказать, что быстрая сортировка работает пропорционально n long.
Эта демонстрационная реализация быстрой сортировки наиболее прозрачна, но у нее есть одна слабина. Если каждый выбор разделителя разбивает массив на две примерно одинаковые группы, то наш анализ корректен, однако если разделение слишком часто происходит неровно, то время работы будет расти скорее как п1. В нашей реализации в качестве разделителя берется случайный элемент, чтобы уменьшить шанс того, что плохие входные данные приведут к слишком большому количеству неровных разбиений массива. Но если все входные значения одинаковы, то наша реализация за каждый проход будет отделять только один элемент, поэтому время работы будет расти как п2.
Поведение некоторых алгоритмов сильно зависит от входных данных. Неправильный или неудачный ввод может заставить в среднем хороший алгоритм работать крайне медленно или использовать огромное количество памяти. В случае быстрой сортировки, хотя простые реализации вроде нашей иногда могут работать медленно, более продуманные реализации способны уменьшить шанс патологического поведения почти до нуля. <
Мы могли бы написать эту

Мы могли бы написать эту функцию в одну строку, но при использовании временных переменных код становится более удобочитаемым.
Мы не можем напрямую использовать strcmp как функцию сравнения, поскольку qsort передает адрес каждого элемента в массиве &s t г [ i ] (типаспаг **), ане str[i] (типа char *), как показано на рисунке:
Для сортировки элементов массива строк

Для сортировки элементов массива строк с st r[0] по st r[N-1 ] функция qsort должна получить массив, его длину, размер сортируемых элементов и функцию сравнения:
char *str[N];
qsort(str, N, sizeof(str[OJ), scmp);
А вот аналогичная функция icmp для сравнения целых:
большое по абсолютному значению отрицательное

Мы могли бы написать
? return v1-v2;
но если v2 — большое положительное число, a v1 — большое по абсолютному значению отрицательное или наоборот, то получившееся переполнение привело бы к неправильному ответу. Прямое сравнение длиннее, но надежнее.
И здесь при вызове qsort нужно передать массив, его длину, размер сортируемых элементов и функцию сравнения:
int arr[N];
qsort(arr, N, sizeof(arr[0]), icmp);
В стандарте ANSI С определена также функция двоичного поиска bsea rch. Как и qso rt, этой функции нужен указатель на функцию сравнения (часто на ту же, что используется для qsort); bsearch возвращает указатель на найденный элемент или на NULL, если такого элемента нет. Вот наша программа для поиска имен в HTML-файле, переписанная с использованием bsearch:
в случае qsort, функция сравнения

Как и в случае qsort, функция сравнения получает адреса сравниваемых значений, поэтому ключевое (искомое) значение должно иметь этот же тип; в данном примере нам пришлось создать фиктивный элемент типа Nameval для передачи в функцию сравнения. Сама функция сравнения nvcmp сравнивает два значения типа Nameval, вызывая st rcmp для их строковых компонентов, полностью игнорируя численные компоненты:
Это похоже на scmp, только

Это похоже на scmp, только с тем отличием, что строки хранятся как члены структуры.
Неудобство передачи ключевого значения показывает, что bsearch предоставляет меньше возможностей, чем qso rt. Хорошая многоцелевая функция сортировки занимает одну-две страницы кода, а двоичный поиск — ненамного больше, чем код для интерфейса с bsearch. Тем не менее лучше использовать bsearch, чем писать свою собственную версию. Как показывает опыт, программистам на удивление трудно написать двоичный поиск без ошибок.
В стандартной библиотеке C++ имеется обобщенная функция sort, которая обеспечивает время работы 0(п log n). Код для ее вызова проще, потому что нет необходимости в преобразовании типов и размеров элементов. Кроме того, для порядковых типов не требуется задавать функцию сравнения:
int arr[N]; sort(arr, arr+N);
Эта библиотека содержит также обобщенные функции двоичного поиска, с теми же преимуществами в вызове.
Данным способом можно сортировать только

Данным способом можно сортировать только типы, наследуемые от класса Object; подобный механизм нельзя применять для базовых типов, таких как int или double. Поэтому мы сортируем элементы типа Integer,
а не int.
С этими компонентами мы теперь можем перенести функцию быстрой сортировки из языка С в Java и вызывать в ней функцию сравнения из объекта Стр, переданного параметром. Наиболее существенное изменение — это использование индексов left и right, поскольку в Java нет указателей на массивы.
sort использует cmp для сравнения

Quicksort. sort использует cmp для сравнения двух объектов, как и раньше, вызывает swap для их обмена.
Генерация случайного номера происходит

Генерация случайного номера происходит в функции rand, которая а возвращает случайное число в диапазоне с left по right включительно:
в Java генератор случайных чисел

