Автоматизация тестирования
Осуществлять тестирование вручную — скучно и ненадежно: при нормальном подходе вам потребуется прогнать множество тестов, перебрать множество вариантов ввода и сравнить множество результатов. Так что тестированием должны заниматься программы: они не устают и не отвлекаются от работы. Стоит потратить время на написание кода простейшей программы или просто скрипта, который включает все тесты, и все тестирование сможет выполниться от (буквально или фигурально) простого нажатия кнопки. Чем проще будет запуск тестирования, тем реже вы станете пренебрегать им из-за спешки. Мы написали набор тестовых утилит, которыми протестировали все программы, созданные для этой книги; этот же набор мы запускали после внесения любых изменений; некоторые утилиты запускались у нас автоматически после каждой успешной компиляции.
Автоматизируйте возвратное тестирование. Одной из основных форм автоматизации является возвратное тестирование (regression testing), при котором выполняется последовательность тестов, сравнивающих очередную новую версию программы с предыдущей. При исправлении ошибок зачастую проверяются только собственно исправленные недочеты, при этом не принимается в расчет возможность внесения новых ошибок. Основное назначение возвратного тестирования — убедиться в том, что поведение программы изменилось только в предусмотренных рамках.
В некоторых системах имеется большой арсенал средств, облегчающих подобную автоматизацию; языки скриптов позволяют писать короткие сценарии для запуска последовательностей тестов. В Unix утилиты сравнения файлов вроде cliff и стр дают возможность отслеживать изменения вывода, sort группирует схожие элементы, дгер фильтрует вывод тестов, we, sum и f req подсчитывают статистику вывода. С помощью этих утилит можно без труда создать подходящие к случаю тестовые оснастки — слабоватые, возможно, для больших проектов, но вполне пригодные для программ, создающихся одним или несколькими программистами.
Ниже приведен скрипт для возвратного тестирования программы ka. (от killer application). Этот скрипт выполняет старую (old_ka) и новую (new_ka) версии программы на большом наборе тестовых файлов данных и выдает сообщения обо всех случаях, когда результаты оказались не идентичными. Скрипт написан для оболочки Unix, но его можно просто модифицировать под Perl или другой язык скриптов:
Дополнительная литература
Один из способов узнать побольше о тестировании — изучить примеры на основе лучших образцов доступных программ. В статье Дона Кнута "Ошибки в ТЕХ", опубликованной в Software — Practice and Experience (Don Knuth. The Errors of TEX. Software — Practice and Experience, 19, 7, p. 607-685, 1989), описываются все ошибки, найденные к тому времени в системе ТЕХ, и обсуждаются использованные Кнутом методы тестирования. Тест TRIP для ТЕХ представляет соб^й отличный пример основательного комплекса тестирования. Perl также предлагает расширенный набор тестирования, предназначенный для проверки его правильности после компиляции и установки на новой системе и включающий такие модули, как MakeMaker и TestHarness, которые помогают в создании тестов для расширений Perl.
Ион Бентли (Jon Bentley) написал серию статей в Communications of the ACM, которые были собраны в сборниках "Programming Pearls" (1986) и "More Programming Pearls" (1988), изданных Addison-Wesley. В этих статьях затрагиваются вопросы тестирования, главным образом структуры для организации и автоматизации расширенных тестов.
<
Кто осуществляет тестирование?
Тестирование, проводимое создателем кода или кем-то другим, имеющим тем не менее доступ к исходному коду, называется тестированием белого ящика. Термин придуман по аналогии с тестированием черного ящика, — это когда тестер не знает, как реализован компонент. Лучше передает суть происходящего, на наш взгляд, термин "прозрачный ящик". Свой код тестировать, конечно, необходимо — не ждите, что некая мифическая тестирующая организация или пользователь сделают это вместо вас. Однако мы зачастую склонны обманывать сами себя и верить в лучшее, поэтому при тестировании вам надо отрешиться от кода и стараться придумать как можно более каверзные ходы. Вот как Дон Кнут (Don Knuth) описывает процесс создания тестов для системы форматирования ТЕХ: "Я роюсь в самых мерзких и отвратительных уголках своего мозга, потом сажусь и пишу самый мерзкий [тестирующий] код, который только могу придумать, после чего стремительно меняюсь и встраиваю его в еще более мерзкие конструкции — такие мерзкие, что и говорить противно". Цель тестирования — найти ошибки, а не объявить, что программа работает. Стало быть, тесты должны быть жесткими, и если с их помощью вы обнаруживаете проблемы, то это является доказательством действенности ваших методов, а не сигналом тревоги.
Тестирование черного ящика означает, что тестер не имеет никакого представления ни о доступе к коду, ни о его внутреннем устройстве. При таком тестировании выявляются несколько иные сшибки, поскольку тестер имеет иные отправные точки для поиска. Хорошо начинать с проверки граничных условий; после этого стоит перейти к большим объемам и некорректному вводу. Естественно, не надо забывать и о "золотой середине": проверке работы программы в нормальных условиях.
Следующий этап — реальные пользователи. Новые пользователи находят новые ошибки, потому что они опробуют программу неожиданными способами. Важно провести этот этап тестирования до того, как вы выпустите свое детище в большой мир, однако, к сожалению, многие программы распространяются без прохождения достаточного тестирования какого бы то ни было вида. Бета-версии программ — попытка привлечь большое количество конечных пользователей к тестированию, однако такие бета-версии нельзя рассматривать как замену нормальному тестированию. Однако чем больше и сложнее становятся системы, чем короче сроки на их разработку, тем выше вероятность появления плохо оттестированных продуктов.
Трудно тестировать интерактивные программы, особенно если в них обрабатывается ввод с помощью мыши. Некоторые тесты можно выполнить с помощью сценариев (их конкретные возможности зависят от языка, среды и т. п.). Интерактивные программы можно контролировать из скриптов, имитирующих поведение пользователя. Здесь есть два способа: первый — перехватить действия реального пользователя и воспроизводить их; второй — создать язык скриптов, позволяющий описать последовательность и протяженность событий.
Наконец, стоит задуматься и о том, как тестировать сами тесты. В главе 5 мы упомянули о проблеме, вызванной некорректностью программы, которая тестирует пакет функций для работы со списками. Набор возвратных тестов, содержащий ошибку, вызовет проблемы во всех версиях, и вообще, результат выполнения набора тестов вряд ли будет что-то значить, если сами тесты окажутся некорректными.
<
Полезные советы
Опытные тестеры имеют в активе большое количество способов тестирования, а также разнообразных уловок и ухищрений, которые делают их работу более продуктивной. В этом разделе мы поделимся с вами своими любимыми приемами.
Программы должны проверять границы массивов (если за них этого не делает собственно язык программирования), однако код таких проверок не обязательно тестировать в том случае, когда размеры массивов достаточно велики по сравнению с типичным вводом. Для выполнения таких проверок временно уменьшите размеры массивов — тогда вам не придется создавать очень больших тестовых случаев. Схожий прием .мы использовали в коде для приращения массива в главе 2 и в библиотеке CSV из главы 4. На самом деле мы даже оставили эти небольшие начальные значения, поскольку дополнительные затраты при запуске в данном случае несущественны.
Пусть при тестировании ваша хэш-функция возвращает константу — тогда каждый элемент будет записываться на одно и то же место. При этом будет работать механизм цепных списков; кроме того, это даст вам представление о быстродействии для самого худшего случая.
Напишите версию выделения памяти, которая специально даст сбой в скором времени — и вы протестируете код, восстанавливающий систему после ошибок нехватки памяти. Вот, например, версия, которая после 10 вызовов возвращает NULL:
Первое граничное условие

