Дополнительная литература
Наше обсуждение спам-фильтра основывалось на работе Боба Флан-дрены (Bob Flandrena) и Кена Томпсона (Ken Thompson). Их фильтр включает в себя регулярные выражения для выполнения более осмысленных проверок и автоматической классификации сообщений ("точно спам", "возможный спам", "не спам") в соответствии со строками, которые были обнаружены.
Профилировочная статья Кнута "An Empirical Study of FORTRAN Programs" появилась в журнале Software — Practice and Experience (1, 2, p. 105-133, 1971). Ее основой стал статистический анализ ряда программ, раскопанных в мусорных корзинах и общедоступных каталогах машин компьютерного центра.
Ион Бентли в своих книгах "Программирование на Pearls" и "Еще программирование на Pearls" (Jon Bentley. Programming Pearls. Addison-Wesley, 1986;Jon Bentley.More Programming Pearls. Addison-Wesley, 1988) приводит ряд хороших примеров улучшений программ, основанных на изменении алгоритма или настройке кода; очень неплохо описано создание оснасток для улучшения производительности и использование профилирования.
Книга Рика Буфа "Внутренние циклы" (Rick Booth. Inner Loops. Addison-Wesley, 1997) — хорошее руководство по настройке программ для PC. Правда, процессоры эволюционируют так быстро, что специфические детали стремительно устаревают.
Серия книг Джона Хеннеси и Дэвида Паттерсона по архитектуре компьютеров (например: John Hennessy, David Patterson. Computer Organization and Design: The Hardware/Software Interface. Morgan Kaufmann, 1997) содер- \ жит вдумчивые рассуждения о вопросах производительности современных компьютеров.
<
Эффективное использование памяти
Память — один из самых дорогостоящих компьютерных ресурсов, которого вечно не хватает; огромное количество плохих программ возникло из попыток выжать все, что можно, из того немногого, что имелось в наличии. Небезызвестная "проблема 2000 года" зачастую причисляется к разряду именно таких проблем: когда память была действительно буквально на вес золота, потратить два байта на число 19 считалось непозволительной роскошью. Действительно ли память является главной причиной проблемы или нет, — возможно, все беды возникли из-за перенесения наших бытовых привычек (мы нечасто указываем в документах, к какому веку они относятся, — это и так очевидно) на программы, — но приведенный пример отлично демонстрирует всю опасность недальновидной оптимизации.
В любом случае, времена меняются, теперь и оперативная память, и внешние носители информации стали просто удивительно дешевыми. Таким образом, главный принцип оптимизации использования памяти — тот же, что и в увеличении быстродействия: не беспокойтесь понапрасну.
Однако и сейчас могут возникнуть ситуации, когда вопрос используемого пространства играет существенную роль. Если программе не хватает имеющейся оперативной памяти, то некоторые ее части (страницы),, выгружаются на диск, а это отрицательно сказывается на производительности. Часто приходится видеть, насколько расточительно относятся к памяти новые версии программ. Как ни печально, но такова сегодняшняя реальность: обновление программного обеспечения часто влечет за собой покупку дополнительной памяти.
Используйте минимально возможный размер типа данных. Первый шаг к более эффективному использованию места — попытаться с минимальными изменениями лучше распределить существующую память, используя, например, минимальные из возможных типов данных. Эта экономия может означать замену int на short, если данные это позволяют, в частности такое представление используется для координат в системах двумерной графики, поскольку 16 битов, по-видимому, достаточно для любых диапазонов экранных координат. Можно экономить память и заменой double на float, но при этом надо опасаться потери точности, ведь float содержит, как правило, только 6 или 7 десятичных знаков.
В описанных и аналогичных им случаях в программу почти наверняка придется внести и другие соответствующие изменения, самым оче-видным из которых будет замена спецификаторов формата в printf и, что особенно важно, в scanf.
Логическим расширением этого подхода является кодирование информации в байте или даже в нескольких битах. Не используйте битовые поля C/C++; они ухудшают переносимость и нередко ведут к неоднозначному и неэффективному коду. Вместо этого поместите нужные операции в функции, которые будут считывать и устанавливать отдельные биты внутри слова или массива слов с помощью сдвигов или битовых масок. Такие функции возвращают группу последовательных битов из середины слова:
Настройка кода
Существует большое количество различных способов уменьшить время исполнения, — естественно, после того как критическое место в программе найдено. Ниже мы приводим ряд рекомендаций в этой области, однако надо всегда помнить, что применять что бы то ни было надо с осторожностью и после каждого изменения непременно выполнять возвратные тесты, чтобы быть уверенными в корректности работы кода. Помните, что хорошие компиляторы сами выполняют некоторые из описываемых усовершенствований, и вы можете только запутать программу. Что бы вы ни применяли, после каждого изменения выполняйте замеры времени.
Объединяйте общие выражения. Если некоторое сложное вычисление встречается в вашем коде несколько раз, выполните его единожды и запомните результат. Например, в главе 1 мы показали вам макрос, который вычислял расстояние, дважды подряд вызывая sq rt с одинаковыми значениями; в результате вычисление выглядело так:
? sqrt(dx*dx + dy*dy) + ((sqrt(dx*dx + dy*dy) > 0) ? ... )
Вычислите корень один раз, а дальше используйте полученное значение. Если вычисление выполняется в цикле, но при этом не зависит ни от каких параметров, изменяющихся в этом цикле, вынесите его из цикла и подставляйте далее его значение:
for (i = 0; i < nstarting[cj;
можно заменить на
n = nstarting[c] ;
for (i = 0; i < n; i++) {
Заменяйте дорогостоящие операции на более дешевые. Термин понижение мощности (reduction of strength) относится к такому виду оптимизации, как замена дорогостоящей операции на более дешевую. Когда-то давно этот термин обозначал в основном замену умножения сложениями или сдвигами, правда, сейчас непосредственно на этом вы вряд ли что-то выгадаете. Однако деление и взятие остатка гораздо медленнее умножения, так что код можно несколько улучшить, заменив деление умножением на обратное значение, а взятие остатка при делителе, являющемся степенью двойки, можно заменить использованием битовой маски. Замена индексации массивов указателями в С или C++ может ускорить код, правда, большинство компиляторов выполняет это автоматически.
и замена вызова функции простым
Может быть вполне выгодной и замена вызова функции простым непосредственным вычислением. Расстояние на плоскости определяется по формуле sqrt(dx*dx+dy*dy), так что для выяснения того, какая из двух точек находится дальше, в принципе надо вычислить два квадратных корня. Но это решение можно принять и сравнивая квадраты расстояний, то есть
if (dx1*dx1+dy1*dy1 < dx2*dx2+dy2*dy2)
....
даст тот же результат, но без вычисления корней.
Другой пример дают сравнения строк с текстовыми образцами, вро-| де нашего спам-фильтра или д rep. Если образец начинается с буквы, то по всему введенному тексту осуществляется быстрый поиск этой буквы, и если вхождений не обнаружено, то более сложные механизмы поиска вообще не вступают в дело.
Избавьтесь от циклов или упростите их. Организация и исполнение цикла требуют некоторых временных затрат, так что, если тело цикла не слишком длинно и выполняется не слишком много раз, может оказаться более эффективным избавиться от цикла вообще и выписать все дей-| ствия последовательно. Таким образом, например,
for (i =0;
i < 3; i++) [i] + cfi];
станет выглядеть так:
Предварительная оценка
Трудно заранее оценить, насколько быстрой получится программа, и вдвойне трудно оценить скорость специфических конструкций языка или машинных инструкций. Однако совсем не трудно создать модель затрат (cost model) языка или системы, которая даст, по крайней мере, общее представление о том, сколько времени занимает выполнение основных операций.
Одним из способов, часто применяемых к стандартным языкам программирования, является использование программы, которая замеряет скорость исполнения задаваемых последовательностей кода. При этом существует ряд сложностей вроде получения воспроизводимых результатов и отсечения случайных затрат времени, обусловленных конкретной средой, однако главное — наличие возможности получить некоторую информацию, хотя бы с точностью до порядка, и при этом без особых усилий. Например, у нас есть программа для создания модели затрат для С и C++ — она приблизительно оценивает затраты на исполнение отдельных выражений, помещая их в цикл, повторяющийся несколько миллионов раз, и вычисляя затем среднее время. На машине MIPS R10000 250 MHz мы получили следующие данные (время измеряется в наносекундах на операцию):
Как можно сделать этот код