Мы вычисляем абсолютное значение (используя функцию Math.abs), поскольку в Java генератор случайных чисел возвращает как положительные, так и отрицательные значения.
Функции sort, swap и rand, а также объект-генератор случайных чисел rgen являются членами класса Quicksort.
Наконец мы готовы написать вызов Quicksort, sort для сортировки массива типа String:
с объектом сравнения строк, созданным

Так вызывается so rt с объектом сравнения строк, созданным для этой цели.
Функция addname возвращает индекс только

Функция addname возвращает индекс только что добавленного элемента или -1 в случае возникновения ошибки.
Вызов reallос увеличивает массив до новых размеров, сохраняя существующие элементы, и возвращает указатель на него или NULL при недостатке памяти. Удвоение размера массива при каждом вызове realloc сохраняет средние "ожидаемые" затраты на копирование элемента постоянными; если бы массив увеличивался каждый раз только на один элемент, то производительность была бы порядка 0(п2). Поскольку при перераспределении памяти адрес массива может измениться, то программа должна обращаться к элементам массива по индексам, а не через указатели. Заметьте, что код не таков:
? nvtab.nameval = (Nameval *) realloc(nvtab.nameval,
? (NVGROW*nvtab.jnax) * sizeof (Nameval));
потому что при такой форме если вызов realloc не сработает, то исход-ный-массив будет утерян.
Мы задаем очень маленький начальный размер массива (NVINIT = 1). Это заставляет программу увеличивать массив почти сразу, что гарантирует проверку данной части программы. Начальное значение может быть и увеличено, когда программа начнет реально использоваться, однако затраты на стартовое расширение массива ничтожны.
Значение, возвращаемое realloc, не обязательно должно приводиться к его настоящему типу, поскольку в С нетипизированные указатели (void *) приводятся к любому типу указателя автоматически. Однако в C++ это не так; здесь преобразование обязательно. Можно поспорить, что безопаснее: преобразовывать типы (это честнее и понятнее) или не преобразовывать (поскольку в преобразовании легко может закрасться ошибка). Мы выбрали преобразование, потому что тогда программа корректна как в С, так и в C++. Цена такого решения — уменьшение количества проверок на ошибки компилятором С, но это неважно, когда мы производим дополнительные проверки с помощью двух компиляторов.
Удаление элемента может быть более сложной операцией, поскольку нам нужно решить, что же делать с образовавшейся "дыркой" в массиве. Если порядок элементов не имеет значения, то проще всего переставить последний элемент на место удаленного. Однако, если порядок должен быть сохранен, нам нужно сдвинуть элементы после "дырки" на одну позицию:
Вызов memmove сдвигает массив, перемещая

Вызов memmove сдвигает массив, перемещая элементы вниз на одну позицию; memmove — стандартная библиотечная функция для копирования блоков памяти любого размера.
В стандарте ANSI
определены две функции: memcpy, которая работает быстрее, но может затереть память, если источник и приемник данных пересекаются, и memmove, которая может работать медленнее, но зато всегда корректна. Бремя выбора между скоростью и корректностью не должно взваливаться на программиста; должна была бы быть только одна функция. Считайте, что это так и есть, и всегда используйте memmove.
Мы могли бы заменить вызов memmove следующим циклом:
Однако мы предпочитаем использовать memmove,

Однако мы предпочитаем использовать memmove, чтобы обезопасить себя от легко возникающей ошибки копирования элементов в неправильном порядке. Если бы мы вставляли элемент, а не удаляли, то цикл должен был бы идти вверх, чтобы не затереть элементы. Вызывая memmove, мы ограждаем себя от необходимости постоянно задумываться об этом.
Альтернатива перемещению элементов — помечать удаленные элементы как неиспользуемые. Тогда для добавления элемента нам надо сначала найти неиспользуемую ячейку и увеличивать массив, только если свободного места не найдено. В данном примере элемент можно пометить как неиспользуемый, установив значения поля name в NULL.
Массивы — простейший способ группировки данных; вовсе не случайно большинство языков имеют эффективные и удобные индексируемые массивы и даже представляют строки в виде массивов символов. Массивы просты в использовании, обладают константным доступом к любому элементу, хорошо работают с двоичным поиском и быстрой сортировкой, а также почти совсем не тратят лишних ресурсов. Для наборов данных фиксированного размера, которые могут быть созданы даже во время компиляции, или же для гарантированно небольших объемов данных массивы подходят идеально. Однако хранение меняющегося набора значений в массиве может быть весьма ресурсоемким, поэтому, если количество элементов непредсказуемо и потенциально неограниченно, может оказаться удобнее использовать другую структуру данных.
Есть несколько важных различий между

