Развитие языка Prolog
Британско-канадская группа, создававшая Prolog, первоначально ориентировалась на задачи математической лингвистики, где сложные преобразования данных сопряжены с проверкой гипотез.
Это естественно навело их на ортогональный Рефалу подход1), формально мотивированный математической логикой. Наличие именно формальной мотивировки оказало медвежью услугу языку Prolog и всему направлению. Его сущность оказалась замаскирована примитивным методологически-теоретическим анализом и неадекватным названием: логическое программирование.
Prolog вдохновлялся ограничением классического исчисления предикатов, предложенным Хорном. Как известно (см., например, книгу [20]), в классической логике в любой достаточно богатой теории появляются чистые теоремы существования, когда из доказательства невозможно выделить построение требуемого объекта. Если ограничиться конъюнкциями импликаций вида



где каждая составляющая является элементарной формулой и само доказанное утверждение имеет такой же вид, то получить построение из доказательства возможно, поскольку у нас не остается даже косвенных способов сформулировать и нетривиально использовать что-либо похожее на A

От лишних кванторов можно избавиться при помощи сколемизации, когда кванторы существования заменяются на функцию, аргументами которой являются все переменные, связанные ранее стоящими кванторами всеобщности2). Таким образом, мы приходим к простейшему виду хорновых формул (хорновы импликации):
Применив к последней формуле преобразование, выполненное лишь в классической логике, мы приходим к хорновым дизъюнктам:
Именно от последней формы представления хорновых утверждений получила имя основная структура данных языка Prolog. Но тот факт, что импликация преобразована в дизъюнкцию, на самом деле нигде в этом языке не используется, он послужил лишь для установления взаимосвязей с алгоритмом метода резолюций [30], который в тот момент был последним криком моды в автоматическом доказательстве теорем (и действительно громадным концептуальным продвижением).
Метод резолюций до сих пор остается одним из нескольких наиболее часто применяемых методов автоматического доказательства, и единственным, известным широкой публике. Этот метод поставил три идеи (унификация, стандартизация цели, стандартизация порядка вывода), красивой программистской реализацией которых явился Prolog. Но находки языка Prolog не исчерпываются реализацией идей, взятых из теории. Они внесли существенный вклад в теорию и методологию программирования3).
Именно на примере языка Prolog западное программистское сообщество четко осознало, что могут быть совсем другие модели исполнения программы, не являющиеся ни традиционными, ни их расширением. Был реабилитирован и стал порою успешно использоваться метод динамического порождения программы. Стала актуальной идея косвенного управления вычислениями. Этих достоинств с лихвой хватит для того, чтобы Prolog мог считаться важным принципиальным достижением.
Развитию языка Prolog мешает, прежде всего, слишком большая привязка к конкретной модели вычислений, которая в погоне за мнимой эффективностью была зафиксирована слишком рано. Совершенно извращено понимание его места и роли. На самом деле Prolog представляет собой великолепную заготовку для языка моделирования идей, а никакое не логическое программирование.
Рассмотрим, что именно этой заготовке мешает в реальности стать таким языком. Как мы уже неоднократно видели, главное препятствие — потеря целостности, вызванная лишними возможностями. В первую очередь, это эклектичные добавки операционных средств, которые провоцируют программиста к операционному мышлению и хакерскому стилю. Так, в задаче о лабиринте было бы естественно не зацикливание исполнения, когда не предусмотрены ограничивающие условия, заставляющие программу продвигаться вперед, а указание того, что в процессе выполнения не хватает условий, что возможны определенные варианты ограничений, делающие программу корректной. В результате разработчикам языка пришлось искать дополнительные средства выражения требуемых, а не предлагаемых, действий.
Ничего лучшего по сравнению с известными операционными методами они не нашли и включили соответствующие средства в язык, полностью потеряв первоначальную концепцию.
Одним из классических примеров применения первоуровневых моделей и плоских, неадекватных практике, но привлекательно звучащих и просто объясняемых, выводов, которые делаются на их основе, является утверждение: "Логика Хорна достаточна для спецификации вычислений, поскольку, как было доказано, она эквивалентна машине Тьюринга4)". С этим утверждением можно было бы согласиться, если бы решения реальных задач, которые апеллируют к базам данных-фактов и должны решаться с использованием баз знаний-утверждений, являющихся следствиями из имеющихся фактов, всегда можно было бы формулировать в такой разделенной манере: сначала задаются факты, затем предложения-соотношения и далее идет манипулирование информацией. На самом деле таким образом формулируемые решения пригодны только для узкого класса задач, которые характеризуются стабильностью фактов, и только в том случае, когда не принимается в расчет эффективность.
Развитие языка Рефал и его диалекты
Язык Рефал был создан В. Ф. Турчиным для аналитических вычислений в физике. Первоначально Турчин продумал саму идею конкретизации и представил ее в виде языка, демонстративно записанного в не слишком прямо представимой форме. Например, не было понятия детерминатива, предложения имели вид, подобный
§1.1.2 E1 + (E2 * E3)= (K E1 + E2 .)* (K E1 + E3 .)
Конкретно-синтаксическая форма языка, данная в теоретической работе Турчина (см., напр. [27]) сразу же была изменена для удобства представления и работы5). Уже при первой реализации был продуман и проверен приведенный выше алгоритм отождествления, были выброшены иерархические комментарии в начале предложений, а вместо них появились понятия детерминатива и функции.
Дальнейшая доработка потребовала процедур ввода-вывода и механизма хранения глобальных данных, что было реализовано через стеки закопанных данных. Получившийся язык Рефал-2 длительное время был практическим стандартом Рефал-систем.
В языке Рефал-4 были сделаны две попытки расширения языка. Во-первых, как и во множестве других систем, к Рефалу были достаточно механически добавлены нарождавшиеся модные объектно-ориентированные средства. Эта попытка быстро зашла в тупик и была оставлена. Во-вторых, были определены метаоперации. Это нововведение доказало свою жизнеспособность и выжило. В языке Рефал-5 [38], который сейчас является фактическим стандартом6), объекты были отброшены, зато последовательно была проведена как стандартная надстройка над языком идея метакодирования. В нем получили свое окончательное оформление вложенные процедуры и дополнительные условия.
Из других существующих версий языка стоит отметить Рефал-6 и Рефал+ [10], которые развивают одну и ту же линию. В реализации Рефал+ отошли от представления, принятого в [25], с тем чтобы воспользоваться современными алгоритмами сборки мусора. Вместо стеков закопанных значений в этих языках предлагаются объекты, которые имеют лишь одно значение. В частности, такие объекты используются для описания графического ввода и вывода, что полностью игнорируется в стандартном Рефале.
В этих версиях позволяется объявить функцию откатной и пытаться при невозможности отождествлений обработать неудачу. Но автор этих версий проигнорировал концептуальную несовместимость неудач с общей структурой управления в языке Рефал. Из находок Рефал+, помимо новой структуры данных, стоит отметить концепцию упорядочения возможных отождествлений и возможность до некоторой степени управлять этим упорядочением (правда, в языке предусмотрен лишь переход от прямого порядка к его обращению, но уже это дает в некоторых случаях большой выигрыш в выразительности).
Наиболее заметным недостатком новых версий языка Рефал7) явилось отсутствие различения абстрактного и конкретного синтаксиса. Можно было бы просто отказаться от фиксации оформления в определении языка и дать возможность определять синтаксические расширения и представления самим разработчикам.
Стоит заметить, что нынешний язык Рефал находится в мягком концептуальном противоречии со столь блестяще реализованной в нем же идеей динамического вычисления программ. Решение исполнять ту функциональную скобку, внутри которой нет других таких скобок, было оправдано и логично при создании Рефала, а теперь оно уже мешает эффективно использовать аппарат метапреобразований. Необходимо заметить, что Рефал созрел для настоящего представления мультииерархической структуры, что позволит языку выйти на новые классы приложений. Таким образом, в ближайшее время можно ожидать появления нового сентенциального языка, реализующего идею конкретизации. Будет просто беда, если под красивой оберткой кто-нибудь подсунет в эту область концептуально непродуманное 'прагматическое' решение. Выигрыш от прагматизма будет минимальным, временным и локальным, а потери — длительными, на порядок превосходящими аналогичные для традиционных языков, и к тому же глобальными.
Именно в языке Рефал было четко показано, как выбирать структуры данных и алгоритм работы абстрактной машины для нетрадиционных вычислений и насколько это важно. В нем впервые избавились от жесткой привязки к конкретному синтаксису.Он продемонстрировал советскому программистcкому сообществу возможность альтернативных моделей вычислений, выполнив на востоке ту же роль, что Prolog на западе. В нем впервые была реализована концепция встроенных частичных вычислений программ. Он не поддался давлению моды, и этим способствовал осознанию наличия альтернатив даже в том случае, когда подходы в принципе близки. Всего этого достаточно для признания пионерской роли этого языка.
Сравнение версий сентенциального программирования
Прежде всего, методы управления языка Prolog и языка Рефал принципиально отличаются. В Prolog'е неудача глобальна, но исправима, а в Рефале — локальна, но фатальна.
Унификация в Prolog и конкретизация в Рефале являются операциями примерно одного и того же уровня общности. Но направления унификации и конкретизации ортогональны.
Конкретизация имеет дело с выражениями, подвыражения в которых могут выделяться различными способами, и древовидная иерархическая структура сочетается с линейной структурой внутри одного уровня иерархии, а при унификации в Prolog и в логике все выражения жестко ограничены скобками либо запятыми, то есть присутствует лишь иерархическая структура.Конкретизация не заглядывает внутрь иерархии глубже, чем это явно указано в соответствующем правиле, а унификация может двигаться по уровням иерархии вглубь настолько, насколько это необходимо.При конкретизации переменные локальны, и их значения не влияют на интерпретацию остальной области памяти, а при унификации переменные глобальны, полученная в результате унификации подстановка производится сразу во всем поле зрения, а не только в его активной части.При конкретизации в ходе установления значений переменных возможны неудачи и возвраты, а при унификации значения переменных рекурсивно набираются в соответствии с алгоритмом нахождения унифицирующей подстановки, и неудача этого единственного варианта означает неудачу всей попытки унификации.
Внимание!
Модели унификации и конкретизации формально несовместимы, поскольку, соединив их, мы получаем алгоритмически неразрешимое понятие отождествления (Н. К. Косовский и др., 1990).
Это — глубочайший теоретический результат и одно из редких прямых предупреждений, сделанных теорией практике8). Поэтому при сходстве многих идей, положенных в их основу, эти модели развиваются и должны дальше развиваться независимо (что не исключает творческого заимствования идей из одной ипостаси подхода в другую). Обратите внимание, что мы столкнулись с той же самой ситуацией, которая имеет место для циклической и рекурсивной ипостасей структурного программирования.
Точно так же, как циклическая ипостась структурного программирования, Рефал приспособлен для работы с данными, развернутыми в основном вширь и для развертывания процесса в ширину. Точно так же, как рекурсивная ипостась, Prolog приспособлен для развертывания процесса в глубину и для работы с данными, имеющими ограниченную ширину, но зато большую глубину.
Даже машинная реализация этих языков сродни двум ипостасям структурного программирования. В Рефале вызовы, которые выглядят как рекурсивные, на самом деле рекурсией не являются9), поскольку мы заканчиваем породивший вызов, и лишь после этого переходим к отработке порожденных. Prolog больше похож на рекурсию, поскольку после вызова внутреннего предиката мы можем возвратиться к внешнему и продолжить попытки его унификации. В Рефале достаточно общего поля памяти, а в Prolog вынуждены запоминать также управляющие данные ( точки возврата10)).
Стоит заметить, что сентенциальное программирование, и особенно его разновидность, базирующаяся на модели отождествления-замены, великолепно сочетается с идеей ассоциативной памяти (см. стр. 31), и здесь возможен прорыв одновременно на аппаратном и программном уровнях.
Вариант сентенциального программирования, базирующийся на возвратах и унификации, отлично сочетается с идеей машины потоков данных. Японцы попытались использовать его в своем проекте ЭВМ пятого поколения. Провал данного проекта надолго дискредитировал направление соединения сентенциального программирования с потоками данных, но к нему придется вернуться в будущем на другой технической и, видимо, на гораздо более концептуально выверенной программистской основе.
Концепция унификации и возвратов после неудач исключительно хорошо подходит для выражения
Рефал, в свою очередь, великолепно подходит для &-параллелизма. Подстановки значений переменных в результирующее выражение можно осуществлять независимо друг от друга.
Более того, в принципе можно было бы даже в нынешнем варианте Рефала вычислять различные функциональные скобки в параллель, помешать этому могут лишь значения, передаваемые через аппарат закапывания-выкапывания. Но это — стандартная проблема синхронизации для параллельных вычислений, с которой можно справляться хорошо разработанными средствами, тем более что аппарат для соответствующей разметки программы еще в ходе ее составления концептуально подготовлен в языке.
Таким образом, две ветви сентенциального программирования ориентированы даже на разные классы параллельных вычислений. Именно на примере сентенциального программирования нами был сделан вывод о том, что и для других стилей должны быть альтернативные реализации. Их выявлению мешал прежде всего закон экологической ниши.
При создании и развитии языков PROLOG и Рефал ярко проявились сильные и слабые стороны русской и англо-американской школ науки.
В. Ф. Турчин проделал адекватный анализ, не устаревший за 40 лет, но он не стремился к общепонятности и слишком большой популяризации (может быть, потому, что ему не нужно было выбивать гранты). Его последователи четко восприняли идею и развивали ее, практически полностью избегая концептуально противоречащих ей возможностей. Но популяризация языка и внешняя сторона работы с ним (удобные системы, интерфейсы и т. п.) оказались практически полностью проигнорированными, и поэтому язык остается достоянием узкой группы приверженцев11).
Создатели Prolog с самого начала в значительной мере использовали теорию и методологию как заклинания либо молитвы, не имеющие отношения к сути дела и произносимые для его освящения. Тем самым теоретическая база сразу же оказалась неадекватной, что и привело к быстрому расползанию системы и потере концептуального единства. Язык в значительно большей мере, чем Рефал, оказался загрязнен чужеродными элементами12).
Неадекватность теории практике помешала осознанию реальных достижений подхода, основанного на унификации, поскольку они часто противоречили мифам и саморекламе.
Зато развитие внешнего оформления и удобных ( с точки зрения дизайна) средств работы с языком шло адекватными темпами, а реклама его действительных и мнимых достижений далеко опережающими. Язык вошел в практику обучения многих университетов мира и попал даже в стандарты программ обучения специалистов IFAC.
Если говорить о практических задачах, то Prolog значительно лучше подходит для поиска, а Рефал — для синтаксических преобразований. Стоит также помнить, что в нынешнем состоянии Prolog не может служить даже для прототипирования, это язык лишь для моделирования решений и логики поведения программы.Но это — особенность нынешних конкретных реализаций идеи унификации и возвратов, она связана с тем, что примитивный концептуальный механизм пришел в противоречие с выявившимися богатейшими потенциальными возможностями подхода.
Рефал делает символьные преобразования столь же эффективно, как и программа на традиционном языке, и поэтому может быть использован на всех уровнях: и для создания прототипа программы, и для написания надпрограммы, и для написания подпрограммы.
Таким образом, Рефал по эффективности и ясности представления уже сейчас может служить языком прототипирования, и, если бы его снабдить удовлетворительными интерфейсами, вполне мог бы служить и для окончательных решений, работающих в многоязыковой среде. В момент написания книги существует единственный имеющийся надежно работающий интерфейс Рефала: с языком PHP преобразования HTML-текстов.
В особенности Рефал хорош в тех случаях, когда нужно произвести нетривиальное преобразование символьных входных либо выходных файлов. Его использование, как показала практика автора и студентов в многоязыковом программировании, зачастую оправдывается даже тогда, когда ведется передача данных через файл.
У Prolog ныне интерфейсы имеются, но они, как правило, ориентированы лишь на C++ и LISP13) и совершенно не стандартизованы. Каждая реализация имеет свой интерфейс.
Мы затронули общий недостаток нынешних систем сентенциального программирования.
Это — плохая проработка связей с другими языками. При создании средств высших уровней необходимо с самого начала продумать вопросы связи с другими языками и использования языка в многоязыковой и многостилевой методологии программирования.
 |
|
|
Они не имели никаких сведений о Рефале и работали совершенно независимо. Просто потребность сентенциального программирования назрела. К счастью для информатики, обе группы инициаторов не были осведомлены о работах друг друга, иначе, скорее всего, одна из двух ортогональных концепций осталась бы неразвитой. Это подтверждает история других стилей: тот, кто первым добился успеха, захватывает экологическую нишу и видоизменяет условия в ней таким образом, чтобы ничто другое не могло в ней выжить (причем часто нет никакого злого умысла, просто работают законы развития науки и вообще эволюционирующих систем).
2)
Как именно это делается, сейчас неважно.
3)
Одновременно данное направление нанесло и существенный вред этой теории и методологии, который был бы еще глубже, если бы у Prolog'а с самого начала не было бы друга-соперника Рефала.
4)
Слишком прямое применение теории, особенно когда получается привлекательное на вид следствие — бич современной науки. Именно оно приводит к тому, что многие серьезные практики попросту игнорируют теорию, из-за этого делают другие, не менее глупые и вредные, и не менее привлекательные на вид, ошибки. Пример такой глобальной ошибки — С++, лишь обостривший все проблемы традиционного программирования. Он создавался практиками, по их же собственному признанию, принципиально игнорировавшими теории.
5)
Если человек не привязан к конкретным словам, то обычно это доказывает, что он ясно осознал идеи, которые отстаивает.
6)
Внимание! В самых последних реализациях, называемых PZ SciTE, язык без огласки чуть-чуть пересмотрен, и отражено это лишь в файлах news.txt.
7)
Подавляющее большинство систем программирования имеют этот недостаток, но в данном случае он ощущается наиболее остро.
8)
Даже прямые предупреждения, как правило, игнорируются практиками, многие из которых не понимают самого понятия алгоритмической неразрешимости; в качестве примера можно взять безвременно скончавшийся Рефал-6.
9)
Примером того, насколько многие привыкли судить о явлениях по внешнему виду, а не по сущности, является кочующее из книги в книгу утверждение о том, что Рефал — язык функционального рекурсивного программирования.
10)
После этой аналогии становится более ясно, почему программисты трактуют использование отсечения ! в языке PROLOG как хакерство. Представьте себе, что было бы, если бы Вам в C++ предоставили явный доступ к отложенным из-за рекурсии вызовам процедур и разрешили по своему произволу их убирать!
11)
Сами представители Рефал-сообщества объясняли свою позицию относительно интерфейсов примерно следующим образом.
— Чайники и ламеры все равно Рефалом не пользуются, а квалифицированный человек сам легко напишет переходник, тем более, что код системы открыт.
Автор в свое время вынужден был писать переходник между Рефалом-2 и Алголом 68, но, конечно же, такое решение и приведенная выше аргументация неудовлетворительны.
12)
История отказа от введения объектов в Рефал является практически исключительным в мире современной информатики примером понимания вреда концептуальных противоречий. В конце концов, разум должен стоять выше моды!
13)
Некоторые коммерческие системы Prolog имеют интерфейсы еще и с Java.
с краткого сравнения путей развития
Начнем с краткого сравнения путей развития двух ветвей сентенциального программирования.
Модель вычислений LISP
Для LISP (как и для любого другого функционального языка) не обязательно2) говорить, где и как размещаются структуры данных (списки).
Рис. 8.1. Структура информации, сопоставленной атому языка LISP
Их стоит рассматривать как сугубо математические объекты со сложной структурой, которая всегда точно указывает на текущие вычислительные элементы:
До выполнения шага вычисления — это список, включающий имя функции и ее аргументы.Во время выполнения шага вычисления — это те фрагменты списочной структуры поля зрения, которые доступны для использования вычисляемой функцией (в частности, среди них есть список, связанный с именем функции, который определяет ее вычислительный процесс).После выполнения шага вычислений — это результаты вычислений. Результаты можно разделить на три группы: значение, выдаваемое вызовом функции: оно замещает в поле зрения отработанный вызов функции;побочные эффекты, разбросанные по структуре поля данных;очередная функция, которая будет вычисляться далее. В традиционном программировании обычно возвращаются к вычислениям той функции, которая активизировала завершаемую. В функциональном программировании может быть и по-другому. Результат может оказаться функцией, либо описанной в статическом тексте программы, либо скомпонованной в ходе вычислений.
Общую структуру данных и программы функционального языка можно рассматривать как связный нагруженный граф, динамически изменяющийся в ходе вычислений, у которого имеются активные вершины, т. е. функции, вычисляемые в данный момент, потенциально активные вершины, соответствующие функциям, которым назначено вычисление или продолжение вычисления (отложенного, приостановленного и т. п.), и пассивные вершины, участие которых в вычислениях в данный момент не запланировано. Дуги графа отмечают связи по управлению или по данным между функциями. Такой граф далее называется абстрактным графом функциональных вычислений.
Конкретизировать такой граф и стратегию отработки активных вершин можно разными способами.
При этом могут появляться разные ипостаси функционального программирования.
Для абстрактного вычислителя граф функциональных зависимостей естественно считать полем памяти функциональной программы, в котором выделено поле зрения: активные (либо активные и потенциально активные) вершины-функции со своими аргументами.
В практике реализации функциональных систем программирования имеется три варианта конкретизации представления графа:
Списки LISP, которые связаны с последовательными вычислениями. Структура графа задается как совокупность линейных списков, объединяющих имена функций и указатели аргументов. Голова списка трактуется как указание функции, а хвост — как аргументы.Коммутационные схемы, которые строятся на основе разделения функций и данных: функции представляются вершинами графа, а их аргументы-данные передаются по дугам, соединяющим вершины. Дуги рассматриваются в качестве каналов связи. Функция активизируется, когда ее аргументы появляются в каналах.Ассоциативные схемы, в которых вершины-функции остаются виртуальными. Они образуются в результате связывания данных, имеющих одинаковый ключ. Ситуация, когда такие данные появляются в ассоциативной памяти, трактуется как готовность аргументов для вычисления функции, идентифицируемой этим ключом.
Коммутационные и ассоциативные схемы рассмотрены при обсуждении неимперативных моделей вычислений (см. § 1.2 и 3.1). Выбор последовательно просматриваемой структуры для первого функционального языка обусловлен единственной для того времени возможностью реализации функциональности путем моделирования ее операционными средствами традиционной модели вычислений. Списочная структура также строится посредством более или менее стандартного для традиционной модели адресного представления. С языковой точки зрения именно этот выбор обеспечивает однородность структуры программы и данных, на базе которой Дж. Маккарти удалось построить систему средств, достаточную для практического функционального программирования.
Программа на языке LISP задается как список применений функций, часть из которых может вычисляться во время исполнения самой программы.
Как правило, заданные в программе списки интерпретируются как применения функций и вычисляются, если другое не определяют ранее активированные функции (вы видели, что функция quote запрещает вычисление своего аргумента, функция setq запрещает вычисление лишь первого из двух аргументов, а функция setf заставляет вычислить первый аргумент лишь до стадии, когда получена ссылка на его значение). Любое выражение выдает значение, что используется, в частности, при диалоговой работе с LISP (на примере которой иллюстрируются понятия).
Основные управляющие функции концептуально едины и позволяют динамически строить блочную структуру программы. В частности, функция
(block name e1 . . . en) (8.1)
вычисляет свои аргументы, начиная со второго, один за другим, тем самым задавая последовательность команд. Первый ее аргумент, name, служит именем блока. В любой момент из любого объемлющего блока можно выйти и выдать значение с помощью функции
(return-from name value) (8.2)
Этим LISP выгодно отличается от большинства языков, где такие структурные переходы либо неполны, либо некорректно реализованы.
Далее, блоком считается любое описание функции. Описание функции производится при помощи функции defun, которая, в свою очередь, определяется через примитивы function и lambda. Первый из них задает, что имя, являющееся его аргументом, рассматривается как функция (он часто сокращается в конкретном синтаксисе до #’), второй образует значение функционального типа. Имя функции является и именем функционального блока.
Пример 8.4.1. В данном примере иллюстрируются определение факториала, вызов анонимной функции и возможность вычисления произвольного функционального выражения, созданного в программе.
[1]> (defun fact (n) (if (= n 0) 1 (* (fact (- n 1)) n))) FACT [2]> (fact 40) 815915283247897734345611269596115894272000000000 [3]> ((lambda (x) (fact (* x x))) 5) 15511210043330985984000000 [4]> (setq g ’(lambda (x) (fact (* x x)))) (LAMBDA (X) (FACT (* X X))) [5]> (eval (list g 3)) 362880
Нужно заметить, что определение функции с данным именем и значение имени могут задаваться независимо. Например, мы можем в этом же контексте задать (setq fact 7), хотя, конечно же, это отвратительный способ программирования.
Все формальные параметры функций являются локальными переменными. Никакие изменения их значений не выходят наружу. Но все другие свойства остаются глобальными! Приведем пример.
[23]> (defun f (x) (progn (setf (get ’x ’weight) ’(25 kg)) (+ x 3))) F [24]> (setf (get ’x ’weight) ’(30 kg)) (30 KG) [25]> (get ’x ’weight) (30 KG) [26]> (setq x 5) 5 [27]> (f 3) 6 [28]> x 5 [29]> (get ’x ’weight) (25 KG)
В LISP имеется возможность создать анонимный блок со своими локальными переменными, не объявляя его функцией. Создание такого блока называется связыванием переменных и производится функцией let.
Значение имени, унаследованного извне, все равно будет внешним! Смотрите пример ниже.
[32]>(setq a ’(b c d)) (B C D) [33]>(setq b 5) 5 [34]> (list (let ((b 6)) (eval (car a))) (eval (car a))) (5 5) [35]> (list (let ((b 6)) b) (eval (car a))) (6 5) [36]> (list (let ((b 6)) (list b a)) (eval (car a))) ((6 (B C D)) 5) [37]> (list (let ((b 6)) (eval (car (list ’b a)))) (eval (car a))) (5 5)
Важнейшей особенностью функционального программирования как стиля, впервые использованной в языке LISP, являются функционалы с аргументами-функциями. Рассмотрим пример возведения всех членов кортежа в квадрат.
[57]> (setq a (list 1 5 7 9 11 13 15 19 22 28)) (1 5 7 9 11 13 15 19 22 28) [58]> (mapcar (function (lambda (x) (* x x))) a) (1 25 49 81 121 169 225 361 484 784)
Функционал mapcar применяет свой первый аргумент ко всем членам второго.
Такие функционалы, в частности, делают циклы практически ненужными. Тем не менее в языке LISP есть конструкции циклов как дань программистской традиции. Чужеродность циклов подчеркивается тем, что они всегда выдают значение NIL.
И, наконец, приведем пример3).
Пример 8.4.2. Данная программа строит автомат для нахождения всех вхождений некоторой системы слов во входной поток.
Позже она анализируется с точки зрения автоматного программирования.
;================================================== ; ; свертка/развертка системы текстов ; текст представлен списком ;((Имя Вариант ...)...) ; первое имя в свертке - обозначение системы текстов ; (Элемент ...) ; (Имя Лексема (Варианты)) ; ((пример (ма (ш н) ; (ш а) ) ; ( ш н ) ) ; ((н ина)) ) ;================================================== ; реализация свертки: unic, ass-all, swin, gram, bnf
(defun unic (vac) (remove-duplicates (mapcar ’car vac) )) ;; список уникальных начал
(defun ass-all (Key Vac) ;; список всех вариантов продолжения ( что может идти за ключом) (cond ((Null Vac) Nil) ((eq (caar Vac) Key) (cons (cdar Vac) (ass-all Key (cdr Vac)) )) (T (ass-all Key (cdr Vac)) ) ) )
(defun swin (key varl) (cond ;; очередной шаг свертки или снять скобки при отсутствии вариантов ((null (cdr varl))(cons key (car varl))) (T (list key (gram varl)) ) ))
(defun gram (ltext) ;; левая свертка, если нашлись общие начала ( (lambda (lt) (cond ((eq (length lt)(length ltext)) ltext) (T (mapcar #’(lambda (k) (swin k (ass-all k ltext ) )) lt ) ) ) ) (unic ltext) ) )
(defun bnf (main ltext binds) (cons (cons main (gram ltext)) binds)) ;; приведение к виду БНФ
;=================================================== ; реализация развертки: names, words, lexs, d-lex, d-names, ; h-all, all-t, pred, sb-nm, chain, level1, lang
(defun names (vac) (mapcar ’car vac)) ;; определяемые символы
(defun words (vac) (cond ;; используемые символы ((null vac) NIL) ((atom vac) (cons vac NIL )) (T (union (words(car vac)) (words (cdr vac)))) ))
(defun lexs (vac) (set-difference (words vac) (names vac))) ;; неопределяемые лексемы
(defun d-lex ( llex) ;; самоопределение терминалов (mapcar #’(lambda (x) (set x x) ) llex) ) (defun ( llex)
;; определение нетерминалов (mapcar #’(lambda (x) (set (car x )(cdr x )) ) llex) )
(defun h-all (h lt) ;; подстановка голов (mapcar #’(lambda (a) (cond ((atom h) (cons h a)) (T (append h a)) ) ) lt) )
(defun all-t (lt tl) ;; подстановка хвостов (mapcar #’(lambda (d) (cond ((atom d) (cons d tl)) (T(append d tl)) ) ) lt) )
(defun pred (bnf tl) ;; присоединение предшественников (level1 (mapcar #’(lambda (z) (chain z tl )) bnf) ))
(defun sb-nm (elm tl) ;; постановка определений имен (cond ((atom (eval elm)) (h-all (eval elm) tl)) (T (chain (eval elm) tl)) ) )
(defun chain (chl tl) ;; сборка цепочек (cond ((null chl) tl) ((atom chl) (sb-nm chl tl))
((atom (car chl)) (sb-nm (car chl) (chain (cdr chl) tl) ))
(T (pred (all-t (car chl) (cdr chl)) tl)) ))
(defun level1 (ll) ;; выравнивание (cond ((null ll)NIL) (T (append (car ll) (level1 (cdr ll)) )) ))
(defun lang ( frm ) ;; вывод заданной системы текстов (d-lex (lexs frm)) (d-names frm) (pred (eval (caar frm)) ’(()) ) )
Листинг 8.4.1. Автомат для нахождения всех вхождений некоторой системы слов во входной поток
Объекты и LISP
Стандартная надстройка над Common Lisp, имитирующая объектно-ориентированный стиль, это модуль CLOS — Common Lisp Object System. Сама по себе объектность не дает никакого выигрыша по сравнению с языком LISP, поскольку возможности динамического вычисления функций в LISP даже шире. Видимо, именно поэтому в CLOS имеются две интересных модификации, делающие его не совсем похожим на стандартное ООП.
Начнем с понятия структуры данных в языке Common Lisp. Структура определяется функцией defstruct вида
(defstruct pet name (species ’cat) age weight sex)
Задание структуры автоматически задает функцию-конструктор структуры make-pet, которая может принимать ключевые аргументы для каждого из полей:
(make-pet :nick ’Viola :age ’(3 years) :sex ’femina))
и функцию доступа для каждого из полей, например pet-nick, использующуюся для получения значения поля или ссылки на него. Если поле не инициализировано (ни по умолчанию, ни конструктором), оно получает начальное значение NIL. Никакой дальнейшей спецификации полей структур нет6).
В объекте для каждого поля могут явно указываться функции доступа и имена ключевых параметров для инициализации аргументов. Приведем пример класса, определенного на базе другого класса.
(defclass pet (animal possession) ( (species :initform ’cat) (nick :accessor nickof :inintform ’Pussy :initarg namepet) )
Этот класс наследует поля, функции доступа и прочее от классов animal и possession. Например, поле cost имеется в значении класса, если оно имеется в одном из этих классов. Поскольку статических типов у полей нет, нет и конфликтов.
Основная функция наследования в CLOS — определение упорядочения на классах. С каждым классом связано свое упорядочение. Наследник меньше своих предков, из предков меньшим считается тот, который раньше перечислен в списке наследования при определении класса. CLOS достраивает этот частичный порядок до линейного. Способ пополнения порядка может быть в любой момент и без оповещения изменен, и хакерское использование особенностей конкретного пополнения считается грубой стилистической ошибкой.
Если система находит несовместимость в определении порядка, то она выдает ошибку, как в следующем примере:
[6]> (defclass init () ()) #<STANDARD-CLASS INIT> [7]> (defclass a (init) ()) #<STANDARD-CLASS A> [8]> (defclass b (init) ()) #<STANDARD-CLASS B> [9]> (defclass c1 (a b) ()) #<STANDARD-CLASS C1> [10]> (defclass c2 (b a) ()) #<STANDARD-CLASS C2> [11]> (defclass contr (c1 c2) ()) *** - DEFCLASS CONTR: inconsistent precedence graph, cycle (#<STANDARD-CLASS A> #<STANDARD-CLASS B>)
В CLOS могут задаваться методы, отличающиеся от функций тем, что их аргументы специфицированы, например
(defmethod inspectpet ((x pet) (y float)) (setf weightofanimal 3.5))
Как видно из этого примера, методы не обязательно связаны с классами. Они могут быть связаны с любыми типами. Методы в CLOS могут иметь дополнительные спецификации. Для того, чтобы разобраться, как эти спецификации взаимодействуют с упорядочением типов классов, рассмотрим следующую программу и генерируемый при ее исполнении результат.
(defclass thing () ((weight :initform ’(0 kg) :accessor weightof :initarg :weight))) (defclass animal (thing) ((specie :accessor specieof :initarg :spec) (sex :accessor sexof :initform ’m :initarg :sex))) (defclass possession (thing) ((owner :accessor ownerof :initform ’nnn) (cost :accessor costof :initform ’(0 bucks) :initarg :cost)) ) (defclass person (animal) ((specie :initform ’human) (name :initarg :thename :accessor nameof))) (defclass pet (animal possession) ((nick :initarg :thenick :accessor nickof) (specie :initform ’cat)))
(defmethod act :before ((p pet)) (print "Cat mews")) (defmethod act :after ((p pet)) (print "Cat turns")) (defmethod act :around ((p pet)) (progn (print "You have a cat") (call-next-method)))
(defmethod act ((p animal)) (progn (print "Animal is close to you") (call-next-method))) (defmethod act :before ((p animal)) (print "You see an animal")) (defmethod act :after ((p animal)) (print "You send the animal off")) (defmethod act :around ((p animal)) (progn (print "You don’t like wild animals") (call-next-method)))
(defmethod act ((p possession)) (progn (print "You test your property") (call-next-method))) (defmethod act :before ((p possession)) (print "You see your property")) (defmethod act :after ((p possession)) (print " You are pleased by your property")) (defmethod act :around ((p possession)) (progn (print "You admire your property if it is in good state") (call-next-method)))
(defmethod act ((p thing)) (print "You take the thing")) (defmethod act :before ((p thing)) (print "You see something")) (defmethod act :after ((p thing)) (print "You identified this thing")) (defmethod act :around ((p thing)) (progn (print "You are not interested in strange things") (call-next-method)))
(act (make-instance ’pet :thenick "Viola" :cost ’(25 kop)))
Листинг 8.6.1. Взаимодействие дополнительных спецификаций методов в CLOS с упорядочением типов классов
При загрузке этого файла происходит следующее:
[1]> (load ’myclasses) ;; Loading file E:\clisp-2000-03-06\myclasses.lsp ... "You have a cat" "You don’t like wild animals" "You admire your property if it is in good state" "You are not interested in strange things" "Cat mews" "You see an animal" "You see your property" "You see something" "Cat purrs" "Animal is close to you" "You test your property" "You take the thing" "You identified this thing" "You are pleased by your property" "You send the animal off" "Cat turns" ;; Loading of file E:\clisp-2000-03-06\myclasses.lsp is finished. T
Пример 8.6.2. Результат загрузки программы 8.6.1
Видно, что упорядоченность классов по отношению наследования позволяет выстраивать целые последовательности действий при вызове одного метода.
Поскольку в CLOS нет ни механизмов скрытия конкретных представлений, ни механизмов замены прямого доступа к данным на функции, ни других характерных особенностей ООП, мы видим еще один пример того, как модным словом (в данном случае ООП) прикрывается другая, не менее интересная сущность: начатки планирования действий по структуре типов данных.
В связи с этим стоит напомнить блестящий эксперимент планирования вычислений по структуре данных, в настоящий момент (судя по всему, временно) забытый: эстонскую систему PRIZ [28].
Неадекватное теоретизирование мешает увидеть и развить реальные достоинства системы и закрепляет слабые места.
|
|
|
И уж точно первый из выживших, поскольку Plankalkul Цузе умер вместе с его машинами.
2)
А для предотвращения хакерских трюков и нежелательно!
3)
Любезно предоставленный Л. Городней (ИСИСО РАН и НГУ)
4)
Как сделано в системе TEX-LATEX.
5)
Примером, иллюстрирующим ситуацию, может служить XML, линейность конкретного синтаксиса которого является лишь следствием стихийных стандартов.
6)
Имеется редко используемая возможность указать, какого типа должно быть поле.
Поле зрения и поле памяти
Если не применены специальные операции блокирования вычислений, первый аргумент списка интерпретируется как функция, аргументами которой являются оставшиеся элементы списка. Это позволяет программу также задавать списком.
Таким образом, в LISP, так же, как в сентенциальных языках, структура данных программы и поля памяти, обрабатываемого программой, совпадают. Видимо, это одна из удачнейших форм поддержания концептуального единства для высокоуровневых систем.
В поле памяти с каждым атомом-именем могут быть связаны атрибуты. Стандартный атрибут — значение атома. Для установки этого атрибута есть функция (setq atom value), аналогичная присваиванию. Эта функция не вычисляет свой первый аргумент, она рассматривает его как имя, которому нужно приписать значение.
Значение в языке LISP может быть локальным. Если мы изменили значение атома внутри некоторого блока, то такое ‘присваивание’ действует лишь внутри минимальных объемлющих его скобок и исчезает снаружи блока. Кроме значения, имена могут иметь сколько угодно других атрибутов, которые обязательно глобальны. Они принадлежат самому имени, а не блоку. Способ установки значений этих атрибутов несколько искусственный. Имеется еще одна функция setf, вычисляющая свой первый аргумент, дающий ссылку на место, которому можно приписать значение (например, на атрибут). Функция получения значения атрибута get, даже если атрибута еще нет, указывает на его место. Следующий пример демонстрирует, как это работает.
[38]> (setf (get ’b ’weight) ’(125 kg)) (125 KG) [39]> (get ’b ’weight) (125 KG)
Рассмотрим подробнее структуру данных языка LISP. Она является двухуровневой. На верхнем уровне имеется структура списков. На нижнем находится структура информации, сопоставленной атому. Она изображена на рис. 8.1. Оба этих уровня рекурсивно ссылаются друг на друга, например, атрибуты атома являются списками.
Типы данных (в смысле программирования) в LISP есть, но они определяются динамически. В частности, если действительное число придано атому как значение, то тип атома становится float.
Прагматические добавления и динамическое порождение программ
Разберем возможности языка LISP в комплексе.
Выразительные средства конкретно-синтаксического представления общей структуры данных и программ языка LISP крайне скупы. Но это представление позволяет практически однозначно связать синтаксис и реализационную структуру.
Реализационное представление как нельзя лучше соответствует соглашению об общности функциональной структуры и структуры данных: в каждом списке голова рассматривается как указание (имя, ссылка или что-то подобное) на функцию, а хвост — как последовательность указаний на аргументы. Задание свойства списка не быть функцией, т. е. отмена выделенного статуса головы, обозначающей функцию, достигается с помощью блокировок. Это удачное решение в условиях принятого соглашения, позволяющее трактовать нефункциональный список как константную функцию, "вычисляющую" свое изображение (представление). Еще более важно то, что оно обеспечивает гибкость представления: функцию eval, заставляющую список принудительно вычисляться, естественно трактовать просто как снятие блокировок. Заметим, что на уровне абстрактного синтаксиса функция eval обязана быть универсально применимой к любому списку.
К сожалению, такой универсализм провоцирует крайне ненадежное и неэффективное программирование, поэтому это решение нельзя считать удачным. Справедливости ради заметим, что в те времена, когда разрабатывался язык, задача надежности еще не была поставлена, но плохо то, что сформировался стихийный стандарт, не способствующий качеству программирования.
Для обеспечения практической пользы функции eval следовало бы предусмотреть компенсирующие регламенты ее корректного применения на уровне конкретного синтаксиса, режимов вычислений и системных механизмов.
Внимание!
На уровне абстрактного и конкретного синтаксиса разные семантические возможности имеют разный статус, поэтому в конкретном представлении необходимо предусматривать механизм скрытия и даже полного запрета тех возможностей, которые концептуально разумны лишь на уровне абстрактного синтаксиса4).
Структура списков LISP идеальна для представления абстрактного синтаксиса языка. И хотя злые языки называют этот синтаксис "утомительным нагромождением скобок", он в точности соответствует абстрактному синтаксису. Если даже не учитывать преимущества указанного соответствия, то остается простота представления программ и данных в виде линейной текстовой последовательности символов.
Другие гипотетические кандидаты на роль конкретного синтаксиса по этому критерию явно проигрывают. Традиционные математические формы задания функций и их применений являются текстуально избыточными (как префиксная, так и постфиксная записи требуют обязательного обрамления параметров скобками), а бесскобочная нотация Лукасевича (и прямая, и обратная) еще более запутывали бы тексты по сравнению с "утомительным нагромождением скобок". Но за счет внеязыковых прагматических соглашений о том, как располагать на двумерном носителе (на бумаге или на экране) скобочную структуру, можно существенно облегчить. Если же система программирования будет поддерживать (и проверять!) прагматические соглашения (что характерно для развитых систем), то вид программ станет вполне читаемым. Таким образом преодолеваются неудобства линейного представления.
Сегодня можно было бы говорить о других форматах конкретного синтаксиса LISP, в том числе и не связанных с линейным представлением. Использование развитых средств графики при экранном наборе программ позволяет на полную мощь подключить двумерную работу. Однако традиции и стихийно сформировавшиеся стандарты не оставляют возможности для внедрения таких форматов. Здесь в очередной раз и в полной мере проявились вредные эффекты ранней стандартизации, мешающие развитию направления, остающегося одним из самых концептуально богатых и перспективных.
Диктат линейности укоренился настолько глубоко, что даже в тех случаях, когда он мог бы быть преодолен безболезненно, языковая система чаще всего все равно строится как линейная. Это касается не только функционального стиля5).
что может идти за ключом)
|
;================================================== ; ; свертка/развертка системы текстов ; текст представлен списком ;((Имя Вариант ...)...) ; первое имя в свертке - обозначение системы текстов ; (Элемент ...) ; (Имя Лексема (Варианты)) ; ((пример (ма (ш н) ; (ш а) ) ; ( ш н ) ) ; ((н ина)) ) ;================================================== ; реализация свертки: unic, ass-all, swin, gram, bnf (defun unic (vac) (remove-duplicates (mapcar ’car vac) )) ;; список уникальных начал (defun ass-all (Key Vac) ;; список всех вариантов продолжения ( что может идти за ключом) (cond ((Null Vac) Nil) ((eq (caar Vac) Key) (cons (cdar Vac) (ass-all Key (cdr Vac)) )) (T (ass-all Key (cdr Vac)) ) ) ) (defun swin (key varl) (cond ;; очередной шаг свертки или снять скобки при отсутствии вариантов ((null (cdr varl))(cons key (car varl))) (T (list key (gram varl)) ) )) (defun gram (ltext) ;; левая свертка, если нашлись общие начала ( (lambda (lt) (cond ((eq (length lt)(length ltext)) ltext) (T (mapcar #’(lambda (k) (swin k (ass-all k ltext ) )) lt ) ) ) ) (unic ltext) ) ) (defun bnf (main ltext binds) (cons (cons main (gram ltext)) binds)) ;; приведение к виду БНФ ;=================================================== ; реализация развертки: names, words, lexs, d-lex, d-names, ; h-all, all-t, pred, sb-nm, chain, level1, lang (defun names (vac) (mapcar ’car vac)) ;; определяемые символы (defun words (vac) (cond ;; используемые символы ((null vac) NIL) ((atom vac) (cons vac NIL )) (T (union (words(car vac)) (words (cdr vac)))) )) (defun lexs (vac) (set-difference (words vac) (names vac))) ;; неопределяемые лексемы (defun d-lex ( llex) ;; самоопределение терминалов (mapcar #’(lambda (x) (set x x) ) llex) ) (defun ( llex) ;; определение нетерминалов (mapcar #’(lambda (x) (set (car x )(cdr x )) ) llex) ) (defun h-all (h lt) ;; подстановка голов (mapcar #’(lambda (a) (cond ((atom h) (cons h a)) (T (append h a)) ) ) lt) ) (defun all-t (lt tl) ;; подстановка хвостов (mapcar #’(lambda (d) (cond ((atom d) (cons d tl)) (T(append d tl)) ) ) lt) ) (defun pred (bnf tl) ;; присоединение предшественников (level1 (mapcar #’(lambda (z) (chain z tl )) bnf) )) (defun sb-nm (elm tl) ;; постановка определений имен (cond ((atom (eval elm)) (h-all (eval elm) tl)) (T (chain (eval elm) tl)) ) ) (defun chain (chl tl) ;; сборка цепочек (cond ((null chl) tl) ((atom chl) (sb-nm chl tl)) ((atom (car chl)) (sb-nm (car chl) (chain (cdr chl) tl) )) (T (pred (all-t (car chl) (cdr chl)) tl)) )) (defun level1 (ll) ;; выравнивание (cond ((null ll)NIL) (T (append (car ll) (level1 (cdr ll)) )) )) (defun lang ( frm ) ;; вывод заданной системы текстов (d-lex (lexs frm)) (d-names frm) (pred (eval (caar frm)) ’(()) ) ) |
| Листинг 8.4.1. Автомат для нахождения всех вхождений некоторой системы слов во входной поток |
| Закрыть окно |
Списки и функциональные выражения
Основной единицей данных для LISP-системы является список.
Списки задаются следующим индуктивным определением.
Пустой список () (обозначаемый также nil) является списком.Если l1,. . . , ln, n

Элементами списка (l1, . . . , ln) называются l1, . . . , ln. Равенство списков задается следующим индуктивным определением.
l = nil тогда и только тогда, когда l также есть nil.(l1, . . . , ln) = (k1, . . . , km) тогда и только тогда, когда n = m и соответствующие li = ki.
Пример 8.2.2. Все списки (), (()), ((())) и т. д. различны. Различны также и списки nil, (nil, nil), (nil, nil, nil) и так далее. Попарно различны и списки ((A,B), C), (A, (B,C)), (A,B,C), где A, B, C — различные атомы.
Поскольку понятие, задаваемое индуктивным определением, должно строиться в результате конечного числа шагов применения определения, мы исключаем списки, ссылающиеся сами на себя. Списки в нашем рассмотрении изоморфны упорядоченным конечным деревьям, листьями которых являются nil либо атомы.
Вершины списка L задаются следующим индуктивным определением.
Элементы списка являются его вершинами.Вершины элементов списка являются его вершинами.
Длиной списка называется количество элементов в нем. Глубиной списка называется максимальное количество вложенных пар скобок в нем. Соединением списков (l1, . . . , ln) и (k1, . . . , km) называется список
(l1, . . . , ln, k1, . . . , km).
Замена вершины a списка L на атом либо список M получается заменой поддерева L, соответствующего a, на дерево для M. Замена обозначается L[a | M]. Через L[a || M] будем обозначать результат замены нескольких вхождений вершины a на M.
Атомами в языке LISP являются числа, имена, истина T. Ложью служит пустой список NIL, который в принципе атомом не является, но в языке LISP при проверке на то, является ли он атомом, выдается истина. Точно так же выдается истина и при проверке, является ли он списком. Однако все списковые операции применимы к NIL, а те, которые работают с атомами, часто к нему неприменимы.
Например, попытка присваивания значения выдает ошибку.
Основная операция для задания списков (list a b . . . z). Она вычисляет свои аргументы и собирает их в список. Для этой операции без вычисления аргументов есть скоропись ’(a b . . . z). Она является частным случаем функции quote (сокращенно обозначаемой ’), которая запрещает всякие вычисления в своем аргументе и копирует его в результат так, как он есть.
По традиции, элементарные операции разбора списков обозначаются именами, которые начинаются с c и кончаются на r, а в середине идет некоторая последовательность букв a и d; (car s) выделяет голову (первый член списка), (cdr s) — хвост (подсписок всех членов, начиная со второго). Буквы a и d применяются, начиная с конца. Общее число символов в получающемся атоме должно быть не больше шести. Рассмотрим фрагмент диалога, иллюстрирующий эти операции. Как только в диалоге вводится законченное выражение, оно вычисляется либо выдается ошибка.
[13]>(setq a ’(b c (d e) f g)) (B C (D E) F G) [14]> (cddr a) ((D E) F G) [15]> (cddar a) *** - CDDAR: B is not a list 1. Break [16]> ^Z [17]> (caaddr a) D [18]> (cdaddr a) (E)
?-абстракции
В некоторых случаях осознанное усвоение концепций даже на самом низком уровне нереально без базовых теоретических сведений. А знакомство с таким базисом, в свою очередь, стимулирует значительно более глубокий интерес к теории и способствует пониманию того, что на высшие уровни знаний и умений не подняться без овладения теорией.
Теоретической основой языка LISP является логика функциональности: комбинаторная логика или (по наименованию одного из основных понятий в наиболее популярной из нынешних ее формализаций) ?-исчисление.
В ?-исчислении выразительные средства, на первый взгляд, крайне скупы. Имеются две базисные операции: применение функции к аргументу (?x) и квантор образования функции по выражению ?x t[x]. В терминах ?-исчисления функция возведения числа в квадрат записывается как ?x (sqrx) или, если быть ближе к обычным математическим обозначениям, ?x x2.
Основная операция — символьное вычисление применения функции к аргументу: (?x t[x] u) преобразуется в t[u]. Но эта операция может применяться в любом месте выражения, так что никакая конкретная дисциплина вычислений не фиксируется. Более того, функции могут вычисляться точно так же, как аргументы. Уже эта маленькая тонкость приводит к принципиальному расширению возможностей ?-исчисления по сравнению с обычными вызовами процедур. Если мы желаем ограничиться лишь ею, рассматривается типизированное ?-исчисление, в котором, как принято в большинстве современных систем программирования, значения строго разделены по типам. В типизированном ?-исчислении есть только типы функций, но этого хватает, поскольку функции могут принимать в качестве параметров и выдавать функции.
Но в исходной своей форме ?-исчисление является нетипизированным, любой объект может быть и функцией, и аргументом, и, более того, функция может применяться к самой себе. Конечно же, при этом появляется возможность зацикливания, но без нее не обойдется ни одна "универсальная" алгоритмическая система. Например, выражение
(?x (xx) ?x (xx))
вычисляется бесконечно, а чуть более сложное выражение
((?x ?y x a) (?x (xx) ?x (xx)))
может либо дать a, либо зациклиться, в зависимости от выбора порядка его вычисления. Но все равно, если мы приходим к результату, то он определяется однозначно. Так что совместность вычислений не портит однозначности, если язык хорошо сконструирован.
Дж. Маккарти перенес идеи ?-исчисления в программирование, не потеряв практически ничего из исходных концепций. Далее, он заметил, что в рудиментарном виде в ?-исчислении появилось понятие списка, и перенес списки в качестве основных структур данных в свой язык. ?-исчислением было навеяно и соглашение языка LISP о том, что первый член списка трактуется как функция, применяемая к остальным.
Автоматные задачи
Многие программистские задачи удобно решать с помощью методов, формализацией которых могут служить таблицы состояний и переходов (напр., их собрание см. в [32] и на сайте http://is.ifmo.ru).
Пример 9.1.1. Модель изменяющейся системы.
Пусть мы моделируем динамическую либо экологическую систему, у которой в различных областях принципиально разное поведение. Вместо того, чтобы совмещать внутри одного и того же программного модуля анализ, какой области принадлежит точка, и вычисление следующего состояния системы, мы можем написать несколько простых модулей моделирования поведения системы в каждой из областей (единственная проверка, которая при этом может понадобиться, вышли мы при очередном шаге моделирования за границы области или нет). Как отдельный модуль строится глобальная управляющая программа, которая проверяет, в каком состоянии находится система, и вызывает соответствующий вычислительный модуль.
В данном случае выигрыш не столько в длине программы, сколько в ее обозримости и модифицируемости (хотя именно эти важнейшие качества программы начинающие программисты чаще всего недооценивают). Но если при входе в новую область нужно проделать ряд организационных действий (в каждой области различных), а уже в зависимости от их результата выбрать дальнейшую траекторию системы, то описание в виде автомата становится все более выигрышным.
Если при анализе задачи удается выявить набор состояний описываемого процесса, условия перехода между состояниями и действия, ассоциированные с состояниями, то задачу уместно решать методами таблиц состояний. При анализе таких методов можно применять конечные автоматы Мура.
Теоретически автомат Мура представляется как матрица переходов, строками которой служат состояния автомата, а столбцами - входные символы1). В качестве входных символов на практике можно рассматривать результаты проверки некоторых условий. Неявное в теории, но важнейшее на практике содержимое каждого состояния автомата - процедура, приводящая к глобальному изменению состояния вычислительной системы.
Такие процедуры назовем действиями.
Таблицы автоматов часто также представляются в виде графов, что особенно удобно, когда не все возможные переходы между состояниями реализуемы. См., напр., рис. 9.1, где представлены и таблица, и граф.

Рис. 9.1. Таблица состояний. Граф переходов.
Здесь состояния идентифицируются порядковыми номерами, а воздействия - буквами.
На таблице состояний или на ее графовом аналоге все действия предполагаются по умолчанию глобальными, и каждое действие соединено с распознаванием, какое из перечисленных на выходящих из него ребрах условий выполнено. В зависимости от того, какое из них выполнено, автомат переходит в соответствующее состояние, которому опять-таки, если оно не заключительное, сопоставлено действие и распознавание.
Имеется вариация понятия автоматов, порождающая другой метод автоматного программирования. В теории автомат Мили отличается тем, что результат, записываемый на выходную ленту автомата, может зависеть от выбранного перехода. На практике действия в таблице состояний и переходов могут ассоциироваться либо с состояниями (с вершинами графа, автомат Мура), либо с переходами (с дугами графа, автомат Мили). Ниже Вы увидите примеры, когда при программировании естественно возникают оба этих варианта2). Модель вычислений автомата Мили лучше использовать, если проверки в каждом состоянии по существу различны, а модель автоматов Мура - если проверки по существу однородны, как в примере 9.1.1.Метод программирования, когда действия сопоставляются переходам, назовем преобразованиями на переходах (сокращенно просто "на переходах"), метод, когда действия производятся в состояниях, назовем преобразованиями в состояниях (сокращенно просто "в состояниях").
Заметим, что естественно рассматривать таблицы состояний и переходов как недетерминированные, поскольку после выполнения действия вполне может оказаться истинно сразу несколько условий, соответствующих выходящим ребрам.
Внимание!
В данном случае мы видим один из неистощимых источников ошибок в программах, который впервые заметил Д.
Грис. Если по сути задачи нам все равно, какое из действий будет выполнено, а язык (как те стандартные языки, на которых обычно работают) заставляет детерминировать переходы, либо ранжировав их по порядку, либо принудительно сделав их условия логически противоречивыми, то при изменении программы часто возникают трудности. Они связаны с тем, что после изменения детерминировать-то надо было по-другому, но уже нельзя различить, какие из условий существенны, а какие вставлены лишь для детерминации.
Как было показано в нашем примере, таблицы переходов и состояний являются естественным способом программирования для модуля, имеющего дело с глобальными операциями над некоторой средой (эти глобальные операции сами, как правило, программируются в другом стиле). Для автоматного программирования характерно go to, и здесь оно на месте.
Есть много конкретных методик автоматного программирования, укладывающихся в рамки двух главных методов. Автоматное программирование хорошо демонстрирует то, как варьируются практические методы решения логически и математически, вроде бы, однородных задач. Небольшое изменение в ресурсных ограничениях - и, хотя старые методы, как правило, остаются уместными, но лучше перейти к другим.
Методы действий в состояниях и на переходах: анализ состояний и построение таблицы
В данном разделе начинается детальный показ двух методов автоматного программирования, основанных на модели Мура и Мили. Методика работы в них почти одна и та же, но, как чаще всего бывает, маленькое и вроде бы техническое различие (чему сопоставляются действия: состояниям или переходам?) порождает два несовместимых метода. Их несовместимость не столь грубая, как во многих других случаях (два таких случая - несовместимость между автоматами и присваиваниями и между циклами и рекурсиями - рассмотрены ниже). Если это и противоречие, то противоречие технологическое. Произвольно перемешивая эти два метода, мы в дальнейшем затрудняем модификацию программы, а в настоящем вынуждены множить число подпорок.
Человек даже грубые противоречия игнорирует или обходит 4). Для применения правила важно знать не только его, но и когда можно его нарушать. Общеметодологический принцип здесь такой: если уж нарушать, то на полную катушку (проехав перекресток на красный свет, глупо останавливаться сразу за ним)! Второй принцип: если нельзя, но очень нужно, то надо! А. А. Шалыто указал, что в теории 5) есть и такое смешанное понятие, как автоматы Мили-Мура. Одной из моделей таких автоматов является автомат с двумя выходными лентами: на одну пишется результат в состояниях, на другую - на переходах. Программной интерпретацией такой теоретической модели является, например, модуль, который в состояниях ведет диалог с окружающей средой, в результате чего получает данные для определения очередного перехода, а на переходах производит внутренние вычисления.
Для отработки методики используется простая задача, не затемняющая ее суть частными тонкостями и пригодная для реализации любым из двух методов. Полученная методика переносится на широкий класс задач и не отказывает вплоть до тысяч состояний.
Основные структуры автоматного программирования
Информационное пространство всех блоков и процедур при автоматном программировании в первом приближении одно и то же: состояния системы, моделируемой совокупностью программных действий. Но на самом деле многие блоки либо процедуры работают с подсистемами. Подсистемы, ввиду их автономности, могут иметь характеристики, прямо недоступные для общей системы, и ограниченный доступ к общему системному пространству данных. Более того, подсистемы могут общаться прямо, в обход иерархически вышестоящей системы (см. рис. 9.2). Таким образом, структура информационного пространства при автоматном программировании в общих чертах соответствует той, которая навязывается современными системами с развитой модульностью3). В системах модульности есть понятия, предоставляемые для пользования другими модулями, есть модули, которые автоматически получают доступ ко всем понятиям дружественного модуля, и есть интерфейсы между модулями.

Рис. 9.2. Информационное пространство систем
Светло-серые области - традиционный общий контекст системы и подсистемы. Темно-серые иллюстрируют, что доступность может быть односторонней, и не только по иерархии. Одна из систем может влиять на часть информационного пространства другой, а та может лишь пассивно следить, что натворил коллега. Области, связанные двусторонними стрелками, иллюстрируют прямое общение в обход иерархии.
Исторически первой моделью автоматного программирования, использованной как на практике, так и для теоретических исследований, было представление программы в виде блок-схемы (см., напр., рис. 9.3), узлы которой являлись состояниями. Узлы блок-схемы делятся на пять типов:
начальная вершина, в которую нет входов и где производится инициализация переменных либо состояния вычислительной системы;действия, при которых исполняется вызов процедуры либо оператор и после которых автомат однозначно переходит в следующее состояние;распознаватели, проверяющие значение переменной либо предиката и затем передающие управление по разным адресам;соединения, в которые имеется несколько входов и один выход;выход, попав в который, программа заканчивает работу.

Рис. 9.3. Блок-схема
Представление программ в виде блок- схем было целесообразно для многих классов программ, писавшихся в машинных кодах без средств автоматизации программирования. Блок-схемы тогда были основным средством планирования разработки программ и их документирования. Традиционные блок-схемы - предмет изучения, в частности, теоретического программирования (см. книги Котова [16], [17]).
Таблицы переходов концептуально противоречат такому фундаментальному понятию программирования, как присваивание. В блок-схеме произвольной формы исключительно трудно проследить, как будет изменяться значение переменной, какие существуют зависимости между данными переменными, и т. п.
Действия в автоматном программировании глобальны, а условия локальны. Проверка условия не изменяет состояния всей системы (ни одного из ее параметров или характеристик), она лишь переводит саму программу в то или иное состояние.
Это подтверждает и анализ практических систем, для моделирования которых удобно применять автоматное программирование. Например, открытие или закрытие одного вентиля в трубопроводной системе изменяет все потоки в системе, а проверка - открыт ли вентиль - локальная операция. Изменение температуры рабочего вещества в системе опять-таки влияет на все ее характеристики, а измерить эту температуру можно, сняв показания всего одного датчика.
Здесь мы сталкиваемся с необходимостью четко различать внешние понятия, описывающие систему, которая связана с решаемой программой задачей, и внутренние понятия самой программы. Для системы в целом безразличны состояния автомата, который ее моделирует либо взаимодействует с ней. Для нее важно, какие изменения в ней самой происходят. Таким образом, состояние памяти вычислительной системы вполне может рассматриваться как внешняя характеристика по отношению к программе, которая в ней работает.
Необходимость одновременного и согласованного рассмотрения внешних и внутренних характеристик приводит к тому, что, когда внутренние характеристики раздробляются и детализируются (например, при соединении стиля автоматного программирования с присваиваниями), программист начинает путаться, согласованность понятий исчезает и возникают ошибки.
Внимание!
Если пользоваться произвольными таблицами переходов, то надо позаботиться о том, чтобы присваивания встречались как можно реже, в идеале обойтись без них совсем либо присваивать лишь значения переменным, которые немедленно после этого используются в качестве основания для выбора в операторе типа case.
Граф состояний и переходов, называемый также таблицей переходов — нагруженный ориентированный граф G. Каждой вершине графа G сопоставлено наименование состояния, а каждой дуге — условие.
Условие AB, сопоставленное дуге, ведущей из a в b, содержательно интерпретируется следующим образом. При выполнении AB в состоянии a управление передается состоянию b (или же в другом смысле осуществляется переход по данной дуге).
Когда граф состояний и переходов используется для документирования программы, наименования состояний, как правило, совпадают с именами процедур, выполняющихся в данном состоянии.
Постановка задачи и первичный анализ
Пусть требуется решить следующую задачу. Словом называется любая непустая последовательность букв латинского алфавита (для простоты - только строчных букв). Перепечатать из входной последовательности символов все максимальные входящие в нее слова в следующем виде:
<слово> - <длина слова><конец строки печати>
Ввод заканчивается пустой строкой.
Например, по строкам
попугай бегемот 1мот2крот1мот
нужно выдать что-либо вроде
попугай 7 бегемот 7 мот 3 крот 4 мот 3
Для решения задачи входную последовательность символов естественно считать потоком, читаемым слева направо, пока не будет прочитана пустая строка. При чтении букв, других символов и конца строки действия, которые необходимо выполнять, различны. Кроме того, различаются действия для первой буквы и для последующих букв слова.
Построение графа состояний
Прежде всего, определим набор состояний, исходя из различных реакций на прочитанный символ.
Вот полный перечень вариантов реакций:
Символ буква: инициализировать обработку слова (счетчику длины слова присвоить единицу).Символ буква: продолжить обработку слова (счетчик длины слова увеличить на единицу).Символ не буква: закончить обработку слова (напечатать длину прочитанного слова).Символ не буква: пропустить символ.Символ конец строки: закончить обработку слова (напечатать длину прочитанного слова).Символ конец строки: пропустить символ.Символ конец строки: завершить процесс.
Есть еще одно действие, не отраженное в этом списке, но подразумеваемое: стандартное действие, происходящее перед началом отработки нового состояния. В данном случае это чтение очередного символа, которое должно выполняться, когда переход срабатывает. В других случаях автоматных моделей роль чтения очередного символа может играть, скажем, последующий шаг моделирования. Для данного и для большинства других автоматных примеров стандартное действие не нужно указывать явно, поскольку оно автоматически сопоставляется каждому переходу и полностью соответствует математической модели.
Из перечня действий для рассматриваемой задачи следует, что должно быть, как минимум, два класса состояний, имеющие разные действия-реакции.
Следующий методический прием - это определение начального состояния, т. е. того, в котором вычислительный процесс активизируется. Нужно указать, какие действия возможны в данном состоянии и какие условия перехода в нем должны быть.
Для рассматриваемого случая в начальном состоянии (St1), возможны переходы:
с переходом в другое состояние - St2 (поскольку следующая буква требует другой реакции),с сохранением состояния иотработка первого перевода строки.

Рис. 9.4. Начало построения графа состояний по Муру
Результат только что проведенного анализа можно представить в виде графа, изображенного на рис. 9.4. С каждой дугой графа связано условие перехода. С каждым состоянием может быть связано действие.
В состояниях St1 и St3 действием является пропуск очередного символа и чтение следующего, но соединить их сейчас нельзя, поскольку в первом из них переход на завершение работы невозможен, так что перевод строки анализируется по-разному. Это позволяет предположить, что в данной задаче действия стоит ассоциировать с переходами, а не с состояниями. Правильный выбор того, с чем ассоциировать действия, может сильно оптимизировать программу. Для показа двух возможных вариантов, которые в данном случае почти эквивалентны по сложности, мы будем действовать как на переходах, так и в состояниях. В частности, предварительный анализ состояний при методе преобразований на переходах дан на рис. 9.5.

Рис. 9.5. Начало построения графа состояний при использовании метода на переходах
Внимание!
Если у Вас есть две близкие, но концептуально противоречивые, модели, в начале развития программы нужно сделать выбор в пользу одной из них. Небольшие эксперименты и отступления в начале оборачиваются большой экономией сил в конце.
На схемах вход и выход обозначаются черными прямоугольными блоками. При желании их можно считать специальными состояниями, с которыми ассоциированы действия инициализации и завершения процесса. Состояние St2 изображено штриховой линией, поскольку анализ его еще не проведен. Для каждого из еще не проанализированных состояний (в данном случае для St2) следует определить условия перехода (и соответствующие им действия, если выбрали работу на переходах).
В рассматриваем случае в состоянии St2 возможны переходы:
с сохранением состояния;окончание слова и отработка вывода слова, поскольку следующий символ не буква, с переходом в другое состояние, которому дается временное имя St4;отработка окончания слова и перевода строки, ему можно дать временное имя St5.
После этого построения проверяется, не является ли новое состояние копией уже имеющихся как по действиям, так и по переходам. Если это так, то новое состояние можно отождествить (склеить) с одним из ранее построенных.
Вновь появляющиеся состояния анализируются аналогично.
Для решаемой задачи легко выяснить, что состояние St3 требует тех же действий и переходов, что и St5, а St4 изоморфно St1. Следовательно, возможна склейка этих двух состояний со старыми и построение графа завершается, так как новых состояний нет (см. рис. 9.6). С тем, чтобы не дублировать действия <Завершить процесс>, можно определить еще одно, заключительное состояние, с выходом из которого будет ассоциировано это действие (один раз!).

Рис. 9.6. Полученный граф состояний при действиях на переходах
Аналогично можно поступить и когда мы работаем в состояниях. Здесь процесс удлиняется на один шаг, поскольку необходимо выделить завершение обработки слова в отдельное действие (причем в двух вариантах: после перевода строки и после других небуквенных символов). Полученный результат показан на рис. 9.7.
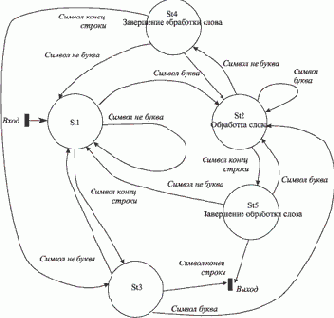
Рис. 9.7. Полученный граф состояний при действиях в состояниях
Программные представления графа состояний
Отметим, что программные представления графа состояний сильно зависят от динамики данного графа. Стоит выделить четыре подслучая.
Состояния и таблица переходов жестко заданы постановкой задачи (например, такова задача синтаксического анализа). В этом случае лучшее программное представление переходов между состояниями - go to, независимо от размера таблицы.Состояния и таблица переходов пересматриваются, но фиксированы между двумя модификациями задачи. При небольших размерах таблицы по-прежнему предпочтительней всего реализация через переходы, а при достаточно больших - необходима ее декомпозиция, в связи с чем часто целесообразно представление состояний объектами.Состояния и таблица переходов динамически порождаются перед выполнением данного модуля и фиксированы в момент его выполнения. Лучший способ реализации - задание таблицы переходов в виде структуры данных и написание интерпретирующей программы для таких таблиц."Живая таблица": модифицируется в ходе исполнения. Пока что дать методологические советы для таких таблиц мы не можем, хотя очевидно, что, несмотря на внешнюю рискованность, такой путь чрезвычайно выигрышен для многих систем адаптивного реагирования. Заранее нужно обговорить, что модули, перестраивающие таблицу, и модули, исполняющие ее, должны быть как можно более жестко разделены.
Табличное представление графа состояний
Графическое или иное представление графа состояний конечного автомата, явно отражающее наименования состояний, условия переходов между состояниями и ассоциированные с ними действия, называют таблицей переходов. Такое представление является одним из центральных компонентов широко используемого в индустриальном программировании языка объектно-ориентированного дизайна UML (в частности, в форме, реализованной в системе Rational Rose) - state transition diagrams (диаграммы состояний и переходов).
Различают визуальные представления таблиц переходов, которые предназначены для человека, и их программные представления. Требования к визуальным представлениям - понятность для человека, статическая проверяемость свойств; требования к программным представлениям - выполнимость при посредстве какой-либо системы программирования; общее требование к представлениям обоих видов - однозначное соответствие между ними, позволяющее обоснованно утверждать вычислительную эквивалентность.
Ответ на вопрос, какое представление графа состояний лучше всего использовать, зависит от сложности графа, статичности либо динамичности его и того, для каких целей требуется спецификация в виде графа состояний. Понятно, что важнейшей для нас промежуточной целью является программа на алгоритмическом языке. Но подходы к построению такой программы могут быть различны. Существует две принципиально различные методики применения спецификаций:
трансляционная - генерируется программа, структура управления которой определяется графом состояний;интерпретационная - строится специальная программа, которая воспринимает некое представление графа как задание для интерпретации.
Как при трансляционной, так и интерпретационной позиции возможен целый спектр реализаций. Ближайшая же цель в том, чтобы научиться удобно для человека представлять граф состояний и переходов. Наиболее естественно описывать его в виде таблицы. Для методов на переходах и в состояниях таблицы несколько различаются. На табл. 9.1 представлен случай Мили.
Опишем значение колонок таблицы.
Наименование состояния - входы в таблицу.Условие (срабатывания) перехода - логическое выражение или служебное слово failure, которое указывает на действие, выполняемое, если ни одно из условий не срабатывает.Действие, ассоциированное с переходом, - последовательность операторов, выполняемая, когда условие перехода истинно.Адрес перехода - наименование состояния-преемника.
Кроме того, определяется специальная (первая) строка, в которой помещаются операторы, инициирующие процесс, и адрес перехода начального состояния.
В табличном представлении графа переходов в состояниях (таблица 9.2) действия помещаются во втором столбце, сразу после обозначения состояния, а уже затем идут переходы. Анализируя таблицу 9.2, можно заметить ряд повторяющихся действий. Конечно же, если бы эти действия были более сложными, их просто описали бы как процедуры. Но такие повторения заставляют задуматься, а нельзя ли сократить число состояний? Введя дополнительную булевскую переменную, отметившую, что последним символом был перевод строки, мы могли бы избавиться от пары состояний. Но такой переменной нужно присваивать новое значение в процессе проверки условий, и при этом в строго определенный момент: сначала проверить, не является ли символ концом строки, а уже затем переприсваивать данную переменную. Это решение сильно отдает хакерством, и, если Вы хотите писать качественные, легко перестраиваемые программы, то таких решений нужно избегать.
Еще раз показать тонкую грань между хакерством и естественностью можно, рассмотрев один из моментов, возникающих в наших программах. При работе в состояниях нам приходится обнулять счетчик букв слова в тот момент, когда кончается очередное слово, поскольку иначе пришлось бы выделять еще одно состояние, соответствующее середине обработки слова. Но это гораздо менее искусственное решение: неплохо восстанавливать начальные значения и делать другие действия по приведению в порядок информации в тот момент, когда заканчивается очередной этап работы; неплохо делать это всегда в начале нового этапа; плохо лишь произвольно перемешивать эти две дисциплины.
|
char symbol; // Чтение потока символов неявное // Чтение происходит перед выполнением проверок и действий int Cnt; . . . // Инициализация | St1|
| 'a'<=symbol && symbol <= 'z' | printf ("%c", symbol); Cnt = 1; | St2
| /*(symbol<'a'|| 'z'<symbol) &&*/ symbol!='\n' | /* Действий нет */ | St1
| symbol='\n' | /* Действий нет */ | St3
| 'a'<=symbol && symbol <= 'z' | printf ("%c", symbol);cnt++; | St2
| /*(symbol<'a'|| 'z'<symbol) &&*/ symbol != '\n' | printf ("- %i\n", Cnt); | St1
| symbol='\n' | printf ("- %i\n", Cnt); | St3
| 'a'<=symbol && symbol <= 'z' | printf ("%c", symbol); Cnt = 1; | St2
| /*(symbol<'a'|| 'z'<Symbol) &&*/ symbol!='\n' | /* Действий нет */ | St1
| symbol='\n' | Второй '\n' дальше не нужно читать | exit
| /* Нет неявного чтения потока */ | return 0; // Считать данную секцию таблицы состоянием или нет - дело вкуса |
|
char symbol; // Чтение потока символов неявное // Чтение происходит после выполнения действия, перед проверками int Cnt; ...Cnt=0; // Инициализация | St1|
| /* Действий нет */ | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z'<symbol) &&*/ symbol!='\n' | St1|
| symbol='\n' | St3|
| printf ("%c", symbol); Cnt++; | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z'<symbol) &&*/ symbol != '\n' | St4|
| symbol='\n' | St5|
| /* Действий нет */ | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z'<Symbol) &&*/ symbol!='\n' | St1|
| Второй '\n' дальше не нужно читать symbol='\n' | exit|
| printf ("- %i\n", Cnt); Cnt=0; | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z'<symbol) &&*/ symbol != '\n' | St1|
| symbol='\n' | St3|
| printf ("- %i\n", Cnt); Cnt=0; | 'a'<=symbol && symbol <= 'z' | St2
| /*(symbol<'a'|| 'z'<symbol) &&*/ symbol != '\n' | exit|
| Второй '\n' дальше не нужно читать symbol='\n' | exit|
| /* Нет неявного чтения потока */ | return 0; // Считать данную секцию таблицы состоянием или нет - дело вкуса |
|
|
|
Если Вы посмотрите точное определение, то есть еще один компонент: преобразование состояний в выходные символы. Аналогом этого компонента в программировании может служить массив процедур, вызовы которых сопоставлены состояниям, но для принципиальных рассмотрений у нас он не важен.
2)
Конечно же, в каждом конкретном модуле нужно использовать лишь одну из структур, концептуально несовместимых, хотя формально эквивалентных.
3)
Интересно, что необходимость развитых средств поддержки модуляризации программ первоначально провозглашалась для структурного программирования, но оказалась прекрасно приспособлена совсем к другому стилю. Впрочем, в современных программах самый верхний (часто полуавтоматически генерируемый системами визуального программирования и поэтому обычно мало интересный для программистов) этаж структуры программ, как правило, записан именно в стиле автоматного программирования.
4)
Данный абзац добавлен после обсуждения с проф. А.А. Шалыто.
5)
Сделаем общее замечание насчет доказательной силы аргумента: "Это исследовано в теории". При применении теории необходимо всегда помнить, что вовсю исследуются не только разумные понятия, но и извращения.
Анализ состояния дел
Построение таблиц заканчивает этап спецификации нашей программы. Таблицы 9.1 и 9.2-другое формализованное представление рисунков 9.6 и 9.7. Как всегда, разные формализмы отличаются по практической направленности. Граф в некоторых случаях может быть автоматизированно преобразован в прототип программы (попытайтесь сами проделать это со спецификацией на языке UML), но получающиеся программы всегда требуют ручной доработки. Табличное же представление допустимо рассматривать как мини-язык программирования. Для него возможно построение транслятора или интерпретатора, которые в частных типах таблиц давно уже используются (их широкому применению мешает привязка к конкретным предметным областям и приложениям, поскольку профессиональные системные программисты свысока смотрели на столь простые задачи).
Обратимся к семантике вычислений на языке таблиц. Рассматривается контекст некоторой программы на языке C++ (или на другом языке традиционного типа). В этом контексте определяется значение переменной Entry (множество ее значений совпадает с множеством наименований состояний), далее выполняются следующие действия:
Выбрать вход в таблицу, соответствующий значению Entry (текущее состояние).Если Условие отсутствует, то перейти к шагу 4.Вычислить совместно все Условия срабатывания переходов (клетки второй колонки для данного входа):
Если среди результатов есть значения True, то выбрать одну из строк, Условие которой истинно, и перейти к шагу 4 для выбранной строки1);Если все значения Условий ложны и есть строка failure, то выбрать эту строку и перейти к шагу 4 для нее;Если все значения Условий ложны и нет строки failure, то завершить вычисления.
Выполнить Действие.В качестве значения переменной Entry установить наименование состояния-преемника (из четвертой колонки таблицы). Перейти к шагу 1.
Для рассматриваемого сейчас примера указанной семантики вычислений недостаточно. Во многих случаях полезно расширение выразительных возможностей таблиц за счет добавления действий, которые выполняются в начале и в конце обработки текущего состояния.
Это достигается, например, с помощью специальных служебных слов:
start - указание действий, которые выполняются до основных действий и проверок условий перехода (здесь таким действием является чтение очередного символа из файла);finish-указание действий, которые выполняются после основных действий и проверок, но до перехода.
Можно также определять локальные данные для состояний (в примере такие данные определены только для начального состояния), но это должно быть согласовано с правилами локализации имен языка программирования и с общим стилем, в котором написана программа. Заметим, что локальные данные всех состояний конечного автомата должны быть помещены в общий контекст, а приписывание их к конкретным состояниям является ограничением видимости, подобным тому, которое используется в модульном программировании (если Вы уже программировали на Object Pascal Delphi, Java либо Oberon, то знакомы с модульностью). Это прагматически следует из того положения, что работа теоретического конечного автомата не требует привлечения памяти2).
Озаботимся теперь тем, как запрограммировать требуемые действия, когда нет возможности воспользоваться языком таблиц непосредственно. С таблицами, представляющими таблицу переходов, можно сделать следующее.
Оттранслировать вручную.Отдать препроцессору для превращения в нормальнуюпрограмму.Использовать интерпретатор.
Рассмотрим последовательно эти три возможности.
Автоматизированное преобразование таблиц переходов
Если автоматизировать работу с табличным представлением, то прежде всего требуется строго определить структуру данных, представляющих таблицу переходов. Способ задания таблицы зависит от стратегии дальнейшей обработки. В частности, если вручную строится текстовое представление таблицы, которое в дальнейшем преобразуется к исполняемому виду, то приемлемо, например, такое представление.
_1 char symbol; // Чтение потока символов неявное int cnt; . . . // Инициализация _4 St1 _5 _1 St1 _2 'a'<=symbol && symbol <= 'z' _3 printf ("%c", symbol); cnt = 1; _4 St2 _5 _1 _2 //symbol <'a' && 'z'< symbol && symbol != '\n' _3 //Так как нужно печатать только слова, //действий нет _4 St1 _5 _1 _2 failure _3 // symbol == '\n' не нужно читать _4 St3 _5 _1 St2 _2 'a'<=symbol && symbol <= 'z' _3 printf ("%c", symbol); cnt++; _4 St2 _5 _1 _2 //(symbol <'a'||'z'< symbol)&&*/ symbol!='\n' _3 printf (" - %i\n", Cnt); _4 St1 _5 _1 _2 failure _3 printf (" - %i\n", Cnt); _4 St3 _5 _1 St3 _2 'a'<=symbol && symbol <= 'z' _3 printf ("%c", symbol); cnt = 1; _4 St2 _5 _1 _2 //symbol <'a' && 'z'< symbol && symbol != '\n' _3 //Так как нужно печатать только слова, //действий нет _4 St1 _5 _1 _2 failure _3 // symbol == '\n' не нужно читать _4 exit_5 _1 exit_2 // условие истина, но без неявного чтения потока _3 return 0; _4 _5
Листинг 10.3.1. Программа в виде размеченного текста.
Здесь <_i>, i = 1, . . . , 5 обозначают позиции таблицы. Эти сочетания символов, нигде в обычной программе не встречающиеся, легко могут распознаваться препроцессором. Размещаемые между ними последовательности символов разносятся по соответствующим полям нужной структуры, которая, в зависимости от выбранной стратегии, интерпретируется либо транслируется. С помощью этих сочетаний осуществляется разметка текста, которая дает возможность распознавать и осмысливать его фрагменты.
Стоит обратить внимание на то, что за счет специального взаимного расположения символов в данном тексте представляемая им таблица автомата вполне обозрима. Если нет более подходящего представления, то данную структуру можно рекомендовать для ввода.
Однако непосредственная интерпретация универсального текстового размеченного представления довольно затруднительна. Предпочтительнее, чтобы единицами интерпретации были бы сами поля таблицы. Вообще, этому противоречит наличие в таблице полей, значения которых - фрагменты исполняемого кода на языке программирования (такая запись удобна для человека, так как для заполнения таблицы не приходится прибегать ни к каким дополнительным соглашениям). На самом деле противоречие возникает только для поля действий, поскольку последовательности символов между <_2> и <_3> имеют ясно выраженную семантику: это проверка условия. Если всегда рассматривать условия как проверку того, чему равен входной символ, то вполне понятны, легко задаются, распознаются и интерпретируются специальные обозначения: перечисления значений, их диапазоны и т.д. Трактовка этих обозначений не вызывает осложнений, а потому подобные приемы кодирования применяются довольно часто.
Если говорить о полях действий, то их представление для большинства языков программирования плохо разработано. Данное обстоятельство препятствует использованию автоматного программирования: кодирование действий усложняет обработку. Но если в языке можно задавать подпрограммы как данные, то описание структуры таблицы, которое будет согласовано с дальнейшей трансляцией или интерпретацией, возможно, в частности, в языках функционального программирования (семейство LISP и ML) и в языке Prolog. Но функциональное и сентенциальное программирование хорошо интерпретируют лишь частные случаи таблиц.
Пусть тип T_StructTableLine описывает структуру одной строки таблицы, а вся таблица представлена в виде массива Table таких структур. Пусть далее iSt - переменная, используемая для индексирования массива Table, некоторые из ее значений представляют состояния конечного автомата (но не все, а только те, к которым определен переход!).
Наконец, пусть
int handler ( int );
-обработчик строки (ее интерпретатор или транслятор), <понимающий> структуру T_StructTableLine, специфицируемый как функция, при выполнении которой должно быть определено очередное значение iSt. Значение iSt, не указывающее ни на какую строку таблицы, служит сигналом для завершения обработки (при желании можно заняться кодированием того, как завершилась обработка с помощью задания различных таких значений).
Тогда схема программы, которая оперирует с таблицей с помощью функции handler, может быть задана следующим циклом:
iSt = 0; do { iSt = handler ( iSt ); } while ( OUTSIDE ( iSt ) );
Понятно, что выбор массива в качестве представления автомата непринципиален. Допустимо, а иногда и предпочтительнее, работать со списком строк. Также непринципиален способ вычисления предиката OUTSIDE, проверяющего условие окончания цикла, хотя он и зависит от выбранного представления автомата. Возможность не рассматривать явно имена состояний, напротив, принципиальна: тот факт, что строки таблицы сгруппированы вокруг (поименованных) состояний, ничего не значит ни для обработки, ни для интерпретации, поскольку у конечного автомата следующее состояние всегда определяется явно.
Логика функции handler, интерпретирующей таблицу, проста. Для правильной таблицы, не содержащей состояний, в которых возможны неопределенные переходы, она строится следующим образом:
Извлечь значение Table[iSt];Активизировать вычисление условия обрабатываемой строки таблицы;Если условие истинно, то
активизировать подпрограмму действий;читать очередной символ;завершить handler со значением, извлекаемым из поля следующего состояния;
Если условие ложно, то
iSt++;Перейти к 1;
Осталось предусмотреть детали для заключительных состояний, но это сделать уже легко.
Таким образом, нужно научиться описывать структуру строки таблицы. На языке C++/С# эта задача может решаться довольно просто:
struct T_StructTableLine { // поле для имени состояния избыточно int (*condition)(); // поле условия void (*action)(); // поле действия int ref; // поле перехода: индекс строки таблицы, // которая будет обрабатываться следующей, // или признак завершения процесса }
Сама таблица описывается следующим образом:
T_StructTableLine Table[]
или
T_StructTableLine Table [Размер таблицы]
если значения строк задаются вне этого описания.
Однако сразу же видно ограничивающее соглашение, которое пришлось принять в связи с особенностями языка реализации: все условия и все действия оформлены как функции, тогда как задача, по своей сути, этого не требует. Более того, отделенное от таблицы описание функций, предписываемое языком С++/C#, резко снижает выразительность представления:
int Cond_St1_1() - условие в Table[1]
и
void Act_St1_1() - действие в Table[1] (строка 1 состояния St1);
int Cond_St1_2() - условие в Table[2]
и
void Act_St1_2() - действие в Table[2] (строка 2 состояния St1);
и т. д.
Еще один неприятный момент данного представления - невозможность единообразно с действиями представить их общий контекст (нулевая строка таблицы), а поскольку инициализацию естественно рассматривать как задание предварительных действий, готовящих собственно обработку, то ее предпочтительнее соединять с контекстом, а не с функциями, реализующими проверки и действия.
Последний недостаток неустраним ни в каком языке, если проверки и действия трактовать как процедуры, которые работают в общем контексте, задаваемом в заголовке таблицы. Так что лучше сразу отказаться от описания этого контекста в рамках таблицы (задание инициализации в ней возможно). Что касается первого недостатка, то он носит почти синтаксический характер, и если бы можно было задавать тела процедур как значения полей структур, то наглядность представления можно было бы сохранить. В языковом оформлении, похожем на С/С++/C#, это выглядело бы как следующее присваивание значения Table в качестве инициализации.
Table[]= { {{return true;}, /* инициализация */, 1}, /*St1*/{{return 'a'<=symbol && symbol <= 'z';}, {printf ("%c", symbol); cnt = 1;}, 4}, {{return symbol != '\n';}, /* Так как нужно печатать только слова, действия не заполняются */, 1}, {{return true}, /* Переход не требует чтения, symbol == '\n' не нужно читать */, 0}, /*St2*/{{return 'a'<=symbol && symbol <= 'z';}, {printf ("%c", symbol); cnt++;}, 4}, {{return symbol!='\n';}, {printf ("-%i\n",cnt);}, 1}, {{return true }, {printf ("- %i\n",cnt);}, 0} };
Листинг 10.3.2.
Но для С/С++/C#, а также для других языков, не ориентированных на работу с таблицами, говорить о естественности представления не приходится. По-видимому, наиболее разумно строить автоматический преобразователь (типа препроцессора, но не путать этот термин с С!), который составляет текст программы по таблице. В этом случае снимается много проблем:
для программиста сохраняется наглядность;при исполнении достигается алгоритмичность;легко разносить фрагменты таблицы по разным участкам программы;можно жертвовать наглядностью результирующего текста, поскольку с ним никто, кроме транслятора, не работает (пример: вставка новых строк в таблицу - проблема для человека, но не для препроцессора);по той же причине можно жертвовать даже структурностью результирующего текста (в рассматриваемом примере, в частности, можно отказаться от представления условий и действий процедурами и функциями).
Это решение часто является приемлемым, однако и у него есть свои недостатки. Прежде всего, поиск ошибок, допущенных в текстах условий и действий, затруднен, возникает проблема двойной интерпретации (приходится понимать как исходное представление, так и внутреннее). Так что ручной перевод остается важным методом преобразования таблиц.
Проанализировав исходную таблицу, легко заметить, что используется фактически два варианта функций-условий и три - функций-действий. Из-за нестандартности работы с инициализацией (нулевая строка таблицы) удобно пополнить этот набор еще двумя функциями: <условием> и <действием>, выполняемыми при переходе к этой строке, которая интерпретируется как завершение работы автомата (таким образом, предикат OUTSIDE (iSt) можно представить как равенство аргумента нулю).
Теперь почти все готово для составления программы 10.3.3, реализующей интерпретатор таблицы переходов. Осталось решить вопрос о неявном для таблицы, но с необходимостью явно м для программы способе чтения потока символов. Этот вопрос имеет три аспекта:
Когда читать? Поскольку прочитанный символ используется после его распознавания, естественно "не терять" его, пока выполняется действие.
Следовательно, читать очередной символ целесообразно после отработки действия.Как поступать в начале процесса: должен ли быть прочитан символ перед первым вызовом функции handler? Понятно, что чтение символов является частью функциональности этой функции. Если в ней реализовать чтение до вызовов условия и действия, то это противоречит предыдущему соглашению, а противоположное решение делает нестандартным начало процесса. В предлагаемой программе принято решение об особой обработке нулевой строки. Поскольку, являясь инициализацией, она действительно особая, это соответствует сделанному соглашению.Как поступать в конце процесса? Чтение заключительного символа ('\n') должно прекращать возможные попытки последующего обращения к чтению. Следовательно, необходимо позаботиться о завершающих переходах. В предлагаемой программе принято решение о завершающем переходе к нулевой строке, которая, согласно предыдущему, является нестандартной.
Отметим, что данные соглашения не являются абсолютными, и поставленные вопросы нуждаются в решении всякий раз, когда реализуется переход от табличного представления к программе. В предыдущем параграфе Вы уже видели, как практически в каждой реализации метод чтения слегка изменялся.
С учетом сделанных замечаний программа, решающая задачу подсчета длин строк методом интерпретации таблицы, может быть записана следующим образом.
#include <stdio.h> char symbol; // переменная для чтения потока символов int cnt; // переменная для счета длин слов
int c0(), c1(), c2(); // функции-условия void a0(), a1(), a2(), a3(); // функции-действия int handler ( int i ); // обработчик строк таблицы struct T_StructTableLine { // поле для имени состояния избыточно int (*condition)(); // поле условия void (*action)(); // поле действия int ref; // поле перехода: индекс строки таблицы, // которая будет обрабатываться следующей, // или признак завершения процесса } T_StructTableLine Table[]={ {c0,a0,1}, // таблица инициализируется статически, {c1,a1,2}, // альтернативное решение - специальная {c2,a0,1}, // функция задания начальных значений. {c0,a0,3}, // Оно более гибкое, но менее {c1,a2,2}, // эффективно. {c2,a3,1}, // О наглядности см.комментарий {c0,a3,3}; // в тексте. {c1,a2,2}, {c2,a3,1}, {c0,a3,0}}; void main() { int iSt=0; do { iSt = handler ( iSt ); } while ( iSt); }
int handler ( int i ) { if (Table[i].condition()) { Table[i].action(); if (Table[i].ref) { symbol = getchar (); return Table[i].ref; } } else return ++i; }
// Описания используемых функций: int c0(){return symbol == '\n';} int c1(){return 'a'<=symbol && symbol <= 'z';} int c2(){return 'a'>symbol ||symbol > 'z';}
void a0(){} void a1(){printf ("%c", symbol);cnt = 1;} void a2(){printf ("%c", symbol);cnt++;} void a3(){printf ("- %i\n", cnt);}
Листинг 10.3.3. Длины слов: интерпретатор конечного автомата.
Обсуждение решения
Как уже отмечалось, фрагменты, описывающие условия и действия в таблице переходов и реализованные как процедурные вставки, с точки зрения препроцессора (не препроцессора системы программирования, а специального преобразователя, генерирующего представление таблицы для интерпретации), являются нераспознаваемыми данными, которые он просто пропускает без изменений для обработки компилятором. Интерпретатор же, наоборот, не в силах сам исполнять процедуры, а потому трактует ссылки на них (в соответствующих полях) как данные. Таким образом, условия и действия в таблице двойственны: они являются одновременно и данными, и программными фрагментами. Автоматический преобразователь таблицы, не понимая языка таких двойственных данных, пытается, тем не менее, их объединить с обычными данными (в рассматриваемом случае это индексы строк переходов) в одной структуре.
На первый взгляд кажется, что ситуация существенно упростилась бы в языке, в котором есть возможность воспринимать данные как выполнимые фрагменты. Пример такого рода - команда <Вычислить строку>. Эта команда давала бы возможность интерпретатору понимать программы-данные, не оставляя их нераспознанными. Подобная команда порою встречается в языках скриптов, ориентированных на интерпретацию. А в языке LISP, в котором структуры данных и программы просто совпадают, указанная двойственность не возникает. Но по опыту известно, что столь общее решение чревато столь же общими и вездесущими неприятностями, и нужно искать частный его вариант, адекватный данной задаче.
Метод решения задач с помощью построения таблиц и графов состояний и переходов часто удобен для обработки потоков данных. В книгах [32], [33], а особенно в задачнике [2] и на сайте http://is.ifmo.ru, имеется ряд задач такого рода. Решения стоит оценить количественно и качественно: сколько требуется состояний и действий, как лучше получается в данном случае (в состояниях или на переходах). Может оказаться, что понадобятся средства, выходящие за рамки описанных методов.
Это допустимо, следует только осознавать грань между использованием конечного автомата и применением другого подходящего метода, а также четко разделять внутри программы возможности, относящиеся к разным стилям программирования.
Подведем итоги
Таблица и граф - два теоретически эквивалентных (но практически разных) представления. Каждое из них имеет свои достоинства и недостатки (на графе информация беднее, но обозримость может быть лучше). Одна из этих спецификаций чаще всего делает ненужной другую.
Таблицы и графы гораздо лучше самой программы с точки зрения модифицируемости и преобразований.
Таким образом, табличное и графовое представления автомата являются спецификациями №1, о которых нужно думать в первую очередь, когда составляется автоматная программа.
Главный недостаток табличных и графовых методов представления автоматов в том, что их приходится дополнительно преобразовывать в программу. А в дальнейшем возникает соблазн модифицировать непосредственно программу, и спецификация перестает быть адекватной программе.
В связи с этим возникает вопрос об улучшении поддержки методов табличного и графового представления автоматных программ.
|
|
|
В этом пункте заложено недетерминированное поведение получаемой программы. Как правило, при применении метода таблиц переходов возможность недетерминированного поведения игнорируется. Вместо этого задается какое-либо произвольное детерминированное правило, например, выбирается текстуально первое из действий, для которого условие истинно. Это похоже на то, как определяются условные выражения и оператор переключения в традиционных языках.
2)
Памятью можно считать номер текущего состояния (замечание проф. А. А.Шалыто).
3)
Это верно и для унификационного варианта.
4)
Этот вариант сознательно запрограммирован на Object Pascal, поскольку разница между языками традиционного типа несущественна, а изменение языка заодно выделяет и тот факт, что данный вариант ориентирован на другую модель автоматного программирования.
Вторая программа, чуть дальше от
| ENTRY Go{=<Open 'r' 1 'input.txt'><Open 'w' 2 'output.txt'><Init<Get 1>>}; Letters {='abcdefghijklmnopqrstuvwxyz';}; Init{=; e.1=<St1 e.1>;}; St1 { s.1 e.3,<Letters>: e.A s.1 e.B =<St2 e.3 (s.1)>; = <Init<Get 1>>; s.1 e.3 =<St1 e.3>; }; St2 {(e.2)= <Outstr e.2> <Init<Get 1>>; s.1 e.3 (e.2),<Letters>: e.A s.1 e.B =<St2 e.3 (e.2 s.1)>; s.1 e.3 (e.2)=<Outstr e.2><St1 e.3 >; }; * St3 не нужно Outstr { e.2, <Lenw e.2>: {s.1 e.2 = <Putout 2 e.2 " - " <Symb s.1>>;}; }; * * Вторая программа, чуть дальше от непосредственной автоматной модели * $ENTRY Go{=<Open 'r' 1 'input.txt'><Open 'w' 2 'output.txt'><Init <Get 1>>}; Letters {='abcdefghijklmnopqrstuvwxyz';}; Init {=; e.1=<Parse e.1()>;}; Parse { s.1 e.3 (e.2),<Letters>: e.A s.1 e.B =<Parse e.3 (e.2 s.1)>; (e.2)= <Outstr e.2> <Init<Get 1>>; s.1 e.3 (e.2)=<Outstr e.2><Parse e.3 ()>; }; Outstr { = ; e.2, <Lenw e.2>: {s.1 e.2 = <Putout 2 e.2 " - " <Symb s.1>>;}; }; |
| Листинг 10.2.1. Длины слов: рефал |
| Закрыть окно |
|
// Реализация автомата с табл. 9.1 #include <stdlib.h> #include <stdio.h> #include <time.h> char symbol; int cnt; enum States { St1, St2, St3 } State; void main( void ) {fstream a,b; a.open("input.txt",ios::in); b.open("output.txt",ios::out); State = St1; while (true ) {symbol=a.get(); switch ( State ) { case St1: if ('a'<=symbol && symbol <= 'z') { b<<symbol; cnt = 1; State = St2; } else if (symbol != '\n') {State = St1;} else if (symbol == '\n') State = St3; break; case St2: if ('a'<=symbol && symbol <= 'z') {b<< symbol; cnt++; // State = St2; } else if (symbol != '\n') { b<<" - "<<cnt<<endl; State = St1; } else if (symbol == '\n') { b<<" - "<<cnt<<endl; State=St3; }; break; case St3: if ('a'<=symbol && symbol <= 'z') { b<< symbol; cnt = 1; State = St2; } else if (symbol != '\n') {State = St1;} else if (symbol == '\n') { a.close(); b.close(); return;}; } } } |
| Листинг 10.2.2. Длины слов: явный цикл обработки потока |
| Закрыть окно |
|
#include <stdlib.h> #include <stdio.h> #include <time.h> char symbol; int cnt; enum States { St1, St2, St3, Exit } State; inline States f_St1 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return } else {symbol = getchar (); return } inline States f_St2 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt++; symbol = getchar (); return St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); return St1; } else { printf (" - %i\n", cnt); symbol = getchar (); return St3; } } inline States f_St3 () { if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return St1; } else return Exit; } void main( void ) { symbol = getchar (); State = St1; for (;;) { switch ( State ) { case St1: State = f_St1 (); break; case St2: State = f_St2 (); break; case St3: State = f_St3 (); break; default: return; } } } |
| Листинг 10.2.3. Длины слов: использование процедур для описания состояний. |
| Закрыть окно |
|
program funcgoto; {$APPTYPE CONSOLE} {$T+} uses SysUtils; type P=procedure; type Pp= ^P; const maxstate = 7; const maxcond = 3; type states = 1.. maxstate; conds = 1.. maxcond; type table = array [states, conds] of states; type act = array [states] of P; const gotos: table = ((2,2,2),(3,2,4),(3,5,6),(3,2,7),(3,2,4),(3,2,7),(1,1,1)); var Symbol: char; var Cnt: integer; var Inf, Outf: text; var state: states; procedure Start; begin Cnt:=0; AssignFile(Inf, 'input.txt'); Reset(Inf); AssignFile(Outf, 'output.txt'); Rewrite(Outf); end; procedure Finish; begin Closefile(Inf); Closefile(Outf); Abort; end; procedure St1; begin {No actions} end; procedure St2; begin write(outf,Symbol); Inc(Cnt); end; procedure St4; begin writeln(outf,' - ',Cnt); Cnt:=0; end; const actions: act = (Start, St1,St2,St1,St4,St4,Finish); begin state:=1; while true do begin actions[state]; if (state <>1) and (state<>7) then begin read(inf,Symbol); if Ord(Symbol)=10 then read(inf,Symbol) end; if Symbol in ['a'..'z'] then state:= gotos[state,1]; if not(Symbol in ['a'..'z']) and (Ord(Symbol)<>13) then state:=gotos[state,2]; if Ord(Symbol)=13 then state:=gotos[state,3]; end; end. |
| Листинг 10.2.4. Длины слов: массив функций и переходов |
| Закрыть окно |
|
#include <stdlib.h> #include <stdio.h> #include <time.h> char symbol; int cnt; void main( void ) { symbol = getchar (); St1: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ {symbol = getchar (); goto St3;}; St2: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt++; symbol = getchar (); goto St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); goto St1; } else { printf (" -%i\n", cnt); symbol = getchar (); goto St3; }; St3: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ return; } |
| Листинг 10.2.5. Длины слов: состояния - метки в программе. |
| Закрыть окно |
Ручная трансляция таблиц переходов
В решениях 1 и 2 возникает следующий вопрос: во что транслировать таблицу переходов? Вариантов множество, ниже рассматриваются лишь некоторые из них.
Вариант 1.Можно считать St1 и St2 функциями, реализующими все действия состояний.При использовании верно подобранных стиля и инструментальных средств этот подход дает отличный результат. Рассмотрим, в частности, как может быть реализована наша задача (еще точнее, автомат таблицы 9.1) на языке Рефал.
ENTRY Go{=<Open 'r' 1 'input.txt'><Open 'w' 2 'output.txt'><Init<Get 1>>}; Letters {='abcdefghijklmnopqrstuvwxyz';}; Init{=; e.1=<St1 e.1>;}; St1 { s.1 e.3,<Letters>: e.A s.1 e.B =<St2 e.3 (s.1)>; = <Init<Get 1>>; s.1 e.3 =<St1 e.3>; }; St2 {(e.2)= <Outstr e.2> <Init<Get 1>>; s.1 e.3 (e.2),<Letters>: e.A s.1 e.B =<St2 e.3 (e.2 s.1)>; s.1 e.3 (e.2)=<Outstr e.2><St1 e.3 >; }; * St3 не нужно Outstr { e.2, <Lenw e.2>: {s.1 e.2 = <Putout 2 e.2 " - " <Symb s.1>>;}; }; * * Вторая программа, чуть дальше от непосредственной автоматной модели * $ENTRY Go{=<Open 'r' 1 'input.txt'><Open 'w' 2 'output.txt'><Init <Get 1>>}; Letters {='abcdefghijklmnopqrstuvwxyz';}; Init {=; e.1=<Parse e.1()>;}; Parse { s.1 e.3 (e.2),<Letters>: e.A s.1 e.B =<Parse e.3 (e.2 s.1)>; (e.2)= <Outstr e.2> <Init<Get 1>>; s.1 e.3 (e.2)=<Outstr e.2><Parse e.3 ()>; }; Outstr { = ; e.2, <Lenw e.2>: {s.1 e.2 = <Putout 2 e.2 " - " <Symb s.1>>;}; };
Листинг 10.2.1. Длины слов: рефал
Эти программы настолько коротки и естественны, что практически не требуют комментариев. Единственная новая возможность, использованная здесь, в принципе излишняя, но делает программу красивее. Конструкции <Letters>: e.A s.1 e.B и e.2, <Lenw e.2>: являются, соответственно, вложенной проверкой условия на выражении, порождаемом вызовом <Letters>, и вызовом определяемой дальше анонимной функции на выражении, получившемся после запятой.
Стандартная функция <Lenw e.2> добавляет первым символом к выражениюего длину (количество термов в нем). При проверке и при вычислении вспомогательной функции переменные, уже получившие значения, не изменяются.
Таким образом, структура управления на переходах хорошо согласуется со структурой управления в конкретизационном варианте сентенциального программирования3). Вновь отметим, что, хотя некоторые описания функций кажутся рекурсивными, рекурсий нет, так как исходный вызов завершается до активизации порожденных им вызовов. Каждый шаг конкретизации начинается с проверки условий, поэтому действия естественно сопоставить именно переходам.
В данном случае удалось добиться столь красивого результата потому, что действия также полностью соответствовали той области, где применение языка Рефал наиболее выигрышно. Но даже в таком простом случае после минимальной ручной доработки программа стала еще лучше.
Формально функциональное представление состояний возможно как на языке традиционного типа, так и на LISP и Prolog. Но в этом случае мы проигрываем в выразительности и естественности программы, а также еще по одному важному критерию. Во всех этих случаях то, что выглядит как рекурсия, действительно ею является, а рекурсия в данном случае лишь мешает.
Вариант 2. Считать St1, St2, St3 значениями некоторого перечислимого типа State.
// Реализация автомата с табл. 9.1 #include <stdlib.h> #include <stdio.h> #include <time.h>
char symbol; int cnt;
enum States { St1, St2, St3 } State; void main( void ) {fstream a,b; a.open("input.txt",ios::in); b.open("output.txt",ios::out); State = St1; while (true ) {symbol=a.get(); switch ( State ) { case St1: if ('a'<=symbol && symbol <= 'z') { b<<symbol; cnt = 1; State = St2; } else if (symbol != '\n') {State = St1;} else if (symbol == '\n') State = St3; break; case St2: if ('a'<=symbol && symbol <= 'z') {b<< symbol; cnt++; // State = St2; } else if (symbol != '\n') { b<<" - "<<cnt<<endl; State = St1; } else if (symbol == '\n') { b<<" - "<<cnt<<endl; State=St3; }; break; case St3: if ('a'<=symbol && symbol <= 'z') { b<< symbol; cnt = 1; State = St2; } else if (symbol != '\n') {State = St1;} else if (symbol == '\n') { a.close(); b.close(); return;}; } } }
Листинг 10.2.2. Длины слов: явный цикл обработки потока
Программа 10.2.2 хороша только в том случае, если ограничиться автоматными моделями в достаточно узком смысле. Программа точно соответствует табличному представлению автомата, почти все дублирования действий, связанные с таким представлением, остались. Возникает некоторая неудовлетворенность тем, что появилось лишнее действие: выбор выполняемого фрагмента по значению переменной State. Если ограничиться управляющими средствами методологии структурного программирования, то это - наилучший выход. Попытки применить циклы внутри фрагментов, помеченных как case St1: и case St2:, приводят лишь к уменьшению наглядности по сравнению с табличным представлением.
Есть еще один вопрос, который требуется решить при таком подходе, - выбор типа результата функций-состояний и способа возвращения результата. Естественный результат такой функции - это новое состояние, в которое попадает автомат при переходе. Он может быть представлен, например, глобальной переменной (такой как State в программе 10.2.2, которой присваивается новое значение при выполнении функции-состояния). Но предпочтительнее не трогать State в каждой из функций, а предоставить задачу фактического изменения состояния общему их контексту. Наиболее правильной реализацией состояний при таком подходе являются функции, которые вырабатывают в качестве результата значение типа, перечисляющего все состояния.
Следующая программа 10.2.3 почти буквально реализует данную идею. В отличие от программы 10.2.2, тип States содержит четыре значения: St1, St2, St3 и Exit. Последнему из них не соответствует ни одна функция из-за тривиальности переходов и действий в данном состоянии.
#include <stdlib.h> #include <stdio.h> #include <time.h>
char symbol; int cnt; enum States { St1, St2, St3, Exit } State;
inline States f_St1 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return } else {symbol = getchar (); return }
inline States f_St2 () { if ('a'<=symbol && symbol <= 'z') printf ("%c", symbol); cnt++; symbol = getchar (); return St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); return St1; } else { printf (" - %i\n", cnt); symbol = getchar (); return St3; } }
inline States f_St3 () { if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); return St2; } else if (symbol != '\n') { symbol = getchar (); return St1; } else return Exit; }
void main( void ) { symbol = getchar (); State = St1; for (;;) { switch ( State ) { case St1: State = f_St1 (); break; case St2: State = f_St2 (); break; case St3: State = f_St3 (); break; default: return; } } }
Листинг 10.2.3. Длины слов: использование процедур для описания состояний.
Следует обратить внимание на то, что программа наглядна, строго соответствует таблице автомата. Можно сказать, что граф автомата определяет распределенную по состояниям схему потоковой обработки. На самом деле она гораздо лучше подходит модели вычислений в состояниях, а не на переходах. Более того, эта программа при небольшом увеличении числа состояний быстро теряет наглядность, если программировать на переходах, поскольку следующие состояния упрятаны внутри соответствующих процедур, но сохранит ее, если программировать в состояниях.
Таким образом, мы пришли к тому, что в рамках стандартной методики программирования все решения имеют некоторые недостатки. Надо искать другое, и здесь стоит вспомнить пословицу (на самом деле отражающую один из приемов творческого мышления): "Новое - хорошо забытое старое". Поищем решение среди того, что забраковано стандартными методиками.
Проанализировав граф автомата или таблицу, можно заметить, что в данном примере, наряду с циклом потоковой обработки, имеется еще один цикл: передача управления между состояниями. Это причина, из-за которой в двух предыдущих вариантах появились присваивание переменной State значения и выбор выполняемого фрагмента по этому значению.
Особенность последовательностей действий
State = <значение>;
switch ( State )
которая выполняется всякий раз в конце действий, ассоциированных с состояниями (точнее - реализаций действий в программах), в том, что в каждой точке программы, где встречается данное присваивание, можно точно указать результат динамически следующего оператора переключения, причем эта информация не зависит от обрабатываемого потока и может быть определена до вычислений статически.
А нельзя ли использовать это явно для организации управления конечным автоматом? Можно, это демонстрирует четвертый вариант решения обсуждаемой задачи.
Вариант 4. Матрица переходов и вектор-функций, соответствующих состояниям4)
program funcgoto; {$APPTYPE CONSOLE} {$T+} uses SysUtils;
type P=procedure; type Pp= ^P; const maxstate = 7; const maxcond = 3; type states = 1.. maxstate; conds = 1.. maxcond; type table = array [states, conds] of states; type act = array [states] of P; const gotos: table = ((2,2,2),(3,2,4),(3,5,6),(3,2,7),(3,2,4),(3,2,7),(1,1,1)); var Symbol: char; var Cnt: integer; var Inf, Outf: text; var state: states;
procedure Start; begin Cnt:=0; AssignFile(Inf, 'input.txt'); Reset(Inf); AssignFile(Outf, 'output.txt'); Rewrite(Outf); end;
procedure Finish; begin Closefile(Inf); Closefile(Outf); Abort; end;
procedure St1; begin {No actions} end;
procedure St2; begin write(outf,Symbol); Inc(Cnt); end;
procedure St4; begin writeln(outf,' - ',Cnt); Cnt:=0; end;
const actions: act = (Start, St1,St2,St1,St4,St4,Finish);
begin state:=1; while true do begin actions[state]; if (state <>1) and (state<>7) then begin read(inf,Symbol); if Ord(Symbol)=10 then read(inf,Symbol) end; if Symbol in ['a'..'z'] then state:= gotos[state,1]; if not(Symbol in ['a'..'z']) and (Ord(Symbol)<>13) then state:=gotos[state,2]; if Ord(Symbol)=13 then state:=gotos[state,3]; end; end.
Листинг 10.2.4. Длины слов: массив функций и переходов
Это решение неплохое, но оно годится лишь для вычислений в состояниях.
Фактически оно резко расходится с канонами структурного программирования, где даже не предполагалось переключение между функциями внутри массива функций. Оно несколько утяжелено деталями, связанными с отработкой особых состояний ввода входного потока. Зато повторяющиеся действия не дублируются.
Рассмотрим последний вариант.
Вариант 5. Использование статической информации о разветвлениях вычислений.
#include <stdlib.h> #include <stdio.h> #include <time.h>
char symbol; int cnt; void main( void ) { symbol = getchar (); St1: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ {symbol = getchar (); goto St3;}; St2: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt++; symbol = getchar (); goto St2; } else if (symbol != '\n') { printf (" -%i\n", cnt); symbol = getchar (); goto St1; } else { printf (" -%i\n", cnt); symbol = getchar (); goto St3; }; St3: if ('a'<=symbol && symbol <= 'z') { printf ("%c", symbol); cnt = 1; symbol = getchar (); goto St2; } else if (symbol != '\n') { symbol = getchar (); goto St1; } else /* (symbol == '\n') */ return; }
Листинг 10.2.5. Длины слов: состояния - метки в программе.
В данном варианте исчезает необходимость вычисляемого перехода (результат внедрения статической информации в текст программы), и, как следствие, становятся избыточными описания типа States и переменной State этого типа. В программе появляются операторы безусловного перехода, из-за этого структура управления программы полностью расходится с канонами структурного программирования, что дает повод догматически мыслящим программистам и теоретикам подвергать критике такой вариант программы. Но в данном случае отступление от канонов структурного программирования полностью оправдано, поскольку за счет специального расположения фрагментов текста вся программа оказалась похожа на таблицу конечного автомата, а структура передач управления копирует граф конечного автомата.Более того, такое представление нейтрально по отношению к моделям Мура и Мили. Таким образом, лишь после полного отхода от канонов структурности программа стала адекватна своей спецификации.
Постановка задачи
При обсуждении программы 10.3.1 было показано, что предложенный текст размечен символами _i, i=1,...,5 а также то, как от размеченного текста переходить к программе на языке С++ или к интерпретации таблицы. У такой разметки только один недостаток: она не стандартизована, а потому о распространении за пределы среды разработчиков системы, предназначенной для поддержки применения таблиц, говорить не приходится.
В настоящее время используются следующие языки разметки, которые можно считать стандартными:
TEX и, в первую очередь, надстройка над ним LATEX — для типографской подготовки текстов.HTML — стандартный язык разметки текстов в Интернет.XML — язык разметки текстов в Интернет, ориентированный на активную работу с ними.
Их основное назначение — структурированное представление визуализации информации. С точки зрения автоматической трансляции таблиц целесообразно обсудить алгоритмический аспект этих языков, т. е. ответить, в какой мере разметка текста позволяет описывать требуемые преобразования. Но предварительно зададимся вопросами о том, правомерно ли языки разметки считать языками программирования, и если да, то какие стили программирования они в принципе могут поддерживать.
Построение разного рода визуализаций текстов и сопутствующей им информации — определяющая функция языков разметки, которая реализуется путем размещения разметочных команд вместе с предъявляемой информацией. Эти команды являются управляющими сигналами для вычислителя, который отвечает за визуализацию. Внутреннее совместное представление команд и данных для их выполнения естественно рассматривать в качестве операционной и одновременно информационной среды вычислителя–визуализатора. Язык разметки от языка программирования отличает в первую очередь совмещение данных и задания на их обработку.
Пример 11.2.1. Текст данного примера в языке разметки LATEX (точнее, в том пакете определений над ним, который разработан для верстки данного текста и других работ автора) для автоматического размещения заголовка, создания идентификатора, по которому в дальнейшем можно ссылаться на Пример 11.2.1, форматирования тела примера и отработки его конца, окружен командами
\begin{example}\label{markupeample0} и \end{example}.
Для того, чтобы напечатать первуюи з этих команд, пришлось применить дополнительнуюразметку (чтобы команда была проинтерпретирована как часть текста)
\verb|\begin{example}\label{markupeample0}|\\.
И, наконец, предыдущая строка также потребовала дополнительной разметки, но, во избежание бесконечного регресса, на этом закончим.
Для употребляющихся в Интернет языков разметки визуализатором служит браузер. Но визуализация — далеко не единственное вычисление, которое можно связывать с браузером или другой программой, обрабатывающей размеченный текст. Над информацией можно задавать разные обобщенные вычисления. Эти вычисления могут быть либо совмещены в одном процессе, либо разнесены во времени, что непринципиально. Применительно к числовой разметке, использованной в §10.3 для задания таблицы конечного автомата, правомерно трактовать разметку как команды трех видов вычислений:
визуализация таблицы — трактовка разметочных символов как команд, предписывающих взаимное расположение фрагментов текста для его показа и печати;трансляция таблицы — автоматическое построение программы, выполняющей действия автомата;интерпретация таблицы — трактовка разметочных символов как команд, выполняющих действия с операндами, в качестве которых используются текстовые фрагменты.
Подобные вычисления можно определять для любого языка разметки, рассматривая подходящие абстрактные вычислители. Иными словами, существует программирование на языке разметки. Наиболее полно эта концепция прослеживается в технологии XML/XSL.
Если обратиться к стилю программирования, который в принципе может поддерживать язык разметки, то это сентенциальное программирование. Характерным видом вычислений этого стиля являются не просто порождение новых данных с сохранением операндов, а глобальные трансформации данных, существенно зависящие от контекста. Заметим, что в настоящий момент верно и обратное: любой сентенциальный язык можно рассматривать в качестве языка разметки перерабатываемых данных.
Иногда такая разметка явно расставляется по структуре данных (пример — язык Рефал), иногда она выносится в специальную структуру (Prolog), но в обоих случаях контекст, определяющий выполнение команд, и замена данных путем порождения результатов команд остаются. В развитии языков разметки прослеживается тенденция отделять распознавание структуры текста — сентенциальная часть обработки — от использования этой структуры для задания действий, которые определяют обобщенные вычисления2).
Ниже описывается решение задачи автоматической трансформации таблиц конечного автомата с использованием наиболее подходящего для этих целей языка XML (см. книгу [19]).
Если описывать тексты в современных языках разметки, таких, как LATEX [15] или XML, то возникает задача описывать и программировать преобразования подобных текстов. Решением этой задачи могут быть специализированные языки преобразований текстов либо соответствующие методики программирования, поддержанные автоматизированным преобразованием спецификаций в программу. Здесь мы рассмотрим методику, базирующуюся на автоматах.
Применим возможности системы XML/XSL к нашей задаче: описание конечного автомата (за основу взята таблица переходов 9.1).
<?xml version="1.0" encoding="windows-1251" ?> <automat name="Test"> <action><![CDATA[char symbol; int cnt;]]> </action> <ref>St1</ref> <state name="St1"> <if> <condition><![CDATA[’a’<=symbol & symbol <= ’z’]]> </condition> <action><![CDATA[printf ("%c", symbol); cnt = 1;]]> </action> <ref>St2</ref> </if> <eif> <condition> <![CDATA[ symbol != ’\n’]]> </condition> <action><![CDATA[/*Так как нужно печатать только слова, действия не заполняются */ ]]> </action> <ref> St1 </ref> </eif> <eif> <condition> <![CDATA[ symbol == ’\n’]]> </condition> <action><![CDATA[/*Так как нужно печатать только слова, действия не заполняются */ ]]> </action> <ref> St3 </ref> </eif> </state> <state name="St2"> <if> <condition><![CDATA[ ’a’<=symbol & symbol <= ’z’]]> </condition> <action><![CDATA[printf ("%c", symbol); cnt++;]]> </action> <ref>St2</ref> </if> <eif> <condition><![CDATA[ symbol != ’\n’]]> </condition> <action><![CDATA[printf (" - %i\n", cnt);]]> </action> <ref>St1</ref> </eif> <eif> <condition> <![CDATA[ symbol == ’\n’]]> </condition> <action><![CDATA[printf (" - %i\n", cnt);]]> </action> <ref>St3</ref> </eif> </state> <state name="St3"> <if> <condition><![CDATA[’a’<=symbol & symbol <= ’z’]]> </condition> <action><![CDATA[printf ("%c", symbol); cnt = 1;]]> </action> <ref>St2</ref> </if> <eif> <condition> <![CDATA[ symbol != ’\n’]]> </condition> <action><![CDATA[/* Так как нужно печатать только слова, действия не заполняются */ ]]> </action> <ref> St1 </ref> </eif> <eif> <condition> <![CDATA[ symbol == ’\n’]]> </condition> <action><![CDATA[/* Переход не требует чтения, symbol == ’\n’ не нужно читать */ ]]> </action> <ref>Exit</ref> </eif> </state> </automat>
Листинг 11.2.1. Решение задачи автоматической трансформации таблиц конечного автомата
В этом описании нашли отражение следующие свойства нашего конечного автомата (за основу взята таблица переходов 9.1):
Конечный автомат (тег <automat>) включает в себя теги <state> — перечень всех состояний в любом порядке, а также теги <action> — действие и <ref> — ссылка на исходное состояние3).Каждый <state> содержит атрибут name, чтобы на него можно было ссылаться, и набор условий: один тег <if> и любое количество тегов <eif> (означающих "else if"). Эти два тега также можно было бы заменить одним универсальным, тем более что структура их потомков не различается, но опять же этого не сделано по соображениям облегчения форматирования.Каждый <if> или <eif> включает в себя три тега: <condition> — собственно условие и уже описанные теги <action> и <ref> — действие при выполненном условии и ссылка на следующее состояние.Теги <action> и <condition> содержат специальный тег <![CDATA[...]]> для включения строк на языке C++.
В описание не включено состояние Exit. Эта часть одинакова у различных автоматов, а потому нецелесообразно ее описывать явно.
Данное описание служит основой для построения различных визуализаций автомата с помощью XSL. Например, достаточно просто строится табличная визуализация, практически не отличающаяся от ранее составленной таблицы:
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <DIV STYLE="font-family:Courier; font-size:12pt"> <xsl:for-each select="automat"> <TABLE border="1" width="75%"> <TR> <TD colspan="3"><xsl:value-of select="action" /></TD> <TD width="10%"><xsl:value-of select="ref" /></TD> </TR> <xsl:for-each select="state"> <TR> <td rowspan="3" width="10%" valign="top"> <xsl:value-of select="@name" /></td> <td><xsl:value-of select="if/condition" /></td> <td><xsl:value-of select="if/action" /></td> <td><xsl:value-of select="if/ref" /></td> </TR> <xsl:for-each select="eif"> <TR> <TD><xsl:value-of select="condition" /></TD> <TD><xsl:value-of select="action" /></TD> <TD><xsl:value-of select="ref" /></TD> </TR> </xsl:for-each> </xsl:for-each> </TABLE> </xsl:for-each> </DIV> </xsl:template> </xsl:stylesheet>
Листинг 11.2.2. Решение задачи автоматической трансформации таблиц конечного автомата
Следующая визуализация — это автоматическое преобразование XML–основы в программу на языке С/С++. Стоит обратить внимание на то, что результирующий текст оказывается практически тем же, что и в программе 10.2.5. Причины тому глубже, чем простота преобразования. Существование локального (без использования контекстно"=зависимой информации) описания следует из структуры конечного автомата, не требующей для определения перехода ничего вне состояния.
<?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <blockquote> <pre STYLE="font-family:Courier; font-size:12pt;" > <xsl:for-each select = "automat">//C code for automat "<xsl:value-of select="@name" />" <![CDATA[ #include <stdio.h> #define failure true void main( void ) {]]> <xsl:value-of select = "action"/> goto <xsl:value-of select = "ref"/>;<br/> <xsl:for-each select="state"> <xsl:value-of select="@name" />: symbol = getchar (); <blockquote>if (<xsl:value-of select="if/condition" /> ) <blockquote>{ <xsl:value-of select="if/action" /> goto <xsl:value-of select="if/ref" />; } </blockquote> <xsl:for-each select="eif"> else if (<xsl:value-of select="condition" /> ) <blockquote>{ <xsl:value-of select="action" /> goto <xsl:value-of select="ref" />; } </blockquote> </xsl:for-each> </blockquote> </xsl:for-each> Exit: return;<br/>} </xsl:for-each> </pre> </blockquote> </xsl:template> </xsl:stylesheet>
Листинг 11.2.3. Решение задачи автоматической трансформации таблиц конечного автомата
Как легко видеть, разница этого и предыдущего стилевых файлов только в том, что там, где для визуализации в таблицу вставляются графические элементы, изображающие рамки, для трансляции помещаются части синтаксиса языка С++/C# и отступы в целях лучшей читаемости получаемой программы.
Итак, благодаря использованию формата представления данных XML, мы получили возможность автоматически создавать программы для данной задачи путем простой замены стилевых таблиц!
Отметим теперь еще несколько интересных возможностей, которые мы бы могли использовать.
Хотя данная технология позволяет легко создавать С++/С# программы, основой для них остается язык XML. Чтобы составить новый автомат, программист должен как минимум знать синтаксис этого языка. Следующим естественным шагом будет исключение этого звена: требуется скрыть внутреннее представление данных от конечного пользователя, оставив только интуитивно понятное представление в виде таблицы. Но для этого в первую очередь необходимо выбрать:
преобразование таблица => XML представление исредство для удобного редактирования таблиц.
Естественно редактировать таблицы там же, где мы их уже научились генерировать — в окне браузера. Доступ к редактированиюэтих таблиц может предоставить DOM (стандарт, реализованный в браузерах Internet Explorer 5.0 и Netscape Navigator 6.0). Изменения, добавления и другие редактирующие действия определяются довольно просто. Например, на языке Java script добавление новой ячейки в таблицу можно описать следующим образом:
var oRow; var oCell;
oRow = oTable.insertRow(); oCell = oRow.insertCell(); oCell.innerHTML = "This cell is <b>new</b>."
Точно так же можно создавать таблицы, строки и ячейки в них. Реализация же самого интерфейса (кнопочек, средств выделения, полей ввода) зависит только от вашей фантазии.
Тот же DOM, точно таким же образом, может работать с XML, реплицируя все действия конечного пользователя с таблицей в XML представление для записи последнего в виде готового файла со структурой нового конечного автомата.
Еще одним шагом в развитии проекта, использующим язык XML, может быть формализация представления: ведь как только определены все теги представления, правила их вложения и способы задания, получается новый язык (по аналогии с современными языками, построенными таким же образом, мы можем назвать его automatML).
Пока теги и элементы XML используются исключительно ради удобства для вашего собственного проекта (как если бы вы применяли CSS на своей домашней страничке), то не имеет никакого значения, что вы даете этим элементам и тегам имена, смысл которых отличается от стандартного и известен только вам. Если же Вы хотите предоставлять данные внешнему миру и получать информацию от других людей, то это обстоятельство приобретает огромное значение. Элементы и атрибуты должны употребляться вами точно так же, как и всеми остальными людьми, или, по крайней мере, вы должны документировать то, что делаете.
Для этого придется использовать определения типов документов (Document Type Definition, DTD). Хранимые в начале файла XML или внешним образом в виде файла *.DTD, эти определения описывают информационную структуру документа. DTD перечисляют возможные имена элементов, определяют имеющиеся атрибуты для каждого типа элементов и сочетаемость одних элементов с другими.
Каждая строка в определении типа документа может содержать декларацию типа элемента, именовать элемент и определять тип данных, которые элемент может содержать. Она имеет следующий вид:
<!ELEMENT имя_элемента (тип_данных)>
Например, декларация
<!ELEMENT action (#PCDATA)>
определяет элемент с именем action, содержащий символьные данные (т. е. текст). Декларация
<!ELEMENT automat (state_1, state_2, state_3)>
определяет элемент с именем special_report, содержащий подэлементы state_1, state _2 и state_3 в указанном порядке, например:
<automat> <state_1>XML : время пришло</state_1> <state_2>XML превосходит самое себя</state_2> <state_3>Управление сетями и системами с помощью XML</state_3> </automat>
После определения элементов DTD могут также определять атрибуты с помощью команды !ATTLIST. Она указывает элемент, именует связанный с ним атрибут и затем описывает его допустимые значения. Команда !ATTLIST позволяет управлять атрибутами и многими другими способами: задавать значения по умолчанию, подавлять пробелы и т.
д. DTD могут содержать декларации !ENTITY, где приводятся ссылки на объекты, и декларации !NOTATION, указывающие, что делать с двоичными файлами, представленными не в формате XML.
Серьезное и несколько удивительное ограничение DTD состоит в том, что они не допускают типизации данных, т. е. ограничивают данные конкретным форматом (таким, как дата, целое число или число с плавающей точкой). Как вы, вероятно, уже заметили, DTD используют иной синтаксис, нежели XML, и не очень-то интуитивно понятный. По названным причинам DTD будут, видимо, заменены более мощными и простыми в использовании схемами, работа над которыми ведется в настоящее время.
|
|
|
В связи с этим данная лекция может быть опущена при изучении курса.
2)
Тенденция отделения распознавания от обработки характерна и для других стилей программирования. Но для сентенциального стиля она оказывается решающей.
3)
Можно было бы оформить эти теги с помощьюо особого состояния Init, но при этом мы бы потеряли универсальность тега <state>, т. к. состояние Init, например, не нуждается в чтении символа, не содержит условий и должно быть всегда первым. Как будет понятно впоследствии, универсальность составных частей модели упрощает работу с ней.
Так как нужно печатать только
| <?xml version="1.0" encoding="windows-1251" ?> <automat name="Test"> <action><![CDATA[char symbol; int cnt;]]> </action> <ref>St1</ref> <state name="St1"> <if> <condition><![CDATA[’a’<=symbol & symbol <= ’z’]]> </condition> <action><![CDATA[printf ("%c", symbol); cnt = 1;]]> </action> <ref>St2</ref> </if> <eif> <condition> <![CDATA[ symbol != ’\n’]]> </condition> <action><![CDATA[/* Так как нужно печатать только слова, действия не заполняются */ ]]> </action> <ref> St1 </ref> </eif> <eif> <condition> <![CDATA[ symbol == ’\n’]]> </condition> <action><![CDATA[/*Так как нужно печатать только слова, действия не заполняются */ ]]> </action> <ref> St3 </ref> </eif> </state> <state name="St2"> <if> <condition><![CDATA[ ’a’<=symbol & symbol <= ’z’]]> </condition> <action><![CDATA[printf ("%c", symbol); cnt++;]]> </action> <ref>St2</ref> </if> <eif> <condition><![CDATA[ symbol != ’\n’]]> </condition> <action><![CDATA[printf (" - %i\n", cnt);]]> </action> <ref>St1</ref> </eif> <eif> <condition> <![CDATA[ symbol == ’\n’]]> </condition> <action><![CDATA[printf (" - %i\n", cnt);]]> </action> <ref>St3</ref> </eif> </state> <state name="St3"> <if> <condition><![CDATA[’a’<=symbol & symbol <= ’z’]]> </condition> <action><![CDATA[printf ("%c", symbol); cnt = 1;]]> </action> <ref>St2</ref> </if> <eif> <condition> <![CDATA[ symbol != ’\n’]]> </condition> <action><![CDATA[/* Так как нужно печатать только слова, действия не заполняются */ ]]> </action> <ref> St1 </ref> </eif> <eif> <condition> <![CDATA[ symbol == ’\n’]]> </condition> <action><![CDATA[/* Переход не требует чтения, symbol == ’\n’ не нужно читать */ ]]> </action> <ref>Exit</ref> </eif> </state> </automat> |
| Листинг 11.2.1. Решение задачи автоматической трансформации таблиц конечного автомата |
| Закрыть окно |
| <?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <DIV STYLE="font-family:Courier; font-size:12pt"> <xsl:for-each select="automat"> <TABLE border="1" width="75%"> <TR> <TD colspan="3"><xsl:value-of select="action" /></TD> <TD width="10%"><xsl:value-of select="ref" /></TD> </TR> <xsl:for-each select="state"> <TR> <td rowspan="3" width="10%" valign="top"> <xsl:value-of select="@name" /></td> <td><xsl:value-of select="if/condition" /></td> <td><xsl:value-of select="if/action" /></td> <td><xsl:value-of select="if/ref" /></td> </TR> <xsl:for-each select="eif"> <TR> <TD><xsl:value-of select="condition" /></TD> <TD><xsl:value-of select="action" /></TD> <TD><xsl:value-of select="ref" /></TD> </TR> </xsl:for-each> </xsl:for-each> </TABLE> </xsl:for-each> </DIV> </xsl:template> </xsl:stylesheet> |
| Листинг 11.2.2. Решение задачи автоматической трансформации таблиц конечного автомата |
| Закрыть окно |
| <?xml version="1.0"?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/TR/WD-xsl"> <xsl:template match="/"> <blockquote> <pre STYLE="font-family:Courier; font-size:12pt;" > <xsl:for-each select = "automat">//C code for automat "<xsl:value-of select="@name" />" <![CDATA[ #include <stdio.h> # define failure true void main( void ) {]]> <xsl:value-of select = "action"/> goto <xsl:value-of select = "ref"/>;<br/> <xsl:for-each select="state"> <xsl:value-of select="@name" />: symbol = getchar (); <blockquote>if (<xsl:value-of select="if/condition" /> ) <blockquote>{ <xsl:value-of select="if/action" /> goto <xsl:value-of select="if/ref" />; } </blockquote> <xsl:for-each select="eif"> else if (<xsl:value-of select="condition" /> ) <blockquote>{ <xsl:value-of select="action" /> goto <xsl:value-of select="ref" />; } </blockquote> </xsl:for-each> </blockquote> </xsl:for-each> Exit: return;<br/>} </xsl:for-each> </pre> </blockquote> </xsl:template> </xsl:stylesheet> |
| Листинг 11.2.3. Решение задачи автоматической трансформации таблиц конечного автомата |
| Закрыть окно |
Требования к автоматической трансляции таблиц
Серьезный недостаток предложенного в §10.3 решения задачи автоматического преобразования таблиц переходов в программы связан с идеей препроцессорного построения, удобного для обработки представления таблиц переходов. Игнорирование обратной связи между исходным представлением автомата и его интерпретируемым представлением порождает проблемы. Если не рассматривать развитие программы, то отслеживать эту связь не нужно. Но как только встает вопрос хотя бы о минимальных переделках, возникают проблемы.
Внесение изменений в таблицу не влечет за собой автоматического изменения внутреннего представления, а возможные нарушения соглашений, связанных с исходным решением, могут сделать бессмысленным переиспользование. Это особенно заметно, если обратить внимание на то, что в результирующей таблице отсутствуют имена состояний.Поиск и диагностика ошибок (речь идет не только о синтаксисе) возможны лишь на уровне интерпретируемого представления, что противоречит осмыслению программы в прежних терминах.Наличие программы, не зависящей от исходного представления, провоцирует на ее модификации, которые не будут перенесены в исходное представление. В результате концептуальная и реализационная модели расходятся между собой.Таким образом, предложенное решение не является технологичным. Оно может быть распространено на другие ситуации лишь для ограниченного класса задач.
Разработка технологии включает в себя создание и использование инструментов поддержки всех этапов, из которых состоит технологическая цепочка оперирования с таблицами. Ключевым моментом является выбор формата представления таблиц, приспособленный как к ручной, так и к автоматической обработке. Есть смысл попытаться отыскать универсальное решение. Если, вдобавок, оно будет стандартизовано, то появится возможность создать технологию. Сегодня предпосылки для такого решения существуют, в частности, использование так называемых языков разметки текстов и, в первую очередь, XML.
Данная лекция предназначена для тех,
Данная лекция предназначена для тех, кто уже имеет начальные навыки работы на языке разметки XML1).