Как можно сделать этот код более быстрым? Нам нужно искать в строке, а лучшим способом для этого является функция st rst r из библиотеки языка С: она стандартна и эффективна.
Благодаря профилированию — технологии, о которой мы поговорим в следующем параграфе, — мы выяснили, что реализация st rst г такова, что использование ее в спам-фильтре неприемлемо. Изменив способ работы st rst г, можно было сделать ее более эффективной для данной конкретной проблемы.
Существующая реализация st rst г выглядела примерно так:
с расчетом на эффективную работу,

Функция была написана с расчетом на эффективную работу, и действительно, для типичных случаев использования этот код оказывался достаточно быстрым, поскольку в нем используются хорошо оптимизированные библиотечные функции. Сначала вызывается st rch r для поиска следующего вхождения первого символа образца, а затем strncmp — для проверки, совпадают ли остальные символы строки с остальными символами образца. Таким образом, изрядная часть сообщения пропускалась — до первого символа образца, и проверка начиналась только с него. Почему же возникли проблемы с производительностью?
На это есть несколько причин. Во-первых, strncmp получает в качестве аргумента длину образца, которая должна быть вычислена с помощью st rlen. Однако длина образца у нас фиксирована, так что нет необходимости вычислять ее заново для каждого сообщения.
Во-вторых, strncmp содержит достаточно сложный внутренний цикл. В нем не только осуществляется сравнение байтов двух строк, но и производится поиск символа окончания строки \0 в обеих строках, да еще при этом отсчитывается длина строки, переданной в качестве параметра. Поскольку длина всех строк известна заранее (хотя и не в функции st rncmp), в этих сложностях нет необходимости, мы знаем, что подсчеты верны, поэтому проверка на \0 — пустая трата времени.
В-третьих, strchr также сложна, поскольку она должна просматривать символы и при этом отслеживать \0, завершающий строку. При каждом конкретном вызове isspam сообщение фиксировано, поэтому время, использованное на поиск \0, опять же тратится зря, так как мы знаем, где окончится сообщение.
И наконец, даже если решить, что strncrnp, strchr и strlen достаточно эффективны сами по себе, затраты на вызов этих функций сравнимы с затратами на вычисления, которые они осуществляют. Более эффективно выполнять все действия в отдельной аккуратно написанной версии st rst r, а не вызывать другие функции.
Трудности подобного рода — обычный источник проблем с производительностью: функция или интерфейс хорошо работают в обычных ситуациях, но недостаточно производительны для нестандартного случая, а именно этот случай и является основным для решаемой задачи.
Существующая версия strstr работала вполне
Существующая версия strstr работала вполне удовлетворительно, когда и образец, и строка были достаточно коротки и менялись при каждом новом вызове, но когда строка оказалась длинной и при этом фиксированной, издержки оказались чрезмерно высоки.
Исходя из вышеизложенных соображений, st rst r была переписана так, чтобы и обход строк образца и сообщения, и поиск совпадений осуществлялись прямо в ней, причем без вызова дополнительных функций. Поведение получившейся реализации было предсказуемо: в некоторых случаях она работала несколько медленнее, но зато в спам-фильтре — гораздо быстрее, и что самое главное, не встретилось случаев, когда бы она работала очень медленно. Для проверки корректности и производительности этой новой реализации был создан набор тестов производительности. В этот набор вошли не только обычные примеры вроде поиска слова в предложении, но и патологические случаи, такие как поиск образца из одной буквы х в строке из тысячи е и образца из тысячи х в строке с одним-един-ственным символом е, а надо сказать, что оба эти случая могли бы стать настоящей проблемой для непродуманной реализации. Подобные экстремальные случаи — ключевая часть оценки производительности.
Наша новая st rst r была добавлена в библиотеку, и в результате спам-фильтр стал работать примерно на 30 % быстрее, чем раньше, — хороший результат для изменения одной функции.
К сожалению, и это было слишком медленно.
Чтобы решить задачу, важно задавать себе правильные вопросы. До сего момента мы искали самый быстрый способ поиска текстового образца в строке. Но на самом деле наша проблема заключается в поиске большого фиксированного набора текстовых образцов в большой строке переменной длины. Если исходить из этого, то наша st rst г не представляется, очевидно, лучшим решением.
Наиболее эффективный способ ускорить программу — применить алгоритм получше. Теперь, когда у нас есть четкое определение проблемы, можно подумать и об алгоритме.
Основной цикл
в точности npat раз; таким

сканирует сообщение в точности npat раз; таким образом, в случае, если совпадений нет, он просматривает каждый байт сообщения npat раз, выполняя strlen(mesg)*npat сравнений.
Разумнее было бы поменять циклы местами, обходя сообщение единожды — во внешнем цикле, а сравнения со всеми образцами осуществлять в параллельном или вложенном цикле:
Повышение производительности достигнуто на основании

Повышение производительности достигнуто на основании простейшего наблюдения. Для того чтобы выяснить, не совпадает ли какой-нибудь образец с текстом сообщения, начиная с позиции j, нам не надо просматривать все образцы — интересовать нас будут только те, что начинаются с того же символа, что и mesg[ j ]. В первом приближении, имея 52 буквы верхнего и нижнего регистров, мы можем ожидать выполнения только strlen(mesg)*npat/52 сравнений. Поскольку буквы распределены не одинаково — слова гораздо чаще начинаются с s, чем с х, — мы, конечно, не добьемся увеличения производительности в 52 раза, но все же кое-что у нас получится. Так что фактически мы создали хэш-таблицу, в которой в качестве ключей используются первые буквы образцов.
Благодаря выполнению предварительных действий по созданию таблицы, определяющей, какой образец с какой буквы начинается, код isspam по-прежнему остался достаточно лаконичным:

с индексы образцов, которые начинаются

Двумерный массив starting[c][ ] хранит для каждого символа с индексы образцов, которые начинаются с этого символа, а его напарник nstarting[c] фиксирует, сколько образцов начинается с этого с. Без этих таблиц внутренний цикл выполнялся бы от 0 до npat, то есть около тысячи раз; в нашем варианте он выполняется от 0 до примерно 20. Наконец, элемент массива patlen[k] содержит вычисленный заранее результат strlen(pat[k]), то есть длину k-ro образца.
На приводимом ниже рисунке показаны эти структуры данных для трех образцов, начинающихся с буквы b.
Пример 7.7. Код для построения этих таблиц весьма прост

Код для построения этих таблиц весьма прост:

В теперешнем варианте — в зависимости от ввода — спам-фильтр стал работать от пяти до десяти раз быстрее, чем в версии с улучшенной st rst г, и от семи до пятнадцати раз быстрее, чем в исходной реализации. Мы не достигли показателя в 52 раза — отчасти из-за неравномерного распределения букв, отчасти из-за того, что цикл в новом варианте стал более сложным, и отчасти из-за неизбежного выполнения бессмысленных сравнений строк, но все же спам-фильтр перестал быть слабым звеном в обеспечении доставки почты. Проблема производительности решена.
Оставшаяся часть главы будет посвящена технологиям, используемым для выявления проблем производительности, вычленения медленного кода и его ускорения. Однако перед тем, как двигаться дальше, обратимся еще раз к спам-фильтру и посмотрим, чему же он нас научил. Самое главное — убедиться, что производительность имеет критическое значение. Во всех наших действиях не было бы никакого смысла, если бы спам-фильтр не являлся узким местом почтовой системы. Поскольку мы знали, что проблема заключается именно в нем, мы применили профилирование и другие технологии для изучения его поведения и выяснения главных недостатков. Далее мы убедились, что проблема сформулирована правильно и решать надо именно ее — глобально, а не концентрироваться на улучшении st rst r, на которую падало небезосновательное, однако же, неверное подозрение. Наконец, мы решили эту проблему, применив более удачный алгоритм, и, проверив, выяснили, что скорость действительно возросла. Поскольку она возросла в достаточной степени, мы остановились — зачем заниматься ненужными усовершенствованиями?
и возвращает три числа, означающих

Эта команда запускает программу и возвращает три числа, означающих время в секундах: время real — физическое время, израсходованное до завершения работы программы; время user — время процессора, потраченное на исполнение самой программы; время sys — время, потраченное на программу операционной системой. Если в вашей системе есть аналогичная команда, используйте ее — числа будут более информативными и надежными, и делать отсчеты будет проще, чем при использовании секундомера. Ведите подробные записи. При работе над программой — внесении модификаций и/или проведении измерений -т у вас накопится огромное количество данных, в которых вам будет трудно разобраться по памяти уже через день-два. (Какая именно версия работает на 20 % быстрее?) Многие технологии, которые мы обсуждали в главе о тестировании, могут быть адаптированы и к измерениям времени и улучшению производительности. Используйте компьютер для запуска набора тестов и измерения времени их работы, а самое главное — используйте регрессивное тестирование, чтобы удостовериться в том, что "улучшения" производительности не нарушили корректности программы.
Если в вашей системе нет команды time или вы хотите замерить время работы отдельно взятой функции, не так трудно создать себе оснастку для таких замеров — по аналогии с тестовой оснасткой. В С и C++ существует стандартная функция clock, которая сообщает, сколько процессорного времени программа использовала до текущего момента. Ее можно вызвать перед интересующей вас функцией и после нее и таким образом вычислить время ее исполнения процессором:
Масштабирующий коэффициент CLOCKS_PEfi_SEC характеризует разрешение
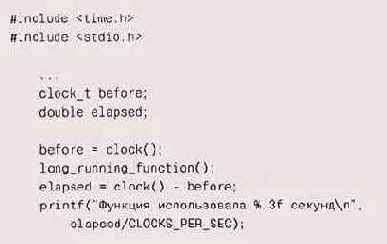
Масштабирующий коэффициент CLOCKS_PEfi_SEC характеризует разрешение таймера, возвращаемое clock. Если функция выполняется за доли секунды, запустите ее в цикле, но (если измерения должны быть особо точными) не забудьте компенсировать затраты времени на сам цикл:
В Java функции класса Date

В Java функции класса Date выдают текущее системное время, которое приблизительно равно времени, использованному процессором:
Используйте профилировщик. Не считая такого

Значение, возвращаемое getTime, измеряется в миллисекундах.
Используйте профилировщик. Не считая такого надежного и достоверного способа, как замер времени исполнения программы, самым важным инструментом для анализа производительности является система для генерации профилей. Профиль (profile) -- это измерение того,,где именно программа "тратит время". Некоторые профили предоставляют список всех функций, количество вызовов каждой из них и долю потребляемого каждой функцией времени от общего времени исполнения программы. Другие показывают, сколько раз было выполнено каждое выражение. Выражения, которые выполняются часто, сильнее влияют на время исполнения, а те, которые не выполняются никогда, скорее всего, являются бесполезным или неадекватно оттестированным кодом.
Профилирование — эффективный способ поиска горячих точек (hot spots), или критических мест программы, то есть функций ши^фрагмен-тов кода, которые расходуют львиную долю всего времени исполнения программы. Однако же интерпретировать результаты профилирования надо с достаточной степенью осторожности. Из-за изощренности компиляторов, сложности организации кэширования и работы с памятью, а также из-за того, что сам процесс профилирования влияет на производительность, статистические показатели в профилях могут быть только приблизительными.
В 1971 году в работе, где впервые был представлен термин "профилирование", Дон Кнут написал, что, "как правило,-менее 4 % программы поглощают более половины от всего времени исполнения". Принимая во внимание это замечание, можно сделать вывод о способах применения профилирования: с его помощью определяются участки программы, поглощающие большую часть времени работы, в них вносятся улучшения, и процесс повторяется еще раз для поиска новых критических мест. Выясняется, что после одной-двух подобных итераций характерных "горячих точек" не остается.
Профилирование обычно включается специальным флагом или опцией компилятора. Программа выполняется, и после этого показываются результаты работы профилировщика. В Unix таким флагом является, как правило, -р, а профилировщик называется prof:
В приводимой далее таблице показан