Есть несколько важных различий между массивами и списками. Во-первых, размер массивов фиксирован, а список всегда имеет именно такой размер, который нужен для хранения содержимого, плюс некоторое дополнительное место для указателей на каждый элемент. Во-вторых, списки можно перестраивать, изменяя несколько указателей, что дешевле, чем копирование блоков, необходимое при использовании массива. Наконец, при удалении или вставке элементов остальные элементы не перемещаются; если мы будем хранить указатели на отдельные элементы в другой структуре данных, то при изменениях в списке они останутся корректными.
Эти различия подсказывают, что если набор данных будет часто меняться, особенно при непредсказуемом количестве элементов, то нужно использовать список; напротив, массив больше подходит для относительно статичных данных.
Фундаментальных операций со списком совсем немного: добавить элемент в начало или конец списка, найти указанный элемент, добавить новый элемент до или после указанного элемента и, возможно, удалить элемент. Простота списков позволяет при необходимости легко добавлять новые операции.
Вместо того чтобы определить специальный тип List, обычно в С начинают определение списка с описания типа для элементов, вроде нашего Nameval, и добавляют в него указатель на следующий элемент:

Инициализировать непустой список во время компиляции трудно, поэтому списки, не в пример массивам, создаются динамически. Для начала нам нужен способ создания элемента. Наиболее простой подход — выделить под него память специальной функцией, которую мы назвали newitem:
Функцию emalloc мы будем использовать

Функцию emalloc мы будем использовать и далее во всей книге; она вызывает mall ос, а при ошибке выделения памяти выводит сообщение и завершает программу. Мы представим код этой функции в главе 4, а пока считайте, что эта функция всегда корректно и без сбоев выделяет память.
Простейший и самый быстрый способ собрать список — это добавлять новые элементы в его начало:
у него может измениться первый

При изменении списка у него может измениться первый элемент, что и происходит при вызове addf ront. Функции, изменяющие список, должны возвращать указатель на новый первый элемент, который хранится в переменной, указывающей на список. Функция addfront и другие функции этой группы передают указатель на первый элемент в качестве возвращаемого значения; вот типичное использование таких функций:
nvlist = addf ront(nvlist, newitem( "smiley", Ox263A));
Такая конструкция работает, даже если существующий список пуст (NULL), она хороша и тем, что позволяет легко объединять вызовы функций в выражениях. Это более естественно, чем альтернативный вариант — передавать указатель на указатель на голову списка.
Добавление элемента в конец списка — процедура порядка 0(п), поскольку нам нужно пройтись по всему списку до конца:
Чтобы сделать addend операцией порядка

Чтобы сделать addend операцией порядка 0(1), мы могли бы завести отдельный указатель на конец списка. Недостаток этого подхода, кроме того, что нам нужно заботиться о корректности этого указателя, состоит в том, что список теперь уже представлен не одной переменной, а двумя. Мы будем придерживаться более простого стиля.
Для поиска элемента с заданным именем нужно пройтись по указателям next:
в принципе, эту оценку не

Поиск занимает время порядка 0(п), и, в принципе, эту оценку не улучшить. Даже если список отсортирован, нам все равно нужно пройтись по нему, чтобы добраться до нужного элемента. Двоичный поиск к спискам неприменим.
Для печати элементов списка мы можем написать функцию, проходящую по списку и печатающую каждый элемент; для вычисления длины списка — функцию, проходящую по нему, увеличивая счетчик, и т. д. Альтернативный подход — написать одну функцию, apply, которая проходит по списку и вызывает другую функцию для каждого элемента. Мы можем сделать функцию apply более гибкой, предоставив ей аргумент, который нужно передавать при каждом вызове функции. Таким образом, у apply три аргумента: сам список, функция, которую нужно применить к каждому элементу списка, и аргумент для этой функции:
указатель на функцию, которая принимает

Второй аргумент apply — указатель на функцию, которая принимает два параметра и возвращает void. Стандартный, хотя и весьма неуклюжий, синтаксис
* void (*fn)(Nameval*, void*)
определяет f n как указатель на функцию с возвращаемым значением типа void, то есть как переменную, содержащую адрес функции, которая возвращает void. Функция имеет два параметра — типа Nameval * (элемент списка) и void * (обобщенный указатель на аргумент для этой функции).
Для использования apply, например для вывода элементов списка, мы можем написать тривиальную функцию, параметр которой будет восприниматься как строка форматирования:
тогда вызывать мы ее будем

тогда вызывать мы ее будем так:
apply(nvlist, printnv, "%s: %x\n");
Для подсчета количества элементов мы определяем функцию, параметром которой будет указатель на увеличиваемый счетчик:
He каждую операцию над списками

He каждую операцию над списками удобно выполнять таким образом. Например, при удалении списка надо действовать более аккуратно:
Память нельзя использовать после того,