-
Представьте себе, что вы только что написали этот цикл. Теперь мысленно выполните за него обработку строки. Первое граничное условие, которое надо проверить, очевидно: пустая строка. Если представить строку, содержащую единственный символ перевода строки, то нетрудно убедиться, что цикл остановится на пертой итерации со значением i, равным 0, так что в последней строке i будет уменьшено до -1 и, следовательно, запишет нулевой байт в элемент s[-1 ], который находится вне границ массива. Итак, проверка первого же граничного условия обнаружила ошибку.
Если переписать цикл так, чтобы он использовал идиоматическую форму заполнения массива вводимыми символами, он будет выглядеть следующим образом:
в уме первый reef, мы

Повторив в уме первый reef, мы удостоверимся, что теперь строка, содержащая только символ перевода строки, обрабатывается корректно: i равно 0, первый же введенный символ прерывает работу цикла, а '\0- сохраняется в s[0]. Проверив схожим образом варианты с вводом одного и двух символов, замыкаемых символом перевода строки, мы убедимся, что цикл работает корректно вблизи нижней границы ввода.
Теперь надо проверить и другие граничные условия. Ситуации, когда во вводе содержится очень длинная строка или не содержится символов перевода строки, предусмотрены кодом — на этот случай существует ограничение i значением МАХ-1. Однако что будет, если ввод абсолютно пуст (в нем нет вообще ни одного символа) и первый же вызов getchar возвратит значение EOF? Надо добавить проверку и для такого случая:
Проверка граничных условий может обнаружить

Проверка граничных условий может обнаружить много ошибок, но, конечно, не все. Мы еще вернемся к рассмотренному примеру в главе 8, где покажем, что в нем осталась еще ошибка переносимости.
Следующим шагом будет проверка ввода около другой границы, когда массив почти заполнен, полностью заполнен и наконец переполнен, особенно если как раз в этот момент и встречается символ перевода строки. Мы не будем расписывать здесь все детали этих тестов; выполните их самостоятельно, — это очень хорошее упражнение. Задумавшись о всевозможных граничных условиях, нам придется решить, что делать в случае, если буфер заполнится до того, как во вводе встретится ' \п '; этот пробел в спецификации должен быть ликвидирован на ранней стадии написания программы.
Тестирование граничных условий особенно эффективно для поиска ошибок выхода за границы массива на 1 (off-by-one errors). Попрактиковавшись, вы сделаете такую проверку своей второй натурой, и множество тривиальных ошибок будет устранено в самый момент возникновения.
Тестируйте пред- и постусловия. Еще один способ предотвратить возникновение проблем — удостовериться в том, что ожидаемые или необходимые условия удовлетворяются до (предусловие) или после (постусловие) выполнения некоторого блока кода. Проверяя вводимые значения на соответствие допустимому диапазону, мы встретились как раз с примером тестирования предусловий. Ниже приведена функция для вычисления среднего из п элементов массива. При значениях л, меньших или равных 0, функция работает некорректно:
Что будет делать эта функция,

Что будет делать эта функция, если n будет равно 0? Массив, не содержащий элементов, — вполне осмысленный элемент программы, а вот среднее значение его элементов не имеет никакого смысла. Должна ли функция позволять системе отлавливать деление на 0? Прерывать функцию? Сообщать об ошибке? Без предупреждения возвращать какое-нибудь нейтральное значение? А что если n вообще отрицательно, что абсолютно бессмысленно, но не невозможно? Как мы уже говорили в главе 4, нам представляется правильным в случае, если n меньше либо равно нулю, возвращать 0 в качестве среднего значения:
return n <= 0 ? 0.0
но однозначно правильного ответа здесь не*существует.
Имеется, правда, гарантированно неверное мнение — игнорировать проблему. В ноябре 1998 в журнале Scientific American был описан инцидент, произошедший на борту американского ракетного крейсера Yorktown. Член команды по ошибке вместо значимого числа ввел 0, что привело к ошибке деления на нуль; ошибка разрослась и в конце концов силовая установка корабля оказалась выведена из строя. Несколько часов Yorktown дрейфовал по воле волн — а все из-за того, что в программе не была осуществлена проверка диапазона вводимых значений.
Используйте утверждения. В С и C++ существует возможность использования специального щ механизма утверждений (assertions) (в <assert. h>), который позволяет включать в программу проверку пред- и постусловий. Поскольку невыполненное утверждение прерывает работу программы, используют их, как правило, в ситуациях, когда сбой на самом деле не ожидается, а при его возникновении нет возможности продолжить работу нормально. Только что рассмотренный пример можно было бы дополнить утверждением, вставленным перед началом цикла:
assert(n > 0);
Если утверждение не выполнено, программа прерывается; сопровождается это выдачей стандартного сообщения:
Assertion failed: n > О,
file avgtest.с, line 7
Abort(crash)
Утверждения особенно полезны при проверке свойств интерфейса, поскольку они привлекают внимание к несовместимости вызывающего и вызываемого блоков системы и зачастую помогают найти виновника этой несовместимости. Так, если наше утверждение, что n больше О, не проходит при вызове функции, это сразу указывает на ошибку в вызывающей функции, а не в самой функции avg. Если интерфейс изменился, а внести соответствующие коррективы мы забыли, утверждения помогут выловить ошибку до того, как она приведет к возникновению серьезных проблем.
Используйте подход защитного программирования. Полезно вставлять некоторый код для обработки (хотя бы просто предупреждения пользователю) случаев, которых "не может быть никогда", то есть ситуаций, которые теоретически не должны случиться, но все же имеют место (например, из-за сбоя где-то в другом участке программы). Хороший пример — добавление проверки на нулевой или отрицательный размер массива в функцию avg. Еще одним примером может стать программа, выставляющая оценки по американской системе; очевидно, что отрицательных или очень больших значений появиться в ней не может, но лучше все же это проверить:
в том, что программа защищена

Это пример защитного программирования (defensive programming), при котором вы убеждаетесь в том, что программа защищена от неправильного использования или некорректных данных. Пустые указатели, индексы вне диапазона, деление на ноль и другие ошибки можно обнаружить на ранних стадиях жизни программы или нейтрализовать. Если бы все программисты применяли принципы защитного программирования, с Yorktown ничего бы не произошло, что бы там ни вводил оператор.
Проверяйте коды возврата функций. Одним из приемов защиты, которым программисты почему-то незаслуженно пренебрегают, является проверка возвращаемого значения библиотечных функций и системных вызовов. Значения, возвращаемые функциями, обслуживающими ввод, такими как f read и fscant, надо всегда проверять. Также обязательно надо проверять и возвращаемые значения вызовов открытий файлов типа f open. Если чтение или открытие файла по каким-то причи- i нам не выполняется, не может быть и речи о нормальном продолжении работы программы.
Проверка возвращаемого значения функций вывода типа f p rintf или fwrite поможет поймать ошибки, происходящие при попытке записи в файл, когда свободного места на диске не осталось. Также полезно на всякий случай проверить значение, возвращаемое fclose, — если при выполнении произошла какая-нибудь ошибка, эта функция возвратит EOF, в противном случае возвращается ноль.
Последствия ошибок вывода могут быть