В приводимой далее таблице показан профиль, сгенерированный рабочей версией спам-фильтра, которую мы создали специально для того, чтобы разобраться в его поведении. В ней используется фиксированное сообщение и фиксированный набор из 217 фраз, который сравнивается с сообщением 10 000 раз. Запуск производился на машине MIPS R10000 250 MHz; использовалась изначальная версия st rst r — с вызовами других стандартных функций. Результаты были переформатированы для более удачного размещения на странице. Обратите внимание на то, что размер ввода (217 фраз) и количество запусков (10 000) можно использовать для проверки правильности работы — эти числа появляются в колонке "calls" (вызовы), в которой показано количество вызовов каждой функции.
12234768552: Total number of instructions executed
13961810001: Total computed cycles
55.847: Total computed execution time (sees.)
1.141: Average cycles / instruction
| secs | % | cum% | cycles | instructions | calls | function |
| 45.260 | 81.0 | 81.0 | 11314990000 | 9440110000 | 48350000 | strchr |
| 6.081 | 10.9 | 91.9 | 1520280000 | 1566460000 | 46180000 | strncmp |
| 2.592 | 4.6 | 96.6 | 648080000 | 854500000 | 2170000 | strstr |
| 1.825 | 3.3 | 99.8 | 456225559 | 344882213 | 2170435 | strlen |
| 0.088 | 0.2 | 100.0 | 21950000 | 28510000 | 10000 | isspam |
| 0.000 | 0.0 | 100.0 | 100025 | 100028 | 1 | main |
| 0.000 | 0.0 | 100.0 | 53677 | 70268 | 219 | memccpy |
| 0.000 | 0.0 | 100.0 | 48888 | 46403 | 217 | memcmp |
| 0.000 | 0.0 | 100.0 | 17989 | 19894 | 219 | isspam |
| 0.000 | 0.0 | 100.0 | 16798 | 17547 | 230 | strlen |
| 0.000 | 0.0 | 100.0 | 10305 | 10900 | 204 | realfree |
| 0.000 | 0.0 | 100.0 | 6293 | 7161 | 217 | estrdup |
| 0.000 | 0.0 | 100.0 | 6032 | 8575 | 231 | cleanfree |
| 0.000 | 0.0 | 100.0 | 5932 | 5729 | 1 | readpat |
| 0.000 | 0.0 | 100.0 | 5899 | 6339 | 219 | getline |
| 0.000 | 0.0 | 100.0 | 5500 | 5720 | 220 | malloc |
Очевидно, что в затратах времени доминируют две функции: strchr и strncmp, причем обе вызываются из strstr. Итак, Кнут ориентирует нас правильно: небольшая часть программы поглощает большую часть времени ее исполнения.
При первом профилировании программы очень
При первом профилировании программы очень часто выясняется, что лидирующие в профиле две-три функции поглощают половину времени и более, как в приведенном случае, и, соответственно, становится сразу же ясно, на чем сконцентрировать внимание.
Концентрируйтесь на критических местах. Переписав st rst r, мы еще раз выполнили профилирование для spamtest и выяснили, что теперь 99.8 % времени тратит собственно strstr, хотя в целом программа и стала работать быстрее. Когда одна функция является таким явным узким местом программы, существует только два способа исправить положение: улучшить саму функцию, применив более эффективный алгоритм, или/ке избавиться от этой функции вообще, переписав всю программу.
Мы выбрали второй способ — переписали программу. Ниже приведены первые несколько строк профиля работы программы sparest, использующей последнюю, наиболее быструю реализацию isspam. При этом общее время работы программы существенно уменьшилось, критической точкой стала функция memcmp, a isspam стала заш'мать более существенную долю от общего времени. Эта версия гораздо сложнее предыдущей, однако эта сложность окупается с лихвой благодаря отказу от использования strlen и strchr в isspam и замене sees % cum% cycles instructions calls function strncmp на memcmp, которая тратит меньше усилий и» обработку каждого байта.
| secs | % | cum% | cycles | instructions | calls | function |
| 3.524 | 56.9 | 56.9 | 880890000 | 1027590000 | 46180000 | memcmp |
| 2.662 | 43.0 | 100.0 | 665550000 | 902920000 | 10000 | isspam |
| 0.001 | 0.0 | 100.0 | 140304 | 106043 | 652 | strlen |
| 0.000 | 0.0 | 100.0 | 100025 | 100028 | 1 | main |
Весьма поучительно будет потратить некоторое время на сравнение счетчиков циклов и количества вызовов различных функций в двух профилях. Отметьте, что количество" вызовов strlen упало от нескольких миллионов до 652, a strncmp и memcmp вызываются одинаковое количество раз. Обратите внимание и на то, что isspam, которая сейчас взяла на себя и функцию st rch r, умудряется обойтись гораздо меньшим количеством циклов благодаря тому, что она проверяет на каждом шаге только нужные образцы.
и многие другие детали хода
Изучение чисел может раскрыть и многие другие детали хода выполнения программы.
"Горячая точка" нередко может быть уничтожена или, по крайней мере, существенно "охлаждена" гораздо более простыми способами, чем мы применили для спам-фильтра. Когда-то давным-давно профилирование Awk показало, что одна функция вызывается примерно миллион раз — в таком цикле:
? for (j ='i; j < MAXFLD; j++)
? clear(j);
Выполнение этого цикла, в котором поля очищались перед считыванИем каждой новой строки ввода, занимало почти 50 % от всего времени исполнения. Константа MAXFLD — максимальное количество полей в строке ввода — была равна 200. Однако в большинстве случаев использования Awk реальное количество полей не превышало двух-трех. Таким образом, огромное количество времени тратилось на очистку полей, которые никогда и не устанавливались. Замена константы на предыдущее значение максимального количества полей дало выигрыш в скорости 25 %. Все исправления свелись к изменению верхней границы цикла:
for (j = i; j < rnaxfld; j++)
clear(j);
maxfld = i;
Постройте график. Особенно удачным получается представление замеров производительности в виде графиков. Графики помогут более наглядно представить информацию о влиянии изменения параметров, сравнить алгоритмы и структуры данных, а иногда и указать на неожиданное поведение программы. Графики длин цепочек для нескольких хэш-мультипликаторов в главе 5 явно продемонстрировали преимущества одних мультипликаторов перед другими.
На представленном ниже графике показано влияние размера массива хэш-таблицы на время исполнения С-версии программы ma rkov; в качестве вводимого текста использовались Псалмы (42 685 слов, 22 482 префикса)., Мы поставили два эксперимента. В первой серии запусков программа использовала размеры массивов, которые являлись степенями двойки — от 2 до 16 384; в другой версии использовались размеры, которые являлись максимальным простым числом, меньшим каждой степени двойки. Мы хотели посмотреть, приведет ли использование простых чисел в качестве размеров массивов к ощутимой разнице в производительности.
На графике ясно видно, что

На графике ясно видно, что время исполнения для такого ввода не зависит от размера таблицы при размерах, больших 10 000 элементов; также нет и существенной разницы между использованием в качестве размеров таблицы степеней двойки или простых чисел.
на самом деле вовсе не

на самом деле вовсе не линейный, а квадратичный: если s содержит п символов, то цикл выполняется п раз и при каждом исполнении вызов st rlen обходит п символов строки.
Используйте оптимизацию компилятора. Одно улучшение, часто приводящее к достаточно неплохим результатам, вы можете сделать совершенно "бесплатно" — включить всю возможную оптимизацию компилятора. Современные компиляторы справляются с оптимизацией достаточно хорошо, так что необходимости во внесении мелких улучшений вручную, как правило, не возникает.
По умолчанию большинство компиляторов С и C++ не используют все свои возможности по оптимизации, но у них есть опции, позволяющие включить оптимизатор (optimizer). Он не применяется по умолчанию из-за того, что оптимизация обычно конфликтует с отладчиками исходного кода, поэтому включать оптимизатор явным образом можно только после того, как вы будете абсолютно уверены в том, что программа как следует отлажена.
Оптимизация компилятора обычно увеличивает производительность программы в диапазоне от нескольких процентов до двух раз. Иногда, однако, она может даже замедлить программу, так что не забудьте произвести новые замеры времени. Мы сравнили результаты неоптимизированной и оптимизированной компиляции пары версий спам-фильтра. В тестовых примерах для окончательной версии алгоритма сравнения изначальное время исполнения равнялось 8.1 секунды и упало до 5.9 секунды после включения оптимизации, так что улучшение составило более 25 %. В то же время версия, которая использовала исправленную strstr, после включения оптимизации не показала никаких видимых улучшений, поскольку библиотечная функция strstr уже была оптимизирована при инсталляции; оптимизатор обращается только к исходному коду, компилируемому непосредственно в данный момент, но не к системным библиотекам. Правда, некоторые компиляторы имеют глобальный оптимизатор, который в поисках возможных улучшений анализирует всю программу целиком. Если такой компилятор есть в вашей системе, попробуйте использовать его, — может, он ужмет еще несколько циклов.
Надо предупредить, что чем агрессивнее оптимизация компилятора, тем : больше вероятность внесения им ошибок в скомпилированную программу. Поэтому после применения оптимизатора, как, собственно, и после внесения любого изменения, не забудьте запустить набор возвратных тестов.
Тонкая настройка кода. Если объемы данных достаточно существенны, серьезное значение имеет правильный выбор алгоритма. Более того, улучшенный алгоритм будет работать на любых машинах, компиляторах и языках. Но если и при должном алгоритме вопрос быстродействия по-прежнему стоит на повестке дня, то можно попробовать тонко настроить (tune) код — отполировать детали циклов и выражений, чтобы заставить их работать еще быстрее.
Версия isspam, которую мы рассмотрели в конце параграфа 7.1, небыла тонко настроена. Теперь мы покажем, как можно ее улучшить, изменив цикл. Итак, последний вариант выглядел следующим образом:
На этой версии после компиляции