Память нельзя использовать после того, как мы ее освободили, поэтому до освобождения элемента, на который указывает listp, указатель listp->next нужно сохранить в локальной переменной next. Если бы цикл, как и раньше, выглядел так:
? for ( ; listp != NULL; listp = listp->next) ?
free(listp);
то значение listp->next могло быть затерто вызовом free и код бы не работал.
Заметьте, что функция freeall не освобождает память, выделенную под строку listp->name. Это подразумевает, что поле name каждого элемента типа Nameval было освобождено где-то еще либо память под него не была выделена. Чтобы обеспечить корректное выделение памяти под элементы и ее освобождение, нужно согласование работы newitem и f гее-all; это некий компромисс между гарантиями того, что память будет освобождена, и того, что ничего лишнего освобождено не будет. Именно здесь при неграмотной реализации часто возникают ошибки. В других языках, включая Java, данную проблему за вас решает сборка мусора. К теме управления ресурсами мы еще вернемся в главе 4.
Удаление одного элемента из списка — более сложный процесс, чем добавление:
f reeall, delitem не освобождает

Как и в f reeall, delitem не освобождает память, занятую полем namе.
Функция eprintf выводит сообщение об ошибке и завершает программу, что в лучшем случае неуклюже. Грамотное восстановление после произошедших ошибок может быть весьма трудным и требует долгого обсуждения, которое мы отложим до главы 4, где покажем также реализацию eprintf.
Представленные основные списочные структуры и операции применимы в подавляющем большинстве случаев, которые могут встретиться в ваших программах. Однако есть много альтернатив. Некоторые библиотеки, включая библиотеку стандартных шаблонов (Standard Template Library, STL) в C++, поддерживают двухсвязные списки (double-linked lists: списки с двойными связями), в которых у каждого элемента есть два указателя: один — на последующий, а другой — на предыдущий элемент. Двухсвязные списки требуют больше ресурсов, но поиск последнего элемента и удаление текущего — операции порядка О( 1). Иногда память под указатели списка выделяют отдельно от данных, которые они связывают; такие списки несколько труднее использовать, но зато одни и те же элементы могут встречаться более чем в одном списке одновременно.
Кроме того, что списки годятся для ситуации, когда происходят удаления и вставки элементов в середине, они также хороши для управления данными меняющегося размера, особенно когда доступ к ним происходит по принципу стека: последним вошел, первым вышел (last in, first out — LIFO). Они используют память эффективнее, чем массивы, при наличии нескольких стеков, которые независимо друг от друга растут и уменьшаются. Они также хороши в случае, когда информация внутренне связана в цепочку неизвестного заранее размера, например как последовательность слов в документе. Однако если вам нужны как частые обновления, так и случайный доступ к данным, то разумнее будет использовать не такую непреклонно линейную структуру данных, а что-нибудь вроде дерева или хэш-таблицы.
В качестве конкретного примера на

Комментарии "большие" и "меньшие" относятся к свойствам связей: левые "дети" хранят меньшие значения, правые — большие.
В качестве конкретного примера на приведенном рисунке показано подмножество таблицы символов в виде дерева двоичного поиска для структур Nameval, отсортированных по ASCII-значениям имен символов.
в каждой вершине дерева хранится

Поскольку в каждой вершине дерева хранится несколько указателей на другие элементы, то многие операции, занимающие время порядка О(п) в списках или массивах, занимают только 0(log n) в деревьях. Наличие нескольких указателей в каждой вершине сокращает время выполнения операций, так как уменьшается количество вершин, которые необходимо посетить, чтобы добраться до нужной.
Дерево двоичного поиска (которое в данном параграфе мы будем называть просто "деревом") достраивается рекурсивным спуском по дереву; на каждом шаге спуска выбирается соответствующая правая или левая ветка, пока не найдется место для вставки новой вершины, которая должна быть корректно инициализированной структурой типа Nameval: имя, значение и два нулевых указателя. Новая вершина добавляется как лист дерева, то есть у него пока отсутствуют дочерние вершины.

Мы ничего еще не сказали о дубликатах — повторах значений. Данная версия insert сообщает о попытке вставки в дерево дубликата (cmp == 0). Процедура вставки в список ничего не сообщала, поскольку для обнаружения дубликата надо было бы искать его по всему списку, в результате чего вставка происходила бы за время О(п), а не за 0(1). С деревьями, однако, эта проверка оставляется на произвол программиста, правда, свойства структуры данных не будут столь четко определены, если будут встречаться дубликаты. В других приложениях может оказаться необходимым допускать дубликаты или, наоборот, обязательно их игнорировать.
Процедура weprintf — это вариант eprintf; она печатает сообщение, начинающееся со слова warning (предупреждение), но, в отличие от eprintf, работу программы не завершает.
Дерево, в котором каждый путь от корня до любого листа имеет примерно одну и ту же длину, называется сбалансированным. Преимущество сбалансированного дерева в том, что поиск элемента в нем занимает время порядка 0(log n), поскольку, как и в двоичном поиске, на каждом шаге отбрасывается половина вариантов.
Если элементы вставляются в дерево в том же порядке, в каком они появляются, то дерево может оказаться несбалансированным или даже весьма плохо сбалансированным. Например, если элементы приходят уже в отсортированном виде, то код каждый раз будет спускаться на еще одну ветку дерева, создавая в результате список из правых ссылок, со всеми "прелестями" производительности списка. Если же элементы поступают в произвольном порядке, то описанная ситуация вряд ли произойдет и дерево будет более или менее сбалансированным.
Трудно реализовать деревья, которые гарантированно сбалансированы; это одна из причин существования большого числа различных видов деревьев. Мы просто обойдем данный вопрос стороной и будем считать, что входные данные достаточно случайны, чтобы дерево было достаточно сбалансированным.
Код для функции поиска похож на функцию insert:
У нас есть еще пара

У нас есть еще пара замечаний по поводу функций lookup и i nse rt. Во-первых, они выглядят поразительно похожими на алгоритм двоичного поиска из начала главы. Это вовсе не случайно, так как они построены на той же идее "разделяй и властвуй", что и двоичный поиск, — основе логарифмических алгоритмов.
Во-вторых, эти процедуры рекурсивны. Если их переписать итеративно, то они будут похожи на двоичный поиск еще больше. На самом деле итеративная версия функции lookup может быть создана в результате элегантной трансформации рекурсивной версии. Если мы еще не нашли элемента, то последнее действие функции заключается в возврате результата, получающегося при вызове себя самой, такая ситуация называется хвостовой рекурсией (tail recursion). Эта конструкция может быть преобразована в итеративную форму, если подправить аргументы и стартовать функцию заново. Наиболее прямой метод — использовать оператор перехода goto, но цикл while выглядит чище:
После того как мы научились

После того как мы научились перемещаться по дереву, остальные стандартные операции реализуются совершенно естественно. Мы можем использовать технологии управления списками, например написать общую процедуру обхода дерева, которая вызывает заданную функцию для каждой вершины. Однако в этом случае нужно сделать выбор: когда выполнять операцию над данной вершиной, а когда обрабатывать оставшееся дерево? Ответ зависит от того, что представляет собой дерево: если оно хранит упорядоченные данные, как в дереве двоичного поиска, то мы сначала посещаем левую часть, а затем уже правую.
Иногда структура дерева отражает какое-то внутреннее упорядочение данных, как в генеалогических деревьях, и порядок обхода листьев будет зависеть от отношений, которые дерево представляет.
Фланговый порядок (in-order) обхода выполняет операцию в данной вершине после просмотра ее левого поддерева и перед просмотром правого:
Эта последовательность действий используется, когда

Эта последовательность действий используется, когда вершины должны обходиться в порядке сортировки, например для печати их по порядку, что можно сделать так:
applyinorder(treep, printnv, "%s: %x\n");
Сразу намечается вариант сортировки: вставляем элементы в дерево, выделяем память под массив соответствующего размера, а затем используем фланговый обход для последовательного размещения их в массиве. Восходящий порядок (post-order) обхода вызывает операцию для данной вершины после просмотра вершин-детей:
Восходящий порядок применяется, когда операция

Восходящий порядок применяется, когда операция для вершины зависит от поддеревьев. Примерами служат вычисление высоты дерева (взять максимум из высот двух поддеревьев и добавить единицу), обработка дерева в графическом пакете (выделить место на странице для каждого поддерева и объединить их в области для данной вершины), а также вычисление общего занимаемого места.
Нисходящий порядок (pre-order) используется редко, так что мы не будем его рассматривать.
На самом деле деревья двоичного поиска применяются редко, хотя В-деревья, обычно сильно разветвленные, используются для хранения информации на внешних носителях. В каждодневном программировании деревья часто используются для представления структур действий и выражений. Например, действие
mid = (low + high) / 2;
может быть представлено в виде дерева синтаксического разбора (parse tree), показанного на рисунке ниже. Для вычисления значения дерева нужно обойти его в восходящем порядке и выполнить в каждой вершине соответствующее действие.

Более детально мы будем рассматривать деревья синтаксического разбора в главе 9.
а массив соответствующего размера выделяется

На практике хэш-функция предопределена, а массив соответствующего размера выделяется нередко даже во время компиляции. Каждый элемент массива — это список, который сцепляет вместе элементы, имеющие общее хэш-значение. Другими словами, хэш-таблица из п элементов — это массив списков, средняя длина которых равна п/'(размер_массива). Получение элемента является константной (О(1)) операцией, если мы взяли хорошую хэш-функцию и списки не становятся слишком большими.
Поскольку хэш-таблица — массив списков, то тип элементов для нее такой же, как и для списка:

Способы работы со списками из раздела 2.7 можно использовать для управления отдельными хэш-цепочками. Как только у вас есть хорошая хэш-функция, все становится легко: получаете цепочку и дальше спокойно проходите вдоль списка, ища подходящий элемент. Приведем текст процедуры поиска/вставки в хэш-таблицу. Если элемент найден, то он возвращается. Если элемент не найден и задан флаг создания create, то lookup добавляет элемент в таблицу. Копия имени символа не создается — считается, что вызывающая сторона сама сделала себе надежную копию.
и возможная вставка комбинируются часто.

