Модификации традиционной архитектуры
После того, как выяснилось, что традиционная архитектура препятствует повышению производительности, она стала изменяться. Ниже приведены самые распространенные ее модификации:
Вводятся ячейки внутри процессора со специальной адресацией, не требующие обращения к памяти. С их помощью можно уменьшать адресность команд машины, передавать промежуточные результаты вычислений от команды к команде, выполнять иные локальные действия. Они называются быстрыми регистрами процессора.
Появляются команды, кодирующие довольно сложные действия над операндами.
Процессор снабжается памятью для команд (кэш команд) и для данных (кэш данных). Кэш команд заполняется одновременно с выполнением текущей команды теми командами, которые, как кажется процессору, будут выполняться после текущей. В кэш данных дублируются значения, которые, как кажется процессору, будут операндами следующих команд.
Память разбивается по уровням доступа: регистры процессора; область быстрого доступа с непосредственной адресацией; область, адресация которой требует предварительного указания некоторого сегмента, ячейки которого адресуются непосредственно, и т. д.
Полезность подобных модификаций очевидна. Но кэширование, прочие изменения классической канонической модели, и даже многопроцессорность, - это лишь полумеры, позволяющие расширить, но никак не ликвидировать узкое место.
Внимание!
Важным следствием традиционной структуры компьютера является следующее: в машинной программе все действия и условия локальны.
Для повышения эффективности в оборудовании порой отказываются от принципа однородности памяти. Упомянем две архитектурные модификации традиционной машины.
В некоторых (в первую очередь специализированных) машинах предусмотрено явное выделение в памяти областей данных и областей команд. В обычном режиме выполнения программ процессору не разрешается записывать что-либо в область команд, в результате повышается надежность программ. Для записи чего-либо в область команд нужно аппаратно включить соответствующий режим4).
Но разделение между командами и данными достаточно грубое. Полезно рассмотреть архитектуру, в которой предлагается так называемое тегирование. Смысл его заключается в том, что в ячейках (основной памяти) выделены специальные разряды, именуемые тегом, которые указывают тип хранимого в остальной части значения (см. рис. 2.2).

Рис. 2.2. Структура ячейки при тегировании
Тегирование, реализованное аппаратно, дает следующие преимущества.
На аппаратном уровне происходит дополнительный контроль корректности вычислений и улучшается диагностика ошибок. Элементарные операции становятся более адекватными данным (например, сложение модифицируется в соответствии с типами операндов: целые, действительные, ссылки). Время выполнения программ сокращается по сравнению с традиционными машинами соответствующей мощности.
В языковых терминах тегирование выражается как динамическая (определяемая при выполнении программы) типизация данных. В этом отношении тегирование в аппаратуре лет на десять опередило первые экспериментальные попытки динамической типизации в языках программирования. Сейчас динамическая типизация, с логической точки зрения полностью аналогичная тегированию, является одним из инструментов объектно-ориентированного программирования.
В языке C тегированное данное соответствует описанию структуры, подобному этому:
struct tagged { int type_tag; union { int x; float y; } }
В языке Pascal тегированная ячейка может быть представлена следующей вариантной структурой:
record case tag : Boolean of true: (i :integer); false: (r :real) end;
Тегирование великолепно сочетается со структурным программированием, и поэтому практически всегда используется вместе с модификацией адресации и структуры памяти, называемой стековой архитектурой. При реализации языков высокого уровня на современных системах программирования практически всегда создается структура контекстов.
В стековой архитектуре машины уже физическая память организована как структурированный стек контекстов (см.
рис. 2.3).
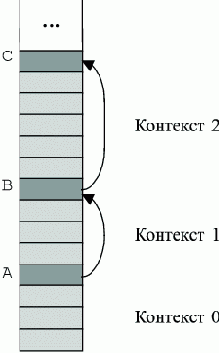
Рис. 2.3. Стек и контексты
Стек растет вниз. Нынешний контекст назван Контекст 0. Самая нижняя единица в стеке - текущий результат. Стек структурирован как стек стеков. Каждый подстек включает данные для блока программы. Таким образом, каждый из подстеков задает контекст для вычислений в соответствующем блоке. В начале каждого подстека находится его маркер, который содержит всю необходимую служебную информацию о подстеке, в частности ссылку на предыдущий маркер.
Для абстрактного вычислителя со стеком в начале обработки каждой конструкции нужно запомнить в стеке текущий экземпляр состояния контекста. Далее можно выполнять обычные действия по вычислению конструкции.
Стековая архитектура была воплощена в системах команд машин серий Barroughs и Эльбрус. Они прекрасно зарекомендовали себя как машины для сложных ответственных вычислений, но не выдержали конкуренции с армадой PC, задавивших их числом и дешевизной.
Есть и противоположное направление развития аппаратуры. В машинах с так называемой RISC-архитектурой машинные команды исключительно просты, но в полупостоянной части оперативной памяти заложены подпрограммы для команд `нормального' или даже `высокого' уровня, так что в принципе RISC-процессор может в зависимости от режима эмулировать5) машины разной архитектуры. Например, такая система была использована в машинах знаменитой серии Power PC - Power Mac, которые могли выступать для пользователя и программиста и как PC, и как Macintosh. Эта серия потерпела коммерческую неудачу скорее из-за ошибок в продвижении на рынок, чем из-за отсутствия реальных достоинств.
Нетрадиционные архитектуры
Крутой подумал. Ему понравилось. Он решил когда-нибудь на досуге подумать еще раз. Русский анекдот
Исторический экскурс
Во время Великой французской революции в связи с введением метрической системы мер, да и для улучшения качества артиллерии и флота, возникла необходимость быстро и качественно пересчитать множество таблиц: артиллерийские, навигационные, астрономические, геодезические и т. п.
Решение этой задачи (вдохновителем и организатором работ был выдающийся математик и администратор Л. Карно) было гениально с точки зрения концептуальной и организационной проработки. Вначале с помощью методов интерполяции все функции были заменены их кусочно-полиномиальными приближениями, не имеющими разрывов (современный термин - сплайн). Полиномы могут вычисляться методом конечных разностей, поэтому алгоритм вычисления полинома был распределен на сложения, вычитания и небольшое число умножений на константы. Для организации таких вычислений было использовано две параллельно работающие роты грамотных солдат под руководством математиков. Одни и те же расчеты проводились ротами независимо. Каждый солдат получал аргументы от двух указанных ему товарищей, складывал либо вычитал их (действие было предопределено заранее и не менялось). Самые грамотные солдаты получали аргумент от одного товарища и умножали его на заданную константу. По команде результаты действий передавались далее. Математики-надзиратели проверяли полученные результаты на правдоподобие и пересчитывали их выборочно. В случаях расхождения результатов рот счет производился заново. Таким образом таблицы были пересчитаны практически без ошибок, с минимальными затратами, высокой точностью и в кратчайшее время. В результате артиллерийские таблицы французской армии оставались лучшими более пяти лет, до тех пор, пока русские артиллеристы под руководством гр. Аракчеева не посчитали их еще лучше6).
Так что в том первом историческом случае, когда значительный объем вычислений был индустриализирован, была весьма квалифицированно выбрана модель вычислений.
Именно этим примером руководствовался при создании первой программно-управляемой механической вычислительной машины Чарльз Бэббидж, поскольку на механических элементах невозможно было добиться приемлемой скорости без распараллеливания вычислений. Быстродействующие, но ненадежные элементы первых ЭВМ практически вынудили отказаться от параллельной модели вычислений и перейти к более примитивной последовательной модели. Все преподавание и математическое обеспечение стало развиваться с ориентацией на последовательные вычисления. И когда появилась возможность электронной реализации параллельных вычислений, к ней оказались не готовы ни математики, ни программисты.
Прежде всего, можно просто иметь несколько процессоров. Многопроцессорность может быть использована несколькими способами.
Можно увеличить надежность вычислений. В некоторых бортовых машинах, рассчитанных на длительную работу без обслуживания, три процессора считают каждую очередную команду. Тем самым сбой одного из них не страшен.
Можно вычислять одновременно несколько программ. В принципе, наибольшая производительность машины с несколькими процессорами достигается именно тогда, когда каждый из них работает со своей программой, расположенной в своей области памяти. В современных машинах по сути дела именно так совмещается работа центрального процессора и устройств управления вводом, выводом и отображением информации. Но переносу этого принципа на саму архитектуру машины мешает привычка к рассмотрению ее как устройства для выполнения непосредственно нужной в данный момент задачи.
В связи с этим имеется, насколько известно автору, ни разу не использованное решение (предложенное автором еще в начале 70-х гг., но тогда отвергнутое). Поскольку каналы связи с памятью являются неустранимым узким местом, можно было бы снабдить процессор несколькими каналами и одновременно выполнять на одном процессоре несколько независимых программ. Вследствие этого можно было бы обойтись маленьким кэшем, состоящим из действительно нужных команд и данных (следующих команд и данных каждого из процессов).
И, наконец, можно попытаться использовать несколько процессоров для одного и того же процесса над общей памятью. В этом случае нужны изощренные алгоритмы кэширования и распределения программ между процессорами, а производительность растет всего лишь пропорционально корню квадратному от числа процессоров (и то в лучшем случае!) Получается, как зачастую бывает в современной информатике, круто, но весьма нерационально.
Прямое развитие данной идеи наталкивается также на массу тонких вопросов синхронизации. Простейший и наиболее очевидный из конфликтов синхронизации - попытка одновременной записи результатов нескольких команд в одну ячейку памяти, поэтому присваивания становятся тормозом на пути программирования.
Рассмотрим теперь те архитектуры, где до известной степени ликвидируется централизованное управление и появляется возможность глубокого распараллеливания вычислений.
Здесь стоит обратить внимание на два взаимосвязанных момента. Во-первых, часто нет нужды в хранении промежуточных результатов счета и, как следствие, потребность в пассивной памяти существенно снижается. Во-вторых, ликвидируется примитивное устройство управления, а его роль принимают на себя элементы оборудования, отвечающие за выяснение готовности команд к выполнению. Это - одна из схем, которая подчиняет управление потокам данных (data flow). Такие схемы противопоставляются управляющим потокам (control flow) традиционных вычислений.
Рассмотрим гипотетическую схему машины, управляемой потоком данных. Каждая команда имеет ссылку на те команды, от которых она зависит (предпосылки команды). Если выполнены все предпосылки, команда имеет право выполниться. Например, рассмотрим следующую схему.
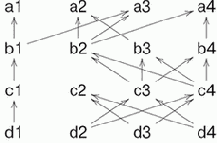
Рис. 2.4. Поток данных
На схеме вершины означают команды. Каждая команда зависит не более чем от двух, но зависеть от нее может сколько угодно других.
Представленная идея неоднократно воплощалась в оборудовании (так называемые машины потоков данных). Но каждый раз узким местом для подобных машин оказывалось несоответствие стиля программ, требуемого для них, тем стилям, к которым привыкли программисты.
Как следствие, в каждом из таких процессоров делались грубые системные ошибки, приводившие к затруднениям в программировании, а также к понижению скорости и гибкости вычислений. Тем не менее поскольку скорость света очень скоро поставит предел механическому увеличению пропускной способности каналов, к подобным схемам придется вернуться на другом уровне.
Конечно же, при реализации идеи возникают сложности. Пару из них демонстрирует следующий поток.
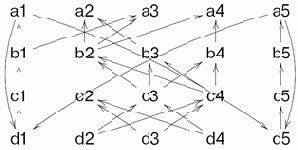
Рис. 2.5. Поток данных с взаимодействующими циклами
В потоке имеются два цикла, подготавливающие данные друг для друга. Возникает вопрос, а если один из циклов вторично подошел к точке, где требуются данные из другого, не устарели ли уже имеющиеся данные и не нужно ли подождать, пока они обновятся? Далее, здесь видно, что инициализацию потока данных часто необходимо выделять в самостоятельный блок, поскольку формально вычисление обоих циклов просто не сможет начаться.
Машины потоков данных уже несколько десятилетий используются на практике, так называемые суперЭВМ считают вычислительные задачи колоссальной трудоемкости (например, метеорологические). В подобных задачах, как правило, вычисление может быть записано в матричной алгебре, и новые матрицы строка за строкой вычисляются по старым. Таким образом, можно организовать конвейер, когда элементы целого вектора данных параллельно считаются по элементам предшествующего вектора, а переход к следующему происходит, когда все новые элементы посчитаны (так что вопрос о старении данных решается радикально: все, что использовалось для предыдущего вектора, по умолчанию считается устаревшим для следующего). Особенно хорошо конвейер работает, когда подпрограммы вычисления для каждого из элементов массива практически не изменяются (конечно же, для разных элементов они могут быть разные), поскольку инициализация процесса занимает много времени и сил. Конвейер с 1024 процессорами увеличивает производительность вычислений для некоторых реальных задач примерно в 300 раз, и для многих приблизительно в 100 раз.
Первой серийной суперЭВМ, успешно применившей конвейерную организацию, стала система машин Cray.
Одной из особенностей машин потоков данных является повышение активности памяти, в которой размещаются команды и их операнды. По этому пути можно пойти еще дальше, сделав всю память активной. Во избежание полной анархии, память обычно имеет общее устройство управления, задающее одну команду (или несколько команд, в зависимости от какого-то быстро проверяемого условия), которую выполняют все ячейки (ассоциативная память). История реализации этой идеи аналогична истории машин потоков данных: аппаратные предпосылки есть, но эффективных способов программирования нет.
Несмотря на очевидные преимущества для отдельных классов задач других моделей вычислений и на очевидную неэффективность классической модели вычислений, не происходит переход к другим, более перспективным с точки зрения ускорения счета, моделям. Почему? Это очень непростой вопрос, связанный как со сложившимися традициями, так и с огромным грузом накопленного программного обеспечения. В частности, другие модели вычислений, очевидно, не универсальны, ориентированы на некоторые классы задач, а иллюзия универсальности, основанная на примитивно истолкованной теореме об универсальном алгоритме, сопутствует традиционной модели вычислений. Но, пожалуй, более всего консерватизм обусловлен тем, что сегодняшняя армия программистов воспитана на традиционной модели, и она уже не в состоянии перестроиться.
Уже в машине потоков данных мы видим, что приказ выполнить следующую команду может быть заменен на разрешение ее выполнить. Таким образом, в программировании имеется возможность перехода от повелительного наклонения к изъявительному. Реализация идеи внедрения изъявительного наклонения в языки программирования возможна по следующим направлениям:
Системы продукций. Соотношения записываются как правила вывода предложения в некоторой грамматической или логической форме. Обрабатываемые данные сопоставляются с шаблонами, задаваемыми частями правил, отвечающими за распознавание ситуации, когда правило может быть применено.
Соответствие данных шаблону трактуется как разрешение применить данное правило. Применение правила состоит в замене выделенного при сопоставлении фрагмента данных на что-то другое. Однократное выполнение такой замены трактуется как атомарный акт вычисления. Системы функций. Программа есть соотношение между функциями, связанными между собой аргументами, которые, в свою очередь, могут быть функциями. Таким образом, атомарный акт вычислений - это подготовка аргументов для использующей функции. Готовность аргументов трактуется как разрешение вычисления функции. Коммутационные системы. Элемент системы - вершина графа, имеющая входные и выходные места. Входные места служат концами дуг, а выходные, соответственно, их началами. Дуги - это каналы передачи значений. Вершины, в свою очередь, могут иметь внутреннюю графовую структуру, и так далее по рекурсии. Программа есть граф с двумя выделенными вершинами, одна из которых не имеет входных мест (генератор перерабатываемых данных), а вторая не имеет выходных мест (получатель результата). Элементарное вычисление на графе может активизироваться, когда ко всем входам вершины поступают значения, и в этом случае либо производятся предопределенные языком действия (когда вершина атомарна), либо значения передаются по внутренней структуре к вложенным вершинам. Результатом вычисления являются значения на выходных местах.
Способ передачи данных и активизации вычислений в коммутационной системе может рассматриваться как одна из реализаций потока данных в системе функций. В частности, если граф не имеет циклов, то коммутационная система становится формой представления нерекурсивной системы функций. Если граф коммутационной системы содержит циклы, то он может быть интерпретирован как рекурсивная система функций. Такая система может быть теоретически представлена как бесконечный ациклический граф.