На этой версии после компиляции с оптимизатором наш набор тестов исполнялся за 6.6 секунды. Внутренний цикл в своем условии содержал индекс массива (nstarting[c]), а его значение фиксировано для каждой итерации внешнего цикла. Мы можем избежать его многократного вычисления, единожды сохранив значение в локальной переменной:
После этого изменения время уменьшилось

После этого изменения время уменьшилось до 5.9 секунды, то есть примерно на 10 % — типичное значение для ускорения, которого можно достичь с помощью тонкой настройки. Есть и еще одна переменная, которую мы можем вытащить из тела цикла, — startingfc] также фиксировано. Вроде бы, если мы уберем ее вычисление из цикла, то это улучшит производительность, однако наши тесты не показали никакого изменения. Надо сказать, что это тоже типично при тонкой настройке, — некоторые вещи помогают, а некоторые нет, и это можно определить только замерами времени. Кроме того, результаты могут варьироваться для разных машин и компиляторов.
Есть и еще одно изменение, которое можно внести в спам-фильтр. Внутренний цикл сравнивает образец со строкой, однако алгоритм построен на том, что их первые символы совпадают. Соответственно, мы можем настроить код так, чтобы memcmp начинала сравнение со второго байта. Мы попробовали так сделать, и результатом стал З-процентньп прирост производительности. Это, конечно, немного, но от нас требовалось изменить всего три строчки кода, что не так уж сложно.
Не оптимизируйте то, что не имеет значения. Иногда настройка не приводит ни к каким результататам только потому, что оказывается направленной на вещи, которые не играют никакой роли. Не забывайте убедиться в том, что оптимизируемый вами код — это именно то место, где теряется драгоценное время. За подлинность следующей истории ручаться не можем, но вам будет полезно ее услышать. Некая старинна машина закрывшейся уже к настоящему времени компании была проанализирована с помощью монитора производительности компонентов Выяснилось, что исполнение одной и той же последовательности из нескольких команд занимало 50 % машинного времени. Инженеры создали специальную команду, выполняющую функции этой последовательности, собрали систему заново и обнаружили, что это не изменило ровным счетом ничего — они оптимизировали цикл ожидания операционной системы.
Сколько времени стоит тратить на увеличение скорости работы программы? Главный критерий — будут ли изменения достаточно результативны, чтобы окупиться. В качестве простейшего принципа можно принять следующее требование: время, потраченное на увеличение производительности программы, не должно быть больше, чем тот выигрыш во времени, который накопится благодаря внесенным изменениям за жизненный цикл программы. Исходя из этого правила, можно сказать, что изменения алгоритма в isspam были оправданы, — они потребовали дня работы, а сэкономили (и продолжают экономить) по нескольку часов каждый день. Удаление индекса массива из внутреннего цикла не сыграло столь глобальной роли, однако все равно имело смысл, поскольку программа эксплуатируется большим количеством пользователей. Оптимизация программ, которые используются коллективно, — вроде спам-фильтра или библиотеки — выгодна практически всегда, а оптимизация тестовых программ не выгодна почти никогда. Программу, которая будет считать что-нибудь в течение года, стоит доводить до максимального совершенства; более того, если через месяц ее работы вы придумаете способ 10-процентного ее ускорения, то эту программу стоит запустить заново.
Программы, продающиеся на рынках с сильной конкуренцией, — игры, компиляторы, текстовые процессоры, электронные таблицы, системы управления базами данных — также относятся к категории программ с окупающимися затратами на улучшения, поскольку коммерческий успех нередко сопутствует тем из них, что быстрее прочих, по крайней мере судя по публикуемым в прессе результатам тестирования.
Важно производить замер времени после внесения каждого изменения, чтобы быть уверенными в том, что ситуация действительно улучшается. Иногда два изменения, каждое из которых порознь улучшает программу, аннулируют эти улучшения при совместном использовании. Кроме того, надо помнить о том, что механизмы, лежащие в основе измерений времени, могут быть настолько непостоянны в работе, что вынести однозначное решение о пользе изменений весьма проблематично. Даже в однопользовательских системах врем^исполнения может изменяться непредсказуемым образом. Если разброс внутреннего таймера (или, по крайней мере, тех результатов, которые он вам возвращает) составляет 10 %, то изменения, которые увеличивают производительность менее чем на эти 10 %, будет очень трудно отличить от нормальной погрешности результатов. <
При этом мы избавляемся от

При этом мы избавляемся от затрат на организацию цикла, особенно от ветвления, которое может существенно замедлять современные процессоры, прерывая поток исполнения.
Если цикл более длинный, тот же тип преобразования можно применить для уменьшения количества операций:
Обратите внимание на то, что

Обратите внимание на то, что это можно осуществить только в том случае, если длина в кратное количество раз отличается от размера шага, в противном случае надо обрабатывать дополнительный код на границах, а в таких местах очень часто возникают ошибки, заодно теряется и часть отыгранной эффективности.
Кэшируйте часто используемые значения. Кэшированные значения не надо вычислять заново. Кэширование использует преимущества локолъ-ности (locality) — тенденции программ (да и людей) чаще использовать те элементы, обращение к которым происходило недавно. В вычислительном оборудовании кэши используются очень широко; оснащение компьютера кэшем серьезно ускорило его работу. То же самое относится и к программам. Например, web-браузеры кэшируют страницы и рисунки для того, чтобы как можно меньше прибегать к повторному получению данных из Интернета. Много лет назад мы писали программу просмотра текста для вывода на печать; в этой программе специальные символы, вроде %, приходилось выбирать из специальной таблицы. Измерения показали, что по большей части специальные символы использовались для рисования линий (строк), состоящих из многократного
повторения одного и того же символа. Кэширование только одного последнего использованного символа серьезно улучшило быстродействие программы при обработке типичного ввода.
Лучше всего, если операция кэширования будет невидима снаружи, то есть не будет влиять на программу никаким образом, кроме как ускорять ее исполнение. В случае с нашим предпечатным просмотром интерфейс функции отрисовки не изменился, вызов всегда выглядел как
drawchar(c);
В исходной версии drawchaг осуществлялся вызов show(lookup(c)). В реализации с кэшированием для запоминания последнего вызванного символа и его кода использовались внутренние статические переменные:
Напишите специальную функцию захвата памяти