Последствия ошибок вывода могут быть серьезными. Если записываемый файл является обновленной версией уже существующего файла, такая проверка спасет вас от удаления старой версии при отсутствии сформировавшейся новой.
Усилия, потраченные на тестирование кода при написании, минимальны и окупаются сторицей. Мысли о тестировании в момент написания улучшают код, так как в, этот момент вы яснее всего отдаете себе отчет в том, что он должен делать. Если же вы начинаете проверку только после того, как что-нибудь сломается, то к этому моменту вы можете забыть, как код работает. Работая под давлением, вам будет трудно восстановить всю картину заново, что отнимет много времени, а внесенные исправления окажутся менее продуманными и, следовательно, менее эффективными, поскольку ваше понимание, скорее всего, окажется неполным.
Этот отрывок должен распечатывать символы

2. Этот отрывок должен распечатывать символы строки, каждый в отдельной строке:
что эта функция будет копировать

3. Предполагается, что эта функция будет копировать строку из одного места в другое (из источника s гс в приемник dest):
Еще один пример копирования строк

4. Еще один пример копирования строк — на этот раз копируется n сим- 1 волов из s в t:
в конце 1998 года, поэтому

Упражнение 6-2
Мы пишем эту книгу в конце 1998 года, поэтому призрак проблемы 2000 года неотступно стоит перед нами как самая глобальная ошибка граничных условий.
1. Какие даты вы используете для поверки программы на работоспособность в 2000 году? Предположим, что выполнять тесты очень дорого, в каком порядке вы будете их осуществлять после ввода даты 1 января 2000 года?
2. Как вы будете тестировать стандартную функцию ctime, которая возвращает строковое представление даты в такой форме:
Fri Dec 31 23:58:27 EST 1999\n\0
Предположим, что вы в своей программе вызываете ctime. Как вы будете предохранять свой код от некорректной реализации этой функции?
3. Опишите, как вы будете тестировать программу-календарь, которая генерирует вывод в таком виде:
в используемой вами системе? Как

4. Какие еще граничные условия в отношении времени и дат существуют в используемой вами системе? Как бы вы оттестировали их? <
Простейшая программка, но утилиты для

Простейшая программка, но утилиты для тестирования и не должны быть сложными (естественно, при желании можно расширить возможности этой утилиты), их единственная задача — избавить вас от монотонных ручных проверок.
Четко определите, чего вы ожидаете на выходе теста. При проведении всех тестов вы должны четко знать правильный результат; если вы его не знаете, то напрасно теряете время. На первый взгляд мысль кажется самоочевидной, поскольку для многих программ очень просто определить, работают они или нет. Например, создается ли копия файла или нет, отсортированы ли данные на выходе или нет и т. п.
Однако для большинства программ работоспособность определить труднее, например: для компиляторов (полностью ли правильно преобразованы входные данные?), численных алгоритмов (не превышена ли допустимая погрешность вычислений?), графики (все ли пиксели находятся на своих местах?) и т. п. Для таких программ необходимо сравнивать результаты тестов с заранее известными значениями.
Для теста компилятора скомпилируйте и запустите тестовые файлы. Результаты работы этих программ надо сравнить с заранее определенными значениями.
Для теста вычислительной программы выберите случаи, которые позволят проверить алгоритм со всех сторон, — как простые случаи, так и сложные. Где возможно, вставляйте код, удостоверяющий корректность параметров вывода. Например, вывод программы, численно считающей интегралы, может быть проверен на непрерывность и на соответствие результату, полученному по формуле.
Для тестирования графической программы недостаточно удостовериться, что она в состоянии нарисовать ящик; вместо этого прочтите этот ящик обратно с экрана и проверьте, что его стороны находятся там, где требуется.
Если в программе выполняются какие-то обратимые действия, убедитесь, что вы можете обратить данные в исходное состояние. Шифровка и дешифровка во многих случаях обратимы; если вы что-то зашифровали и не смогли расшифровать, значит, что-то тут не так. То же самое относится и к программам сжатия данных. Иногда существует несколько способов обратного преобразования — тогда необходимо проверить все комбинации.
Проверяйте свойства сохранности данных. Многие программы сохраняют некоторые свойства вводимых данных. Инструменты вроде we (подсчитывает строки, слова и символы) и sum (вычисляет контрольную сумму) помогут удостовериться в том, что вывод имеет тот же размер, то же количество слов или те же байты в некотором порядке и т. п. Другие программы проверяют файлы на идентичность (стр) или перечисляют их различия (cliff). Эти программы (или сходные с ними) доступны в большинстве сред программирования, и пренебрегать ими не стоит.
Программа определения частоты появления байтов может быть использована для проверки сохранности данных; кроме того, она может выявить аномалии вроде наличия нетекстовых символов в текстовых файлах. Вот версия такой программы, которую мы назвали f req:
Сохранность данных можно также проверять
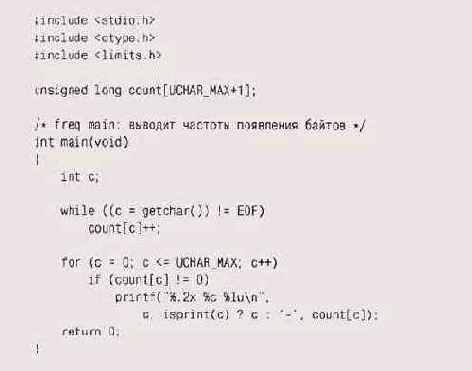
Сохранность данных можно также проверять и внутри самой программы. Функция, подсчитывающая количество элементов в структуре, осуществляет простейший тест целостности данных. Для хэш-таблицы должно выполняться ее основное свойство: каждый записанный в нее элемент может быть считан. Проверить это свойство нетрудно - достаточно написать функцию, которая бы выводила содержимое таблицы в файл или массив. В любой момент для любой структуры данных разность числа включений и числа исключений должна равняться числу хранимых элементов. Проверить это условие совсем не сложно.
Сравните независимые реализации. Независимые реализации библиотек или программ должны выдавать одни и те же результаты. Например, два компилятора должны из одного и того же текста создавать программы, которые на одной и той же машине будут вести себя одинаково, — по крайней мере, в большинстве случаев.
Иногда искомый ответ можно получить двумя различными способами, а иногда — написать тривиальную версию программы, не заботясь о быстродействии и используемых ресурсах, для сравнения результатов. Если две программы независимо друг от друга выдают одни и те же ответы, с большой долей уверенности можно считать, что обе они работают корректно; если же ответы их разнятся, значит, по крайней мере, в одной из них есть ошибки.
Один из нас однажды работал над компилятором для новой машины в паре с другим программистом. Мы разделили работу по отладке кода, генерируемого компилятором, таким образом: один писал программу, кодирующую инструкции для машины, а другой — дизассемблер для отладчика. При таком разделении ошибки интерпретации или реализации набора инструкций, для того чтобы остаться незамеченными, должны были возникнуть синхронно в обеих программах, иначе же, как только компилятор неправильно кодировал инструкцию, это сразу замечал отладчик. На ранних стадиях весь вывод компилятора прогонялся через дизассемблер и сравнивался с распечатками собственно отладчика ком- | пилятора. Такая стратегия разделения давала хорошие результаты, и благодаря ей было найдено немало ошибок в обеих частях.
Единственный сложный случай, затянувший работу,
Единственный сложный случай, затянувший работу, возник, когда оба программиста одинаково неверно истолковали громоздкую маловразумительную фразу из описания архитектуры машины.
Оценивайте охват тестов. Одна из главных целей тестирования — убедиться, что каждое выражение в программе было выполнено хотя бы единожды при проведении последовательности тестов; тестирование нельзя считать завершенным, пока этого не произошло. Однако надо признать, что полного охвата добиться достаточно трудно. Не принимая даже во внимание выражений, обрабатывающих ситуации "не может быть", с помощью нормального ввода вынудить программу обойти все возможные ветки не так-то просто.
Для оценки охвата существуют специальные коммерческие утилиты.' Профайлеры (программы-протоколисты), часто включаемые в комплект поставки компиляторов, предоставляют возможность осуществить подсчет частоты выполнения каждого выражения программы, — отсюда можно узнать и охват каждого теста.
Мы использовали комбинацию описанных выше методов для тестирования программы markov из главы 3, эти тесты будут подробно описаны в последнем разделе главы.
в идеале должен работать молча,

