Нейрокомпьютинг и его применения в экономике и бизнесе
Обобщение данных. Прототипы задач
В этой лекции рассматривается новый тип обучения нейросетей - обучение без учителя (или для краткости - самообучение), когда сеть самостоятельно формирует свои выходы, адаптируясь к поступающим на ее входы сигналам. Как и прежде, такое обучение предполагает минимизацию некоторого целевого функционала. Задание такого функционала формирует цель, в соответствии с которой сеть осуществляет преобразование входной информации.
В отсутствие внешней цели, "учителем" сети могут служить лишь сами данные, т.е. имеющаяся в них информация, закономерности, отличающие входные данные от случайного шума. Лишь такая избыточность позволяет находить более компактное описание данных, что, согласно общему принципу, изложенному в предыдущей лекции, и является обобщением эмпирических данных. Сжатие данных, уменьшение степени их избыточности, использующее существующие в них закономерности, может существенно облегчить последующую работу с данными, выделяя действительно независимые признаки. Поэтому самообучающиеся сети чаще всего используются именно для предобработки "сырых" данных. Практически, адаптивные сети кодируют входную информацию наиболее компактным при заданных ограничениях кодом.
Длина описания данных пропорциональна, во-первых, разрядности данных



- Понижение размерности данных с минимальной потерей информации. (Сети, например, способны осуществлять анализ главных компонент данных, выделять наборы независимых признаков.)
- Уменьшение разнообразия данных за счет выделения конечного набора прототипов, и отнесения данных к одному из таких типов. (Кластеризация данных, квантование непрерывной входной информации.)
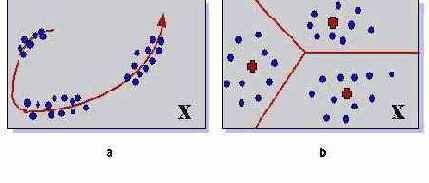
Рис. 4.1. Два типа сжатия информации. Понижение размерности (a) позволяет описывать данные меньшим числом компонент. Кластеризация или квантование (b) позволяет снизить разнообразие данных, уменьшая число бит, требуемых для описания данных
Возможно также объединение обоих типов кодирования. Например, очень богат приложениями метод топографических карт (или самоорганизующихся карт Кохонена - по имени предложившего их финского ученого), когда сами прототипы упорядочены в пространстве низкой размерности. Например, входные данные можно отобразить на упорядоченную двумерную сеть прототипов так, что появляется возможность визуализации многомерных данных.
Как и в случае с персептронами начать изучение нового типа обучения лучше с простейшей сети, состоящей из одного нейрона.