Напишите специальную функцию захвата памяти (аллокатор). Довольно часто единственной горячей точкой программы с точки зрения быстродействия является захват памяти, который проявляется в огромном количестве обращений к malloc или new. Когда по большей части за-прашиваются блоки одного размера, то можно существенно ускорить программу, заменив вызовы общего аллокатора вызовами специализированной подпрограммы. Такой специальный аллокатор один раз вызывает malloc, получая большой массив элементов, а потом "выдает" их по одному; в результате получается более дешевая операция. Освобождаемые элементы помещаются обратно в список свободных элементов '(free list), благодаря чему их можно сразу же использовать снова.
Если запрашиваемые блоки примерно равны, то можно пожертвовать J местом ради выигрыша во времени и выделять сразу столько памяти, чтобы хватило на самый большой запрос. Например, для работы с короткими строками может оказаться эффективным использование одного и того же размера для всех строк, не превышающих фиксированной длины.
Некоторые алгоритмы могут использовать выделение памяти, осуще- i ствляемое по принципу стека: когда выполняется сразу целая последовательность выделений памяти, а затем она освобождается вся целиком. При таком подходе аллокатор получает сразу большой блок памяти, который использует как стек, по необходимости заталкивая в него новые элементы и в конце высвобождая их все одной операцией. Некоторые библиотеки С содержат специальную функцию alloca для такого способа выделения памяти, хотя она и не входит в стандарт. В качестве источника памяти она использует локальный стек вызовов; высвобождаются элементы в тот момент, когда заканчивает работу функция, вызвавшая alloca.
Буферизуйте ввод и вывод. При буферизации трансакции объединяются в блоки с тем, чтобы часто исполняемые операции выполнялись с минимально возможными затратами, а очень дорогостоящие операции выполнялись только в случае крайней необходимости. Стоимость операции, таким образом, распределяется между несколькими значениями данных.
в буфере, но не передаются
Например, когда программа на С вызывае-Aprintf, символы сохраняются в буфере, но не передаются операционной системе до тех пор, пока буфер не будет заполнен или не поступит явный запрос на его очистку. В свою очередь, операционная система может задержать запись данных на диск. Помеха в том, что данные становятся видимыми после очистки буферов вывода; и в.худшем случае — информация, содержащаяся в буфере, при аварийной остановке программы пропадает.
Специальные случаи обрабатывайте отдельно. Обрабатывая объекты одинакового размера в отдельном коде, специализированные аллокато-ры уменьшают затраты места и времени и при этом уменьшают степень фрагментации памяти. В графической библиотеке для системы Inferno основная функция d raw была написана насколько возможно просто и непосредственно. После того как она заработала в таком виде, началась оптимизация различных частных случаев, выбранных в результате профилирования (по одному изменению за раз). Большим плюсом являлось то, что оптимизированную версию всегда можно было сравнить с исходной (мы уже говорили о прототипах, — это тот самый случай). В конце концов оптимизации подверглось лишь незначительное число случаев — из-за того, что динамическое распределение вызовов функции рисования очень сильно зависело собственно от вывода символов на экран; для многих случаев просто не имело смысла писать какой-то особо умный код.
Используйте предварительное вычисление результатов. Иногда ускорить работу программы можно предварительно вычислив некоторые значения. Мы проделали это в спам-фильтре, вычислив заранее strlen(pat[i]) и сохранив его в массиве patlen[i ]. Если графической системе приходится постоянно вычислять математическую функцию вроде синуса, но только Для какого-то дискретного набора значений, например только для целых значений градусов, то быстрее заранее вычислить таблицу из 360 элементов (или вообще включить ее в программу в виде данных) и обращаться к этой таблице по индексу. Это типичный пример экономии времени за счет места.
Существует множество способов замены кода
Существует множество способов замены кода данными или выполнения вычислений при компиляции для сохранения времени, а иногда и места. Например, функции из библиотеки ctype, вроде isdigit, почти всегда реализованы с помощью индексации в таблице битовых флагов, а не посредством вычисления последовательности тестов.
Используйте приближенные значения. Если идеальная аккуратность; вычислений не нужна, лучше использовать типы данных с низкой точностью. На старых или маломощных машинах, а также на машинах, симулирующих плавающую точку программно, вычисления с плавающей точкой, выполняемые с обычной точностью, происходят быстрее, чем с двойной точностью, так что для экономии времени стоит использовать float вместо double. Подобный прием используется в некоторых совре-'; менных графических редакторах. Стандарт IEEE для плавающей точки требует "чистого выхода за пределы точности" (graceful underflow) no мере приближения вычислений к нижней границе точности значений, однако такие вычисления достаточно накладны. Для изображений подобные изыски не обязательны, гораздо быстрее отсекать малозначимые части значений; главное, при этом абсолютно ничего не теряется. Это не только экономит время при уменьшении значимости чисел, но и позво- ] ляет использовать для вычислений более простые аппаратные средства. | Использование целочисленных функций sin и cos — еще один пример использования приближенных вычислений.
Перепишите код на языке более низкого уровня. Как правило, чем | ниже уровень языка, тем более быстрым оказывается код, хотя за это и приходится платить большими затратами на его написание. Так, переписав некоторый критичный фрагмент программы с C++ или Java на С или заменив интерпретируемый скрипт программой на компилируемом языке, вы, скорее всего, добьетесь сокращения времени исполнения.
Порой использование машинно-ориентированного (и, стало быть, машинно-зависимого) кода может дать существенный выигрыш в быстродействии. Это скорее последняя надежда, чем часто применяемый ход, поскольку это прямо-таки уничтожает переносимость и вызывает большие трудности при дальнейшей поддержке и модернизации программы.Почти всегда операции, которые надо выражать на языке ассемблера, — это небольшие функции, которые следует объединить в библиотеку: типичными примерами являются memset и memmove или графические операции. Общий подход должен быть таким: сначала надо написать максимально понятный код на языке высокого уровня и проверить его на корректность, старательно оттестировав; мы проделывали такое для memset в главе 6. Получается переносимая версия, которая будет работать всегда и везде, хотя и довольно медленно. Теперь при переходе в новую среду вы всегда будете иметь версию, которая с гарантией работает, и работает правильно, и, написав версию на ассемблере, сравните ее с работающим прототипом. При возникновении ошибок проверять надо в первую очередь, естественно, новую версию. Вообще, полезно и удобно иметь под рукой реализацию для сравнения.
Если эти функции окажутся слишком

Если эти функции окажутся слишком медленными, их можно улучшить с помощью технологий, описанных ранее. В C++ переопределение операторов позволяет сделать доступ к битам похожим на простое индексирование.
Не храните то, что можете без труда вычислить. Надо сказать, что подобные изменения — не самые эффективные; они похожи на тонкую настройку кода. Глобальные улучшения, как правило, достигаются только подбором более удачной структуры данных и соответствующим изменением алгоритма. Приведем пример. Много лет назад к одному из нас обратился за помощью наш коллега: он пытался производить некоторые вычисления над матрицей, которая была так велика, что для того, чтобы она уместилась в памяти, приходилось перезагружать компьютер, сильно урезая операционную систему. Очень хотелось найти какую-нибудь альтернативу, потому что работать в подобном режиме было ужасно неудобно. Мы сразу попросили рассказать, что же представляет собой эта матрица, и выяснили, что она содержала целые числа, большая часть из которых была нулями' . И лишь менее 5 % элементов матрицы были отличны от нуля. Подобная структура тут же навела нас на мысль о представлении, в котором хранились бы только ненулевые элементы матрицы, а доступ к каждому элементу m[i][j] заменялся бы вызовом функции m(i, j ). Существует несколько способов хранить данные. Наверное, самый простой из них — это массив указателей, по одному на столбец, каждый из которых указывает на компактный массив номеров строк и соответствующих значений. При такой организации на каждый ненулевой элемент тратится больше места, однако суммарное место все же экономится; доступ к каждому элементу получается более медленным, но это все равно быстрее, чем перезагружать машину. Наш коллега принял наше предложение и был вполне доволен результатом.
Аналогичный подход мы использовали и при решении современного варианта этой проблемы. Некая система проектирования должна была представлять данные о виде поверхности и силе радиосигнала, относящиеся к достаточно большим площадям (от 100 до 200 километров в поперечнике), с разрешением в 100 метров. Сохранение этих данных в одном большом прямоугольном массиве неизбежно привело бы к переполнению памяти на машинах, для которых эта система разрабатывалась, и, соответственно, к активному дисковому обмену. Однако было ясно, что для достаточно больших территорий данные о поверхности Земли и о силе сигнала будут одинаковы, так что для решения проблемы можно было применить иерархическое представление данных, при котором регионы с одинаковыми параметрами хранились в одном элементе.
Вариации на эту тему встречаются на практике достаточно часто, и их проявления различны, но для решения можно применять один и тот же подход: храните одинаковые значения в неявном виде или просто в компактной форме, а время и пространство тратьте на оставшиеся значения. Если одинаковые данные действительно встречаются в вашей задаче достаточно часто, вы сможете добиться впечатляющих результатов.
Программа должна быть организована таким образом, чтобы специфическое представление данных сложного типа было спрятано в классе или в наборе функций, оперирующих внутренними типами данных. Подобная предосторожность даст гарантию, что возможные изменения в представлении данных не затронут остальную часть программы.
Проблемы эффективного использования места иногда проявляются и по отношению к внешнему представлению информации — и к преобразованию, и к хранению. В общем и целом, всегда, когда это возможно, информацию лучше хранить в текстовом виде, а не в каком-то двоичном представлении. Текст хорошо переносится, удобно читается; для его обработки создано великое множество инструментов; двоичное же представление лишено этих преимуществ. Аргументом в защиту двоичных данных служит обычно "скорость", однако к нему стоит относиться с изрядной долей скептицизма, поскольку различия между текстовой и двоичной формой, как правило, не столь глобальны.
Более эффективное распределение пространства зачастую покупается ценой увеличения времени исполнения программы. Некое приложение должно было передавать большой рисунок из одной программы в другую. Рисунки в достаточно простом формате РРМ занимали, как правило, около мегабайта, так что мы подумали, что было бы гораздо быстрее кодировать их для передачи в сжатом формате GIF, — тогда файлы получались бы размером примерно 50 килобайтов. Однако кодирование и декодирование GIF занимало столько времени, что это сводило на нет всю экономию от передачи файла меньшего размера, то есть мы ничего не выгадывали. Код для обработки формата GIF состоял примерно из 500 строк, а для РРМ — из 10. Таким образом, для облегчения поддержки кода мы отказались от преобразования в GIF, и программа до сих пор работает с форматом РРМ. Естественно, если бы речь шла о передаче файлов по сети, то предпочтение было бы отдано формату GIF. <
Целочисленные операции достаточно быстры, за