Тестовый скрипт в идеале должен работать молча, выводя какие-то сообщения только при возникновении непредвиденных ситуаций, — как это делает приведенный фрагмент. Можно было бы, конечно, печатать имя каждого тестируемого файла, при необходимости дополняя его сообщением об ошибке. Подобный индикатор процесса полезен для выявления проблем, связанных с бесконечными циклами или пропуском нужных тестовых файлов, однако при нормальном течении тестов лишние подсказки на экране несколько раздражают.
Аргумент -s заставляет стр возвращать результат прохождения теста и ничего не выводить. Если сравниваемые файлы оказываются эквивалентными, стр возвращает результат "истина", тогда ! стр оказывается "ложью", и, стало быть, ничего не печатается. Однако, если файлы вывода старой и новой версий различаются, стр возвращает значение "ложь", и выводится имя файла и предупреждение.
При регрессивном тестировании предполагается, что предыдущая версия работала правильно. Это должно быть изначально (для первой версии) тщательнейшим образом проверено, поскольку, если ошибочный ответ каким-то образом проникает в систему возвратного тестирования, его очень трудно вычислить и, кроме того, все последующие версии программы будут обречены на его повторение. Поэтому хорошей практикой следует признать периодическую проверку самого возвратного теста.
Создавайте замкнутые тесты. В дополнение к возвратным тестам полезно использовать и замкнутые тесты, которые содержат в себе и вводимые данные, и ожидаемые результаты. Здесь может оказаться поучительным наш опыт в тестировании программ на Awk. Многие конструкции языка тестируются посредством запуска крошечных программ на различных входных данных и проверкой выводимых результатов. Приведенный кусок взят из большого набора разнообразных тестов, он проверяет некоторое хитроумное инкрементное выражение. Тест запускает очередную версию программы (newawk), записывает ее выходные результаты в файл, правильные ответы записывает в другой файл с помощью команды echo, файлы сравнивает и в случае их различия сообщает об ошибке.
важная часть входных данных теста,

Первый комментарий — важная часть входных данных теста, ибо в нем описывается, что же именно проверяет данный тест.
Иногда большой набор тестов можно создать без особых усилий. Для простых выражений мы создали небольшой специализированный язык описания тестов, вводимых данных и ожидаемых результатов. Вот небольшая последовательность, тестирующая некоторые способы представления числового значения 1 в Awk:
Каждая последующая строка является набором

Первая строка — тестируемая программа (все после слова try). Каждая последующая строка является набором вводимых значений и ожидаемого результата, разделенных знаками табуляции. В первом тесте вводится значение 1 и ожидается вывод слова yes. Первые семь тестов должны все напечатать yes, а два последних — nо.
Программа на Awk (а на чем же еще?) преобразует каждый тест в полноценную же программу на Awk, далее пропускает через него каждый возможный вариант ввода и сравнивает полученные результаты с ожидаемыми; сообщается только о тех случаях, когда результат сравнения окажется отрицательным.
Схожие механизмы используются для тестирования соответствия регулярных выражений и команд замещения. Специальный малый язык для написания тестовых программ облегчит вам создание большого количества тестов; использование программы для написания программы для тестирования программы своеобразно увеличивает "плечо рычага", и работа облегчается в несколько раз. (В главе 9 мы еще вернемся к разговору о небольших языках и о программах, пишущих программы.)
Всего у нас есть около тысячи тестов для Awk; весь их набор можно запустить одной-единственной командой, и если все прошло хорошо, то никаких сообщений не появится. Каждый раз, когда в программу добавляется новая возможность или исправляется какая-нибудь ошибка, мы добавляем новые тесты для поверки новых свойств. Каждый раз, когда программа изменяется, пусть даже совсем немного, запускается весь набор тестов — его исполнение занимает лишь пару минут. Нередко при этом выявляются совершенно неожиданные ошибки; применение такого набора не раз спасало авторов Awk от конфуза.
Что же делать, если вы обнаружили ошибку? Если она не была найдена существующими тестами, создайте новый текст, нацеленный на эту конкретную проблему, и проверьте его на некорректной версии. Обнаруженная ошибка зачастую является стимулом не только для создания одного нового теста, но и вообще нового направления проверок. Кстати, не надо забывать и о том, что иногда программу можно просто снабдить механизмом защиты, который отлавливал бы ошибку.
Никогда не удаляйте созданный тест. Он может помочь вам в определении того, исправлены ли уже те или иные ошибки. Ведите учет всех ошибок, изменений, исправлений — это поможет вам опознать старые проблемы и справиться с новыми. В большинстве коммерческих программистских фирм ведение подобных записей является строго обязательным. Для вас же эти записи станут способомтюхранения времени.
Но как только главным параметром

Но как только главным параметром становится быстродействие, приходится прибегать к различным трюкам, вроде записи слов в 32 или 64 бита за раз. Подобные изыски могут вызвать появление ошибок, поэтому глобальное тестирование становится строго обязательным.
Тестирование базируется на комбинации всесторонних проверок (в частности, естественно, проверок граничных условий в потенциально опасных точках). Для memset граничными, очевидно, являются такие значения п, как ноль, один и два, числа, являющиеся степенями двойки, а также соседние с ними значения — от самых маленьких до громадных, вроде 216, что соответствует естественной границе во многих машинах — 16-битовому слову. Степени двойки привлекают внимание из-за того, что один из способов ускорить работу memset — устанавливать одновременно несколько байтов; это может быть выполнено с помощью специальных инструкций или посредством установки сразу не байта, а слова. Также надо проверять начальные значения массивов при различных выравниваниях — на случай, если ошибка возникает из-за стартового адреса или длины. Мы поместим используемый массив внутрь большего массива, создав тем самым некую буферную зону, или запасной отступ с каждой стороны — для того, чтобы можно было не особо ограничивать себя в выборе выравнивания.
Кроме перечисленного нам надо проверить еще множество значений для с — включая ноль, Ox7F (самое большое значение для числа со знаком при 8-битовых байтах)-, 0x80 и OxFF (проверяя на потенциальные ошибки, связанные со знаковыми и беззнаковыми символами) и значения, превышающие один байт (чтобы удостовериться, что используется только один байт). Нам надо также записать в память некий шаблон, отличающийся от любого из этих значений, — с тем чтобы иметь возможность проверить, не производила ли memset запись вне границ предназначенной области.
Мы можем использовать нашу простую реализацию как стандарт для сравнения в тесте, который размещает в памяти два массива, а затем сравнивает поведение разных реализаций при разных значениях п, с и отступа внутри массива:
вынуждающая memset писать вне границ

Ошибка, вынуждающая memset писать вне границ своего массива, скорее всего, проявится в байтах рядом с началом и концом массива, так что, оставив буферную зону, проще увидеть поврежденные байты. Уменьшается и вероятность того, что будут перезаписаны какие-то части программы в памяти. Для проверки записи вне границ мы должны проверить все значения sO и s1, а не только те п байтов, которые должны были быть записаны.
Таким образом, наш набор тестов должен включить в себя проверку всех комбинаций значений:
n должны быть подставлены, по

Для n должны быть подставлены, по крайней мере, значения 2' - 1, 2' и 2' + 1 для всех г от 0 до 16.
Все перечисленные значения, естественно, не надо встраивать в основную часть оснастки — надо предусмотреть возможность записывать их в отдельные массивы — вручную или программно. Лучше генерировать их программно — тогда не составит труда задать больше степеней двойки, включить большее количество разных отступов или больше символов.
Наши тесты заставят memset поработать на совесть; написать же их совсем не долго, не говоря уже об исполнении — всего надо проверить менее 3500 комбинаций. Все тесты полностью переносимы, так что при необходимости их можно использовать в любой среде.
С тестированием memset связана одна история, которая может послужить вам хорошим уроком. Однажды мы дали копию тестов для memset одному программисту, разрабатывавшему операционную систему и библиотеки для нового процессора. Через несколько месяцев мы (авторы тестов) начали работать с этой новой машиной. В какой-то момент большое приложение не прошло своего набора тестов. Мы стали искать причины и после кропотливого труда докопались до истоков — проблема состояла в трудноуловимой неточности, связанной со знаковым расширением" в реализации memset на ассемблере. По непонятным причинам создатель библиотеки изменил тесты для memset, исключив из них проверку значений, больших Ox7F. Естественно, ошибка была найдена при запуске изначальной версии теста сразу после того, как подозрение пало на memset.
Функции типа memset хорошо поддаются проверке замкнутыми тестами, потому что они достаточно просты для того, чтобы можно было подобрать тестовые данные, перебрав все возможные варианты и охватив тем самым весь код. Так, для функции memmove можно перебрать все возможные комбинации различных значений перекрытия, направления и выравнивания. Этого, конечно, недостаточно для проверки всех операций копирования, но достаточно для тестирования всех возможных значений вводимых параметров.
Как в любом тестовом методе, тестовой оснастке для проверки результатов операций нужно знать правильные ответы.
Важнейшим является способ, использованный нами
Важнейшим является способ, использованный нами для тестирования memset, — создание простейшей версии тестируемой функции и сравнение ее результатов с результатами основных тестов. Это можно осуществлять в несколько этапов, как будет показано в следующем примере.
Один из авторов некогда создавал библиотеку для работы с растровой графикой; среди прочих в этой библиотеке существовал оператор для копирования блоков пикселей из одного изображения в другое. В зависимости от параметров эта операция осуществлялась как простое копирование памяти, или требовала преобразования пикселей из одного цветового пространства в другое, или выполняла мозаичное размещение введенного образца в прямоугольной области, или использовала комбинацию этих и некоторых других способов. Спецификация оператора выглядела просто, реализация же его требовала написания большого количества специфического кода для обработки всех возможных случаев. Для того чтобы убедиться в правильности всего кода, требовалась хорошая стратегия тестирования.
Сначала вручную был написан простейший кож, осуществляющий корректные операции для одного пикселя, который использовался для тестирования работы функций библиотеки с одним пикселем. Завершив этот этап, можно было быть уверенным в том, что для случая одного пикселя оператор библиотеки работает корректно.
Далее был написан код, использующий эту отлаженную однопиксельную обработку, — получился прообраз (медленный и неудобный, но это неважно) оператора, работающего с одной горизонтальной строкой пикселей; с этим прообразом и производилось сравнение библиотечной обработки строк. По окончании данного этапа библиотека была проверена на обработку строк пикселей.
Далее так же последовательно строки использовались для обработки прямоугольных областей, те в свою очередь — для создания мозаик и т. д. По ходу дела было обнаружено немало ошибок, в том числе и в тестовой программе, но это-то как раз и является одним из преимуществ методики: тестируются две независимые версии, при этом обе — корректируются.
в первую очередь распечатываются результаты
Если какой-то тест не проходит, в первую очередь распечатываются результаты работы тестирующей программы, и на их основе выясняется место возникновения ошибки и проверяется корректность самой тестирующей версии.
Библиотека изменялась и переписывалась под разные платформы много лет, и тестирующая версия не раз оказывалась незаменимым инструментом для поиска ошибок.
При использованном поэтапном подходе тестирующая программа должна была запускаться каждый раз заново для проверки уверенности в работе библиотеки. Кстати, в данном случае тесты были не замкнутыми, а скорее вероятностными: тестовые задания генерировались случайным образом, и при достаточно большом количестве запусков можно было с хорошей вероятностью считать, что все возможные варианты (и, стало быть, все ветви кода) оказались проверенными. При большом количестве вариантов тестовых случаев такая стратегия более удачна, чем создание наборов тестов вручную, и гораздо более эффективна, чем замкнутое тестирование.
Компилятор предупреждает нас, что им

Компилятор предупреждает нас, что им было сгенерировано имя переменной с замечательной длиной в 1594 символа, но только 255 из них были сохранены в отладочной информации. Не все программы защищают себя от таких необычно длинных строк.
Выбор вводимых значений (не обязательно корректных) случайным образом — еще один достойный способ испытания программы на прочность. Это как бы дальнейшее развитие подхода "человек бы так не сделал". Некоторые коммерческие компиляторы С, например, тестируются посредством сгенерированных случайным образом (но синтаксически корректных) программ. Смысл состоит в том, чтобы использовать спецификацию проблемы — в данном случае стандарт С — для создания программы, генерирующей допустимые, но неестественные тестовые данные.
Подобные тесты полагаются на встроенные в программу механизмы защиты; поскольку удостовериться в правильности результатов удается не всегда, главной целью может быть провоцирование сбоя или непредусмотренной ситуации. При этом также проверяется и код, обрабатывающий ошибки. Если вводить только осмысленные, реалистичные данные, большинство ошибок ввода никогда не случится, и, следовательно, обрабатывающий их код не будет исполнен, а в нем могут таиться ошибки. Надо сказать, что иногда тестирование случайными данными может зайти слишком далеко и обнаружить ошибки, которые настолько маловероятны в реальности, что их можно и не исправлять.
Некоторые виды тестов основаны на введении преднамеренно некорректных данных. При попытках взлома часто используют объемистый или некорректный ввод, который перезаписывает ценные данные: имеет смысл самому проверить свою программу на восприимчивость к такому вводу. Некоторые функции стандартных библиотек оказываются уязвимы для подобных атак. Например, в функции gets из стандартной библиотеки не предусмотрено никакого способа ограничения размера вводимой строки, поэтому ее нельзя использовать никогда; вместо нее нужно применять функцию fgets(buf, sizeof(buf), stdin). В обычном своем простейшем формате функция scanf ("%s", buf) также не ограничивает размер вводимой строки, поэтому ее можно использовать, только указывая размер строки в явном виде: scanf ("%20s", buf). В разделе 3.3 мы показали, как решить эту проблему для буфера произвольного размера.
Любой блок, который может получать данные извне программы (прямо или косвенно), должен проверять полученные значения перед тем, как их использовать. Следующая программа, взятая из учебника, по идее должна читать целое число, введенное пользователем, и, если это число слишком велико, выдавать предупреждение. Цель создания этой программы — продемонстрировать, как можно справиться с проблемой gets, однако предложенное решение работает не всегда:
Если вводимое число состоит из

Если вводимое число состоит из 10 символов, оно перепишет последний нуль массива num ненулевым значением, и по теории это может быть замечено после возврата gets. К сожалению, подобное решение нельзя признать удовлетворительным. Злонамеренный взломщик введет еще более длинную строку, которая перепишет какие-нибудь критические значения, — может быть, адрес возврата вызова, — и тогда программа никогда не вернется к выполнению условия if, а выполнит вместо этого инструкции взломщика. Вообще стоит запомнить, что любой неконтролируемый ввод есть, кроме всего прочего, еще и потенциальная лазейка для взлома системы.
Чтобы вы не думали, что описанные проблемы возможны только в программах из плохих учебников, вспомните о том, как в июле 1998 года ошибка подобного рода обнаружилась в нескольких основных программах электронной почты. Как писала New York Times:
«Лазейка в системе безопасности была вызвана тем, что принято называть "ошибкой переполнения буфера". Программисты должны включать в свои программы код, который проверяет, что вводимые данные имеют нужный тип и размер. Если элемент данных слишком велик, or может выйти за границу "буфера" — кусок памяти, специально выделенный для его хранения. В этом случае программа электронной'почты даст сбой, и злоумышленник может заставить ваш компьютер выполнять его программу». Среди атак во время знаменитого инцидента "Internet Worm" ("Сетевой червь") 1988 года была и такая.
Программы, производящие разбор форм HTML, также могут быть чувствительны к атакам, основанным на хранении очень длинных строк ввода в маленьких массивах:
В этом коде предполагается, что

В этом коде предполагается, что ввод никогда не будет длиннее 1024 байтов, поэтому он, как и gets, открыт для атак переполнения буфера.
Более привычные виды переполнения также могут вызвать проблемы. Если переполнение целого числа происходит без предупреждения, результат может быть губительным для программы. Рассмотрим такое выделение памяти:
? char *p;
? р = (char *) malloc(x * у * z);
Если результат перемножения х, у и z вызывает переполнение, вызов malloc приведет к созданию массива приемлемого размера, но р[х] может ссылаться на раздел памяти вне выделенной области. Предположим, что целые числа являются 16-битовыми, а каждая из переменных х, у и z равна 41. Тогда x*y*z равно 68 921, то есть 3385 по модулю 216. Так что вызов malloc выделит только 3385 байтов, а любая ссылка по индексу вне этого значения будет выходить за заданные границы.
Еще одной причиной переполнения может стать преобразование типов, и обработки таких ошибок не всегда возможны корректным об-, разом. Ракета "Ariane 5" взорвалась во время своего первого запуска в июне 1996 года только из-за того, что навигационный пакет был унаследован от "Ariane 4" и не прошел тщательного тестирования. Новая ракета имела большую скорость, и, соответственно, навигационным программам приходилось иметь дело с большими числами. Вскоре после запуска попытка преобразовать 64-битовое число с плавающей точкой в 16-битовое целое со знаком вызвала переполнение. Ошибка была отловлена, но коду, обработавшему ее, пришлось прервать работу подсистемы. Ракета ушла с курса и взорвалась. Самое обидное, что код, в котором произошел сбой, генерировал данные, необходимые только до момента запуска; если бы при запуске эта часть программы была отключена, трагедии бы не произошло.
На более приземленном уровне двоичный ввод иногда выводит из строя программы, ожидающие текстового ввода, особенно если предполагается, что этот ввод должен относиться к 7-битовому набору символов ASCII. Полезно, а для многих ситуаций и просто необходимо ввести двоичные значения в тестируемую программу, ожидающую ввода текста, и посмотреть на ее реакцию.
и тестовые случаи нередко могут
Хорошие тесты и тестовые случаи нередко могут быть использованы для большого количества программ. Так, каждая программа, читающая файлы, должна быть проверена вводом пустого файла. Каждая программа, читающая текст, должна быть оттестирована двоичным вводом. Каждая программа, читающая строки текста, должна быть проверена вводом очень длинных строк, пустых строк и файлом без символов перевода строки вообще. Таким образом, полезно сохранять подобные общие тесты и всегда иметь их под рукой — тогда можно будет быстрее и с меньшими затратами тестировать любую программу. Полезно также раз и навсегда написать хорошую программу, которая бы создавала тестовые файлы в соответствии с запросами.
Когда Стив Борн (Steve Bourne) писал свою оболочку для Unix (которая теперь известна как Bourne shell), он создал каталог, содержащий 254 файла с именами из одного символа: по одному на каждое возможное значение байта, за исключением ' \0' и косой черты — двух символов, которые не могут встретиться в именах файлов Unix. Этот каталог он всячески использовал для тестирования поисков по шаблону и программ разбиения входного потока. (Надо ли говорить, что каталог этот был создан программно.) Через много лет этот каталог стал настоящим проклятием программ обхода дерева файлов — множество тестов с его участием приводили к плачевным для этих программ результатам.
Перед тем как распространять свой

Перед тем как распространять свой код, уберите из него все тестовые ограничения — они могут повлиять на его производительность. Однажды мы долго бились над проблемой производительности одного коммерческого компилятора и в конце концов нашли причину: некая хэш-функция всегда возвращала 0 из-за того, что из нее не был удален код для тестирования.
Инициализируйте массивы и переменные некоторым запоминающимся характерным значением, а не 0, как это принято, — тогда, если произойдет выход за заданные границы или обнаружится неинициализированная переменная, вам будет проще заметить это. Будьте изобрета-" тельны, — например, константу OxDEADBEEF легко опознать в отладчике.
Варьируйте тестовые случаи, особенно при ручном тестировании, — иначе нетрудно попасть в узкую колею и все время тестировать одно и то же; при этом можно пропустить ошибку в каком-то другом месте.
Никогда не продолжайте писать новые блоки кода или даже тестировать старые, если существуют уже найденные ошибки — они могут повлиять на результаты тестов.
Вывод тестов должен включать в себя полный набор параметров ввода, с тем чтобы тест можно было в точности воспроизвести. Если ваша программа использует случайные числа, найдите способ устанавливать и выводить начальные условия вне зависимости от того, случайно ли выбираются сами тесты. Убедитесь в том, что тестовые ввод и вывод идентифицируются должным образом, чтобы их без труда можно было сопоставить, осмыслить и воспроизвести.
Полезно предусмотреть способы управления количеством отладочной выдачи и ее видом — дополнительная выходная информация может облегчить тестирование.
Тестируйте на разных машинах, компиляторах и операционных системах. Каждая новая комбинация может вскрыть ошибки, незаметные (или несуществующие) в других случаях, такие как порядок байтов, размер целых чисел, обработка пустых указателей, обработка символов возврата каретки и перевода строки, а также некоторые специфические свойства библиотек и заголовочных файлов. Тестирование на разных машинах может также выявить проблемы с окончательной сборкой компонентов и, как мы обсудим в главе 8, указать на неумышленную зависимость от среды разработки.
Тесты быстродействия мы обсудим в главе 7. <
каждого из приведенных файлов вывод

Для . каждого из приведенных файлов вывод должен быть тождественен вводу. При этой проверке были обнаружены несколько ошибок на единицу при инициализации таблицы, а также при запуске и остановке генератора.
Второй тест проверял сохранность данных. Для префиксов из двух слов каждое слово, каждая пара слов и каждая тройка слов в выходном тексте должны содержаться также и во введенном тексте. Мы написали программу на Awk, которая считывает входной текст в гигантский массив, строит массивы пар и троек слов, потом считывает вывод программы в другой массив и сравнивает массивы:
Проверка сохранности данных