Ассоциативные системы. Элементы системы - активные данные, представляющие собой пары: (значение, ключ) Пары, имеющие одинаковые ключи, соединяются и используются в качестве аргументов действия, закодированного ключом.
Алгоритм действия может быть задан в любом стиле (например, в рамках традиционного программирования), его результатом для системы является набор пар, порождаемых в ходе локального действия, а исходные аргументы при этом уничтожаются. Легко заметить, что ассоциативная система может рассматриваться как иная форма коммутационной системы, и с точки зрения возможностей, предоставляемых для программирования, они теоретически эквивалентны. Однако эта форма соответствует иному взгляду на описываемые вычисления, который лучше подходит, в частности, для работы с базами знаний7). Аксиоматические системы. Если система отождествлений и замен фиксирована для целых классов задач и предметных областей, то мы работаем в фиксированном классе исчислений, и на первый план выходит задача описания знаний и предпочтений на фиксированном языке. Знания и предпочтения записываются в виде аксиом. Таким образом, формально аксиоматические системы являются частным случаем сентенциальных, но фиксированные правила замен позволяют перейти от общего пошагового моделирования символьных преобразований к неизмеримо более эффективному выводу, когда планируется сразу целая система преобразований8).
В случае наиболее распространенной классической логики и языка исчисления предикатов либо некоторого его расширения на систему аксиом можно смотреть как на описание предметной области (либо, что то же самое, на задание соотношений между данными). Вычислительные действия в подобной системе активизируются по запросам, целью которых является вывод некоторой формулы (что для классической логики и элементарных формул соответствует выводу истинности либо ложности некоторого факта; такой вывод уже не назовешь проверкой, поскольку он не является элементарной операцией). Программиста в такой системе обычно интересует не способ вывода, а лишь его осуществимость.
Все описанное выше если и может быть сегодня реализовано в оборудовании, то крайне ущербным и частным способом. Но еще в 60-е гг. ХХ века стало видно, что программное обеспечение настолько сильно экранирует физическую структуру компьютера, что для всех пользователей и большинства программистов компьютер вместе с базовым программным обеспечением является единой системой.
В связи с этим все чаще говорят о системе программирования как о машине. Например, реализация языка Java определяется через Java-машину, в терминах которой понимаются все вычисления. Достаточно часто такая программная машина, реализующая некоторую модель вычислений, служила основой для аппаратной реализации ключевых особенностей данной модели. Например, Алгол-машина легла в основу компьютеров со стековой архитектурой и тегированием.
 |
|
|
В подавляющем большинстве книг она называется по имени фон Неймана, опубликовавшего под своим именем результаты английских коллег-союзников, а также результаты фон Цузе, находившегося тогда в США в фактическом рабстве как военнопленный.
2)
Такой взгляд полезен программисту при разработке интерпретирующих программ, когда ему нужно промоделировать передачи управления.
3)
Схема выполнения команды на рис. 2.1 иллюстрирует интенсивность работы канала машины фон Цузе. Для выполнения двухадресной команды КО1О2 требуется шесть обращений к каналу. Интересно, что первоклассный программист, посмотрев на рисунок, увидел лишь четыре обращения. Дело в том, что на физическом уровне при чтении ячейки происходит ее стирание, и поэтому требуется восстановление ее содержимого. Для прочтения трех ячеек нужно шесть операций, а факт перезаписи некоторых из них не увеличивает числа обращений к памяти в том случае, если сама команда запрограммирована корректно на аппаратном уровне.
4)
Частичным аналогом этого может служить BIOS в общераспространенных персональных компьютерах.
5)
Эмуляция - программное моделирование некоторых особенностей вычислительной системы, реализованное таким образом, что оно невидимо не только для пользователя, но и для обычного программиста.
6)
Никто не знает, каким способом!
7)
Теоретическая эквивалентность понятий означает для программиста выбор между двумя формами представления, которые практически неэквивалентны!
8)
Говорить о цепочке преобразований здесь слишком скромно, поскольку в развитых аксиоматических системах вывод является сложной иерархической структурой, а алгоритмы поиска вывода сразу планируют эту структуру.
Традиционная модель
Из материалов предыдущего раздела видно, что подходы к решению программистских задач при использовании различных языков отличаются друг от друга. Иногда эти различия непринципиальны и сводятся лишь к текстовому представлению программы, а иногда они довольно существенны. Если различия непринципиальны, то мы говорим, что языки имеют сходную модель вычислений.
Модель вычислений языка не обязательно совпадает с моделью вычислений, заложенной в оборудование. Эти модели расходятся, если сама машина имеет традиционную архитектуру. Более того, даже машины другой архитектуры программно моделируются на машинах традиционной архитектуры. В дальнейшем мы будем пользоваться термином традиционные языки, понимая под этим языки, модель вычислений которых унаследована от традиционной архитектуры машин. Архитектура, впервые использованная Конрадом фон Цузе1) еще на рубеже 30-40-х гг. XX в., в несколько модифицированной форме до сих пор принята почти для всех вычислительных машин.
В этой архитектуре вычислительной системы имеются следующие три элемента:
Память,предназначенная для хранения произвольных значений. Значения на аппаратном уровне представляются как последовательности битов. Процессор, способный выполнять команды, т. е. интерпретировать последовательности битов как инструкции для активизации предписываемых этими инструкциями действий. Управляющее устройство, способное указывать команды, которые должен выполнять процессор (иногда управляющее устройство рассматривается как составная часть процессора).
Эти элементы обладают следующими особенностями.
Однородность памяти. Память машины рассматривается как вектор, состоящий из одинаковых ячеек, способных принимать (от процессора) любые значения.
Значение в ячейке, с точки зрения процессора, является последовательностью битов фиксированной длины без каких бы то ни было ограничений.
Линейная адресация. Ячейки памяти идентифицируются адресами: числами от нуля до максимально возможной для данной машины величины (обозначающей последнюю ячейку).
Адреса служат указателями для процессора, откуда следует извлекать или куда помещать значение.
Из однородности памяти следует, что команды и данные (перерабатываемые значения) располагаются в единой общей памяти и одинаково адресуются.
Пассивность памяти. Ячейка памяти всегда содержит какое-то значение. Полученное ячейкой значение не может быть изменено иначе как при выполнении специальной команды процессора, предназначенной для этого действия, - команды засылки, или присваивания, значения. Изменяемая ячейка указывается своим адресом. Активность процессора. Процессор всегда выполняет некоторую команду, закодированную последовательностью битов в ячейке и извлеченную из памяти. Команды могут иметь операнды, т. е. в них, как правило, указываются адреса ячеек, над которыми выполняются предписываемые действия. Именно процессор, в соответствии с тем, какую команду он должен выполнить, интерпретирует значение ячейки-операнда как число, символ, адрес в памяти и др. Число операндов команды называется ее адресностью, а адресность большинства команд - адресностью машины. Различаются одно-, двух- и (в настоящее время реже) трехадресные машины, а также машины с нефиксированной адресностью. Централизация управления. Управляющее устройство содержит адрес команды, назначаемой для выполнения процессором. Если эта команда является командой передачи управления, при ее выполнении определяется адрес ячейки, содержащей команду, которая должна выполняться после текущей, и этот адрес становится новым содержимым устройства управления. В противном случае адрес команды, назначаемой процессором для выполнения следующей, есть текущее содержимое устройства управления, увеличиваемое на единицу (очередная выполняемая команда содержится в ячейке памяти, следующей за текущей). Таким образом, управляющее устройство можно моделировать как регистр, называемый счетчиком команд. Этот регистр модифицируется автоматически либо командами передачи управления2). Наличие канала связи между памятью и процессором.
Для передачи данных или команд между памятью и процессором используется специальное оборудование, называемое каналом связи. Работа канала осуществляется в случаях, когда требуется: подать очередную команду процессору для выполнения (активизируется управляющим устройством); получить операнды для выполнения команды (активизируется процессором); изменить значение ячейки при выполнении команды (активизируется процессором).
Такую архитектуру будем называть традиционной.
Традиционная архитектура машины конкретизируется для соответствующей среды применения. В частности, она всегда дополняется устройствами ввода и вывода данных.
На рис. 2.1 показано взаимодействие устройств традиционной машины.
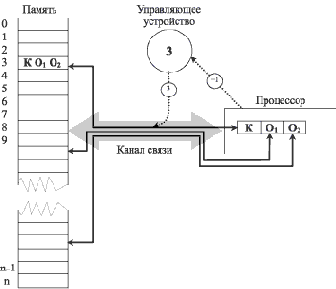
Рис. 2.1. Схема выполнения двухадресной команды на машине традиционной архитектуры
В команде КО1О2 К — код операции, O1 и O2 — адреса операндов. Команда размещена по адресу 3. Сплошными стрелками отмечена передача информации по каналу. Пунктирные стрелки обозначают действия, которые осуществляются непосредственно до исполнения команды (запрос кода команды по адресу 3) и после нее (указание на необходимость запроса команды, следующей в памяти за исполняемой).
Традиционная архитектура ЭВМ сформировалась в условиях ненадежности физических элементов. В частности, по этой причине выбран довольно примитивный способ управления: переход к следующей команде или к команде по принудительно задаваемому адресу. А в дальнейшем, несмотря на появление качественно новой элементной базы, стремительный рост производства машин такого типа препятствовал смене архитектуры.
Есть причина, из-за которой увеличение эффективности традиционных машин принципиально ограничено. Повышение быстродействия процессора как активного элемента оборудования приводит к росту скорости счета лишь в пределах, определяемых скоростью канала связи между процессором и памятью: если она невысока, то процессор будет простаивать, ожидая очередной команды, операндов или окончания выполнения присваивания3).
Темпы роста скорости процессора выше, чем у канала связи.
На эти принципиально непреодолимые ограничения классической модели вычислений указал Бэкус еще в середине семидесятых годов (Тьюринговская лекция Бэкуса [35]), назвав канал связи памяти с процессором узким местом (буквально bottleneck) традиционной модели.
Традиционная архитектура машин менее всего связана с конкретным классом решаемых задач. Она скорее связана с двумя наиболее распространенными и наиболее низкоуровневыми стилями программирования: структурным и автоматным программированием.
Под стилем программирования мы понимаем внутренне концептуально согласованную совокупность средств, базирующуюся на некоторой логике построения программ. Теоретические исследования последних десятилетий показали, что различным классам задач и методов соответствуют различные логики построения программ, и эти логики несовместимы друг с другом. Логики (и, соответственно, стили программирования) дают самую общую оболочку, не зависящую от конкретных предметных областей и даже от конкретных методов. Как только мы уясняем себе особенности методов, стили начинают конкретизироваться далее. Так, известный Вам (поскольку именно он преподается в качестве единственно существующего во всех современных учебных пособиях по началам программирования) структурный стиль конкретизируется в циклический либо рекурсивный варианты (ипостаси).
Для разных стилей логики построения несовместимы, поэтому прежде чем обсуждать стили в системе, мы познакомимся с примерами реализации различных стилей. Но еще до этого целесообразно рассмотреть другие архитектуры машин.
Конструкции традиционных языков
Рассмотрим традиционные языки, ключевые средства которых "выросли" из традиционной архитектуры машин. Ниже перечислены те средства языков, которые унаследованы от этой архитектуры.
Оператор. Основной конструкцией, выражающей действия, является оператор. Выполнение одного оператора зависит от выполнения другого только в том смысле, что более ранние вычисления могут менять память.
Присваивание значений — наиболее часто встречающийся вид операторов. В большинстве языков программирования понятие переменной рассматривается как аналог ячейки (или группы ячеек) памяти. Присваивание предназначено для локального запоминания результата вычислений. Оно прямой потомок передачи значения по каналу связи от процессора к памяти.
Структура управления. Если явно не предписано иначе, то операторы выполняются текстуально друг за другом. Это соответствует последовательному выполнению команд процессором. Оператор перехода трактуется как явное указание того оператора, который должен выполняться следующим. Он соответствует машинной команде безусловной передачи управления по адресу. То же можно сказать и о ситуациях, когда вычисления определяют, какой оператор будет выполняться следующим (условные операторы, циклы и т. п.). Прообразом этих операторов явились часто используемые приемы программирования на языке команд.
Приведение. В традиционных языках обычным является употребление значения одного типа, которое присваивается переменной другого типа. Автоматические приведения вырабатываемых значений к типам, определяемым контекстом использования, — прямое следствие соглашения об однородности памяти. В развитых языках программирования (кроме семейства C) стремятся избегать неконтролируемых приведений1).
Подпрограмма — группа операторов, имеющая собственное имя. К такой последовательности можно обращаться неоднократно. Подпрограммы появились еще на машинных языках, поскольку они необходимы для накопления программистских знаний и облегчения работы со сложными программами. Особенность подпрограмм в том, что их описание отделено от оператора вызова подпрограммы, а после исполнения оператора вызова управление возвращается в тот же контекст, который был до вызова, а управление передается оператору, непосредственно следующему за вызовом.
Заметим, что в достаточно развитых языках программист строит тексты программ в соответствии с особенностями решаемой задачи, отходя от тех правил, которые явно поддерживаются языком (писать в другом стиле). Но если в языке не хватает возможностей, адекватных для такого построения (а это, вообще говоря, обычная ситуация), то приходится прибегать к хакерскому2) моделированию нужных возможностей. Когда при этом требуется высокая эффективность (а это опять-таки обычно) необходимо учитывать реалии конкретного компьютера. Как следствие, весьма вероятны нарушение адекватности моделирования и потеря наглядности решения.
Примеры традиционных языков
Приведем с небольшими комментариями далеко не полный перечень традиционных языков.
1. FORTRAN. Патриарх среди языков программирования, постепенно вбирающий в себя новые веяния, но полностью сохраняющий преемственность в ее лучшем и худшем смысле. Сегодня FORTRAN — это эклектическое собрание как полезных, так и архаичных средств. Упоминая FORTRAN, мы имеем в виду язык, сформировавшийся в середине семидесятых, так называемый FORTRAN-77 (дальнейшие модификации уже не столь принципиальны). Модель вычислений языка FORTRAN в точности соответствует представлению о том, что нужно для реализации вычислительных алгоритмов и что можно реализовать на компьютерах традиционного типа, сложившемуся в 50-х гг. XX века. Таким образом, это наиболее последовательный пример традиционного языка.
Разработчики ранних версий языка FORTRAN не принимали в расчет полезности определения языка, независимого от системы программирования. И формальное определение языка, по существу, задавалось транслятором. В результате случайные решения, принятые в ранних трансляторах, последующие разработчики вынуждены сохранять на многие годы. Для этого языка такое положение дел объяснимо и простительно3).
FORTRAN служит классическим примером языка со статическим определением памяти: еще на стадии трансляции точно устанавливается, где что лежит.
2. Algol 60. Язык, сформировавшийся как реализация идеи представления алгоритмов, одновременно понятного и для компьютеров, и для человека. Очень скоро утопичность идеи выяснилась, и Algol 604) стал в глазах программистов-практиков5) лишь более строгим, но зато более многословным, менее привычным и эффективным аналогом языка FORTRAN. На самом деле в Алголе появились принципиальные новшества, выгодно отличающие его от предшественника. Это, прежде всего, определение языка, не зависящее от транслятора, далее, структурность описания языка и определение действий абстрактного вычислителя на базе понятий из строгого описания языка.
В Алголе впервые предложена структурная организация контекстов выполнения конструкций, которая выводит вычислитель языка за рамки канона однородности и прямой произвольной индексной адресации памяти, — так называемая блочная структура программы.
Тем самым была изобретена стековая дисциплина распределения памяти в рабочих программах. При таком распределении памяти место для понятий, описанных в некотором блоке, выделяется при входе в данный блок и освобождается после его завершения.
Стековая дисциплина с тех пор повсеместно используется при реализации языков программирования.
Хотя понятие структурного программирования еще не было осознано, в Algol 60 появилась вся необходимая база для него.