Целочисленные операции достаточно быстры, за исключением деления и взятия остатка. Операции для чисел с плавающей точкой так же быстры или даже быстрее — сюрприз для тех, кто вырос во времена, когда операции с плавающей точкой были на порядок медленнее, чем целочисленные.
Другие базовые операции также достаточно быстры, включая и вызовь функций (они представлены в последних трех строках данного фрагмента)
вывода стоят гораздо дороже шинство

А вот операции ввода- вывода стоят гораздо дороже шинство других библиотечных функций:
и malloc, вряд ли точно

Время, показанное дош f гее и malloc, вряд ли точно соответствует их реальной производительности, поскольку освобождение памяти сразу после выделения — не самое распространенное действие.
И наконец, математические функции:
эти цифры будут разными на

Естественно, эти цифры будут разными на разных машинах, однако общие тенденции сохранятся, так что мы можем их использовать для прикидочной оценки тех или иных конструкций, или для сравнения операций ввода-вывода с базовыми операциями, или для принятия решения о том, стоит ли переписывать выражение или использовать встраиваемую (inline) функцию.
Различие при замерах на разных машинах обусловлено разными причинами. Одной из них является уровень оптимизации компилятора. Современные компиляторы способны создать оптимизацию, до которой большинству программистов не додуматься. Более того, современные процессоры настолько сложны, что лишь хороший компилятор способен воспользоваться их возможностями одновременной выборки нескольких команд, конвейерному их исполнению, заблаговременной выборке данных и команд и т.
Еще одна важная причина того, что показатели производительности трудно предсказать заранее, кроется в самой архитектуре компьютеров. Наличие кэш-памяти значительно изменяет скорость исполнения программ, и большая часть аппаратных ухищрений направлена на то, чтобы нивелировать разницу в быстродействии кэш-памяти и обычной памяти. Показатели частоты процессора вроде "400 MHz" дают некоторое представление о быстродействии машины, но не более того: один из наших старых компьютеров Pentium-200 работает гораздо медленнее, чем еще более старый Pentium-100, потому только, что последний имеет гораздо больший кэш второго уровня. А разные поколения процессоров — даже при одинаковом наборе команд — тратят для исполнения одной и той же операции разное количество циклов процессора.
Производительность
Он был силен и много обещал, — Свершений нет, а силы растерял.
Шекспир. Король Генрих VIII
Когда-то программисты затрачивали огромные усилия на то, чтобы сделать свои программы эффективными, так как компьютеры были очень медленными и очень дорогими. В наши дни компьютеры стали гораздо быстрее и сильно подешевели, так что необходимость в идеальной эффективности заметно снизилась. Стоит ли по-прежнему волноваться из-за производительности?
Да, но только в том случае, если проблема действительно важна, если программа действительно работает слишком медленно, а главное, есть надежды на то, что ее удастся ускорить, не потеряв при этом в корректности, строгости и ясности. Быстрая программа, выдающая неправильные результаты, никому времени не сэкономит.
Таким образом, первым принципом оптимизации можно считать принцип не делать лишнего. Достаточно ли хороша программа в своем теперешнем состоянии? Мы знаем, как и где она будет использоваться; будут ли заметны выгоды от ее ускорения? Программы, которые пишутся в качестве заданий в колледже, никогда больше не используются, их скорость редко имеет значение. Скорость также редко имеет значение для программ, написанных для собственного использования, временных утилит, испытательных стендов, экспериментов и программ-прототипов. Однако же скорость исполнения коммерческого продукта или центрального компонента системы, например графической библиотеки, может иметь первостепенную важность, так что нам надо знать, как подходить к вопросам производительности.
Когда надо пытаться ускорить программу? Как это можно сделать? На какие результаты мы можем рассчитывать? В этой главе мы обсудим, как добиться того, чтобы программа выполнялась быстрее или использовала меньше памяти. Как правило, больше всего нас интересует скорость программы, так что в основном речь пойдет о ней. Проблемы с памятью, оперативной или внешней, возникают реже, но иногда они могут быть критичными, так что мы затронем и этот аспект.
Как мы уже выяснили в главе 2, для выполнения задания сначала лучше выбрать самые простые и понятные алгоритмы и структуры данных. После этого надо измерить производительность и решить, нужны ли изменения. Далее следует настроить опции компилятора на создание наибо- : лее быстрого кода; потом оценить, какие изменения в самой программе могут дать наибольший эффект; потом начинать вносить изменения — по одному за раз! — и после каждого повторять предыдущие шаги. При этом J всегда надо сохранять простые версии, чтобы продолжать сравнения.
Измерение необходимо при повышении производительности, поскольку умозаключения и интуиция — не вполне надежные советники, и без дополнительных инструментов, таких как команды измерения времени и профилировщики, не обойтись. Увеличение производительности име- 5 ет много общего с тестированием, в этом процессе в той же мере важны такие вещи, как автоматизация, ведение тщательных записей об изменениях и использование возвратных тестов, чтобы видеть, что состояние программы улучшается и не придется откатываться к предыдущим версиям. Если вы выбрали алгоритмы достаточно разумно и пишете аккуратно с самого начала, то очень может быть, что никаких мер для убыстрения ваших программ не потребуется. Нередко для разрешения проблем с производительностью в грамотно спроектированном коде хватает совсем небольших изменений, а вот в плохо спроектированном коде придется переписывать очень многое.
<
Стратегии ускорения
Перед тем как начинать изменять программу, чтобы сделать ее более быстрой, убедитесь, что она действительно работает слишком медленно, а затем используйте инструменты для замера времени и профилировщики для выяснения, на что именно уходит время. После того как вы получили представление о том, что происходит в действительности, можно следовать различным стратегиям ускорения. Мы перечислили некоторые из них, упорядочив их по уменьшению эффективности.
Улучшайте алгоритм и структуру данных. Наиболее важным фактором в уменьшении времени работы программы является выбор алгоритма или структуры данных — между эффективным алгоритмом и неэффективным разница может быть просто огромной. Для нашего спам-фильт-ра мы изменили структуру данных и получили выигрыш в десять раз; еще более внушительным улучшением могло стать применение нового алгоритма, который бы сократил вычисления на порядок, скажем с 0(п2) до 0(п log n). Мы уже обсуждали эту тему в главе 2, так что теперь не будем к ней возвращаться.
Убедитесь в том, что сложность такая, как надо; если она завышена, то именно в ней может крыться источник недостаточной производительности. Этот, линейный на первый взгляд, алгоритм для сканирования строки
с него, стала основой существенного