Мы не пытались сделать этот тест особо эффективным, наоборот, хотели лишь написать как можно более простую программу. Сравнение 10 000 слов вывода с 42 685 словами ввода занимает у нее шесть или семь секунд — не дольше, чем компилируются некоторые версии самой программы markov. Проверка сохранности данных обнаружила важную ошибку в версии, написанной на Java: программа иногда переписывала значения таблицы, поскольку использовала ссылки вместо того, чтобы создавать копии префиксов.
Приведенный тест иллюстрирует принцип, согласно которому проще бывает проверить свойства результата, чем получить этот результат. Например, проще удостовериться в том, что файл отсортирован, чем выполнить саму сортировку.
Третий тест — статистический по своей природе. Ввод состоит из последовательностей
abcabc ... abd ...
в которых на одно вхождение abd приходится десять вхождений abc. Теперь, если генератор случайных чисел работает правильно, в выводе должно быть примерно в десять раз больше с, чем d. Проверяли мы это, естественно, с помощью f req.
Статистический тест показал, что ранняя Java-версия программы, в которой с каждым суффиксом ассоциировался счетчик, выводит около, двадцати с на каждое d, то есть в два раза больше, чем предполагалось. Немного поломав голову, мы осознали, что генератор случайных чисел в Java возвращает как положительные, так и отрицательные целые значения; множитель два появился, таким образом, из-за того, что диапазон значений для генератора был в два раза больше ожидаемого и поэтому первый элемент в списке выпадал чаще (а это была именно буква с). Исправить ошибку оказалось гораздо проще, чем найти, — достаточно взять значения по модулю. Без этого теста мы никогда не нашли бы ошибки, на глаз вывод выглядел совершенно нормально.
Наконец, мы скормили программе нормальный английский текст для того, чтобы убедиться, что на выходе будет очаровательная нелепица. Естественно, этот тест мы производили и на ранних стадиях написания программы. Однако теперь, даже убедившись, что программа нормально обрабатывает те данные, для которых, собственно, и создавалась, мы не прекратили тестирования. Всегда приятно оттестировать простые случаи и убедиться, что все в порядке, однако трудные случаи также должны быть проверены. Автоматизированное, систематическое тестирование — единственный способ обойти все ловушки.
Весь процесс тестирования программы markov был автоматизирован. Специальный скрипт генерировал необходимые входные данные, запускал тесты, отмечал время их работы и распечатывал аномальные результаты вывода. Скрипт мы написали настраиваемый, так что одни и те же тесты можно было применить к версии на любом языке: каждый раз при внесении изменений в одну из программ мы без дополнительных усилий прогоняли на ней все тесты. <
Систематическое тестирование
Очень важно тестировать программу систематически — на каждом этапе надо четко представлять, что вы тестируете в данный момент и каких результатов ожидаете. Тестирование должно производиться последовательно, чтобы ничего не упустить: текущие результаты тестирования надо обязательно записывать, чтобы представлять, что уже сделано и что предстоит сделать.
Тестируйте по возрастающей. Тестирование должно идти рука об руку с созданием кода. Тестирование методом "большого скачка", когда сначала пишется вся программа, а потом тестируется целиком, гораздо сложнее и отнимает гораздо больше времени, чем постепенное. Напишите часть программы, оттестируйте ее, напишите очередной кусок кода, оттестируйте его и т. д. Если у вас есть два блока, которые писались и тестировались раздельно, оттестируйте их взаимодействие.
Например, когда мы тестировали программу CSV из главы 4, на первом шаге было достаточно написать только код, читающий ввод, и отладить его. На следующем шаге мы разделяли вводимые строки запятыми. Добившись работоспособности этих кусков, мы перешли к полям с кавычками и так мало-помалу подошли к тестированию всего вместе.
Тестируйте сначала простые блоки. Общий подход к тестированию по возрастающей применим и к отдельным деталям программы. В первую очередь тестированию подлежат самые простые и чаще всего исполняющиеся блоки; только после того, как вы удостоверитесь в их корректности, можно двигаться дальше. Таким образом, на каждом этапе вы увеличиваете объем тестируемого кода, будучи при этом уверенными в работоспособности основных его частей. Простые тесты обнаруживают простые ошибки. Каждый тест выполняет свой минимум по поиску новой потенциальной проблемы. И несмотря на то что каждую новую ошибку выловить труднее, чем предыдущую, вовсе не факт, что ее будет труднее и исправить.
В этом параграфе мы поговорим о путях выбора эффективных тестов и о порядке их применения, а в двух следующих параграфах обсудим способы механизации процесса для наиболее эффективного тестирования.
Первый шаг, по крайней мере
Первый шаг, по крайней мере для маленьких программ и отдельных функций, — расширение тестов на граничные условия, описанных в предыдущем разделе: систематическое тестирование отдельных случаев.
Предположим, что у нас есть функция, осуществляющая двоичный поиск в массиве целых чисел. Начнем со следующих тестов (как нетрудно заметить, расположены они в порядке увеличения сложности):
поиск в пустом массиве;
поиск в массиве с одним элементом — пробное значение:
- меньше чем элемент массиша;
- равно элементу массива;
- больше чем элемент массива;
поиск в массиве с двумя элементами — пробные значения:
- тестируем все пять возможных вариантов;
проверяем поведение при дублировании элемента — пробные значения:
- меньше значения в массиве;
- равно значению в массиве;
- больше значения в массиве;
поиск в массиве с тремя элементами (так же, как и с двумя);
поиск в массиве с четырьмя элементами (так же, как с двумя и тремя).
Если функция пройдет эти тесты без ошибок, она, по всей видимости, находится в неплохой форме, однако ее можно тестировать и дальше.
Приведенный набор тестов достаточно мал, чтобы выполнять их все вручную, но лучше создать оснастку (test scaffold — подмости тестирования) для механизации процесса. С этой целью мы напишем простейшую программу (по сути, драйвер). Она будет считывать строки, содержащие ключ, по которому будет производиться поиск, и размер массива; после этого будет создан массив указанного размера, содержащий значения 1, 3, 5 и т. п.; результат поиска будет выводиться на экран.
Стрессовое тестирование
Еще один эффективный прием тестирования — проверка программ большими объемами вводимых данных, сгенерированных компьютером. Входные данные, сгенерированные машиной, оказывают на программы несколько иное влияние, чем созданные вручную. Большие объемы сами по себе могут стать причиной сбоев, вызывая переполнение буферов ввода, массивов, счетчиков; они весьма эффективны для поиска неоправданно ограниченных в размерах структур данных. Кроме того, люди часто неосознанно избегают "невозможных" значений (вроде пустой строки ввода или ввода недопустимых значений) и нечасто вводят очень длинные имена или очень большие значения. Компьютеры же генерируют данные точно в соответствии с запрограммированными зада-; ниями; у них нет никаких личных предпочтений или антипатий.
Вот для иллюстрации одна строка вывода, произведенного компиля-. тором Microsoft Visual C++ версии 5.0 при компиляции нашей программы markov (версия C++ с использованием STL):
Тестирование
В практике вычислений вручную или с помощью настольной машины, надо, взять за правило проверять каждый шаг вычисления и, при нахождении ошибки, локализовать ее, повторив процесс в обратном порядке с той точки, где ошибка была обнаружена впервые.
Норберт Винер. Кибернетика
Тестирование и отладка часто упоминаются вместе, однако это две разные вещи. Сильно упрощая, можно сказать, что отладкой называется то, что вы делаете, когда знаете, что программа не работает. Тестирование же — это последовательные, систематические попытки добиться ошибки от программы, которая считается работающей.
Эдсгеру Дейкстре (Edsger Dijkstra) принадлежит известное высказывание о том, что тестирование может показать лишь наличие ошибок, но не их отсутствие. Он надеется на то, что создатели программ смогут писать их корректно, то есть без ошибок вообще, и, следовательно, в тестировании не будет никакой необходимости. Это, конечно, отличная цель, и к ее достижению стоит стремиться, но для настоящих (коммерческих) программ это пока нереально. Так что в данной главе мы остановимся на том, как тестировать программы с целью находить ошибки быстро, рационально и эффективно.
Задумываться о потенциальных проблемах вашего кода полезно всегда. Систематическое тестирование, от простейших до самых хитроумных тестов, позволит удостовериться в том, что программа является корректной с самого начала и остается таковой по мере усовершенствования. Автоматизация позволяет во многом избежать нудного ручного тестирования, заменив его экстенсивным автоматическим тестированием. Существует великое множество приемов и ухищрений, которым опыт научил программистов.
Один из способов написания кода, не содержащего ошибок, — генерировать его программно. Если некоторое задание на программирование понятно настолько, что работа по написанию кода кажется механической, ее следует механизировать. Так бывает, когда программу можно сгенерировать из спецификации, написанной на специализированном языке. Например, мы компилируем код на языке высокого уровня в ассемблерный код, используем регулярные выражения для задания шаблонов текста, используем нотации типа SUM(A1: A50) для представления операций в некотором диапазоне ячеек электронной таблицы. В подобных случаях при наличии корректного генератора или транслятора и корректной спецификации результирующая программа будет также корректна. Более детально эту обширную тему мы обсудим в главе 9, в этой же главе мы в общих чертах осветим способы создания тестов из компактных спецификаций.
<
Тестирование программы markov
Программа ma rkov из главы 3 достаточно сложна, поэтому ее надо особенно тщательно оттестировать. Производит она белиберду, которую трудно проверить на корректность, и, кроме того, мы написали несколько версий на разных языках. И последнее затруднение — вывод программы случаен по определению, и по идее при каждом запуске должен изменяться. Как же применить уроки данной главы к тестированию такой программы?
Первый набор тестов состоит из нескольких крошечных файлов — для проверки граничных условий. Цель этого этапа — убедиться в том, что программа работает нормально при вводе размером всего в несколько слов. Для префиксов длиной два мы использовали пять файлов, содержащих, соответственно (по одному слову-символу на строку!):
Тестируйте при написании кода
Чем раньше обнаружена проблема, тем лучше. Если вы будете постоянно задумываться о том, что вы пишете, еще когда вы пишете, то сможете проконтролировать простейшие свойства программы прямо на этапе ее создания. В результате ваш код как бы пройдет один круг тестирования еще до того, как будет скомпилирован. Ошибки определенных видов даже никогда не появятся.
Тестируйте граничные условия кода. Одним из важнейших методов тестирования является тестирование граничных условий: каждый раз, написав небольшой кусок кода, например цикл или условное выражение, проверьте, что тело цикла повторится нужное количество раз, а условное выражение правильно разветвляет вычисление. Этот процесс называется тестированием граничных условий потому, что вы проверяете крайние, экстремальные значения алгоритма или данных, такие как пустой ввод, единственный введенный элемент, полностью заполненный массив и т. п. Основная идея состоит в том, что большинство ошибок возникает как раз на границах — при каких-то экстремальных значениях. Если какой-то блок кода содержит ошибку, то, скорее всего, эта ошибка происходит на границе, и наоборот — если при экстремальных значениях код работает корректно, то он практически наверняка будет работать корректно и повсюду.
Приводимый фрагмент кода, моделирующий f gets, считывает симво-'j лы, пока не найдет символ перевода строки или не заполнит буфер:
Тестовые оснастки
Тестирование, о котором мы вели разговор до этого момента, относилось в основном к одной обособленной программе в завершенном виде. Это, однако, не единственный вид автоматизации тестов, так же как и не единственный способ тестирования частей большой программы в период ее написания, особенно при работе в команде. Это также и не самый эффективный способ тестирования отдельных компонентов, которые со временем должны быть объединены во что-то глобальное.
Для тестирования отдельного компонента большой программы, как правило, необходимо создать некие строительные леса (scaffold -подмости), или оснастку, которая предоставит в ваше распоряжение достаточную поддержку и достаточное взаимодействие с остальной частью системы. Мы уже приводили маленький пример подобного рода — для тестирования двоичного поиска.
Нетрудно разработать оснастку для тестирования математических, строковых функций, алгоритмов поиска и тому подобных вещей, поскольку ее создание в этих случаях сводится к установлению параметров ввода, вызову тестируемых функций и проверке результатов. Куда сложнее создать оснастку для тестирования незавершенной программы.
Чтобы проиллюстрировать повествования, мы создадим тест для memset, одной из функций семейства mem... стандартной библиотеки C/C++. Эти функции часто пишутся на языке ассемблера для,конкретных машин, поскольку их быстродействие очень важно. Однако чем более тонко они настраиваются на конкретные условия, тем больше вероятность возникновения в них ошибок и тем более тщательно должны они тестироваться.
Первый шаг — создать наиболее простые версии на С, заведомо работоспособные; они будут эталоном для сравнения быстродействия и, что более важно, проверки правильности. При переходе в новую среду разработки наши простейшие версии останутся эталоном до тех пор, пока не заработает специально созданная "родная" версия.
Функция memset (s, с, п) записывает байт с в п байтов памяти, начиная с адреса s, и возвращает s. Если нет ограничений на скорость работы, написать такую функцию,— не проблема:
Проверьте приводимые фрагменты на граничные
Проверьте приводимые фрагменты на граничные условия и при необходимости исправьте их, руководствуясь принципами хорошего стиля, изложенными в главе 1, и советами из этой главы.
1. Этот код должен вычислять факториалы:
f req, которая подсчитывала бы
Спроектируйте и реализуйте версию f req, которая подсчитывала бы частоты для других типов данных — таких, как 32-битовые целые или числа с плавающей точкой. Сможете ли вы добиться того, чтобы программа элегантно обрабатывала данные различных типов? <
Спроектируйте набор тестов для printf,
Спроектируйте набор тестов для printf, используя при этом как можно больше автоматических способов. <
основываясь на описанных нами приемах,
Создайте, основываясь на описанных нами приемах, тестовую оснастку для memset.
Создайте тесты для остальных функций
Создайте тесты для остальных функций семейства mem. . . .
Определите режим тестирования для числовых
Определите режим тестирования для числовых методов типа sq rt, s i n и им подобных из библиотеки math. h. Какие вводимые значения имеют смысл? Какие независимые проверки могут быть осуществлены?
Определите механизмы для тестирования функций
Определите механизмы для тестирования функций С семейства st г. . . (например, st rcmp). Некоторые из этих функций, особенно те, что служат для разбиения на лексемы — типа st rtok или st rcspn, значительно сложнее, чем функции семейства mem. .., и, следовательно, для их проверки потребуются более изощренные тесты. <
Постарайтесь создать файл, который бы
Постарайтесь создать файл, который бы вызвал сбой в вашем любимом текстовом редакторе, компиляторе или другой программе. <
Чем лучше вы пишете код
Чем лучше вы пишете код изначально, тем меньше ошибок он будет содержать. Тестирование граничных условий непосредственно при написании кода — эффективный способ удалить множество мелких глупых ошибок. Систематическое тестирование проверяет потенциально уязвимые места в строгом порядке; опять же, сбои чаще всего происходят на каких-то границах, которые можно проверить вручную или программно. Как можно шире используйте автоматизированное тестирование, поскольку машины не делают ошибок, не устают и не занимаются самообманом. Возвратные тесты проверяют, что результаты работы программы изменились при внесении изменений только так, как надо. Вообще, тестирование после внесения каждого, даже небольшого, изменения — верный способ локализации источника проблем, поскольку новые ошибки появляются, как правило, именно в новом коде.
Главное же правило тестирования — делать его.