Не случайно именно Алгол стал отправной точкой развития большинства языков программирования, а также основой многих теоретических разработок, прояснивших языковые и программистские понятия. Появились и до эры персональных компьютеров были популярны вычислительные архитектуры, явно поддерживающие алголовскую организацию памяти. Наиболее известными из них являются машины фирмы Burroughs (США) и линия многопроцессорных вычислительных комплексов Эльбрус (СССР).
Таким образом, Algol 60 стал существенным шагом вперед, а в отношении концептуального единства он до сих пор остается непревзойденным среди традиционных языков.
3. Симула 67 характеризуется разработчиками как универсальный язык моделирования. Это, как и его предшественник Симула 1, — правильное расширение Algol 60, а потому сохраняет его достоинства и недостатки. Впрочем, именно недостатки этой базы стали главной причиной того, что данные языки оказались недооценены практиками. Разработчики Симулы 67 показали, как нужно выражать программистский опыт в языковых формах: воплощать не конкретные решения, а содержательные сущности, их обобщающие. В результате новые для того времени конструкции, отражающие объектный взгляд на обрабатываемые данные, стали основой для перспективных методологий программирования, в частности для методологии объектно-ориентированного программирования.
4. PL/1. Этот язык разрабатывался как попытка объединения всего, что в принципе может потребоваться программисту. Неизвестно, так это или нет, но вполне правдоподобно, что число "1" в названии языка есть амбициозное "единственный", т.
е. способный сделать бессмысленными любые другие языки программирования. Совсем не заботясь о чистоте объединения всех известных программистских средств, разработчики языка предложили изначально эклектичную коллекцию, которая лишь с натяжкой может быть названа системой. Непознаваемость языка отмечается многими критиками. По выражению Э. Дейкстры, PL/1 — это "рождественская елка", а не инструмент, который можно эффективно использовать. Разрозненность и несводимость к единым концепциям создает большие трудности и для реализации: системы программирования для PL/1 всегда выделяли некоторый диалект, по существу, определяя соответствующее подмножество средств, зависящее от транслятора.
5. Алгол 68 — язык программирования, который, как и PL/1, претендовал на всеобщность, но уже на базе математического обобщения разрозненных средств программирования в традиционной модели вычислений. Можно сказать, что это PL/1 с элементами научности (С. Костер). Попытка распространения средств, хорошо себя зарекомендовавших в одной сфере, на уровень максимального обобщения в целом удалась, но разработчики зафиксировали в языковых формах лишь то, что уже было известно на момент появления проекта языка. По этой причине в Алголе 68 нет хороших средств поддержки модульного построения программ, в точном соответствии с традиционной архитектурой перерабатываемые данные не являются активными. К недостаткам языка следует отнести тяжеловесное формальное описание, совершенно недоступное для практического применения в качестве руководства для программиста6). Основная заслуга разработчиков Алгола 68 в том, что они сумели реализовать на практике принцип обобщения без потерь, продемонстрировали продуктивность этого принципа. Наличие в данном курсе ссылок на фактически не используемый сейчас язык Алгол 68 объясняется тем, что в этом языке, несмотря на явные недостатки в форме описания языка, одновременно имелся ряд блестящих концептуально важных находок, таких, в частности, как система понятий, остающаяся до сего дня наиболее последовательной и строгой.
Некоторые из концепций Алгола 68 были восприняты в языках C и Ada, но сама система была при этом утеряна. До сих пор в журнале "Communications of the ACM" периодически появляются комментарии к опубликованным статьям, озаглавленные приблизительно в следующем стиле: "Algol 68 ignorance considered harmful", сводящиеся к тому, что очередные "новые" предложения являются лишь ухудшенной версией того, что уже давно было реализовано в Алголе 68.
Одной из побудительных причин создания языка стало осознание стройной концепции системы типов, вычисляемых статически, т. е. во время трансляции программы.
Базовая машина допускает произвольную трактовку смысла хранимых значений (принцип однородности памяти), но для человека смысл значений первичен, поэтому в программе нужно фиксировать не только вычисления, но и типы значений. Появляется возможность смыслового контроля программы, отделенного от обработки данных. Для этого нужно строго определить типы и дать точные механизмы построения одних типов через другие. Такое определение позволяет, не зная конкретных значений переменных, входящих в выражение, определять тип выражения. В результате целый ряд содержательных потенциальных ошибок в программе может быть выявлен уже при трансляции. Но в Алголе 68 эта концепция была недостаточно хорошо реализована.
6. Pascal — один из самых распространенных языков программирования. По этой причине он представлен множеством диалектов и версий. Первый Pascal был предложен Н. Виртом (N.Wirth) в ответ на принципиальное несогласие с позицией руководства рабочей группы по созданию Алгола 68, в частности с ван Вейнгаарденом. Главное в критике Вирта — чрезмерная сложность языка и особенно метода его формального описания.
В частности, Pascal дал более изящную и приемлемую для программистов реализацию идеи статической системы типов, возникшей еще в то время, когда первоначальная рабочая группа по Алголу 68 не распалась7).
Есть и другие особенности языка Pascal, которые делают этот язык строгим, есть и естественные ограничения возможностей, которые упрощают понимание языковых средств программистом.
Язык создан так, чтобы поддержать написание хороших программ (в понимании, которое сложилось к концу шестидесятых годов). Все это позволило утверждать Вирту, что он разработал язык для обучения студентов программированию. Это утверждение не лишено основания, особенно если иметь в виду, что существует методика обучения с его помощью, которую разработал сам Вирт. В учебных заведениях, где имеются серьезные курсы информатики, Pascal остается самым распространенным языком обучения.
Вскоре после своего появления Pascal становится популярным языком программирования. Но программирование продолжало развиваться, появлялись новые концепции. Сам Вирт разрабатывает на базе языка Pascal языки-наследники, которые в большей степени поддерживают составление программ с независимыми модулями: Modula и Modula-2.
Заслуживают внимания и более близкие родственники стандартного языка Pascal, последовательно версией за версией предлагавшиеся коллективом фирмы Borland: языки и системы программирования линии Turbo Pascal. В них новые, весьма развитые возможности органично укладываются в строй родительского языка, не нарушая концепций. К сожалению, в разработанной этой же фирмой системе Delphi язык Object Pascal выпадает из этого ряда: концептуальной целостности сохранить не удалось.
7. Язык С и другие машинно-ориентированные языки. Осознание того, что программирование с использованием универсального языка, не отражающего особенности конкретного вычислительного оборудования, не дает возможности достичь предельной эффективности программ на этом оборудовании, привело к появлению так называемых машинно-ориентированных языков. Популярность таких языков зависит не только от распространенности оборудования, для которого они рассчитаны, но и от успешности выполненных с их помощью проектов.
В этом отношении показателен язык С, успех которого был во многом обеспечен удачным решением операционной системы Unix. Для разработки этой системы на машины серии PDP и был построен язык C, с помощью которого, в частности, предложен технологичный метод переноса программного обеспечения.
Справедливости ради следует сказать, что хотя вклад системы Unix в успех С очень велик, но не менее важно и то, что этот язык предоставляет достаточно удобную для составления эффективных программ оболочку, закрывающую невыразительные средства машинного уровня. Растущая популярность этого языка повлияла на то, что компьютеры стали конструировать так, чтобы их архитектура соответствовала модели вычислений языка C. В результате популярность таких архитектур выросла. В этом процессе наиболее преуспела фирма Intel, процессоры которой становятся стандартом де-факто в сфере разработки персональных компьютеров. Сегодня уже нельзя представить массовый компьютер, который не поддерживал бы программное обеспечение, разработанное под эти процессоры8).
Язык С если не первый, то один из первых языков программирования, в которых с самого начала существования провозглашалась идея рассматривать в качестве вычислителя не уровень команд конкретного компьютера, а уровень операционной системы. Иными словами, в данном языке присутствуют конструкции, выполнение которых не может осуществляться без соответствующего обращения к средствам операционной системы. Конечно же, это не новшество. Во всех практически используемых языках программирования такие средства есть, и всегда они расширяют программистский взгляд на среду функционирования программы. Но чаще всего они представлены в языке как подчиненные средства, вынесенные на уровень библиотек, и далеко не всегда точно специфицированы. В С ситуация иная. В частности, наряду с автоматическим распределением памяти, в языке определены механизмы предоставления участков памяти по запросам и возврата их, когда они перестают быть нужными.
На фоне заслуженной популярности С уместно упомянуть менее распространенный язык Bliss. Этот машинно-ориентированный язык программирования мог бы быть концептуально более выверенной альтернативой С, но отсутствие разработанного с его помощью проекта, сравнимого по значимости с Unix, не позволило ему выделиться. И хотя в идейном плане Bliss повлиял на языкотворчество, интерес к нему не вышел за рамки академических исследований.
Отечественный опыт разработки машинно- ориентированных языков демонстрирует поддержку архитектуры, отличную от Intel-подобной. Укажем на два проекта этого рода. Первый — язык ЯРМО (аббревиатура: язык реализации машинно-ориентированный), построенный для ЭВМ БЭСМ-6 и отражающий все тогдашние веяния в информатике. О качестве и востребованности этого языка можно судить хотя бы по тому, что было реализовано несколько его версий. Второй пример — Эль-76, разработанный в качестве аналога ассемблерного языка для многопроцессорного вычислительного комплекса Эльбрус. Оставаясь в целом традиционной машиной, архитектура этого комплекса достаточно далеко отходит от канонических принципов. В частности, в ней предусмотрена аппаратная поддержка вызова процедур, стековая организация памяти, тегирование и другие высокоуровневые средства программирования.
Все архитектурные особенности Эльбруса отражены в Эль-76, что позволило рассматривать данный язык в качестве единственного инструмента программирования системных программ. Конечно, нельзя говорить о механическом переносе этого языка в архитектурную среду другого типа, а потому время использования его, как и любого машинно-ориентированного языка, ограничено временем жизни данной архитектуры9).
8. Язык Ada. Он разрабатывался по заказу Министерства обороны США на конкурсной основе с предварительным сбором и анализом требований, с обширной международной экспертизой. По существу, в нем воплощена попытка определить язык программирования как экспертно обоснованный комплекс средств программирования. На завершающем этапе конкурса приняли участие около ста коллективов. В результате проверки на соответствие представленных разработок сформулированным требованиям для обсуждения общественности было отобрано четыре языка, зашифрованных как Red, Green, Blue и Yellow. В разной степени критике подверглись все четыре кандидата. Особенно острым критиком оказался Э. Дейкстра, который камня на камне не оставил от Red, Blue и Yellow, но чуть-чуть "пожалел" Green, доказывая, что все недостатки языка связаны с несвободой в выборе решений, обусловленных жестко фиксированными требованиями: там, где авторы могли бы решать какие-либо проблемы по-своему, они были вынуждены идти на поводу у априорных предписаний.
Тем не менее Green стал приемлемым вариантом и получил одобрение. Как оказалось, это был единственный из финалистов язык, предложенный не американцами. Конкурсная комиссия утвердила его в качестве единого официального языка Министерства обороны США для разработки программ для встроенных систем и дала ему имя Ada — в честь Ады Августы Лавлейс, дочери Байрона и ученицы Бэббиджа — первой в истории программистки.
Отметим, что успеха разработчики языка добились благодаря акценту на концептуальную целостность — именно это выделяло Green среди конкурентов. Заметим, что в ходе последующего развития в язык Ada стали включать новые средства в угоду появившимся пользователям. В результате к концу девяностых годов Ada по стилю построения стала подобна PL/1: в ней есть средства поддержки всего, что можно найти в работе программистов в конце XX века. Как отмечал известный советский программист В. Ш. Кауфман, язык Ada 9х можно рассматривать как добротную энциклопедию программистского знания и опыта, но никак не в качестве инструмента, ориентированного на пользователя.
9. Объектно-ориентированные языки. Последним достижением в области программистского языкотворчества считается поддержка объектно-ориентированной методологии. Эта сфера интересует многих разработчиков языков начиная с восьмидесятых годов. Первым проектом, провозгласившим принцип перехода от пассивных данных к активным объектам, стал Smalltalk. В этом языке объектам предоставляется возможность действовать в ответ на получаемые ими сообщения без каких бы то ни было иных способов активизации действий. Эта возможность реализована в рамках идеи динамической типизации (в отличие от статической типизации, тип выражения может в определенных пределах вычисляться наряду с его значением). В качестве наглядной демонстрации мощи идеи была предложена система программирования Smalltalk-80 с очень богатой библиотечной поддержкой конструирования графических интерфейсов.
Smalltalk — последний крупный проект, который был представлен на всестороннее обсуждение программистской общественностью.
В результате таких обсуждений выяснилось, что нужно для поддержки объектной ориентированности в языках промышленного производства программ. Такие языки появились достаточно скоро.
Заметными объектными языками стали Turbo Pascal версий с 5.5 до 7.0 и Object Pascal системы Delphi.
Общим для промышленного развития линии языка Smalltalk является возврат к статическим типам данных, повышенное внимание к вопросам защиты. Появились системы программирования, приемлемые по эффективности объектного кода и удовлетворяющие требованиям технологичного программирования. Однако, как это обычно бывает с производственными системами, на смену аналитическим исследованиям границ применимости и роли языка пришли реклама достоинств и замалчивание недостатков.
10. Язык C++. Наибольшее распространение из объектно-ориентированных языков получил С++, по-видимому, из-за огромной популярности С.
C++ был создан в конце 80-х гг., он практически являлся расширением C. В отличие от языков семейства Simula, в С++ воплощались не столько концепции, сколько конкретные, полезные для его создателей, приемы. Язык С++ по конструкции намного сложнее С, а определение его производит впечатление еще большей эклектичности. Но С++, усугубив недостатки С с точки зрения человека, сохранил при колоссальном расширении возможностей языка все достоинства С, касающиеся машинной ориентированности и эффективности.
С++ отличается прежде всего значительным усилением системы описаний (объектно-ориентированные возможности являются одним из наиболее применяемых расширений)10).
Еще более укрепляют позиции языка С++ многие современные инструментальные системы, создававшиеся на нем без учета потребностей других языковых средств. В частности, системы работы с динамически подключаемыми программами (middleware) CORBA и COM практически требуют, чтобы программа, к ним обращающаяся, была написана на С++, поскольку вся система интерфейсов ориентирована на типы данных этого языка и порою даже на конкретные их представления.
11. Язык Java.
Заметным этапом в развитии объектно- ориентированного подхода стало появление языка Java, который был предложен как средство программирования не для отдельного компьютера, а сразу для всех машин, имеющих реализацию так называемой Java-машины — исполнителя программ на промежуточном языке более высокого уровня, нежели командный язык обычных машин. Иными словами, реализуется система программирования с явно определенным промежуточным языком. Другая особенность Java-проекта — его ориентация на Интернет-программирование: поддерживается возможность построения приложений, работающих сразу на нескольких машинах.
Схема трансляции с выделенным промежуточным языком, не зависящим от исходного языка, не нова. В шестидесятые годы ее пытались применять для сокращения расходов на разработку трансляторов (например, в США в качестве промежуточного языка был разработан язык Uncol, в Советском Союзе для тех же целей предлагался язык АЛМО).
Пусть требуется реализация m языков на n машинах. В схеме без промежуточного языка в этом случае нужно запрограммировать m ? n трансляторов, тогда как использование такого языка позволяет сократить это число до m + n: для каждого языка пишется транслятор в промежуточный язык (m) и для каждой машины создается транслятор или интерпретатор промежуточного языка (n). Можно предположить, что затраты на 'половинки' трансляторов сократятся. Схема может быть реализована, если удается построить промежуточный язык, удовлетворяющий следующим условиям:
все реализуемые языки можно вложить в промежуточный язык, т. е. их модели вычислений совместимы;все целевые машины можно непротиворечиво представить в одной модели вычислений промежуточного языка так, чтобы трансляция программ для этой общей модели давала бы эффективный код для конкретных вычислителей.
Выполнить эти условия весьма сложно даже для близких языков и машин, близких по архитектуре. Затраты на решение этих задач часто неизмеримо и неоправданно превышают стоимость пресловутых m ? n трансляторов, поэтому после серии экспериментальных проектов идея промежуточного языка была предана забвению.
В проекте Java она возродилась (правда, в урезанном до одного языка варианте) благодаря почти унифицированной архитектуре массовых компьютеров и значительному росту технических возможностей машин.
Именно эти дополнительные условия, а также квалифицированное сужение исходного языка С++, позволили воплотить старую идею в промышленной разработке11).
В контексте обсуждения традиционности языков необходимо рассмотреть вопрос о том, насколько далеко язык Java и Java-машина отходят от традиционной модели вычислений. Совместная разработка этих двух компонентов системы программирования для нового языка позволила прийти к достаточно практичным компромиссам, удовлетворить условиям выбранной схемы реализации, о которых шла речь выше.
Условие (1) выполняется почти автоматически, и можно сосредоточить внимание на том, чтобы обеспечить наиболее рациональное вложение модели вычислений языка в модель машины. Что касается условия (2), то здесь ставка делалась на фактическое сходство архитектуры конкретных вычислителей, для которой уже накоплен опыт программистских решений во многих типовых ситуациях. В результате отход от традиционной модели вычислений в Java-системе хотя и заметен, но не столь значителен. Достаточно сказать, что Java-машина построена на принципах, предложенных еще в 1963 году для организации вычислений в рабочей программе Ветстоунского компилятора для Algol 6012) [24].
Важным новым качеством Java-машины является поддержка работы программиста с потенциально неограниченной памятью. При выполнении конкретной программы на языке Java можно не заботиться о том, что какая-то часть памяти перестает быть нужной. Система программирования сама сделает так, что та память, которая оказалась недоступной, а значит, ненужной, возвращается для использования в новых запросах. Такие ситуации выявляются в процессе вычислений, когда фактические ресурсы, предоставляемые для размещения данных, требуется пополнить для переиспользования. В угоду этому соглашению отказались от ряда приемов организации ручного переиспользования памяти, необходимых, например, при программировании на С.
Модель вычислений Java в точности соответствует тому, что требуется от объектно-ориентированного программирования: активность памяти на уровне методов объектов, совместное описание данных и программ методов, отделение предоставляемых средств от их реализации. Все это сочетается с традиционной схемой управления вычислениями при описании алгоритмов обработки.
Следует отметить, что разработчики языка не стали включать в него средства, с трудом укладывающиеся в концептуальную схему Java-машины и обычно предоставляемые через довольно произвольные реализационные соглашения (как, например, в С++). Ориентация Java-машины на классическую со времен Algol 60 схему организации вычислений, повлияла на язык в том отношении, что все, выходящее за рамки принятой модели, представлено таким образом, чтобы это можно было вычислить в период трансляции. К примеру, проблемы статической типизации в данном языке решены радикально: в нем просто нет средств конструирования структурных типов, отличных от классов объектов. В результате язык стал лаконичнее, например, по сравнению с С++.
Для первого опыта Java достаточно гармонично соединила ряд нововведений, которые в разрозненном виде появлялись в различных языках, и которые в совокупности повышают уровень исходных понятий примерно до второго типа в иерархии типов. Программирование на Java принципиально отходит от ориентации на особенности конкретных вычислителей. Остается лишь предположить (далеко не всегда оправданно!), что используемые машины выполняют требуемые действия с приемлемым уровнем эффективности.
В значительной степени для того, чтобы перехватить инициативу у языка Java, и был создан C#, эффективно работающий прежде всего с системами middleware, и стремящийся сохранить в новой области эффективность C/C++. Для наших целей в большинстве случаев различия между С++ и С# несущественны.
Как видим, традиционные языки прошли путь серьезной эволюции. Посмотрим, как трансформируются традиционные принципы вычислений при использовании объектной модели.
Очевидно, что отход от однородности памяти для этой модели более радикален, нежели, к примеру, в языке Pascal. Если рассматривать объекты как хранимые в памяти данные, то за счет связанности этих данных с программами (методами объектов) память в объектной модели приобретает активность. На концептуальном уровне рассмотрения можно увидеть, что модернизируется управление: объект сам знает, какую программу-метод нужно активизировать, чтобы выполнить то или иное действие. Несомненно, все это повышает гибкость программирования, способствует расширению возможности отхода от традиционного взгляда на программу как на автомат, выполняющий предписания-команды. Однако на уровне реализации программ-методов все остается по-старому: то же последовательное выполнение операторов, те же подходы к разветвлениям вычислений и к организации циклической обработки.
Более того, последовательный характер вычислений остается и при задании взаимодействия объектов. Следовательно, объектный подход, хотя и способствует взгляду на вычислительные процессы, отличающемуся от традиционного стиля, сам по себе не приводит к смене базовой модели вычислений.
Объектно-ориентированный подход применяется в настоящее время для организации вычислений на основе моделей, отличных от традиционных. При этом совершенно не принимается во внимание концептуальная совместимость объектно-ориентированного подхода с новым базисом и относительный уровень базиса и надстройки. Пример рассматривается в главе, посвященной функциональному программированию.
|
|
|
1)
Даже в семействе С слишком необычные приведения рассматриваются всеми нынешними трансляторами как события, требующие выдачи предупреждений программисту.
2)
Хакерство — неестественное применение конструкций, а также использование недокументированных возможностей либо явных недоработок языка.
3)
Удивительно, что и сегодня, в XXI веке, появляются языки, зависимые от реализации, которые претендуют на универсальное применение (например, Delphi Object Pascal, C#, Java).
4)
До него был еще Algol 58, но лишь Algol 60 был утвержден в качестве стандарта и получил широкое распространение. Его часто называют в литературе просто Алгол.
5)
Прежде всего, физиков и американцев; европейцы, не являвшиеся физиками, приняли его хорошо.
6)
Такова цена, которую пришлось заплатить за полную формальную точность описания.
7)
Одно из центральных понятий программирования — это призрак: то, что нужно для понимания программы, но в программу не входит. Pascal и Алгол 68 позволили многим призракам стать реальными программными сущностями.
8)
Безусловно, это тормозит развитие машинных архитектур.
9)
Это утверждение не противоречит долголетию С. Как уже отмечалось, данный язык сегодня фактически навязывает архитектуру машин, которая не противоречит его эффективной реализации. Например, использование С в качестве базового языка для Эльбруса явно ограничивало бы доступ ко многим развитым машинным возможностям.
10)
В качестве анекдота заметим, что система описаний С++ настолько мощна, что на стадии трансляции в принципе можно вычислить любую программу, например, выдавая результат в качестве сообщения об ошибке.
11)
Про новые условия данного проекта говорят обычно с неохотой или же вовсе замалчивают их. К примеру, в книге "Java-технология" успех старой идеи в новом проекте объясняется тем, что в прежние времена эту идею изучали в университетах, тогда как сегодня за нее взялись промышленники.
12)
В этой связи уместно следующее замечание. Если бы книга [24] не была бы сегодня библиографической редкостью, то ее главу 2 "Рабочая программа" можно было бы рекомендовать в качестве пособия для тех, кто желает изучить устройство Java-машины. После прочтения понимание Java-машины окажется более глубоким.
Абстрактный и конкретный синтаксис
При рассмотрении приемов программирования и примеров на разных языках необходимо как можно больше отвлекаться от частных особенностей и учиться видеть за ними общее с тем, чтобы оставшиеся различия были бы уже принципиальными. Отделить существенное от несущественного помогает, в частности, соотношение между синтаксисом и семантикой. Например, оказывается, что некоторые синтаксические особенности КС-грамматики языка не нужны для описания его семантики.
Обычное синтаксическое определение языка задает конкретные синтаксические правила построения программы как строки символов. При этом определяется, какие структурные элементы могут быть выделены в тексте программы (конкретное представление программы).
Действия абстрактного вычислителя определяются на структурном представлении программы и не зависят от многих особенностей конкретного синтаксиса. Например, для присваивания важно лишь то, что в нем есть получатель и источник, сам по себе знак присваивания (=, := или, скажем, LET) совершенно не важен. Более того, неважно, в каком порядке расположены составные части присваивания в тексте программы. Например, конструкция языка COBOL
MOVE X+Y TO Z
выражающая присваивание получателю Z значения выражения X+Y, совершенно аналогична обычному оператору присваивания.
Для того, чтобы четко отличать конкретное представление от существенной структуры, стоит рассматривать конкретный и абстрактный синтаксис. Скажем, абстрактный синтаксис всех перечисленных форм операции присваивания один и тот же.
Аналогично, три оператора
X = a * b + c * d; X = (a * b) + (c * d); (4.1) X = ((a * b) + (c * d));
и подобные им полностью эквивалентны с точки зрения абстрактного синтаксиса, тогда как с точки зрения текстового представления — различны.
Таким образом, нужна структура синтаксических понятий, которая соответствует некоторому алгоритмически разрешимому8) (см., напр. [20]) понятию эквивалентности программ. Но это понятие эквивалентности должно быть исключительно простым, поскольку теоретические результаты показывают, что нетривиальные понятия эквивалентности программ неразрешимы.
Выбранное понятие эквивалентности определяет структурное представление синтаксиса, используемого для задания абстрактного вычислителя (абстрактно-синтаксическое представление).
Фрагментом абстрактно-синтаксического представления является чаще всего применяемый на практике ход. Задают понятие синтаксической эквивалентности, которое очевидным образом согласуется с функциональной эквивалентностью. Так, например, предложения, перечисленные в примере 4.1, могут описываться следующим понятием синтаксической эквивалентности: скобки вокруг подвыражений, связанных операцией более высокого приоритета, чем операция, примененная к их результату, могут опускаться. В данном смысле присваивание рассматривается как операция, имеющая более низкий приоритет, чем любая из арифметических операций. Таким образом, например, определяется эквивалентность выражений в языке Prolog. Подвыражение X + 3, скажем, является в нем всего лишь другим вариантом записи для +(X,3), и при вычислении характеристик выражения оно прежде всего преобразуется в форму без знаков операций.
Еще одну возможность, открываемую переходом к абстрактно-синтаксическим определениям, можно увидеть, если определить эквивалентность подвыражений для сложения и умножения
A + B - B + A.
Здесь абстрактная эквивалентность выражает свойство самой операции. Опыт показывает, что дальше учета ассоциативности и коммутативности в абстрактном синтаксисе двигаться весьма опасно.
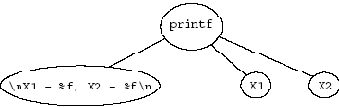
Рис. 4.1. Оператор печати
Пример на рис. 4.1 иллюстрирует вызов функции:
printf ("\nX1 = %f, X2 = %f\n", X1, X2);
Показанная на рисунке структура абстрактного синтаксиса данного оператора показывает, как можно ликвидировать привязку конструкции языка к конкретному синтаксису: остались только имя функции, строка и два параметра.
Рассмотрим более сложный пример, показывающий родство абстрактного синтаксиса традиционных языков. На рис. 4.2 показано абстрактное представление фрагмента текста следующей программы:
. . . if ( D > 0 ) { D = sqrt ( D );
Пример 4.5.1.
Текст некоторой программы
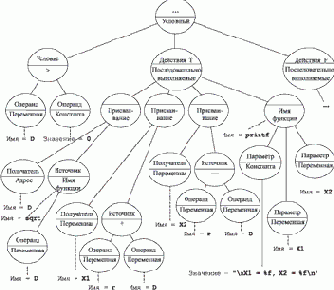
Рис. 4.2. Представление фрагмента текста программы
|
|
|
Язык программирования и алгоритмический язык почти всегда являются синонимами. В данном пособии они синонимичны.
2)
Нельзя абсолютизировать это требование. Совместные вычисления могут производиться в неизвестном программисту порядке. Более того, автору известен случай, когда прагматика (системы Common Lisp) четко отмечает, что в некотором случае нельзя пользоваться конкретным линейным порядком, который система порождает, пополняя заданный пользователем частичный порядок зависимостей, поскольку алгоритм упорядочивания может быть в любой момент и без предупреждения заменен. На самом деле такая прагматика часто полностью соответствует содержательному смыслу создаваемых программ: если два действия независимы, нельзя предполагать, что одно из них происходит раньше другого (хотя обычно программист вынужден это предполагать ввиду идиотизма "современных" систем). Если бы такие прагматические замечания встречались почаще!
3)
Поскольку синтаксис порою (особенно раньше) отождествлялся с контекстно-свободной его частью, в литературе иногда можно встретить термин "статическая семантика" для описания контекстных зависимостей. Вспоминая определение семантики, мы видим, что такой термин вводит в заблуждение.
4)
Даже возможная противоречивость библиотек друг другу соответствует стилю содержательного мышления (И.Н. Скопин).
5)
Вообще говоря, данная подсказка избыточна для современных трансляторов, поскольку распознать шаблон вида <переменная> ":=" <переменная /* та же самая */> "+" 1 и им подобные не представляет труда не только в тех случаях, когда <переменная> указана явно, но и тогда, когда она вычисляется (индексирование, косвенная адресация и т. д.).
6)
Сегодня с помощью семантической прагматики выражают также расширения модели вычислений, выводящие за рамки исходного абстрактного исполнителя. К примеру, — системы параллельного программирования над C++ и FORTRAN MPI и OPEN MP (И. Н. Скопин).
7)
Модель вычислений препроцессора можно охарактеризовать следующими свойствами. Исходные перерабатываемые данные — это текст (любой структуры, не обязательно на языке С), в котором имеются строки, начинающиеся с символа '#'. Такие строки представляют команды, управляющие работой препроцессора. Например, #include . . . заставляет препроцессор вставить некоторый файл в перерабатываемый текст (не следует понимать это буквально — нужно просто обеспечить соответствующий эффект). Другой пример: #define two 2 дает указание препроцессору на то, что в оставшейся части текста идентификатор two должен заменяться числом 2. Результат вычислений препроцессора — текст, который не содержит его команд.
8)
Как принято в современной теории, "алгоритмически разрешимое" далее называется просто "разрешимое".
Прагматика
До сих пор речь шла об определении языка его абстрактным вычислителем. Прагматика задает конкретизацию абстрактного вычислителя для данной вычислительной системы. Большая часть прагматики размазана по тексту документации о реализации языка (эту часть прагматики программист варьировать не может). Например, прагматическим является замечание, что тип Longint в системе Visual C++ определяется как 32-разрядное двоичное число с фиксированной точкой, занимающее слово памяти.
Та часть прагматики, которую может варьировать программист, требует отдельного синтаксического оформления. В языке Pascal есть так называемые прагматические комментарии, например, {$I+}, {$I-} (включение/выключение контроля ввода-вывода). Многие из таких комментариев практически во всех версиях одни и те же. В самом стандарте языка явно предписана лишь их внешняя форма: {$...}.
Даже если язык ориентирован на реализацию в единственной операционной обстановке (например, это какой-нибудь язык скриптов для микропроцессора, встроенного в собачий ошейник), для понимания сути того, что относится к действиям, а что — к их оптимизации, прагматику нужно выделить хотя бы в документации для программистов.
Принципиально различаются два вида прагматики языка программирования: синтаксическая и семантическая.
Синтаксическая прагматика — это правила сокращения записи, можно сказать, скоропись для данного языка. Пример, который можно рассматривать как синтаксическую прагматику — команды увеличения и уменьшения на единицу. В С/С++ они представлены операторами
<переменная>++; или ++<переменная>;
и
<переменная>--; или --<переменная>;
В С/С++ команды такого рода следует относить к модели вычислений языка, так как для нее постулируется, что язык является машинно-ориентированным и отражает особенности архитектуры вычислительного оборудования, а команды увеличения и уменьшения на единицу предоставляются программисту на уровне оборудования достаточно часто.
В Turbo Pascal и Object Pascal эти команды выражены следующим образом:
Inc (<переменная>)
и
Dec (<переменная>)
соответственно. Если рассматривать Turbo Pascal как правильное расширение стандартного языка Pascal, не содержащего обсуждаемые команды, то эти команды — просто подсказка транслятору, как надо программировать данное вычисление. Следовательно, указанные операторы для данного языка можно относить к прагматике 5).
Другой пример — возможность записи в языке Prolog вместо вызова +(X,Y) выражения X+Y.
Семантическая прагматика — это определение того, что в описании языка оставлено на усмотрение реализации или предписывается в качестве вариантов вычислений.
Например, стандарт языка Pascal утверждает, что при использовании переменной с индексом на уровне вычислений контролируется выход индекса за диапазон допустимых значений. Однако в объектном коде постоянные проверки этого свойства могут показаться накладными и избыточными (например, когда программа написана настолько хорошо, что можно гарантировать соответствующие значения индексов). Стандарт языка для таких случаев предусматривает сокращенный, т. е. без проверок, режим вычислений. Выбор режимов управляется пользователем с помощью прагматических указаний для транслятора, выражаемых в конкретном синтаксисе как прагматические комментарии {$R+} и {$R-}6).
Разработчики системы программирования должны прилагать специальные усилия, чтобы обеспечить явное выделение прагматического уровня. Без этого может сложиться превратное представление как о предлагаемой модели вычислений, так и о ее реализации. Вдобавок, резко ограничиваются возможности программиста в применении методов абстрагирования. Проиллюстрируем это.
Пример 4.4.1. Стандарт языка С предписывает, что системы программирования на нем должны предусматривать специальный инструмент для обработки программных текстов, который называется препроцессором. Препроцессор делает массу полезных преобразований. Как уже упоминалось, он берет на себя решение задачи подключения к программе внешних (библиотечных) файлов, с его помощью можно скрывать утомительные детали программирования, достигать ряда нужных эффектов, не предусмотренных в основных средствах языка (например, именованные константы).
Постулируется, что программа на языке С есть то, что получается после работы препроцессора с текстом (разумеется, если результат такой работы окажется корректным). Следовательно, использование препроцессора — синтаксическая прагматика языка. Но это противоречит практике работы программиста: он просто не в состоянии написать содержательную программу, которая может быть оттранслирована без использования препроцессора. Работа препроцессора не очень затрудняет понимание получившейся программы, если при программировании на С ограничиваются употреблением препроцессорных команд подключения файлов определений и определения констант. Но когда применяются, к примеру, условные препроцессорные конструкции, возможно появление программ-химер, зрительно воспринимаемый текст которых дезинформирует относительно их реальной структуры.
Пусть написано
if (x > 0) Firstmacro else PerformAction;
Кажется, что действие выполняется, если x

PrepareAction; if (x <= 0) CancelAction
Даже автор данной программы через некоторое время не поймет, почему же она так себя ведет.
Как это ни странно, подобные построения используются в практике программирования на С: они применяются, чтобы в одном тексте задать несколько вариантов выполняемых программ, которые разграничиваются при работе препроцессора, т. е. до выполнения.
Наложение команд препроцессора на текст программы — это смешение двух моделей вычислений: одна из них — модель базового языка С, другая — модель препроцессора7). В результате программист при составлении и изучении программ вынужден думать на двух уровнях сразу, а это трудно и провоцирует ошибки.
Разработчики С и С++ с самого начала не задумывались о соблюдении концептуальной целостности. Это приводило к тому, что при развитии языка он становился все более эклектичным.
Во многих языках, в частности в Object Pascal, для подобных целей используется более концептуально подходящее средство, так называемая условная компиляция. Суть его в том, что программисту дана возможность указать, что некоторый фрагмент компилируется, если при компиляции задан соответствующий параметр, и не компилируется в противном случае.
При этом оказывается исключенной ситуация, приведенная в предыдущем примере, поскольку чаще всего способ задания фрагмента привязан к синтаксическим конструкциям языка (т. е. условную компиляцию можно задавать не для произвольных фрагментов, а лишь для тех, которые являются языковыми конструкциями). При условной компиляции проверяется корректность синтаксиса и, что не менее существенно, зримый образ программы явно отражает ее вариантность (именно это свойство нарушено в примере 4.4.1).
Даже концептуально целостные системы в результате развития часто сползают к эклектичности. В этой связи поучительно обсудить развитие языка Pascal линии Turbo.
Модель вычислений стандартного языка Pascal изначально была довольно целостна, поскольку в ней четко проводились несколько хорошо согласованных базовых идей и не было ничего лишнего. Но она не во всем удовлетворяла практических программистов. В языке Pascal, в частности, не было модульности, и требовалась значительно более глубокая проработка прагматики, что стало стимулом для развития языка, на которое повлияла конкретная реализация: последовательность версий Turbo Pascal. Разработчики данной линии смогли сохранить стиль исходного языка вплоть до версии 7, несмотря на значительные расширения. В этом им помогло появление нового языка Modula, построенного как развитие языка Pascal в направлении модульности. Идея модульности и многие конкретные черты ее реализации, созданные в Modula, были добавлены к языку Pascal.
Далее пришел черед модных средств ООП, которые также были интегрированы в язык с минимальным ущербом для его концептуальной целостности.
Таким образом, создатели линии Turbo Pascal успешно решили трудную задачу расширения языка при сохранении концептуального единства и отделения прагматики от развивающейся модели вычислений.
Однако со столь трудной проблемой не удалось справиться тем же разработчикам, когда они взялись за конструирование принципиально новой системы программирования Delphi и ее языка Object Pascal. Одним из многих отрицательных следствий явилась принципиальная неотделимость языка от системы программирования.А далее история Delphi с точностью до деталей повторяет то, что было с языком С/С++. В последовавших версиях системы, вынужденных поддерживать преемственность, все более переплетаются модель вычислений и прагматика. Заметим, что "прагматизм" не принес никакого прагматического выигрыша: все равно Delphi плохо поддерживает современные системы middleware, ориентированные на C++ и Java.
Внимание!
Есть большая опасность, связанная с добавлением новых возможностей к хорошей системе без глубокой концептуальной проработки. Сплошь и рядом то, что хорошо работало раньше, после таких модификаций перестает устойчиво работать.
Текст некоторой
| . . . if ( D > 0 ) { D = sqrt ( D ); |
| Пример 4.5.1. Текст некоторой программы |
| Закрыть окно |
Различные стороны определения языка
Для создания, проверки и преобразования программ, построения систем программирования, а также для многих других нужд нам необходимо если не определение, то хотя бы описание алгоритмического языка. При этом требуются точные описания как текстов, так и их интерпретации. Рассмотрим существующие варианты.
Сама программа-транслятор считается описанием языка. Тут сразу точно описаны и тексты (правильная программа — та, на которой транслятор не выдает ошибки), и их интерпретация (интерпретация программы — то, как исполняется ее текст после перевода транслятором).
Именно так пытались поступать на заре программирования, когда, скажем, легендарный язык FORTRAN создавался одновременно с первым транслятором с данного языка.
Определением языка считается формальная лингвистическая система (грамматика). Впервые этот подход был последовательно применен в Алголе. Встречавшиеся вам при изучении языков синтаксические диаграммы являются непосредственными потомками того, что было сделано в Алголе.Определением языка считается соответствие между структурными единицами текста и правилами интерпретации. Этот вариант был полностью реализован при определении языка Алгол 68.
Первый вариант — совершенно неудовлетворительный путь, поскольку всякое изменение в программе-трансляторе может полностью изменить смысл некоторых конструкций языка со всеми вытекающими отсюда последствиями.
Второй вариант соответствует взгляду на язык как на множество правильно построенных последовательностей символов. Если последовательность символов принадлежит языку, то она считается синтаксически правильной. Для программы это означает, что транслятор на ней не выдает ошибки. Но синтаксическая правильность не гарантирует даже осмысленности программы. Таким образом, здесь определяется лишь одна сторона языка.
Третий вариант работает только вместе со вторым, поскольку структурные единицы должны соединиться в синтаксически правильную систему. Он раскрывает еще одну сторону языка.
Таким образом, мы видим, что каждый язык имеет три стороны: синтаксис (второй вариант), семантика (третий вариант), прагматика (первый вариант).
Синтаксис алгоритмического языка — совокупность правил, позволяющая:
формально проверить текст программы (выделив множество синтаксически правильных программ); разбить эти программы на составляющие конструкции и в конце концов на лексемы.
Семантика алгоритмического языка — соответствие между синтаксически правильными программами и действиями абстрактного исполнителя, позволяющее определить, какие последовательности действий абстрактного исполнителя будут правильны в случае, если мы имеем данную программу и данное ее внешнее окружение.
Под внешним окружением понимаются характеристики машины, на которой исполняется программа (точность представления данных, объем памяти, другие программы, которые можно использовать при выполнении данной, и т. д.), и потоки входных данных, поступающие в программу в ходе ее исполнения.
Прагматика алгоритмического языка — то, что связывает программу с ее конкретной реализацией. При этом, в частности, происходит следующее.
Все определения становятся явными (изгоняются такие понятия, как "не определено", "определяется реализацией" и т. п.)2).Появляются дополнительные конструкции, описатели и др., обусловленные реализацией. Они обязательно учитывают: особенности вычислительной машины и среды вычислений;особенности принятой схемы реализации языка;обеспечение эффективности вычислений;ориентацию на специфику пользователей.
Прагматика иногда предписывается стандартом языка, иногда нет. Это зависит от того, для каких целей предназначены язык и его реализация.
Описание языка требует точного задания синтаксиса и семантики. На практике, однако, чем точнее и чем лучше для построения транслятора описан язык, тем, как правило, такое описание более громоздко и менее понятно для обычного человека, и поэтому точные описания существуют не для всех реальных языков программирования. Даже если они имеются, то в виде стандартов, к которым обращаются лишь в крайних случаях.
Семантика
Мы определили семантику как соответствие между синтаксически правильными программами и действиями абстрактного исполнителя. Но остается вопрос, как задавать это соответствие. Семантика чаще всего определяется индукцией (рекурсией) по синтаксическим определениям.
Цель программиста - получить нужный ему эффект в результате исполнения программы на конкретном оборудовании. Но, составляя программу, он думает о программе как об абстрактной сущности и чаще всего совсем не хочет знать о регистрах, процессоре и других объектах конкретного оборудования. В соответствии с позицией программиста моделью вычислений языка программирования естественно считать то, какой абстрактный вычислитель задается описанием языка. Эта позиция подкрепляется также тем, что трансляция и исполнение может осуществляться на разных конкретных вычислителях. Следуя этой точке зрения, мы, говоря о модели программы, всегда имеем в виду ее образ в виде команд абстрактного, а не конкретного вычислителя.
Понятие модели вычислений языка естественно распространяется на случаи, когда используются библиотеки программ. Библиотеки, стандартизованные описанием языка, можно считать частью реализации языка независимо от того, как реализуются библиотечные средства: на самом языке или нет. Иными словами, библиотечные средства - дополнительные команды абстрактного вычислителя языка. Не зависящие от определения языка библиотеки можно рассматривать как расширения языка, т. е. как появление новых языков, включающих в себя исходный язык. И хотя таких расширений может быть много, рассмотрение модели вычислений для языка вместе с его библиотеками хорошо соответствует стилю мышления человека, конструирующего программу4).
Задаваемое семантикой соответствие между входными данными, программой и действиями, вообще говоря, определяется лишь полным текстом программы, включающим, в частности, все тексты используемых библиотечных модулей, но для понимания программы и работы над ней необходимо, чтобы синтаксически законченные фрагменты программы могли интерпретироваться автономно от окружающего их текста. Надо заметить, что современные системы практически никогда этому требованию не удовлетворяют. Слишком часто для понимания ошибки в программе нужно анализировать необъятные тексты библиотек.
Реализованный язык всегда является прагматическим компромиссом между абстрактной моделью вычислений и возможностями ее воплощения.
и самая разработанная часть описания
Синтаксис — самая простая и самая разработанная часть описания алгоритмического языка.
Грамматика определяется системой синтаксических правил (чаще всего в описаниях языков называемых просто правилами). На уровне грамматики определяются понятия, последовательное раскрытие которых, называемое выводом, в конце концов дает их представление в виде последовательностей символов. Символы называются также терминальными понятиями, а все остальные понятия нетерминальными. Понятия бывают смысловые, т. е. языковые конструкции, для которых определено то или иное действие абстрактного вычислителя, и вспомогательные, нужные лишь для построения текста, но самостоятельного смысла не имеющие. Минимальные смысловые понятия соответствуют лексемам. Некоторые понятия вводятся лишь для того, чтобы сделать текст читаемым для человека. Минимальные из них (они подобны знакам пунктуации) естественно считать вспомогательными лексемами.
Но даже задача полного описания синтаксиса достаточно сложна и требует выделения подзадач.
Синтаксис принято разделять на две части:
контекстно-свободную грамматику (КС-грамматику) языка;правила задания контекстных зависимостей (например, соответствия между описаниями и именами).
Понятие контекстно-свободной грамматики стало первым строгим понятием в описаниях практических алгоритмических языков. За понятием КС-грамматики при внешней его простоте стоит достаточно серьезная теория. Эта грамматика представляется во многих формах (синтаксические диаграммы, металингвистические формулы Бэкуса-Наура либо расширенные металингвистические формулы) и, как правило, сопровождает систематизированное изложение конкретного языка. Каждое такое конкретное представление КС-грамматики достаточно просто, и может быть изучено по любому учебнику программирования.
Содержательно можно охарактеризовать КС-грамматику языка как ту часть его синтаксиса, которая игнорирует вопросы, связанные с зависимостью интерпретации лексем от описаний имен в программе.
Контекстные зависимости сужают множество правильных программ.
Например, правило " все идентификаторы должны иметь описания в программе" указывает на то, что программа с неописанными именами не принадлежит данному языку (хотя она и допустима с точки зрения контекстно-свободного синтаксиса).
Неоднократные попытки формально описывать контекстные зависимости при определении языков показали, что эта задача гораздо более сложная, чем задание контекстно-свободного синтаксиса. Вдобавок ко всему, даже такие естественные правила, как только что представленное, при формальном описании становятся громоздкими и весьма трудными для понимания человека. По этой причине в руководствах редко прибегают к формализации описаний контекстных зависимостей (одним из немногих исключений является Алгол 68).
Пример 4.2.1. Требование о том, что каждое имя должно быть описано (в частности, в языках Pascal и C), конкретизируется в следующей форме.
Для каждого имени должно быть описание, в котором оно встречается.Это описание должно стоять либо в данном, либо в охватывающем его блоке и предшествовать в тексте программы использованию данного имени.Два описания одного и того же имени в одном и том же блоке не считаются ошибкой лишь в том случае, если первое из них является предварительным упоминанием, а второе — полноценным описанием.Если есть несколько описаний одного и того же имени в разных блоках, действующим считается то из них, которое стоит в самом внутреннем блоке.Если действующее описание определяет имя как глобальное, то оно не должно противоречить никакому другому глобальному описанию того же имени, встречающемуся в других блоках программы.
Такая совокупность требований достаточна для того, чтобы человек мог проверить по тексту программы, как в данном месте понимается данное имя3).
В практических описаниях языков и в курсах программирования обычно довольствуются неформальным, но достаточно точным описанием контекстных зависимостей. Приведем пример такого описания.
Алгоритм для сопоставления объектного выражения E с образцом P в Рефал-5.
Вхождения атомов, скобок и переменных будут называться элементами выражений. Пропуски между элементами будут называться узлами. Сопоставление E : P определяется как процесс отображения, или проектирования, элементов и узлов образца P на элементы и узлы объектного выражения E. Графическое представление успешного сопоставления приведено на рис. 5.2. Здесь узлы представлены знаками o.
Следующие требования являются инвариантом алгоритма сопоставления и их выполнение обеспечивается на каждой его стадии.
Дополнительные возможности
В нашей программе 5.3.1 алфавит определен статически. Было бы хорошо иметь возможность заменять эту глобальную информацию. Для хранения динамической глобальной информации (чаще всего числовых характеристик либо словарей) в языке Рефал имеются стандартные функции работы со стеками закопанных данных. Функция
<Br e.N '=' e.Е >
рассматривает свой первый аргумент (который должен быть строкой символов, не включающей '=') как имя стека, и помещает свой второй аргумент на вершину этого стека. Если стек был пуст, то он создается. Соответственно, функция
<Dg e.N>
выкапывает верхушку стека. Если стек пуст, то ошибки нет, просто выдается пустое выражение. Несколько других функций дополняют возможности работы с глобальной информацией. Cp копирует верхушку стека без ее удаления, Rp замещает верхушку стека на свой аргумент, DgAll выкапывает сразу весь стек.
Ввод-вывод организован в Рефале довольно лаконично, без излишеств. Имеется функция открытия канала ввода, которая открывает файл либо для ввода, либо для вывода (в этом случае первым аргументом служит 'r' и присваивает ему номер. Одна строка символов из файла читается с помощью функции Get, заменяющей свой вызов на прочитанную строку, одна строка пишется в файл путем функций
<Put s.Channel e.Expression>
либо
<Putout s.Channel e.Expression>
Вторая функция стирает свое поле зрения, а первая оставляет в качестве результата напечатанное выражение.
Следует заметить, что эти функции читают и пишут именно последовательности символов. При их использовании программист должен сам преобразовать последовательности цифр в числа, а скобки-символы в структурные скобки. Более того, при выводе часть информации теряется: невозможно различить последовательность букв и идентификатор, последовательность цифр и число, структурные скобки и скобки-символы. Поэтому имеется еще одна совокупность функций, автоматизирующих преобразование. Каждая из этих функций обрабатывает сбалансированное по скобкам выражение. При вводе это выражение заканчивается пустой строкой.
<Input s.Channel> или <Input e.File-name> <Xxin e.File-name> или <Xxin s.Channel> <Xxout s.Channel e.Expr> или <Xxout (e.File-name)e.Expr>
Первая из функций предназначена для ввода файлов, подготовленных вручную. Вторая и третья — для обмена промежуточной информацией с диском.
Только что перечисленные функции вместе с функцией Go требуют объяснения инструментов модульности в Рефале. Рефал-модуль — просто Рефал-программа, не обязательно включающая Go. Функции, предоставляемые в пользование другим модулям, описываются спецификатором $ENTRY как входы. В свою очередь, использующий модуль должен описать внешние функции:
$EXTRN F1,F2,F3;
Вызов программы, состоящей из нескольких модулей, производится оператором примерно следующего вида:
refgo prog1+functions+reflib
Модуль основной программы должен идти первым. Никаких средств включить требование вызова модуля в текст другого модуля нет, модули сопрягаются внешним образом. При конфликтах имен берется определение функции из первого в порядке подключения модуля.
В частности, только что описанные расширенные функции ввода-вывода определяются в стандартном модуле reflib.
Важнейшими средствами современного Рефала является работа с метавыражениями. Базовое ее средство — встроенная функция Mu, которая заключает свой аргумент в функциональные скобки и тем самым дает возможность вычислить динамически построенное выражение. По словам Турчина, Mu работает так, как работало бы определение
Mu { s.F e.X = <s.F e.X> },
если бы оно было синтаксически допустимо.
В частности, через Mu работает стандартный модуль Рефала e (Evaluation), дающий возможность вычислить динамически введенное выражение. Он обрабатывает это выражение через функцию Upd, которая должна быть добавлена к модулю, где осуществляется динамическое вычисление выражений. Например, если добавить описание
$ENTRY Upd {e.X = <Mu e.X>;}
то командная строка refgo e+prog1 приведет к требованию написать выражение. Это выражение будет сделано полем памяти программы prog1 и вычислено, а результат выведен.
Например, написав для программы 5.3.1
<Alphabet>
мы получим в качестве результата
'abcdefghijklmnopqrstuvwxyz'
Естественно возникает вопрос об обработке внутри языка не только объектных, но и произвольных выражений. Для этого имеются стандартные функции Up и Dn. Первая из них превращает объектное выражение в выражение произвольного вида, вторая кодирует свою область зрения (ею, по семантике языка, может быть лишь объектное выражение) в форме, годящейся для общих выражений и даже метавыражений. В стандартном комплекте Рефала есть даже модуль прогонки, который позволяет подать на вход программы метавыражение и вычислить его настолько, насколько это возможно без знания значений переменных.
При решении сложных задач на Рефале естественно возникла задача представления мультииерархической структуры. Для частного случая двух независимых иерархий, одна из которых считается главной, а вторая начнет работать после исчерпания главной, в Рефале разработано мультискобочное представление выражений.Оно поддерживается библиотечными функциями кодирования и декодирования выражений и программ, переводящих мультискобочное выражение в его стандартный код и наоборот. Для частного случая, когда вторичная иерархия — наши обычные скобки, а первичная иерархия — ссылка глубоко внутрь скобочного выражения, неявно задающая одноуровневую скобочную структуру, независимую от стандартной, алгоритм кодирования исключительно прост. Выражение разбито на две несбалансированные по скобкам части: левую и правую. В обеих частях непарные скобки заменяем на пары )(. Открывающую скобку высшего уровня представляем как ((, место, куда ведет ссылка — как ))(, закрывающую скобку высшего уровня как )).
И в заключение рассмотрим достаточно сложный алгоритм на Рефале, иллюстрирующий многие приемы программирования: хранение промежуточной информации, обработку ошибок, ввод-вывод.
Пусть у нас дано выражение с различными парными скобками (в конкретном случае мы используем пары '()[]{}<>', но программа составлена так, чтобы эти пары можно было заменить в любой момент).
Для эффективной работы на Рефале это выражение нужно закодировать, используя структурные скобки. Кодом пары скобок Левая Правая будут скобки (Левая и Правая). Ниже дан алгоритм кодировки.
При записи данного алгоритма используется еще одна возможность Рефала-5. После образца через запятую может идти произвольное выражение, включающее свободные переменные образца, а затем другой образец. Во втором образце мы отождествляем вспомогательное выражение, не изменяя значений переменных, унаследованных из предыдущего образца. Если после второго образца идут фигурные скобки, то мы задаем безымянную функцию внутри функции. Если же их нет, то это отождествление рассматривается как дополнительное условие успешности первого отождествления. Эта иерархия вложенности может продолжиться на несколько уровней, причем переменные внешних уровней на внутренних уровнях остаются связанными, уже не изменяя значений.
Иерархически вложенные функции и условия в принципе не нужны для Рефала, но их использование позволяет сократить и, главное, лучше структурировать текст программы.
$ENTRY Go{=<Init>;} $EXTRN Xxout; * Инициализация поля зрения и констант Init{=<Open 'r' 1 'Input.txt'><Trans <Acquire(<Get 1>)";} Acquire { e.Got ()= e.Got; * Конец ввода - пустая строка e.Got (e.New)=<Acquire e.Got e.New (<Get 1>)>; } Brackets {=('()')('[]')('')('<>');} Trans { e.A =<Result <Pairing () e.A > >; } Pairing { * В первой скобке содержится последовательность всех незакрытых * скобок вместе с сегментами данных, подлежащими помещению * в даннуюпару скобок; * каждый сегмент данных также заключен в скобки (e.Unclosed (e.LastUn)(s.Lbrack e.Middle)) s.Rbrack e.Last, <Brackets>: e.A(s.Lbrack s.Rbrack ) e.B = * Встретилась правая скобка, парная последней незакрытой; * выбрасываем отработанный сегмент из поля зрения <Pairing (e.Unclosed (e.LastUn (s.Lbrack e.Middle s.Rbrack))) e.Last>; ((s.Lbrack e.Middle)) s.Rbrack e.Last, <Brackets>: e.A(s.Lbrack s.Rbrack ) e.B = * Парная незакрытой, находящейся внутри другой незакрытой (s.Lbrack e.Middle s.Rbrack) <Pairing () e.Last>; (e.Unclosed (e.LastUn)(s.Lbrack e.Middle)) s.Rbrack e.Last, <Brackets>: e.A(s.Lbrack1 s.Rbrack ) e.B = * Непарные скобки <Prout "Brackets Mismatch!"> Error; (e.Unclosed ) s.Lbrack1 e.Last, <Brackets>: e.A(s.Lbrack1 s.Rbrack ) e.B = * Еще одна открывающая скобка; создаем новую группу данных <Pairing (e.Unclosed (s.Lbrack1)) e.Last>; () s.Lbrack e.Last, <Brackets>: e.A(s.Lbrack s.Rbrack ) e.B = * Первая открывающая скобка <Pairing ((s.Lbrack)) e.Last>; () s.Rbrack e.Last, <Brackets>: e.A(s.Lbrack s.Rbrack ) e.B = * Первая скобка - закрывающая <Prout "Extra right bracket"> Error; * Нейтральный символ вне скобок () s.Other e.Last = s.Other <Pairing () e.Last>; * Выражение и скобки исчерпаны - успех () =; * Выражение исчерпано, а скобки - нет (e.Unclosed (e.Lastun))=<Prout "Not all brackets are closed" Error; * Нейтральный символ в очередной скобке (e.Unclosed (e.Lastun))s.Other e.Last= <Pairing (e.Unclosed(e.Lastun s.Other)) e.Last>; } Result { * Если была ошибка, выйти e.A Error=; * Иначе вывести результат для дальнейшего использования e.A =<Xxout ('output.rdt') e.A>; }
Листинг 5.4.1. Мультискобочное выражение: Рефал
Для того, чтобы нагляднее увидеть влияние стиля на программные решения, сравните эту программу с развитием программы в традиционном стиле, приведенным в § 11.5 книги [22]. Данная программа намного выразительнее, короче, легче модифицируема и не менее эффективна, чем программа 11.5.3 из указанного параграфа.
В практике работы со студентами автору приходилось сталкиваться с ситуацией, когда программа для одной и той же задачи, написанная на традиционном языке, была более чем в пять раз длиннее программы на Рефале. Так что использование специализированных инструментов окупается (естественно, когда они применены в подходящих случаях).
Из литературы по языку Рефал можно рекомендовать учебные пособия [38], первое из которых имеется в общедоступном русском переводе, в частности на сайте http://www.refal.ru/diaspora.html.
|
|
|
Здесь слово 'структура' понимается не в узко программистском, а в научном и математическом смысле.
2)
Здесь у языка Рефал общая особенность с языками Prolog и LISP!
3)
Заметьте тонкую разницу между словами 'формироваться' и 'задаваться'! Имена функций заданы статически, но конкретное имя из заданного конечного множества функций может быть сформировано динамически.
4)
При реализации языка Рефал В. Ф. Турчин задумался, как избежать слишком частых обращений к каким-то суррогатам возможностей традиционных языков. Он решил заранее описать алгоритм преобразования выражений и подобрать для него подходящую структуру данных. Описанный им алгоритм хорошо работает с целым классом случаев, включая те, которые заранее не предусматривались, — отличительный признак концептуально продуманного решения. В лекции, относящийся к языку PROLOG можно увидеть, что происходит, если структуру данных хорошо не продумать на ранних этапах, а тем более зафиксировать случайные промежуточные результаты как стандарт.
Более того, описанные Турчиным алгоритм и структуры данных являются отличной базой для точного определения семантики на базе абстрактного синтаксиса языка Рефал.
5)
Изменение, введенное в ныне работающую реализацию Refal-PZ. В учебнике Турчина двойные кавычки являются альтернативным вариантом ограничителя строк.
6)
К этой концептуальной конфетке еще бы красивую обертку!
Конкретизация
Язык Рефал был создан В. Ф. Турчиным для программирования символьных преобразований. Исходный толчок он получил от идеи алгорифмов Маркова (см., например, теоретическое приложение к книге [21]), но эта идея была полностью пересмотрена в ходе работы по созданию языка. Идейный и математический уровень проработки языка исключительно высокий, но вопросы дизайна почти проигнорированы.
В основе языка лежит (другой по сравнению с языком PROLOG) частный случай операции отождествления: конкретизация метавыражения.
Под конкретизацией понимается такой частный случай отождествления, при котором переменные встречаются лишь в метавыражении и поиск их значений происходит путем подбора без рекурсии.
Язык Рефал определен через три компонента: структуру данных, Рефал-машину, обрабатывающую эти данные, и собственно конкретный синтаксис языка.
Модель вычислений и Рефал-программа
Основные два шага в Рефал-вычислениях — конкретизация переменных в образце в соответствии с областью зрения и подстановка полученных значений в другое метавыражение. В языке рассматривается лишь частный случай конкретизации.
Конкретизация образца Me в объектное выражение E называется такая подстановка значений вместо переменных Me, что после применения данной подстановки Me совпадет с E.
Заметим, что одно и то же метавыражение может иметь много конкретизаций в одно и то же объектное выражение. Например, рассмотрим метавыражение
e.Begin s.Middle e.End (5.3)
и объектное выражение
AhAhAh 'OhOhOh' (Ugu','Udgu) '(((' Basta'!' (5.4)
Имеется 11 вариантов конкретизации (5.3) в (5.4) (проверьте!).
Если у метавыражения Me есть много вариантов конкретизации в E, то они упорядочиваются по предпочтительности в следующем порядке.
Пусть Env1 и Env2 — два варианта конкретизации Me в P. Рассмотрим все вхождения переменных в Me. Если Env1 и Env2 не совпадают, они приписывают некоторым переменным различные значения. Найдем в P самое первое слева вхождение переменной, которому Env1 и Env2 приписывают разные значения и сравним длину этих значений. Та из конкретизаций, в которой значение, приписываемое данному вхождению переменной, короче, предшествует другой и имеет приоритет перед ней.
Например, сопоставим объектное выражение (A1 A2 A3)(B1 B2) с образцом e.1 (e.X s.A e.Y) e.2. В результате получится следующее множество вариантов сопоставления:
{e.1 = , eX = , sA = A1, eY = A2 A3, e.2 = (B1 B2) } {e.1 = , eX = A1, sA = A2, eY = A3, e.2 = (B1 B2) } {e.1 = , eX = A1 A2, sA = A3, eY = , e.2 = (B1 B2) } {e.1 = (A1 A2 A3), eX = , sA = B1, eY = B2, e.2 = } {e.1 = (A1 A2 A3), eX = B1, sA = B2, eY = , e.2 = }
Пример 5.1. Множество вариантов сопоставления
Варианты сопоставления перечислены в соответствии с их приоритетами, т. е. самый первый вариант находится на первом месте и т. д. Описанный способ упорядочения вариантов сопоставления называется сопоставлением слева направо.
Тот алгоритм конкретизации, который используется в Рефале, называется проецированием и согласован с введенным нами отношением порядка. Опишем его (описание взято из учебника Турчина [38]). Обратите внимание, как в данном случае общая и не всегда эффективно реализуемая операция 'проецируется' на свою частную реализацию, одновременно повышающую эффективность, сохраняющую общность и предписывающую методику программирования.
Общие требования к отображению P на E (сопоставлению E : P)
Если узел N2 расположен в P правее узла N1, то проекция N2 в E может либо совпадать с проекцией N1, либо располагаться справа от нее (линии проектирования не могут пересекаться).Скобки и атомы должны совпадать со своими проекциями.
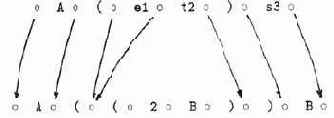
Рис. 5.2. Сопоставление E : P является отображением P на E. Здесь объектным выражением E является 'A'((2'B'))'B', а образцом P является 'A'(e.1 t.2)s.3
Проекции переменных должны удовлетворять синтаксическим требованиям их значений; т. е., быть в соответствии с типом переменной атомами, термами или произвольными выражениями. Различные вхождения одной переменной должны иметь одинаковые проекции.
Предполагается, что в начале сопоставления граничные узлы P отображаются в граничные узлы E. Процесс отображения описывается при помощи следующих шести правил. На каждом шаге отображения правила 1–4 определяют следующий элемент, подлежащий отображению; таким образом, каждый элемент из P получает при отображении уникальный номер.
Правила отображения
После того как отображена скобка, следующей подлежит отображению парная ей скобка.Если в результате предыдущих шагов оба конца вхождения некоторой переменной для выражений уже отображены, но эта переменная еще не имеет значения (ни одно другое ее вхождение не было отображено), то эта переменная отображается следующей. Такие вхождения называются закрытыми e-переменными. Две закрытые e-переменные могут появиться одновременно; в этом случае та, что слева, отображается первой.Вхождение переменной, которая уже получила значение, является повторным. Скобки, атомы, символьные и термовые переменные и повторные вхождения переменных для выражений в P являются жесткими элементами. Если один из концов жесткого элемента отображен, проекция второго конца определена однозначно. Если Правила 1 и 2 неприменимы, и имеется несколько жестких элементов с одним спроектированным концом, то из них выбирается самый левый. Если возможно отобразить этот элемент, не вступая в противоречие с общими требованиями 1–3, приведенными выше, тогда он отображается, и процесс продолжается дальше. В противном случае объявляется тупиковая ситуация.Если Правила 1–3 неприменимы и имеются несколько переменных для выражений с отображенным левым концом, то выбирается самая левая из них.Она называется открытой e-переменной. Первоначально она получает пустое значение, т. е. ее правый конец проектируется на тот же узел, что и левый. Другие значения могут присваиваться открытым переменным через удлинение (см. Правило 6).Если все элементы P отображены, это значит, что процесс сопоставления успешно завершен.В тупиковой ситуации процесс возвращается назад к последней открытой e-переменной (т. е. к той, что имеет максимальный номер проекции), и ее значение удлиняется; т. е. проекция ее правого конца в E продвигается на один терм вправо. После этого процесс возобновляется. Если переменную нельзя удлинить (из-за Общих требований 1–3), удлиняется предшествующая открытая переменная, и т. д. Если не имеется подлежащих удлинению открытых переменных, процесс сопоставления не удался.
На рис. 5. 2 сопоставление производится следующим образом. Вначале имеется два жестких элемента с одним отображенным концом: 'A' и s.3. В соответствии с Правилом 3 отображается 'A', и этот элемент получает при отображении номер 1.Номера 2 и 3 будут назначены левой и правой скобкам согласно Правилам 3 и 1. Внутри скобок начинается перемещение справа налево, так как t.2 является жестким элементом, который может быть отображен, в то время как значение e.1 еще не может быть определено. На следующем шаге обнаруживается, что e.1 является закрытой переменной, чью проекцию не требуется обозревать для того, чтобы присвоить ей значение; что бы ни было между двумя узлами, это годится для присвоения (на самом деле, значение e.1 оказывается пустым). Отображение s.3 завершает сопоставление. Расположение отображающих номеров над элементами образца дает наглядное представление описанного алгоритма:
1 2 5 4 3 6 'A' ( e.1 t.2 ) s.3
Этот сложный алгоритм упрятан в простые программные конструкции.
Программа на Рефале является последовательностью определений функций. Каждое описание функции в Рефале имеет вид
Имя функции {Последовательность сопоставлений}
Каждое сопоставление имеет вид
Образец = Метавыражение;
Относительное расположение членов последовательности определений никакой роли не играет, и функции можно группировать из логических или технологических соображений. Относительное расположение сопоставлений внутри определения функции существенно.
Пример 5.3.2. Рассмотрим пример Рефал-программы.
Pre_alph { *1. Отношение рефлексивно s.1 s.1 = T; *2. Если буквы различны, проверить, входит ли * первая из них в алфавит до второй s.1 s.2 = <Before s.1 s.2 In <Alphabet>>; } Before { s.1 s.2 In e.A s.1 e.B s.2 e.C = T; e.Z = F; } Alphabet { = 'abcdefghijklmnopqrstuvwxyz'; }
Листинг 5.3.1. Программа вычисления предиката предшествования одного символа другому в заданном алфавите
Строки, начинающиеся с *, служат комментариями. Последняя из функций Alphabet введена для технологичности, чтобы определение алфавита было в одном месте и его легко было изменять.
A1 A2, sA
| {e.1 = , eX = , sA = A1, eY = A2 A3, e.2 = (B1 B2) } {e.1 = , eX = A1, sA = A2, eY = A3, e.2 = (B1 B2) } {e.1 = , eX = A1 A2, sA = A3, eY = , e.2 = (B1 B2) } {e.1 = (A1 A2 A3), eX = , sA = B1, eY = B2, e.2 = } {e.1 = (A1 A2 A3), eX = B1, sA = B2, eY = , e.2 = } |
| Пример 5.1. Множество вариантов сопоставления |
| Закрыть окно |
Структура данных
Данные, обрабатываемые языком Рефал, представляют собой последовательности атомов, структурированные несколькими согласованными между собою видами скобок. Например, в некотором конкретном синтаксисе такое выражение могло бы иметь вид {a+[b-(c+d)**2]/3}*(a+d). В поле памяти Рефал-машины задействованы два вида скобок: структурные и функциональные.
Выражения языка Рефал.
Атомы являются выражениями.Любая последовательность выражений является выражением.Выражение E, заключенное в структурные скобки, является выражением. Атомы и выражения в структурных скобках носят общее имя термов.Если E — выражение, A — описанный в программе атом, AE, заключенное в функциональные скобки, является выражением (называемым функциональным выражением). A называется детерминативом этого выражения.
В конкретном синтаксисе Рефала функциональные скобки обозначаются < >, структурные -- ( ). Атомы делятся на:
Символы (байты, простые символы).Составные символы (имена, определенные в программе) представлены идентификаторами, начинающимися с большой буквы.Целые числа без знака, меньшие 232, например, 123456789.Действительные числа, например, 123456789.E-5.
В поле памяти выделяется основная часть, а также стеки глобальных данных - закопанные данные. Перед каждым шагом исполнения в основной части поля памяти выделяется активная часть - поле зрения. Данные в поле зрения и закопанные данные имеют общую структуру1), которая является подструктурой структуры поля памяти. Поскольку и программа имеет практически ту же самую структуру2), в ходе развития языка появилась третья структура данных (метаданные), расширяющая поле памяти.
Дадим точные определения.
Объектное выражение — выражение, не содержащее функциональных скобок.
Минимальное функциональное выражение — выражение, имеющее вид <E>, где E — объектное выражение.
поле памяти Рефал-машины представляет собой набор выражений, одно из которых называется основной частью. В основной части в любой момент, за исключением момента выдачи окончательного результата и остановки программы, есть функциональные скобки.
Поле зрения (активная часть) поле памяти — первое из встречающихся в основной части поля памяти минимальных функциональных выражений.
Детерминатив — первый символ в функциональной скобке.
Детерминатив интерпретируется как имя функции, обрабатывающей содержимое функциональных скобок. Эта функция должна определяться статически, поэтому в ходе вычислений не могут образовываться выражения вида < <e.1> e.2>. В подавляющем большинстве случаев детерминатив должен быть именем, но некоторые обычные символы, например +, также могут использоваться в качестве детерминативов.
Пример 5.2.3. Рассмотрим пример памяти Рефал-машины в ходе вычислений.
Поле памяти:
'aaxzACDE' <Sort <Perm 'G'1.5E5> <Perm 115 'F'> <Perm 112 -2.0E-5>><Sort AllRight Sort Perm 'QRTS'>'XZ<(')
Поле зрения выделено в поле памяти жирным шрифтом. Заметим, что в поле памяти можно выделить данные, обработка которых уже завершена и которые не изменятся до конца исполнения программы (те, которые находятся вне программных скобок; в нашем случае 'aaxzACDE' и 'XZ<('). У символов, представляющих скобки, есть 'обычные' двойники, не обязательно имеющие парные и не влияющие на структурирование выражения. Первый атом Perm стоит в позиции функции, а последний из атомов Perm стоит в позиции данных, так что имена функций могут формироваться3) динамически. При записи программы пробелы, если они не находятся внутри символьных констант, игнорируются, за исключением тех, которые отделяют один символ от другого (эти пробелы просто опускаются после того, как на этапе лексического анализа сыграли роль разделителей). И, наконец, еще одна тонкость. 123 — это один атом, '123' — три атома, -123.0 — опять один атом, -123 — два атома: символ '-', после которого стоит число.
Кроме основной части поля памяти, в ходе исполнения может появиться несколько стеков закопанных выражений, например:
Stack1 '=' 15 Stack2 '=' Perm B A 21 Perm C2 C1 -45 Perm 'X' 20 60
В принципе, несколько стеков — избыточная конструкция.
Но, поскольку здесь стеки рассматриваются как общие области памяти, лучше в каждом модуле иметь свой стек. К сожалению, явной связи между стеками и модулями в Рефал-программах нет.
Допустим, есть строка < AB(CD)(E)F>. Она во всех известных нам Рефал-системах представляется двунаправленным списком, изображенным на рис. 5.1. Этот формат представления стал общераспространенным для Рефал-систем, начиная с реализации, описанной в [25]. Однако
Рис. 5.1. Реализация структуры данных Рефала
он не является обязательным4). Преобразование выражений в формат для обработки делается один раз, при вводе информации либо при трансляции программы.
Рассмотрим конкретный синтаксис выражений.
Идентификатор — любая последовательность цифр и букв, начинающаяся с большой буквы. Идентификатор является символьным литералом и представляет составной символ. Символы, заключенные в одинарные ' ' кавычки, являются символьными литералами, представляют сами себя. Дважды повторенная кавычка представляет кавычку. Двойные кавычки " " используются для ограничения имени составного символа, не обязательно являющегося идентификатором5). Если вне кавычек встречается символ, не являющийся скобкой, частью идентификатора или числа, это трактуется как ошибка.
Определение метавыражения Рефала получается из определения выражения добавлением еще одного базисного случая: переменная является метавыражением.Переменные не могут быть детерминативами.
Метавыражение называется образцом, если оно не содержит функциональных скобок.
В конкретном синтаксисе обозначение переменной включает тип и символ переменной, записываемые как тип.атом. В стандартном Рефале имеются переменные трех типов: символьные (s.First), термовые (t.Inner) и общие (e.Last).
Значением символьной переменной служит атом, термовой — терм (символ или выражение в скобках), общей — произвольное (может быть, пустое) объектное выражение.
Рефал развивался как язык символьных преобразований в самом широком смысле этого слова, и поэтому в него была заложена возможность обрабатывать собственные программы.Он предоставляет стандартные функции метакодирования, взаимно-однозначно и взаимнообратно преобразующие произвольное метавыражение в объектное и наоборот. Таким образом, появляется возможность создавать программы в ходе выполнения других программ и затем выполнять их "на лету". Такая возможность, просто гибельная для программ в большинстве систем и стилей программирования, в данном случае не приводит ни к каким отрицательным последствиям из-за уникального концептуального единства и продуманности языка6).
Динамическое пополнение и порождение программы
Поскольку структура программы и структура Поля зрения практически изоморфны, естественно ставить вопрос о динамическом порождении PROLOG-программ. Кроме этого высокоуровневого соображения, есть и прагматическое, которое можно извлечь из нашей программы 6.3.2. В нашу программу мы были вынуждены записать и определение лабиринта.Конечно же, можно было бы прочитать с помощью встроенной функции read определение лабиринта и записать его в список, но тогда мы почти утратили бы все преимущества языка PROLOG, не избавившись при этом ни от одного его недостатка. Гораздо естественнее иметь возможность прочитать базу данных из файла.
Для этой цели в PROLOG был введен встроенный предикат consult(file[.pl]). Он читает предложения и факты из файла и помещает их в конец программы, тем самым оставляя в неприкосновенности ранее данные определения предикатов. С его использованием наша программа может быть переписана в следующем виде.
way0(X,Y,Z):-consult(labyr),way(X,Y,Z). way(X,X,[X]). way(X,Y,[Y|Z]):-connect(U,Y), not member(Y,Z),way(X,U,Z). way(X,Y,[Y|Z]):-connect(U,Y), way(X,U,Z).
Листинг 6.4.1. Вводимый лабиринт
Пример файла labyr.pl:
connect(begin,1). connect(1,begin). connect(1,2). connect(2,3). connect(3,1). connect(3,4). connect(4,end).
Программа 6.4.1 представляет лишь идею решения, но эту идею она представляет исключительно выразительно. PROLOG приспособлен для нахождения решения, но не для его оптимизации. Например, если стремиться найти в некотором отношении оптимальный путь, то предыдущая программа окажется затемнена частностями языка PROLOG, которые испортят выразительность, и тем не менее не дадут возможность решить задачу столь же эффективно, как это делается на традиционном языке.
Есть еще один класс встроенных отношений, которые действуют как встроенные функции, но не требуют явной активизации операцией is. К ним, в частности, относятся многие действия над списками. Рассмотрим, например, предикат append(E1,E2,E3). Он корректно унифицируется, когда объединение первых двух списков является третьим.
Соответственно, он может использоваться для вычисления любого из своих трех аргументов, если два других заданы. Например,
append(X,Y,Z)
при Z=[a,b,c,d], Y=[c,d] унифицируется как X=[a,b].
Очень жаль, что в PROLOG таким же образом не реализованы арифметические функции!
Для динамического порождения фактов и предложений имеются функции, разбирающие предложения и синтезирующие их. Функторы могут быть объявлены метапредикатами, и тогда некоторые из их аргументов могут быть предложениями. Из метапредикатов важнее всего два, перечисленных ниже.
Метапредикат assert(P:-P1,. . . ,Pn) помещает свой аргумент в PROLOG- программу. Имеются несколько его вариантов, располагающие новое предложение или факт в начало или в конец программы. Метапредикат retract(P:-P1,. . . ,Pn), наоборот, удаляет из программы предложение или факт, унифицируемый с его аргументом.
С их помощью можно, в частности, имитировать различные более эффективные алгоритмы перебора для работы с лабиринтом, но при этом программа до некоторой степени теряет ясность структуры и становится крайне трудно ее отладить и модифицировать. А эффективности, сравнимой с традиционными методами, достичь все равно не удастся.
Но, например, если Вы анализируете сложную систему правил и ищете вывод, то результат анализа часто можно записать как файл динамически порожденных предложений, и это, наоборот, делает программу красивее, а ее отладку легче. Так что есть смысл использовать динамическое порождение в том случае, когда программа сначала коллекционирует и анализирует информацию, а лишь затем начинает действовать. А порождение, перемешанное с действиями, — кратчайший путь к провалу программы, и должно рассматриваться как хакерство.
Далее, после того, как использованы динамически порожденные факты или предложения, их можно удалить из программы при помощи предиката
retractall(Name / Arity)
Этот предикат удаляет все предложения и факты, говорящие о предикате Name арности Arity. Естественно, при этом удаляется лишь определение. Если Вы его использовали, то нужно потрудиться удалить также использующие предложения.
Поэтому предикаты лучше удалять целыми содержательно связанными группами, и концентрировать все такие удаления в одном предложении для каждой группы.
Динамическое порождение программ — метод, исключительно сильный, когда применен в подходящей обстановке и корректно, и исключительно опасный, когда применен в неподходящем окружении либо хоть чуть-чуть некорректно. В традиционных языках ему всячески препятствуют. Там он (по причине очень многих практических провалов) имеет одиозную репутацию. Но эта репутация связана прежде всего с тем, что такой рискованный и красивый метод требует высокой проработки идей, а в традиционном программировании мы, пытаясь его применить, вынуждены прорабатывать глупейшие технические проблемы (строить множество подпорок, см. словарь).
Внимание!
В новых версиях языка PROLOG предикаты, которые Вы намерены динамически видоизменять, нужно объявить. Например, dynamic(connect).
Для проверки типов термов имеются, в частности, следующие встроенные предикаты.
var(Term). Унифицируется, если Term свободная переменная.nonvar(Term). Унифицируется, если textsfTerm не свободная переменная.integer(Term) Успешен, если Term является целым числом (именно числом, а не выражением).float(Term) Успешен, если Term является действительным числом.number(Term) Успешен, если Term является числом.atom(Term) Успешен, если Term является атомом.string(Term). Успешен, если Term является строкой.atomic(Term). Успешен, если Term является неделимым значением (число, строка или атом).compound(Term). Успешен, если Term является сложным выражением.ground(Term). Успешен, если Term не содержит свободных переменных.
Для анализа и построения термов имеются, в частности, следующие предикаты.
functor(Term, Functor, Arity) Унифицируется, если Term является термом с главным функтором Functor арности Arity. Term, являющийся переменной, унифицируется с новой переменной. Если Term является атомом либо числом, то его арностью считается 0, а функтором он сам.arg(Arg, Term, Value) Выделение аргумента терма Term по его номеру Arg.Номера начинаются с 1.Естественно, что данный предикат может быть использован и для определения номера аргумента в терме.Term =.. List Унифицируется, если List является списком, головой которого является функтор терма Term, а оставшиеся члены задают аргументы (сравните с тем, что ниже рассматривается в языке LISP!) Если не использовать его как операцию, то имя этого предиката Univ. Естественно, он может работать в обе стороны, разбирая либо собирая терм.
Примеры.
?- send(hello, X) =.. List. List = [send, hello, X] ?- Term=.. [send, hello, X] Term = send(hello,X)
free_variables(Term, List) List унифицируется как список новых переменных, каждая из которых равна свободной терма Term.
atom_codes(Atom, String) Преобразование атома в строку и наоборот.
Многие из реализаций языка PROLOG включают пакет прогонки, позволяющий осуществлять частичное вычисление PROLOG-программы.
Общие концепции
Язык логического программирования PROLOG представляет собой одну из моделей сентенциального программирования. Мы используем лишь те возможности языка PROLOG, которые согласуются с принятым в 1996 г. стандартом [36]. Как руководство по программированиюна языке PROLOG можно использовать, скажем, книгу [6]. В ней содержится наименьшее число недочетов и откровенных ошибок, а также наибольшее число практических советов по сравнениюс другими известными автору пособиями.
Первой находкой создателей языка PROLOG явилось понятие унификации, изобретенное в методе резолюций для доказательства формул классической логики предикатов.
Два выражения называются унифицируемыми, если они могут быть приведены к одному и тому же виду подстановкой значений вместо свободных переменных. Унификация—вид конкретизации, при котором границы всех синтаксических единиц фиксированы, структура выражения однозначно определена и подстановка, приводящая два выражения к одному и тому же виду, вычисляется рекурсивно.
Второй находкой, перенесенной авторами языка PROLOG из специализированных программ (для логики и искусственного интеллекта) в языки программирования, стала система обработки неудач. Успешно произведенная унификация является лишь разрешением выполнить некоторое действие. После проверки других условий, возможно, мы будем вынуждены вернуться и выбрать другой вариант.
Третья находка языка PROLOG, перенесенная в программирование из метода резолюций, — это стандартизация цели. Целью доказательства в методе резолюций всегда является получение пустого дизъюнкта, то есть стирание доказываемого выражения (с логической точки зрения, приведение его к абсурду). Точно так же и в языке PROLOG: успешное исполнение программы означает стирание поля зрения.
Четвертая находка создателей языка PROLOG взята из ограничения классической логики. Хорновские формулы
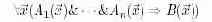
обладают важным свойством. Для нахождения вывода в системе хорновских формул достаточно производить так называемую линейную резолюцию, когда на каждом шаге делается вывод из исходной формулы и наследника цели. Никаких сочетаний исходных формул между собой либо различных вариантов раскрытия цели между собой делать, в принципе, не нужно.
Организация вычислений и ввода-вывода
Во многих случаях даже в поисковой программе необходимо производить вычисления. В языке PROLOG имеется способ вычисления значения по аргументам. Это так называемые встроенные функции, которые могут быть заменены на свое значение, если их аргумент известен. Такими функциями служат, в частности, числовые арифметические операции. Заметим, что даже встроенная функция не вычисляется, пока не будет дан явный сигнал. У Вас в программе может, скажем, накопиться в качестве значения переменной выражение 1 + 1 + 1, но оно не будет равно 3.
Для организации вычисления имеется специальное отношение X is E. В этом отношении Е является таким выражением, которое после подстановки текущих значений переменных конкретизируется7) в композицию встроенных функций от константных аргументов. Эта композиция вычисляется, и переменная Х унифицируется как ее значение.
Таким образом, можно постепенно накапливать вычисления, а затем в подходящий момент их произвести. Смотрите пример.
?- assert(a(1+1)). Yes ?- assert(b(2 * 2)). Yes ?- a(X), b(Y), Z is X + Y. X = 1+1 Y = 2*2 Z = 6
Внимание!
is не является присваиванием! Для того, чтобы убедиться в этом, исполните простейшее предложение языка PROLOG:
?- X is 1, X is X + 1.
Лучше всего и естественней всего вводятся в PROLOG-программу данные, полностью соответствующие синтаксису предложений и фактов языка. Если файл данных не очень велик, то для ввода достаточно воспользоваться уже описанным нами предикатом consult.
Конечно же, имеется и более традиционная система ввода-вывода. Опишем ее базовые возможности.
open(SrcDest, Mode, Stream, Options)
Открытие файла. SrcDes является атомом, содержащим имя файла в обозначениях системы Unix. Mode может быть read, write, append или update. Два последних способа открытия используются, соответственно, для дописывания в существующий файл и для частичного переписывания его. Stream либо переменная, и тогда ей присваивается целое число, которое служит для идентификации файла, либо атом, и тогда он служит внутри программы именем файла.
Options могут быть опущены, среди них нам важна одна опция: type(binary), которая позволяет записать коды в двоичный файл. Опции образуют список.
Конечно же, имеется возможность вручную установить текущую позицию внутри файла:
seek(Stream, Offset, Method, NewLocation)
Method — это метод отсчета относительной позиции. bof отсчитывает ее с начала файла, current от нынешней точки, eof от конца. Переменная NewLocation унифицируется с новой позицией, отсчитываемой обязательно с начала.
Предикат close(Stream) комментариев не требует.
read(Stream, Term)
Переменная Term унифицируется с термом, прочитанным из потока Stream.
read_clause(Stream, Term)
Читается предложение. По умолчанию пользователя предупреждают о переменных, которые отсутствуют в голове и лишь однажды присутствуют в хвосте.
read_term(Stream, Term, Options)
Аналогично read, но позволяет установить целый ряд возможностей, регулирующих представление терма. Смотрите подробнее в документации конкретной PROLOG-системы.
writeq(Stream, Term)
Term пишется в Stream, вставляются кавычки и скобки, где нужно.
write_canonical(Stream, Term)
Term пишется в Stream таким способом, чтобы его однозначно прочитала любая PROLOG-программа, а не только Вы и Ваша программа на Вашей системе.
Есть способ читать и писать символы, а через них строки и прочее, но это настолько примитивно и уродливо, что можно дать практический совет:
Внимание!
Если Вам нужно ввести в PROLOG файл иноязычного или просто обычного формата либо вывести из него в предписанном Вам не укладывающемся в систему термов формате, напишите переходник на Рефале или на Perl.
Тем не менее вот минимальный (и практически полный) список предикатов символьного и двоичного ввода и вывода.
get_byte(Stream, Byte)
Byte рассматривается как целое число и унифицируется со следующим байтом входного потока. Конец файла читается как -1.
get_char(Stream, Char)
Аналогично, но следующий байт рассматривается как имя атома, состоящее из одного символа. Конец файла унифицируется с атомом end_of_file.
Русские буквы, пробелы и прочие нестандартные символы могут вызвать неприятности.
get(Stream, Char)
Аналогично, но пропускаются невидимые символы.
skip(Stream, Char)
Пропускает все, пока не встретится символ Char либо конец файла. Само первое вхождение Char также будет пропущено.
put(Stream, Char)
Вывод одного символа либо байта. Char унифицируется либо как целое число из диапазона [0, 255], либо как атом с именем из одного символа.
nl(+Stream)
Вывести перевод строки.
|
|
|
В отличие от клауз, посылки логических формул ни в каком смысле не могут считаться последовательно достигаемыми.
2)
Внутри языка они называются атомами.
3)
В части реализаций эти ограничения могут распространяться и на функции, определенные программистом.
4)
Мысознательно отказались от сопоставления двух видов целей в PROLOG с конъюнкцией и дизъюнкцией, поскольку их семантика принципиально отличается от семантики этих логических связок.
5)
Более того, можно было бы унифицировать любые соответственные друг другу внутренние подвыражения в произвольном порядке, лишь бы объемлющие унифицировались после подчиненных. Автору неизвестно ни одно использование этого естественного и многообещающего обобщения алгоритма унификации.
В первой реализации языка PROLOG, основные особенности которой стали в дальнейшем фактическим стандартом, создатели допустили ошибку в понимании и, соответственно, в реализации алгоритма унификации, которая, к примеру, разрушает свойство частичного исполнения и может привести к излишней конкретизации, в то время как можно было бы найти более общую конкретизирующую подстановку. Эта ошибка несущественна, она не влияет на подавляющее большинство программ, но иногда она приводит к появлению бесконечных термов, и некоторые реализаторы языка PROLOG с гордостью пишут, что они умеют печатать и показывать на экране даже такие термы.
Желающие в качестве упражнения выловить ошибку самостоятельно, сравните алгоритмы унификации, описанные в книге [30] и [12].
6)
Здесь мы не оговорились: в данном случае предложения лучше трактовать как операторы, поскольку как утверждения их в данном случае рассматривать невозможно.
7)
Здесь мы употребили термин конкретизация, поскольку используются именно текущие значения переменных, согласования не происходит.
Поле зрения, поле памяти и PROLOG-программа
Когда рассматривается исполнение программы в нетрадиционном языке (например, PROLOG-программы), то естественно воспринимать конкретную реализацию языка как новую машину нетрадиционной архитектуры с высокоуровневыми командами (в данном случае как PROLOG-машину).
Данные, используемые PROLOG-машиной, размещаются во всех частях поля памяти и имеют общую структуру.
Рассмотрим на уровне абстрактного синтаксиса структуру данных, обрабатываемых языком PROLOG. Все данные языка PROLOG являются термами. Термы построены из атомов при помощи функциональных символов. Атомами могут быть переменные и константы, в свою очередь, делящиеся на имена и числа. Функциональные символы являются именами и называются функторами. Среди функторов выделяются детерминативы, которые в реализации делятся на предикаты и встроенные функции (функции обычно используются внутри выражений, а предикаты являются основными единицами управления и обычно используются вне скобок как основной функциональный символ выражения). Детерминативы должны быть описаны в программе, а остальные функторы рассматриваются просто как структурные единицы и могут оставаться неописанными.
В поле памяти выделяется поле зрения, содержащее непосредственно обрабатываемые программой данные. Оно называется также целью и состоит из последовательности термов.
Поле памяти имеет скрытую (при использовании стандартных возможностей языка) часть, в которой прослеживается история выполнения программы с тем, чтобы в случае необходимости произвести обработку неудачи.
И, наконец, в поле памяти помещается сама PROLOG-программа, которая естественно структурируется на две части, нередко перемешанные в тексте самой программы, но обычно разделяемые при использовании внешней памяти: база данных и база знаний.
База данных состоит из фактов, представляющих собой предикат, примененный к термам.
База знаний состоит из предложений (клауз). Каждое предложение имеет вид, подобный хорновской формуле
grandfather(X,Z) :- parent(X,Y), father(Y,Z).
Предложение состоит из головного выражения (соответствующего заключению хорновской формулы) и его раскрытия: нескольких выражений, соединенных как последовательно достигаемые подцели (они соответствуют посылкам хорновской формулы)1).
В любой момент исполнения программы
В любой момент исполнения программы база данных и база знаний могут быть модифицированы.
Теперь перейдем к конкретному представлению данных.
В конкретном синтаксисе переменные языка представлены именами, состоящими из букв и начинающимися с большой буквы либо с символа подчеркивания _. Переменная _ называется анонимной переменной и считается различной во всех своих вхождениях.
Константы языка PROLOG2) в конкретном синтаксисе делятся на имена (идентификаторы, начинающиеся с маленькой буквы либо совокупность нескольких специальных символов типа <, =, $), символы и числа (символы отождествляются с целыми числами, являющимися их кодами). Произвольная последовательность символов может быть сделана единой константой, например:
'C:\"SICS Prolog"\program.pl'.
Любое константное имя может служить функтором. Функторы различаются арностью (т. е. количеством аргументов), таким образом, может быть сразу несколько функторов с одним и тем же именем. Например, write(a(1)) и write(a(1),file1) используют различные функторы. Некоторые функции могут быть описаны как операции (инфиксные, префиксные либо постфиксные). В отличие от почти всех остальных языков, операции рассматриваются лишь как сокращение для выразительности. Например, x+y означает в точности то же, что и +(x,y).
Для некоторых из предопределенных в системе функций и предикатов имеются дополнительные ограничения на аргументы3). Например, в функции load(f) f должно быть именем файла.
Поле зрения (цель), содержащее непосредственно обрабатываемые программой данные, состоит из последовательности термов, разделенных либо запятыми (в этом случае они понимаются как "последовательно достигаемые подцели"), либо символами |, в этом случае подцели "альтернативны".Наиболее важным и классическим является случай последовательно достигаемых подцелей, через который определяется и семантика альтернативных подцелей4).
В конкретном представлении предложение, например,
grandfather(X,Z) :- parent(X,Y), father(Y,Z).
также рассматривается как терм, поскольку имена , (здесь символ запятой — имя операции) и :- рассматриваются как инфиксные операции, причем запятая связывает сильнее.
Как правило, предложения, относящиеся к одному и тому же предикату, группируются вместе, например:
parent(X,Y) :- mother(X,Y). parent(X,Y) :- father(X,Y).
Порядок предложений существенен.
База данных состоит из фактов. Факты могут выражаться в одном из двух видов. Во-первых, факт может рассматриваться как предложение, немедленно приводящее к успеху (успех— это стирание целей). Поэтому он может быть записан:
father(ivan,vasilij):-true.
Здесь мы встретились с одной из двух стандартных целей: true обозначает очевидную удачу, а fail — очевидную неудачу.
Во-вторых, специально для фактов имеется скоропись, означающая то же самое:
father(ivan,vasilij).
В принципе, все остальные структуры языка PROLOG выражаются через элементарные, определенные выше. Но некоторые из структур прагматически настолько важны, что получили отдельное оформление и более эффективную реализацию. Это, прежде всего, списки и строки. Список, в принципе, определяется как терм, построенный из других термов и пустого списка [] применением двухместного функтора .(head,tail). Выстроенная в стандартном порядке композиция
.(a,.(b,. . . , .(z,[]). . . ))
понимается как линейный список и обозначается [a,b,. . . ,z].
Для обозначения присоединения нескольких данных термов к началу списка имеется стандартная операция
[t,u|L].
Строки рассматриваются как линейные списки кодов символов и обозначаются последовательностью символов, взятой в двойные кавычки:
"Ну, получили то, что искали? Ответьте y или n."
Заслуживает упоминания механизм введения новых операций в язык PROLOG. Каждый пользователь может определить свои собственные унарные или бинарные операции или переопределить стандартные. Приведем в качестве примера описания некоторых стандартных операторов языка PROLOG:
:- op(1200,xfx, ':-'). :- op(1200,fx, [':-','?-']). :- op(1000,xfy, ','). :- op(700, xfx, [=,is,<,=<,==]). :- op(500, yfx, [+,-]). :- op(500, fx, [+,-,not]). :- op(400, yfx,[*,/,div]).
Первый аргумент в этих описаниях — приоритет операции. Он может быть от 1 до 1500. Второй аргумент — шаблон операции; x обозначает выражение с приоритетом, строго меньшим приоритета операции; y — выражение с приоритетом, который меньше или равен приоритету операции, f — положение самого символа операции относительно аргументов. Таким образом, шаблон yfx для операции - означает, что выражение X-Y-Z понимается как (X-Y)-Z, шаблон xfy для запятой означает, что t,u,r понимается как t,(u,r),шаблон xfx для :- означает невозможность использования нескольких таких операций подряд без дополнительных скобок. Операции с меньшими приоритетами связывают свои аргументы сильнее. Один и тот же атом может быть определен и как унарная, и как бинарная операция.
Пример описаний операций показывает, что даже локальное использование различения конкретно- и абстрактно-синтаксических представлений программы дает возможность получить большие преимущества. В PROLOG не пришлось отдельно заниматься семантикой операций, поскольку в абстрактном синтаксисе их нет. Автоматически устраняются многие тонкие вопросы, связанные, в частности, с возможностью PROLOG-программы преобразовывать саму себя (см. упр. 7).
Пример greater(X,Y):-greater1(X,Y).
| greater(X,Y):-greater1(X,Y). greater(X,Y):-greater1(Z,Y),greater(X,Z). greater1(X,f(X)). estimation(X,Y):-greater(X,Y),known(Y). known(f(f(f(f(a))))). unknown(a). unknown(b). |
| Пример 6.3.1. |
| Закрыть окно |