Таблица, которая соотносит отдельный символ с набором образцов, начинающихся с него, стала основой существенного повышения производительности. Напишите версию isspam, которая использует в качестве индекса два символа. Насколько это будет лучше? Это — простейший особый случай структуры данных, которая называется "бор" (trie)'. Большинство подобных структур данных основаны на затратах места ради экономии времени. <
Вне зависимости от того, есть
Вне зависимости от того, есть на вашей машине команда time или нет, используйте clock или getTime для создания собственного измерителя времени. Сравните его результаты с системным временем. Как влияет на результаты другая активность на машине?
В первом профиле st rch
В первом профиле st rch г вызывалась 48 350 000 раз, a st rncmp — только 46 180 000 раз. Объясните это различие. <
Один из способов ускорить функцию
Один из способов ускорить функцию типа memset — переписать ее так, чтобы она записывала данные порциями в слово, а не в байт; такая версия почти наверняка будет ближе к аппаратнымт1редставлениям, и затраты на цикл снизятся в четыре или восемь раз. Отрицательной стороной является то, что при этом возникает большое количество вариантов окончаний блоков, если объект приложения функции не выровнен по границе слова (или не кратен слову).
Напишите версию memset, выполняющую подобную оптимизацию. Сравните ее производительность с существующей библиотечной версией и с простейшим вариантом побайтового цикла.
Упражнение 7-5
Напишите функцию выделения памяти smalloc для строк С, которая бы использовала специальный аллокатор для коротких строк, но вызывала непосредственно malloc для больших. Для представления тех и других строк вам придется определить структуру struct. Как вы определите, где переходить от вызова smalloc к malloc? <
Создайте набор тестов для оценки
Создайте набор тестов для оценки времени исполнения основных операций на используемых вами компьютерах и компиляторах. Изучите похожие и различающиеся аспекты производительности.
Создайте модель затрат для высокоуровневых
Создайте модель затрат для высокоуровневых операций в C++ — таких как создание, копирование и удаление объектов классов, вызовы функций-членов класса, виртуальных функций, встраиваемых (inline) функций, библиотеки lost ream, STL. Это упражнение не имеет фиксированного завершения, так что сосредоточьтесь на небольшом репрезентативном наборе операций.
Узкое место
Нам хотелось бы начать с описания того, как мы избавились от узкого места в важной программе нашей вычислительной системы.
Наша входящая почта поступала к нам через одну машину, называемую шлюзом (gateway), которая объединяла нашу внутреннюю сеть с внешним Интернетом. Электронная почта, приходящая извне, — в нашу организацию, насчитывающую несколько тысяч человек, приходят десятки тысяч писем в день — поступает на шлюз и затем передается во внутреннюю сеть; такое разделение изолирует нашу локальную сеть от доступа из Интернета и позволяет указывать адрес только одной машины (этого самого шлюза) для всех членов организации.
Одной из услуг, предоставляемых шлюзом, является защита от "спама" (spam — мясные консервы, содержащие в основном сало), незатребованной почты, рекламирующей услуги сомнительных достоинств. После первых успешных испытаний спам-фильтр был установлен на шлюз и включен для всех пользователей нашей внутренней сети — и немедленно возникла проблема. Машина, исполняющая роль шлюза, уже несколько устаревшая и без того достаточно загруженная, была буквально парализована: поскольку фильтрующая программа работала слишком медленно, она отнимала гораздо больше времени, чем вся остальная обработка сообщений, и в результате доставка почты задерживалась на часы.
Это пример настоящей проблемы производительности: программа была не в состоянии уложиться во время, отводимое ей на работу, и пользователи серьезно от этого страдали. Программа должна была работать гораздо быстрее.
Несколько упрощая, можно сказать, что спам-фильтр работает примерно так: каждое входящее сообщение рассматривается как единая строка, которая обрабатывается программой поиска образцов с целью обнаружить, не содержит ли она фраз из заведомого спама — таких, как "Make millions in your spare time" (сделайте миллион в свободное время) или "XXX-rated" (крутые порно). Подобные сообщения имеют тенденцию появляться многократно, так что подобный подход достаточно эффективен, тем более что если какой-то спам проходил через фильтр, то характерные фразы из него добавлялись в список.
Ни одна из существующих утилит сравнения строк — вроде д rep — не устраивала нас по соотношению производительности и возможностей, поэтому для спам-фильтра была написана специальная программа. Первоначальный код ее был весьма прост, он просматривал каждое сообщение и проверял наличие в нем заданных фраз (образцов):
Если вы выбрали верный алгоритм,
Если вы выбрали верный алгоритм, то, как правило, об оптимизации его производительности можно уже особо и не задумываться. Однако, если необходимость в ней все же возникла, основной цикл процесса должен выглядеть так: выполните замеры; займитесь местами, изменения в которых дадут максимальный эффект; проверьте корректность изменений и выполните замеры снова. Останавливайтесь сразу же, как только достигнете приемлемых показателей; не забывайте сохранить первоначальную версию как эталон для проверки новых версий на корректность и быстродействие.
Улучшая скорость программы и ее потребность в памяти, создайте для себя набор эталонных тестов, чтобы было проще оценить и впоследствии отслеживать быстродействие программы. При наличии стандарных тестов используйте и их тоже. Если программа получается достаточно изолированной, самодостаточной, то нередко создают набор "типичных" вариантов ввода — такой подход является основой тестов быстродействия коммерческих и академических систем вроде компиляторов, вычислительных программ и т. п. Так, для Awk создан набор примерно из 20 маленьких программ, которые в совокупности перекрывают большую часть широко используемых конструкций языка. Эти программы применяются для того, чтобы удостовериться, что результаты работы верны и нет сбоев в производительности. Кроме того, у нас есть набор больших стандартных файлов ввода, которые мы также используем для тестирования времени исполнения программ. Полезно придать таким файлам какие-то легко проверяемые свойства, например размер их может быть степенью двух или десяти.
Замеры и шаблонные сравнения можно осуществлять с помощью оснасток того же типа, что $h>i использовали в главе 6 для тестирования: замеры времени запускаются автоматически; в выводимых результатах достаточно информации для того, чтобы они были понятны и воспроизводимы; записи ведутся аккуратно, чтобы можно было отследить основные тенденции и наиболее значительные изменения.
На самом деле создать хорошие тесты-замеры весьма непросто, и об этом прекрасно осведомлены компании, которые специально настраивают свои продукты так, чтобы те показывали как можно более высокие результаты именно на подобных тестах. Так что к их результатам надо относиться с известной долей скептицизма. <
Замеры времени и профилирование
Автоматизируйте замеры времени. В большинстве систем существуют команды, позволяющие выяснить, сколько времени работала программа. В Unix такая команда называется time: