Нотация
Из всех творений человека
самым удивительным является язык.Джайлс Литтон Страчи. Слова и поэзия
Правильный выбор языка может решающим образом влиять на простоту написания программы. Поэтому в арсенале практикующего программиста находятся не только языки общего назначения вроде С и его родственников, но и программируемые оболочки, языки скриптов, а также большое количество языков, ориентированных на конкретные приложения.
Преимущества хорошей нотации — способа записи — появляются при переходе от традиционного программирования к узкоспециальным проблемным областям. Регулярные выражения позволяют использовать компактные (из-за этого подчас превращающиеся в тайнопись) описания классов строк. Язык HTML позволяет определять внешний вид интерактивных документов, нередко используя встроенные программы на других языках, вроде JavaScript. PostScript рассматривает целый документ — например эту книгу — как стилизованную программу. Электронные таблицы и текстовые процессоры часто содержат в себе языки программирования типа Visual Basic, они используются для вычисления выражений, доступа к информации, управления размещением данных в документе.
Если вы ловите себя на том, что приходится писать слишком много кода' для выполнения рутинных операций, или если у вас возникают проблемы с тем, чтобы в удобной форме описать весь процесс, знайте — скорее всего, вы выбрали неправильный язык. Отсутствие правильного языка можно считать хорошим поводом написать его самостоятельно. Придумать свой язык вовсе не означает создать преемника Java: просто нередко самые запутанные проблемы проясняются при выборе должной нотации. В связи с этим вспомните форматные строки семейства printf, которые дают нам компактный и выразительный способ для управления выводом.
В этой главе мы говорим о том, как способ записи может помочь в решении наших проблем, а также демонстрируем ряд приемов, которые вы мо-Ц «ете использовать для создания собственных специализированных языков. Мы даже заставим программу писать другую программу, такова экстремальное использование способа записи распространено гораздо пире и осуществляется гораздо проще, чем думают многие программисты.
Форматирование данных
Между тем, что мы хотим сказать компьютеру ("реши мою проблему"), и тем, что нам приходится ему говорить для достижения нужного результата, всегда существует некоторый разрыв. Очевидно, что чем этот разрыв меньше, тем лучше. Хорошая нотация поможет нам сказать лменно то, что мы хотели, и препятствует ошибкам. Иногда хороший ;пособ записи освещает проблему в новом ракурсе, помогая в ее решении и подталкивая к новым открытиям.
Малые языки (little languages) — это нотации для узких областей применения. Эти языки не только предоставляют удобный интерфейс, но| л помогают организовать программу, в которой они реализуются. Хоро-лим примером является управляющая последовательность printf:
printf("%d %6.2f %-10.10s\n", f, s);
Здесь каждый знак процента обозначает место вставки значения сле-гующего аргумента printf ; за ним следуют необязательные флаги и раз- \ меры поля и, наконец, буква, которая указывает тип параметра. Такая нотация компактна, интуитивно понятна и легка в использовании; ее реализация достаточно проста и прямолинейна. Альтернативные возможности в C++ (lost ream) и Java ( j ava . io) выглядят гораздо менее привле-сательно, поскольку они не предоставляют специальной нотации, хотя могут расшириться типами, определяемыми пользователем, и обеспечив 5ают проверку типов.
Некоторые нестандартные реализации printf позволяют добавлять] ;вои приведения типов к встроенным. Это удобно, когда вы работаете] : другими типами данных, нуждающимися в преобразованиях при вы- р| зоде. Например, компилятор может использовать знак %1_ для обозначе- ; шя номера строки и имени файла; графическая система — использовать »Р для точки, a %R — для прямоугольника. Строка шифра из букв и номе- , юв — сведения о биржевых котировках, которая рассматривалась нами главе 4, относится к тому же типу: это компактный способ записи та-сих котировок.
Схожие примеры можно придумать и для С и C++. Представим себе, что нам нужно пересылать пакеты, содержащие различные комбинации типов данных, из одной системы в другую. Как мы видели в главе 8, самым чистым решением была бы передача данных в текстовом виде. Однако для стандартного сетевого протокола лучше иметь двоичный формат по причинам эффективности и размера. Как же нам написать код для обработки пакетов, чтобы он был переносим, эффективен и прост в эксплуатации?
Для того чтобы дальнейшее обсуждение было конкретным, представим себе, что нам надо пересылать пакеты из 8-битовых, 16-битовых и 32-битовых элементов данных из одной системы в другую. В стандарте ANSI С оговорено, что в char может храниться как минимум 8 битов, 16 битов может храниться в sho rt и 32 бита — в long, так что мы, не мудрствуя лукаво, будем использовать именно эти типы для представления наших данных. Типов пакетов может быть много: пакет первого типа содержит однобайтовый спецификатор типа, двухбайтовый счетчик, однобайтовое значение и четырехбайтовый элемент данных:

Пакет второго типа может состоять из одного короткого и двух длинных слов
данных:

Один из способов — написать отдельные функции упаковки и распаковки для
каждого типа пакета:
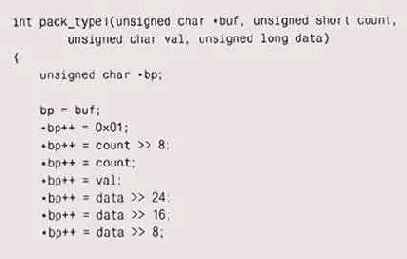
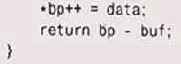
Для настоящего протокола потребовалось бы написать не один десяток сих
функций — на все возможные варианты. Можно было бы несколь-упростить процесс,
используя макросы или функции для обработки ювых типов данных (short,
long и т. п.), но и тогда подобный повто-ющийся код было бы трудно воспринимать,
трудно поддерживать, 5 итоге он стал бы потенциальным источником ошибок.
Именно повторяемость кода и является его основной чертой, и здесь-то м и может помочь грамотно подобранный способ записи. Позаимство-в идею у printf, мы можем определить свой маленький язык специфи-ции, в котором каждый пакет будет описываться краткой строкой, дающей информацию о размещении данных внутри него. Элементы пакета даруются последовательно: с обозначает 8-битовый символ, s — 16-би-iBoe короткое целое, а 1 — 32-битовое длинное целое.Таким образом, на-зимер, пакет первого типа (включая первый байт определения типа) моет быть представлен форматной строкой cscl. Теперь мы в состоянии :пользовать одну-единственную функцию pack для создания пакетов обых типов; описанный только что пакет будет создан вызовом
pack(buf, "cscl", 0x01, count, val, data);
В нашей строке формата содержатся только описания данных, поэтому ам нет нужды использовать какие-либо специальные символы — вроде в printf.
На практике о способе декодирования данных могла бы сообщать риемнику информация, хранящаяся в начале пакета, но мы предположим, что для определения формата данных используется первый байт пакета. Передатчик кодирует данные в этом формате и передает их; приемник считывает пакет, анализирует первый байт и использует его для (екодирования всего остального.
Ниже приведена реализация pack, которая заполняет буфер buf кодированными в соответствии с форматом значениями аргументов. Мы сделали значения беззнаковыми, в том числе байты буфера пакета, чтобы избежать проблемы переноса знакового бита. Чтобы укоротить описания, мы использовали некоторые привычные определения типов:

Точно так же, как sprinth, strcopy и им подобные, наша функция предполагает,
что буфер имеет достаточный размер, чтобы вместить результат; обеспечить
его должна вызывающая сторона. Мы не будем делать попыток определить несоответствия
между строкой формата и списком аргументов.


Функция pack использует заголовочный файл stda rg . h более активно, чем
функция eprintf в главе 4. Аргументы последовательно извлекаются с помощью
макроса va_arg, первым операндом которого является переменная типа va_list,
инициализированная вызовом va_start; а в качестве второго операнда выступает
тип аргумента (вот почему va_arg — то именно макрос, а не функция). По
окончании обработки должен быть осуществлен вызов va_end. Несмотря на
то что аргументы для ' с ' ; ' s ' представлены значениями char и short
соответственно, они должны извлекаться как int, поскольку, когда аргументы
представлены многоточием, С переводит char и short в int.
Теперь функции pack_type будут состоять у нас всего из одной строки, которой их аргументы будут просто заноситься в вызов pack:

Для распаковки мы делаем то же самое и вместо того, чтобы писать тдельный
код для обработки каждого типа пакетов, вызываем общую функцию unpack
с соответствующей форматной строкой. Это централизирует преобразования
типов:


Так же как, например, scanf, функция unpack должна возвращать вызвавшему
ее коду множество значений, поэтому ее аргументы являются указателями
на переменные, где и будут храниться требуемые результаты. Значением функции
является количество байтов в пакете, его можно использовать для контроля.
Все значения у нас беззнаковые. Мы придерживались размеров, которые ANSI С определяет для типов данных, и поэтому наш код можно переносить даже между машинами, имеющими разные размеры для типов short и long. Если только программа, использующая pack, не будет пытаться переслать как long (к примеру) значение, которое не может быть представлено 32 битами, то значение будет передано корректно; на самом деле мы передаем младшие 32 бита числа. Если же потребуется передавать более длинные значения, то нужно придумать другой формат.
Благодаря использованию unpack, функции для распаковки пакетов в зависимости от их типа стали выглядеть гораздо проще:


Перед тем как вызывать unpack_type2, мы должны сначала убедиться,, о имеется
пакет именно 2-го типа; распознаванием типа пакетов зани-сется цикл получателя,
примерно такой:

Подобный стиль описания функций довольно размашист. Можно более мпактно
определить таблицу указателей на распаковывающие функ-:и, причем номер
в таблице будет типом пакета:

Каждая функция в таблице разбирает пакет своего типа, проверяет ре-пьтат
и инициирует дальнейшую обработку этого пакета. Благодаря эй таблице работа
приемника получается более прямолинейной:

Итак, теперь код для обработки каждого пакета стал компактен; основная
часть всей обработки происходит в одной функции и потому поддерживать
такой код нетрудно. Код приемника теперь мало зависит от самого протокола;
код его также прост и однозначен.
Этот пример основан на некоем реальном коде настоящего коммерческого сетевого протокола. Как только автор осознал, что этот, в общем, не-хитрЦй подход работоспособен, в небытие ушли несколько тысяч строк повторяющегося кода, напичканного ошибками (скорее даже, описками), и вместо него появились несколько сот строк, поддерживать которые можно без всякого напряжения. Итак, хороший способ написания существенным образом улучшил как сам процесс работы, так и ее результат.
Упражнение 9-1
Измените pack и unpack так, чтобы можно было передавать и значения со знаком, причем даже между машинами, имеющими разные размеры short и long. Как вы измените форматную строку для обозначения элемента данных со знаком? Как можно протестировать код, чтобы убедиться, что он корректно передает, например, число -1 с компьютера с 32-битовым long на компьютер с 64-битовым long?
Упражнение 9-2
Добавьте в pack и unpack возможности обработки строк. (Есть вариант включать длину строки в форматную строку.) Добавьте возможность обработки повторяющихся значений с помощью счетчика. Как это соотносится с кодировкой строк?
Упражнение 9-3
Вспомните таблицу указателей на функции, которую мы применили олько что в программе на С. Такой же принцип лежит в основе механиз-ia виртуальных функций C++. Перепишите pack, unpack и receive на ;++, чтобы прочувствовать все удобство этого способа.
Упражнение 9-4
Напишите версию printf для командной строки: пусть эта функция ечатает свой второй и последующие аргументы в формате, заданном первом аргументе. Надо отметить, что во многих оболочках имеется строенный аналог такой функции.
Упражнение 9-5
Напишите функцию, реализующую спецификации.формата, .исполь-/емого в какой-нибудь программе работы с электронными таблицами ли в Java-классе Decimal Format, где числа отображаются в соответствии некоторым заданным шаблоном, указывающим количество обязатель-ых и возможных символов, положение десятичной точки и тысячных шятых и т. п. Для иллюстрации рассмотрим строку
##,##0.00
Эта строка задает число с двумя знаками после десятичной точки, э крайней мере одним знаком перед десятичной точкой, запятой в качестве разделителя тысяч и заполняющими пробелами до позиции 10 000. аким образом, число 12345.67 будет представлено как 12, 345. 67, а .4 — ж **,**0.40 (для наглядности вместо пробелов мы вставили звездоч-i). Для получения полной спецификации можете обратиться к описа-«о DecimalFormat или программам работы с электронными таблицами.
Регулярные выражения
Спецификаторы формата для pack и unpack — достаточно простой юсоб записи, описывающий компоновку пакетов. Следующая тема iniero обсуждения — несколько более сложный, но гораздо более фазительный способ записи -- регулярные выражения (regular pressions), определяющие шаблоны текста (patterns of text). В этой [иге мы время от времени использовали регулярные выражения, не вая им точного описания; они достаточно знакомы, чтобы понять их без особых пояснений. Хотя регулярные выражения широко распространены в средах программирования под Unix, в других системах они применяются гораздо реже, поэтому в данном разделе мы решили показать некоторые их преимущества. На случай, если у вас нет под рукой библиотеки с регулярными выражениями, мы приведем ее простейшую реализацию.
Существует несколько разновидностей регулярных выражений, но суть у них у всех одинакова — это способ описания шаблона буквенных символов, включающего в себя повторения, альтернативы и сокращения для отдельных классов символов вроде цифр или букв. Примером такого шаблона могут служить всем знакомые символы замещения (wildcards), используемые в процессорах командной строки или оболочках для задания образцов поиска имен файлов. Как правило, символ * используется для обозначения "любой строки символов", так что команда
С:\> del *.exe
использует шаблон, которому соответствуют все имена файлов, оканчивающиеся на ".-. ехе". Как это часто бывает, детали меняются от системы к системе и даже от программы к программе.
Причуды отдельных программ могут навести на мысль, что регулярные выражения являются механизмом? создаваемым ad hoc, для каждого случая отдельно, но на самом деле регулярные выражения — это язык с формальной грамматикой и точным значением каждого выражения. Более того, при должной реализации конструкция работает очень быстро: благодаря соединению теории и практического опыта; вот пример в пользу специализированных алгоритмов, упоминавшихся нами в главе 2.
Регулярное выражение есть последовательность символов, которая определяет множество образцов поиска. Большинство символов просто-напросто соответствуют сами себе, так что регулярное выражение abc будет соответствовать именно этой строке символов, где бы она ни появлялась. Но, кроме того, существует несколько метасимволов, которые обозначают повторение, группировку или местоположение. В принятых в Unix регулярных выражениях символ ~ обозначает начало строки, а $ — конец строки, так что шаблон ~х соответствует только символу х в начале строки, х$ — только х в конце строки. Шаблону ~х$ соответствует только строка, содержащая единственный символ х, и, наконец, ~$ соответствует пустая строка.
Символ . (точка) обозначает любой символ, так что выражению х. у будут соответствовать хау, х2у и т. п., но не ху или xaby; выражению ~. $ соответствует строка из одного произвольного символа.
Набору символов внутри квадратных скобок соответствует любой ия этих символов. Таким образом, [0123456789] соответствует одной цифре, это выражение можно записать и в сокращенном виде: [0-9]1.
Эти строительные блоки комбинируются с помощью круглых скобок' для группировки, символа | — для обозначения альтернатив, * — для обозначения нуля или более совпадений, + — для обозначения одного или более совпадений и ? — для обозначения нуля или одного совпадения. Наконец, символ \ применяется в качестве префикса перед метасимволом для исключения его специального использования, то есть \* обозначает просто символ *, а \\ — собственно символ обратной косой черты \.
Наиболее известным инструментом работы с регулярными выраже-йийми является программа g rep, о которой мы уже несколько раз упоминали. Эта программа — чудесный пример, показывающий важность нотации. В ней регулярное выражение применяется к каждой строке вводимого файла и выводятся строки, которые содержат образцы поиска, описываемые этим выражением. Эта простая спецификация с помощью регулярных выражений позволяет справиться с большим количеством ежедневной рутинной работы. В приведенных ниже примерах обратите внимание на то, что синтаксис регулярных выражений, используемых в качестве аргументов g rep, отличается от шаблонов поиска, применяемых для задания набора имен файлов; различие обусловлено разным назначением выражений.
Какой исходный файл использует класс Regexp?
% grep Regexp *.java
В каком файле этот класс реализован?
% grep 'class.*Regexp' *.java
Куда я подевал это письмо от Боба?
% grep '"From:.* bob@' mail/*
Сколько непустых строк кода в этой программе?
grep *. с++ 1 we
Благодаря наличию флагов, позволяющих выводить номера соответствующих выражению строк, подсчитывать количество соответствий, осуществлять сравнение без учета регистра, инвертировать смысл выражения (то есть отбирать строки, не соответствующие шаблону) и т. п., программа grep используется сейчас настолько широко, что стала уже классическим примером программирования с помощью специальных инструментов.
К сожалению, не во всех системах имеется grep или ее аналог. Некоторые системы включают в себя библиотеку регулярных выражений, которая называется, как правило, regex или regexp, и ее можно использовать для создания собственной версии g rep. Если же нет ни того, ни другого, то на самом деле не так трудно реализовать какое-то скромное подмножество языка регулярных выражений. Здесь мы представляем реализацию регулярных выражений и grep, чтобы работать с ними; для простоты мы ограничимся метасимволами $ . и * , причем * обозначает повторение предыдущей точки или обычного символа. Выбор этого подмножества обеспечивает почти все возможности регулярных выражений, тогда как его программировать значительно проще, чем в исходном общем случае.
Начнем с самой функции, осуществляющей проверку на соответствие. Ее задача — определить, соответствует ли строка текста регулярному выражению:

Если регулярное выражение начинается с ", то текст должен начинаться
с символов, соответствующих остальной части выражения. При другом начале
мы проходим по тексту, используя matchhere для выяснения, соответствует
ли текст каждой позиции выражения. Как только мы находим соответствие,
миссия наша завершена. Обратите внимание на использование do-while: выражениям
может соответствовать пустая строка (например, шаблону $ соответствует
пустая строка, а шаблону . * — любое количество символов, включая и ноль),
поэтому вызвать matchhere мы должны даже в том случае, если строка текста
пуста.
Большая часть работы выполняется в рекурсивной функции matchhere:

Если регулярное выражение пусто, это означает, что мы дошли до его конца
и, следовательно, нашли соответствие. Если выражение оканчива- i ется
символом $, оно имеет соответствие только в том случае, если текст также
расположен в конце. Если выражение начинается с точки, то первый символ
соответствующего текста может быть любым. В противном случае выражение
начинается с какого-то обычного символа, который) в тексте соответствует
только самому себе. Символы ~ и $, встречающиеся в середине регулярного
выражения, рассматриваются как простые литеральные, а не метасимволы.
Отметьте, что matchhe re, убедившись в совпадении одного символа из; шаблона и подстроки, вызывает себя самое, таким образом, глубина ре] курсии может быть такой же, как и длина шаблона (при полном соответветствии).
Единственный сложный случай представляет собой выражение, начинающееся с символа и звездочки, например х*. В этом случае мы осуществляем вызов matchstar, где первым аргументом является операнд звездочки (то есть х), а следующими аргументами — шаблон после звездочки и сам текст.

Здесь мы опять используем do-while — из-за того, что регулярному выражению
х* может соответствовать и ноль символов. Цикл проверяет, совпадает ли
текст с остатком регулярного выражения, пытаясь сопоставить их, пока первый
символ текста совпадает с операндом звездочки.
Наша реализация получилась довольно простенькой, однако она работает и занимает всего лишь три десятка строк кода — можно утверждать, что для того, чтобы ввести в обращение регулярные выражения, не нужно применять никаких сложных средств.
Скоро мы представим некоторые соображения по расширению возможностей нашего кода, а пока напишем свою версию g rep, использующую match. Вот как выглядит основная часть:

По соглашению программы на С возвращают 0 при успешном заверше-и и ненулевое
значение — при различных сбоях. Наша программа Ф, так же как и Unix-версия,
считает выполнение успешным, если ла найдена строка, соответствующая шаблону.
Поэтому она возвращает 0, если было найдено хотя бы одно соответствие;
1 — если соответ-зий найдено не было, и 2 (посредством eprintf) — если
произошла шбка. Эти значения можно протестировать, использовав в качестве
олочки какую-то другую программу.
Функция grep сканирует один файл, вызывая match для каждой его строки:

Если открыть файл не удается, то программа не прекращает работу. Такое
поведение было выбрано для того, чтобы при вызове
% grep herpolhode *.*
даже если какой-то файл в каталоге не может быть открыт, g rep уведомляла об этом и продолжала работу; если бы на этом она останавливалась, пользователю пришлось бы вручную набивать список всех файлов в каталоге, кроме недоступного. Обратите внимание и на то, что grep выводит имя файла и строку, соответствующую шаблону, однако имя файла не выводится, если чтение происходит из стандартного потока ввода или из одного файла. Может быть, такое поведение покажется кому-то старомодным, однако оно отражает идиоматический стиль, в основе которого лежит опыт. Когда задан только один источник ввода, миссия дгер состоит, как правило, в выборе соответствующих строк, и имя файла никого не интересует. А. вот если поиск происходит в нескольких файлах, то, как правило, задачей является найти все совпадения с какой-то строкой, и здесь имя файла будет весьма информативно. Сравните
% strings markov.exe | grep 'DOS mode'
и
% grep grammer chapter*.txt
Продуманность нюансов — одна из тех черт, что сделали grep столь популярным инструментом; здесь мы видим, что для создания хороших программ нотация обязательно должна учитывать человеческую психологию.
В нашей реализации match завершает работу сразу же, как только найдено соответствие. Для g rep это вполне подходит в качестве поведения по умолчанию, но для реализации оператора подстановки (найти и заменить) в текстовом редакторе больше подошел поиск крайне левого самого длинного совпадения (leftmost longest). Например, если нам задан текст "ааааа", то шаблону а* соответствует, в частности, и пустая строка в начале текста, однако более естественным было бы включить в совпадение все пять а. Для того чтобы match искала крайне левую и самую длинную строку, matchstar надо переписать так, чтобы добиться жадного (greedy) поведения1 алгоритма: вместо того чтобы просматривать каждый символ текста слева направо, он должен каждый раз пытаться пройти до конца самой длинной строки, соответствующей оператору-звездочке, и откатываться назад, если оставшаяся часть обрабатываемого текста не соответствует оставшейся части шаблона. Другими словами, она должна выполняться справа налево. Вот как выглядит версия matchstar, осуществляющая поиск крайне левого максимального совпадения:


Для g rep абсолютно неважно, какое именно совпадение будет обнаруже-ю,
поскольку эта программа проверяет лишь наличие соответствий во-эбще и
выводит всю строку, содержащую соответствие. Таким образом, поиск крайне
левого максимального совпадения, жизненно необходимый для оператора замещения,
хоть и делает некоторую ненужную для g rep работу, все же может быть применен
без изменений и для этой программы.
Наша версия g rep вполне сравнима с версиями, поставляемыми с различными системами (неважно, что синтаксис наших регулярных выражений несколько скуднее). Существуют некоторые патологические выражения, которые приводят к экспоненциальному возрастанию трудоемкости поиска, — например, выражение а*а*а*а*а*Ь при введенном тексте ааааааааас, однако экспоненциальный поиск присутствует и в некоторых коммерческих реализациях. Вариант g rep, применяемый в Unix (он называется eg rep), использует более сложный алгоритм поиска соответствий; этот алгоритм гарантирует линейный поиск, избегая отката, когда не подходит частичное соответствие.
А как насчет того, чтобы match умела обрабатывать полноценные регулярные выражения? Для этого надо добавить возможность сопоставления классов символов типа [a-zA-Z] конкретному символу алфавита, возможность исключать значение метасимволов (например, для поиска точки нужно обозначить этот символ как литеральный), предусмотреть скобки для группировки, а также ввести альтернативы (аос или clef). Первый шаг здесь — облегчить match работу, скомпилировав шаблон в некое новое представление, которое было бы проще сканировать: слишком накладно производить разбор класса символов для каждого нового сравнения его с одним символом; предварительно вычисленное представление, основанное на битовых массивах, сделает классы символов гораздо более эффективными. Полная реализация регулярных выражений, со скобками и альтернативами, получится гораздо более сложной; облегчить написание помогут некоторые средства, о которых мы поговорим далее в этой главе.
Упражнение 9-6
Как соотносится быстродействие match и strstr при поиске простого текста (без метасимволов)?
Упражнение 9-7
Напишите версию matchhere без рекурсии и сравните ее быстродействие с рекурсивной версией.
Упражнение 9-8
Добавьте в g rep несколько ключей командной строки. К наиболее популярным ключам относятся -у для инвертирования смысла шаблона, -i для поиска без учета регистра и ~п для вывода номеров строк. Как должны выводиться номера строк? Должны ли они печататься на той же строке, что и совпавший текст?
Упражнение 9-9
Добавьте в match операторы + (один или более) и ? (ноль или один). Шаблону a+bb? соответствует строка из одного или более а, за которыми следует одно или два b.
Упражнение 9-10
В нашей реализации match специальное значение символов " и $ отключается, если они не стоят, соответственно, в начале или конце выражения, а звездочка * рассматривается как обычный символ, если она не стоит непосредственно после литерального символа или точки. Однако более стандартным поведением является~отключение значения метасимвола постановкой перед ним символа обратной косой черты (\). Измените match так, чтобы она обрабатывала этот символ именно таким образом.
Упражнение 9-11
Добавьте в match классы символов. Класс символов определяет соответствие любому из символов, заключенных в квадратные скобки. Для Удобства лучше ввести диапазоны, например [a-z] соответствует любой строчной букве (английского алфавита!), а также определить способ инвертирования смысла, — например, [~0-9] соответствует любому символу, кроме цифры.
Упражнение 9-12
Измените match так, чтобы в ней использовалась версия matchstar, ( которой ищется крайне левое максимальное соответствие. Кроме того, :ледует добиться возвращения позиции символов начала и конца текста, ;оответствующего шаблону. Теперь создайте новую версию дгер, кото- j рая вела бы себя как старая, но выполняла замену текста, соответству-. ющего шаблону, заданным новым текстом и выводила полученные стро-1 ки. Пример вызова:
grep 'homoiousian' 'homoousian' mission.stmt
Упражнение 9-13
Измените match и дгер так, чтобы они-работали со строками символов Unicode формата UTF-8. Поскольку UTF-8 и Unicode являются расширением набора 7-битового ASCII, такое изменение будет совместимо с предыдущей версией. Регулярные выражения, так же как и текст, в котором происходит поиск, должны корректно работать с UTF-8. Как в этом случае должны быть реализованы классы символов?
Упражнение 9-14
Напишите программу для автоматического тестирования регулярных выражений: она должна генерировать тестовые выражения и строки, в которых будет происходить поиск. Если можете, используйте уже существующую библиотеку как прототип для ответов, — возможно, вы найдете какие-то ошибки и в ней.
Программируемые инструменты
Множество инструментов группируется вокруг языков специального.'! назначения. Программа g rep — всего лишь одна из целого семейства инструментов, которые используют регулярные выражения или другие языки для разрешения программистских проблем.
Одним из первых подобных инструментов стал командный интерпретатор, или язык управления заданиями. Достаточно быстро стало понятно, что последовательность команд можно поместить в отдельный файл, а потом запустить экземпляр интерпретатора команд, или оболочки /(shell), указав этот файл в качестве источника ввода. Следующим шагомстало уже добавление параметров, условных выражений, циклов, переменных и т. п., то есть всего того, из чего в нашем представлении состоит нормальный язык программирования. Единственное отличие заключалось в том, что существовал только один тип данных — строки, а операторами в программах-оболочках являлись различные программы, осуществлявшие порой достаточно интересные вычисления. Несмотря на то что программирование под конкретные оболочки сейчас уже уходит в прошлое, уступая место работе с инструментами типа Perl в командных средах или щелканью по кнопкам в графических средах, этот "старинный" подход по-прежнему остается простым и достаточно эффективным способом создания каких-то сложных операций из простых частей.
Еще один программируемый инструмент, Awk, представляет собой небольшой специализированный язык, который предназначен для отбора и преобразования элементов входного потока; он ищет в этом потоке соответствия заданным шаблонам, а когда находит, то выполняет связанные с шаблонами действия. Как мы уже видели в главе 3, Awk автоматически читает входные файлы и разделяет каждую прочитанную строку на поля, обозначаемые от $1 до $NF, где NF есть количество полей в строке. Его поведение "по умолчанию" удобно для выполнения большого числа типовых действий, поэтому многие полезные программы пишутся на Awk в одну строчку. Так, например, программа
# split.awk: расщепляет текст на отдельные слова { for (i = 1; i <=
NF; i+3-) print $i }
выводит "слова" по одному в строке. И напротив, вот программа f mt, которая заполняет каждую выводимую строку словами (до 60 символов); пустая строка означает конец параграфа:


Мы часто используем f mt для того, чтобы заново разбить на абзацы почтовые
сообщения и другие короткие документы; ее же мы использовали главе 3 для
форматирования вывода программы markov.
Программируемые инструменты часто берут свое начало от малых ыков программирования, созданных для более простого выражения шений проблем в какой-то узкой предметной области. Прелестным шмером является инструмент Unix под названием eqn, который обра-тывает математические формулы. Язык, применяемый в нем для вво-., очень похож на обычный: например, выражение f мы прочитали бы лух как "пи на два" (pi over two), и в этом языке оно так и записывается - pi over 2. Тот же подход применяется и в ТЕХ, в нем это выраже-ie было бы записано как \pi \over 2. Если для проблемы, которую вы пытаетесь разрешить, уже существует естественный или привычный :особ записи, используйте его или, на худой конец, попробуйте его дотировать: не пытайтесь писать с нуля.
Awk развился из программы, которая использовала регулярные выражения для выявления аномалий в записях телефонного трафика; теперь же] ffk содержит в себе переменные, выражения, циклы и т. п., — и это делает о полноценным языком программирования. Perl и Tel первоначально проектировались с целью совместить удобство и выразительность малых ыков с мощью полноценных языков программирования. В результате получились действительно удобные языки программирования общего назначения, хотя, конечно, чаще всего их используют для обработки текста.
Для подобных инструментов применяют общий термин — языки скрип-~>в
(scripting languages). Такое название объясняется их происхождением
ранних командных интерпретаторов, вся "программируемость" ко-рых
ограничивалась исполнением заранее записанных "сценариев" cript)
программ. Языки скриптов позволяют использовать регулярные выражения более
творчески: не только для поиска соответствий шаблону — простого обнаружения
соответствия, но и для определения участ-iB текста, которые должны быть
изменены. Именно это осуществляется в двух командах regsub (от regular
expression substitution — замена с помощью регулярных выражений), реализованных
в приводимой ниже программе на языке Tel. Программа эта является несколько
более общей фор-)й программы из главы 4, получающей биржевые котировки;
новая версия выполняет это, получая данные из URL, передаваемого ей в
качестве первого аргумента. Первая замена удаляет строку http://, если
она присутствует; вторая — удаляет символ / и заменяет его пробелом, разбивая,
таким образом, аргумент на два поля. Команда lindex получает поля из строки
(начиная с индекса 0). Текст, заключенный в квадратные скобки, выполняется
как команда Tel и заменяется результирующим текстом; последовательность
$х заменяется значением переменной х.

Этот скрипт, как правило, производит весьма объемистый вывод, большую
часть которого составляют тэги HTML, заключенные между < и >. Perl
удобен для текстовых подстановок, так что нашим следующим инструментом
станет скрипт на Perl, который использует регулярные выражения и подстановки
для удаления тэгов:

Для тех, кто не знаком с Perl, этот код будет загадкой. Конструкция
$str =" s/regexp/repl/g
строке str подставляет строку repl вместо текста, соответствующего регулярному выражению readexp (берется крайне левое максимальное соответствие); завершающий символу (от "global") означает, что действия надо произвести глобально, для всех найденных соответствий, и не только для первого. Последовательность метасимволов \s является сокращенным обозначением символа пустого места (пробел, знак табуляции, символ перевода строки и т. п.); Это означает перевод строки. Строка " " — это символ HTML, как и те, о которых мы упоминали I главе 2, он означает non-breakable space — неразрывный пробел.
Собрав все написанное воедино, мы получим совершенно идиотский, но функционирующий web-браузер, реализованный как скрипт командного интерпретатора, состоящий из одной строки:

Такой вызов получит web-страницу, отбросит все управление и форма-гирование
и отформатирует текст по своим собственным правилам. Получился быстрый
способ достать страницу текста из web.
Отметьте, что мы неспроста использовали сразу несколько Жыков (Tel, Perl, Awk) и в каждом из них — регулярные выражения. Собственно говоря, мощь различных нотаций и состоит как раз в подборе наилучшего варианта для каждой проблемы. Teм особенно хорош для получения текста из сети, Perl и Awk прекрасно редактируют и форматируют текст, а регулярные выражения — отличный способ определения фрагментов текста, которые должны быть найдены и изменены. Объединение всех этих языков получается гораздо более мощным, чем любой из них в отдельности. Целесообразно разбить задачу на части, если можнс выиграть за счет составления правильной нотации в каждой из них.
Интерпретаторы, компиляторы и виртуальные машины
Какой путь проходит программа от исходного кода до исполнения? Если язык достаточно прост, как в printf или в наших простейших регулярных выражениях, то исполняться может сам исходный код. Это несложно; таким образом можно запускать программу сразу же по написании.
Нужно искать компромисс между временем на подготовку к запуску и скоростью исполнения. Если язык не слишком прост, то для исполнения желательно преобразовать исходный код в некое приемлемое и эффективное внутреннее представление. На это начальное преобразование исходного кода тратится определенное время, но оно вполне окупается более быстрым исполнением. Программы, в которых преобразование и исполнение объединены в один процесс, читающий исходный текст, преобразующий его и его исполняющий, называются интерпретаторами (interpreter). Awk и Perl, как и большая часть других языков скриптов и языков специального назначения, являются именно интерпретаторами.
Третья возможность — генерировать инструкции для конкретного типа компьютера, на котором должна исполняться программа; этим занимаются компиляторы. Такой подход требует наибольших затрат времени на подготовку, однако в результате ведет и к наиболее быстрому последующему исполнению.
Существуют и другие комбинации. Одна из них — мы рассмотрим ее подробно в данном разделе — это компиляция программы в инструкции для воображаемого компьютера (виртуальной машины — virtual machine), который можно имитировать на любом реальном компьютере. Виртуальная машина сочетает в себе многие преимущества обычной интерпретации и компиляции.
Если язык прост, то какой-то особо большой обработки для определения структуры программы и преобразования ее во внутреннюю форму не требуется. Однако при наличии в языке каких-то сложных элементов — определений, вложенных структур, рекурсивно определяемых выражений, операторов с различным приоритетом и т. п. — провести синтаксический разбор исходного текста для определения структуры становится труднее.
Синтаксические анализаторы часто создаются с помощью специальных автоматических генераторов, называемых также компиляторами компиляторов (compiler-compiler), таких как уасс или bison. Подобные программы переводят описание языка, называемое его грамматикой, как правило, в программу на С или C++, которая, будучи однажды скомпилирована, переводит выражения языка во внутреннее представление. Конечно же, генерация синтаксического анализатора непосредственно из грамматики языка является еще одной впечатляющей демонстрацией мощи хорошей нотации.
Представление, создаваемое анализатором, — это обычно дерево, в котором внутренние вершины содержат операции, а листья — операнды. Выражение
а = max(b, с/2);
эжет быть преобразовано в такое синтаксическое дерево:
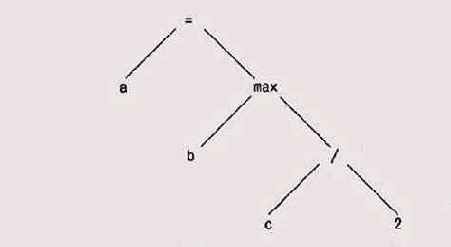
Многие из алгоритмов работы с деревьями, описанных в главе 2, вполне]
огут быть применимы для создания и обработки синтаксических деревьев.
После того как дерево построено, обрабатывать его можно множе- j гвом способов. Наиболее прямолинейный метод, применяемый, кста-1 я, в Awk, — это прямой обход дерева с попутным вычислением узлов. | 'прощенная версия алгоритма такого вычисления для языка, основанного на целочисленных выражениях, может включать в себя восходя-] щи обход типа такого:


Первые несколько выражений case вычисляют простые выражения вроде констант
или значений; следующие вычисляют арифметические выражения, а дальше может
идти обработка специальных случаев, условных выражений и циклов. Для реализации
управляющих структур нашему дереву потребуется не показанная здесь дополнительная
информация, которая представляет собой поток управления.
Подобно тому, как мы делали в pack и unpack, здесь можно заменить явный переключатель таблицей указателей на функции. Отдельные операции при этом будут выглядеть практически так же, как и в варианте с переключателем:

Таблица указателей сопоставляет операции и функции, выполняющие операции:

Вычисление использует операции для индексирования в таблице указа-1бй
на функции для вызова этих функций; в этой версии другие функ-и вызываются
рекурсивно.

Обе наши версии eval применяют рекурсию. Существуют способы уст-нить ее
— в частности, весьма хитрый способ, называемый шитым кодом ireaded code),
который практически не использует стек вызовов. Самым ящным способом избавления
от рекурсии будет сохранение функций в 1ссиве, с последующим выполнением
этих функций в записанном поряд-:. Таким образом, этот массив становится
просто последовательностью гструкций, исполняемых некоторой специальной
машиной.
Для представления частично вычисленных значений из нашего выра-ения мы, так же как и раньше, будем использовать стек, так что, не-ютря на изменение формы функций, преобразования отследить будет трудно. Фактически мы изобретаем некую стековую машину, в которой инструкции представлены небольшими функциями, а операнды хранятся в отдельном стеке операндов. Естественно, это не настоящая машина, но мы можем писать программу так, как будто подобная машина все же существует: в конце концов, мы можем без труда реализовать ее в виде интерпретатора.
При обходе дерева вместо подсчета его значения мы будем генерировать массив функций, исполняющих программу. Массив будет также содержать значения данных, используемых командами, такие как константы и переменные (символы), так что тип элементов массива должен быть объединением:

Ниже приведен блок кода, генерирующий указатели на функции и помещающий
их в специальный массив code. Возвращаемым значением функции generate
является не значение выражения — оно будет подсчитано только после выполнения
сгенерированного кода, — а индекс следующей операции в массиве code, которая
должна быть сгенерирована:


Для выражения а - max( b , с/2 ) сгенерированный код будет выглядеть так:

Функции-операции управляют стеком, извлекая из него операнды и за-ружая
результаты.
Код интерпретатора организован в виде цикла, в котором командный :четчик рс обходит массив указателей на фрикции:


Этот цикл моделирует в программном виде на изобретенной нами стековой
машине то, что происходит на самом деле в настоящем компьютере:

Обратите внимание на то, что проверка делимого на ноль осуществляется
в divop, а не в generate.
Условное исполнение, ветвление и циклы модифицируют счетчик программы внутри функции-операции, осуществляя тем самым доступ к массиву функций с какой-то новой точки. Например, операция goto всегда переустанавливает значение переменной рс, а операция условного ветвления — только в том случае, если условие есть истина.
Массив code является, естественно, внутренним для интерпретатора, однако представим себе, что нам захотелось сохранить сгенерированную программу в файл. Если бы мы записывали адреса функций, то результат получился бы абсолютно непереносимым, да и вообще ненадежным. Однако мы могли бы записывать константы, представляющие функции, например 1000 для addop, 1001 для pushop и т. д., и переводить их обратно в указатели на функции при чтении программы для интерпретации.
Если внимательно посмотреть на файл, который создает эта процеду-, можно понять, что он выглядит как поток команд виртуальной машины. Эти команды реализуют базовые операции нашего рабочего языка, рункция generate — это компилятор, транслирующий язык на вирту-. ьную машину. Виртуальные машины — стародавняя идея, обретшая госледнее время новую популярность благодаря Java и виртуальной шгане Java (Java Virtual Machine, JVM); виртуальные машины предо-авляют простой способ создавать переносимые и эффективные реали-, ции программ, написанных на языках высокого уровня.
Программы, которые пишут программы
Возможно, самым примечательным в функции generate является то, о она представляет собой программу, которая пишет другую програм-г. ее вывод есть поток исполнимых команд для другой (виртуальной) шшны. Собственно, подобная идея нам привычна, именно это делают е компиляторы, только команды они генерируют для реальных ма-ин. На самом деле формы, в которых появляются программы, пишу- \ ие программы, очень разнообразны.
Один обычный пример дает динамическая генерация HTML для web-раниц. HTML — это язык, хоть и достаточно ограниченный; кроме то, в себе он может содержать и код JavaScript. Web-страницы часто нерируются "на лету" программами на Perl или С, содержание таких раниц (например, результаты поиска или реклама, нацеленная на определенную аудиторию) зависит от приходящих запросов. Мы использовали специализированные языки для графиков, картинок, таблиц, математических выражений и индекса этой книги. Еще одним примером эжет служить PostScript — язык программирования, тексты на котором создаются текстовыми процессорами, программами рисования и множеством других источников; на финальном этапе обработки книга, которую вы держите в руках, представлена как программа на PostScript, держащая 57 000 строк.
Документ — это статическая программа, однако идея использования языка программирования как способа записи любой проблемы является весьма многообещающей. Много лет назад программисты мечтали о том, что компьютеры когда-нибудь смогут сами писать для себя программы, энечно же, эта мечта никогда не осуществится в полной мере, однако годня можно сказать, что машины нередко пишут программы за нас и иногда в таких областях, где совсем недавно это трудно было себе представить.
Наиболее распространенные программы, создающие программы, — это компиляторы, которые переводят программу с языка высокого уровня в машинный код. Однако нередко оказывается удобным переводить код программы сначала на один из широко известных языков высокого уровня. В предыдущем параграфе мы упоминали о том, что генератор синтаксического анализатора преобразует определение грамматики языка в программу на С, которая и занимается синтаксическим разбором языка. Язык С достаточно часто используется подобным образом -в качестве "языка ассемблера высокого уровня". Modula-З и C++ относятся к тем языкам общего назначения, для которых первые компиляторы создавали код на С, обрабатывавшийся затем уже стандартным компилятором. У такого подхода есть ряд преимуществ — одним из главных является эффективность, поскольку получается, что в принципе программа может выполняться так же быстро, как и программы на С. Еще один плюс — переносимость: такие компиляторы могут быть перенесены на любую систему, имеющую компилятор С. Подобный подход сильно помог этим языкам на ранних стадиях их внедрения.
В качестве еще одного примера возьмем графический интерфейс Visual Basic. Он генерирует набор операторов присваивания Visual Basic для инициализации объектов. Этот набор пользователь выбирает из меню и располагает на экране с по'мощью мыши. Во множестве других языков есть "визуальная" среда разработки и "мастера" (wizard), которые синтезируют код пользовательского интерфейса по щелчку мыши.
Несмотря на мощь программ-генераторов и на большое количество примеров их удачного применения, этот подход еще не признан так широко, как он того заслуживает, и нечасто используется программистами. Однако существует уйма простых возможностей программного создания кода, и вы вполне можете использовать их преимущества. Ниже приведены несколько примеров генерации кода на С или C++.
Операционная система Plan 9 генерирует сообщения об ошибках по заголовочному файлу, содержащему программные имена ошибок и комментарии к ним; эти комментарии механически конвертируются в строки, заключенные в кавычки, они помещаются в массив, который может быть индексирован перечислимым значением. В приведенном ниже фрагменте показана структура такого заголовочного файла:


Имея такой фрагмент на входе, несложная программа сможет произнес* и следующий
набор деклараций для сообщений об ошибках:

У такого подхода есть несколько достоинств. Во-первых, соотношение лежду
значениями enum и строками, которые они представляют, получается самодокументированным,
и его нетрудно сделать независимым от роднoro языка пользователя. Во-вторых,
информация хранится только в однтом месте, в одном "истинном месте",
из которого генерируется весь эстальной код, так что и всё обновление
информации выполняется лишь в одном месте. В случае, когда таких мест
несколько, после ряда обновлений они неизбежно начнут друг другу противоречить.
И наконец, нетрудно сделать так, чтобы файлы программ на С создавались
заново и перекомпилировались при каждом изменении заголовочного файла.
Когда потребуется изменить сообщение об ошибке, все, что надо будет сделать,
— это изменить заголовочный файл и компилировать таким способом операционную
систему, и тогда сообщения автоматически обновятся.
Программа-генератор может быть написана на любом языке. Особенно просто это сделать на языке, специально предназначенном для обработки строк, таком как Perl:

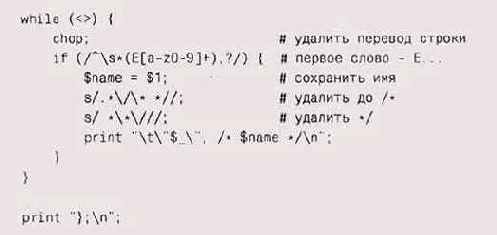
Опять в дело пошли регулярные выражения. Выбираются строки, у которых
первое поле выглядит как идентификатор, после которого стоит запятая.
Первая замена удаляет все символы до первого непустого символа строки
комментария, а вторая — символы конца комментария и все предшествующие
им пробелы.
Среди прочих способов для тестирования компилятора Энди Кёниг (Andy Koenig) разработал метод написания кода C++, позволяющий проверить, нашел ли компилятор ошибки в программе. Фрагменты кода, которые должны вызвать реакцию компилятора, снабжаются специальными комментариями, в которых описываются ожидаемые сообщения. Каждая строка такого комментария начинается с /// (чтобы их можно было отличить от обычных комментариев) и регулярного выражения, которое должно соответствовать диагностике компилятора, выдаваемой для этой строки. Таким образом, например, следующие два фрагмента кода должны вызвать реакцию компилятора:
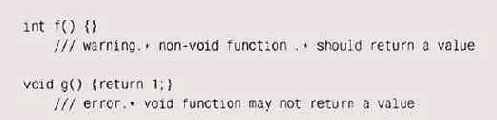
Если мы пропустим второй тест через компилятор C++, то он напечатает ожидаемое
сообщение, вполне соответствующее регулярному выражению:
% СС х.с
"х.с", line 1: error(321): void function may
not return a value
Каждый такой фрагмент кода пропускается через компилятор, и вывод сравнивается с прогнозируемой диагностикой, этим процессом управляет схемная оболочка и программа на Awk. Сбоем считается ситуация, гда вывод компилятора не совпадает с ожидаемым. Поскольку комментарии представлены регулярными выражениями, у них получается которая свобода в оценке вывода: ее можно делать более или менее эогой к отклонениям в зависимости от надобности.
Идея использования семантических комментариев не нова. Такие комментарии используются в языке PostScript, где они начинаются с символа %. Комментарии, начинающиеся с %%, могут содержать дополнительную информацию о номерах страниц, окаймляющем прямоугольнике ounding Box), именах шрифтов и т. п.:

В языке Java комментарии, которые начинаются с /** и заканчиваются */,
пользуются для создания документации для следующего за ними опи-НЕИЯ класса.
Глобальным вариантом самодокументации кода является к называемое грамотное
программирование (literate programming), и котором программа и ее документация
интегрируются в один доку-нт, и при одной обработке документ готовится
для чтения, а при дру-й программа готовится к компиляции.
Во всех рассмотренных выше примерах важно отметить роль нотации, смерения языков и использования инструментов. Их комбиниро-ние усиливает и подчеркивает мощь отдельных компонентов.
Упражнение 9-15
В программировании давно известна забавная задачка: написать про-шму, которая при выполнении точно воспроизводила бы саму себя — в виде исходного кода. Это такой гипертрофированный случай программы, пишущей программу. Попробуйте выполнить это — на своем любимом языке.
Использование макросов для генерации кода
Опустившись на пару уровней, можно говорить о макросах, которые шут код во время компиляции. На протяжении всей книги мы предостегали вас от использования макросов и условной компиляции, по-зльку этот стиль программирования вызывает множество проблем, щако же они все равно существуют, и иногда текстуальная подстановка — это именно то, что нужно для решения данной проблемы. Один из таких примеров - использование препроцессора C/C++ для компоновки программы с большим количеством повторяющихся частей.
Например, программа из главы 7, оценивающая скорость конструкций простейшего языка, использует препроцессор С для компоновки тестов, составляя из них последовательность стереотипных кодов. Суть теста — заключить фрагмент кода в цикл, который запускает таймер, выполняет этот фрагмент много раз, останавливает таймер и сообщает о результатах. Весь повторяющийся код заключен в пару макросов, а измеряемый код передается в качестве аргумента. Первичный макрос имеет такой вид:

Обратная косая черта (\) позволяет записывать тело макроса в нескольких
строках. Этот макрос используется в "операторах", которые имеют
такой вид:
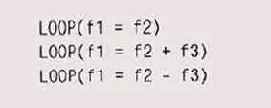
Для инициализации иногда применяются и другие операторы, но основная часть,
производящая замеры, представлена в этих одноаргументных фрагментах, которые
преобразуются в значительный объем кода.
Иногда макросы могут использоваться и для генерации нормального коммерческого
кода. Барт Локанти (Bart Locanthi) однажды написал эффективную версию
оператора двумерной графики. Этот оператор, называемый bitblt, или rasterop,
трудно было сделать быстрым, поскольку он использовал большое количество
аргументов, которые могли комбинироваться самыми хитрыми способами. Проведя
тщательный разбор вариантов, Локанти уменьшил комбинации до независимых
циклов, которые можно было оптимизировать по отдельности. Затем каждый
случай был воссоздан с помощью макроподстановки, аналогичной той, что
показана в примере на тестирование производительности, и все варианты
были перебраны в одном большом выражении switch. Оригинальный исходный
код представлял две-три сотни строк, после выполнения макроподстановок
он разрастался до многих тысяч строк. Этот конечный код был не самым оптимальным,
но, учитывая сложность задачи, весьма
эактйчным и простым в написании. И кстати, как и весь код самого вы-iKoro
уровня, неплохо переносимым.
Упражнение 9-16
В упражнении 7-7 вам предлагалось написать программу, оценивающую траты на различные операции в C++. Используя идеи, изложенные в последнем параграфе, попробуйте написать новую версию этой программы.
Упражнение 9-17
В упражнении 7-8 надо было построить модель оценки затрат для tva, а в этом языке нет макросов. Попробуйте решить эту проблему, написав другую программу — на любом другом языке (или языках), которая создавала бы Java-версию и автоматизировала бы запуск тестов на эоизводительность.
Компиляция "на лету"
В предыдущем разделе мы говорили о программах, которые пишут программы. В каждом примере программы генерировались в виде исходного ада и, стало быть, для запуска должны были быть скомпилированы или нтерпретированы. Однако возможно сгенерировать код, который можно шускать сразу, создавая машинные инструкции, а не исходный текст, акой процесс известен как компиляция "налету" (on the fly) или "как раз :вовремя" (just in time); первый термин появился раньше, однако последний — включая его акроним JIT — более популярен.
Очевидно, что скомпилированный код по определению получается епереносимым — его можно запустить только на конкретном типе процессора, зато он может получиться весьма скоростным. Рассмотрим такое выражение:
max (b, c/2)
Здесь нужно вычислить с, поделить его на 2, сравнить результат с b и вы-рать большее из значений. Если мы будем вычислять это выражение, используя виртуальную машину, которую мы в общих чертах описали в начале этой главы, то хотелось бы избежать проверки деления на ноль в divop: поскольку 2 никогда не. будет нулем, такая проверка попросту бессмысленна. Однако ни в одном из проектов, придуманных нами для реализации этой виртуальной машины, нет возможности избежать этой проверки — во всех реализациях операции деления проверка делителя на ноль осуществляется в обязательном порядке.
Вот здесь-то нам и может помочь динамическая генерация кода. Если мы будем создавать непосредственно код для выражения, а не использовать предопределенные операции, мы сможем исключить проверку деления на ноль для делителей, которые заведомо отличны от нуля. На самом деле мы можем пойти еще дальше: если все выражение является константой, как, например, тах(3*3, 2/2), мы можем вычислить его единожды, при генерации кода, и заменять константой-значением, в данном случае числом 9. Если такое выражение используется в цикле, то мы экономим время на его вычисление при каждом проходе цикла. При достаточно большом числе повторений цикла мы с лихвой окупим время, потраченное на дополнительный разбор выражения при генерации кода.
Основная идея состоит в том. что способ записи позволяет нам вообще выразить суть проблемы, а компилятор для выбранного способа записи может специально оптимизировать код конкретного вычисления, Например, в виртуальной машине для регулярных выражений у нас, скорее всего, будет оператор для сравнения с символом:

Однако, когда мы генерируем код для конкретного шаблона, значение этого
literal фиксировано, например ' х ' , так что мы можем вместо показанного
выше сравнения использовать оператор вроде следующего:

И затем, вместо того чтобы предварительно определять специальный оператор
для значения каждого символа-литеры, мы можем поступить проще: генерировать
код для операторов, которые нам будут действительно нужны для данного
выражения. Применив эту идею для полного набора операторов, мы можем написать
JlT-компилятор, который будет анслировать заданное регулярное выражение
в специальный код, оп-мизированный именно под это выражение.
Кен Томпсон (Ken Thompson) именно это и сделал в 1967 году для реализации регулярных выражений на машине IBM 7094. Его версия генерировала в двоичном коде небольшие блоки команд этой машины для разных операторов выражения, сшивала их вместе и затем запускала шучившуюся программу, просто вызвав ее, совсем как обычную функцию. Схожие технологии можно применить для создания специфических юледовательностей команд для обновлений экрана в графических системах, где может быть так много различных случаев, что гораздо более эффективно создавать динамический код для каждого из них, чем расписать с все заранее или включить сложные проверки в более общем коде.
Демонстрация того, что же включает в себя создание полноценного Т-компилятора, неизбежно вынудит нас обратиться к деталям конкретных наборов команд, однако все же стоит потратить некоторое время, гобы на деле понять, как работает такая система. В оставшейся части :ого параграфа для нас важно будет понимание сути, идеи происходя-,его, а не деталей конкретных реализаций.
Итак, вспомним, в каком виде мы оставили нашу виртуальную маши-у, — структура ее выглядела примерно так:
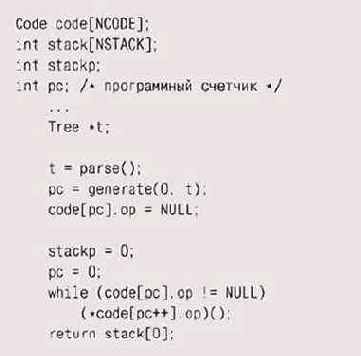
Для того чтобы адаптировать этот код для JIT-компиляции, в него [адо внести
некоторые изменения. Во-первых, массив code будет теперь» re массивом
указателей на функции, а массивом исполняемых команд.
Будут ли эти команды иметь тип char, int или long — зависит только от того процессора, под который мы компилируем; предположим, что это будет int. После того как код будет сгенерирован, мы вызываем его как функцию. Никакого виртуального счетчика команд программы в новом коде не будет, поскольку обход кода за нас теперь будет выполнять собственно исполнительный цикл процессора; по окончании вычисления результат будет возвращаться — совсем как в обычной функции. Далее, мы можем выбрать — поддерживать ли нам отдельный стек операндов для нашей машины или воспользоваться стеком самого процессора. У каждого из этих вариантов есть свои преимущества; мы решили остаться верными отдельному стеку и сконцентрироваться на деталях самого кода. Теперь реализация выглядит таким образом:

После того как generate завершит работу, gen return вставит команды, которые
обусловят передачу управления от сгенерированного кода к eval.
Функция f lushcaches отвечает за шаги, необходимые для подготовки процессора к запуску свежесозданного кода. Современные машины работают быстро, в частности благодаря наличию кэшей для команд и данных, а также конвейеров (pipeline), которые отвечают за выполнение сразу нескольких подряд идущих команд. Эти кэши и конвейеры исходят из предположения, что код не изменяется; если же мы генерируем этот код непосредственно перед запкуском, топроцессор может оказаться в затруднении: ему нужно обязательно очистить свой конвейер и кэши для исполнения новых команд. Эти операции очень сильно зависят от энкретного компьютера, и, соответственно, реализация f lushcaches будет в каждом случае совершенно уникальной.
Замечательное выражение (void (*)(void)) code преобразует адрес :ассива, содержащего сгенерированные команды, в указатель на функцию, который можно было бы использовать для вызова нашего кода.
Технически не так трудно сгенерировать сам код, однако, конечно, для ого чтобы сделать это эффективно, придется позаниматься инженерной .еятельностью. Начнем с некоторых строительных блоков. Как и раньше, [ассив code и индекс внутри него заполняются во время компиляции. Для [ростоты мы повторим свой старый прием — сделаем их оба глобальными. Затем мы можем написать функцию для записи команд:

Сами команды могут определяться макросами, зависящими от процессора, или
небольшими функциями, которые собирали бы код, заполняя поля в командном
слове инструкции. Гипотетически мы могли бы завести функцию pop reg, которая
бы генерировала код для выталкивания значения из стека и сохраняла его
в регистре процессора, и функцию push reg, которая бы генерировала код
для получения значения, хранящегося в регистре процессора, и заталкивания
его в стек. Наша обновленная функция addop будет использовать некие их
аналоги, применяя некоторые предопределенные константы, описывающие команды
(вроде ADDINST) и их расположение (различные позиции сдвигов SHIFT, которые
определяют формат командного слова):
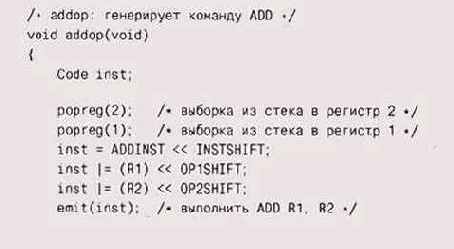

Это, однако, только самое начало. Если бы мы писали настоящий JIT-ком-пилятор,
нам бы пришлось заняться оптимизацией. При прибавлении константы нам нет
нужды грузить ее в стек, вынимать оттуда и после этого прибавлять: мы
можем прибавить ее сразу. Должное внимание к подобным случаям помогает
избавиться от множества излишеств. Однако даже в теперешнем своем виде
функция addop будет выполняться гораздо быстрее, чем в наших более ранних
версиях, поскольку различные операторы уже не сшиты воедино вызовами функций.
Вместо этого код, исполняющий их, располагается теперь в памяти в виде
единого блока команд, и для нас все сшивается непосредственно счетчиком
команд процессора.
Теперешняя реализация функции generate выглядит весьма похоже на реализацию виртуальной машины, но на этот раз она задает реальные машинные команды вместо указателей на предопределенные функции. Чтобы генерировать более эффективный код, следовало бы потратить усилия на избавление от лишних констант и другие виды оптимизации.
В нашем ураганном экскурсе в генерацию кода мы бросили лишь самый поверхностный взгляд на некоторые из технологий, применяемых в настоящих компиляторах, некоторые же вообще обошли молчанием. При этом мы лишь попутно затронули ряд аспектов, связанных со сложностью организации современных процессоров. Но мы показали, как программа может анализировать описание проблемы, чтобы создать специальный код, который наиболее эффективен для конкретной задачи. Изложенные выше идеи вы можете использовать для создания быстрой версии grep, для реализации небольшого языка программирования имени себя, для проектирования и создания виртуальной машины,' оптимизированной для решения специфических задач, или даже для создания компилятора для какого-нибудь интересного языка.
Между регулярным выражением и программой на C++ есть, конечно, немалая разница, но суть у них одна — это всего лишь нотации для решения проблем. При правильной нотации многие проблемы становятся гораздо более простыми. А проектирование и реализация выбранной нотации может дать массу удовольствия.
Упражнение 9-18
JIT-компилятор сгенерирует более быстрый код, если сможет заменить выражения,
содержащие только константы, такие как тах(3*3, 4/2), их значением. Опознав
такое выражение, как он должен вычислять его значение?
Упражнение 9-19
Как бы вы тестировали JIT-компилятор?
Дополнительная литература
В книге Брайана Кернигана и Роба Пайка "The Unix Programming nvironment" (Brian Kernighan, Rob Pike. The Unix Programming nvironment. Prentice Hall, 1984) широко обсуждается инструментальный подход к программированию, который так хорошо поддерживается! Unix. В восьмой главе ее содержится полная реализация — от грамматики уасс до выполнимого кода — простого языка программирования.
Дон Кнут в своей книге "ТЕХ: The Program" (Don Knuth. TEX: The\ rogram. Addison-Wesley, 1986) описывает этот сложнейший текстовый эоцессор, приводя всю программу целиком — около 13 000 строк на ascal — в стиле "грамотного программирования", при котором пояснения жбинируются с текстом программы, а для форматирования документами и выделения соответствующего кода используются соответствующие эограммы. То же самое для компилятора ANSI С проделано у Криса Фрейзера и Дэвида Хэнсона в книге "A Retargetable С Compiler" (Chris raser, David Hanson. Л Retargetable С Compiler. Addison-Wesley, 1995).
Виртуальная машина Java описана в книге Тима Линдхольма и Франк Еллина "Спецификация виртуальной Java-машины", 2-е издание fim Lindholm, Frank Yellin. The Java Virtual Machine Specification. 2"d ed. ddison-Wesley, 1999).
Кен Томпсон (Ken Thompson) описал свой алгоритм (это один из самых первых патентов в области программного обеспечения) в статье legular Expression Search Algorithm" в журнале Communications of the CM (11, 6, p. 419-422, 1968). Работа с регулярными выражениями весьма подробно освещена в книге Джеффри Фридла "Mastering Regular xpressions" (Jeffrey Friedl. Mastering Regular Expressions. O'Reilly, 1997).
JIT-компилятор для операций двумерной графики описан в статье эба Пайка, Барта Локанти (Bart Locanthi) и Джона Рейзера CJonn eiser) "Hardware/Software Tradeoffs for Bitmap Graphics on the Blit", губликованной в Software — Practice and Experience (15, 2, p. 131-152, ;bruary 1985).