Поиск и возможная вставка комбинируются часто. Иначе приходится прилагать лишние усилия. Если писать
if (lookup("name") == NULL)
additem(newitem("name", value));
то хэш-функция вычисляется дважды.
Насколько большим должен быть массив? Основная идея заключается в том, что он должен быть достаточно большим, чтобы любая хэш-цепочка была бы длиной всего в несколько элементов и поиск занимал время О(1). Например, у компилятора размер массива должен быть порядка нескольких тысяч, так как в большом исходном файле — несколько тысяч строчек и вряд ли различных идентификаторов имеется больше, чем по одному на строчку кода.
Теперь нам нужно решить, что же наша хэш-функция, hash, будет вычислять. Она должна быть детерминированной, достаточно быстрой и распределять данные по массиву равномерно. Один из наиболее распространенных алгоритмов хэширования для строк получает хэш-значение, добавляя каждый байт строки к произведению предыдущего значения на некий фиксированный множитель (хэш). Умножение распределяет биты из нового байта по всему до сих пор не считанному значению, так что в конце цикла мы получим хорошую смесь входных байтов. Эмпирически установлено, что значения 31 и 37 являются хорошими множителями в хэш-функции для строк ASCII.
В вычислениях символы принимаются неотрицательными

В вычислениях символы принимаются неотрицательными принудительно (тем, что используется тип unsigned char), так как ни в С, ни в C++ наличие знака у символов не регламентировано, а мы хотим, чтобы наша хэш-функция оставалась положительной.
Хэш-функция возвращает результат по модулю размера массива. Если хэш-функция распределяет данные равномерно, то точный размер массива неважен. Трудно, однако, гарантировать, что хэш-функция независима от размера массива, и даже у хорошей функции могут быть проблемы с некоторыми наборами входных данных. Поэтому имеет смысл сделать размер массива простым числом, чтобы слегка подстраховаться, обеспечив отсутствие общих делителей у размера массива, хэш-мультипликатора и, возможно, значений данных.
Эксперименты показывают, что для большого числа разных строк трудно придумать хэш-функцию, которая работала бы гораздо лучше, чем эта, зато легко придумать такую, которая работает хуже. В ранних версиях Java была хэш-функция для строк, работавшая более эффективно, если строка была длинной. Хэш-функция работала быстрее, анализируя только 8 или 9 символов через равные интервалы в строках длиннее, чем 16 символов, начиная с первого символа. К сожалению, хотя хэш-функция работала быстрее, у нее были очень плохие статистические показатели, что сводило на нет выигрыш в производительности. Пропуская части строки, она нередко выкидывала именно различающиеся части строк. Имена файлов начинаются с длинных идентичных префиксов — имен каталогов — и могут отличаться только несколькими последними символами (например, .Java и .class). Адреса в Internet обычно начинаются с http://www. и заканчиваются на . html, поэтому все различия у них в середине. Хэш-функция частенько проходила только по неразличающейся части в имени, в результате чего образовывались более длинные хэш-цепочки, что замедляло поиск. Проблема была решена заменой хэш-функции на эквивалентную той, что мы привели выше (с мультипликатором 37), которая исследует каждый символ в строке.
Хэш-функция, которая неплохо подходит для одного набора данных (например, имен переменных), может плохо подходить для другого (адреса Internet), так что потенциальная хэш-функция должна быть протестирована на разных наборах типичных входных данных.
Хорошо ли она перемешивает короткие
Хорошо ли она перемешивает короткие строки? Длинные строки? Строки одинаковой длины с небольшими изменениями?
Хэшировать можно не только строки. Можно "смешать" три координаты частицы при физическом моделировании, тем самым уменьшив размер хранилища до линейной таблицы (0(количество точек)) вместо трехмерного массива (0(размер_по_х хразмер_nojj X размер_no_z)).
Один примечательный случай использования хэширования — программа Джерарда Холзманна (Gerard Holzmann) для анализа протоколов и параллельных систем Supertrace. Supertrace берет полную информацию о каждом возможном состоянии наблюдаемой системы и хэширует эту информацию для получения адреса единственного бита в памяти. Если этот бит установлен, то данное состояние наблюдалось и раньше; если нет, то не наблюдалось. В Supertrace используется хэш-таблица длиной во много мегабайт, однако в каждой ячейке хранится только один бит. Цепочки не строятся; если два разных состояния совпали по своей хэш-функции, то программа этого не заметит. Supertrace рассчитана на то, что вероятность коллизии мала (она не обязана быть нулем, поскольку Supertrace использует вероятностные, а не детерминированные вычисления). Поэтому хэш-функция здесь очень аккуратна; она использует циклический избыточный код (cyclic redundancy check — CRC) — функцию, которая тщательно перемешивает данные.
Хэш-таблицы незаменимы для символьных таблиц, поскольку они предоставляют (почти всегда) доступ к каждому элементу за константное время. У них есть свои ограничения. Если хэш-функция плоха или размер массива слишком мал, то списки могут стать достаточно длинными. Поскольку списки не отсортированы, это приведет к линейному доступу (0(и)). Элементы нельзя напрямую получить в отсортированном виде, однако их легко подсчитать, выделить память под массив, заполнить его указателями на элементы и отсортировать их. Что и говорить, константное время операций поиска, вставка и удаление — это такое свойство хэш-таблицы, которого не достичь никакими другими технологиями.
Сортировка
Двоичный поиск работает только в том случае, если элементы отсортированы. Если по одному и тому же набору данных планируется неоднократный повторный поиск, то выгоднее один раз отсортировать данные, а затем использовать двоичный поиск. Если набор данных известен заранее, то он может быть отсортирован при написании программы и проинициализирован во время компиляции. Иначе придется сортировать его во время выполнения программы.
Один из самых лучших алгоритмов сортировки — быстрая сортировка (quicksort), которая была придумана в 1960 году Чарльзом Хоаром (С. A. R. Ноаге). Быстрая сортировка — замечательный пример того, как можно избежать лишних вычислений. Она работает при помощи разделения массива на большие и маленькие элементы:
выбрать один элемент массива ("разделитель"):
разбить оставшиеся элементы на две группы:
"маленькие", то есть меньшие, чем разделитель,
"большие", то есть большие или равные разделителю,
рекурсивно отсортировать обе группы.
Когда этот процесс закончится, то массив будет отсортирован. Быстрая сортировка работает быстро, потому что, как только мы узнаем, что элемент меньше, чем разделитель, нам уже не нужно его сравнивать с большими элементами; аналогично, большие элементы не сравниваются с маленькими. Поэтому данный алгоритм существенно быстрее, чем такие простые методы сортировки, как сортировка вставкой или пузырьком, когда каждый элемент сравнивается напрямую со всеми остальными.
Алгоритм быстрой сортировки практичен и эффективен; он хорошо изучен, и существует множество его вариаций. Версия, которую мы здесь представим, является одной из самых простых реализаций, но, конечно, далеко не самой быстрой.
Наша функция quicksort сортирует массив целых чисел:
Списки
По своей встречаемости в типичных программах списки занимают второе место после массивов. Многие языки имеют встроенные типы списков, некоторые, такие как Lisp, даже построены на них, но в языке С мы должны конструировать их самостоятельно. В C++ и Java работа со списками поддерживается стандартными библиотеками, но и в этом случае нужно знать их возможности и типичные применения. В данном параграфе мы собираемся обсудить использование списков в С, но уроки из этогр обсуждения можно извлечь и для более широкого применения.
Простым цепным списком (single-linked list) называется последовательность элементов, каждый из которых содержит данные и указатель на следующий элемент. Головой списка является указатель на первый элемент, а конец помечен нулевым указателем. Ниже показан список из четырех элементов:
Алгоритм быстрой сортировки проще всего
Алгоритм быстрой сортировки проще всего выразить рекурсивно. Реализуйте его итеративно и сравните две версии. (Хоар рассказывает, как было трудно разработать итеративный вариант быстрой сортировки и как легко все оказалось, когда он сделал ее рекурсивной.) <
в Java делает несколько преобразований
Наша реализация быстрой сортировки в Java делает несколько преобразований типов, сначала переводя исходные данные из их первоначального типа (вроде Integer) в Object, а затем обратно. Поэкспериментируйте с версией Quickso rt. so rt, которая использует конкретный тип при сортировке, и попробуйте вычислить, какие потери производительности вызываются преобразованием типов. <
Каковы входные данные для алгоритма
Каковы входные данные для алгоритма quicksort, которые заставляют его работать медленнее всего, как в наихудшем случае? Попробуйте найти несколько наборов данных, сильно замедляющих библиотечную версию алгоритма. Автоматизируйте процесс, чтобы вы легко могли задавать параметры и проводить большое число экспериментов.
и реализуйте алгоритм, который будет
Придумайте и реализуйте алгоритм, который будет сортировать массив из п целых как можно медленнее. Только напишите его честно: алгоритм должен постепенно прогрессировать и в конце концов завершиться, и ваша реализация не должна использовать всяческие трюки вроде лишних пустых циклов. Какова получилась сложность вашего алгоритма как функция от n? <
В приведенном выше коде функция
В приведенном выше коде функция delname не вызывает realloc для возврата системе памяти, освобожденной удалением элемента. Имеет ли смысл это делать? Как решить, стоит это делать или нет?
и addname, чтобы удаленные элементы
Внесите необходимые изменения в функции delname и addname, чтобы удаленные элементы помечались как неиспользуемые. Насколько остальная программа не зависит от этого изменения? <
Реализуйте некоторые другие операции над
Реализуйте некоторые другие операции над списком: копирование, слияние, разделение списка, вставку до или после указанного элемента. Как эти две операции вставки отличаются по сложности? Много ли вы можете использовать из того, что мы написали, и много ли вам надо написать самому?
и итеративную версии процедуры reverse,
Напишите рекурсивную и итеративную версии процедуры reverse, переворачивающей список. Не создавайте новых элементов списка; используйте старые.
Напишите обобщенный тип List для
Напишите обобщенный тип List для языка С. Простейший способ — в каждом элементе списка хранить указатель void *, который ссылается на данные. Сделайте то же для C++, используя шаблон (template), и для Java, определив класс, содержащий списки типа Obj ect. Каковы сильные и слабые стороны этих языков с точки зрения данной задачи?
и реализуйте набор тестов для
Придумайте и реализуйте набор тестов для проверки того, что написанные вами процедуры работы со списками корректны. Стратегии тестирования подробнее обсуждаются в главе 6. <
и nrlookup. Насколько рекурсия медленнее
Сравните быстродействие lookup и nrlookup. Насколько рекурсия медленнее итеративной версии?
Используйте фланговый обход для создания
Используйте фланговый обход для создания процедуры сортировки. Какова ее временная сложность? При каких условиях она может работать медленно? Как ее производительность соотносится с нашей процедурой quicksort и с библиотечной версией?
и реализуйте набор тестов, удостоверяющих,
Придумайте и реализуйте набор тестов, удостоверяющих, что процедуры работы с деревьями корректны. <
функция замечательна для повседневного хэширования
Наша хэш- функция замечательна для повседневного хэширования строк. Однако на нарочно придуманных данных она может работать плохо. Сконструируйте набор данных, приводящий к плохому поведению нашей хэш-функции. Проще ли найти плохой набор для других значений NHASH?
Напишите функцию для доступа
Напишите функцию для доступа к последовательным элементам хэш-таблицы в несортированном порядке.
Измените функцию lookup так, что
Измените функцию lookup так, что если средняя длина списка превысит некое значение х, то массив автоматически расширяется в у раз и хэш-таблица перестраивается.
функцию для хранения координат точек
Спроектируйте кэш- функцию для хранения координат точек в двумерном пространстве. Насколько легко ваша функция адаптируется к изменениям в типе координат, например при переходе от целого типа данных к значениям с плавающей точкой, или при переходе от декартовой к полярной системе координат, или при увеличении количества измерений?
При выборе алгоритма нужно сделать
При выборе алгоритма нужно сделать несколько шагов. Во-первых, следует изучить существующие алгоритмы и структуры данных. Подумайте, какой объем данных может обработать программа. Если задача предполагает скромные размеры данных, то выбирайте простые технологии; если количество данных может расти, то исключите решения, плохо приспосабливающиеся к этому росту. Там, где возможно, используйте библиотеку или специальные средства языка. Если ничего готового нет, то напишите или достаньте короткую, простую, понятную реализацию. Попробуйте ее в действии. Если измерения показывают, что она слишком медленная, только тогда вам стоит перейти к более продвинутым технологиям.
Хотя есть много структур данных, часть которых просто необходима для приемлемой производительности в определенных условиях, большинство программ основано на массивах, списках, деревьях и хэш-таб-лицах. Каждая из этих структур поддерживает набор операций-примитивов, обычно включающий в себя: создание нового элемента, поиск элемента, добавление элемента куда-либо, возможно, удаление элемента и применение некоторой операции ко всем элементам.
У каждой операции есть ожидаемое время выполнения, которое часто определяет, насколько выбранный тип данных или его реализация подходит для конкретного приложения. Массивы предоставляют доступ к элементам за константное время, но зато плохо изменяют свои размер; Списки хорошо приспособлены для вставки и удаления, но случайный доступ к элементам происходит лишь за линейное время. Деревья и хэш-таблицы предоставляют разумный компромисс: быстрый доступ к заданным элементам в сочетании с легкой расширяемостью, пока в их структуре соблюдается определенный баланс.
Есть еще множество изощренных структур данных для специальных задач, однако этот базовый набор вполне достаточен для написания подавляющего большинства программ <